







Languages
Pages
Legal


Optimized Distributed Data Sharing Substrate
in Multi-Core Commodity Clusters: A
Comprehensive Study with Applications
K. Vaidyanathan, P. Lai, S. Narravula and D. K. Panda
Network Based Computing Laboratory (NBCL)
The Ohio State University

Presentation Outline
• Introduction and Motivation
• Distributed Data Sharing Substrate
• Proposed Design Optimizations
• Experimental Results
• Conclusions and Future Work

Introduction and Motivation
• Interactive data-driven applications
– Stock trading, airline tickets, medical imaging, online auction, online
banking, web streaming, …
– Ability to interact, synthesize and visualize data
• Datacenters enable such capabilities
– Processes data and reply to client queries
– Common and increasing in size (IBM, Amazon, Google)
• Datacenters unable to meet increasing client demands
Stock markets Airline industries Medical imaging Online auction
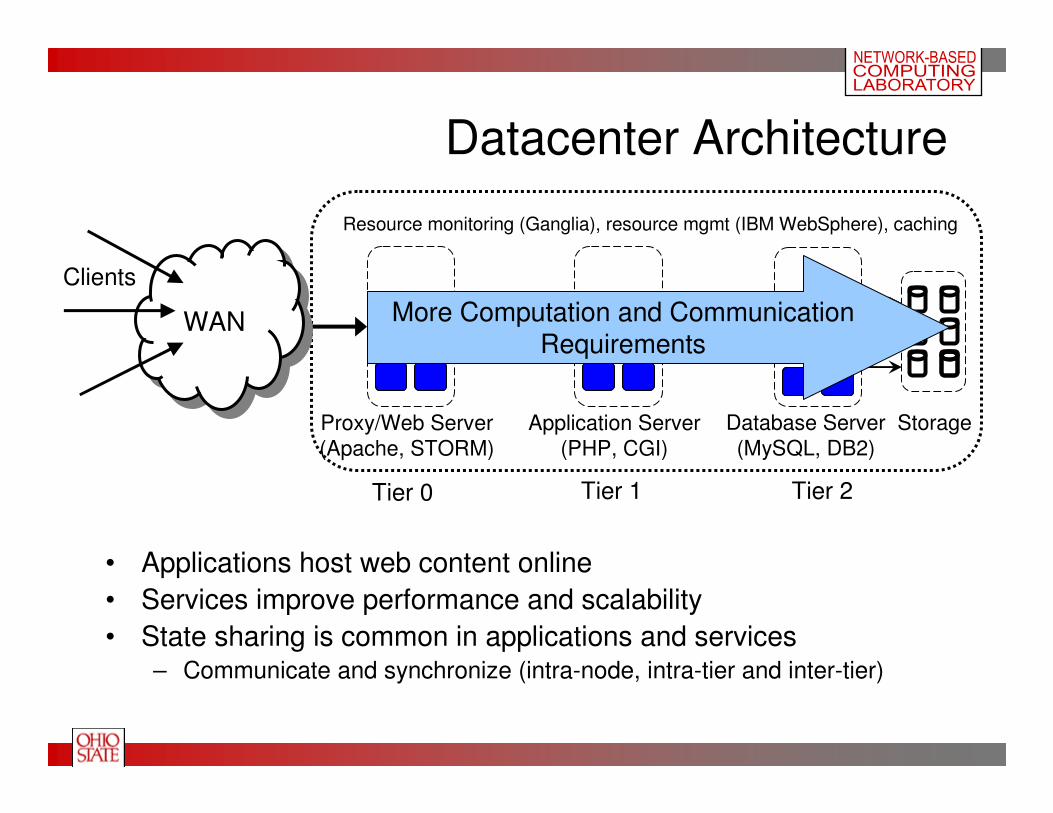
Proxy/Web Server
(Apache, STORM)
Application Server
