







Languages
Pages
Legal


Multiple Multiple Sequence Sequence
Alignment (MSA)Alignment (MSA)andand
Phylogeny Phylogeny

MSA input: multiple sequence MSA input: multiple sequence Fasta fileFasta file
>gi|10835167|ref|NP_000607.1| CD4 antigen precursor [Homo sapiens] >gi|10835167|ref|NP_000607.1| CD4 antigen precursor [Homo sapiens] MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQIKILGNQGSFLT MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQIKILGNQGSFLT KGPSKLNDRADSRRSLWDQGNFPLIIKNLKIEDSDTYICEVEDQKEEVQLLVFGLTANSDTHLLQGQSLT KGPSKLNDRADSRRSLWDQGNFPLIIKNLKIEDSDTYICEVEDQKEEVQLLVFGLTANSDTHLLQGQSLT LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV RCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI RCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI
>gi|57113961|ref|NP_001009043.1| CD4 antigen [Pan troglodytes] >gi|57113961|ref|NP_001009043.1| CD4 antigen [Pan troglodytes] MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQTKILGNQGSFLT MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQTKILGNQGSFLT KGPSKLNDRVDSRRSLWDQGNFTLIIKNLKIEDSDTYICEVGDQKEEVQLLVFGLTANSDTHLLQGQSLT KGPSKLNDRVDSRRSLWDQGNFTLIIKNLKIEDSDTYICEVGDQKEEVQLLVFGLTANSDTHLLQGQSLT LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV RCRHRRRQAQRMSQIKRLLSEKKTCQCPHRFQKTCSPI RCRHRRRQAQRMSQIKRLLSEKKTCQCPHRFQKTCSPI
>gi|50054438|ref|NP_001001908.1| CD4 antigen [Sus scrofa] >gi|50054438|ref|NP_001001908.1| CD4 antigen [Sus scrofa] MDPGTSLRHLFLVLQLAMLPAASGTQEKYLVLGKAGDLAELPCHSSQKKNLPFNWKNSNQTKILGGHGSF MDPGTSLRHLFLVLQLAMLPAASGTQEKYLVLGKAGDLAELPCHSSQKKNLPFNWKNSNQTKILGGHGSF WHTASVTELTSRLDSKKNMWDHGSFPLIIKNLEVTDSGIYICEVEDKRIEVQLLVFRLTASVTRVLLGQS WHTASVTELTSRLDSKKNMWDHGSFPLIIKNLEVTDSGIYICEVEDKRIEVQLLVFRLTASVTRVLLGQS LTLTLEGPSGSHPTVQWKGPGNKSKNDVKSLLLPQVGLEDSGLWTCTVSQDQKTLVFRSNIFVLAFQKVP LTLTLEGPSGSHPTVQWKGPGNKSKNDVKSLLLPQVGLEDSGLWTCTVSQDQKTLVFRSNIFVLAFQKVP STVYVKEGDQVALSFPLTFEAESLSGELMWRQTKGASSPQSWITFSLKDRKVTVQKSLQNLKLRMAEKLP STVYVKEGDQVALSFPLTFEAESLSGELMWRQTKGASSPQSWITFSLKDRKVTVQKSLQNLKLRMAEKLP LQITLLQALPQYAGSGNLTLVLPEGRLHREVNLVVMRATQSKNEVTCEVLGPTPPKVVLSLKLGNQSMKV LQITLLQALPQYAGSGNLTLVLPEGRLHREVNLVVMRATQSKNEVTCEVLGPTPPKVVLSLKLGNQSMKV SDQQKLVTVLDPEAGMWRCLLRDKDKVLLESQVEVLPTAFTRAWPELLASVIGGIIGLLFLAGFCIACVK SDQQKLVTVLDPEAGMWRCLLRDKDKVLLESQVEVLPTAFTRAWPELLASVIGGIIGLLFLAGFCIACVK CWHRRRRAERMSQIKRLLSEKKTCQCAHRQQKNYSLT CWHRRRRAERMSQIKRLLSEKKTCQCAHRQQKNYSLT
>gi|6978631|ref|NP_036837.1| Cd4 molecule [Rattus norvegicus] >gi|6978631|ref|NP_036837.1| Cd4 molecule [Rattus norvegicus] MCRGFSFRHLLPLLLLQLSKLLVVTQGKTVVLGKEGGSAELPCESTSRRSASFAWKSSDQKTILGYKNKL MCRGFSFRHLLPLLLLQLSKLLVVTQGKTVVLGKEGGSAELPCESTSRRSASFAWKSSDQKTILGYKNKL LIKGSLELYSRFDSRKNAWERGSFPLIINKLRMEDSQTYVCELENKKEEVELWVFRVTFNPGTRLLQGQS LIKGSLELYSRFDSRKNAWERGSFPLIINKLRMEDSQTYVCELENKKEEVELWVFRVTFNPGTRLLQGQS LTLILDSNPKVSDPPIECKHKSSNIVKDSKAFSTHSLRIQDSGIWNCTVTLNQKKHSFDMKLSVLGFAST LTLILDSNPKVSDPPIECKHKSSNIVKDSKAFSTHSLRIQDSGIWNCTVTLNQKKHSFDMKLSVLGFAST SITAYKSEGESAEFSFPLNLGEESLQGELRWKAEKAPSSQSWITFSLKNQKVSVQKSTSNPKFQLSETLP SITAYKSEGESAEFSFPLNLGEESLQGELRWKAEKAPSSQSWITFSLKNQKVSVQKSTSNPKFQLSETLP LTLQIPQVSLQFAGSGNLTLTLDRGILYQEVNLVVMKVTQPDSNTLTCEVMGPTSPKMRLILKQENQEAR LTLQIPQVSLQFAGSGNLTLTLDRGILYQEVNLVVMKVTQPDSNTLTCEVMGPTSPKMRLILKQENQEAR VSRQEKVIQVQAPEAGVWQCLLSEGEEVKMDSKIQVLSKGLNQTMFLAVVLGSAFSFLVFTGLCILFCVR VSRQEKVIQVQAPEAGVWQCLLSEGEEVKMDSKIQVLSKGLNQTMFLAVVLGSAFSFLVFTGLCILFCVR CRHQQRQAARMSQIKRLLSEKKTCQCSHRMQKSHNLI CRHQQRQAARMSQIKRLLSEKKTCQCSHRMQKSHNLI

Clustal XClustal X
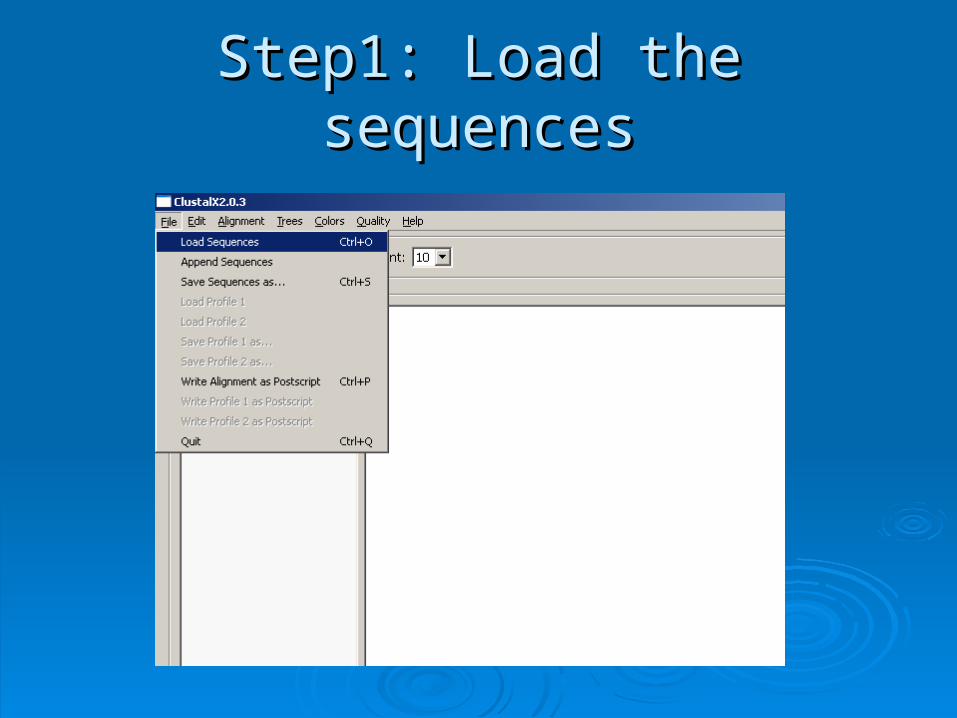
Step1: Load the sequencesStep1: Load the sequences
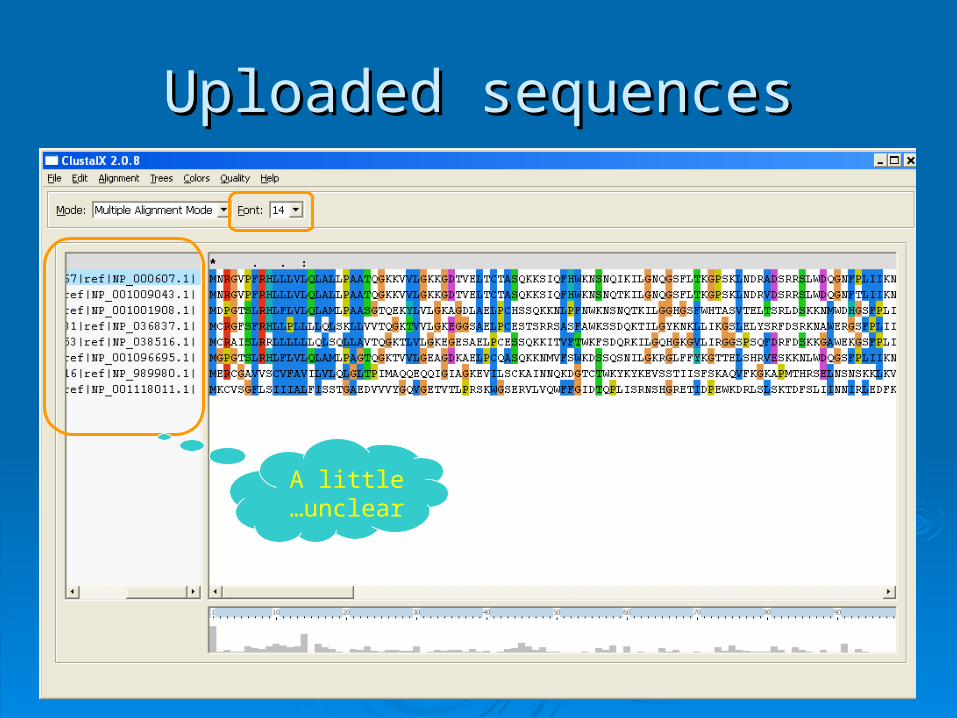
Uploaded sequencesUploaded sequences
A little unclear…

