






Languages
Pages
Legal


THE VISION DESIGNERS

THE VISION DESIGNERS
A high tech spin-off from one of the French main Research Organization, Centre National de la Recherche Scientifique (CNRS), at CerCo, the Brain & Cognition Research Center.
An original angle on information processing in the brain, that succeeds in proposing a disruptive technology for artificial vision.
A core technology with small footprint, scalable, easy to use, fast and efficient pattern recognition.
Active all over the world with more of 80% export sales in different business sectors : SECURITY – ITS – MEDIA ANALYSIS – GAMING - MACHINE VISION & ROBOTICS Asia (China, Singapore, Malaysia), Australia, North America, Europe.
Innovative Image & Video Analytics solutions using a breakthrough technology for pattern recognition in real-time based on Spiking Neuron Network.
BIOLOGY INSPIRED
NEUROCOMPUTING ASYNCHRONOUS SPIKING NEURON NETWORK
HUMAN VISION STRATEGIES
SINCE 1988
FEED FORWARD TEMPORAL CODING, RANK ORDER
VISUAL PATTERN MATCHING
LEARN SUPERVISED - UNSUPERVISED LEARNING
DETECT
RECOGNIZE ANY VISUAL PATTERN, OBJECT
REAL-TIME
MEMORIZE

THE VISION DESIGNERS
Since the beginning of 2010, technology trend shows high interest in Neurocomputing and Artificial Intelligence (US DARPA program SYNAPSE, EU Human Brain, Google Brain).
SPIKENET builds already operational solutions for the industry with a proven artificial intelligence technology based on spiking neuron network.
Market for Vision Systems with traditional Image Analysis solutions is growing. More requirements for video analytics in all domain (CCTV, Machine Vision), need for more automation, etc.
SPIKENET is all about Neurocomputing, Artificial Vision, Deep Learning since the 80s and, most of all, we deliver products.
High investments in the recent years in ROBOTICS but robot vision systems are still limited.
What if Robots can really see and understand what it sees by itself.
What if SMARTPHONES have simulated neuron network in order to recognize faces, objects, the scene, identify the user environment (Qualcom).
The crave for Image Analysis and Robotics companies acquisition GOOGLE
NEVEN VISION PITTPATT
VIEWDLE 45M USD LIKE.COM
DNN RESEARCH Inc. DEEP MIND TECHNOLOGIES
800 MUSD JETPACK DARK BLUE LABS
VISION FACTORY
BOSTON DYNAMICS SHAFT INC.
INDUSTRIAL PERCEPTION REDWOOD ROBOTICS
MEKA ROBOTICS BOT & DOLLY
FACEBOOK FACE.COM
INSTAGRAM 1 BILLION RECREC
100M USD

