







Languages
Pages
Legal


NextGen Infrastructure for Big Data
Anil Vasudeva, President & Chief Analyst, IMEX Research
Author: Anil Vasudeva, IMEX Research

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
2 2
SNIA Legal Notice
The material contained in this tutorial is copyrighted by the SNIA and author unless otherwise noted. Member companies and individual members may use this material in presentations and literature under the following conditions:
Any slide or slides used must be reproduced in their entirety without modification The SNIA must be acknowledged as the source of any material used in the body of any document containing material from these presentations.
This presentation is a project of the SNIA Education Committee. Neither the author nor the presenter is an attorney and nothing in this presentation is intended to be, or should be construed as legal advice or an opinion of counsel. If you need legal advice or a legal opinion please contact your attorney. The information presented herein represents the author's personal opinion and current understanding of the relevant issues involved. The author, the presenter, and the SNIA do not assume any responsibility or liability for damages arising out of any reliance on or use of this information. NO WARRANTIES, EXPRESS OR IMPLIED. USE AT YOUR OWN RISK.

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
3 3
Abstract
NextGen Infrastructure for Big Data This session will appeal to Business Planning, Marketing, Technology System Integrators and Data Center Managers seeking to understand the drivers behind the demand for and rise of Big Data.
Abstract The internet has spawned an explosion in data growth in the form of data sets, called Big Data, that are so large they are difficult to store, manage and analyze using traditional RDBMS which are tuned for Online Transaction Processing (OLTP) only. Not only is this new data heavily unstructured, voluminous and streams rapidly and difficult to harness but even more importantly, the infrastructure cost of HW and SW required to crunch it using traditional RDBMS, to derive any analytics or business intelligence online (OLAP) from it, is prohibitive. To capitalize on the Big Data trend, a new breed of Big Data technologies (such as Hadoop and others) many companies have emerged which are leveraging new parallelized processing, commodity hardware, open source software and tools to capture and analyze these new data sets and provide a price/performance that is 10 times better than existing Database/Data Warehousing/Business Intelligence Systems.
Learning Objectives The presentation will illustrate the existing operational challenges businesses face today using RDBMS systems despite using fast access in-memory and solid state storage technologies. It details how IT is harnessing the emergent Big Data to manage massive amounts of data and new techniques such as parallelization and virtualization to solve complex problems in order to empower businesses with knowledgeable decision-making. It lays out the rapidly evolving big data technology ecosystem - different big data technologies from Hadoop, Distributed File Systems, emerging NoSQL derivatives for implementation in private and hybrid cloud-based environments, Storage Infrastructure Requirements to Store, Access, Secure, Prepare for analytics and visualization of data while manipulating it rapidly to derive business intelligence online, to run businesses smartly.

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
4 4
Big Data in IT Industry Roadmap
Cloudization On-Premises > Private Clouds > Public Clouds DC to Cloud-Aware Infrast. & Apps. Cascade migration to SPs/Public Clouds.
Integrate Physical Infrast./Blades to meet CAPSIMS ®IMEX Cost, Availability, Performance, Scalability, Inter-operability, Manageability & Security
Integration/Consolidation
Standard IT Infrastructure- Volume Economics HW/Syst SW (Servers, Storage, Networking Devices, System Software (OS, MW & Data Mgmt. SW)
Standardization
Virtualization Pools Resources. Provisions, Optimizes, Monitors Shuffles Resources to optimize Delivery of various Business Services
Automatically Maintains Application SLAs (Self-Configuration, Self-Healing©IMEX, Self-Acctg. Charges etc.)
Automation
IT Industry Roadmap
Analytics – BI Predictive Analytics - Unstructured Data From Dashboards Visualization to Prediction Engines using Big Data.

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
5 5
NextGen IT Infrastructure
Enterprise VZ Data Center On-Premise Cloud
Home Networks
Web 2.0 Social Ntwks.
Facebook, Twitter, YouTube…
Cable/DSL… Cellular
Wireless
Internet ISP
Core Optical
Edge ISP
ISP ISP
ISP
ISP
Supplier/Partners
Remote/Branch Office
Public CloudCenter©
Servers VPN IaaS, PaaS SaaS
Vertical Clouds
ISP
Tier-3 Data Base
Servers Tier-2 Apps
Management Directory Security Policy Middleware Platform
Switches: Layer 4-7, Layer 2, 10GbE, FC Stg.
Caching, Proxy, FW, SSL, IDS, DNS,
LB, Web Servers
Application Servers HA, File/Print, ERP, SCM, CRM Servers
Database Servers, Middleware, Data Mgmt.
Tier-1 Edge Apps
FC/ IPSANs
Request for data from a remote client to a Data Center or Cloud crosses a myriad of systems and devices. Key is identifying bottlenecks & improving performance

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Harnessing Big Data for Business Insights
6
Majority of data growth is being driven by unstructured data and billions of large objects
Information is at the center of New Wave of opportunity
80% of world’s data is unstructured driven by rise in Mobility devices, collaboration machine generated data.
Data Sources
Big Data Infrastructure
Business Insights

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Unstructured Big Data can provide Next Gen Analytics to help businesses make informed, better decision in: ▪ Product Strategy ▪ Targeting Sales ▪ Just-In-Time Supply-Chain Economics ▪ Business Performance Optimization ▪ Predictive Analytics & Recommendations ▪ Country Resources Management
Corporate Need: Business Perf... Optimization
7
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
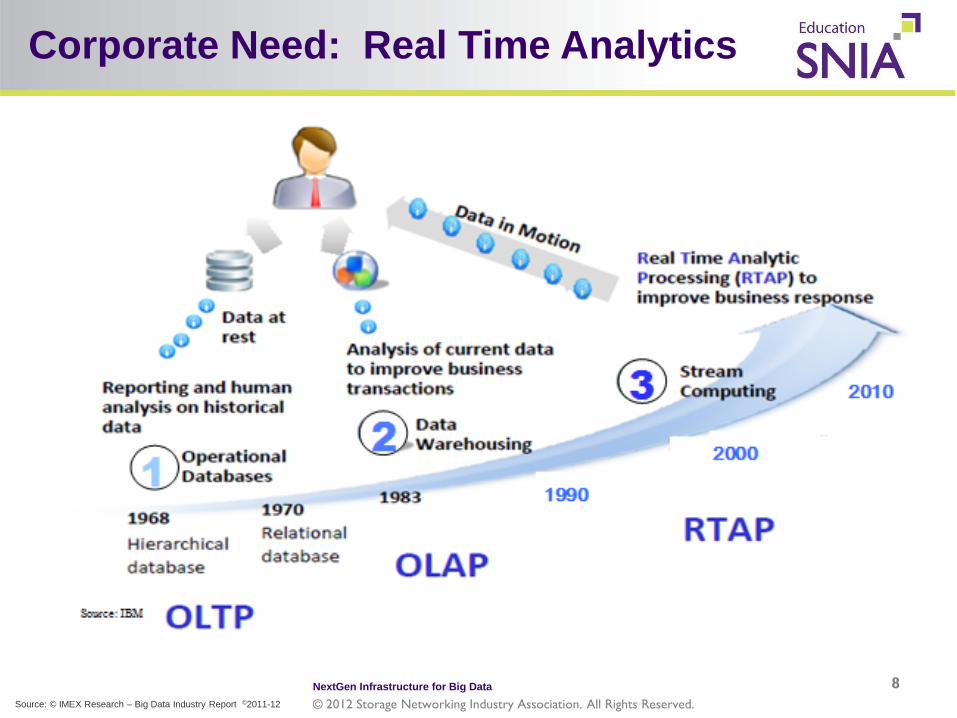
Corporate Need: Real Time Analytics
8
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
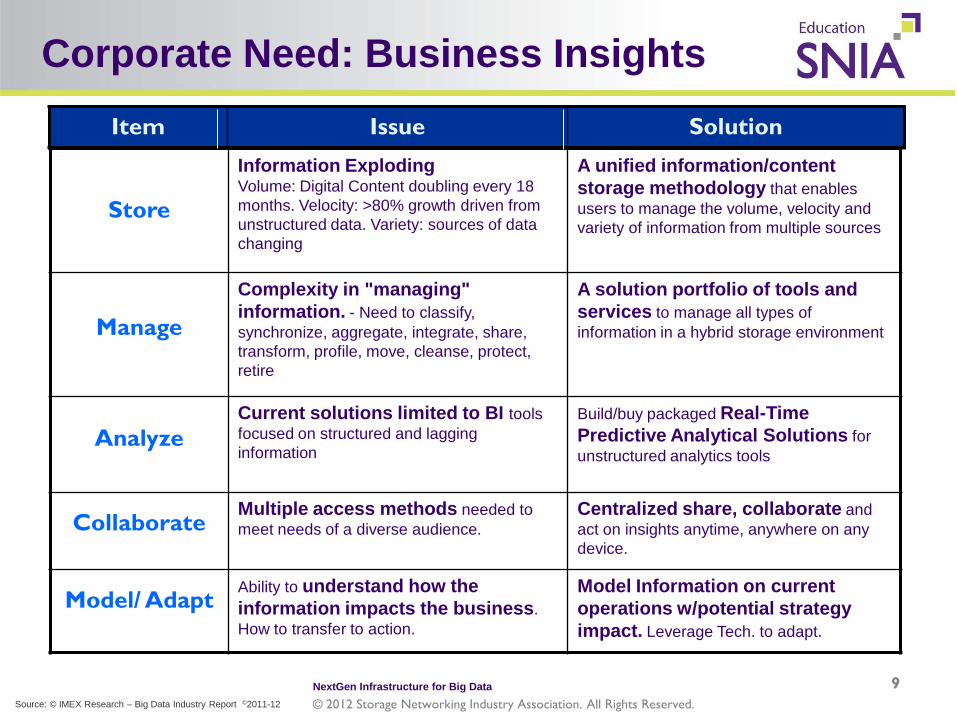
Corporate Need: Business Insights
.
Store
Information Exploding Volume: Digital Content doubling every 18 months. Velocity: >80% growth driven from unstructured data. Variety: sources of data changing
A unified information/content storage methodology that enables users to manage the volume, velocity and variety of information from multiple sources
Manage
Complexity in "managing" information. - Need to classify, synchronize, aggregate, integrate, share, transform, profile, move, cleanse, protect, retire
A solution portfolio of tools and services to manage all types of information in a hybrid storage environment
Analyze Current solutions limited to BI tools focused on structured and lagging information
Build/buy packaged Real-Time Predictive Analytical Solutions for unstructured analytics tools
Collaborate Multiple access methods needed to meet needs of a diverse audience.
Centralized share, collaborate and act on insights anytime, anywhere on any device.
Model/ Adapt Ability to understand how the information impacts the business. How to transfer to action.
Model Information on current operations w/potential strategy impact. Leverage Tech. to adapt.
Item Issue Solution
9
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
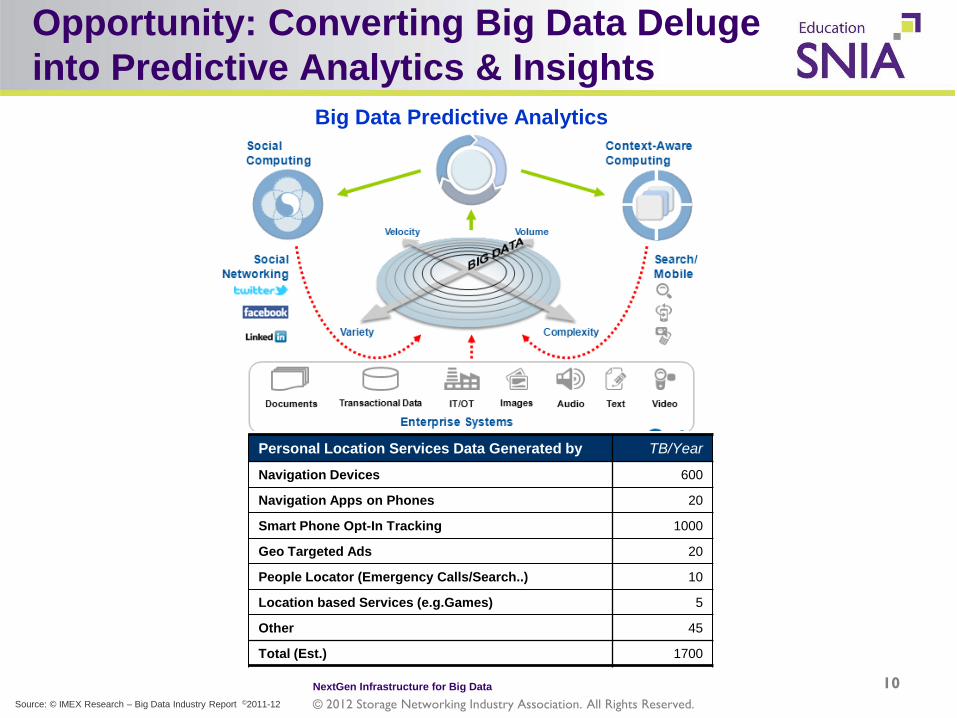
Opportunity: Converting Big Data Deluge into Predictive Analytics & Insights
Personal Location Services Data Generated by TB/Year
Navigation Devices 600
Navigation Apps on Phones 20
Smart Phone Opt-In Tracking 1000
Geo Targeted Ads 20
People Locator (Emergency Calls/Search..) 10
Location based Services (e.g.Games) 5
Other 45
Total (Est.) 1700
Big Data Predictive Analytics
10

