







Languages
Pages
Legal


MÉTODOS
ESTADÍSTICOS Y
PRINCIPIOS DE
DISEÑO
EXPERIMENTAL

i
UNIVERSIDAD POLITÉCNICA ESTATAL DEL CARCHI
FACULTAD DE INDUSTRIAS AGROPECUARIAS Y CIENCIAS
AMBIENTALES
Escuela de Desarrollo Integral Agropecuario
Modalidad PRESENCIAL
Módulo
“ESTADÍSTICA INFERENCIAL”
CUARTO NIVEL
DOCENTE(S) / INVESTIGADOR(ES):
ING. FAUSTO MONTENEGRO ARELLANO.
ING. RAMIRO MORA QUILISMAL
PERÍODO ACADÉMICO Sep. 2012 – Feb 2013
Tulcán, marzo 2015

ii
CONTENIDO
Introducción ....................................................................................................................................................... 17
1.1 Función de la estadística y del diseño experimental ................................................................................ 17
1.2 Definición. ............................................................................................................................................... 17
1.3 Campos en los que se aplica la Estadística .............................................................................................. 18
1.4 Algunos datos históricos. ......................................................................................................................... 20
1.5 La Estadística y el Método Científico ..................................................................................................... 21
Capítulo 2 .............................................................................................................................................................. 23
Variación – Variables ........................................................................................................................................ 23
2.1 Variación ambiental y variación hereditaria. ........................................................................................... 23
2.2 Variables. ................................................................................................................................................. 24
2.3 Observaciones, hechos. ............................................................................................................................ 25
2.4 Población y muestra................................................................................................................................. 25
2.5 Distribuciones. ......................................................................................................................................... 26
2.6 Presentación de datos............................................................................................................................... 28
Capítulo 3 .............................................................................................................................................................. 32
Muestreo ............................................................................................................................................................ 32
3.1 Poblaciones. ............................................................................................................................................. 32
3.2 Muestras: ................................................................................................................................................. 33
3.3 Estimación. .............................................................................................................................................. 33
3.4 Teorema del límite central. ...................................................................................................................... 33
3.5 Tipos de muestreo. ................................................................................................................................... 34
Capítulo 4 .............................................................................................................................................................. 38
Medidas de tendencia central y de dispersión ................................................................................................... 38
4.1 Simbología matemática. .......................................................................................................................... 38
4.2 Funciones. ................................................................................................................................................ 41
4.3 Redondeo de cifras. ................................................................................................................................. 41
4.4 Parámetros y estadísticas. ........................................................................................................................ 41

iii
4.5. La media y otras medidas de tendencia central. ..................................................................................... 42
4.6 La desviación típica y otras medidas de dispersión ................................................................................. 45
4.7. Cambios en las observaciones y su influencia en 𝝁 y 𝝈𝟐 . ..................................................................... 49
4.8. Desviación típica de las medias. ............................................................................................................. 50
4.9. Coeficiente de variación, (C.V.). ............................................................................................................ 51
4.10. Modelo lineal aditivo. ........................................................................................................................... 52
4.11. Intervalos de confianza. ........................................................................................................................ 52
Capítulo 5 .............................................................................................................................................................. 56
Cuadros de Curvas de Frecuencia –Histogramas .............................................................................................. 56
5.1 Cuadros de frecuencia ............................................................................................................................. 56
5.2 Histogramas y polígonos de frecuencia ................................................................................................... 58
Capítulo 6 .............................................................................................................................................................. 62
Probabilidad ....................................................................................................................................................... 62
6.1. Sucesos independientes. ......................................................................................................................... 63
6.2. Sucesos dependientes ............................................................................................................................. 65
6.3. Sucesos mutuamente excluyentes ........................................................................................................... 66
6.4. Análisis combinatorio ............................................................................................................................. 68
6.5. Factorial N. ............................................................................................................................................. 68
6.6. Permutaciones. ........................................................................................................................................ 69
6.7 Combinaciones. ...................................................................................................................................... 70
Capítulo 7 ............................................................................................................................................................. 72
Distribuciones Teóricas de Frecuencias ........................................................................................................... 72
7.1 La distribución binomial. ......................................................................................................................... 72
7.2 La distribución normal............................................................................................................................. 78
Capítulo 8 .............................................................................................................................................................. 87
Pruebas de Hipótesis .......................................................................................................................................... 87
8.1 La hipótesis nula, HO. .............................................................................................................................. 87
8.2 Prueba de hipótesis y nivel de significación ............................................................................................ 88

iv
8.3 Errores tipo I y tipo II. ............................................................................................................................. 89
8.4 Potencia de la prueba. .............................................................................................................................. 90
8.5 Pruebas de una y de dos colas. ................................................................................................................ 90
Capítulo 9 .............................................................................................................................................................. 94
La Distribución de X2 ........................................................................................................................................ 94
9.1 Cálculo de X2. .......................................................................................................................................... 94
9.2 Cuadros con dos criterios de clasificación. .............................................................................................. 98
9.3 Corrección de Yates............................................................................................................................... 102
La Distribución de t. ........................................................................................................................................ 103
10.1 Prueba t para observaciones no pareadas............................................................................................. 104
10.2 Prueba de t para observaciones pareadas. ............................................................................................ 105
Capítulo 11 .......................................................................................................................................................... 110
Correlación ...................................................................................................................................................... 110
11.1 Coeficiente de Correlación .................................................................................................................. 111
11.2 Propiedades del Coeficiente De Correlación ....................................................................................... 113
Capítulo 12 .......................................................................................................................................................... 115
Regresión ......................................................................................................................................................... 115
12.1 Ecuación de la línea recta .................................................................................................................... 117
12.2 El método de los cuadrados mínimos. ................................................................................................. 118
12.3 Cálculo del coeficiente de regresión y de la ecuación de regresión. ................................................... 119
12.4 Valores ajustados. ................................................................................................................................ 121
12.5 Fuentes de variación en regresión ....................................................................................................... 122
12.6 Desviación y límites de confianza ....................................................................................................... 123
12.7 Propiedades y suposiciones en regresión lineal. ................................................................................ 124
Capítulo 13 .......................................................................................................................................................... 125
Covariancia ...................................................................................................................................................... 125
13.1 Usos del ANACOVA .......................................................................................................................... 126
13.2 Suposiciones en el ANACOVA y el modelo lineal aditivo. ................................................................ 127

v
13.3 Modelo matemático ............................................................................................................................. 127
Generalidades .................................................................................................................................................. 130
1.1 INTRODUCCIÓN ................................................................................................................................ 130
1.2 ESTADÍSTICA Y MÉTODO CIENTÍFICO ........................................................................................ 133
1.3 DEFINICIONES Y CONCEPTOS ....................................................................................................... 135
CAPÍTULO 2 ...................................................................................................................................................... 141
Presentación, resumen y caracterización de la información ............................................................................ 141
2.1 TABLAS DE DISTRIBUCIÓN DE FRECUENCIA ............................................................................ 141
2.2 GRÁFICOS ESTADÍSTICOS .............................................................................................................. 147
2.2.1 Histograma ......................................................................................................................................... 148
2.3 MEDIDAS DE TENDENCIA CENTRAL Y DE DISPERSIÓN ......................................................... 152
2.3.1 Medidas de tendencia central. ............................................................................................................ 152
CAPÍTULO 3 ...................................................................................................................................................... 182
Conceptos básicos de Probabilidad ................................................................................................................. 182
3.1. INTRODUCCIÓN ................................................................................................................................ 182
3.2 CONCEPTOS BÁSICOS PARA EL ESTUDIO DE LAS PROBABILIDADES ................................ 183

1
I. DIRECCIONAMIENTO ESTRATÉGICO
UPEC - MISIÓN MISIÓN – ESCUELA
Formar profesionales humanistas, emprendedores y competentes,
poseedores de conocimientos científicos y tecnológicos; comprometida
con la investigación y la solución de problemas del entorno para contribuir con el desarrollo y la integración fronteriza”.
La Escuela de Desarrollo Integral Agropecuario contribuye al desarrollo
Provincial, Regional y Nacional, entregando profesionales que participan
en la producción, transformación, investigación y dinamización del sector agropecuario y agroindustrial, vinculados con la comunidad, todo esto con
criterios de eficiencia y calidad
UPEC - VISIÓN
VISIÓN - ESCUELA
“Ser una Universidad Politécnica acreditada por su calidad y
posicionamiento regional”.
Liderar a nivel regional el proceso de formación y lograr la excelencia
académica generando profesionales competentes en Desarrollo Integral Agropecuario, con un sólido apoyo basado en el profesionalismo y
actualización de los docentes, en la investigación, criticidad y creatividad
de los estudiantes, con una moderna infraestructura que incorpore los últimos adelantos tecnológicos, pedagógicos y que implique un ejercicio
profesional caracterizado por la explotación racional de los recursos
naturales, producción limpia, principios de equidad, participación,
ancestralidad, que den seguridad y consigan la soberanía alimentaria
ÁREA CONOCIMIENTO ESCUELA CINE-UNESCO
SUB-ÁREA CONOCIMIENTO CINE-UNESCO
CIENCIAS
Matemática y Estadística (46)
II. DATOS BÁSICOS DEL MÓDULO “Biología Molecular y Celular”:
CÓDIGO NIVEL CUARTO
DOCENTE: Ing. Fausto Montenegro A
TELÉFONO: 0993331913 e-mail: [email protected]
CRÉDITOS T 1,5 CRÉDITOS P 1,5 TOTAL CRÉDITOS 3
HORAS T 48 HORAS P 48 TOTAL HORAS 96
PRE-REQUISITOS: (Módulos obligatorios que DEBEN estar aprobados antes de éste módulo) CÓDIGOS
1. Estadística Descriptiva.
CO-REQUISITOS: (Módulos obligatorios que TIENEN que aprobar en paralelo a éste módulo) CÓDIGOS
1.
EJE DE FORMACIÓN: (En la malla ubicado en un eje con un nombre) Básica

2
ÁREA DE FORMACIÓN: (En la malla agrupado con un color y un nombre) Exactas.
LIBRO(S) BASE DEL MÓDULO: (Referencie con norma APA el libro, físico o digital, disponible en la UPEC para estudio )
MARTINEZ BECARDINO, C. (2012). Estadística y Muestreo. Bogotá.: ECOE Ediciones.
LIBRO(S) REFERENCIAL/COMPLEMENTARIO DEL MÓDULO: (Referencie con norma APA el libro, físico o digital, disponible en la UPEC para
estudio)
LIND, D. M. (2012). Estadística aplicada a los negocios y la Economía. México: Mc Graw Hill. GONZÁLEZ BAHAMONDE, G. Métodos Estadísticos y Principios de Diseño Experimental. Universidad Central del Ecuador. Quito. 1989.
MONTGOMERY, D., RUNGER, G. (2002) “Probabilidad y Estadística aplicada a la Ingeniería”, Limusa Wiley, Segunda Edición,
México – México.
MENDENHALL, W., WACKERLY, D., SHEAFFER, R. (1990)”Estadística Matemática con Aplicaciones”, Grupo Editorial
Iberoamérica, Segunda Edición, México – México.
El curso de Estadística Inferencial comprende el estudio de modelos de variables aleatorias continuas utilizadas frecuentemente en ingeniería estudiadas
de formas univariada y bivariada, también se presentan las propiedades de los estimadores y métodos de estimación así como las distribuciones
muestrales a partir de las cuales se realiza la Estadística Inferencial a través de estimadores puntuales, intervalos de confianza y Pruebas de Hipótesis para medias, varianzas, proporciones para una o dos muestras independientes, así como independencia estocástica y bondad de ajuste. Finalizando el
curso se presentan modelos lineales y la estimación a través de mínimos cuadrados.
III. RUTA FORMATIVA DEL PERFIL
Nodo Problematizado: (Elija uno de la propuesta GENÉRICA de la UPEC o GLOBAL de la ESCUELA). Formulación de problemas
Restringido conocimiento sobre el área de estudio y la profesión.(4)
Competencia GENÉRICA - UPEC: (Elija una que guarde coherencia con el NODO PROBLEMATIZADO)
Capacidad de aplicar los conocimientos en la práctica (2).
Competencia GLOBAL - ESCUELA: (Elija una que guarde coherencia con el NODO PROBLEMATIZADO y las COMPETENCIAS GENÉRICA)
Interpretar, difundir y transferir conocimientos científicos y tecnológicos de la producción agrícola (2)
Competencia ESPECÍFICA - MÓDULO: (Escriba una que guarde coherencia con el NODO PROBLÉMICO y las COMPETENCIAS GENÉRICA y
GLOBAL)
Lograr interiorizar en los estudiantes los conocimientos teóricos y aplicaciones de los mètodos estadìsticos y aplicaciones de los mètodos estadìsticos en el
estudio y soluciòn de problemas diversos en el campo de la Ingeniería.

3
NIVELES DE
LOGRO
PROCESO
COGNITIVO
| |1
1. TEÓRICO
BÁSICO
RECORDAR
MLP
El estudiante logra recordar: La Inferencia estadística para
variables cualitativas:
Tablas de contingencia y medidas de asociación: prueba chi cuadrado, de Pearson, razón de verosimilitud, coeficiente de
linealidad.
Corrección de Yates, coeficiente phi, riesgo relativo
Medidas de asociación para variables de escala nominal:
coeficiente de contingencia y otros. (2)
Factual.- listar definiciones de vocabulario y conocimiento
referente a la Estadística inferencial.
2. TEÓRICO
AVANZADO
ENTENDER
El estudiante logra explicar: Inferencia estadística para variables
cuantitativas: Prueba t de Student: elementos fundamentales,
prueba para una muestra, prueba para dos muestras relacionadas, prueba para dos muestras independientes, prueba para varias
muestras, con prueba de Levene. Prueba Z o normal: elementos
fundamentales, aplicaciones Prueba F de Fisher: elementos fundamentales, prueba de Levene, aplicaciones
Pruebas de bondad de ajuste para una muestra: prueba de la binomial, prueba ji cuadrado, pruebas de Kolmogorov,
Kolmogorov-Smirnov-Liliefors y gráficas de probabilidad
normal PP-QQ. (35)
Conceptual.- Explica las diferentes operaciones estadísticas y su proceso.
3. RÁCTICO
BÁSICO
APLICAR Regresión lineal simple
Formulación del problema, análisis de correlación entre pares de
variables, estimación de parámetros, análisis de los residuos,
prueba de Levene y transformaciones para estabilizar la varianza, análisis de varianza y coeficiente de determinación,
pruebas de hipótesis. (41)
Procesal.- resolución de ejercicios prácticos reales con la ayuda del ordenador, lecturas, trabajos y evaluación.
4. PRÁCTICO
AVANZADO
ANALIZAR
El estudiante logra: Regresión lineal múltiple
El coeficiente de correlación múltiple, coeficiente de
determinación, análisis de varianza, coeficiente de correlación parcial, estimación de parámetros, violación de los supuestos del
modelo clásico: multicolinealidad, heterocedasticidad,
autocorrelación
(14)
Procesal
Resolución de ejercicios y elaboración de ensayos o informes
que impliquen el intercambio y la discusión de ideas, mostrando gran respeto por la opinión de los demás.
5. TEÓRICO
PRÁCTICO
BÁSICO
EVALUAR
El estudiante logra: Modelos probabilísticos de regresión
(5)
Conceptual.-
Explica modelos probabilísticos de regresión
6. TEÓRICO
PRÁCTICO
AVANZADO
El estudiante logra: Análisis de componentes principales ACP y
cluster análisis (53)
Conceptual.- Explica Análisis bivariante de variables
cuantitativas: distribución de frecuencias e histogramas, estadísticos descriptivos

4
CREAR
Trabajo interdisciplinar: (Saberes integrados de los módulos recibidos y recibiendo que tributan directamente a la formación de la COMPETENCIA
ESPECÍFICA).
El curso de Estadística Inferencial para la formación de un ingeniero contribuye con:
Los conocimientos que le permiten realizar inferencias estadísticas y proyecciones a partir de muestras.
Tomar decisiones de manera óptima y basada fundamentalmente en evidencia estadística.
Bases teóricas necesarias para el curso de muestreo y análisis multivariado de datos.

5
IV. METODOLOGÍA DE FORMACIÓN DEL PERFIL:
LOGROS DE APRENDIZAJE
(Acciones sistémicas, ELEMENTOS DE
COMPETENCIA, SUB -
COMPETENCIAS)
CONTENIDOS DE APRENDIZAJE PARA QUE EL ESTUDIANTE ALCANCE LOS LOGROS ESPERADOS
ESTRATEGIAS
DIDÁCTICAS
Estrategias, métodos y
técnicas
HORAS
CLASE
COGNITIVOS
¿Qué TIENE que saber?
PROCEDIMENTALES
¿Saber cómo TIENE que aplicar el
conocimiento?
AFECTIVO MOTIVACIONALES
¿Saber qué y cómo TIENE actuar
axiológicamente?
T
P
El estudiante logra recordar: La Inferencia
estadística para variables cualitativas:
Tablas de contingencia y medidas de asociación: prueba ji cuadrado de
Pearson, razón de verosimilitud,
coeficiente de linealidad.
Corrección de Yates, coeficiente phi,
riesgo relativo
Medidas de asociación para variables de escala nominal: coeficiente de
contingencia y otros. (2)
Factual.- listar definiciones de vocabulario y
conocimiento referente a la Estadística
inferencial.
Explicación teórica con la ayuda de
diapositivas, preguntas y respuestas,
resolución de ejercicios prácticos reales con la ayuda del ordenador, lecturas,
trabajos y evaluación.
•Exposiciones
Audiovisuales
•Pizarra • Internet.
8
8
El estudiante logra explicar: Inferencia
estadística para variables cuantitativas:
Prueba t de Student: elementos fundamentales, prueba para una muestra,
prueba para dos muestras relacionadas,
prueba para dos muestras independientes, prueba para varias muestras, con prueba
de Levene. Prueba Z o normal: elementos
fundamentales, aplicaciones Prueba F de Fisher: elementos fundamentales, prueba
de Levene, aplicaciones
Conceptual.- Explica las diferentes operaciones
estadísticas y su proceso.
Explicación teórica con la ayuda de diapositivas, preguntas y respuestas,
resolución de ejercicios prácticos reales
con la ayuda del ordenador, lecturas,
trabajos y evaluación.
•Exposiciones Audiovisuales
•Pizarra
• Internet.
8
8

6
LOGROS DE APRENDIZAJE
(Acciones sistémicas, ELEMENTOS DE
COMPETENCIA, SUB -
COMPETENCIAS)
CONTENIDOS DE APRENDIZAJE PARA QUE EL ESTUDIANTE ALCANCE LOS LOGROS ESPERADOS
ESTRATEGIAS
DIDÁCTICAS
Estrategias, métodos y
técnicas
HORAS
CLASE
COGNITIVOS
¿Qué TIENE que saber?
PROCEDIMENTALES
¿Saber cómo TIENE que aplicar el
conocimiento?
AFECTIVO MOTIVACIONALES
¿Saber qué y cómo TIENE actuar
axiológicamente?
T
P
Pruebas de bondad de ajuste para una
muestra: prueba de la binomial, prueba ji
cuadrado, pruebas de Kolmogorov, Kolmogorov-Smirnov-Liliefors y gráficas
de probabilidad normal PP-QQ. (35)
Regresión lineal simple
Formulación del problema, análisis de correlación entre pares de variables,
estimación de parámetros, análisis de los
residuos, prueba de Levene y transformaciones para estabilizar la
varianza, análisis de varianza y
coeficiente de determinación, pruebas de hipótesis. (41)
Procesal.- resolución de ejercicios prácticos
reales con la ayuda del ordenador, lecturas, trabajos y evaluación.
Explicación teórica con la ayuda de
diapositivas, preguntas y respuestas, resolución de ejercicios prácticos reales
con la ayuda del ordenador, lecturas,
trabajos y evaluación.
•Exposiciones Audiovisuales
•Pizarra
• Internet.
8
8
El estudiante logra: Regresión lineal múltiple
El coeficiente de correlación múltiple,
coeficiente de determinación, análisis de varianza, coeficiente de correlación
parcial, estimación de parámetros,
violación de los supuestos del modelo clásico: multicolinealidad,
heterocedasticidad, autocorrelación
(14)
Procesal
Resolución de ejercicios y elaboración de
ensayos o informes que impliquen el
intercambio y la discusión de ideas, mostrando gran respeto por la opinión de los
demás.
Explicación teórica con la ayuda de diapositivas, preguntas y respuestas,
resolución de ejercicios prácticos reales
con la ayuda del ordenador, lecturas, trabajos y evaluación.
•Exposiciones
Audiovisuales
•Pizarra
• Internet.
.
8
8

7
LOGROS DE APRENDIZAJE
(Acciones sistémicas, ELEMENTOS DE
COMPETENCIA, SUB -
COMPETENCIAS)
CONTENIDOS DE APRENDIZAJE PARA QUE EL ESTUDIANTE ALCANCE LOS LOGROS ESPERADOS
ESTRATEGIAS
DIDÁCTICAS
Estrategias, métodos y
técnicas
HORAS
CLASE
COGNITIVOS
¿Qué TIENE que saber?
PROCEDIMENTALES
¿Saber cómo TIENE que aplicar el
conocimiento?
AFECTIVO MOTIVACIONALES
¿Saber qué y cómo TIENE actuar
axiológicamente?
T
P
El estudiante logra: Modelos
probabilísticos de regresión
Modelo logit
Modelo probit (5)
Conceptual.-
Explica modelos probabilísticos de
regresión
Explicación teórica con la ayuda de
diapositivas, preguntas y respuestas,
resolución de ejercicios prácticos reales con la ayuda del ordenador, lecturas,
trabajos y evaluación.
•Exposiciones
Audiovisuales •Pizarra
• Internet.
8
8
El estudiante logra: Análisis de
componentes principales ACP y cluster análisis (53)
Conceptual.- Explica Análisis bivariante
de variables cuantitativas: distribución de frecuencias e histogramas, estadísticos
descriptivos
Explicación teórica con la ayuda de
diapositivas, preguntas y respuestas, resolución de ejercicios prácticos reales
con la ayuda del ordenador, lecturas,
trabajos y evaluación.
•Exposiciones
Audiovisuales •Pizarra
• Internet.
8
8

8
V. PLANEACIÓN DE LA EVALUACIÓN DEL MÓDULO
LOGROS DE APRENDIZAJE
(Acciones sistémicas, ELEMENTOS DE
COMPETENCIA, SUB - COMPETENCIAS)
FORMAS DE EVALUACIÓN DE LOGROS DE APRENDIZAJE
indicar las políticas de evaluación para éste módulo según los resultados esperados
DIMENSIÓN
(Elija el grado de
complejidad que
UD. EXIGIRÁ
para alcanzar el
logro)
INDICADORES DE
LOGRO DE INGENIERÍA
Descripción
TÉCNICAS e INSTRUMENTOS
de EVALUACIÓN 1° PARCIAL 2° PARCIAL 3° PARCIAL SUPLETORIO
El estudiante logra recordar: La Inferencia estadística
para variables cualitativas:
Tablas de contingencia y medidas de asociación: prueba ji cuadrado de Pearson, razón de
verosimilitud, coeficiente de linealidad.
Corrección de Yates, coeficiente phi, riesgo relativo
Medidas de asociación para variables de escala
nominal: coeficiente de contingencia y otros. (2)
Factual.- listar definiciones
de vocabulario y
conocimiento referente a la Estadística inferencial.
• Pruebas
individuales
• Trabajos grupales e
individuales de
consulta • Exposiciones
individualess
• Trabajos de
clase grupales e
individuales
• Talleres
Poligrafiado
básico del
docente.
Internet.
Debate dirigido
Organizadores del
conocimiento
Lluvia de Ideas.
Exposición
Individual y grupal.
Aulas virtuales.
Pruebas
individuales
60%.
Trabajos
grupales e
individuales de
consulta 20%.
Aulas virtuales
20 %.
Pruebas
individuales
60%.
Trabajos
grupales e
individuales de
consulta 20%.
Aulas virtuales
20 %.
Pruebas
individuales
60%.
Trabajos
grupales e
individuales de
consulta 20%.
Aulas virtuales
20 %.
Pruebas
individuales
90%.
Portafolio 10%.
El estudiante logra explicar: Inferencia estadística
para variables cuantitativas: Prueba t de Student: elementos fundamentales, prueba para una muestra,
prueba para dos muestras relacionadas, prueba para
dos muestras independientes, prueba para varias
Conceptual.- Explica las diferentes operaciones estadísticas y su
proceso.
• Pruebas
individuales • Trabajos
grupales e
individuales de
Poligrafiado
básico del docente.
Internet.
Pruebas
individuales 60%.
Pruebas
individuales 60%.
Pruebas
individuales 60%.
Pruebas
individuales 90%.
9
LOGROS DE APRENDIZAJE
(Acciones sistémicas, ELEMENTOS DE
COMPETENCIA, SUB - COMPETENCIAS)
FORMAS DE EVALUACIÓN DE LOGROS DE APRENDIZAJE
indicar las políticas de evaluación para éste módulo según los resultados esperados
DIMENSIÓN
(Elija el grado de
complejidad que
UD. EXIGIRÁ
para alcanzar el
logro)
INDICADORES DE
LOGRO DE INGENIERÍA
Descripción
TÉCNICAS e INSTRUMENTOS
de EVALUACIÓN 1° PARCIAL 2° PARCIAL 3° PARCIAL SUPLETORIO
muestras, con prueba de Levene. Prueba Z o normal:
elementos fundamentales, aplicaciones Prueba F de Fisher: elementos fundamentales, prueba de Levene,
aplicaciones
Pruebas de bondad de ajuste para una muestra: prueba de la binomial, prueba ji cuadrado, pruebas de
Kolmogorov, Kolmogorov-Smirnov-Liliefors y
gráficas de probabilidad normal PP-QQ. (35)
consulta
• Exposiciones individualess
• Trabajos de
clase grupales e individuales
• Talleres
Debate dirigido
Organizadores del
conocimiento
Lluvia de Ideas.
Exposición
Individual y grupal.
Aulas virtuales.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
Portafolio 10%.
Regresión lineal simple
Formulación del problema, análisis de correlación
entre pares de variables, estimación de parámetros,
análisis de los residuos, prueba de Levene y transformaciones para estabilizar la varianza, análisis
de varianza y coeficiente de determinación, pruebas de hipótesis. (41)
Procesal.- resolución de ejercicios prácticos reales
con la ayuda del ordenador,
lecturas, trabajos y evaluación.
• Pruebas individuales
• Trabajos
grupales e individuales de
consulta • Exposiciones
individualess
• Trabajos de clase grupales e
individuales
• Informes de investigaciones
realizadas
• Talleres
Poligrafiado básico del
docente.
Internet.
Debate dirigido
Organizadores del
conocimiento
Lluvia de Ideas.
Exposición
Individual y
Pruebas individuales
60%.
Trabajos grupales e
individuales de consulta 20%.
Aulas virtuales 20 %.
Pruebas individuales
60%.
Trabajos grupales e
individuales de consulta 20%.
Aulas virtuales 20 %.
Pruebas individuales
60%.
Trabajos grupales e
individuales de consulta 20%.
Aulas virtuales 20 %.
Pruebas individuales
90%.
Portafolio 10%.

10
LOGROS DE APRENDIZAJE
(Acciones sistémicas, ELEMENTOS DE
COMPETENCIA, SUB - COMPETENCIAS)
FORMAS DE EVALUACIÓN DE LOGROS DE APRENDIZAJE
indicar las políticas de evaluación para éste módulo según los resultados esperados
DIMENSIÓN
(Elija el grado de
complejidad que
UD. EXIGIRÁ
para alcanzar el
logro)
INDICADORES DE
LOGRO DE INGENIERÍA
Descripción
TÉCNICAS e INSTRUMENTOS
de EVALUACIÓN 1° PARCIAL 2° PARCIAL 3° PARCIAL SUPLETORIO
grupal.
Aulas virtuales.
El estudiante logra: Regresión lineal múltiple
El coeficiente de correlación múltiple, coeficiente de
determinación, análisis de varianza, coeficiente de correlación parcial, estimación de parámetros,
violación de los supuestos del modelo clásico:
multicolinealidad, heterocedasticidad, autocorrelación
(14)
Procesal
Resolución de ejercicios y
elaboración de ensayos o informes que impliquen el
intercambio y la discusión de
ideas, mostrando gran respeto por la opinión de los demás.
• Pruebas
individuales
• Trabajos grupales e
individuales de
consulta • Exposiciones
individualess
• Trabajos de clase grupales e
individuales
• Talleres
Poligrafiado
básico del
docente.
Internet.
Debate dirigido
Organizadores del
conocimiento
Lluvia de Ideas.
Exposición
Individual y grupal.
Aulas virtuales.
Pruebas
individuales
60%.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
Pruebas
individuales
60%.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
Pruebas
individuales
60%.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
Pruebas
individuales
90%.
Portafolio 10%.
El estudiante logra: Modelos probabilísticos de
regresión
Modelo logit
Modelo probit (5)
Conceptual.-
Explica modelos
probabilísticos de regresión
• Pruebas
individuales
• Trabajos grupales e
individuales de
consulta • Exposiciones
individualess
Poligrafiado
básico del
docente.
Internet.
Pruebas
individuales
60%.
Pruebas
individuales
60%.
Pruebas
individuales
60%.
Pruebas
individuales
90%.
Portafolio 10%.

11
LOGROS DE APRENDIZAJE
(Acciones sistémicas, ELEMENTOS DE
COMPETENCIA, SUB - COMPETENCIAS)
FORMAS DE EVALUACIÓN DE LOGROS DE APRENDIZAJE
indicar las políticas de evaluación para éste módulo según los resultados esperados
DIMENSIÓN
(Elija el grado de
complejidad que
UD. EXIGIRÁ
para alcanzar el
logro)
INDICADORES DE
LOGRO DE INGENIERÍA
Descripción
TÉCNICAS e INSTRUMENTOS
de EVALUACIÓN 1° PARCIAL 2° PARCIAL 3° PARCIAL SUPLETORIO
• Trabajos de
clase grupales e individuales
• Talleres
Debate dirigido
Organizadores del
conocimiento
Lluvia de Ideas.
Exposición
Individual y grupal.
Aulas virtuales.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
El estudiante logra: Análisis de componentes principales ACP y cluster análisis (53)
Conceptual.- Explica Análisis bivariante de
variables cuantitativas:
distribución de frecuencias e histogramas, estadísticos
descriptivos
• Pruebas individuales
• Trabajos
grupales e individuales de
consulta • Exposiciones
individualess
• Trabajos de clase grupales e
individuales
• Talleres
Poligrafiado básico del
docente.
Internet.
Debate dirigido
Organizadores
del
conocimiento
Lluvia de Ideas.
Exposición
Individual y grupal.
Pruebas individuales
60%.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
Pruebas individuales
60%.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
Pruebas individuales
60%.
Trabajos
grupales e individuales de
consulta 20%.
Aulas virtuales
20 %.
Pruebas individuales
90%.
Portafolio 10%.

12
LOGROS DE APRENDIZAJE
(Acciones sistémicas, ELEMENTOS DE
COMPETENCIA, SUB - COMPETENCIAS)
FORMAS DE EVALUACIÓN DE LOGROS DE APRENDIZAJE
indicar las políticas de evaluación para éste módulo según los resultados esperados
DIMENSIÓN
(Elija el grado de
complejidad que
UD. EXIGIRÁ
para alcanzar el
logro)
INDICADORES DE
LOGRO DE INGENIERÍA
Descripción
TÉCNICAS e INSTRUMENTOS
de EVALUACIÓN 1° PARCIAL 2° PARCIAL 3° PARCIAL SUPLETORIO
Aulas virtuales.
ESCALA DE VALORACIÓN
Nivel ponderado de aspiración y alcance
9.0 a 10.0 Acreditable - Muy Satisfactorio 7.0 a 7.9 Acreditable – Aceptable
8.0 a 8.9 Acreditable – Satisfactorio 4.0 a 6.9 No Acreditable – Inaceptable

13
VI. GUÍA DE TRABAJO AUTÓNOMO / PRODUCTOS / TIEMPOS
LOGROS DE APRENDIZAJE
(Acciones sistémicas, ELEMENTOS DE COMPETENCIA, SUB - COMPETENCIAS)
APRENDIZAJE CENTRADO EN EL ESTUDIANTE
HORAS
AUTÓNOMAS
INSTRUCCIONES RECURSOS
PRODUCTO
T P
El estudiante logra recordar: La Inferencia estadística para variables cualitativas:
Tablas de contingencia y medidas de asociación: prueba ji cuadrado de Pearson, razón de
verosimilitud, coeficiente de linealidad.
Corrección de Yates, coeficiente phi, riesgo relativo
Medidas de asociación para variables de escala nominal: coeficiente de contingencia y
otros. (2)
Impóngase un horario para su trabajo autónomo, consulte en libros e internet,
construya cuadros sinópticos. Respete
posiciones de sus compañeros si el trabajo lo hace en equipo.
Internet
Textos
Entrevistas a técnicos
Presentación en medio
magnético para socializar la
consulta utilizando organizadores gráficos.
Presentación de resultados
Fundamentación de la
revisión bibliográfica.
8
8
El estudiante logra explicar: Inferencia estadística para variables cuantitativas: Prueba t de Student: elementos fundamentales, prueba para una muestra, prueba para dos muestras
relacionadas, prueba para dos muestras independientes, prueba para varias muestras, con
prueba de Levene. Prueba Z o normal: elementos fundamentales, aplicaciones Prueba F de Fisher: elementos fundamentales, prueba de Levene, aplicaciones
Pruebas de bondad de ajuste para una muestra: prueba de la binomial, prueba ji cuadrado,
pruebas de Kolmogorov, Kolmogorov-Smirnov-Liliefors y gráficas de probabilidad normal PP-QQ. (35)
Impóngase un horario para su trabajo
autónomo, consulte en libros e internet,
construya cuadros sinópticos. Respete posiciones de sus compañeros si el trabajo lo
hace en equipo.
Internet
Textos
Entrevistas a
técnicos
Cuadro comparativo
8
8
Regresión lineal simple
Formulación del problema, análisis de correlación entre pares de variables, estimación de parámetros, análisis de los residuos, prueba de Levene y transformaciones para estabilizar
la varianza, análisis de varianza y coeficiente de determinación, pruebas de hipótesis. (41)
Impóngase un horario para su trabajo
autónomo, consulte en libros e internet,
construya cuadros sinópticos. Respete posiciones de sus compañeros si el trabajo lo
hace en equipo.
Revistas Científicas
Textos
Internet
Presentación de Informe sobre las prácticas realizadas
Socialización en grupos
sobre el tema estudiado
8
8

14
LOGROS DE APRENDIZAJE
(Acciones sistémicas, ELEMENTOS DE COMPETENCIA, SUB - COMPETENCIAS)
APRENDIZAJE CENTRADO EN EL ESTUDIANTE
HORAS
AUTÓNOMAS
INSTRUCCIONES RECURSOS
PRODUCTO
T P
El estudiante logra: Regresión lineal múltiple
El coeficiente de correlación múltiple, coeficiente de determinación, análisis de varianza,
coeficiente de correlación parcial, estimación de parámetros, violación de los supuestos del modelo clásico: multicolinealidad, heterocedasticidad, autocorrelación
(14)
Impóngase un horario para su trabajo autónomo, consulte en libros e internet,
construya cuadros sinópticos. Respete
posiciones de sus compañeros si el trabajo lo hace en equipo.
Revistas
Científicas
Textos
Internet
Informe de prácticas
realizadas
Presentación en forma
magnética sobre las trabajos técnicos
8
8
El estudiante logra: Modelos probabilísticos de regresión
Modelo logit
Modelo probit (5)
Impóngase un horario para su trabajo
autónomo, consulte en libros e internet,
construya cuadros sinópticos. Respete posiciones de sus compañeros si el trabajo lo
hace en equipo.
Internet
Textos
Fichas técnicas
Resultados de Investigaciones
Consulta a expertos
Recursos
económicos
para la
investigación
Presentación y exposición.
8
8
El estudiante logra: Análisis de componentes principales ACP y cluster análisis (53)
Impóngase un horario para su trabajo autónomo
Consulte en libros e internet
Construya cuadros sinópticos Valore la creatividad de cada presentación.
Respete posiciones de sus compañeros si el
Revistas Científicas
Textos
Internet
Guías de
Presentación en forma
magnética sobre las trabajos técnicos
8
8

15
LOGROS DE APRENDIZAJE
(Acciones sistémicas, ELEMENTOS DE COMPETENCIA, SUB - COMPETENCIAS)
APRENDIZAJE CENTRADO EN EL ESTUDIANTE
HORAS
AUTÓNOMAS
INSTRUCCIONES RECURSOS
PRODUCTO
T P
trabajo lo hace en equipo. laboratorio.
Fichas técnicas
PROYECTO INTEGRADOR DE SABERES: (Proyecto Integrador de conocimientos con los módulos del Nivel )
TOTAL
48 48
CRÉDITOS
1.5 1.5
3

16
VII. BIBLIOGRAFíA
BÁSICA: (Disponible en la UPEC en físico y digital – REFERENCIAR con normas APA)
MONTGOMERY, D., RUNGER, G. (2002) “Probabilidad y Estadística aplicada a la Ingeniería”, Limusa Wiley, Segunda Edición, México – México.
MENDENHALL, W., WACKERLY, D., SHEAFFER, R. (1990)”Estadística Matemática con Aplicaciones”, Grupo Editorial Iberoamérica, Segunda Edición, México – México. GONZÁLEZ BAHAMONDE, G. Métodos Estadísticos y Principios de Diseño Experimental. Universidad Central del Ecuador. Quito. 1989.
LIBRO(S) REFERENCIAL/COMPLEMENTARIO DEL MÓDULO: (Referencie con norma APA el libro, físico o digital, disponible en la UPEC para estudio)
1. ANDER-EGG, E. (1995). Técnicas de Investigación Social. Buenos Aires: Lumen.
2. MARTINEZ BECADRDINO, C. (2012). Estadìstica y Muestreo. Bogota.: ECOE Ediciones. 3. LIND, D. M. (2012). Estadística aplicada a los negocios y la Economía. México: Mc Graw Hill.
DOCENTES:
Guillermo Fausto Montenegro Arellano.
DOCENTE EDIA-UPEC
ENTREGADO: 2012-09-03

17
Capítulo 1
Introducción
1.1 Función de la estadística y del diseño experimental
El progreso en el campo agropecuario así como en otros a los que el hombre dedica su atención
tiene que basarse en la investigación o experimentación.
Esta verdad, que ha sido reconocida en los últimos años, han permitido el incremento del trabajo
experimental en muchos países y ha estimulado a grupos cada vez más numerosos de
profesionales jóvenes, para que se adiestren y dediquen su tiempo y esfuerzo a la investigación,
en los diferentes campos.
La experimentación, en su forma moderna, tiene que planearse y ejecutarse sobre bases
científicas para, de esta manera, poder llegar a conclusiones válidas y confiables, que más tarde
se traducirán en recomendaciones de tipo práctico para el público y que significan incremento
de rendimientos, calidad, eficacia, etc.
El conocimiento de los Métodos Estadísticos permite una clara compresión del Diseño
Experimental, a base del que es posible identificar el problema, plantear una hipótesis de
trabajo, conducir el ensayo e interpretar sus resultados en forma correcta.
1.2 Definición.
La palabra Estadística es de uso generalizado. Desafortunadamente aún para muchos hombres
cultos es una simple recolección de datos.
Así se oye hablar, por ejemplo, de estadísticas de consumo, de accidentes, censos de población,
etc., que si bien son colecciones importantes de datos, a base de las que se puede hacer un
verdadero trabajo estadístico posterior no representan sino una pequeña porción del alcance de
la Estadística.
La simple colección y ordenación de datos, se llama Estadística Descriptiva, mientras que la
obtención sistemática de una o más conclusiones a partir de los datos, se llama Inferencia
Estadística. Así vemos que los datos obtenidos por la Estadística Descriptiva, constituyen un fin
para ésta, pero tan solo un medio para llegar a la Inferencia Estadística.

18
Steel y Torrie (1960), definen a la Estadística como "la ciencia pura y aplicada que crea,
desarrolla y aplica procedimientos, en tal forma, que se pueda evaluar la certeza de la inferencia
– inductiva”.
De acuerdo con Spiegel (1961),”La Estadística es la ciencia que usa métodos para reunir,
organizar, resumir y analizar datos, así como para obtener conclusiones válidas y tomar
decisiones razonables, a base de tales análisis”.
Para la mayoría de científicos, la Estadística es Lógica o sentido común, en combinación con
procedimientos aritméticos. La lógica daría el método para la toma de datos y la aritmética
proporciona el material sobre el que ha de basarse la inferencia. La aritmética constituye
generalmente la parte rutinaria del Procedimiento.
Finalmente se dice que la Estadística es el estudio científico del análisis de datos numéricos.
De acuerdo con lo expuesto, se usa en forma común la palabra Estadística, por lo que, en
realidad, corresponde Métodos Estadísticos.
1.3 Campos en los que se aplica la Estadística
En los últimos años se ha podido apreciar cambios notables en la Estadística. Nuevas teorías
han estado surgiendo continuamente. Seguidamente, se describen algunas aplicaciones de la
Estadística.
1.3.1 Genética. Ciencia de comunicación biológica entre generaciones. Lo que se transmite de
padre a hijo (tercer principio dilucidado por Johan Gregor Mendel, en 1865).
Mendel tenía una .mente brillante - física, matemática, estadística -. Su capacidad como
experimentador para seleccionar individuos que diferían en ciertas características cualitativas y
su meticulosidad para realizar, tabular y analizar contajes de las progenies resultantes de sus
cruzamientos, permitió llegar, más tarde, a una clara comprensión de la genética de poblaciones
(Srb y colaboradores, 1965).
Algunos atributos importantes de plantas, animales y del hombre, se ubican en escalas continuas
de medida y se expresan mejor como kilogramos, centímetros, cocientes de inteligencia, etc.
Estas variaciones son de naturaleza cuantitativa y se llaman caracteres cuantitativos. La
descripción y análisis de éstos, requiere de métodos especiales, dados por !a rama de las
matemáticas, llamada Estadística.
El conocimiento de las leyes de azar (probabilidad), es básico para comprender la transmisión
de, factores heredables. Así podemos preguntar, “en familias que tienen dos hijos, ¿qué

19
proporción de ellas tendrán dos varones?; ¿varón y mujer?; ¿dos mujeres?; ¿ojos claros y cafés?
La expansión binomial daría respuesta a estas preguntas.
La prueba de x2 indicaría si el número y clase de progenie obtenida en cruzamientos de alfalfa
está de acuerdo a la hipótesis mendeliana. Tal sería el caso del cálculo de recombinaciones de
genes, por sobre cruzamiento, cuando los genes se hallan ligados en cromosomas homólogos.
Dentro del trabajo de creación de nuevas variedades, la determinación de la aptitud
combinatoria general y específica, utiliza modelos estadísticos como los presentados de Sprague
y Tatum (1942), Griffing (1956), Gates y Wilcox (1964), entre otros, que son considerados
clásicos en el campo de fitomejoramiento.
Por considerar de interés para los fito-mejoradores, hemos añadido el Capítulo 19, en el que se
demuestra el uso de uno de los métodos de Griffing (1956), para el cálculo de aptitud
combinatoria general y específica.
Para el efecto, se utilizaron datos provenientes de cruzamientos di alélicos en alfalfa analizados
por el que escribe.
1.3.2 Nutrición. Tanto en nutrición humana como animal el control de calidad de alimentos es
utilizado extensamente para mantener la uniformidad de productos elaborados. Continuamente
se está probando la bondad de nuevas dietas, que se traduzcan en mayores ganancias de peso en
aves, porcinos, etc. Un diseño experimental que permita evaluar a nuevos balanceados
producidos por casas comerciales frente a un testigo deja la oportunidad l investigador para
seleccionar el .mejor y recomendarlo al público.
1.3.3 Comercialización. A las entidades encargadas de controlar la distribución de productos
agrícolas interesa conocer zonas de cultivo, época de siembra y cosecha, costos de producción,
canales por los que se distribuye el producto. Una encuesta bien diseñada y un muestreo
adecuado, pueden dar resultados económicos satisfactorios tanto para el agricultor corno para el
consumidor.
1.3.4 Industria. Los fabricantes de piezas de repuesto, necesitan conocer el porcentaje de
unidades defectuosas qué produce una máquina.
En esta forma será posible determinar si la máquina se halla funcionando en forma eficiente y
económica, o si debe hacerse algún cambio para conseguir tal propósito. Por ejemplo
suponiendo que los diámetros de arandelas de presión, permiten una tolerancia establecida,
usando una prueba de x es posible determinar el porcentaje de arandelas defectuosas.

20
Así mismo, usando la distribución normal, se puede determinar la probabilidad de que, en una
muestra de 10 tuercas sacadas al azar, dos de ellas sean defectuosas.
1.3.5 Medicina. La prensa informa diariamente sobre nuevos productos para controlar o
prevenir tal enfermedad; o sobre el resultado de varios métodos para curar el cáncer. Para
conseguir esos nuevos productos o métodos, el investigador médico puede usar conejos o ratas,
a los que se inocula el organismo causante de la enfermedad, quizás en varias dosis, frente a un
testigo. Después de tomar cuidadosamente los datos y del análisis estadístico respectivo, es
posible multiplicar nuevas vacunas, sueros, etc.
En el mismo campo médico, por medio de un simple muestreo, et profesional obtiene
inferencias sobre la sangre de sus pacientes, a través del examen de una sola gota.
Así mismo, se puede calcular la probabilidad de que el tercer de una familia que padece de
hemofilia, herede este carácter. O se puede establecer quién es el padre de un niño, cuya madre
tiene grupo sanguíneo O.
1.3.6 Agronomía. El ensayo más sencillo sería la prueba de adaptación de algunas variedades de
trigo, en cierta localidad. Si las condiciones de fertilidad, riego, cuidados culturales, etc., se las
mantiene constantes, el único factor en estudio estará formado por las variedades y así se podrá
establecer cuál es la de mayor rendimiento. Si se quiere obtener mayor información, es posible
usar dosis de fertilizante y/o sembrar las variedades en varias localidades, con lo que se amplía
el alcance de las inferencias.
1.3.7 Información general. Un muestreo bien diseñado puede predecir el resultado de las
próximas elecciones, o informar sobre las preferencias del consumidor.
1.4 Algunos datos históricos.
La Estadística moderna es considerada como una herramienta de trabajo para el investigador.
Producto del siglo 20, para el biólogo cobró especial auge en 1925, cuando Sir Ronald Fisher
publicó sus Métodos Estadísticos para Investigadores.
El término Estadística es muy antiguo y quiere decir aritmética del Estado. Con el objeto de
conseguir para librar guerras, el gobernante antiguo pedía que aquellos se acerquen al
“estadístico" más cercano a cumplir con sus obligaciones.
Posteriormente encontramos una aplicación empírica del cálculo de probabilidades en el seguro
de barcos de que disponían, los flamencos en el siglo XIV. El sistema pudo haber sido

21
especulación o juego de azar, pero ha devenido modernamente en el lucrativo negocio de
seguros.
Los juegos de azar condujeron a la teoría de probabilidades, originada por Pascal y Fermat, a
mediados del siglo XVII.
Charles Darwin, en el siglo IX, basó su trabajo biológico en métodos estadísticos sin embargo,
los problemas planteados por su Teoría de la Evolución, hicieron evidente la necesidad de usar
métodos más refinados y fue Karl Pearson (1936), inicialmente un físico-matemático, quien
aplicó sus conocimientos para mejorar la toma de datos y las evaluaciones respectivas.
Un alumno de Pearson, William S. Gosset -científico y cervecero, desarrolló en forma empírica
lo que hoy se conoce como la distribución de "t de Student", que fue el seudónimo que
empleaba Gosset en sus publicaciones en Biométrica.
Sir Ronald Fisher ha hecho numerosas y valiosas contribuciones en el campo de la Estadística,
particularmente con el análisis de variancia, que es el procedimiento más usado por
investigadores, prácticamente en todo tipo de experimento. Igual es el caso de los análisis de
covarianza y regresión.
1.5 La Estadística y el Método Científico
Es conocido que los investigadores usan métodos científicos dentro de su trabajo diario. Resulta
difícil definir lo que es el método científico, puesto que, en investigación, puede usarse
cualquier sistema ideado por una persona, para llegar a obtener un resultado. Sin embargo, la
mayoría de los procedimientos tienen algunas características en común:
a) Una revisión de hechos, teorías, con miras a
b) Formular una hipótesis lógica, sujeta a ser probada por métodos experimentales.
c) Diseño y conducción del experimento.
d) Evaluación objetiva de la hipótesis, en base a los resultados experimentales.
e) Publicación o divulgación de los resultados.
La ciencia es una rama de estudio que tiene que ver con la observación y clasificación de
hechos. El investigador debe estar en capacidad de observar un evento, como resultado de un
plan o diseño. Este es el experimento, la sustancia del método científico.
La evaluación objetiva de una hipótesis, presenta un problema: no es posible observar todos los
eventos posibles en la naturaleza y, por cuanto las leyes exactas de causa y efecto, son
generalmente desconocidas, va a haber variación entre las observaciones. El científico debe

22
siempre partir de casos particulares, para llegar a generalizaciones (proceso inductivo). Por
cuanto es imposible, o poco práctico, estudiar todo el universo (población), por razones de
costo, tiempo y esfuerzo el investigador debe contentarse con estudiar la muestra y, a partir de
ella, obtener conclusiones sobre la población (inferencia estadística). El proceso inverso, como
nos enseña la lógica, es la deducción, por la que, de una norma o ley generales, se llega a casos
particulares.

23
Capítulo 2
Variación – Variables
Los seres vivos plantas, animales y el hombre difieren, aún dentro de la misma especie, en
muchos caracteres. Puede generalizarse que, inclusive en el caso de gemelos homocigóticos, no
existen dos seres vivos idénticos. Trabajos experimentales realizados en Australia, demostraron
que dos terneras gemelas homocigóticas, llevadas la una a un hato en el que el manejo y
alimentación fueron adecuados; y la otra a un hato en el cual estos aspectos fueron deficientes,
se comportaron de acuerdo con el ambiente en que crecieron, siendo este el último factor,
responsable en 85% de la precocidad y ganancia de peso obtenidos.
Si observamos un potrero de raigrás cultivo de fecundación cruzada a primera vista puede
impresionarnos la uniformidad de las plantas: altura y desarrollo de los tallos; forma, tamaño y
disposición de las hojas; forma y tamaño de la espiga, etc. Pero, si comparamos dos plantas de
raigrás, arrancadas al azar, en detalle y se mide cuidadosamente caracteres cuantitativos de
diferentes partes de la planta, encontraremos que los individuos difieren en varios aspectos.
Habrá notables diferencias en vigor de plántulas, días a floración, producción de forraje,
producción de semilla, etc. De este tipo de variación es justamente de lo que se sirve el fito-
mejorador para la selección y creación de nuevas variedades.
2.1 Variación ambiental y variación hereditaria.
La variación dentro de una especie se deben a:
1) Variaciones debidas al ambiente en que desarrolla una especie y
2) Variaciones debidas a la herencia.
2.1.1 La variación provocada por causas ambientales, puede probarse sembrando plantas de
igual genotipo en diferentes localidades. Esta situación da lugar a la formación de agro tipos y
eco tipos como en el caso de la alfalfa “Nacional”. La semilla de alfalfa, introducida
originalmente del Perú y sembrada en diferentes regiones de la Sierra ecuatoriana, ha dado
origen a eco tipos cuyos individuos varían en caracteres morfológicos y constitución fisiológica
que resultan en mayor o menor altura de planta, resistencia al frío, a la altura, a las
enfermedades, etc.
Dos plantas de trigo de la misma variedad, tendrán desarrollo y rendimiento diferentes, si la una
es atacada por el “polvillo”, mientras a la otra se protege de la infección.

24
Estas variaciones provienen del ambiente en el que desarrollaron las plantas y pueden o no
pueden presentarse en las respectivas progenies.
2.1.2 Las variaciones hereditarias son resultado de la diferente constitución genética
(genotipo), de las plantas o animales. Generalmente, estas variaciones pueden probarse
sembrando diferentes especies o variedades, en condiciones ambientales similares.
Las variaciones hereditarias pueden ser fácilmente observadas: plantas de trigo enanas o altas;
diferencia en el color de la planta, flor o semilla; cantidad de pubescencia en tallos y hojas;
presencia o ausencia de aristas, etc. Existen, desde luego, caracteres más difíciles de identificar
como vigor de plántula, capacidad de macollamiento, resistencia a enfermedades, etc.
Por cuanto estas variaciones son heredables, ellas se manifiestan en la progenie, aun cuando la
intensidad con que se expresen, varíe con el ambiente.
Todo lo expuesto sugiere que genotipo y ambiente no son dos identidades independientes. Más
bien, se sabe que el individuo es el resultado de los dos factores, más la interacción
correspondiente.
2.2 Variables.
Asertos como “Juan es moreno” o “él pasa sobre las 150 libras”, son comunes e informativos.
Se refieren a características que no son constantes y que varían de un individuo a otro.
Variable es, entonces, la cantidad o carácter que pueden ser medidos y se hallan, en
consecuencia, sujetos a variación: edad, peso, altura, temperatura, etc. Las variables pueden ser
cualitativas o cuantitativas.
2.2.1 Variable cualitativa. Es aquella en que cada individuo pertenece a una de varias
categorías mutuamente excluyentes, generalmente no numéricas: color, sabor, nacionalidad. Así
podríamos decir que el color blanco, excluye automáticamente al negro; el sabor agrio, excluye
al dulce. Es claro que el color puede calificarse de acuerdo a una escala relativa numérica, en
cuyo caso podrían analizarse los datos como si fueran cuantitativos.
2.2.2 Variable cuantitativa. Se refiere a datos numéricos: contajes, medidas, pesos, etc.
Variable cuantitativa discreta. Es aquella en que los valores son clasificados en categorías
específicas: número de plantas por surco, número de sépalos en una flor.
Variable cuantitativa continua. Es aquella en que es posible tener todos los valores dentro de
una escala o rango, en forma continua: altura, peso, temperatura.

25
2.3 Observaciones, hechos.
Son elementos o atributos de información: altura de una planta o persona; peso de novillos.
Las observaciones son la materia prima con que trabaja el investigador. Para poder analizarlas,
esas observaciones tienen que estar en forma de números. En agronomía, las cifras pueden ser
rendimientos por parcela o por hectárea; en investigación médica o veterinaria, tiempo de
duración de una vacuna, número de pústulas de acuerdo a varias dosis de un producto dado; en
industria, número de piezas defectuosas en lotes producidos en serie; etc.
Los números constituyen los “datos” y su característica común es la variación o variabilidad.
2.4 Población y muestra.
La primera preocupación del investigador frente a un grupo de datos, es saber si ellos
constituyen la totalidad de individuos u observaciones, o si forman parte de un grupo mayor.
Aun cuando la diferencia entre los dos casos, parezca trivial, es en realidad de gran importancia.
Población. La población o universo consiste de todos los valores posibles dentro de una
variable: todos los estudiantes de un curso, el número de caras en 100 lanzamientos de una
moneda.
Muestra. Es una parte de la población; es una selección de individuos tomados del universo o
población.
La muestra debe ser representativa si vamos a llegar a una inferencia valida sobre la población.
Tal sería el caso de la toma muestras de suelos, encuestas políticas, encuestas sobre preferencias
del público, etc.
Muestra al azar. Es una porción del todo, en la que cada individuo tiene igual oportunidad de
ser incluido (verdadera muestra al azar). No es posible tomar una muestra al azar, si no es por
métodos mecánicos. La influencia subjetiva de una persona, impediría que esa muestra sea al
azar.
Los mecanismos para extraer una muestra al azar se refiere al uso de papeles numerados (caso
de la lotería) o de tablas de números al azar. Si se va a nombrar un jurado parcial, dentro de una
clase, se podría seleccionar a los alumnos de acuerdo con los números impares de la lista. El
caso típico está dado por “las experiencias de papas”: ni al agricultor ni al comprador les
interesa efectuar la compra-venta “al ojo”. Si el primero estima el rendimiento de una hectárea
en 400 quintales, por ejemplo, y el comprador obtiene 500, aquel se abría perjudicado; en caso
contrario, si el cálculo es de 400 quintales y el comprador cosecha 300, éste habría perdido.