THE VISION DESIGNERS
Get a new class of proven Vision technology with a large spectrum of use cases.
Enrich your existing products with smart vision capabilities.
INNOVATION KEY ADVANTAGE AGAINST
COMPETITION ENRICH EXISTING PRODUCTS
DESIGN NEW
PRODUCTS
Design new products for everyday life.
CREATE THE
SMART VISION
FUTURE
Spikenet, a technology to capture the Value from the Big Data Image world, for today and tomorrow. SHAPING THE FUTURE WITH YOU
Prepare the future technology disruptions: - Camera with spiking retina and unsupervised learning process - Neuromorphic chipset
THE VISION DESIGNERS
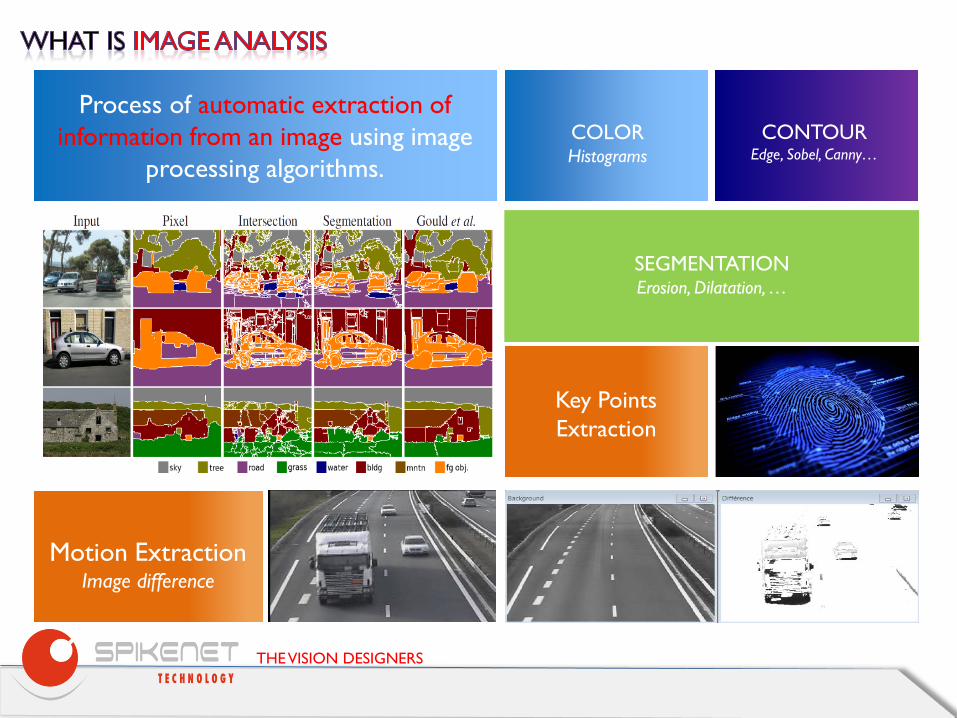
Process of automatic extraction of information from an image using image
processing algorithms. COLOR Histograms
CONTOUR Edge, Sobel, Canny…
SEGMENTATION Erosion, Dilatation, …
Motion Extraction Image difference
Key Points Extraction
THE VISION DESIGNERS
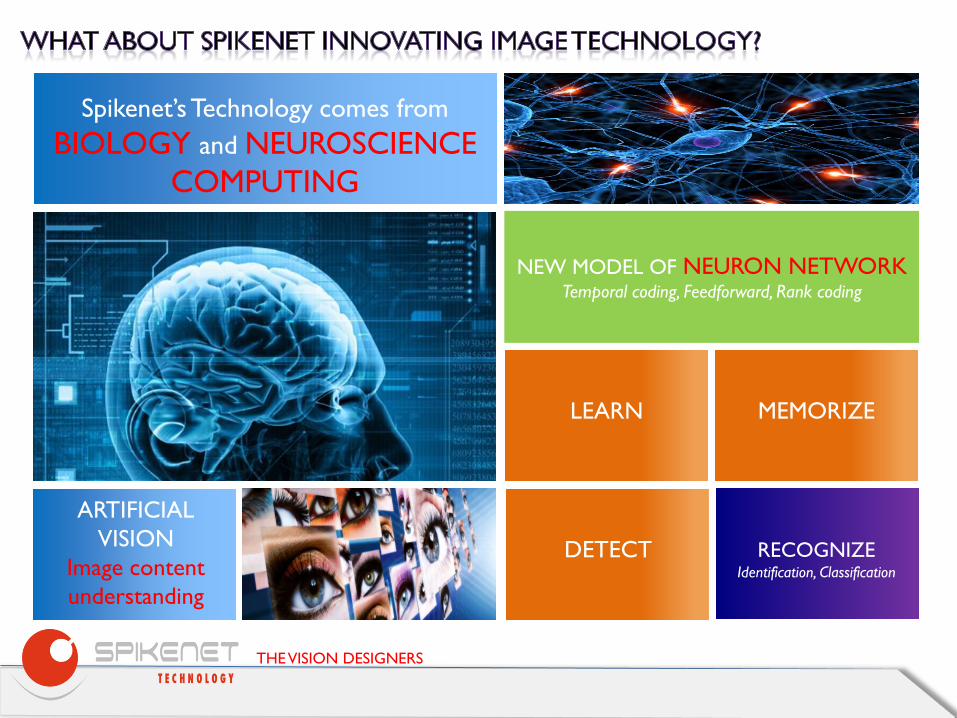
Spikenet’s Technology comes from BIOLOGY and NEUROSCIENCE
COMPUTING
ARTIFICIAL VISION
Image content understanding
RECOGNIZE Identification, Classification
NEW MODEL OF NEURON NETWORK Temporal coding, Feedforward, Rank coding
LEARN MEMORIZE
DETECT

