







Languages
Pages
Legal


High Performance Computing with AMD Opteron
Maurizio Davini

Agenda
• OS
• Compilers
• Libraries
• Some Benchmark results
• Conclusions

64-Bit Operating Systems64-Bit Operating SystemsRecommendations and StatusRecommendations and Status
SUSESUSE SLES 9 with latest Service Pack available SLES 9 with latest Service Pack available Has technology for supporting latest AMD processor featuresHas technology for supporting latest AMD processor features Widest breadth of NUMA support and enabled by defaultWidest breadth of NUMA support and enabled by default Oprofile system profiler installable as an RPM and modularizedOprofile system profiler installable as an RPM and modularized complete support for static & dynamically linked 32-bit binariescomplete support for static & dynamically linked 32-bit binaries
Red Hat Enterprise Server 3.0 Service Pack 2 or laterRed Hat Enterprise Server 3.0 Service Pack 2 or later NUMA features support not as complete as that of NUMA features support not as complete as that of SUSE SLES 9SUSE SLES 9 Oprofile installable as an RPM but installation is not modularized and may Oprofile installable as an RPM but installation is not modularized and may
require a kernel rebuild if RPM version isn’t satisfactoryrequire a kernel rebuild if RPM version isn’t satisfactory only SP 2 or later has complete 32-bit shared object library support (a only SP 2 or later has complete 32-bit shared object library support (a
requirement to run all 32-bit binaries in 64-bit)requirement to run all 32-bit binaries in 64-bit)
Posix-threading library changed between 2.1 and 3.0, Posix-threading library changed between 2.1 and 3.0, may require users to rebuild applicationsmay require users to rebuild applications

AMD Opteron CompilersAMD Opteron Compilers
PGIPGI , , Pathscale , GNU , , GNU , AbsoftIntel, Microsoft and SUN
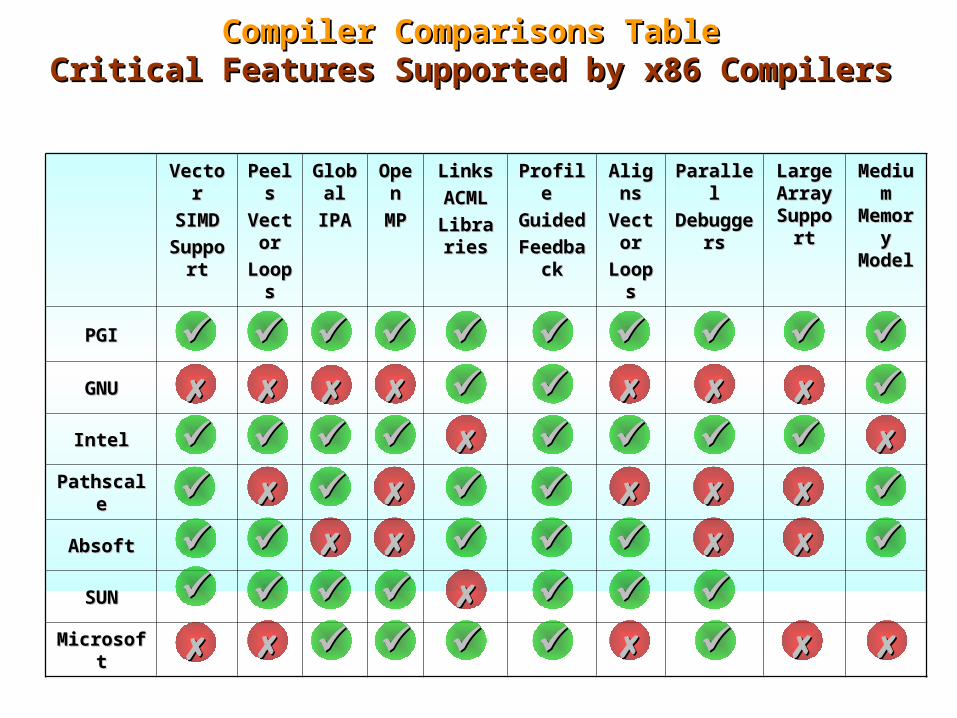
Compiler Comparisons TableCompiler Comparisons TableCritical Features Supported by x86 CompilersCritical Features Supported by x86 Compilers
VectorVector
SIMDSIMD
SuppoSupportrt
PeelPeelss
VectVectoror
LoopLoopss
GlobGlobalal
IPAIPA
OpeOpenn
MPMP
LinksLinks
ACMLACML
LibrariLibrarieses
Profile Profile
GuidedGuided
FeedbaFeedbackck
AlignAlignss
VectVectoror
LoopLoopss
ParallelParallel
DebuggeDebuggersrs
Large Large Array Array SuppoSuppo
rtrt
MediuMedium m
MemorMemory y
ModelModel
PGIPGI
GNUGNU
IntelIntel
PathscalePathscale
AbsoftAbsoft
SUNSUN
MicrosoftMicrosoft