26
Con el objeto de que la compra-venta sea equitativa para las dos partes, se procede a realizar las
“experiencias”, que no son sino un muestreo al azar, que consiste en lo siguiente: se cosecha de
tres a cinco surcos separadamente, dentro de una “tabla”. Se multiplica luego el peso promedio
por surco por el número de surcos y así se puede estimar el rendimiento por hectárea.
Otro sistema más preciso, aun cuando requiere de más tiempo, se refiere a “cavar” de tres a
cinco matas por surco, de un total de tres a cinco surcos de la “tabla”. Una vez obtenido el
promedio por mata, se cuenta el número de matas por surco y el número de surcos, con lo que se
puede llegar a estimar el rendimiento por hectárea. De acuerdo con la superficie ocupada por la
cementera, se optara por uno u otro sistema de muestreo.
La tabla N° 1 del Apéndice presenta un grupo de números al azar.
Estadística. Escrita con minúscula, es una cantidad que se refiere o describe a la muestra.
Parámetro. Es una cantidad que se refiere a la población.
2.5 Distribuciones.
Los valores de una variable sirven para describir o clasificar individuos o para distinguirlos
unos de otros. Muchos de nosotros hacemos algo más que describir o clasificar datos, porque
tenemos cierta idea sobre la frecuencia relativa de los valores de una variable. No daríamos
crédito si nos hablan de personas de tres metros de estatura; un niño de ocho libras de peso al
nacimiento, sería algo común, excepto para sus padres. Generalmente asociamos una medida
cualquiera con el valor de una variable, una medida de que tan común o raro es ese valor. En
Estadística se dice que la variable tiene una distribución, una distribución de frecuencias o de
probabilidades. Para una moneda, por ejemplo, la probabilidad de obtener sello o cara es de 0.5.
En la distribución binomial, por ejemplo, los elementos pueden ser clasificados en una de dos
clases o categorías: cara o sello; macho o hembra; defectuoso o no defectuoso; inoculado o no
inoculado, etc. Generalmente se considera a las dos clases como éxito y fracaso, tal como se
verá en la Sec. 7.1.
Otra distribución a la que se adaptan datos correspondientes a variables cuantitativas discretas,
es la distribución de Poisson. Este resulta un modelo apropiado para la distribución de un
número de elementos por unidad de tiempo o espacio, cuando el número promedio de elementos
por unidad es relativamente pequeño. Tal sería el caso que resulta del contaje de huevos de
insectos o larvas por determinada área foliar en papa, por ejemplo; el número de focos que
deben ser remplazados en los semáforos de la ciudad, cada mes; el número de radios
defectuosos producidos en una semana, etc., etc. Como se verá más adelante, este tipo de datos

27
0
10
20
30
40
50
60
0 10 20 30 40 50 60 70 80 90 100
Distribución de frecuencias del coeficiente intelectual
no se distribuyen en forma “normal”, es decir, no se agrupan bajo la campana simétrica que
caracteriza a la distribución normal, la misma que se describe ligeramente a continuación y en
forma amplia en la Sec. 7.2.
Si registramos y tabulamos datos como el cociente intelectual o pesos de un numero d
individuos, vamos a conformar cuadros de frecuencia tal como se verá en la Sec. 5.1. Es decir,
se determina las clases o categorías (el cociente intelectual o el peso en libras) y seguidamente
de frecuencia o número de personas dentro de cada clase. A partir del cuadro de frecuencias, es
posible ubicar los datos dentro de un sistema de coordenadas, en el que las clases se localizan en
el eje de las abscisas(x) y la frecuencia en el de las ordenadas (y). Para la Fig. 2.1, podemos
apreciar que la media o promedio del cociente intelectual de un número dado de personas, es
100, registrándose el mayor número de ellas alrededor de este valor; a los extremos de la curva
(los cocientes más altos y más bajos) y en menor número, se encuentran los individuos de
mayor y menor cociente intelectual. En igual forma, en la Fig. 2.2 se ve que el peso promedio de
30 personas es de 150 libras; aquellas de peso más alto y más bajo se ubican, en menor número
en las colas derecha e izquierda, respectivamente, de la distribución, encontrándose el mayor
número alrededor del valor promedio.
Cuando se grafican datos como altura, edad, peso de personas, temperatura y muchas otras
variables de naturaleza continua, vemos que los datos dan una curva parecida a las Figs. 2.1 y
2.2.
Obreros calificados
Normal 50% Comerciantes
Alumnos escuelas especiales Dirigentes
estudiantiles y profesionales
23%
23%

28
0
10
20
30
40
50
60
0 10 20 30 40 50 60 70 80 90 100
Peso en libras de un grupo de personas
Diferencia mental Atrasados
Superdotados Inteligencia superior
2%
2%
Fig. 2.1 Distribución de frecuencias del coeficiente intelectual
Fig. 2.2 Peso en libras de un grupo de personas
2.6 Presentación de datos.
De acuerdo con el grupo de personas para quien se escribe y presenta datos, puede usarse varios
tipos de Cuadros, figuras y Tablas. Los títulos de Tablas y cuadros se escriben sobre ellos y los
de Figuras en la parte inferior de las mismas. Se numera como Figuras, dibujos a mano, ejes de
coordenadas, fotografías, etc.; se llama Cuadros a los grupos de datos obtenidos de un ensayo
experimental, en tesis de grado, etc.
En caso de que las escalas usadas en ejes de coordenadas no aumentan en forma continua a
partir de cero, se rompe la línea del eje respectivo, como se indica en la Fig. 2.6.
Seguidamente, se presenta algunos tipos de Figuras, las que van de lo más simple a lo más
complicado, debiendo usarse cualquiera de ellas, de acuerdo al grupo de lectores para quienes
va dirigida la publicación.

29
Fig. 2.3 Distribución de estudiantes por Facultades
Fig. 2.4 Numero de insectos atrapados.
Estudiantes por facultades
Filosofía Medicina Ingenieía Arquitectura Leyes
Veterinaria Agropecuaria Oddontología Administración
0
1
2
3
4
5
6
7
8
9
10
Lepidóp. Ortóp. Otros
Numero de Insectos atrapados
Insectos

30
Fuente: Intern. Agric. Develop. Vol. I (9), Octubre, 1981
0
1
2
3
4
5
69 70 71 72
Ton
. mét
r. (
mile
s)
Fig. 2.5 Sistema de "barras" con dos variables
trigo maiz
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
5
0 50 100 150 200 250 300
Ton
/ h
a
Urea (Kg / ha)
Fig. 2.6 Sistema de línea continua
0
100
200
300
400
500
600
700
7 3 7 4 7 5 7 6 7 7 7 8 7 9 8 0 8 1
Fig. 2.7 Precio mundial del azucar en libras esterlinas por toneladas

31
La forma de presentar cifras en cuadros (bloques compactos de números), podrá ser como sigue:
CUADRO Nº 2.1 Población de ganado Holstein en tres provincias del ecuador, en 1977 y 1978,
por sexo.
1977 1978
Sexo Pichincha Cotopaxi Tungurahua Pichincha Cotopaxi Tungurahua
Machos ------ ------ ------ ------ ------ ------
Hembras ------ ------ ------ ------ ------ ------
CUADRO Nº 2.2 Importación de fertilizantes de Holanda y Alemania de 1976 a 1978, por
Ecuador, Colombia y Chile, en toneladas métricas.
Países Holanda Alemania
Ecuador 1976 1977 1978 1976 1977 1978
Colombia ------ ------ ------ ------ ------ ------
Chile ------ ------ ------ ------ ------ ------
CUADRO Nº 2.3 Matrícula estudiantil en la Universidad Central, por sexo, de 1978 a 1981
Agronomía Medicina Ingeniería Odontología Economía
Año M. F. M. F. M. F. M. F. M. F.
1978 ---------------- ---------------- ---------------- ---------------- ----------------
1979 ---------------- ---------------- ---------------- ---------------- ----------------
1980 ---------------- ---------------- ---------------- ---------------- ----------------
1981 ---------------- ---------------- ---------------- ---------------- ----------------

32
Capítulo 3
Muestreo
3.1 Poblaciones. De acuerdo con la definición común, la población está formada por la
totalidad de habitantes dentro de un área geográfica determinada. Desde el punto de vista
estadístico, una población o universo, está constituida por la totalidad de elementos que poseen
una o más características en común. Así hablamos de la población de radios marca “X”,
producida por una fábrica durante un año; de la población de animales vacunos que posee una
hacienda; de la población de plantas de abacá dentro de un lote; del número de estudiantes del
curso, etc., etc.
La definición estadística de población, no incluye solamente a poblaciones de individuos u
objetos, sino que considera poblaciones de valores numéricos obtenidos al medir una o más
características de personas u objetos como la altura o peso de individuos, el diámetro de tuercas
producidas por una fábrica; o pueden consistir de todos los valores posibles que se puede
conseguir cuando se hace observaciones repetidas, como sería el caso de registrar al número de
caras o sellos al lanzar una moneda mil veces.
El principal objetivo de la inferencia estadística es sacar conclusiones a partir de la muestra,
sobre poblaciones. En consecuencia, es de fundamental importancia específica o definir la
población con la que estamos trabajando. Muchas veces, la población para la que se han
obtenido ciertas inferencias, difiere en algún aspecto importante de la población que produjo los
datos en los que se basó la inferencia.
Siempre existe riesgo cuando se generalizan conclusiones para una población amplia, partiendo
de una población limitada o que no es representativa de aquella. Cuando se realizan pruebas de
adaptación de una nueva variedad en varias localidades o haciendas, dentro de un cantón o
provincia, tendremos seguridad de recomendarla si los resultados fueron satisfactorios para las
localidades o haciendas en las que se hizo el ensayo. Sería peligroso generalizar las
conclusiones y afirmar que la nueva variedad puede sembrase indistintamente en todo el cantón
o provincia.
Esto es así por cuanto conocemos la variabilidad de suelos, clima, prácticas culturales que
existen dentro de un mismo cantón o provincia.

33
Para estudios de tipo sociológico, industrial, económico, etc., nos interesa obtener una muestra
representativa y suficiente que refleje lo más exactamente que sea posible las características de
la población para la que se sacara conclusiones si vamos a tener confianza en las poblaciones.
Cuando se trata de establecer, por ejemplo, la edad promedio de los estudiantes de la
Universidad, o los ingresos de sus padres para adoptar una decisión de carácter económico
debemos realizar un muestreo estratificado formando clases o grupos con características
similares dentro de cada uno.
3.2 Muestras: Cuando queremos obtener datos sobre una población cualquiera, sería ideal si
pudiéramos analizar cada elemento de la población. En la mayoría de los casos, tal
procedimiento seria descartado por razones de tiempo y costo principalmente. Por ejemplo lado,
no se justificaría debido a que, en la práctica, pueden obtenerse resultados precisos, en forma
rápida y con menor costo, estudiando solo una parte de la población. Esta parte de la población
constituye la muestra. En la Sec. 3,5 veremos los diferentes tipos de muestreos que pueden
utilizarse con diversas poblaciones.
3.3 Estimación. En general, debido a que difícilmente se pueden estudiar y analizar una
población íntegra, desconocemos el valor real de los parámetros de la distribución teórica de la
que suponemos que los datos tomados por nosotros constituyen una muestra. Aspiramos
entonces, a que la muestra tomada sea un estimado insesgado (no viciado, confiable) de los
valores poblacionales o paramétricos. Por ejemplo, cuando se cumple con lo que dice el
teorema del límite central (Sec. 2.4), la media de la muestra �� es un estimador de la media
poblacional µ; la desviación típica de la muestra s, es un estimador de la desviación típica de la
población ơ.
3.4 Teorema del límite central. Uno de los teoremas más importantes en lo que se refiere a
distribuciones de muestreo, para series de variables tomadas al azar, independientes,
idénticamente distribuidas, es el teorema del límite central. Se dice que un juego de
observaciones al azar es idénticamente distribuida cuando todos los miembros o elementos del
juego de observaciones han sido seleccionadas de la misma distribución (población).
El teorema en su forma más simple, dice: si se seleccionan muestras al azar de una población
determinada, conforme aumenta el tamaño de la muestra, la distribución se aproxima a la
distribución normal. (Ver Secs. 2.5 y 7.2). Es decir que podemos hacer uso de la teoría sobre
distribuciones normales y de distribuciones de muestreo derivadas de poblaciones normales, con
el objeto de obtener inferencias acerca de la población involucrada, sin tomar en cuenta la forma
o tipo de esta, con tal de que el tamaño de la muestra sea suficientemente grande. El tamaño de

34
la muestra que puede considerarse suficiente en una situación dada, depende del grado en que la
población involucrada se desvía de la normalidad.
3.5 Tipos de muestreo. Sabemos que, a partir de la muestra, se obtienen generalizaciones sobre
la población. La exactitud de aquellas depende del cuidado con que se diseña y ejecuta el
análisis muestral.
Trabajar con la muestra no solo reduce el tiempo sino el costo de obtener la información. Por ser
imposible o impráctico trabajar con la población total, se han creado diseños muestrales,
algunos de los que se trata seguidamente.
El procedimiento o diseño de muestreo que ha de utilizarse depende:
1) El tipo de población de que se trata;
2) De la información deseada; y,
3) De los fondos y tiempo disponibles.
El diseño de muestreo es un plan que especifica cómo se seleccionara la muestra que se ha de
extraer de una población dada.
En general, las poblaciones pueden ser finitas o infinitas. Las casas de un barrio, los agricultores
de una parroquia, el número de cabezas de ganado de una hacienda, son ejemplos de
poblaciones finitas.
Poblaciones infinitas se asocian con algún proceso repetitivo como el de lanzar una moneda,
que puede dar caras o sellos, en forma indefinida; también constituyen poblaciones infinitas, los
individuos u observaciones cuyo contaje o mensuración sería difícil o imposible de establecer:
las bacterias Azotobacter del suelo.
3.5.1 Muestreo aleatorio simple. Si bien el término aleatorio (al azar) puede implicar que las
observaciones son seleccionadas de manera fortuita o casual, las verdaderas muestras aleatorias
requieren de un cuidadoso diseño y ejecución a fin de asegurar la independencia de dichas
observaciones. Si la muestra no es aleatoria, no se puede tener confianza sobre las conclusiones
derivadas de ella.
La selección de muestras aleatorias de una población finita puede ser una tarea larga y tediosa.
Supongamos que se desea estimar la edad promedio de los estudiantes de la Universidad
Central; una persona podría instalarse en la puerta principal y preguntar la edad de cada 100
estudiantes que entren. Esta no sería una muestra aleatoria porque la probabilidad de usar esa
puerta es mayor para cierto grupo de estudiantes que para otros.

35
También se podría telefonear, una determinada noche, al 10% de alumnos que habitan en
Residencia Universitaria; esta tampoco sería una muestra aleatoria, porque es posible que
estudiantes de ciertos cursos tengan mayor acceso a la Residencia o porque determinados
grupos de estudiantes no permanezcan en ella las noches.
Una manera de lograr una muestra aleatoria, sería conseguir una lista completa de todos los
estudiantes matriculados, asignar un número a cada uno, anotarlos en pedazos de papel y, luego
de colocarlos en una caja, seleccionar los números, reponiéndolos cada vez y mezclando los
papeles antes de cada extracción. Esta sería una verdadera muestra al azar, para la que
estaríamos trabajando con todo el universo o población. El proceso, claro está, duraría varios
días y sería impráctico y tedioso dado el alto número de estudiantes que conforman la población
universitaria. Este tipo de muestreo seria utilizable cuando se trata de poblaciones pequeñas,
bien definidas; las rifas o sorteos, como el juego de lotería de Guayaquil emplean muestreos
aleatorios simples, en los que la población está constituida por los números cero a nueve, para
cada una de las cinco fichas que dan los diferentes premios.
3.5.2 Muestreo probabilístico. En este caso, lo primero es fijar el tamaño de la muestra, a fin de
obtener un determinado grado de precisión a la estimación de un parámetro.
Supongamos que el rector de la escuela quiere determinar el coeficiente intelectual de los
estudiantes, a partir de una muestra aleatoria. Al efecto, decide usar la media aritmética y una
muestra al azar formada por los datos contenidos en 50 tarjetas de archivo, el total de alumnos
es de 1000. En este caso el rector estaría trabajando con 5% del estudiantado. Por cuanto sería
impráctico emplear pedazos de papel en los que se halle el número de cada uno de los alumnos,
de acuerdo con el listado de archivo, resulta más fácil recurrir a una tabla de números
randomizados, como la Tabla Nº1 del Apéndice. Dicha Tabla está formada por dígitos
obtenidos……
Estratos Clasificación Número Proporción por
estrato
1 Obreros 800 0,80
2 Administrativo 150 0,15
3 Ejecutivos 50 0,05
Total 1000 1,00
Si seleccionamos una muestra de 80 empleados (8%), por muestreo proporcional, obtendríamos:

36
80 x 0,8 = 64 Obreros
80 x 0,15 = 12 Administrativos
80 x 0,05 = 4 Ejecutivos
Dando un total de 84 empleados, los que serán seleccionados al azar, dentro de cada estrato o
categoría.
En esta forma daríamos cumplimiento a lo establecido por este tipo de muestreo, puesto que a la
población total, se habría dividido en tres subpoblaciones cuyos promedios de ingresos son
diferentes unos de otros, existiendo homogeneidad dentro de cada estrato o subpoblación.
3.5.4 Muestreo sistemático. Para este tipo de muestreo, se incluye cada k-esimo elemento de
una población ordenada, por ejemplo, en forma alfabética. El punto de partida se elige al azar
entre los primeros k elementos y el muestreo se continua, de acuerdo con el intervalo decidido,
hasta completar los n objetos u observaciones. Se podría, por ejemplo, hacer una encuesta
telefónica, llamando a cada quincuagésimo nombre.
El principal inconveniente radica en que las muestras sistemáticas no siempre. Son aleatorias. Si
la población esta ordenada en forma sistemática con respecto a la característica de interés, es
posible que se incluyan más elementos de una clase que de otra. Por ejemplo, si se trata de
averiguar el ingreso de empleados administrativos y obreros de una fábrica.
De gran tamaño, posiblemente van a parecer en la lista de pagos, más obreros que empleados
administrativos, sesgando el ingreso medio general.
En algunos casos, pueden modificarse el sistema cambiando ocasionalmente el punto de partida
y el intervalo entre muestra y muestra.
3.5.5. Muestreo por áreas. O por conglomerados, en que las subdivisiones pueden ser barrios,
distritos, parroquias, cantones, etc.
Se usa este tipo de muestreo, especialmente en encuestas sociológicas, en las que se asignan al
encuestador una porción (conglomerado), de los distintos tipos de personas que han de ser
entrevistadas (grupos sociales, religiosos, profesionales, económicos, etc.). El encuestador hace
la selección aleatoria dentro de conglomerado.
El muestreo por áreas elimina al tener que hacer un listado completo de los elementos de una
población finita. Es adecuado para encuestas a nivel nacional y se puede aumentar el tamaño de
la muestra sin mayor problema.

37
3.5.6 Muestreo dirigido. En este tipo de muestreo, el criterio desempeña un papel importante en
la selección. Puede ser de utilidad si el investigador está bien familiarizado con la población y
puede elegir elementos representativos para la integración de la muestra. El analista debe aplicar
su propio criterio para decidir si una muestra es “buena” o “mala”. La muestra debe ser
representativa si vamos a llegar a obtener una inferencia valida sobre la población. Tal sería el
caso de la toma de muestras de suelo, encuestas políticas, encuesta sobre preferencias del
público, etc. Para la primera situación, el profesional divide el campo de acuerdo con la
homogeneidad aparte de la vegetación y la topografía para, dentro de cada sector o lote
relativamente uniforme, tomar al lazar las muestras que serán analizadas en el laboratorio. Las
recomendaciones sobre el uso de fertilizantes, por ejemplo, se harán en forma separada para los
lotes de los que se extrajo las muestras. Si este trabajo hubiera sido hecho de forma
indiscriminada, para lotes obviamente diferentes, no tendría valor recomendación del
laboratorio.
En el caso de encuestas de tipo político sobre preferencias del público, debe procederse de
manera similar. Diferentes grupos de personas (aspectos raciales, religiosos, económicos,
educativos, etc.), van a tener diversas preferencias y, en consecuencia, conviene separarlas en
grupos a fin de obtener inferencias más precisas sobre las poblaciones involucradas. Como
vemos, este tipo de muestreos son partes dirigidos y parte aleatorios.
3.5.7 Muestreo por cuotas. Es un tipo de muestreo dirigido en el que se fijan cuotas de acuerdo
con ciertos, para, dentro de ellas realizar la selección en base al criterio personal del
entrevistador. Supongamos que se va a investigar sobre el uso de un nuevo detergente y se
decide entrevistar a 500 personas en esta forma: 50% amas de casa; 20% ganaderos y 30%
lavanderías comerciales. Ajustándose a las cuotas señaladas, el entrevistador puede tener cierta
preferencia por ciertos sectores de la ciudad o del campo; o de trabajar ciertas horas del día o
ciertos días de la semana, en las que puede o no puede encontrar a la persona indicada. Para
resolver este problema, la persona podría hacer en la encuesta a la mitad de las amas de casa,
ganaderos y lavanderías pasadas las seis de la tarde o durante los fines de semana.

38
Capítulo 4
Medidas de tendencia central y de dispersión
4.1 Simbología matemática. En estadística se usan algunos símbolos para representar
observaciones. La utilización de dichos símbolos, es lo que constituye la notación de una
expresión matemática.
Como se indica en la Sec. 2.2, la base del trabajo en estadística está formada por variables, las
que se designan generalmente con las letras mayúsculas X, Y, Z. Las primeras letras del
alfabeto, en minúsculas, sirven para designar constantes.
Uno de los signos de mayor uso en Estadística, es la letra griega mayúscula ∑ (sigma), que
significa “la suma de” o “sumatoria de”.
Una observación cualquiera se representa por X1 y, si existen varias observaciones, ellas serán
x1, x2, x3,…….,xn. Es decir que la letra i en X1, llamada subscrito o índice, representa cualquiera
de los valores 1, 2, 3,………,..n. Si tenemos los números 6, 8, 4, 12, la suma de ellos está dada
por
∑4i=1 Xi = X1 + X2 + X3 + X4
= 6 + 8 + 4 + 12 = 30
En general ∑4 i=1 Xi = X1 + X2 + X3 +……..+Xn, que dice la suma de las X1, desde i = 1 hasta n
(la enésima o última observación), es igual a la suma total de las observaciones. Algunos
autores representan ∑ Xi como ∑X.
∑ni=2 Xi = X2 + X3 +…. + Xn
En las que no se toman en cuenta x1 y se suma desde x2 hasta xn.
Otras dos expresiones de uso común son ∑Xi2 y (∑xi)2. La primera representa “la suma de los
cuadros de las X”, es decir
∑4i=1 Xi
2 = X12+ X2
2+ X32+……+ Xn
2
En el ejemplo anterior,
∑4i=1 Xi
2 = X12+ X2
2+ X32 +……+ Xn
2

39
La segunda expresión (∑ Xi)2 representa “el cuadrado de la suma de X”, es decir
(∑n Xi)2 i=1 = (x1 + X2 + X3 + Xn)2
En el ejemplo,
(∑4 Xi)2 i=1 = (6 + 8+ 4 + 12)2 = 302 = 900
Seguidamente, se da algunas notaciones y su desarrollo:
a) ∑nj=1 XjYj= X1 Y1 + X2 Y2 +X3 Y3 +…….+ XnYn
b) ∑5i=1 (xi+2) = (x1 + 2) + (x2 + 2) + (x3 + 2) + (x4 + 2) + (x5 + 2)
= x1+ x2 + x3 +x4+ x5+ 10
c) ∑5i=2(4 Xi Yi) = 4 X2Y2+ 4 X3Y3+ 4 X4Y4+ 4 X5Y5
d) ∑4j=2(FjXj
3)= F1X13+ F2X2
3+ F3X33+ F4X4
3
e) Si x1 = 2, x2 = -5, x3 = 4, x4 = -8
Y1 = -3, y2 = -8, y3 = 10, y4 = 6, calcular:
∑Xi, ∑Yi, ∑XiYi, ∑Xi2, ∑Yi
2, (∑Xi) (∑Yi), ∑XiYi2
∑Xi= (2) + (-5) + (4) + (-8) = -7
∑Yi = (-3) + (-8) + (10) + (6) = +5
∑Xi Yi= [(2) (-3) + (-5) (-8) + (4) (10) + (-8) (6)] = +26
∑Xi2= (2)2 + (-5)2+ (4)2 + (-8)2= 109
∑Yi2= (-3)2 + (-8)2 + (10)2 + (6)2 = 209
(∑Xi) (∑Yi) = (-7) (5) = -35
∑Xi Yi2 = [(2) (-3)2 + (-5) (-8)2 + (4) (10)2 + (-8) (6)2] = -190

40
Cuando se trata de una observación formada por dos o tres componentes, se usa el símbolo Xjj y
Xijk, respectivamente, en cuyo caso la suma total de las X se representa así:
∑ni=1 ∑n
j=1 Xij y ∑ni=1 ∑n
j=1 ∑nk=1 Xijk
O simplemente, ∑i ∑jXij y ∑i ∑j∑k Xijk
Si, para un cálculo dado, los componentes j son mayores que los i, se escribe,
∑i<∑jo ∑i ≠ ∑jXij
Como puede apreciarse en el cap. IX, existen combinaciones más complejas que las expuestas al
comienzo del presente Capitulo. En esos casos es necesario comprender claramente las
notaciones, a fin de evitar errores. Si, para cruzamientos di alélicos, por ejemplo, el número de
progenitores p= 3, tendríamos el siguiente cuadro de 3 x 3:
(Progenitor i)
(Progenitor i)
X11 X12 X13 X 1.
X21 X22 X23 X 2.
X31 X32 X33 X 3.
∑ X.1 X.2 X.3 X. .
El cruzamiento, u observación x23, corresponde a xij. El cuadro presentado correspondería
también a cualquiera combinación de dos factores, cada uno de los cuales tiene tres niveles.
Haciendo nuevamente referencia el cap. 19, las notaciones para los diferentes cruzamientos,
serian:
Xi. = ∑j Xij= Xi1Xi2 + Xi3
X.j = ∑iXij= X1jX2j + X3j
X... = ∑j ∑i Xij= X11 X12+…..+ X33 (todas las nueve observaciones)
X... = ∑i ≤∑jXij= X11 + X12+ X13+ X22+ X23+ X33

41
Xi. = ∑j≠iXij = p. ej: X2.= X21+ X23
X.j = ∑i ≠j Xij = p. ej: X.2= X12+ X32
X... = ∑∑i ≠ j Xij= X12+ X13+ X21+ X23+ X31 + X32
4.2 Funciones.
Decimos que Y es función de X, corresponde un valor de Y; es decir, existe dependencia
funcional de Y en X, la que se representa como Y =f (X).
Si suponemos que el rendimiento R, es función de fertilizante Escribimos: R = f (F).
Si Y = f (X), se acostumbra a indicar “Y” es función de X, cuando X vale tanto”. Por ejemplo,
si X =5, Y =3, sería igual a
Y = 3 (5) – 3 = 12
4.3 Redondeo de cifras.
Cuando se trabaja con decimales, y se necesita cierto grado de precisión, el investigador debe
ser consistente en el redondeo de números. Así de evita acumular errores por redondeo, cuando
se trabaja con un número crecido de cifras.
En general, la idea es aproximar el número a la cifra que se encuentra más cerca, superior o
inferior. En el caso de 103.7 el redondeo es hacia 104. 0, puesto que 103.7 está más cerca a
104.0 1que a 103.0. Así mismo, 34.2246, se redondearía, si se quiere dos decimales, a 34.22 y
no a 34.23. En el caso de 34.465, la cifra quedaría como 34.46 y no 34.47, de acuerdo al criterio
generalizado de redondear al centésimo más bajo, cuando este es un número par y el milésimo
es 5 o mayor, si el centésimo fuera un número impar, el redondeo seria el centésimo más alto:
34.475 quedaría como 34.48.
4.4 Parámetros y estadísticas.
Como se ha indicado en la Sec. 2.4, los parámetros son cantidades fijas, que describen o definen
la población, en tanto que las estadísticas son cantidades variables que definen la muestra. En el
último caso, la estadística es una cifra y no una ciencia que nos ocupa. Son de uso común en
Estadística, los símbolos que se indican seguidamente, para representar parámetro y estadísticas.

42
Parámetros (Población) Estadística
(Muestra)
Media µ (miu) X
Varianza 𝜎2 𝑆2
Desviación típica 𝜎 s
Desviación típica de las medias Sx
Desviación típica de la diferencia Sd
z
t
𝑋2
Por cuanto el investigador trabaja generalmente con muestras, para a base de ellas, sacar
conclusiones sobre la población, se hace constar solo como estadísticas las cantidades dadas por
z, t, y X2, así como Sx y Sd.
4.5. La media y otras medidas de tendencia central.
Cuando se presenta datos, generalmente se hace referencia a un valor central (𝑥−), y a otro que
denote el grao de dispersión o variación en un juego de datos. Esta última cifra nos indicaría que
valores se hallan alrededor de la media (del centro) y cuales se alejan hacia los extremos.
Expresiones como “Juan es de altura mediana”, son vagas, aun cuando dan alguna información
general. Se refieren a que, si la altura promedio de la población ecuatoriana, por ejemplo, es de
1.65, la estatura de Juan se halla alrededor de esa cifra.
Sin embargo, cuando el investigador colecta datos que implican gasto de tiempo, dinero y
esfuerzo, él no puede darse el lujo de tener informaciones vagas. En investigación de cualquier
tipo, es necesario una medida precisa de tendencia central, la que nos da un resumen parcial de
los datos.

43
A pesar de que estas medidas de tendencia central son útiles, nos dan información alguna sobre
la variación de los datos, es decir, qué valores se hallan al centro y cuáles se ubican hacia los
extremos. Tal sería el caso al determinar el sueldo promedio mensual de una institución: si el
jefe gana $15.000,00; ocho funcionaros intermedios ganan $ 8.000,00 y 10 empleados inferiores
ganan $ 2.500,00, el sueldo promedio mensual para la institución, sería de $ 5.473,00 valor que
no refleja la remuneración del jefe, ni la de los empleados inferiores.
Seguidamente, vamos a tratar sobre las medidas más comunes de tendencia central, que son la
media aritmética o promedio, la mediana y el modo.
4.5.1. La media aritmética
La media de un grupo formado por n números, x1, x2, x3……..xn, se denota por x- (equis barra) y
se define como,
�� = 𝑥1 + 𝑥2 + 𝑥3 + ⋯ … … … … … . + 𝑥𝑛
𝑛= ∑ 𝑥1
𝑛
𝑖=1
/𝑛 = ∑𝑥
𝑛
Por ejemplo la media de los números 6, 8, 10, 12 y 14 es
�� = 6 + 8 + 10 + 12 + 14
5=
50
5= 10
Si los números x1, x2, x3……..xn, aparecen con frecuencia f1, f2, f3……….fn, la media será,
�� = 𝑓1𝑥1 + 𝑓2𝑥2 + 𝑓3𝑥3 + ⋯ + 𝑓𝑘𝑥𝑛
𝑓1 + 𝑓2 + 𝑓3 … … … . + 𝑓𝑘=
∑ 𝑓1𝑥1𝑛𝑖=1
∑ 𝑓1𝑛𝑖=1
= ∑ 𝑓𝑥
𝑛
𝐷𝑜𝑛𝑑𝑒 𝑛 = ∑ 𝑓 , 𝑙𝑙𝑎𝑚𝑎𝑑𝑎 𝑓𝑟𝑒𝑐𝑢𝑒𝑛𝑐𝑖𝑎 𝑡𝑜𝑡𝑎𝑙
Por ejemplo si tenemos los números 4, 8, 12 y 14, que aparecen con frecuencia 2, 4, 3 y 1,
respectivamente, la media será,
�� = (2)(4) + (4)(8) + (3)(12) + (1)(14)
2 + 4 + 3 + 1=
8 + 32 + 36 + 14
10=
90
10= 9
Media ponderada. A veces se asocia a los números x1, x2, x3……..xn con ciertos factores
llamados de ponderación w1, w2, w3……..wk; cuyo caso
�� = 𝑤1𝑥1 + 𝑤2𝑥2 + 𝑤3𝑥3 + ⋯ + 𝑤𝑘𝑥𝑛
𝑤1 + 𝑤2 + 𝑤3 … … … . + 𝑤𝑘=
∑ 𝑤1𝑥1𝑛𝑖=1
∑ 𝑤1𝑛𝑖=1

44
Propiedades de la media aritmética
a) La suma algébrica de las desviaciones de un grupo de números, desde su media, es igual
a cero. Por ejemplo, la media de los números 4, 8, 12, 14 y 16, es �� = 54
5= 10.8.
𝐿𝑎𝑠 𝑑𝑒𝑠𝑣𝑖𝑎𝑐𝑖𝑜𝑛𝑒𝑠 𝑑𝑒 𝑐𝑎𝑑𝑎 𝑛ú𝑚𝑒𝑟𝑜, 𝑐𝑜𝑛 𝑟𝑒𝑠𝑝𝑒𝑐𝑡𝑜 𝑎 𝑙𝑎 𝑚𝑒𝑑𝑖𝑎 𝑠𝑜𝑛:
𝑥1 �� 𝑥1 − ��
4 10.8 -6.8
8 - 2.8
12 +1.2 = 0; ∑ (𝑥1 − ��𝑛𝑖=1 ) = 0
14 + 3.2
16 + 5.2
b) La suma de los cuadrados de las desviaciones de un grupo de números 𝑥1, desde un
número cualquiera a es un mínimo, si y solo si 𝑎 = ��.
c) Si 𝑓1 números tiene media 𝑚1, 𝐹2números tienen media 𝑚2 ………. 𝐹𝑘 números tienen
media 𝑚𝑘, la media de todos los números es,
�� = 𝐹1𝑚1 + 𝐹2𝑚2 + 𝐹3𝑚3 + ⋯ + 𝐹𝑘𝑚𝑛
𝐹1 + 𝐹2 + 𝐹3 … … … . + 𝐹𝑘
Es decir que �� es una media ponderada de todas las medias.
4.5.2. La mediana
La mediana de un grupo de números arreglados en orden de magnitud, es el valor medio (en
posición), o la aritmética de los valores centrales. Por ejemplo en las series,
4, 8, 8, 10, 12, 14, 18, 18 20, la mediana es 12
4, 6, 8, 8, 12, 13, 13, 16, la mediana es 8 +12/2 = 10
4.5.3 El modo
El modo de un grupo de números, es el valor que aparece con mayor frecuencia. Es decir que no
puede existir modo, o ‘este puede no ser único.
= -9.6
= +9.6

45
4.6 La desviación típica y otras medidas de dispersión
Como se indicó en la Sección precedente, se llama variación o dispersión de los datos, al grado
en que éstos se ubican hacia los extremos de un valor promedio. Las dos medidas más comunes
de dispersión son el rango y la variancia.
4.6.1 El rango
Es una medida muy fácil de establecer y se refiere a la diferencia entre el valor más alto y el
más bajo, dentro de un grupo de datos. Por ejemplo, en los números,
4, 6, 7, 8, 12 y 23, el rango es 23 – 4 =19
Como puede verse, el rango nos da una idea sobre el grado de variación de los datos.
4.6.2 La variancia
Llamada también varianza o cuadrado medio, es el cuadrado de la desviación típica (Sec.
4.6.3) y todas las propiedades de ésta, se aplican a aquélla. Se representa a la variancia de la
población por 𝜎2 y a la de la muestra por 𝑠2.
Estadísticamente, se define a la variancia como la suma de cuadrados de las desviaciones de un
grupo de números con respecto a su media, dividida por el número de desviaciones menos uno
(para el caso de la muestra. Para poblaciones finitas, se divide la suma de cuadrados de las
desviaciones para N (el total de observaciones). Este concepto tiene que ver con el de grados de
libertad, el cual se discute ampliamente en la Sec. 15.2.
El concepto de varianza puede ser algo difuso para el estudiante. Para aclararlo, vamos a
servirnos de un ejemplo que es familiar para todos.
En caso de la clasificación de huevos para la venta al público, encontramos que al momento de
recoger los huevos, en el criadero avícola, van a ver huevos muy grandes y otros muy pequeños,
en cuyo caso su varianza va a ser grande, Después de clasificarlos por tamaño, para ponerlos en
los cartones conocidos, los huevos serán más o menos uniformes, en cuyo caso la varianza será
pequeña. Si todos los huevos fueran idénticos, su varianza sería cero.
La fórmula de definición de la varianza está dada por,
𝜎2 = ∑ (𝑥1 − 𝜇)2𝑛
𝑖=1
𝑁=
∑ 𝑥2
𝑁, 𝑝𝑎𝑟𝑎 𝑙𝑎 𝑝𝑜𝑏𝑙𝑎𝑐𝑖ó𝑛
𝑠2 = ∑ (𝑥1 − ��)2𝑛
𝑖=1
𝑛 − 1=
∑ 𝑥2
𝑛 − 1, 𝑝𝑎𝑟𝑎 𝑙𝑎 𝑚𝑢𝑒𝑠𝑡𝑟𝑎

46
Si x1, x2, x3……..xn observaciones ocurren con frecuencia f1, f2, f3……….fk, la fórmula sería,
𝜎2 = ∑ 𝑓1(𝑥1 − 𝜇)2𝑛
𝑖=1
𝑁=
∑ 𝑓𝑥2
𝑁, 𝑝𝑎𝑟𝑎 𝑙𝑎 𝑝𝑜𝑏𝑙𝑎𝑐𝑖ó𝑛 𝑦
𝑠2 = ∑ 𝑓1(𝑥1 − ��)2𝑛
𝑖=1
𝑛 − 1=
∑ 𝑓𝑥2
𝑛 − 1, 𝑝𝑎𝑟𝑎 𝑙𝑎 𝑚𝑢𝑒𝑠𝑡𝑟𝑎
Las fórmulas de definición pueden usarse cuando el número de observaciones es pequeño. Para
el caso de análisis de datos provenientes de ensayos experimentales, en los que el número de
datos es crecido, se usa la fórmula de trabajo, que da idénticos resultados:
𝜎2 = ∑ 𝑥1
2 −(∑ 𝑥1)
2
𝑁𝑛𝑖=1
𝑁, 𝑝𝑎𝑟𝑎 𝑙𝑎 𝑝𝑜𝑏𝑙𝑎𝑐𝑖ó𝑛 𝑦
𝜎2 = ∑ 𝑥1
2 −(∑ 𝑥1)2
𝑛𝑛𝑖=1
𝑛 − 1, 𝑝𝑎𝑟𝑎 𝑙𝑎 𝑚𝑢𝑒𝑠𝑡𝑟𝑎
Como se verá en el Cap. 15, ∑ 𝑥12𝑛
𝑖=1 en lo que se llama la suma de cuadrados no corregidos, y
(∑ 𝑥1𝑛𝑖=1 )2/𝑛, el factor de corrección y n – 1, los grados de libertad. Los dos términos del
numerador constituyen la suma de cuadrados y el cociente que resulta de dividir la suma de
cuadrados por los grados de libertad, se denomina la variancia o cuadrado medio.
Para demostrar el uso de las dos fórmulas para el cálculo de la variancia –la fórmula de
definición así como la de trabajo –vamos a utilizar la muestra constituida por los siguientes
datos. Por definición, el resultado debe ser idéntico.
3, 5, 6, 2, 4, 6, 2,
La fórmula de definición para la muestra está dada por:
𝑠2 = ∑ (𝑥1 − ��)2𝑛
𝑖=1
𝑛 − 1
Peso 1: encontrar la suma de cuadrados (el numerador):
∑ 𝑋1 = 3 + 5 + 2 + 6 + 4 + 6 + 2 = 28
�� = ∑𝑥1
𝑛
𝑛
𝑖=1
= 28
7= 4

47
𝑥1 − �� -1 1 +2 -2 0 +2 -2
(𝑥1 − ��)2 1 1 4 4 0 4 4 = 18
∑(𝑥1 − ��)2 = 18
7
𝑖=1
Paso 2: para obtener la variancia, dividir la suma de cuadrados (el numerador), para los grados
de libertad (n – 1).
𝑠2 = ∑ (𝑥1 − ��)2𝑛
𝑖=1
𝑛 − 1=
18
6= 3.00
Paso 3: para calcular la desviación típica, extraemos la raíz cuadrada de la variancia:
𝑆 = √𝑆2 = √3.00 = 1.73
Si queremos usar la fórmula de trabajo, para el mismo juego de datos, procederíamos así:
Paso 1: calcular la suma de cuadrados no corregidos (el primer término del numerador):
𝑆2 = ∑ 𝑥1
2 −(∑ 𝑥1)2
𝑛𝑛 − 1
∑ 𝑥12 = 32 + 52 + 62 + 22 + 42 + 62 + 22 = 9 + 25 + 36 + 4 + 16 + 36 + 4 = 130
Paso 2: calcular el factor, de corrección (segundo término del numerador):
(∑ 𝑥1)2
𝑛=
282
7= 112
Paso 3: calcular la suma de cuadrados, corregidos:
∑ 𝑥12 −
(∑ 𝑥1)2
𝑛= 130 − 112 = 18
Paso 4: dividir la suma de cuadrados corregidos para los grados de libertad:
𝑆2 = 18
6= 3.00

48
Y la desviación típica: 𝑆 = √3.00 = 1.73
A pesar de que las dos fórmulas dan igual resultado, es preferible usar la fórmula de trabajo, la
que elimina o reduce errores por redondeo, los que se producen al usar la fórmula de definición.
4.6.3 La desviación típica.
Como se anotó en la Sección precedente, la desviación típica no es sino la raíz cuadrada de la
variancia,
𝜎 = √∑ (𝑥1 − 𝜇)2𝑛
𝑖=1
𝑁=
√∑ 𝑥12 −
(∑ 𝑥1)2
𝑁𝑁
, 𝑝𝑎𝑟𝑎 𝑙𝑎 𝑝𝑜𝑏𝑙𝑎𝑐𝑖ó𝑛 𝑦
𝑆 = √∑ (𝑥1 − ��)2𝑛
𝑖=1
𝑛 − 1=
√∑ 𝑥12 −
(∑ 𝑥1)2
𝑛𝑛 − 1
, 𝑝𝑎𝑟𝑎 𝑙𝑎 𝑚𝑢𝑒𝑠𝑡𝑟𝑎
Para demostrar la relación entre el rango y la variancia, vamos a comprar cinco grupos de datos
(poblaciones):
Grupo ∈ 𝝁 rango 𝝈𝟐 𝝈
a) 6, 6, 6 18 6 0 0 0
b) 4, 6, 8 18 6 4 2.66 1.63
c) 3, 7, 8 18 6 5 4.66 2.15
d) 2, 6, 10 18 6 8 10.66 3.26
e) 0, 1, 17 18 6 17 60.66 7.78
𝑎) 𝜎2 = (6 − 6)2 + (6 − 6)2 + (6 − 6)2
3= 0
a) 𝜎2 = (4−6)2+(6−6)2+(8−6)2
3=
8
3= 𝟐, 𝟔𝟔
b) 𝜎2 = (3−6)2+(7−6)2+(8−6)2
3=
14
3= 𝟒, 𝟔𝟔
c) 𝜎2 = (2−6)2+(6−6)2+(10−6)2
3=
32
3= 𝟏𝟎, 𝟔𝟔

49
d) 𝜎2 = (0−6)2+(1−6)2+(17−6)2
3=
182
3= 𝟔𝟎, 𝟔𝟔
Como vemos, la media de los cinco grupos es la misma, pero el rango, 𝜎2 y 𝜎 van creciendo,
conforme aumenta el grado de dispersión de los datos, alrededor de 𝜇 = 6; esta es la variación
que se pretendió ilustrar con el ejemplo de los huevos.
4.7. Cambios en las observaciones y su influencia en 𝝁 y 𝝈𝟐 .
Es de esperar que, al cambiar las observaciones, la media y la varianza cambiarán. Al respecto,
se puede establecer dos teoremas.
4.7.1. Si se suma o resta.- Un valor fijo a cada una de las observaciones, la media aumentará o
disminuirá en tal valor, pero la varianza y la desviación típica no se alteran.
En el juego de datos, 12, 13 y 14, su media es𝝁 = 𝟑𝟗
𝟑= 𝟏𝟑.
Si sumamos 10 a cada observación, los nuevos valores son 22, 23 y 24, y su media 𝝁 = 𝟑𝟗
𝟑=
𝟏𝟑, que es justamente 10 más que la media original.
Si restamos 10 de cada observación, los nuevos valores son 2, 3 y 4 y su media 𝝁 = 𝟗
𝟑= 𝟑, que
es 10 menos que la media original. La varianza, en cambio, no se altera.
𝜎2 = (12 − 13)2 + (13 − 13)2 + ( 14 − 13)2
3=
1 + 0 + 1
3=
2
3= 𝟎, 𝟔𝟔
Si añadimos 10 a cada observación,
𝜎2 = (22 − 23)2 + (23 − 23)2 + (24 − 23)2
3=
1 + 0 + 1
3=
2
3= 𝟎, 𝟔𝟔
4.7.2. Si se multiplica.- Cada observación por un valor fijo m, la nueva media es m veces la
original; la nueva varianza es 𝑚2 veces la varianza original y la nueva desviación típica es m
veces la desviación típica original.
En el ejemplo anterior, 12, 13 y 14, sabemos que 𝜇 = 13.
La varianza original es 0,66. La nueva varianza será:
𝜎2 =2
3 ; 𝜎 = √
2
3=√0,66 = 𝟎, 𝟖𝟏

50
Si multiplicamos las observaciones por m=10, los nuevos valores serán 120, 130 y 140, su
media 𝜇 = 30, que es justamente m veces, o sea 10 veces mayor que la media original 13.
𝜎2 = (120 − 130)2 + (130 − 130)2 + (140 − 130)2
3=
100 + 0 + 100
3=
200
3= 𝟔𝟔, 𝟔𝟔
Que es justamente 𝑚2 veces la varianza original.
La nueva desviación típica será:
𝜎 = √200
3=√66,66 = 𝟖, 𝟏, que es m veces la 𝜎 original.
Estos mismos principios se aplican a la división, puesto que no es sino una multiplicación
fraccionaria.
4.8. Desviación típica de las medias.
De una población de observaciones, es posible sacar sub-muestras, las que tendrán su propia
�� 𝑦 𝑠. Dichas estadísticas constituyen una población de �� 𝑦 𝑠 y, naturalmente, se hallan sujetas a
variación. Se esta que esta variación va a ser menor que la existente entre las observaciones
individuales, a las cuales representan.
Para la población,
𝝈𝝁𝟐 =
𝝈
𝑵; 𝝈𝝁 = √
𝝈𝟐
𝑵=
𝝈
√𝑵
Para la muestra,
𝑺𝒙𝟐 =
𝑺𝟐
𝒏 ; 𝑺𝒙
− = √𝑺𝟐
𝒏=
𝑺
√𝒏
Supongamos que tenemos la muestra formada por los números 4, 6, 8 y 10; para los que
𝑆2=6,66 y S= 2,58.
𝑆𝑥− =
𝑆
√𝑛=
2,58
√4=
2,58
2= 𝟏, 𝟐𝟗
O también, 𝑆𝑥− = √
𝑆2
𝑛= √
6,66
4= √1,64 = 𝟏, 𝟐𝟗

51
4.9. Coeficiente de variación, (C.V.).
Es una medida relativa de variabilidad, independiente de las unidades de medida, en contraste
con la desviación típica, la que se expresa en las mismas unidades de medida que las
observaciones cuyo grado de homogeneidad establece.
El coeficiente de variación para peso de estudiantes será el mismo si los datos se registran en
libras, kilogramos, toneladas, etc. Se puede comparar el coeficiente de variación para pesos de
caballos con el de pollos. De hecho, si queremos comparar el grado de dispersión de dos juegos
de datos que tienen diferentes medias, es más interesante comparar los coeficientes de variación
que las desviaciones típicas correspondientes. Si un tipo de vacuna da una protección de 12
meses con S= 30 días, y otro tipo de vacuna con una duración de 24 meses con S=60 días, y otro
tipo de vacuna con una duración de 24 meses con S=60 días, parecía que el segundo tipo es el
más variable. Sin embargo, si observamos que los coeficientes de variación son de 25 y 14%,
respectivamente, concluiremos que, con relación a su duración promedio, la primera vacuna es
más variable.
El coeficiente de variación es generalmente mayor en ensayos con animales que con plantas y
en el campo que en ensayos de invernadero, donde las condiciones ambientales son controladas.
El investigador usa el C.V. para evaluar resultados de diferentes experimentos que tratan sobre
el mismo factor y que han sido llevados a cabo por diferentes personas. El C.V. mide también el
grado de precisión del diseño y de la conducción del experimento. Por ejemplo, si en la siembra
de las parcelas experimentales, o en la fertilización, se emplea jornaleros, podemos estar seguros
de que el C.V. puede acercarse al doble de lo que sería, en caso de usar maquinaria o equipos
calibrados. Esto es especialmente cierto en situaciones en las que se utiliza varios jornaleros
indistintamente para efectuar cierta labor, la misma que debiera realizarse uniformemente para
todas las parcelas dentro del bloque o repetición.
Para decidir si un C.V. es grande o pequeño, es necesario tener experiencia sobre datos
similares.
Se define al C.V. como la desviación típica de la muestra, expresada como porcentaje de la
muestra.
𝑪. 𝑽. =𝑺
𝒙(𝟏𝟎𝟎)
En la Sec. 4.11 se ilustra el uso del C.V.

52
4.10. Modelo lineal aditivo.
El desdoblamiento de los componentes que forman una observación cualquiera Xi da lugar a un
modelo que, en su forma más simple, consiste de la media más un error.
𝑿𝒊 = 𝝁 + 𝝐𝒊
Se supone que los 𝜖𝑖 son al azar y provienen de una población de ∈ con media cero, es decir que
la población de 𝑋𝑖 ha ido muestreada al azar.
El tamaño del error será menor conforme aumenta el tamaño de la muestra y, en ese caso,
podemos decir que �� es un buen estimador de 𝜇.
En el caso de un diseño de bloques completos al azar (ver Sec. 16.2), el modelo lineal aditivo
está dado por:
𝑿𝒊𝒋 = 𝝁 + 𝝉𝒊 + 𝜷𝒋 + 𝝐𝒊𝒋
En el que, a la medida de una observación 𝑋𝑖𝑗, se suman los efectos de tratamientos, bloques y
del error experimental.
4.11. Intervalos de confianza.
A partir de los datos de la muestra, es posible inferir sobre la ubicación de 𝜇. Este es un proceso
inductivo, en el que se razona de la parte al todo. Puesto que �� es una variable (población de ��),
dudaríamos de afirmar que 𝜇 está en ��. Sería preferible llegar a un intervalo, quizás con �� al
centro, y afirmar que confiamos en que 𝜇 se halla dentro de ese intervalo.
En la forma más simple, esta afirmación podría escribirse así,
𝑃(3 < 𝜇 < 6) = 𝟗𝟓
Es decir, que la probabilidad de que 𝜇 se encuentre comprendida entre tres, límite inferior, y
seis, límite superior, es de 95%. En otras palabras, hay cinco probabilidades entre 100 o una
entre 20, de que esta afirmación sea equivocada.
A fin de tener mayor grado de confianza en la predicción, se utiliza la estadística t. de Student,
la que se presenta con amplitud en el Cap. 10.
𝒕 =�� − 𝝁
𝑺��

53
Fórmula en que la única incógnita es 𝜇. Para el cálculo estadístico de los intervalos de
confianza, buscamos el valor tabular de t el que es parte de la fórmula.
𝑃 = [𝑥 − (𝑡.05)(𝑆��) < 𝜇 <��+ (𝑡.05)(𝑆��)] = 𝟎, 𝟗𝟓
Donde t es el valor tabular al 95% de probabilidades, de acuerdo con el número de grados de
libertad (n-1). En la tabla V del Apéndice encontramos, por ejemplo, que el valor de t al 95%
(0,05), para seis grados de libertad, es 2,447.
Como la ilustración, supongamos que se ha probado siete muestras de una nueva variedad de
maíz y queremos predecir el rendimiento de la variedad (población), en una localidad dada. Los
siguientes son los rendimientos obtenidos:
Localidad Rendimiento
1 80
2 62
3 75
4 48
5 76
6 82
7 60
483
�� =483
7= 𝟔𝟗
𝑺𝟐 =∑𝑿𝒊
𝟐 − (∑𝑿𝒊𝟐)/𝒏
𝒏 − 𝟏
=34,273 − 233,289/7
7 − 1=
34,273 − 33,327
6
=946
6= 158; 𝑠 = √158 = 𝟏𝟐, 𝟓𝟔 𝒒𝒒

54
𝑠𝑥 : √𝑠2
𝑛= √
158
7= √22,57 = 𝟒, 𝟕𝟓
𝑠𝑥 :12,56
√7= 𝟒, 𝟕𝟓
𝐶. 𝑉. = 𝑠
��(100) =
12,56
69(100)=18%
𝑡.05 = (6𝑔. 𝑑𝑒 𝑙. ) = 𝟐, 𝟒𝟒𝟕
Intervalo de confianza, al 95%,
𝑃[�� − (𝑡.05)(𝑠𝑥 ) < 𝜇 < �� + (𝑡.05)(𝑠𝑥 )] =, 𝟗𝟓
69 − (2,447)(4,75) < 𝜇 < 69 + (2,447)(4,75)
𝟓𝟕, 𝟑𝟖 < 𝜇 < 80,62
Fig. 3.1. Ubicación de 𝝁 e intervalos de confianza.
La media de la muestra ��=69 y la desviación típica s=12,56, nos dan los mejores estimados de
los parámetros correspondientes 𝜇 𝑦 𝜎, respectivamente. Puesto que nuestro interés está en el
rendimiento de la población (variedad de maíz), cuya muestra hemos probado, se ha calculado
un intervalo y afirmamos que 𝜇 se encuentre entre 57,40 y 80,60, con una probabilidad de 95%
de estar en lo cierto.
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0,16
0,18
0,2
0 5 10 15 20

55
Para aclarar de otro modo el significado del intervalo de confianza, digamos que queremos
determinar si la utilización de un balanceado X es económica. El costo del producto es tal, que
su uso sería económico solo en el caso de que deje una ganancia de peso, en novillos de
engorde, de 1,5 libras diarias, en promedio. Si después de realizar el experimento respectivo,
encontramos que los límites de confianza al 95%, sor de 1,8 y 2,0 libras diarias, estaríamos
seguros de que conviene usar el balanceado. Pero si los límites de confianza son de 1,0 y 1,2
libras, se descartaría el empleo del producto. Habría duda, en caso de que los límites fueran 1,0
y 2,0 libras, porque puede haber una pequeña ganancia o una pequeña pérdida; en todo caso
habría riesgo al hacer la recomendación. Lo adecuado sería repetir el ensayo.

