







Languages
Pages
Legal


4/7/2015
1
MA5232 Modeling and Numerical
Simulations
Lecture 2
Iterative Methods for Mixture-Model Segmentation
8 Apr 2015
National University of Singapore 1
Last time
• PCA reduces dimensionality of a data set while
retaining as much as possible the data variation.
– Statistical view: The leading PCs are given by the
leading eigenvectors of the covariance.
– Geometric view: Fitting a d-dim subspace model via
SVD
• Extensions of PCA
– Probabilistic PCA via MLE
– Kernel PCA via kernel functions and kernel matrices
National University of Singapore 2

4/7/2015
2
This lecture
• Review basic iterative algorithms for central
clustering
• Formulation of the subspace segmentation
problem
National University of Singapore 3
Segmentation by Clustering
From: Object Recognition as Machine Translation, Duygulu, Barnard, de Freitas, Forsyth, ECCV02

4/7/2015
3
Example 4.1
• Euclidean distance-based clustering is not
invariant to linear transformation
• Distance metric needs to be adjusted after
linear transformation
National University of Singapore 5
Central Clustering
• Assume data sampled from a mixture of
Gaussian
• Classical distance metric between a sample
and the mean of the jth cluster is the
Mahanalobis distance
National University of Singapore 6

4/7/2015
4
Central Clustering: K-Means
• Assume a map function provide each ithsample a label
• An optimal clustering minimizes the within-
cluster scatter:
i.e., the average distance of all samples to their respective cluster means
National University of Singapore 7
Central Clustering: K-Means
• However, as K is user defined, when
each point becomes a cluster itself: K=n.
• In this chapter, would assume true K is known.
National University of Singapore 8

4/7/2015
5
Algorithm
• A chicken-and-egg view
National University of Singapore 9
Two-Step Iteration
National University of Singapore 10

4/7/2015
6
Example
• http://util.io/k-means
National University of Singapore 11
Source: K. Grauman
Feature Space
4/7/2015
7
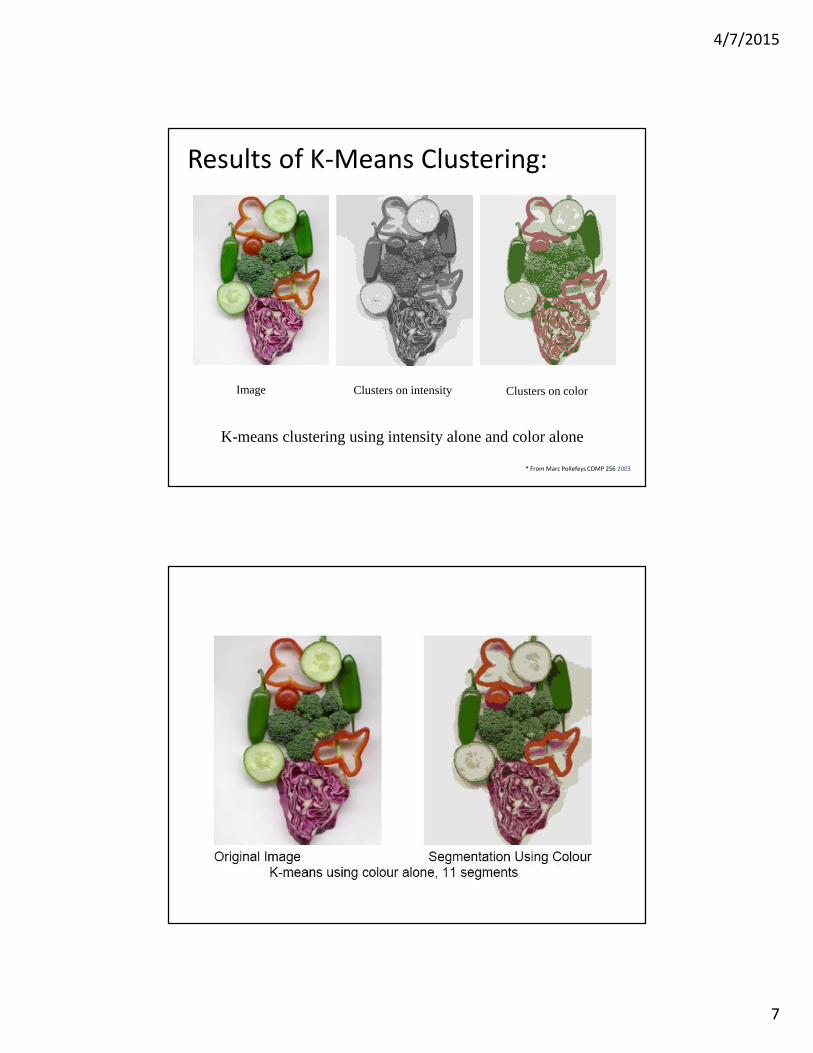
K-means clustering using intensity alone and color alone
Image Clusters on intensity Clusters on color
* From Marc Pollefeys COMP 256 2003
Results of K-Means Clustering:

4/7/2015
8
National University of Singapore 15
A bad local optimum
Characteristics of K-Means
• It is a greedy algorithm, does not guarantee to
converge to the global optimum.
• Given fixed initial clusters/ Gaussian models, the
iterative process is deterministic.
• Result may be improved by running k-means
multiple times with different starting conditions.
• The segmentation-estimation process can be
treated as a generalized expectation-
maximization algorithm
National University of Singapore 16

4/7/2015
9
EM Algorithm [Dempster-Laird-Rubin 1977]
• Expectation Maximization (EM) estimates the model parameters and the segmentation in a ML sense.
• Assume samples are independently drawn from a mixed probabilistic distribution, indicated by a hidden discrete variable z
• Cond. dist. can be Gaussian
National University of Singapore 17
The Maximum-Likelihood Estimation
• The unknown parameters are
• The likelihood function:
• The optimal solution maximizes the log-
likelihood
National University of Singapore 18

4/7/2015
10
The Maximum-Likelihood Estimation
• Directly maximize the log-likelihood function
is a high-dimensional nonlinear optimization
problem
National University of Singapore 19
• Define a new function:
• The first term is called expected complete log-
likelihood function;
• The second term is the conditional entropy.
National University of Singapore 20

4/7/2015
11
• Observation:
National University of Singapore 21
The Maximum-Likelihood Estimation
• Regard the (incomplete) log-likelihood as a
function of two variables:
• Maximize g iteratively (E step, followed by M
step)
National University of Singapore 22

4/7/2015
12
Iteration converges to a stationary
point
National University of Singapore 23
Prop 4.2: Update
National University of Singapore 24

4/7/2015
13
Update
• Recall
• Assume is fixed, then maximize the
expected complete log-likelihood
National University of Singapore 25
• To maximize the expected log-likelihood, as an
example, assume each cluster is isotropic
normal distribution:
• Eliminate the constant term in the objective
National University of Singapore 26

4/7/2015
14
Exer 4.2
National University of Singapore 27
• Compared to k-means, EM assigns the
samples “softly” to each cluster according to a
set of probabilities.
EM Algorithm
National University of Singapore 28

4/7/2015
15
Exam 4.3: Global max may not exist
National University of Singapore 29
Alternative view of EM:
Coordinate ascent
National University of Singapore 30
w
w1
4/7/2015
16
Alternative view of EM:
Coordinate ascent
National University of Singapore 31
w
w1
Alternative view of EM:
Coordinate ascent
National University of Singapore 32
w
w1
w2
4/7/2015
17
Alternative view of EM:
Coordinate ascent
National University of Singapore 33
w
w1
w2
Alternative view of EM:
Coordinate ascent
National University of Singapore 34
w
w1
w2
4/7/2015
18
Alternative view of EM:
Coordinate ascent
National University of Singapore 35
w
w1
w2
Visual example of EM

4/7/2015
19
Potential Problems
• Incorrect number of Mixture Components
• Singularities
Incorrect Number of Gaussians

