








Languages
Pages
Legal


HathiTrust Research Center Secure Commons
Beth Plale Co-‐Director, HathiTrust Research Center
Professor of Informa:cs Director, Data To Insight Center
Indiana University
@bplale University of Toronto, 25 June 2015

HathiTrust is...
• A trusted digital preserva:on service enabling the broadest possible access worldwide.
• An organiza:on with over 100 research libraries making up its membership.
• A distributed set of services operated by different members (California Digital Library, Illinois, Indiana, Michigan).
• A range of programs enabled by the large scale collec:on of digi:zed materials.

Mission To contribute to research, scholarship, and the common good by collabora:vely collec:ng, organizing, preserving, communica:ng, and sharing the record of human knowledge.
…building comprehensive collec:ons and infrastructure co-‐owned and managed by partners. …infrastructure for digital content of value to scholars and researchers …enabling access by users with print disabili:es. …suppor:ng research with the collec:ons. …s:mula:ng shared collec:on storage strategies.

Collec:ons
University of Toronto, 25 June 2015

Preserva:on with Access
• Preserva:on – TRAC-‐cer:fied
• Discovery – Bibliographic and full-‐text search of all materials
• Access and Use – Full text search (all users) – Public domain and open access works (all users) – Collec:ons and APIs (all users) – Lawful uses of in-‐copyright works (members)

HathiTrust in April 2015
• 13.3 million total items – 6.8 million book :tles – 355,000 serial :tles – 612,000 US federal government documents – 5.03 million items open (public domain & CC-‐licenses)
The collec:on primarily includes published materials in bound form, digi:zed from library collec:ons.

7 16 April 2015
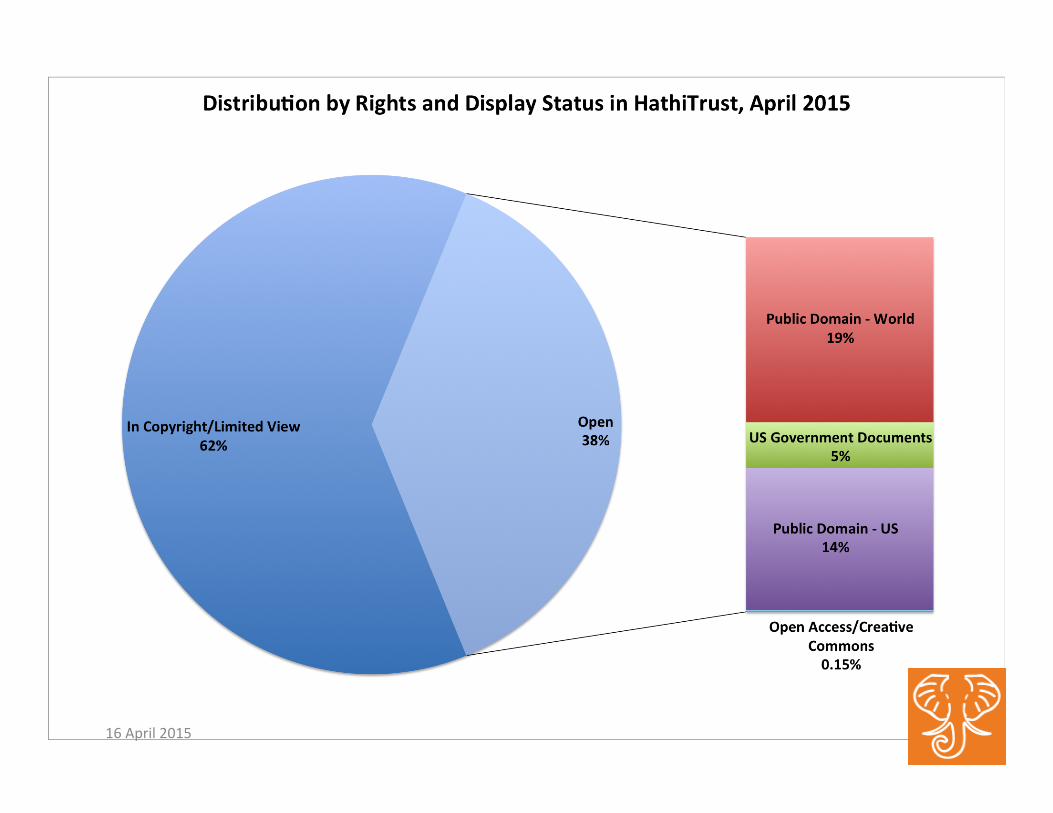
8 16 April 2015

HathiTrust Research Center Secure Commons
University of Toronto, 25 June 2015

Mission of the HT Research Center
• Research arm of HathiTrust • Established: July, 2011 • Collabora:ve center: Indiana University & University of Illinois
• Mission: Enable researchers world-‐wide to accomplish tera-‐scale text data-‐mining and analysis
• Major effort to date: – Build secure and trusted environment surrounding the sensi:ve text and image data: Trust Ring
– Make the data more useable and accessible to researcher