56
Capítulo 5
Cuadros de Curvas de Frecuencia –Histogramas
5.1 Cuadros de frecuencia
En el Sec. 2.6 se indicó la forma de presentar datos numéricos en formas gráficas. A veces
este sistema llama la atención del lector no especializa dado, más que si los datos tuvieran
instruidos en un cuadro numérico. De todos modos, cuando se dispones de una gran cantidad de
cifras, es útil para el investigador, tabularlas antes de confeccionar cuadros, figuras o proceder
a cualquier tipo de análisis. Por otro lado, para ciertos tipos de revistas científicas , es
importante presentar en un cuadro compacto, el resumen de los datos incluye la frecuencia de
las observaciones dentro de cada clase o categoría . A este resumen se llama justamente
cuadro de frecuencia .Los datos que se encuentran desordenados en el libro de campo
pueden, en esa forma ser manejado más fácilmente finalmente , de esos cuadros de frecuencia
se puede calcular x, s2 y s, en forma más fácil que a partir de los datos originales .
Supongamos que tenemos los pesos de los de 10 cerdos en libras.
80, 85, 80,70, 75, 80, 75, 80,70y75
Para determinar la frecuencia de clase, es útil confeccionar un cuadro de control, como el
cuadro N° 5.1
CUADRO Nº 5.1 Control de datos
Clase Control Recuento
70
75
80
85
//
///
////
/
TOTAL
2
3
4
1
10

57
Del cuadro puede apreciarse que existen dos cerdos de 70 libras, tres de 75, cuatro de 80 y6
uno de 85 libras .Es decir que del grupo desordenado de datos, se a formado un cuadro
subgrupos o clase
El número de observaciones o individuos dentro de cada clase, se llama frecuencia de clase.
El número total de observaciones de toda la clase, se llama frecuencia total. Una vez
establecidas la clase, se puede determinar la frecuencia relativa y acumulada de las
observaciones, como se indica en el cuadro Nº 5.2.
CUADRO Nº 5.2 Frecuencia relativas y acumuladas de clase:
Peso (x) Frecuencia (f) Frecuencia relativa
(f. r)
Frecuencia
acumulada
(f. a )
70
75
80
85
2
3
4
1
20%
30%
40%
10%
20%
50%
90%
100%
Total : 10 100%
La frecuencia relativa indica el porcentaje de individuos dentro de cada clase, con relación a
la frecuencia total; la frecuencia acumulada, indica el porcentaje de individuos que se
encuentran hasta un peso dado. Por ejemplo vemos que el 50% de los cerdos llegan hasta
las 75 libras el 90% hasta las 80 libras y, obviamente , el 100% de los cerdos alcanza las 85
libras
El cuadro Nº 5.3 demuestra la forma de cálculo x, s2 y s, a partir de un cuadro de frecuencia
CUADRO Nº 5.3 cálculo de x, s2 y s de un cuadro de frecuencia
X F fx (X-x) (X-x)2 f(X-x)2
70 2 140 7.0 49 98
75 3 225 2.0 4 12

58
80 4 320 3.0 9 36
85
∑
1
10
80
770
8.0
X=770/10=77,0
64
64
210
Puede llamar la atención del lector, el hecho de que ∑(X-x), no sea igual a cero como lo
establece una propiedad de la media aritmética
Esto se debe a que en el cuadro Nº 5.3, consta solamente los cuatro pesos (clase), y no los 10
pesos consideran dados. Si se resta la media de los 10 pesos, la suma de las desviaciones dará
cero.
×=770
10= 77
S2= ∑𝑓(𝑋−𝑥)
𝑛−1=210/9=23.33
S=√23.33 = 4.83
5.2 Histogramas y polígonos de frecuencia
Se llama histogramas al grafico construido a partir del cuadro de frecuencias. Consta de un
conjunto de rectángulos, cuya altura es proporcional a la frecuencia de clase
Para nuestro ejemplo la Fig. 5.1 representa el número de cerdos dentro de cada clase y el
porcentaje con respecto al total
0
20
40
60
80
100
1 2 3 4
peso
frecuencia

59
Por medio del histograma, se puede observar de un vistazo, la naturaleza de la distribución de
los datos. Si se desea compara una distribución teórica con la real, se puede graficar la una
sobre la otra, y n averiguar la razón de la diferencia.
El polígono de la frecuencia, se prepara uniendo los puntos medios de cada clase, por medio de
líneas rectas. El polígono de la frecuencia tiende a sugerir el tipo de curva de la población de la
que se extrajo la muestra.
El histograma y el polígono de la frecuencia son formas más objetivas que el cuadro de
frecuencias, para presentar datos
El siguiente ejemplo permitirá una clara compresión sobre la forma en que se construye un
histograma y el polígono de frecuencia respectivo.
Se ha registrado la altura de 100 plantas tomadas al azar, de una parcela de pasto azul.
Los datos constan el cuadro Nº 5.4
Límite de
verdaderos de la
clase
Intervalos de la
clase
(Altura en cm9
Frecuencia
(Nº plantas )
Marca de clase
59.5-62.5
>62.5-65.5
>65.5-68.5
>68.5-71.5
>71.5-74.5
60-62
63-65
66-68
69-71
72-74
5
18
42
27
8
∑=100
61
64
67
70
73
Como puede apreciarse, la menor altura encontrada fue de 60 cm.
Por redondeo aritmético, todas las plantas que midan entre 59.5 y 62.5 pertenecen al primer
intervalo. Una planta que mida 62.6 cm., entraría al segundo intervalo. En la práctica, se
obtiene los verdaderos límites de clase, sumando el límite superior de una clase, al límite
inferior de la siguiente y dividiendo para dos.
62+63/2= 62.5

60
Por conveniencia, se ha establecido que el tamaño de clase sea tres; al restar 62.5 – 3.0 = 59.5,
en cuyo caso tenemos el limite verdadero e inferior, que es el punto de partida. La marca de
clase se obtienes sumando los límites verdaderos inferior y 6 superior de una clase y dividiendo
para 2.
59.5+62.5/2=61
O sumando los límites inferior o superior del intervalo de clase y dividiendo para dos:
60+62/2=61
De todos los modos, la diferencia entre los límites verdaderos de clase así como entre las
marcas de clase deben ser tres.
Con los datos del cuadro Nº 5.4 estaríamos listos para construir el histograma y el polígono
de la frecuencia, que se vería como la Fig. 5.2
Como regla generales para la construcción de histogramas se puede mencionar:
a) Determinar el rango
b) Dividir el rango en un número conveniente de intervalo de clase del mismo tamaño.
Este número va generalmente de 5 a 20 desacuerdos a los datos.
c) Determinar el número de observaciones dentro de cada intervalo de clase.
d) A partir de estos datos, puede construirse histogramas y polígonos de frecuencia.
En el ejemplo propuesto
a) Rango:74-60=14
b) Para intervalos de clase tamaño 3.14/3=4.66≅ 5 clases.
Para terminar el número de clases, se puede también usar la relación empírica
K=1+3.3 log n
Donde k es el número de clases, n es el número de valores u observaciones y log n es el
logaritmo común (base 10), de n.
Para los 10 pesos de cerdo del cuadro Nº 5.1, tenemos
k=1+3.3 log (10)
=1+3.3 (1)=4.3≅4-5 clases
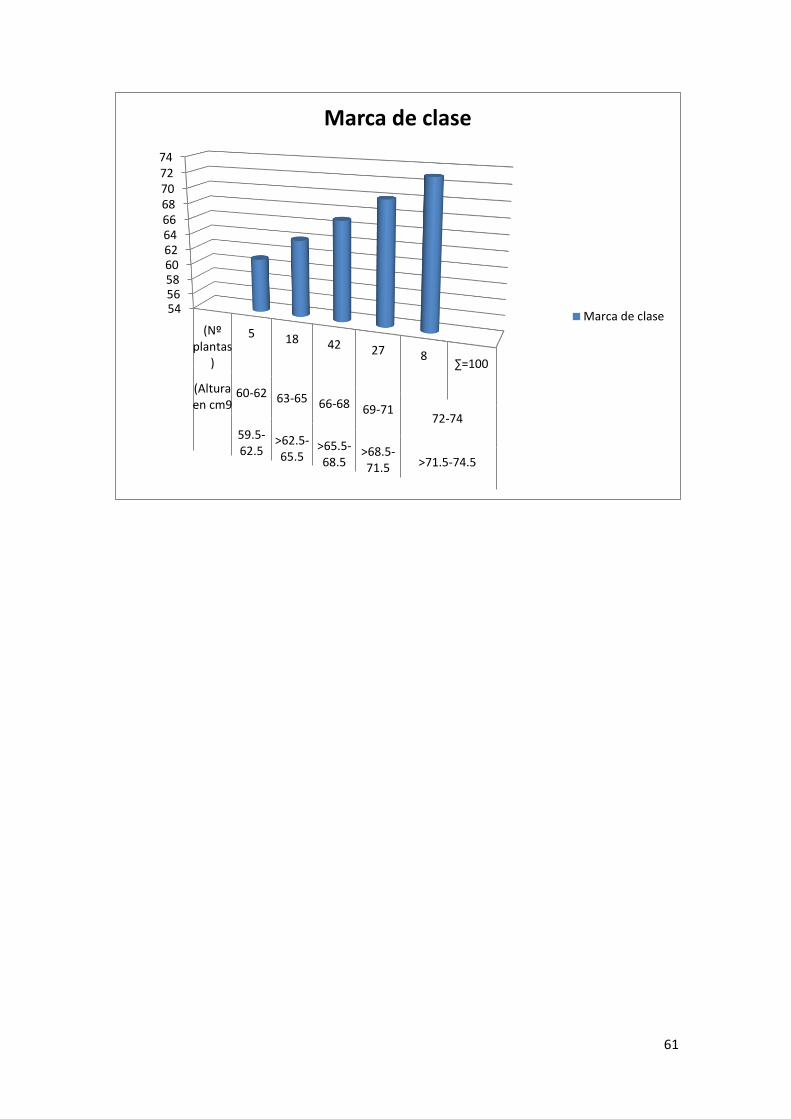
61
5456586062646668707274
(Nºplantas
)
5 18 42 27 8∑=100
(Alturaen cm9
60-62 63-65 66-68 69-7172-74
59.5-62.5
>62.5-65.5
>65.5-68.5
>68.5-71.5 >71.5-74.5
Marca de clase
Marca de clase

62
Capítulo 6
Probabilidad
Sucesos comunes o raros, son aquellos cuyas probabilidades de que ocurran son grandes o
pequeñas, respectivamente. En la vida diaria usamos todo el rango de probabilidades, de una u
otra manera. Así decimos “la muerte de X pudo deberse a que manejaba descuidadamente”,
cuando no estamos muy seguros de la causa del fallecimiento; o, “la muerte de X seguramente
se debió a que se le rompieron los frenos del automóvil”, cuando tenemos mayor seguridad
sobre la causa del accidente.
En estadística se remplazan las palabras “pudo” y “seguramente”, por números que varían de
cero a uno. Es decir, se indica con precisión qué tan probable o improbable puede ser un seceso
o evento.
El cálculo de probabilidades tiene que ver con variedades discretas, involucradas en problemas
de muestreo, como encuestas, estudio de caracteres genéricos, etc. Lógicamente cuando se habla
de muestreos, no es posible disponer de toda la población. Se ha anotado en el Cap. II que se
razona a partir de la muestra, para luego pasar inferencias sobre la población; en consecuencia,
no es posible obtener todas las predicciones correctas. En el proceso de predicción, el azar juega
un papel predominante.
Sin embargo, la Estadística dispone de métodos que permiten afirmar con qué frecuencia las
afirmaciones serán correctas, en promedio.
El uso de un número fraccionario o relación, es común en Estadística. Así, se dice que el equipo
“Nacional” tiene cinco chances contra tres (5:3), de ganar al Emelec. Esto se interpretaría como
que el equipo de casa puede ganar por un margen estrecho o que, se dos equipos jugaran varias
veces, el “Nacional” ganaría 5 / 8 o el 62% de los juegos.
5 / (5 + 3) = 5 / 8 = 0,62
Los chances de perder, o de que gane el Emelec, serian de 3 / 8 = 0,38 = 38%. Como se ve, las
probabilidades de ganar o perder, son valores que pueden estar entre 0 y 1, como se anotó al
comienzo del Capítulo.
Supongamos que un evento E, puede ocurrir en r formas de un total de N formas, igualmente
posibles. La probabilidad P de que el evento ocurra (probabilidad de éxito) está dada por:

63
𝑃 (𝐸𝑖) =𝑃
𝑁 𝑒𝑠 𝑑𝑒𝑐𝑖𝑟 𝑃(𝐸𝑖) =
𝑛ú𝑚𝑒𝑟𝑜 𝑑𝑒 é𝑥𝑖𝑡𝑜𝑠
𝑛ú𝑚𝑒𝑟𝑜 𝑡𝑜𝑡𝑎𝑙 𝑑𝑒 𝑒𝑣𝑒𝑛𝑡𝑜𝑠
El número total de eventos está dado por el total de éxitos más fracasos, llamándose fracaso a la
probabilidad de que un evento no ocurra.
La probabilidad de fracaso (q) se calcula así,
𝑃 (𝑁𝑜 𝐸𝑖) = 𝑞 = 𝑁 − 𝑝
𝑁= 1 − 𝑃 = 1 − 𝑃 (𝐸𝑖)
De lo expuesto, vemos que p + q = 1. O P (Ei) + P (No Ei) = 1
Se ha anotado antes que el cálculo de probabilidades se aplica a muchos campos de orden
práctico. Experimentos simples de orden repetitivo, como el lanzamiento de una moneda,
pueden ilustrar cómo funciona el cálculo de probabilidades. Supongamos que tiramos una
moneda dos veces o lo que es lo mismo, Tiremos dos monedas una vez. En los dos casos existen
cuatro posibilidades: CC, CS, SC, SS; la combinación SC, en el tercer cao, significaría que se
ha obtenido sello en el primer lanzamiento y cara en el segundo. Si en lugar de dos, tiramos tres
monedas, pueden producirse cualquiera de ocho resultados.
CCC, CCS, CSC, SCC, CSS, SCS, SSC, o SSS
Para experimentos de este tipo, es necesario conocer la totalidad de los resultados posibles y
hacer una lista de aquellos que son de nuestro interés. Tal sería el caso al averiguar la
probabilidad de sacar siete al tirar dos dados. Como cada dado puede dar seis resultados, las
combinaciones posibles son 36, siendo de nuestro interés, las siguientes:
(3, 4) (2, 5) (1, 6) y las reciprocas
(4,3) (5, 2) (6, 1)
Es decir que la probabilidad de sacar siete, en este caso sería = 6
36=
1
6
6.1. Sucesos independientes.
Si E1, E2, E3,…, En, corresponden a n eventos independientes, los cuales tienen probabilidades
p1, p2, p3,…, pn, la probabilidad de que dichos eventos se cumplan, será p1p2p3. . . pn, es decir
que la ocurrencia E1 no afecta a que E2 o E3 se produzcan.

64
En este caso tenemos lo que se llama la regla de la multiplicación y que se expresa así,
𝑃 ( 𝐸1, 𝐸2, 𝐸3
) = P (𝐸1) P (𝐸2) P (𝐸3
)
Cuando se produce un evento 𝐸1y este no afecta la ocurrencia de 𝐸2, la expresión seria:
𝑃 ( 𝐸1, 𝐸2) = P (𝐸1) P (𝐸2 / 𝐸1, ),
O lo que es igual, para sucesos independientes.
𝑃 ( 𝐸1, 𝐸2) = P (𝐸1) P (𝐸2)
Ejemplos:
a) Calcular la probabilidad de que, al sacar dos cartas de una baraja ordinaria de 52 cartas,
con reemplazo, la primera sea el as de diamante y la segunda el as de trébol. Si
llamamos E1 al evento “as de diamante” y E2 al evento “as de trébol”; tenemos que,
(,-1.) = ,1-52.; (, 𝐸-2.) = ,1-52.
𝑃 ( 𝐸1) = 1
52; 𝑃 ( 𝐸2) =
1
52
𝑃 ( 𝐸1, 𝐸2) = 1
52×
1
52=
1
2704
a) Si se lanza un dado dos veces, encontrar la probabilidad de sacar 2, 3 0 5 en el primer
lanzamiento y 1, 4, 5 o 6 en el segundo.
Si llamamos E1 al evento “2, 3, 5” y E2 al evento “1, 4, 5 o 6”, vemos las seis formas en que
puede caer el segundo; es decir; existen 6×6=36 combinaciones. Las tres formas en que puede
caer el segundo, para dar 3×4=12 formas en que E1 y E2 pueden ocurrir entonces,
𝑃 ( 𝐸1, 𝐸2) = P (𝐸1) P (𝐸2 ) = 3
6 ×
4
6=
12
36=
1
3
a) Si lanzamos una moneda cuatro veces, la probabilidad de obtener cuatro caras en forma
sucesiva es:
P (4 caras)= 1 2⁄ × 1 2⁄ × 1 2⁄ × 1 2⁄ = (1/2)4 = 1 16⁄

65
a) Si una urna contiene cinco bolas blancas y tres negras y otra urna tiene tres bolas
blancas y dos negras y extraemos una de cada urna, la probabilidad de que dos sean
blancas es:
P (B, B) = P (B) P (B) = 5/8 × 3/5 = 3/8
6.2. Sucesos dependientes
La probabilidad de que un seceso dependiente de otro, se llama probabilidad condicional, en la
que la probabilidad de que ocurra E2, depende de la ocurrencia de E1, así,
𝑃 ( 𝐸1, 𝐸2) = P (𝐸1) P (𝐸2 / 𝐸1, )
Ejemplos:
a) ¿Cuál es la probabilidad de sacar un as de diamante, de una baraja ordinaria de 52
cartas, después de haber sacado sin reemplazo, el as de trébol?
Si designamos al evento as de diamante E2 y al evento as de trébol E1, tendremos
𝑃 ( 𝐸1) = 1
52; 𝑃 ( 𝐸2 𝐸1) =
1
51
𝑃 ( 𝐸1, 𝐸2) = 𝑃 (𝐸1) P (𝐸2 / 𝐸1)
= 1
52×
1
51=
1
2652
Por cuanto se ha extraído una carta, sin reemplazo, quedan 51 cartas en la baraja, para la
segunda extracción.
a) En un ánfora hay 25 papeletas, cinco de las cuales son premiadas.
¿Cuál es la probabilidad de sacar dos premios al extraer las dos primeras papeletas?
𝑃 ( 𝐸1, 𝐸2) = 5
25×
4
24=
1
30
a) Una urna contiene cuatro bolas blancas y cinco negras; sacamos dos en forma sucesiva
sin reemplazo. ¿Cuál es la probabilidad de que las dos bolas sean blancas? La
probabilidad de que la primera sea blanca es 4/9. Si la primera bola fue blanca, la
probabilidad de que la segunda también lo sea es 3/8, en cuyo caso:
𝑃 ( 𝐸1, 𝐸2) = P (𝐸1) P (𝐸2)

66
= 4/9 × 3/8 = 1/6
6.3. Sucesos mutuamente excluyentes
Son aquellos en los que la ocurrencia de uno de ellos excluye la ocurrencia de otros eventos. Es
decir, que si 𝐸2 y 𝐸3 son dos eventos mutuamente excluyentes, P (𝐸1 𝐸2 ) = 0; los dos eventos
no pueden ocurrir, como en el caso del nacimiento de un hijo en que 𝐸1 seria “varón” y 𝐸2 es
“mujer”.
En estos casos se aplica la regla de la adición,
𝑃 ( 𝐸1 + 𝐸2 ) = 𝑃 (𝐸1) + P (𝐸2)
Si dos presentan el caso de que 𝐸1 o 𝐸2o los dos ocurran,
𝑃 ( 𝐸1 + 𝐸2 ) = 𝑃 (𝐸1) + P (𝐸2) − 𝑃 ( 𝐸1 𝐸2 ) ,
Como en el siguiente ejemplo,
a) Calcular la probabilidad de que la primera carta sacada de una baraja, sea jota ( 𝐸1 ) o
corazones ( 𝐸2 ),
(𝐸1 + 𝐸2 ) = 𝑃 (𝐸1) + P (𝐸2) − 𝑃 ( 𝐸1 𝐸2 )
4
52 +
13
52 −
1
52 =
16
52
En este caso estamos restando la posibilidad de que la carta sacada sea “la jota de corazones”,
que tiene una probabilidad de 1/52.
a) Encontrar la probabilidad de que una k, en 8 de trébol o el 5 de picas, aparezca en una
extracción de una de 52 barajas.
El evento puede ocurrir en una de seis formas:
4
52 +
1
52+
1
52 =
6
52=
3
26

67
¿Cuál es la probabilidad de que, en el próximo lanzamiento de un dado salgan el tres o el
cuatro? Hay seis formas en que puede caer el dado: 1, 2, 3, 4, 5, o 6. Si E1 puede ocurrir en dos
de las seis formas:
P (E1) = 1/6 + 1/6 = 2/6 = 1/3
P (N0 E1) = 1 – 1/3 = 2 /3
d) Queremos comprar tres tomates de un camión que va a descargarlos en el mercado; elegimos
uno al azar y lo calificamos como bueno (B) y lo dejamos en su lugar. Repetimos la operación
con otros dos tomates. En esta muestra de tres hemos encontrado dos buenos y uno malo (M).
¿Cuál es la probabilidad de este resultado si sabemos que, por un muestreo previo, existe 10%
de tomates en mal estado en el camión?
X (variable aleatoria) = cantidad de tomates en mal estado. Por tanto, X puede valer 0, 1, 2 o 3,
El resultado fue X= 1
La probabilidad de elegir un tomate malo en una determinada extracción es p= 0,10; la
probabilidad de que sea bueno es (1 - p) = 0,90
Hay tres formas en las que un tomate malo pueda salir en la muestra de tres.
M, B, B
B, M, B
B, B, M
Formas que son mutuamente excluyentes, en cuyo caso sumamos la probabilidad total de cada
extracción. Dentro de cada extracción, se trata de eventos independientes, porque el resultado de
la primera extracción no afecta a la segunda ni a la tercera. Por tanto, tenemos:
P (M, B, B)= P (1 - p) (1 - p) = (0,1) (0,9) (0,9) = 0,081
P (B, M, B)=( 1 – p ) (p) ( 1 – p ) = (0,9)(0,1)(0,9) = 0,081
P (B, B, M)= )=( 1 – p ) ( 1 – p ) =(0,9)(0,9)(0,1) = 0,081
P(X = 1) = P (M, B, B) + P (B, M, B) + P (B, B, M) = = 0,243
P(X = 1) = 0,243= ¼, la probabilidad de sacar en una extracción cualquiera, dos tomates Buenos
y uno malo.

68
6.4. Análisis combinatorio
Para resolver probabilidades de eventos complejos, como algunos juegos de azar, es
conveniente disponer de fórmulas que ahorran tiempo y trabajo, el que, de otro modo, sería
difícil y tedioso.
El análisis combinatorio utiliza dichas formulas, como se indica en esta Sección. Supongamos
que deseamos aplicar tres niveles de nitrógeno, tres de fosforo y tres de potasio, todas las
combinaciones posibles serian:
Con un total de 27 tratamientos o niveles. Se identifica a la dosis cero como niveles; tal es el
caso de No. Po y K0.
6.5. Factorial N.
Se define a N! (N factorial), en la siguiente forma:
N! = N (N – 1) (N – 2) (N – 3)… 1
Por ejemplo, 4! = 4 × 3 × 2 × 1 = 24
7! 3! = (7 × 6 × 5 × 4 × 3 × 2 × 1) (3 × 2 × 1) = 30.240
7! 3! = (7 × 6 × 5 × 4 × 3 × 2 × 1) (3 × 2 × 1) = 1.200
4! 4 × 3 × 2 × 1
0! = 1
Se puede simplificar valores iguales del numerador y del denominador, para ahorrar trabajo.
K0 K0 K0
P0 K1 P0 K1 P0 K1
K2 K2 K2
K0 K0 K0
N0 P1 K1 N1 P1 K1 N2 P1 K1
K2 K2 K2
K0 K0 K0
P2 K1 P2 K1 P2 K1
K2 K2 K2

69
6.6. Permutaciones.
La permutación es una selección de N objetos, tomados r a la vez, respetando el orden de
arreglo,
N P r = (N – 1) (N – 2)… (N – r + 1) = 𝑁!
(𝑁−𝑟)!
Al símbolo N P r, se llama la permutación de N objetos tomados r a la vez. Así, hay N formas
de seleccionar el objeto para el primer lugar; luego, N – 1 formas para el segundo lugar, hasta
llegar a la r-ésima forma, para el último lugar, para el que quedan N – r + 1 formas posibles de
seleccionar el objeto dado.
Supongamos que se quiere formar todos los grupos posibles de dos letras cada uno, a partir de
las letras a, b, c y d, sin que ninguna de ellas se repite. Podemos imaginar que las letras se hallan
pegadas en dados y que se juntaran dos dados a la vez. Aplicando la formula respectiva
tenemos,
4 P 2 = 𝑁 ¡
( 𝑁−𝑟)! =
4 ¡
(4−2)!=
4!
2! =
4 ×3×2
2
= 12 grupos, que estarían formados así:
Ab, ba, ac, ca, ad, da, bc, cb, bd, db, dc, cd
Ejemplos:
𝑎) 𝐸𝑛 𝑐𝑢𝑎𝑛𝑡𝑎𝑠 𝑓𝑜𝑟𝑚𝑎𝑠 𝑝𝑢𝑒𝑑𝑒 𝑎𝑐𝑜𝑚𝑜𝑑𝑎𝑟𝑠𝑒 𝑎 8 𝑝𝑒𝑟𝑠𝑜𝑛𝑎𝑠, 𝑠𝑖 𝑒𝑥𝑖𝑠𝑡𝑒𝑛 3 𝑎𝑠𝑖𝑒𝑛𝑡𝑜𝑠 𝑑𝑖𝑠𝑝𝑜𝑛𝑖𝑏𝑙𝑒𝑠?
8P3=8!
(8−3)!=
8×7×6×5×4×3×2
5×4×3×2= 336 𝑓𝑜𝑟𝑚𝑎𝑠
b) Si en una carrera de caballos, participan siete, en cuantas formas pueden tres de ellos terminar
primero, segundo y tercero ?
7P3 = 7!
(7−3)!=
7!
4!= 7x 6 x 5 = 210
c) La facultad ha contratado a seis nuevos jornaleros para Rumi pamba. El administrador decide
ubicar a tres de ellos en tres lugares claves. ¿De cuántas formas puede conseguirse este objeto?
O sea, ¿cuántas permutaciones de seis hombres existen, tomados de tres en tres?
6P3= 6!
(6−3)!=
6!
3!= 6 x 5 x4 = 120
d) Evaluar: 1) 5p5, 2) 8P3, 3) 10P8

70
1) 5P5=5!
(5−5)!= 120
2) 8 P3=8!
(8−3)!= 336
3) 10 P 8=10!
(10−8)!= 181. 320
6.7 Combinaciones.
La combinación es una selección de r de los N objetos u observaciones, sin tomar en cuenta el
orden de arreglo.
N C r = 𝑁(𝑁−1)(𝑁−2)….(𝑁−𝑟+1)
𝑟(𝑟−1)….1=
𝑁!
𝑟!(𝑁−𝑟)!
En el caso de las letras a, b, c, d, todas las combinaciones posibles tomadas de dos en dos
estarían dadas por,
4 C 2=𝑁!
𝑟!(𝑁−𝑟)!=
4!
2!(4−2)!
=4!
2!2!=
4 𝑥 3 𝑥 2
2 𝑥 2=
24
4= 6
Y serían: ab, ac, ad, bc, bd, cd. Nótese que ab es la misma combinación que va, pero no la
misma permutación.
Ejemplos:
a) En cuantas formas puede formarse un jurado de doce hombres y mujeres, de un total de
18 personas?
18 C 12= 18!
12!(18−12)!=
18!
12!(6)!=
18 𝑥 17 𝑥 16 𝑥 15 𝑥 14 𝑥 13
6 𝑥 5 𝑥 4 𝑥 3 𝑥 2= 18.564 𝑓𝑜𝑟𝑚𝑎𝑠
Nótese que se ha simplificado 12! del denominador con la cifra equivalente del numerador.
b) Evaluar: 1) 8 C 8, 2) 4 C 2, 3) 7 C 3
1) 8 C 8= 8!
8!(8−8)!=
8!
8!0!= 1 , 𝑝𝑜𝑟 𝑐𝑢𝑎𝑛𝑡𝑜 0! = 1
2) 4 C 2=4!
2!(4−2)!=
4 𝑥 3 𝑥 2
2 𝑥 2=6

71
3) 7 C 3=7!
3!(7−3)!=
7!
3!4!=
7 𝑥 6 𝑥 5
3 𝑥 2= 35

72
Capítulo 7
Distribuciones Teóricas de Frecuencias
En el capítulo cinco se trató sobre cuadros y polígonos de frecuencia. En el presente capitulo se
presenta las distribuciones de frecuencia y sus propiedades.
La distribución de frecuencia de una muestra sugiere el tipo de distribución de la población a la
que aquella representa. Si el tamaño de la muestra es suficientemente grande, es de esperar que
la distribución de frecuencias de la muestra sea una buena aproximación de la distribución de
frecuencias de la población. Por ejemplo, si en una encuesta sobre preferencias de consumo de
una población de diez mil habitantes, se entrevista a 50 personas, no se puede esperar que las 2
distribuciones de frecuencias sean similares; si, en cambio, el tamaño de la muestra es de 3000
individuos las distribuciones de frecuencias, serán similares:
El cálculo de probabilidades en relación con los juegos de azar, ofrece ejemplos de
distribuciones de frecuencias teóricas, para ciertas variables discretas. Tal es el caso de las Figs.
7.1 y 7.2.
7.1 La distribución binomial.
En un evento binomial – lance de una moneda, posibilidad de que un hijo sea varón o mujer–
existen solo dos alternativas en cuyo caso solo una de ellas puede tener lugar: cara o sello; y
varón o mujer, en los dos ejemplos propuestos.
En estadística, estos eventos se conocen como ‘éxito’’ o ‘’fracaso’’, tal como vimos en el cap.
6. El procedimiento usual consiste en observar un número dado de eventos y registrar la
frecuencia de éxitos.
El muestreo de una distribución binomial es similar al sacar papeles numerados de un ánfora,
con remplazo. Es decir que la probabilidad asociada con un evento, como el de sacar un ficha
roja de una bolsa, es constante para cada extracción en cuyo caso se dice que los eventos sean
independientes.
Si p es la probabilidad de que un suceso tenga lugar en una sola prueba (probabilidad de éxito) y
q= 1- p, la probabilidad de que no suceda, (probabilidad de fracaso) la probabilidad de que el
evento tenga lugar exactamente X veces en N pruebas (O sea X éxitos y N- X fracasos) está
dada por,

73
P(X)=N C X 𝑝𝑥𝑞𝑁−𝑋=𝑁!
𝑋!(𝑁−𝑋)!𝑝𝑥𝑞𝑁−𝑋
Por ejemplo, preguntamos, ¿cuál es la probabilidad de que en una familia con seis hijos, habrá
seis mujeres? O, ¿lo que es igual, seis varones?
Se supone que la probabilidad de varón o mujer antes del nacimiento es ½ y que se trata de
eventos independientes, o sea que la probabilidad de varón o mujer permanece constante para
cada nacimiento la probabilidad es entonces,
6 C 6(1/2)6(1/2)0=6!
6!0!(1/2)0 (1/2)0 = 0.0156 = 1/64
Es decir que la probabilidad es de que una familia tenga 6 hijos del mismo sexo es muy baja; en
otras palabras, de una a dos familias de cada 100 que tienen 6 hijos podrán contar con 6 hijos
del mismo sexo.
Ejemplo: La probabilidad de que los padres con ojos azul-cafés tengan un hijo con ojos azules
es de ¼ (carácter recesivo). Si existen 6 hijos en la familia, ¿cuál es la probabilidad de que por
lo menos la mitad de ellos tenga ojos azules? Ya sabemos que se trata de eventos
independientes, para los que la probabilidad de éxito, en un solo intento es de ¼ y la
probabilidad de fracaso es de ¾; entonces N= 6 Y p = ¼.
Es necesario calcular P (3), P (4), P (5), y P (6), y sumar las probabilidades correspondientes,
debido a que ellas equivalen a las maneras mutuamente excluyentes en que pueden ocurrir el
evento.
P (3)=6!
3!3!= (
1
4)3(3/4)3=
540
4096
P (4)=6!
4!2!= (
1
4)4(3/4)2 =
135
4096
P (5)=6!
5! 1!= (
1
4)5(3/4)1=
18
4096
P (6)=6!
6!0!= (
1
4)6(3/4)0=
1
4096
La probabilidad de obtener los éxitos deseados, se consigue sumando las probabilidades
individuales, lo que se representaría por p (X)≥ 3.
p (X≥ 3)= 694
4096= 0.169

74
Lo cual demuestra, como en el caso anterior, la baja probabilidad de que este tipo de familia
tenga tantos hijos de ojos azules.
Ejemplo: La probabilidad de sacra exactamente dos caras en seis lanzamientos de una moneda:
6 C 2 (1
2)
2 (
1
2)
6−2=
6!
2!4!= (
1
2)
2 (
1
2)
4=
15
64
Ejemplo: La probabilidad de que al lanzar una moneda tres veces, aparezcan a) tres caras, b) dos
caras un sello, c) tres sellos.
a) P(tres caras)=3 C 3(1
2)3(
1
2)0=
3!
3! 0! (
1
2)3 (
1
2)0 = 1(
1
8) 1 =
1
8
b) P(2caras, 1 sello)= 3 C 2(1
2)
2(
1
2)
1=
3!
2! 1!(
1
2)
2(
1
2)
1= 3(
1
4) (
1
2) =
3
8
c) P (1 cara, 2 sellos) = por simetría con b)= 3/8
d) P ( 3 sellos) = 3 C 0(1
2)0(
1
2)3= por simetría con a)= 1/8
Ejemplo: Una agencia de publicidad sostiene que 25% de los estudiantes que fuman, fuman
Winston. Si obtenemos una muestra al azar de cuatro estudiantes que fuman y aquella
afirmación es cierta, cual es la probabilidad de que por lo menos uno de ellos fume tal marca?
Suponiendo que el aserto es verdadero, la distribución del número de estudiantes que fuman
Winston en una muestra de cuatro seria:
P(x)= 4!
𝑋!(4−𝑋)! (
1
4)𝑥(
3
4)4−𝑥
Donde X= 0, 1, 2, 3,4
La probabilidad de encontrar por lo menos uno está dada por:
P(X ≥ 1)= P (1) + P (2) + P (3) +P (4)
P (1)=4!
1!(4−1)! (
1
4) (
3
4)3 = 4 (
1
4) (
27
64) = 108/256
P (2) =4!
2! 2! (
1
4)2(
3
4)2 = 6 (
1
16) (
9
16) =
54
256
P (3) =4!
2! 2! (
1
4)3(
3
4)1 = 4 (
1
64) (
3
4) = 12/256

75
P (4) =4!
2! 2! (
1
4)4(
3
4)0 = 1 (
1
256) 1 = 1/256
Entonces, P(X ≥ 1)= P (1) + P (2) + P (3) +P (4)
=108/256+54/256+12/256+1/256= 175/256
O, lo que es igual,
P(X ≥ 1)= 1- p (0)=1- [(4!
0!4!(
1
4)0(
3
4)4]
= 1 - 81/256 = 175/ 256
Ejemplo: La probabilidad de que un estudiante nuevo apruebe el curso es de 0,4; determinar la
probabilidad de que, de 5 estudiantes nuevos, a) ninguno, b) uno y, c) por lo menos uno apruebe
el curso.
a) P ( Ninguno) = 5!
0!5!(0.4)0(0.6)5= 1 * 1( 0.07776) =0.08
b) P (uno) = 5!
1!4!(0.4)1(0.6)4= (5) (0,4) (0,1296)= 0.26
c) P (A! menos uno)= 1 – P ( Ninguno)
= 1 – 0.08 = 0.92
La distribución de frecuencias para un lanzamiento de dos datos, es como sigue:

76
Para esta distribución binomial, vemos que la probabilidad de que los eventos mutuamente
excluyentes 2, 3, 4, 5 ,6 y 7 tengan lugar, va aumentando de 1/36 a 2/36…………………….
6/36, respectivamente. En igual forma, disminuye para los eventos 8, 9, 10 y 12. Los
numeradores corresponden a los coeficientes de la expansión binomial, tal como nos indica en
la próxima sección. La distribución de probabilidades para 5 lanzamientos de una moneda, está
indicada en el cuadro 7.1.
CUADRO 7.1 Distribución de probabilidades para el binomial p= ½, N= 5.
Caras (X) 0 1 2 3 4 5
P (X) 1/32 5/32 10/32 10/32 5/32 1/32
Para esta distribución binomial vemos que la probabilidad de que tengan lugar los eventos
mutuamente excluyentes (cuya suma es igual a 32/32 =1), 0, 1 y 2 caras, va aumentando de 1/32
a 5/32 y 10/32; en igual forma, disminuye para los eventos 3, 4 y 5, de 10/ 32 a 5/32 y 1/32. Los
numeradores, como en el caso anterior, corresponden a los coeficientes de la expansión
binomial. La fig. 7.2 muestra los mismos resultados del Cuadro7.1
5
36
2 3 4 5 6 7 8 9 10 11 12
1
36
2
36
3
36
4
36
6
36
5
36
4
36
3
36
2
36
1
36

77
Fig. 7.2 Probabilidad de obtener caras para el binomial p= 1/2, N= 5
7.1.1 La expansión binomial.
La distribución de probabilidades se llama distribución binomial, puesto que para X= 0, 1, 2,
3,…, N, hay valores sucesivos correspondientes en la expansión binomial:
(𝑝 + 𝑞)𝑁 = 𝑝𝑁 + 𝑁𝐶 1 𝑝𝑁−1𝑞 + 𝑁𝐶 2𝑝𝑁−2𝑞2 + ⋯ + 𝑞𝑁
Donde 1, NC1, NC2, se llaman coeficientes binomiales. Por ejemplo,
(𝑝 + 𝑞)5 = 𝑝5 + 5 𝑝4𝑞 + 10 𝑝3𝑞2 + 10 𝑝2𝑞3 + 5 𝑝1𝑞4 + 𝑞5
Los coeficientes binomiales están dados por el Triángulo de Pascal:
También se puede obtener los coeficientes binomiales en forma directa: se multiplica el
coeficiente por el exponente de p del término involucrado y se divide para el número de orden
del mismo término. Se inicia en esta forma desde el primer término y se hace el mismo cálculo
para los términos siguientes:
(𝑝 + 𝑞)5 = 1𝑝5 + 5 𝑝4𝑞 + 10 𝑝3𝑞2 + 10 𝑝2𝑞3 + 5 𝑝1𝑞4 + 1 𝑞5
1𝑋 5
1= 5;
5 𝑋 4
2= 10;
10 𝑋 3
3= 10;
10 𝑋 2
4= 5;
5 𝑋 1
5= 1

78
7.1.2 Algunas propiedades de la distribución binomial.
Mediante el uso de algunos procedimientos algebraicos, es posible hacer cálculos para la
distribución binomial. Esos cálculos dan lugar a fórmulas para la media, la variancia y la
derivación típica, que pueden emplearse en todos los problemas de tipo binomial. Por salir del
alcance de este texto, no se describen los procedimientos algebraicos. Las tres propiedades más
importantes de la distribución binomial son:
μ = N p
σ2= N p q
σ= √𝑁 𝑝 𝑞
Donde N es el número de observaciones, p la probabilidad de éxito y q la probabilidad de
fracaso de un evento.
Ejemplo: Si la probabilidad de que las tuercas producidas por una máquina sean defectuosas es
0.1, encontrar a) la media, b) la desviación típica para la distribución de tuercas defectuosas, en
un total de 400.
a) ẋ= N p =400(0.1) =40, es decir que podemos esperar que existan 40 tuercas
defectuosas;
b) σ2 = 𝑁𝑝𝑞 = 400(0.1)(0.9) = 36; σ = √36 = 6
7.2 La distribución normal.
La distribución binomial de la Sec. 7.1 es la distribución teórica de frecuencias más usadas para
variables discretas.
En esta Sección se estudiará la distribución de frecuencias para casos de variables continuas,
como el caso de altura, peso o ingresos de individuos. La variable pasa sin interrupción de un
individuo al siguiente, una variable continua, sin límite con respecto al número de individuos
con diferentes medidas.
Muchos fenómenos biológicos proporcionan datos que se distribuyen en forma suficiente
“normal”, como para que esta distribución sea la base de la teoría estadística empleada por el
investigador. El gráfico de esta distribución, la curva normal, llamada también curva de Laplace
o de Gauss, tiene forma acampanada, siendo el tamaño de σ2, el que determina que tan aplanada
o alargada sea la curva. La curva de la Fig. 7.3 es la gráfica de una distribución normal. Igual es
el caso de la Fig.2.1, sobre cociente intelectual y de la Fig. 2.2 sobre peso corporal.

79
1 Fig. 7.3 Distribución normal típica
La localización y forma de la curva normal está dado por los valores de μ y σ. El valor de μ
establece el centro de la curva, en forma simétrica es decir que 50% de las observaciones se
hallan a la derecha de μ y 50% a su izquierda; en tanto que el valor de σ determina el grado de
dispersión de los datos. En la Fig. 7.4 podemos apreciar tres curvas normales, todas con igual
media, pero con diferente variancia (ver Sec. 4.6.3).
La curva A es la que menor grado de dispersión presenta; la curva B es intermedia y la curva C
tiene la mayor variancia. En todas las curvas, el área total, o sea el total de las observaciones o
individuos, es equivalente a 100% o uno.
2Fig. 7.4 Tres curvas normales con igual μ y diferente σ
Debido a la propiedad de simetría de la curva normal, como se ilustra en la Fig. 7.3, en el
intervalo de μ hasta μ + σ, se encuentran aproximadamente, 34% de las observaciones (valor
obtenido por cálculo superior). Mediante integración, se puede conocer la frecuencia relativa de
las observaciones, pero siendo este un trabajo largo y tedioso, es más conveniente usar tablas
que existen para el objeto, las que dan los valores de las ordenadas (altura de la curva) o las
áreas bajo la curva. En la tabla N°III del Apéndice, puede verse los valores desde cero hasta
Y
F
μ -
3σ
μ -
2σ
μ -
1σ
μ
μ+
1 σ

80
zeta, que estarían en el eje de las abscisas. En la columna de la izquierda se lee los valores de z,
desde 0.0 hasta 3.9, es decir para unidades y décimas; en la fila horizontal superior, se lee esos
valores para las centésimas, por ejemplo, para z= 2.5, leemos (un valor de área bajo la curva,
que significa porcentaje de individuos u observaciones del total que es 100%), en la siguiente
forma: columna izquierda, 2.5, seguimos en forma horizontal, hasta interceptar el valor
correspondiente a la columna 8= 0.4951. si el valor del área bajo toda la curva equivale a 100%
o uno, esto quiere decir que entre z=0 y z=2.58, se halla 49.51% del total de los individuos u
observaciones.
Puesto que en el eje de las X se tiene los valores de z, desde μ (z=0), hasta el extremo de la
curva μ+3σ (z=3.99), el valor derecho inferior de la Tabla N° III del Apéndice, muestra la cifra
0.5000, que corresponde justamente a la mitad del área total bajo la curva. Cuando existen
valores de z negativos, por la propiedad de simetría de la curva, los valores tabulares son los
mismos, pero sabemos que corresponden al lado izquierdo de la curva.
Las tablas de z están hechas para la llamada curva típica, con media cero y desviación típica y
variancia uno, pero pueden usarse con cualquier distribución normal si se aplica los teoremas
4.7.1 y 4.7.2, cuya generalización para la observación transformada, constituye la estadística z,
que expresa el valor de la variable X, en términos de unidades típicas; se dice entonces que z es
normalmente distribuida con media cero y variancia y desviación típica uno, y es independiente
de las unidades usadas (libras, centímetros, etc.).
z= 𝑋− μ
σ
Ejemplo: Si la distribución de las observaciones de una población es normal, con media= 50 y
desviación típica=10, al restar 50 de cada observación, la media de (X – 50) será igual a 10
(Teorema 4.7.1). Ahora, si cada valor (X-50) se divide por 10, la nueva media será 0/10 = 0 y la
nueva desviación típica será 10/10 = 1 (Teorema 4.7.2), de modo que la observación
transformada z= (X−50)
10, viene a ser la correspondiente a la fórmula de z, que, como sabemos es
igual a z= 𝑋− μ
σ , o sea que el valor de z de la observación 60 será: z=
60−50
10 = 1
El valor de z de la observación 45 será: z= 45−50
10 = -0.5, que es otra forma de decir que 60 es
una desviación típica sobre la media 50 y que 45 es media desviación típica bajo la media 50.
En la curva normal típica de la Fig. 7.4, se indica las áreas incluidas entre z= -1; y+1; z=-2; y
z=-3y + 3, que corresponden al 68,27%, 95,45% y 99,73%, respectivamente, del área total que
es igual a 100% o uno. De la Fig. 7.4 se desprende que el área bajo la curva termina
prácticamente en -3σ y +3σ. Sin embargo, la ecuación de la curva va de -∞ a + ∞.

81
3 Fig. 7.5 Áreas bajo la curva normal
68.27
95.45
99.73
Para encontrar el área o porcentaje bajo la curva normal (zona sombreada), debe usarse la Tabla
N° III del Apéndice, en la siguiente forma:
0 1.6
-3 -2 -1 0 1 2 3

82
a) Z= 1.6
Área entre 0 y 1.6= 0.4452
b) Z= -0.97
Área entre 0 y 0.97=0.3340
c) 𝑧1= -0.30 y 𝑧2= 1.88
Área entre 0 y -0.30= 0.1179 + área entre 0 y 1.88= 0.4699
0.5878
-.97 0
-.30 0 1.88

83
d) 𝑧1= 1.12 y 𝑧2=2,46
Área entre 0 y 2.46= 0.4931- área entre 0 y 1.12= 0.3686
0.1245
e) Z= < -2.08
1
2 de curva = 0.5000 -área entre 0 y -2.08=
0.4812
0.0188
f) z=>-2.35
½ curva= 0.5000
+ Área entre 0 y -2.35= 0.4906/0.9906
-2.08 0
0 1.12 2.46

84
g) z1 = < -0.77 y z2 => 0.23
1- (área entre 0 y -0.77 + área entre 0 y 0.23)
1- (0.2794 + 0.0910) = 1 - 0.3704 = 0.6296
O también:
0.5000 – área entre 0 y -0.77
+ 0.5000 – área entre 0 y 0.23
90 -
Ejemplo:
La media en un examen de Estadística fue 68/10; s = 12. Sólo el 10% de notas superiores
recibirán A. ¿Cuál es la nota mínima para obtener A?
Área de 0 a z = 0.3997 = 0.4000 = 1.28
En el cuerpo de la tabla de z podemos ver que la cifra más próxima a 0.4000, es 0.3997.

85
z = (x − xˉ)/s; 1.28 (x − 68)/12
(1.28)(12)=x-68
X= (1.28) (12)+68
X=83.36
La nota mínima para obtener A es 83.4
Ejemplo: La estatura promedio de 300 estudiantes es de 160 cm; la desviación típica, 18 cm.
Suponiendo que la estatura es normalmente distribuida, averiguar cuántos estudiantes miden, a)
entre 140 y 170 cm. Y b) más de 180 cm.
a) 140 en unidades típicas= (140 − 160)/18 = −1.11
170 en unidades típicas= (170 − 160)/18 = 0.55
-1.11=0.3665
0.55=0.2088/0.5753
Si 300 estudiantes constituyen 100% de la población, 57%, es decir 171 individuos,
miden entre 140 y 170 cm.
b) 180 en unidades típicas= (180 − 160)/18 = 1.11
1.11 = 0.3665
0.5000
-0.3665/0.1335
De 300 estudiantes, 13.35%, es decir 40, miden más de 180 cm.
Ejemplo: El diámetro promedio de una muestra de 100 pernos producidos por una máquina es
de 0.42 cm; la desviación típica es de 0.08 cm. La tolerancia máxima en diámetro es de 0.48 y
0.36 cm; fuera de estos límites, los pernos son considerados defectuosos. Determinar el
porcentaje de pernos defectuosos producidos por la máquina.

86
0.48 en unidades típicas= (0.48 − 0.42 = 0.75)/0.08
0.36 en unidades típicas=(0.36 − 0.42)/0.08 = −0.75
0.75=0.2734
0.2734x2=0.5468=55%
100-55=45%
Es decir que 55% de los pernos se ajustan a la tolerancia permitida; la diferencia a 100%, el
total de la muestra, se considera defectuosa.

87
Capítulo 8
Pruebas de Hipótesis
Se define a la hipótesis como una teoría tentativa o una suposición adoptada provisionalmente
para explicar ciertos hechos y guiar la investigación de otros.
Toda comprobación de hipótesis, incluye los siguientes aspectos:
a) Enunciación de hipótesis.
b) Deducción de alguna o algunas teorías.
c) La verificación de estas teorías.
d) Conclusiones en base a los resultados experimentales.
Cuando una persona se halla investigando sobre la naturaleza de un fenómeno cualquiera, le
obligan a proponer una teoría. Para que esa teoría tenga valor debe estar de acuerdo con lo que
en realidad sucede en la práctica, ella debe ser revisada o descartada.
Podemos suponer que la teoría puede ser expresada como una hipótesis estadística, es decir que
cuando se plantea una hipótesis existe más de una alternativa.
Supongamos que la vida promedio e cierta marca de baterías X, es de 30 meses, con una
desviación típica de cuatro meses. Si decidimos probar una nueva marca Y, cuyo precio es más
bajo, vamos a esperar que la duración promedio de la segunda marca sea, por lo menos, igual a
la que hemos venido usando; de otro modo no valdría la pena cambiar la marca conocida. Si se
encuentra que la vida útil de Y es 24 meses, con una desviación típica de cinco meses, podemos
plantear el problema de la siguiente forma:
HO: μ=30
H1: μ <30
Se plantea H1 en la manera indicada, puesto que si la calidad de Y no es igual a la de X,
entonces la marca Y sería inferior a X.
8.1 La hipótesis nula, HO.
Es preferible plantear la hipótesis en el sentido de que las marcas son iguales en calidad, en
lugar de la hipótesis de que son diferentes. Así se establece la hipótesis,
HO: μ1 – μ2 = 0, o lo que es igual, HO: μ1 – μ2

88
A este tipo de hipótesis se le conoce como hipótesis nula, debido a que supone que no existe
diferencia entre tratamientos.
8.2 Prueba de hipótesis y nivel de significación.
Al momento de plantear la hipótesis nula, se escoge el nivel de probabilidad o nivel de
significación, se concluye que la hipótesis nula es falsa y la hipótesis alternativa verdadera. Si se
escoge el nivel de significación de 0.05, se rechaza la hipótesis nula afirmando que existen
diferencias significativas al 5%. Los procedimientos que nos permiten aceptar o rechazar
hipótesis se llaman pruebas de hipótesis o pruebas de significación.
Por ejemplo, antes de lanzar una moneda, suponemos que la moneda no está “cargada” y
esperamos 50% de sellos y 50% de caras. Si al lanzar esa moneda 100 veces, registramos 75
caras y 25 sellos, rechazaríamos la hipótesis de que la moneda es correcta.
Fig. 8.1 Zonas de aceptación y rechazo de H0´ al 1% de significación.
Prueba de dos “colas”.
De z estará comprendido entre -2.58 y +2.58, fuera de las zonas críticas o de rechazo de H0.
El valor de 2.58 viene dado por la resta de 0.5 (mitad de la curva) de 0.005 (mitad de 0.01, que
es el nivel de probabilidad escogido):
0.5000
- 0.0050
9 9
ACEPTACIÓN
DE Ho.
005 005
Z = -2.58 Z = 0 Z = +2.58
Zona Crítica

89
0.4950 = 2.58
El valor de 0.4950 consta en el cuerpo de la Tabla de z; buscando hacia la columna de la
izquierda, entonces el valor 2.5 y hacia arriba, en la fila superior de la Tabla, vemos .08, con lo
que el valor correspondiente de z es 2.58.
Si el nivel escogido hubiera sido el 5%, se reemplaza 2.58 por 1.96:
0.5000
- 0.0250
0.4750 = 1.96
La significación al 5% se indica poniendo un asterisco junto al valor calculado y dos asteriscos
cuando la significación es al 1% en este último caso se habla de un valor altamente
significativo. La no significación se denota por NS.
8.3 Errores tipo I y tipo II.
Si rechazamos una hipótesis que debiera ser aceptada, hipótesis verdadera, cometemos un error
tipo I. Si aceptamos una hipótesis falsa (que debiera ser rechazada), se comete un error tipo II.
La única forma de reducir los dos tipos de error, es aumentando el tamaño de la muestra, es
decir, incrementando el número de observaciones.
El error tipo I se comete siempre que, siendo la hipótesis de trabajo verdadera, por error de
muestreo, el valor utilizado en la decisión queda comprendido en la zona de rechazo (Fig. 8.1).
Se designa con la letra griega ∞, la probabilidad de cometer este tipo de error.
Así mismo, se comete el error tipo II, siempre que, siendo falsa la hipótesis de trabajo, por error
de muestreo, el valor utilizado en la decisión queda comprendido en la zona de aceptación (Fig.
8.1). La probabilidad de cometer este tipo de error, se designa con la letra griega β.
Seguidamente, se presenta un resumen de las características de los dos tipos de error.
CUADRO N° 8.1 Tipos de error I y II
Decisión SITUACIÓN VERDADERA
La H0 es cierta La H0 es
falsa
Símbolo

90
8.4 Potencia de la prueba.
Está estrechamente relacionada con la probabilidad de cometer un error tipo II. Es decir se
refiere a la probabilidad de aceptar la hipótesis alternativa cuando la hipótesis nula es verdadera.
La potencia de la prueba se denota 1 – β.
8.5 Pruebas de una y de dos colas.
En la Sec. 8.2 se ha presentado valores de z a la derecha e izquierda de µ. Es decir que, los
valores pueden hallarse en los dos extremos o “colas” de la distribución y por esto a prueba se
llama de “dos colas”. A veces podemos tener interés únicamente en valores a la derecha de µ,
como sería el caso de probar que la aplicación de un fertilizante da mayor rendimiento que el
testigo. En este caso tenemos una prueba de “una cola”, que presentaría una zona de aceptación
y rechazo de H0, tal como se puede apreciar en la Fig. 8.2.
0.5000
- 0.0100
0.4900 = 2.33
Aceptación de
la H0
No hay error Error tipo II β
Rechazo de la
H0
Error tipo I No hay
error
∞

91
Fig. 8.2 Zonas de aceptación y rechazo de H0 al 1% de significación.
Prueba de una “cola”.
Al comparar la Fig. 8.1 con la 8.2, podemos concluir que las dos áreas sombreadas de la
primera, son equivalentes al área sombreada de la Fig. 8.2.
Ejemplo: El fabricante de una medicina sostiene que el producto tiene 80% de efectividad para
el control de una enfermedad. En una muestra de 300 individuos que tenían la enfermedad, la
medicina alivió a 220 personas. Determinar si la afirmación del fabricante es cierta al 5% de
probabilidades.
H0: p = 0.8 y la afirmación es verdadera
H1: p < 0.8 y la afirmación es falsa
Escogemos una prueba de una cola, puesto que nos interesa solo valores < 0.8, es decir,
inferiores a 80% de efectividad del producto.
0.5000
- 0.05
0.4500 = z = - 1.65
9 9
ACEPTACIÓN
DE Ho. .01
Z = 0 Z = 2.33
Zona Crítica

92
De acuerdo con la Sec. 7. 1. 2:
X = Np = 300 (0.8) = 240
𝑠 = √𝑁𝑝𝑞 = √300 (0.8)(0.2) = √48 = 6.92
𝑧 = 220 − 240
6.92= −2.89
El valor (absoluto) de z calculada es mayor que el tabular, es decir aquel cae en la zona de
rechazo de H0, por lo que aceptamos la hipótesis alternativa y concluirnos que la afirmación del
fabricante es falsa.
Ejemplo: En una muestra de 200 semillas, germinaron 172; al nivel de 1% podemos rechazar la
afirmación de que el poder germinativo de la semilla es, por lo menos, del 90%?
H0: p ≥0.9
H1: p < 0.9
En este caso, escogeremos una prueba de una cola – del lado izquierdo, negativo- puesto que
nos interesa solo valores <0.9
X = 200 (0.9) = 180
𝑠 = √𝑁𝑝𝑞 = √(200)(0.9)(0.1) = √18 = 4.24
𝑧 = 172 − 180
4.24= −1.88
0.5000
- 0.01
0.49 = z = - 2.33
El valor absoluto de z calculada es menor que el tabular, por lo que aceptamos H0: p ≥ 0.9 y
concluimos que el poder germinativo de la semilla llega, por lo menos al 90%.
En el caso de distribuciones binomiales, como hemos visto en los ejemplos anteriores, la
estadística

93
𝑧 = 𝑥 − µ
ợ=
𝑋 − 𝑝
√𝑝𝑞𝑁
Hay situaciones en las que podemos trabajar con X o con valores fraccionales X/N, como en el
siguiente ejemplo:
Nos dan un par de datos con el objeto de establecer si están o no cargados, al nivel del 5%. Si
decidimos probar la H0 de que la probabilidad de obtener 7 es igual 1/6, H0: p = 1/6; la H1 seria
p ≠ 1/6; en este caso usaríamos una prueba de dos colas por cuanto la probabilidad puede ser
mayor que 1/6. Si tiramos los dados 300 veces y encontramos que el 7 aparece 38 veces:
𝑧 = 𝑋 − 𝑝
√𝑝𝑞/𝑁=
𝑋𝑁
− 𝑝
√𝑝𝑞/𝑁=
38300
−16
√(16
) (56
) (1
300)
= 0.126 − 0.166
0.02= −2.0
Por tratarse de una prueba de dos colas restamos de 0.5 (la mitad de la curva), el valor de 0.025
(estamos trabajando al nivel del 0.05 de probabilidades); la diferencia es de 0.4750, que, en
valores de z= -1.96. El valor calculado cae fuera de la zona de aceptación de H0, en cuyo caso
rechazamos H0: p = 1/6, al nivel del 5%; sin embargo, no podríamos hacerlo al nivel del 1%.
Por esta razón y por cuanto sabemos que la probabilidad de sacar 7 es 1/6, pensaríamos que 300
lanzamientos fue un número insuficiente de pruebas y repetiríamos el ensayo.

