







Languages
Pages
Legal


GPU-Accelerated Ab-Initio Simulations of Low-Pressure Turbines
Richard D. Sandberg, Richard Pichler Aerodynamics and Flight Mechanics Research Group
Vittorio Michelassi GE Global Research
NVIDIA GPU Technology Conference, session on “Extreme-Scale Supercomputing with Titan Supercomputer”
2 GPU-acceleration
3/26/2014
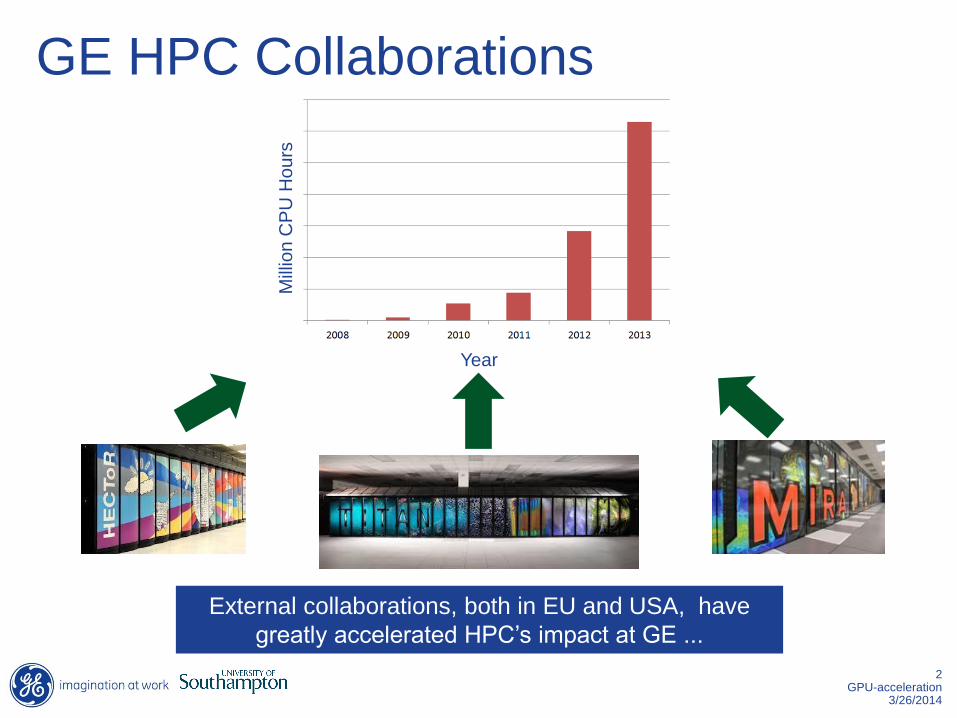
GE HPC Collaborations
Mill
ion
CP
U H
ou
rs
External collaborations, both in EU and USA, have
greatly accelerated HPC’s impact at GE ...
Year
3 GPU-acceleration
3/26/2014
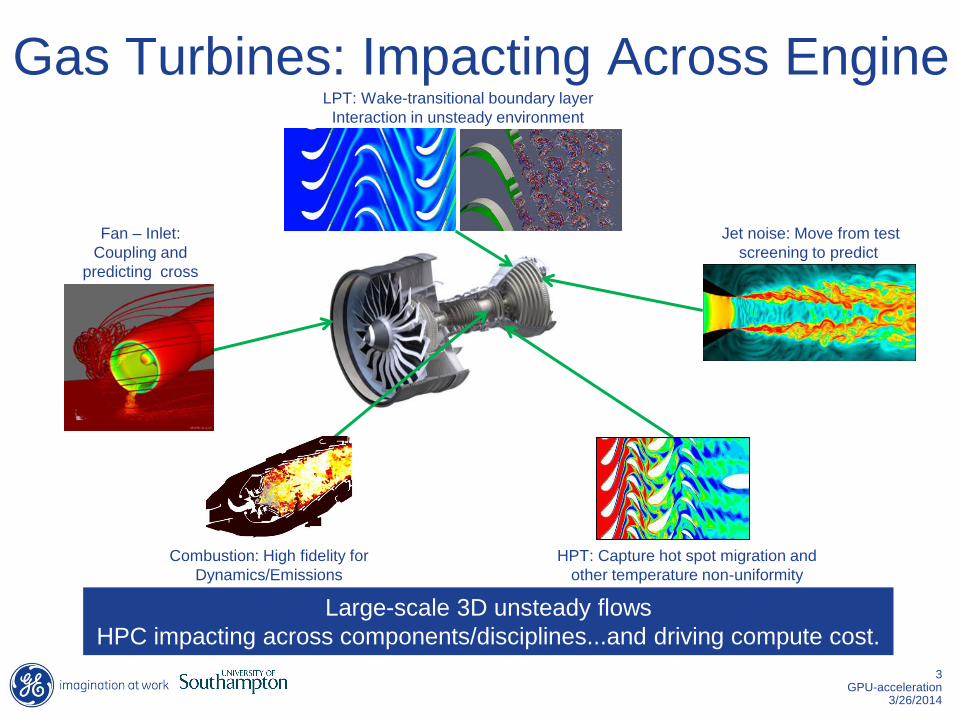
HPT: Capture hot spot migration and
other temperature non-uniformity
Large-scale 3D unsteady flows
