






Languages
Pages
Legal


High Performance Hadoop with Python

Presenter BioKristopher Overholt received his Ph.D. in Civil Engineering from The University of Texas at Austin.
Prior to joining Continuum, he worked at theNational Institute of Standards and Technology (NIST),Southwest Research Institute (SwRI), andThe University of Texas at Austin.
Kristopher has 10+ years of experience in areas including applied research, scientific and parallel computing, system administration, open-source software development, and computational modeling.
2
Kristopher Overholt Solution Architect
Continuum Analytics

Presenter Bio
Matthew Rocklin received his Ph.D. in computer science from the University of Chicago and is currently employed at Continuum Analytics as a computational scientist.
He is an active contributor to many open source projects in the PyData ecosystem and is the lead developer of Dask.
3
Matthew RocklinComputational Scientist
Continuum Analytics

Overview
4
• Overview of Continuum and Anaconda
• Overview of Dask (Distributed Processing Framework)
• Example parallel workflows with Anaconda and Dask
• Distributed dataframes on a cluster with CSV data
• Distributed natural language processing with text data
• Analyzing array-based global temperature data
• Parallelizing custom code and workflows
• Using Anaconda with Dask
• Solutions with Anaconda and Dask

Overview of Continuum and Anaconda

The Platform to Accelerate, Connect & Empower
Continuum Analytics is the company behind Anaconda and offers:
6
is…. the leading open data science platform powered by Python the fastest growing open data science language
• Consulting
• Training
• Open-Source Software
• Enterprise Software

Bokeh
Founders
– Travis Oliphant, creator of NumPy and SciPy
– Peter Wang, creator of Chaco & Bokeh visualization libraries
Engineers
– Antoine Pitrou, Python core developer
– Jeff Reback, Pandas maintainer and core developer
– Carlos Cardoba, Spyder maintainer and core developer
– Damian Avilla, Chris Colbert, Jupyter core team member
– Michael Droettboom, Matplotlib maintainer and core developer7
Deep Domain & Python Knowledge

Financial Services – Risk Mgmt., Quant modeling, Data exploration and processing, algorithmic trading, compliance reporting
Government – Fraud detection, data crawling, web & cyber data analytics, statistical modeling
Healthcare & Life Sciences – Genomics data processing, cancer research, natural language processing for health data science
High Tech – Customer behavior, recommendations, ad bidding, retargeting, social media analytics
Retail & CPG – Engineering simulation, supply chain modeling, scientific analysis
Oil & Gas – Pipeline monitoring, noise logging, seismic data processing, geophysics 8
Trusted by Industry Leaders

Leading Open Data Science Platform powered by Python
Quickly Engage w/ Your Data
9
• 720+ Popular Packages
• Optimized & Compiled
• Free for Everyone
• Extensible via conda Package Manager
• Sandbox Packages & Libraries
• Cross-Platform - Windows, Linux, Mac
• Not just Python - over 230 R packages
• Foundation of our Enterprise Products
Anaconda

10
AnacondaAccelerating Adoption of Python for Enterprises
COLLABORATIVE NOTEBOOKSwith publication, authentication, & search
Jupyter/ IPython
PYTHON & PACKAGE MANAGEMENTfor Hadoop & Apache stack Spark
PERFORMANCEwith compiled Python for lightning fast execution
Numba
VISUAL APPSfor interactivity, streaming, & BigBokeh
SECURE & ROBUST REPOSITORYof data science libraries, scripts, & notebooks
Conda
ENTERPRISE DATA INTEGRATIONwith optimized connectors & out-of-core
processing
NumPy & Pandas
DaskPARALLEL COMPUTING scaling up Python analytics on your cluster
for interactivity and streaming data
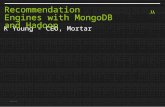
YARN
JVM
Bottom Line 10-100X faster performance • Interact with data in HDFS and
Amazon S3 natively from Python • Distributed computations without the
JVM & Python/Java serialization • Framework for easy, flexible
parallelism using directed acyclic graphs (DAGs)
• Interactive, distributed computing with in-memory persistence/caching
Bottom Line • Leverage Python &
R with Spark
Batch Processing Interactive
Processing
HDFS
Ibis
Impala
PySpark & SparkRPython & R ecosystem MPI
High Performance, Interactive,
Batch Processing
Native read & write
NumPy, Pandas, … 720+ packages
11

