







Languages
Pages
Legal


Multi-Agent Planning in Complex Uncertain
Environments
Daphne KollerStanford University
Joint work with:Carlos Guestrin (CMU)Ronald Parr (Duke)

©2004 – Carlos Guestrin, Daphne Koller
Collaborative Multiagent Planning
Search and rescue, firefighting Factory management Multi-robot tasks (Robosoccer) Network routing Air traffic control Computer game playing
Long-termgoals
Multiple agents
Coordinateddecisions
CollaborativeMultiagentPlanning

©2004 – Carlos Guestrin, Daphne Koller
Joint Planning Space
Joint action space: Each agent i takes action ai at each step
Joint action a= {a1,…, an} for all agents
Joint state space: Assignment x1,…,xn to some set of variables X1,…,Xn
Joint state x= {x1,…, xn} of entire system
Joint system: Payoffs and state dynamics depend on joint state and joint action
Cooperative agents: Want to maximize total payoff

©2004 – Carlos Guestrin, Daphne Koller
Exploiting Structure
Real-world problems have:
Hundreds of objects Googles of states
Real-world problems have structure!
Approach: Exploit structured representation to obtain efficient approximate solution

©2004 – Carlos Guestrin, Daphne Koller
Outline
Action Coordination Factored Value Functions Coordination Graphs Context-Specific Coordination
Joint Planning Multi-Agent Markov Decision Processes Efficient Linear Programming Solution Decentralized Market-Based Solution
Generalizing to New Environments Relational MDPs Generalizing Value Functions

©2004 – Carlos Guestrin, Daphne Koller
One-Shot Optimization Task
Q-function Q(x,a) encodes agents’ payoff for joint action a in joint state x
Agents’ task: To compute
#actions is exponential Complete state observability Full agent communication
)a,x(maxarga
Q

©2004 – Carlos Guestrin, Daphne Koller
Factored Payoff Function
Approximate Q function as sum of Q sub-functions
Each sub-function depends on local part of system Two interacting agents Agent and important resource Two inter-dependent pieces of machinery
[K. & Parr ’99,’00][Guestrin, K., Parr ’01]
Q(A1,…,A4, X1,…,X4)¼Q2(A1, A2, X1,X2)Q1(A1, A4,
X1,X4) Q3(A2, A3, X2,X3)+
++
Q4(A3, A4, X3,X4)

©2004 – Carlos Guestrin, Daphne Koller
Distributed Q Function
Q(A1,…,A4, X1,…,X4)
2
3
4
1
Q4
¼Q2(A1, A2, X1,X2)
Q4(A3, A4, X3,X4)
Q1(A1, A4,
X1,X4) Q3(A2, A3, X2,X3)+
++
[Guestrin, K., Parr ’01]
Q sub-functions assigned to relevant agents
©2004 – Carlos Guestrin, Daphne Koller
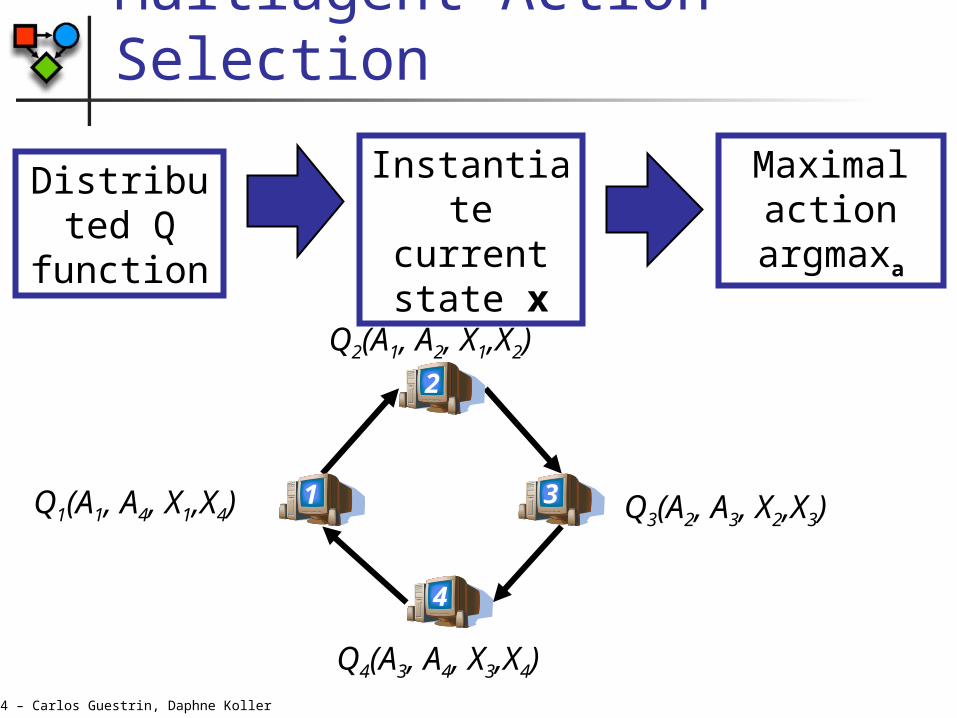
Multiagent Action Selection
2
3
4
1
Q2(A1, A2, X1,X2)
Q4(A3, A4, X3,X4)
Q1(A1, A4,
X1,X4)
Q3(A2, A3, X2,X3)
Distributed Q
function
Instantiate current state x
Maximal action
argmaxa
©2004 – Carlos Guestrin, Daphne Koller
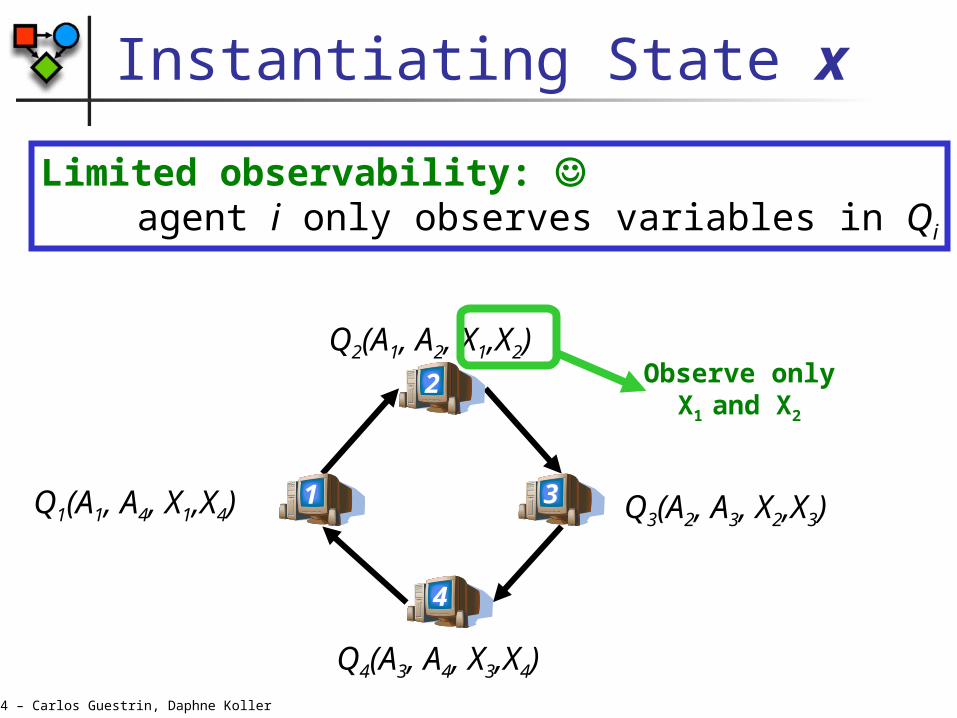
Instantiating State x
2
3
4
1
Q2(A1, A2, X1,X2)
Q4(A3, A4, X3,X4)
Q1(A1, A4,
X1,X4)
Q3(A2, A3, X2,X3)
Observe only
X1 and X2
Limited observability: agent i only observes variables in Qi