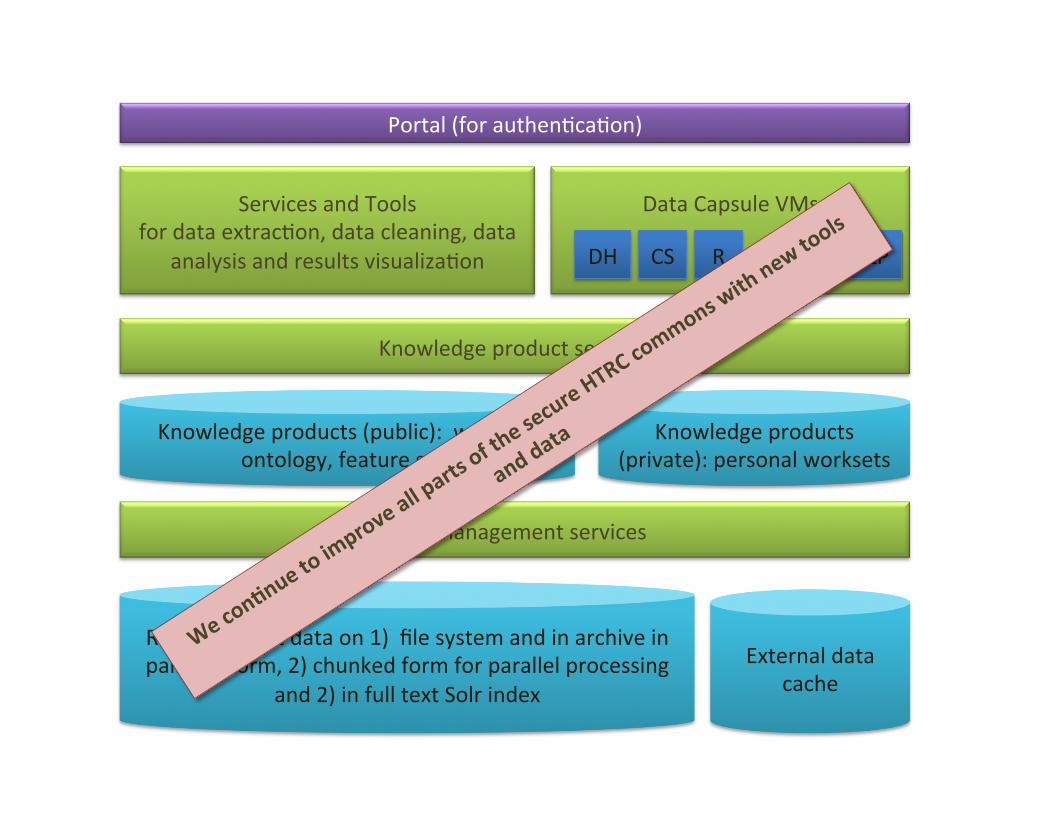
Secure Commons “Trust Ring”
• Logical ring within which exist trusted services and computers that protect and provide access to the sensi:ve (copyright) data
• Computa:on moves to the data not vice versa • Computa:on carried out in the trust ring
IU UIUC

Raw copyright data on 1) file system and in archive in pairtree form, 2) chunked form for parallel processing
and 2) in full text Solr index
Knowledge product services
Data Capsule VMs
Services and Tools: data discovery, extrac:on, cleaning,
mining/analysis, visualiza:on
Knowledge products (public): workset, ontology, feature sets
HTRC Portal (for authen:ca:on)
Knowledge products (private): personal worksets
External data cache
DH CS NLP R . . .
Data management services
Secure Commons Services Stack

Trust Ring gains core of its trustworthiness from the highly secure and heavily managed storage and compute environment at Indiana University

Researcher Interac:on Interac:on with HTRC is through one of three op:ons:
1. Services and tools for data extrac:on, data cleaning, data analysis and results visualiza:on. Self service, browser-‐based.
2. Check out a Data Capsule VM. Researcher checks out and configures for their use (currently for the technology savvy)
3. Direct engagement with HTRC staff HTRC Portal: h.ps://sharc.hathitrust.org/
Self service portal for services and tools
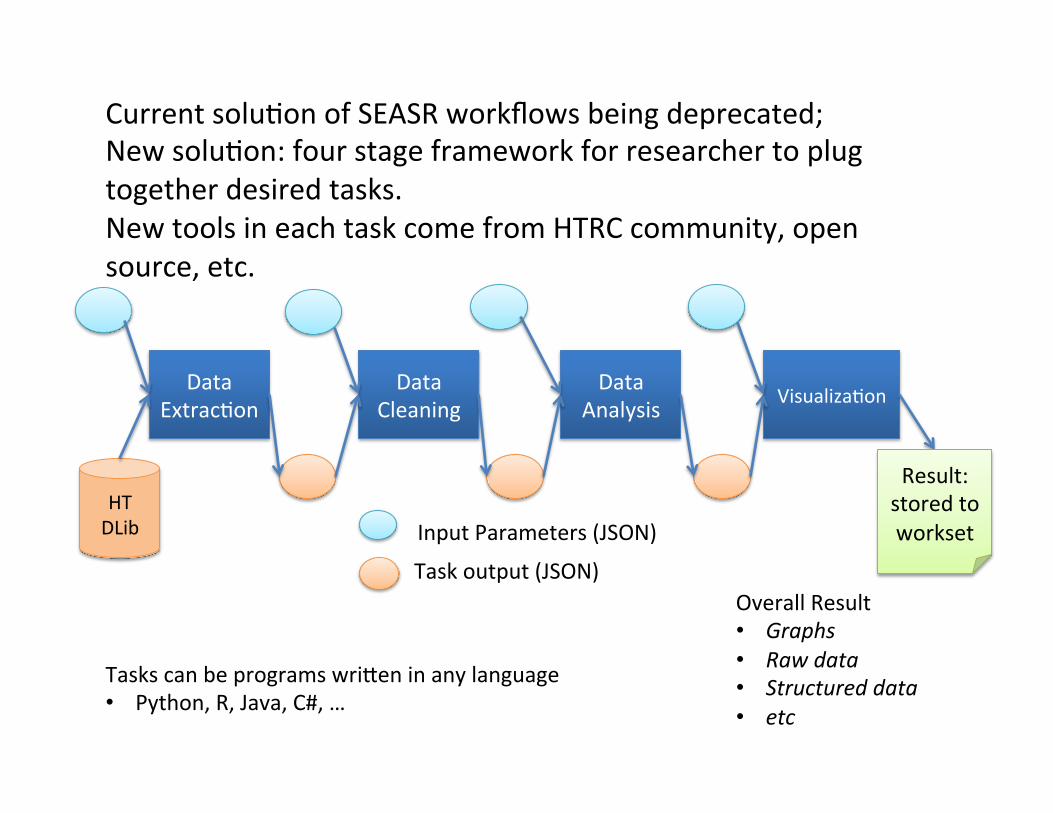
Data Extrac:on
Data Cleaning
Data Analysis Visualiza:on
HT DLib
Result: stored to workset Input Parameters (JSON)
Task output (JSON) Overall Result • Graphs • Raw data • Structured data • etc
Tasks can be programs wrifen in any language • Python, R, Java, C#, …
Current solu:on of SEASR workflows being deprecated; New solu:on: four stage framework for researcher to plug together desired tasks. New tools in each task come from HTRC community, open source, etc.

Data Capsule
Founda:ons of HT Data Capsule: K. Borders, E. V. Weele, B. Lau, and A. Prakash. Protec:ng confiden:al data on personal computers with storage capsules. 18th USENIX Security Symposium, pp 367–382. USENIX Associa:on, 2009.