HPC impacting across components/disciplines...and driving compute cost.
Gas Turbines: Impacting Across Engine
Fan – Inlet:
Coupling and
predicting cross
wind behavior
Combustion: High fidelity for
Dynamics/Emissions
Jet noise: Move from test
screening to predict
LPT: Wake-transitional boundary layer
Interaction in unsteady environment
4 GPU-acceleration
3/26/2014
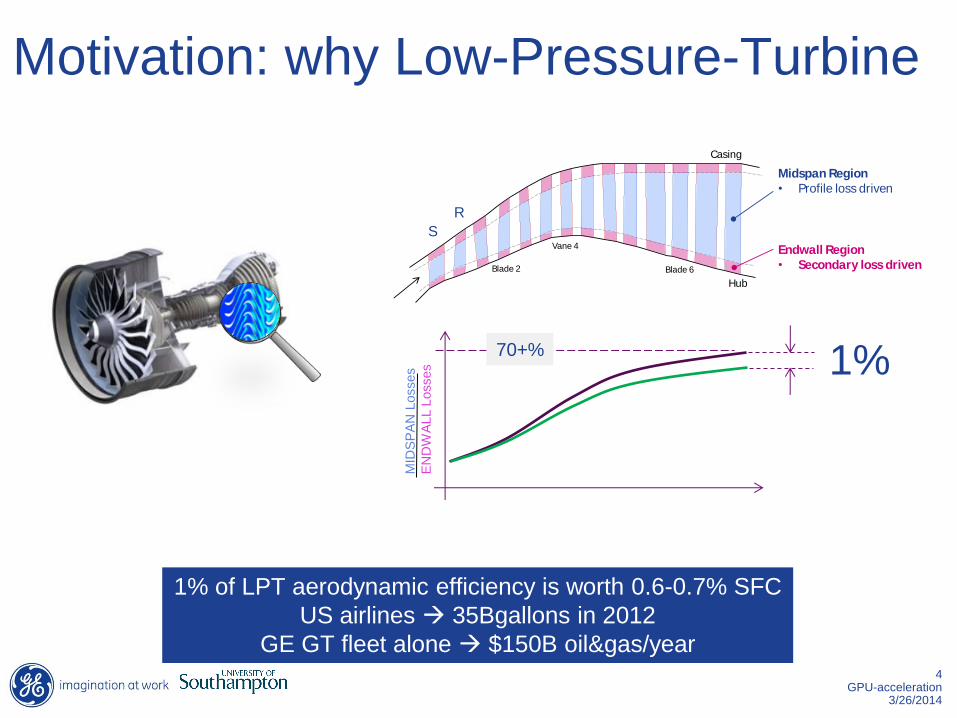
Motivation: why Low-Pressure-Turbine
Casing
Hub
Midspan Region
• Profile loss driven
Endwall Region
• Secondary loss drivenBlade 2
Vane 4
Blade 6
S
R
MID
SP
AN
Losses
EN
DW
ALL L
osses 1%
1% of LPT aerodynamic efficiency is worth 0.6-0.7% SFC
US airlines 35Bgallons in 2012
GE GT fleet alone $150B oil&gas/year
70+%