Edit Fasta headersEdit Fasta headers…… MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQIKILGNQGSFLT MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQIKILGNQGSFLT KGPSKLNDRADSRRSLWDQGNFPLIIKNLKIEDSDTYICEVEDQKEEVQLLVFGLTANSDTHLLQGQSLT KGPSKLNDRADSRRSLWDQGNFPLIIKNLKIEDSDTYICEVEDQKEEVQLLVFGLTANSDTHLLQGQSLT LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV RCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI RCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI
MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQTKILGNQGSFLT MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQTKILGNQGSFLT KGPSKLNDRVDSRRSLWDQGNFTLIIKNLKIEDSDTYICEVGDQKEEVQLLVFGLTANSDTHLLQGQSLT KGPSKLNDRVDSRRSLWDQGNFTLIIKNLKIEDSDTYICEVGDQKEEVQLLVFGLTANSDTHLLQGQSLT LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV RCRHRRRQAQRMSQIKRLLSEKKTCQCPHRFQKTCSPI RCRHRRRQAQRMSQIKRLLSEKKTCQCPHRFQKTCSPI
MDPGTSLRHLFLVLQLAMLPAASGTQEKYLVLGKAGDLAELPCHSSQKKNLPFNWKNSNQTKILGGHGSF MDPGTSLRHLFLVLQLAMLPAASGTQEKYLVLGKAGDLAELPCHSSQKKNLPFNWKNSNQTKILGGHGSF WHTASVTELTSRLDSKKNMWDHGSFPLIIKNLEVTDSGIYICEVEDKRIEVQLLVFRLTASVTRVLLGQS WHTASVTELTSRLDSKKNMWDHGSFPLIIKNLEVTDSGIYICEVEDKRIEVQLLVFRLTASVTRVLLGQS LTLTLEGPSGSHPTVQWKGPGNKSKNDVKSLLLPQVGLEDSGLWTCTVSQDQKTLVFRSNIFVLAFQKVP LTLTLEGPSGSHPTVQWKGPGNKSKNDVKSLLLPQVGLEDSGLWTCTVSQDQKTLVFRSNIFVLAFQKVP STVYVKEGDQVALSFPLTFEAESLSGELMWRQTKGASSPQSWITFSLKDRKVTVQKSLQNLKLRMAEKLP STVYVKEGDQVALSFPLTFEAESLSGELMWRQTKGASSPQSWITFSLKDRKVTVQKSLQNLKLRMAEKLP LQITLLQALPQYAGSGNLTLVLPEGRLHREVNLVVMRATQSKNEVTCEVLGPTPPKVVLSLKLGNQSMKV LQITLLQALPQYAGSGNLTLVLPEGRLHREVNLVVMRATQSKNEVTCEVLGPTPPKVVLSLKLGNQSMKV SDQQKLVTVLDPEAGMWRCLLRDKDKVLLESQVEVLPTAFTRAWPELLASVIGGIIGLLFLAGFCIACVK SDQQKLVTVLDPEAGMWRCLLRDKDKVLLESQVEVLPTAFTRAWPELLASVIGGIIGLLFLAGFCIACVK CWHRRRRAERMSQIKRLLSEKKTCQCAHRQQKNYSLT CWHRRRRAERMSQIKRLLSEKKTCQCAHRQQKNYSLT
MCRGFSFRHLLPLLLLQLSKLLVVTQGKTVVLGKEGGSAELPCESTSRRSASFAWKSSDQKTILGYKNKL MCRGFSFRHLLPLLLLQLSKLLVVTQGKTVVLGKEGGSAELPCESTSRRSASFAWKSSDQKTILGYKNKL LIKGSLELYSRFDSRKNAWERGSFPLIINKLRMEDSQTYVCELENKKEEVELWVFRVTFNPGTRLLQGQS LIKGSLELYSRFDSRKNAWERGSFPLIINKLRMEDSQTYVCELENKKEEVELWVFRVTFNPGTRLLQGQS LTLILDSNPKVSDPPIECKHKSSNIVKDSKAFSTHSLRIQDSGIWNCTVTLNQKKHSFDMKLSVLGFAST LTLILDSNPKVSDPPIECKHKSSNIVKDSKAFSTHSLRIQDSGIWNCTVTLNQKKHSFDMKLSVLGFAST SITAYKSEGESAEFSFPLNLGEESLQGELRWKAEKAPSSQSWITFSLKNQKVSVQKSTSNPKFQLSETLP SITAYKSEGESAEFSFPLNLGEESLQGELRWKAEKAPSSQSWITFSLKNQKVSVQKSTSNPKFQLSETLP LTLQIPQVSLQFAGSGNLTLTLDRGILYQEVNLVVMKVTQPDSNTLTCEVMGPTSPKMRLILKQENQEAR LTLQIPQVSLQFAGSGNLTLTLDRGILYQEVNLVVMKVTQPDSNTLTCEVMGPTSPKMRLILKQENQEAR VSRQEKVIQVQAPEAGVWQCLLSEGEEVKMDSKIQVLSKGLNQTMFLAVVLGSAFSFLVFTGLCILFCVR VSRQEKVIQVQAPEAGVWQCLLSEGEEVKMDSKIQVLSKGLNQTMFLAVVLGSAFSFLVFTGLCILFCVR CRHQQRQAARMSQIKRLLSEKKTCQCSHRMQKSHNLI CRHQQRQAARMSQIKRLLSEKKTCQCSHRMQKSHNLI
>Homo_sapiens_CD4
>Pan_troglodytes_CD4
>Sus_scrofa_CD4
>Rattus_norvegicus_CD4
>gi|10835167|ref|NP_000607.1| CD4 antigen precursor [Homo sapiens]
>gi|57113961|ref|NP_001009043.1| CD4 antigen [Pan troglodytes]
>gi|50054438|ref|NP_001001908.1| CD4 antigen [Sus scrofa]
>gi|6978631|ref|NP_036837.1| Cd4 molecule [Rattus norvegicus]
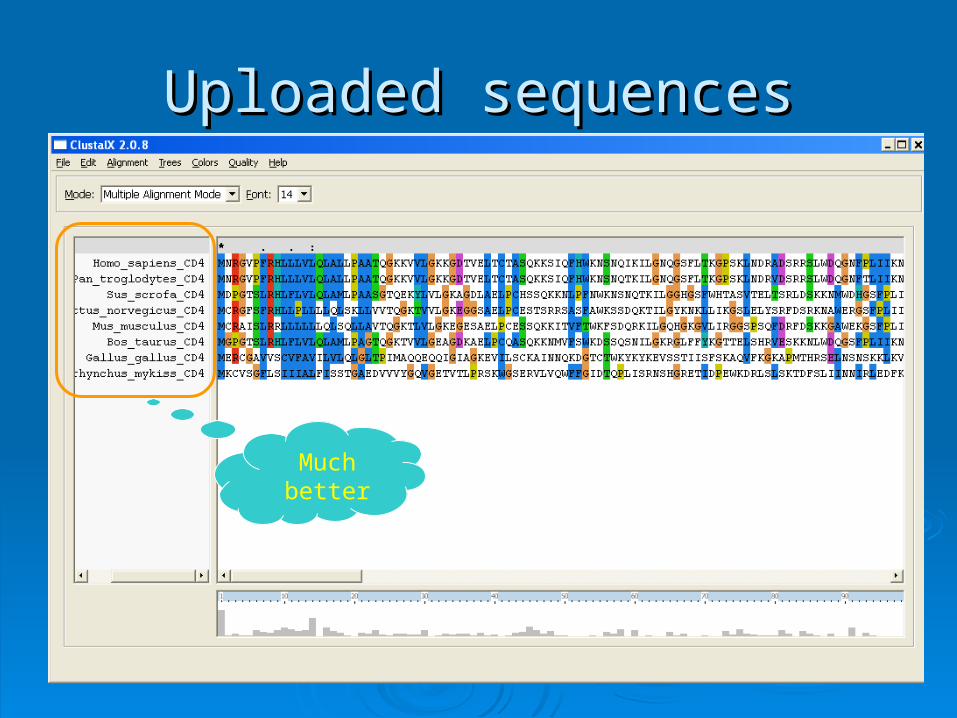
Uploaded sequencesUploaded sequences
Much better
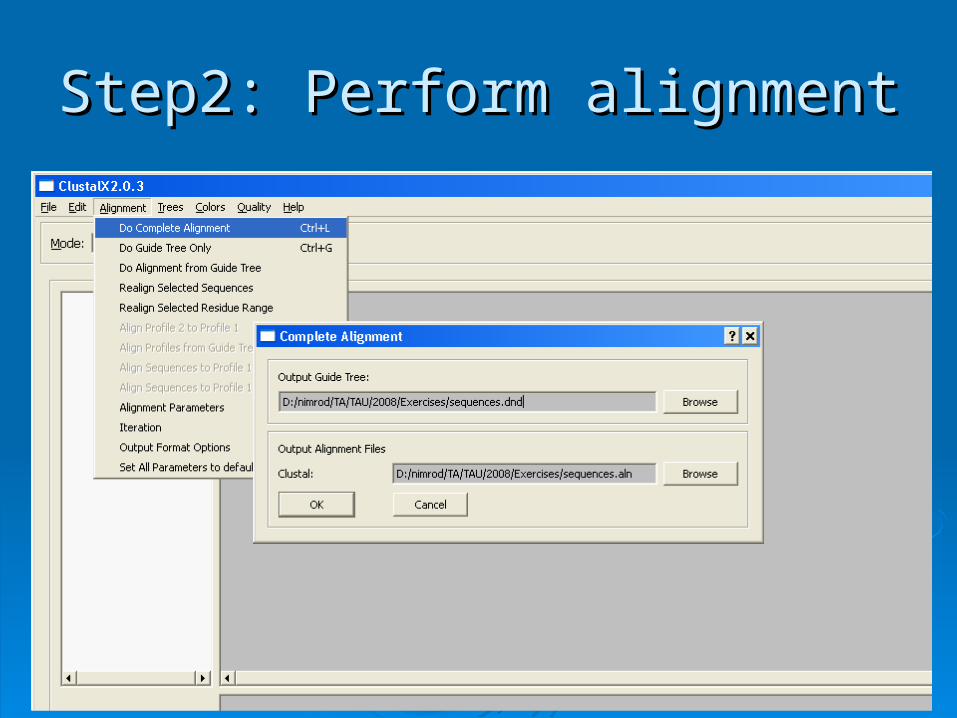
Step2: Perform alignmentStep2: Perform alignment
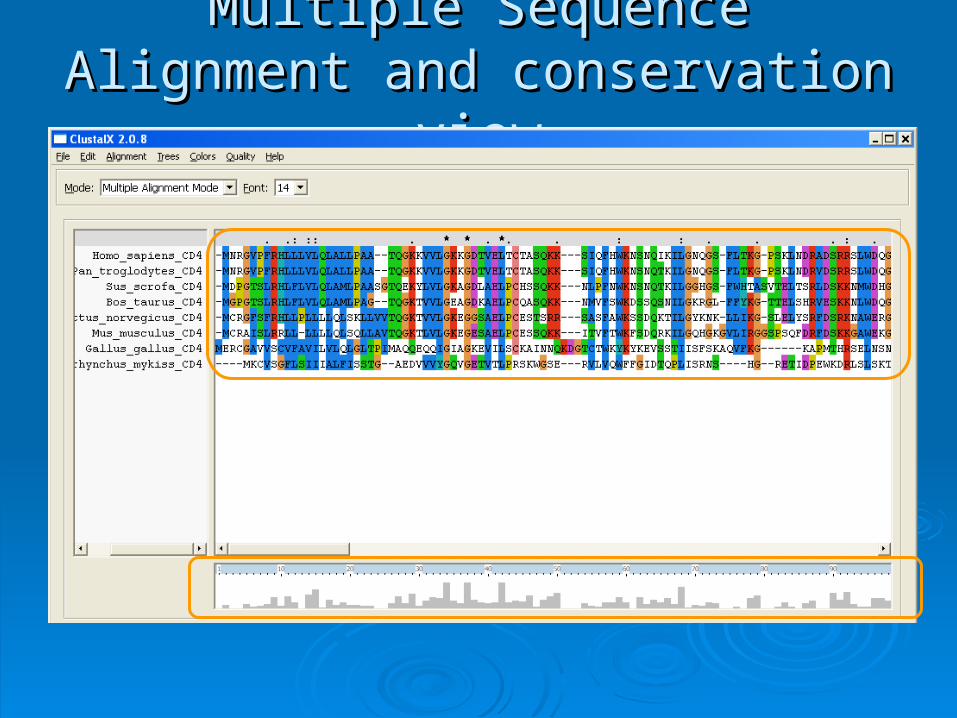
Multiple Sequence Alignment and Multiple Sequence Alignment and conservation viewconservation view
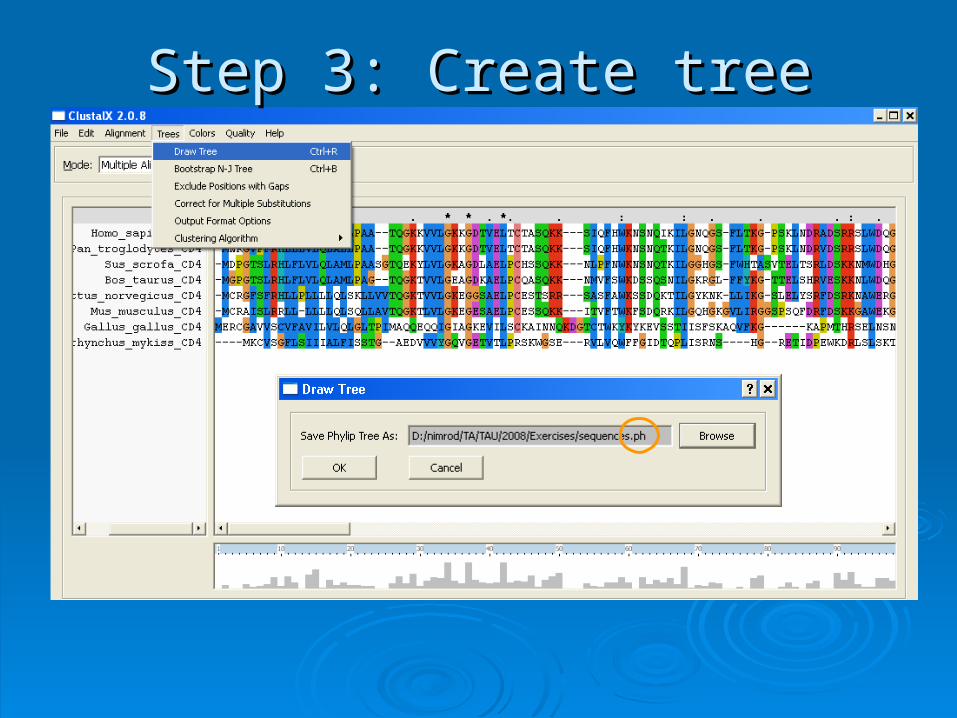
Step 3: Create treeStep 3: Create tree

