







Languages
Pages
Legal


From
SVN to
Git

Note / disclaimer: these slides may be shared asa PDF for the sake of interoperability, but they are
intended to be seen as an animation. It is recommendedto disable the “Continuous View” feature of your PDF reader so you can see one slide at a time.

So you are familiar with SVN

So you are familiar with SVN(or maybe even CVS)

and want to learn about Git?

Very good!

First thing you need to know is that

SVN is a centralisedversion control system
(so is CVS and others)

while

Git is a distributedversion control system
(so is Mercurial and others)

The second thing you need to know is that

● centralised is– older
– more common (for now)
● distributed is– newer
– better

It is easy to verify that centralised is more common

and that distributed is more modern, so we will not talk about that.

We will explain why distributedis also better in a second,

but there is a third thing you must know

just in case you are looking at theseslides trying to figure out whether to
learn one or the other.

Learning one is as easy as learning the other as long as
you do not know anything of either.

If you already know about distributedversion control systems, changing to
centralised is easy.

If you already know about distributedversion control systems, changing to
centralised is easy.The opposite is not true.

So if you have never used a versioncontrol system, close these slides,
learn about Git, and move on.

But you, reader who are already familiar with SVN,
please continue.

Let me convince you to change to Git

Let me convince you to change to Git
(or Mercurial, or any distributed VCS)

and never look back.

and never look back.

Ready?

Let's start by looking at how SVN works

In SVN there is a server...

...and several clients

...and several clients
(in between, the network)
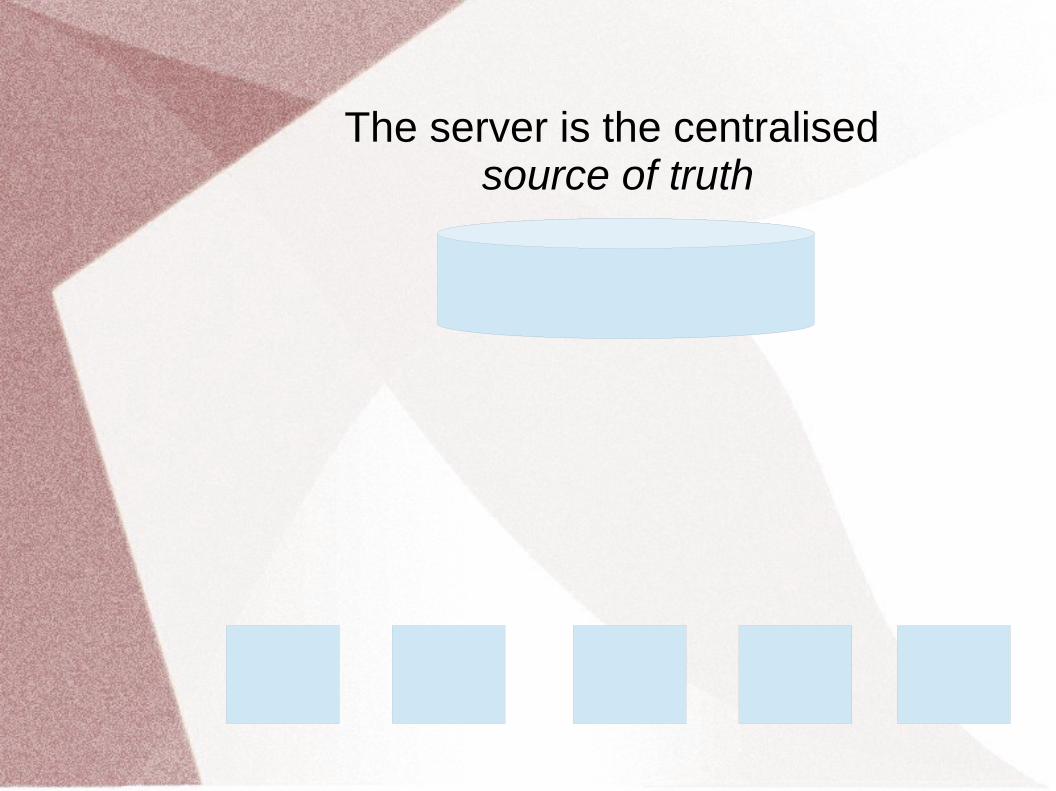
The server is the centralised source of truth

The source code is initialised at the server

and then clients can get it.
svn checkout

After making a change, clientscommit to the server
svn commit

Other clients can check out too...
svn checkout

If a client has made changes thatare not on the server,
svn update

they must update before committing.
svn commit: FAIL

they must update before committing.
svn update

they must update before committing.
svn commit: SUCCESS

At update time, if the code on the server cannot be merged with the client code
svn update

there is a conflict
svn update: CONFLICT

that must be solved before committing.
svn commit: FAIL because CONFLICT

This apparently simple explanationof SVN is enough to highlight
its three main limitations.

