







Languages
Pages
Legal


1
AdvancedComputerArchitecture
FedericoDominguez
WardVanHeddeghem
Literaturestudy:theTriMedia,C6000,SODAandEVPprocessorarchitectures
December19,2008
1 IntroductionThisreportdescribesandcomparesthemicro‐architecturalaspectsandISArationaleof4processors:
• theTriMediamediaprocessor(NXP,formerlyPhilipsSemiconductor),
• theC6000platform(TexasInstruments),
• theSODAarchitecture(UniversityofMichigan)
• andtheEVP(NXP).
These4processorscanallbebroadlycategorizedasapplicationspecificdigitalsignalprocessors(DSPs).Thefirsttwoprocessors(TrimediaandTI’sC6000)aretargetedasmediaprocessors,thelattertwo(SODAandEVP)areprocessorsdevelopedalmostexclusivelyforSoftwareDefinedRadio(SDR).
MediaprocessorsaretypicallyfoundonDVDplayers,digitalTV,IPTV,videosecuritysystems,videoeditingsystems,etc.SDRprocessorstrytoreplacetheRFprocessinghardwarebysoftware,andareaimedmainlyatconsumerhandhelddevicessuchasPDAs,SmartPhones,MobilePhonesetc.
2 GeneralcomparisonofmediaandSDRprocessors
2.1 MultimediaProcessing
Multimediaprocessingisthehandlingofvideoandaudiodatainelectronicdevices.Thisissometimesaccomplishedbyspecificpurposeintegratedcircuits,butthelackofflexibilityandhighcostofthisapproachhasledtothedevelopmentofmultimediaprocessors,programmableprocessorsspeciallydesignedtoefficientlyexecutealltasksrelatedtomultimediaprocessing.MultimediaprocessorsaretypicallyfoundonDVDplayers,digitalTV,IPTV,videosecuritysystems,videoeditingsystems,etc.[5]
Themostcommontasksforamultimediaprocessorare[10]:
• Image,videoandaudiodecodingandencoding• Image,videoandaudiocompression• Image,videoandaudiotransmission• Image,videoandaudioenhancement,filtering• Patternrecognition• Motiondetection
Sincemultimediaprocessorsaremostoftenfoundonbatteryoperatedembeddeddevicesandsincethenatureofmultimediaprocessingrequiresrealtimedeadlines,thedesignchoicesinthisfamilyofmicroprocessorsaimtoachievehighperformanceprocessingofmultimediadatastreamswithminimumpowerconsumptionandunitcost.[5]
Multimediaprocessorsachievethesegoalsbyoptimizingtheexecutionofthemultimediatasksmentionedabove.Thisimplies:
• Highlevelofparallelism:VLIW,SIMDtoboostperformanceandtoallowforalowcostsiliconimplementation.
• Largecachememories:Toaccommodatetypicallylargeimagesandvideoframesclosetotheprocessorsavingcostlymemoryaccessandbandwidth.

2
• Penaltyfreeunalignedmemoryaccess:Processingalgorithmstypicallyaccessimageblocksinanun‐alignedmanner.
• Dataprefetching:Multimediaprocessingalgorithmsaccessmemorylocationsinpredictablestridesandblocks.
• Largeregisterfiles:Largedataworkingsetscanbekeptinregisters,preventingcostlyloadandstoreoperations.
• DMAstylememorytransfers:Increasesoverallsystemperformance.• Applicationspecificinstructions:Typicalmultimediaoperationscanbedoneinoneora
fewclockcycles,savingenergyandgainingperformance.• Smalldatawords:8and16‐bitdatawordsaretypicallysufficientformostmultimedia
processingtask.Limitingthesizeofdatawordsallowsforhighermemorydensityandparallelism.
TriMediaandTIC6000aretwocompetingfamiliesofmultimediamicroprocessorsthatinonewayoranotherimplementthearchitecturaldesignchoiceslistedabove.
2.2 Software‐definedradio(SDR)
Thephysicallayerofmostwirelessprotocolsistraditionallyimplementedincustomhardwaretosatisfytheheavycomputationalrequirementswhilekeepingpowerconsumptiontoaminimum.Theseimplementationsaretimeconsumingtodesignanddifficulttoverify.Aprogrammablehardwareplatformcapableofsupportingsoftwareimplementationsofthephysicallayer,orsoftwaredefinedradio(SDR),hasanumberofadvantages:supportformultipleprotocols(i.e.multimodeoperation),fastertime‐to‐market,higherchipvolumes,andsupportforlateimplementationchanges.SDRcanbeconsideredasahigh‐enddigitalsignalprocessing(DSP)application.[13]
ThedigitalbasebandprocessingforSDRcanbedividedintothreestages:filterstage,modemstage,andcodecstage.
• Thefilterstagerequiresahighcomputationalloadanditsimplementationisuniformbetweendifferentstandardsandalgorithms,aprogrammablesolutionwouldnotbethemostefficientone.
• Themodemstageisdiverseamongdifferentstandards,inthisstagethereisplentyofspacefordifferentvendorstodifferentiatetheirproductsbyapplyingdifferentalgorithmsandstandards.Thisstageisidealforafullyprogrammablesolution.
• Thecodecstageisimplementedbysimilaralgorithmsacrossseveralstandardsmakingaprogrammablesolutionnotdesirable.[17]
ThemodemstageofdigitalbasebandprocessingisanidealapplicationforaprogrammableSDRprocessor.SODAandEVParetwosuchprocessors.
ThemaindesigngoalsoftheseSDRprocessorsaretypicallyhighperformance(imposedbythehighthroughputrequirementsofcurrentwirelessprotocols),energyefficiency(batteryoperateddevices)andprogrammability(multi‐protocolsupport,higherchipvolumes).
2.3 Commoncharacteristics
Asisclearfromthediscussionabove,bothmediaandSDRprocessorsarecharacterizedbyanumberofcommonproperties:theyshouldachievehighperformanceprocessingofdatastreams,mustmeetrealtimedeadlines,shouldbeenergyefficientsincetheyaretypicallyusedonmobile(batteryoperated)devices,andtheyshouldbehighlyprogrammableastoprovidesupportfordifferentandnewmediaandradioprotocols.Thedatastreamstheyoperateonarerelativelysmall(8or16bit).
Figure1showsthethroughputandpowerrequirementsofanumberofwirelessprotocols,aswellastheperformanceoftwoprocessorsdiscussedinthispaper:theTIC6000andtheSODAprocessor.Thisfiguregivesagoodnotiononthepowerefficiencytheseprocessorstargettoachieve.

