







Languages
Pages
Legal


Julia Stoyanovich, William Mee, Kenneth A. Ross
New England DB Summit 2010
Semantic Ranking and Result Visualizationfor Life Sciences Publications
2

3
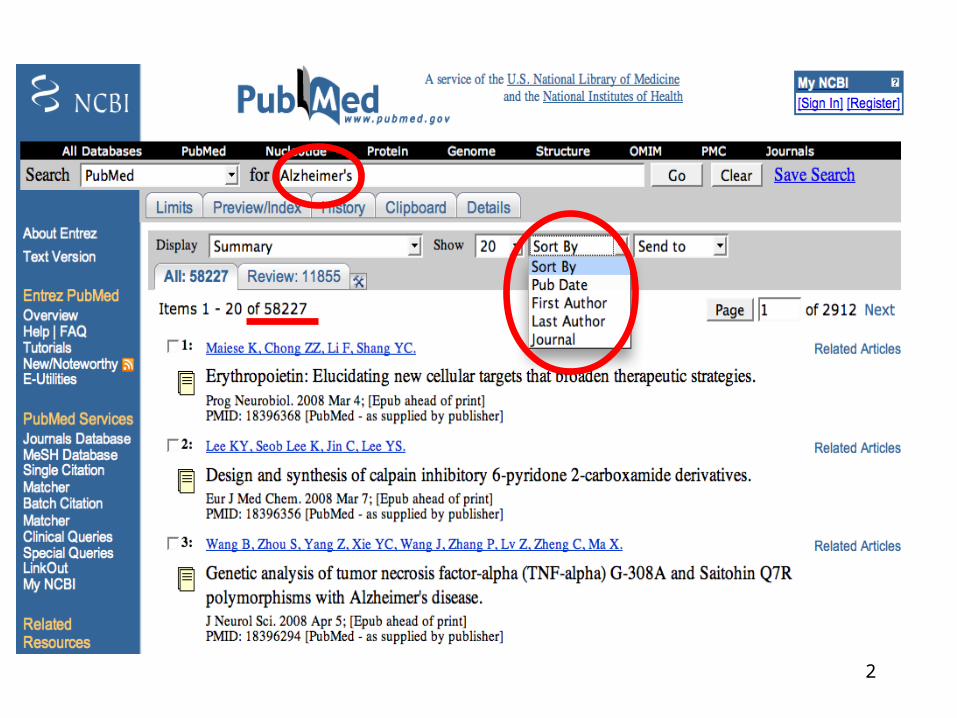
Data and Query Processing• PubMed corpus
– over 19 million articles and growing– articles annotated with MeSH terms– annotators are instructed to annotate with the most specific term
possible
• Medical Subject Headings (MeSH) annotations– over 25K term descriptors– organized into a polyhierarchy– 17 trees, almost no cycles
• Entrez search engine– query translation, synonym & ontology expansions
mosquito -> "culicidae"[MeSH Terms] OR "culicidae"[All Fields] OR "mosquito"[All Fields]
4
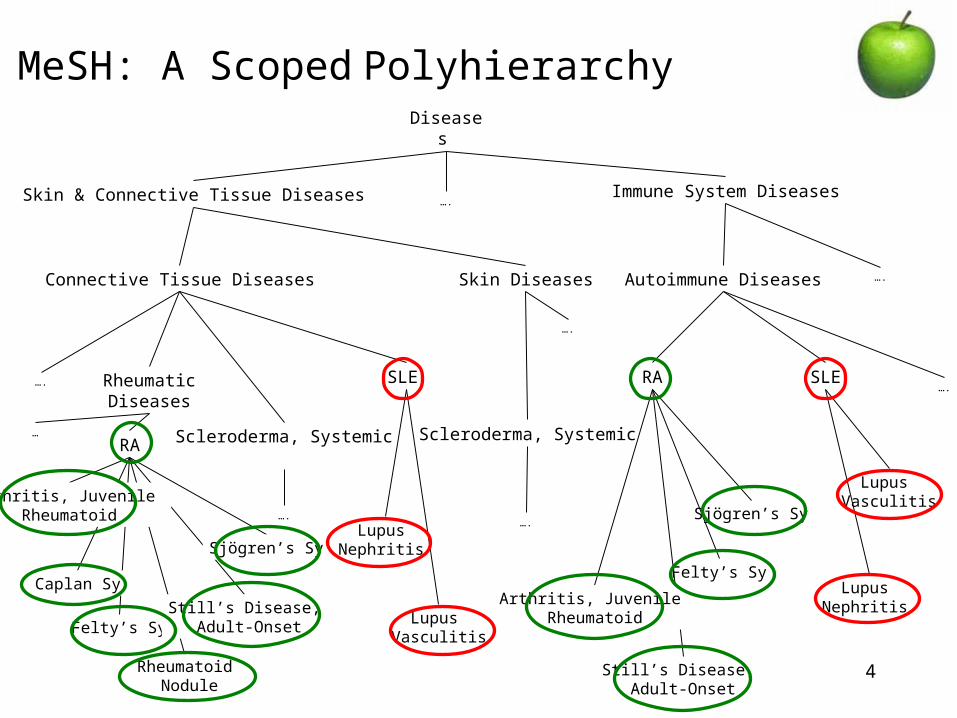
Connective Tissue Diseases Autoimmune Diseases
Rheumatic Diseases
Diseases
Skin & Connective Tissue Diseases
RA
Felty’s Sy
Arthritis, Juvenile Rheumatoid
Rheumatoid Nodule
Still’s Disease, Adult-Onset
Skin Diseases
….
….
….
…
Immune System Diseases
….
RASLE SLE….
Lupus Nephritis
Lupus Vasculitis
Lupus Nephritis
Lupus Vasculitis
Felty’s Sy
Sjögren’s Sy
Still’s Disease, Adult-Onset
Arthritis, Juvenile Rheumatoid
Caplan Sy
Sjögren’s Sy
Scleroderma, SystemicScleroderma, Systemic
….….
MeSH: A Scoped Polyhierarchy