● SVN...– ...is slow
– ...cannot work offline
– ...does not scale
● And on top of all that– ...branches are a nightmare
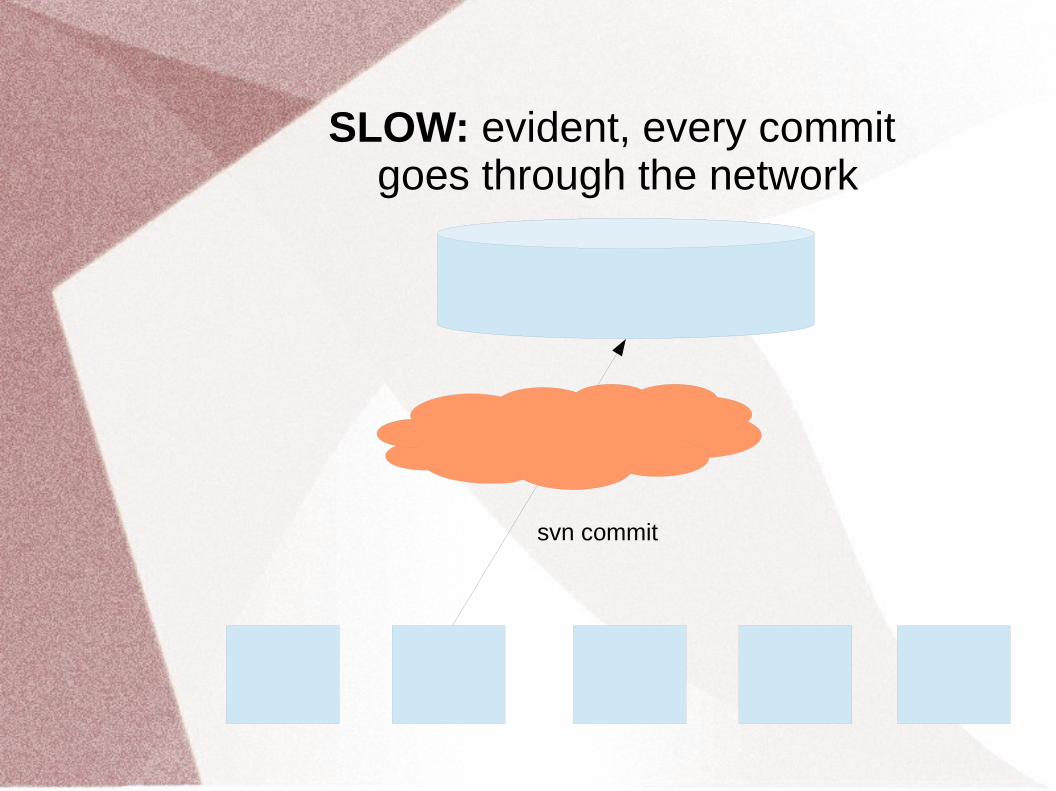
SLOW: evident, every commit goes through the network
svn commit

● Being slow is not only a nuisance● It provides a unconsciously powerful
incentive to use version control sparingly instead of profusely (as it should)
● “I just changed a line, there is no need to commit yet”
● “I will fix this other thing first and then commit all”
● Wrong: commits should be atomic● Remember that the main use of version
control is finding bugs retroactively. The smaller the commits, the better.

ONLY ONLINE: evident,all goes through the network
svn commit svn update -r 32144

● But the network is not always there!– Planes, mountain retreats, 3G/4G
failures, airports, bad hotels...
● What do you do when you do not have network connectivity?
– Do you stop working?
– Or do you stop using version control and then commit a huge 200-lines commit fixing five bugs and adding two features?

● But the network is not always there!– Planes, mountain retreats, 3G/4G
failures, airports, bad hotels...
● What do you do when you do not have network connectivity?
– Do you stop working?
– Or do you stop using version control and then commit a huge 200-lines commit fixing five bugs and adding two features?
– Both options are wrong!

NO SCALABILITY: this is not evident...
svn commit svn update

...but we have seen that every timethere is a commit on the system...
svn commit svn update

...there is a chance of creating a conflictwith someone else.
svn commit svn update: CONFLICT

This is quite annoyingand breaks the flow of work.
svn commit svn update: CONFLICT

In a project of 3 programmers,conflict happens sometimes.
svn commit svn update: CONFLICT

In a project of 30 programmers,conflict happens often.
svn commitsvn update: CONFLICT

In a project of 300 programmers,conflict happens all the time to everybody.
svn commit
svn update: CONFLICT

Additionally, creating and merging branches in SVN is a nightmare.