Tuning Performance with CompilersTuning Performance with CompilersMaintaining Stability while OptimizingMaintaining Stability while Optimizing
STEP 0: Build application using the following procedure:STEP 0: Build application using the following procedure: compile all files with the most aggressive optimization flags below:compile all files with the most aggressive optimization flags below:
-tp k8-64 –fastsse-tp k8-64 –fastsse if compilation fails or the application doesn’t run properly, turn off vectorization:if compilation fails or the application doesn’t run properly, turn off vectorization:
-tp k8-64 –fast –Mscalarsse-tp k8-64 –fast –Mscalarsse if problems persist compile at Optimization level 1:if problems persist compile at Optimization level 1:
-tp k8-64 –O0-tp k8-64 –O0
STEP 1: Profile binary and determine performance critical routinesSTEP 1: Profile binary and determine performance critical routines
STEP 2: Repeat STEP 0 on performance critical functions, one at a time, and run STEP 2: Repeat STEP 0 on performance critical functions, one at a time, and run binary after each step to check stabilitybinary after each step to check stability

PGI Compiler FlagsPGI Compiler FlagsOptimization FlagsOptimization Flags
Below are 3 different sets of recommended PGI compiler flags for flag mining Below are 3 different sets of recommended PGI compiler flags for flag mining application source bases:application source bases:
Most aggressive: -tp k8-64 –fastsse –Mipa=fastMost aggressive: -tp k8-64 –fastsse –Mipa=fast enables instruction level tuning for Opteron, O2 level optimizations, sse
scalar and vector code generation, inter-procedural analysis, LRE optimizations and unrolling
strongly recommended for any single precision source codestrongly recommended for any single precision source code Middle of the ground: -tp k8-64 –fast –MscalarsseMiddle of the ground: -tp k8-64 –fast –Mscalarsse
enables all of the most aggressive except vector code generation, which can reorder loops and generate slightly different results
in double precision source bases a good substitute since Opteron has the in double precision source bases a good substitute since Opteron has the same throughput on both scalar and vector codesame throughput on both scalar and vector code
Least aggressive: -tp k8-64 –O0 (or –O1)Least aggressive: -tp k8-64 –O0 (or –O1)

PGI Compiler FlagsPGI Compiler FlagsFunctionality FlagsFunctionality Flags
-mcmodel=medium-mcmodel=medium
use if your application statically allocates a net sum of data structures greater than 2GB
-Mlarge_arrays-Mlarge_arrays use if any array in your application is greater than 2GB
-KPIC -KPIC use when linking to shared object (dynamically linked) libraries
-mp -mp process OpenMPOpenMP/SGISGI directives/pragmas (build multi-threaded code)
-Mconcur-Mconcur attempt auto-parallelization of your code on SMP system with OpenMP

Absoft Compiler FlagsAbsoft Compiler FlagsOptimization FlagsOptimization Flags
Below are 3 different sets of recommended PGI compiler flags for flag mining Below are 3 different sets of recommended PGI compiler flags for flag mining application source bases:application source bases:
Most aggressive: -O3Most aggressive: -O3 loop transformations, instruction preference tuning, cache tiling, & SIMD
code generation (CG). Generally provides the best performance but may cause compilation failure or slow performance in some cases
strongly recommended for any single precision source codestrongly recommended for any single precision source code Middle of the ground: -O2Middle of the ground: -O2
enables most options by –O3, including SIMD CG, instruction preferences, common sub-expression elimination, & pipelining and unrolling.
in double precision source bases a good substitute since Opteron has the in double precision source bases a good substitute since Opteron has the same throughput on both scalar and vector codesame throughput on both scalar and vector code
Least aggressive: -O1Least aggressive: -O1

Absoft Compiler FlagsAbsoft Compiler FlagsFunctionality FlagsFunctionality Flags
-mcmodel=medium-mcmodel=medium
use if your application statically allocates a net sum of data structures greater than 2GB
-g77-g77 enables full compatibility with g77 produced objects and libraries
((must use this option to link to GNU ACML librariesmust use this option to link to GNU ACML libraries))
-fpic-fpic use when linking to shared object (dynamically linked) libraries
-safefp -safefp performs certain floating point operations in a slower manner that avoids
overflow, underflow and assures proper handling of NaNs

Pathscale Compiler FlagsPathscale Compiler FlagsOptimization FlagsOptimization Flags
Most aggressive: -OfastMost aggressive: -Ofast
Equivalent to –O3 –ipa –OPT:Ofast –fno-math-errno
Aggressive : -O3Aggressive : -O3 optimizations for highest quality code enabled at cost of compile time Some generally beneficial optimization included may hurt performance
Reasonable: -O2Reasonable: -O2 Extensive conservative optimizations Optimizations almost always beneficial Faster compile time Avoids changes which affect floating point accuracy.

Pathscale Compiler FlagsPathscale Compiler FlagsFunctionality FlagsFunctionality Flags
-mcmodel=medium-mcmodel=medium use if static data structures are greater than 2GB
-ffortran-bounds-check -ffortran-bounds-check (fortran) check array bounds
-shared-shared generate position independent code for calling shared object libraries
Feedback Directed OptimizationFeedback Directed Optimization STEP 0: Compile binary with -fb_create_fbdata STEP 1: Run code collect data STEP 2: Recompile binary with -fb_opt fbdata
-march=(opteron|athlon64|athlon64fx)-march=(opteron|athlon64|athlon64fx) Optimize code for selected platform (Opteron is default)

ACML 2.1 ACML 2.1
FeaturesFeatures
BLAS, LAPACK, FFT PerformanceBLAS, LAPACK, FFT Performance
Open MP PerformanceOpen MP Performance
ACML 2.5 Snap Shot – Soon to be releasedACML 2.5 Snap Shot – Soon to be released