5
6
C C
T
A
D
B
E
G H F G
F
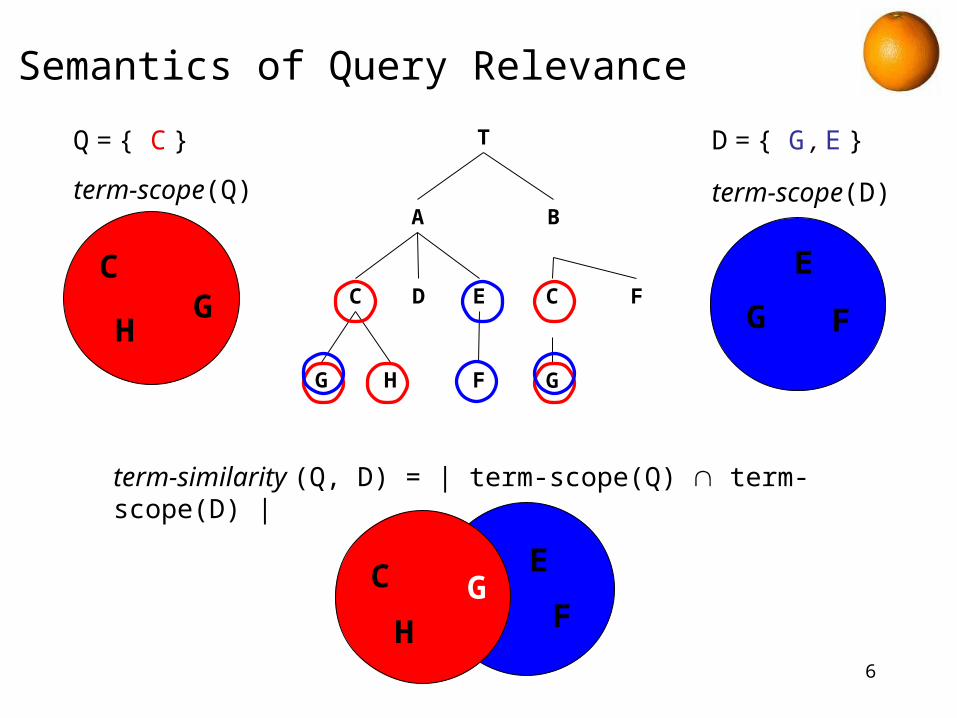
Q = { C } D = { G , E }
term-scope(D)
F
E
G
C
term-scope(Q)
GH
GC
H
E
F
term-similarity (Q, D) = | term-scope(Q) term-scope(D) |
Semantics of Query Relevance