3
Figure1–Throughputandpowerrequirementsoftypical3Gwirelessprotocols[13]
2.4 DifferencesbetweenmediaandSDRprocessors
Asmuchastheyhaveincommon,thesetwogroupsofprocessorsalsoaredistinctlycharacterizedbytheirintendedapplication:mediaandSDR.Inthenextparagraphswewillhighlightsomeofthemajordesigndistinctionsbetweenthesetwoprocessorgroups.
Differencesbetweenthetwomediaprocessors,anddifferencesbetweenthetwoSDRprocessorswillbediscussedin§3.3and§4.3respectively.Table1givesthespecificationofeachofthefourprocessors.
SIMDwidth—Sincemediaprocessorstypicallyoperateonsmallmacroblocks(amacroblockisausedinvideocompressingandrepresentsablockof16by16pixels[1]),smallervectorssuffice.ThistranslatesinnarrowSIMDdesignsformediaprocessors.ForSDR,ontheotherhand,mostofthecomputationallyintensivealgorithmshaveabundantdatalevelparallelism,muchmorethaninstructionlevelparallelism,sowideSIMDisveryefficient.[13]ItshouldalsobenotedthatSIMDingeneralispowerefficientcomparedtootherarchitectures,sincethe‘overhead’ofaddresscalculation,addressdecoding,instructionfetchingetc.issharedperpoperations.[16]
Predication—Predicationisavailableonbothmediaprocessors.Thisseemslogicalsinceinvideocompressing,acommonthingtodoiscomparedatawithpreviousdata(e.g.inmotionestimation).Predicationcouldthenbeapowerefficientwaytomakedecisions,asopposedtocostlybranching.Wehavenotfoundanyhardreferencestobackupthisassumption.However,onedocumentexplicitlymentionspredicationastechniqueforincreasingperformanceinmediaprocessors.[2]ForSDRprocessorswedidn’tfindanyindicationsthatpredicationisused.
Datawidth—Bothmediaprocessorshaveadatawidthof32bits,incontrastwiththeSDRprocessorswhichhaveonlyhalfofthat.Thisprovidesmediaprocessorswithamuchlargeraddressablememoryrange,notinvaingivennewvideostandardslikeHDTV,whichcurrentlyreachesuptoresolutionsof1920x1080pixels(i.e.atotalof2.073.600pixels,farbeyondwhatisaddressablewith16bits).[1]AlgorithmsrunningonSDRprocessorstypicallyoperateonvariableswithsmallvalues.Analysisoftwotypicalwirelessprotocolsshowsthatthereshouldbestrongsupportfor8and16‐bitoperations.[13]Also,wirelesspacketshandledbytheseprocessorsdon’tpotentiallyconsumeasmuchmemoryspaceasthemediaprocessors.
Unalignedloads—Mediaprocessingalgorithmstypicallyaccessimageblocksinanun‐alignedmanner.Asalreadymentioned,whendealingwithvideocompression,mediaprocessorshandlemacroblocks.Thelocationofthesemacroblocksisnotfixed,neitheronscreen,norinmemory.Itseemslogicalthatprovidingforunalignedloadsallowstheseblockstobefetchedfaster.We
4
don’thaveanyreferencestobackupthisassumption.ForSDRprocessorswedidn’tfindanyindicationsthatunalignedloadsaresupported.
Cache—Onmediaprocessors,cachesareimplemented(oroptional),toaccommodatefortypicallylargeimagesandvideoframesclosetotheprocessor,savingcostlymemoryaccessandbandwidth.SDRprocessorsdon’timplementcachessincetheyoperateonstreamingdata(cachingisofusethen),andtheyrequirereal‐timebehavior.[13]
Delayslots—Delayslotsareavailableonmediaprocessorstoimproveperformance.OnSDRprocessors,delayslotsarenotusedsincebranchpredictionisn’tuseeither.
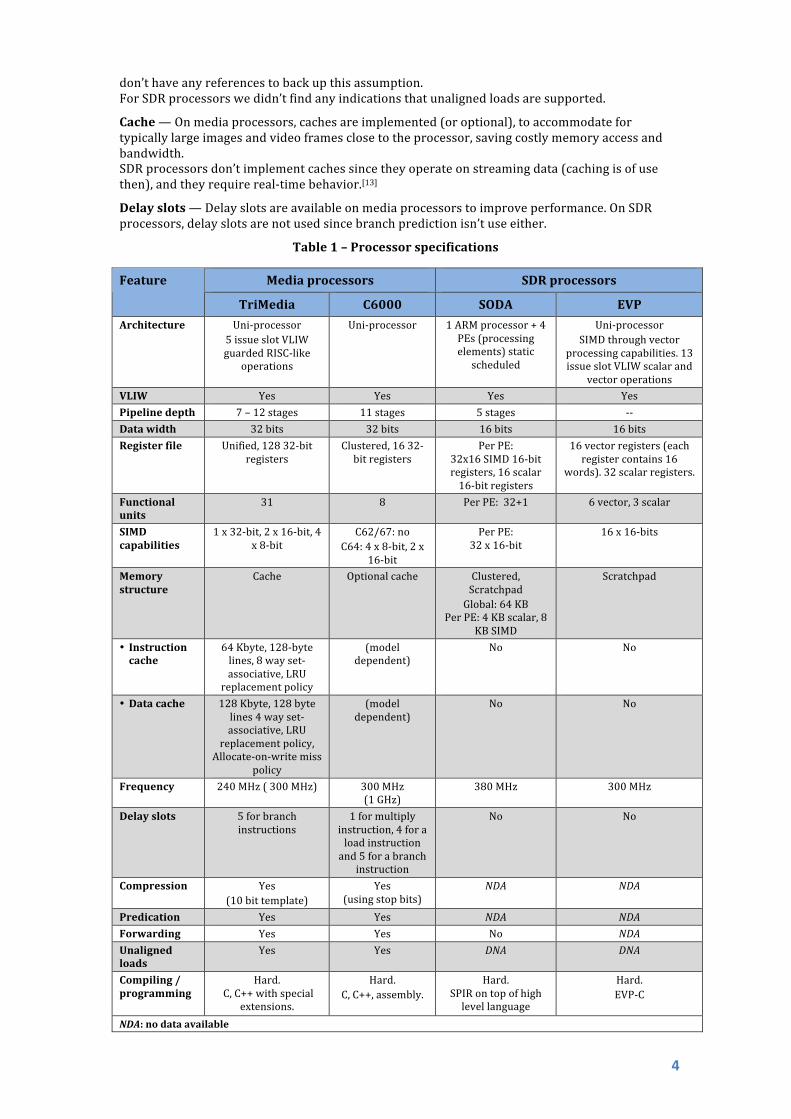
Table1–Processorspecifications
Mediaprocessors SDRprocessorsFeature
TriMedia C6000 SODA EVP
Architecture Uni‐processor5issueslotVLIWguardedRISC‐like
operations
Uni‐processor 1ARMprocessor+4PEs(processingelements)staticscheduled
Uni‐processorSIMDthroughvector
processingcapabilities.13issueslotVLIWscalarand
vectoroperationsVLIW Yes Yes Yes YesPipelinedepth 7–12stages 11stages 5stages ‐‐Datawidth 32bits 32bits 16bits 16bitsRegisterfile Unified,12832‐bit
registersClustered,1632‐bitregisters
PerPE:32x16SIMD16‐bitregisters,16scalar16‐bitregisters
16vectorregisters(eachregistercontains16
words).32scalarregisters.
Functionalunits
31 8 PerPE:32+1 6vector,3scalar
SIMDcapabilities
1x32‐bit,2x16‐bit,4x8‐bit
C62/67:noC64:4x8‐bit,2x
16‐bit
PerPE:32x16‐bit
16x16‐bits
Memorystructure
Cache Optionalcache Clustered,ScratchpadGlobal:64KB
PerPE:4KBscalar,8KBSIMD
Scratchpad
• Instructioncache
64Kbyte,128‐bytelines,8wayset‐associative,LRUreplacementpolicy
(modeldependent)
No No
• Datacache 128Kbyte,128bytelines4wayset‐associative,LRU
replacementpolicy,Allocate‐on‐writemiss
policy
(modeldependent)
No
No
Frequency 240MHz(300MHz) 300MHz(1GHz)
380MHz 300MHz
Delayslots 5forbranchinstructions
1formultiplyinstruction,4foraloadinstructionand5forabranch
instruction
No No
Compression Yes(10bittemplate)
Yes(usingstopbits)
NDA NDA
Predication Yes Yes NDA NDA
Forwarding Yes Yes No NDAUnalignedloads
Yes Yes DNA DNA
Compiling/programming
Hard.C,C++withspecial
extensions.
Hard.C,C++,assembly.
Hard.SPIRontopofhighlevellanguage
Hard.EVP‐C
NDA:nodataavailable