The Newick tree format is used to represent trees as strings
CA D
In Newick format: ((A,C),(B,D));
B
• Each pair of parenthesis () encloses a clade in the tree • A comma “,” separates the members of the corresponding clade• A semicolon “;” is always the last character

Step 4: View tree with NJPlotStep 4: View tree with NJPlot
Note :unrooted tree
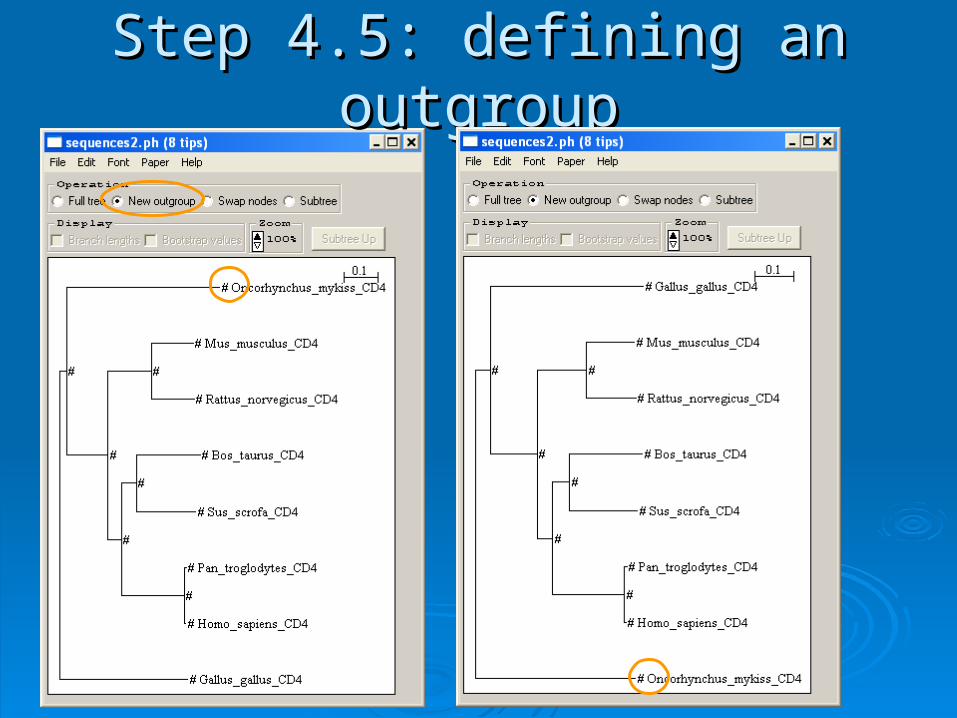
Step 4.5: defining an outgroupStep 4.5: defining an outgroup
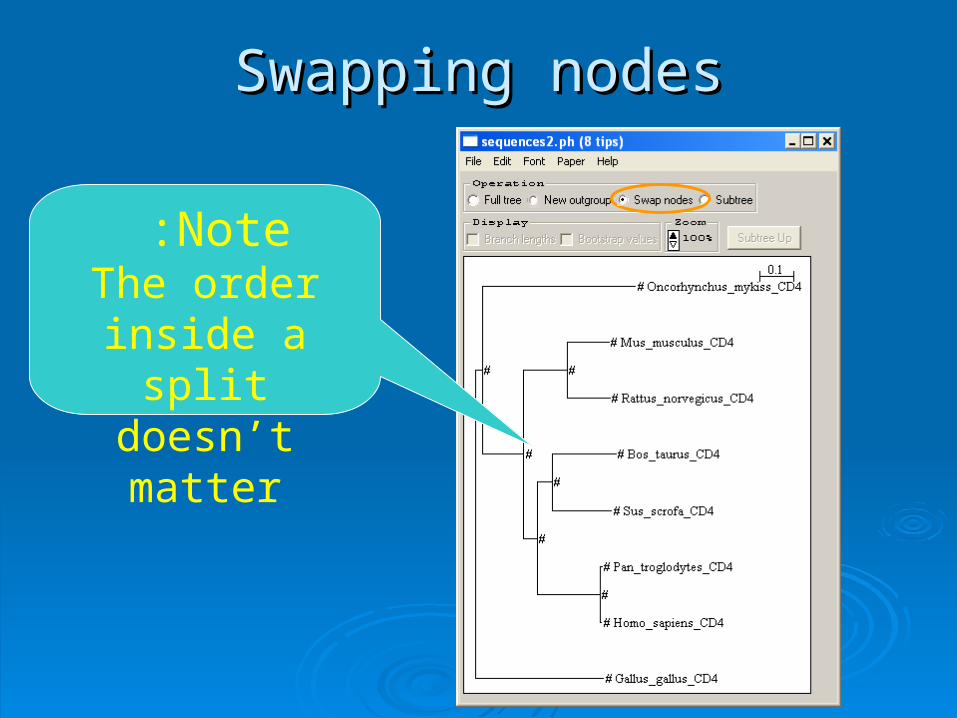
Note :The order
inside a split doesn’t matter
Swapping nodesSwapping nodes