©2004 – Carlos Guestrin, Daphne Koller
Choosing Action at State x
2
3
4
1
Q2(A1, A2, X1,X2)
Q4(A3, A4, X3,X4)
Q1(A1, A4,
X1,X4)
Q3(A2, A3, X2,X3)
Q2(A1, A2)
Q3(A2, A3)
Q4(A3, A4)
Q1(A1, A4)
Instantiate current state x
Maximal action maxa

©2004 – Carlos Guestrin, Daphne Koller
Variable Elimination
Q2(A1, A2)
Q3(A2, A3)
Q4(A3, A4)
Q1(A1, A4)
maxa
+ + +
Use variable elimination for maximization:
Limited communication for optimal action choice
Comm. bandwidth = tree-width of coord. graph
),(),(),(max 421212411,, 421
AAgAAQAAQA A A
),(),(max),(),(max 434323212411,, 3421
AAQAAQAAQAAQAA A A
),(),(),(),(max 434323212411,,, 4321
AAQAAQAAQAAQA A A A
A2 A4 Value of optimal A3
action
Attack Attack 5
Attack Defend
6
Defend
Attack 8
Defend
Defend
12

©2004 – Carlos Guestrin, Daphne Koller
Choosing Action at State x
),(),(),(max 421212411,, 421
AAgAAQAAQA A A
),(),(max),(),(max 434323212411,, 3421
AAQAAQAAQAAQAA A A
),(),(),(),(max 434323212411,,, 4321
AAQAAQAAQAAQA A A A

©2004 – Carlos Guestrin, Daphne Koller
Choosing Action at State x
2
3
4
1
Q2(A1, A2)
Q3(A2,
A3)
Q4(A3,
A4)
Q1(A1,
A4)
maxA3
[ +
]
g1(A2, A4)
),(),(),(max 421212411,, 421
AAgAAQAAQA A A
),(),(max),(),(max 434323212411,, 3421
AAQAAQAAQAAQAA A A
),(),(),(),(max 434323212411,,, 4321
AAQAAQAAQAAQA A A A

©2004 – Carlos Guestrin, Daphne Koller
Coordination Graphs
Communication follows triangulated graph Computation grows exponentially in tree
width Graph-theoretic measure of “connectedness” Arises in BNs, CSPs, …
Cost exponential in worst case,fairly low for many real graphs
A4
A1
A3
A2
A7
A5
A6 A9
A8
A10 A11

©2004 – Carlos Guestrin, Daphne Koller
Context-Specific Interactions
Payoff structure can vary by context Agents A1, A2 both trying to pass
through same narrow corridor Can use context-specific “value
rules”<At(X,A1), At(X,A2),
A1 = fwd A2 = fwd : -100> Hope: Context-specific payoffs will
induce context-specific coordination
A1A2
X

©2004 – Carlos Guestrin, Daphne Koller
Context-Specific Coordination
Instantiate current state: x = true
A1
A4 A2
A3
A5 A6
1.0:32 xaa
3:43 xaa
3:421 xaaa
5:21 xaa 1:31 xaa
7:6 xa 4:51 xaa 2:65 xaa 3:61 xaa
1:4 xa

©2004 – Carlos Guestrin, Daphne Koller
Context-Specific Coordination
A1
A4 A2
A3
A5 A6
3:43 aa
3:421 aaa
5:21 aa
7:6a4:51 aa 2:65 aa
1:4a1.0:32 aa
Coordination structure varies based on context

©2004 – Carlos Guestrin, Daphne Koller
Context-Specific Coordination
A1
A4 A2
A3
A5 A6
3:43 aa
3:421 aaa
5:21 aa
7:6a4:51 aa 2:65 aa
1:4a
Maximizing out A1
11 aA
1.0:32 aa
Rule-based variable elimination [Zhang & Poole ’99]
4:5a5:2aCoordination structure varies
based on communication

©2004 – Carlos Guestrin, Daphne Koller
Context-Specific Coordination
A1
A4 A2
A3
A5 A6
1.0:32 aa
3:43 aa
7:6a
2:65 aa
1:4a
4:5a5:2a
Eliminate A1 from the graph Rule-based variable elimination [Zhang &
Poole ’99]
Coordination structure varies based on agent decisions

©2004 – Carlos Guestrin, Daphne Koller
Robot Soccer
UvA Trilearn 2002 won German Open 2002, but placed fourth in Robocup-2002.
“ … the improvements introduced in UvA Trilearn 2003 … include an extension of the intercept skill, improved passing behavior and especially the usage of coordination graphs to specify the coordination requirements between the different agents.”
Kok, Vlassis & GroenUniversity of Amsterdam

©2004 – Carlos Guestrin, Daphne Koller
RoboSoccer Value Rules
Coordination graph rules include conditions on player role and aspects of global system state
Example rules for player i, in role of passer:
Depends on distance of j to goal after move

©2004 – Carlos Guestrin, Daphne Koller
UvA Trilearn 2003 ResultsRound 1 Opponent Score
Round 1 Mainz Rolling Brains (Germany)
4-0
Iranians (Iran) 31-0
Sahand (Iran) 39-0
a4ty (Latvia) 25-0
Round 2 Helios (Iran) 2-1
AT-Humboldt (Germany) 5-0
ZJUBase (China) 6-0
Aria (Iran) 6-0
Hana (Japan) 26-0
Round 3 Zenit-NewERA (Russia) 4-0
RoboSina (Iran) 6-0
Wright Eagle (China) 3-1
Everest (China) 7-1
Aria (Iran) 5-0
Semi-final Brainstormers (Germany) 4-1
Final TsinghuAeolus (China) 4-3
177-7
UvA Trilearn won • German Open 2003• US Open 2003• RoboCup 2003• German Open 2004

