







Languages
Pages
Legal


Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
KSU CIS Department How-To
William H. Hsuhttp://www.cis.ksu.edu/~bhsu
Laboratory for Knowledge Discovery in Databases (www.kddresearch.org)
Department of Computing and Information Sciences
Kansas State University
Slides for this tutorial:
Getting Started with Google MapReducein C++, Apache Hadoop, and R

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Overview of MapReduce
Basic Definitions and Brief Synopsis
Deciding When to Use: Pros and Cons
Installation/Compilation Guide for MapReduce
C++
Apache Hadoop
R
Programming Resources and References
What This How-To IsWhat This How-To Is

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Lecture or Seminar on MapReduce Algorithm
Functional Programming Foundations
Analyzing Performance
Applications Survey
Tutorial on Platforms: C++, Hadoop, R
Full Workshop
Parallel Computing
Distributed Computing
What This How-To Is NotWhat This How-To Is Not

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Overview of MapReduce
Basic Definitions and Brief Synopsis
Deciding When to Use: Pros and Cons
Installation/Compilation Guide for MapReduce
C++
Apache Hadoop
R
Programming Resources and References
What This How-To IsWhat This How-To Is

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Simple Motivating Example [1]:Distributed Grep
Very
large
text
collection
Split data
Split data
Split data
Split data
grep
grep
grep
grep
matches
matches
matches
matches
catAll
matches
Adapted from slide © 2006 Hendra Setiawan, National University of Singapore
http://bit.ly/9KOR3b

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Simple Motivating Example [2]:Distributed Word Count
Very
large
text
collection
Adapted from slide © 2006 Hendra Setiawan, National University of Singapore
http://bit.ly/9KOR3b
Split data
Split data
Split data
Split data
count
count
count
count
count
count
count
count
sumtotal
count

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Overview of MapReduce
Basic Definitions and Brief Synopsis
Deciding When to Use: Pros and Cons
Installation/Compilation Guide for MapReduce
C++
Apache Hadoop
R
Programming Resources and References
OutlineOutline

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
What Is MapReduce?What Is MapReduce?
Programming Model and Associated Implementation
Characteristics and Purpose
Processing large data sets
Exploiting large sets of commodity computers
Executing processes in distributed manner
Offers high degree of transparency
Other Goals: Simplicity, Generality, Scalability
May Be Suitable for Your Task
Adapted from slide © 2006 Hendra Setiawan, National University of Singapore
http://bit.ly/9KOR3b

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Building Blocks: MapBuilding Blocks: Map
Adapted from slide © 2009 Christoph Meinel, Hasso-Plattner Institute
http://bit.ly/bToUx2

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Building Blocks: ReduceBuilding Blocks: Reduce
Adapted from slide © 2009 Christoph Meinel, Hasso-Plattner Institute
http://bit.ly/bToUx2