Bootstrap

Bootstrap
A. Resample (100-1000 time).
12345 1001 : ATCTG…A 2 : ATCTG…C3 : ACTTA…C 4 : ACCTA…T
12345 1001 : AATTT…T2 : AATTT…G3 : AACTT…T4 : AACTT…T 11244 x
12345 1001 : TTTAT…T2 : TAACC…G3 : TAACC…T4 : TGGGA…T 4 7789…x
12345 1001 : AGGTA…T2 : AGGAC…G3 : AAAAC…A4 : AAAGG…C 15578… x
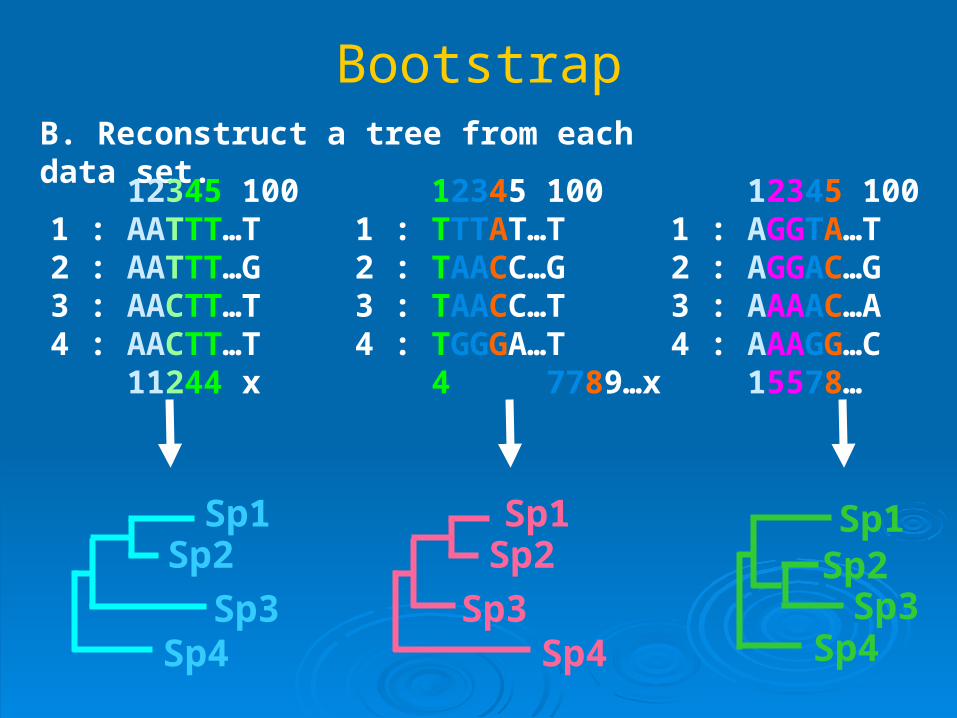
BootstrapB. Reconstruct a tree from each data set.
12345 1001 : AATTT…T2 : AATTT…G3 : AACTT…T4 : AACTT…T 11244 x
12345 1001 : TTTAT…T2 : TAACC…G3 : TAACC…T4 : TGGGA…T 4 7789…x
12345 1001 : AGGTA…T2 : AGGAC…G3 : AAAAC…A4 : AAAGG…C 15578… x
Sp1Sp2
Sp3Sp4
Sp1Sp2
Sp3Sp4
Sp1Sp2
Sp3Sp4
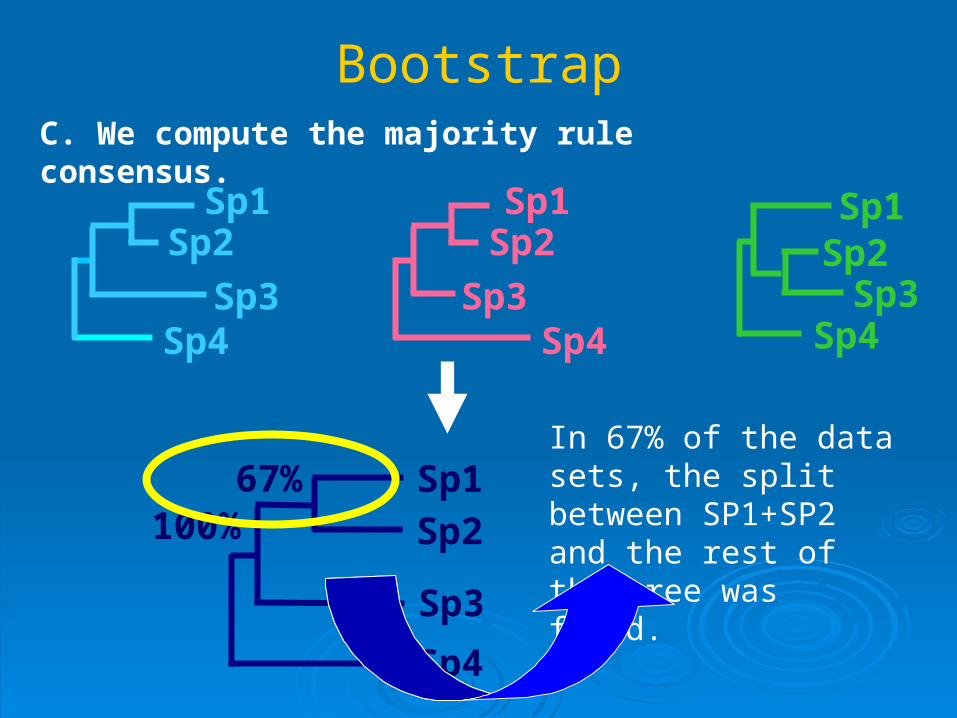
C. We compute the majority rule consensus.
Sp1Sp2
Sp3Sp4
Sp1Sp2
Sp3Sp4
Sp1Sp2
Sp3Sp4
Sp1Sp2
Sp3
Sp4
67%100%
In 67% of the data sets, the split between SP1+SP2 and the rest of the tree was found.
Bootstrap
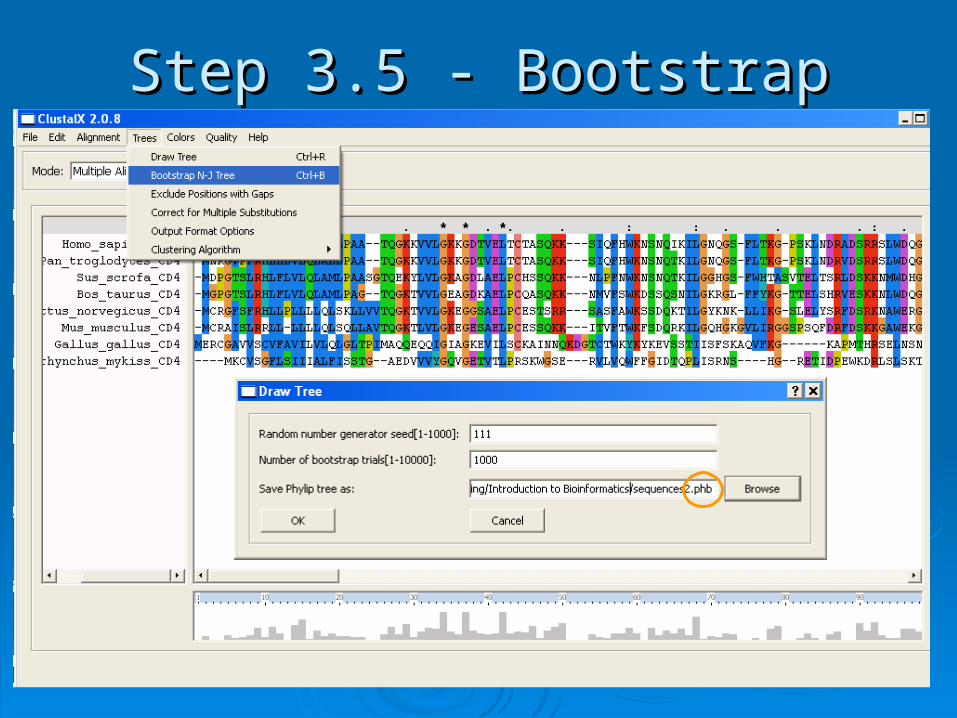
Step 3.5 - BootstrapStep 3.5 - Bootstrap
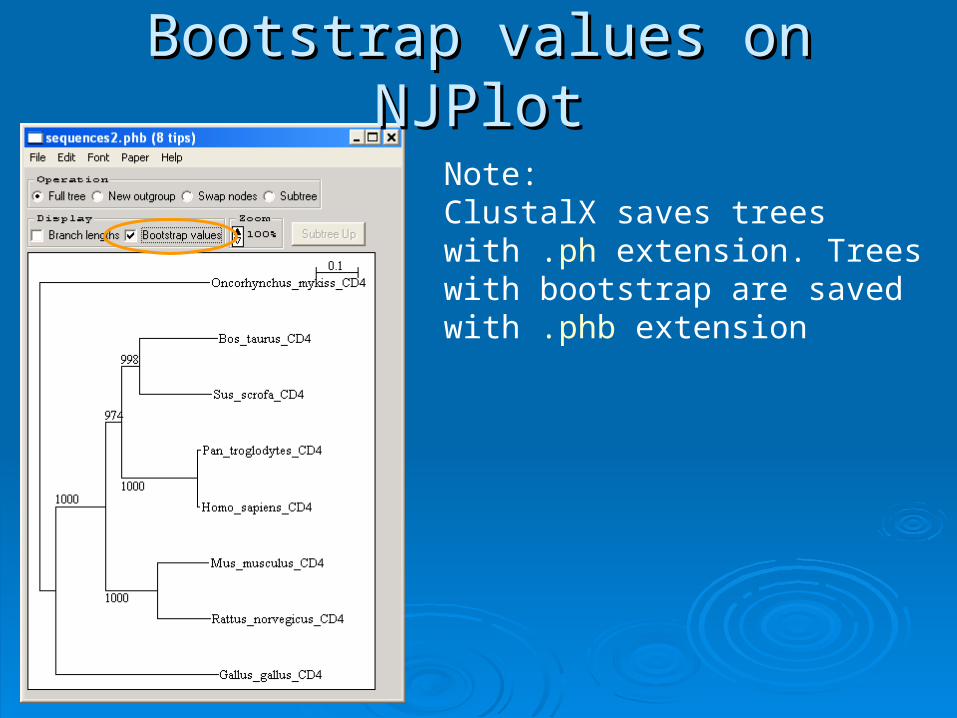
Bootstrap values on NJPlotBootstrap values on NJPlot
Note:ClustalX saves trees with .ph extension. Trees with bootstrap are saved with .phb extension