Overview of Dask as a Distributed Processing Framework

Overview of Dask
13
Dask is a Python parallel computing library that is:
• Familiar: Implements parallel NumPy and Pandas objects
• Fast: Optimized for demanding for numerical applications
• Flexible: for sophisticated and messy algorithms
• Scales up: Runs resiliently on clusters of 100s of machines
• Scales down: Pragmatic in a single process on a laptop
• Interactive: Responsive and fast for interactive data science
Dask complements the rest of Anaconda. It was developed withNumPy, Pandas, and scikit-learn developers.
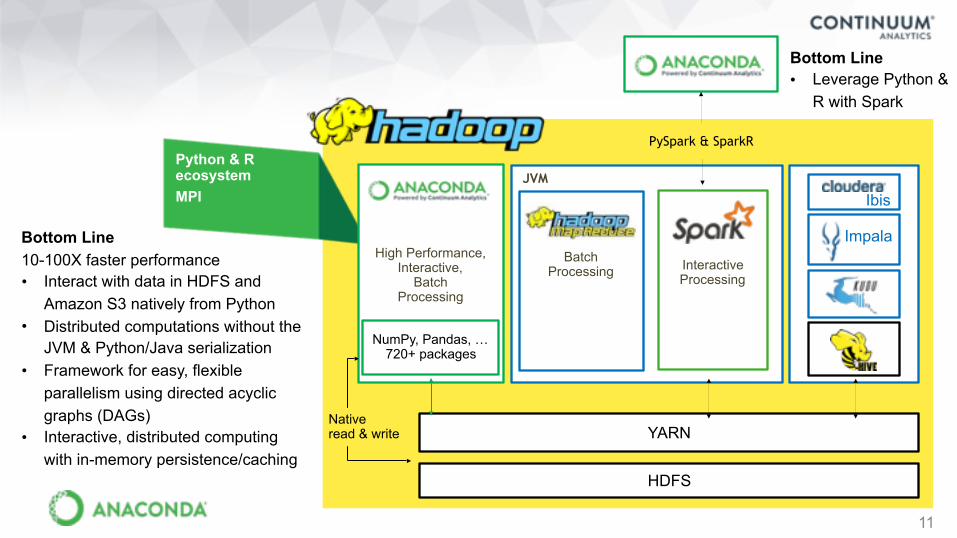
Spectrum of Parallelization
14
Threads Processes
MPI ZeroMQ
DaskHadoop Spark
SQL: Hive Pig
Impala
Implicit control: Restrictive but easyExplicit control: Fast but hard
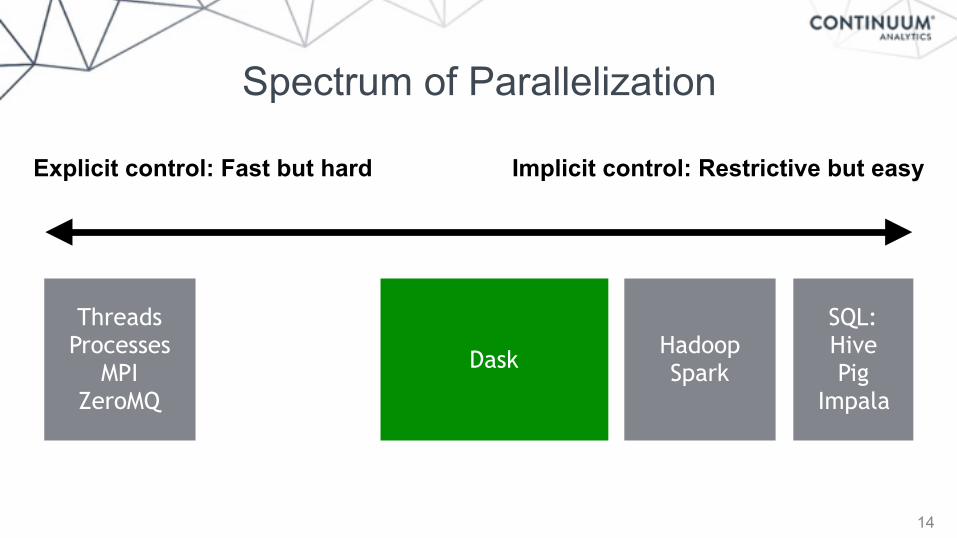
Dask: From User Interaction to Execution
15