5 GPU-acceleration
3/26/2014
Aerodynamic design is assisted by tools based on modelling of turbulence However: modelling generally inaccurate
Want (model-free) DNS based on first principles, all length/time-scales must be resolved
Challenge: computational effort required increases approximately as ~Re3
Motivation
Spanwise vorticity for Ekman layer at Ret=1,241 Spanwise vorticity for Ekman layer at Ret=403

6 GPU-acceleration
3/26/2014
Motivation (why bother with DNS?)
• Reward for expending enormous computational resources:
wealth of reliable data free from modeling uncertainties used to answer
basic questions regarding the physics and modeling of a variety of flows
Advances in computing power mean DNS of Reynolds
numbers/ geometries of interest now possible
TOP500 Global Trends
from Jack Dongarra,
IESP

7 GPU-acceleration
3/26/2014
Aim of this presentation:
Introduce novel Navier-Stokes solver purposely developed to exploit
modern HPC architectures for DNS
1) Present key ingredients for an efficient algorithm
2) Performance study of original hybrid OMP/MPI code
3) Porting of code to GPU-accelerated architecture (Titan) using Open-ACC
4) Performance study of Open-ACC code
5) Preliminary results of LPT at real operating conditions
Motivation

8 GPU-acceleration
3/26/2014
Numerical Method • In-house multi-block structured curvilinear compressible Navier-Stokes solver
HiPSTAR (High-Performance Solver for Turbulence and Aeracoustics Research)
developed for DNS studies on today’s computing architectures
• To minimize computation time for given problem numerical algorithm designed with
these requirements
1) Stability of the scheme
2) Resolution of flow features with minimal amplitude and phase errors
3) Efficiency of the scheme (i.e. high ratio of accuracy to computational cost)
4) High parallel efficiency on HPC systems
• Due to very high processor clock-speeds of modern HPC systems, memory access
limiting factor in the total performance of simulations and not number of operations

9 GPU-acceleration
3/26/2014
Numerical Method • Important ingredient to increase performance of code on bandwidth-limited
system:
Minimizing the allocated memory:
1) Improve efficiency of algorithm to reduce number of allocated arrays
ultra-low storage five-step, fourth-order accurate Runge-Kutta
scheme only requires two registers
2) Reduce the grid-cell count required to
spatially resolve flow
a) Use novel parallelizable compact-
difference schemes
b) FFTW for spanwise homogeneous
direction
3) Small number of 2D metric terms
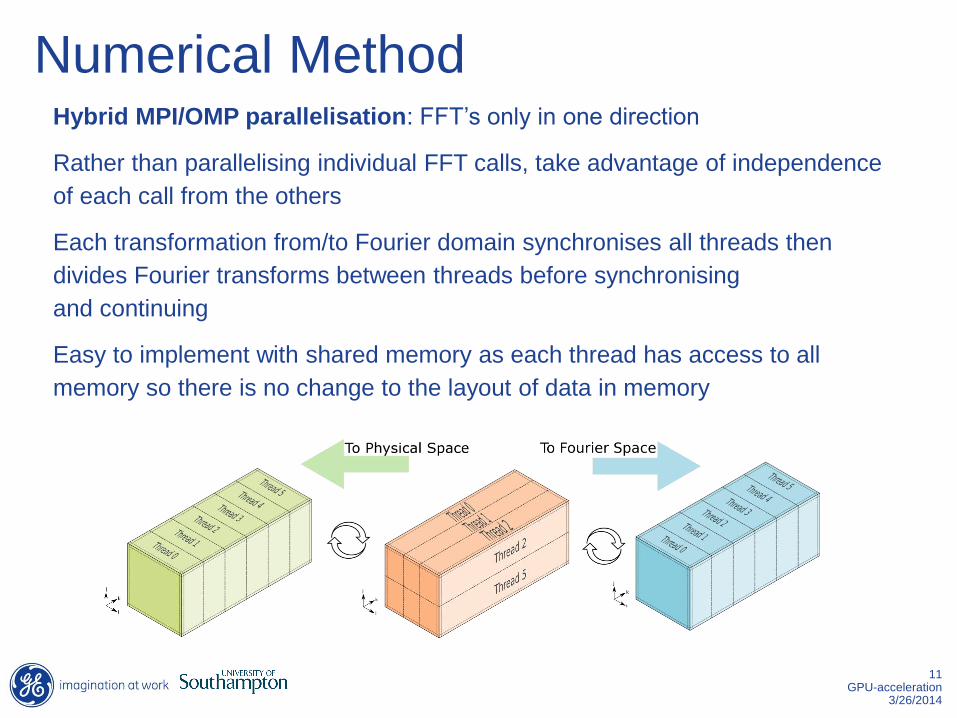
Domain Decomposition
11 GPU-acceleration
3/26/2014
Numerical Method Hybrid MPI/OMP parallelisation: FFT’s only in one direction
Rather than parallelising individual FFT calls, take advantage of independence
of each call from the others
Each transformation from/to Fourier domain synchronises all threads then
divides Fourier transforms between threads before synchronising
and continuing
Easy to implement with shared memory as each thread has access to all
memory so there is no change to the layout of data in memory