7
Q = { E , B }
D = { F , G }
C C
T
A
D
B
E
G H F G
F
term-similarity (Q, D) = 2
term-scope(Q)
GC
E
term-scope(D)
F
B
But F contributes to both query terms, while G only contributes to one!
Idea: count occurrences of document terms within the context of query terms.
Semantics of Query Relevance

8
conditional-similarity (Q, D): count the # of ancestor-descendant pairs
balanced-similarity (Q, D): normalize the contribution of each query term
C C
T
A
D
B
E
G H F G
F
B C E F G
F G
Semantics of Query Relevance
Q = { E , B }
D = { F , G }

9
Q = { q1, …, qn } D = { d1, …, dm }
1. term-scope (Q) = term-scope(q1) … term-scope( qn )
2. term-scope (D) = term-scope(d1) … term-scope(dm )
3. term-similarity (Q, D) = | term-scope(Q) term-scope(D) |
Can be expensive for queries, documents with large term scopes!
| (A B) (Y Z) |
= | (A Y) (A Z) (B Y) (B Z) |
< |A Y| + |A Z| + |B Y| + |B Z|
• Pre-compute term-similarity (s,t) for all (s,t)– Practical, since 160K pairs have term-similarity(s,t) > 0, out of over 600M
• At query time– Compute score upper-bounds for all documents– Compute term-similarity only for the promising documents
• Useful upper-bounds also hold for conditional and balanced-similarity
Computation of term-similarity
a bc
a bc c

10
System Architecture
batch3
Query Manager
1
query
eUtils API
batch2
batch1
Java RMI
23
4
In-memoryDB PubMed

11
Performance: Ranked Retrieval
* results for 150 queries in our workload
Term Similarity
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
>0% >10% >20% >30% >40% >50% >60% >70% >80% >90%% improvement
% queries
top-1top-10top-100
12
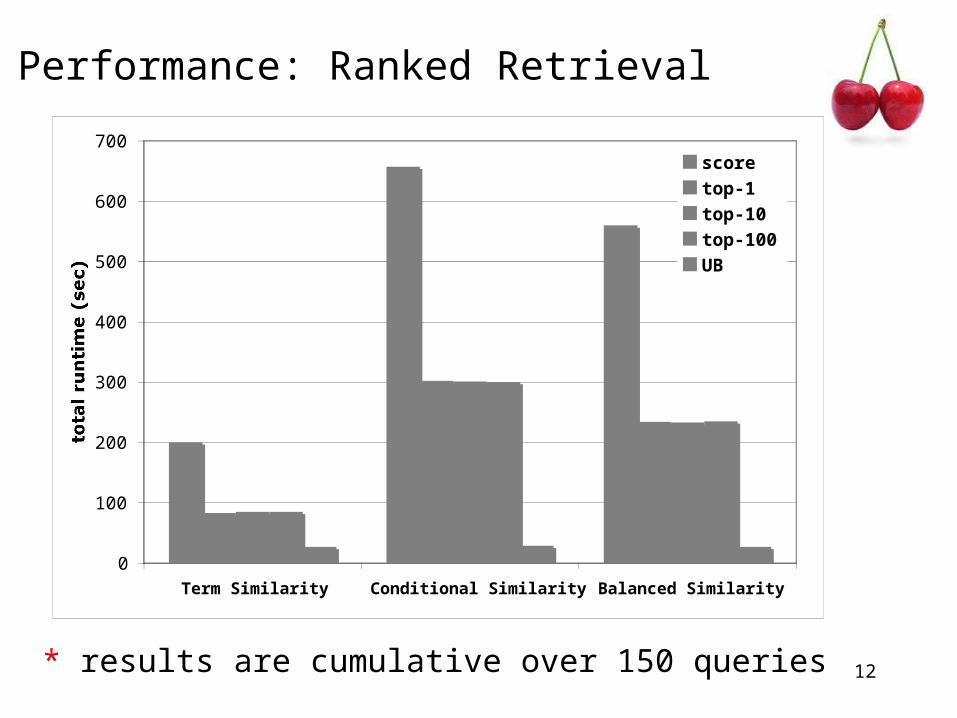
Performance: Ranked Retrieval
* results are cumulative over 150 queries
0
100
200
300
400
500
600
700
Term Similarity Conditional Similarity Balanced Similarity
total runtime (sec)
scoretop-1top-10top-100UB