THE VISION DESIGNERS
Speed : detection and recognition time in milliseconds for a pattern. Over 2000 patterns in one second on a standard PC with no dedicated hardware.
Accuracy : recognition of exact image and similar patterns with controllable selectivity.
Robustness to image alterations: detection stability against noise, blur, occlusion, variable lighting conditions, image vibrations. Perfect for low resolution, real life images conditions, still and moving camera, outdoor constraints.
Detection Sensitivity: recognition of visual patterns as small as 30x30 pixels while classic approach by key points extraction (Sift/Surf) requires bigger size image.
30x30 PIXEL MODEL
RECOGNITION IN MILLISECONDS
VERY SMALL FOOTPRINT 30000 SOURCE CODE LINES CORE ENGINE
AVAILABLE FOR ARM CHIPSET CAN RUN ON MOBILE PHONE
SMALL SIZE PATTERN RECOGNITION
STILL PICTURE – LIVE VIDEO STREAM
ONLY 2K BYTES PER MODEL
LEARN ANY PATTERN

THE VISION DESIGNERS
Video input : from low cost webcam, to high end industrial camera (high resolution, fast frame rate). Support for USB, IP, GigE, ieee1394 camera interface. Different bandwidth: visible, IR, UV
30x30 PIXEL MODEL
A kernel for pattern learning and recognition with only 30000 lines source code ANSI C++ representing about 600k bytes binary.
Simple and efficient spiking neuron net model can work without floating point computation. Full integer computing version available on entry level chipsets.
A spikenet model for recognition weights maximum 2k bytes. Thus millions of models over thousands of objects can be stored on simple SD card. RECOGNITION IN MILLISECONDS
VERY SMALL FOOTPRINT 30000 SOURCE CODE LINES CORE ENGINE
AVAILABLE FOR ARM CHIPSET CAN RUN ON MOBILE PHONE
SMALL SIZE PATTERN RECOGNITION
STILL PICTURE – LIVE VIDEO STREAM
ONLY 2K BYTES PER MODEL
LEARN ANY PATTERN

THE VISION DESIGNERS
COMPETITION SPIKENET TECHNOLOGY
Computer Vision world using classic signal analysis functions to process an image.
Artificial Vision technology inspired from biology mimicking human vision process.
Little use of neuron network or use of the classic model for neuron net based on frequency coding with feedback loop processing.
Unique and innovative way of modeling asynchronous spiking neuron network using temporal coding and feedforward architecture
A pattern in computer vision world is generally characterized by its key points extraction (SIFT).
Spikenet model of an object is constituted of its main orientations (saliencies) and their associations.
One different imaging process for each task face OR number plate OR simple shapes detection. One cannot for example take a solution for face detection and try to learn car shape for detection other targets than face.
Capability of learning any visual pattern (face, car, logo, user pattern, 2D, 3D objects, etc.) Generic technology can learn anything. Truly cognitive, i.e. capable to learn and interpret. All by one same unique engine!

THE VISION DESIGNERS
COMPETITION SPIKENET TECHNOLOGY
200kb of memory for a model (pattern) descriptor 2kb only for Spikenet model
Most of existing video analytics are based on motion detection and extraction.
Capability to detect and recognize a pattern even in still picture.
Key points approaches requires much larger size picture (thousands to mega pixels).
Capability of learning a visual pattern even with very little size of only 30x30 pixels (down to 20x20).
No capability of live dynamic learning of pattern. Capability of learning a pattern either off line (pre-processing) from an available set of pictures of the pattern, but also capability of dynamic learning of a pattern in live video flow.
None Unsupervised learning process.