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Issues with Existing RDBMS Key Issues with RDBMS Technologies Handling Mixed Unstructured Data - RDBMs don’t handle non-tabular data
(Notorious for doing a poor job on recursive data structure) Legacy Archaic Architecture - RDBMS don’t parallelize well to accommodate commodity HW clusters Speed - Seek time of physical Storage has not kept pace with network speed improvements Scale - Difficult to scale-out RDBMS efficiently – Clustering beyond few servers notoriously hard Integration - Data processing tasks need to combine data from non-related sources, over a network Volume - Data volumes have grown from 10s GB >100s TB > PBs in recent years. Existing Tabular RDBMS can’t handle such large DBs
11
Fault Tolerance
Availability Deep Insights
EU Adhoc Analytics
Cost
Unstructured Data
Latency
Scalability
Big Data Analytics

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Issues with Existing RDBMS Present RDBMS struggling to Store & Analyze Big Data
12

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Big Data - Database Solutions
13

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Big Data – The New Face of DBs
Big Data Paradigm - The New face of DB Systems • Adopts Schema-Free Architecture • Can do away with Legacy Relational DB Systems Some data have sparse attributes, do not need relational property • Key Oriented Queries Some data stored/retrieved mainly by primary key, w/o complex joins • Trade-off of Consistency, Availability & Partition Tolerance • Scale Out, not up, - Online Load balancing cluster growth
14