Components of ACMLComponents of ACMLBLAS, LAPACK, FFTsBLAS, LAPACK, FFTs
Linear Algebra (LA)Linear Algebra (LA)
BBasic asic LLinear inear AAlgebra lgebra SSubroutinesubroutines ((BLASBLAS))
o Level 1Level 1 (vector-vector operations) (vector-vector operations)
o Level 2Level 2 (matrix-vector operations) (matrix-vector operations)
o Level 3Level 3 (matrix-matrix operations) (matrix-matrix operations)
o Routines involving sparse vectorsRoutines involving sparse vectors LLinear inear AAlgebra lgebra PACKPACKageage (LAPACK) (LAPACK)
o leverage BLAS to perform complex operationsleverage BLAS to perform complex operations
o 28 Threaded LAPACK routines28 Threaded LAPACK routines
Fast Fourier TransformsFast Fourier Transforms ( (FFTsFFTs)) 1D, 2D, single, double, r-r, r-c, c-r, c-c support1D, 2D, single, double, r-r, r-c, c-r, c-c support
C and Fortran interfacesC and Fortran interfaces
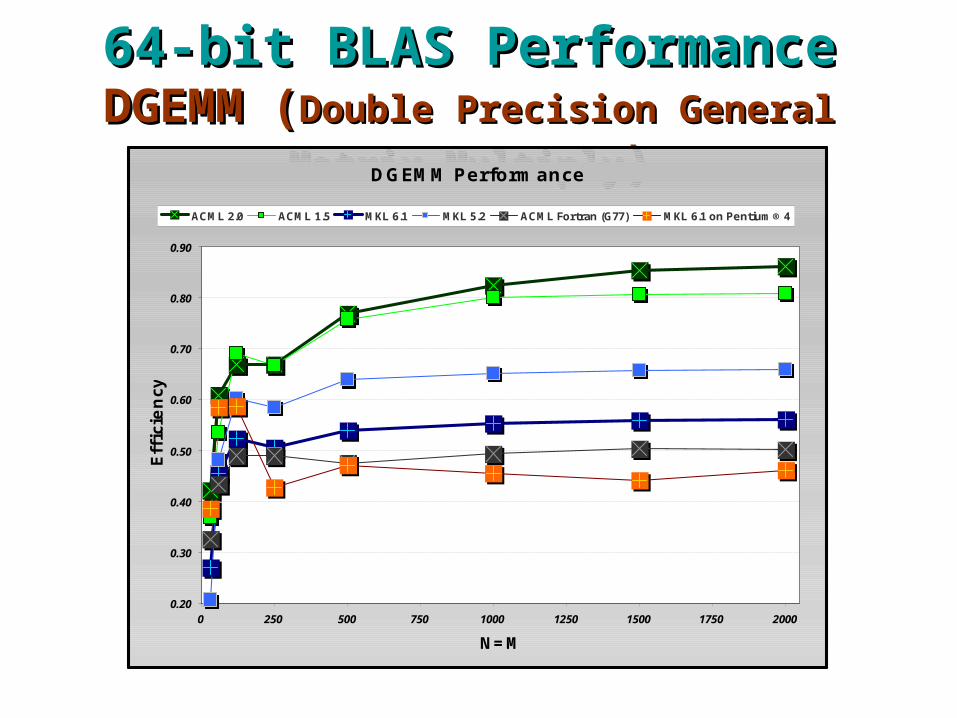
64-bit BLAS Performance64-bit BLAS PerformanceDGEMM (DGEMM (Double Precision General Matrix Double Precision General Matrix
MultiplyMultiply))DGEMM Performance
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
0 250 500 750 1000 1250 1500 1750 2000
N=M
Effi
ciency
ACML 2.0 ACML 1.5 MKL 6.1 MKL 5.2 ACML Fortran (G77) MKL 6.1 on Pentium® 4