Detecting selection Detecting selection forces using forces using phlogeny phlogeny
(ConSeq, ConSurf, (ConSeq, ConSurf, Selecton)Selecton)

““ImportantImportant”” sites evolvesites evolve
slowerslowerthan “unimportantunimportant” onesones.

Conservation = functional/structural Conservation = functional/structural importanceimportance

Use Phylogenetic informationUse Phylogenetic information 11223344556677
HumanHumanDDMMAAAAHHAAMM
ChimpChimpDDEEAAAAGGGGCC
CowCowDDQQAAAAWWAAPP
FishFishDDLLAAAACCAALL
S. S. cerevisiaecerevisiae
DDDDGGAAFFAAAA
S. pombeS. pombeDDDDGGAALLGGEEAA
GG
AA
AA
AA
GG
AA
AA
AA
AA
GG
GG
http://http://conseqconseq.tau.ac.il.tau.ac.ilSite-specific rate computation toolSite-specific rate computation tool
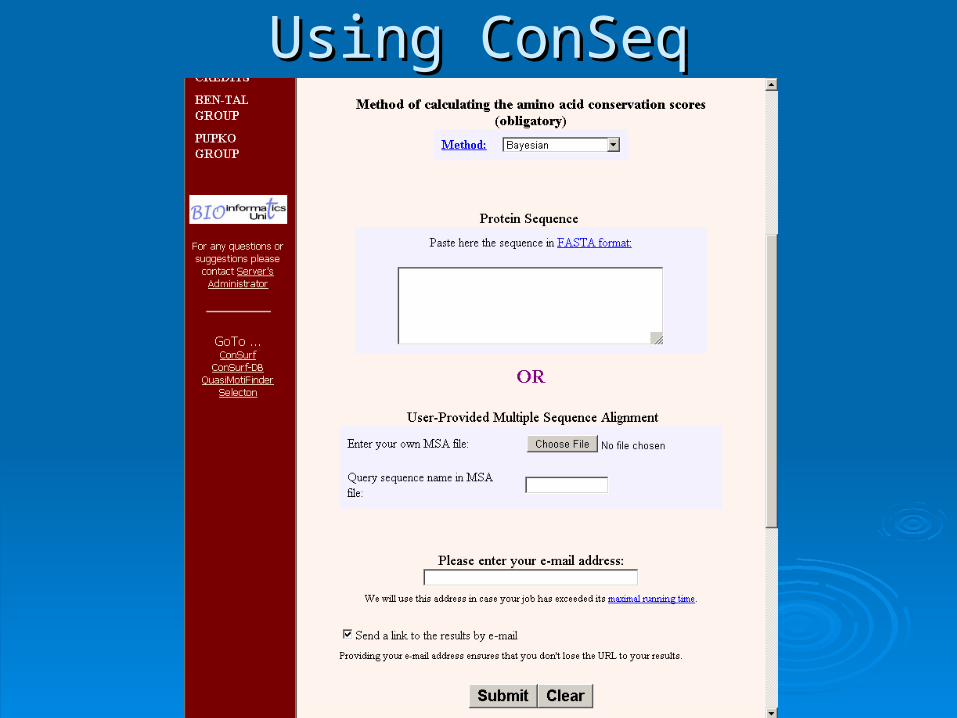
Using ConSeqUsing ConSeq
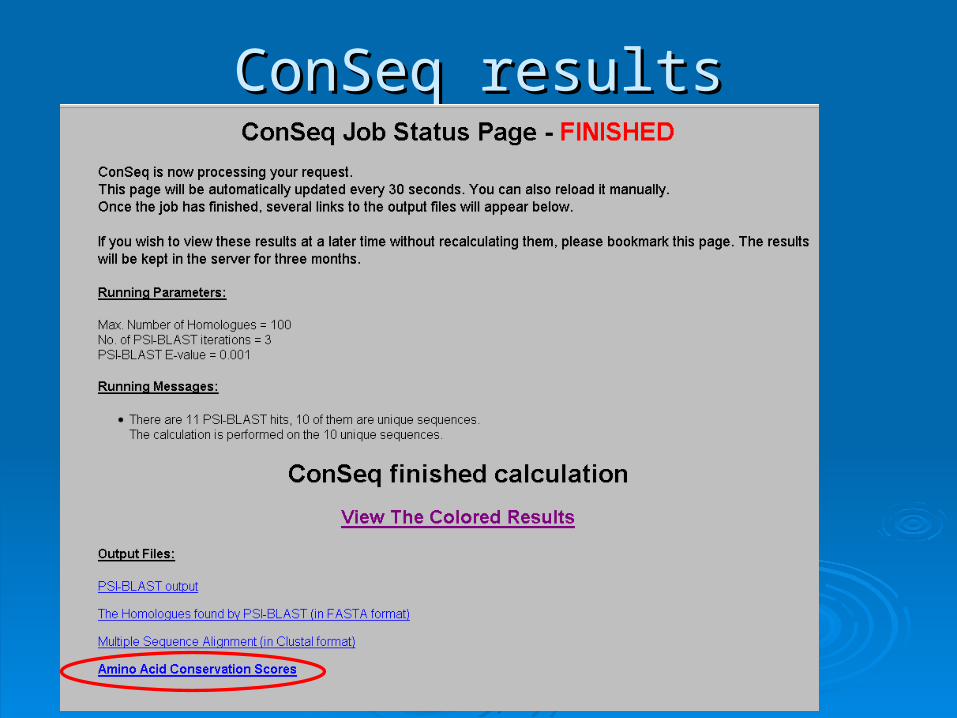
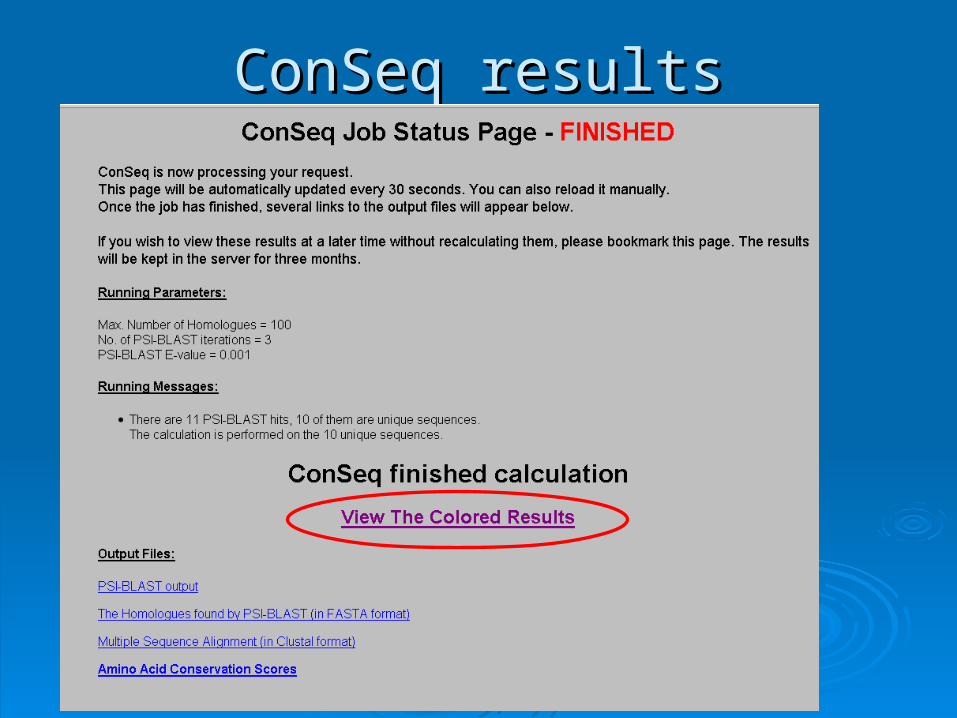
ConSeq resultsConSeq results
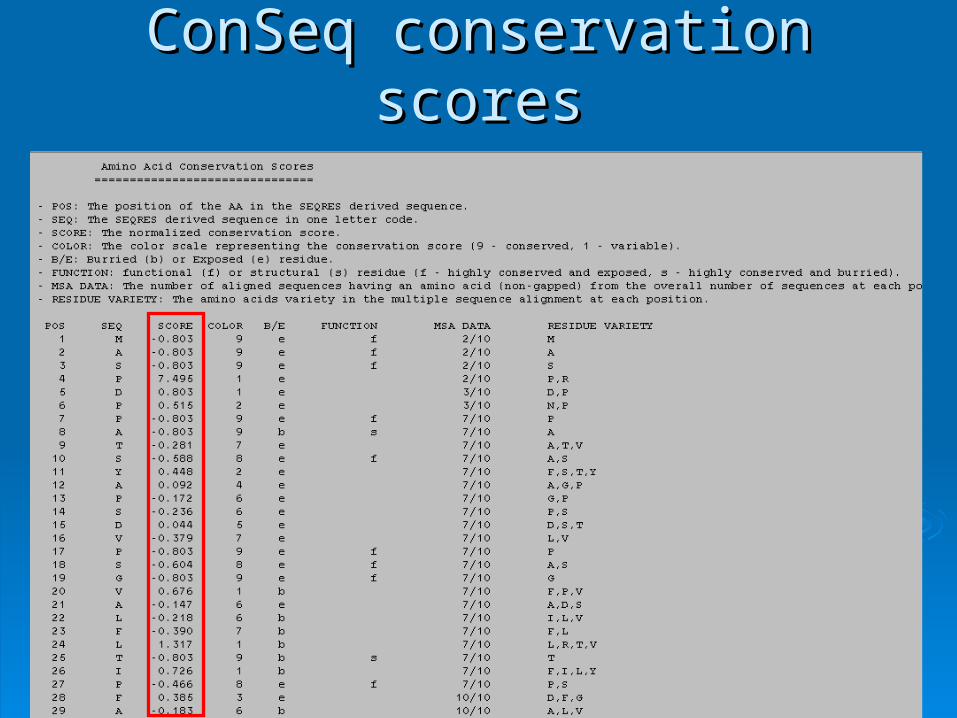
ConSeq conservation scoresConSeq conservation scores

