







Languages
Pages
Legal


INTRODUCTION TO ARTIFICIAL INTELLIGENCE
Massimo Poesio
LECTURE 16: Unsupervised methods, IR, and lexical acquisition
2
.
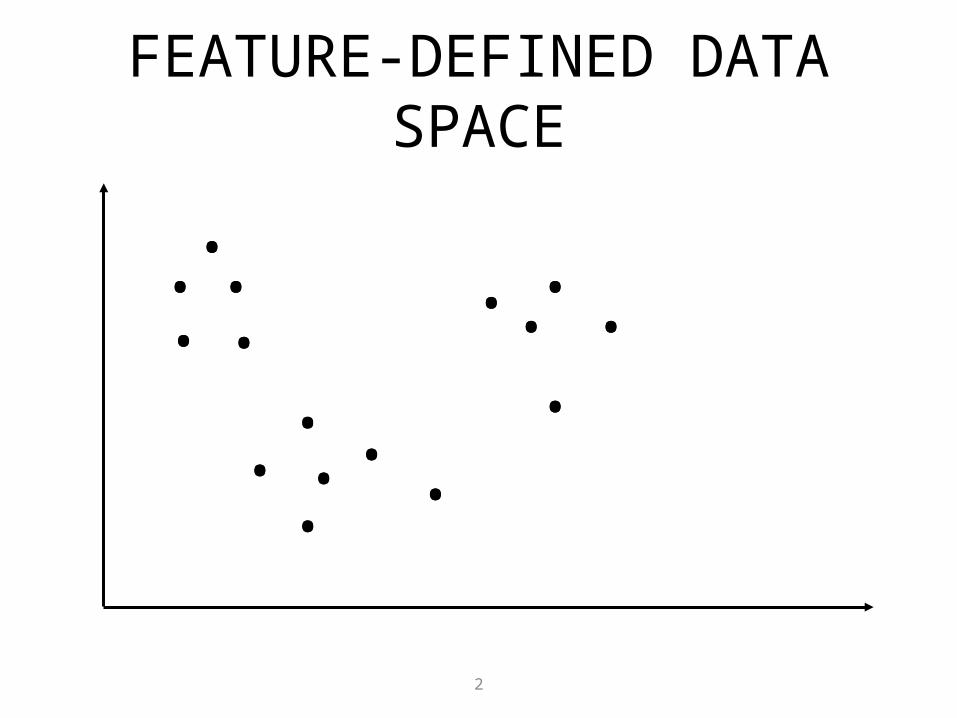
FEATURE-DEFINED DATA SPACE
.
...
. .. ..
..
....
.
...
. .. ..
. ....
.

UNSUPERVISED MACHINE LEARNING
• In many cases, what we want to learn is not a target function from examples to classes, but what the classes are– I.e., learn without being told

EXAMPLE: TEXT CLASSIFICATION
• Consider clustering a large set of computer science documents
NLP
Graphics
AI
Theory
Arch.

6
CLUSTERING• Partition unlabeled examples into disjoint
subsets of clusters, such that:– Examples within a cluster are very similar– Examples in different clusters are very different
• Discover new categories in an unsupervised manner (no sample category labels provided).

Deciding what a new doc is about
• Check which region the new doc falls into– can output “softer” decisions as well.
NLP
Graphics
AI
Theory
Arch.
= AI

8
Hierarchical Clustering
• Build a tree-based hierarchical taxonomy (dendrogram) from a set of unlabeled examples.
• Recursive application of a standard clustering algorithm can produce a hierarchical clustering.
animal
vertebrate
fish reptile amphib. mammal worm insect crustacean
invertebrate

9
Agglomerative vs. Divisive Clustering
• Agglomerative (bottom-up) methods start with each example in its own cluster and iteratively combine them to form larger and larger clusters.
• Divisive (partitional, top-down) separate all examples immediately into clusters.

10
Direct Clustering Method
• Direct clustering methods require a specification of the number of clusters, k, desired.
• A clustering evaluation function assigns a real-value quality measure to a clustering.
• The number of clusters can be determined automatically by explicitly generating clusterings for multiple values of k and choosing the best result according to a clustering evaluation function.