5
3 Multimediaprocessors:TriMediaandTIC6000
3.1 TriMedia
Remark:unlessotherwisespecified,theinformationinthissectionistakenfromthemainTriMediapaperbyVandeWaerdt,etal.[3]
3.1.1 Introduction
TriMediaisafamilyofmicroprocessorsdevelopedbyNXP.ThemainapplicationoftheTriMediamicroprocessorsismultimediadataprocessinginembeddedsystems.ThisparticularapplicationdomainshapestheTriMediamicroprocessordesign,divergingdrasticallyfromgeneralpurposeprocessors.
TriMediaprocessorsaredeployedonconsumerdevicesasaSystemOnChipsolution.TriMediaisprogrammable,sothatitcanbeadaptedtomanydifferentapplicationsandsothatproductscanbechangedthroughsoftwaretomeetevolvingstandardsrequirements[5].
TriMediaprocessorsemployVLIWarchitecture.Thelatestmodel’sCPUcore(TM3270)has31functionalunitswithfiveissueslots.ThisfamilyofprocessorsalsosupportsSIMDoperations.VLIWandSIMDprovideahighdegreeofinstructionparallelism,optimizingtheoverallperformanceofthesystem.
3.1.2 Architectureoverview
TriMediainstructionanddatalevelparallelism
TriMediaimplementsinstructionanddatalevelparallelismthrougha5‐issueslotVLIWandthroughSIMD,respectively.VLIWsupportsupto5operationsperinstructionword.SIMDinstructionscanworkontwo16‐bitdatawordsorfour8‐bitdatawords.
Figure2showsthefunctionalunitsoftheTM1000,thefirstmemberoftheTriMediafamily.TheTM1000has28functionalunitsdividedamongfiveissueslots.TheTM3270hasaddedthreenewfunctionalunits(totaling31units)butmaintainsthesamebasicdesignstructureastheTM1000.Ascanbeseeninthefigure,eachissueslothasmultipletypesoffunctionalunits,allowingthecompilermorefreedomwhenschedulingtheVLIWinstructions.
TheTM3270implementssuperoperationsortwo‐slotoperations.Theseoperationsareexecutedbytwofunctionalunitsthatoccupytwoneighboringissueslots.Theseoperationscantakeuptofouroperandsanduptwodestinationoperands.Two‐slotoperationscanimproveoverallsystemperformancesincetheequivalentseparateoperationsrequiremorecyclestocomplete.
Figure2TriMediaTM1000FunctionalUnits[5]

6
Cachepoliciesandmemoryprefetching
TheTM3270hasa128Kbytedatacachewith128cachelines.Thecachesupportspenalty‐freeunalignedaccesses;imageprocessingtypicallyrequiresfetchingblocksofunalignedimagedatafrommemory.Thecachehasawrite‐backpolicyandanallocate‐on‐write‐misspolicy.Thecombinationofthesetwopoliciesreducestherequiredbandwidthtooff‐chipmemory.
TheTM3270supportsprefetchingandisbasedonmemoryregions.Theprefetchingpatternandregioncanbespecifiedbytheprogrammerandisdesignedtomatchthememoryaccesspatternoftypicalmultimediacodecalgorithms(typicallyunalignedandnon‐sequential).TheTM3270supportsfourseparatememoryregions.Thepatternisdefinedbyastartandendaddressandastride.Theregionspecifiedbythestartandendaddressisusuallyacompleteimageorframe,andthestridecorrespondstothesizeoftheblockswithintheimagethatarebeingprocessed.Themaingoalofprefetchingistoreducecachemissesandthereforeavoidcostlystallcyclesandimprovesystemperformance.
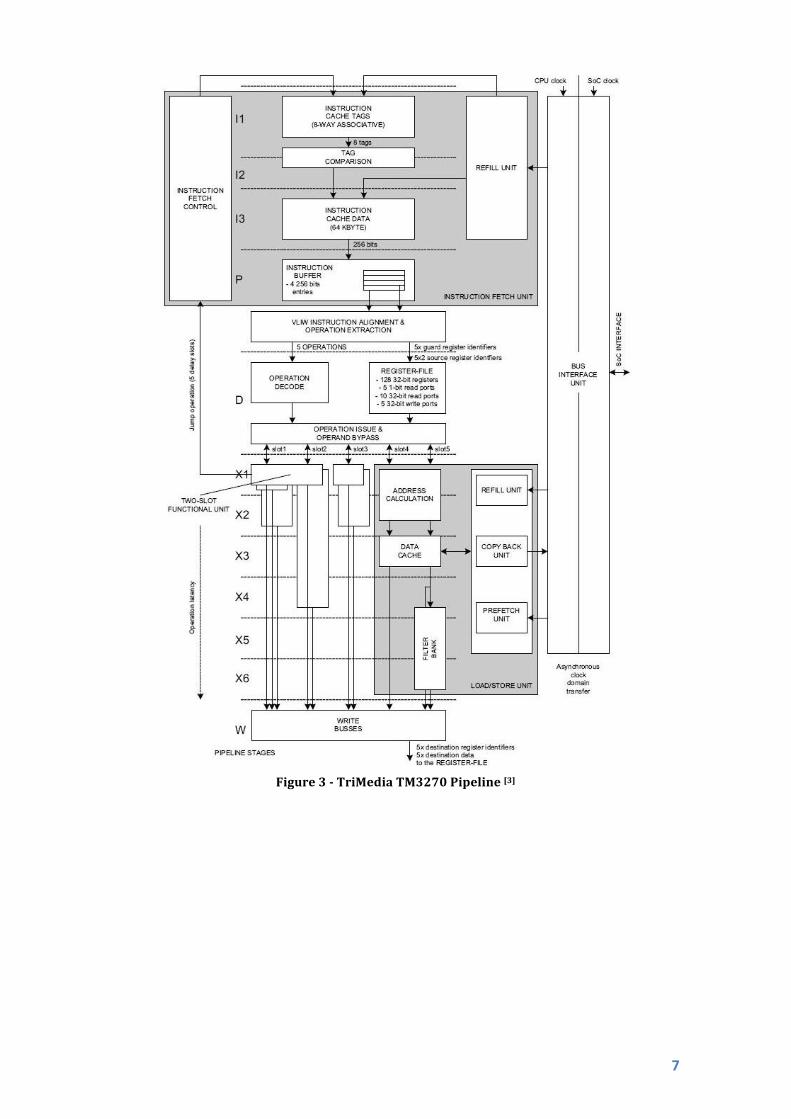
Pipeline
Figure3showsabasicblockdiagramoftheTM3270pipeline.Thepipelinehasaminimumdepthof7stagesforsinglecyclelatencyoperationsandamaximumof12stagesformorecomplexinstructions.Thefrontendofthepipelineconsistsofinstructionfetch(I1–I3)andinstructionpre‐decode(P).Theinstructionfetchcontrolunitatthefrontendofthepipelinesupports5delayslotsforthejumpoperation,thenumberofdelayslotscorrespondstothedistancebetweenthefirststageandthefunctionalunits.Thebackendofthepipelineconsistsofoperationdecode(D),execution(X1‐X6)andwrite(W).
DataforwardingfromtheCacheWriteBufferiscurrentlynotimplementedintheTriMediapipelinebecauseitsinclusioncausespathdelaysbeyondthedesireddesignparameters.Predicationissupportedbyusingguardregisters;eachoperationexecutionispredicatedwiththeleastsignificantbitofitsguardregister.[6]
3.1.3 Compilersupport
TheTriMediaprocessorfamilycomeswithcompilersupportfromthemanufacturer.Binarycompatibilityisnotguaranteedbetweendifferentmodelswithinthefamilyrequiringadifferentcompilerforeachmodel.ThesupportedprogramminglanguageisC/C++.
ProgramswritteninC/C++arecompatiblebetweenmodelsprovidedtheyarerecompiledforeachmodel.Someperformanceislostwhenportingprogramswrittenforonemodeltoanewermodelwithoutincludingmodelspecificoptimizations.ForexamplewhenportingaprogramfromtheTM3260totheTM3270,aperformancegainof20%canbeobtainedwhenapplyingnewdataprefetchingtechniques.
7
Figure3TriMediaTM3270Pipeline[3]