HathiTrust Data Capsule concept
• Researcher “checks out” a virtual machine (VM)
• VM runs in the Trust Ring • Researcher owns their VM through weeks/months of analysis
• Geong stuff into VM is easy, but there is a controlled and audited process for geong results out of the VM

Data Capsule with i-‐Python installed

Mode switch protec:on: maintenance mode
Data Capsule Data Capsule User traffic from desktop allowed
Arbitrary network download allowed
Arbitrary network upload allowed
during maintenance mode, researcher installs new soqware and loads data into capsule
HTRC raw data sources
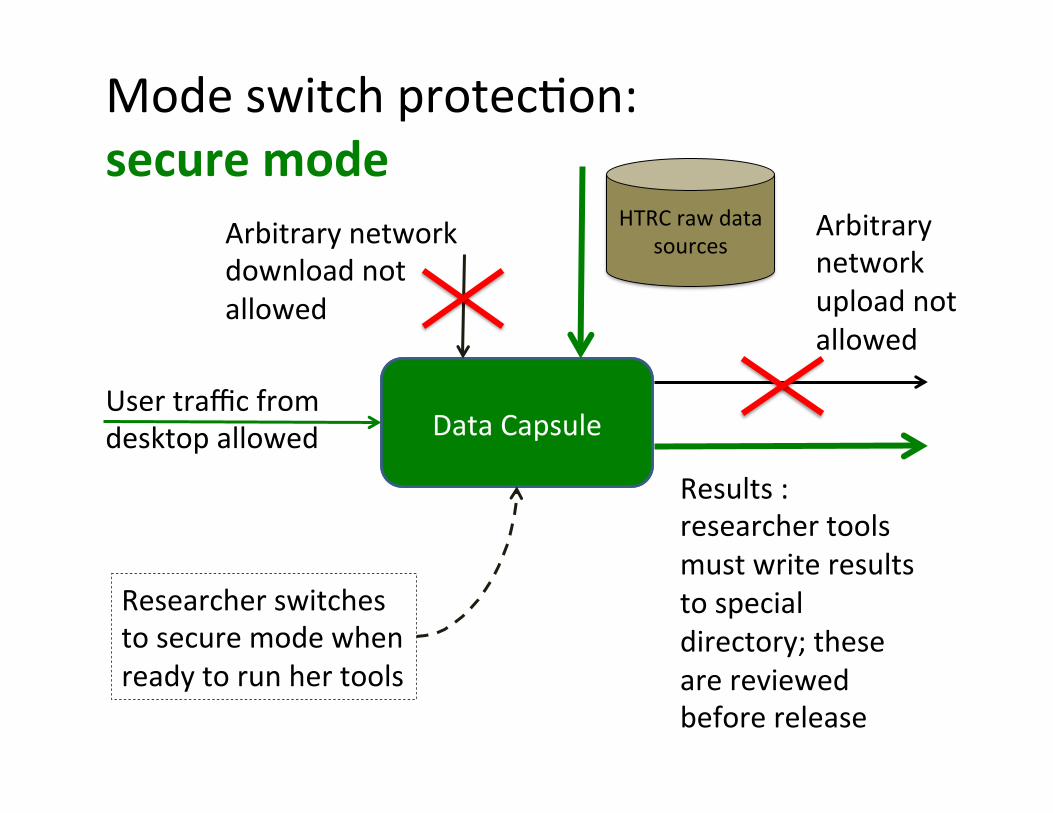
Mode switch protec:on: secure mode
Data Capsule Data Capsule User traffic from desktop allowed
Arbitrary network download not allowed
Arbitrary network upload not allowed
Researcher switches to secure mode when ready to run her tools
HTRC raw data sources
Results : researcher tools must write results to special directory; these are reviewed before release

Threat Model
• User is trustworthy • Virtual machine (VM) manager and the host it runs on are also trusted.
• VM is NOT trusted. We assume the possibility of malware being installed as well as other remotely ini:ated afacks on the VM, which are undetectable to the user.
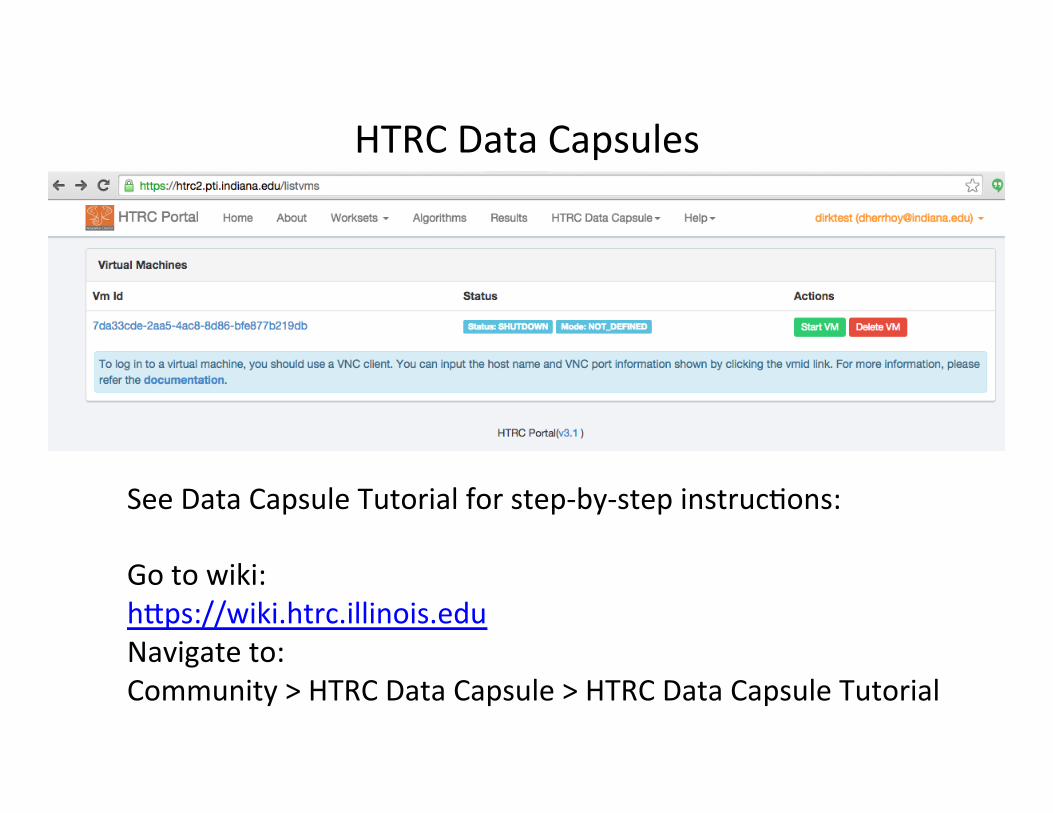
HTRC Data Capsules
See Data Capsule Tutorial for step-‐by-‐step instruc:ons: Go to wiki: hfps://wiki.htrc.illinois.edu Navigate to: Community > HTRC Data Capsule > HTRC Data Capsule Tutorial