11
Hierarchical Agglomerative Clustering (HAC)
• Assumes a similarity function for determining the similarity of two instances.
• Starts with all instances in a separate cluster and then repeatedly joins the two clusters that are most similar until there is only one cluster.
• The history of merging forms a binary tree or hierarchy.

12
Cluster Similarity• Assume a similarity function that determines the
similarity of two instances: sim(x,y).– Cosine similarity of document vectors.
• How to compute similarity of two clusters each possibly containing multiple instances?– Single Link: Similarity of two most similar members.– Complete Link: Similarity of two least similar members.– Group Average: Average similarity between members.

13
Non-Hierarchical Clustering
• Typically must provide the number of desired clusters, k.
• Randomly choose k instances as seeds, one per cluster.
• Form initial clusters based on these seeds.• Iterate, repeatedly reallocating instances to different
clusters to improve the overall clustering.• Stop when clustering converges or after a fixed
number of iterations.

CLUSTERING METHODS IN NLP
• Unsupervised techniques are heavily used in :– Text classification– Information retrieval – Lexical acquisition

CLUSTERING METHODS IN NLP
• Unsupervised techniques are heavily used in :– Text classification– Information retrieval
– Lexical acquisition

2004/05 ANLE 16
Feature-based lexical semantics
• Very old idea in lexical semantics: the meaning of a word can be specified in terms of the values of certain `features’ (`DECOMPOSITIONAL SEMANTICS’)– dog : ANIMATE= +, EAT=MEAT, SOCIAL=+– horse : ANIMATE= +, EAT=GRASS, SOCIAL=+– cat : ANIMATE= +, EAT=MEAT, SOCIAL=-

Feb 21st Cog/Comp Neuroscience 17
FEATURE-BASED REPRESENTATIONS IN PSYCHOLOGY
• Feature-based concept representations assumed by many cognitive psychology theories (Smith and Medin, 1981, McRae et al, 1997)
• Underpin development of prototype theory (Rosch et al)• Used, e.g., to account for semantic priming (McRae et al,
1997; Plaut, 1995)• Underlie much work on category-specific defects (Warrington
and Shallice, 1984; Caramazza and Shelton, 1998; Tyler et al, 2000; Vinson and Vigliocco, 2004)

Feb 21st Cog/Comp Neuroscience 18
SPEAKER-GENERATED FEATURES (VINSON AND VIGLIOCCO)

2004/05 ANLE 19
Vector-based lexical semantics
• If we think of the features as DIMENSIONS we can view these meanings as VECTORS in a FEATURE SPACE– (An idea introduced by Salton in Information
Retrieval, see below)

2004/05 ANLE 20
Vector-based lexical semantics
DOG
CAT
HORSE

2004/05 ANLE 21
General characterization of vector-based semantics (from Charniak)
• Vectors as models of concepts• The CLUSTERING approach to lexical semantics:
1. Define properties one cares about, and give values to each property (generally, numerical)
2. Create a vector of length n for each item to be classified3. Viewing the n-dimensional vector as a point in n-space,
cluster points that are near one another• What changes between models:
1. The properties used in the vector2. The distance metric used to decide if two points are
`close’3. The algorithm used to cluster

2004/05 ANLE 22
Using words as features in a vector-based semantics
• The old decompositional semantics approach requires i. Specifying the featuresii. Characterizing the value of these features for each lexeme
• Simpler approach: use as features the WORDS that occur in the proximity of that word / lexical entry– Intuition: “You can tell a word’s meaning from the company it keeps”
• More specifically, you can use as `values’ of these features – The FREQUENCIES with which these words occur near the words whose meaning we
are defining– Or perhaps the PROBABILITIES that these words occur next to each other
• Alternative: use the DOCUMENTS in which these words occur (e.g., LSA)• Some psychological results support this view. Lund, Burgess, et al (1995, 1997):
lexical associations learned this way correlate very well with priming experiments. Landauer et al: good correlation on a variety of topics, including human categorization & vocabulary tests.