12 GPU-acceleration
3/26/2014
HiPSTAR – OMP/MPI Performance
• Performance of DNS code evaluated on UK national HPC facilities
1) HECToR (CRAY XE6):
90,112 cores with 0.83 PFLOPs
Nodes contains two 16-core AMD Opteron 2.3GHz
Interlagos processors, each with 16Gb of memory.
Each 16-core socket coupled with Cray Gemini
routing/communications chip achieving
MPI point-to-point bandwidth of 5 GB/s and
latency between two nodes of around 1-1.5μs
2) Blue Joule (IBM Blue Gene/Q):
114,688 cores with 1.47 PFLOPs
Nodes equipped with 16-core Power BQC
processors with 1.6GHz
and 16Gb of memory
13 GPU-acceleration
3/26/2014
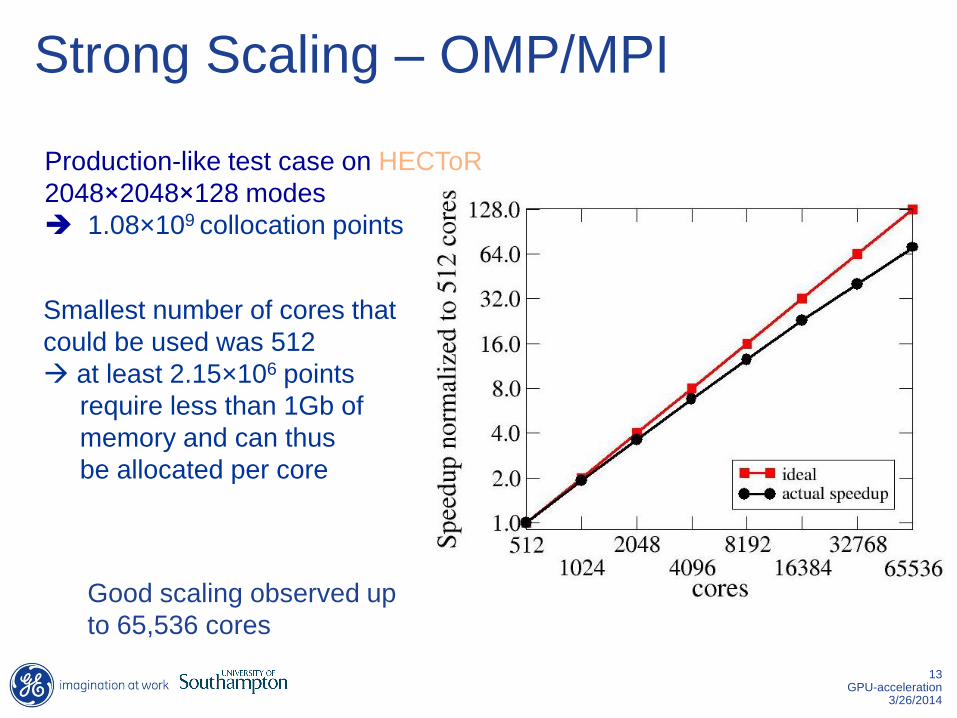
Strong Scaling – OMP/MPI
Smallest number of cores that
could be used was 512
at least 2.15×106 points
require less than 1Gb of
memory and can thus
be allocated per core
Production-like test case on HECToR
2048×2048×128 modes
1.08×109 collocation points
Good scaling observed up
to 65,536 cores
14 GPU-acceleration
3/26/2014
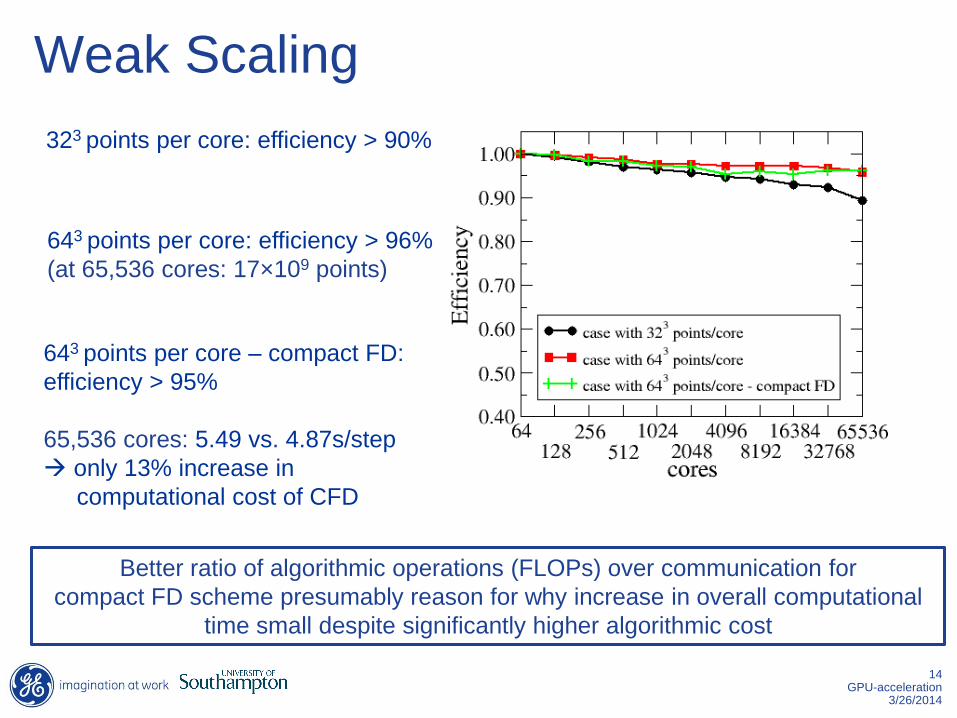
Weak Scaling
323 points per core: efficiency > 90%