94
Capítulo 9
La Distribución de X2
En el Cap. VII se trató de casos en los que la población consistía de dos clases de individuos y
en los que el muestreo se refería a una o dos poblaciones. En el presente Capítulo vamos a
considerar poblaciones clasificadas en más de dos categorías y a muestras extraídas de más de
dos poblaciones. Se define a X2 (letra griega que se lee Ji cuadrado), como la suma de
cuadrados de variables independientes, normalmente distribuidas, con media cero y varianza
uno.
La distribución de X2 depende del número de grados de libertad, existiendo una distribución
(curva dentro del eje de coordenadas), para cada grado de libertad. En la Tabla de X2 (Tabla N°
IV del Apéndice), se da el nivel de probabilidad a la cabeza de la tabla, los grados de libertad en
la columna izquierda equivale y los valores X2 en el cuerpo de la Tabla. El número de grados de
libertad equivale al número de clases que se comparan menos uno.
La mayoría de los problemas en que se usa X2, implican a la cola derecha de la distribución, al
contrario de la distribución de z, en la que podemos estar interesados tanto en una, cualquiera,
como en las dos colas de la distribución.
La distribución de X2 se usa generalmente para la enumeración de datos. Sin embargo, X2 es
una distribución continua que se basa en la distribución normal.
9.1 Cálculo de X2.
Como se ha visto en el Cap. VI, los resultados provenientes de muestreo no siempre coinciden
con resultados teóricos, de acuerdo a las reglas de probabilidad. Por ejemplo, aun cuando
teóricamente esperaríamos obtener 250 caras y 250 sellos, en 500 lanzamientos de una moneda,
llamaría la atención que obtengamos exactamente esa proporción en la práctica.
La prueba de X2, o prueba de bondad de ajuste, nos indica como los valores observados se
comparan con los valores esperados.
Supongamos que, en una muestra dada, esperamos, de acuerdo a la teoría de probabilidades, que
una serie de eventos E1, E2, E3,… En, se produzcan frecuencias e1, e2, e3,… en, llamadas
frecuencias esperadas; después de realizado el experimento, observamos que dichos eventos se
presentan con frecuencias o1, o2, o3,… on, llamadas frecuencias observadas. La primera

95
pregunta que se nos ocurre, en presencia de los resultados, es la siguiente: ¿se hallan éstos de
acuerdo con los que esperábamos?; ¿son los resultados confiables?
La medida en que los valores observados y esperados discrepan, está dada por la estadística X2,
la que, en su forma más simple, se expresa así,
𝑋2 = (𝑜1 + 𝑒1)2
𝑒1+
(𝑜2 − 𝑒2)2
𝑒2+ . . . +
(𝑜𝑛 − 𝑒𝑛 )2
𝑒𝑛
∑(𝑜1
𝑛
1=1
−𝑒1 )
2
𝑒1
Si el valor de X2 = 0, las frecuencias teóricas y las observadas, se hallarían totalmente de
acuerdo. Tal sería el caso a obtener exactamente 250 caras y 250 sellos, en 500 lanzamientos de
una moneda. Mientras mayor en el valor X2, mayor sería la diferencia entre las frecuencias.
Ejemplo: En 500 lanzamientos de una moneda, se observaron 275 caras y 225 sellos. Probar la
hipótesis de que la moneda no está “cargada”, al nivel de 5 y del 1% de probabilidades.
𝑋2 = (275 − 250)2
250+
(225 − 250)2
250= 5.0
Puesto que el número de categorías en n= 2 (caras y sellos), el número de grados de
libertad sería 2 – 1 = 1. Los valores de X205 y X2
01 para un grado de libertad son 3,84 y
6,63, respectivamente.
El valor calculado de X2 = 5,0 es mayor de 3,84 en consecuencia, podemos afirmar que las
frecuencias esperadas difieren significativamente de las frecuencias observadas, y rechazamos
la hipótesis de que la moneda no está cargada, al nivel de 5% de probabilidades. Sin embargo,
puesto que 5,0 es menos que 6,63, no podemos rechazar la hipótesis al 1% de probabilidades.
En este caso, lo correcto sería repetir la prueba.
Ejemplo: Alguien nos proporciona un par de dados, de los que sospechamos que están
“cargados”. Para probarlo, efectuamos 36 lanzamientos y obtenemos los resultados indicados
abajo. ¿Podemos concluir que los dados están “cargados”, al 1% de probabilidades?
_____________________________________________________________________
Resultado 2 3 4 5 6 7 8 9 10 11 12
Frecuencia 1 0 5 0 4 5 6 5 0 10 0

96
H0: los dados son correctos
H2: los dados están “cargados”
La distribución de frecuencias para el lanzamiento de dos dados está indicada abajo; los
numeradores de las frecuencias de las fracciones que corresponden a cada resultado, serían las
frecuencias esperadas, de un total de 36, como corresponde al total de las posibles
combinaciones al lanzar dos dados.
Resultado 2 3 4 5 6 7 8 9 10 11 12
Frec. Esperada 1
36
2
36
3
36
4
36
5
36
6
36
5
36
4
36
3
36
2
36
1
36
Frecuencia 1 0 5 0 4 5 6 5 0 10 0
𝑥2=(1−1)2
1+
(0−2)2
2+
(5−3)2
3+
(0−4)2
4+
(4−5)2
5+
(6−5)2
6+
(5−4)2
4+
(0−3)2
3+
(10−2)2
2+
(0−1)2
1=
44.14
X2.01 (10g.l.) = 23.21; por cuanto el valor calculado de x2 es mayor que el valor tabular,
rechazamos H0 y concluimos que los dados están “cargados”, lo cual salta a la vista, puesto que
sería raro que ,de 36 lanzamientos, no salgan una sola vez el 3, 5 , 10 o 12
Ejemplo: En cruzamiento de dos tipos de frejol, se encontraron, en la segunda generación,
cuatro tipos de plantas. En una muestra de hojas de 1.301 plantas se encontró:
773 verdes
231 doradas
238 verdes - rayadas
59 doradas- verdes- rayadas
1.301

97
De acuerdo a la teoría mendeliana sobre la herencia, la proporción de tipos de hojas debe ser, 9:
3: 3: 1. La Hipótesis nula sería que los resultados están de acuerdo con la teoría mendeliana. El
número de plantas dentro de cada clase, de acuerdo a las frecuencias esperadas, seria:
9
16(1.301) = 731.9
3
16(1.301) = 243.9
3
16(1.301) = 243.9
1
16(1.301) =
81.3
1.301,0
𝑥2 =(773.0 − 731.9)2
731.9+
(231.0 − 243.9)2
243.9+
(238.0 − 243.9)2
243.9+
(59.0 − 81.3)2
81.3= 9.25
= 9.25, con 4-1= 3 grados de libertad
El valor x2.05 para tres grados de libertad es 7.81. Por cuanto el valor calculado 9.25 es mayor
que tabular 7.81, estaríamos dispuestos a rechazar la hipótesis nula y aceptar la alternativa: los
resultados obtenidos no concuerdan con la teoría sobre la herencia propuesta. Como en el
ejemplo anterior, se justificaría el ensayo.
Ejemplo: la relación hombres – mujeres en un pequeño pueblo de Escocia fue 1940, de 7 a 1, en
favor de los hombres; es decir, había 7 mujeres por cada hombre. Supongamos que en una
encuesta reciente se encontró que, en una muestra tomada al azar, formada por 300 personas
había 72 hombres. Podríamos afirmar que la relación 7: 1 ha cambiado?
Si la relación es de 7 a 1, una de cada 8 personas es hombre; en consecuencia, si la relación no
ha cambiado, la proporción de hombre es P= 1/8
Vamos a probar, entonces:
H0: p = 1/8, contra la hipótesis alternativa de dos colas
H1: p ≠1/8, al 5% de probabilidades
Si X es el número de hombres:
X= 72, N – X = 300 – 72 = 228 mujeres

98
La frecuencia separada sería:
Hombres = 1/8 (300) = 37.5
Mujeres = 7/8 (300) = 262.5
𝑥2 =(72.0 − 37.5)2
37.5+
(228.0 − 262.5)2
262.5= 31.74 + 4.53 = 36.27
En la tabla Nº IV del apéndice, vemos que el valor de x2.05 (1 g. l.) = 3.84; por cuanto el valor
calculado es mayor que el tabular, rechazaríamos H0 y concluiríamos que, desafortunadamente,
la relación ha cambiado.
9.2 Cuadros con dos criterios de clasificación.
Llamados también cuadros de doble entrada, en los que las filas representan un criterio de
clasificación y las columnas el otro. Para ilustrar el procedimiento, vamos a usar los siguientes
ejemplos:
Para una prueba con pasta dentífrica, se dividió a cierto número de niños en tres grupos. Cada
uno de ellos usó una marca distinta durante un año. Los resultados fueron:
Marca de pasta Cantidad de caries nuevas Total
0 – 1 2 – 3 4+ filas
____________________________________________________________________________
A 40 10 10 60
B 50 20 20 90
C 60 10 20 90
Total columnas 150 40 50 240

99
Es cierta la afirmación que hacen los fabricantes de A, en el sentido de que hay “significativas
diferencias” entre su producto y los otros, en ¿cuánto a su capacidad para reducir el número de
caries?
La hipótesis planteada sería:
H0: las tres marcas de pasta son iguales
H1: la marca A disminuyó significativamente el número de caries, con relación a B y C.
El cuadro presenta los valores observados. Para calcular los valores esperados, teóricos,
procedemos de la siguiente forma, para llenar las celdas, dentro de cada columna
𝑒11 =(150)(60)
240= 37.5; 𝑒21 =
(150)(90)
240= 56.25; 𝑒31 =
(150)(60)
240= 56.25
𝑒12 =(40)(60)
240= 10.0; 𝑒22 =
(40)(90)
240= 15.0; 𝑒32 =
(40)(90)
240= 15.0
𝑒13 =(50)(60)
240= 12.5 ; 𝑒23 =
(50)(90)
240= 18.75; 𝑒33 =
(50)(90)
240= 18.75
El cuadro final de valores observados y esperados (entre paréntesis) sería como sigue:
Marca de pasta Cantidad de caries nuevas
0 – 1 2 – 3 4+
A 40 10 10
(37.5) (10.0) (12.5)
B 50 20 20
(56.26) (15.0) (18.75)
C 60 10 20
(56.25) (15.0) (18.75)

100
𝑥2 =(40.0 − 37.5)2
37.5+
(50.0 − 56.25)2
56.25+
(60.0 − 56.25)2
56.25+
(10.0 − 10.0)2
10.0
+(20.0 − 15.0)2
15.0+
(10.0 − 15.0)2
15.0+
(10.0 − 12.5)2
12.5+
(20.0 − 18.75)2
18.75
+(20.0 − 18.75)2
18.75= 8.76
Los grados de libertad se calculan así:
g. l. = (filas – 1) (columnas – 1)
= (3 – 1) (3 – 1) = 4
El valor tabular de x2.05 (4 g. l.) = 9.49
x2.05 (4 g. l.)=13.28
Por cuanto el valor calculado de x2 = 8.76 es menor que los valores tabulares al 5 al 1 % de
probabilidad, aceptamos la hipótesis nula y concluimos que las tres marcas de pasta dentífrica
son iguales y, en consecuencia, falsa la afirmación de los fabricantes de A, en el sentido de que
su producto es superior a los otros. Los fabricantes de A pudieron sostener que, en total, su
producto disminuyó 30 caries con relación a B y C o, en otras palabras, que fue 33% más
efectivo; pero, como hemos visto; la diferencia no fue estadísticamente significativa.
Ejemplo: Para probar la efectividad de una vacuna, se administró el producto a 170 conejos; un
grupo formado por 220, no recibió la vacuna, es decir, constituyó el lote testigo. Los 390
animales fueron infectados artificialmente con el agente causal de la enfermedad. Del grupo de
animales vacunados, murieron ocho, en tanto que del testigo, murieron 19. Podemos concluir
que la vacuna fue efectiva. La hipótesis nula sería:
H0: la tasa de mortalidad entre los dos grupos es igual; o, lo que es lo mismo, la vacuna no fue
efectiva
H1: la tasa de mortalidad para el grupo de animales vacunados es menor; es decir, la vacuna fue
efectiva
El cuadro de doble entrada para los valores observados sería:

101
Muertos Vivos Total
Vacunados 8 162 170
No vacunados 19 201 220
Total 27 363 390
Los valores esperados son:
𝑒11 =(27)(170)
390= 11.76; 𝑒21 =
(27)(220)
390= 15.23
𝑒12 =(363)(170)
390= 158.23; 𝑒22 =
(363)(220)
390= 204.76
El cuadro de valores observados y esperados (entre paréntesis) es:
Muertos Vivos
Vacunados 8 162
(11.76) (158.23)
No vacunados 19 201
………………………………………………………(15.23) (204.76)
𝑥2 =(8.0 − 11.76)2
11.76+
(19.0 − 15.23)2
15.23+
(162.0 − 158.23)2
158.23+
(201.0 − 204.76)2
204.76= 2.29
Los grados de libertad, como en el caso anterior:
g. l = (filas - 1) (columnas – 1)
= (2 – 1) (2 – 1) = 1

102
X2.05 (1 g. l.) = 3.84 Por cuanto el valor calculado es menor que el valor tabular, no podemos
rechazar H0 y concluimos que la vacuna no fue efectiva en cuanto a reducir la tasa de
mortalidad
Los ejemplos precedentes sirven para demostrar que, en estudios de este tipo, no se debe sacar
conclusiones rápidas, previas al análisis estadístico. Es común que la prensa o revistas no
científicas presenten resultados similares en forma de porcentajes y que podrían no estar
basados en un análisis matemático. Sería precipitado concluir de los valores observados del
ejemplo anterior, que el porcentaje de muertes dentro del lote de animales vacunados fue de
42%, con respecto al lote de animales no vacunados. No sólo es de interés conocer el número de
muertes en cada grupo, sino que se debe tomar en cuenta el tamaño de la muestra, puesto que
los números observados nos dicen algo cuando están relacionados con el número total de
individuos dentro del experimento. Supongamos que en un ensayo similar, el número de
muertes permanecía igual, pero que el total de animales dentro de cada grupo era de 30. En este
caso x2
Sería igual a 8, 14, mayor que el valor tabular de 3,84, en cuyo caso habríamos rechazado la
hipótesis nula y habríamos concluido que la vacuna resultó efectiva. No es lo mismo comparar
ocho muertes de entre 170 animales, que ocho muertes de entre 30
9.3 Corrección de Yates
Esta corrección se usa generalmente, cuando el número de grados de libertad es uno y está dada
por,
𝑥2𝑐𝑜𝑟𝑟𝑒𝑔𝑖𝑑𝑎 =[(01 − 𝑒1) − 0.5]
𝑒1+
[(02 − 𝑒2) − 0.5]
𝑒2+ ⋯ +
[(01 − 𝑒1) − 0.51]
𝑒1
De la comparación de los valores de x2, corregidos y no corregidos, pues de sacarse la
conclusión pertinente: en caso de que los dos valores sugieran conclusiones diferentes, la
solución estaría en aumentar el número de observaciones, es decir, incrementar el tamaño de la
muestra.

103
Capítulo 10
La Distribución de t.
Como en el caso de X2, t presenta una distribución diferente, de acuerdo al número de grados de
libertad. En la tabla N° V de Apéndice podemos ver que, para una muestra de 14 pares de
observaciones por ejemplo, (n=14-1=13), en la columna de grados de libertad 13 y al nivel de
probabilidades del 1%(0,01), en el cuerpo de la tabla encontramos el valor 3.012, el mismo que
debe ser sobrepasado por el valor de t calculado, en cuyo caso decimos que los resultados son
significativos al 1%. Si el valor calculado fuera menor que 3.012 aceptaríamos la hipótesis nula
de que los resultados no son significativos.
Conforme aumenta el número de grados de liberación, la distribución de t se aproxima a la
normal. Se ha visto en capítulos anteriores que, para muestras mayores que 30 (30
observaciones), llamadas muestras “grandes”, las distribuciones de muestreo a ola normal,
disminuye conforme se reduce el número de observaciones.
Así, William S. Gasset, industrial cervecero y estadístico, pudo apreciar que el uso de s para
predecir α, al calcular valores de z no era confiable para pequeños muestras. Este autor ideo la
estadística t, llamada “t de Student”, seudónimo usado por Gasset.
Por definición,𝑡 =��−𝜇
𝑠𝑥
𝑡 = 𝑥1 − 𝑥2 = ��
𝑠(𝑥1 − 𝑥2 ) = 𝑠𝑑
Por la que t está dada por la diferencia entre medias de tratamientos, dividida por el error típico
de la diferencia.
En definitiva, la prueba de t resulta un análisis de variancia para dos tratamientos.
En la práctica, para probar la hipótesis nula de que
no hay diferencia entre dos juegos de muestras, se
aplica.

104
10.1 Prueba t para observaciones no pareadas.
Tanto para observaciones pareadas como para las no pareadas, el valor d, reemplaza el de𝑥1 −
𝑥2 , proveniente de los dos juegos de muestras.
Para observaciones no pareadas.
𝑠𝑑 = √𝑠2 (1
𝑛1+
1
𝑛2) = √𝑠2 (
𝑛1 + 𝑛2
𝑛1𝑛2)
Ejemplo: El cuadro N° 10.1 presencia la ganancia de peso en novillos con y sin suministro
proteínico.
𝐻0: 𝜇𝐴 = 𝜇𝐵
𝐻1: 𝜇𝐴 ≠ 𝜇𝐵
A (sin suplemento) B(con suplemento)
25 48
30 42
28 50
26 38
32 46
35 40
34
Suma de cuadrados SC 𝑆𝐶(𝑥2) = ∑ 𝑥21 − (∑ 𝑥1)2/𝑛1
∑ 𝑥1 = 210 264
∑ 𝑥21 = 6.390 11.728
(∑ 𝑥1)2/𝑛 = 6.300 11.661
𝑥 = 30 44

105
= 6.390 −44.100
7= 6.390 − 6.300 = 90
𝑆𝐶(𝑥2) = ∑ 𝑥22 − (∑ 𝑥1)
2
/𝑛2
= 11.728 −69.696
6= 11.728 − 11.616 = 112
𝑠2 =𝑆𝐶(𝑥1) + 𝑆𝐶(𝑥2)
(𝑛1 − 1) + (𝑛2 − 1)=
90 + 112
6 + 5=
202
11= 18,36
18,36 es un estimado de la varianza común para los dos grupo; los grados de libertad =(𝑛1 −
1) + (𝑛2 − 1) = 6 + 5 = 11
𝑠𝑑 = √𝑠2 (𝑛1 + 𝑛2
𝑛1𝑛2) = √18.36 (
42
7 + 6) = √59.32 = 7.70 𝑙𝑖𝑏𝑟𝑎𝑠
El valor de 𝑡05(11𝑔. 𝑑 1) = 2.201
El valor de 𝑡01(11 𝑔. 𝑑 1. ) = 3.106
𝑡 =𝑑
𝑠𝑑=
30 − 44
7.70=
−14
7.70= −1.82(𝑁.𝑆)
Es decir, la diferencia no es significativa, puesto que el valor calculado no sobrepasa el valor
tabular. En consecuencia, aceptamos la H0, de que no hay diferencia entre los tratamientos.
10.2 Prueba de t para observaciones pareadas.
Frecuentemente, las observaciones dentro de un ensayo son pareadas: cuando se va a comparar
dos raciones usando dos animales de cada una de las 20 camadas de cerdos, asignando los
animales de cada camada al azar, uno a cada ración, o en el caso de comparar el contenido de
aceite de dos variedades de ajonjolí, sembradas en 14 localidades.
Ejemplo: los rendimientos de dos variedades de avena en 10 localidades fueron:
𝐻0: 𝜇𝐴 = 𝜇𝐵
55 46 9 81
89 81 8 64
53 60 -7 49

106
𝐻1: 𝜇𝐴 ≠ 𝜇𝐵
64 54 10 100
84 89 -5 25
86 74 12 144
52 59 -7 49
32 29 3 9
X1 625 582 43
729
X 62,5 58,2 d= 4,3
𝑆2�� =∑ 𝐷2 − (∑ 𝐷)2/𝑛
𝑛(𝑛 − 1)=
729 − 184.9
10(9)=
544.1
90= 6.04
𝑆2�� = 6.04; 𝑆�� = √6.04 = 2.45
𝑔. 𝑑𝑒 𝐼. = 10 − 1 = 9; 𝑡05(9𝑔. 𝑑𝑒 1. ) = 2.262
𝑡 =��
𝑆𝑑=
4,30
2,45= 1.76(𝑁𝑆)
Aceptamos 𝐻0: no hay diferencia en rendimientos entre las variedades.
De los ejemplos propuestos anteriormente, se desprende que cuando el valor de t calculado es
superior, en términos absolutos, al valor tabular, se rechaza la hipótesis nula de que la media del
tratamiento A es igual a la de B y optamos por la hipótesis alternativa. Normalmente, no existe
ninguna hipótesis alternativa; puede haber varios tipos de ellas, las que pueden ser designadas
como alternativas de una o dos colas o lados. El uso de la prueba de una o dos colas está
determinada por la forma de plantear el problema o la pregunta dentro del experimento. En los
dos ejemplos anteriores escogimos la prueba de dos colas por cuanto los tratamientos B con
(con suplemento proteínico y variedad B respectivamente), pueden ser mayores o menores que
los tratamientos A, en cuyo caso se justifica usar la hipótesis alternativa 𝜇𝐴 ≠ 𝜇𝐵.
Rechazaremos entonces, la hipótesis nula cuando los valores absolutos de t calculados, sean
mayores que los tabulares en los dos lados de la distribución es decir cuando aquellos se hallen
en la región crítica o zona de rechazo, fuera de la zona de aceptación de la hipótesis nula.

107
En el primer ejemplo el valor tabular de t01 para 11 grados de libertad, es de 3.106, el valor
calculado de t fue de -1.82, que cae en la zona de aceptación de la hipótesis nula. Por tanto,
declaramos los resultados no significativos.
En resumen para pruebas e dos colas o de dos alternativas, se lee el valor respectivo en la Tabla
N° V del Apéndice, de arriba hacia abajo, de acuerdo con los grados de libertad y el nivel de
probabilidad escogido. Para pruebas de una cola, o de una sola alternativa, es decir cuando
tenemos interés solamente en valores extremos a un solo lado de �� , se lee los valores de abajo
hacia arriba, así mismo de acuerdo con los grados de libertad y el nivel escogido. En este último
caso, si 𝐻0: 𝜇𝐴 ≡ 𝜇𝐵, las alternativas nativas pueden ser:
𝜇𝐴 < 𝜇𝐵 𝑜 𝜇𝐴 > 𝜇𝐵
Para ilustrar los casos en que se utilizan pruebas de una o de dos colas, presentamos
seguidamente los siguientes ejemplos:
Ejemplo: Un fabricante de motores o gasolina sostiene que, en promedio, ellos gastan no más de
0.6 galones de gasolina por ahora. Se probó una muestra de 24 motores y se encontró que el
consumo promedio fue de 0.84 galones con s=0.26. Con estos resultados, podemos decir que la
afirmación del fabricante es cierta
L H0 seria que la afirmación es correcta en cuyo caso 𝐻0: 𝜇 = 0.6. Puesto que nuestro interés
seria rechazarla solamente en caso de que el consumo sea mayor que 0.6 galones escogerías una
prueba de una cola,𝐻1: 𝜇 > 0.6 . Si el nivel de probabilidad es del 5% vamos a comparar el
valor calculado de t con el tabular para 23 grados de libertad.
𝑡 =�� − 𝜇
𝑠��=
�� − 𝜇
𝑠/√𝑁=
0.84 − 0.6
0.26/√24=
0.24
0.05= 4.8

108
En la tabla N° V vemos que t05 (23g. I)= 1.714; por consiguiente, rechazamos la hipótesis nula y
concluimos que el consumo promedio de los motores es mayor que 0.6 galones por hora del
fabricante es falsa.
Ejemplo: el pago promedio mensual por consumo de luz en la ciudad, el año pasado, fue de
s/320,00; quisiéramos saber si ha habido algún aumento esta año. Para probarlo tomamos una
muestra al azar de varias familias y estimados los pagos realizados por ellas. Vamos a utilizar la
hipótesis de que no habido cambio, es decir 𝐻0: 𝜇 = 320 , contra la alternativa de dos colas,
𝐻1: 𝜇 ≠ 320 , al nivel de probabilidad del 1%.
Optamos por una prueba de dos colas porque el valor de las planillas pue haber aumentado o
disminuido.
Tomamos una muestra de 50 familias y encontramos que el gasto promedio es de s/.280, con
S=s/.70
𝑡 =�� − 𝜇
𝑠��=
280 − 320
70/√50=
−40
9.9= −4.04
Valor que supera el de 𝑡.005(49 𝑔. 𝐼. ) = −2.684. En consecuencia, rechazamos Ho y
concluimos que ha habido un cambio significativo en el valor de las planillas de luz.
Ejemplo: la ganancia promedio de 30 conejos a los que se alimentó con una dieta experimental,
fue de 275 gramos. 𝑆�� = 15.6𝑔; Al nivel del 5%, podemos concluir que la ganancia promedio
con esa ración es no menor de 300g
𝐻0 ∶ 𝜇 ≥ 300
𝐻1 ∶ 𝜇 < 300
𝑡 =275 − 300
15.6=
−25
15.6= −1.602
El valor tabular de 𝑡05(29 𝑔. 𝐼. ) = −1.699, por cuanto el valor tabular es mayor que el
calculado, no podemos rechazar Ho y concluimos que la ganancia promedio que podemos
esperar con la dieta experimental es de, por lo menos, 30 g.
En los ejemplos propuestos podemos apreciar los siguientes aspectos:
1) La hipótesis nula se presenta siempre como una igualdad es decir 𝐻0 ∶ 𝜇𝐴 = 𝜇𝐵 la
forma como se presenta la hipótesis alternativa depende del tipo de pregunta que
plantea el problema.

109
𝐻1 ∶ 𝜇𝐴 ≠ 𝜇𝐵; 𝜇𝐴 > 𝜇𝐵; 𝜇𝐴 < 𝜇𝐵
2) Se usará una prueba de una o dos colas, dependiendo de nuestro interés y la forma como
se plantea la pregunta dentro el problema. Si existe la posibilidad de que el tratamiento
o factor B pude ser tanto mayor como menor (cualquiera de los dos casos) que el
tratamiento o factor A usaremos una prueba de dos colas, plateando 𝐻1 ∶ 𝜇𝐴 ≠ 𝜇𝐵en
caso de que tengamos interés en determinar si B tiene valores únicamente mayores o
únicamente menores que A es decir valores extremos solamente de la distribución,
usaremos una prueba de una cola, plantando 𝐻1 ∶ 𝜇𝐴 > 𝜇𝐵 o 𝜇𝐴 < 𝜇𝐵.
3) En el caso de pruebas de una cola, leemos el valor tabular de t, para el nivel de
probabilidad establecido, directamente en la tabla N° V, de abajo hacia arriba; para
pruebas de dos colas se lee el valor tabular, de acuerdo al nivel e probabilidad escogido,
de arriba hacia abajo.
4) Cuando la diferencia entre dos tratamiento A y B es de tal magnitud que el valor
calculado de t cae en una de las dos colas de la distribución (zonas críticas o de
rechazo), rechazamos Ho y optamos por la alternativa H1.

110
Capítulo 11
Correlación
En muchos problemas de investigación, tiene especial interés conocer el grado de relación que
existe entre dos o más variables. Por ejemplo, existe alguna relación entre dosis de fertilizantes
o fungicidas y el rendimiento de un cultivo; entre el grado de instrucción de una persona y su
inteligencia; entre la edad y la cantidad de cigarrillos que fuma un individuo.
La correlación mide la correlación, el grado de la intensidad de asociación entre dos variables o
el grado en que las variables cambian una con respecto a la otra.
Los valores de correlación (r) varían de -1 a +1, cuando existe una relación perfecta negativa y
positiva, respectivamente. Cuando no existe relación alguna entre las variables, r=0. En la
práctica, los valores se distribuyen entre los dos extremos y, más bien, debemos dudar de un
valor de r= 1.0.
El diagrama de dispersión de los datos, o dispersograma, dentro de los ejes X, Y, da una idea
del grado de asociación entre las variables. A cada valor de X, en el eje de las abscisas,
corresponde uno de Y, en el eje de las ordenadas, ubicándose en esta forma el punto, dentro de
los ejes de coordenadas.
En la Fig. 11.1 vemos que, en el primer caso, cuando la correlación es pequeña, r se aproxima a
cero, es decir no existe relación entre las variables.
Y
X
r=0
X
Y
r= +1
r=-1

111
Al centro se puede ver una relación positiva estrecha que, teóricamente, es igual a 1 y, en el
tercer caso, una relación negativa, en la que r = -1.
A pesar de lo expuesto, puede ser difícil y riesgoso tratar de interpretar visualmente un valor de
correlación, puesto que si no se escoge escalas adecuadas para los ejes de las X e Y, la simple
observación puede sugerir una correlación falsa o esconder una verdadera. El primer caso sería
el de un vendedor que, para impresionar al público, presenta una línea ascendente pronunciada,
que representa volumen de ventas la cual no guarda relación con la proporción real. Para evitar
conclusiones falsas, el investigador debe indicar, junto con el diagrama de dispersión de los
datos, el valor de la desviación típica y el valor r.
11.1 Coeficiente de Correlación
Cuando se trata de establecer el grado de relación entre dos variables, se calcula el coeficiente
de determinación (r² x 100), que determina el porcentaje de asociación entre las variables. Es
decir que este valor denota el porcentaje de la variación de Y atribuible a X; el resto de esa
variación no se puede explicar.
El coeficiente de indeterminación, está dado justamente por 1-r² = l², que constituye la
proporción no explicable de una suma de cuadrados total.
r= √𝑣𝑎𝑟𝑖𝑎𝑐𝑖𝑜𝑛 𝑒𝑥𝑝𝑙𝑖𝑐𝑎𝑏𝑙𝑒
𝑣𝑎𝑟𝑖𝑎𝑐𝑖𝑜𝑛𝑛 𝑡𝑜𝑡𝑎𝑙
La raíz cuadrada de coeficiente de determinación es lo que se llama coeficiente de correlación,
el cual está dado por
r=∑ 𝑋𝑌−(∑ 𝑋) (∑ 𝑌)/𝑛
√[∑ 𝑋²−(∑ 𝑋)²/𝑛] [∑ 𝑌²−(∑ 𝑌)²/𝑛]
o sea que r es el cociente de dividir la suma de productos XY[SP(XY)], por la raíz cuadrada de
la suma de cuadrados de X[SC(X)] por la suma de cuadrados de Y [(SC(Y)].
Supongamos que tenemos dos variables X, Y, con seis pares de observaciones correspondientes
a dosis de fungicidas (X) y rendimiento (Y)
X
Fig. 11.1 grado de relación entre dos variables

112
(X)
Fungicida
(Y)
Rendimiento
2 3
5 7
4 3
7 9
3 5
9 10
30 37
SC(x)= ∑ 𝑋1²6
𝑖=1 − (∑61=1 𝑥1) ²/n
= 2²+5²+……+9²-(30)²/6
184-150= 34
SC (Y) = 3²+…..+10²-(37)²/6
= 273 -228= 45
SP (XY) = ∑ 𝑋𝑌6𝑖=1 − (∑ 𝑋6
𝑖=1 (∑ 𝑌6 )/6
= (2x3) + (5x7) +….. (9x10) – (30)(37)/6
221-185=36
r= 36
√(34)(45)= +0.92 + +
La significación del coeficiente de correlación r depende del número de pares de observaciones.
Mientras mayor es un número, mayor es la probabilidad de obtener significación, pues que el
número de grados de la libertad se basa en (n-2), en lugar de (n-1), como en casos y
distribuciones anteriores.

113
El valor de r tabular debe ser sobre pasado por el valor calculado para obtener significación. En
nuestro ejemplo, los valores tabulares para 6-2=4 de grados de libertad, a los niveles del 5 y del
1% son, 0,811y 0,917, respectivamente; por cuanto el valor calculado en nuestro ejemplo es de
0,92, podemos rechazar la hipótesis nula de que no existe relación entre las variables y aceptar
la hipótesis alternativa: existe relación entre ellas, más de lo que pudiera atribuirse al azar…
El coeficiente de determinación viene dado por,
r² (100)= (0,92)² X 100 = 84,64 %
Es decir que 85% del aumento en rendimiento, se puede atribuir a la aplicación el fungicida. El
resto no se puede explicar
11.2 Propiedades del Coeficiente De Correlación
a) r es independiente del origen de las variables; indica, más bien, la consistencia del
cambio: no importa si comparamos lluvia con toneladas, libras con centímetros, etc.
b) Es independiente de la escala
c) Es independiente del número de medidas, aun cuando generalmente se considera que
son más necesarios por lo menos 20 pares para tener confianza en un valor de r
significativo.
d) Las variables deben ser pareadas por alguna razón lógica
e) Las muestras deben ser tomadas al azar
f) Correlación espuria es una condición en que las variables no están causalmente
relacionadas entre sí sino que más bien, lo están a una tercera.
g) Se debe tener mucho cuidado al inferir causa y efecto de un coeficiente de correlación
significativo.
Con relación al último literal, debe añadirse que, de todas las medidas estadísticas estudiadas, el
coeficiente de correlación es la que está más sujeta a ser mal interpretada. Esto se debe a la
suposición frecuentemente errónea de que por cuanto dos variables tienen relación, el cambio de
una de ellas ocasiona un cambio en la otra. Así, muchas veces podemos usar un coeficiente de
correlación significativo, para “probar” una relación de causa y efecto, que puede no existir.
Se ha demostrado que existe una correlación negativa entre el hábito de fumar y la obtención de
buenas calificaciones. Si uno fuma, podría usarse este hecho como evidencia de que fumar es
nocivo, de que fumar causa o se refleja en la obtención de notas bajas. Esto puede ser cierto,

114
pero los fumadores podrían argüir que el obtener bajas calificaciones causa tensión nerviosa lo
cual, a su vez, estimula al estudiante a fumar más.
Podría suceder que también fumar y obtener malas notas no estén directamente relacionados
entre sí, pero se hallan correlacionados porque los dos hechos tiene relación con un tercer factor,
tal vez el grado en que el individuo se dedica a actividades sociales o que no tengan que ver con
el estudio. Esto es justamente lo que se conoce como correlación espuria, tal como se anote en
el literal F.
Finalmente hay que notar que, debido a la variación a las muestras, podemos obtener una
correlación significativa aun cuando las variables no estén relacionadas; esto puede ser
controlado seleccionado el nivel de significación.

115
Capítulo 12
Regresión
Como se ha visto en el capítulo precedente, en el campo de la investigación frecuentemente se
encuentra dependencia entre dos variables. Así por ejemplo, decimos que existe relación entre la
cantidad de fertilizante aplicado y el rendimiento de cultivos; o entre la longitud y diámetro de
mazorca y el peso del grano; entre la altura de una persona y su peso, etc.
El coeficiente de correlación determina la intensidad de asociación entre dos variables, pero
nada nos dice sobre la gradiente de la línea de asociación, ni tiene capacidad de predicción.
Regresión tiene que ver con la dependencia de la variable Y, llamada variable dependiente, de
otra variable X, la variable independiente. En matemáticas, se conoce a Y como función de X.
es decir, en el caso de dosis de fertilizante X, y rendimiento de trigo, por ejemplo, a una serie de
valores 𝑥1,𝑥2,𝑥3 … .. corresponde otra de 𝑦1,𝑦2,𝑦3 … ..
Como en el caso del diagrama de dispersión o dispersograma, en correlación, estos valores se
disponen dentro de los dos ejes de coordenadas, y el dispersograma puede sugerir si existe una
relación lineal como en la
Fig. 12.1 a, o si ella es curvilineal (Fig. 12.1b).

116
Distancia entre surcos
Fig. 12.1 Respuesta lineal y curvilineal
En estadística, no nos contentamos con la apreciación visual del dispersograma, sino que
tratamos de encontrar ecuaciones que describan dichas curvas de respuesta, lo que se llama
ajuste de curvas de respuesta.
Pero, además de determinar la función matemática, que nos diga de qué manera están
relacionadas las variables, o sea que nos de la “mejor” relación funcional entre ellas, es de
interés saber con qué precisión se puede predecir el valor de una variable, si se conoce los
valores de la otra. Puede tener interés tratar de predecir valores futuros como la producción de
frutas, accidentes automovilísticos (Compañías de Seguro), posible ingreso de estudiantes a la
facultad, etc. O, puede ser posibles observar un valor de X e imposible o poco práctico, observar
el valor correspondiente de Y.
Sin embargo, es necesario advertir que, simplemente en base de nuestra suposición de que existe
dependencia de Y en X, y por haber seguido el procedimiento mecánico de cálculo, no se debe
concluir automáticamente que existe relación causal entre X e Y. solo el investigador, con
conocimiento cabal del material y la forma como se llevó a cabo el experimento, está en
capacidad de tomar esa decisión.
Sin bien el termino regresión no describe, dentro de la estadística, los usos que tiene, su empleo
es de origen histórico. Galton, en 1886. Postulo la teoría de que existe relación entre la estatura
de los padres y la de los hijos. Sin embargo, este autor encontró que la altura promedio de los
hijos de matrimonios altos, no era tan grande como la de estos, ni que los hijos de pareas de baja
estatura, eran tan pequeños como sus padres. Galton concluyo que parecía existir una tendencia
del carácter altura, a acercarse a los valores promedios de la población; es decir una regresión
hacia los valores promedios.
0
0,2
0,4
0,6
0,8
1
1,2
0 0,2 0,4 0,6 0,8 1 1,2
(b)

117
Resumiendo, podemos decir que los usos de la regresión en estadística pueden ser:
a) Determinar si la variable dependiente Y, depende de X; es decir, nos da la medida de la
proporción de cambio en Y, por una unidad de cambio en X.
b) Conocidos los valores de la variable independiente X, predecir valores de Y,
desconocidos en ese momento.
c) Algunos investigadores pueden estar interesados en determinar el error en Y, dentro de
un experimento, después de hacer los ajustes del efecto que puede tener X en Y.
d) Un investigador puede postular su teoría sobre causa y efecto: para probarla, puede
usar varios métodos de regresión.
12.1 Ecuación de la línea recta.
Si dentro del dispersograma, las observaciones se sitúan alrededor de la línea recta, (repuesta
lineal), podemos determinar, por geometría analítica, la ecuación de esa línea recta.
�� − �� = b (X- ��)
�� − �� = bX- b��
�� = �� - b�� + 𝑏𝑋; �� - b�� = a
��= a + bX (relación funcional)
Donde �� : valor de la ordenada (valor precedido)
X: valor de la abscisa (valor conocido)
��: media de x
��: media de y
B: coeficiente de regresión

118
La Fig. 12.2 ilustra la forma como se traza la línea recta, en base de su ecuación matemática.
Fig. 12.2 Ecuación y trazado de la línea recta.
De la fig. 12.2 se desprende que, cuando X = 0, Y = a, es decir que a es el punto donde la línea
recta corta al eje Y, o sea el intercepto en Y. cuando a = 0, la línea pasa por el punto de origen
(0,0).
El cambio de una unidad en el eje de las X, provoca un cambio b en el eje de las Y, de tal
manera que b mide la gradiente de la línea de regresión. Cuando b es positivo, las dos variables
aumentan o disminuyen juntas. Tal sería el caso cuando X es kg. De fertilizante por hectárea, e
Y, toneladas de grano por hectárea. Cuando b es negativo, mientras el valor de una variable
aumenta, el de la otra disminuye: si X es distancia entre surcos e Y rendimiento, a mayor
distancia el rendimiento tiende a disminuir.
12.2 El método de los cuadrados mínimos.
Se ha anotado antes, que la cualidad principal de establecer un valor de regresión, consiste en
poder predecir resultados de Y, cuando solo se conoce el de X. sin embargo, estos parámetros
no se pueden determinar sin error, debido a que los valores observados de la variable
dependiente, rara vez coinciden con los valores esperados. Esto se demostró claramente en el
Cap. 9, al tratar sobre 𝑥2.
Cuando se traza líneas de regresión, es necesario ser objetivo al tratar de ajustar una serie de
datos a esas líneas de regresión. Para ello, se debe escoger la línea de “mejor ajuste” de estos
datos.
Como se ilustra en la fig. 12.2, los datos observados se disponen alrededor del eje o línea de
regresión. Se dice que la línea de regresión trazada es la que “mejor se ajusta” a los datos. En
Y
X
1 Unid. X
b. Unid
(x.y)

119
otras palabras, si se trazara otra línea de regresión, la suma de cuadrados de las desviaciones de
los puntos observados, tendría un valor más grande.
12.3 Cálculo del coeficiente de regresión y de la ecuación de regresión.
El cuadro 12.1 presenta, a manera de ilustración, los pesos promedios de cinco camadas de
cerdos y el consumo correspondiente de balanceado.
CUADRO 12.1 pesos iniciales promedios de cinco camadas de cerdos y consumo de
balanceado.
Peso corporal
(X)
Consumo (Y) Desviaciones
X Y
Cuadrados
𝑥2𝑦2
Productos
XY
85
75
80
68
82
720
680
700
630
715
+7 +31
-3 -9
+2 +11
-10 -59
+4 +26
49 961
9 81
4 121
100 3481
16 676
217
27
22
590
104
390
�� 78
3445
689
0 0 178 5320 960
Coeficiente de regresión b= ∑𝑥𝑦
∑𝑥2 = 960
178 = 2,39 lbs. De balanceado por libra de peso corporal de
los cerdos.
A este valor de b, el coeficiente de regresión, se ha llegado aplicando la fórmula.
𝑏𝑦.𝑥 =∑(𝑋 − 𝑥)(𝑌 − 𝑦)
(𝑋 − ��)2

120
𝑏𝑦.𝑥 = 𝑆𝑃 (𝑋𝑌)
𝑆𝐶(𝑥)
La suma de productos cruzados XY, dividida por la suma de cuadrados de X. la fórmula de
trabajo usual es
𝑏𝑦.𝑥 = ∑𝑋𝑌 − (∑𝑋)(∑𝑦)/𝑛
∑𝑥2 − (∑𝑥)2 /𝑛
En el ejemplo propuesto,
SP(xy) = (85 x 720) + (75 x680) + …. + (82 x 715) – (390) (3445)/5
= 269.670- 268.710 = 960.
SC (X) = 852 + 752 +….+ 822 − (390)2/5
= 30.598 – 30. 420 = 178
𝑏𝑦.𝑥 =960
178= 5.39
Lo que se interpreta diciendo que, para conseguir el aumento de 1 lb. De peso de los cerdos, se
necesita 5.39 lbs. De balanceado.
La ecuación de regresión se escribiría
�� − �� = b (X- ��)
�� − 689 = 5.39 (X- 78)
�� = 689 + 5.39 (X – 78)
��= 268.58 + 5.39X = a + b X
El intercepto en Y, a =�� − 𝑏��
a = 689 – 5.39 (78)
= 689 – 420.42
= 268.58

121
La función de predicción puede apreciarse con el siguiente ejemplo: queremos determinar la
cantidad de balanceado que consumiría un grupo de cerdos, cuyo peso promedio es de 90 lbs.
Como puede verse en el cuadro 12.3, no existe el valor de X = 90. Sin embargo, podemos
estimar el valor correspondiente Y, aplicando la ecuación: �� = 𝑎 + 𝑏 𝑋
��(90) = 268.58 + 5.39 (90)
=268.58 + 485.10
= 753.68 lbs. De balanceado.
12.4 Valores ajustados.
Son aquellos que se esperarías si todo los valores de Y tuvieran un valor promedio de X, o algún
otro valor fijo. El cuadro 12.2 presenta los valores ajustados de consumo de balanceado, que
serían aquellos que esperaríamos si todos los cerdos tuvieran un peso promedio de 78 libras.
CUADRO Nº 12.2 valores de regresión y valores ajustados de consumo para los datos del
cuadro Nº 12.1
Peso
corporal (x)
Consumo
(y)
Consumo
estimado ��
Desviación
𝒃𝒚.𝒙 = 𝒚 − ��
𝒅𝟐𝒚.𝒙
Consumo
ajustado
85
75
80
68
82
720
680
700
630
715
726.73
672.83
699.78
635.10
710.56
-6.73
+7.17
+0.22
-5.10
+4.44
45.29
51.41
0.05
26.01
19.71
682.27
696.17
689.22
683.90
693.44
3.445 3.445,00 0 142.47 3.445,00
�� = 𝑎 + 𝑏𝑋

122
= 268.58 + 5.39 (85) =726.73
12.5 Fuentes de variación en regresión
Tal como se indica ampliamente en el capítulo 15, el análisis de variancia es un procedimiento
aritmético que consiste en desdoblar la variación total en un juego de datos, de acuerdo con las
diferentes fuentes de variación presentes. Para el caso de regresión lineal, la variación total
puede desdoblarse en las siguientes fuentes: debido a regresión (X) y desviación de regresión
(residual).
El análisis de variancia (ADEVA), para los datos del cuadro 12.1 sería como sigue.
X (debido a regres.) 1 (∑𝑥𝑦)2/∑𝑥2 1 5.177,53 5.177,53 109,02**
Residual (desv. Regr.) n-2 por diferencia 3 142,47 47,49
Total n-1 ∑𝑦245.320,00
SC (residual) = (∑𝑥𝑦)2/∑𝑥2
= 5.320,00 – (920)2 / 178
5.320,00 - 5.177,53 = 142.47
SC (X), debido
A regresión = (∑𝑥𝑦)2/∑𝑥2
= (920)2 / 178
= 5.177,53
La prueba de f del ADEVA es una prueba de la hipótesis nula de que el coeficiente de regresión
poblacional β = 0, o sea de que la variación en X no contribuye a la variación en Y.
El valor altamente significativo de F para X (debido a regresión), nos permite rechazar la 𝐻0 y
afirmar que el peso de los cerdos explica fácilmente la variabilidad en la cantidad de balanceado
consumida.

123
12.6 Desviación y límites de confianza.
Un estimado insesgado de la verdadera variancia en regresión, está dado por el cuadrado medio
de la desviación de regresión, con n-2 grados de libertad.
𝑆2y.x = ∑𝑦2 −/ (∑𝑥𝑦)2 / ∑𝑦2
n - 2
= 5.320,00 – (920)2 / 178 = 47,50
3
La raíz cuadrada de este valor S y.x = 6,89 se denomina la desviación típica de Y para X fija.
La variancia de un valor estimado 𝑌 = 𝑌 + 𝑏𝑥, de la media de una población, está dada por la
suma de las variancias de 𝑌 y bx, así.
𝑆2y.x [1
𝑛+
(𝑋− 𝑥) 2
∑𝑥2 ]
Esta variancia aumenta conforme X aumenta. Para establecer los límites de confianza para una
media estimada, al nivel del 95%, tendríamos.
LC (𝑌 )= 𝑌 + 𝑏𝑥 ± .05 𝑆𝑦. 𝑥 √1
𝑛+
(𝑋− 𝑥) 2
∑𝑥2
El valor de ţ.05, con n-2 g. de 1 en el ejemplo de los cerdos, los límites de confianza para X =
90, son.
LC = 689 + 5.39 (90-78) ± 3.182 (6,89) √1
5+
122
178
= 731.76 Y 775.60
A veces, e necesario determinar los límites de confianza para β, el parámetro estimado por b.
para ello usamos.
𝑆2b = 𝑆2y.x / ∑𝑥2, dentro de la ecuación b±ţ.05 𝑆2y.x
√∑𝑥2
En el ejemplo, 5,39 ± 3.182 (6,89)
178 = 3,75 y 7,03.

124
Concluimos que β se encuentre entre 3.75 y 7.03 lbs. De balanceado por libra de peso corporal
de los cerdos, con 95% de seguridad de estar en lo cierto.
12.7 Propiedades y suposiciones en regresión lineal.
El problema de regresión lineal tiene las siguientes propiedades:
a) El punto 𝑥, 𝑦 , está situado sobre la línea de regresión.
b) La suma de las desviaciones de y de la línea de regresión es igual a cero.
c) La suma de los cuadrados de las desviaciones es un mínimo. Es decir, si reemplazamos
la línea de regresión calculada con cualquiera otra línea, la suma de cuadrados del
nuevo grupo de desviaciones será un valor más grande.
En lo posible, las variables independientes (X), deben ser igual o convenientemente espaciadas,
a fin de tener mayor eficiencia en la conducción del experimento y en la interpretación de los
datos: temperatura, distancias de siembra, dosis de herbicidas etc.
Cuando se supone que existe una variancia común, se puede usar el cuadrado medio del error,
para obtener inferencias validas sobre la media de una población, sin tomar en cuenta el valor de
X. si las variancias no son homogéneas, es necesario transformar los datos, a fin de
homogeneizar las variancias. Tal sería el caso de contajes de insectos o daños causados por
ellos, en que las variancias se ajustan a la distribución de Poisson y no a la normal.

125
Capítulo 13
Covariancia
El análisis de covariancia (ANACOVA), es un procedimiento de gran importancia en
experimentación y que, desafortunadamente, no es usado con la frecuencia que se debiera.
El ANACOVA utiliza el análisis de variancia (sobre el que se trata ampliamente en el Cap. 15)
y regresión, para remover la variabilidad que generalmente existe en la variable independiente
X, ajustar media de tratamiento y, sobre esta base, estimar con mayor fidelidad el efecto de X
sobre la variable dependiente Y.
Para los datos del cuadro 12.1 en el que se presenta pesos corporales de cerdos (X) y el
consumo de alimento balanceado (Y), si se hubiera usado varias raciones o dietas, las
diferencias entre los efectos de raciones podían o no podían ser significativas; es decir puede o
no puede haber diferencias en cuanto a la calidad de las raciones. Sin embargo, antes de sacar
conclusiones al respecto, debemos preguntarnos: al existir variación en los pesos promedios
iniciales de las camadas (68 y 85 lbs.), podemos atribuir la diferencia en los pesos finales de los
cerdos (a la terminación del ensayo), a la bondad de algunas de las raciones ¿O, quizás, buena
parte de las diferencias en los pesos iniciales de las camadas? Con respecto a esta última
pregunta, es sabido que lechones grandes y de mayor peso al nacimiento son más agresivos y,
en consecuencia, consumen mayor cantidad de alimento y ganan peso más fácilmente que
lechones pequeños y livianos.
Al ajustar los valores de Y, de acuerdo con los valores correspondientes de X, es posibles
analizar e interpretar con precisión los resultados del ensayo. Por medio del ANACOVA, la
contribución al erro experimental para ganancia de peso- contribución que, como se ha notado,
puede deberse a diferencias de peo inicial- puede ser calculada y eliminada.
En general, e ensayos de alimentación de animales, las diferencias entre medias de tratamientos
no ajustadas, puede deberse al valor nutritivo de las raciones, a diferencias en la cantidad
consumida por los animales o a las dos causas. Tal sería el caso de una dieta de alto valor
nutritivo en la que, un exceso de harina de pescado, puede volver impalatable al alimento; o
cuando se adiciona niveles subidos de melaza o torta de algodón a la dieta: en el primer caso
pueden producirse diarreas y en el segundo intoxicaciones por el contenido de gosipol de la
torta.

126
13.1 Usos del ANACOVA
a) Aumentar la precisión de experimentos. En estos casos, el covariado X (ejemplo de las
raciones consumidas por cerdos), es la medida que se toma dentro de cada unidad
experimental (animales), antes de aplicar los tratamientos (dietas), medida que tiende a
predecir la respuesta de la unidad experimental (X), al tratamiento (Y).
b) Como se ha anotado antes, una fuente importante de error proviene del azar, del hecho de
que, por randomización, cerdos más grandes sean asignados a ciertas raciones. Al remover
las diferencias de peso inicial, se obtiene un error experimental. Por ejemplo, podemos
suponer que ciertos tratamientos influyen no solo en la variable dependiente (Y), sino
también en la variable independiente (X). la utilización del ANACOVA nos permitirá
confirmar o negar esta suposición.
c) Ajustar medias de tratamiento frente a posibles fuentes de error. Los ejemplos de consumo
de alimentos por animales y de parcelas de maíz afectadas por causas ambientales, tipifican
este uso del ANACOVA. Después de ajustar medias de tratamientos, es importante
determinar si los tratamientos están influyendo sobre la variable independiente (X), en cuyo
caso la interpretación de los datos variaría. Esto se debe a que las medias de tratamientos
ajustadas, estiman o predicen valores, suponiendo que las medias de tratamientos de la
variable independiente X son iguales.
El ajuste remueve parte de los efectos de tratamientos cuando las medias de la variable
independiente son afectadas por los tratamientos; en estos casos, se debe interpretar los
resultados del ensayo con cuidado.
d) Control de error. El objetivo del ANACOVA es incrementar la precisión al medir efectos de
tratamientos, cuando la variable independiente mide efectos ambientales y no está
influenciada por los tratamientos. En un ensayo de aplicación de úrea a parcelas de raigrás,
la cantidad de nitrógeno aplicada, puede determinar diferencias en la población, remueve
parte del efecto de la aplicación de nitrógeno y, en esta forma, es posible equivocarse en la
interpretación de los datos.
e) Estudiar el tipo de respuesta. Cuando se trata de relacionar aplicación de urea y rendimiento
de forraje, es interesante estudiar si el tipo de respuesta es lineal o curvilineal. Este sería un
caso típico de regresión, cuando se establece un ensayo de fertilización como el anotado, en
varias localidades y a lo largo de varios años.
f) Desdoblamiento de la covariancia en sus partes constitutivas; y,

127
g) Estimar datos perdidos.
13.2 Suposiciones en el ANACOVA y el modelo lineal aditivo.
Las suposiciones en covariancia deben ser una combinación de aquellas propuestas en el
ADEVA y en regresión.
1. Las medias deben medirse sin error y tener valores fijos.
2. Debe haber homogeneidad en la regresión, luego de haber removido los efectos de bloques
y tratamientos; además, se supone que la regresión de Y en X, es lineal e independiente de
bloques y tratamientos.
3. Los residuos, son normal e independientemente distribuidos, con media cero y variancia
común.
Para un diseño de bloques completos al azar, la descripción del modelo lineal aditivo, está dado
por,
𝑌𝑖𝑗 = µ + 𝑇𝑖 + 𝑃𝑖 + 𝛽 (𝑋𝑖𝑗 − ��. . ) + 𝜖𝑖𝑗
Dónde:
µ: media
𝑋𝑖𝑗: Variable independiente o concomitante
𝑌𝑖𝑗 : Variable dependiente
𝑇𝑖: Efecto de tratamientos
𝑃𝑖: Efecto de bloques
β: coeficiente de regresión
��. . : Media de la variable independiente
𝜖𝑖𝑗: Error
13.3 Modelo matemático
El cuadro Nº 13.1 presenta el modelo del NACOVA y el procedimiento para obtener los valores
de acuerdo a las diferentes fuentes de variación.

128
El análisis de los valores ajustados representa los puntos alrededor de la línea de regresión. La
suma de cuadrados debida a regresión, significa la dependencia de Y en X, si el valor de F
(cociente entre el cuadrado medio de tratamientos, sobre el cuadrado medio del error), resulta
significativo, existen diferencias entre tratamientos. La tabla Nº VI del apéndice, da los valores
de F.

129
BIOESTADÍSTICA

130
CAPÍTULO 1 Generalidades
1.1 INTRODUCCIÓN
Es usual encontrar en varios textos la palabra biometría como sinónimo de
bioestadística. Etimológicamente biometría proviene de dos raíces griegas, bios (vida) y
metron (medida). En consecuencia la biometría se ocupa del desarrollo teórico y
práctico para llevar a cabo mediciones en seres vivos, mientras que la bioestadística
facilita la aplicación de los métodos y técnicas estadísticas para analizar diversos
aspectos propios de los seres vivos, lo que indica una relación e integración obligatoria
entre la biología y la estadística. De todas maneras, en el lenguaje de los investigadores,
los dos términos se utilizan como equivalentes.
En las ciencias biológicas, como en todas las ciencias, mediante el proceso investigativo
se trata de entender una gran cantidad de fenómenos observados, por tanto se requiere
tener un conocimiento, lo más amplio posible, de un fenómeno particular y utilizar con-
ceptos y procedimientos estadísticos que conduzcan a encontrar explicaciones válidas
sobre el comportamiento del mismo y establecer las relaciones causa-efecto, lo cual
ayudará a tomar decisiones oportunas y acertadas.
Ahora bien, la palabra estadística tiene muchas definiciones de tipo lingüístico usual-
mente encontradas en enciclopedias y diccionarios; sin embargo, dado que en la época
actual el uso de la estadística abarca prácticamente todas las áreas del saber, entre las
que pueden mencionarse las ciencias sociales, la ingeniería, la química y, por supuesto,
las ciencias biológicas en sus diferentes aplicaciones, se hace difícil, en cierto modo,
expresar una definición única y categórica, así que antes que la definición, es más im-
portante tener una clara idea de la utilidad y conocer algunos aspectos importantes de la
evolución histórica de la estadística.

131
De acuerdo con Steel y Torrie (1986), la estadística debió comenzar como una
aritmética estatal para asistir a los gobernantes.
Los mismos autores señalan que una aplicación de la probabilidad empírica para asegu-
rar los embarques se puede encontrar en la historia de la navegación flamenca del siglo
XIV que, si bien hoy en día se puede considerar especulativa, seguramente dio origen a
la estadística utilizada en la actualidad por las empresas aseguradoras.
En el siglo XVII se originó la teoría de las probabilidades, desarrollada por Pascal y
Fermat. Un hecho histórico trascendental para el desarrollo contemporáneo de la es-
tadística fue la ecuación planteada para la curva normal de errores, publicada ori-
ginalmente en 1733 por de Moivre. El mencionado texto permaneció en el anonimato
hasta que Karl Pearson lo redescubrió en 1924. También es importante destacar que dos
astrónomos matemáticos, Laplace y Gauss, en el siglo XVIII, trabajando en forma
independiente, llegaron a las mismas conclusiones que obtuvo de Moivre, sin que tu-
vieran conocimiento de sus trabajos. La curva normal conserva gran importancia en
salud y producción animal y se la conoce universalmente con los nombres de Curva de
Gauss o Curva Laplaciana.
La utilización de la estadística para el análisis de fenómenos biológicos comenzó
aproximadamente en 1925, año en que el profesor Ronald Fisher publicó el libro
titulado Statistical methods for research workers. Searle (1989) y Hofer (1998)
presentaron un recuento histórico del uso de los componentes de varianza en los que se
puede apreciar que, después de Fisher, Tippett clarificó y extendió el método ANOVA
(analysis of variance) de estimación. En 1935, Yates utilizó la metodología ANOVA en
experimentos con cereales; Neyman, et al en 1935 consideraron la eficiencia de los
diseños de bloques aleatorizados y los diseños en cuadrado latino e hicieron uso
extensivo de los modelos lineales. Quizás estos trabajos son la primera aparición
reconocible de los modelos mixtos.
Entre 1943 y 1987 se extendió el uso de los modelos de componentes de varianza para
resolver problemas prácticos, especialmente por parte de los genetistas quienes apli-
caron esta técnica en humanos, ganado lechero, ganado de carne, maíz, trigo y aves,
entre otros. La mayoría de estas aplicaciones involucraron datos desbalanceados. Una
revisión histórica detallada de estos tópicos se puede encontrar en Solarte (2000).

132
En la actualidad se presenta un continuo crecimiento y auge de la estadística, dadas las
nuevas necesidades del hombre, que a diario requiere más respuestas a nuevos interro-
gantes por la ampliación del espectro investigativo.
Según Steel y Torrie (1986), "La estadística es la ciencia pura y aplicada, que crea,
desarrolla y aplica técnicas de modo que pueda evaluarse la incertidumbre de
inferencias inductivas". De la anterior definición se deduce que la estadística como
ciencia pura desarrolla conocimiento nuevo o teorías estadísticas, mientras que como
ciencia aplicada desarrolla métodos para recopilar, representar, condensar y analizar los
datos obtenidos con una técnica particular, según los objetivos del estudio y cualquiera
sea la disciplina interesada en alcanzarlos.
Sierra (1991) define a la estadística como "Ciencia formada por el conjunto de teorías y
técnicas cuantitativas que tienen por objeto la organización, presentación, descripción,
resumen y comparación de conjuntos de datos numéricos, obtenidos de poblaciones de
individuos o fenómenos en su conjunto o bien de muestras que representan las
poblaciones estudiadas, así como el estudio de su variación, propiedades, relaciones,
comportamiento probabilístico y la estimación, inferencia o generalización de los
resultados obtenidos de las muestras, respecto a las poblaciones que aquellas
representan".
Otra manera de definir a la estadística, usada con mayor frecuencia en varios textos
especializados, es la siguiente: "Conjunto de métodos que se utilizan para obtener,
recolectar, presentar, analizar e interpretar datos numéricos, con el objeto de extractar
conclusiones válidas, con base en las cuales se puedan tomar decisiones".
Algunos autores aseguran que la estadística no es una ciencia, sino un grupo de métodos
con base científica. Para dirimir discusiones de esta naturaleza, el lector interesado
puede remitirse a Bunge (1976) y Popper (1971).
Convencionalmente, la estadística se divide en dos grandes ramas: Estadística descrip-
tiva y Estadística inferencial. La primera hace referencia al conjunto de métodos para
resumir y presentar en forma clara una serie de observaciones. Aquí se incluyen Ios
cuadros, los gráficos, las medidas de tendencia central y de dispersión o variabilidad. La
estadística inferencial comprende el conjunto de métodos necesarios para obtener

133
conclusiones válidas para una población, como resultado del análisis de una muestra
extraída de la misma.
En este texto, tanto la parte descriptiva como la inferencial son temas de interés; sin
embargo, la estadística inferencial será de mayor importancia puesto que la producción
y la salud animal son áreas con intenso trabajo investigativo en procura de lograr
animales más productivos y eficientes, menos susceptibles a enfermedades y, por ende,
más útiles a la humanidad.
El profesional de las ciencias pecuarias debe cimentar una sólida formación en el campo
investigativo. Éste es uno de los aspectos de mayor relevancia en los planes de forma-
ción de recursos humanos con miras a lograr niveles de producción internacionalmente
competitivos, acorde con la actual tendencia mundial.
1.2 ESTADÍSTICA Y MÉTODO CIENTÍFICO
La investigación en producción y salud animal tiene como objetivo fundamental generar
nuevo conocimiento o nuevas aplicaciones, por lo que utiliza de manera rigurosa el
Método Científico.
La aplicación del método científico parte del conocimiento disponible sobre un pro-
blema concreto; para ello se revisan profundamente los hechos y teorías existentes, se
formulan hipótesis para ser contrastadas mediante la experimentación, se lleva a cabo
una evaluación objetiva de las hipótesis y, finalmente, con base en resultados experi-
mentales, se emiten las conclusiones del caso.
Un punto de bastante complejidad es el referente a la evaluación objetiva de las hi-
pótesis, especialmente cuando se trabaja con organismos vivos, ya que en muchas si-
tuaciones se desconocen, con la precisión deseada, las relaciones causa-efecto, dada la
amplia variación natural a que están sometidas las especies animales. Muchas veces los
investigadores de las ciencias animales estudian casos particulares para extenderlos a
situaciones generales, cumpliéndose así el procedimiento de inferencia incierta.