Using neighboring words to specify lexical meanings

Learning the meaning of DOG from text

Learning the meaning of DOG from text

Learning the meaning of DOG from text

Learning the meaning of DOG from text

Learning the meaning of DOG from text

The lexicon we acquire

Meanings in word space

2004/05 ANLE 32
Acquiring lexical vectors from a corpus(Schuetze, 1991; Burgess and Lund, 1997)• To construct vectors C(w) for each word w:
1. Scan a text2. Whenever a word w is encountered, increment all cells of
C(w) corresponding to the words v that occur in the vicinity of w, typically within a window of fixed size
• Differences among methods:– Size of window– Weighted or not– Whether every word in the vocabulary counts as a
dimension (including function words such as the or and) or whether instead only some specially chosen words are used (typically, the m most common content words in the corpus; or perhaps modifiers only). The words chosen as dimensions are often called CONTEXT WORDS
– Whether dimensionality reduction methods are applied

2004/05 ANLE 33
Variant: using probabilities (e.g., Dagan et al, 1997)
• E.g., for house
• Context vector (using probabilities)– 0.001394 0.016212 0.003169 0.000734 0.001460 0.002901 0.004725 0.000598 0
0 0.008993 0.008322 0.000164 0.010771 0.012098 0.002799 0.002064 0.007697 0 0 0.001693 0.000624 0.001624 0.000458 0.002449 0.002732 0 0.008483 0.007929 0 0.001101 0.001806 0 0.005537 0.000726 0.011563 0.010487 0 0.001809 0.010601 0.000348 0.000759 0.000807 0.000302 0.002331 0.002715 0.020845 0.000860 0.000497 0.002317 0.003938 0.001505 0.035262 0.002090 0.004811 0.001248 0.000920 0.001164 0.003577 0.001337 0.000259 0.002470 0.001793 0.003582 0.005228 0.008356 0.005771 0.001810 0 0.001127 0.001225 0 0.008904 0.001544 0.003223 0

2004/05 ANLE 34
Variant: using modifiers to specify the meaning of words
• …. The Soviet cosmonaut …. The American astronaut …. The red American car …. The old red truck … the spacewalking cosmonaut … the full Moon …
cosmonaut
astronaut moon
car truck
Soviet 1 0 0 1 1
American 0 1 0 1 1
spacewalking
1 1 0 0 0
red 0 0 0 1 1
full 0 0 1 0 0
old 0 0 0 1 1

2004/05 ANLE 35
Another variant: word / document matrices
d1 d2 d3 d4 d5 d6
cosmonaut 1 0 1 0 0 0
astronaut 0 1 0 0 0 0
moon 1 1 0 0 0 0
car 1 0 0 1 1 0
truck 0 0 0 1 0 1

2004/05 ANLE 36
Measures of semantic similarity• Euclidean distance:
• Cosine:
• Manhattan Metric:
n
i ii yxd1
n
i i
n
i i
n
i ii
yx
yx
1
2
1
2
1)cos(
n
i ii yxd1
2

SIMILARITY IN VECTOR SPACE MODELS: THE COSINE MEASURE
kj
kj
qd
qd *cos
θ
dj
qk
N
i ij
N
i ik
N
iijik
jk
ww
wwdqsim
1
2,1
2,
1,,
,

EVALUATION
• Synonymy identification• Text coherence• Semantic priming

SYNONYMY: THE TOEFL TEST

TOEFL TEST: RESULTS

2004/05 ANLE 41
Some psychological evidence for vector-space representations
• Burgess and Lund (1996, 1997): the clusters found with HAL correlate well with those observed using semantic priming experiments.
• Landauer, Foltz, and Laham (1997): scores overlap with those of humans on standard vocabulary and topic tests; mimic human scores on category judgments; etc.
• Evidence about `prototype theory’ (Rosch et al, 1976)– Posner and Keel, 1968
• subjects presented with patterns of dots that had been obtained by variations from single pattern (`prototype’)
• Later, they recalled prototypes better than samples they had actually seen
– Rosch et al, 1976: `basic level’ categories (apple, orange, potato, carrot) have higher `cue validity’ than elements higher in the hierarchy (fruit, vegetable) or lower (red delicious, cox)

2004/05 ANLE 42
The HAL model (Burgess and Lund, 1995, 1996, 1997)• A 160 million words corpus of articles
extracted from all newsgroups containing English dialogue
• Context words: the 70,000 most frequently occurring symbols within the corpus
• Window size: 10 words to the left and the right of the word
• Measure of similarity: cosine