643 points per core: efficiency > 96%
(at 65,536 cores: 17×109 points)
643 points per core – compact FD:
efficiency > 95%
65,536 cores: 5.49 vs. 4.87s/step
only 13% increase in
computational cost of CFD
Better ratio of algorithmic operations (FLOPs) over communication for
compact FD scheme presumably reason for why increase in overall computational
time small despite significantly higher algorithmic cost
15 GPU-acceleration
3/26/2014
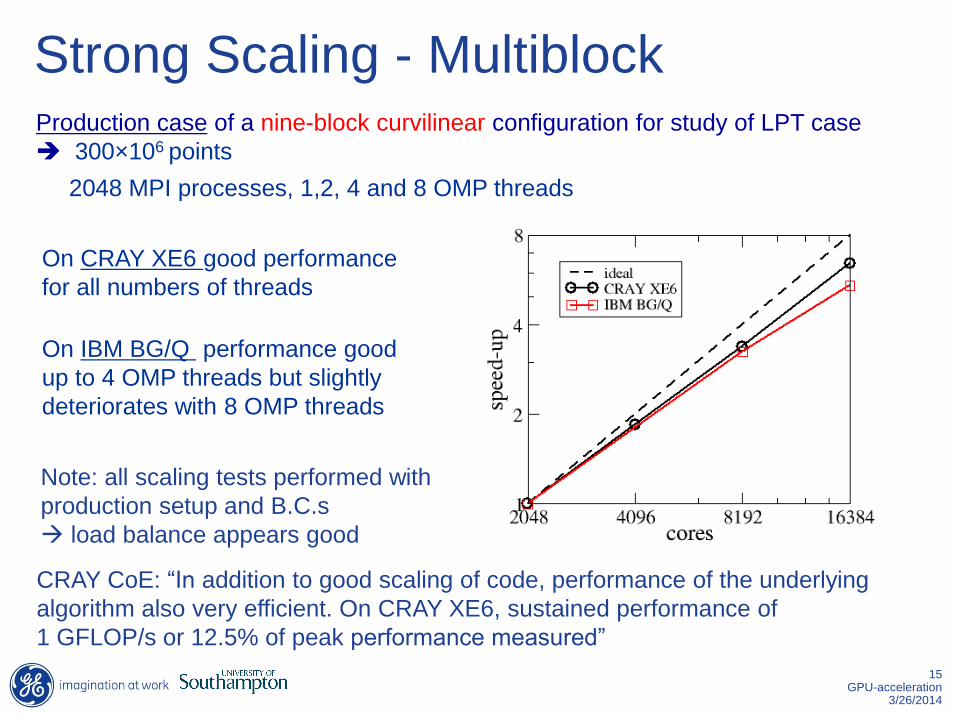
Strong Scaling - Multiblock Production case of a nine-block curvilinear configuration for study of LPT case
300×106 points
2048 MPI processes, 1,2, 4 and 8 OMP threads
On CRAY XE6 good performance
for all numbers of threads
On IBM BG/Q performance good
up to 4 OMP threads but slightly
deteriorates with 8 OMP threads
Note: all scaling tests performed with
production setup and B.C.s
load balance appears good
CRAY CoE: “In addition to good scaling of code, performance of the underlying
algorithm also very efficient. On CRAY XE6, sustained performance of
1 GFLOP/s or 12.5% of peak performance measured”