THE VISION DESIGNERS
COMPETITION SPIKENET TECHNOLOGY
One to several seconds are required from keypoints extraction to matching on dual core PC.
Detects and recognizes a pattern in less than 10 millisecond.
Machine vision solutions require constraint lighting sources and performs badly outdoor.
Very robust to noise, blur, low contrast, changing lighting conditions, works in natural scenes.
Most performing image recognition engine have big footprint.
A kernel engine of 30,000 lines of source code.
Computation intensive with floating point operations.
Can use integer only. Works on simple ARM9.

THE VISION DESIGNERS
AIRPORT SECURITY
ADVANCED VIDEO
ANALYTICS
SECURITY POLICE FORCES
SAFE CITY
GAMING MEDIA
ANALYSIS
MOBILE DEVICE
MACHINE VISION
HUMAN SAFETY
ITS EMBEDDED
VISION SENSOR
KEY REFERENCES FRENCH GOVERNMENT
BORDEAUX AIRPORT
SCOTLAND YARD
GENEVA AIRPORT
SHANGHAI POLICE
SIEMENS VAI ARCELOR MITTAL US
AIRBUS DEFENSE & SPACE COFELY INEO – GDF SUEZ
POLICE FORCES INTELLIGENCE SERVICES
BORDER POLICE

THE VISION DESIGNERS
SNVISION : the image recognition engine capable of learning and detection of any visual pattern in real time in still pictures and from video streams.
MIND: the video indexing engine to generate unique signature per image and to recognize one image among +100 Millions in one second on simple PC.
OBSERVER: the live video processing solution with selective detection and alarm based on pattern recognition and not only motion detection. OBSERVER is currently applied in video surveillance applications as well as machine vision systems.
AGATHA: the datamining system for automatic extraction of visual patterns (face, car, user defined objects), meta data generation, album creation, and pattern matching.
LISA: Facial Biometry solution for matching 1 face picture against Millions in one second.
REBECA: Rebar electronic counting automation system for steel industry.
eRIS: Detection of potential danger for human operator in hazardous environment.
OBSERVER
AGATHA
LISA
REBECA
E-RIS

THE VISION DESIGNERS
August 2012, after one year trial, Spikenet has been awarded a contract from Bordeaux International Airport for its innovative video surveillance solution SAM, capable of selective alarm based on pattern detection (human, vehicle, aircraft).
→ OBSERVER is currently deployed to watch over all aircraft parking stands to detect illicit intrusion. It has reduced by 80% the false alarm rate generated by existing intrusion detection system (BOSCH) which is based only on motion detection.
→ Other customers using OBSERVER include Geneva International Airport, Sita-Suez Environment.
All existing video surveillance solutions are based on motion detection. Motion detection generates a lot of false alarms. The machines do not understand what it see. Bordeaux Airport system was generating +1200 false alarms per month. Only object recognition can filter good from bad alarm. SAM allows all movements except illicit intrusion.

THE VISION DESIGNERS
15
SAM Intelligent Video Analytics for your CCTV
SECURITY SAFETY
Facilitation Flow Management
The unique Video Analysis system based on image recognition and not only motion detection.
Combined analysis of pattern and motion in real-time. Selective alarm strategy upon identification of moving target.
Flow management: people, vehicle, aircraft. Crowd estimation. Queue management Surveillance of critical areas.

THE VISION DESIGNERS
Plug & Play. Use existing CCTV camera & network. No change in your infrastructure. Modularity. Maintenability. Flexibility. Scalability. As many AGENTs and MANAGERs as needed.