(PHP, CGI)
Storage
Tier 0 Tier 1 Tier 2
Database Server
(MySQL, DB2)
Resource monitoring (Ganglia), resource mgmt (IBM WebSphere), caching
Datacenter Architecture
WANWAN
Clients
• Applications host web content online
• Services improve performance and scalability
• State sharing is common in applications and services– Communicate and synchronize (intra-node, intra-tier and inter-tier)
More Computation and CommunicationRequirements
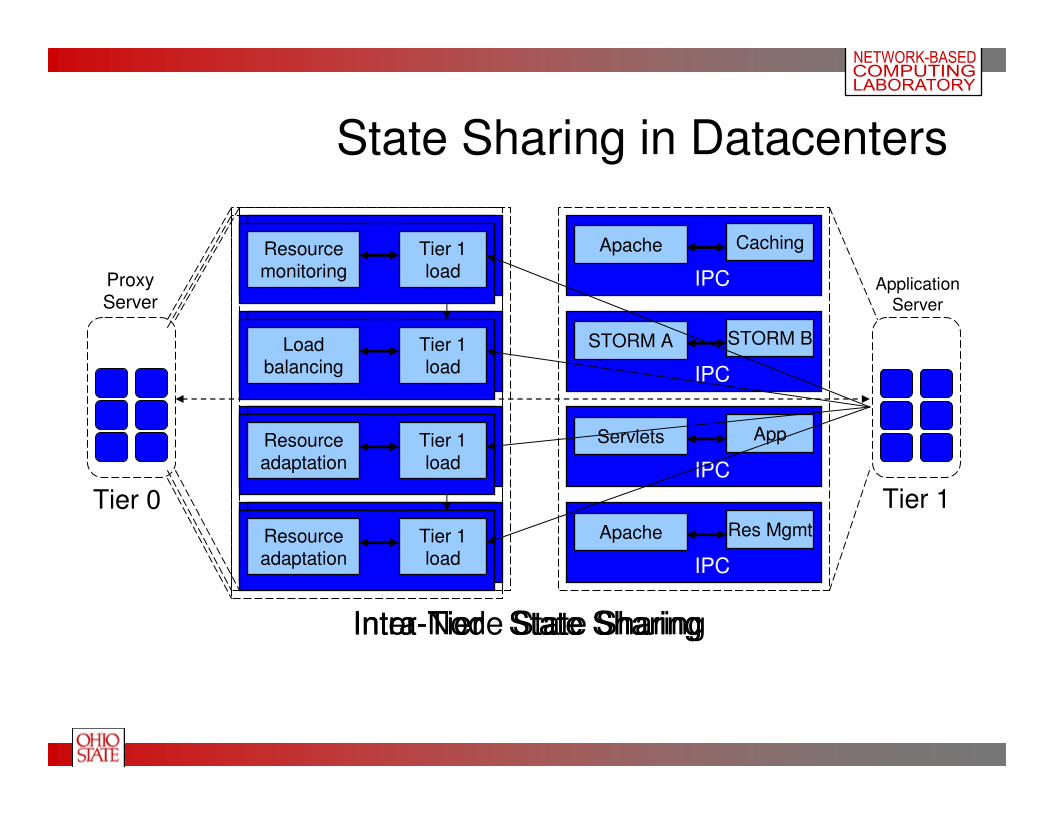
State Sharing in Datacenters
ProxyServer
Tier 0
Application
Server
Tier 1
Memory copies
Apache Network
Memory copies
STORM Network
Memory copies
Caching Network
Memory copies
Res Mgmt Network
IPC
Apache Caching
IPC
STORM A STORM B
IPC
Servlets App
IPC
Apache Res Mgmt
Intra-Node State SharingIntra-Tier State SharingInter-Tier State Sharing
Resourceadaptation
Systemstate
Resourceadaptation
Systemstate
Caching Data
Caching Data
Resourcemonitoring
Tier 1load
Loadbalancing
Tier 1load
Resourceadaptation
Tier 1load
Resourceadaptation
Tier 1load