©2004 – Carlos Guestrin, Daphne Koller
Outline
Action Coordination Factored Value Functions Coordination Graphs Context-Specific Coordination
Joint Planning Multi-Agent Markov Decision Processes Efficient Linear Programming Solution Decentralized Market-Based Solution
Generalizing to New Environments Relational MDPs Generalizing Value Functions

©2004 – Carlos Guestrin, Daphne Koller
peasant
footman
building
Real-time Strategy GamePeasants collect resources and buildFootmen attack enemiesBuildings train peasants and footmen

©2004 – Carlos Guestrin, Daphne Koller
Planning Over Time
Action space: Joint agent actions a= {a1,…,
an}
State space: Joint state descriptions x= {x1,
…, xn}
Momentary reward function R(x,a) Probabilistic system dynamics P(x’|x,a)
Markov Decision Process (MDP) representation:

©2004 – Carlos Guestrin, Daphne Koller
Policy
Policy: (x) = aAt state x, action a for all agents
(x0) = both peasants get woodx0
(x1) = one peasant gets gold, other builds barrack
x1
(x2) = Peasants get gold, footmen attack
x2
©2004 – Carlos Guestrin, Daphne Koller
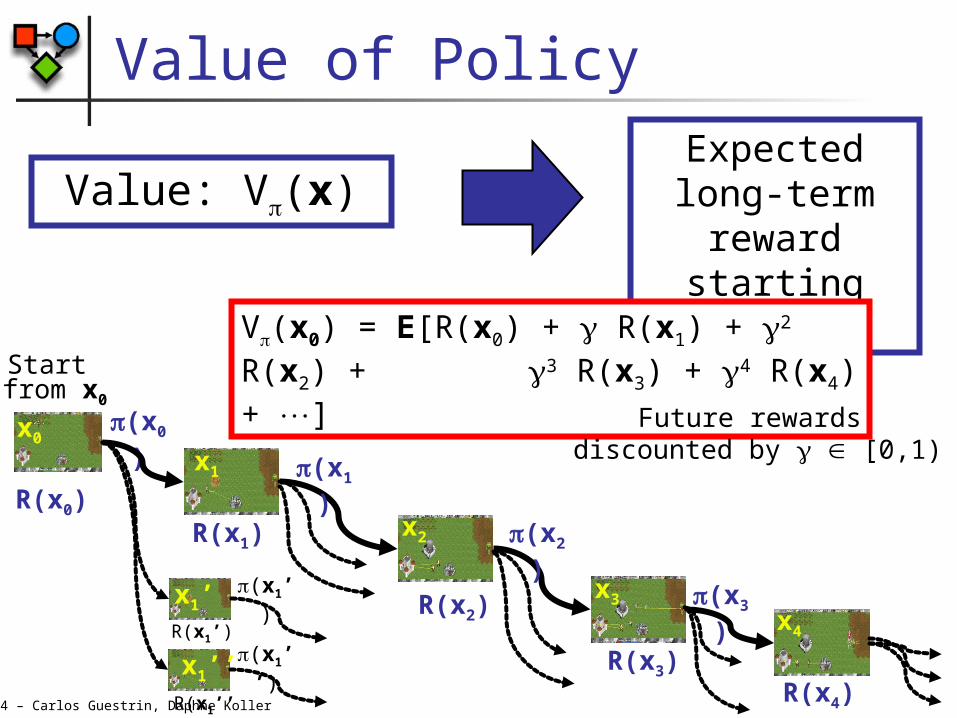
Value of Policy
Value: V(x)Expected long-term
reward starting from
xStart
from x0
x0
R(x0)
(x0
)
V(x0) = E[R(x0) + R(x1) + 2 R(x2) + 3 R(x3) + 4 R(x4) + ]
Future rewards discounted by [0,1)x1
R(x1)
x1’’
x1’R(x1’)
R(x1’’)
(x1
)x2
R(x2)
(x2
)x3
R(x3)
(x3
) x4
R(x4)
(x1’)
(x1’’)

©2004 – Carlos Guestrin, Daphne Koller
Optimal Long-term Plan
Optimal policy *(x)
Optimal Q-function Q*(x,a)
)a,x(max)x(a
QV
'x
)'x()a,x|'x()a,x()a,x( VPRQ
Optimal policy:)a,x(maxarg)x(
a
Q
Bellman Equations:
©2004 – Carlos Guestrin, Daphne Koller
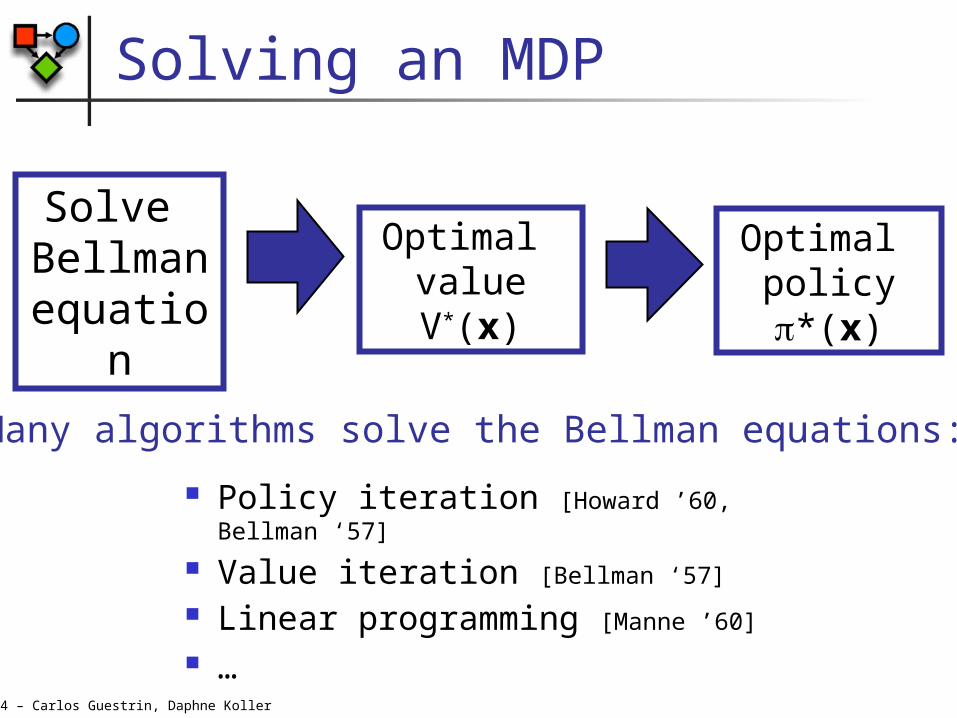
Solving an MDP
Policy iteration [Howard ’60, Bellman ‘57]
Value iteration [Bellman ‘57]
Linear programming [Manne ’60]
…
Solve Bellman equation
Optimal value V*(x)
Optimal policy *(x)
Many algorithms solve the Bellman equations:

©2004 – Carlos Guestrin, Daphne Koller
LP Solution to MDP
,
),()( :subject to
)(:minimize
ax
xax
xx
QV
V
One variable V (x) for each state One constraint for each state x and action a Polynomial time solution

©2004 – Carlos Guestrin, Daphne Koller
Are We Done?
Planning is polynomial in #states and #actions
#states exponential in number of variables
#actions exponential in number of agents
Efficient approximation by exploiting structure!
©2004 – Carlos Guestrin, Daphne Koller
F’
E’
G’
P’
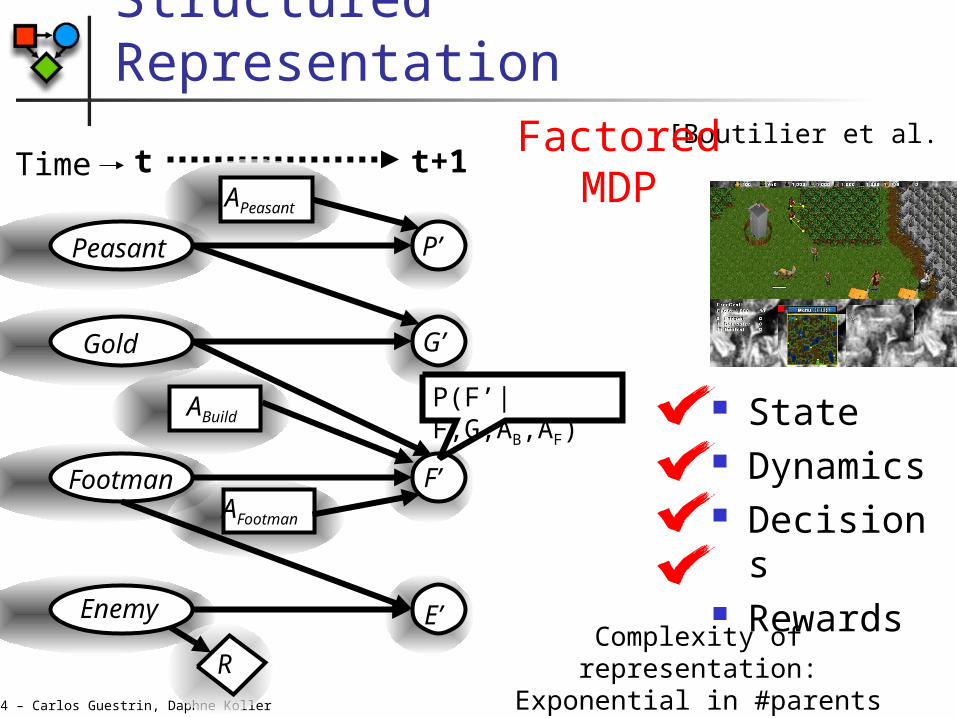
Structured Representation
State Dynamics Decisions Rewards
Peasant
Footman
Enemy
Gold
RComplexity of representation:Exponential in #parents (worst
case)
[Boutilier et al. ’95]t t+1Time
APeasant
ABuild
AFootman
P(F’|F,G,AB,AF)
FactoredMDP
©2004 – Carlos Guestrin, Daphne Koller
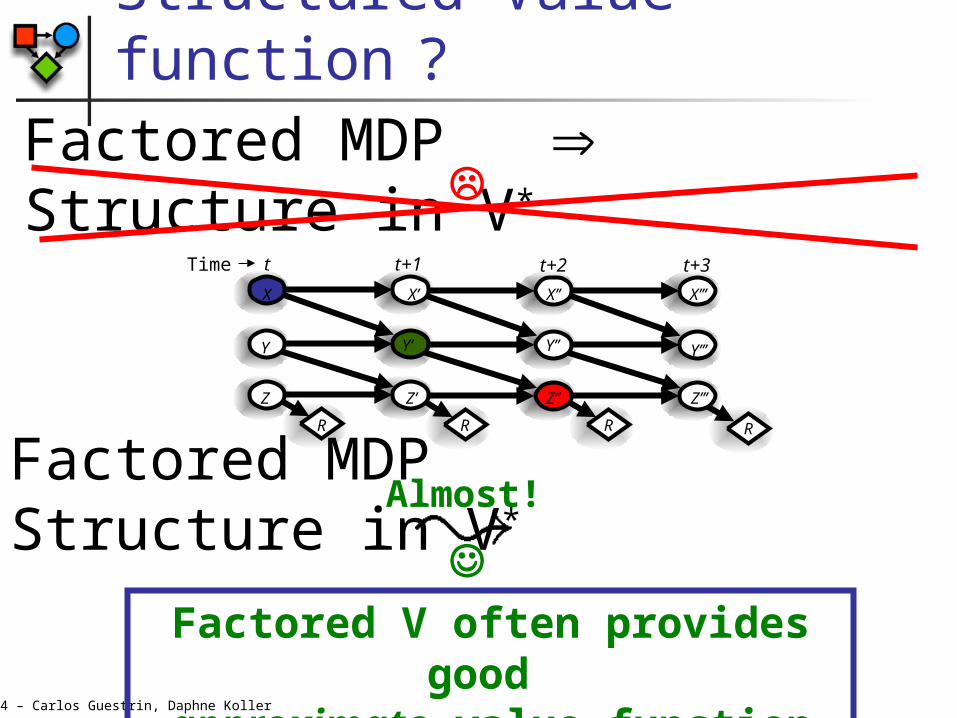
Structured Value function ?Factored MDP Structure in V*
Y’’
Z’’
X’’
R
Y’’’
Z’’’
X’’’
Time t t+1
R
Y’
Z’
X’
t+2 t+3
R
Z
Y
X
R
Factored MDP Structure in V*
Almost!
Factored V often provides
good approximate value function

©2004 – Carlos Guestrin, Daphne Koller
[Bellman et al. ‘63], [Tsitsiklis & Van Roy ‘96][K. & Parr ’99,’00]
Structured Value Functions
Approximate V* as a factored value function
In rule-based case: hi is a rule concerning small part of the system wi is the value associated with the rule
Goal: find w giving good approximation V to V*
i iihwV )()( xx
Factored value function V = wi hi
Factored Q function Q = Qi
Can use coordination graph

©2004 – Carlos Guestrin, Daphne Koller
Approximate LP Solution
:subject to
, ax
:minimize x
),( xaQ)(xV
)(xV
),( xa
iiQ)( x
iii hw
)( xi
ii hw
One variable wi for each basis function Polynomial number of LP variables
One constraint for every state and action Exponentially many LP constraints
, ax
)( xi
ihwi
)( xi
hwi i

©2004 – Carlos Guestrin, Daphne Koller
,),()( :subject to
axxaxi
ii
ii Qhw
So What Now?
)x()x,a( :to subject max0x,a
i
iii hwQ
Exponentially many linear = one nonlinear constraint
,)(),(0 :subject to
axxxai
iii hwQ
[Guestrin, K., Parr ’01]