134
La estadística es una herramienta de mucha utilidad en el método científico. Su aplica-
ción es palpable en aspectos que van desde la elaboración de un plan para recolectar los
datos o diseñar uno o más experimentos, hacer el análisis de los resultados, el resumen,
presentación y caracterización de los datos hasta concluir con la evaluación de la
incertidumbre de las inferencias.
Para visualizar con más claridad la utilidad de la Biometría en el método científico
positivista, es conveniente analizar la Figura 1.2.1, adaptada de Martínez y Martínez
(1997).
A manera de resumen, se podría asegurar que el profesional pecuario debe incentivar su
capacidad de análisis para recopilar información e interpretar datos numéricos pro-
cedentes de la observación de los múltiples fenómenos que se presentan en las especies
animales, al igual que para el manejo apropiado de las técnicas estadísticas útiles en la
investigación científica.
Es necesario reiterar que la biometría es un instrumento de investigación ya sea en
nutrición animal, genética, farmacología, patología y, en general, en cualquier campo as
acción de los profesionales del agro y sobre estos campos se propondrán problemas
específicos de investigación; por lo tanto, los instrumentos de investigación, como las
técnicas y procedimientos biométricos, deben constituirse en algo familiar para el
profesional, de manera que sean usados en forma eficiente, al igual que las ayudas que
proporciona el software especializado disponible. De este modo, los profesionales
estarán capacitados para presentar resultados en forma crítica, clara y objetiva y
dispondrán de elementos, con base científica, a la hora de proponer soluciones.

135
Figura 1.2.1 Ciclo de La Ciencia: Conexión entre la Biometría y el Método
Científico
1.3 DEFINICIONES Y CONCEPTOS
Para un desarrollo más ágil en la lectura y comprensión de este texto es recomendable
familiarizarse con ciertos términos que se utilizarán en las temáticas siguientes. No es
conveniente memorizar el significado, sino formarse conceptos para su posterior aná-
lisis y aplicación; en algunas ocasiones será necesario diferenciar algunas expresiones
que en estadística significan una cosa y en el lenguaje cotidiano otra.
1.3.1 Datos. En producción y salud animal, los fenómenos naturales son la materia
prima para los trabajos de investigación. Cuando se realizan análisis estadísticos debe
tenerse en cuenta que, en la gran mayoría de situaciones, las observaciones estarán
representadas en forma numérica, así por ejemplo, en farmacología las observaciones
pueden ser los tiempos que tardan los animales en recuperarse luego de la aplicación de
un antibiótico o el número de animales curados; en mejoramiento genético las observa-
ciones podrían estar constituidas por el peso al nacer de los lechones provenientes de un
cruzamiento entre dos razas; en alimentación animal la ganancia de peso de los terneros

136
sometidos a diferentes dietas; en el manejo de praderas el rendimiento por hectárea de
las variedades de pasto. En general, las observaciones corresponden al fenómeno que se
desea estudiar y los números obtenidos de dichas observaciones constituyen los datos
que, en la mayoría de los casos, exhiben variación entre ellos.
1.3.2 Variables. En estadística se emplea la palabra variable para referirse a cualquier
característica o atributo de las entidades que interesan en una investigación; por ejem-
plo, en nutrición se tendrá como objetivo evaluar la calidad nutritiva de un aumento a
través de la medición de las variables conversión alimenticia o consumo del aumento. El
profesional de la acuicultura podría estar interesado en investigar la resistencia de una
variedad del Penaeus vannamei al síndrome de la mancha blanca. En virtud de que cual-
quiera de estas características, por regla general, presenta un valor diferente cuando se
observa en diversas entidades, ella recibe el nombre de variable. Si los valores numéri-
cos que toma una variable provienen de factores fortuitos y si un valor determinado no
se puede predecir con anticipación, ésta se denomina variable aleatoria.
Las variables aleatorias pueden ser cuantitativas o cualitativas. Una variable cuan-
titativa está representada por valores de carácter numérico y expresa una magnitud; por
ejemplo, el peso al nacer de los bovinos, la alzada de los equinos, la edad al primer
servicio de los caprinos, el número de galpones dedicados a la explotación de gallinas
ponedoras en una región, el tamaño de los alevinos de trucha arco iris, el número de co-
lonias de bacterias en un medio de cultivo, el número de animales enfermos, y muchas
otras. Las variables cuantitativas, a su vez, pueden ser continuas o discretas.
Una variable continua está representada por cualquier valor dentro de un intervalo, es
decir, que teóricamente puede tomar cualquier número real entre dos valores dados. La
longitud y el peso de los peces son ejemplos típicos.
Una variable discreta, también llamada discontinua, toma valores posibles que no se
pueden observar en una escala continua debido a la existencia de espacios entre estos
datos y a la ausencia de valores intermedios; en otras palabras, las variables discretas
solo toman valores enteros. Por ejemplo, el número de pezones de una vaca, el número
de productores de cuyes en un corregimiento, el número de lechones en un parto, el
número de ovas por hembra de tilapia, el número de animales recuperados después de
un tratamiento con macrólidos, y muchos otros.

137
Las variables cualitativas no se miden numéricamente, sino que se asignan a una o
varias categorías mutuamente excluyentes, es decir, una observación particular no es
posible asignarla a más de una clase. Un ejemplo común es la clasificación del ganado
Holstein según el color del pelo, que puede ser negro o rojo, caso en el que habrán dos
categorías. En el ganado Shorton, con el mismo criterio, se pueden formar tres catego-
rías; rojo, blanco o roano, este último también conocido como salinero.
En los análisis estadísticos se emplean algunos símbolos, en lugar de escribir la variable
en cada oportunidad. Por ejemplo, si Y representa cualquier variable de interés, entonces
Yi representará la i-ésima observación, es decir, cualquier observación, sin referirse a
una en particular; cuando sea necesario hacer referencia a una en particular, se
reemplazará el subíndice i por un número específico. El Ejemplo 1.3.1, que se ofrece a
continuación, permite una mejor comprensión.
Ejemplo 1.3.1: En una carnada de cuyes (Cavia porcellus) nacen vivos tres gazapos
que pesan 89, 93 y 110 g, respectivamente. Y es la variable peso al nacimiento: Y1 = 89
g, Y2 = 93 g y Y3 = 110 g.
En general, se identifica el conjunto de observaciones como Y1, Y2, Y3,..., Yn donde n
representa la última observación y los puntos el resto de observaciones existentes. En el
Ejemplo 1.3.1 planteado anteriormente, n = 3, Yi = cualquier observación, Y3 = 110 g.
1.3.3 Escalas de medida. Existen cuatro niveles generales de medición: nominal, ordi-
nal, de intervalo y de razón. Estos niveles conducen a cuatro tipos de escalas:
Escala nominal. La medida con una escala nominal implica la clasificación en
categorías, por nombres o designaciones de los fenómenos de interés; por
ejemplo, el sexo y la raza de los bovinos. Si a las categorías se les asigna
números que pueden ser 1, 2, 3 y 4, sólo es posible interpretarlos como
diferentes, esto es 1 ≠ 2 ≠ 3 ≠ 4, sin que se pueda afirmar que una es superior a
otra, así una clasificación de las razas bovinas de carne en hereford, shorton,
angus y limousine, identificadas como 1, 2, 3 y 4 no indica superioridad o

138
inferioridad de alguna de ellas con respecto a cualquier atributo estudiado en
esas razas.
Escala ordinal. La medida ordinal incluye las propiedades de la medida
nominal, pero además las categorías pueden ser ordenadas en el sentido mayor
que o menor que. Por ejemplo, por resistencia a la mastitis de las vacas jersey, se
podría sugerir un agrupamiento en tres categorías 1, 2 y 3, caso en el que el 3 es
el número correspondiente a la mayor resistencia. Sin embargo, el nivel de
medición ordinal no ofrece ningún tipo de información sobre la magnitud de las
diferencias entre categorías. Si éstas vienen dadas en términos de alto, medio y
bajo y se identificarán como 3, 2 y 1 respectivamente, esto no implica que exista
una unidad de diferencia entre cada categoría, sino simplemente que 3 > 2 > 1.
Escala de intervalo. Una medida de intervalo se realiza cuando se asignan
ciertos números a los objetos o acontecimientos estudiados, que además de
poseer las características de la escala ordinal permiten interpretar la diferencia
entre dos medidas, es decir, se puede indicar la cantidad en que un evento se
diferencia de otro. En esta escala el punto cero y la unidad de medida son
arbitrarios. Las escalas de medición en intervalo más conocidas son las
utilizadas para medir la temperatura. Las escalas Celsius y Fahrenheit, por
ejemplo, tienen un punto cero arbitrario, pero esto no indica ausencia de
temperatura, puesto que es posible registrar valores por encima o por debajo de
ese punto.
Escala de razón. Es la escala más potente de las cuatro existentes, ya que posee
todas las propiedades de las escalas anteriores y un punto de cero absoluto; por
lo tanto, es posible indicar cuántas veces un objeto es más grande que otro y la
cantidad que los diferencia. El peso vivo, la alzada, el tiempo de recuperación, el
rendimiento en canal, entre otros atributos, se miden en escala de razón.
Según el nivel de medición aplicado a las variables estudiadas, éstas se pueden clasificar
como nominales, ordinales, de intervalo o de razón. Es importante que el investigador
identifique la escala de medida de las variables, puesto que para cada una de ellas exis-
ten procedimientos estadísticos adecuados que posibilitan el mejor uso de la informa-
ción contenida en los valores del atributo.

139
1.3.4 Población y muestra. Etimológicamente, el término población proviene del latín
populus (pueblo) y éste del griego polós (mucho). En los textos de estadística se
encuentran definiciones más o menos comunes de población, también llamada universo.
En estadística la población se define como el conjunto de todos los valores posibles de
una variable medida en cualquier escala. Estos valores no necesariamente serán
diferentes entre sí, ni tampoco estarán obligatoriamente representados en número finito.
También es aceptado que una población es el conjunto de elementos reunidos bajo una
característica común.
Los conceptos antes mencionados bastan para establecer con claridad el significado del
término población; sin embargo, dado que en este caso el objeto de trabajo son las
poblaciones biológicas, es conveniente analizar la definición expresada por Gomes da
Silva (1982), para una población biológica, en los siguientes términos: "Sistema
constituido por partes que se integran armónicamente entre sí, para adaptarse a las
continuas alteraciones del ambiente en sus múltiples aspectos".
La anterior definición es válida tanto para las poblaciones animales como para las vege-
tales y de microorganismos y sobre todas éstas se realizan los trabajos de investigación
en producción y salud animal.
Las medidas calculadas sobre la población se llaman parámetros y el total de elementos
constituyen una población se denota con la letra N. Si se conocen todos los posibles
valores de una variable en la población, teóricamente podría ser estudiada y descrita
perfectamente.
En general, muestra es toda parte representativa de una población, lo que significa que
la muestra debe conservar las características esenciales de la población. Desde el punto
de vista del método científico, la muestra se considera como una parte extraída
correctamente de una población, para luego ser observada científicamente, con el
objetivo de obtener resultados válidos para la población de donde se obtuvo.
Estadísticamente es factible determinar los límites de error y la probabilidad sobre la
validez de los resultados obtenidos con la muestra cuando éstos se generalizan en toda
la población. Para disponer de una muestra representativa, es necesario incorporar el
principio de aleatoriedad y las leyes de las probabilidades, con el propósito de evitar
sesgos en la selección de las observaciones, lo que en la práctica constituye un proceso

140
de cierta complejidad. Los procedimientos generales para obtener muestras
representativas de una población se indicarán en el Capítulo 4.
Las medidas obtenidas con datos de la muestra se llaman estadígrafos o estadísticos y
el número de elementos que constituyen la muestra se denota por n, que en la gran
mayoría de los casos será menor que N, salvo que la muestra tenga el tamaño de la po-
blación, como sucede en ocasiones realmente excepcionales.
A manera de resumen, en concordancia con los conceptos iniciales contemplados hasta
aquí, un análisis de la Figura 1.3.1, proporciona una visión global de los mismos y una
rápida comprensión de los objetivos del texto.
Figura 1.3.1 Ciclo inferencial
Los parámetros, convencionalmente se identifican con letras griegas. Así la media se
reconoce universalmente como 𝜇, la varianza como 𝜎2, la desviación estándar con 𝜎, el
coeficiente de regresión con 𝛽, el coeficiente de correlación 𝜌 y los correspondientes
estadígrafos como ��, S2, b, r.

141
CAPÍTULO 2
Presentación, resumen y caracterización de la información
En estadística existen dos maneras de presentar y resumir datos, una gráfica y otra
numérica, en las que, por lo general, se utilizan las técnicas y procedimientos
descriptivos.
Por ser la investigación un proceso sistemático, lo más lógico es comenzar por agrupar
los datos, mediante un procedimiento comúnmente empleado en la construcción de las
tablas de distribución de frecuencias y el diseño de histogramas, barras simples, barras
compuestas, barras proporcionales, diagramas circulares o pasteles, polígonos de
frecuencia y gráficos de dispersión, entre los más importantes.
Las tablas de frecuencia y los gráficos son de utilidad para interpretar, presentar y
escribir los datos, pero tienen limitaciones cuando se quiere establecer comparaciones
entre conjuntos de datos. El cálculo de las medidas de tendencia central y dispersión,
que obviamente son métodos numéricos, contribuyen a solucionar, en parte, estos
inconvenientes.
2.1 TABLAS DE DISTRIBUCIÓN DE FRECUENCIA
Para construir una tabla de distribución de frecuencias es oportuno indicar que dichas
tablas se pueden elaborar con cualquier tipo de variable y, para este proceso, es
necesario precisar algunos conceptos de interés.
Se entiende por frecuencia el número de veces que una característica o un valor aparece
en un conjunto de observaciones y por distribución de frecuencia el método estadístico
rara describir el comportamiento de un conjunto de datos; éstos se ubican en categorías
o clases y se indica la frecuencia correspondiente en cada una de ellas.
Para agrupar los datos en categorías es conveniente seguir una serie de reglas que se
resumen a continuación. Sin embargo, es importante indicar que en la actualidad existe
software especializado para desarrollar estos procedimientos estadísticos en forma rá-
pida, eficaz y confiable. En lo que respecta a la presentación, resumen, caracterización

142
de la información y análisis estadístico, en general, los paquetes estadísticos Stat Gra-
phics, SPSS, Minitab, R, Stata y SAS, entre otros, son herramientas eficientes.
2.1.1 Construcción de tablas de distribución de frecuencia. En seguida se describen
cada uno de los pasos para este proceso.
a. Calcular el número de categorías (NC). Depende, fundamentalmente, de la can-
tidad de datos disponibles y del tipo de variable. Con base en estas consideracio-
nes, existen algunas normas para lograr un número óptimo de categorías como la
regla de Sturges (1926), citado por Milton (1994), la tabla sugerida por Milton
(1994), basada justamente en esta regla, y el procedimiento propuesto por
Carvajal, et al (1993):
Regla de Sturges: NC = 1 + 3,3 (log n)
Método sugerido por Carvajal et al: NC = √n
Tabla reportada por Milton (1994), según el tamaño de la muestra (Tabla
1 del Apéndice).
b. Calcular la amplitud del intervalo de clase (AIC). Para calcular el intervalo de
clase se siguen estos pasos:
Establecer el rango (R): R = valor máximo - valor mínimo.
Dividir el rango entre el número de categorías previamente escogido. Si
el resultado de esta división no es entero, puede aproximarse a la unidad
más cercana, cuidando que se tenga el mismo número de decimales que
los datos.
𝐼𝐶 = 𝑅
𝑁𝐶
Con esta operación se encuentra la longitud mínima requerida para
cubrir el rango.
c. Definir el límite inferior (Li) y el límite superior (Ls) de cada intervalo. El
límite inferior de la primera clase es el dato de menor valor, el resto de los

143
límites de clase se obtienen mediante la suma sucesiva de la amplitud a partir del
primer valor.
Debe tenerse en cuenta que el dato mayor no es necesariamente el límite superior de la
última clase, pero debe estar incluido dentro de ésta.
El límite superior es el mismo valor del límite inferior de cada una de las clases
siguientes, pero se recomienda que ninguna observación particular coincida con los
valores de los límites y para esto pueden usarse varias estrategias que se indican más
adelante.
d. Asignar las frecuencias de cada categoría. Para ello se deben tener en cuenta
las siguientes definiciones:
La frecuencia absoluta (fi) es el número de veces que aparece un
determinado valor, perteneciente a una población o muestra analizada,
entre los límites de cada clase.
La frecuencia relativa (fa) es el porcentaje de cada frecuencia absoluta
con respecto al total de datos de la población o muestra analizada.
La frecuencia absoluta acumulada (Fi) es la suma de todas las
frecuencias absolutas anteriores al límite superior de una clase dada. La
frecuencia absoluta acumulada correspondiente a la última categoría
coincide con el número total de observaciones.
La frecuencia relativa acumulada (Fa) es la suma de todas las
frecuencias relativas anteriores al límite superior de una clase dada.
Ejemplo 2.1.1: Solarte y García (2001) recolectaron varias muestras aleatorias
constituidas por 50 cuyes (Cavia porcellus) machos, en la granja Botana, con el fin de
analizar la variable peso al destete. Al pesar cada individuo se encontraron los
siguientes resultados, expresados en gramos:
218, 258, 188, 177, 205, 225, 230, 231, 230, 143, 205, 189, 305, 285, 277, 288, 186,
258, 308, 310, 148, 258, 258, 139, 209, 285, 304, 289, 218, 289, 257, 129, 309, 258,
278, 289, 297, 303, 285, 308, 287, 258, 258, 209, 187, 209, 157, 208, 258, 128.

144
Con los anteriores datos correspondientes a una de las muestras, se construyó una tabla
de distribución de frecuencias cuyo procedimiento se detalla a continuación.
Según la regla de Sturges: NC = 1+3,3 (log 50) = 6,61 7.
Según la fórmula de Carvajal et al: NC = 50 = 7,07 7.
Según Milton (Tabla 1 del apéndice): NC = 6
Cualquiera de las tres opciones es válida; en este caso se escogió NC= 6. Es
conveniente tener en cuenta que escoger muchas clases puede ocasionar problemas ya
que algunas de ellas quedarían si elementos y se originarían clases vacías. Por el
contrario, si se escogen pocas clases se pierde claridad de la información por exceso de
agrupamiento.
Al desarrollar los pasos descritos anteriormente, se tiene:
R = 310 – 128 = 182
AIC = 𝑅
𝑁𝐶=
182
6= 30,33 31
Definir los límites de cada intervalo. para esto es importante tener en cuenta que
los límites de las clases deben ser mutuamente excluyentes, de lo contrario se
deben establecer criterios para no ser ambiguos, es decir, que no debe haber
duda en cuanto a la clase a que pertenece una observación determinada.
El límite inferior de la primera clase se estableció con la observación menor (para este
ejemplo es 128) y, posteriormente, se sumó sucesivamente el valor de AIC (31), hasta
completar todos los límites.
Clases Límite inferior Límite superior
1 128 159
2 159 190
3 190 221
4 221 252
5 252 283

145
6 283 314
Calcular las frecuencias en cada categoría. Para esto, simplemente se cuentan los
datos que caen dentro de cada intervalo.
Clase uno: 128, 129, 139, 143, 148, 157. Subtotal 6 observaciones
Clase dos: 177, 186, 187, 188, 189. Subtotal 5 observaciones
Clase tres: 205, 205, 208, 209, 209, 209, 218, 218. Subtotal 8 observaciones
Clase cuatro: 225, 230, 230, 231. Subtotal 4 observaciones
Clase cinco: 257, 258, 258, 258, 258, 258, 258, 258, 258, 277, 278 subtotal 11
observaciones
Clase seis: 285, 285, 285, 287, 288, 289, 289, 289, 297, 303, 304, 305, 308, 308,
309, 310. Subtotal 16 observaciones
Total: 50 observaciones
Al agrupar los datos de esta manera se debe tener en cuenta que los intervalos se
consideran cerrados por la izquierda y abiertos por la derecha, es decir, intervalos de la
forma [). Por ejemplo, suponiendo que en la muestra apareciera el número 221, este se
lo debe clasificar en el intervalo 221-252 y no en el intervalo 190-221.
Otra manera de agrupar el mismo conjunto de datos es la siguiente:
Clases Límite inferior Límite superior
1 128 158
2 159 189
3 190 220
4 221 251

146
5 252 282
6 283 313
En agrupaciones de este tipo deben tenerse en cuenta los límites reales de clase, que se
definen como el punto medio entre el límite superior de una clase y el límite inferior de
la siguiente, así:
Clases Límite inferior Límite superior
1 127,5 158,5
2 158,5 189,5
3 189,5 221,5
4 221,5 251,5
5 251,5 282,5
6 282,5 313,5
En la tabla 2.1.1 se presenta la información completa para este ejemplo.
Tabla 2.1.1 Peso al destete de cuyes machos (cavia porcellus) en la granja Botana
de la Universidad de Nariño, Pasto, Colombia, 1995
Clase
Intervalos
de clase
Peso al
destete (g)
Frecuencia
absoluta fi
Frecuencia
relativa
(%) fa
Frecuencia
absoluta
acumulada
Fi
Frecuencia
relativa
acumulada
Fa
1 128-159 6 12 6 12
2 159-190 5 10 11 22

147
3 190-221 8 16 19 38
4 221-252 4 8 23 46
5 252-283 11 22 34 68
6 283-314 16 32 50 100
Total 50 100
Para diseñar tablas de este tipo, además de las consideraciones de procedimiento
descritas anteriormente, deben tenerse en cuenta los siguientes aspectos:
El titilo de la tabla debe ser claro y completo de tal manera que responda a las
preguntas ¿Qué es?, ¿Dónde? Y ¿Cuándo? (Carvajal, et al, 1993).
En la primera columna se indica la categoría, en la segunda la variable con su
unidad de medida y el intervalo correspondiente, en el resto de columnas las
respectivas frecuencias.
2.2 GRÁFICOS ESTADÍSTICOS
Los datos también se pueden presentar en forma gráfica mediante figuras geométricas
dibujadas a escala, con la intención de proporcionar una visión de fácil comprensión con
referencia a la variable estudiada; por este motivo el grafico debe ser sencillo y claro.
Para diseñar la figura es necesario construir previamente la respectiva tabla de
distribución de frecuencias, por lo tanto el grafico debe concordar con el de la tabla. En
las publicaciones científicas, la mayoría de editores de revistas especializadas
recomiendan no duplicar la información, es decir, si se decide presentar los datos en
tablas no se debe incluir el grafico para el resumen de los datos, así que el investigador
decidirá sobre la forma que proporcione mayor claridad.
Entre los gráficos más utilizados en estadística se pueden mencionar los histogramas y
polígonos de frecuencia y los diagramas circulares, comúnmente denominados pasteles.
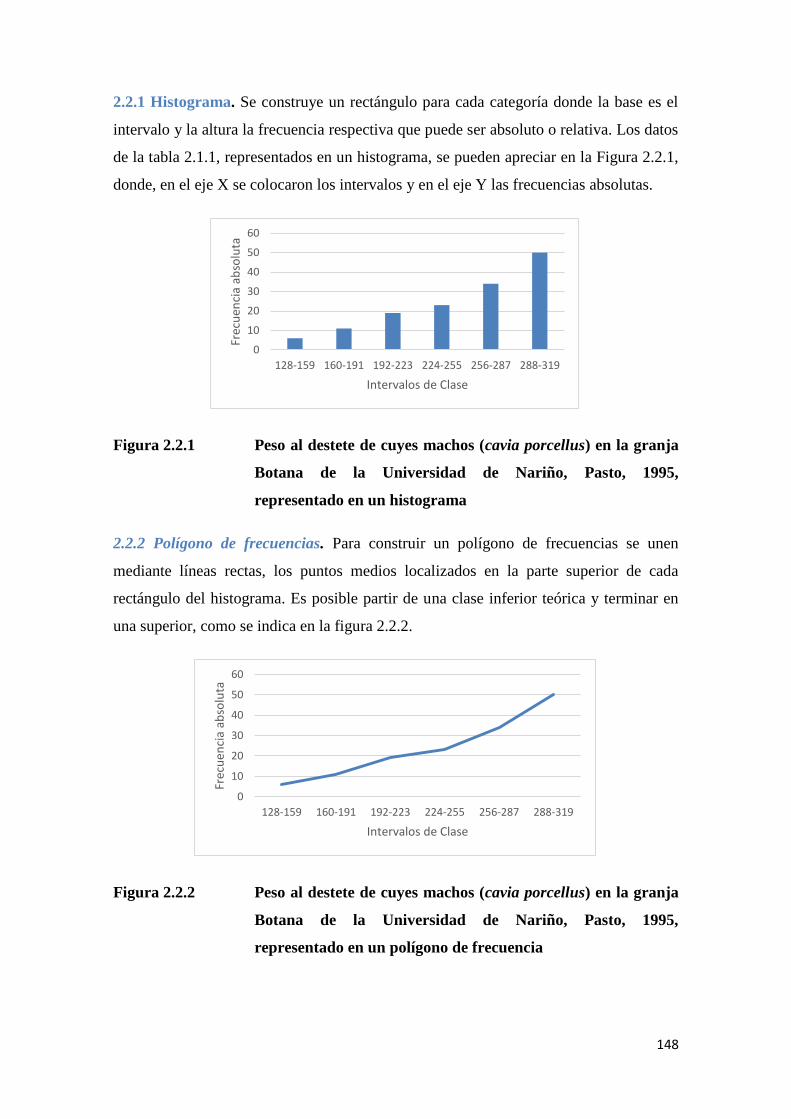
148
2.2.1 Histograma. Se construye un rectángulo para cada categoría donde la base es el
intervalo y la altura la frecuencia respectiva que puede ser absoluto o relativa. Los datos
de la tabla 2.1.1, representados en un histograma, se pueden apreciar en la Figura 2.2.1,
donde, en el eje X se colocaron los intervalos y en el eje Y las frecuencias absolutas.
Figura 2.2.1 Peso al destete de cuyes machos (cavia porcellus) en la granja
Botana de la Universidad de Nariño, Pasto, 1995,
representado en un histograma
2.2.2 Polígono de frecuencias. Para construir un polígono de frecuencias se unen
mediante líneas rectas, los puntos medios localizados en la parte superior de cada
rectángulo del histograma. Es posible partir de una clase inferior teórica y terminar en
una superior, como se indica en la figura 2.2.2.
Figura 2.2.2 Peso al destete de cuyes machos (cavia porcellus) en la granja
Botana de la Universidad de Nariño, Pasto, 1995,
representado en un polígono de frecuencia
0
10
20
30
40
50
60
128-159 160-191 192-223 224-255 256-287 288-319
Frec
uen
cia
abso
luta
Intervalos de Clase
0
10
20
30
40
50
60
128-159 160-191 192-223 224-255 256-287 288-319
Frec
uen
cia
abso
luta
Intervalos de Clase

149
2.2.3 Ojiva o polígono de frecuencia acumulada. Se diseña para representar las
frecuencias acumuladas absolutas o relativas. Para su construcción se forman puntos
haciendo coincidir el límite inferior de cada clase con el valor de la frecuencia
acumulada respectiva, luego se unen estos puntos con líneas rectas. En el eje X se ubica
los intervalos y en el eje Y las frecuencias acumuladas, tal como se aprecia en la figura
2.2.3.
Figura 2.2.3 Peso al destete de cuyes machos (cavia porcellus) en la granja
Botana de la Universidad de Nariño, Pasto, 1995,
representado en una ojiva.
Esta figura corresponde a la ojiva denominada “menor que”, la que debe interpretarse
como el número de observaciones inferiores al límite superior de cada clase. Para este
caso no hay ninguna observación menor de 128, seis menores de 159, 11 menores de
190, y así sucesivamente, hasta concluir que 50 son menores de 314 gramos.
En la figura 2.2.4 se puede apreciar la gráfica de los datos en un diagrama circular,
donde las divisiones distinguibles del círculo representan cada una de las categorías.
0
10
20
30
40
50
60
128-159 160-191 192-223 224-255 256-287 288-319Frec
uen
cia
abso
luta
acu
mu
lad
a
Intervalos de clase
4%8%13%
16%24%
35%
128-159 160-191 192-223 224-255 256-287 288-319

150
Figura 2.2.4 Peso al destete de cuyes machos (cavia porcellus) en la granja
Botana de la Universidad de Nariño, Pasto, 1995,
representado en un diagrama circular.
A manera de resumen, respecto a la representación de la información en forma gráfica,
se deben tener en cuenta las siguientes recomendaciones:
a. Cuando la variable analizada es continua es preferible utilizar el histograma, el
polígono o el grafico de dispersión.
b. Para variables discretas son recomendables los histogramas o los diagramas
circulares. En el ejemplo 2.1.1, se resumieron los datos en un diagrama circular
solo como ilustración.
c. En el titulo de los gráficos no es necesario aclara el tipo de figura. En el ejemplo
se hizo la aclaración, exclusivamente con fines didácticos.
2.2.4 Curvas de frecuencia. En estadística, los datos que se procesan, por lo general,
pertenecen a muestras aleatorias extraídas de una población; por lo tanto, el histograma
y el polígono de frecuencias describen las variaciones que experimenta una variable o
característica en dicha muestra; sin embargo, si se aumenta el número de observaciones
y al mismo tiempo se disminuye la amplitud de los intervalos, el polígono de frecuencia
está formado por pequeños segmentos que se aproximan a una curva, tal como se
aprecia en la Figura 2.2.4 Este tipo de curva ideal recibe el nombre de curva de
frecuencia.
Figura 2.2.5 Representación de una curva de distribución de frecuencias

151
Las curvas de frecuencia son de gran utilidad en el análisis estadístico porque
proporcionan métodos simplificados para describir las características básicas de las
poblaciones, así como también en la inferencia estadística, donde se requiere conocer la
distribución de la variable en la población de donde se obtuvo la muestra. En la Figura
2.2.6 esta representadas las formas de curvas más comunes.
La curva simétrica se denomina distribución normal o curva normal; en ella, las
frecuencias de clase son mayores en el centro y disminuyen hacia los extremos de
manera similar. Esta curva tiene gran importancia en estadística puesto que proporciona
una adecuada representación de las distribuciones de una gran cantidad de variables,
tales como los datos meteorológicos de temperatura y precipitación pluvial, mediciones
efectuadas en organismos vivos, entre las que pueden mencionarse el peso y la talla,
calificaciones en pruebas de aptitud, rendimiento en cultivos y muchas otras.
Figura 2.2.6 formas de curvas de distribución de frecuencias más comunes en
estadística
Las curvas asimétricas con sesgo a la derecha o a la izquierda son modelos de
distribuciones asimétricas, bastante comunes en datos económicos y comerciales.

152
La curva J, llamada así por su forma, es frecuente en muchos estudios biométricos.
La forma de las curvas también proporciona información importante, por ejemplo, en el
caso de las bimodales, la aparición de dos modas pueden implicar un cambio en el
proceso durante el estudio de un fenómeno particular o que los datos provienen de dos
fuentes diferentes.
2.3 MEDIDAS DE TENDENCIA CENTRAL Y DE DISPERSIÓN
Se mencionó anteriormente que los métodos para presentar la información en forma
gráfica o en tablas de frecuencia son útiles cuando se trata de ofrecer al lector una visión
general de los resultados, pero no son tan eficientes cuando se trata de establecer las
características más importantes de los datos en lo referente a su localización y
variabilidad.
Los métodos numéricos permiten extender los análisis y posibilitan comprender, de
modo más claro, la naturaleza de la distribución de cualquier variable de interés en
producción o salud animal. Estos métodos se orientan, básicamente, a describir el centro
de la distribución de las observaciones y la forma como estas varían en torno a ese valor
central. Dicho de otra manera, permiten calcular las medidas de posición, localización o
tendencia central y las medidas del espaciamiento o dispersión de los datos.
2.3.1 Medidas de tendencia central. Las medidas de tendencias central más utilizadas
son la media o promedio, la mediana y la moda o modo. A continuación se hará
referencia a cada una de ellas, con las correspondientes formas de cálculo, con datos
agrupados y sin agrupar.
2.3.1.1 la media o promedio aritmético. Es la medida de la tendencia central más
utilizada; se presenta como µ (mu) para la población y como Ȳ (Y barra) para la
muestra, de tal manera que µes el parámetro, cantidad fija y desconocida, mientras Ȳ es
el estadígrafo, el cual puede tomar diferentes valores al calcularse con diversas muestras
obtenidas de la misma población objeto de estudio. La media aritmética se expresa en
las mismas unidades de la variable original, sean litros, gramos, kilogramos hectáreas,
etc.

153
Conviene aclarar que existen otros tipos de medidas diferentes a la aritmética, tal como
se verá posteriormente, pero el uso generalizado de la palabra media o promedio, ha
hecho que se tome este término para referirse al promedio aritmético, sin indicarlo
expresamente.
La fórmula de cálculo de la media aritmética es la siguiente:
𝜇 =∑ 𝑌𝑖𝑁
𝑖=1
𝑁
Ȳ =∑ 𝑌𝑖𝑛
𝑖=1
𝑛
Dónde:
∑ 𝑌𝑖𝑁𝑖=1 = Sumatoria de los Yi, desde la primera hasta la última observación
𝑌𝑖 = Las observaciones
N y n = Tamaño de la población y muestra respectivamente
Aunque no existen normas precisas para calcular los decimales del valor de la media
algunos autores recomiendan utilizar un decimal más que los datos originales.
Ejemplo 2.3.1: Los datos que se muestran a continuación corresponden a la talla en
(cm) de una muestra de 10 ejemplares de bagre del Patía (Rhamdiaquelem), según
reporte de Ortega y Rodríguez (2004).
Ejemplares 1 2 3 4 5 6 7 8 9 10
Talla (cm) 35,0 27,0 34,5 34,9 34,0 32,0 22,0 37,0 26,0 33,0
De acuerdo con la formula (2.3.2), la media se calcula así:

154
Ȳ =∑ 𝑌𝑖
𝑛=
35,0+27,0+34,5+34,934,0+32,0+22,0+37,0+26,0+33,0
10
=31,54 cm
Como se observa, el valor de la media se calculó con un decimal más que los datos
originales.
En algunas situaciones los valores de la variable están afectados por una frecuencia
particular o peso relativo (W). En estos casos para calcular la media se deben multiplicar
los pesos relativos por los valores correspondientes de la variable y luego se divide este
resultado entre la sumatoria de dichos pesos. La media obtenida de este modo se
denomina media o promedio aritmético ponderado, cuya denominación corriente es
promedio ponderado (Ȳ,). La fórmula de cálculo es la siguiente:
Ȳ𝑤 =∑ 𝑌𝑖𝑊𝑖
∑ 𝑊𝑖
(2.3.3)
Ejemplo 2.3.2: en una estación pisicola localizada en el municipio de Repelon,
Atlantico, se explotan en policulivo cuatro especies icticas a saber: tilapia rojoja
(Oreochromissp), tilapia nilotica (Oreochromisniloticus), carpa espejo
(Cyprinuscaripiovar. Specularis) y cachama blanca (Piaractusbrachipomus), cuyos
pesos se indican en la Tabla 2.3.1 (Valencia y Rey, 1994), cada una en diferente
cantidad y como se sabe, cada especie posee distinta aptitud productora. Para calcular el
promedio lo más indicado es ponderar el peso de acuerdo con el número de animales de
cada especie.
Tabla 2.3.1 Peso individual de cuatro especies ícticas, en una estación
piscícola del municipio Repelón, Atlántico, Colombia
(Valencia y Rey, 1994)

155
Especie Peso (Yi) Nº Peces (Wi) 𝒀𝒊 𝑾𝒊
Orechomis sp 350 2.550 892,500
O. niloticus 320 3.800 1.216.000
C. Carpio var specularis 452 1.280 578.560
P. brachypomus 395 963 380.385
Sumatoria 8.593 3.067.445
Este ejemplo es típico puesto que existe un distinto número (frecuencia) de animales por
cada una de las especies y, como ya se mencionó, con un nivel productivo diferente.
��𝒊 = ∑ 𝒀𝒊𝑾𝒊
∑ 𝑾𝒊=
𝟑. 𝟎𝟔𝟕. 𝟒𝟒𝟓
𝟖. 𝟓𝟗𝟑= 𝟑𝟓𝟔, 𝟗𝟕 𝒈.
En otros casos se presentan relaciones de cambio que afectan a la variable estudiada.
En estas circunstancias lo más aconsejable es calcular la Media geométrica (G) que
permite asignar ponderaciones iguales a dichas relaciones.
Por definición, la Media geométrica es la raíz n-ésima del producto de los valores de la
variable, siempre y cuando estos valores sean positivos. Para su cálculo basta con
aplicar la siguiente formula.
G = 𝑛√(𝒀𝟏) (𝒀𝟐) … … . (𝒀𝒏)
(2.3.4)
Ejemplo 2.3.3: si se quiere medir el promedio de crecimiento a través del número de
colonias de la bacteria E. coli en un cultivo, durante un periodo de tres horas, lo más
recomendable es calcular G, dado que existe una relación entre el tiempo, medido en
horas, y el número de colonias bacterianas que crecen en el medio.

156
Horas de cultivo Número de colonias
1 2
2 4
3 5
Colonias/hora
G = 3√(𝟐) (𝟒)(𝟓) = 3,42
Existen otro tipo de medias tales como la Armónica (H) y la Cuadrática (MQ). La
primera tiene algunas aplicaciones prácticas en genética cuantitativa y en ciertas
comparaciones de medias en el diseño experimental; la segunda, principalmente en
física.
La media armónica se calcula así:
𝑯 = 𝟏
𝟏𝑵
∑𝟏𝒀𝒊
= 𝟏
∑𝟏𝒀𝒊
(2.3.5)
También se puede expresar la fórmula de cálculo mediante los inversos, así:
𝟏
𝑵=
∑𝟏𝒀𝒊
𝑵=
𝟏
𝑵 ∑
𝟏
𝒀𝒊
(2.3.6)
Ejemplo 2.3.4: Para el conjunto de observaciones 5, 7, 9, 6, 8, la madia armónica se
obtiene de la siguiente manera:
𝑯 = 𝟓
𝟏𝟓
+𝟏𝟕 +
𝟏𝟗 +
𝟏𝟔 +
𝟏𝟖
= 𝟓
𝟎, 𝟕𝟒𝟓𝟔𝟑𝟒= 𝟔, 𝟕𝟎

157
Con los inversos:
𝟏
𝑯=
𝟏
𝟓 𝟎, 𝟎𝟒𝟓𝟑𝟒 = 𝟎, 𝟏𝟒𝟗𝟏𝟐𝟔, 𝒂𝒔𝒊 𝒒𝒖𝒆 𝑯 =
𝟏
𝟎, 𝟏𝟒𝟗𝟏𝟐𝟔= 𝟔, 𝟕𝟎
Para calcular MQ, se utiliza la siguiente formula:
𝑀𝑄 = √∑ 𝒀𝒊
𝟐
𝑁
(2.3.7)
Ejemplo 2.3.5: con el mismo conjunto de datos utilizado para el cálculo de la media
armónica:
𝑴𝑸 = √𝟓𝟐 + 𝟕𝟐 + 𝟗𝟐 + 𝟔𝟐 + 𝟖𝟐
𝟓= √𝟓𝟏 = 𝟕, 𝟏𝟒
Hasta ahora se han indicado los procedimientos de cálculo cuando los datos están sin
agrupar, sin embargo, si estos se encuentran agrupados en tablas de distribución de
frecuencias, es decir, organizados en categorías y no se dispone de la información sin
agrupar, es posible tener una aproximación de las medidas de tendencia central, con
procedimientos particulares que se indican a continuación.
Para calcular el promedio aritmético, bajo estas circunstancias, simplemente se aplica la
siguiente formula:
�� = ∑ 𝒇𝒊𝒎𝒊
𝒏𝒊=𝟎
𝒏
(2.3.8)
Dónde:
𝒇𝒊 = Frecuencia absoluta de la i-ésima categoría.

158
𝒎𝒊 = Marca de clase o valor central de cada intervalo, calculado como el promedio
aritmético de los límites superior e inferior de cada clase.
Ejemplo 2.3.6: Para ilustrar la forma de cálculo se utilizarán los datos de la Tabla2.1.1.
Con el fin de facilitar los cálculos posteriores es conveniente organizar la información
tal como se indica a continuación.
Clase Frecuencia absoluta
𝒇𝒊 Marca de clase 𝒎𝒊 𝒇𝒊𝒎𝒊
1 6 143,5 861,0
2 5 174,5 872,5
3 8 205,5 1.644,0
4 4 236,5 946,0
5 11 267,5 294,5
6 16 298,5 4.776,0
Ʃ 50 12.042,0
Al aplicar (2.3.8): �� = 12,042
50= 240,84 𝑔.
Para finalizar, los aspectos generales referentes al promedio aritmético, es importante
tener en cuenta las siguientes características de esta medida de localización:
En el cálculo del promedio intervienen los datos de un conjunto.
El promedio aritmético es calculado en forma rígida, lo que implica que existe
un solo promedio para cada conjunto de datos.
El promedio es sensible a valores extremos.

159
Por estar definido algebraicamente, el promedio permite tratamiento algebraico.
La sumatoria de las desviaciones con respecto a la media es igual a cero:
∑(𝒀𝒊��) = 𝟎
𝑛
𝑖=1
Se utilizan con datos cuya escala es de intervalo o razón.
Puede ser empleado en el análisis de distribuciones simétricas.
Es la base de la inferencia estadística.
2.3.1.2 La Mediana (M). Es otra medida de tendencia central que tiene como propiedad
dividir los valores de un conjunto ordenado de datos en dos fracciones, de tal manera
que el 50 % de las observaciones se sitúan por encima y el 50% restante por debajo de
ella. Es decir, la mediana se define como el numero situado en la mitad de un conjunto
de datos ordenados de menor a mayor.
Cuando n es impar, la mediana es el número situado en la mitad del conjunto, pero
cuando n es par, la mediana será la media aritmética de las dos observaciones situadas
en la mitad. Si n es pequeño, es fácil detectar el centro del conjunto de observaciones,
pero a medida que n aumenta se hace más difícil. Para evitar confusiones, se aplica una
fórmula que permite detectar dicho valor central en un conjunto con un número de
elementos par o impar y ubicarla situación mediana (SM) que indica el sitio en que se
encuentra la mediana, la cual expresa de esta forma:
SM = 𝒏+𝟏
𝟐
(2.3.9)
Ejemplo 2.3.7: El siguiente conjunto impar de datos corresponde a valores de la
habilidad de transmisión predecible (PTA) para la proteína de la leche en lb. La PTA es
un estimativo del rendimiento medio de la progenie por efecto del potencial genético
heredado del padre. Las cifras en mención se obtuvieron de un catálogo de la
Cooperative Resources International (CRI, 2000): 78,81, 77, 56, 69, 41, 54. Para
calcular la mediana, primero deben ordenarse los datos de menor a mayor: 41, 54, 56,
69, 77, 78, 81.

160
A simple vista se puede detectar que 𝑴𝒆 = 69 ya que por debajo de 69 están los valores
41, 54 y 56, mientras que por encima están 77, 78 y 81. En otras palabras, el 50% de las
cifras son menores que 69 y el 50% mayores a esa cantidad.
Al aplicar (2.3.9) se tiene: SM = 𝟕+𝟏
𝟐 = 4
Es decir que la 𝑴𝒆 es la cuarta observación ordenada, o sea 69 lb.
Ejemplo 2.3.8: Con un conjunto par de datos, de la misma fuente y para la misma
variable, se tiene: 85, 78, 55, 69, 82, 70, 63, 84, que ordenado de menor a mayor queda:
55, 63, 69, 70, 78, 82, 84, 85.
Al aplicar (2.3.9): SM = 𝟖+𝟏
𝟐 = 4,5
La 𝑴𝒆 será el promedio de los dos valores centrales.
Por lo tanto: 𝑴𝒆 =𝟕𝟎+𝟕𝟖
𝟐 = 74
Es decir, el promedio de las observaciones 4 y 5. La cuarta observación es 70 y la quinta
es 78; el promedio de estos valores es 74, por lo tanto el 50% de los valores son
inferiores a 74 libras y el 50% restante es superior a la misma cantidad.
Como se observa, a diferencia del promedio, la mediana no se afecta por valores
extremos de la variable, es decir, por datos que están muy distantes del resto de
observaciones. Este tipo de datos se conoce con el nombre de “datos atípidos”,
“outliers” o “números aberrantes” (Milton, 1994). Los “outliers” se presentan en un
conjunto de datos con valores inusualmente grandes o pequeños o porque existen
errores de medición o registro en la base de datos. Si la situación es controlada por
primera vez, el investigador puede optar por efectuar los cálculos con y sin los datos
aberrantes y hacer la aclaración respectiva.
Calculo de la mediana con datos agrupados: Cuando los datos están
organizados en tablas de frecuencias, para calcular 𝑴𝒆 se requiere aplicar la
siguiente fórmula de trabajo:

161
𝑴𝒆 = 𝑳𝒊 +
𝒏𝟐 − 𝑭𝒊−𝟏
𝒇𝒊
(𝒂)
(2.3.10)
Dónde:
𝑳𝒊 = Límite inferior de la clase mediana. Se entiende por clase mediana la clase donde la
frecuencia absoluta acumulada contiene al 50%de los datos.
𝒏
𝟐 = Valor que define la clase mediana, es decir, divide los datos en dos partes iguales.
𝑭𝒊= Frecuencia absoluta de la clase mediana.
a = Tamaño del intervalo.
Ejemplo 2.3.9: Con los mismos datos de la Tabla 2.1.1, que se vuelve a presentar por
comodidad para el lector, se desarrollará la fórmula de cálculo.
Clase Peso al
destete (g)
Frecuencia
Absoluta 𝒇𝒊
Frecuencia
Relativa 𝒇𝒂
Frecuencia
Absoluta
Acumulada 𝑭𝒊
Frecuencia Relativa
Acumulada 𝑭𝒂
1 128-159 6 12 6 12
2 159-190 5 10 11 22
3 190-221 8 16 19 38
4 221-252 4 8 23 46
5 252-283 11 22 34 68
6 283-314 16 32 50 100
Total 50 100

162
Con base en la información de esta tabla se obtienen las siguientes cifras:
n = 50 𝒏
𝟐 =
𝟓𝟎
𝟐= 25
Como se observa, 25 está contenido en la frecuencia absoluta acumulada de la quinta
clase y, por ende, ésta es la clase mediana, cuyo intervalo es 252-283, así que el límite
inferior de la clase mediana (𝑳𝒊) es 252.
La frecuencia absoluta (𝒇𝒊) de la clase mediana es 11.
La frecuencia absoluta acumulada de la clase cuatro (𝒇𝟓−𝟏 = 𝒇𝟒), anterior a la clase
mediana, es 23.
El tamaño del intervalo (a) es 31
Al aplicar la (2.3.10) se tiene:
𝑴𝒆 = 𝟐𝟓𝟐 +
𝟓𝟎𝟐 − 𝟐𝟑
𝟏𝟏(𝟑𝟏) = 𝟐𝟓𝟕, 𝟔𝟑
La mediana tiene las siguientes propiedades:
Para su cálculo no se tienen en cuenta los extremos, por lo tanto no está
influenciada por éstos.
La mediana se utiliza con datos cuya escala es de razón, intervalo u ordinal.
Es aconsejable utilizarla en distribuciones notablemente asimétricas, cuyos
extremos no están bien definidos.
2.3.3.3 Cuartiles, deciles y percentiles. Ya se mencionó que la 𝑴𝒆 es una medida que
indica el punto donde el conjunto de datos se divide en dos fracciones, cada una de las
cuales contiene el 50% de los datos. De la misma manera es posible encontrar otras
medidas, denominadas cuartiles, que indican la división en cuatro fracciones del
conjunto que representan el 25%, el 50%, o el 75% de los datos.
El primer cuartil (𝑸𝟏) deja el 25% de los datos por debajo de su valor; el segundo (𝑸𝟐)
es la mediana, ya que deja el 50% de los datos por debajo de su valor, el tercero (𝑸𝟑)
deja el 75% de los datos por debajo de su valor. (𝑸𝟏) Es el cuartil inferior, (𝑸𝟐) el
cuartil medio y (𝑸𝟑) el cuartil superior.

163
De forma análoga que en la mediana, se puede encontrar la situación de los cuartiles,
mediante una formula, tal como se indica en seguida:
𝑺𝑸𝟏 = 𝒏 + 𝟏
𝟒
(2.3.11)
Si al aplicar (2.3.11) el resultado no es un entero, 𝑺𝑸𝟏 se aproxima al entero más
cercano.
Cuando 𝑺𝑸𝟏 cae entre dos enteros, es decir, en media unidad, entonces se redondea
hacia arriba. En el caso del cuartil 3:
𝑺𝑸𝟏 = 𝟑(𝒏 + 𝟏)
𝟒
(2.3.12)
Si 𝑺𝑸𝟏no es entero, se redondea al entero más cercano, pero si cae entre dos enteros, se
redondea hacia abajo.
Ejemplo 2.3.10: los siguientes datos corresponden a la producción de leche en kg por
lactancia (260dias) de las ovejas milchschaf, basados en la información de Larrosa y
Borean (1990).
380, 410, 410, 410, 430, 440, 445, 450, 453, 455, 458, 460, 460, 460, 464, 466, 470,
475, 480, 484, 485, 487, 490, 490, 490, 493, 493, 495, 495, 497, 497, 499, 499, 502,
502, 502, 505, 505, 505, 510, 510, 515, 520, 520, 530, 540, 540, 545, 548, 548, 550,
550, 550, 550, 555, 555, 560, 562, 563, 565.
Como se puede observar, el conjunto fue ordenado en forma ascendente para determinar
los cuartiles 𝑸𝟏 y 𝑸𝟑 mediante el uso de (2.3.11) y (2.3.12), respectivamente.
𝑺𝑸𝟏 = 𝟔𝟎 + 𝟏
𝟒=
𝟔𝟏
𝟒= 𝟏𝟓, 𝟐𝟓 ≈ 𝟏𝟓

164
Puesto que 𝑺𝑸𝟏 no es un número entero, se aproxima al entero más cercano, en este
caso a 15, lo que indica que 𝑸𝟏= 464, cifra de producción ubicada en la posición 15. Por
lo tanto se concluye que el 25% de los datos de producción lechera de las ovejas está
por debajo de 464 kg.
𝑺𝑸𝟑 = 𝟑(𝟔𝟎 + 𝟏)
𝟒=
𝟑(𝟔𝟏)
𝟒= 𝟒𝟓, 𝟕𝟓 ≈ 𝟒𝟔
Teniendo en cuenta 𝑺𝑸𝟑 no es un número entero, se redondea al entero más cercano, en
este caso a 46, así que 𝑸𝟑 es 540, es decir que el 75% de los animales tienen
producciones por debajo de este valor.
Ejemplo 2.3.11: Según reportes de los mismos autores del Ejemplo 2.3.10, la
producción de leche en kg por lactancia (150 días) de un rebaño de ovejas de la raza
manchega, fue la siguiente:
98, 100, 103, 103, 103, 105, 105, 108, 108, 108, 110, 110, 110, 110, 110, 111, 112, 112,
113, 113, 113, 114, 114, 115, 116, 116, 118, 118, 120, 123, 123, 123, 125, 125, 126,
128, 130, 130, 130, 131, 131, 132, 132, 133, 134, 135, 135, 135, 135, 135, 136, 137,
137, 138, 139, 139, 141, 141, 142, 142, 144, 146, 146, 146, 148, 149, 149, 149, 152.
Igual que en el ejemplo inmediatamente anterior, los datos fueron ordenados en forma
ascendente, con el fin de establecer los cuartiles 𝑸𝟏 y 𝑸𝟑, al aplicar (2.3.11) y (2.3.12),
se tiene.
𝑺𝑸𝟏 = (𝟔𝟗 + 𝟏)
𝟒=
(𝟕𝟎)
𝟒= 𝟏𝟕, 𝟓 ≈ 𝟏𝟖
Puesto que 𝑺𝑸𝟏 está entre dos números enteros (17 y 18), se aproxima al entero mayor,
en este caso a 18, lo que indica que 𝑸𝟏 es 112 kg, de tal modo que el 25% de los ovinos
tienen producciones inferiores a esta cantidad.
𝑺𝑸𝟑 = 𝟑(𝟔𝟗 + 𝟏)
𝟒=
𝟑(𝟕𝟎)
𝟒= 𝟓𝟐, 𝟓 ≌ 𝟓𝟐

165
Como se ve𝑺𝑸𝟑 se encuentra entre dos números enteros (52 y 53), así que debe
aproximarse al entero menor, en este caso a 52, para concluir que 𝑸𝟑 es 137 kg, lo que
significa que el 75% de los animales tienen producciones por debajo de este valor.
Cálculo de cuartiles con datos agrupados. Cuando los datos están agrupados,
los cuartiles pueden ser calculados mediante la fórmula:
𝑸𝒌 = 𝑳𝒊 +
𝒌𝒏𝟒 − 𝑭𝒂−𝟏
𝒇𝒊 (𝒂); 𝒌 = 𝟏, 𝟐, 𝟑
(2.3.13)
Dónde:
𝑳𝒊 = Límite inferior de la clase cuartílica donde está el cuartil.
n = Número total de datos.
𝑭𝒂−𝟏 = Frecuencia absoluta acumulada de la clase anterior a la cuartílica.
K = Posición del cuartil (1,3)
𝒇𝒊 = Frecuencia absoluta de la clase cuartílica.
a = Tamaño del intervalo.
Ejemplo 2.3.12: A continuación se presentan los datos del Ejemplo 2.3.11, agrupados
en una tabla de frecuencias.
Clase Límites de clase Marca de clase Fi Fi fa Fa
1 98,0 - 107,0 102,5 8 0,1159 8 O,1159
2 107 – 116,0 111,5 18 0,2609 26 0,3768
3 116,0 – 125,0 120,5 8 0,1159 34 0,4928
4 125,0 – 134,0 129,5 11 0,1594 45 0,6522

166
5 134,0 – 143,0 138,5 15 0,2174 60 0,8696
6 143,0 – 152,0 147,5 9 0,1304 69 1,0000
En caso de disponer de la información consignada en la tabla de frecuencias, los
cuartiles se calculan con (2.3.13). Antes de aplicar este procedimiento, es necesario
determinar la clase cuartílica que corresponde a la categoría cuya frecuencia acumulada
contiene el cuartil que se desea calcular. Para esto basta con desarrollar el término 𝑘𝑛
4 de
la formula (2.3.13), donde k se reemplaza por cuartil buscado.
Para determinar el primer cuartil, se establece primero la clase cuartílica 1.
𝑘𝑛
4=
1(69)
4= 17,25
Puesto que 17,25 está contenido en la frecuencia acumulada de la segunda categoría,
esta es la clase cuartílica uno y con base en esta información se continua con el
desarrollo de (2.3.13).
𝑸𝟏 = 𝟏𝟎𝟕 +
𝟏(𝟔𝟗)𝟒 − 𝟖
𝟏𝟖 (𝟗) = 𝟏𝟎𝟕 + 𝟎, 𝟓𝟏𝟑𝟗(𝟗) = 𝟏𝟏𝟏, 𝟔𝟐𝟓
𝑸𝟏 Se interpreta del mismo modo indicado en el ejemplo 2.3.6. Observe que el valor
obtenido con la fórmula no es exactamente igual al encontrado con los datos sin
agrupar; sin embargo, la discrepancia es mínima.
Del mismo modo se procede para encontrar el tercer cuartil.
𝑘𝑛
4=
3(69)
4= 51,75
Este valor está contenido en la frecuencia absoluta acumulada de la clase 5, por lo tanto
ésta es la clase cuartílica 3.
𝑸𝟑 = 𝟏𝟑𝟒 +
𝟑(𝟔𝟗)𝟒 − 𝟒𝟓
𝟏𝟓 (𝟗) = 𝟏𝟑𝟒 + 𝟒, 𝟎𝟓 = 𝟏𝟑𝟖, 𝟎𝟓

167
En este caso también existe una ligera discrepancia con respecto al 𝑸𝟑 calculado en el
Ejemplo 2.3.13, hecho que confirma que las medidas estadísticas obtenidas con datos
agrupados son una aproximación de los calores calculados cuando se dispone de la
información sin agrupar.
Los deciles dividen la distribución en 10 partes iguales y los percentiles en 100 partes
iguales. Al igual que en los casos de los cuartiles, los datos deben estar en orden de
magnitud creciente.
En forma análoga a lo que se hizo con la mediana y los cuartiles, la situación de los
percentiles (𝑺𝑷𝒌) viene dada por la fórmula general:
𝑺𝑷𝒌 = 𝒌(𝒏 + 𝟏)
𝟏𝟎𝟎; 𝒌 = 𝟏, 𝟐, 𝟑, … 𝟏𝟓, … 𝟗𝟗
Si al aplicar (2.3.14) 𝑺𝑷𝒌 no es entero, se redondea al entero más cercano.
Ejemplo 2.3.13: Para hallar el percentil 80 con los datos del Ejemplo 2.3.11, en primer
lugar se encuentra la posición del percentil según (2.3.14):
𝑺𝑷𝟖𝟎 = 𝟖𝟎(𝟔𝟗 + 𝟏)
𝟏𝟎𝟎= 𝟓𝟔
Por lo tanto el percentil 80 es el dato 56: 𝑺𝑷𝟖𝟎 = 139 kg.
Significa que el 80% de las producciones de leche de las ovejas manchegas están por
debajo de 139 kg.
Para hallar el percentil 15 con los mismos datos:
𝑺𝑷𝟏𝟓 = 𝟏𝟓(𝟔𝟗 + 𝟏)
𝟏𝟎𝟎= 𝟏𝟎, 𝟓 ≈ 𝟏𝟏
Por lo tanto el percentil 15 es el dato 11: 𝑃15= 108 kg y significa que el 15% de las
producciones de leche de las ovejas manchegas están por debajo de 108 kg.
Cálculo de percentiles con datos agrupados. La fórmula para calcular los
percentiles, cuando los datos agrupados es la siguiente:

168
𝑷𝒌 = 𝑳𝒊 +
𝒌𝒏𝟏𝟎𝟎 − 𝑭𝒊−𝟏
𝒇𝒊(𝒂; 𝒌 = 𝟏, 𝟐, 𝟑, … , 𝟗𝟗
(2.3.13)
Todos los términos de (2.3.15) deben interpretarse como en (2.3.13).
Ejemplo 2.3.14: Con los datos de la tabla del Ejemplo 2.3.12, se procede a determinar
los percentiles 9, 25,95.
P9= 98 +9(69)
100−0
8(9)=98+0.77625 (9)= 104,986
P9= 107 +25(69)
100−8
18(9)=107+0.514(9)= 111,625
P9= 143 +95(69)
100−60
9(9)=143+0.617(9)= 148,55
La utilidad de las medidas calculadas como cuartiles, deciles y percentiles es
fundamentalmente descriptiva y para la clasificación de los individuos en forma
comparativa. Desde el punto de vista práctico ofrecen una orientación general de lo que
sucede en la población analizada. El profesional pecuario puede, de manera ágil,
establecer comparaciones con los estándares de la especie que este bajo su cuidado o
administración.
3.3.3.4 La Moda o Modo (M0). Es el dato que más se repite en un conjunto de
observaciones. En algunos casos ningún valor se repite más que otro y se concluye que
la distribución no tiene moda; cuando hay un solo valor que se repite más que los otros,
la distribución es un unimodal; si dos datos se repiten igual número de veces es
bimodal y, en general, cuando existen más de dos valores que se repiten el mismo
número de veces la distribución es multimodal.
Ejemplo 2.3.15: A continuación se desarrollan algunos ejemplos sobre el cálculo de la
moda.