State Sharing in Datacenters…
• Several applications employ
their own
– data management protocols
– maintain versions of stored data
– synchronization primitives
• Datacenter Services
frequently exchange
– System load, system state, locks
– Cached data
Issues
• Ad-hoc messaging protocols for exchanging data/resource
• Same data/resource at multiple places (e.g., load information, data)
• Protocols used are typically TCP/IP, IPC mechanisms, memory copies, etc
• Performance may depend on the back-end load
• Scalability issues

High-Performance Networks
• InfiniBand, 10 Gigabit Ethernet
• High-Performance– Low latency (< 1 usecs) and high bandwidth (> 32 Gbps with
QDR adapters)
• Novel features– One-sided RDMA and atomics, multicast, QoS
• OpenFabrics alliance (http://www.openfabrics.org/)– Common stack for several networks including iWARP
(LAN/WAN)
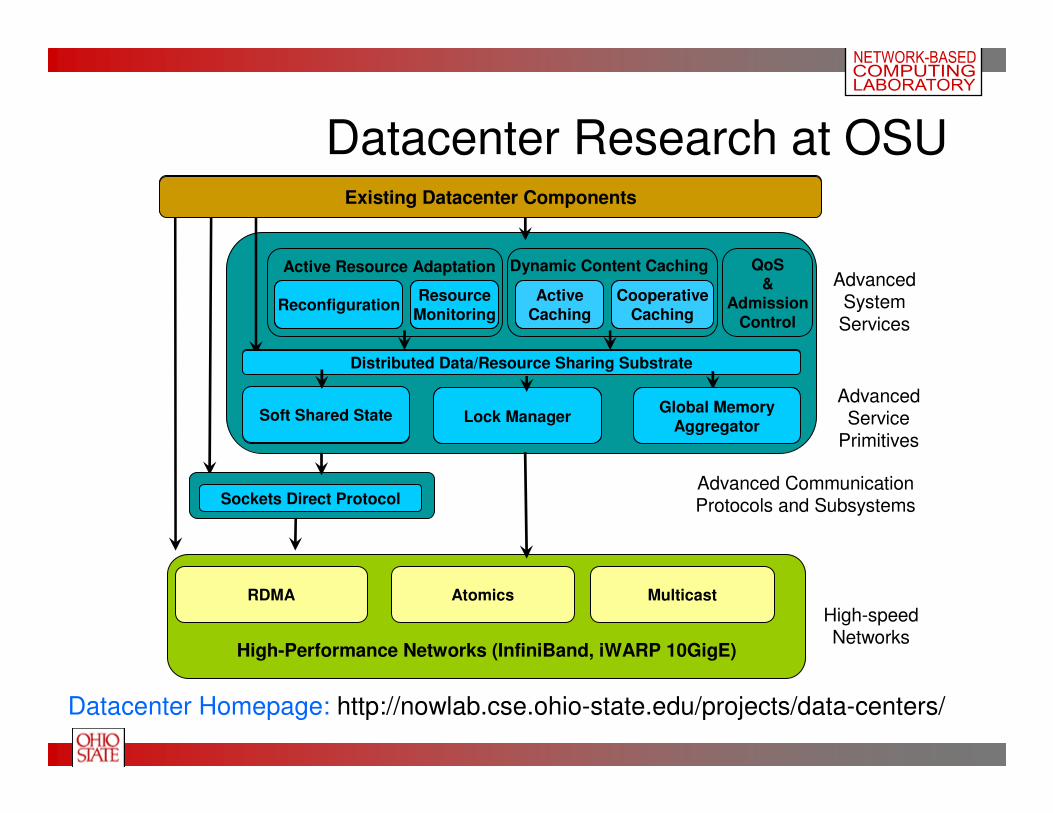
Datacenter Research at OSU
ReconfigurationResource
Monitoring
Soft Shared State Lock ManagerGlobal Memory
Aggregator
Distributed Data/Resource Sharing Substrate
High-Performance Networks (InfiniBand, iWARP 10GigE)
Existing Datacenter Components
Multicast
Advanced System Services
ActiveCaching
CooperativeCaching
Dynamic Content Caching
ActiveCaching
CooperativeCaching
ReconfigurationResource
Monitoring
Active Resource Adaptation
ReconfigurationResource
Monitoring
RDMA Atomics
High-speedNetworks
Advanced CommunicationProtocols and SubsystemsSockets Direct Protocol
QoS&
AdmissionControl
AdvancedService
Primitives
Distributed Data/Resource Sharing Substrate
Soft Shared State Lock ManagerGlobal Memory
Aggregator
Existing Datacenter Components
Datacenter Homepage: http://nowlab.cse.ohio-state.edu/projects/data-centers/

Distributed Data Sharing Substrate
Load InfoSystem State
Meta-dataData
Datacenter
Application
Datacenter
Application
Datacenter
Services
Datacenter
Application
Datacenter
Application
Datacenter
Services
Get
Get
Get
Put
Put
Put

Multicore Architectures
• Increased cores per-chip
– More parallelism available
• Intel, AMD
– Dual-core, quad-core
– 80-core systems are currently built
• Significant benefits for datacenters
– Applications are multi-threaded in nature
– Design Optimizations in state sharing mechanisms
– Opportunities for dedicating one or more cores
Future multicore systems

Objective
• Can we enhance the distributed data sharing
substrate using the features of multicore
architectures by dedicating one or more of
the cores?
• How do these enhancements help in
improving the overall performance with
datacenter applications and services?