HAL AND SEMANTIC PRIMING

INFORMATION RETRIEVAL
• GOAL: Find the documents most relevant to a certain QUERY
• Latest development: WEB SEARCH– Use the Web as the collection of documents
• Related: – QUESTION-ANSWERING– DOCUMENT CLASSIFICATION
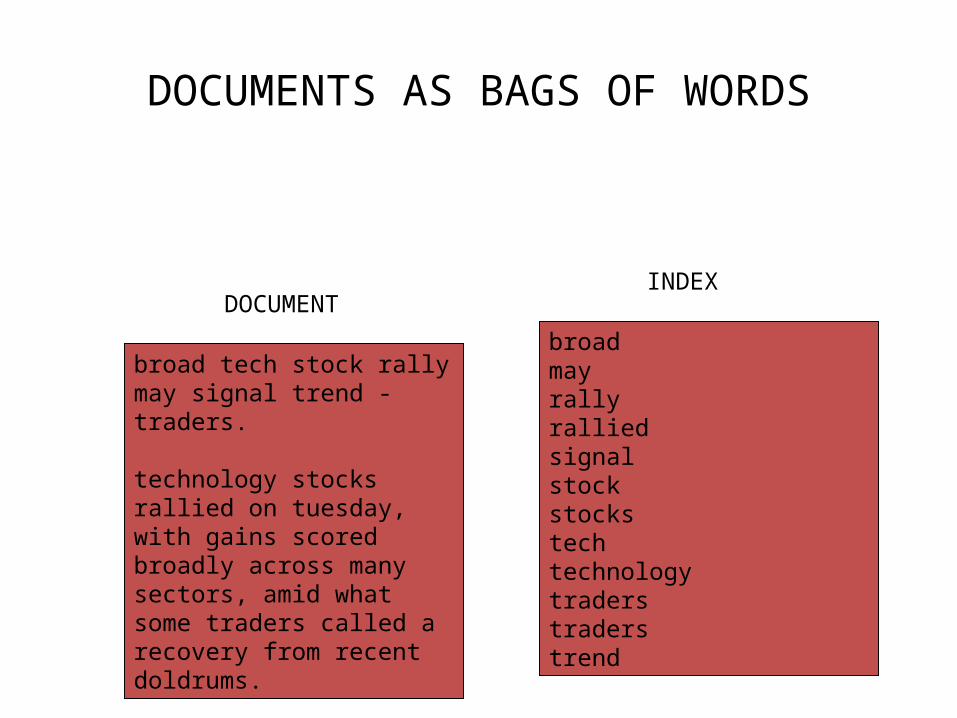
DOCUMENTS AS BAGS OF WORDS
broad tech stock rally may signal trend - traders.
technology stocks rallied on tuesday, with gains scored broadly across many sectors, amid what some traders called a recovery from recent doldrums.
broadmay rallyralliedsignal stockstocks techtechnology traderstraders trend
DOCUMENTINDEX