16 GPU-acceleration
3/26/2014
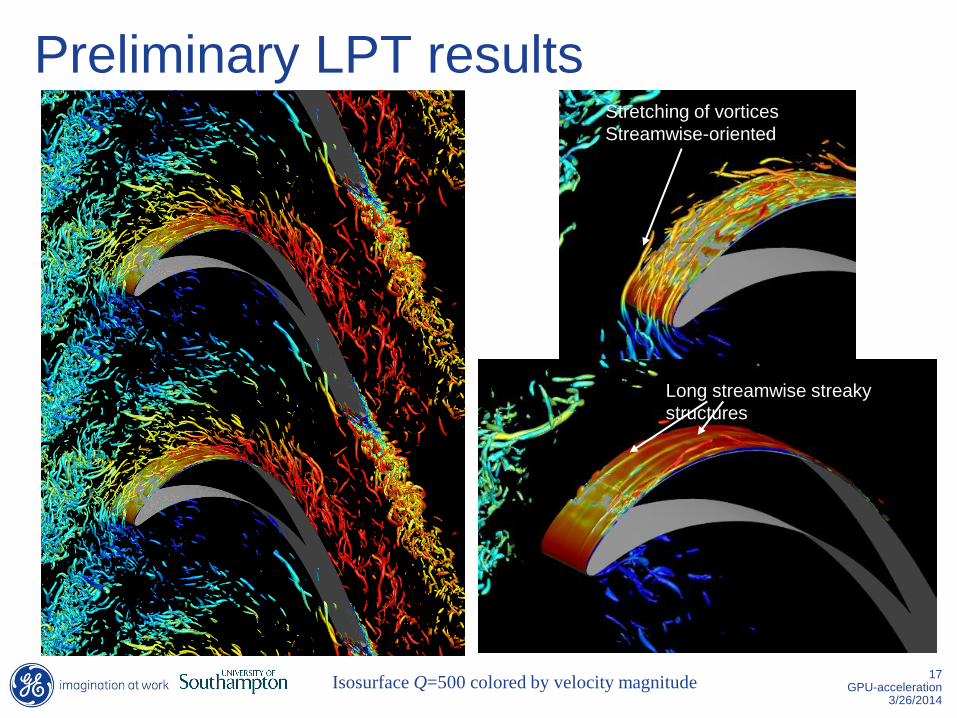
Preliminary LPT results
Simulation on
TITAN at
realistic conditions: • Re = 240,000
• Ma = 0.4
Simulation
key data: • # of grid points:
1.5 billion
• # of GPUs used:
3,552
GPU speed up at same node count : • 1st step of porting: 18%
• 2nd step of porting: estimated 25-30%
17 GPU-acceleration
3/26/2014
Isosurface Q=500 colored by velocity magnitude
Stretching of vortices
Streamwise-oriented
Long streamwise streaky
structures
Preliminary LPT results