Presentation Outline
• Introduction and Motivation
• Distributed Data Sharing Substrate
• Proposed Design Optimizations
• Experimental Results
• Conclusions and Future Work

Distributed Data Sharing Substrate
• Use of a common service thread to get access to the shared state
• Applications get shared state information using the service thread
• Several design optimizations in communicating with the service thread– Message Queues (MQ-DDSS)
– Memory mapped queues for request (RMQ-DDSS)
– Memory mapped queues for request and response (RCQ-DDSS)

Message Queue-based DDSS (MQ-DDSS)
NIC
Produce
Produce
Consume
Consume
Request
Queue
Completion
Queue
Kernel Message Queues
Application
Threads
Service
Thread
User Space
Kernel Space
IPC_SendIPC_Recv IPC_Send
IPC_Recv
Interrupt
Event
Kernel
Thread
Kernel Involvement

Message Queue-based DDSS
• Kernel involvement– IPC Send and Receive operations
– Communication Progress
• Limitations– Several context-switches
– Interrupt overheads

Presentation Outline
• Introduction and Motivation
• Distributed Data Sharing Substrate
• Proposed Design Optimizations
• Experimental Results
• Conclusions and Future Work
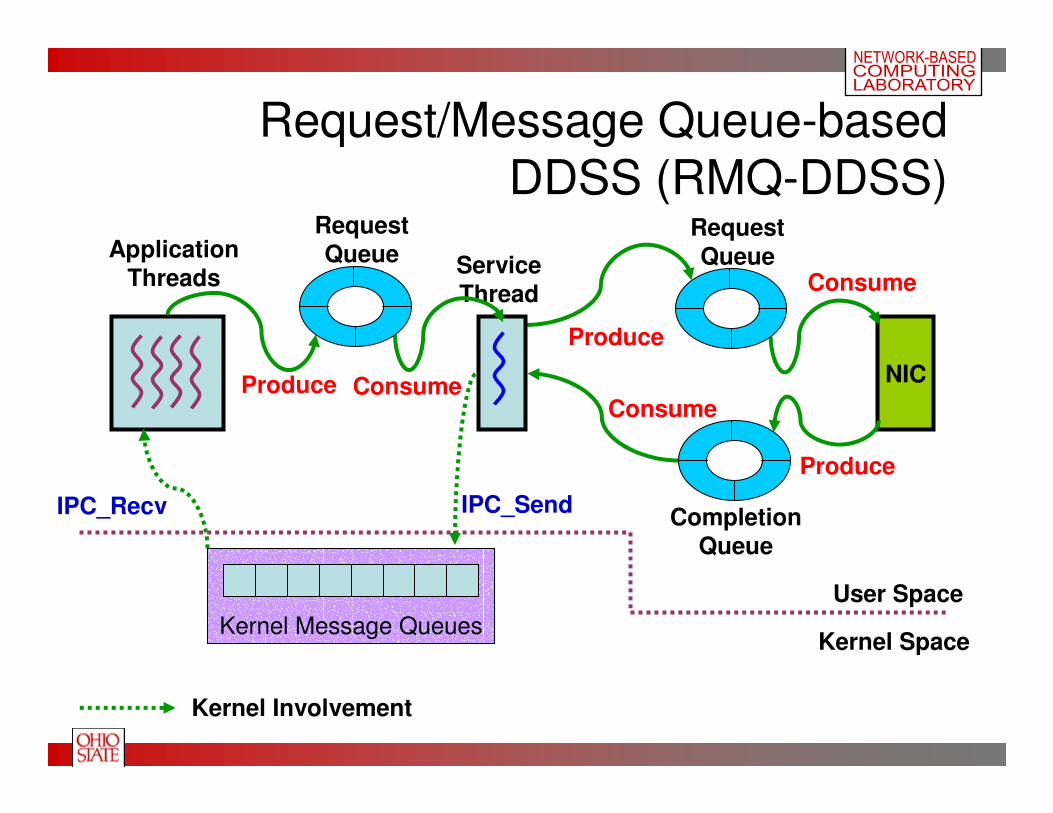
