







Languages
Pages
Legal


F.F. Dragan F.F. Dragan (Kent State)(Kent State)
A.B. Kahng A.B. Kahng (UCSD)(UCSD)
I. Mandoiu I. Mandoiu (Georgia Tech/UCLA)(Georgia Tech/UCLA)
S. Muddu S. Muddu (Silicon Graphics)(Silicon Graphics)
A. Zelikovsky A. Zelikovsky (Georgia State)(Georgia State)
Provably Good Global Buffering Using an Available Buffer Block Plan
Provably Good Global Buffering Using an Available Buffer Block Plan

Global Buffering via Buffer Blocks
• VDSM buffer / inverter insertion for all global nets – 50nm technology 10^6 buffers
• Buffer Block (BB) methodology– isolate buffer insertion from block implementations– improve routing area resources (RAR) utilization
RAR(2k-buffer block) = RAR(k-buffer block)
For high-end designs 1.6
• Buffer block planning [Cong+99] [TangW00]
– given block placement + nets– find shape and location of BBs
• Global buffering via BBs– given nets + BB locations and capacities– find buffered routing for each net
Global Buffering via Buffer Blocks

Global Buffering Problem
Given:• Pin & BB locations, BB capacities
• list of 2-pin nets, each net has
• upper-bound on #buffers
• parity requirement on #buffers
• [non-negative weight (criticality coefficient)]
• L/U bounds on wirelength b/w consecutive buffers/pins
Find: buffered routing of a maximum [weighted] number of nets subject to the given constraints

Global Buffering Problem
Given:• Pin & BB locations, BB capacities
• list of 2-pin nets, each net has
• upper-bound on #buffers new
• parity requirement on #buffers new
• [non-negative weight (criticality coefficient)] new
• L/U bounds on wirelength b/w consecutive buffers/pins
Find: buffered routing of a maximum [weighted] number of nets subject to the given constraints
Previous work: 1 buffer per connection, no weights

Outline of Results
• Provably good algorithm for the Global Buffering Problem
– integer node-capacitated multi-commodity flow (MCF) formulation
– approximation algorithm for solving fractional relaxation
– provably good randomized rounding based on [RaghavanT87]
– allows tradeoff between run-time and solution quality
• Fast heuristic based on ideas from the approximation algorithm
• superior to simpler greedy approaches
• almost matches the provably good algorithm for loosely constrained instances

Integer Program Formulation
}],[:{
BlocksBuffer pins :),(Graph
ULdist(u,v)(u,v)E
VEVG
paths routing legal ofset PPppf
Vuupfts
pf
pu
Pp
}1,0{)(
)(cap)(..
)(max
oncemost at routednet each
1 set to is )(cap ,pin any For
uu

High-Level Approach
• Solve fractional relaxation + rounding
– first introduced for global routing [RaghavanT87]
– fractional relaxation = node-capacitated multi-commodity flow (MCF)
• can be solved exactly using Linear Programming (LP) techniques
• exact LP algorithms are not practical for large instances
• Key idea: approximate solution to the relaxation
– we generalize edge-capacitated MCF approximation of [GargK98, F99]
– [GargK98] successfully applied to global routing by [Albrecht00]

Approximating the Fractional MCF
-MCF algorithmw(v) = , f = 0For i = 1 to N do For k = 1, …, #nets do Find a shortest path p P for net k While w(p) < min{ 1, (1+2)^I } do f(p)= f(p) + 1 For every v p do w(v) ( 1 + /c(v) ) * w(v) End For End While End ForEnd ForOutput f/N
Run time for -approximation = ))BBs#nets(#( 22 O

• Random walk algorithm [RaghavanT87] – probability of routing a net proportional to net’s flow– probability of choosing an arc proportional to fractional
flow along arc– run time = O( #inserted buffers )– To avoid BB overuse, scale-down fractional flow by 1-
before rounding
Rounding to an Integer Solution
• Modifications• approximate MCF underestimates optimum
few violations + unused BB capacity for large • resolve capacity violations by greedily deleting paths• greedily route remaining nets using unused BB capacity

Implemented Heuristics• -MCF w/ greedy enhancement
– solve fractional MCF with approximation – round fractional solution via random walks– apply greedy deletion/addition to get feasible solution
• Greedy – sequentially route nets along shortest available paths
• 1-shot integer MCF– assign weight w=1 to each BB– repeat until total overused capacity does not decrease
• for each net find shortest path• for each BB r increase weight by factor (1 + usage(r) / cap(r))
– apply greedy deletion/addition to get feasible solution