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
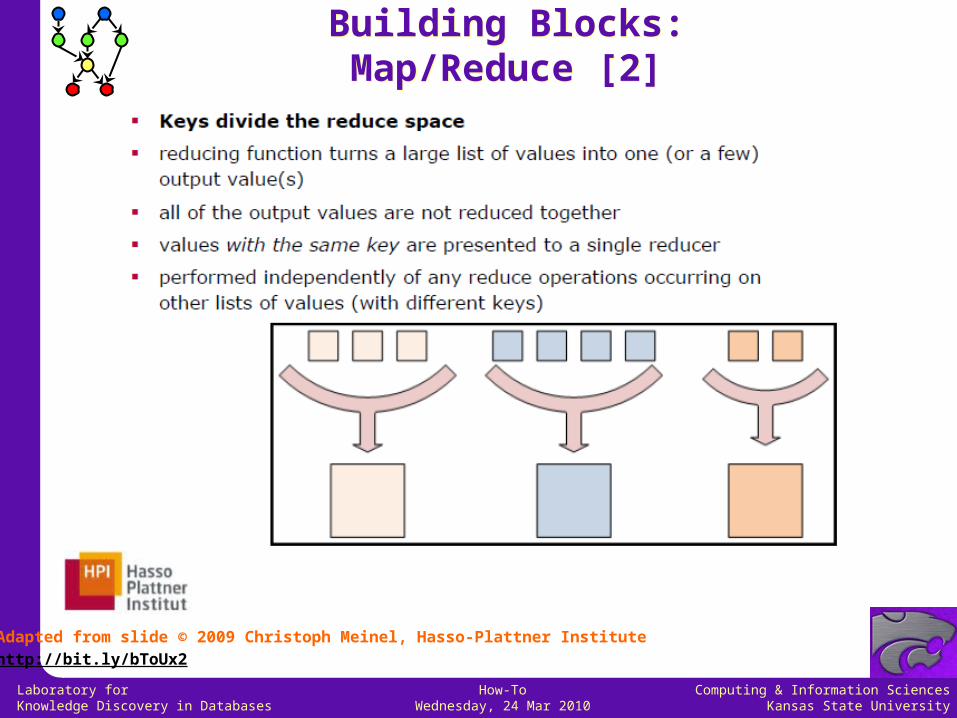
Building Blocks:Map/Reduce [1]Building Blocks:Map/Reduce [1]
Adapted from slide © 2009 Christoph Meinel, Hasso-Plattner Institute
http://bit.ly/bToUx2
Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Building Blocks:Map/Reduce [2]Building Blocks:Map/Reduce [2]
Adapted from slide © 2009 Christoph Meinel, Hasso-Plattner Institute
http://bit.ly/bToUx2
Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
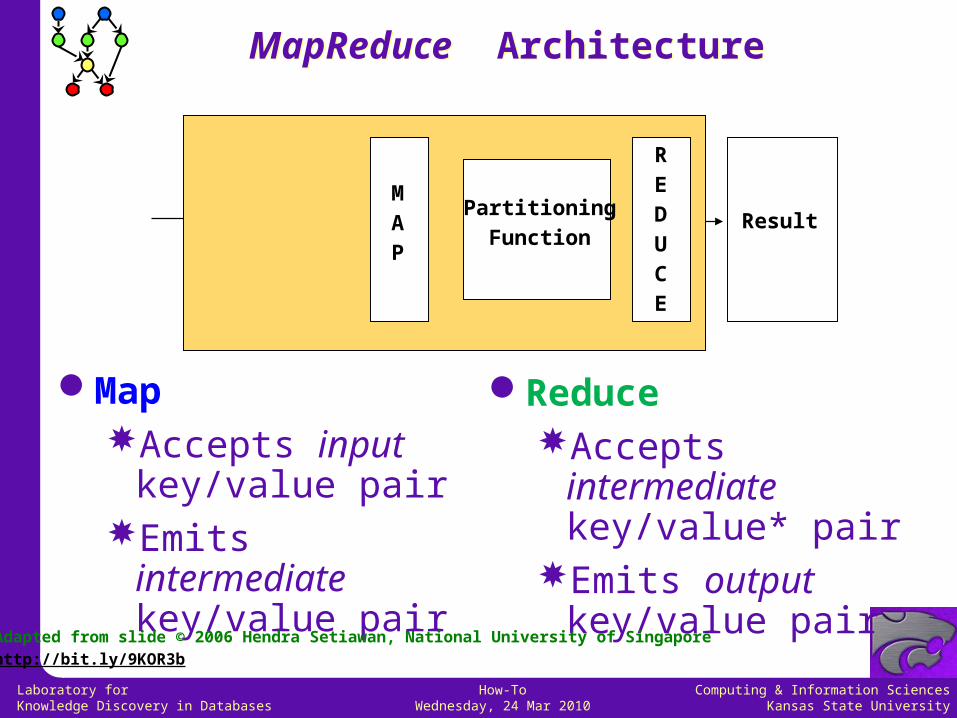
MapAccepts input
key/value pairEmits intermediate
key/value pair
ReduceAccepts intermediate
key/value* pairEmits output
key/value pair
ResultM
A
P
R
E
D
U
C
E
Partitioning
Function
MapReduce ArchitectureMapReduce Architecture
Adapted from slide © 2006 Hendra Setiawan, National University of Singapore
http://bit.ly/9KOR3b