Dask Collections: Familiar Expressions and API
16
x.T - x.mean(axis=0)
df.groupby(df.index).value.mean()def load(filename): def clean(data): def analyze(result):
Dask array (mimics NumPy)
Dask dataframe (mimics Pandas) Dask imperative (wraps custom code)
b.map(json.loads).foldby(...)
Dask bag (collection of data)

Dask Graphs: Example Machine Learning Pipeline
17

Dask Graphs: Example Machine Learning Pipeline + Grid Search
18

Scheduler
Worker
Worker
Worker
Worker
Client
Same network
User Machine (laptop)Client
Worker
Dask Schedulers: Example - Distributed Scheduler
19

Example Parallel Workflows with Anaconda and Dask

Examples
21
Analyzing NYC Taxi CSV data using distributed Dask DataFrames
• Demonstrate
Pandas at scale
• Observe responsive
user interface
Distributed language processing with text data using Dask Bags
• Explore data using
a distributed
memory cluster
• Interactively query
data using libraries from Anaconda
Analyzing global temperature data using Dask Arrays
• Visualize complex
algorithms
• Learn about dask
collections and
tasks
Handle custom code and workflows using Dask Imperative
• Deal with messy
situations
• Learn about
scheduling
1 2 3 4

Example 1: Using Dask DataFrames on a cluster with CSV data
22
• Built from Pandas DataFrames
• Match Pandas interface
• Access data from HDFS, S3, local, etc.
• Fast, low latency
• Responsive user interface
January, 2016
Febrary, 2016
March, 2016
April, 2016
May, 2016
Pandas DataFrame}
Dask DataFrame}

Example 2: Using Dask Bags on a cluster with text data
23
• Distributed natural language processing
with text data stored in HDFS
• Handles standard computations
• Looks like other parallel frameworks
(Spark, Hive, etc.)
• Access data from HDFS, S3, local, etc.
• Handles the common case...
(...)
data
...
(...)
data
function
...
...
(...)
data
function
...
result
merge
... ...
data
function
(...)
...
function

NumPy Array} } Dask
Array
Example 3: Using Dask Arrays with global temperature data
24
• Built from NumPyn-dimensional arrays
• Matches NumPy interface
(subset)
• Solve medium-large
problems
• Complex algorithms

Example 4: Using Dask Delayed to handle custom workflows
25
• Manually handle functions to support messy situations
• Life saver when collections aren't flexible enough
• Combine futures with collections for best of both worlds
• Scheduler provides resilient and elastic execution

Precursors to Parallelism
26
• Consider the following approaches first:
1. Use better algorithms
2. Try Numba or C/Cython
3. Store data in efficient formats
4. Subsample your data
• If you have to parallelize:
1. Start with your laptop (4 cores, 16 GB RAM, 1 TB disk)
2. Then a large workstation (24 cores, 1 TB RAM)
3. Finally, scale out to a cluster