©2004 – Carlos Guestrin, Daphne Koller
Variable Elimination Revisited
Use Variable Elimination to represent constraints: ),(),(max),(),(max0 4321
,,DBfDCfCAfBAf
DCBA
),(),(
),(),(max0
43),(
1
),(121
,,
DBfDCfg
gCAfBAf
CB
CB
CBA
Exponentially
fewerconstraints )x()x,a( :to subject max0
x,a
i
iii hwQ
[Guestrin, K., Parr ’01]
Polynomial LP for findinggood factored approximation to V*

©2004 – Carlos Guestrin, Daphne Koller
Network Management Problem
Ring
Star
Ring of Rings
k-grid
Computer runs processes
Computer status = {good, dead, faulty}
Dead neighbors increase dying probability
Reward for successful processes
Each SysAdmin takes local action = {reboot, not reboot }

©2004 – Carlos Guestrin, Daphne Koller
Scaling of Factored LP
Explicit LP Factored LP
k = tree-width
2n (n+1-k)2k
Explicit LP
0
10000
20000
30000
40000
2 4 6 8 10 12 14 16number of variables
nu
mb
er o
f co
nst
rain
ts
Factored LP
k = 3
k = 5
k = 8
k = 10
k = 12

©2004 – Carlos Guestrin, Daphne Koller
Multiagent Running Time
0
20
40
60
80
100
120
140
160
180
2 4 6 8 10 12 14 16
Number of agents
To
tal
run
nin
g t
ime
(sec
on
ds)
Star single basis
Star pair basis
Ring ofrings
©2004 – Carlos Guestrin, Daphne Koller
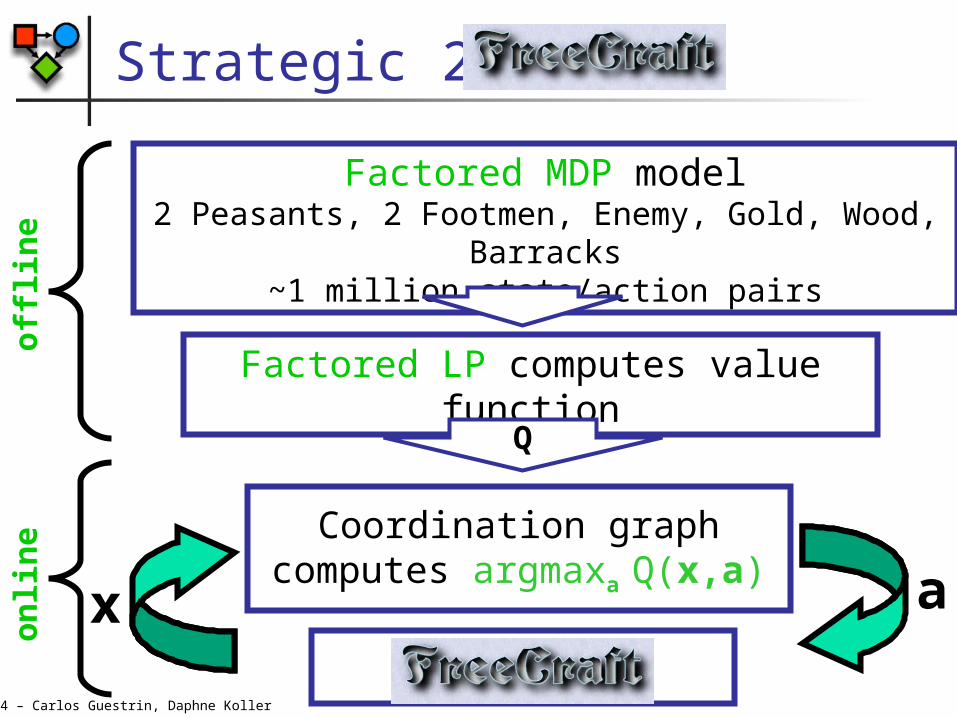
Strategic 2x2
Factored MDP model2 Peasants, 2 Footmen, Enemy, Gold, Wood,
Barracks~1 million state/action pairs
Factored LP computes value function
Q
offl
ine
on
lin
e
Worldx a
Coordination graph computes argmaxa Q(x,a)
©2004 – Carlos Guestrin, Daphne Koller
Demo: Strategic 2x2Guestrin, Koller, Gearhart & Kanodia

©2004 – Carlos Guestrin, Daphne Koller
Limited Interaction MDPs Some MDPs have additional
structure: Agents are largely autonomous Interact in limited ways
e.g., competing for resources
Can decompose MDP as set of agent-based MDPs, with limited interface
A2
A1
X1
R1
X3
X2
X’3
X’2
X’1
h2
h1
R2
R3 A2
A1
X3
X2
X’3
X’2
R2
R3
A1
X1
R1
X2 X’2
X’1
X1
X2X1A1
M2
M1
[Guestrin & Gordon, ’02]

©2004 – Carlos Guestrin, Daphne Koller
Limited Interaction MDPs
In such MDPs, our LP matrix is highly structured
Can use Dantzig-Wolfe LP decomposition to solve LP optimally, in a decentralized way
Gives rise to a market-like algorithm with multiple agents and a centralized “auctioneer”
[Guestrin & Gordon, ’02]
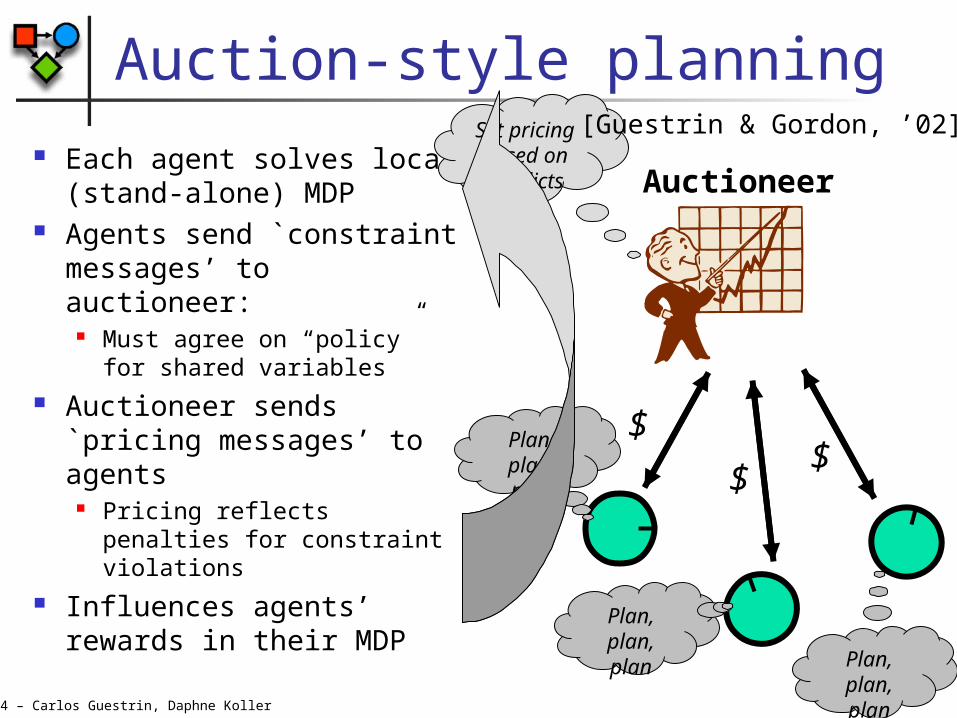
©2004 – Carlos Guestrin, Daphne Koller
Auction-style planning Each agent solves local
(stand-alone) MDP Agents send `constraint
messages’ to auctioneer:
Must agree on “policy” for shared variables
Auctioneer sends `pricing messages’ to agents
Pricing reflects penalties for constraint violations
Influences agents’ rewards in their MDP
Auctioneer
$
$$
Set pricingbased onconflicts
Plan, plan, plan
Plan, plan, plan Plan,
plan, plan
[Guestrin & Gordon, ’02]