8
3.2 TIC6000
Remark:unlessotherwisespecified,theinformationinthissectionistakenfromanumberofTexasInstrumentsreferencedocuments.[7][8][9][10]
3.2.1 Introduction
TheTMS320C6000digitalsignalprocessor(DSP)platformispartoftheTMS320DSPfamilydevelopedbyTexasInstruments.
TheTMS320familyconsistsof16‐bitand32‐bitfixed‐andfloating‐pointDSPs.Therearethreemainplatforms,includingtheTMS320C2000(controlapplications),theTMS320C5000(power‐efficientapplications),andtheTMS320C6000(high‐performancesapplications).Theseprocessorsareusedincellphones,digitalcameras,modemsetc.
TheC6000platformisaverylonginstructionword(VLIW)architecturetargetedathigh‐performanceDSPtasks.Itcomprisesthefollowingthreemaingenerations(i.e.versions):
• TMS320C62x(‘C62x)offeringfixedpointarithmeticupto300MHz,
• TMS320C64x(‘C64x)offeringfixedpointarithmeticupto1GHz,
• TMS32067x(‘C67x)offeringfloatingpointarithmeticupto300MHz.
3.2.2 Architectureoverview
Overview
The‘C6000processorconsistsofthreemainparts:aCPU,peripherals(notdiscussedfurther)andmemory.Theprocessorsoperateatvariousfrequencies,rangingfrom150MHzupto1GHz.
Theprocessorexecutesuptoeight32‐bitinstructionseverycycle.ThecoreCPU,asshowninFigure4,consistsofeightfunctionalunits,tworegisterfilesandtwodatapaths.
Figure4–The‘C6000blockdiagram

9
CPU
TheCPUhastwoclusters(labeleddatapath1and2inFigure4)inwhichprocessingoccurs.Eachdatapathhasfourfunctionalunits(.L,.S,.M,and.D)andaregisterfilecontaining1632‐bitregisters(32forthe‘C64xgeneration).
Thefunctionalunitsexecutelogic,shifting,multiply,anddataaddressoperations.Allinstructionsexceptloadsandstoresoperateontheregisters.Thetwodata‐addressingunits(.D1and.D2)areexclusivelyresponsibleforalldatatransfersbetweentheregisterfilesandmemory.Thecrosspathsbusconnectingbothdatapaths,supportsonereadandwriteoperationpercycle.
VLIWprocessingflowbeginsbyfetchinga256‐bitwidepacket(eight32‐bitwords)fromprogrammemory,whichisthendynamicallydispatchedoverthedifferentfunctionalunits(FUs).DynamicdispatchingreferstothefactthattheorderofinstructionsinaVLIWshouldnotmatchtheorderofthefunctionalunits;insteadinstructionsintheVLIWaredispatchedtotheappropriateFU.
Thepipelinestagesaregroupedinto3phases:instructionfetch(4stages),instructiondecode(2stages)andinstructionexecute(maximum5stages).Thepipelinealsosupportsdelayslotsformultiply(1delayslot),load(4delayslots),andbranch(5delayslots)operations.
Memory
Dataandprogrammemory—TheC6000DSPhasa32‐bit,byte‐addressableaddressspace.Internal(on‐chip)memoryisorganizedinseparatedataandprogramspaces,whichmaybeconfiguredascacheonsomedevices.Whenoff‐chipmemoryisused,thesespacesareunifiedonmostdevicestoasinglememoryspaceviatheexternalmemoryinterface(EMIF).
Memoryports—TheC6000DSPhastwo32‐bitinternalportstoaccessinternaldatamemory.TheC6000DSPhasasingleinternalporttoaccessinternalprogrammemory,withaninstruction‐fetchwidthof256bits.
Memoryalignment—TheC6400,unliketheC6200andC6700,supportsunalignedmemoryaccessforloadandstoreoperations.Wordanddouble‐worddatadoesnotalwaysneedalignmentto32‐bitor64‐bitboundariesasintheothermodels.
‘C64xextensions
Thekeyextensionsbetweenthe‘C62x/’C67xarchitectureandthe‘C64xarchitecturethatallowmoreworkeachclockcycleinclude(seealsoFigure5):
• widerdatapaths(dual64‐bitload/storepathsinsteadof32‐bit),
• alargerregisterfile(32registersinsteadof16),
• moreorthogonality,i.e.moregeneralityinthearchitecture(forexample,the.DFUcanperform32‐bitlogicalinstructionsinadditiontothe.Sand.Lunits).
• unalignedmemoryaccessforloadandstoreoperations.
• MoreSIMDsupport.Forexample,thefunctionalunitsontheC64xcannowexecutetwo32‐bitmultipliesandfour16‐bitmultiplies.OnFigure5,theyellowboxesineachfunctionalunitontheC64xrepresenttheincreaseinSIMDsupport.ThisincreaseinSIMDparallelismispossibleduetotheincreasedregisterfilesizeanddatapathwidth.