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Analytics – The Next Frontier in IT
15
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
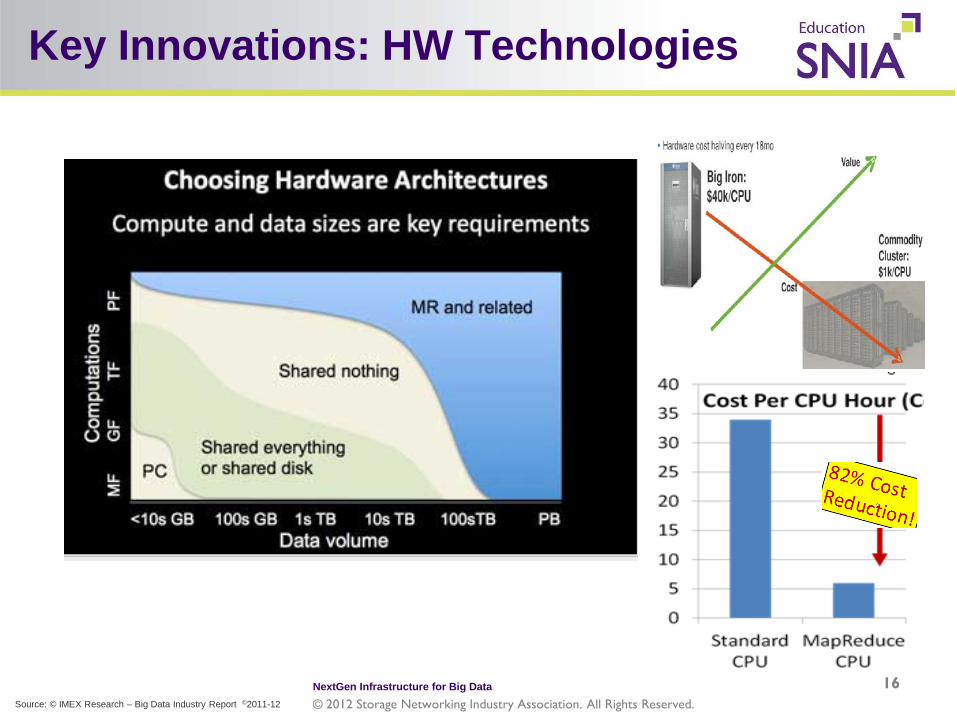
Key Innovations: HW Technologies
16
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
17
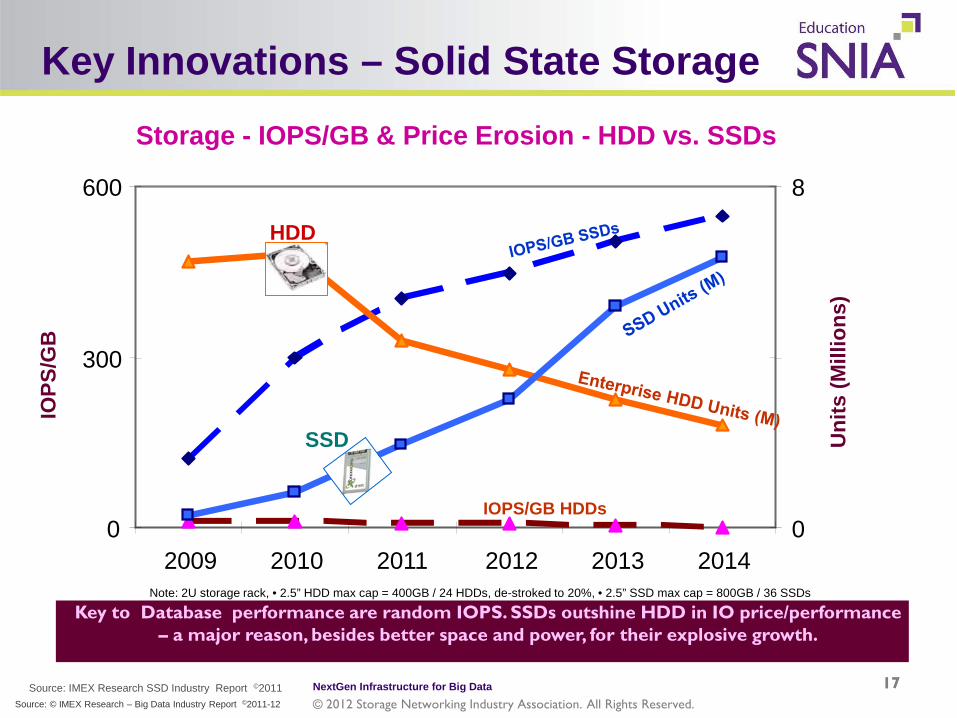
Key Innovations – Solid State Storage
Source: IMEX Research SSD Industry Report ©2011
Note: 2U storage rack, • 2.5” HDD max cap = 400GB / 24 HDDs, de-stroked to 20%, • 2.5” SSD max cap = 800GB / 36 SSDs
0
300
600
2009 2010 2011 2012 2013 2014
Uni
ts (M
illio
ns)
0
8
IOPS
/GB
IOPS/GB HDDs
HDD
SSD
17
Key to Database performance are random IOPS. SSDs outshine HDD in IO price/performance – a major reason, besides better space and power, for their explosive growth.
Storage - IOPS/GB & Price Erosion - HDD vs. SSDs
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
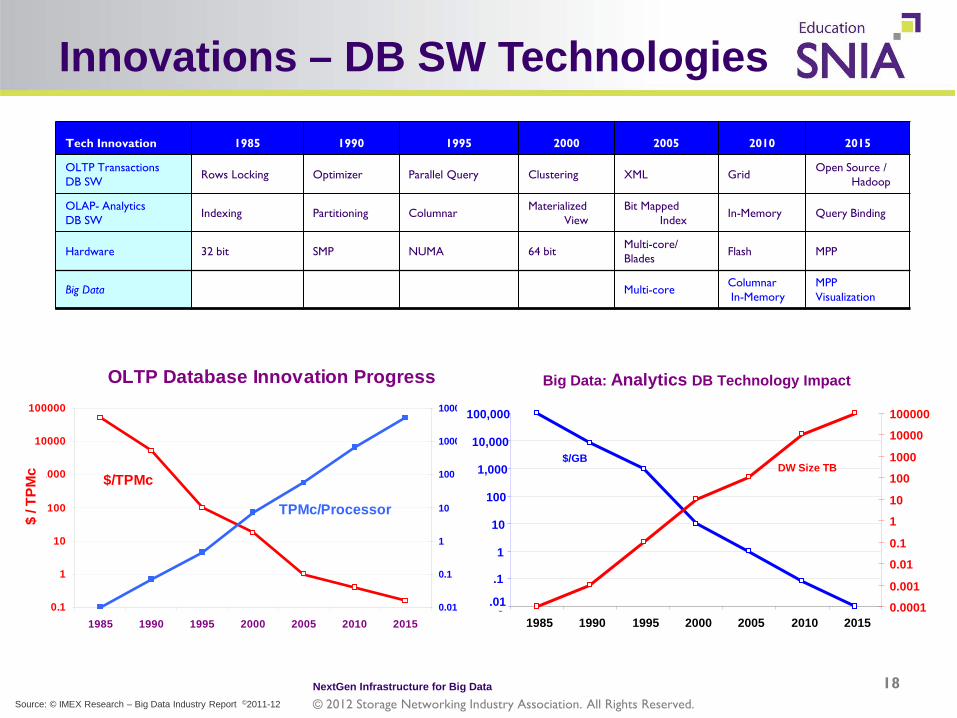
Innovations – DB SW Technologies
Tech Innovation 1985 1990 1995 2000 2005 2010 2015
OLTP Transactions DB SW Rows Locking Optimizer Parallel Query Clustering XML Grid Open Source /
Hadoop
OLAP- Analytics DB SW Indexing Partitioning Columnar Materialized
View Bit Mapped
Index In-Memory Query Binding
Hardware 32 bit SMP NUMA 64 bit Multi-core/ Blades Flash MPP
Big Data Multi-core Columnar In-Memory
MPP Visualization
OLTP Database Innovation Progress
0.1
1
10
100
1000
10000
100000
1985 1990 1995 2000 2005 2010 20150.01
0.1
1
10
100
1000
10000
$/TPMc
TPMc/Processor
$ / T
PMc
TPM
c / P
roce
ssor
Big Data: Analytics DB Technology Impact
0
0
1
10
100
1,000
10,000
100,000
1985 1990 1995 2000 2005 2010 2015 0.0001
0.001
0.01
0.1
1
10
100
1000
10000
100000
.1
.01
DW Size TB $/GB
18
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
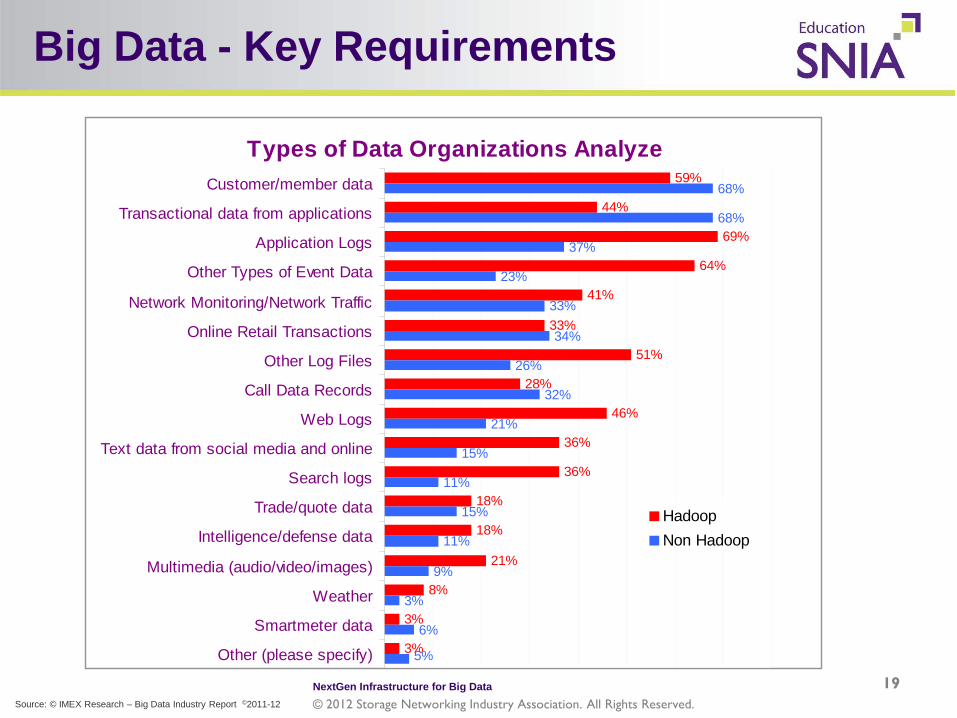
Big Data - Key Requirements
Types of Data Organizations Analyze59%
44%
69%
64%
41%
33%
51%
28%
46%
36%
36%
18%
18%
21%
8%
3%
3%
68%
68%
37%
23%
33%
34%
26%
32%
21%
15%
11%
15%
11%
9%
3%
6%
5%
Customer/member data
Transactional data from applications
Application Logs
Other Types of Event Data
Network Monitoring/Network Traffic
Online Retail Transactions
Other Log Files
Call Data Records
Web Logs
Text data from social media and online
Search logs
Trade/quote data
Intelligence/defense data
Multimedia (audio/video/images)
Weather
Smartmeter data
Other (please specify)
HadoopNon Hadoop
19

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Big Data – Architectural Goals
Big Data Platform
Meet Enterprise Criterion Meet Requirements of V3
Analyze Data in Native Format
20

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
21
Big Data - Market Requirements
Unified system: Pre-integrated for Ease of Installation and Management • Platform – Large Scale Indexing Pre-integrated using Hadoop Foundation, • Integrated Text Analytics - Address Unstructured Data • Usability - User Friendly Admin Console including HDFS Explorer, Query
Languages • Enterprise Class Features – Provisioning, Storage, Scheduler, Advance Security • Supports search-centric, document-based XML data model
o store documents within a transactional repository. • Schema-Free:
o No advance knowledge of the document structure (its "schema") needed o Index words and values from each of the loaded documents together with
its document structure. • Standard commodity hardware leveraged

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Big Data – Market Requirements
Architectural • Shared-nothing clustered DB architecture
o programmable and extensible application servers. • Support massive scalability to petabytes of source data • Support open-source XQuery- and XSLT-driven architecture • Simple to Deploy, Develop and Manage (UI & Restful Interface) • Support extreme mixed workloads - a wide variety of data types including
arbitrarily hierarchical data structures, images, waveforms, data logs etc. • Support thousands of geographically dispersed on--line users and
programs executing variety of requests from ad hoc queries to strategic analysis • Loading data before declaring or discovering its structure • Load data in batch and streaming fashion • Integrate data from multiple sources during load process at very high rates
Spread I/O and data across instances • Provide consistent performance with linear cost • Leverage Open Source SW Lo Costs, Multiple Sources, Hadoop Foundation Tools • Connectivity with Oracle DB, Teradata Warehouse, JDBC Connectivity,
22

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Real Time Analytics Execution • Execute “streaming” analytic queries in real time on incoming load data • Updating data in place at full load speeds • Scheduling and execution of complex multi-hundred node workflows • Join a billion row dimension table to a trillion row fact table without pre-
clustering the dimension table with the fact table Performance • Analyze data, at very high rates >GB/sec • Predictable Sub-ms response time for highly constrained standard SQL
queries Availability • Ability to configure without any single point of failure • Auto-Failover Extreme High Availability
o Automated failover and process continuation without operational interruption when processing nodes fail
23
Big Data - Market Requirements

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Big Data – Product Metrics Choices
Big Data -
Product Metrics
Data Set Size PB
TB
GB
Data Structure
Transaction
Machine
Unstructured
Other
Access/Use Transaction
Search
Analytics
Parallel Processing
Appliance
Cluster < 1K
Cluster > 1K
Memory In-Memory
Flash
DB Technique Columnar
Zero Sharing
No SQL
Data Cataloging SW
Text
Image
Audio
Video
24