©2004 – Carlos Guestrin, Daphne Koller
UAV start Target
Fuel Allocation Problem
UAVs share a pot of fuel Targets have varying
priority Ignore target interference
Bererton, Gordon,Thrun & Khosla

©2004 – Carlos Guestrin, Daphne Koller[Bererton, Gordon, Thrun, & Khosla , ’03]
Fuel Allocation Problem

©2004 – Carlos Guestrin, Daphne Koller
High-Speed Robot Paintball
Bererton, Gordon & Thrun
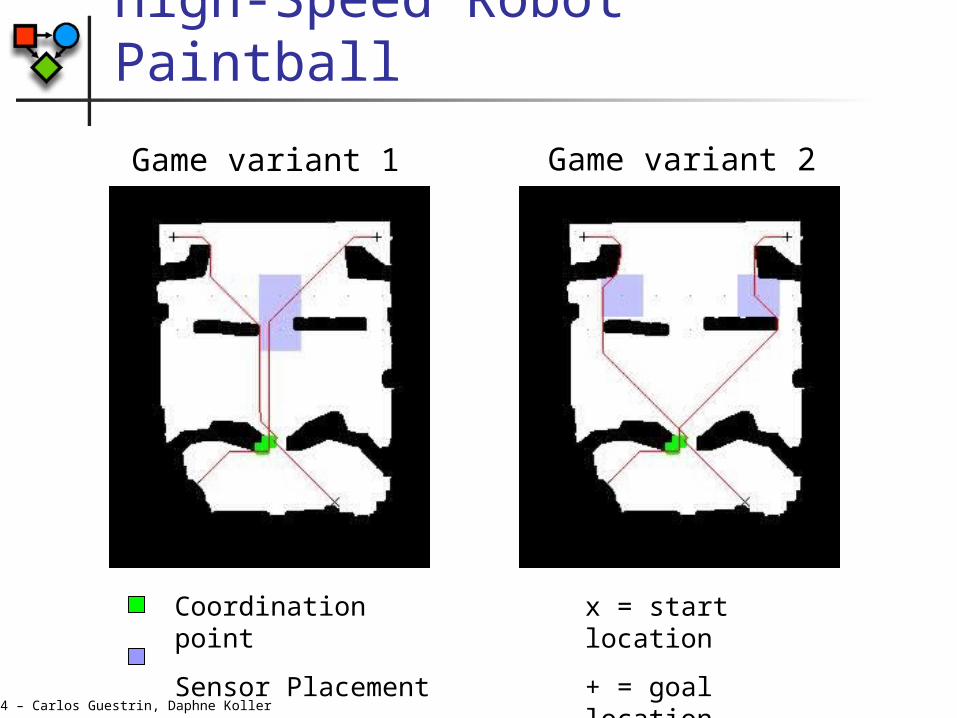
©2004 – Carlos Guestrin, Daphne Koller
High-Speed Robot Paintball
Game variant 1 Game variant 2
Coordination point
Sensor Placement
x = start location
+ = goal location

©2004 – Carlos Guestrin, Daphne Koller
High-Speed Robot Paintball
Bererton, Gordon & Thrun

©2004 – Carlos Guestrin, Daphne Koller
Outline
Action Coordination Factored Value Functions Coordination Graphs Context-Specific Coordination
Joint Planning Multi-Agent Markov Decision Processes Efficient Linear Programming Solution Decentralized Market-Based Solution
Generalizing to New Environments Relational MDPs Generalizing Value Functions
©2004 – Carlos Guestrin, Daphne Koller
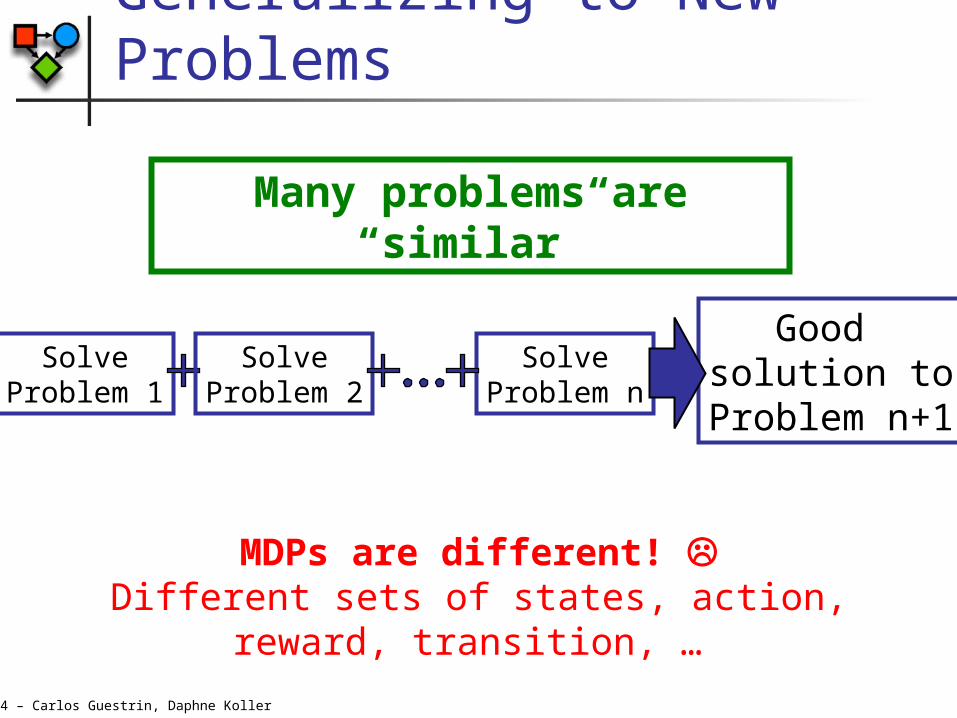
Generalizing to New Problems
SolveProblem 1
SolveProblem n
Good solution to
Problem n+1
SolveProblem 2
MDPs are different! Different sets of states, action, reward,
transition, …
Many problems are “similar”