Conservation scoresConservation scores:: The scores are standardized: the average score for all residues is The scores are standardized: the average score for all residues is
zero, and the standard deviation is one zero, and the standard deviation is one The lowest score represents the most conserved site in the protein The lowest score represents the most conserved site in the protein
negative values: slowly evolving (= low evolutionary rate), negative values: slowly evolving (= low evolutionary rate), conserved sitesconserved sites
The highest score represents the most variable site in the proteinThe highest score represents the most variable site in the protein positive values: rapidly evolving (= fast evolutionary rate), positive values: rapidly evolving (= fast evolutionary rate),
variable sitesvariable sites Scores are relative to the protein. Scores of different proteins Scores are relative to the protein. Scores of different proteins
are incomparable !!!are incomparable !!!
ConSeq resultsConSeq results

Color-coded resultsColor-coded results

Protein core: structurally constrained - usually conserved
Active site: functionally constrained - usually conserved
Surface loops: tolerant to mutations - usually variable
Hydrophobic core
Surface loops
Conservation in the structureConservation in the structure
Active site

Color-coded resultsColor-coded results
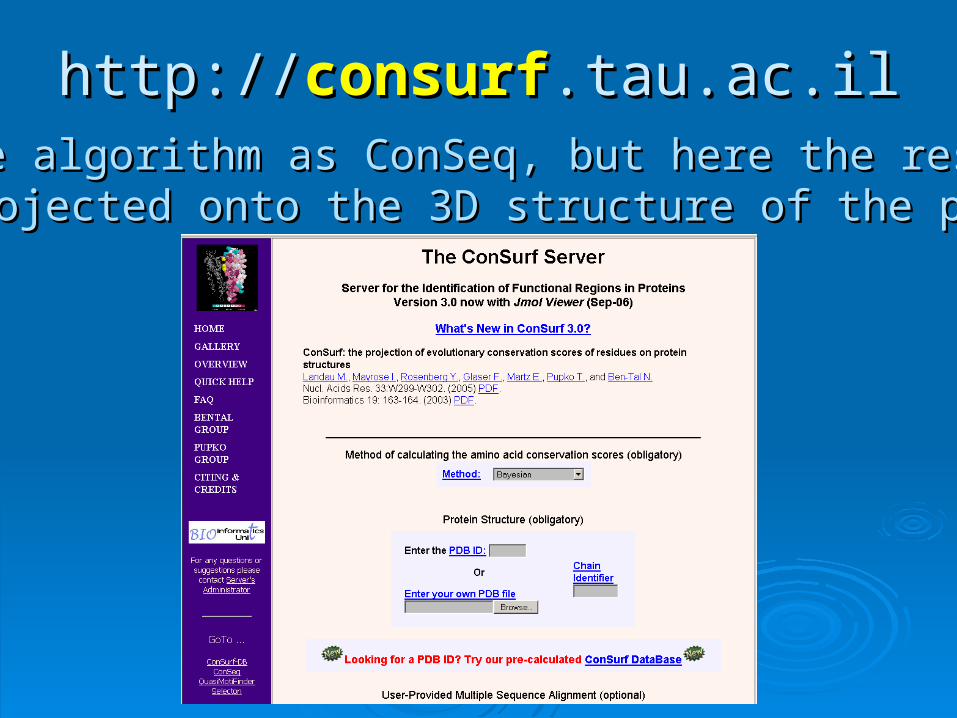
http://http://consurfconsurf.tau.ac.il.tau.ac.ilSame algorithm as ConSeq, but here the resultsSame algorithm as ConSeq, but here the results are projected onto the 3D structure of the proteinare projected onto the 3D structure of the protein
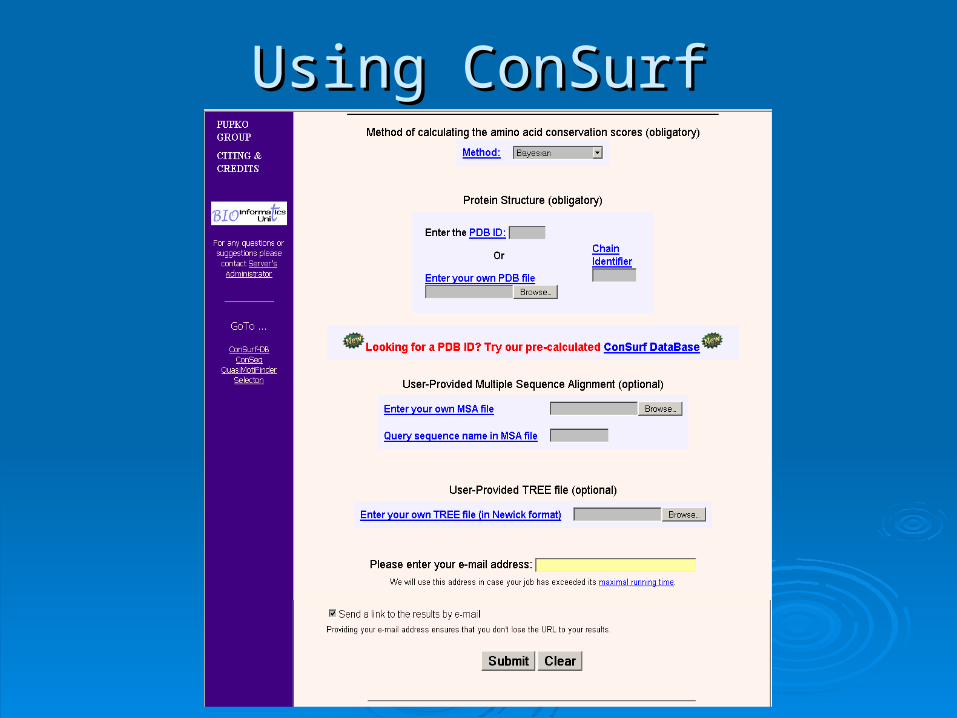
Using ConSurfUsing ConSurf
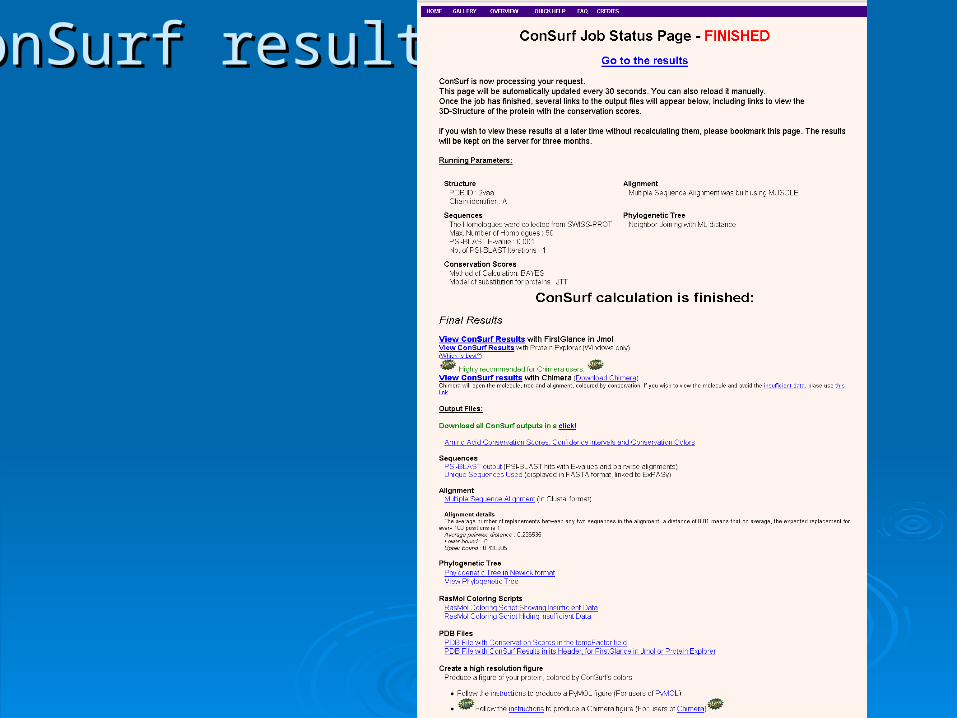
ConSurf resultsConSurf results