THE VECTOR SPACE MODEL
• Query and documents represented as vectors of index terms, assigned non-binary WEIGHTS
• Similarity calculated using vector algebra: COSINE (cfr. lexical similarity models)– RANKED similarity
• Most popular of all models (cfr. Salton and Lesk’s SMART)
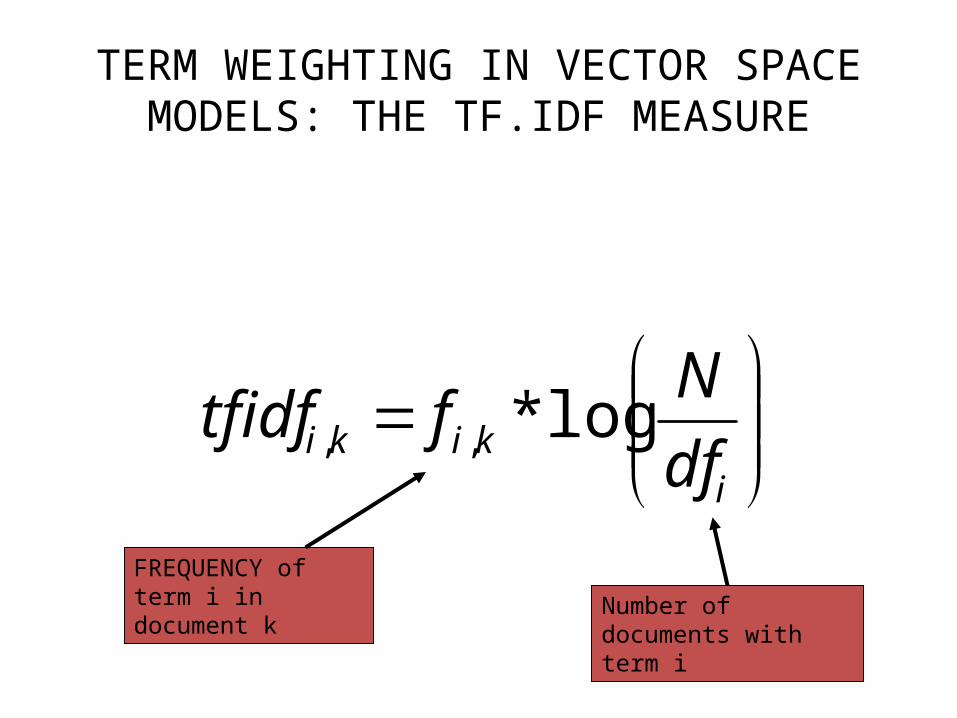
TERM WEIGHTING IN VECTOR SPACE MODELS: THE TF.IDF MEASURE
ikiki df
Nftfidf log*,,
FREQUENCY of term i in document k Number of documents
with term i

2004/05 ANLE 49
VECTOR-SPACE MODELS WITH SYNTACTIC INFORMATION
• Pereira and Tishby, 1992: two words are similar if they occur as objects of the same verbs– John ate POPCORN– John ate BANANAS
• C(w) is the distribution of verbs for which w served as direct object.– First approximation: just counts– In fact: probabilities
• Similarity: RELATIVE ENTROPY

Feb 21st Cog/Comp Neuroscience 50
(SYNTACTIC) RELATION-BASED VECTOR MODELS
attackedattacked foxfox dogdog
<subj,fox><subj,fox> <det,the><det,the> <det,the><det,the>
<obj,dog><obj,dog> <mod,red><mod,red> <mod,lazy><mod,lazy>
attacked
fox dog
the red the lazy
subj obj
det detmod mod
E.g., Grefenstette, 1994; Lin, 1998; Curran and Moens, 2002

2004/05 ANLE 51
SEXTANT (Grefenstette, 1992)
It was concluded that the carcinoembryonic antigens represent cellular constituents which are repressed during the course of differentiation the normal digestive system epithelium and reappear in the corresponding malignant cells by a process of derepressive dedifferentiation
antigen carcinoembryonic-ADJantigen repress-DOBJantigen represent-SUBJconstituent cellular-ADJconstituent represent-DOBJcourse repress-IOBJ……..

2004/05 ANLE 52
SEXTANT: Similarity measure
dog pet-DOBJdog eat-SUBJ dog shaggy-ADJdog brown-ADJdog leash-NN
cat pet-DOBJcat pet-DOBJ cat hairy-ADJcat leash-NN
CATDOG
B andA by possessed attributes Unique
B andA by shared Attributes
Count
CountJaccard:
6
2
ADJ}-shaggyDOBJ,-petNN,-leashADJ,-hairySUBJ,-eatADJ,-{brown
DOBJ}-pet NN,-{leash
Count
Count

MULTIDIMENSIONAL SCALING
• Many models (included HAL) apply techniques for REDUCING the number of dimensions
• Intuition: many features express a similar property / topic

MULTIDIMENSIONAL SCALING

2004/05 ANLE 55
Latent Semantic Analysis (LSA) (Landauer et al, 1997)
• Goal: extract relatons of expected contextual usage from passages
• Two steps:1. Build a word / document cooccurrence matrix2. `Weigh’ each cell 3. Perform a DIMENSIONALITY REDUCTION
• Argued to correlate well with humans on a number of tests