18 GPU-acceleration
3/26/2014
Profiling of Hybrid OMP/MPI code
USER 72%
MPI 14%
ETC 7%
MPI_SYNC 1%
OMP 6%
FOURIER 45%
RHS 32%
DERIV 18%
REST 5%
• Profiling on Titan

19 GPU-acceleration
3/26/2014
Porting to GPU with Open-ACC
Porting strategy:
• 1st step: port routines responsible for most of the
computational time
• 2nd step: port remaining subroutines in Runge-Kutta
• 3rd step: restructure code to obtain better performance
(yet to be done)

20 GPU-acceleration
3/26/2014
• Define memory region and scope for codes to be executed on GPU
• Routines in general consist of 3 nested loops that are ported as
Porting to GPU: 1st step
MPI/OMP ACC
k
k
k
21 GPU-acceleration
3/26/2014
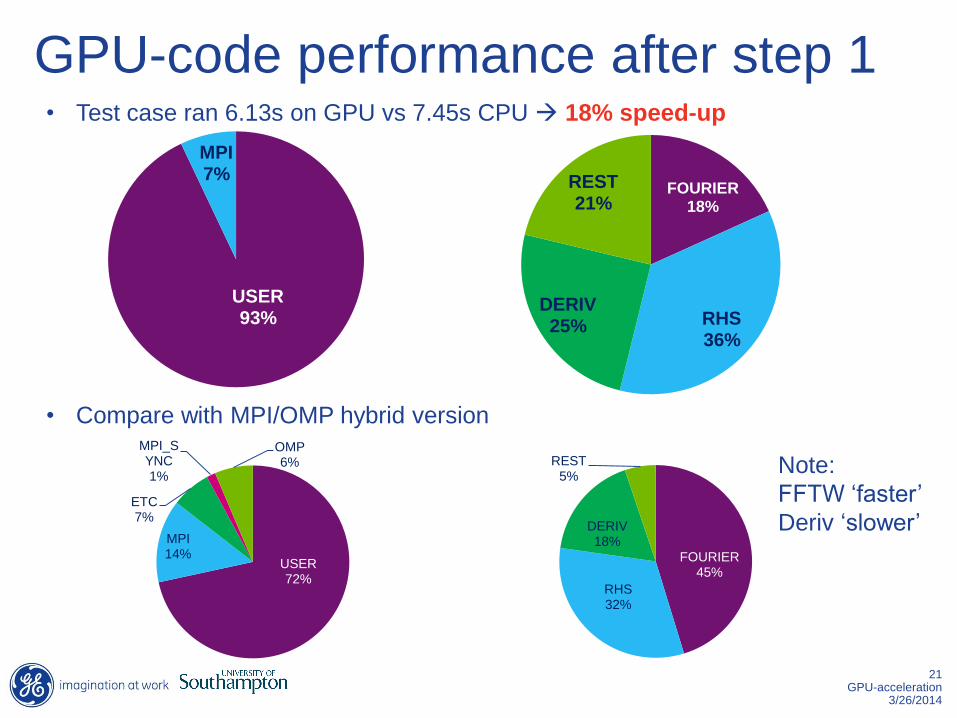
GPU-code performance after step 1
• Compare with MPI/OMP hybrid version
USER 93%
MPI 7%
FOURIER 18%
RHS 36%
DERIV 25%
REST 21%
USER 72%
MPI 14%
ETC 7%
MPI_SYNC 1%
OMP 6%
FOURIER 45%
RHS 32%
DERIV 18%
REST 5%
• Test case ran 6.13s on GPU vs 7.45s CPU 18% speed-up
Note:
FFTW ‘faster’
Deriv ‘slower’

22 GPU-acceleration
3/26/2014
• Profiling: 30% of runtime spent in data transfer CPU ↔ GPU
• Issue: routines in RK steps require copying of main array port
• BC porting straight forward
• MPI communication:
• use GPU address space directives
• Maintain portability of code: also allow these routines on CPU
use conditional execution
• Compared to porting of the core routines significant amount of
coding work for small savings in computational time (saving mainly
memcopy)
Porting to GPU: 2nd step

23 GPU-acceleration
3/26/2014
Summary
• Well tuned hybrid OpenMP/MPI multi-block compressible
flow solver ported to GPU using OpenACC
• To date only main routines of RHS ported
• Despite identified bottlenecks 18% speed-up
• Currently evaluating updated version with better
(less) transfer of data GPU ↔ CPU (see Tuesday keynote?)
• Next step: rewrite entire RHS to group
compute intensive routines better

24 GPU-acceleration
3/26/2014
Acknowledgements
• Director’s Discretionary Grant – Jack Wells
Suzy Tichenor
• Centre of Excellence – John Levesque,
Tom Edwards
Turbulent Jets
Wakes
Compliant TE
HPT tip gap
Other DNS project


HiPSTAR Profile
Top Related