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Advantage: Big Data Products Characteristic Legacy Paradigm Big Data Paradigm Structure •Transactional/Corporate •Unstructured/Derivative/Internet
Mode •Data Collection •Data Analysis
Focus •Find Answers •Find Questions
Facility •Reportive / What Happened? •Analytic / Why did it Happen? Predictive / What will Happen Next?
Opportunity •Very Small Growth •Massive Growth
Players •Legacy Players •Agile Start Ups, well funded
Impact •Analyze Existing Businesses •Create New Businesses
25
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
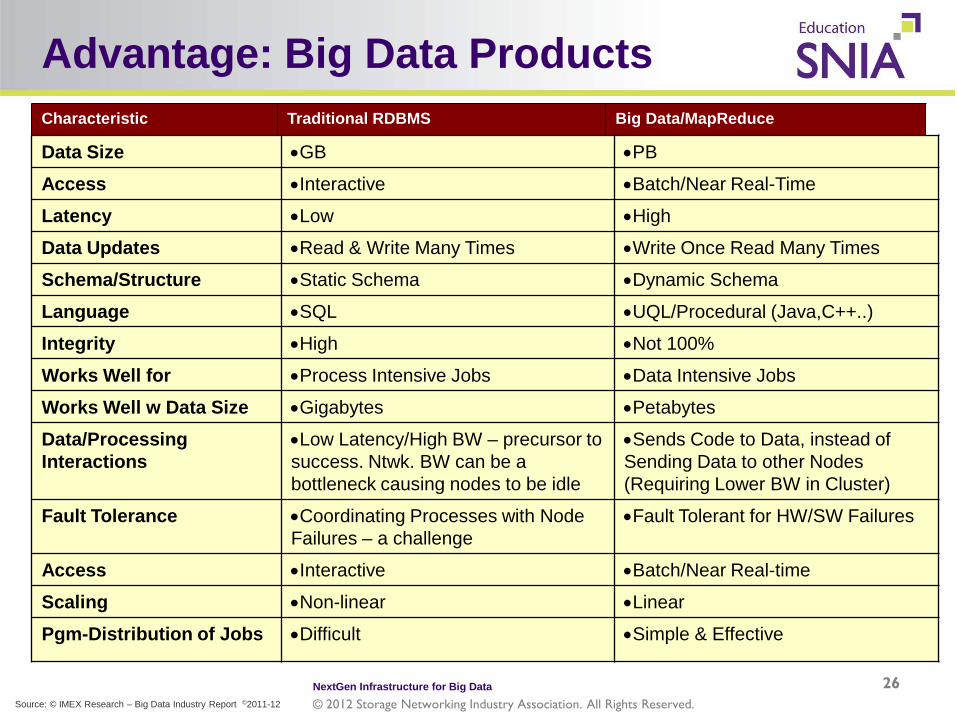
Characteristic Traditional RDBMS Big Data/MapReduce
Data Size •GB •PB
Access •Interactive •Batch/Near Real-Time
Latency •Low •High
Data Updates •Read & Write Many Times •Write Once Read Many Times
Schema/Structure •Static Schema •Dynamic Schema
Language •SQL •UQL/Procedural (Java,C++..)
Integrity •High •Not 100%
Works Well for •Process Intensive Jobs •Data Intensive Jobs
Works Well w Data Size •Gigabytes •Petabytes
Data/Processing Interactions
•Low Latency/High BW – precursor to success. Ntwk. BW can be a bottleneck causing nodes to be idle
•Sends Code to Data, instead of Sending Data to other Nodes (Requiring Lower BW in Cluster)
Fault Tolerance •Coordinating Processes with Node Failures – a challenge
•Fault Tolerant for HW/SW Failures
Access •Interactive •Batch/Near Real-time
Scaling •Non-linear •Linear
Pgm-Distribution of Jobs •Difficult •Simple & Effective
26
Advantage: Big Data Products
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
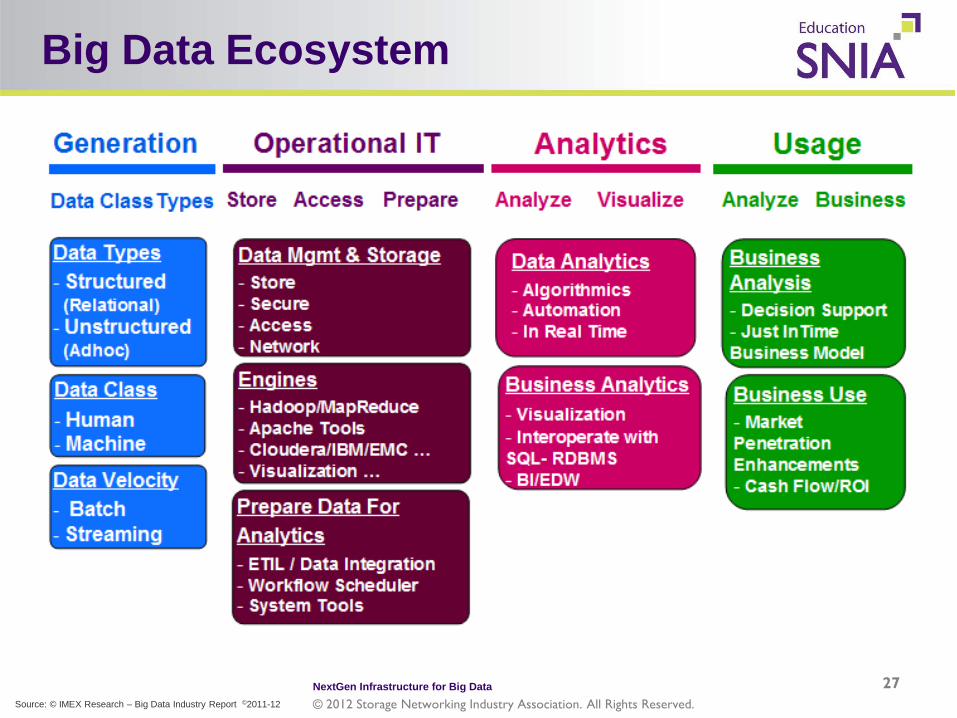
Big Data Ecosystem
27

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Big Data Stack
Collector
Admin Center
Data Importer
Data Importer
RHive
Enterprise
PerfMon, Query Plan
Hive Workflow Oracle-to-Hive
Search
Rest/ JSON API
Data exporter
Databases
Advanced Analytics
OLAP Server
OLTP Server
ETL Ad-hoc query
Data Sources
Data Store (Hadoop)
Oracle IBM
Teradata…
Real-time Queries
DBA
Streaming Data
Devices
Analytics Platform Data Sources Applications
Merging Hadoop innovations into Nextgen DBMS
28

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Hadoop’s Fit in Enterprise Stack
29
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
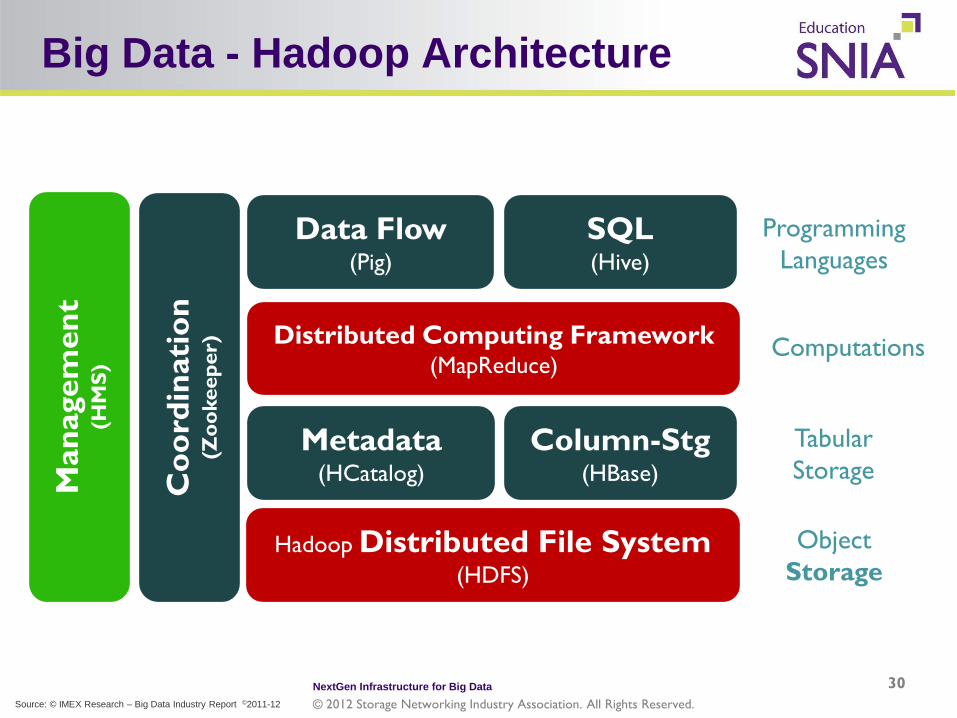
Big Data - Hadoop Architecture
30
Data Flow (Pig)
SQL (Hive)
Distributed Computing Framework (MapReduce)
Metadata (HCatalog)
Column-Stg (HBase) C
oord
inat
ion
(Zoo
keep
er)
Man
agem
ent
(HM
S)
Hadoop Distributed File System (HDFS)
Programming Languages
Computations
Object Storage
Tabular Storage