Direct engagement with HTRC staff
University of Toronto, 25 June 2015

HTRC Advanced Collabora:ve Support Awards for HTRC developer Hme
1st round awards: • Detec:ng Literary Plagiarisms: The Case of Oliver Goldsmith • Taxonomizing the Texts: Towards Cultural-‐Scale Models of Full Text • The Trace of Theory • Tracking technology diffusion thru :me using HT Corpus
Coming: call for 2nd round Proposals. h?p://hathitrust.org/htrc for details … or Dr. Miao Chen, [email protected]

Advanced CollaboraHve Support
• Pairs HT ins:tu:on researchers with expert staff for an extended period during which they work together to address a par:cularly vexing issue (e.g., efficient paralleliza:on and op:miza:on of a machine learning algorithm)
• 20 hours/week available: example: at any one :me 4 ac:ve projects, each receiving 5 hours a week for up to 2 months.
• Resourced at 1.25 FTE • Staffed by HTRC Staff who have signed the staff agreement
26
HathiTrust* HTRC*Advisory*Board*HTRC*Execu7ve*Management*
Administra7ve*Support*
Senior*Library*Personnel**(4*supervisors*at*.05*FTE)**
Senior*Project*Coordinator**(.25*FTE)*
Execu7ve*Assistant*(.5*FTE)*
Core*Development*
Sr.*SoLware*Architect*(1.0*FTE)*
Research*Programmer*(.5*FTE)*
Library*Research*Programmer*
(.5*FTE)*
IU*Systems*Administrator*
(.25*FTE)*
User*Interface*Specialist*(2*years*at*1.0*FTE)*
Informa7cs*Developers*(2*developers*for*2*years*
at*.15*FTE)*
Advanced*Research*
CS*PhD*Students*
LIS*PhD*Students*
UI*Systems*Administrator*
(.5*FTE)*
Advanced*Collabora7ve*Support*(coordinated*by*
M.*Chen)*
Research*Programmer*(.5*FTE)*
Computa7onal*Research*Liaison*(.5*FTE)*
Asst*Dir*Outreach*&*Educa7on*(M.*Chen)*(1*year*at*.25*FTE)**
Scholarly*Commons*
Dig*Humani7es*Specialist*(1.0*FTE)*
CLIR*Postdoctoral*Research*Associate*(2*years*at*1.0*FTE)*
Digital*Research*Librarian*support*
(.2*FTE)*
Scholars*Commons*Support*(.5*FTE)*
LIS*MS*Students*
IU*Managing*Director*(.25*FTE)*
UI*Managing*Director*(.11*FTE)*
Key:%*
*Area**
*Proposed*for*funding*by*HathTrust****Funded*by*Indiana*University*
**Funded*by*University*of*Illinois****Proposed*for*joint*funding*by*HathiTrust*/*Indiana*University*
***Proposed*for*joint*funding*by*HathiTrust*/*University*of*Illinois*
***
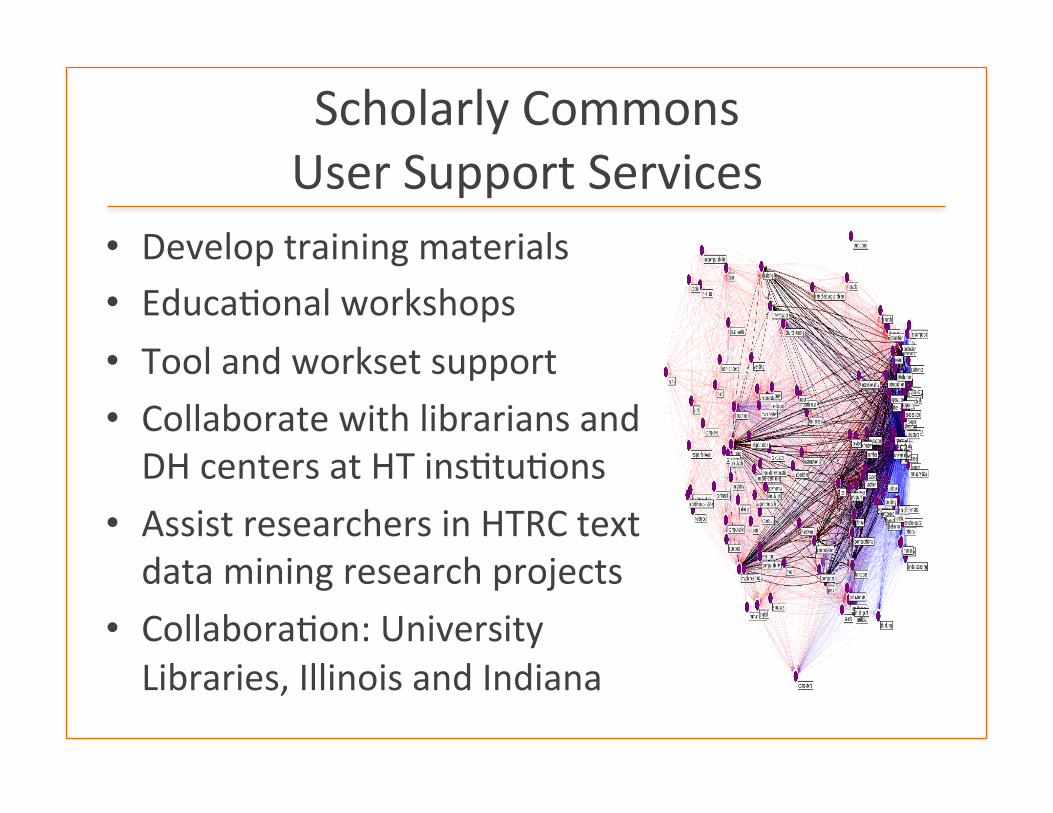
Scholarly Commons User Support Services
• Develop training materials • Educa:onal workshops • Tool and workset support • Collaborate with librarians and DH centers at HT ins:tu:ons
• Assist researchers in HTRC text data mining research projects
• Collabora:on: University Libraries, Illinois and Indiana

Knowledge Products: ongoing projects to
improve
University of Toronto, 25 June 2015

Worksets
• The ability to slice through a massive corpus constructed from many different library collecHons, and out of that to construct the precise workset required for a parHcular scholarly invesHgaHon, is an example of the “game changing” potenHal of the HathiTrust...