169
a). Los siguientes datos son una muestra aleatoria de peso vivo individual a las
12 semanas, medido en gramos, de 14 cuyes (cavia porcellus), recolectados por
García y Solarte (2001) en la granja Botana de la Universidad de Nariño: 984,
967, 768, 872, 849, 1022, 756, 842, 942, 780, 647, 765, 770, 810. Ya que en esta
muestra ningún dato se repite más que otro, se concluye que el conjunto de datos
no tiene M0.
b). En ora muestra aleatoria, recolectada por los mismos autores, se encontraron
los siguientes datos: 984, 900, 768, 872, 849, 1022, 756, 842, 900, 780, 647,
765, 900, 810. El dato que corresponde a 900 g se repite tres veces, por lo tanto
M0 es 900.
c). De esa misma población, se obtuvo una muestra para analizar el tamaño de
camada al nacimiento, en la cual se encontraron los siguientes resultados: 2, 2, 3,
3, 3, 5, 4, 4, 4, 5, 5, 3, 2, 2, 6, 4, 6, 3, 3, 6, 5, 4, 5. En esta muestra, los tamaños
de camada 4 y 3 se repiten seis veces, así que hay dos modas: M01 =4; Mo2 = 3.
d). Una muestra de mayor tamaño para la misma variable condujo a los
siguientes.resultados:2, 1, 2, 3, 7, 3, 3, 5, 4, 5, 4, 4, 4, 5, 5, 3, 2, 7, 2, 6, 4, 6, 3, 3,
6, 5, 4 , 1, 5. En este caso la distribución es multimodal (tremedal) y las modas
son 3,4 y 6, ya que estos tamaños de camada aparecen seis veces cada uno.
Calculo de la moda con datos agrupados. Para calcular la moda con datos
agrupados, se debe utilizar la siguiente formula:
Dónde:
𝑀0 = 𝐿𝑖 + (∆1
∆1+∆2)(a)
Li= límite inferior de la clase modal. Se entiende por clase modal de mayor
frecuencia absoluta.
∆1= Valor resultante de la diferencia entre la frecuencia absoluta de la clase modal
menos la frecuencia absoluta de la clase inmediatamente anterior.
∆2= Valor resultante de la diferencia entre la frecuencia absoluta de la clase modal
menos la frecuencia absoluta de la clase inmediatamente siguiente.
a = amplitud de intervalo.

170
Ejemplo 2.3.16: Para los datos de la Tabla 2.1.1, la moda se calcula de la siguiente
manera:
Li = 283 en el límite inferior de la clase 6, definida como la clase modal, por tener la
mayor frecuencia absoluta.
∆1= 16-11 = 5
∆2= 16-0 = 16
a = 31
Al calcular con (2.316) se tiene:
𝑀0 = 283 + (5
5 + 16) (31) = 290,38
De acuerdo con el anterior resultado, los valores más frecuentes están alrededor de
290,38.
La Moda se puede utilizar con datos cuya escala es de razón, intervalo, ordinal o
nominal. Es aconsejable usarla con distribuciones marcadamente asimétricas.
2.3.2 Medidas de dispersión. Las medidas de tendencia central dan una idea del lugar
hacia done tienden a concentrarse la mayoría de observaciones, si indicar el grado de
dispersión de los valores de la variable con relación a ese “valor central”. Para describir
en forma más completa de comportamiento de cualquier variable de interés, también es
necesario conocer las medidas de variabilidad.
Las medidas de dispersión más utilizadas son la varianza, la desviación estándar, el
rango, el coeficiente de variación y el recorrido intercuartílico.
2.3.2.1 La varianza y la desviación estándar. Son las medidas de dispersión más
utilizadas. La varianza o cuadrado medio se define, matemáticamente, como el

171
promedio aritmético del cuadrado de las desviaciones de cada observación con respecto
a la medida.
En el caso de la varianza, el parámetro se representa por l letra griega sigma al cuadrado
(𝜎2) y el estadígrafo por la letra S al cuadrado (S2). Para la desviación estándar el
parámetro se representa por (𝜎) y el estadígrafo por S. simbólicamente (𝜎2) se define
mediante la siguiente formula:
𝜎2 = (𝑌1 − 𝜇)2 + (𝑌2 − 𝜇)2 + (𝑌3 − 𝜇)2+. . . . . +(𝑌𝑁 − 𝜇)2(𝑌1 − 𝜇)2
𝑁
= ∑(𝑌𝑖 − 𝜇)
𝑁
2
Para calcular S2 se utiliza la siguiente formula:
𝑆2 = (𝑌1 − ��)2 + (𝑌2 − ��)2 + (𝑌3 − ��)2+. . . . . +(𝑌𝑁 − 𝜇)2(𝑌1 − ��)2
𝑛 − 1
= ∑(𝑌𝑖 − ��)
𝑛 − 1
2
La varianza se expresa en las mismas unidades de la variable original, elevada al
cuadrado, y la desviación estándar en las mismas unidades de los datos y por esto en la
presentación y análisis de resultados se prefiere S en lugar de S2. Para facilitar las
labores de cálculo de S2 se puede usar la siguiente fórmula de trabajo:
𝑆2 = ∑ 𝑌𝑖
2 − (∑ 𝑌𝑖)
2
𝑛𝑛 − 1
El término (∑ 𝑌𝑖)2
𝑛 se denomina factor de corrección y se identifica como C.
La expresión ∑ 𝑌𝑖2 se conoce con el nombre de suma de cuadrados sin ajustar.

172
Ejemplo 2.3.17: Los datos consignados en la Tabla 2.3.3 corresponde a las
producciones de leche en kilogramos por vaca/ día, de las campeonas de los terneros y
exposiciones de Gyr lechero, organizadas por la Asociación Brasileña de Criadores de
Cubu (ABCZ, 2001).
Tabla 2.3.3 Producción de leche en kg/vaca/día de las campeonas Gry
lechero en Brasil
Vaca Producción
(Yi )
(Yi )2 Vaca Producción
(Yi) (Yi )2
Hamada 19,62 384,944 Victoria 24,85 617,523
Lagosta 17,06 291,044 Realeza 19,15 366,723
Doncella 19,17 367,489 Brasilia 22,70 515,290
Evilha 18,02 324,720 Amizade 22,70 515,290
Jarra 18,85 355,323 California 24,38 594,384
Mentira 19,10 364,810 Entrancia 21,65 468,723
Gaviota 18,91 357,588 Fagacia 12,25 150,063
Faianca 17,93 321,485 Fada 34,60 1.197,160
Lucrecia 19,81 392,436 Delicia 27,20 739,840
Maravilha 21,25 451,563 Indigena 28,30 800,890
Gabarra 25,94 672,884 Enamorada 27,50 756,250
Amalia 18,75 351,563 Fieira 23,90 571,210
Tala 21,72 471,385 Cabedella 20,30 412,090
Rebarba 19,58 383,376 Fragancia 25,30 640,090

173
Zema 20,43 417,385 FB Gambia 26,40 696,960
Valentia 21,70 470,890 Cabina 17,60 309,760
Omaga 22,36 499,970 Gaviota 30,20 912,040
Varanda 20,91 437,228 ∑ 770,09 17.580,739
En la tabla 2.3.3 se agregó una columna con la producción elevada al cuadrado, para
disponer de todos los datos requeridos en (2.3.19):
(∑ 𝑌𝑖)2
= (770,09) = 593.038,608
(∑ 𝑌𝑖)2
= 17.580,736
n = 35
Al remplazar en (2.3.19) se tiene:
𝑆2 = 17.580,739 −
(770,09)2
3535 − 1
= 18,7288 𝐾𝑔2
𝑆 = √𝑆2 = √18,7288 = 4,3277 𝑘𝑔
Calculo de la varianza con datos agrupados. Cuando los datos están
agrupados, la varianza se calcula de la siguiente manera:
Dónde:
fi= Frecuencia absoluta de la i-ésima clase.
mi = Marca de clase de la i-ésima categoría.
n = Tamaño de la muestra.

174
Ejemplo 2. 3. 18: los datos de la Tabla 2.3.3 se agruparon y, además, para facilitar los
cálculos correspondientes, se complementaron de la siguiente manera:
Clase Límite de
clase mi fi fimi mi2 fimi2
1 12,25-15,98 14,115 1 14,115 199,233 199,233
2 15,98-19,71 17,845 12 214,140 318,444 3.821,328
3 19,71-23,44 21,575 11 237,325 465,480 5.120,286
4 23,44-27,17 25,305 6 151,830 640,343 3.842,058
5 27,17-30,90 29,035 4 116,140 834,031 3.372,124
6 30,90-34,63 32,765 1 32,765 1.073,545 1.073,545
∑ 35 766,315 17.428,574
∑ 𝑓𝑖𝑚𝑖2 =17.428,574
(∑ 𝑓𝑖𝑚𝑖2)2= (766,315)2 = 587.238,679
𝑆2 = 17.428,574 −
(587.238,679)2
3534
= 19,127 𝐾𝑔2
La desviación estándar para estar muestra es la siguiente:
𝑆 = √𝑆2 = √19,127 = 4,373 𝑘𝑔
Usualmente la varianza, tanto con datos agrupados con sin agrupar, se calcula con un
digito decimal más que la medida.
2.3.2.2. El coeficiente de variación o variabilidad (CV). Es una cantidad cuyo uso
más importante es evaluar los resultados experimentales donde se estudia la misma
característica, generalmente por personas distintas y bajo condiciones diferentes.

175
El CV se define como la desviación estándar expresada con porcentaje de la medida, de
acuerdo con la siguiente formula:
𝐶𝑉 = 𝑆
��(100)
Para establecer sin un CV es grande o pequeño es preciso disponer de datos similares
para la variable analizada. Por ejemplo, los materiales vegetales tienen cada uno su
propio CV, lo mismo sucede con las especies animales.
A diferencia dela S, el CV es una medida relativa de variación. La primera se expresa en
las mismas unidades de la variable y la segunda en porcentaje.
Ejemplo: 2.3.19: con la información contenida en la tabla 2.3.3 se calcula el coeficiente
de la variación, de la siguiente manera:
�� = 22,00 𝑘𝑔 S = 4,3277 kg
𝐶𝑉 = 4,3277
22,00(100) = 19,67%
No es posible establecer si este CV es alto o bajo puesto que no se dispone de
información que reporte el CV para el ganado gyr en la característica analizada.
2.3.2.3 El rango (R). Es otra medida de dispersión que se define y calcula de la manera
indicada en la construcción de tablas de frecuencias. Tiene escaso uso en el proceso de
inferencia ya que no es un estadígrafo satisfactorio, aunque con muestras de 10 es
frecuentemente útil.
2.3.2.4 El Rango Intercuartílico (RIQ). Es una medida de variabilidad resistente a los
“outliers”. Si es RIQ es grande debe interpretarse que, en un conjunto de datos
ordenados, existe una grande dispersión de estos con respecto al valor central; si por el
contrario RIQ es pequeño, gran parte de las observaciones se encontraran cerca de
centro. EI RIQ se calcula restando el 𝑄1 del 𝑄3
Ejemplo 2.3.20: en el ejemplo 2.3.11 se calcula 𝑄1= 18 y 𝑄3 = 52, entonces:
𝑅𝐼𝑄 = 52 − 18 = 34

176
En este caso es posible afirmar que no existe una gran dispersión de los datos y que la
tendencia es el agrupamiento en torno al valor central representado por la mediana.
2.3.3 Asimetría y curtosis. Las distribuciones también pueden diferir entre sí en simetría
y grado de apuntamiento. Una distribución es simétrica cuando la media, la mediana y
la moda coinciden en el mismo punto, como se indica en la figura 2.3.1.
Pero si la distribución es asimétrica, entonces la media, la mediana y la moda se ubican
en puntos diferentes. Si Moda <Mediana<Media, la curva es asimétrica con sesgo
positivo. Si Media>Mediana>Moda, la curva es asimétrica con sesgo negativo (Figura
2.3.2).
Figura 2.3.1 Representación de una distribución simétrica.
Una medida asimétrica es el coeficiente de Asimetría (𝐶𝐴), definido por la siguiente
fórmula.
𝐶𝐴 = ∑ (𝑋𝑖 − ��)3𝑛
𝑖=1
𝑛𝑆3
(𝐶𝐴) = 0, la curva es simétrica.
(𝐶𝐴) > 0, la curva es asimétrica con sesgo positivo.
(𝐶𝐴) < 0, la curva es asimétrica con sesgo negativo.

177
Sesgo Positivo
Sesgo Negativo
Figura 2.3.2 distribuciones asimétricas con sesgo positivo y negativo.
La Curtosis es una medida de la agudeza o grado de apuntamiento de una distribución,
determinada por el Coeficiente de Curtosis (𝐶𝐴𝑝) o apuntamiento (figura 2.3.3).
Figura 2.3.3 Tipos de curtosis (A: Mesocúrtosis, B: Leptocúrtica C:
Platicúrtica)

178
El coeficiente de curtosis se calcula mediante (2.3.2.3)
𝐶𝐴𝑝 = ∑ (𝑋𝑖 − ��)4𝑛
𝑖=1
𝑛𝑆4
(𝐶𝐴) = 3, la curva es mesocúrtica o normal.
(𝐶𝐴) > 0, la curva es leptocúrtica.
(𝐶𝐴) < 0, la curva es platicúrtica.
En estadística inferencia es muy importante el concepto de normalidad de las muestras.
Los conceptos de asimetría y curtosis son una herramienta útil para establecer si la
muestra proviene de una población normal. Si la muestra es bastante asimétrica y el
coeficiente de curtosis es bastante alejado de tres, se descarta normalidad; en caso
contrario, es decir, si los datos son simétricos y el coeficiente de curtosis cercano a tres,
los datos provienen de una población bastante parecida a la normal y, en este caso, lo
más razonable es utilizar una prueba estadística de normalidad.
Ejemplo 2.3.21: En un ensayo con peces Ángel o Escalares (Pterophyllum scalare), se
recopilo información sobre longitud estándar medida en centímetros, cuyos valores
están consignados en la tabla 2.3.4.
Tabla 2.3.4 longitud estándar de peces Ángel (pterophyllum scalare), Pasto,
Colombia, 2002.
15 13 12 14 14 10
14 12 11 13 7 8
11 10 10 9 7 8
8 9 7 7 12 13
15 15 11 14 10 5

179
13 14 14 6 5 4
15 12 12 7 6 10
12 13 15 5 7 8
8 9 10 9 11 12
12 12 13 12 12 13
Aplicando (2.3.22) y (2.3.23) se calcularon los coeficientes de asimetría y curtosis,
respectivamente, de la siguiente manera:
CA = ∑ (Xi− X)3n
i=1
nS3 = −578,877
60∗27,1208= −0,3557
𝐶𝐴𝑝 = ∑ (𝑋𝑖 − ��)4𝑛
𝑖=1
𝑛𝑆4=
9.917,46
60 ∗ 81,4838= 2,0285
De acuerdo con estos resultados la muestra analiza no es simétrica, ya que 𝐶𝑎 <0, lo que
indica que tiene sesgo ligeramente negativo. En cuanto a la curtosis, se concluye que la
curva generada por los datos de la muestra es platicúrtica.
Es importante mencionar que en trabajos experimentales el tamaño de la muestra debe
ser suficientemente grande como para establecer de manera confiable de forma de la
curva.
2.3.4 Diagramas de caja. El diagrama de caja es una herramienta útil en el análisis de
un conjunto de datos invariado, debido a que facilita el análisis de la simetría, detecta
valores atípicos y vislumbra un ajuste de los datos a una distribución de frecuencias
determinada.
La mitad central de los datos que va desde el primero hasta el tercer cuartil se los
representa mediante un rectángulo, la mediana se lo identifica con un segmento de recta

180
vertical que va dentro del rectángulo. Un segmento de recta se extiende desde el primer
cuartil hasta el valor mínimo, como se muestra en la figura 2.3.4.
Figura 2.3.4 diagrama de cajas y bigotes
Ejemplo 2.3.22: De un experimento reportado por Milton (1994), donde se administró
CO a diferentes presiones atmosféricas, para establecer la influencia sobre el
crecimiento del Pseudomonas fraji, medido como el cambio porcentual en la más
celular después de una hora, se extractaron los siguientes resultados:
Presión en atmósfera de CO2
0,0 0,083 0,29 0,50
62,6 50,9 45,5 29,5
59,6 44,3 41,1 22,8
64,5 47,5 29,8 19,2
59,3 49,5 38,3 20,6
58,6 48,5 40,2 29,2
64,6 50,4 38,5 24,1
30,2 32,7

181
27,0 24,4
En la figura 2.3.5 se indican los diagramas de cajas para los cuatro tratamientos. Allí se
puede apreciar que en el tratamiento a se presenta el mayor crecimiento de la más
celular y luego en tratamiento b; el tratamiento de menor crecimiento es el d. la mayor
variabilidad se observa en los tratamientos c y d, respectivamente, puesto que sus cajas
son las más largas. En cuanto a la simetría, los tratamientos a y b exhiben las
distribuciones más simétricas puesto que sus respectivas medianas están situadas cerca
de la mitad de las cajas y los tratamientos c y d son asimétricos, el primero con sesgo a
la derecha y el segundo con sesgo a la izquierda.
Figura 2.3.5 Diagramas de caja para el crecimiento de la masa celular del
Pseudomonas fragi, según la presión de CO2

182
CAPÍTULO 3
Conceptos básicos de Probabilidad
3.1. INTRODUCCIÓN
En el Capítulo 1 se mencionó que la teoría de las probabilidades se inició a principios
del siglo XVII, aplicada a los juegos de azar. En la actualidad se considera una rama de
las matemáticas que juega un papel predominante en la inferencia estadística.
Desde el capítulo inicial se ha insistido en la inconveniencia de formular definiciones
exactas de los aspectos estadísticos de mayor importancia, dentro de los cuales las
probabilidades no son la excepción. Al abordar este tema se pretende, básicamente,
manejar en forma adecuada ciertos conceptos y procedimientos que permitan tener una
idea clara de las probabilidades y su importancia en los temas de inferencia estadística
que se estudiarán posteriormente.
La teoría de las probabilidades se utiliza con más frecuencia de lo que se cree, no solo
en las ciencias animales sino en muchas disciplinas. Por ejemplo, en Genética es posible
predecir el desempeño de la progenie con base en la información de los padres y otros
ascendientes; también es factible determinar la frecuencia con que aparecerán ciertos
fenotipos en una determinada población, tales como el color del pelo o una enfermedad
de origen hereditario, entre otros. En el control de calidad de productos lácteos o
cárnicos de una factoría, es posible determinar la proporción de unidades procesadas y
empacadas que no cumplirán con las normas sanitarias o de calidad admitidas para su
comercialización. También se usan los conceptos de la teoría de las probabilidades en la
planificación y seguimiento de programas para el control y/ o erradicación de
enfermedades de los animales.
Se advierte al lector que la teoría de las probabilidades es un campo bastante amplio que
exige niveles de abstracción y conocimientos matemáticos avanzados cuando se estudia
este tema con profundidad. Sin embargo, en esta obra no se intentara abordar estudios
de esa naturaleza. Para los interesados en profundizar en este tema se recomiendan,
entre varias, las obras de Meyer (1973) y Parzen en (1960).

183
3.2 CONCEPTOS BÁSICOS PARA EL ESTUDIO DE LAS PROBABILIDADES
Con el propósito de iniciar el estudio del tema es necesario recalcar que en las ciencias
animales la observación de fenómenos, bajo cierto conjunto de condiciones, constituye
la materia prima para la labor profesional y de investigación. Así por ejemplo, en una
población bovina se observan vacas con o sin cuernos; en una piara, cerdos con o sin
síntomas de alguna enfermedad; en un rebaño, animales de diferente peso al nacimiento;
animales sometidos al mismo tratamiento que tardan tiempos diferentes en su
recuperación; en un medio de cultivo, bacterias resistentes a determinados antibióticos,
y muchos otros fenómenos.
Al observar repetidamente al mismo fenómeno, no siempre se llega a resultados
idénticos y, por el contrario, la variación de estos es una característica notoria, pero en
un gran número de repeticiones, un resultado aparecerá varias veces con cierta
frecuencia, que se denomina regularidad estadística, y los fenómenos donde se aprecia
dicha regularidad reciben el nombre de fenómenos aleatorios.
La representación numérica de la regularidad estadística se hace con números
comprendidos entre cero y uno, como indicación de la frecuencia relativa con que se
presentan los diferentes resultados en una serie de repeticiones independientes entre sí.
Ejemplo 3.2.1: En un matadero se sacrifican novillos de tres razas diferentes: cebú,
normando o shorton. Un profesional agropecuario se encarga de realizar una inspección
generala cada animal, previamente al sacrificio. En un momento dado a la pregunta ¿de
qué raza será el próximo novillo que será inspeccionado? Aparentemente esta pregunta
no tiene respuesta, ya que el novillo puede ser de cualquiera de estas tres razas. Sin
embargo, si se realiza un “experimento” consisten en determinar y anotar la raza de
cada novillo, aparecerán resultados particulares, como los presentados a continuación.
Cebú: 120
Normando: 28

184
Shorton: 2
Total: 150
Con estos resultados se establecen las siguientes frecuencias relativas:
Para el ganado cebú: 150
120= 0,8
Para el normando:28
150= 0,19
Para el shorton:2
150= 0,01
Si se continúa registrando la información seguramente se obtendrán valores de
frecuencia relativa diferentes a los anteriores, pero a medida que se repita este
procedimiento hasta alcanzar un número “grande” de registros, las fluctuaciones de los
valores de dichas frecuencias en las sucesivas repeticiones se volverán más pequeñas,
hasta estabilizarse. A esta estabilización de las frecuencias relativas, cuando el número
de repeticiones de un experimento es grande, se le llama regularidad estadística,
característica típica de los experimentos aleatorios que, por ahora, se definirán como los
procedimientos que se llevan a cabo para registrar una observación.
El evento o suceso aleatorio se define como un resultado posible en un experimento.
Para el ejemplo 3.2.1, los sucesos posible son que el próximo novillo sea cebú,
normando o shorton, es decir, hay tres resultados probables, cuya frecuencia relativa es
una sucesión grande de observaciones llevadas a cabo aleatoriamente, se acerca un valor
límite estable a medida que un número de observaciones tiende al infinito. Por lo tanto,
ese valor límite estable puede considerarse como la probabilidad de ocurrencia del
evento aleatorio. El espacio muestral, denotado con la letra S, contiene las descripciones
de todos los posibles resultados de un experimento.
En el ejemplo 3.2.1 se puede observar, como en todos los experimentos aleatorios, que
los valores de las frecuencias relativas están comprendidos entre 0 y 1, los cuales
reflejan las expectativas de ocurrencia de un suceso determinado, tal modo que
probabilidades próximas a uno indican que ese tipo de evento generalmente se produce,
no que vaya a producirse con certeza; probabilidades cercanas a cero conducen a pesar
que el suceso difícilmente se producirá, mas no indican que no vaya a producirse.

185
Probabilidades cercanas a 0,5 indican que es tan verosímil que el suceso se produzca,
como que no se produzca.
Después de analizados los anteriores conceptos, al formular la pregunta ¿de qué raza
será el próximo novillo a ser inspeccionado?, el profesional responderá que es una
pregunta que no tiene respuesta, pero si se preguntase ¿Cuál es la probabilidad de que el
próximo novillo a ser inspeccionado sea de una raza específica, de las tres que se
sacrifican? Tendrá elementos para responderla correctamente en términos
probabilísticos. Si la frecuencia relativa estable es de 0,8 para la raza cebú, podría
contestar que de los próximos 10 novillos que entran a sacrificio, ocho serán cebú y
seguramente el dato predicho coincidirá con el real y a medida que se incremente el
número de observaciones su predicción coincidirá en mayor medida con lo que ocurrirá
realmente.
De lo expresado hasta esta parte se puede concluir que la estadística no se ocupa de
experimentos donde es posible anticipar el resultado, sino de aquello donde los
resultados están sujetos al azar, es decir, los experimentos aleatorios.
3.3 ESPACIO MUESTRAL
Con el fin de ampliar el concepto de espacio muestral (s), se presentan algunos
ejemplos:
Ejemplo 3.3.1: En un experimento de campo conducente a detectar mastitis con la
prueba CMT, en un hato de 10 vacas, el espacio muestral se describe de la siguiente
manera: S= {0,1,2,3,4,5,6,7,8,9,10}. Esto significa que en S están contenidos todos los
resultados posibles del experimento, 0 indica que ninguna vaca resulte positiva a la
prueba; 1 que se detecta una vaca enferma, y así sucesivamente hasta 10
Ejemplo3.3.2: De un recipiente que contiene seis bolas idénticas, excepto por su color,
ya que cuatro son blancas y dos son rojas se extrae una bola, se observa y anota su color

186
e inmediatamente se devuelve al recipiente. En este caso el espacio muestral es S {roja,
blanca}.
Ejemplo 3.3.3: De un recipiente que contiene seis bolas idénticas, numeradas del 1 al 6
se extraen dos, primero una luego otra, sin devolver al recipiente la primera antes de
sacar la segunda. En este caso, el espacio muestral se describe del siguiente modo:
S= {(1-2), (1-3), (1-4), (1-5), (1-6), (2-1), (2-2), (2-3), (2-4), (2-5), (2-6),(3-1), (3-2), (3-
3), (3-4), (3-5), (3-6), (4-1), (4-2), (4-3), (4-4), (4-5),(4-6), (5-1), (5-2), (5-3), (5-4),(5-
5), (5-6), (6-1), (6-2), (6-3), (6-4), (6-5)}.
Es decir, bajo las condiciones especificadas para el experimento del Ejemplo 3.3.3, hay
treinta resultados posibles.
Ejemplo 3.3.4: En el control de apareamiento, realizado rutinariamente en una piara,
cuando nace una cría se anota, en su correspondiente registro, el tamaño de camada de
donde proviene el padre y el tamaño de camada del cual proviene la madre.
Suponiendo que el padre haya nacido en una camada de tamaño siete y la madre en una
de tamaño cinco, este apareamiento se registrara como el par ordenado (5,7); la
observación (7,12) corresponderá al tamaño de camada 7para el padre y 12 para la
madre. Como los tamaños de camada pueden tomar cualquier valor entero entre 1 y 16,
tanto para los machos como para las hembras, existe una gran cantidad de resultados
difíciles de describir individualmente; por lo tanto, el espacio muestral se describe de
mejor manera así: se denomina X el tamaño de camada de los padres, Y el tamaño de
camada de las madres, en consecuencia el espacio muestral se describe así:
S= {los padres ordenados (X, Y) tal que X es un entero del 1 al 16, Y es un entero del
uno 1 al 16}.
Del análisis de los tres ejemplos se desprenden varios hechos:
El espacio muestral (S) no siempre es fácil de describir.

187
S cambia según las condiciones en que se lleve a cabo el experimento, por eso es
preferible hablar de un espacio muestral referido a un experimento concreto.
S puede ser de tamaño finito, pero existen otros espacios de tamaño infinito que
se describen adoptando alguna notación específica, que se explicara más
adelante.
Un espacio muestral no necesariamente está constituido por números.
En todas las descripciones de S convencionalmente se usan {} con el fin de
indicar que realmente se está trabajando con conjuntos, dentro de los cuales se
hace una lista de todos sus elementos. Por ejemplo se entiende “cualquier
colección de conceptos o de objetos perfectamente especificada” (Meyer, 1974).
El tamaño de un conjunto está definido por el número de elementos que pertenecen a él.
Un conjunto es finito si su tamaño es cualquiera de los números finitos, así por ejemplo,
el conjunto de granjas que posee la universidad de Nariño es de 5, S = {Botanas,
Chimangual, La Quinta. Mar Agrícola, Guamués}; si el conjunto de vacas en
producción láctea en una de las granjas es 10:
S= {01, 02, 03, 04, 05, 06, 07, 08, 09, 10}.
En este caso, los elementos del conjunto se representan con el código que identifica a
cada animal.
Un conjunto infinito puede ser numerable, por ejemplo, el conjunto de los números
impares es infinito numerable, en donde S= {1, 3, 5, 7, 9,…..}; en cambio, el número de
puntos en la recta real en el intervalo 0 a 1 es infinito no numerable y se representa
como S = {𝑋|0 ≤ 𝑋 ≤ 1}
En muchos textos el espacio muestral se representa con la letra U para resaltar que se
trata del conjunto universal que, como se sabe, contiene todas las descripciones.
3.4 EVENTOS
Para definir un evento es necesario relacionarlo con el espacio muestral S, ya que un
evento ocurre si sólo si el resultado observado corresponde a una de las descripciones
contenidas en S; así, en el Ejemplo 3.3.2 se pueden presentar varios eventos: extraer

188
una bola blanca, extraer una bola roja, sacar primero una bola roja y luego una blanca,
sacra primero una bola blanca y luego otra blanca. Se observa que todos los casos
descritos aparecen en S. Hecha esta precisión, un evento se considerará como un
subconjunto de S.
Para especificar un conjunto se utilizan, convencionalmente, letras mayúsculas y
algunos símbolos; por ejemplo, para indicar que un elemento pertenece a un conjunto se
utiliza el símbolo∈; para especificar que un elemento no pertenece a un conjunto se usa
el símbolo∄. El símbolo I debe leerse como “tal que “, que especifica una condición
particular de los elementos del conjunto. El símbolo ∁ indica que todos los elementos de
un conjunto son también elementos de otro, de este modo la expresión A ∁ B, deberá
entenderse como A es un subconjunto de B.
Dado que S contiene todas las descripciones posibles, también es un subconjunto de sí
mismo, por lo que constituye un evento llamado evento seguro.
Cuando se estudian fenómenos aleatorios, realmente el interés se centra en los eventos
que pueden ocurrir y, concretamente, en la probabilidad de su ocurrencia y no en el
espacio muestral, sino en los subconjuntos, que son los eventos.
3.5 OPERACIONES CON CONJUNTOS
Con los eventos y el espacio muestral, considerados en términos de conjuntos, es
posible efectuar varias operaciones algebraicas; las de mayor utilidad son las de adición
y la multiplicación, cuyas reglas se resumen a continuación.
3.5.1 La suma o unión de conjuntos (A U B). Es el conjunto de las descripciones que
están contenidas en A,∩ en B o en ambos, entonces (A U B) ocurre si y solo si ocurre A
o bien ocurre B o si ocurren ambos, es decir, cuando el resultado observado tiene como
descripción muestral un elemento de A, de B o de ambos.

189
Ejemplo3.5.1: Si se define S = {Y} Y es un Bos Taurus puro de las razas angus,
Hertford, Holstein, pardo suizo}.
Considerando los siguientes subconjuntos: A= {Y} Y es una vaca Holstein}, B = {Y} Y
es una vaca pardo suizo}, el conjunto definido como las vacas productoras de leche A U
B = {Y} Y es una de las vacas de las razas Holstein o pardo suizo}.
3.5.2 El producto o intersección de conjuntos (A ∩ B). Corresponde al conjunto de
elementos presentes tanta en A, como en B, o sea que (A ∩ B) ocurre si y solo si A y B
ocurre. Si A y B son eventos mutuamente incluyentes no pueden ocurrir juntos, por lo
tanto (A ∩ B) = ∅
Ejemplo 3.5.2: Definidos los conjuntos:
A = {Y} Y es una vaca pardo suizo lactante}.
B = {Y} Y es una vaca pardo suizo en gestación}
El conjunto restante de:
A ∩ B = {Y} Y es una vaca pardo suizo lactante y gestante a la vez}.
3.5.3 Complemento de A ( �� ). Si A es un evento, puede calcularse la probabilidad de
que A ocurra o no. Si A es el conjunto, �� es su complemento, es decir, representa todas
las descripciones presentes en S que no están en A por lo tanto, �� ocurre si y solo si A
no ocurre.
Ejemplo 3.5.3: Siendo el espacio muestral S = {Y} Y es un perro}, en el cual se define
el conjunto A = {Y} Y es un perro vacunado contra el parvovirus}, entonces �� = {Y }
Y es un perro no vacunado contra el parvovirus}.
Las operaciones de unión, intersección y el complemento se pueden representar con los
diagramas de Venn de la Figura 3.5.1.

190
𝐴 ∪ 𝐵 𝐴 ∩ 𝐵 ��
Figura 3.5.1 Diagramas de Venn para las operaciones con conjuntos
𝑬𝒋𝒆𝒎𝒑𝒍𝒐 𝟑. 𝟓. 𝟒: 𝑈𝑛𝑎 𝑏𝑜𝑙𝑠𝑎 𝑐𝑜𝑛𝑡𝑖𝑒𝑛𝑒 12 𝑏𝑜𝑙𝑎𝑠 𝑖𝑑é𝑛𝑡𝑖𝑐𝑎𝑠, 𝑛𝑢𝑚𝑒𝑟𝑎𝑑𝑎𝑠 𝑑𝑒𝑙 1 𝑎𝑙 12.
S = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,12}
Si se toman dos subconjuntos de S:
A = {1, 2, 3, 4, 5, 6}
B = {4, 5, 6, 7, 8, 9,}
Los resultados de las tres operaciones son los siguientes:
A U B = {1, 2, 3, 4, 5, 6, 7, 8, 9}
A ∩ B = {4, 5, 6}
�� = {7, 8, 9, 10, 11,12}
Conviene también indicar que dos conjuntos son iguales (A = B), si y solo si cada una
de las descripciones en A pertenece también a B y viceversa.
Las operaciones de unión e intersección definidas anteriormente, se pueden extender a
más de dos conjuntos, así:
𝐴 𝑈 𝐵 𝑈 𝐶 = 𝐴𝑈(𝐵𝑈𝐶) 𝑜 ( 𝐴𝑈𝐵) 𝑈𝐶
∩ 𝐴 ∩ 𝐵 ∩ 𝐶 = 𝐴 ∩ (𝐵 ∩ 𝐶) 𝑜 (𝐴 ∩ 𝐵) ∩ 𝐶
𝐿𝑎𝑠 𝑝𝑟𝑜𝑝𝑖𝑒𝑑𝑎𝑑𝑒𝑠 𝑐𝑜𝑛𝑚𝑢𝑡𝑎𝑡𝑖𝑣𝑎𝑠 𝑑𝑒 𝑙𝑜𝑠 𝑐𝑜𝑛𝑗𝑢𝑛𝑡𝑜𝑠 𝑖𝑛𝑑𝑖𝑐𝑎𝑛 𝑞𝑢𝑒:
a. 𝐴 𝑈 𝐵 = 𝐵 𝑈 𝐴
b. 𝐴 ∩ 𝐵 =B ∩ A
S A B S A B A

191
Y las propiedades asociativas:
a. A U (B U C ) = (A U B ) U C
b. A ∩ (B ∩ C ) = (A ∩ B ) ∩ C
Existen otros conjuntos que contienen unión, intersección y complementación. Los más
importantes se indican enseguida:
a. A U (B ∩ C ) = (A U B ) ∩ ( A U C )
b. A ∩ (B U C ) = (A ∩ B ) U (A ∩ C )
c. A ∩ ∅ =∅
d. A U ∅ =A
e. ( 𝐴 ∩ 𝐵) = �� ∪ ��
f. ( 𝐴 ∪ 𝐵) = �� ∩ ��
Como ya se señaló, ∅ es el conjunto vacio que en las operaciones de unión e
intersección se comparta como el cero (0) entre los números.
3.6 PROBABILIDAD DE UN EVENTO
Con los elementos señalados hasta ahora se podría deducir que, dado un experimento,
descrito por un espacio muestral S, la probabilidad es una función que asigna a cada
evento un número real no negativo, denotado por P [ A ], llamada probabilidad del
evento A, que debe satisfacer los siguientes principios:
a. P [ A ] ≥ 0 para todos los eventos A de S
b. P [ S ] = 1
c. Si A y B son eventos que se excluyen mutuamente en S, entonces:
P [A U B] = P [A] + P [B]
d. Si 𝐴1, 𝐴2, … … es una serie de eventos mutuamente excluyentes, entonces
P[𝐴1 ∪ 𝐴2 ∪ … … . ] = 𝑃[𝐴1] + 𝑃[𝐴2] + … … … …
De estos principios fundamentales se derivan las siguientes propiedades:
a. 𝑆𝑖 𝐴1, 𝐴2, … … 𝐴𝑛 son eventos mutuamente excluyentes en un espacio muestral
S, entonces:
𝑃[𝐴1 ∪ 𝐴2 ∪ 𝐴3 ∪ … … .∪ 𝐴𝑛] = 𝑃[𝐴1] + [𝐴2] + [𝐴3] + … … . +[𝐴𝑛]
b. 𝑃[∅] = 0, 𝑑𝑜𝑛𝑑𝑒 ∅ es el evento vacío, también llamado evento imposible.

192
c. 𝑃[��] = 1 − 𝑃[𝐴]
d. 𝑃[𝐴 ∪ 𝐵] = 𝑃[𝐴] + 𝑃[𝐵] − 𝑃[𝐴 ∩ 𝐵], 𝑝𝑎𝑟𝑎 𝑐𝑢𝑎𝑙𝑞𝑢𝑖𝑒𝑟 𝑝𝑎𝑟 𝑑𝑒 𝑒𝑣𝑒𝑛𝑡𝑜𝑠 𝐴 𝑦 𝐵
3.7 CÁLCULO DE PROBABILIDADES CON ESPACIOS MUESTRALES
FINITOS
Con el fin de caracterizar P [A] en modelos con espacio muestral finito se considerara,
en primer lugar, el suceso que está constituido por un solo resultado, denominado
suceso elemental que se denota por A = {a,}. Bajo estas condiciones a cada suceso
elemental {a,} se le asigna un número p., llamado la probabilidad de {a,} que satisface
las siguientes condiciones:
a. 𝑝𝑖 ≥ 0, 𝑖 = 1,2, … … . . , 𝑘
b. 𝒑𝟏 + 𝒑𝟐 + … … … . +𝒑𝒌 = 𝟏
La probabilidad P [A] de un evento A se define, entonces como la suma de las
probabilidades de los sucesos elementales.
Ejemplo 3.7.1: Si se lanza un dado una vez, el espacio muestral asociado a este
experimento será: S= {1, 2, 3, 4, 5, 6}, el evento denotado A = {2} que consiste en el
que el resultado del experimento sea el número 2, es un evento elemental.
En cambio si el resultado del experimento consiste en obtener un numero par, entonces
A = {2, 4, 6,}, y este no es suceso elemental. Debe distinguirse, además, que 2 es un
elemento de un espacio muestral S, mientras que {2} es un evento elemental.
Ejemplo 3.7.2: En una bolsa se colocan seis bolas idénticas, numeradas del 1 al 6; el
experimento consiste en extraer una bola.
El espacio muestral estará dado por S = {1, 2, 3, 4, 5, 6}
Considerando un suceso particular:
A = [x] X = la primera bola extraída es la marcada con el numero 6}, A es un evento
elemental.

193
3.7.1 Suceso igualmente probables. Por lo general se asume q cuando los espacios
muéstrales son finitos, los resultados son igualmente probables o equiprobables; sin
embargo, esta es una apreciación equivocada, puesto que hay muchos experimentos
para los cuales no se garantiza esta suposición. Por ejemplo, no es tan probable que
entren a sacrificio al matadero de pasto novillos blanco azul belga como Holstein
mestizos, es decir, los eventos no son equiprobables pese a que el espacio muestral es
finito.
El procedimiento para calcular P [A], cuando los eventos son iguales probables, está
dado por:
𝑃[𝐴] = 𝑛ú𝑚𝑒𝑟𝑜 𝑑𝑒 𝑐𝑎𝑠𝑜𝑠 𝑓𝑎𝑣𝑜𝑟𝑎𝑏𝑙𝑒𝑠 𝑝𝑎𝑟𝑎 𝐴
𝑛ú𝑚𝑒𝑟𝑜 𝑡𝑜𝑡𝑎𝑙 𝑑𝑒 𝑐𝑎𝑠𝑜𝑠
Se recalca que (3.7.1) es una consecuencia de suponer resultados equiprobables, sólo
aplicable cuando se satisface esta suposición y no constituye una definición general de
probabilidad.
Ejemplo 3.7.3: si se lanza un dado normal y se pregunta ¿cuál es la probabilidad de que
el resultado sea el número 4? El evento es A = {4}; S = {1, 2, 3, 4, 5, 6}. En S hay seis
resultados posibles de los cuales uno es favorable para A; por lo tanto, de acuerdo con
(3.7.1), 𝑃[𝐴] = 1
6
Ejemplo 3.7.4: en el mismo experimento del Ejemplo 3.7.3 se pregunta ¿cuál es la
probabilidad de obtener el número 3? La respuesta es 𝑃[𝐴] = 1
6
Ejemplo 3.7.5: Considerando el mismo experimento del Ejemplo 3.7.3, ¿cuál es la
probabilidad de obtener un número par? Esto es A = {2, 4, 6,}
De acuerdo con el mismo procedimiento [𝐴] = 3
6=
1
2

194
Ejemplo 3.7.6: Se lanza una vez una moneda, ¿cuál es la probabilidad de que el
resultado sea cara?
𝑆 = {𝑐𝑎𝑟𝑎, 𝑠𝑒𝑙𝑙𝑜}, 𝑃[𝐴] = 1
2= 0.5
Ejemplo 3.7.7: ¿Cuál es la probabilidad de obtener tres caras, si se lanzan al mismo
tiempo tres monedas? El problema debe abordarse así:
a. Definir S. En cada moneda hay dos resultados posibles que son cara © y sello
(s); si en el experimento se lanzan tres monedas, se puede obtener los siguientes
resultados:
S= {ccc, css, csc, sss, ssc, scs, ccs, ssc}
b. ¿Cuántos de esos resultados son favorables para A? Hay un solo resultado
favorable que es el evento perdido: A = {ccc}
c. Aplicar (3.7.1): 𝑃[𝐴] = 1
8= 0.125.
Ejemplo 3.7.8: Se lanza una moneda dos veces y se pregunta: ¿cuál es la probabilidad
de obtener una cara? En este caso S = {cc, cs, sc, ss} y A = {aparece una cara}
Como se puede observar, el número de casos favorables en A son dos, cs y sc, luego
𝑃[𝐴] = 2
4=
1
2= 0.5
Ejemplo 3.7.9: En el mismo experimento del Ejemplo 3.7.8, se pregunta: ¿cuál es la
probabilidad de obtener dos caras? La respuesta es 𝑃[𝐴] = 1
4
Ejemplo 3.7.10: En el mismo experimento, si la pregunta fuese: ¿cuál es la
probabilidad de obtener una cara y un sello? La respuesta es 𝑃[𝐴] = 1
2

195
En los ejemplos 3.7.3 a 3.7.10, es claro que el interés se centra en la elección al azar de
uno o más elementos de un conjunto dado; por lo tanto, es necesario formular algunas
indicaciones generales de utilidad, en los siguientes casos.
Escoger al azar un objeto: Si se dispone de n objetos o elementos,
convencionalmente designados como 𝑎1, 𝑎2, … … . . 𝑎𝑛, escoger al azar un objeto
significa que cada uno de ellos tiene la misma probabilidad de ser elegido. En
este caso:
𝑃[𝑒𝑙𝑒𝑔𝑖𝑟 𝑎¡] = 1
𝑛
Escoger al azar dos objetos entre n objetos: significa que cada uno de los
pares de objetos, sin considerar el orden en que son tomados, tienen la misma
probabilidad de ser elegidos.
Si se desea elegir dos objetos al azar de entre {𝑎1, 𝑎2, 𝑎3, 𝑎4}, obtener 𝑎1, 𝑎2 es tan
posible como obtener 𝑎2 𝑦 𝑎3 y así para cualquier par. Este hecho conduce a preguntar
¿cuántos pares diferentes hay en esa colección de objetos? Si hay k de tales pares, la
probabilidad de escoger cada par se define como:
𝑃[𝑒𝑙𝑒𝑔𝑖𝑟 𝑢𝑛 𝑝𝑎𝑟 𝑎1] = 1
𝑘
La manera de calcular k se explicará más adelante.
Escoger al azar n elementos de entre N objetos donde n ≤ N: significa que
cada n-tuplo (en algunos textos llamadas n-adas o r-plas) tiene tanta
probabilidad de ser escogido como cualquier otro n-tuplo una colección de 3, 4,
5 o más objetos.
Si se desea elegir tres objetos al azar de entre {𝑎1, 𝑎2, 𝑎3, 𝑎4, 𝑎5, 𝑎6 }, obtener
𝑎1, 𝑎2 𝑦 𝑎3, es tan probable como obtener 𝑎2, 𝑎3, 𝑎4 y así para cualquier triada y en
general n-tuplo. Este hecho conduce a preguntar ¿cuántos n-tuplo diferentes hay en esa
colección de objetos? Si hay K de tales n-tuplos, la probabilidad de escoger cada uno se
define como:
𝑃[𝑒𝑙𝑒𝑔𝑖𝑟 𝑢𝑛 𝑛 − 𝑡𝑢𝑝𝑙𝑜] = 1
𝑘

196
3.7.2 Métodos de enumeración: en los ejemplos presentados hasta ahora, para el
cálculo P [A], con eventos equiprobables ha sido fácil calcular el número de casos
favorables y el número total de casos posibles, para luego aplicar la correspondiente
fórmula y calcular cualquier probabilidad perdida; sin embargo, existen situaciones
donde estos cálculos se complican, por lo que surge la necesidad de contar con un
procedimiento de enumeración que facilite encontrar una determinada probabilidad.
Ejemplo 3.7.11: En un refrigerador se encuentran almacenados 50 vasos con yogur, de
los cuales 10 no son aptos para su comercialización, porque han sobrepasado la fecha de
vencimiento, y 40 están en perfecto estado, sin que se pueda distinguir, a simple vista,
unos de otros. Se eligen seis vasos al azar, sin devolver el refrigerador el vaso escogido
antes de elegir el próximo, y se pregunta ¿cuál es la probabilidad de que la mitad de los
vasos seleccionados no sean aptos para comercializarse.
Para resolver este problema deben seguirse varias etapas:
a. Se deben sacar seis vasos de entre 50.
b. Establecer de cuántas maneras se pueden escoger seis de entre 50.
c. Entre todos esos resultados posibles, cuáles tienen la característica de
corresponder con el 50% de vasos no aptos para comercializarse.
Como ésta existen situaciones similares donde se dificulta resolver los literales b y c
como condición previa para calcular la probabilidad perdida. En consecuencia se
requiere estudiar algunos procedimientos sistemáticos de enumeración, introduciendo
así el estudio del análisis combinatorio que se trata a continuación.
3.7.2.1 Principio de la multiplicación o del conteo. El análisis combinatorio parte de
un principio básico que indica que “si un suceso cualquier puede ocurrir de n1 maneras
y cuando este ha ocurrido otro suceso puede ocurrir n2 maneras, entonces el número de
maneras en que los dos pueden ocurrir en el orden especificado es n1 x n2” (Spiegel,
1991). De este principio resulta fundamental considerar que las palabras claves en la
definición son “el orden especificado”
Ejemplo 3.7.12: en una finca los animales se identifican individualmente con una placa
metálica cuya numeración está constituida por cuatro dígitos que van del 0 al 9, sin

197
permitir repeticiones. Bajo ese sistema ¿cuántas placas de marcación pueden
elaborarse?
El primer número puede ser cualquiera del 0 al 9, el segundo cualquiera excepto el
primero, el tercero cualquiera diferente al primero y segundo y el cuarto cualquiera
diferente de los tres primeros, puesto que ningún dígito puede estar repetido. Con base
en lo anterior la respuesta es 10 x 9 x 8 x 7 = 5.040 placas de marcación diferentes.
Ejemplo 3.7.13: Si en el mismo sistema del Ejemplo 3.7.12, no se permite que las
placas empiecen por 0, ¿cuántas marcas pueden formarse?
La respuesta es: 9 x 8 x 7 x 6= 3.024
Ejemplo 3.7.14: La clave para acceder al menú principal de un computador está
compuesta por tres letras. ¿Cuántos códigos de acceso pueden formarse si se permiten
repeticiones de letras?
Dado que en el alfabeto español tiene 28 letras y éstas se pueden repetir, entonces:
R= 28 x 28 x 28 = 21.952
Ejemplo 3.7.15: Con la información del ejemplo 3.7.14, sin permitir repeticiones de
letra, ¿cuántas claves pueden formarse?
R= 28 x 27 x 26= 19.656
Ejemplo 3.7.16: Si el sistema de marcación de los animales en una finca tiene siete
dígitos del 0 al 9, no se permiten repeticiones y los dos primeros números corresponden
a las dos últimas cifras del año de nacimiento, ¿cuántas marcas pueden formarse para
los animales nacidos en 1996?
El primer número solo puede ser el 9, así que únicamente hay un resultado posible, al
igual que en el segundo solo puede ser 6, el tercer dígito puede ser cualquiera entre el 0

198
y el 9, así que existen 10 resultados posibles, el cuarto puede ser cualquiera menos el
tercero, y así sucesivamente hasta el séptimo, de tal manera que la respuesta es:
R= 1 x 1 x 10 x 9 x 8 x 7 x 6= 30.240
Ejemplo 3.7.17: si se lanza un mismo dado tres veces, ¿cuántos son los resultados
posibles?
R= 6 x 6 x 6=216
Ejemplo 3.7.18: si se lanza un dado tres veces, imponiendo la condición de que todos
los números sean diferentes en cada lanzamiento, ¿cuántos son los resultados posibles?
R= 6 x 5 x 4 = 120
Ejemplo 3.7.19: si se lanza un dado tres veces ¿Cuál es la probabilidad de que todos los
números sean diferentes?
El número posible de casos está dado por 6 x 6 x 6 = 216
El número de casos favorables para A= 6 x 5 x 4= 120
𝑃[𝐴] = 120
216=
5
9
Ejemplo 3.7.20: si se lanza un dado tres veces ¿Cuál es la probabilidad de que el primer
número sea seis y los demás cualquier número?
Número total de casos 6 x 6 x 6 = 216
Número de resultados favorables para A= 1 x 6 x 6 = 36

199
𝑃[𝐴] = 36
16=
1
6
Ejemplo 3.7.21: El tema de la síntesis de proteínas es complejo, pero por ahora es
suficiente con indicar brevemente algunos aspectos de importancia. Para una revisión
profunda del tema puede consultarse, entre muchas obras, las de Suzuki, et al (1986),
Darnell, et al (1984) y Wallace, et al (1991).
En la síntesis de proteínas los aminoácidos se encadenan para formar péptidos y luego
cadenas polipeptídicas, es decir, una proteína. Para que este mecanismo funcione se
hace necesario la intervención del ADN y ARN.
El ADN o ácido desoxirribonucleico, es una macromolécula de doble hélice compuesta
de un glúcido con cinco átomos de carbono, una pentosa llamada desoxirribosa, un
grupo fosfato y cuatro bases nitrogenadas que son adenina (A), guanina (G), timina (T)
y citosina (C). La unión del azúcar la base nitrogenada y el fosfato recibe el nombre de
nucleótido. El ARN o ácido ribonucleico se sintetiza a partir de una de las dos cadenas
de ADN y en su estructura la desoxirribosa es reemplazada por la ribosa y la timina por
el uracilo (U).
En el código molecular ADN-ARN, el orden en que aparezcan las bases nitrogenadas es
de mucha importancia puesto que, según la secuencia en que se ubiquen los
nucleótidos, se sintetizará una u otra proteína, de hecho las mutaciones puntuales se
originan por alteración en el orden de las bases.
Cada segmento de ARN compuesto por tres nucleótidos, no necesariamente distintos,
forman una “palabra” denominada técnicamente codón, que es específica para
transportar o codificar a un determinado aminoácido, así por ejemplo la palabra UUU
codifica para el aminoácido fenilalanina, AUG para a metionina, UUA para a leucina,
AUU para la isoleucina, ACU para la treonina, GGG para la glicina y así existen
secuencias específicas para transportar los 20 aminoácidos, incluyendo, además, señales
al inicio y terminación de la síntesis.

200
Con base en las anteriores explicaciones ¿cuántas palabras de tres letras para codificar
aminoácidos se puede formar en el código genético?
𝑹 = 𝟒 × 𝟒 × 𝟒 = 𝟔𝟒
Efectivamente, 64 palabras codifican para los 20 aminoácidos e incluyen las señales de
inicio y parada de la síntesis de proteína y constituyen el denominado código genético.
Es importante aclarar que a pesar de la existencia, como ya se dijo, de 20 aminoácidos
que son: fenilalanina, lisina, serina, tirosina, cistina, triptófano, leucina, prolina,
histidina, glicina, arginina, isoleucina, metionina, treonina, aspargina, ácido aspártico,
valina, glutamina, alanina y cisteína, existen 64 codones, hecho que indica que hay más
de un codón para codificar el mismo acido. Así por ejemplo, para la leucina los codones
son CUU, CUC, CUA, CUG.
¿Cuántas palabras que empiecen por U se pueden formar?
𝑅 = 1 × 4 × 4 = 16
¿Cuál es la probabilidad de encontrar nucleótidos que tengan alguna base repetida?
El procedimiento para responder la pregunta es el siguiente:
En primer lugar se define el evento.
𝐴{𝑋|𝑋 𝑒𝑠 𝑢𝑛 𝑛𝑢𝑐𝑙𝑒ó𝑡𝑖𝑑𝑜 𝑐𝑜𝑛 𝑎𝑙𝑔𝑢𝑛𝑎 𝑏𝑎𝑠𝑒 𝑟𝑒𝑝𝑒𝑡𝑖𝑑𝑎}
Determinar el número de casos en que ninguna base se repite:
4 × 3 × 2 = 24
Haciendo uso de la propiedad del evento complementario, se puede establecer el
número de nucleótidos con alguna base repetida, así:
64 − 24 = 40
Calcular la probabilidad con (3.7.1): P [A]=40
64= 0,635
Los ejemplos hasta ahora presentados son casos sencillos en donde se permiten o no
repeticiones. En otras situaciones puede existir un mayor grado de complejidad que

201
hace necesario la aplicación de otros conceptos y procedimientos, como se explica
enseguida.
3.7.2.2. Permutaciones. Una permutación de n objetos tomados de r en r, es una
elección donde importa el orden en que r objetos se toman de entre n. El número de
permutaciones se denota como nPr o P(n, r) o también Pn, r y está dado por la fórmula
general:
nPr = 𝑛!
(𝑛−𝑟)!
Ejemplo 3.7.22: ¿Cuántas permutaciones son posibles con las letras a, b, c tomadas de
dos en dos?
De acuerdo con (3.7.5) 3P2 = 3!
(3−2) != 6
Ejemplo 3.7.23: ¿Cuántas permutaciones son posibles con las letras a, b, c tomadas de
tres en tres?
3P3 =3!
(3−3) != 3! = 6
Se puede generalizar el Ejemplo 3.7.23 así: El número de permutaciones de n objetos
tomados de n en n es igual a n!
Ejemplo 3.7.24: ¿Cuántas permutaciones se pueden formar con las letras de la palabra
microorganismos?
Se puede observar que en este ejemplo la situación es diferente a las estudiadas en los
Ejemplos 3.7.22 y 3.7.23, puesto que ahora hay n objetos, pero n1 son de un tipo, n2 de
otro, y así hasta nk. La palabra tiene 15 letras (objetos), de las cuales tres son o, dos son

202
i, dos son m, dos son r, y sólo una letra para c, g, n, a. Así, el número de permutaciones
será:
𝑃 =15!
3! .2! .2! .2! .2! .1! .1! .1! .1!= 13.621.608.000
Ejemplo 3.7.25: ¿Cuántas permutaciones son posibles con las letras de la palabra
“casas”?
𝑃 =5!
2! .2! .1!= 30
Este caso es idéntico al del ejemplo inmediatamente anterior.
De los ejemplos 3.7.24 y 3.7.25 se puede formular la siguiente generalización: El
número de permutaciones de n objetos, donde n1 son de un tipo, n2, de otro tipo y nk
de otro diferente, y además n1+n2+….+nk=n está dado por la siguiente expresión:
𝑃 =𝑛!
𝑛1! × 𝑛2! × 𝑛𝑘!
3.7.4. Combinaciones. Una combinación de n objetos tomados de r en r es una
selección de r de ellos, sin importar el orden en que se toman. La notación general
para las combinaciones es la siguiente:
nCr = ( 𝑛
𝑟) =
𝑛!
𝑟! (𝑛−𝑟)!
Ejemplo3.7.26: ¿Cuántas combinaciones son posibles con las letras a, b, c tomadas de
dos en dos?
3C2= ( 3
2) =
3!
2! (3−2)!= 3
Ejemplo 3.7.27: En un corral hay 20 novillos brahaman, se escogen siete para
sacrificarlos. ¿De cuántas maneras se pueden escoger los siete novillos?