©2004 – Carlos Guestrin, Daphne Koller
Generalizing with Relational MDPs
Avoid need to replan Tackle larger problems
“Similar” domains have similar “types” of objects
Exploit similarities by computing generalizable value functions
RelationalMDP
Generalization

©2004 – Carlos Guestrin, Daphne Koller
Relational Models and MDPs
Classes: Peasant, Footman, Gold, Barracks, Enemy…
Relations Collects, Builds, Trains, Attacks…
Instances Peasant1, Peasant2, Footman1, Enemy1…
Builds on Probabilistic Relational Models [K. & Pfeffer ‘98]
[Guestrin, K., Gearhart & Kanodia ‘03]
©2004 – Carlos Guestrin, Daphne Koller
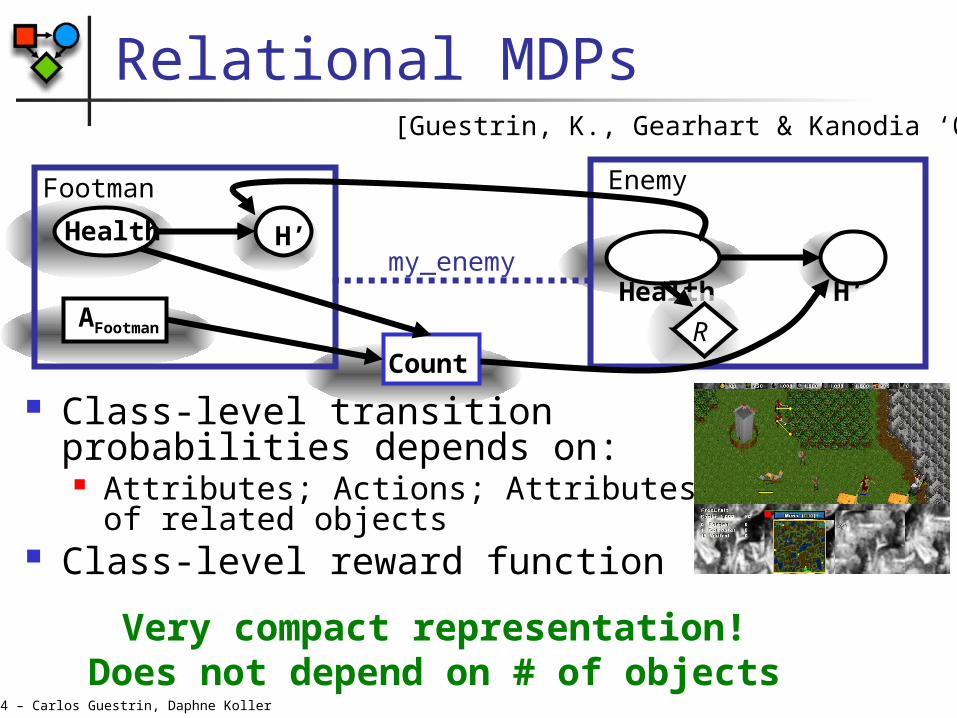
Relational MDPs
Very compact representation!Does not depend on # of objects
Enemy
H’ Health
RCount
Footman
H’ Health
AFootman
my_enemy
Class-level transition probabilities depends on: Attributes; Actions; Attributes of
related objects Class-level reward function
[Guestrin, K., Gearhart & Kanodia ‘03]

©2004 – Carlos Guestrin, Daphne Koller
World is a Large Factored MDP
Instantiation (world): # instances of each class Links between instances
Well-defined factored MDP
RelationalMDP
Linksbetweenobjects
FactoredMDP
# of objects

©2004 – Carlos Guestrin, Daphne Koller
MDP with 2 Footmen and 2 Enemies
F1.Health
F1.A
F1.H’
E1.Health E1.H’
F2.Health
F2.A
F2.H’
E2.Health E2.H’
R1
R2
Footman1
Enemy1
Enemy2
Footman2