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Example Applications:Distributed Grep, WC Revisited
Example Applications:Distributed Grep, WC Revisited
Adapted from slide © 2006 Hendra Setiawan, National University of Singapore
http://bit.ly/9KOR3b
Distributed GrepMap
if match(value, pattern) emit(value,1)
Reduce emit(key, sum(value*))
Distributed Word CountMap
for all w in value do emit(w,1)
Reduceemit(key, sum(value*))

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Word Count ExampleIllustrated
Word Count ExampleIllustrated
Adapted from slide © 2009 Christoph Meinel, Hasso-Plattner Institute
http://bit.ly/bToUx2

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Distributed Sort [1]:Mapping To “Pre-Sorted” Buckets
Distributed Sort [1]:Mapping To “Pre-Sorted” Buckets
Adapted from slide © 2006 Hendra Setiawan, National University of Singapore
http://bit.ly/9KOR3b
See also: HP Labs technical note on TeraSort http://bit.ly/biHbcA

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Distributed Sort [2]:Partition Function
Distributed Sort [2]:Partition Function
Adapted from slide © 2006 Hendra Setiawan, National University of Singapore
http://bit.ly/9KOR3b
See also: HP Labs technical note on TeraSort http://bit.ly/biHbcA
Default: hash(key) mod R
Guarantee
Relatively well-balanced partitions
Ordering guarantee within partition
Distributed Sort
Map
emit(key, value)
Reduce (with R=1)
emit(key, value)

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Overview of MapReduce
Basic Definitions and Brief Synopsis
Deciding When to Use: Pros and Cons
Installation/Compilation Guide for MapReduce
C++
Apache Hadoop
R
Programming Resources and References
OutlineOutline

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Rationale:The Need for MapReduce
Rationale:The Need for MapReduce
Adapted from slide © 2007 Scott Beamer, University of California – Berkeley (CS61C Machine Structures)
http://bit.ly/bhGXiq

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Functional Programmingand Parallelism [1]
Functional Programmingand Parallelism [1]
reduce (aka foldr)
(reduce + (map square '(1 2 3)) (reduce + '(1 4 9)) 14
Pure functional programming: easily parallelizable Do you see how you could parallelize above evaluation? What if reduce function argument were associative? Would that help?
Adapted from slide © 2007 Scott Beamer, University of California – Berkeley (CS61C Machine Structures)
http://bit.ly/bhGXiq

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Functional Programmingand Parallelism [2]
Functional Programmingand Parallelism [2]
Imagine 10,000-machine clusterReady to help you compute anything you could cast
as MapReduce problem!Abstraction
Google famous for developing this … but their Reduce not same as functional programming reduce
Builds a reverse-lookup table Hides lots of difficulty of writing parallel code! System takes care of load balancing, dead machines, etc.
Adapted from slide © 2007 Scott Beamer, University of California – Berkeley (CS61C Machine Structures)
http://bit.ly/bhGXiq

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
MapReduce TransparenciesMapReduce Transparencies
Adapted from slide © 2006 Hendra Setiawan, National University of Singapore
http://bit.ly/9KOR3b
Google Distributed File System
Features
Parallel I/O
Fault-tolerance
Locality optimization
Load-balancing

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
When To Use MapReduceWhen To Use MapReduce
Available Compute Cluster
Large Data Set
Text corpora
Web documents
Raw numerical data (e.g., signals, sequences)
Data (Assumed to Be) Independent
Can Be Cast into map and reduce
Adapted from slide © 2006 Hendra Setiawan, National University of Singapore
http://bit.ly/9KOR3b

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Overview of MapReduce
Basic Definitions and Brief Synopsis
Deciding When to Use: Pros and Cons
Installation/Compilation Guide for MapReduce
C++
Apache Hadoop
R
Programming Resources and References
OutlineOutline