13
Performance: Skyline for term-similarity
* large queries > 20K results; 30% of the workload, 75% of the time

14
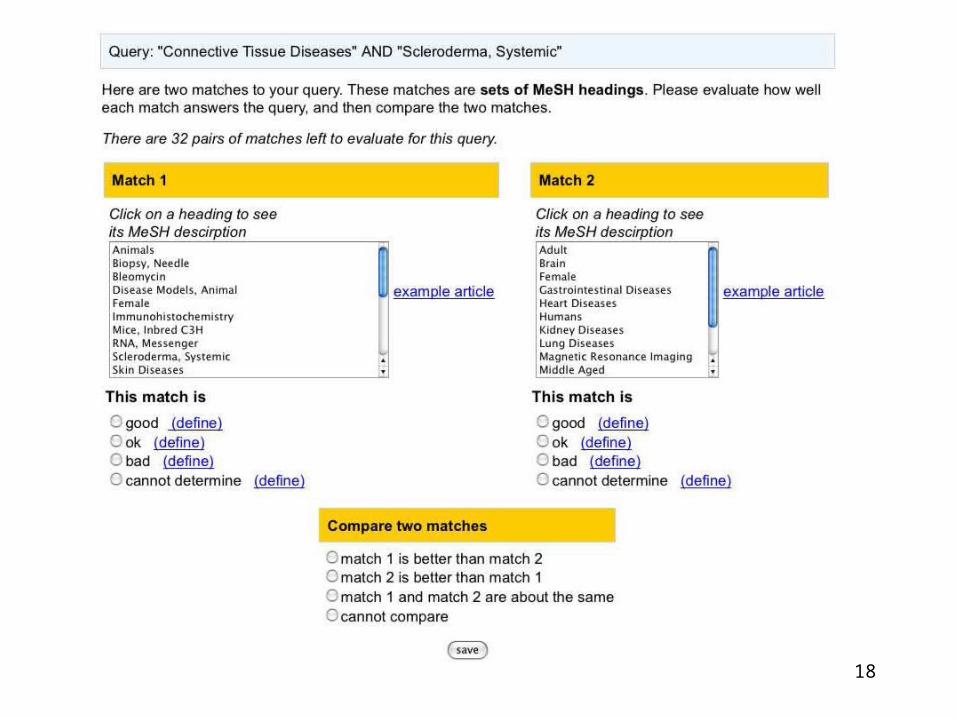
• User study – 8 users, researchers in medicine, biology, bioinformatics
• 1 query per user, total 670 individual, 335 pair-wise relevance judgments• conducted free-form interviews with some users
– 2 baselines• distance-based• information-theoretic
• Quantitative analysis of results– We appear to outperform baselines for queries with polyhierarchy features– Baselines appear to outperform our measures for several other queries– For some queries no measure correlated with user’s perception of quality
• Qualitative analysis of results– Many aspects inform a user’s judgment, ontology is one of them– Both general and specific concepts are important
• Plan to scale up the evaluation by making our system available to the scientific community at large
Evaluation of Effectiveness

15
Related Work
• Hierarchy-based similarity measures – [Ganesan et al, 2003] compare sets / multisets of terms, leaf nodes,
hierarchy is a tree– [Rada & Bicknell, 1989] distance is a mean-path length between
pairs of query & document terms– [Lin & Kim, 1993; Resnik, 1995] information-theoretic measures,
typically distance via ancestor
• Weighted set similarity [Hadjieleftheriou, 2007]
• Bibliographic search in life sciences– Entrez, GoPubMed, NextBio
• Efficient computation of skylines– [Bentley 1980; Borzsonyi et al 2001; ….]

16
Contributions
• Similarity measures for scoped polyhierarchies– Distance is via descendants, not via ancestors– Scoping is exploited– Alternative semantics of combining contributions of individual terms
to the score
• Efficient computation of similarity using score upper-bounds
• Efficient computation of a 2D skyline using score upper-bounds, with lazy evaluation of coordinates
• Experimental evaluation– Efficiency– User study

17
Thank you!
18
Top Related