Request/Message Queue-based
DDSS (RMQ-DDSS)
NIC
Produce
Produce
Consume
Consume
Request
Queue
CompletionQueue
Kernel Message Queues
ApplicationThreads
Service
Thread
User Space
Kernel Space
IPC_Recv IPC_Send
Kernel Involvement
Produce Consume
RequestQueue
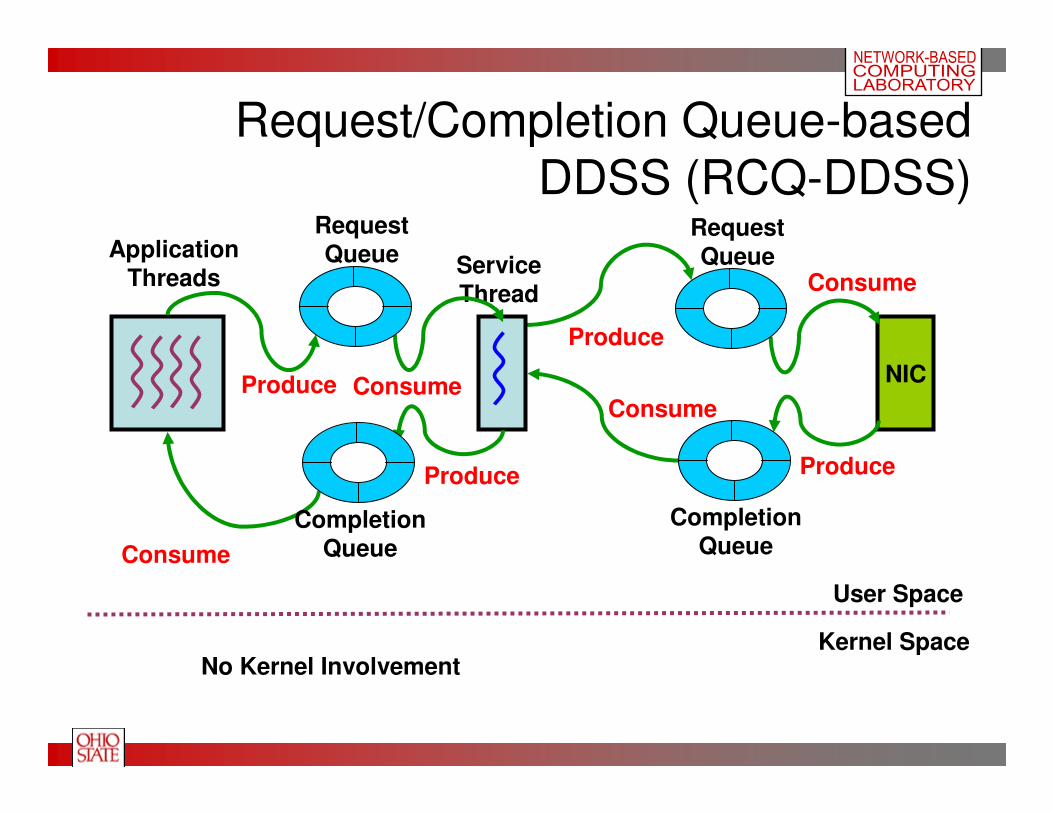
Request/Completion Queue-based
DDSS (RCQ-DDSS)
NIC
Produce
Produce
Consume
Consume
Request
Queue
CompletionQueue
ApplicationThreads
Service
Thread
User Space
Kernel SpaceNo Kernel Involvement
Produce Consume
RequestQueue
Produce
Consume
CompletionQueue

RMQ-DDSS and RCQ-DDSS Schemes
• RMQ-DDSS scheme+ Lesser number of interrupts and context-switches compared to
MQ-DDSS
+ Improvement in response time as request is sent via memory mapped queues
– May occupy significant CPU
• RCQ-DDSS scheme+ Avoids kernel involvement
+ Significant improvement in response time as request and response are sent via memory mapped queues
– May occupy more CPU as compared to RMQ-DDSS - apps & service thread need to poll on the completion queue

Presentation Outline
• Introduction and Motivation
• Distributed Data Sharing Substrate
• Proposed Design Optimizations
• Experimental Results
• Conclusions and Future Work