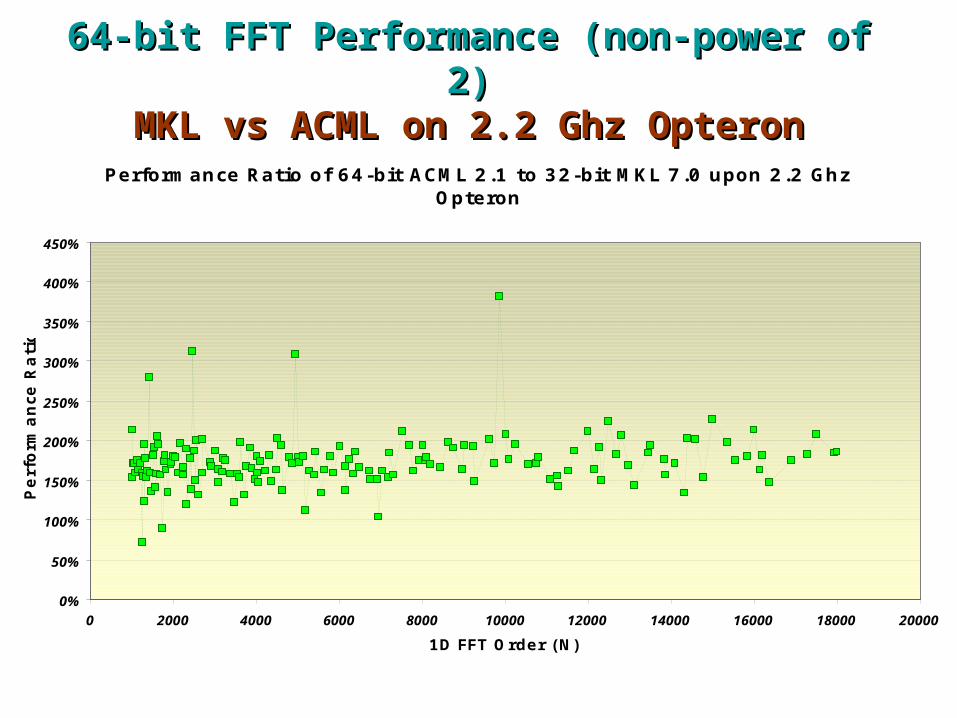
64-bit FFT Performance (non-power of 2)64-bit FFT Performance (non-power of 2)MKL vs ACML on 2.2 Ghz OpteronMKL vs ACML on 2.2 Ghz Opteron
Performance Ratio of 64-bit ACML 2.1 to 32-bit MKL 7.0 upon 2.2 Ghz Opteron
0%
50%
100%
150%
200%
250%
300%
350%
400%
450%
0 2000 4000 6000 8000 10000 12000 14000 16000 18000 20000
1D FFT Order (N)
Perf
orm
ance R
ati
o
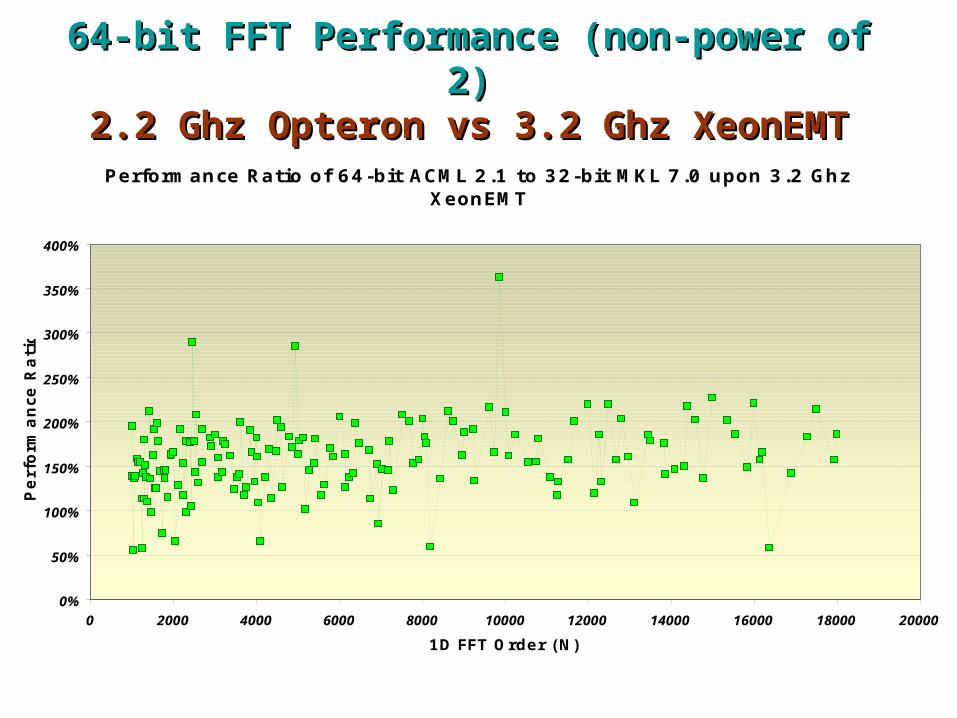
64-bit FFT Performance (non-power of 2)64-bit FFT Performance (non-power of 2)2.2 Ghz Opteron vs 3.2 Ghz XeonEMT2.2 Ghz Opteron vs 3.2 Ghz XeonEMT
Performance Ratio of 64-bit ACML 2.1 to 32-bit MKL 7.0 upon 3.2 Ghz XeonEMT
0%
50%
100%
150%
200%
250%
300%
350%
400%
0 2000 4000 6000 8000 10000 12000 14000 16000 18000 20000
1D FFT Order (N)
Perf
orm
ance R
ati
o
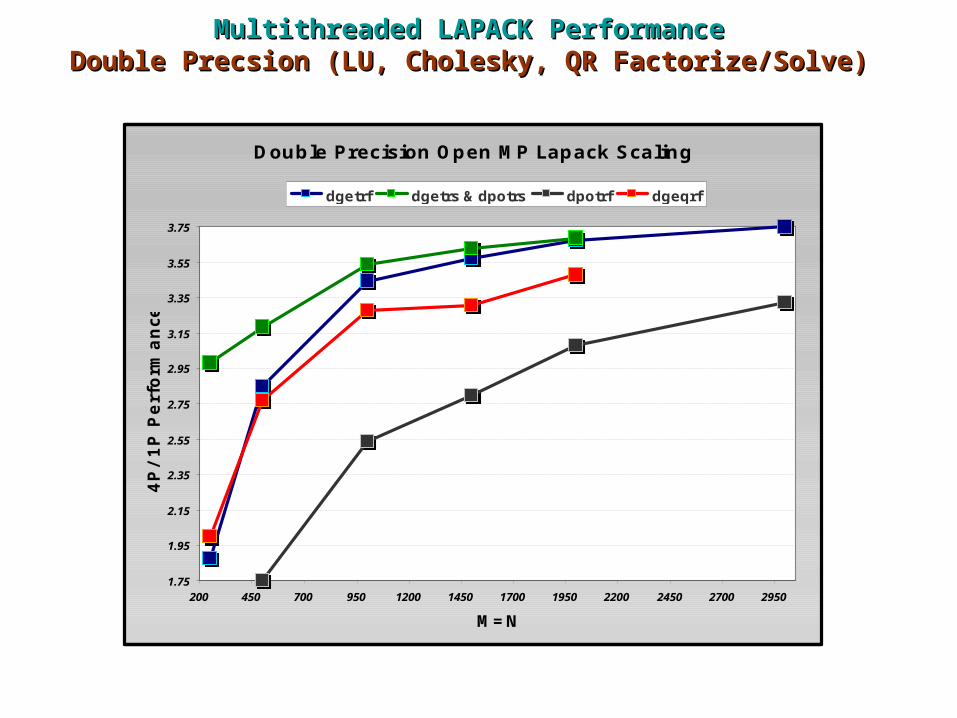
Multithreaded LAPACK PerformanceMultithreaded LAPACK PerformanceDouble Precsion (LU, Cholesky, QR Factorize/Solve)Double Precsion (LU, Cholesky, QR Factorize/Solve)
Double Precision Open MP Lapack Scaling
1.75
1.95
2.15
2.35
2.55
2.75
2.95
3.15
3.35
3.55
3.75
200 450 700 950 1200 1450 1700 1950 2200 2450 2700 2950
M=N
4P
/1P
Perf
orm
ance
dgetrf dgetrs & dpotrs dpotrf dgeqrf