Using Anaconda with Dask
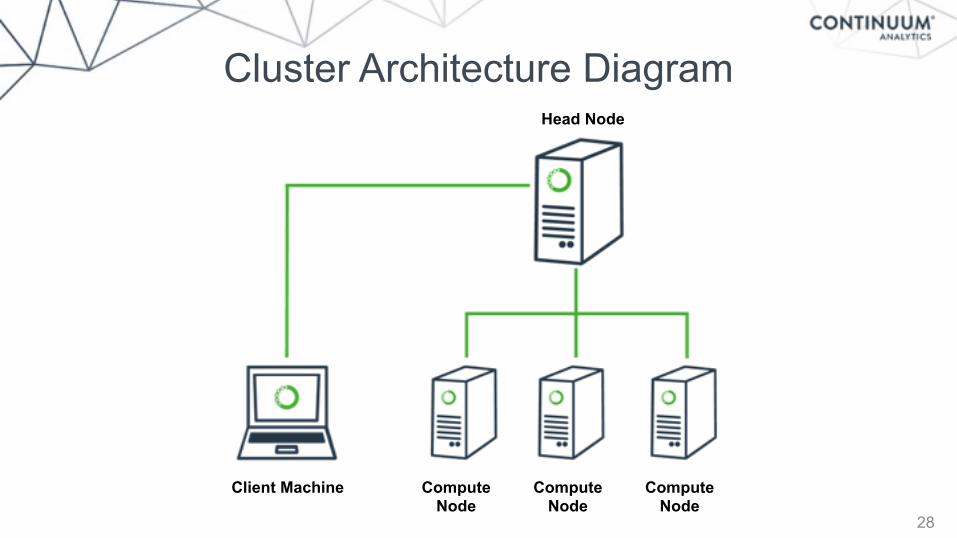
Cluster Architecture Diagram
28
Client Machine Compute Node
Compute Node
Compute Node
Head Node

• Single machine with multiple threads or processes
• On a cluster with SSH (dcluster)
• Resource management: YARN (knit), SGE, Slurm
• On the cloud with Amazon EC2 (dec2)
• On a cluster with Anaconda for cluster management
• Manage multiple conda environments and packages on bare-metal or cloud-based clusters
Using Anaconda and Dask on your Cluster
29

• Dynamically manage Python and conda environments across a cluster
• Works with enterprise Hadoop distributions and HPC clusters
• Integrates with on-premises Anaconda repository
• Cluster management features are availablewith Anaconda subscriptions
Anaconda for Cluster Management
30

Cluster Deployment & OperationsBefore Anaconda for cluster management
Head Node 1. Manually install Python,
packages & dependencies 2. Manually install R, packages &
dependencies
After Anaconda for cluster management
Compute Nodes 1. Manually install Python,
packages & dependencies 2. Manually install R,
packages & dependencies
Bottom Line • Empower IT with scalable and supported Anaconda deployments • Fast, secure and scalable Python & R package management on tens or thousands of nodes • Backed by an enterprise configuration management system • Scalable Anaconda deployments tested in enterprise Hadoop and HPC environments
Compute Nodes
Head Node Easily install conda environments and packages (including Python and R) across cluster nodes
31

Admin
Edge Node
Compute Nodes
Using Dask and Anaconda Enterprise on your Cluster
32
Analyst Machine
Anaconda Repository
Hadoop or HPC Cluster
Dask
Anaconda

Analyst Machine
Anaconda Repository
Hadoop or HPC Cluster
Dask
Anaconda
Analyst ships packages and environments to on-premises repository1.
Using Dask and Anaconda Enterprise on your Cluster
33