Branches are important in projectwhere not all the code is visible
all the time

experimental features

code not mature

different features for different clients

All of that is quite difficult in SVN.

Let's see how Git worksto solve all these problems!

Git is not centralised but distributed

This means that there is not one server...

...but many

Actually, there is one per computer.

In Git, every computer is a server

and version control happens locally...

● ...which means version control is...– fast,
– works offline,
– and scales!
● It also means that setting a new git repo is trivial!
● To start working with SVN you need to put up a server or to have access to a server. In git you just say 'git init' and you are ready to go!

FAST: commits are local, so theyare instantaneus and cheap
git commit

OFFLINE: operations are local,no network needed
git commit git branch

OFFLINE: operations are local,no network needed
(only for sharing with others... we will come to that in a second)
git commit git branch

Let's talk about sharing before wetalk about scalability

How do your share your codewith your project mates in Git
...?

How do your share your codewith your project mates in Git
...if commits are local?

You pull their commits from them(and so do they with yours)

git pull
git pull
git pull

When you pull from someone, youdo two things: you checkout their
commits, and then you merge themwith your code.

git pull = git checkout + git merge

git pull = git checkout + git merge
Beware! This “git checkout” does not mean exactly thesame as “svn checkout”, it only means “get all the commits from that machine”, it does not start a localrepository as in SVN.

Most of the time, most people just pull(instead of first checking out and then merging)

This distributed approach works well, and scales perfectly, but
there is still one small problem...

...how do I know where is your machine?Do I need to remember your IP address
or DNS name (if you have one)?

That is why most people use a public repository where they make their changes public.

(GitHub is just one of the most well-known public repository holders)

In the same way that you can pullsomeone else's repository...

...you can push your local changesinto a remote repository(as long as it is yours,
i.e. you have permission)

and then others can pull from thatpublic repository of yours, because
it is at a well-known location.

So the usual picture looks like this:GitHub
git commit

So the usual picture looks like this:GitHub
git push

So the usual picture looks like this:GitHub
git pull

So the usual picture looks like this:GitHub
git commit git commit

So the usual picture looks like this:GitHub
git push git push

note that the first programmerdoes not pull from the fourth
GitHub
git pull
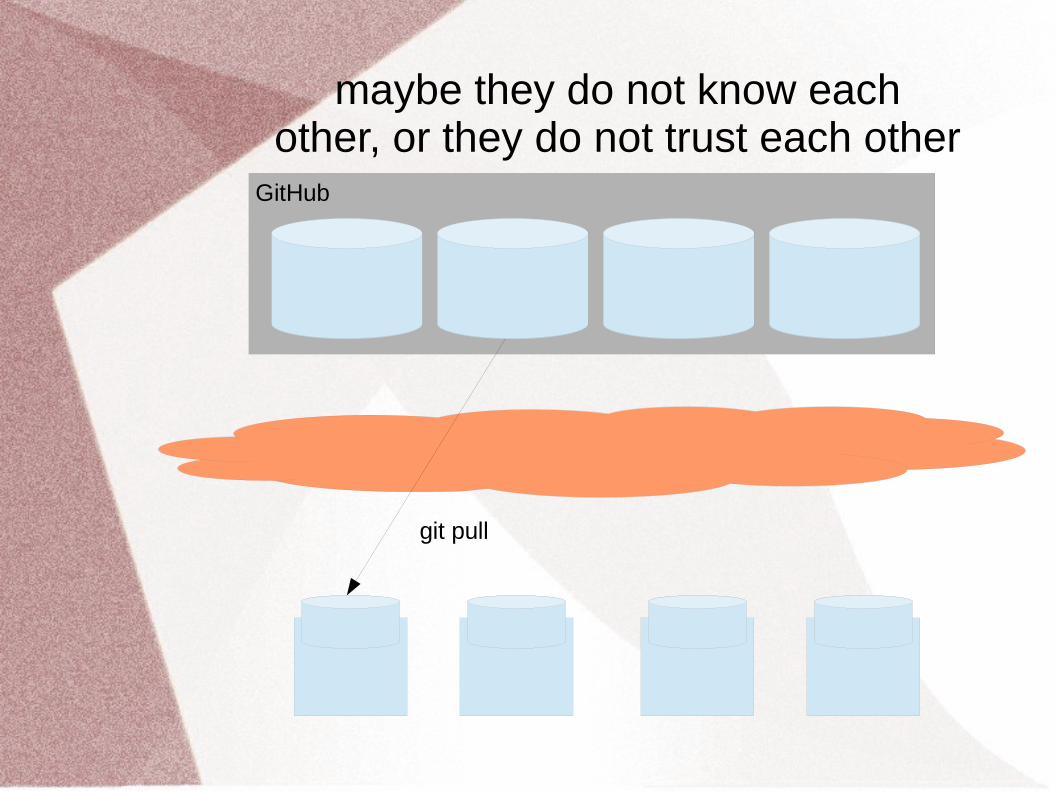
maybe they do not know eachother, or they do not trust each other
GitHub
git pull