Dimensions of Workset Crea:on (Illustra:ve)
My workset should contain (inspired by 2012 UnCamp): • Volumes pertaining to Japan / in Japanese • All volumes relevant to the study of Francis Bacon • Music scores or nota:on extracted from HT volumes • Images of Victorian England extracted from HT vols. • Volumes in HT similar to TCP-‐ECCO novels • 19th c. English-‐language novels by female authors • Representa:ve sample (by pub date & genre) of French language items in HT

What is Workset? #1
• A workset is an aggrega:on of materials brought together for the purpose of discovery and analysis.

What is a Workset? #2
• Worksets are conceptual and must be expressible in a variety of ways • Need to facilitate inclusion of resources
beyond HathiTrust • Need to facilitate the inclusion of
resources at many different levels of granularity beyond the book

What is Workset #3
• Worksets encapsulate the specific materials that underwent analysis • Need to capture provenance informa:on • Possible recording of parameters

What is a Workset? #4
• Worksets should be able to spawn descendants but otherwise immutable
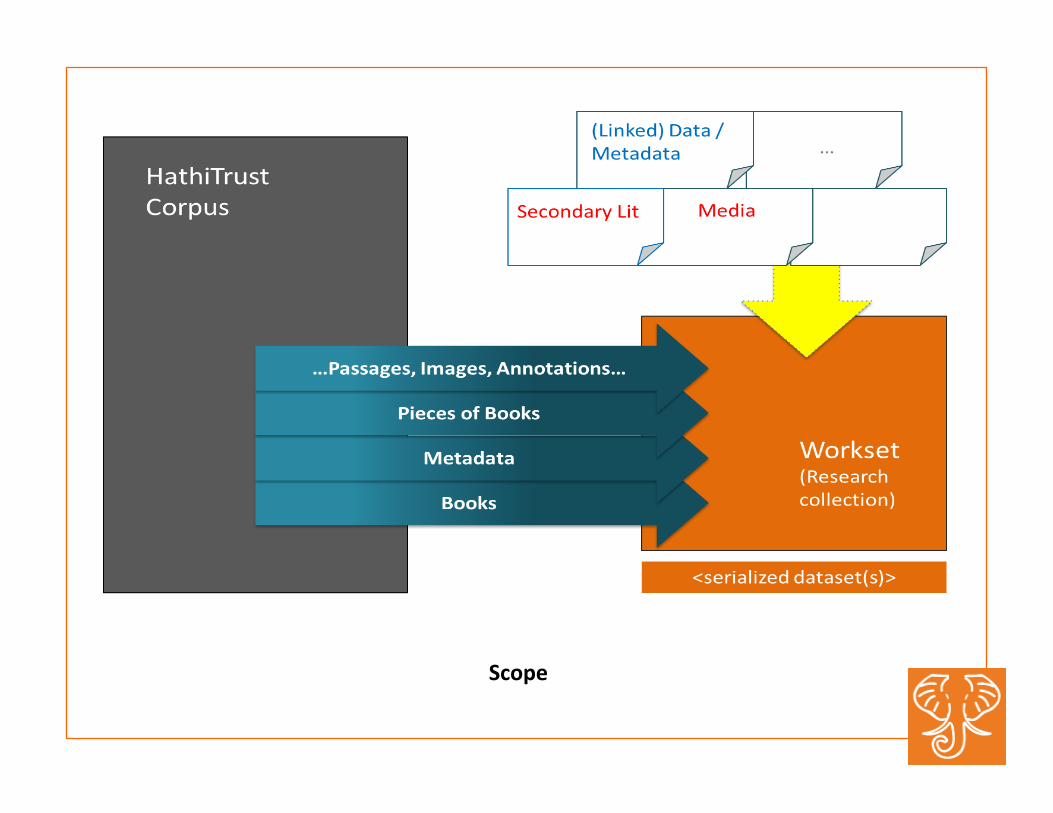
Scope
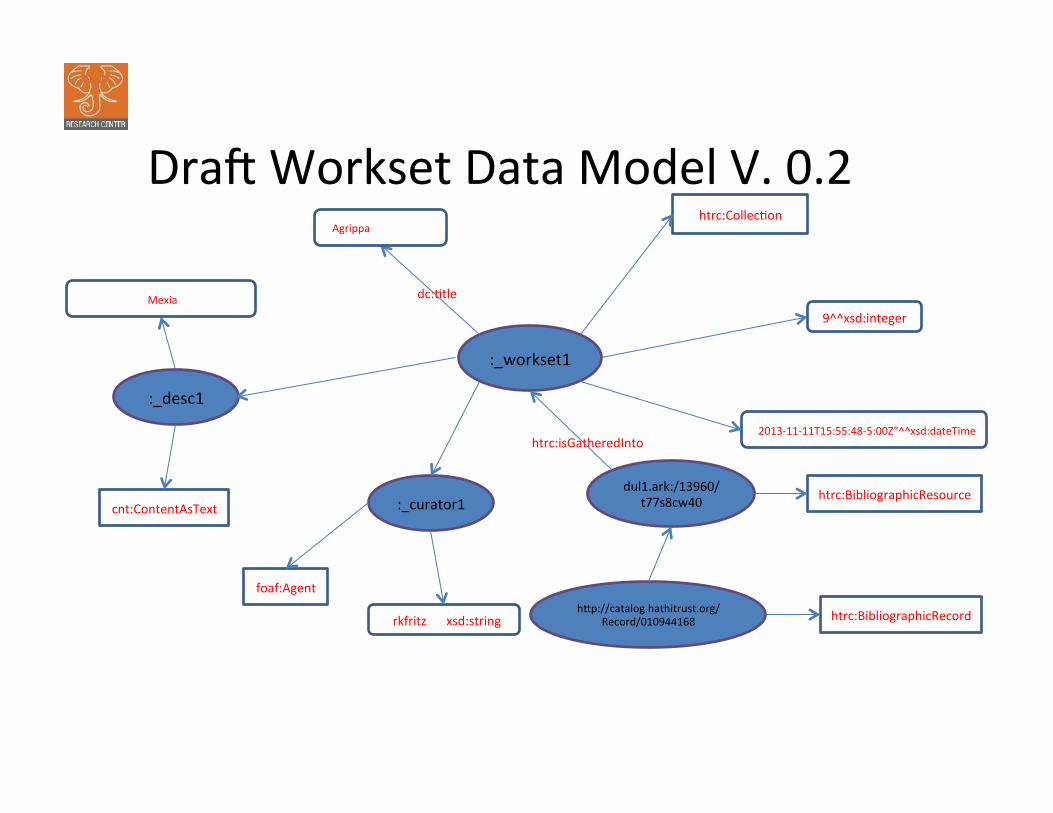
rdf:type
Draq Workset Data Model V. 0.2
cnt:content
rdf:type
htrc:isGatheredInto
dcterms:created
dcterms:extent
rdf:type
rdf:type
foaf:accountName
dc:creator
rdf:type
:_workset1
htrc:Collec:on
dc::tle
:_desc1
dcterms:abstract
cnt:ContentAsText :_curator1
foaf:Agent
“rkfritz”^^xsd:string
9^^xsd:integer
“2013-‐11-‐11T15:55:48-‐5:00Z”^^xsd:dateTime
dul1.ark:/13960/t77s8cw40 htrc:BibliographicResource
“Agrippa”^^xsd:string
“Agrippa and Mexia”^^xsd:string
rdf:about
hfp://catalog.hathitrust.org/Record/010944168 htrc:BibliographicRecord