Conclusion and Closing PointsConclusion and Closing Points
How good is our performance?Averaging over 70 BLAS/LAPACK/FFT routinesAveraging over 70 BLAS/LAPACK/FFT routines
Computation weighted averageComputation weighted average
All measurements performed on an All measurements performed on an 4P AMD Opteron4P AMD OpteronTMTM 844 Quartet Server 844 Quartet Server
ACML 32-bit ACML 32-bit isis 55% faster 55% faster thanthan MKL 6.1 MKL 6.1
19
ACML 64-bit ACML 64-bit isis 80% faster 80% faster thanthan MKL 6.1 MKL 6.1
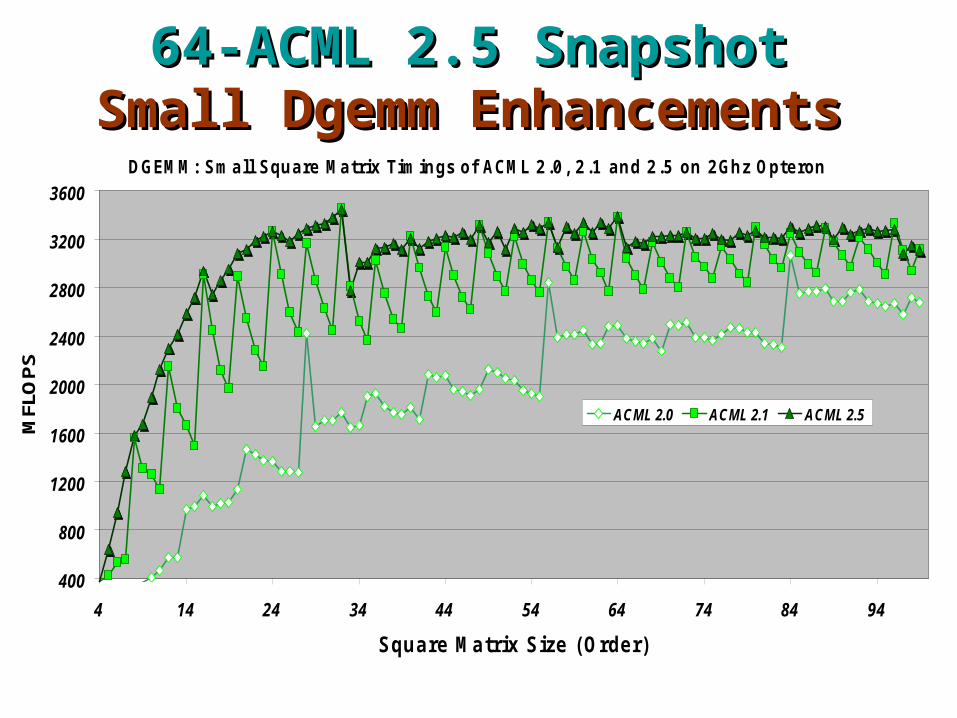
64-ACML 2.5 Snapshot64-ACML 2.5 SnapshotSmall Dgemm EnhancementsSmall Dgemm Enhancements
DGEMM: Small Square Matrix Timings of ACML 2.0, 2.1 and 2.5 on 2Ghz Opteron
400
800
1200
1600
2000
2400
2800
3200
3600
4 14 24 34 44 54 64 74 84 94
Square Matrix Size (Order)
MFL
OP
S
ACML 2.0 ACML 2.1 ACML 2.5