but maybe programmer 2trusts programmer 4
GitHub
git pull

but maybe programmer 2trusts programmer 4
GitHub
git push

and pr1 trusts pr2 to get things right
GitHub
git pull

solving all conflicts that untrusted (for pr1) programmers may cause
GitHub
git pull

Its distributed nature is what makes Git so scalable.

Is SVN you must trust everybody

Is SVN you must trust everybody
because everybody can mess up everybody else

Is SVN you must trust everybody
because everybody can mess up everybody else(e.g. committing code

Is SVN you must trust everybody
because everybody can mess up everybody else(e.g. committing code
but forgetting that new fileand then nothing compiles)

In Git you must only trustyour “selected few”, the few
people you pull from.

There are thousands of peopleworking on the linux kernel

but Linus Torvalds only pullsfrom a handful of them.

If someone messes up, only thosein their circle are affected,

and the issue is fixed before it spreads
to the whole community.

● The only way of doing this in SVN is by not using SVN
– Some people have access to the server and some do not
– Code reviews are performed out-of-the-system before committing is allowed
– Political battles for access to the server
– etc

In Git, everything is under versioncontrol all the time.

Nothing is ever lost.

I will repeat this because it is important: “Nothing is ever lost”

On Git every single machine (potentially) hasthe whole history of the project.

This is total security againstdata loss

Your machine burnt in a fire?Stolen? Eaten by your dog?
No problem! Just clone from somebody and
you have everything again!(except those things you had not pushed today, of course)

In centralised systems like SVNthe server is a central point
of failure. If you lose the server,you lose all your history, your
branches, all your version control.

Sure, having the whole history on every single repo uses a lot of disk space!

But when was the last time youfilled up a hard disk by writing code?
(not downloading movies) ;-)

In summary...
● Distributed version control is great because:
– ...

In summary...
● Distributed version control is great because:
– It is fast

In summary...
● Distributed version control is great because:
– It is fast
– It is local (no network)

In summary...
● Distributed version control is great because:
– It is fast
– It is local (no network)
– It scales seamlessly

In summary...
● Distributed version control is great because:
– It is fast
– It is local (no network)
– It scales seamlessly
– It is safer

In summary...
● Distributed version control is great because:
– It is fast
– It is local (no network)
– It scales seamlessly
– It is safer● And if that were not enough to never look at
SVN again, Git also:

In summary...
● Distributed version control is great because:
– It is fast
– It is local (no network)
– It scales seamlessly
– It is safer● And if that were not enough to never look at
SVN again, Git also:– Makes creating, managing, and merging branches
very easy

In summary...
● Distributed version control is great because:
– It is fast
– It is local (no network)
– It scales seamlessly
– It is safer● And if that were not enough to never look at
SVN again, Git also:– Makes creating, managing, and merging branches
very easy
– Makes repository creation trivial

Quick SVN->Git translation
Let's see quickly what are the commands for the most common
operations in SVN and Git

Quick SVN->Git translation
● Getting a copy of a repository– In SVN, 'svn checkout'
– In Git, 'git clone'– No big differences here

Quick SVN->Git translation
● Committing new code– In SVN, 'svn commit'
– In Git, 'git commit'– But we have seen that git's commit is
● local● very fast

Quick SVN->Git translation
● Committing new code publicly– In SVN, 'svn commit'
– In Git, 'git push'– Commits are local in Git, and that (usually) means non-visible
– In other to publish them to other team members, they have to be pushed to a well-known location
– Pushing is slow, like svn-commit, but it only happens once or twice per day, typically.
– In SVN, your commit reaches everyone. In Git it reaches only people who trust you enough to pull from you.

Quick SVN->Git translation
● Getting code written by others– In SVN, 'svn update'
– In Git, 'git pull'– No big differences here either, but
● in SVN, you always pull from the server● in Git, you can pull from different people's (from their
machines, from their GitHub's account, or similar)

Quick SVN->Git translation
● Most other commands have similar syntaxes to SVN's
– There are also a lot of new commands, but clone + commit + + push + pull will be 95% of your use of Git
– Remember: 'git help <command>' is always your friend

Happy hacking!
Top Related