203
20C7= ( 20
7) =
20!
7! (20−7)!= 77.520 𝑚𝑎𝑛𝑒𝑟𝑎𝑠
Ejemplo 3.7.28: Se dispone de cinco novillas shorton y de siete angus; se escogen al
azar dos novillas shorton y tres angus para un experimento. ¿De cuántas formas se
puede hacer esta elección?
Las novillas shorton se pueden escoger de 5C2 maneras y las angus de 7C3.
El número total de maneras está por 5C2 x 7C3.
𝑅 = (5
2) (
7
3) =
5!
2! (5−2)!×
7!
3! (7−3)!= 10 × 35 = 350
Ahora ya es posible resolver el Ejemplo 3.7.11. La solución contempla los siguientes
pasos:
En primer lugar se establece de cuántas formas en total se pueden escoger seis de entre
50 vasos. Evidentemente se trata de una combinación, ya que no interesa el orden en
que los vasos son elegidos.
50C6= ( 50
6) =
50!
6! (50−6)!
En segundo lugar se debe conocer cuántos resultados cumplen con la condición de tener
el 50% de los vasos no aptos para consumo. Se sabe que entre los 50 vasos hay 10 no
aptos para consumo, se escogen en total seis, lo que implica que en esa muestra la mitad
serían no aptos, así que hay 10C3 maneras de escogerlos.
10C3= ( 10
3) =
10!
3! (10−3)!
Finalmente se debe establecer cuántos resultados cumplen con la condición de tener el
50% de los vasos aptos para consumo. Esto implica que hay 40C3 maneras de escoger
vasos con esta condición:
40C3= ( 40
3) =
40!
3! (40−3)!

204
Es importante notar que el número total de maneras de escoger los seis vasos de entre
50, al igual que el número de maneras de escoger los tres vasos aptos de entre 40 y los
tres vasos no aptos de entre 10 son, en los tres casos, eventos igualmente probables. En
consecuencia, definido A= {3 vasos aptos, 3 vasos no aptos}, la probabilidad de la
ocurrencia de A está dada por (3.7.1):
𝑃[𝐴] =(
103 ) (
403 )
(506 )
=120(9880)
15.890.700=
1.185.600
15.890.700= 0,074
Del ejemplo 3.7.28 se pueden extraer las siguientes generalizaciones:
Cuando se dispone de N objetos y se eligen al azar sin reemplazo n de esos objetos
habrá 𝑁
𝑛 maneras de escogerlos, todas con la misma probabilidad de ser elegidas.
Si N objetos están constituidos por r1 y r2 clases de objetos que satisfacen la condición
r1+r2=N, de donde se eligen al azar n de ellos, la probabilidad de que esos n objetos
escogidos al azar sin reemplazo contengan un evento particular A, con elementos de r1
y r2, elegidos de L1 maneras de entre r1 y L2 maneras de entre r2, donde L2 = n-L1, está
dada por:
𝑃[𝐴] =(
𝑟1
𝐿1) (
𝑟2
𝐿2)
(𝑁𝑛)
La fórmula (3.7.8) puede extenderse a los casos donde N esté constituida por r1, r2,…., rk
clases de objetos y calcular la probabilidad de un evento particular A que contenga
elementos de r1, r2,…., rk escogidos de L1, L2,…., Lk maneras, donde se deben satisfacer
las siguientes condiciones:
𝑟1 + 𝑟2+. . . +𝑟𝑘 = 𝑁
𝐿1 + 𝐿2 + ⋯ + 𝐿𝐾 = 𝑛

205
𝑃[𝐴] =(
𝑟1
𝐿1) (
𝑟2
𝐿2) … (
𝑟𝑘
𝐿𝑘)
(𝑁𝑛)
Ejemplo 3.7.29: En un refrigerador de un laboratorio están depositados 30 frascos
idénticos que contienen medio para cultivos celulares, delos cuales 15 contienen MME
(medio mínimo esencial), 9 con RPMI y 6 con un medio de cultivo ideado en el
laboratorio. Se escoge al azar 6 frascos y se pide calcular las siguientes probabilidades:
¿Cuál es la probabilidad de que se haya extraído 4 con MME, 1 con RPMI y 1 del
laboratorio?
𝐴 = {4 𝑀𝑀𝐸, 1 𝑅𝑃𝑀𝐼, 1 𝐿𝑎𝑏𝑜𝑟𝑎𝑡𝑜𝑟𝑖𝑜}
𝑁 = 30
𝑛 = 6
𝑟1 = 15
𝑟2 = 9
𝑟3 = 6
𝐿1 = 4
𝐿2 = 1
𝐿3 = 1
𝑃[𝐴] =(
154
) (91
) (61
)
(306 )
=(1.365)(9)(6)
593.775= 0,1241
De este ejemplo es posible indicar la siguiente generalización:(𝑛
1) = 𝑛
¿Cuál es la probabilidad de que todos contengan MME?

206
𝑃[𝐴] =(
156 ) (
90) (
60)
(306 )
=(5.005)(1)(1)
593.775= 0,008429
El caso general que se puede deducir de este ejemplo es el siguiente: (𝑛
0) = 1
Cuando se seleccionan objetos al azar es fundamental especificar si estos se escogen
con o sin reemplazo; cuando se duce que la selección es con reemplazo o con
sustitución se indica que un objeto seleccionada tendrá otra oportunidad de ser elegido
en un muestreo siguiente y por lo tanto interesa el orden en que se hace la elección.
Cuando la selección se hace sin reemplazo no existe interés en el orden en que se
escogen los objetos, así que el número total de muestras (NM), de tamaño r, que
pueden obtenerse de una población, bajo esta condición está dado por (𝑁
𝑟)
Cuando el muestreo es con reemplazo, el número total de muestras (NM), de tamaño r,
que pueden obtenerse de una población está dado por 𝑁𝑟.
Ejemplo 3.7.30: En un bioterio hay 20 ratones (Mus musculus). Un veterinario necesita
escoger cuatro individuos para inocularlos con una cepa rugosa de Brucella abortus
¿Cuántas muestras de cuatro ratones son posibles, si el muestreo se hace con
reemplazo?
𝑁𝑀 = 𝑁𝑟 = 204 = 160.0000
¿Cuántas muestras de cuatro ratones son posibles, si el muestreo se hace sin reemplazo?
𝑁𝑀 = (20
4) =
20!
4! (20 − 4)!= 4.845
En la práctica, tanto en producción y salud animal, cuando se trata de escoger unidades
experimentales para investigación, inspección o análisis de animales, insumos o
productos, las muestras se obtienen sin reemplazo.

207
3.7.5. Cálculo de probabilidades cuando los resultados no son equiprobables. En
situaciones como éstas, lo más apropiado es calcular la probabilidad de un evento
particular en términos de frecuencia relativa, tal como se indicó al inicio del capítulo.
Ejemplo 3.7.31: Un laboratorio lanza al mercado una nueva vacuna contra la fiebre
aftosa. En total fueron vacunados 2.600 animales, de los cuales 1.680 no desarrollaron
la enfermedad. Si se pregunta ¿Cuál es la probabilidad de que un animal vacunado no
desarrolle la enfermedad?
𝑃[𝐴] =1.680
2.600= 0,64
El Ejemplo 3.7.31 se puede generalizar para cualquier situación en que un experimento
es repetido varias veces y se registren los resultados observados. Bajo esta condición, la
probabilidad aproximada de que un suceso A se produzca, está dado por:
𝑃[𝐴] ≈𝑓
𝑛=
𝑁ú𝑚𝑒𝑟𝑜 𝑑𝑒 𝑣𝑒𝑐𝑒𝑠 𝑞𝑢𝑒 𝑜𝑐𝑢𝑟𝑟𝑒 𝐴
𝑁ú𝑚𝑒𝑟𝑜 𝑑𝑒 𝑣𝑒𝑐𝑒𝑠 𝑞𝑢𝑒 𝑠𝑒 𝑟𝑒𝑎𝑙𝑖𝑧𝑎 𝑒𝑙 𝑒𝑥𝑝𝑒𝑟𝑖𝑚𝑒𝑛𝑡𝑜
3.7.6. Otras reglas para calcular probabilidades. En el cálculo de probabilidades se
requieren otras reglas que se resumen a continuación.
Regla general de la adición. Si A y B son dos sucesos cualesquiera, la probabilidad de
que ocurra el uno o el otro está dada por:
𝑃[𝐴𝑜𝐵] = 𝑃[𝐴] + 𝑃[𝐵] − 𝑃[𝐴𝑦𝐵]
Donde 𝑃[𝐴𝑜𝐵] = 𝑃[𝐴 ∩ 𝐵] y significa que A y B pueden ocurrir juntos. En esta clase
de problemas resulta clave para saber si se aplica o no (3.6.11), la utilización de la letra
“o” cuando se pide una probabilidad específica.

208
Ejemplo 3.7.32: Se lanza un dado una vez. ¿Cuál es la probabilidad de obtener un 2 o
un 3? Si se define A= {Obtener el número 2} y B= {Obtener el número 3}, la respuesta
está dada por:
𝑃[𝐴𝑜𝐵] = 𝑃[𝐴] + 𝑃[𝐵] − 𝑃[𝐴 ∩ 𝐵] =1
6+
1
6− 0 =
2
6=
1
3
En este ejemplo, la intersección es el conjunto vacío, ya que al lanzar un dado no es
posible obtener un resultado 2 y 3 al mismo tiempo.
En general, la probabilidad de ocurrencia de uno o de otro suceso mutuamente
excluyente, es igual a la suma de las probabilidades individuales de cada suceso.
Ejemplo 3.7.33: Se estima que en el departamento de Nariño el 30% de las vacas en
producción padecen de hipocalcemia (A), el 3% sufren de cetosis (B) y el 2% son
hipocalcémicas y sufren cetosis (A y B). Si se escoge una vaca al azar, ¿Cuál es la
probabilidad de que el animal seleccionado sea hipocalcémico o tenga cetosis?
𝑃[𝐴𝑜𝐵] = 𝑃[𝐴 ∪ 𝐵] − 𝑃[𝐴 ∩ 𝐵] = [0,3 + 0,03] − 0,02 = 0,31
En este ejemplo los sucesos no son mutuamente excluyentes, ya que los dos pueden
ocurrir juntos, es decir, existe la probabilidad de que una vaca sea hipocalcémica y al
mismo tiempo tenga cetosis; por lo tanto, hay intersección y se debe restar esta
probabilidad.
Regla de la multiplicación. La probabilidad de que dos sucesos independientes ocurran
simultáneamente es igual al producto de sus respectivas probabilidades.
Dos sucesos A y B son independientes si y sólo si cumplen con la condición:
𝑃[𝐴 ∩ 𝐵] = 𝑃[𝐴]. 𝑃[𝐵]
}

209
Ejemplo 3.7.34: Se lanza un dado dos veces, ¿Cuál es la probabilidad de obtener el
número 4 en el primer lanzamiento y el 5 en el segundo? Definido A= {4 en el primer
lanzamiento], B= {5 en el segundo lanzamiento}:
𝑃[𝐴𝑦𝐵] = 𝑃[𝐴 ∩ 𝐵] =1
6×
1
6=
1
36
Aquí la clave para saber si se aplica o no (3.6.12) es la utilización de la letra “y” cuando
se pide una probabilidad específica.
En general, dos sucesos se definen como independientes cuando la ocurrencia de un
evento no afecta la ocurrencia de otro.
Ejemplo 3.7.35: Se escogen individuos al azar y se le pregunta sobre su tipo de sangre
y edad. Como se puede observar, los dos eventos, tipo de sangre y edad, son
independientes. Conociendo que la probabilidad de encontrar personas con sangre tipo
A es 0,39 y con más de 30 años de edad es 0,42. ¿Cuál es la probabilidad de encontrar
un individuo con sangre tipo A y más de 30 años de edad?
Definidos: A: {Es el evento tiene sangre tipo A} P [A]=0,39
B: {Es el evento tiene más de 30 años} P [B]=0,42
𝑃[𝐴 ∩ 𝐵] = 𝑃[𝐴]. 𝑃[𝐵] = (0,39). (0,42) = 0,1638
3.7.7. Probabilidad condicional. Muchas veces es necesario encontrar la probabilidad
de un evento A, sabiendo que ha ocurrido antes un evento B que afecta la ocurrencia de
A. En este caso, el evento B es un espacio muestral nuevo. Esta podría denominarse

210
probabilidad del evento A dado que el evento B ha ocurrido P [A/B] o simplemente
probabilidad de A dado B, que se define como:
𝑃 [𝐴
𝐵] =
𝑁ú𝑚𝑒𝑟𝑜 𝑑𝑒 𝑐𝑎𝑠𝑜𝑠 𝑓𝑎𝑣𝑜𝑟𝑎𝑏𝑙𝑒𝑠 𝑎 [𝐴 ∩ 𝐵]
𝑁ú𝑚𝑒𝑟𝑜 𝑑𝑒 𝑐𝑎𝑠𝑜𝑠 𝑓𝑎𝑣𝑜𝑟𝑎𝑏𝑙𝑒𝑠 𝑎 𝐵
Sean A y B dos eventos de un espacio muestral S, donde P[‘B]>0, la probabilidad
condicional de que ocurra el evento A dado que el evento B ya ocurrió, se simboliza por
P[A/B] y se define como:
𝑃 [𝐴
𝐵] =
𝑃 [𝐴 ∩ 𝐵]
𝑃[𝐵], 𝑃[𝐵] > 0
Ejemplo 3.7.36: Estudios demostraron que los ejemplares de una cierta raza de liebres
de alta montaña mueren antes de lo normal, aún en ausencia de depredadores o de
enfermedad conocida alguna. Dos de las causas de muerte identificadas son: baja
cantidad de azúcar en la sangre y convulsiones. Se estima que el 7% de los animales
presenta ambos síntomas, el 40% tienen bajo nivel de azúcar en la sangre y el 25% sufre
convulsiones. ¿Cuál es la probabilidad de que un animal elegido al azar tenga bajo nivel
de azúcar en la sangre, dado que sufre de convulsiones?
El interés se centra en los siguientes eventos:
C: {El animal escogido al azar tiene convulsiones}
S: {El animal escogido al azar tiene bajo nivel de azúcar en la sangre}
Del enunciado del Ejemplo 3.7.36 se tiene que:
P [C] =0, 25
P [S] =0, 40
P [C ∩ S] =0, 07
𝑃 [𝑆
𝐶] =
𝑃 [𝑆 ∩ 𝐶]
𝑃[𝐶]=
0,07
0,25= 0,28

211
La probabilidad de que un animal elegido al azar sufra convulsiones dado que tenga
bajo nivel de azúcar en la sangre es:
𝑃 [𝑆
𝐶] =
𝑃 [𝑆 ∩ 𝐶]
𝑃[𝐶]=
0,07
0,40= 0,175
En el anterior ejemplo se puede apreciar que: P [A/B]≠ P [B/A]
Por lo general esto se cumple si A y B son eventos de un espacio muestral S, con:
P [A]>0 y P [B]>0.
En muchos casos el interés puede reducirse solamente a un subconjunto de la población
inicial. Si se define 𝑛 [𝐴 ∩ 𝐵] como el número de casos favorables a [𝐴 ∩ 𝐵], 𝑛 [𝐵]
como el número de casos favorables a [B] y N como el número total de casos (3.7.13) se
puede expresar así:
𝑃 [𝐴
𝐵] =
𝑛 [𝐴 ∩ 𝐵]
𝑛[𝐵]=
𝑛 [𝐴 ∩ 𝐵]𝑁
𝑛[𝐵]𝑁
=𝑃[𝐴 ∩ 𝐵]
𝑃[𝐵], 𝑃[𝐵] > 0
Donde 𝑃[𝐴 ∩ 𝐵] y 𝑃[𝐵]se determinan a partir del espacio original S.
Algunas veces hay interés en determinar la probabilidad de que ocurran conjuntamente
dos eventos A y B, es decir, la probabilidad de que ocurra el evento A y el evento B.
Si en un experimento pueden ocurrir los eventos A y B, y éstos son sucesos de un
espacio muestral S, entonces:
𝑃[𝐴 ∩ 𝐵] = 𝑃[𝐴]. 𝑃[𝐵/𝐴]
Ejemplo 3.7.37: En un recipiente hay tres bolas blancas y dos negras. Se extraen dos
bolas al azar, primero una y luego otra, sin reemplazo, ¿Cuál es la probabilidad de que
las dos bolas sean negras?
Se define: A= {La primera bola extraída es negra}
B= {La segunda bola extraída es negra}

212
𝐴 ∩ 𝐵 es el evento de que ocurra A y luego B.
La probabilidad de extraer en primer lugar una bola negra es 2
5.
La probabilidad de extraer una segunda bola negra de la que restan es 1
4 ya que el
espacio muestral original se ha modificado, puesto que en el recipiente quedan cuatro
bolas, de las cuales una es negra.
Entonces: 𝑃[𝐴 ∩ 𝐵] = 𝑃[𝐴]. 𝑃[𝐵/𝐴] =2
5×
1
4=
2
20=
1
10
Ejemplo 3.7.38: En la replicación del ADN, a veces se presentan errores que pueden
dar lugar a mutaciones observables en el organismo. En ocasiones, tales errores están
inducidos químicamente. En un experimento se expone un cultivo de bacterias a la
presencia de un producto químico que tiene un 40% de probabilidad de producir error.
Sin embargo, el 65% de los errores es silencioso, en el sentido de no dar lugar a una
mutación observable. ¿Cuál es la probabilidad de que se observe una colonia mutada?
Sean los eventos:
A: {Inducir a error}
B: {Dar lugar a una mutación observable}
La probabilidad de que se observe una colonia mutada es equivalente a la probabilidad
de que se induzca al error y que se produzca o dé lugar a una mutación observable, es
decir:
P [Observar una colonia mutada]= 𝑃[𝐴 ∩ 𝐵]
𝑃[𝐴 ∩ 𝐵] = 𝑃[𝐴]. 𝑃[𝐵/𝐴] = 0,40 × (1 − 0,65)
= 0,40 × 0,35 = 0,14

213
Ejemplo 3.7.39: En un experimento con cabras (Capra hircus) se evalúa la variable
incremento de peso en función del sexo y de dos raciones, una con la adición de
metionina y otra sin este aminoácido. El espacio muestral puede expresarse así:
Hembras Machos Total
Dieta 1 10 15 25
Dieta 2 12 13 25
Total 22 28 50
Se elige una cabra al azar, ¿Cuál es la probabilidad de que hay sido sometida a la dieta
2, dado que es macho? También es posible formular la misma pregunta en estos
términos: si se elige al azar una cabra macho ¿Cuál es la probabilidad de que hay sido
sometida a la dieta 2?
Definidos los eventos:
A: {La cabra elegida es sometida a la dieta 2}
B: {El animal escogido es macho}
𝑃 [𝐴
𝐵] =
𝑛 [𝐴 ∩ 𝐵]
𝑛[𝐵]=
13
28= 0,46
Ejemplo 3.7.39: Los bovinos de la raza normando poseen lunetas, es decir, una aureola
de pelos pigmentos alrededor de los ojos, condición conocida también como “anteojo”.
Algunos animales no poseen tal condición y se los considera más susceptibles a padecer
oftalmias. En una población de normandos se ha calculado que la probabilidad de
encontrar animales sin anteojos es 0,23 y entre éstos, la probabilidad de elegir un animal
con oftalmia es de 0,18. Si se escoge al azar un novillo sin anteojos de esa población,
¿Cuál es la probabilidad de que tenga la enfermedad?
Los eventos son:
A: {El novillo carece de anteojos}

214
B: {El novillo tiene la enfermedad}
La probabilidad de que el novillo elegido al azar tenga la enfermedad, dado que carece
de anteojos, se la expresa como 𝑃[𝐵/𝐴].
𝑃 [𝐵
𝐴] =
𝑃 [𝐵 ∩ 𝐴]
𝑃[𝐴]
Puesto que 𝑃 [𝐵 ∩ 𝐴] = 0,18 y 𝑃[𝐴] = 0,23, entonces:
𝑃 [𝐵
𝐴] =
0,18
0,23= 0,7826
Ejemplo 3.7.40: En un hato dedicado a la producción de leche, una vaca determinada
ha tenido tres partos, en uno de los cuales tuvo un hijo hembra. ¿Cuál es la probabilidad
de que el segundo hijo sea macho? Si se considera únicamente partos de un solo hijo, se
tiene:
M: {Es el evento de que el hijo sea macho}
N: {Es el evento de que sea una hembra}
El espacio muestral S estará formado por los siguientes eventos.
𝑆 = {𝑀𝑀𝑀, 𝑀𝑀𝐻, 𝑀𝐻𝑀, 𝐻𝑀𝑀, 𝑀𝐻𝐻, 𝐻𝑀𝐻, 𝐻𝐻𝑀, 𝐻𝐻𝐻}
Sea:
A: {La vaca señalada tenga por lo menos una cría hembra}. Este evento es equivalente a
que la vaca tenga una a más crías hembras y se expresa como:
𝐴 = {𝑀𝑀𝐻, 𝑀𝐻𝑀, 𝐻𝑀𝑀, 𝑀𝐻𝐻, 𝐻𝑀𝐻, 𝐻𝐻𝑀, 𝐻𝐻𝐻}
B: {Evento de que el segundo hijo sea macho}. Entonces:
𝐵 = {𝑀𝑀𝑀, 𝑀𝑀𝐻, 𝐻𝑀𝑀, 𝐻𝑀𝐻}

215
Entonces la probabilidad de que el segundo hijo sea macho, dado que esta vaca tienen
por lo menos una cría hembra, se la expresa como:
𝑃 [𝐵
𝐴] =
𝑛 [𝐴 ∩ 𝐵]
𝑛[𝐴]
𝑛[𝐴] = 7
𝐵 ∩ 𝐴 = {𝑀𝑀𝑀, 𝐻𝑀𝑀, 𝐻𝑀𝐻}
𝑛[𝐴 ∩ 𝐵] = 3
Por lo tanto: 𝑃 [𝐵
𝐴] =
𝑛 [𝐴∩𝐵]
𝑛[𝐴]
3.7.8. Eventos independientes. Cuando se presentan dos eventos, la ocurrencia del
primero, de alguna manera, puede alterar o no la probabilidad de ocurrencia del
segundo, estos es, los eventos pueden ser dependientes o independientes. El concepto de
independencia estática es muy importante en las áreas de la estadística aplicada.
Sean A y B dos eventos de una espacio muestral S, se dice que los eventos A y B son
independientes si y sólo si:
𝑃 [𝐵
𝐴] = 𝑃[𝐴] 𝑦 𝑃 [
𝐵
𝐴] = 𝑃[𝐵]
3.7.9. Teorema de Bayes. Este teorema se utiliza para hallar 𝑃 [𝐴
𝐵] cuando 𝑃[𝐴 ∩ 𝐵] y
𝑃[𝐵] no se conocen de inmediato. Es muy empleado en Teoría de la Decisión para
evaluar nueva información y revisar estimaciones anteriores de la probabilidad de que
las cosas se encuentran en un estado o en otro.
Teorema de Bayes: Si A1, A2,…, An son n eventos mutuamente excluyentes, cuya unión
es el conjunto universal, B es un evento arbitrario tal que 𝑃[𝐵] > 0, 𝑃 [𝐵
𝐴𝑘] 𝑦 𝑃[𝐴𝑘] son
conocidos para k=1, 2,…, n, entonces:

216
𝑃 [𝐴𝑖
𝐵] =
𝑃[𝐴𝑖]𝑃 [𝐵𝐴𝑖]
𝑃[𝐴1]𝑃 [𝐵𝐴1
] + 𝑃[𝐴2]𝑃 [𝐵𝐴2
] + ⋯ + 𝑃[𝐴𝑛]𝑃 [𝐵
𝐴𝑛]
Ejemplo 3.7.41: En una estación acuícola de la costa Pacífica de Nariño, se presenta
con alta frecuencia el síndrome viral de la mancha blanca (White spot) en camarones
(Penaeus vannamei), cuyo principal síntoma es la coloración rojiza de la cola. Se ha
encontrado en diferentes muestras tomadas que el 90% de los animales con coloración
rojiza tienen el virus de la mancha blanca, mientras que únicamente el 5% de los
camarones que no tiene esta característica están afectados por la mancha blanca. Si la
proporción de camarones con coloración rojiza es de 0,45, ¿Cuál es la probabilidad de
que un camarón atacado por la mancha blanca, seleccionado al azar, tenga coloración
rojiza?
Sean los eventos:
A1= {El camarón tiene coloración rojiza en la cola}
A2= {El camarón no tiene coloración rojiza}
B= {El camarón se encuentra afectado por la mancha blanca}
Según el enunciado del ejemplo se tiene que:
𝑃 [𝐵
𝐴1] = 0,90
𝑃 [𝐵
𝐴2] = 0,05
𝑃[𝐴1] = 0,45
𝑃[𝐴2] = 0,55
El evento, el camarón tiene coloración rojiza dado que está afectado por la mancha
blanca se simboliza como 𝑃 [𝐴1
𝐵], según el Teorema de Bayes en (3.7.1.6)

217
𝑃 [𝐴1
𝐵] =
𝑃[𝐴1]𝑃 [𝐵𝐴1
]
𝑃[𝐴1]𝑃 [𝐵𝐴1
] + 𝑃[𝐴2]𝑃 [𝐵𝐴2
]=
(0,45)(0,90)
(0,45)(0,90) + (0,55)(0,05) = 0,94
Ejemplo 3.7.42: Las estadísticas indican que en Estados Unidos la probabilidad de que
una madre muera durante el parto es de 0,00022. Si no es de raza negra, la probabilidad
de muerte es de 0,00017, mientras que si lo es ésta aumenta a 0,00064; se supone que el
10% de los partos corresponden a mujeres negras. Hallar la probabilidad de que una
madre que muere en el parto sea de raza negra.
Sean los eventos:
A1= {La mujer es de raza negra}
A2= {La mujer no es de raza negra}
B= {La mujer muere}
Según el enunciado del problema:
𝑃 [𝐵
𝐴1] = 0,00064
𝑃 [𝐵
𝐴2] = 0,00017
𝑃[𝐴1] = 0,10
𝑃[𝐴2] = 0,90
La probabilidad de que una madre que muere en el parto sea de raza negra se simboliza
mediante
𝑃 [𝐴1
𝐵] =
𝑃[𝐴1]𝑃 [𝐵𝐴1
]
𝑃[𝐴1]𝑃 [𝐵𝐴1
] + 𝑃[𝐴2]𝑃 [𝐵𝐴2
]

218
=(0,10)(0,00064)
(0,10)(0,00064) + (0,9)(0,00017)
= 0,295

219
CAPÍTULO 4
FUNCIONES DE PROBABILIDAD PARA VARIABLES ALEATORIAS,
DISCRETAS Y CONTINUAS
Hasta ahora se han estudiado los principios básicos más importantes del cálculo de
probabilidades; en este capítulo se intentará relacionar dichos conceptos con el análisis
de datos encaminados a extraer conclusiones para la población con base en la
información obtenida de la muestra y, de este modo, concatenar la teoría de
probabilidad con la estadística aplicada. Antes de abordar esta temática es necesario
recordar inicialmente el concepto de las variables aleatorias, también conocidas con el
nombre de variables estocásticas y su clasificación en continuas y discretas, lo que en
gran ida determina la capacidad para predecir el valor que tomarán las variables bajo
determinada situación, sin perder de vista que, dada la condición del azar, las
predicciones se hacen en términos de incertidumbre, por lo que resulta más apropiado
describir el comportamiento de las variables con las funciones de probabilidad y de
probabilidad acumulada.
4.1 VARIABLE ALEATORIA
Cuando se describe un espacio muestral en un experimento, un resultado particular no
necesariamente un número. Por ejemplo, un animal en un hato puede ser clasificado
"enfermo" o "sano"; en cambio, en otras situaciones experimentales se realiza una
observación y el resultado se registra como un número, es decir, se asigna un número
real x a cada elemento de un espacio muestral S.
Una variable aleatoria X es una función que asocia un número real con cada elemento
del espacio muestral. En este capítulo se utilizará la letra mayúscula X para denotar una
variable aleatoria, y su correspondiente letra minúscula para algunos de sus valores.

220
4.1.1 Rango de una variable aleatoria X. Es el conjunto de los valores posibles que
puede remar la variable cuando se realiza un experimento particular.
Ejemplo 4.1.1: Un experimento consiste en lanzar dos monedas normales. Si X es la
variable aleatoria número de caras que aparecen, el espacio muestral se lo puede
expresar como: S ={cc, es, se, ss}.
Al punto muestral ss, la variable aleatoria X le hace corresponder el número O, puesto
que no hay caras, a los puntos muéstrales es y se les hace corresponder el número 1 y al
punto muestral ce le hace corresponder el número 2. Entonces, el rango de la variable
aleatoria X es el conjunto {0, 1, 2}.
Ejemplo 4.1.2: Si el experimento consiste en lanzar dos dados corrientes, el espacio
muestral viene dado S = {(1, 1), (1, 2),..., (6, 6)}. Sea X la variable aleatoria que hace
corresponder a cada punto (a, b) de S el máximo de sus números, es decir:
X(a, b) = máximo (a, b)
Para los casos: X(1, 5) = 5, X(5, 6)= 6, X(6, 6) = 6. Aquí el rango de X viene dado por el
conjunto {1, 2, 3, 4, 5, 6}
4.1.2 Variables aleatorias discretas. Una variable aleatoria X es discreta cuando toma
solamente un número finito o infinito numerable de valores, es decir, su rango es finito
o infinito numerable.
4.1.3 Función de probabilidad para variables aleatorias discretas. Luego de definir
una variable aleatoria X sobre el espacio muestral de un experimento, se determina la

221
probabilidad de que ésta tome un valor determinado, entonces, la función de
probabilidad hace corresponder a cada valor posible de X el valor de su probabilidad.
La probabilidad de que la variable aleatoria X tome un valor determinado x es igual a la
suma de las probabilidades de los puntos muéstrales para los cuales X = x y se
simboliza por:
p[x] = P [X = x], donde deben cumplirse las siguientes propiedades:
a. 𝑝[𝑥] ≥ 0, para todo x de X.
b. ∑ 𝑝[𝑥] = 1
A la colección de pares (Xi, P(Xi)) se la denomina Distribución de probabilidad de X y
es posible representarla en forma de tabla.
Ejemplo 4.1.3: En el ejemplo 4.1.2 se quiere calcular (Xi, P[Xi]).
S= {(1, 1), (1, 2), … , (6, 6)}
X(a, b) = máximo (a, b)
Rango = {1, 2, 3, 4, 5, 6}
Se puede apreciar que la probabilidad de cada punto muestral de S = 1
36 detallada en la
siguiente forma:

222
p[1] = P[X = 1] = P[{(1,1) }] = 1
36
p[2] = P[X = 2] = P[{(1,2), (2,2), (2,1)}] = 3/36
p[3] = P[X = 3] = P[{(1,3), (2,3), (3,3), (3,2), (3,1)}] = 5/36
p[4] = P[X = 4] = P[{(1,4), (2,4), (3,4), (4,4), (4,3), (4,2), (4,1)}] = 7/36
En forma similar: p[5] = P[X = 5] = 9
36— y p[6] = P[X - 6] =
11
36
Esta distribución de probabilidad representada en forma de tabla se esquematiza del
siguiente modo:
Xi 1 2 3 4 5 6
P[Xi| 1/36 3/36 5/36 7/36 9/36 11/36
A su vez, la tabla representada gráficamente adopta la forma de la Figura 4.1.1:
Figura 4.1.1 Representación gráfica de la distribución de probabilidad

223
4.1.4 función de distribución acumulativa. La función de distribución acumulativa de
la variable aleatoria X es la probabilidad de que X sea menor o igual a un valor
específico x y está dado por:
F(x)=P[ X ≤ x ] = ∑ 𝑝(𝑋𝑖)Xi ≤ x
Ejemplo 4.1.4: Para el ejemplo 4.1.3:
F(1)= P[X ≤ 1] = p[1] = 1/36
F(2) = P[X ≤ 2] = p[1] + p[2] = 1/36 + 3/36 = 4/36
F(3) = P[X ≤ 3] = p[1] + p[2] + p[3] = 9/36
F(4) = P[X ≤ 4] = p[1] + p[2] + p[3] + p[4] = 16/36
F(5) = P[X ≤ 5] = p[1] + p[2] + p[3] + p[4]+ p[5]= 25/36
F(6) = P[X ≤ 6] = p[1] + p[2] + p[3] + p[4]+ p[5] + p[6] = 36/36
La función de distribución acumulativa F(x) de una variable aleatoria discreta X cumple
las siguientes propiedades:
a. 0 ≤ F(x) ≤ 1, para todo x.
b. Si Xi ≥ Xj, entonces F(Xi) > F(Xj), lo que significa que es una función no
decreciente.

224
Si se desea hallar la probabilidad de que una variable aleatoria tome un valor mayor que
x, se tiene:
c. P[X>x] = 1 - F(x)
Para variables aleatorias de valor entero, se tiene además que:
d. P[ xi ≤ X ≤ xj ] = F (xj) – F(x i -1)
e. P[X ≥ x] = 1 - F(x i -1)
Ejemplo 4.1.5: En el Ejemplo 4.1.3 se tiene que:
P[X > 3] = 1 - F(2)= 1 – 4/36 = 32/36
P[ 3 ≤ X ≤ 5 ] = F (5) – F(2) = 25/36 – 4/36 = 21/36
Ejemplo 4.1.6: En una planta procesadora de camarón, se sabe por experimentación
que el número de colas por libra al empacar es como se muestra enseguida:
Colas por libra 49 50 51 52 53 54 55
Probabilidad 0,05 0,12 0,20 0,24 0,17 0,14 0,08
Con base en esta información, se pide calcular las siguientes probabilidades:

225
a. ¿Cuál es la probabilidad de que al tomar una bolsa ésta tenga por lo menos 53
colas/lb?.
b. ¿Cuál es la probabilidad de que tenga 50 colas/libra o más?.
c. ¿Cuál es la probabilidad de que tenga como mínimo 50 colas/Ib?.
Si se define X como la variable aleatoria número de colas/libra al empacar, entonces:
a) P[X > 53] = 1 - F(53) = 1- (p[49J +p[50] + p[51] + p[52]) = 1- 0,61 = 0,39
b) P[X>50] = 1-F(50) = 1-0,05 =0,95
c) P[X < 50] = F(50) = p[49] + p[50] + p[51] = 0,37
4.1.5 Valor esperado o esperanza matemática de una variable aleatoria discreta. El
valor esperado de una variable aleatoria, se obtiene al hallar el valor medio de la
variable, t todos sus valores posibles. El valor esperado es una media técnica o ideal.
El valor esperado de una variable aleatoria X se representa, generalmente, por E[X] o la
Ietra griega 𝜇 y se expresa como:
E[X] = µ = ∑ 𝑥 . 𝑝(𝑥)𝑥 ∈𝑋
El valor esperado posee propiedades análogas a las establecidas para la media
aritmética:
a. Si c es una constante, entonces E[c] = c
b. Si a y b son constantes, entonces E[aX + b] = aE[X] + b

226
c. Si g(x) y h(x) son funciones de una variable aleatoria X, entonces
E [g(x) ± h(x) = E [g(x) ± E [ h(x) ]
e. E [ X - µ] = 0
Ejemplo 4.1.7: Hallar el valor esperado en el Ejemplo 4.1.6.
µ = E[X] = ∑ xi 9𝑖=3 . Ptxil = 49 x 0,05 + 50x0,12 + 51x0,2 + 52x0,24 + 53x0,17 +
54x0,14 + 55x0,08 = 52,1 = 52 colas/Ib
Lo que significa que en promedio se espera que las bolsas tengan 52 colas/Ib.
4.1.6 Varianza de una variable aleatoria. Si X es una variable aleatoria con valor
esperado de E[X], la varianza de X se representa por V[X] o cr2 y se la puede expresar
como:
V[X]= ὂ 2 = E[X2] - (E[X])2 = ∑ 𝑥𝑖2 𝑝[𝑥] − µ2
La raíz cuadrada positiva de la varianza es la desviación típica o. La varianza, como se
indicó en el primer capítulo, mide la dispersión de los datos alrededor de la media.
Propiedades análogas a las de la varianza de observaciones se cumplen para la varianza
de una variable aleatoria:
a. Si a es una constante, entonces V[a] = O
b. Si a y b son constantes, entonces V[aX + b] = a2 V[X]

227
Ejemplo 4.1.8: Con la información indicada en el Ejemplo 4.1.6, la varianza se calcula
de la siguiente manera:
ὂ 2 = ∑ 𝑥𝑖2 𝑝[𝑥] − µ2
µ = 52,1, Entonces µ2 = 2.714,41
∑ 𝑥𝑖2 9𝑖=9 • p[Xi] = 2.401x0,05 + 2.500x0,12 + 2.601x0,2 + 2.704x0,24 + 2.809x0,17 +
2.916x0,14+ 3.025x0,08 =39,78
ὂ2 = 2716,98 - 2714,41 = 2,57
4.2 DISTRIBUCIONES DE PROBABILIDAD ESPECIALES PARA VARIABLES
DISCRETAS
4.2.1 La Distribución binomial: La variable aleatoria binomial es un tipo específico de
variable discreta, que representa únicamente dos clases de respuesta: éxito o fracaso,
obtenidos en un número n de pruebas independientes. Los casos que se mencionan a
continuación ilustran de mejor manera este enunciado.
• Si 1.000 partos no gemelares de vacas holstein son sucesos independientes; sólo
existen dos posibles resultados en cuanto al sexo de las crías: que sean machos o que
sean hembras. Al disponer de los resultados de todos esos partos será posible
contabilizar las crías que corresponden a cada sexo.

228
• Se vacunan 5.000 cerdos contra la PPA (peste porcina africana). Hay dos posibles
resultados: que los animales contraigan la enfermedad (no fueron protegidos por la
vacuna) o que no contraigan la enfermedad (fueron protegidos por la vacuna); al final
del ensayo es posible contabilizar el número de animales sanos y enfermos. Se asume
que la efectividad de la vacuna (probabilidad de protección) se mantiene constante de
un ensayo a otro.
Generalmente se define como "éxito" la constatación de la característica de interés para
el investigador; así en el ejemplo de la vacuna, "éxito" se referirá a la probabilidad de
encontrar un animal enfermo.
Si las n pruebas son independientes, significa que el resultado de una no afecta el
resultado de cualquier otra y, además, la probabilidad de éxito permanece constante a lo
largo del experimento, es posible establecer la función de probabilidad de este tipo de
variables, así:
P(x,n,p) = (𝑛𝑥
) px (1-P) n - x x = 0,l,2,...,n
Dónde:
p = probabilidad de éxito en una sola prueba
1-p = q: probabilidad de fracaso
n = número de pruebas
x = número de éxitos en n pruebas
(𝑛
𝑥) =
𝑛 !
𝑥! (𝑛 − 𝑥)!

229
El valor esperado de la variable aleatoria binomial es E[X] = \í = np y la varianza es
V[X]= ὂ2 = np(1-p).
La función de distribución acumulativa de la variable aleatoria binomial está dada por:
F(x) = P[X≤x] = p[0] + p[1] + … + p(x)
Ejemplos 4.2.1: Al lanzar una moneda tres veces, ¿cuál es la probabilidad de que
aparezcan los siguientes resultados?:
a) 3 caras, b) 2 caras, c) 1 cara, d) Ninguna cara, e) Por lo menos 2 caras, f) Como
máximo 2 caras.
n = 3, ya que el experimento se repite 3 veces.
p = 0,5 es la probabilidad de obtener una cara en un lanzamiento, la probabilidad del
fracaso (q) se obtiene así: ( q = 1 - p = 1 -0,5 = 0,5.
Los experimentos son independientes, ya que el resultado del primer lanzamiento no
afecta el de los siguientes. En consecuencia, se cumplen los supuestos del modelo
binomial, por lo tanto es posible calcular las probabilidades pedidas con la fórmula
(4.2.1), donde X es el número de caras que podrían aparecer:
a) P[X = 3] = (33) |0,53 . 0,53-3 =
3 ¡
3!(3−3)! 0,53 . 0,53-3 = (6
6) . 0,125 . 1 = 0,725
b) P[X = 2] = (32) |0,52 . 0,53-2 =
3 ¡
2!(3−2)! 0,52 . 0,53-2

230
= 6/ 2 . 0,25 . 0,5 = 0,375
c) P [X = 1] = (31) |0,51 . 0,53-1 =
3 ¡
1!(3−1)! 0,51 . 0,53-1
= 6/ 2 . 0,5 . 0,25 = 0,375
d) P [X = 0] = (30) |0,50 . 0,53-0 =
3 ¡
0!(3−0)! 0,50 . 0,53 = 0,125
e) P[X ≥ 2] = p[2] + p[3] = 0,375 + 0,125 = 0,5
Al aplicar las propiedades de las variables aleatorias discretas
P[X ≤ 2] = 1 - F(1) = 1 - (p[0] + p[1] = 1-0,5 = 0,5 se tiene:
f) P[X ≤ 2] = F(2) = p[0] + p[l] + p[2] = 0,875
Cuando el tamaño de muestra es grande, el cálculo de probabilidades mediante la
ecuación (4.2.1) es dispendioso, por lo tanto, se recurre al uso de valores que ya están
tabulados para diferentes valores de n, p, x. En la Tabla 2 del Apéndice se presentan las
cifras de la función de distribución acumulativa binomial.
Ejemplo 4.2.2: El cálculo de probabilidades para el literal f) del Ejemplo 4.2.1, con el
uso de la mencionada tabla, se lleva a cabo de la siguiente manera:
Se halla F(2), ya que F(2) = P[X ≤ 2]

231
Teniendo en cuenta que, en el lanzamiento de una moneda, la probabilidad de que
aparezca una cara es p = 0,5 y que n = 3, ya que se lanzan tres monedas, en la Tabla 2
del Apéndice, en lugar se localiza n = 3 y aquí se ubica x = 2, luego en la intersección
entre p = 0,5 y x = 2 se encuentra F(2) = 0,875.
En esta tabla también se puede hallar P(X = x), con la siguiente fórmula:
P[X = x] = F(x) - F(x-1)
Para el literal b) del Ejemplo 4.2.1 se procede así:
P[X = 2] = F(2) - F(1) = 0,875 - 0,5 = 0,3750
Ejemplo 4.2.3: En una población de cerdos afectados de Neumonía por Bortedella,
enfermedad caracterizada por tos, disnea, debilitamiento, taquinea y alta mortalidad, el
40% se recupera después de recibir tratamiento a base de quinolonas. Si se extrae una
muestra aleatoria de 20 cerdos, calcular las siguientes probabilidades:
a) Que cinco o menos se recuperen
b) Por lo menos seis se recuperen
c) Entre 7 y 10 inclusive se recuperen
d) ¿Cuál es el valor esperado de animales recuperados?
Se define X como la variable aleatoria "número de cerdos que se recuperan". Se tiene
que n = 20 y p = 0,4. Así que las respuestas serán:
• P[X ≤ 5] =F(5) = 0,1256

232
• P[X ≥ 6] = 1- F(5) = 1 - 0,1256 = 0,8744
• P [7 ≤ X ≤ 10] = F(10) - F(6) = 0,8725 - 0,2500 = 0,6225
• E[X] = np = 20 x 0,4 = 8, lo que significa que en una muestra aleatoria de 20 cerdos
se espera que en promedio se recuperen ocho animales.
4.2.2 La Distribución Poisson. Es una familia de distribuciones discretas, llamada de
esta forma en homenaje a Simeón Denis Poisson, quien la describió a finales del siglo
XIX. Las variables aleatorias de Poisson implican la observación de un conjunto discre-
to de sucesos en un intervalo continuo de tiempo, longitud o espacio, pero el concepto
de intervalo no se trata, en este contexto, como en la forma matemática usual. Por
ejemplo, si al analizar una muestra de 1,0 ce de semen bovino se buscan espermatozoi-
des con cola enrollada, el suceso es el espermatozoide con la característica anotada y el
"intervalo" es el centímetro cúbico de semen. Un veterinario contabiliza semanalmente
el número de llamadas que recibe en su consultorio solicitándole realizar cesáreas en
equinos; en este caso, el suceso que toma valores discretos es el número de llamadas y
el intervalo es una semana.
Definida X como el número de sucesos de interés en un intervalo de unidades de tamaño
S, con el propósito de establecer la función de probabilidad de X es necesario considerar
los siguientes aspectos:
a. La unidad de medida básica del problema
b. La media del número de sucesos ocurridos por unidad de medida
c. El tamaño del intervalo de observación
Establecidos los anteriores criterios, la función de probabilidad de X estará dada por:
𝑝[𝑥] = 𝑒Ằ𝑠 (Ằ𝑠)𝑥
𝑥 ¡

233
x = 1,2, …, k
Ằ > 0
S > 0
Dónde:
e = Base del logaritmo natural (2,718282)
Ằ = µ : Media de la ocurrencia del suceso particular
s = Intervalo del experimento
ὂ = Ằ
F(x) = P[X≤x] = p[0] + p[1] + … + p[x]
Cuando una variable aleatoria discreta adopta esta forma recibe el nombre de variable
aleatoria Poisson y su función de probabilidad está expresada en (4.2.2).
Los anteriores conceptos se resumen al indicar que una distribución Poisson describe la
frecuencia de un evento que puede tomar valores discretos 0, 1, 2, 3,...., k,
correspondientes un suceso cuyo número promedio de ocurrencias es bajo en relación
con el número total e reces que éste podría ocurrir, tal como se observa en los ejemplos
antes anotados. Dado que la probabilidad del suceso es pequeña, frecuentemente se
menciona a la distribución Poisson como una función de distribución de sucesos
"raros".
Ejemplo 4.2.4: Luria y Delbruck, citados por Suzuki et al (1992), realizaron una prueba
experimental, conocida con el nombre de prueba de fluctuación, con células de E. Coli,
para calcular la tasa de mutación. Un estudio específico tenía como objetivo determinar

234
un tipo particular de mutación consistente en detectar bacterias que se vuelven
resistentes al Fago T1, virus que ataca y mata a la mayoría de células de E. coli.
Cuando se siembra un número elevado de bacterias y de fagos, la mayoría de las
bacterias muere, pero las resistentes al Fago T1 sobreviven y producen colonias que se
pueden aislar. Este tipo de células imitantes se conocen con el nombre de células
resistentes a T1 o Tonr. Con el método de Luna y Delbruck se estableció que la media
(𝜇) de los sucesos mutacionales por división celular era de 3 x 108. Si se observan 108
células, ¿cuál es la probabilidad de que ninguna sea mutante?
Para responder la pregunta, se aplica el siguiente procedimiento:
a. Calcular Ằ = 3x10-8 , s = 108, Ằs = 3
b. Aplicar la fórmula (4.2.1), teniendo en cuenta que el valor de X = O
P[X = 0] = 𝑒−3(3)0
0! =0,04978
Ejemplo 4.2.5: Mediante análisis de cariotipo se ha establecido que una de las
anomalías específicas en cromosomas sexuales es el síndrome de Klinefelter, donde el
individuo afectado presenta cariotipo anormal XXY, que en el fenotipo se expresa con
disminución del tamaño de los testículos, hialinización de los túbulos seminíferos,
escaso desarrollo de los caracteres sexuales secundarios, de tal suerte que los pacientes
tienen apariencia de varón, pero son positivos para la prueba de la cromatina sexual.
Diversos estudios han estimado una tasa promedio del síndrome en 1,2 por cada 1.000
nacimientos. Si se analizan 5.000 láminas con preparados celulares para establecer el
cariotipo, ¿cuál es la probabilidad de encontrar la anormalidad en tres de ellas?
Se procede de la misma manera que en el ejemplo inmediatamente anterior:

235
a. Ằs = 0,0012 x 5.000 = 6
b. Aplicar la fórmula (4.2.1)
P[X = 3] = 𝑒−6(6)3
3 ! =0,089
Existe una importante aplicación de la distribución Poisson cuando se considera una va-
riable aleatoria binomial, donde n es grande y la probabilidad de éxito (p) es muy
pequeña, de tal modo que la probabilidad de fracaso (q) se acerca a 1,0. En estos casos
se ha demostrado que la distribución Poisson con parámetro Xs = np se aproxima a la
Binomial; en la práctica, esta aproximación es buena si n es mayor o igual a 30 y p
menor o igual a 0,05, y muy buena cuando n es mayor o igual a 100 y np es menor o
igual a 10.
Ejemplo 4.2.6: La probabilidad de que un perro muera como consecuencia de la
aplicación de una vacuna pentavalente contra moquillo, hepatitis infecciosa,
parvovirosis, parainfluenza canina y leptospirosis es de 0,00002. Si se administra la
vacuna a 100.000 caninos, asumiendo éstos como un conjunto independiente de
ensayos, ¿cuál es la probabilidad en cada uno de los siguientes casos?:
a. Que mueran como máximo 2 perros
b. Que mueran 3 o más animales
c. Que mueran entre 5 y 8 inclusive
d. Que mueran exactamente 3 perros
Esencialmente se trata de un experimento binomial, con n = 100.000 y p = 0,00002.
Puesto que p está muy próxima a cero y n es muy grande, para calcular las
probabilidades pedidas se aproximará a una distribución de Poisson con
Ằ = np = 100.000x0,00002 = 2

236
Al igual que para la distribución binomial, para la distribución de Poisson también
existen tablas. En el Tabla 3 del Apéndice se dan los resultados correspondientes de la
función de distribución F(x, Xs), para diferentes valores de x y Ks.
Si X es la variable aleatoria: muere un determinado número de perros, entonces:
a. P[X ≤ 2] = F(2) = 0,6767.
En la tabla de la distribución de Poisson se encuentra que para hs = 2 y X = 2, por lo
tanto F(2) = 0,6767.
b. P[X ≥ 3] = 1-F(2) = 1-0,6767 = 0,3233.
c. P[5 ≤ X ≤ 8] = F(8) - F(4) = 0,9998 - 0,9473 = 0,0525.
d. P[X = 3] = F(3) - F(2) = 0,8571 - 0,6767 = 0,1804.
4.2.3 La distribución Multinomial: Es una generalización de la distribución binomial,
donde, si los sucesos ay ay...., a^ pueden ocurrir con frecuencias
pv py ...., p^ respectivamente, entonces, la probabilidad J de que av ay ...., ak ocurran xv xy
...., xk veces, respectivamente, se calcula de la siguiente forma:
F(Xk) = 𝑁 !
𝑋1! 𝑋2! 𝑋𝑘 !
𝑃1𝑋1 𝑃2
𝑋2… 𝑃𝐾𝑋 𝑘
P[𝑋1, 𝑋2,…, 𝑋𝑘 ]=
𝑛!
𝑋1! 𝑋2! 𝑋𝑘 !
𝑃1𝑋1 𝑃2
𝑋2… 𝑃𝐾𝑋 𝑘
Dónde:
X1 + x2+... +xk = n
P1+p2+...+pk = 1 y (4.2.3) es el término general en el desarrollo multinomial

237
(p1 + p2’ + pk)n
Ejemplo 4.2.7: Si se lanza un dado 15 veces, ¿cuál es la probabilidad de obtener dos
veces cada cara del dado?
De acuerdo con (4.2.2), la respuesta es:
P[xv xy xy xv xy x6] = 15!
2! 2! 2! 2! 2! 2!(
1
6)2 (
1
6) 2 (
1
6) 2 (
1
6) 2 (
1
6) 2 (
1
6) 2
= 1307674368000
64(9,8464)10-15 =0,00020
Ejemplo 4.2.8: En el cruzamiento entre animales heterocigóticos para el color del
manto en la raza holstein, en 12 nacimientos, ¿cuál es la probabilidad de que tres crías
sean negras homocigóticas, cinco negras heterocigóticas y cuatro rojas?
Con la aplicación del mismo procedimiento, se tiene:
P[𝑋1, 𝑋2,…, 𝑋𝑘 ]=
12!
3! 5! 4! (
1
4) 3 (
2
4) 5 (
1
4) 4 =
479001600
17280 ( 1, 9073)10−6 = 0,0528
La probabilidad de que las doce crias próximas a nacer, tres sean negras homocigotas,
cinco negras heterocigotas y cuatro rojas es 5,28%.
En los experimentos multinominales, se espera que el número de veces que ocurrirá a1,
a2,…. ak en n ensayos, se estima por np1, np2,….npk. asi, en en ejemplo 4.2.8, sobre las
crías holstein, se esperan tres negras homocigóticas (12*0,25) y tres rojas (12*0,25).