Page-‐level Sta:s:cs Extrac:on Over HathiTrust Corpus for Tech Terms
Acknowledgements: collabora:on with Michelle Alexopolous, University of Toronto. Extrac:on and analysis by Guangchen Ruan, CS PhD student at Indiana University
University of Toronto, 25 June 2015

Mo:va:on and Problem • Given a list of terms (n-‐grams), extract page-‐level sta:s:cs for each term For instance, seek frequency of appearance of term “diesel engine” at volume level and page level: in which volumes, and on which pages with frequency count per page
• We undertook to compare the accuracy of two approaches: one that extracts terms from Solr index, and other that extracts terms using a single-‐pass processing framework we developed to work directly on the raw data

• Sample output for page-‐level stats for “diesel engine”
{ "tech_name": "diesel engine", "volumes": [ { "volumeID": "uc1.b4125277", "pageLevelStats": [ { "pageSeq": "146", "pageLabel": "136", "count": 3}, { "pageSeq": "649", "pageLabel": "639", "count": 2}] }, … ]}

Approach one: page level index using Solr
§ Build page-‐level index from raw text. Obtain page-‐level stats through Solr query
§ Computa:on and :me cost high to build page-‐level index for each tech term, so build single page-‐level index for group of words with similar seman:cs § e.g., “diesel engine”, “diesel motor”, “diesel powered engine”

Approach two: single-‐pass processing distributed compu:ng framework
§ For each volume, directly scan tcontent of each page to check match using regular expression
§ Divide volumes and computa:on across mul:ple machines to speed up
§ Not computa:on sensi:ve to the # of tech terms being searched so can provide page-‐level stats for each tech term rather than one for a group

• We compare results of approaches under 8 tech term groups or equivalently 57 tech terms
• Overall, results from two approaches have over 95% consistency
• For inconsistent por:on, we manually inspect the raw text content to verify the ground truth
• Evalua:on shows that single-‐pass processing approach is more accurate (less false posi:ves and nega:ves) than Solr approach
Quality evalua:on: Solr-‐based vs. Single-‐pass processing

Tech term groups
Tech term group Tech terms
diesel engine (6 terms)
“diesel engine”, “diesel engines”, “diesel motor”, “diesel motors”, “diesel powered engine”, “diesel powered engines”
gas engine (20 terms)
“gas engine”, “gas engines”, “gas motor”, “gas motors”, “gas powered engine”, “gas powered engines”, “gas powered motor”, “gas powered motors”, “gasoline engine”, “gasoline engines”, “gasoline motor”, “gasoline motors”, “gasoline powered engine”, “gasoline powered engines”, “gasoline powered motor”, “gasoline powered motors”, “gasoline-‐powered engine”, “gasoline-‐powered engines”, “gas-‐powered engines” “gas-‐powered motors”