Admin deploys conda packages and environments to cluster nodes2.
Using Dask and Anaconda Enterprise on your Cluster
34
Admin
Head Node
Compute Nodes
Anaconda Repository
Hadoop or HPC Cluster
Dask
Anaconda
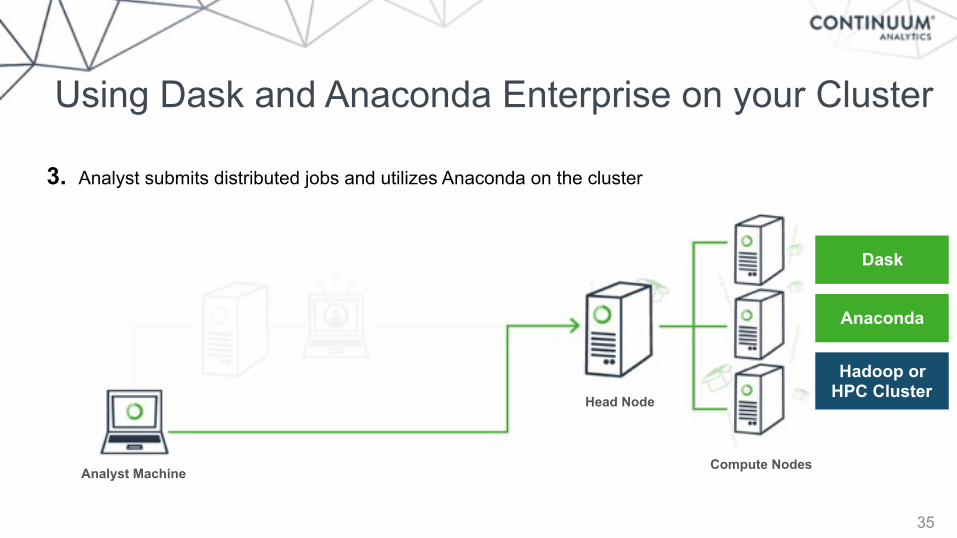
Analyst submits distributed jobs and utilizes Anaconda on the cluster3.
Using Dask and Anaconda Enterprise on your Cluster
35
Analyst Machine
Head Node
Compute Nodes
Hadoop or HPC Cluster
Dask
Anaconda

Service Architecture Diagram
36
HMS
CM
S
HS
NN
RM
JN
ID
SG
SNN
NM
DN
G
WHCS
HS2
ACH Anaconda Cluster Head
ACC
AR
CM G
AR ACH
Head Node
DS JN
YG
YG G
Secondary Head Node
ICS
ISS S
YG
Edge Node
HFS
HFS
G
H
HS2
HMS WHCS
Edge Node
H
SG
Anaconda Repository
Jupyter Notebook
Hadoop Manager
Zookeeper Server
Impala Daemon
History Sever (Spark)
Spark Gateway
Resource Manage (YARN) Other Services
Hue
NameNode (HDFS)
Secondary NameNode
DataNode
HttpFS
Hive Metastore
Gateway
WebHCat Server
HiveServer2
Yarn GateWay
NodeManager
Anaconda Cluster Compute
ACCACC
Compute Nodes
DN ID
SG ACC
DS Dask Scheduler
DW Dask Worker
DW

acluster conda install numpy scipy pandas numba
acluster conda create -n py34 python=3.4 numpy scipy pandas
acluster conda list
acluster conda info
acluster conda push environment.yml
Remote Conda Commands
37
Install packages
List packages
Create environment
Conda information
Push environment

Cluster Management Commands
38
Create cluster
Install plugins
List active clusters
SSH to nodes
Put/get files
Run command
acluster create dask-cluster -p dask-profile
acluster list
acluster install notebook distributed
acluster ssh
acluster put data.hdf5 /home/ubuntu/data.hdf5
acluster 'cmd apt-get install ...'

Solutions with Anaconda and Dask

• Open source foundational components
• Dask, Distributed scheduler, HDFS reading/writing,YARN interoperability, S3 integration, EC2 provisioning
• Enterprise products / subscriptions
• Anaconda Workgroup and Anaconda Enterprise
• Package management on Hadoop and HPC clusters
• Integration with on-premises repository
• Provisioning and managing Dask workers on a cluster
Working with Anaconda and Dask
40