ATLSIM : A full-scale GEANT3 simulation of ATLAS detector (P.Nevski) (typical LHC Higgs events) SixTrack : Tracking of two particles in a 6-dimensional phase space including synchrotron oscillations (F.Schmidt) (http://frs.home.cern.ch/frs/sixtrack.html) Sixtrack benchmark code: E.McIntosh (http://frs.home.cern.ch/frs/Benchmark/benchmark.html)
CERN U : Ancient “CERN Units” Benchmark (E.McIntosh)
Recent Caspur Results ( thanks to M.Rosati)
Benchmark suites

What was measured
On both platforms, we were running one or two simultaneous jobs for each of the benchmarks. On Opteron, we used the SuSE “numactl” interfaceto make sure that at any time each of the two processors makes use of the right bank of memory.
Example of submission, 2 simultaneous jobs:Intel: ./TestJob; ./TestJob
AMD: numactl –cpubind=0 –membind=0 ./TestJob; numactl –cpubind=1 –membind=1 ./TestJob

ResultsCERN Units SixTrack
(seconds/run)
ATLSIM
(seconds/event)
1 job 2 jobs 1 job 2 jobs 1 job 2 jobs
Intel Nocona 491 375,399 185 218,21
8 394 484,484
AMD Opteron
528 528,528 165 165,16
6 389 389,389
While both machines behave in a similar way when only one job is run, the situation changes in a visible manner in the case of two jobs. It may takeup to 30% more time to run two simultaneous jobs on Intel, while on AMDthere is a notable absence of any visible performance drop.
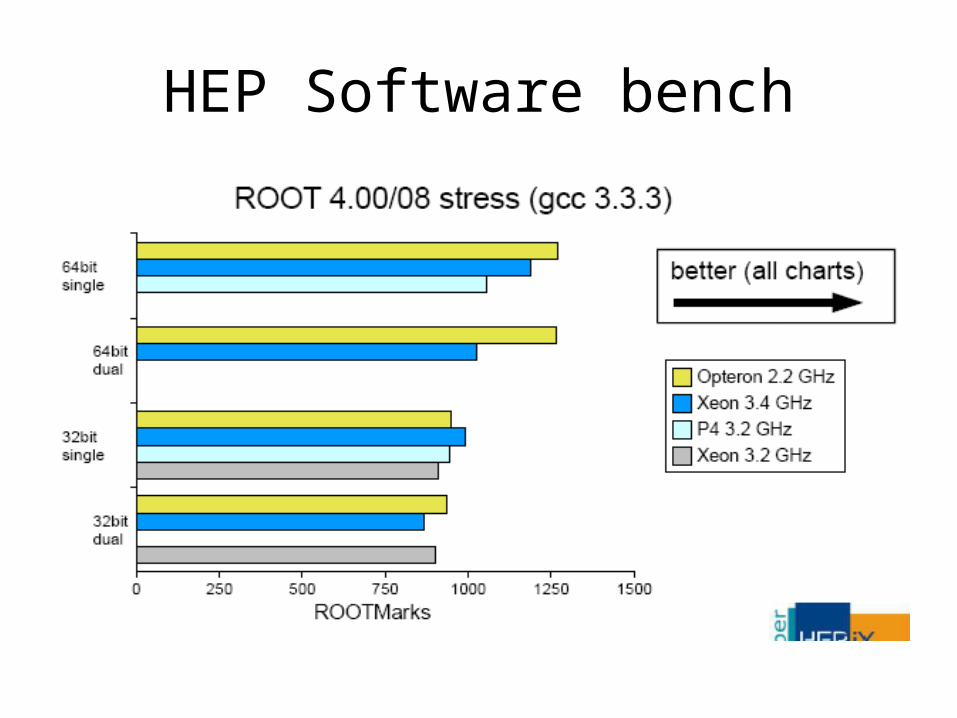
HEP Software bench
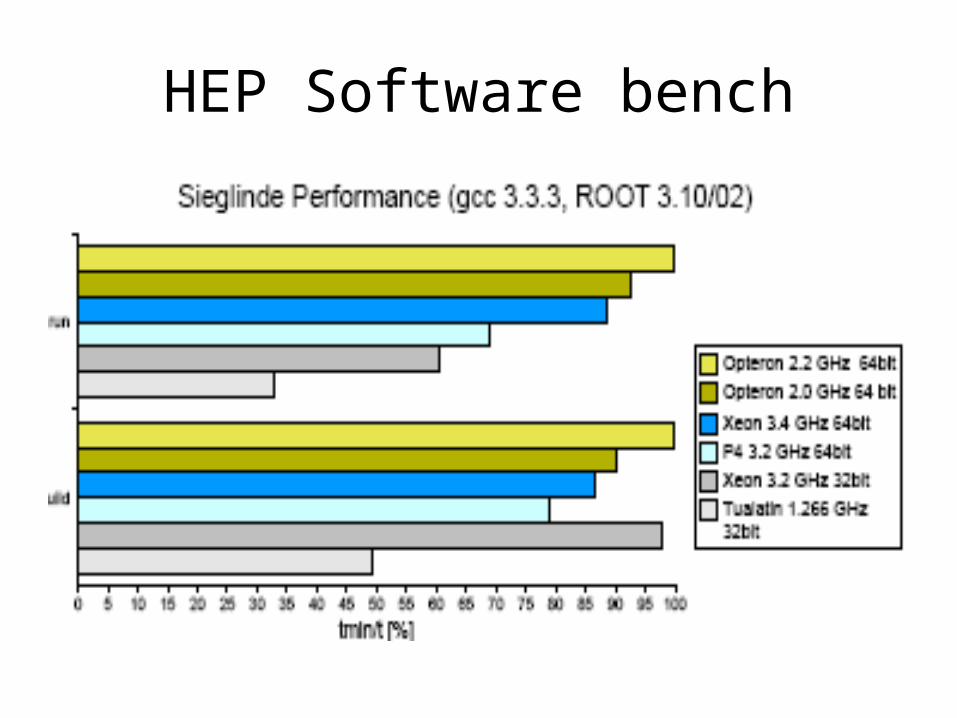
HEP Software bench
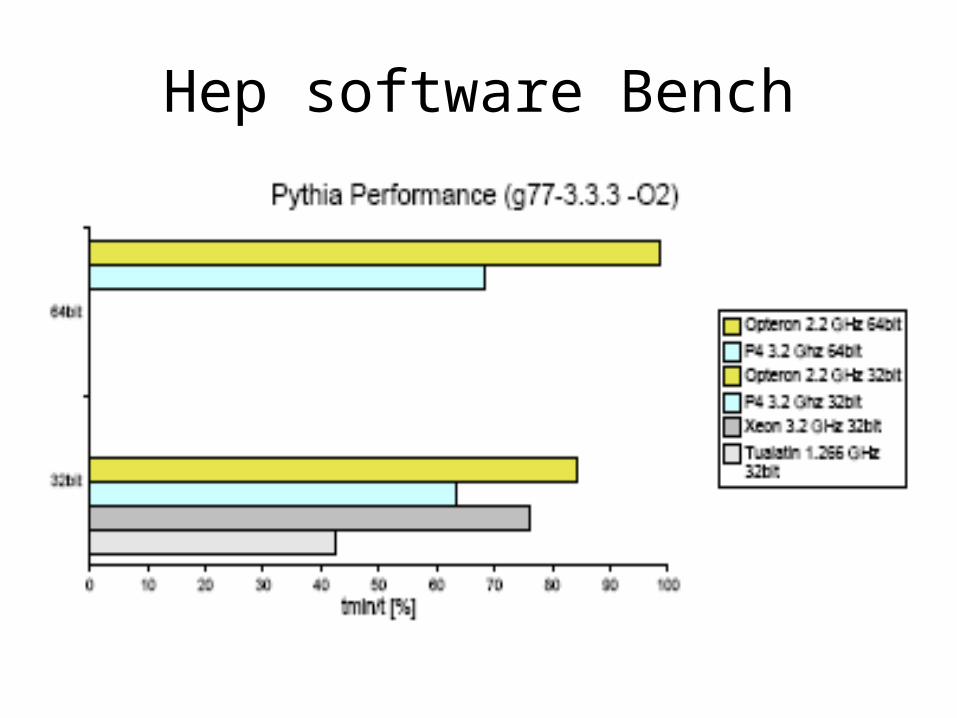
Hep software Bench
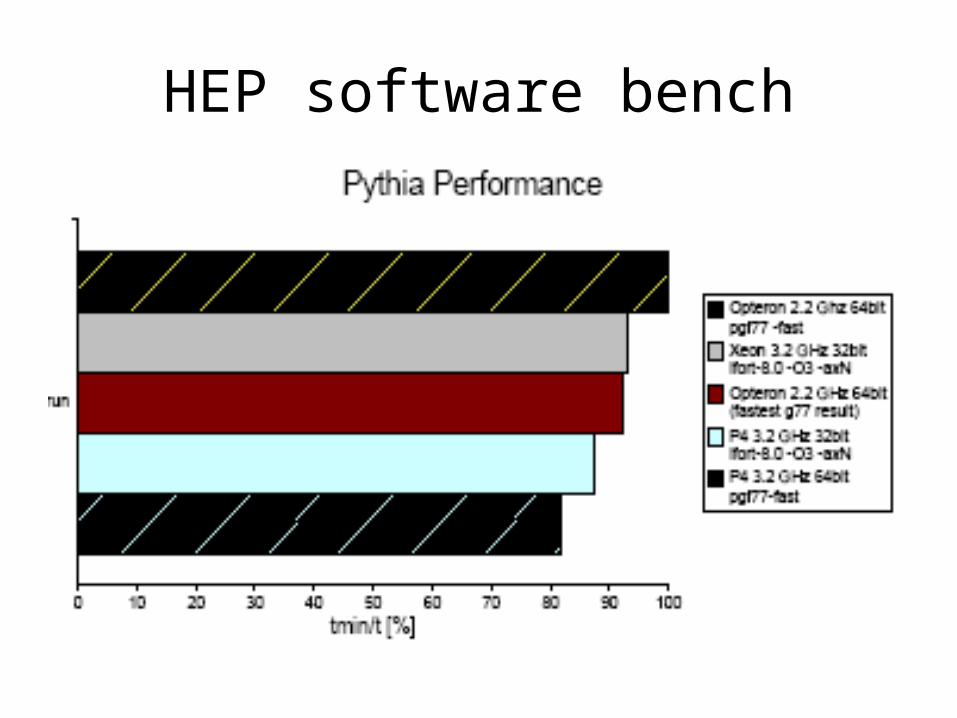
HEP software bench
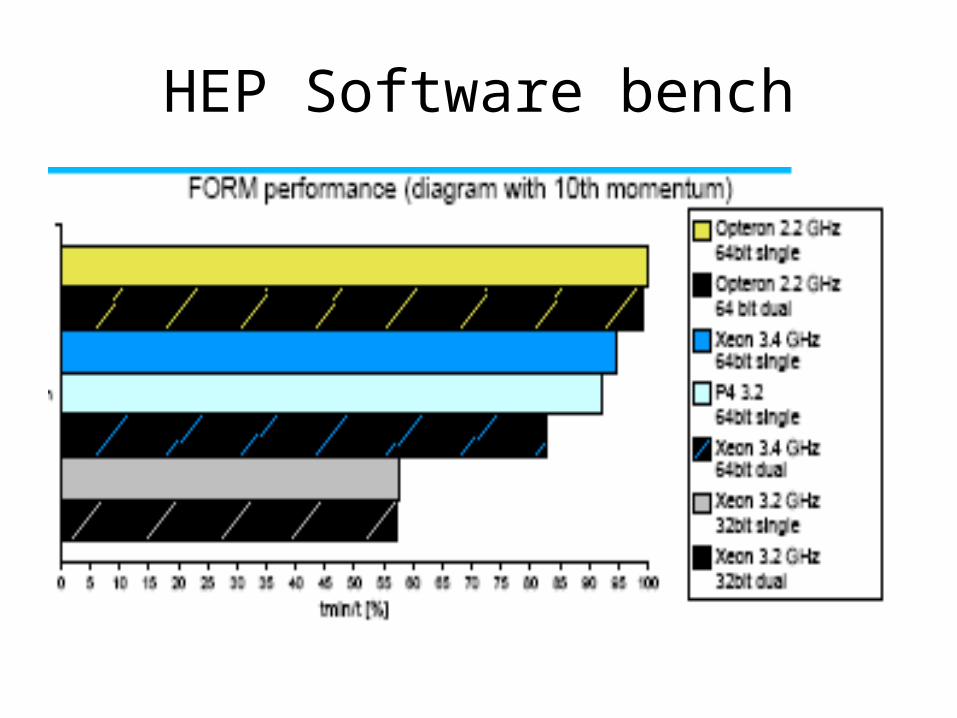
HEP Software bench