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Big Data Connectors to EDW/BI
Servers
Operating System Hypervisor/VMs
Big Data Storage Framework (HDFS)
Big Data Processing Framework (MapReduce)
Big Data Access Framework Pig Hive Sqoop
Big Data (Connectors)
Big Data Orchestration Framework HBase Avro Flume ZooKeeper
BI APPLICATIONS (Query, Analytics, Reporting, Statistics)
EDW
Backup &
Recovery
Managem
ent
Security
Network
BI Framework - Interoperable with Enterprise Data Warehousing
31
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
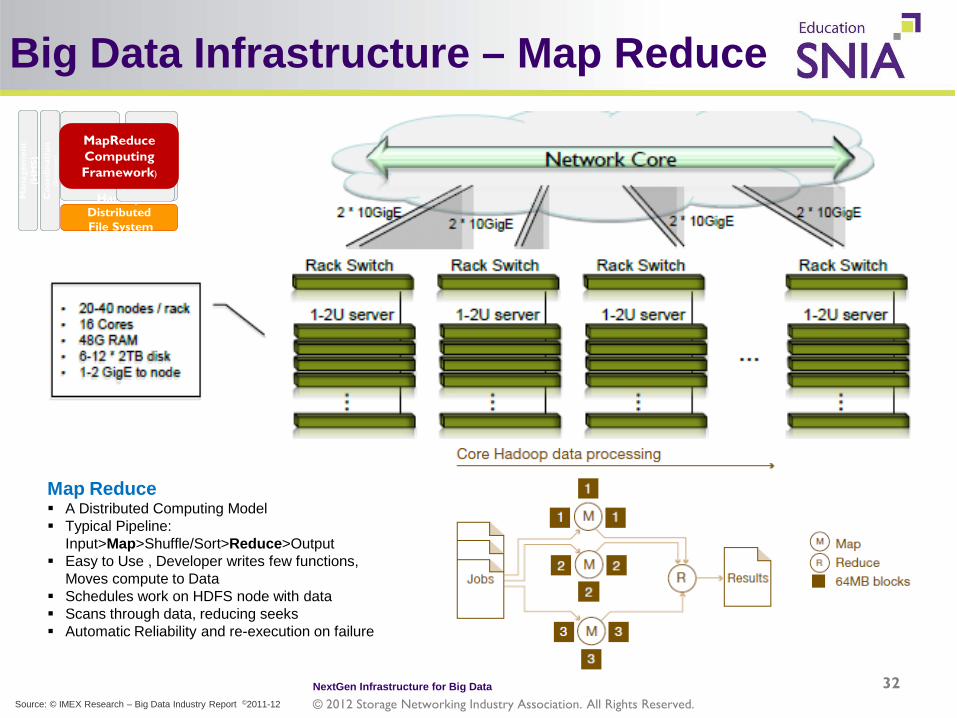
Big Data Infrastructure – Map Reduce
32
Map Reduce A Distributed Computing Model Typical Pipeline:
Input>Map>Shuffle/Sort>Reduce>Output Easy to Use , Developer writes few functions,
Moves compute to Data Schedules work on HDFS node with data Scans through data, reducing seeks Automatic Reliability and re-execution on failure
Column-Stg (HBase)
Data Flow (Pig)
SQL (Hive)
Metadata (HCatalog)CV
Coo
rdin
atio
n (Z
ooke
eper
)
Man
agem
ent
(HM
S)
Hadoop Distributed File System
(HDFS)
Metadata (HCatalog)CV
MapReduce Computing Framework)
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
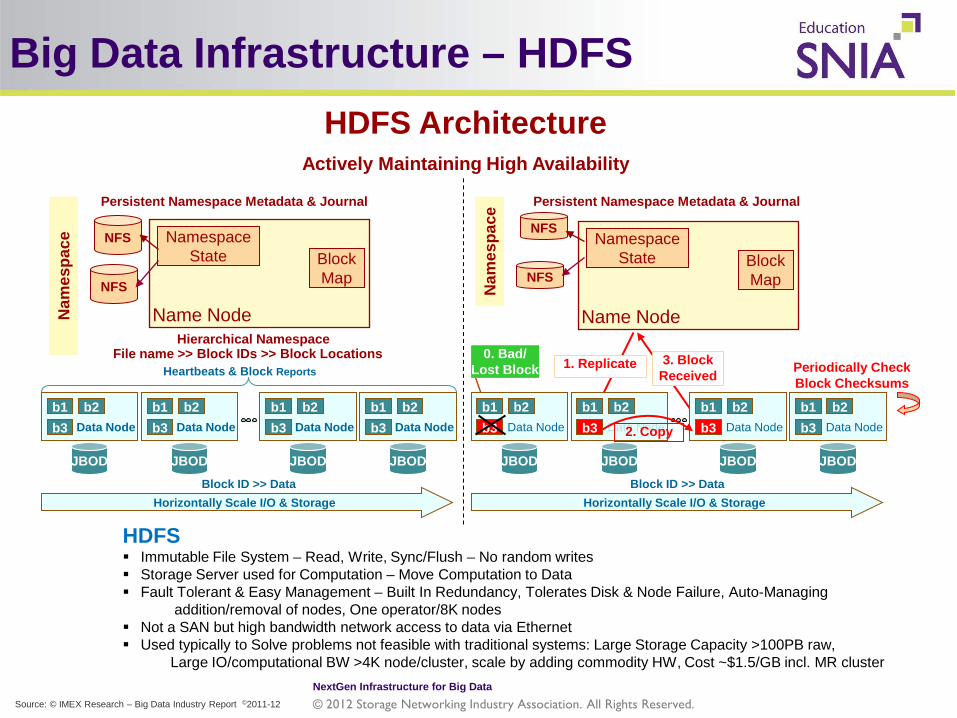
HDFS Architecture Actively Maintaining High Availability
Persistent Namespace Metadata & Journal
Name Node
Block Map
Namespace State
NFS
NFS
Nam
espa
ce
Hierarchical Namespace File name >> Block IDs >> Block Locations
1. Replicate 3. Block Received Periodically Check
Block Checksums
0. Bad/ Lost Block
Block ID >> Data
JBOD
Data Node b1 b3
b2
JBOD
Data Node b1 b3
b2
JBOD
Data Node b1 b3
b2
JBOD
Data Node b1 b3
b2
Horizontally Scale I/O & Storage
JBOD
Data Node b1 b3
b2
JBOD
Data Node b1 b3
b2
JBOD
Data Node b1 b3
b2
JBOD
Data Node b1 b3
b2
2. Copy
Block ID >> Data Horizontally Scale I/O & Storage
Name Node
Block Map
Namespace State
Persistent Namespace Metadata & Journal
NFS
NFS
Nam
espa
ce
Heartbeats & Block Reports
HDFS Immutable File System – Read, Write, Sync/Flush – No random writes Storage Server used for Computation – Move Computation to Data Fault Tolerant & Easy Management – Built In Redundancy, Tolerates Disk & Node Failure, Auto-Managing
addition/removal of nodes, One operator/8K nodes Not a SAN but high bandwidth network access to data via Ethernet Used typically to Solve problems not feasible with traditional systems: Large Storage Capacity >100PB raw,
Large IO/computational BW >4K node/cluster, scale by adding commodity HW, Cost ~$1.5/GB incl. MR cluster
Big Data Infrastructure – HDFS
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
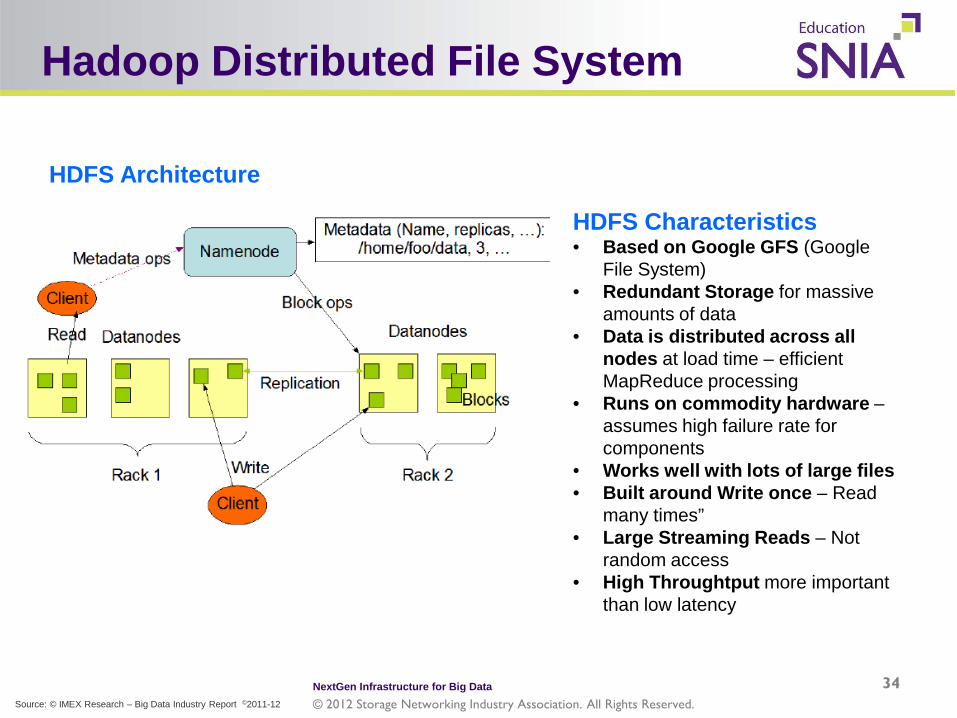
Hadoop Distributed File System
HDFS Architecture
HDFS Characteristics • Based on Google GFS (Google
File System) • Redundant Storage for massive
amounts of data • Data is distributed across all
nodes at load time – efficient MapReduce processing
• Runs on commodity hardware – assumes high failure rate for components
• Works well with lots of large files • Built around Write once – Read
many times” • Large Streaming Reads – Not
random access • High Throughtput more important
than low latency
34
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
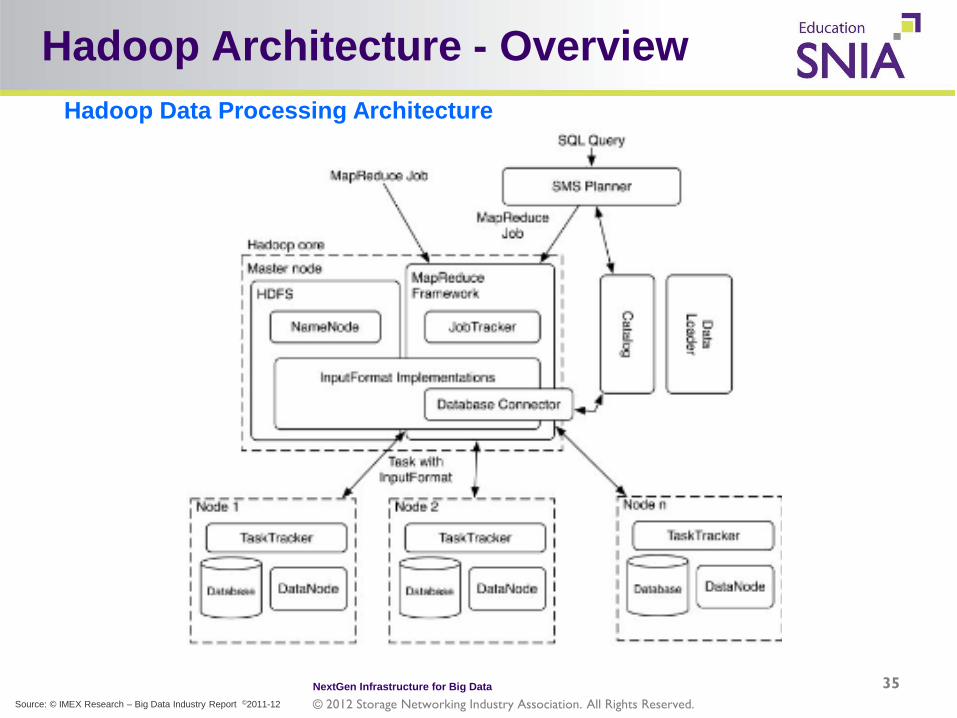
Hadoop Architecture - Overview Hadoop Data Processing Architecture
35