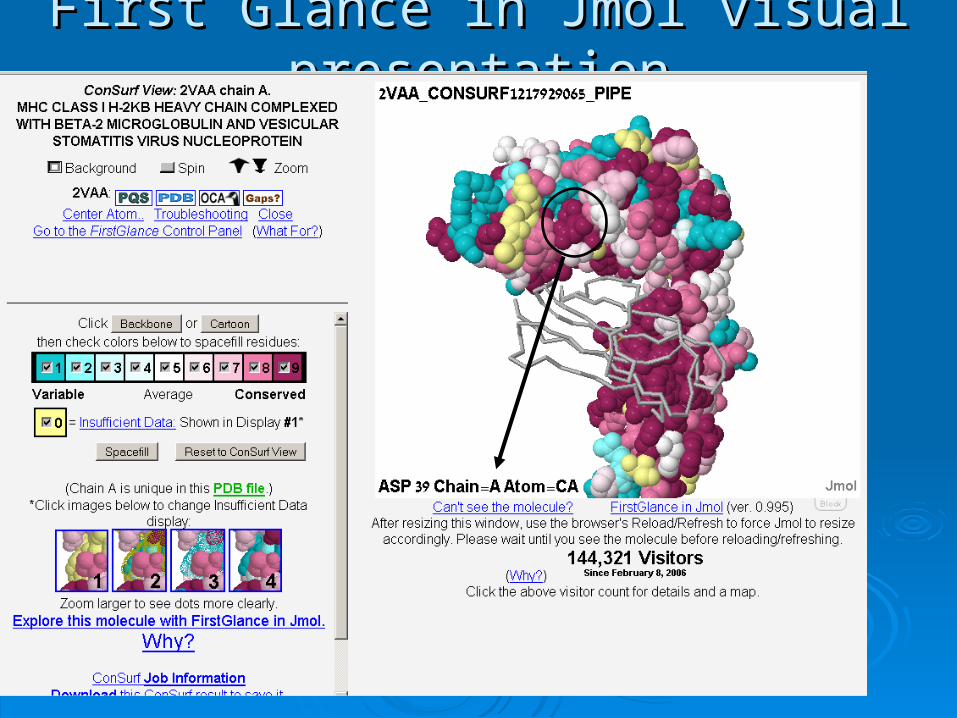
First Glance in Jmol visual presentationFirst Glance in Jmol visual presentation
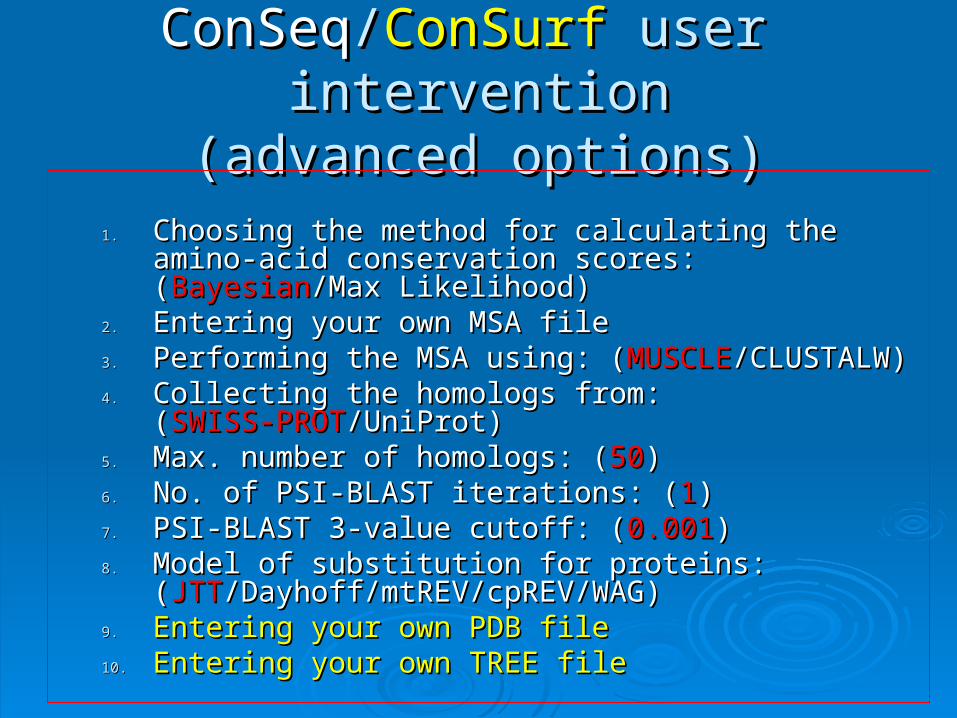
ConSeqConSeq//ConSurfConSurf user intervention user intervention(advanced options)(advanced options)
1.1. Choosing the method for calculating the amino-acid Choosing the method for calculating the amino-acid conservation scores: (conservation scores: (BayesianBayesian/Max Likelihood)/Max Likelihood)
2.2. Entering your own MSA fileEntering your own MSA file3.3. Performing the MSA using: (Performing the MSA using: (MUSCLEMUSCLE/CLUSTALW)/CLUSTALW)4.4. Collecting the homologs from: (Collecting the homologs from: (SWISS-PROTSWISS-PROT/UniProt)/UniProt)5.5. Max. number of homologs: (Max. number of homologs: (5050))6.6. No. of PSI-BLAST iterations: (No. of PSI-BLAST iterations: (11))7.7. PSI-BLAST 3-value cutoff: (PSI-BLAST 3-value cutoff: (0.0010.001))8.8. Model of substitution for proteins: Model of substitution for proteins:
((JTTJTT/Dayhoff/mtREV/cpREV/WAG)/Dayhoff/mtREV/cpREV/WAG)9.9. Entering your own PDB fileEntering your own PDB file10.10. Entering your own TREE fileEntering your own TREE file
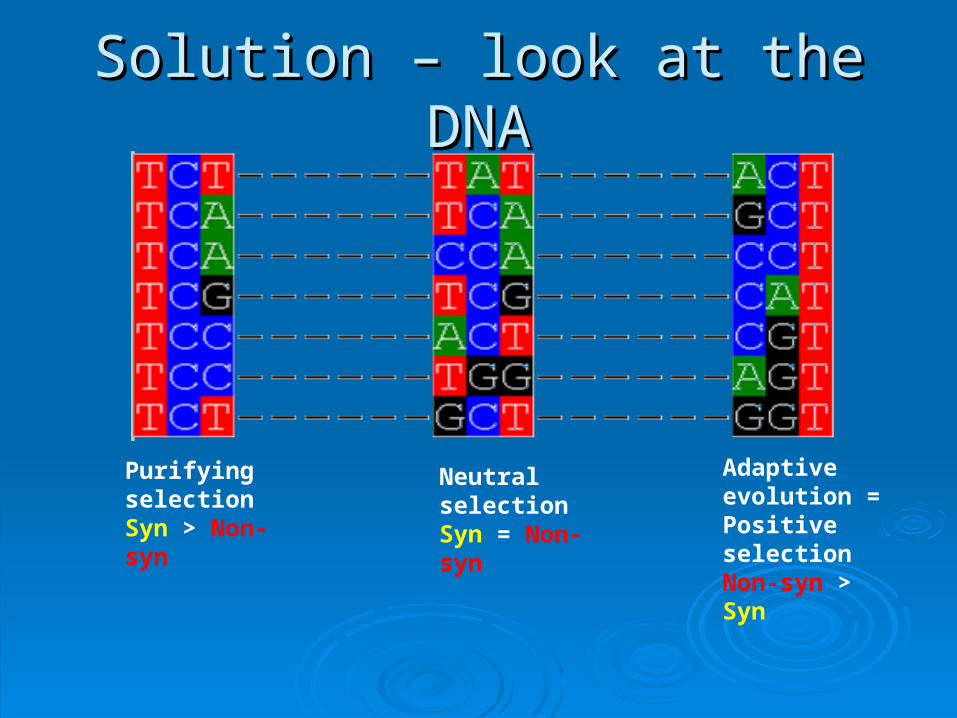
Solution – look at the DNASolution – look at the DNA
Purifying selectionSyn > Non-syn
Adaptive evolution = Positive selectionNon-syn > Syn
NeutralselectionSyn = Non-syn

Selection score Selection score ((Ka/KsKa/Ks) < 1) < 1 purifying selectionpurifying selection
Selection score Selection score ((Ka/KsKa/Ks) > 1) > 1 positive selectionpositive selection
Selection score Selection score ((Ka/KsKa/Ks) = 1) = 1 no selectionno selection
Ka/Ks also known as… Ka/Ks also known as… (or dn/ds, or (or dn/ds, or ωω))
Non-synonymous mutation rate
Synonymous mutation rate
http://selecton.tau.ac.il