Experimental Testbed
• InfiniBand experiments– 560-core cluster consisting of 70 compute nodes with dual 2.33
GHz Intel Xeon quad-core processors
– Mellanox MT25208 dual port HCA
• 10-Gigabit experiments– Intel dual quad-core Xeon 3.0 GHz, 512 MB memory
– Chelsio T3B 10 GigE PCI-Express adapters
• OpenFabrics stack– OFED 1.2
• Experimental outline– Microbenchmarks (performance and scalability)
– Application performance (R-Trees, B-Trees, STORM, checkpointing)
– Dedicating cores for datacenter services (resource monitoring)

Basic Performance of DDSS
0
10
20
30
40
50
60
70
80
1 4 16 64 256 1K 4K 16K
Message Size (bytes)
Late
ncy (usecs)
RCQ-DDSS RMQ-DDSS MQ-DDSS
• RCQ-DDSS scales with increasing client threads
• RCQ-DDSS performs better than RMQ-DDSS and MQ-DDSS
0
10
20
30
40
50
60
70
1 2 3 4 5 6 7
Number of Client Threads
IPC
La
ten
cy
(u
se
cs
)
RCQ-DDSS RMQ-DDSS MQ-DDSS
0
10
20
30
40
50
60
1 4 16 64 256 1K 4K 16K
Message Size (bytes)
Late
ncy (usecs)
RCQ-DDSS RMQ-DDSS MQ-DDSS
InfiniBand
10-Gigabit Ethernet

DDSS Scalability
0
50
100
150
200
250
1 2 4 8 16 32 64 128 256 512
Number of Client Threads
Late
ncy (
usecs)
RCQ-DDSS RMQ-DDSS MQ-DDSS
• Hybrid approach is required for scalability with large number of threads
• DDSS scales when keys are distributed
0
1
10
100
1000
10000
100000
1 2 4 8 16 32 64 128
256
512
Number of Client Threads
IPC
Late
ncy (
usecs)
RCQ-DDSS RMQ-DDSS MQ-DDSS
0200400600800
1000120014001600
1 2 4 8 16 32 64 128
256
512
Number of Client Threads
Late
ncy (
usecs)
RCQ-DDSS RMQ-DDSS MQ-DDSS
Keys are on a single node
Keys are distributed