An original MPI work on AMD Opteron
• We got access to the MPI wrapper-library source• Environment:
– 4 way servers– Myrinet interconnect– Linux 2.6 kernel– LAM MPI
• We inserted libnuma calls after MPI_INIT to bind the newly-created MPI tasks to specific processors – We avoid unnecessary memory traffic by having each
processor accessing its own memory
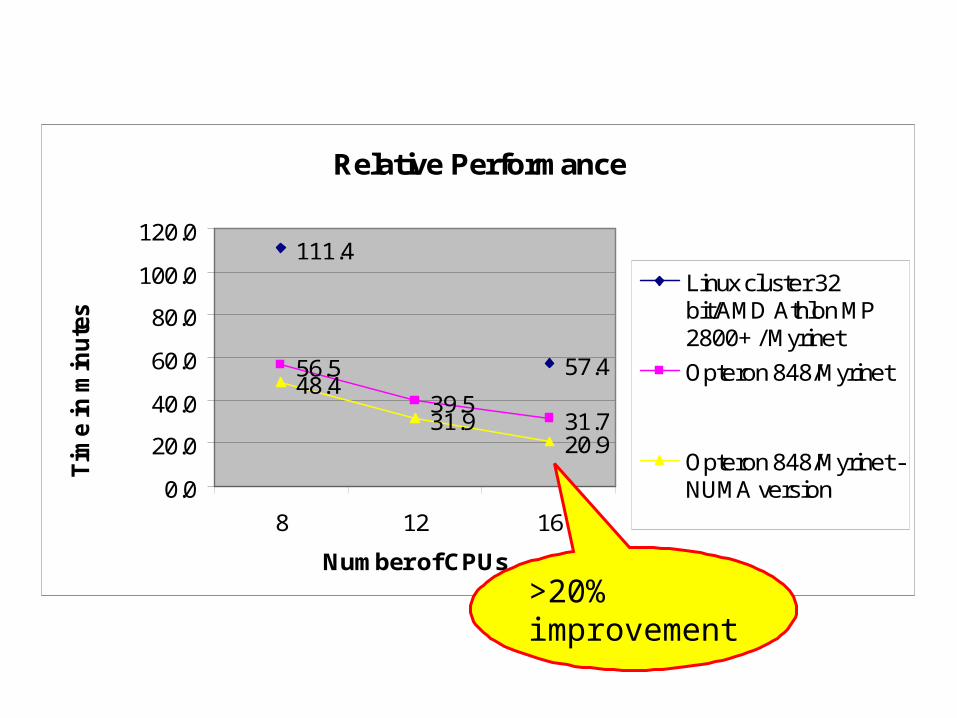
Relative Performance
111.4
57.456.5
39.531.7
48.4
31.920.9
0.0
20.0
40.0
60.0
80.0
100.0
120.0
8 12 16
Number of CPUs
Tim
e in
min
ute
s fo
r 500
itera
tio
ns
Linux cluster 32bit/AMD Athlon MP2800+ / Myrinet
Opteron 848/Myrinet
Opteron 848/Myrinet -NUMA version
>20% improvement

Conclusioni
• AMD Opteron: HPEW
High
Performance
Easy
Way
Top Related