Selecton inputSelecton input
The user must provide the sequences – no psi-blast option The user must provide the sequences – no psi-blast option Coding sequencesCoding sequences Only ORFOnly ORF No stop codonsNo stop codons If an MSA is provided it must be If an MSA is provided it must be codon alignedcodon aligned ((RevTransRevTrans))
Codon-level sequences !!!
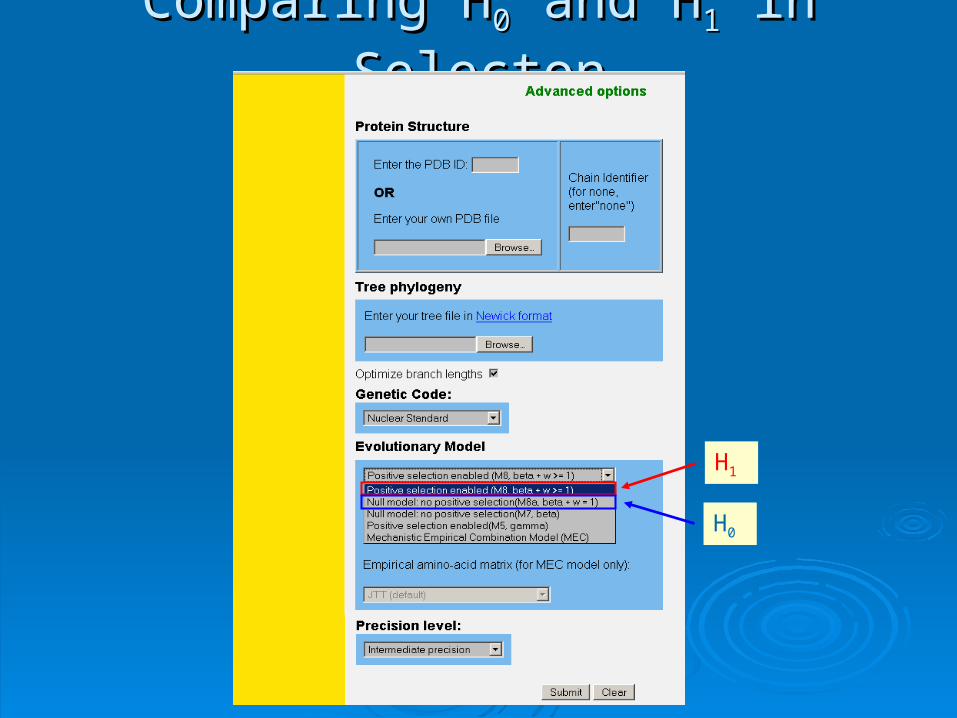
Comparing HComparing H00 and H and H11 in Selecton in Selecton
H0
H1
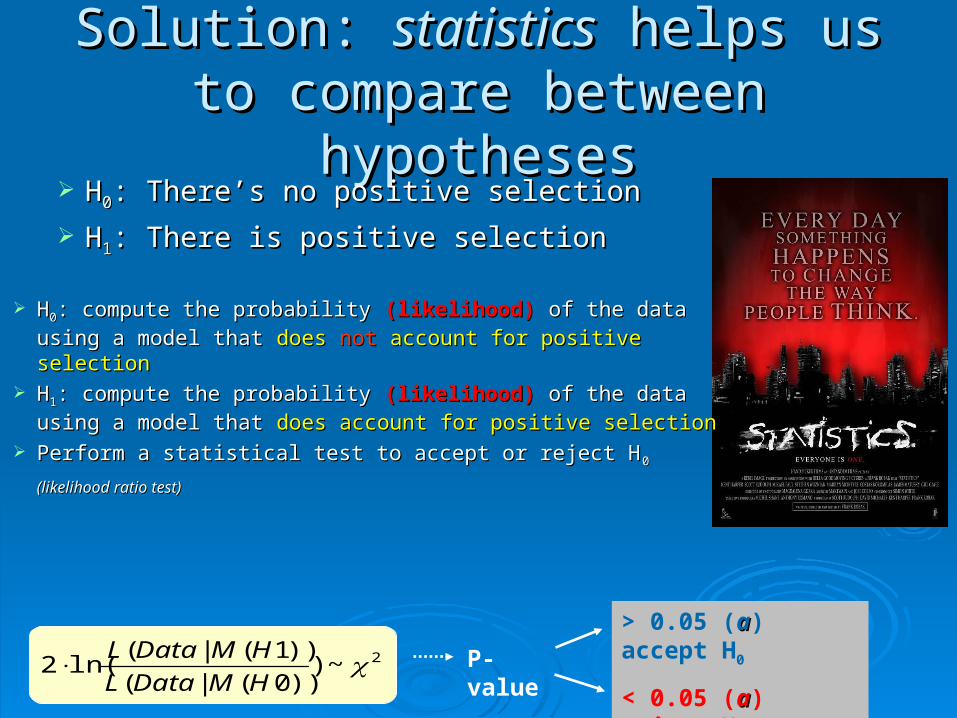
Solution: Solution: statisticsstatistics helps us to helps us to compare between hypothesescompare between hypotheses
HH00: There’s no positive selection: There’s no positive selection
HH11: There is positive selection: There is positive selection
2~)))0(|(
))1(|(ln(2
HMDataL
HMDataL
HH00: compute the probability: compute the probability (likelihood) (likelihood) of the data using of the data using
a model that a model that does does not not account for positive selectionaccount for positive selection HH11: compute the probability: compute the probability (likelihood) (likelihood) of the data using of the data using
a model that a model that does account for positive selectiondoes account for positive selection Perform a statistical test to accept or reject HPerform a statistical test to accept or reject H00
(likelihood ratio test)(likelihood ratio test)
P-value
> 0.05 (aa) accept H0
> 0.05 (aa) reject H0
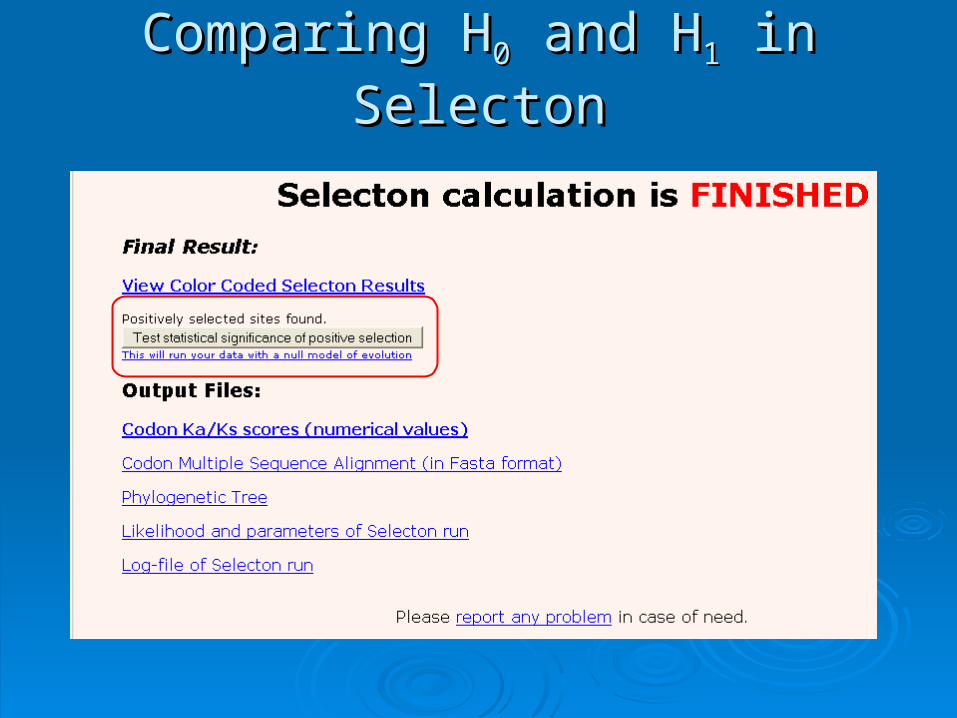
Comparing HComparing H00 and H and H11 in Selecton in Selecton
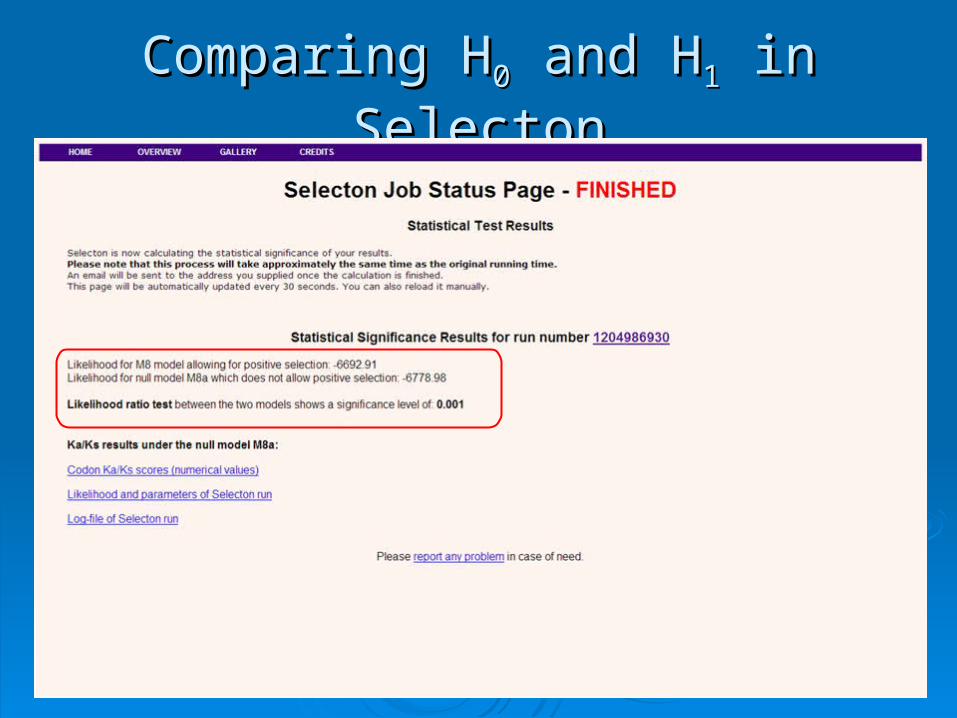
Comparing HComparing H00 and H and H11 in Selecton in Selecton
Selecton resultsSelecton results::
ResultsResults
Human rhesus swaps at sites 332, 335-340 confer human resistance to HIV and rhesus resistance to SIV
Top Related