THE VISION DESIGNERS
Association Camera – Functions – Operator « à la carte » Capability to import 3rd party analytics.
Cam/OP OP 1 OP 2 OP 3 OP 4 OP 5
Camera 1 fonction 1 fonction 2
Camera 2 fonction 1 fonction 2
Camera 3 fonction 1 fonction 2
fonction 1
Camera 4 fonction 1 fonction 2
fonction 2
Camera 5 fonction 1 fonction 2
fonction 3 fonction 3
Camera 6 fonction 1 fonction 2
fcnction 3 fonction 4
Caméra 7 fonction 3
Caméra 8 fonction 3 fonction 5
. fonction 3 fonction 5
. fonction 5 fonction x
. fonction x
Caméra N fonction x
F1 : intrusion detection per motion.
F2 : aircraft parking surveillance
F3 : people detection.
F4 : face detection with/without blurring option.
F5 : people flow estimation.
F6 : vehicle flow estimation.
F7 : people counting with gender estimation.
F8 : vehice count.
F9 : number plate recognition
Fx…
THE VISION DESIGNERS
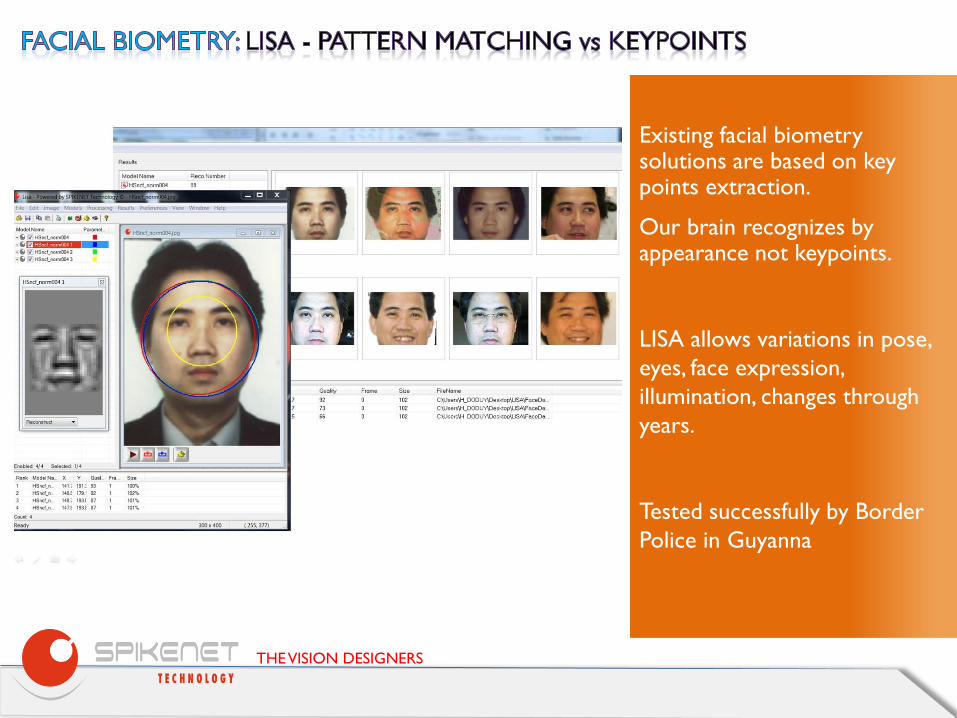
Existing facial biometry solutions are based on key points extraction.
Our brain recognizes by appearance not keypoints. LISA allows variations in pose, eyes, face expression, illumination, changes through years. Tested successfully by Border Police in Guyanna

THE VISION DESIGNERS
Since 2010
Game Card reader
Card recognition
Bet Tracking
Approved by Nevada Gaming Authority Card reader in operation over 20 properties throughout the world
CASH COUNT YIELD MANAGEMENT
GAME PROTECTION
GAME OUTCOME