Tech term group
Tech terms
internal-‐combusGon-‐engine (4 terms)
“internal combus:on engine”, “internal combus:on engines”, “internal combus:on motor”, “internal combus:on motors”
steam boat (2 terms)
“steam boat”, “steam boats”
steam engine (12 terms)
“Corliss engine”, “Corliss engines”, “Corliss steam engine”, “Corliss steam engines”, “Newcomen steam engine”, “Newcomen steam engines”, “steam engine”, “steam engines”, “waf engine”, “waf engines”, “waf steam engine”, “waf steam engines”
steam locomoGve (4 terms)
“steam locomo:ve”, “steam locomo:ves”, “steam train”, “steam trains”
steam ship (2 terms)
“steam ship”, “steam ships”
Telegraph (7 terms)
“cable gram”, “cablegram”, “cable grams”, “telegram”, “telegrams”, “telegraph”, “telegraphs”
Tech term groups
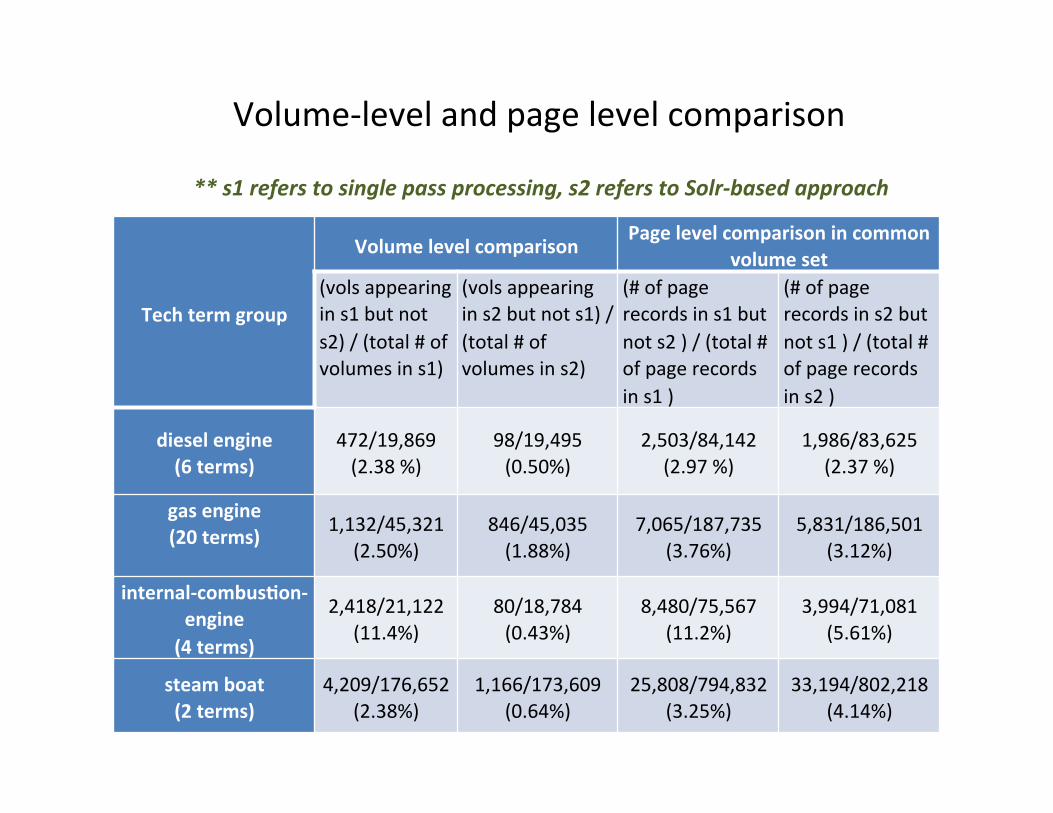
Volume-‐level and page level comparison
Tech term group
Volume level comparison Page level comparison in common
volume set (vols appearing in s1 but not s2) / (total # of volumes in s1)
(vols appearing in s2 but not s1) / (total # of volumes in s2)
(# of page records in s1 but not s2 ) / (total # of page records in s1 )
(# of page records in s2 but not s1 ) / (total # of page records in s2 )
diesel engine (6 terms)
472/19,869 (2.38 %)
98/19,495 (0.50%)
2,503/84,142 (2.97 %)
1,986/83,625 (2.37 %)
gas engine (20 terms)
1,132/45,321 (2.50%)
846/45,035 (1.88%)
7,065/187,735 (3.76%)
5,831/186,501 (3.12%)
internal-‐combusGon-‐engine (4 terms)
2,418/21,122 (11.4%)
80/18,784 (0.43%)
8,480/75,567 (11.2%)
3,994/71,081 (5.61%)
steam boat (2 terms)
4,209/176,652 (2.38%)
1,166/173,609 (0.64%)
25,808/794,832 (3.25%)
33,194/802,218 (4.14%)
** s1 refers to single pass processing, s2 refers to Solr-‐based approach
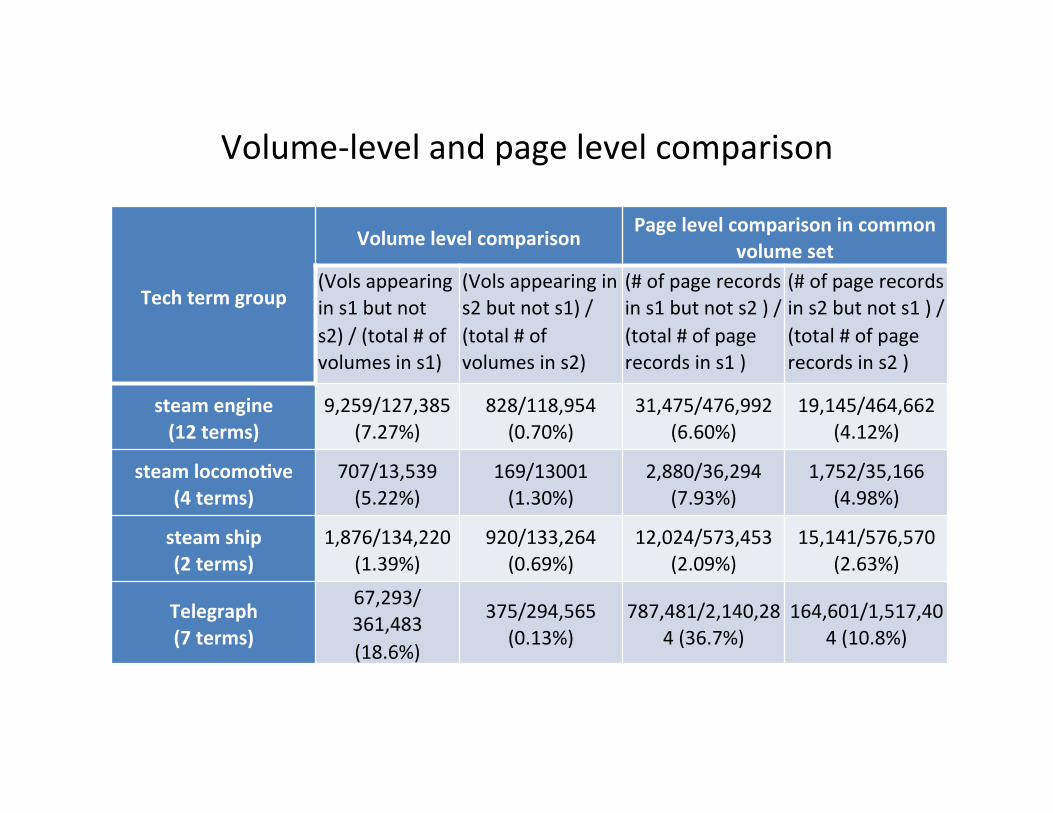
Volume-‐level and page level comparison
Tech term group
Volume level comparison Page level comparison in common
volume set (Vols appearing in s1 but not s2) / (total # of volumes in s1)
(Vols appearing in s2 but not s1) / (total # of volumes in s2)
(# of page records in s1 but not s2 ) / (total # of page records in s1 )
(# of page records in s2 but not s1 ) / (total # of page records in s2 )
steam engine (12 terms)
9,259/127,385 (7.27%)
828/118,954 (0.70%)
31,475/476,992 (6.60%)
19,145/464,662 (4.12%)
steam locomoGve (4 terms)
707/13,539 (5.22%)
169/13001 (1.30%)
2,880/36,294 (7.93%)
1,752/35,166 (4.98%)
steam ship (2 terms)
1,876/134,220 (1.39%)
920/133,264 (0.69%)
12,024/573,453 (2.09%)
15,141/576,570 (2.63%)
Telegraph (7 terms)
67,293/ 361,483 (18.6%)
375/294,565 (0.13%)
787,481/2,140,284 (36.7%)
164,601/1,517,404 (10.8%)