Experimental Setup
• Test instances extracted from next-generation SGI microprocessor
• ~4,000 nets• U=4,000 m, L=500-2,000 m• 50 buffer blocks• BB capacity
– 400 (fully routable instances)– 50 (hard instances, 50-60% routable)
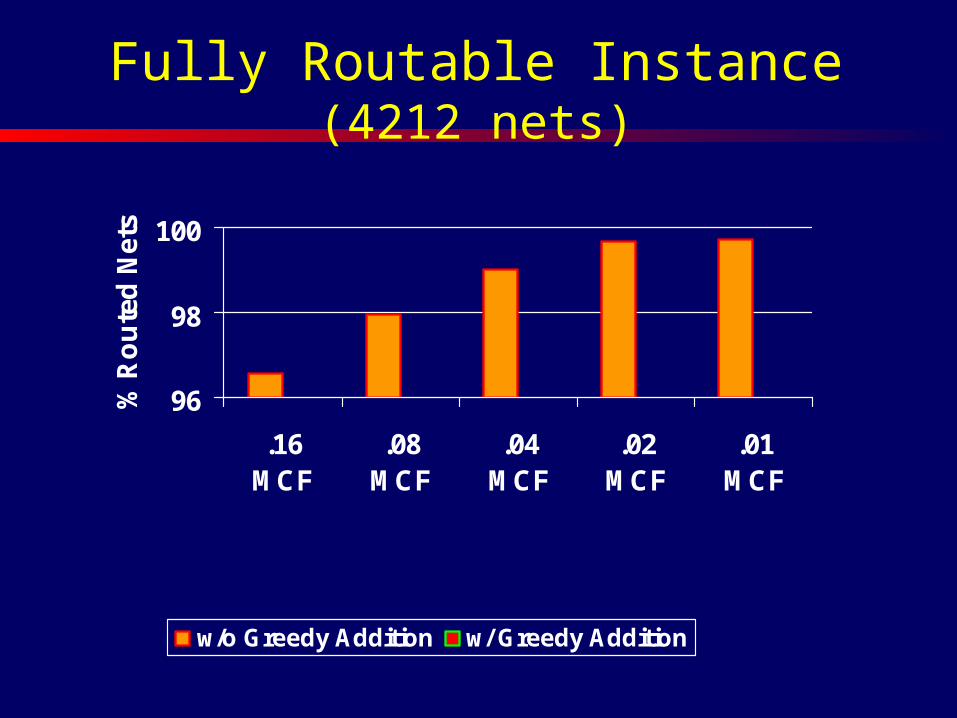
96
98
100
.16MCF
.08MCF
.04MCF
.02MCF
.01MCF
% R
ou
ted
Net
s
w/o Greedy Addition w/ Greedy Addition
Fully Routable Instance (4212 nets)