10
Figure5–Differences‘C62/67xand‘C64xgeneration
3.2.3 Compilersupport
TheC6000platformcanbeprogrammedusingC,C++orassemblylanguage.
TexasInstrumentsprovidesaproprietarytoolchainandIDE,calledCodeComposerStudio,todoso.NoothercompilersareavailablefortheC6000platform;however,adepartmentattheChemnitzUniversityofTechnologydevelopedpreliminarysupportfortheTMS320C6xseriesintheGNUCompilerCollection(GCC).[12]
ThefactthatonlyonepropertoolchainisavailablefortheC6000platform,andthatTIprovideshand‐optimizedlibrariesforvariousalgorithms(forexample,FFT),seemstoindicatethatitcanbeacomplextaskfortheprogrammertomanuallydevelopsoftwarethatefficientlyusesthearchitecturalresourcesandcapabilitiesoffered.
ThisassumptionisenforcedbyanInternetforumpostcitingaTICcompilerdeveloper:“Hisanswer[tothequestionwhytherearenoothercompilerssupportingC6000]wasthatwhenTIdevelopedtheC6000core,itwasasidebysidedevelopmenteffortbyboththehardwareandsoftwaredevelopers,andthattheCcompilerbynecessitywouldberathercomplexandhenceveryhardforathirdpartytodevelop.”[11]
3.3 ComparingTriMediaandTIC6000
Remark:unlessotherwisespecified,theinformationinthissectionistakenfromanumberofTexasInstrumentsreferencedocuments[7][8][9][10]andthemainTriMediapaperbyVandeWaerdt,etal.[3]
TriMediaandTIC6000achievehighperformance,lowpowerconsumptionandlowunitcostbyimplementingthearchitecturalfeaturesdescribedin§2.1.However,thedetailsofhowtheyaccomplisheachfeaturemaydifferbetweenthem.Eacharchitecturalfeatureimpliesdesigncompromisesthatweresometimessolveddifferentlyineachprocessor.
Mostofthearchitecturaldesignchoicescanbedividedbythegoaltheytrytoreach:highperformanceorlowpowerconsumption.Althoughthesetwogoalscertainlyoverlapattimes,forclaritythemaincomparisonbetweenthetwoprocessorfamiliesisdividedassuch.
3.3.1 Highperformance
ParallelismonTriMedia—ThealgorithmsrequiredtoimplementvideoprocessingcodecsaresuitableforparallelizationusingVLIWandSIMD.Theytypicallyrequiresimilarindependentoperationsonmultiplesmalldatawords.TriMediaprocessorsprovideinstructionsandsuperinstructionsthataccomplishtypicaltasksinthesecodecsinfewcyclesandwithminimummemorybandwidthconsumption.TheVLIWinTriMediaisimplementedwith5issueslotsandcompressedwitha10‐bittemplatefield.
ParallelismonTIC6000—VLIWandSIMDprovideinstructionanddatalevelparallelismintheTIC6000.Inaddition,compressionthroughstopbitsissupported:parallelismofinstructionsin

11
thefetched256‐bitVLIWcanbecontrolledbyusingastopbit,whensettingtheleastsignificantbit(LSB)ofeachoftheeightcontainedindividualinstructionstoeither0or1.Whensetto1,theindividualinstructionwillbeexecutedinparallelwiththesubsequentindividualinstruction.Thisallowseightinstructionstobeexecutedfullyserial,partiallyserialorfullyparallel.
LargeregisterfileonTrimedia—Videoprocessingrequiresworkingwithalargedataset;alargeregisterfilepreventsoveruseofexpensiveloadandstoreinstructions.TriMediaprocessorTM3270hasaunifiedregisterfilewith12832‐bitregisters.
SpecificdomainISAinstructions—Notalltasksfoundinvideoprocessingcodecsareparallelizable,forexampleinH.264Context‐BasedAdaptiveBinaryArithmeticCoding(CABAC)intrinsicsequentialbehaviorcannotbeproperlyoptimizedwithSIMD.TheTriMediaISAisequippedwithseveralnativeinstructionstosimplifyCABACprogrammingtocompensateforthisdisadvantageandminimizesequentialexecution.TIC6000providesalsospecificdomaininstructionsdesignedtooptimizetheexecutionofimageprocessingkernels.
Fixedpointarithmetic—OntheTIC6000processorsfixed‐pointarithmeticislesscomputationallydemandingthanfloating‐pointarithmetic,andthusasuitabledesignchoicetoincreasearithmeticprocessingspeed.
Predication—Bothfamiliesofprocessorsallowinstructionstobeexecutedconditionally(predication),thusreducingcostlybranching.
Delayslots—OntheTIC6000,forfixed‐pointinstructions,anumberofdelayslotsareavailable.Thenumberofdelayslotsisequivalenttothenumberofadditionalcyclesrequiredafterthesourceoperandsarereadfortheresulttobeavailableforreading:foramultiplyinstructionthisis1,foraloadthisis4,andforabranchthisis5.OnTriMedia,fivedelayslotsareprovidedonlyforbranchinstructions.
3.3.2 Lowpowerconsumption
ClockgatingandfrequencyscalingonTriMedia—TriMediaappliestwomainpowersavingtechniques:clockgatingandvoltage‐frequencyscaling.ThelatestTrimediaimplements70clockdomains,forexampleallstagesofallfunctionalunitsaregated.Thenormalsupplyvoltageis1.2VbuttheTriMediaguaranteesnormaloperationsat0.8Vatalowerfrequency.ThemaximumoperatingfrequencyfortheTM3270is350Mhz,ampleroomforscalingdownitsfrequencywhenprocessingtypicaltaskssuchasMP3decoding(only8Mhzneeded).
ClusteringonTIC6000—Ontheotherhand,theTIC600family,toavoidaslowandpower‐hungryregisterfile(read/writeportsfromeachregistertoeachofthe8FUs)andalargeforwardingnetwork,twodatapaths(i.e.clusters)areavailable.Thisallowshigherfrequenciesandlowerpowerconsumption.TriMedia’sregisterfileistwicethesizeoftheTIC6000andisunified.InthiswayTriMediadesignerschoosetosavememorybandwidthwithalargeregisterfileandTIC6000designerschoosetosaveonpowerconsumptionandtoreachhigherfrequencieswithasmallerdividedregisterfile.
MemoryAccess—OnTIC6000,4interleavedsingle‐portedmemorybanksassurelowerpowerconsumption.ThishowevercanleadtoreducedperformanceinaVLIWarchitecture:onlyoneaccesstoeachbankisallowedpercycle;iftwoparallelloadinstructionsarebothtryingtoaccessthesamebank,oneloadmustwait,resultinginamemorystall.OnTriMedia,lowpowerconsumptionisalsoaccomplishedwitha4‐waysetassociativecache.