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Key Technologies Required for Big Data
Key Technologies Required for Big Data • Cloud Infrastructure • Virtualization • Networking • Storage
o In-Memory Data Base (Solid State Memory) o Tiered Storage Software (Performance Enhancement) o Deduplication (Cost Reduction) o Data Protection (Back Up, Archive & Recovery)
36

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Cloud Infrastructure for Big Data
37
Examples eMail - Yahoo!,Google… Collaboration - Facebook,Twitter … Bus.Apps - SalesForce, GoogleApps, Intuit…
Examples Amazon EC2 Force.com Navitaire
Examples Amazon S3 Nirvanix
Infrastructure HW & Services
- Servers, Network, Storage - Management, Reporting
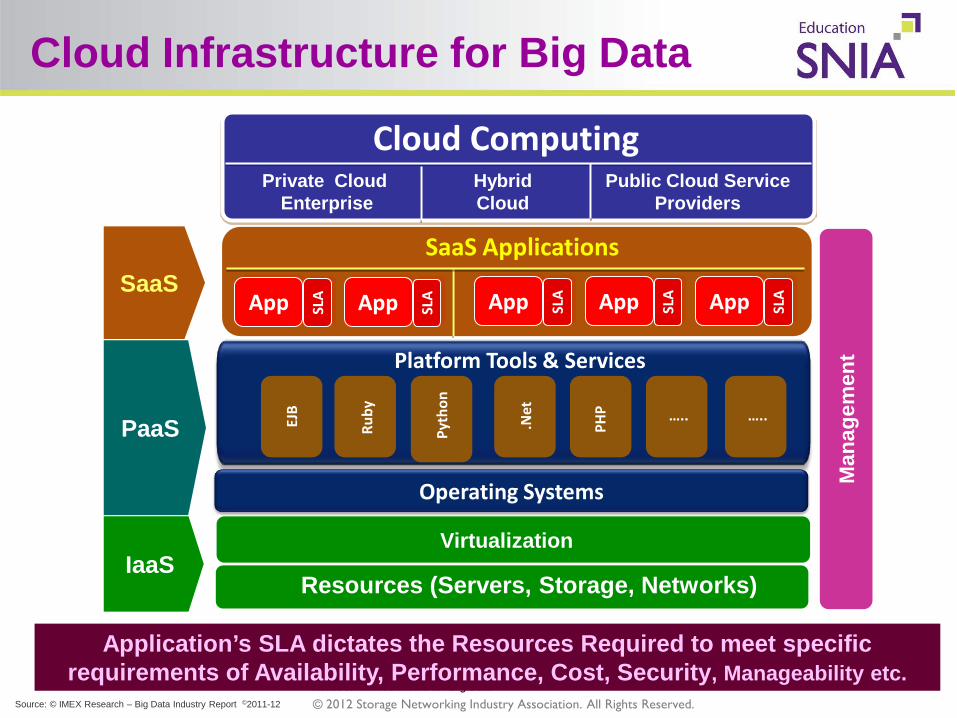
SaaS
PaaS
IaaS
Platform Tools & Services - Deploy developed platforms ready for Application SW on Cloud Aware Infrastructure
Software-as-a-Service - Servers, Network, Storage - Management, Reporting
Service Providers
Examples Public - BT, Telstra, T-Systems France Telecom Private – Hybrid – IBM/Cloudburst,
Cloud Services Providers Public – Mutitenancy,OnDemand Private - On Premises, Enterprise Hybrid – Interoperable P2P
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Platform Tools & Services
Operating Systems
Cloud Computing Public Cloud Service
Providers Private Cloud
Enterprise
App SLA
SaaS Applications
….. .Net
Pyth
on
EJB
Ruby
PHP ….. PaaS
IaaS
SaaS
Virtualization Resources (Servers, Storage, Networks)
Hybrid Cloud
App SLA App SLA App SLA App SLA
Man
agem
ent
Cloud Infrastructure for Big Data
Application’s SLA dictates the Resources Required to meet specific requirements of Availability, Performance, Cost, Security, Manageability etc.
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
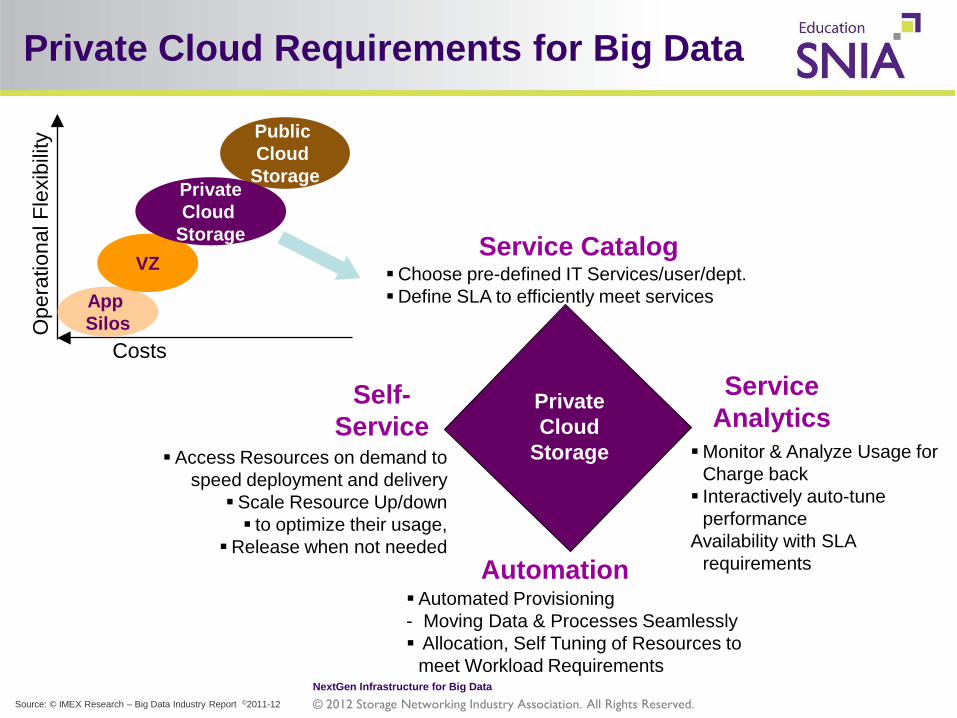
Private Cloud Requirements for Big Data
Public Cloud
Storage
Costs
Ope
ratio
nal F
lexi
bilit
y
App Silos
VZ
Private Cloud
Storage
Automation Automated Provisioning - Moving Data & Processes Seamlessly Allocation, Self Tuning of Resources to
meet Workload Requirements
Self- Service
Access Resources on demand to speed deployment and delivery
Scale Resource Up/down to optimize their usage,
Release when not needed
Service Catalog Choose pre-defined IT Services/user/dept. Define SLA to efficiently meet services
Service Analytics
Monitor & Analyze Usage for Charge back Interactively auto-tune
performance Availability with SLA
requirements
Private Cloud
Storage

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Virtualization: Workloads Consolidation
Source: Dan Olds & IMEX Research 2009
• A single server 1.5x larger than standard 2-way server will handle consolidated load of 6 servers. • VZ manages the workloads + important apps get the compute resources they need automatically w/o operator intervention. • Physical consolidation of 15-20:1 is easily possible • Reasonable goal for VZ x86 servers – 40-50% utilization on large systems (>4way), rising as dual/quad core processors becomes available • Savings result in Real Estate, Power & Cooling, High Availability, Hardware, Management

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Virtualization: TCO Savings
$-
$4,000
$8,000
$12,000
$16,000
w/o VZ w VZ
Provisioning
HardwareSAN
NetworkPower & Cooling
DC Real EstateDisaster Recovery
Downtime
Cos
t ove
r 3
year
s 995 Pre-Virtualization (VZ) Servers 78 VZ Servers
VZ SW &
Support For T
CO
Ana
lysi
s, E
M: i
mex
@ im
exre
sear
ch.c
om
(408
) 268
-080
0

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Storage Infrastructure for Big Data
42
Storage Efficiency
Virtualization Mapping P > V, VM Management Performance In-Memory DB, Auto-Tiering-SSD/HDD Costs Reduction Thin Provisioning Deduplication Availability RAID/Auto recover HA, Snapshots, CDP, Cloning, DRS Security Encryption/DLP
Service Efficiency
Storage -as-a Service Service Catalogs by Workloads etc. Policy Infrastructure
• Service Level Attributes • Service Measurements
Performance Analytics • IOPS/Response Time, Bandwidth
Automation • Unified SAN/NAS Protocols • Auto learning Workload Forensics • Provisioning to Match Workloads • Assured Auto recovery

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Storage Architecture - Impact from VZ
Source: IMEX Research SSD Industry Report ©2011
43
Replication
RAID – 0,1,5,6,10
Virtual Tape
Back Up/Archive/DR Data Protection
Virtualization
MAID
Deduplication Thin Provisioning
Storage Efficiency
Auto Tiering
Virtualization (VZ) requires Shared Storage for - VMotion - Storage VMotion - HA/DRS - Fault Tolerance
Additional Capacity Consumed for - VZ snapshots, - VM Kernel etc.