Fully Routable Instance (4212 nets)
96
98
100
.16MCF
.08MCF
.04MCF
.02MCF
.01MCF
% R
ou
ted
Net
s
w/o Greedy Addition w/ Greedy Addition
Greedy
1-Shot
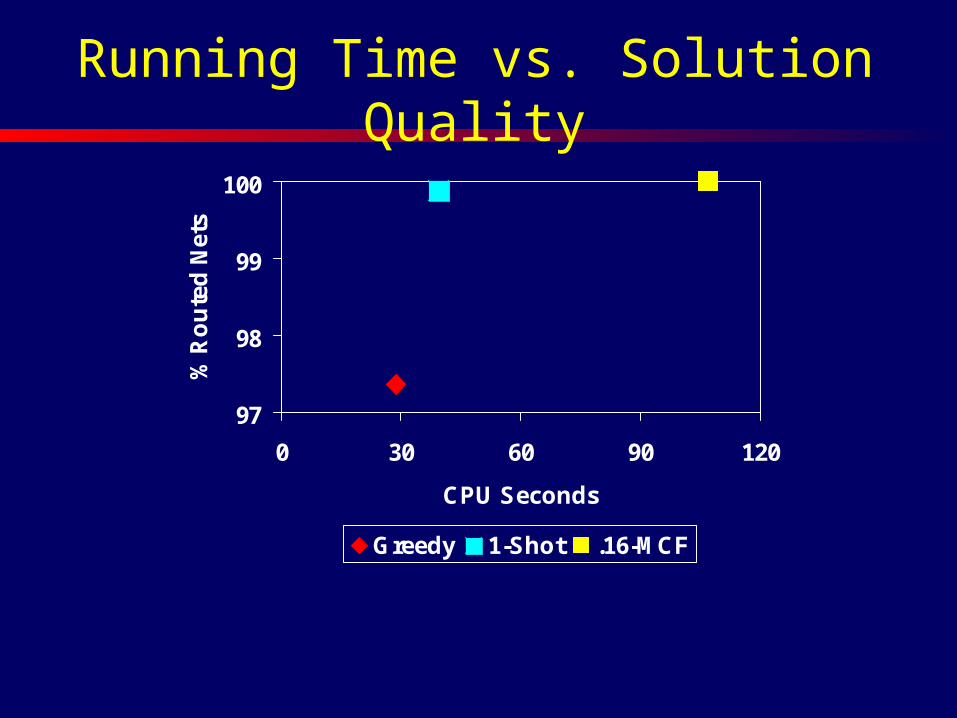
Running Time vs. Solution Quality
97
98
99
100
0 30 60 90 120
CPU Seconds
% R
ou
ted
Net
s
Greedy 1-Shot .16-MCF
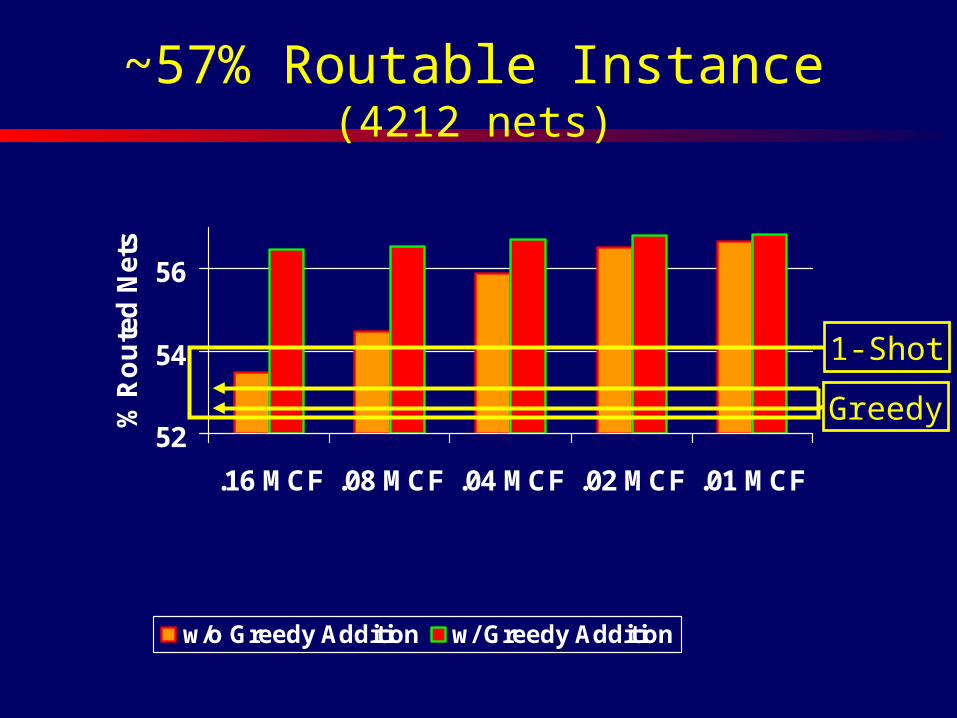
~57% Routable Instance (4212 nets)
52
54
56
.16 MCF .08 MCF .04 MCF .02 MCF .01 MCF
% R
ou
ted
Net
s
w/o Greedy Addition w/ Greedy Addition
Greedy
1-Shot

Conclusions and Ongoing Work
• Provably good algorithm based on node-capacitated MCF approximation
• Extensions:– combine global buffering with BB planning
• combine with compaction
Combining with compaction

Combining with compaction

Combining with compaction
• Sum-capacity constraints: cap(BB1) + cap(BB2) const.

Conclusions and Ongoing Work
• Provably good algorithm based on node-capacitated MCF approximation
• Extensions:– combine global buffering with BB planning
• combine with compaction
– enforce channel capacity constraints – multi-terminal nets (ASPDAC-01)
Top Related