12
4 SDRprocessors:SODAandEVP
4.1 SODA
Remark:unlessotherwisespecified,theinformationinthissectionistakenfromthemainSODApaperbyYuanLinetal.[13]
4.1.1 Introduction
SODA(Signal‐processingOn‐DemandArchitecture)isa(proposed)SDRprocessorarchitecturedevelopedattheUniversityofMichigan.Itsmaindesigngoalsare:highperformance,energyefficiency,andprogrammabilitythroughacombinationoffeaturesthatincludesingle‐instructionmultiple‐data(SIMD)parallelism,andhardwareoptimizedfor16‐bitcomputations.
Theproposedarchitecturehasbeenimplementedon180nmprocesstechnologies,anditisprojectedtomeetthethroughputandpowerrequirementsofcurrentwirelessprotocols(seeFigure1)whenimplementedon65nm.
4.1.2 Architectureoverview
Overview
TheSODAsystemiscomposedof(seeFigure6):fourprocessingelements(PEs),ascalarARMcontrolprocessorandaglobalscratchpadmemory,allconnectedthroughasharedbus.
Figure6–OverviewofSODAmulticoreDSParchitecture
ProcessingElement
EachPEconsistsof3pipelinesthatruninlockstep:awideSIMDpipeline,ascalarpipelineandanAGU(addressgenerationunit)pipeline.
• ThewideSIMDunitrunsmostofthecomputeintensivealgorithms(FFT,Viterbi,Turbodecoder,etc.).TheSIMDpipelineconsistsof32clusterswitha16‐bitdatapath(seeFigure7).Eachclustercontains1ALUandasimpleregisterfilewith2readportsand1writeport.Ashuffleexchangenetworkinterconnectstheclusters.
• ThescalarunitisusedtosupportmanyoftheDSPalgorithmsthatarescalarinnatureandcannotbeparallelized.Thescalarpipelineconsistsofone16‐bitdatapath.
• AnAGU(addressgenerationunit)pipelinehandlesDMAtransfersandmemoryaddresscalculationsforboththescalarandSIMDpipelines.

13
TheSIMDShuffleNetwork(SSN)supportintra‐processordatamovements.Itcontainsashuffleexchangenetworkandaninverseshuffleexchangenetwork,whichallowstoefficientlyperformpermutationsonvectors,acommontaskinwirelesscommunicationalgorithms.
Figure7–ProcessingElementarchitecture
Controlprocessor
TheARMprocessorismainlyusedasasystemcontrollertohandleprotocols’controlcodeandstatetransitions.
Memory
Therearenocachestructures:boththelocalPEmemories(4KBscalar,8KBSIMD)andtheglobalscratchpadmemory(64KB)aremanagedbysoftwarethrougheachPE’sDMAcontrollertowhichalllocalandglobalmemoriesarevisible.
TheSIMDmemorycontainstwo512‐bitports(oneread,onewrite).Thescalarmemorycontainstwo16‐bitports(oneread,onewrite).
CommunicationsbetweenPEsareviascalarstreams,butintra‐PEcomputationsarevectoroperations.Therefore,supportforascalar‐vectorinterfacebetweenthescalarandSIMDpipelineisnecessary.ThisisshowninFigure6asWtoSandStoW.
4.1.3 Compilersupport
ItisclearthatheterogeneousmultiprocessorchipssuchasSODAprovidedifficultchallengesforprogrammersandcompilerstoefficientlymapapplicationsontothehardware.Especiallysincemanyoftheprojectedhigh‐performancefeaturesrelyonstaticscheduling.
Anewdataflowprogrammingmodel,calledSPIR(SignalProcessingIntermediateRepresentation),designedformodelingSDRapplicationshasbeenresearchedbyLinetal[14].Itactsasanintermediaterepresentationthatcanbeautomaticallygeneratedfromexistinghigh‐levellanguages(suchasC)throughacompilerfront‐end.ThegeneralideaisthatSPIRrepresentsataskgraphconsistingofasetofnodes(tasks,forexampleadescrambler)interconnectedwitharrows(dataflow).Eacharrowspecifiestheinputandoutputstreamratesforthesourceanddestinationnodes.Thispropertyallowsacompilertogeneratestaticexecutionschedules.

14
4.2 EVP
Remark:unlessotherwisespecified,theinformationinthissectionistakenfromthemainEVPpaperbyVanBerkeletal.[16]
4.2.1 Introduction
EmbeddedVectorProcessor(EVP)isanapplicationspecificprocessordevelopedbyNXP.TheEVPwasdevelopedalmostexclusivelyforSDRapplicationsandisaimedmainlyatconsumerhandhelddevicessuchasPDA,SmartPhones,MobilePhones,etc.
EVPhasbeendesignedtoexecutethetypicalalgorithmsfoundinthemodemstage(see§2.2)inrealtimeandinapowerefficientmanner.EVPaccomplishesthiswithdataandinstructionlevelparallelism(vectorprocessingandVLIW)andbyprovidingapplicationspecificinstructions.
4.2.2 ArchitectureOverview
Figure8showsablockdiagramoftheEVParchitecture.Theprocessorconsistsofageneralscratchpadprogrammemory,aVLIWcontroller,anAddressCalculationUnit(ACU),avectorregisterfile,ascalarregisterfile,avectormemory,asetofvectorfunctionalunits(FUs),andasetofscalarfunctionalunits.Themainwordis16bits.
TheVLIWcontrollerdispatchesaVLIWinstructionoverthevariousvectorandscalarfunctionalunits.ThemaximumVLIW‐parallelismavailableequalsfivevectoroperationsplusfourscalaroperationsplusthreeaddressupdatesplusloop‐control.
ThevectorFUssupportSIMD,allowingfordataparallelism.TheSIMDwidthoftheEVPis16(256bits).ThisimpliesthattheEVPcanexecutethesameinstructionon16wordsof16bits,32wordsof8bitsor8wordsof32bits.
SomeofthevectorFUsareveryspecific:theMACunitprovidesforMultiply‐Accumulates,theshuffleunitcanrearrangetheelementsofsinglevector,theintravectorunitprovidesvectorspecificoperationssuchasdeterminingthemaximumelementofavector,thecodegenerationunitprovidessupportorCDMAspecificfunctionality(i.e.socalled“codechip”generation).
Figure8EVPArchitecture
4.2.3 CompilerSupport
TheEVPcomeswithitsownlanguageandowncompiler.EVPprogramsarewritteninEVP‐CasupersetofANSI‐C.CprogramsaremappedexclusivelytothescalarunitsoftheEVP.ToexploittheVLIW,SIMD,andvectorparallelismitismandatorytousetheEVPlanguageextensionsandsomelibraries.ItisstillataskoftheprogrammertomanuallymaptheDSPbasebandalgorithmstotheir“vectorized”versioninEVP‐C.