Analysis of Solr false posi:ve/nega:ve
• False posi:ve
§ Example one: false posi:ve match for “diesel engine” “17 Engines and Turbines (Excludes aircraq and rocket engines; automo:ve engines, except diesel; engine generator sets; and locomo:ves.)”
§ Example two: false posi:ve match for “diesel motor” “Fossil fuel consump:on (gasoline, diesel, motor oil) would decrease as a result of this alterna:ve.”
§ Cause analysis: Solr builds page-‐level index by Lucene tokenizaHon which removes non-‐word character. One-‐pass processing can correctly handle such cases as it matches by regular expression against raw text

Cause analysis of Solr’s false posi:ve/nega:ve (Cont.)
• False nega:ve
§ Example one: false nega:ve match for “diesel engine” “Steam boilers and equipment, steam and gas turbines, nuclear reactors, steam engines, diesel en-‐ gines, and other prime movers”
§ Example two: false posi:ve match for “diesel motor” “The introduc:on of commercial-‐model diesel engines, in a rela:vely small quan:ty of trucks.”
Lucence tokeniza:on splits en-‐gines into “en” and “gines”, Thus leads to false nega:ve
End of line
Single-‐pass processing will handle word con:nua:on case by concatena:ng “en-‐gines” into “engines” first before matching
Solr failed to detect this straigh�orward case, we do not know the reason and need further inves:ga:on

False nega:ve caused by OCR errors
• Example one: “Burdick, R. H. Performance of diesel.engine plants in Texas.”
• Example two: “from gasoline-‐powered to fuel-‐efficient diesel-‐_powered engines”
• One-‐pass processing approach failed to detect them in such cases
Tokens generated as result of OCR error
Raw copyright data on 1) file system and in archive in pairtree form, 2) chunked form for parallel processing
and 2) in full text Solr index
Knowledge product services
Data Capsule VMs
Services and Tools for data extrac:on, data cleaning, data
analysis and results visualiza:on
Knowledge products (public): workset, ontology, feature sets
Portal (for authen:ca:on)
Knowledge products (private): personal worksets
External data cache
DH CS NLP R . . .
Data management services
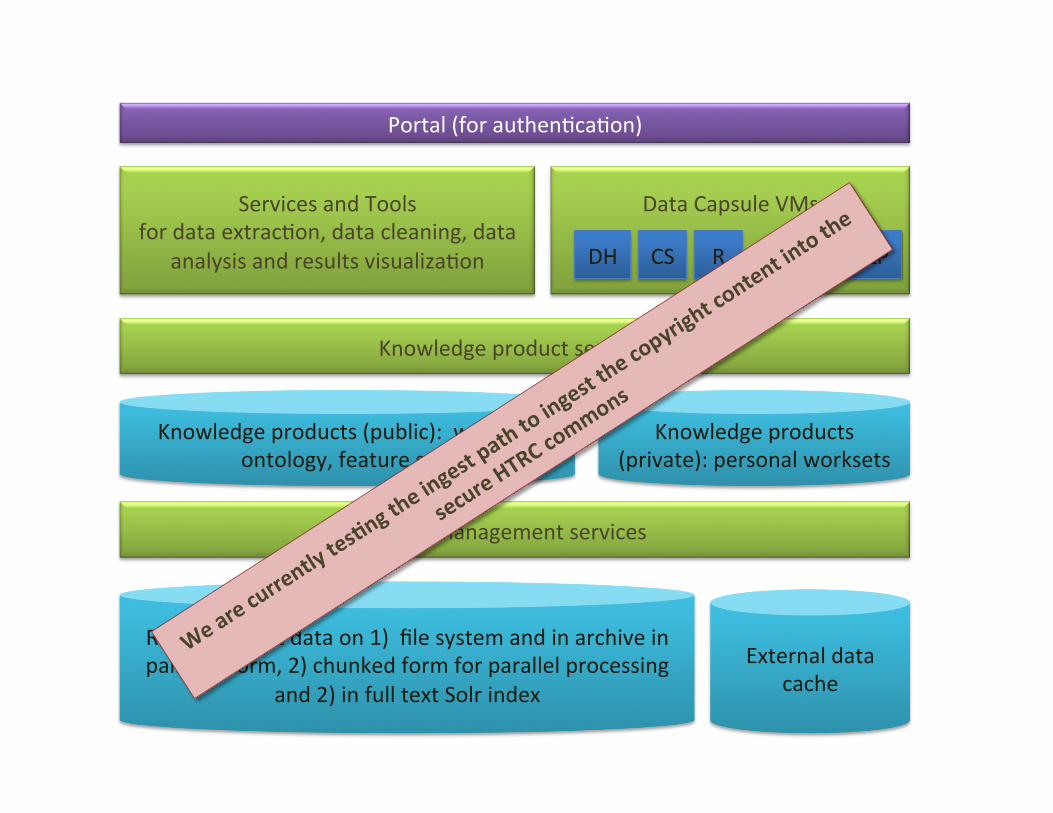
Raw copyright data on 1) file system and in archive in pairtree form, 2) chunked form for parallel processing
and 2) in full text Solr index
Knowledge product services
Data Capsule VMs
Services and Tools for data extrac:on, data cleaning, data
analysis and results visualiza:on
Knowledge products (public): workset, ontology, feature sets
Portal (for authen:ca:on)
Knowledge products (private): personal worksets
External data cache
DH CS NLP R . . .
Data management services
Top Related