Performance with R-Trees, B-Trees, STORM
0
5
10
15
20
25
20% 40% 60% 80% 100%
Records Accessed
Tim
e (
msecs)
BTREE-RCQ-SS BTREE-RMQ-SS
BTREE-MQ-SS BTREE
0
20
40
60
80
20% 40% 60% 80% 100%
Records Accessed
Tim
e (
msecs)
RTREE-RCQ-SS RRTEE-RMQ-SS
RTREE-MQ-SS RTREE
02000
40006000
800010000
1200014000
10K 100K 1000K
Number of Records
Tim
e (
msecs)
STORM-RCQ-SS STORM-RMQ-SS
STORM-MQ-SS STORM
• MQ-SS shows significant improvement compared to
traditional implementations but
RCQ-SS shows marginal improvements compared to MQ-SS
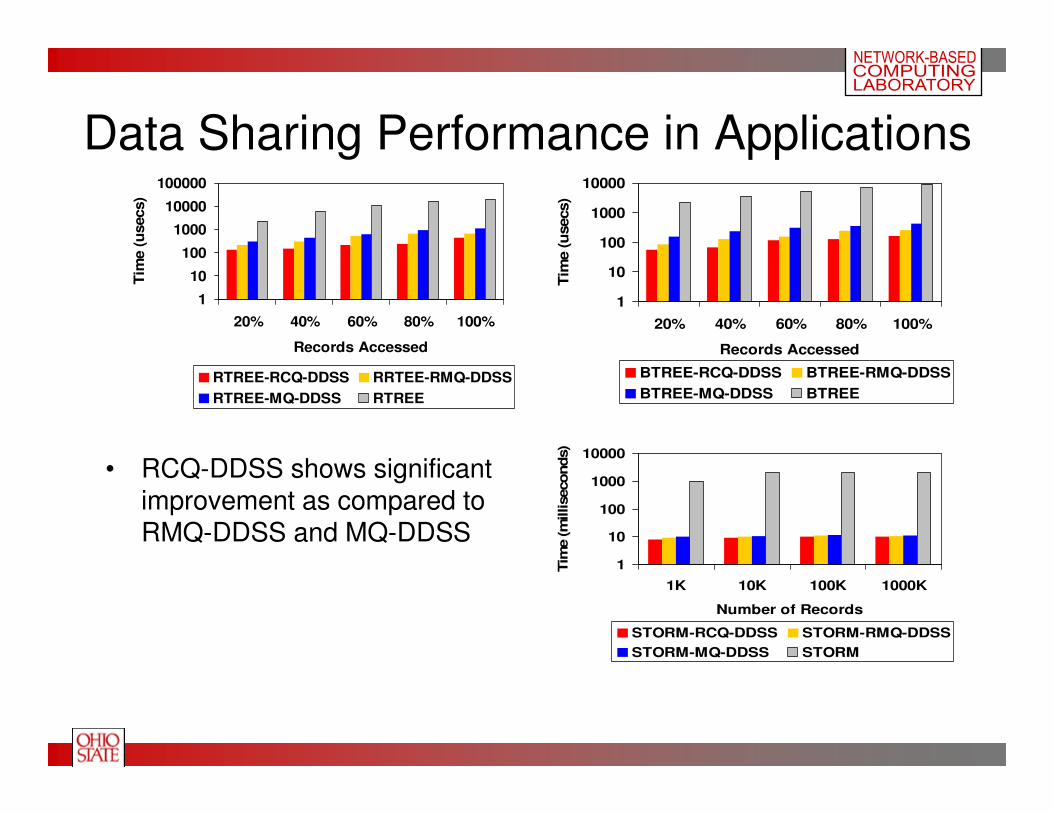
Data Sharing Performance in Applications
1
10
100
1000
10000
20% 40% 60% 80% 100%
Records Accessed
Tim
e (
usecs)
BTREE-RCQ-DDSS BTREE-RMQ-DDSS
BTREE-MQ-DDSS BTREE
• RCQ-DDSS shows significant improvement as compared to RMQ-DDSS and MQ-DDSS
1
10
100
1000
10000
100000
20% 40% 60% 80% 100%
Records Accessed
Tim
e (
usecs)
RTREE-RCQ-DDSS RRTEE-RMQ-DDSS
RTREE-MQ-DDSS RTREE
1
10
100
1000
10000
1K 10K 100K 1000K
Number of Records
Tim
e (m
illiseconds)
STORM-RCQ-DDSS STORM-RMQ-DDSS
STORM-MQ-DDSS STORM

Performance with checkpointing
0
20000
40000
60000
80000
100000
120000
140000
160000
1 4 16 64 256 1024 4096
Number of Client Threads
Late
ncy (usecs)
RCQ-DDSS RMQ-DDSS MQ-DDSS
• Hybrid approach is required for scalability with large number of threads
1
10
100
1000
10000
100000
1 2 4 8 16 32 64
Number of Client Threads
Execu
tio
n T
ime (
usecs)
RCQ-DDSS RMQ-DDSS MQ-DDSS
1
10
100
1000
10000
1 4 16 64 256
Number of Client Threads
Execu
tio
n T
ime (
usecs)
RCQ-DDSS RMQ-DDSS MQ-DDSS
Clients on diff node (non-distributed)
Clients on diff node (non-distributed)
Clients on single node (non-distributed)

Performance with Dedicated Cores
• Dedicating a core for resource monitoring can avoid up
to 50% degradation in client response time
0 200 400 600 800 1000800
1000
1200
1400
1600
1800
2000
Iterations
La
ten
cy(M
icro
se
co
nd
s)
4Servers8Servers16Servers32Servers
0 200 400 600 800 1000800
1000
1200
1400
1600
1800
2000
Iterations
Late
ncy(M
icro
seconds)
4Servers8Servers16Servers32Servers

Conclusions & Future Work
• Proposed multicore optimizations for
distributed data sharing substrate
• Evaluations with several applications shows
significant improvement
• Showed the benefits of dedicating cores for
services in datacenters
• Future work on dedicating other datacenter
services, datacenter-specific operations

Web Pointers
Datacenter Homepage: http://nowlab.cse.ohio-state.edu/projects/data-centers/
Emails: {vaidyana, laipi, narravul, panda}@cse.ohio-state.edu
NBC-LAB
Top Related