4/7/2015
20
Incorrect Number of Gaussians
Singularities
• A minority of the data can have a
disproportionate effect on the model
likelihood.
• For example…
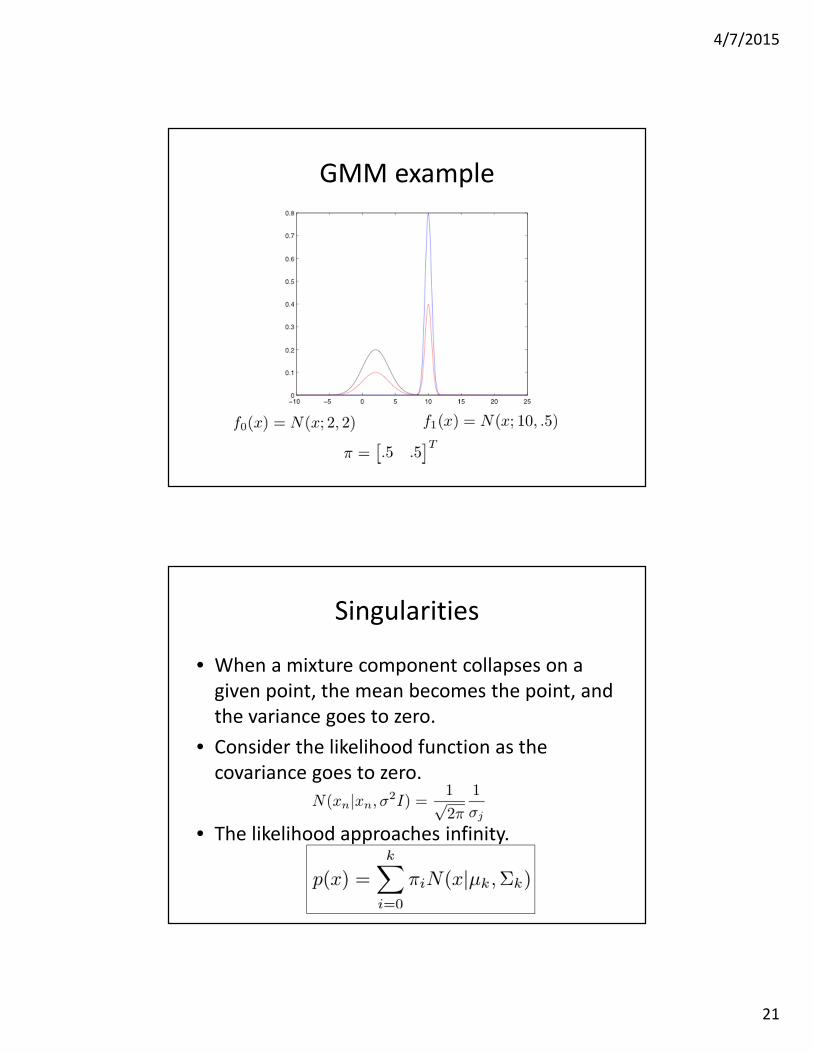
4/7/2015
21
GMM example
Singularities
• When a mixture component collapses on a
given point, the mean becomes the point, and
the variance goes to zero.
• Consider the likelihood function as the
covariance goes to zero.
• The likelihood approaches infinity.

4/7/2015
22
K-means VS EM
National University of Singapore 43
k-means clustering and EM clustering on an artificial dataset ("mouse"). The
tendency of k-means to produce equi-sized clusters leads to bad results, while
EM benefits from the Gaussian distribution present in the data set
So far
• K-means
• Expectation Maximization
National University of Singapore 44

4/7/2015
23
Next up
• Multiple-Subspace Segmentation
• K-subspaces
• EM for Subspaces
National University of Singapore 45
Multiple-Subspace Segmentation
National University of Singapore 46

4/7/2015
24
K-subspaces
National University of Singapore 47
K-subspaces
National University of Singapore 48
• With noise, we minimize
• Unfortunately, unlike PCA, there is no constructive solution to the above minimization problem. The main difficulty is that the foregoing objective is hybrid – it is a combination of minimization on the continuous variables {Uj} and the discrete variable j.

4/7/2015
25
K-subspaces
National University of Singapore 49
K-subspaces
National University of Singapore 50
Exactly the same as
in PCA

4/7/2015
26
K-subspaces
National University of Singapore 51
K-subspaces
National University of Singapore 52

4/7/2015
27
EM for Subspaces
National University of Singapore 53
EM for Subspaces
National University of Singapore 54

4/7/2015
28
EM for Subspaces
National University of Singapore 55
EM for Subspaces
National University of Singapore 56

4/7/2015
29
EM for Subspaces
National University of Singapore 57
EM for Subspaces
• In the M step
National University of Singapore 58

4/7/2015
30
EM for Subspaces
National University of Singapore 59
EM for Subspaces
National University of Singapore 60

4/7/2015
31
EM for Subspaces
National University of Singapore 61
EM for Subspaces
National University of Singapore 62

4/7/2015
32
Relationship between K-subspaces and
EM
• At each iteration,
• K-subspaces algorithm gives a “definite”
assignment of every data point into one of the
subspaces;
• EM algorithm views the membership as a
random variable and uses its expected value
to give a “probabilistic” assignment of the
data point.
National University of Singapore 63
Homework
• Read the handout “Chapter 4 Iterative
Methods for Multiple-Subspace
Segmentation”.
• Complete exercise 4.2 (page 111) of the
handout
National University of Singapore 64