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Storage – Issues & Solutions
Traditional Data Growth
Sto
rage
Cos
ts R
educ
tion
Capacity Requirements
Snapshots ~ 75%
Thin Provisioning ~30%
DeDuplication ~ 25-95%
Auto-Tiering 65-95%
Thin Replication ~ 95%
RAID*DP ~ 40% vs. R10
Virtual Clones ~80%
CAPACITY SAVINGS ~ xx %
Technologies Reducing Storage Costs
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
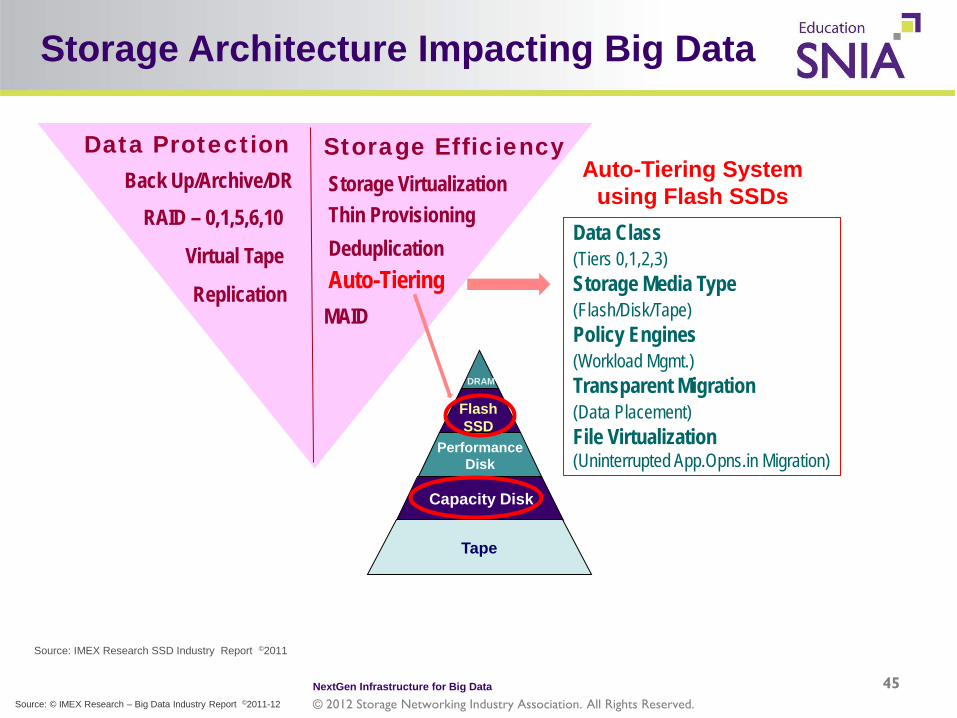
Storage Architecture Impacting Big Data
Auto-Tiering System using Flash SSDs
Data Class (Tiers 0,1,2,3) Storage Media Type (Flash/Disk/Tape) Policy Engines (Workload Mgmt.) Transparent Migration (Data Placement) File Virtualization (Uninterrupted App.Opns.in Migration)
Source: IMEX Research SSD Industry Report ©2011
Replication
RAID – 0,1,5,6,10
Virtual Tape
Back Up/Archive/DR Data Protection
Storage Virtualization
MAID
Deduplication Thin Provisioning
Storage Efficiency
Auto-Tiering
45
DRAM
Flash SSD
Performance Disk
Capacity Disk
Tape

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
46 46
I/O Access Frequency vs. Percent of Corporate Data
SSD • Logs • Journals • Temp Tables • Hot Tables
FCoE/ SAS
Arrays
• Tables • Indices
• Hot Data
Cloud Storage
SATA • Back Up Data • Archived Data
• Offsite DataVault
2% 10% 50% 100% 1% % of Corporate Data
65%
75%
95%
% o
f I/O
Acc
esse
s
Data Storage: Hierarchical Usage
Source:: IMEX Research - Cloud Infrastructure Report ©2009-12
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
47 47
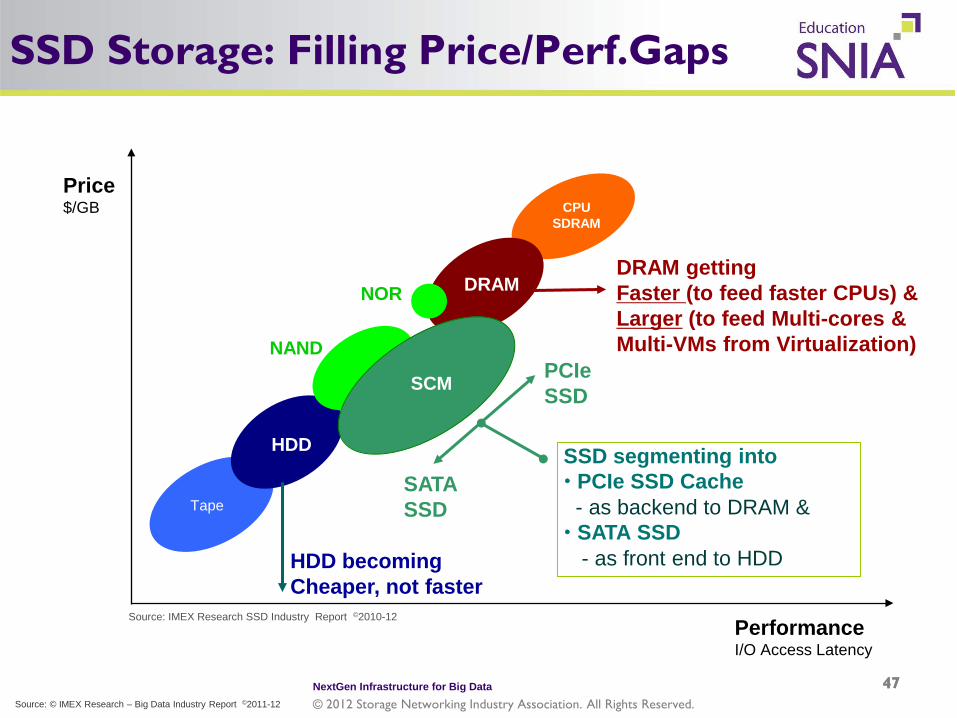
SSD Storage: Filling Price/Perf.Gaps
HDD
Tape
DRAM
CPU SDRAM
Performance I/O Access Latency
HDD becoming Cheaper, not faster
DRAM getting Faster (to feed faster CPUs) & Larger (to feed Multi-cores & Multi-VMs from Virtualization)
SCM
NOR
NAND PCIe SSD
SATA SSD
Price $/GB
Source: IMEX Research SSD Industry Report ©2010-12
SSD segmenting into PCIe SSD Cache - as backend to DRAM & SATA SSD - as front end to HDD

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
48 48
SSD Storage - Performance & TCO
SAN TCO using HDD vs. Hybrid Storage
14.2 5.2
75
28
0
64
0
36
145
0
0
50
100
150
200
250
HDD Only HDD/SSD
Cos
t $K
Power & Cooling RackSpace SSDs HDD SATA HDD FC
Pwr/Cool
RackSpace
SSD
HDD-SATA
HDD-FC
SAN PerformanceImprovements using SSD
0
50
100
150
200
250
300
FC-HDD Only SSD/SATA-HDD
IOPS
0
1
2
3
4
5
6
7
8
9
10
$/IO
P
Performance (IOPS) $/IOP
$/IOPS Improvement
800%
IOPS Improvement
475%
Source: IMEX Research SSD Industry Report ©2011

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Workloads Characterization
*IOPS for a required response time ( ms) *=(#Channels*Latency-1)
(RAID - 0, 3)
500 100 MB/sec
10 1 50 5
Data Warehousing
OLAP
Business Intelligence (RAID - 1, 5, 6)
IOPS
* (*L
aten
cy-1
)
Web 2.0 Audio
Video
Scientific Computing
Imaging HPC
TP HPC
10K
100 K
1K
100
10
1000 K OLTP
eCommerce Transaction Processing
Source:: IMEX Research - Cloud Infrastructure Report ©2009-12

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Storage performance, management and costs are big issues in running Databases
Data Warehousing Workloads are I/O intensive
• Predominantly read based with low hit ratios on buffer pools • High concurrent sequential and random read levels Sequential Reads requires high level of I/O Bandwidth (MB/sec) Random Reads require high IOPS)
• Write rates driven by life cycle management and sort operations OLTP Workloads are strongly random I/O intensive
• Random I/O is more dominant Read/write ratios of 80/20 are most common but can be 50/50 Can be difficult to build out test systems with sufficient I/O characteristics
Batch Workloads are more write intensive • Sequential Writes requires high level of I/O Bandwidth (MB/sec)
Backup & Recovery times are critical for these workloads • Backup operations drive high level of sequential IO • Recovery operation drives high levels of random I/O
Workloads Characterization
Source: IMEX Research SSD Industry Report ©2011 50