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Overview of MapReduce
Basic Definitions and Brief Synopsis
Deciding When to Use: Pros and Cons
Installation/Compilation Guide for MapReduce
C++
Apache Hadoop
R
Programming Resources and References
OutlineOutline

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Download using lynx
bzcat mapreduce.tar.bz2 | tar -xf –
Set up rsync
Start inetd (or xinetd)
Fix Type Errors in MapReduceScheduler.c
Compile using make
Preliminaries Under LinuxPreliminaries Under Linux
Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
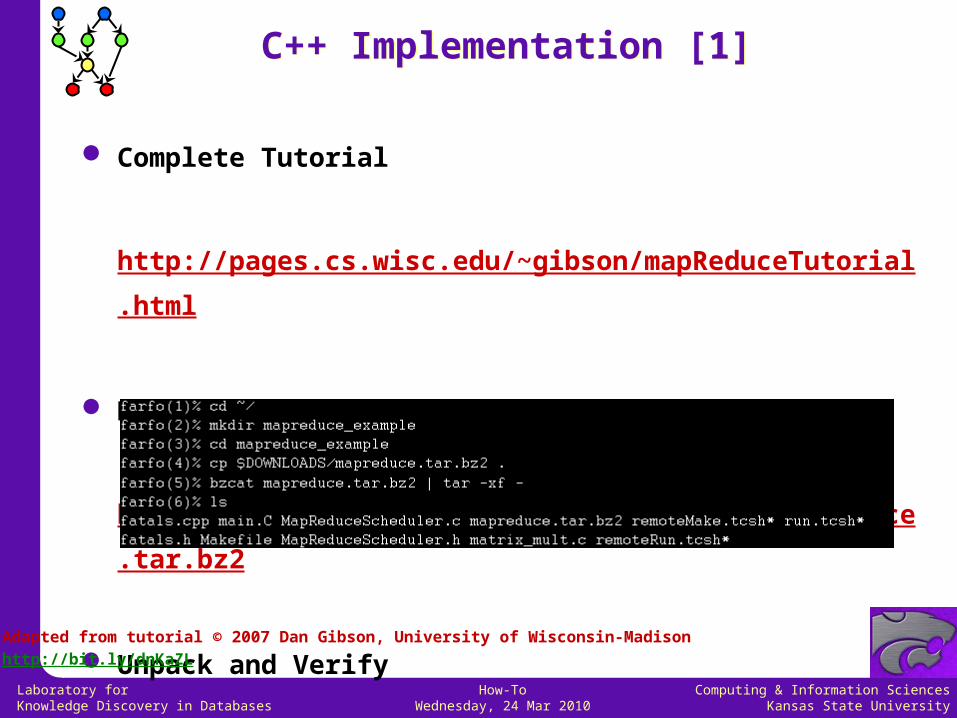
Complete Tutorial
http://pages.cs.wisc.edu/~gibson/mapReduceTutorial.html
Download
http://pages.cs.wisc.edu/~gibson/filelib/mapreduce.tar.bz2
Unpack and Verify
C++ Implementation [1]C++ Implementation [1]
Adapted from tutorial © 2007 Dan Gibson, University of Wisconsin-Madison
http://bit.ly/dnKaZL

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
http://pages.cs.wisc.edu/~gibson/mapreduceexample/main.C.html
Setting up sched_args
C++ Implementation [2]:(Function) Arguments to Scheduler
C++ Implementation [2]:(Function) Arguments to Scheduler
Adapted from tutorial © 2007 Dan Gibson, University of Wisconsin-Madison
http://bit.ly/dnKaZL

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
http://bit.ly/98Hnfi
map Function Setup
C++ Implementation [3]:Map Function
C++ Implementation [3]:Map Function
Adapted from tutorial © 2007 Dan Gibson, University of Wisconsin-Madison
http://bit.ly/dnKaZL

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
http://bit.ly/9AhCIt
reduce Function Setup
C++ Implementation [3]:Reduce Function
C++ Implementation [3]:Reduce Function
Adapted from tutorial © 2007 Dan Gibson, University of Wisconsin-Madison
http://bit.ly/dnKaZL