15
Furthermore,manualoptimizationisrequiredtoachieveefficientvectorizedcode.Asanexample,thecodeproducedbyaprototypeEVP‐CcompilerforaspecificFFTimplementationrequired25%morecyclesthanhand‐scheduledassemblycode.[16]
4.3 ComparingSODAandEVP
ThissectionwilldiscusswhycertaindesigndecisionswerechosenforbothSODAandEVP.
4.3.1 Designgoals
Asstatedin§2.1,themaindesigngoalsforanSDRprocessorarehighperformance,energyefficiency,andprogrammability.Thetablebelowsummarizesthetechniquesusedtoachievethis.Moredetailonthedifferenttechniquesisprovidedinthesubsequentparagraphs.
Unlessotherwisementioned,alltechniquesanddiscussionsapplytobothSODAandEVP.
Highperformance Energyefficiency Programmability
• Multipleparallelism
• VLIW• SIMD• Multiplecores(SODA
only)
• Nobranchprediction • VLIW/SIMD
• Hardwareoptimizedfor16‐bitfixed‐pointoperations
• Fixed‐pointoperations
• Scratchpadmemory • Nocache
• SpecialDSPinstructions • SpecialDSPinstructions
• SeparatedSIMDmemory
4.3.2 Wirelessprotocolcharacteristics
Wirelessprotocolsarecharacterizedbyanumberofspecificproperties,whichhaveanimportantimpactonthedesignofaDSPsystem.
• HighDataLevelParallelism—MostofthecomputationallyintensiveDSPalgorithmshaveabundantdatalevelparallelism(forexamplethe“searcher”inaW‐CDMAprotocol,canberepresentedby320‐widevectors),muchmorethaninstructionlevelparalellism.[13]Parallelismiselaboratedonin§4.3.3.
• 8to16bitdatawidth—Mostalgorithmsoperateonvariableswithsmallvalues.Analysisoftwotypicalwirelessprotocolsshowsthatthereshouldbestrongsupportfor8and16‐bitfixed–pointoperations.32‐bitfixed‐pointoperationsandfloating‐pointsupportisnotnecessary.[13]
• Realtimerequirements—Strictreal‐timerequirementinwirelessprotocolsrequiresdeterministicarchitecturalbehaviour.Thereforefeaturessuchascaching,multithreadingandpredictionarenotwellsuited.[13]
• Vectoroperations—Intravectoroperations(vectorreductions)andshufflingofdatawithinavectoriskeytoanumberofcommonalgorithms(e.g.FFT).Thereforespecific,powerandperformanceoptimal,supportfortheseoperationsshouldbeprovided.[16]Thisiselaboratedonin§4.3.4.
4.3.3 Parallelism
ThekeytoachievethehighperformancerequiredforSDRistomaximallyexploittheparallelismavailable.
SODAprovidesthreelevelsofparallelism:multiplecores(PEs),VLIWandSIMD.[13]
• Multiplecores—Periodicreal‐timedeadlinesrequirealgorithmstocomputewithdifferentdataratesanddifferentlatencies.Realizingthisforcomplexprotocolsusingasinglethreadedsystemistooexpensive(forexample,complexcontextswitchingsoftware).

16
However,itisnecessarytosupportefficientconcurrentDSPalgorithmexecution.Theretomultiplecores,implementedasPEs,areused.(Eachprotocolpipelineisbrokenupintokernels,andeachkernelisassignedtoaPE.)Sincethetaskinthewirelessprotocolsanalysedcanbepartitionedinto4majortaskgroups,4PEshasbeenchosen.
• VLIW—Thethreepipelines–scalar,SIMDandAGU–canbeconsideredasanasymmetricVLIWpipeline(asymmetric,sincee.g.scalarinstructionscannotbescheduledontheSIMDpipelineandviceversa).Thescalarpipelineisnecessarybecausetherearemanysmall,importantscalaralgorithms.WideSIMDunitswouldbetooinefficientinsupportingthesescalarandnarrowSIMDoperations.
• SIMD—ThecomputationintensiveDSPalgorithmsinwirelessprotocolsusuallycontainoperationsonverywidevectors.Inaddition,vectorwidthsandstridesareknownatcompiletime.Althoughthismakesagoodfitforvectorarchitectures,theextrahardwaresupportfordynamicvectormanagementisunnecessary,asalldataoperationscanbestaticallyscheduled.ThisfavorsawideSIMD‐styleexecution.ThewidthoftheSIMDunitisnotchosentobe32clustersbyaccident.Itistheoptimalpowerconsumptionconfiguration,giventheestimatedcomputationrequirementof10GOPSperPE.Figure9mapsthepowerconsumptiontoSIMDwidth.Therequired10GOPScanbeachievedthroughanumberofSIMD/frequencycombinations,forexamplea2‐wideSIMDrunningat5GHz.Highfrequenciesrequireunrealisticdeeppipelines(indicatedby‘I’),andsufferfromhighpowerconsumption.
Figure9–AveragenormalizedpowerrequirementsofaPE(180nm)
EVPonlyprovidestwolevelsofparallelism:VLIWandSIMD.However,EVPdiffersinitsVLIWorganization:itcanexecutemultipletypesofwideSIMDoperationsinparallel.WhilethisprovidessupportforahigherdegreeofILP,italsorequiresamorecomplexregisterfile.BecausethereisverylimitedILPamongvectorcomputations(i.e.datalevelparallelismismuchmoreprevalentthaninstructionlevelparallelism),thisextralevelofparallelismdoesnotaddmuchtoperformance.[13]
TheEVPSIMDwidthisscalable,buthasbeensetto16forthefirstEVPprototype,labeledEVP16.[16]Theexactreasonofchoosing16isnotspecificaswasthecaseforSODA.Ofcourse,higherSIMDwidthwillprovideforhigherdataparallelism.
4.3.4 SpecialDSPinstructions
SODAcontainsspecialDSPinstructions,bothtooptimizeperformanceandpowerconsumption.ProvidedarespecialvectoroperationssupportedbytheSIMDshufflenetwork(forexample,thebutterflyoperationtoenhanceFFTperformance)andvectortoscalaroperations(forexample,determiningthemaximumvalueinavector).Multiply‐Accumulate(MAC)instructionsarenotprovidedbutinsteadhandledbyvectorlogicoperations(predicatednegation)sincemanyofthesemultiplicationoperationsarewith1bitvalues,consumingsignificantlylesspower.[13]