THE VISION DESIGNERS
Vehicle detection, extraction, and identification combining Motion extraction and Pattern Matching for robust count. Robust to noise, shadows, camera vibration, low light.
SPEED ESTIMATION
TRAFFIC FLOW
MONITORING
VEHICLE CLASSIFICATION
VEHICLE COUNTING
THE VISION DESIGNERS
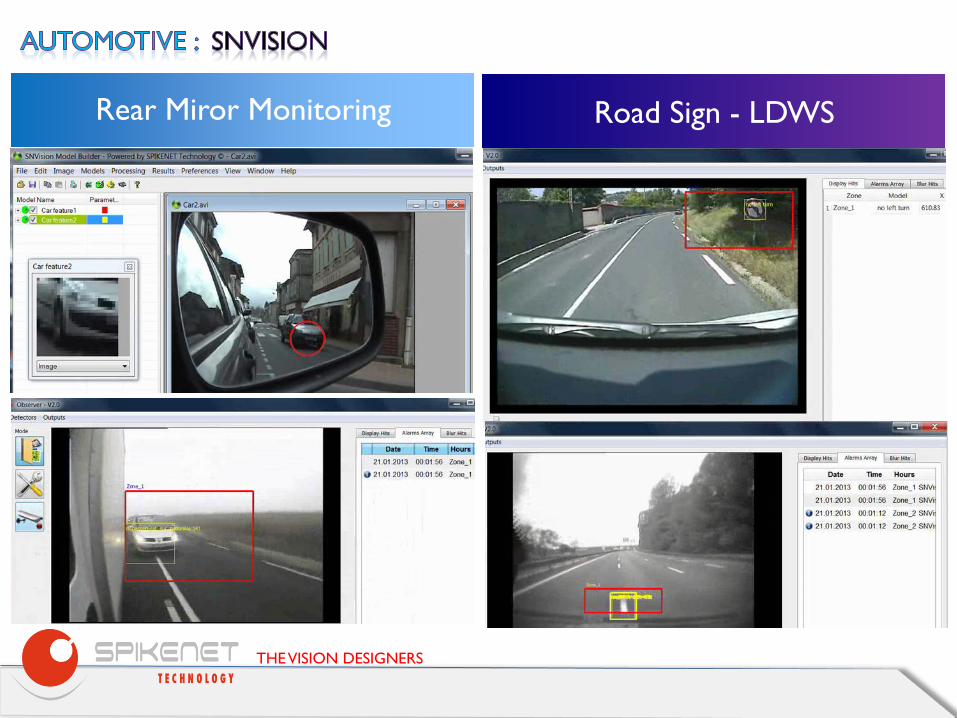
Rear Miror Monitoring Road Sign - LDWS

THE VISION DESIGNERS
In operation since 2006
Detection and Identification of Brand logos in Sport Events. Automatic extraction of : number of display, duration, size, location on the TV screen, etc. +620 PCs in a datacenter processing 24/7 all sport broadcast events worldwide, and thousands of brands analyzed in the database.
BRAND EXPOSURE SPORT SPONSORSHIP Efficiency Measurement

THE VISION DESIGNERS
Project in 2008
Detection and identification of TV Commercials diffusion.
Day, Time, Channel, Duration, Conformity to original footage.
No need of watermarking. Based on Spikenet’s patented video indexing engine MIND.
Broadcast Content Monitoring
WEB TV TV Commercials Identification

THE VISION DESIGNERS
- Signature pixel based
- 50 bytes per image signature
- 1h of movie in 2Mb
- Works on simple PC
Match 1 image among +100 Million in 1 second ! Finds exact and similar images Massive visual search
MIND
Copyright Infringement Detection
TV Commercials Identification
Search Engine
Metadata propagation
PC Storage Place
Optimisation

THE VISION DESIGNERS
Rebar counting automation.
Counting rebar on the fly.
Any size. Any shape.
First system delivered in April 2013

THE VISION DESIGNERS
PATTERN RECOGNITION EMBEDDED IN STANDALONE IMAGE SENSOR Very small footprint image recognition engine SNVISION. No horse computing power needed. Millions of patterns for recognition can be stored in simple SD card. Protoypes already on Blackfin and linux ARM platforms (Rasberry, Panda, Odroid,…)
ROBOTS UAV AUTOMOTIVE ITS
Top Related