©2004 – Carlos Guestrin, Daphne Koller
World is a Large Factored MDP
Instantiate world Well-defined factored MDP Use factored LP for planning
We have gained nothing!
RelationalMDP
Linksbetweenobjects
FactoredMDP
# of objects
©2004 – Carlos Guestrin, Daphne Koller
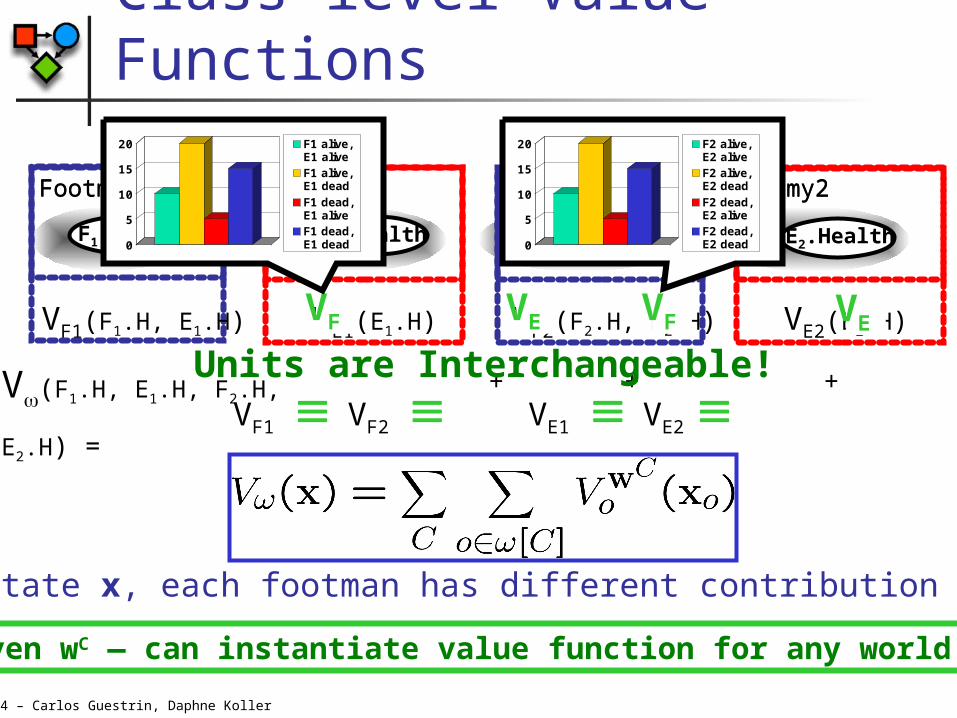
Class-level Value Functions
F1.Health E1.Health F2.Health E2.Health
Footman1
Enemy1
Enemy2
Footman2
VF1(F1.H, E1.H) VE1(E1.H) VF2(F2.H, E2.H) VE2(E2.H)
V(F1.H, E1.H, F2.H, E2.H) = + + + Units are Interchangeable!VF1 VF2 VF VE1 VE2
VE
At state x, each footman has different contribution to V
Given wC — can instantiate value function for any world
Footman1
Enemy1
Enemy2
Footman2
VF VF VE VE
0
5
10
15
20 F1 alive,E1 aliveF1 alive,E1 deadF1 dead,E1 aliveF1 dead,E1 dead 0
5
10
15
20 F2 alive,E2 aliveF2 alive,E2 deadF2 dead,E2 aliveF2 dead,E2 dead
©2004 – Carlos Guestrin, Daphne Koller
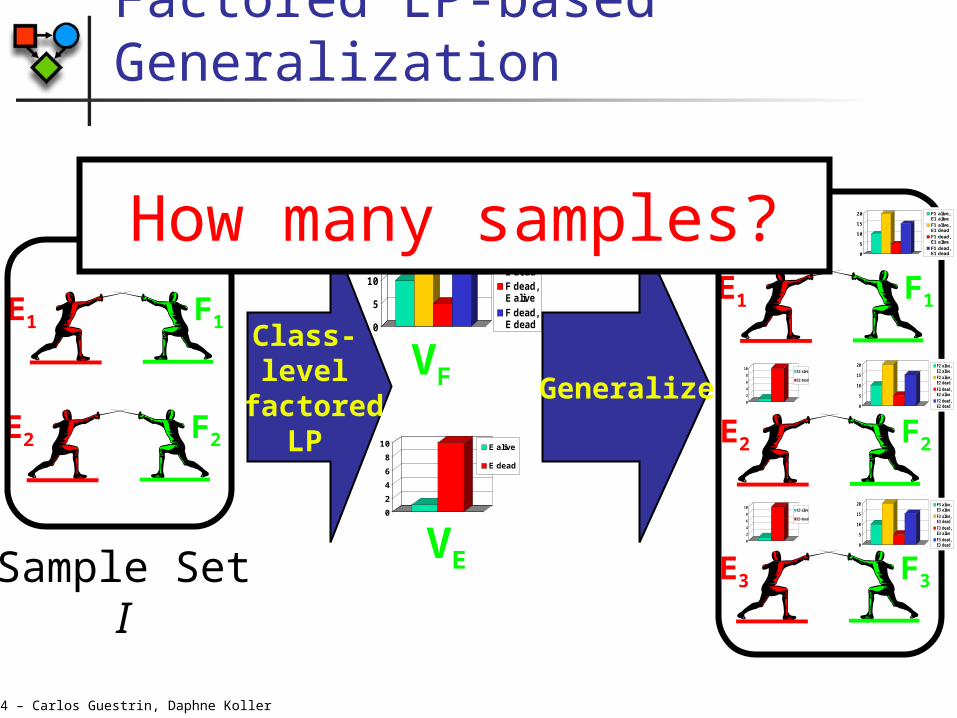
Factored LP-based Generalization
E1 F1
E2 F2
Sample SetI
0
5
10
15
20 F alive,E aliveF alive,E deadF dead,E aliveF dead,E dead
VF
0
2
4
6
8
10 E alive
E dead
VE
Generalize
E1 F1
E2 F2
E3 F3
0
5
10
15
20 F1 alive,E1 aliveF1 alive,E1 deadF1 dead,E1 aliveF1 dead,E1 dead
0
2
4
6
8
10E1 alive
E1 dead
0
5
10
15
20 F2 alive,E2 aliveF2 alive,E2 deadF2 dead,E2 aliveF2 dead,E2 dead
0
2
4
6
8
10E2 alive
E2 dead
0
5
10
15
20 F3 alive,E3 aliveF3 alive,E3 deadF3 dead,E3 aliveF3 dead,E3 dead
0
2
4
6
8
10E3 alive
E3 dead
Class-level
factored LP
How many samples?

©2004 – Carlos Guestrin, Daphne Koller
Sampling Complexity
NO!
Exponentially many worlds need
exponentially many samples?
# objects in a world is unbounded must sample
very large worlds?

©2004 – Carlos Guestrin, Daphne Koller
Theorem
samples
Value function within O() of class-level value function optimized for all worlds,
with prob. at least 1-
Rcmax is the maximum class reward
Sample m small worlds of up to O( ln 1/ ) objects
m =

©2004 – Carlos Guestrin, Daphne Koller
Strategic 2x2
Relational MDP model
2 Peasants, 2 Footmen, Enemy, Gold, Wood,
Barracks~1 million state/action pairs
Factored LP computes value function
Q
offl
ine
on
lin
e
Worldx a
Coordination graph computes argmaxa Q(x,a)

©2004 – Carlos Guestrin, Daphne Koller
Relational MDP model
9 Peasants, 3 Footmen, Enemy, Gold, Wood,
Barracks
Factored LP computes value function
Qo
offl
ine
on
lin
e
Worldx a
Coordination graph computes argmaxa Q(x,a)
~3 trillion state/action pairs
grows exponentially in #
agents
Strategic 9x3

©2004 – Carlos Guestrin, Daphne Koller
Strategic Generalization
Relational MDP model
2 Peasants, 2 Footmen, Enemy, Gold, Wood,
Barracks~1 million state/action pairs
Factored LP computes class-level value function
wC
offl
ine
on
lin
e
Worldx a
Coordination graph computes argmaxa Q(x,a)
9 Peasants, 3 Footmen, Enemy, Gold, Wood,
Barracks~3 trillion state/action pairs
instantiated Q-functionsgrow polynomially in #
agents

©2004 – Carlos Guestrin, Daphne Koller
Demo: Generalized 9x3Guestrin, Koller, Gearhart & Kanodia

©2004 – Carlos Guestrin, Daphne Koller
Tactical Generalization
Planned in 3 Footmen versus 3 Enemies
Generalized to 4 Footmen versus 4 Enemies
3 v. 3 4 v. 4
Generalize

©2004 – Carlos Guestrin, Daphne Koller
Demo: Planned Tactical 3x3Guestrin, Koller, Gearhart & Kanodia

©2004 – Carlos Guestrin, Daphne Koller
Demo: Generalized Tactical 4x4
[Guestrin, K., Gearhart & Kanodia ‘03]
Guestrin, Koller, Gearhart & Kanodia

©2004 – Carlos Guestrin, Daphne Koller
Summary
Structured Multi-Agent MDPs
Effectiveplanning
under uncertainty
Distributedcoordinated
action selection
Generalization
to new problems

©2004 – Carlos Guestrin, Daphne Koller
Important Questions
Continuousspaces
Partialobservability
Complexactions Learning
to act
How far can we go??

http://robotics.stanford.edu/~koller
Carlos Guestrin Ronald Parr
Chris Gearhart Neal KanodiaShobha Venkataraman
Curt BerertonGeoff GordonSebastian Thrun
Jelle KokMatthijs SpaanNikos Vlassis
Top Related