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Best Practices – Storage in Big Data Apps
Goals & Implementation Establish Goals for SLAs (Performance/Cost/Availability), BC/DR (RPO/RTO) & Compliance Increase Performance for DB, OLTP and OLAP Apps:
Random I/O > 20x , Sequential I/O Bandwidth > 5x Remove Stale data from Production Resources to improve performance
Use Partitioning Software to Classify Data By Frequency of Access (Recent Usage) and Capacity (by percent of total Data) using general guidelines as: Hyperactive (1%), Active (5%), Less Active (20%), Historical (74%)
Implementation Optimize Tiering by Classifying Hot & Cold Data
Improve Query Performance by reducing number of I/Os Reduce number of Disks Needed by 25-50% using advance compression software achieving 2-4x compression
Match Data Classification vs.Tiered Devices accordingly Flash, High Perf Disk, Low Cost Capacity Disk, Online Lowest Cost Archival Disk/Tape
Balance Cost vs. Performance of Flash More Data in Flash > Higher Cache Hit Ratio > Improved Data Performance
Create and Auto-Manage Tiering (Monitoring, Migrations, Placements) without manual intervention
51
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
52 52
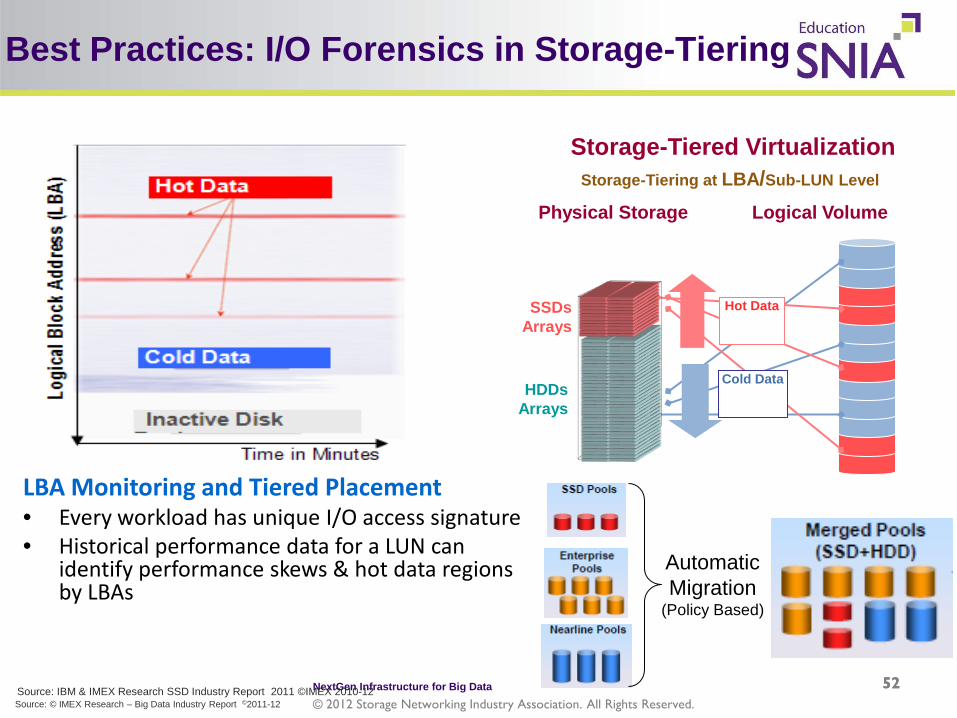
Best Practices: I/O Forensics in Storage-Tiering
Source: IBM & IMEX Research SSD Industry Report 2011 ©IMEX 2010-12
LBA Monitoring and Tiered Placement • Every workload has unique I/O access signature • Historical performance data for a LUN can
identify performance skews & hot data regions by LBAs
Storage-Tiering at LBA/Sub-LUN Level Storage-Tiered Virtualization
Physical Storage Logical Volume
SSDs Arrays
HDDs Arrays
Hot Data
Cold Data
Automatic Migration
(Policy Based)

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Best Practices: Cached Storage
App/DB Server
LSI MegaRAID CacheCade Pro 2.0
Application Improvement over Cached vs.HDD only
Oracle OLTP Benchmarks 681%
SQL Server OLTP Benchmark
1251%
Neoload (Web Server Simulation
533%
SysBench (MySQL OLTP Server)
150%
0
373
655
0
100
200
300
400
500
600
700
All HDD Smart Flash Cache
Persist Data on Warpdrive
TPS
0
330
660
0 100 200 300 400 500 600 700
All HDD Smart Flash Cache
Persist Data on
Warpdrive
Response Time
53

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Big Data Targets: Analytics Key Industries Benefitting from Big Data Analytics
CAG
R %
(201
0-15
)
Global IT Spending by Industry Verticals 2010-15 $B
5 Year Cum Global IT Spending 2010-15 ($B)
54

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Big Data Targets – Storage Infrastructure
Data Intensity by Industry Vertical
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Banking & Financial ServicesMedia & Entrertainment
Healthcare ProvidersProfessional ServicesTelecommunications
Pharma, Life Sciences & Medical PdctsRetail & Wholesales
UtilitiesInd'l Elex & Electrical EquipmentSW Publishing & Internet Srvcs
Consumer ProductsInsurance
TransportationEnergy
Installed Terabytes/$M Rev 2010
Value Potential of Using Big Data by Data Intensive Verticals
55

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Big Data Targets: Storage Infrastructure
Data Stored by Large US Enterprises
Big Data Storage Potential Data Stored by Large US Enterprise
14%
12%
10%
10%
9%
6%
6%
6%
5%
4%
4%
3%
3%
3%
2%
2%
1%
Discrete Manafacturing
Government
Communications and Media
Process manufacturing
Banking
Health Care Providers
Securities & Investment Srvcs
Professional Services
Retail
Education
Insurance
Transportation
Wholesale
Utilities
Resource IndustriesConsumer and Recreational
ServicesConstruction 967
1,312
1,792
831
1,931
370
3,866
278
697
319
870
801
536
1,507
825
150
231
Big Data Storage Potential Data Stored by Large US Enterprises
Stored Data by Industry (in US 2009 PB)
Stored Data TB/Firm (>1K Employees US)
56
NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
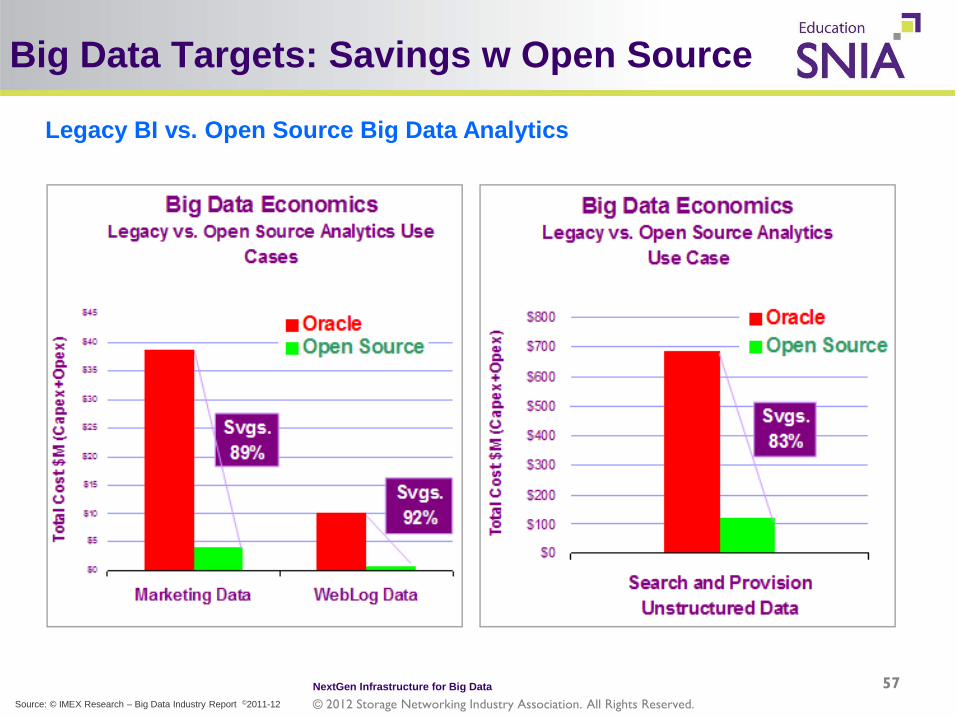
Big Data Targets: Savings w Open Source
Legacy BI vs. Open Source Big Data Analytics
57

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
Rise of Big Data Adoption
58

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
59
Key Takeaways
Big Data creating paradigm shift in IT Industry Leverage the opportunity to optimize your computing infrastructure with Big Data Infrastructure after making a due diligence in selection of vendors/products, industry testing and interoperability. Apply best storage technologies listed in this presentation and elsewhere
Optimize Big Data Analytics for Query Response Time vs. # of Users Improving Query Response time for a given number of users (IOPs) or Serving more users (IOPS) for a given query response time
Select Automated Storage Management Software Data Forensics and Tiered Placement
• Every workload has unique I/O access signature • Historical performance data for a LUN can identify performance skews & hot data regions by
LBAs.Non-disruptively migrate hot data using auto-tiering Software Optimize Infrastructure to meet needs of Applications/SLA • Performance Economics/Benefits • Typically 4-8% of data becomes a candidate and when migrated for higher performance
tiering can provide response time reduction of ~65% at peak loads. Many industry Verticals and Applications will benefit using Big Data
Source: IMEX Research SSD Industry Report ©2011

NextGen Infrastructure for Big Data © 2012 Storage Networking Industry Association. All Rights Reserved. Source: © IMEX Research – Big Data Industry Report ©2011-12
60 60
Q&A / Feedback
Many thanks to the following individuals for their contributions to this tutorial.
Source: IMEX Research
Joseph White Anil Vasudeva
Send any questions or comments on this presentation to SNIA: [email protected]
Top Related