Application
Analytics
Data andResource Management
Server
Jupyter/IPython Notebook
pandas, NumPy, SciPy, Numba, NLTK, scikit-learn, scikit-image,
and more from Anaconda …
HDFS, YARN, SGE, Slurm or other distributed systems
Bare-metal or Cloud-based Cluster
Ana
cond
a
Parallel Computation Dask Spark Hive / Impala
Clu
ster
41
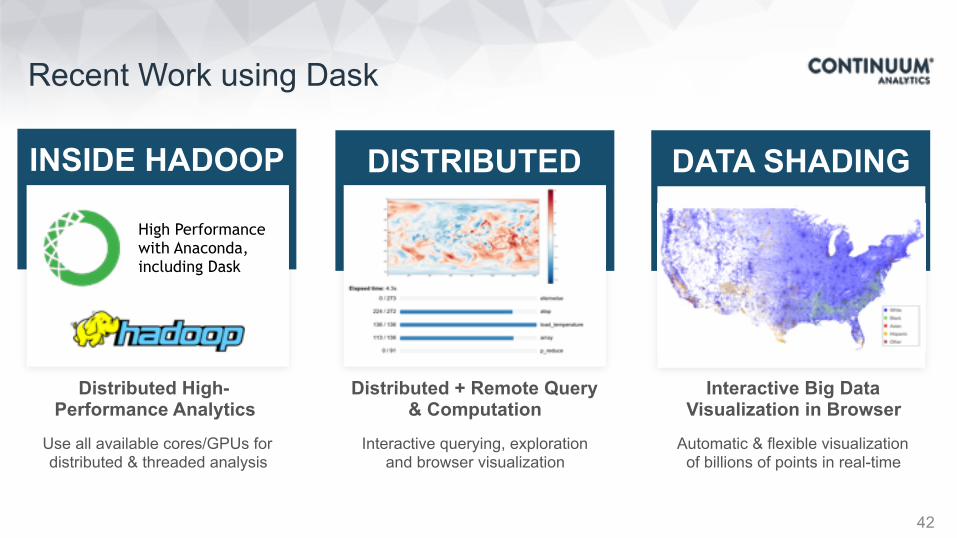
DISTRIBUTED
42
Automatic & flexible visualization of billions of points in real-time
Interactive querying, exploration and browser visualization
Distributed + Remote Query & Computation
Interactive Big Data Visualization in Browser
DATA SHADINGINSIDE HADOOP
High Performance with Anaconda, including Dask
Use all available cores/GPUs for distributed & threaded analysis
Distributed High-Performance Analytics
Recent Work using Dask

Use Cases with Anaconda and Dask
43
• Runs on a single machine or 100s of nodes
• Works on cloud-based or bare-metal clusters
• Works with enterprise Hadoop distributions and HPC environments
• Develop workflows with text processing, statistics, machine learning, image processing, etc.
• Works with data in various formats and storage solutions

Solutions with Anaconda and Dask
44
• Architecture consulting and review
• Manage Python packages and environments on a cluster
• Develop custom package management solutions on existing clusters
• Migrate and parallelize existing code with Python and Dask
• Architect parallel workflows and data pipelines with Dask
• Build proof of concepts and interactive applications with Dask
• Custom product/OSS core development
• Training on parallel development with Dask

Anaconda Subscriptions
45

Additional Resources

$ conda install anaconda-client
$ anaconda login
$ conda install anaconda-cluster -c anaconda-cluster
$ acluster create cluster-dask -p cluster-dask
$ acluster install distributed
Test-Drive Anaconda and Dask on your Cluster1. Register for an Anaconda Cloud account at Anaconda.org
2. Download Anaconda for cluster management using Conda
3. Create a sandbox/demo cluster
4. Install Dask and the distributed scheduler
47

Contact Information and Additional Details
• Contact [email protected] for information about Anaconda subscriptions, consulting, or training and [email protected] for product support
• More information about Anaconda Subscriptions continuum.io/anaconda-subscriptions
• View Dask documentation and additional examples at
dask.pydata.org
48

Kristopher Overholt
Twitter: @koverholt
Matthew Rocklin
Twitter: @mrocklin
Thank you
49
Email: [email protected]
Twitter: @ContinuumIO
Top Related