2004/05 ANLE 56
LSA: the method, 1

2004/05 ANLE 57
LSA: Singular Value Decomposition

2004/05 ANLE 58
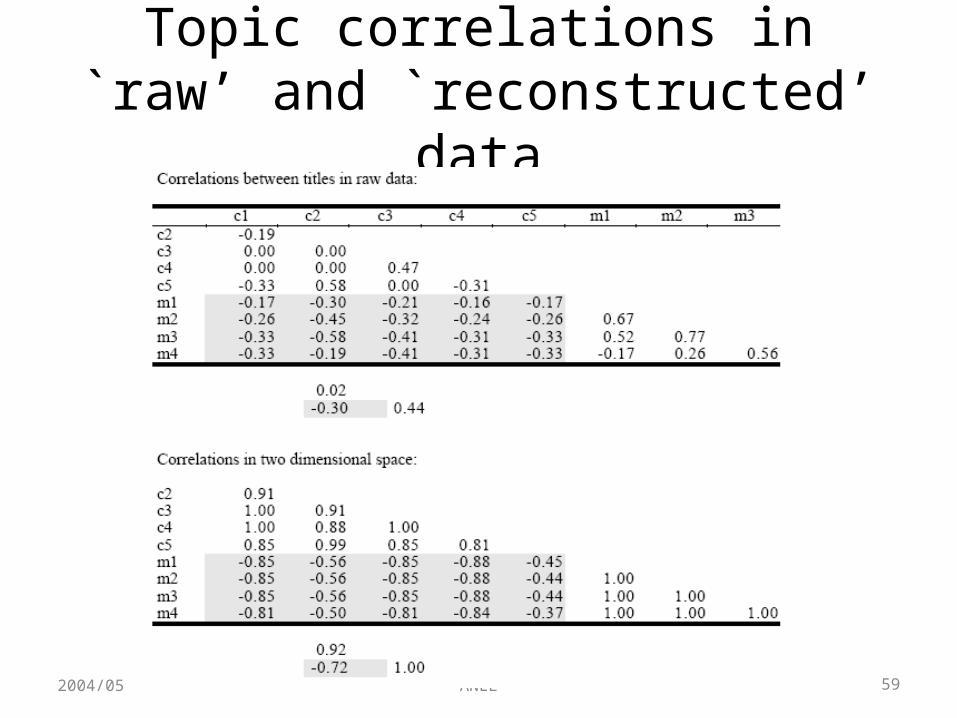
LSA: Reconstructed matrix
2004/05 ANLE 59
Topic correlations in `raw’ and `reconstructed’ data

2004/05 ANLE 60
Some caveats• Two senses of `similarity’
– Schuetze: two words are similar if one can replace the other– Brown et al: two words are similar if they occur in similar
contexts• What notion of `meaning’ is learned here?
– “One might consider LSA’s maximal knowledge of the world to be analogous to a well-read nun’s knowledge of sex, a level of knowledge often deemed a sufficient basis for advising the young” (Landauer et al, 1997)
• Can one do semantics with these representations?– Our own experience: using HAL-style vectors for resolving
bridging references– Very limited success– Applying dimensionality reduction didn’t seem to help

REMAINING LECTURES
DAY HOUR TOPIC
Wed 25/11 12-14 Text classification with Artificial Neural Nets
Tue 1/12 10-12 Lab: Supervised ML with Weka
Fri 4/12 10-12 Unsupervised methods & their application in lexical acq and IR
Wed 9/12 10-12 Lexical acquisition by clustering
Thu 10/12 10-12 Psychological evidence on learning
Fri 11/12 10-12 Psychological evidence on language processing
Mon 14/12 10-12 Intro to NLP

REMAINING LECTURES
DAY HOUR TOPIC
Tue 15/12 10-12 Machine learning for anaphora
Tue 15/12 14-16 Lab: Clustering
Wed 16/12 14-16 Lab: BART
Thu 17/12 10-12 Ling. & psychological evidence on anaphora
Fri 18/12 10-12 Corpora for anaphora
Mon 21/12 10-12 Lexical & commons. knowledge for anaphora
Tue 22/12 10-12 Salience
Tue 22/12 14-16 Discourse new detection

ACKNOWLEDGMENTS
• Some of the slides come from – Ray Mooney’s Utexas AI course– Marco Baroni
Top Related