17
EVPprovidesanumberofspecializedFUs(seealsoFigure8).TheshuffleunitprovidesfunctionalitysimilartoSODA’sSSN(SIMDshufflenetwork).TheintravectorunitprovidesfunctionalitysimilartoSODA’sspecialinstructionsforvectortoscalaroperations(forexampleitcanalsodeterminethemaximumvalueinavector).ThecodegenerationunitsupportsCDMA‘codechip’generation(acodechipisafundamentalunitoftransmissioninCDMA,awirelesschannelaccessmethod).Inasingleclockcycle16successivecomplexcodechipsaregenerated.Theunitisconfigurablefordifferentstandard(UMTS,GPS,etc.).ContrarytoSODA,theMACunitprovidessupportforMACinstructions.[16]
4.3.5 Other
Nobranchprediction—Branchpredictionisnotimplemented,becauseformostDSPalgorithmsthecorekernelsconsistofshallownestedloops.Instead,forSODA,aloopcounter‐basedbranchinstructionisavailable.[13]
Scratchpadmemory/nocache—Tomeettheneedforhighmemorybandwidthandlowpowerconsumption,anon‐chipscratchpadmemoryisusedwhichissmallandhencefast.Withnodatatemporallocality(streamingdata),cachestructuresprovidelittleadditionalbenefits,intermsofpowerandperformance,oversoftwarecontrolledscratchpadmemories.[13]
SeparatedSIMDmemory—BothSODAandEVPhaveadedicatedSIMDmemory.Ingeneraltwomemoriesconsumelowerpowerthanoneunifiedmemory.Inaddition,thisseparationallowsoptimizationoftheread/writeportsforitsintendeduse(inthecaseofSODA:512‐bitfortheSIMDmemoryand16‐bitforthescalarmemory).[13]
Powerconsumption—At180nm,SODA’spowerconsumptionis3W.Thisistoohighforembeddedmobiledevices(200mWisatypicalcellularphone’spowerbudgetforthephysicallayer).Scalingto65nmpredictsthepowerconsumptiontoaround250mW.[13]NopracticalcomparabledataisgivenfortheEVP’spowerconsumption,althoughEVPliteraturesomewhatunclearlymentionsthatrunningcertainUMTSprotocolsontheEVPresultsinapowerconsumptioncloseto1W(at90nm);otherprotocolsperformbetter.[16]
BothEVPandSODAliteraturedoesnotmentionsupportunalignedloads,forwardingandcompression,whichseemstoindicatethatitisnotsupported.
4.4 FinalthoughtsonSODAandEVP
ItshouldbeclearfromthepreviousoverviewthatkeytoachievingtheperformancerequiredforSDRliesinexploitingasmuchaspossibletheavailableparallelism.How,then,canbothSODAandEVPreachthisperformance,giventhatSODAismuchbetterequippedforexploitingparallelism(runningatapproximatelythesamefrequency)?SODAinadditionnotonlyhasfourcores,itsSIMDpipelineis2timeswider.
AresponsefrombothaSODAandEVPdevelopertothissamequestionclarifiesanumberofthings:
• BothcitethedifferenceinVLIWorganization—theEVPcanexecutemultipletypesofwideSIMDoperationsinparallel.[15][18]
• TheEVP‘outsources’anumberofalgorithmstootherprocessors(suchastheViterbidecoding),whereasSODAperformsthesefunctionalitiesonchip(i.e.ondesignatedPEs).[15]
• ForEVPtocatchupwithnewandmoredemandingprotocols,multiplecoresareindeednecessary.[18]
• Finally,SDRisarelativelynewresearchtopic.Itislackingstandardizedbenchmarks,andeachwirelessprotocolhascountlessnumberofdifferentimplementationsandconfigurations.Thesedifferentconfigurationsandimplementationscanaffectperformance/powersignificantly.Hence,itisveryhardtocomparetwoseparateddevelopedandtestedprocessors.[15]

18
5 Literature
5.1 General[1] Wikipedia[2] JasonFritts,WayneWolfandBeddeLiu,Understandingmultimediaapplication
characteristicsfordesigningprogrammablemediaprocessors,1999
5.2 TriMedia
TheTriMediasectionwasbasedmainlyonVanDeWaerdt’spaper.Hedesignedthisprocessorforhisthesisthereforehewasabletoexplainthoroughlymanytechnicaldetailswithenoughclarityandtothepoint.Theremainingsourceswereusedmainlytoseethe“bigpicture”oftheTriMedia,theyarelesstechnicalandmoreconcernedwithconsumerapplicationsandbusinessaspects.[3] VandeWaerdt,etal.TheTM3270MediaProcessor.Proceedingsofthe38thAnnual
IEEE/ACMInternationalSymposiumonMicroarchitecture(MICRO’05).2005[4] HoogerbruggeJanetal.InstructionSchedulingforTriMedia.PhilipsResearchLaboratories.[5] BoresSignalProcessing.TriMediaOverview.
http://www.bores.com/courses/tm_overview/index.htm.Lastupdated:March2007.[6] VandeWaerdt,TheTM3270Mediaprocessor,October2006,TUDelft,ISBN90‐9021060‐1,
PhDThesis
5.3 TIC6000
TexasInstrumentsprovidesextensivedocumentationontheC6000platformandthedifferencesbetweenspecificgenerations.Thesedocumentsareingeneralverycomplete,however,informationonwhycertainfeaturesareimplementedarenotincluded.[7] TexasInstruments,TMS320C6000CPUandInstructionSetReferenceGuide,SPRU189d,July
2006[8] TexasInstruments,TMS320C6000TechnicalBrief,SPRU197d,February1999[9] TexasInstruments,TMS320C64xTechnicalOverview,SPRU395b,January2001[10] TexasInstruments,TMS320C62xDSPCPUandInstructionSetReferenceGuide,SPRU731,July
2006[11] Internetforumpost“CcompilersforTITMS320DSPs”,2005‐3‐02,
http://www.dsprelated.com/showmessage/30734/1.php[12] JanPartheyandRobertBaumgartl,PortingGCCtotheTMS320C6000DSPArchitecture,
AppearedintheProceedingsofGSPx’04,SantaClara,September2004
5.4 SODA
Thepaper“SODA,ALowpowerArchitectureForSoftwareRadio”seemsverycompleteandthorough,discussingtheSODAarchitectureaswellastherationalebehindthedifferentdesigndecisions,whilealsosettingthemofagainstthealternatives.Itwaslackinghoweverindiscussinghowsuchacomplexarchitecturecanbereasonablyprogrammed.[13] YuanLinetal.SODA,ALowpowerArchitectureForSoftwareRadio.InProceedingsofthe
33rdAnnualInternationalSymposiumonComputerArchitecture,2006.[14] YuanLinetal,HierarchicalCoarsegrainedStreamCompilationforSoftwareDefinedRadio,In
CASES’07,2007[15] PersonalemailcommunicationwithKeesMoerman,2008‐12‐16.

19
5.5 EVP
TherewasaverylimitedamountofinformationavailableintheWebontheEVP.ThissectionwasbasedmainlyonVanBerkel’spaper.ThispaperdoesnotfocusontheEVPbutonSDRapplicationsonvectorprocessorsandofferstheEVPasanexample;itdoesnotexploreindepthitsarchitecturalfeatures.Moerman’sarticleoffersabriefbusinessorientedviewoftheEVPcapabilitiesandapplications.[16]VanBerkeletal.VectorProcessingasanEnablerforSoftwareDefinedRadioinHandheld
Devices.EURASIPJournalonAppliedSignalProcessing2005.[17]Moerman,Kees.Embeddedvectorprocessorisonewaytotunesoftwaredefinedradios.
WirelessNetDesignLine.http://www.wirelessnetdesignline.com/202403292;jsessionid=5UPHUZ4YXPVRYQSNDLRSKHSCJUNN2JVN?pgno=1.Lastupdated:October2007.
[18] PersonalemailcommunicationwithKeesMoerman,2008‐12‐16.
Top Related