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
http://bit.ly/aYvcVp
Setting up intcmp
C++ Implementation [4]:Key Comparison FunctionC++ Implementation [4]:Key Comparison Function
Adapted from tutorial © 2007 Dan Gibson, University of Wisconsin-Madison
http://bit.ly/dnKaZL

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
http://pages.cs.wisc.edu/~gibson/mapReduceTutorial.html
Output of make
C++ Implementation [5]:Compilation
C++ Implementation [5]:Compilation
Adapted from tutorial © 2007 Dan Gibson, University of Wisconsin-Madison
http://bit.ly/dnKaZL

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
http://pages.cs.wisc.edu/~gibson/mapReduceTutorial.html
Call to map_reduce_scheduler and Follow-Up Statements
C++ Implementation [6]:Execution
C++ Implementation [6]:Execution
Adapted from tutorial © 2007 Dan Gibson, University of Wisconsin-Madison
http://bit.ly/dnKaZL

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Overview of MapReduce
Basic Definitions and Brief Synopsis
Deciding When to Use: Pros and Cons
Installation/Compilation Guide for MapReduce
C++
Apache Hadoop
R
Programming Resources and References
OutlineOutline

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Download and Documentation: http://hadoop.apache.org/mapreduce/
Tutorials Cloudera (Video): http://vimeo.com/cloudera/videos/ Apache (Written): http://bit.ly/b0whwX
Hadoop ImplementationHadoop Implementation
Cover slide from tutorial © 2009 Cloudera
http://vimeo.com/3584536

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Overview of MapReduce
Basic Definitions and Brief Synopsis
Deciding When to Use: Pros and Cons
Installation/Compilation Guide for MapReduce
C++
Apache Hadoop
R
Programming Resources and References
OutlineOutline

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Downloads and Documentation
Comprehensive R Archive Network (CRAN) package
R interpreter: http://cran.r-project.org/
MapReduce in CRAN: http://bit.ly/9a0AqL
Example from Open Data Group: http://bit.ly/9EKWxC
R ImplementationR Implementation
Adapted from tutorial © 2009 Cloudera
http://vimeo.com/3584536

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Overview of MapReduce
Basic Definitions and Brief Synopsis
Deciding When to Use: Pros and Cons
Installation/Compilation Guide for MapReduce
C++
Apache Hadoop
R
Programming Resources and References
OutlineOutline

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Programming Resources and References
Basic Tutorials Setiawan, National University of Singapore – http://bit.ly/9KOR3b
Meinsel, Hasso-Plattner Institute – http://bit.ly/bToUx2
Beamer, Berkeley – http://bit.ly/bhGXiq
Algorithm Design Google - http://labs.google.com/papers/mapreduce.html
Apache - http://bit.ly/b0whwX, http://vimeo.com/3584536
Implementations Gibson, C++ version for Linux & Solaris - http://bit.ly/dnKaZL
Cutting, Hadoop version – http://vimeo.com/3584536
Brown, R version (CRAN) – http://bit.ly/9a0AqL
Other Tutorials Chris Olston, Yahoo Research – http://bit.ly/a28mkl
Google Code – http://bit.ly/9CeBSd

Computing & Information SciencesKansas State University
How-ToWednesday, 24 Mar 2010
Laboratory forKnowledge Discovery in Databases
Tutorial Material Hendra Setiawan – National University of Singapore
Christoph Meinel – Hasso-Plattner Institute
Scott Beamer – Berkeley
Algorithm Design Google (Jeffrey Dean, Sanjay Ghemawat) – Original MapReduce
Apache Software Foundation (Doug Cutting, now of Cloudera) – Hadoop
Implementations Dan Gibson, University of Wisconsin-Madison – C++ version
Doug Cutting, Cloudera – Hadoop version
Chris Brown, Open Data Group – R version (CRAN)
Thanks Also To Alley Stoughton, Kansas State University – K-State CIS How-To Series
Chris Olston, Yahoo Research – talks on data parallelism, PIG (DSSI-2007)
Acknowledgements
Top Related