238
4.3 VARIABLES ALEATORIAS CONTINUAS
Antes de iniciar este tema e conveniente indicar que por simple convención las variables
aleatorias continuas se identificaran en este texto con la letra Y.
Una variable aleatoria Y es continua si los valores que toma consisten en uno o más
intervalos de la recta real, es decir, si su rango es infinito no numerable.
Para las variables aleatorias discretas se asignan probabilidades a todos los valores
puntuales de la variable. Para el caso continuo esto no es posible, puesto que el rango es
no numerable así que la probabilidad de Y tome un valor específico: P[Y=y] = 0.
Una variable aleatoria continua está caracterizada por una función f(y) que recibe el
nombre de función de densidad y esta proporciona un medio para calcular la
probabilidad en un intervalo a ≤ Y ≤ b.
La función f(y) es una función de densidad de probabilidad así:
a) f(y) ≥ 0 para -∞ < y < ∞
b) ∫ 𝑓 (𝑦)𝑑𝑦 = 1+∞
−∞
c) P [ a ≤ Y ≤ b] = ∫ 𝑓 (𝑦)𝑑𝑦𝑏
𝑎
La primera propiedad dece que f es no negativa, la segunda afirma que f se
constituye de manera que el área bajo su curva, limitada por el eje de las Y, es igual
a uno cuando se calcula en el rango de Y para el que está definido f(y), y la tercera
propiedad expresa como calcular la probabilidad de que Y tome un valor desde y=a
hasta y=b está caracterizada por una función f(y)
Dado que para una variable aleatoria continua la probabilidad de que Y tome un valor
específico es cero se tiene que:
𝑃[á ≤ 𝑦 ≤ 𝑏] = 𝑃[𝑎 ≤ 𝑦 < 𝑏] = 𝑃[𝑎 < 𝑦 ≤ 𝑏] = 𝑃[𝑎 < 𝑦 < 𝑏]
Gráfico 1

239
𝑃[𝑎 < 𝑦 < 𝑏] = ∫ (𝑦)𝑑𝑦𝑏
𝑎
La función de distribución acumulativa F(y) de una variable aleatoria continua Y, con
función de densidad de probabilidad f(Y) está dada por.
𝐹(𝑦) = 𝑃[𝑌 ≤ 𝑦] = ∫ 𝑓(𝑡)𝑑𝑡 𝑝𝑎𝑟𝑎 − ∞ < 𝑦 < ∞
𝑃[𝑌 ≤ 𝑦]
De aquí se desprende que 𝑃[𝑎 < 𝑌 < 𝑏] = 1 − 𝐹(𝑦)
También se tiene que 𝑃[𝑌 > 𝑦] = 𝑃[𝑌 ≥ 𝑦] = 1 − 𝐹(𝑦)
El valor esperado de una variable aleatoria continúa Y, se define como:
𝐸[𝑌] = ∫ 𝑌𝑓(𝑦)𝑑𝑦∗∞
−∞
La varianza se define como
𝑉{𝑌} = 𝜕2 = ∫ (𝑌 − 𝜇)∗∞
−∞2∫(𝑌)𝑑𝑦

240
4.3.1 La distribución normal. La distribución normal es una “familia” de variables
aleatorias continuas, descritas por primera vez por Moivre 1773, como el valor límite
de la densidad binomial con un numero de ensayo grande. Los resultados encontrados
por de Moivre pasaron prácticamente inadvertidos durante 50 años y fueron Gauss
Laplace, quienes al estudiar problemas de astronomía, en forma independiente,
presentaron la distribución normal como una descripción de los errores en las medidas
astronómicas.
La distribución normal es de gran utilidad ya que constituye una excelente
aproximación para una cantidad apreciable de distribuciones que tiene mucha
importancia práctica y posee varias propiedades matemáticas que conducen a deducir
resultados teóricos de interés.
La distribución normal ha tenido especial importancia en producción y salud animal
para el correcto análisis e interpretación de datos especialmente experimentales. El
desarrollo de la teoría de selección animal, así como el estudio de una amplia gama de
variables relacionados con la fisiología de los animales domésticos ha tenido como
base a la distribución normal.
Una variable aleatoria Y, que toma todos los valores reales -−∞ < 𝑦 < ∞ tiene una
distribución normal o Gaussiana así su función de densidad de probabilidad es de la
siguiente forma:
𝑓(𝑦) =1
√2𝜋𝜎𝑒[
−12
{𝑟−𝜇
𝜎)], −∞ < 𝑌 < ∞
Donde 𝜎2 es la varianza µ es la media y la base de los logaritmos naturales, para lo cual
se cumple la condición −∞ < 𝜇 < ∞ 𝑦 𝜎 > 0
En adelante aparecerán con muchas frecuencias a la distribución normal, por lo que será
necesario abreviar la anterior notación con una más breve donde se indica que Y tiene
distribución N(µ, 𝜎2), si su función densidad está determinada por(4.3.3)
Como se puede apreciar en (4.3.3) existirán muchas distribuciones normales que se
diferenciaran una de otra por su media o varianza .la formula antes mencionada no es
difícil de desarrollar, ya que para calcular probabilidades será necesario establecer áreas
bajo la curva mediante el uso de integrales; sin embargo, el trabajo con tablas de

241
distribución de probabilidades facilita enormemente este labor, por lo tanto no interesa
la complejidad de la ecuación.
4.3.1.1.1 Propiedad de la distribución normal. La distribución normal tiene las
siguientes propiedades:
a) La grafica de la densidad para cualquier variable aleatoria normal es una curva
simétrica en forma de campana, conocida como Curva de Gauss o Curva
Laplaciana, cuyo centro es µ punto en el que indica donde está centrada la curva
la curva a lo largo del eje horizontal , tal como indica la figura (4,3,1)
b) La curva tiene unos puntos de inflexión los cuales indican los valores de Y
iguales a una desviación estándar a cada lado de µ, entonces cada punto de
inflexión representa 𝑌 = 𝜇_ + 𝜎 La situación de estos puntos determina la forma
de curva, de tal modo que entre más grande es 𝜎mas lejos estarán localizados
los puntos de inflexión Y, en consecuencia, la curva será mas plana, por lo tanto
es fácil esclarecer con claridad que µ es el parámetro de localización, y 𝜎 es el
parámetro de forma.
c) Todas las variables aleatorias normales son continuas y su probabilidad de
ocurrencia se calcula al encontrar las áreas correspondientes bajo la curva.
d) En una distribución normal la media, la moda y la mediana son iguales.
e) El coeficiente de asimetría en una curva normal, es igual a cero y el de la
curtosis se hace ,por lo general, con referencias a la normales.
f) La curva es simétrica, lo que indica que a cada lado de la media se localiza el
50% de los datos, lo que quiere decir que el área total bajo la curva es uno, tal
como se aprecia En la Figura 4.3.1
Funciones de probabilidad para variables aleatorias, discretas y continúas.

242
Figura 4.3.1 CURVA NORMAL
FIGURA 4.3.2. AREA BAJO LA CURVA EN UNA DISTRIBUCCION NORMAL
g) Entre µ±𝜎 se localiza aproximadamente el 68% de los datos, entre 𝜇 ± 2𝜎 el
95% de los datos entre 𝜇 ± 3𝜎𝑒𝑙 99% de los datos, de la manera indicada en la
figura 4.3.2.
4.3.1.2. Función de distribución normal de una distribución normal. Si Y es una
variable aleatoria normal, con media µ y varianza 𝜎 es decir Y-N (𝜇, 𝜎2) entonces la
función de distribución acumulada F (y) es:
𝐹(𝑌)𝑌 = 𝑃[𝑌 ≤ 𝑦]
Esto corresponde al área bajo la función de densidad a la izquierda de y, como se ilustra
en la figura 4.3.3

243
Figura 4.3.3 Función de distribución normal
Cualquier probabilidad puede obtenerse a partir de la función de distribución
acumulada; por ejemplo, la probabilidad acumulada en un intervalo (a,b) está
determinada por 𝑃[𝑎 < 𝑦 << 𝑏] = 𝐹𝑏𝑦 − 𝐹𝑎𝑌
Como la normal es variable continua, la probabilidad en un punto es cero, por lo tanto
𝑃[𝑎 < 𝑦 < 𝑏] = 𝑃[𝑎 ≤ 𝑦 ≤ 𝑏] = 𝑃[𝑎 < 𝑦 ≤ 𝑏] = 𝑃[𝑎 ≤ 𝑦 ≤ 𝑏]
También se tiene que: 𝑃[𝑌 ≥ 𝑦 ≥] = 𝑃[𝑌 > 𝑦] = 𝐹[𝑌𝑌]
Ya se mencionó que para calcular estas probabilidades se tendrá que resolver integrales
de funciones de densidad normales, para diferentes valores de µ𝑦𝜎2.afortunadamente la
probabilidad de cualquier distribución normal puede expresarse en términos de las
probabilidades de una normal determinada, denominada normal estandarizada o
tipificada Z que tiene como media cero y varianza uno, para lo cual ya se ha calculado
y tabulado las probabilidades. Esto puede realizarse por medio de la transformación.
𝑍 =𝑌 − 𝜇
𝜎
Es decir si Y se distribuye N (µ y𝜎2) entonces Z= 𝑦−𝜇
𝜎 se distribuye en N(0,1)
En la tabla 4 del apéndice se encuentra tabulada la función de distribución acumulada
de una variable aleatoria normal estándar. En esta tabla se dan valores de:
𝐹(𝑍)𝑍 = 𝑃[𝑍 ≤ 𝑧]
Con el fin de ilustrar el uso de la tabla. Para valores de z desde -3,5 hasta 3,5 se allá la
probabilidad de que z sea menor o igual que 1.96. en la columna de la izquierda de la
tabla 4 del apéndice se localiza el número 1.9 y luego en esta fila se desplaza

244
horizontalmente hasta encontrar la columna bajo 0,06 donde se encuentra el valor
0,975. Es decir 𝑃[𝑍 ≤ 0,975] que geométricamente se puede expresar como el área
bajo la curva a la izquierda 1,96
1,96
EJEMPLO 4.3.1: dado una distribución normal estándar, calcular 𝑃[𝑍 > 1,96]
1,96
La probabilidad que se pide es
𝑃[𝑍 > 1,96 ≫] = 1 − 𝑃[𝑍 ≤ 1,96]
= 1 − 𝐹𝑍(1,96)
= 1 − 0,975
= 0,0250
EJEMPLO 4.3.2 Dada una distribución normal estándar
Calcular 𝑃[−1,97 ≤ 𝑧 ≤ 0,86]. La probabilidad pedida corresponde al área de la parte
sombreada en la figura siguiente
Esta probabilidad se calcula así:

245
𝑃[−1,97 ≤ 𝑧 ≤ 𝑜, 86] = 𝐹𝑍(0,86) − 𝐹𝑍(−1,97)
Al utilizar la tabla 5 del apéndice se obtiene 𝐹𝑍(0,86) = 0,8050𝑦
𝑭𝒁(−𝟏, 𝟗𝟕) = 𝟎, 𝟎𝟐𝟒𝟒. 𝑷𝒐𝒓 𝒍𝒐 𝒕𝒂𝒏𝒕𝒐 ∶ 𝑷[−𝟏, 𝟗𝟕 ≤ 𝒛𝟎 ≤ 𝟎, 𝟖𝟔]
= 𝟎, 𝟖𝟎𝟓𝟏 − 𝟎, 𝟎𝟐𝟒𝟒 = 𝟎, 𝟕𝟖𝟎𝟕
En ocasiones es necesario calcular probabilidades de una variable aleatoria normal Y,
con media µ y varianza 𝜎2 en un intervalo, por ejemplo (a≤ 𝑦 ≤ 𝑏).
𝑃[𝑎 ≤ 𝑦 ≤ 𝑏] = 𝑝 [𝑎 − 𝜇
𝜎≤ 𝑧 ≤
𝑏 − 𝜇
𝜎] = 𝐹𝑍 [
𝑏 − 𝜇
𝜎] − 𝐹𝑍 [
𝑎 − 𝜇
𝜎]
Donde Z es la variable aleatoria normal estándar y 𝐹𝑍(𝑍) representa la función de
distribución acumulada.
Ejemplo 4.3.3: Si Y, representa el peso al sacrificio de los cerdos Pietrain y se
distribuye según una normal, con µ=100 y𝜎 = 10, calcular las siguientes
probabilidades:
Funciones de probabilidades para variables aleatoria, discretas y continuas.
a. Encontrar pesos de cerdos entre 95 y 120 kg = 𝑃[95 ≤ 𝑌 ≤ 120]
b. Encontrar pesos de cerdos menores a 𝑎 85 𝑘𝑔 = 𝑃[𝑦 < 85]
c. Encontrar pesos de cerdos mayores o iguales a 108 kg =𝑃[𝑦 ≥ 108]
Las probabilidades perdidas obtiene la siguiente forma:
a)P[95 ≤ 𝑦 ≤ 120] = 𝑃 [95−𝜇
𝜎≤ 𝑧 ≤
120−𝜇
𝜎]
= 𝑃 [95−100
10≤ 𝑧 ≤
120−100
10]
= 𝑃[−0,5 ≤ 𝑧 ≤ 2]
= 𝑍𝑧(2)−𝑍𝑍(−0,5)
=0.9772-0,3085=0,6687

246
b)P[𝑦 < 85] =P[𝑧85−𝜇
𝜎]
= 𝑃 [𝑧 <85 − 100
10]
= 𝑃[𝑧 < 1,5] = 𝐹𝑍 − (−1,5) = 0,0668
c) 𝑃[𝑦 ≥ 108] = 𝑃 [𝑧 >108−𝜇
𝜎] = 𝑃 [𝑧 >
108−100
10]
= 𝑃[𝑧 > 0,8] = 1 >> −𝑃[𝑧 ≤ 0,8]
= 1 − 𝐹𝑧(0,8) = 1 − 0,7881 = 0,2119
Ejemplo 4.3.4. Si la producción de vacas Holstein se aproxima a una distribución
normal, con media de 5.000L y la varianza de 16.000L2. Hallar la probabilidad de
encontrar vacas con producción mayor o igual de 5.180L.
La probabilidad buscada es
𝑃[𝑦 ≥ 5.180] = 𝑃 [𝑧 ≥5.180 − 𝜇
𝜎]
Como 𝜇 = 5000𝑦𝜎2 = 16.000 𝑒𝑛𝑡𝑜𝑛𝑐𝑒𝑠 𝜎 = 126,49 se tiene que
𝑃[𝑦 ≥ 5.180] 𝑃 [𝑧 ≥5.180−5.000
126.49] = 𝑃(𝑧 ≥ 1,42)
= 1 − 𝑃[𝑧 ≤ 1.42]
= 1 − 𝐹𝑍(1,42) = 1 − 0,925.22 = 0,778
La probabilidad de encontrar vacas con producciones con lactancia mayor o iguales a
5.180 L es del 7,78%, es decir se esperaría que el 7,78% de los animales tengan una
producción igual o superior al valor indicado
Ejemplo 4.3.5 E en la misma población ¿cuál es la probabilidad de encontrar vacas
con producciones superior a 5.300 L y menores de 5.400L?
LA PROBABILIDAD ES

247
𝑃[5.300 < 𝑦 < 5.400] = 𝑃 [5.300−5.00
126.49< 𝑧 <
5.400−5.000
126.49]
= 𝑃[2,37 < 𝑧 << 3,16] = 𝐹𝑧(3,16)-𝐹𝑧(2,37)
0.9992-0,9911=0,0083
Esto significa que el 0,83% de las vacas de la población analizada tienen producciones
en el rango indicado. Si se conoce N, es posible estimar el mínimo de los animales con
la producción indicada. Por ejemplo: Si en la población hay 600 vacas, se espera que
0,083multiplicado por 600= 4,98≈5 vacas estén produciendo la cantidad en el intervalo
indicado
Ejemplo 4.3.6. En una ex población truchicola se calculó µ=17,8cm de longitud
estándar y 𝜎2 = 64𝑐𝑚2.En el mercado nacional no se aceptan truchas con longitud
menor de 15,3 cm ¿Cuál es la probabilidad de encontrar animales con esa condición?
Asumiendo que la variable se distribuya aproximadamente con un normal, la
probabilidad se la calcula de la siguiente manera
𝑃[𝑦 < 15,3] = 𝑃 [𝑧 <15,3−17,8
8] = 𝑃[𝑧 < −0,3125]
𝐹𝑧(−0,3125) = 0,3783
Ejemplo 4.3.7 Si en la mencionada explotación hay 4.000 animales, se espera que de
estos 4.000 * 0,3783=1.513,2≈1.513 individuos no cumplan las condiciones del
mercado
Ejemplo 4.3.8. Suponiendo que las truchas con talla superior a 21 cm se pagan mejor
en el mercado, ¿Cuál es la probabilidad de encontrar animales con esa producción.
𝑃[𝑦 > 21] = 𝑃 [𝑧 <21−17,8
8] = 𝑃[𝑧 > 0,4] = 1 − 𝑃[𝑧 ≤ 0,4]
= 1 − 𝐹𝑧(0,4) = 1 − 0.6554 = 0,3446
Lo que quiere decir que aproximadamente el 34,5% de los animales tienen la talla que
garantiza el mejor precio, y en un numero seria 4.000*0,3446≈1.378 animales,
aproximadamente.

248
En los cálculos de la probabilidad efectuados hasta el momento se conoce el valor de un
Z0 determinado; sin embargo; muchas veces es necesario hacer lo contrario, es decir,
dada la probabilidad hallar Z0. A continuación se ilustra estos casos
Ejemplo 4.3.9. Dada una distribución normal estándar, encuentre el valor𝑍0 , tal que
a. 𝑃[𝑍 ≤ 𝑧0] =0,9750
b. 𝑃[𝑍 > 𝑧0] = 0,6500
La solución siguiente
a. En la figura anterior se observa que el área a la izquierda de 𝑧0es de 0,975. En
el interior de la tabla 4 del Apéndices se busca el numero 0,975 o el que más
se aproxime. Una vez hallado este número, se observa que a la izquierda, en la
primera columna se encuentra 1,9 y hacia arriba en la primera fila, se encuentra
el número 0,06, es decir 𝑧0= 1,96
b. P(𝑍 > 𝑧0) = 0,6500
Con el área a la derecha de 𝑧0 es de 0,6500, entonces el área a la izquierda de 𝑧0es
0,3500; en la tabla 4 se busca el numero mas próximo es 0,3483 y en consecuencia
𝑧0 =-0,39
0,975
0,6500

249
Ejemplo 4.3.10 Con los datos del ejemplo 4.3.6, hallar la longitud mínima del 10% de
las truchas de mayor tamaño
Sea 𝑧0 la longitud mínima necesaria para estar en el 10% de los animales de mayor
tamaño
𝑃[𝑦 > 𝑧0] = 0,10, 𝑒𝑛𝑡𝑜𝑛𝑐𝑒𝑠
𝑃[𝑦 ≤ 𝑧0] = 0,90
𝑃 [𝑧 ≤𝑧0−17,8
8] = 0,90 En la tabla 4 de apéndice se encuentra z que le corresponde a
0,90 es decir,
𝑧0, 90 = 1,28
Por lo tanto 𝑧0−17,8
8= 1,28
𝑧0 = 1,28𝑦8 + 17,8 = 28,04
Es decir la longitud mínima es de 28,04 cm para estar en el 10% superior
4.3.2 Teorema central del límite Muchas de la variables aleatorias que se encuentran
en la práctica son promedio de variables aleatorias independientes la media Y es un
estadístico muy importante en problemas de toma de decisiones para medias
poblacionales desconocidas.
El problema central del límite dice como se distribuye la media muestra Y. sea 𝑌1,𝑌2,,,,,,
variables aleatorias independientes, con idéntica distribución de la media µ y varianza
𝜎2 el promedio muestra y𝑌1,𝑌2,,,,,, Yn
𝑛 tiene una distribución con media

250
CAPÍTULO 5
Distribución de muestrales y estimación
Una vez analizados los conceptos fundamentales de probabilidad y de distribución de
probabilidad, se puede abortar la estadística inferencial, la cual se encarga de
generalizar las conclusiones que se obtienen en la muestra, para tomar decisiones sobre
la población de donde se obtuvo la muestra.
Para hacer afirmaciones que tengan validez sobre toda la población, con base en el
comportamiento observado en la muestra, es necesario que esta conserve las
características esenciales de la población, es decir. Que sea representativa. Para
garantizar inferencias válidas a cerca de la población es importante que la muestra reúna
ciertos requisitos, entre otros la de ser aleatoria.
5.1 MUESTRA ALEATORIA
Un conjunto de observaciones 𝑌1, 𝑌2,… , 𝑌𝑛 extraídas de una población finita de tamaño
N, es una muestra aleatoria de tamaño n, si se elige de tal manera que cada subconjunto
de n elementos de la población tenga la misma probabilidad de ser seleccionado.
Una manera de seleccionar una muestra aleatoria de una población finita es enumerar
todos los elementos de la población mediante fichas y extraer n miembros de manera
aleatoria; en este sentido, aleatorio significa total imparcialidad en la selección de la
muestra. Otra técnica más formal consiste en emplear una tabla de números aleatorios
como la indicada en la Tabla 5 del Apéndice (Steel y Torrie, 1.985). Esta tabla está
formada por los dígitos 0,1,2,3,4,5,6,7,8 y 9, distribuidos en 100 filas por 100 columnas,
dando origen a 10.000 números aleatorios, de los cuales 5.094 son pares y 4.906 son
impares. Si un número apareciese con más frecuencia que otro, sólo se debe al azar. En
la citada Tabla existen 1.015 ceros, 1.026 unos, 1.013 doses, 975 treses, 976 cuatros,
932 cincos, 1.067 seis, 1.013 sietes, 1.023 ochos y 960 nueves. Su uso se ilustra con el
siguiente ejemplo:

251
Ejemplo 5.1.1: Se define una población conformada por 40 cerdos Large White de la
que se necesita conformar una muestra al azar con 10 de ellos, a fin de analizar la
variable peso a los 90 días. Para esto es necesario disponer de los registros donde esté
consignado el peso individual a esa edad y la correspondiente identificación de cada
animal, tal como se aprecia en la Tabla 5.1.1.
Suponiendo que, para los fines de un estudio particular, una muestra aleatoria de 10
datos es suficiente para tener una idea clara y confiable del comportamiento productivo
de toda la piara habría que responder la pregunta, ¿cuáles son los 10 cerdos que se
deben elegir para desarrollar el estudio?
Tabla 5.1.1 Registro del peso individual a los 90 días, de una población de
cerdos Large White.
N° del
animal Peso (kg)
N° del
animal Peso (kg)
N° del
animal Peso (kg)
00 72 14 68 28 68
01 89 15 78 29 69
02 69 16 81 30 74
03 78 17 88 31 69
04 85 18 74 32 77
05 80 19 103 33 59
06 73 20 87 34 85
07 61 21 68 35 61
08 68 22 59 36 63
09 87 23 61 37 68
10 89 24 68 38 68
11 72 25 85 39 64

252
12 67 26 67
13 92 27 66
Para garantizar la elección al azar pueden seguirse estos pasos:
1.- Disponer del listado de animales, identificados con un código, en este caso con dos
dígitos del 00 al 39. Cada animal tendrá registrado su peso.
2.- En la Tabla 5 del Apéndice se marca arbitrariamente la fila. En el ejemplo se marcó
el 15 y con el mismo procedimiento se marcó la columna 20. Luego se empiezan a
seleccionar los dígitos de dos en dos, a partir del punto de corte de la fila 15 con la
columna 20, y se leen los números de izquierda a derecha, hasta completar diez parejas.
Así se encontraron las parejas de 6 y 3, 8 y 5, 2 y 4, 4 y 8, 4 y 0,0 y 2, 5 y 9, 2 y 8, 8 y 5
y 7 y 2. Según las cifras encontradas deberían seleccionarse como parte de la muestra
los cerdos 63, 85, 24, 48, 40, 02, 59, 28, 85, y 72.
Como el tamaño de la población es N=40, las cifras 63, 85, 24, 48, 40, 02, 59, 28, 85, y
72 no existen en el listado, por lo tanto se descartan. En consecuencia, hasta el
momento, de los 10 cerdos que se necesitan, únicamente se han logrado seleccionar tres
que son 24, 02 y 28, aún faltan 7. Para seleccionar los 7 restantes, simplemente se
continúa formando parejas de dígitos desde el punto donde se encontró la última cifra,
es decir en 72. Por lo tanto las siguientes cifras son: 03, 10 y 01 sirven para la muestra y
se seleccionan, así que ya se dispone de seis animales seleccionados. Los dígitos 79 y
69 se descartan. Todavía hacen falta cuatro animales, pero ya se terminó la fila de
números. Por lo tanto se debe bajar una fila y se procede a formar nuevas parejas, pero
de derecha a izquierda, descartando las cifras que nos sirvan, hasta completar la
muestra.
En el ejemplo se tuvo esta situación: 20, 07, 56, 09 y 00, de estos dígitos el 56 se
descarta, el resto se aceptan y así se completa el tamaño requerido de la muestra. En
conclusión, se han seleccionado al azar los cerdos identificados con los códigos 24, 02,
28, 03, 10, 01, 20, 07, 09 y 00, tal como se observa en la Tabla 5.1.2

253
3.- Estos números corresponden a las 10 animales escogidos al azar, consignados en la
Tabla 5.1.2.
Tabla 5.1.2. Muestra aleatoria de 10 cerdos Large White para analizar la
variable peso a los 90 días
N° del
animal
Peso a los 90 días
(kg)
24 68
02 69
28 68
03 78
10 89
01 89
20 87
07 61
09 87
00 72
El procedimiento antes descrito equivale a introducir 40 balotas marcadas con los
dígitos 00 y 39 en una bolsa y extraer al azar 10 de ellas, mezclando bien las balotas
luego de cada extracción y volviendo a meter en la bolsa la balota que se ha sacado, es
por esta razón que este procedimiento se denomina muestreo con reemplazo. Si no ese
introdujera de nuevo en la bolsa las balotas ya sacadas, el muestreo será sin
reemplazo.

254
Para obtener tamaños de muestra mayores, por ejemplo, tomar 100 observaciones de
una muestra de 500, el procedimiento es el mismo, sólo que la numeración de los
individuos a muestrear se hace con tres dígitos, iniciando con 000 y terminando con
499. Luego se escogen de la tabla combinándose de tres cifras, hasta completar el
tamaño requerido.
Es importante reiterar que la técnica antes detallada no es el único procedimiento de
elegir individuos al azar de una población; existen otros procedimientos alternativos de
muestreo donde se incluye el uso de calculadora e incluso computadores personales.
Se ha indicado en repetidas ocasiones que, al hacer inferencias estadísticas, el interés
radica en hacer afirmaciones sobre los parámetros de las poblaciones como la media μ y
la varianza 𝜎2, utilizando los estadísticos X y 𝑆2 , que se calculan a partir de las
muestras aleatorias.
Si se tiene una población finita de tamaño, se podrán obtener varias muestras de tamaño
n. Por lo general, para cada muestra extraída se obtendrán valores diferentes de los
estadísticos X y 𝑆2 , así que se puede pensar en cada cantidad como una variable
aleatoria con cierta distribución de probabilidad. Por ejemplo, si el estadístico es la
media, la distribución se conoce como distribución muestral de medias, o si es la
varianza, la distribución se denomina distribución muestral de varianzas. La
distribución de probabilidades de los posibles resultados muestrales proporciona una
base para realizar inferencias.
5.2 DISTRIBUCIÓN DE MUESTREO DE LA MEDIA MUESTRAL ��
Sea 𝑋1, 𝑋2, … , 𝑋𝑛 una muestra aleatoria de una población, de tal manera que E[𝑋𝑖] =μ
y V[𝑋𝑖]=𝜎2 , i= 1, 2, 3, …, n, ��= 𝑋1+𝑋2+⋯+𝑋𝑛
𝑛 entonces la estadística se denomina
media muestral.
El valor esperado o media de ��, simbolizado como 𝜇��, se lo halla de la siguiente
manera:
𝜇�� = 𝐸[��] = 𝐸 [𝑋1 + 𝑋2 + ⋯ + 𝑋𝑛
𝑛] =
1
𝑛(𝐸[𝑋1] + 𝐸[𝑋2] + ⋯ + 𝐸[𝑋𝑛])

255
= 1
𝑛[𝜇 + 𝜇 + ⋯ + 𝜇] =
1
𝑛𝑛𝜇 = 𝜇
Es decir, la media de la distribución de muestreo de la media muestral es la media
poblacional μ.
La varianza de la media muestral ��, simbolizada por 𝜎��2, se calcula como:
𝜎��2 = V[��] = 𝑉 [
𝑛] =
1
𝑛2(𝑉[𝑋1] + 𝑉[𝑋2] + ⋯ + 𝑉[𝑋𝑛])
= 1
𝑛2 𝑛𝜎2 =
𝜎2
𝑛
Es decir, la varianza de la distribución maestral de la media es 𝜎2
𝑛
La desviación estándar de la distribución muestral de la media es
d.e. (��) = 𝜎2
√𝑛
esta cantidad se conoce con el nombre de error estándar de la media. Se puede
apreciar que a medida que el tamaño de la muestra crece, el error estándar de la media
disminuye, es decir, si el tamaño de la muestra crece, la precisión de la media muestral
para estimar la media poblacional aumenta. Si n es mayor que el 5% de N, la varianza
V[��] hay que multiplicarla para el factor de corrección para población finita, con lo
que: 𝑁−𝑛
𝑁−1.
V [��]= 𝜎2
𝑛*
𝑁−𝑛
𝑁−1 y d.e.( ��)=
𝜎
√𝑛√
𝑁−𝑛
𝑁−1
Se puede demostrar que si la muestra aleatoria 𝑌1 + 𝑌2 + ⋯ + 𝑌𝑛, proviene e una
población normal con media μ y varianza 𝜎2, entonces la estadística �� se disminuye
normal con media μ y varianza 𝜎2
𝑛, es decir, la variable aleatoria
�� − 𝜇𝜎
√𝑛
= 𝑍
Donde Z es normal estándar.

256
Si la población de donde se extrajo la muestra no es normal, el teorema central del
límite asegura que la aproximación (5.2.5) es buena para muestras grandes n≥30.
La aproximación (5.2.5) es buena para muestras pequeñas si la distribución de donde se
extrajo la muestra es normal o es bastante parecida a una normal, es decir, es simétrica y
tiene una alta concentración de los datos alrededor del punto de simetría.
Ejemplo 5.2.1: En una población comercial de cuyes, el peso vivo individual promedio
a la semana 12 de edad es 850g y la desviación estándar 200g. Hallar la probabilidad de
que en una muestra de 60 animales, el peso promedio sea menor que 900g.
El problema pide calcular P [�� < 90 ], conociendo que n=60, μ=850 y σ=200, como n
es grande, se tiene que:
��− 𝜇��
𝜎��= 𝑍, donde 𝜇�� = 𝜇 𝑦 𝜎 =
𝜎
√𝑛
Es decir, ��− 𝜇
𝜎
√𝑛
= 𝑍 por lo tanto:
P [�� < 90 ]= P [ ��− 𝜇
𝜎
√𝑛
< 900− 𝜇
𝜎
√𝑛
]= P [𝑍 < 900− 850
200
√60
]= P[Z<1,93] = 𝐹𝑍(1,93)= 0,9732
que es el valor correspondiente a la probabilidad pedida.
5.3 DISTRIBUCIÓN DE MUESTREO DE LA PROPORCIÓN MUESTRAL
Sea X el número de éxitos en una muestra binomial de n observaciones, donde p es la
probabilidad de éxitos, en la mayoría de aplicaciones, el parámetro p será la proporción
de individuos de una población que poseen ciertas características de interés, tal como la
presencia de una determinada patología.
Un estimador de p es la proporción muestral, ��= 𝑥
𝑛 por lo tanto:

257
E [��] = E[𝑋
𝑛]=
𝐸[𝑋]
𝑛 =
𝑛𝑝
𝑛 = p
Es decir, el valor esperado o media de la proporción muestral es la proporción p de
éxitos en la población:
V [��] = V[𝑋
𝑛]=
𝑉[𝑋]
𝑛2 = 𝑛𝑝(1−𝑝)
𝑛2 = 𝑝(1−𝑝)
𝑛
Esto es:
𝜎2𝑝=
𝑝(1−𝑝)
𝑛
De la aproximación de la distribución binomial a la normal se tiene que para n grande
𝑥−𝑛𝑝)
√𝑛𝑝(1−𝑝) es aproximadamente normal estándar, siendo posible demostrar que:
𝑝−𝑝
𝜎 ��
=
𝑝−𝑝
√𝑝(1−𝑝)
𝑛
es normal estándar.
Ejemplo 5.3.1: De una población de cíclicos Herus serverus, se toma una muestra de
200 individuos. Suponiendo que la proporción de machos es p=0,40; hallar la
probabilidad de que en la muestra la proporción estimada de machos esté entre 0,35 y
0,45.
Se tiene que p= 0,40 y n= 200, entonces:
P[0,35≤ �� ≤ 0,45] = P [0,35−𝑝
𝜎 ��
≤ 𝑍 ≤0,45−𝑝
𝜎 ��
]
Ahora: 𝜎 𝑝 =√
𝑝(1−𝑝)
𝑛 = √
0,40∗0.60
200= 0,035 entonces:
P[0,35≤ �� ≤ 0,45] = P [0,35−0,40
0,035≤ 𝑍 ≤
0,45−0,40
0,035]
= P[-1,43≤ 𝑍 ≤ 1,43]
= 𝐹𝑍(1,43) − 𝐹𝑍(−1,43)
= 0,9236 – 0,0764 = 0,8472

258
5.4 DISTRIBUCIÓN MUESTRAL DE LA VARIANZA 𝐒𝟐
Es necesario recordar que la varianza muestral S2 = ∑(𝑋𝑖− ��)2
𝑛−1 es una medida de la
variabilidad e indica la dispersión de los datos alrededor de la media. El estadístico S2
es un estimador de la varianza poblacional 𝜎2. Antes de desarrollar la distribución de
muestreo S2 es conveniente hacer una introducción a una nueva distribución,
denominada Chi-cuadrado.
5.4.1 Distribución chi-cuadrado. Si 𝑋1 + 𝑋2 + ⋯ + 𝑋𝑣 son variables aleatorias
independientes y cada una de ellas se distribuye como una variable normal estándar,
entonces la suma de 𝑋12 + 𝑋2
2 + ⋯ + 𝑋𝑣2 se distribuye como chi-cuadrado (𝑋𝑣
2) con v
grados de libertad.
Los grados de libertad v se construyen en un parámetro asociado a la distribución y
representa el número de variables cuyos cuadrados se suman.
Figura 5.4.1 Distribución 𝑿𝒗𝟐
El rango es el intervalo [0,∞]
El valor esperado o media E [𝑋𝑣2] = v
La varianza V [𝑋𝑣2]= 2v

259
Como se puede observar, la forma de la distribución es asimétrica con sesgo positivo y
la función de distribución acumulativa está dada por:
𝑃 = [𝑋 ≤ 𝑋(1−∝;𝑉)2 ] = 1−∝
Donde 0≤∝≤ 1 𝑦 𝑋(1−∝;𝑉)2 es el valor del cuartil que le corresponde a la 𝑋2 para 1-∝ y
v dados.
En la Tabla 6 del Apéndice están tabulados los valores de los cuantiles para diferentes
cifras de 1-∝ y v.
Ejemplo 5.4.1: Se pide calcular es el valor de X correspondientes a una variable
distribuida como chi-cuadrado, en una muestra aleatoria de 10 elementos, con una
confiabilidad del 95%.
Simbólicamente el anterior enunciado se resume de este modo:
𝑃 = [𝑋 ≤ 𝑋(0,95;10)2 ] = 𝑃 = [𝑋 ≤ 18,13] = 0,95.
Para encontrar el valor pedido se busca en la Tabla 6 del Apéndice, en el punto de cruce
entre v=10, que son los grados de libertad, es decir, n y 1-∝= 0,95. En este punto se
encuentra el valor 18,31, cuya representación gráfica aparece en la Figura 5.4.2.

260
Figura 5.4.2 Valor de X en una distribución chi- cuadrado para una
muestra de 10 observaciones con 𝜶= 0,5
Las aplicaciones más importantes de la distribución chi-cuadrado para resolver
problemas específicos aplicados a la producción y salud animal aparecerán más
adelante.
5.4.2. Distribución muestral de la varianza 𝑺𝟐. Si S2 es la varianza calculada en una
muestra aleatoria de tamaño n, extraída de una población con varianza 𝜎2, entonces:
E[S2]= 𝜎2.
Si la población de donde se extrajo la muestra normal, entonces se tiene que la
estadística.
(𝑛 − 1)S2
𝜎2≈ 𝑋(𝑛−1)
2
Donde 𝑋(𝑛−1)2 es la distribución chi-cuadrado con (n-1) grados de libertad.
Ejemplo 5.4.2: Un programa de mejoramiento genético de ovinos africanos pretende
seleccionar los reproductores por la conversión alimenticia, de tal manera que se
seleccionan los individuos de mejor valor genético para la característica en cuestión. Se
sabe que el valor genético es una variable que sigue una distribución normal con

261
varianza 1,75. Se extrae una muestra aleatoria de 20 animales y se pide hallar la
probabilidad de que la varianza muestral sea superior a 3,10.
Se tiene que n=20 y 𝜎2 = 1,75
La probabilidad que se pierde es:
𝑃[S2 > 3,10] = 𝑃[(𝑛 − 1)S2
𝜎2 > (𝑛 − 1)3,10
1,75]
Como, (𝑛 − 1)S2
𝜎2 ≈ 𝑋192 entonces
𝑃[S2 > 3,10] = 𝑃[𝑋192 > 19
3,10
1,75]
= 𝑃[𝑋192 > 33,66]= 1- P[𝑋19
2 ≤ 33,66]
En la Tabla 6 del Apéndice, para 19 grados de libertad, se encuentra que el valor
próximo a 33,66 es 32,85; en la parte superior de esta columna se halla el valor de la
probabilidad 0,975, entonces:
P [𝑋192 ≤ 33,66] ≈ 0,975 𝑦 por lo tanto:
P [𝑋192 > 33,66] ≈ 1 − 0,975 ≈ 0,025 , es decir: P[𝑆
2 > 33,66] ≈ 0,025.
5.4.3 Estimador. En párrafos anteriores de ese texto se ha mencionado varias veces que
un aspecto de gran importancia en la estadística inferencial radica en la estimación de
parámetros a partir de sus correspondientes estadísticos, así que es oportuno ahora
definir el término estimador.

262
Dado un parámetro ϴ, un estimador ϴ de ϴ es una estadística que estima a ϴ. Por
ejemplo, el estadístico �� es un estimador de μ, S2 es un estimador de 𝜎2 y la proporción
muestral p es un estimador de la proporción P, que se pueden simbolizar de la siguiente
manera:
�� = μ
𝑆 2
= 𝜎2
��= P
A esta clase de estimadores se los denomina estimadores puntuales.
Para estimar un parámetro es posible definir varios estadísticos, por ejemplo, a la media
poblacional μ se la puede estimar con la mediana muestral. Existen algunas
características deseables de los estimadores puntuales que sirven para decidir en
términos de éstas, qué estimador es mejor.
5.4.3.1 Estimador insesgado. Un estimador 𝜃 de 𝜃, es insesgado si E[𝜃] = 𝜃, es decir,
el valor medio del estimador es igual al parámetro que se busca estimar. Es importante
que el estimador sea insesgado, puesto que la distribución muestral del estimador se
encontrará alrededor del parámetro objetivo y, en consecuencia, los valores de estos
estimadores difieren del verdadero valor del parámetro con menor probabilidad que los
otros estimadores. Entre los estimadores insesgado se tiene la media muestral ��, la
proporción muestral p, la varianza muestral 𝑆2 = ∑ (𝑋1− ��)2𝑛
𝑖=1
𝑛−1 es decir, E[��] =
𝜇, 𝐸 [ ��] = 𝑝 𝑦 𝐸[𝑆2] = ��2
El estimador ��2 = ∑ (𝑋1− ��)2
𝑛−1 es sesgado, es decir, E[��2] ≠ ��2. Es por esto que, para
estimar la varianza 𝜎, se utiliza 𝑆2 𝑦 𝑛𝑜 ��2.
Dado un parámetro 𝜃 pueden existir dos estimadores insesgados que estiman al
parámetro; en este caso, para decidir qué estimador es “mejor”, se utilizan el criterio de
eficacia relativa.

263
5.4.3.2 Eficiencia relativa. Sean 𝜃 1 𝑦 𝜃 2 dos estimadores insesgados del parámetro 𝜃,
la eficiencia relativa de 𝜃 1 respecto de , 𝑠𝑒 𝑙𝑎 𝑑𝑒𝑓𝑖𝑛𝑒 𝑐𝑜𝑚𝑜 𝑉[�� 2 ]
𝑉[�� 1 ] .
SI, 𝑉[𝜃 1 < 𝑉[𝜃 2 ] entonces 𝜃 1 es más eficiente que 𝜃 2 . Es decir, entre dos
estimadores insesgados de un parámetro es más eficiente el que menos variabilidad
tenga. Por ejemplo,
𝑉[𝑚𝑒𝑑𝑖𝑎]
𝑉[𝑚𝑒𝑑𝑖𝑎𝑛𝑎]= 0,6369
De aquí se deduce que 𝑉[𝑚𝑒𝑑𝑖𝑎] < 𝑉[𝑚𝑒𝑑𝑖𝑎𝑛𝑎], o sea, la media es más eficiente que
la mediana para estimar la media poblacional μ.
5.4.3.3 Estimadores insesgados de varianza mínima. Sea 𝜃 un estimador insesgado
del parámetro 𝜃. Si 𝑉[𝜃 ] es menor que la varianza de cualquier otro estimador
insesgado de 𝜃, se dice entonces que 𝜃 es un estimador insesgado de varianza mínima
de 𝜃. Entre los estimadores insesgados de varianza mínima más comunes se tiene:
c.- La media muestral, cuando la muestra proviene de una distribución normal.
d.- La varianza muestral, cuando la muestra proviene de una distribución normal.
e.- La proporción muestral binomial.
Por lo tanto, se puede concluir que la media muestral, la varianza muestral y la
proporción muestral son estimadores aceptables de la media poblacional, la varianza
poblacional y la proporción poblacional, respectivamente.
5.5 INTERVALOS DE CONFIANZA
En ciertos casos, los estimadores puntuales, aunque poseen ciertas propiedades
deseables, no coinciden con el parámetro que buscan estimar; algunas veces es
preferible estimar un parámetro mediante un intervalo, es decir, un rango de valores
entre los que posiblemente se encuentren el verdadero parámetro que se quiere estimar.

264
5.5.1 Estimador por intervalo. Dado un parámetro 𝜃, un estimador por intervalo es un
intervalo 𝜃 1 < 𝜃 < 𝜃 2 , donde 𝜃 1 𝑦 𝜃 2 se denominan límite inferior y superior,
respectivamente, y dependen del valor del estadístico 𝜃 para una muestra en particular
y de la distribución muestral de 𝜃 . A los estimadores por intervalo se los conoce como
intervalos de confianza.
A la probabilidad de que un intervalo de confianza contenga al parámetro a estimar, se
le denomina coeficiente de confianza.
P (𝜃 1 < 𝜃 < 𝜃 2 ) = 1- ∝
Donde 0 <∝< 1 y 1- ∝ es el coeficiente de confianza.
Es importante tener en cuenta que uno o los dos extremos del intervalo varían de
manera aleatoria de una muestra a otra, es decir, la longitud y la localización del
intervalo son aleatorias y no se podrá estar seguros de que el parámetro objetivo esté
contenido en el intervalo.
Si se estima un parámetro 𝜃 mediante un intervalo de confianza con una confiabilidad
(1- ∝)100 =95%, es decir, P(𝜃 1 < 𝜃 < 𝜃 2 ) = 95%, en la práctica significa que si se
realiza un muestreo repetitivo en la población estudiada, se espera que el 95% de los
intervalos que se calculen deberán contener al parámetro 𝜃 y, sólo por el azar, un 5% de
ellos no contendrá el parámetro.
5.5.2 Intervalo de confianza para media μ. Suponiendo que se tiene una muestra
aleatoria grande (𝑛 ≥ 30) de una población con media desconocida μ y varianza 𝜎2
conocida, además, la población de donde se extrajo la muestra es normal o bien, si no
fuera así, el teorema central del límite asegura que n grande la distribución de
�� es normal con 𝜇�� = 𝜇 y 𝜎 𝑌2 =
𝜎2
𝑛 entonces, un intervalo de confianza para la media
poblacional 𝜇 al (1 - ∝)100% de confiabilidad está dado por:
�� ± 𝜎
√𝑛 𝑍1−∝ 2⁄

265
Donde 𝑍1−∝ 2⁄ es el valor que se encuentra en la Tabla de la distribución normal
estándar para un coeficiente de confianza 1-∝ y �� ± 𝜎
√𝑛 𝑍1−∝ 2⁄ y son los límites de
�� ± 𝜎
√𝑛 𝑍1−∝ 2⁄ confianza ϴ1 𝑦 ϴ2, respectivamente (Figura 5.5.1).
Para calcular un intervalo de confianza para μ con una confiabilidad del (1 - ∝)100%, se
ha supuesto que se conoce 𝜎2, pero en la práctica 𝜎2no se conoce; por lo tanto, para
efecto del cálculo de los límites de confianza, se reemplazará 𝜎2 por la varianza de la
muestra 𝑆2, siempre que n≥ 30.
Ejemplo 5.5.1: En la granja de Botana de la Universidad de Nariño, se tomó una
muestra aleatoria de 39 cuyes (Cavia porcellus), con el fin de estimar el peso promedio
a las 12 semanas mediante un intervalo de confianza al 90% de confianza. Los datos
obtenidos fueron los siguientes: 661, 861, 702, 733, 720, 708, 985, 1030, 812, 798, 800,
968, 1002, 981, 700, 721, 1100, 1090, 1032, 847, 580, 920, 710, 830, 945, 975, 875,
810, 1005, 1050, 945, 925, 940, 936, 1050, 884, 1025, 975, 885.
De los anteriores datos se tiene que: ��= 885,15
𝑠 = √∑(𝑌𝐼 − ��)2
𝑛 − 1
𝑛
𝑖=1
= √17625 = 132,76
𝜎2=S= 132,76
Al calcular 𝑍1−∝ 2⁄ para una confiabilidad del 90%, se tiene que:

266
1- ∝= 0,90
∝ = 0,10
∝ 2⁄ = 0,05
1− ∝ 2⁄ = 0,05
En la Tabla 4 del Apéndice, para 1− ∝ 2⁄ = 0,95 le corresponde un valor Z= 1,64, es
decir, 𝑍1− ∝ 2⁄ = 𝑍0,95=1,64.
�� − 𝜎
√𝑛 𝑍1−∝ 2⁄ = 885,15 −
132,76
√39 1,64 = 850,28 ≈ 850,30
�� − 𝜎
√𝑛 𝑍1−∝ 2⁄ = 885,15 −
132,76
√39 1,64 = 920
Expresándolo en términos de probabilidad se tiene que:
P [850,3 <μ< 920] = 0,90.
Esto significa que la verdadera media del peso a las 12 semanas de los cuyes de la
granja estudiada está en el intervalo comprendido entre 850,3g y 920g, con una
probabilidad del 90%.
.5.3 Tamaño de la muestra para estimar μ. Cuando se realiza un experimento, surge
la pregunta: qué tan grande debe ser la muestra? Si se toma una muestra demasiado
grande se puede ocasionar desperdicio de tiempo y dinero, en cambio, si la muestra es
demasiado pequeña, los resultados podrían carecer de validez desde el punto de vista de
la inferencia estadística.
El tamaño de la muestra necesario para estimar la media poblacional μ a partir de la
media muestral ��, con una confiabilidad (1 - ∝)100% y un error de estimación е, está
dado por:

267
𝑛 = 𝑍 (1−∝ 2)⁄
2 𝜎2
𝑒2
Si se conoce el tamaño de la población N y éste es pequeño, se puede utilizar:
𝑛 = 𝑁𝑍 (1−∝ 2)⁄
2 𝜎2
𝑒2(𝑁 − 1) + 𝑍 (1−∝ 2)⁄2 𝜎2
Donde 𝑍1−∝ 2⁄ es el valor que se encuentra en la tabla normal estandarizada para una
confiabilidad de 1−∝. Esta confiabilidad la fija el investigador y, por lo general, se
trabaja con nivel del 95% y 99%, dependiendo de los alcances de las conclusiones y
recomendaciones. Para los niveles antes indicados los valores Z son 1,96 y 2,57,
respectivamente.
El error máximo de estimación e, es la distancia máxima que podrían admitirse entre la
estimación de la verdadera media con respecto al parámetro |�� – μ|. Esta cantidad es
arbitraria y la fija el investigador.
La desviación estándar 𝜎 corresponde al valor de este parámetro en la población de
donde se extraerá la muestra, lo que indica que (5.5.3) y (5.5.4) se pondrán utilizar para
calcular el tamaño de muestra, siempre y cuando 𝜎 sea conocida. Sin embargo, como se
ha mencionado, en la mayoría de los casos este valor no se conoce; por lo tanto, habrá
necesidad de estimarlo, utilizando cualquiera de los procedimientos indicados a
continuación:
a. De la población objeto de estudio, se extrae una muestra piloto o preliminar,
cuyo tamaño debe ser n≥ 30. Con los datos obtenidos se calcula S y este valor
“reemplaza” a 𝜎 en las fórmulas correspondientes.
b. Se puede utilizar 𝜎 de estudios similares realizados previamente.
c. Si los datos se distribuyen aproximadamente normal, se puede emplear una
estimación burda de 𝜎 con la expresión (1
6rango), para lo cual se requiere
conocer los valores máximo y mínimo de la variable en la población.

268
Ejemplo 5.5.2: Un estudio pretende estimar el peso medio del barbudo negro (Rhamdia
quelem) a la edad de un año, en un estanque experimental ubicado en la cuenca media
del río Cauca. De antemano se debe establecer el número de animales a capturar,
sabiendo que la desviación estándar para la característica en cuestión es de 50g, la
confiabilidad del 95% y el error de estimación máximo admitido de 5 gramos.
De acuerdo con los anteriores datos, ¿Cuál debe ser el tamaño de muestra para estimar
la media?
Como ejemplo de poblaciones grandes utiliza (5.5.3), sabiendo que: ơ = 50,1 –α es 95%
por lo tanto 𝑍1−∝/2 = 1,96, 𝔢 = 5/𝑔.
𝑛 =1.962𝑥502
52= 384,16 ≈ 384 𝑎𝑛𝑖𝑚𝑎𝑙𝑒𝑠
Ejemplo 5.5.3: Con los mismos datos del ejemplo 5.5.2, pero utilizando un error de
estimación de 10g, ¿Cuál sería el tamaño de muestra?
𝑛 =1.962𝑥502
102= 96,04 ≈ 96 𝑎𝑛𝑖𝑚𝑎𝑙𝑒𝑠
Ejemplo 5.5.4: Con los mismos datos del ejemplo 5.5.3, pero utilizando 1-α de 99%;
¿Cuál será el tamaño de la muestra?
𝑛 =2.572𝑥502
102= 165,12 ≈ 165 𝑎𝑛𝑖𝑚𝑎𝑙𝑒𝑠
Ejemplo 5.5.5: Con los mismos datos del ejemplo 5.5.4, pero utilizando error de
estimación de 5g, ¿Cuál sería el tamaño de muestra?
𝑛 =2.572𝑥502
52= 660,49 ≈ 660 𝑎𝑛𝑖𝑚𝑎𝑙𝑒𝑠
De los ejemplos anteriores se podrá establecer claramente que entre mayor sea el nivel
de confiabilidad y menos el error de estimación requerido, el tamaño de la muestra
aumenta.

269
Muchas veces trato al estimar la media de una población cuando se desconoce la
varianza 𝜎2 Y es imposible obtener una muestra De tamaño n mayor igual 30, es decir,
se trata de poblaciones pequeñas. En estos casos (n<30), no es apropiado pretender
estimar 𝜎2Con el puesto que: Ŷ−𝜇
𝑆
√𝑛
no se distribuye normal estándar.
Para enfrentar este tipo de situaciones, es necesario introducir una nueva distribución
denominada distribución t de student.
5.5.4 DISTRIBUCIÓN T DE STUDENT. Dado una muestra aleatoria de tamaño n,
procedente de una población normal con media 𝜇 , La estadística:
Ŷ − 𝜇
𝑆
√𝑛
Sigue una propiedad t con n– 1 grados de libertad.
Entre las propiedades de la distribución t de student se tienen las siguientes:
a.- es simétrica respecto al centro
b. la forma es similar a la normal pero es menos elevada en el centro y tiene colas más
largas.
c. el rango esta entre - ∞ y + ∞
d. la distribución t de Student se aproximan a la normal a medida que los grados de
libertad n-1 se aproximan al infinito.
e. el valor esperado o media es cero, E(t)=0

270
Normal
t de Student
Figura 5.5.2 Curva de densidad de t de Student
La varianza de un t con v grados de libertad es
𝑉(𝑡𝑣) =𝑣
𝑣 − 2, 𝑣 > 2
L a función de distribución acumulativa está dada por P (T≤𝑡1−𝛼,𝑣) = 1 − 𝛼, donde 0 ≤
α ≤ 1 y 𝑡1−𝛼,𝑣es el valor cuantil que le corresponde a la distribución t para 1-α y v
dados.
𝑡1 − 𝛼, 𝑣
Así para: P (T≤𝑡0,90,15) = T ≤ 1,341 = 0,90
En la tabla 6 del Apéndice, en el cruce entre v=15 y 1-α= 0, 90, se encuentra el valor
1,341.
1-α

271
1,341
P (T≤𝑡0,10,15) = 𝑃( T ≤ −1,341) = 0,10
0,10
-1,341
Así para: P (T≤𝑡0,90,15) = T ≤ 1,341 = 0,90
5.5.5 Intervalo de confianza para u con una muestra pequeña y varianza 𝝈𝟐
desconocida.
Dada una muestra aleatoria de tamaño n < 30, con media Ŷ y varianza 𝑆2, procedente
de una población aproximadamente normal con media µ y varianza 𝜎2desconocida, un
intervalo de confianza para µ y varianza 𝜎2 desconocida, un intervalo de confianza para
µ al (1-α) 100% de confiabilidad viene dado por:
Ŷ-𝑡1−𝛼
2,𝑛−1
𝑆
√𝑛 < 𝜇 < �� + 𝑡1−
𝛼
2,𝑛−1
𝑆
√𝑛
(5.5.7)
0,90

272
Donde 𝑡1−𝛼
2,𝑛−1es el valor de t con n-1 grados de libertad y 𝑃 [𝑇 ≤ 𝑡1−
𝛼
2,𝑛−1] = 1 −
𝛼
2
Ejemplo 5.5.6: Un veterinario tomo una muestra al azar 15 perros de raza Labrador
dorado para estimar el consumo medio del alimento en un periodo de un mes,
calculando una media de 22,5 kg y una varianza de 35𝑘𝑔2, se pregunta ¿Cuál es el
intervalo de confianza al 95% para el verdadero consumo medio?. De acuerdo con
(5.5.7) la respuesta esta dad por el desarrollo de las siguientes operaciones:
�� = 22.5
𝑆2= 35
S= √35 = 5,916
IC= �� ± 𝑆
√𝑛 𝑡1−
𝛼
2,𝑛−1 = 22,5 ±
5,916
√14 2,160 = 22,5 ± 3,415
Este mismo intervalo de confianza expresado con una probabilidad, según la o indicado
en (5.5.7) es del siguiente modo:
𝑃 [22.5 − 5,916
√14 2,160 < 𝜇 < 22,5 +
5,916
√14 2,160 ] = 95 %
𝑃[19,085 < 𝜇 < 25,915] = 95%
En este caso se plantea que la probabilidad de que la verdadera media de consumo se
encuentra entre 19,085 y 25,915 kg es del 95%.
Ejemplo 5.5.7: En el caso del problema planteado en el Ejemplo 5.5.6, asumiendo que
no s posible tomar una muestra de más de 10 animales, con los que se calcula un
consumo de 19,7 kg y una varianza de 8 𝑘𝑔2, ¿Cuál es el intervalo de confianza de 95%
de confiabilidad?
El procedimiento para resolverlo es exactamente igual. Se dispone del valor medio y de
la varianza; con este último dato se calcula el error estándar que, en este caso, es de
0,2828; por lo tanto, el intervalo de confianza se calcula de la siguiente manera:

273
𝑃[19,7 − (0,2828)2,262 < 𝜇 < 19,7 + (0,2828)2,262 ] = 95%
𝑃[19,0603 < 𝜇 < 20,3396] = 95%
En este caso, se interpretaría este resultado como una probabilidad, cuyo significado es
que la verdadera media se encuentra entre 19,0603 y 20,3396, es decir, que en una serie
grande de muestreos sucesivos sobre la misma población, el valor medio calculado se
encontrara entre los límites indicados, en el 95% de las veces.
5.5.6 Intervalo de confianza para la diferencia de medias. Un problema se presenta
con frecuencia en inferencia estadística, es el que se refiere a la comparación entre dos
medias poblacionales.
Para completar las medias poblacionales está en dos muestras aleatorias independientes,
una de cada población, con tamaño 𝑛1 y 𝑛2 y la inferencia sobre µ1 - µ2 se basa en los
resultados muéstrales de Ŷ1 - Ŷ2.
Si las poblaciones de donde provienen las muestras son normales e independientes, con
varianzas 𝜎12 y 𝜎2
2 conocidas, las distribución muestral de (Ŷ1 - Ŷ2) es normal con
media (µ1 - µ2) y varianza 𝜎1
2
𝑛1 +
𝜎22
𝑛2. Por lo tanto, la variable aleatoria es normal estándar.
(Ŷ1 − Ŷ2) − (µ1 − µ2)
√𝜎1
2
𝑛1+
𝜎22
𝑛2
= 𝑍
(5.5.8)
Si 𝑛1 y 𝑛2 son grandes, la distribución de (Ŷ1 - Ŷ2) ser aproximadamente normal con
media
(µ1 - µ2) y varianza 𝜎1
2
𝑛1 +
𝜎22
𝑛2 , sin tener en cuenta las distribuciones de las poblaciones de
donde se extrajeron las muestras.

274
5.5.7 Intervalo de confianza para µ𝟏 - µ𝟐, con varianzas 𝝈𝟏𝟐 y 𝝈𝟐
𝟐 conocidas. Dadas
dos muestras aleatorias con tamaños 𝑛1 y 𝑛2 y con medias muestrales (Ŷ1 - Ŷ2)
respectivamente, procedentes de dos poblaciones normales e independientes, con
medias (µ1 - µ2) y varianzas conocidas 𝜎12 y 𝜎2
2 respectivamente, un intervalo de
confianza para (µ1 - µ2) al (1-α) 100% de confiabilidad viene dado por:
(Ŷ1 − Ŷ2) − 𝑍1−𝛼
2 √
𝜎12
𝑛1+
𝜎22
𝑛2< (µ1 − µ2) < (Ŷ1 - Ŷ2) + 𝑍1−
𝛼
2 √
𝜎12
𝑛1+
𝜎22
𝑛2
(5.5.9)
Donde 𝑍1−𝛼
2 es tal que 𝑃 [𝑍 < 𝑍1−
𝛼
2 ] = 1- α/2
Si las poblaciones no son normales, se obtiene un intervalo de confianza bastante
aceptable cuando 𝑛1 y 𝑛2 ≥ 30; además, es posible reemplazar 𝜎12 y 𝜎2
2 por 𝑆12 y 𝑆2
2
respectivamente.
Ejemplo 5.5.8: Un mejorador asegura que, gracias a su programa de selección genética,
ha obtenido un nuevo fenotipo de oreochromis aureus, cuyo rendimiento medio en peso
final comercial es superior al fenotipo estándar de la estándar de la misma especie. Se
sabe que las varianzas para cada una de las especies son 𝜎12= 0,012 y 𝜎2
2= 0,018. Se
tomó una muestra al azar de 90 ejemplares para cada uno de los grupos, calculando un
valor medio de Ŷ1= 0,523 kg y Ŷ2= 0,475. Se pregunta ¿Cuál es el intervalo de
confianza para la verdadera diferencia de medias entre el grupo mejorado y el grupo
estándar?
(0,523 − 0,475) − 1,96√0,012
90+
0,018
90< (µ1 − µ2) <(0,523 −
0,475)+1,96√0,012
90+
0,018
90
𝑃[0.048 − 1,96 (0,01825) < (µ1 − µ2) < 0.048 + 1,96 (0,01825) ]
𝑃[0,0122 < (µ1 − µ2) < 0,0837] = 95 %

275
Con una confiabilidad del 95 %, se asegura que la diferencia de las medias de los dos
grupos esta entre 0,0122 y 0,0837 kg.
Si 𝜎12 y 𝜎2
2 no se conocen, pero se pueden suponer iguales 𝜎12 = 𝜎2
2= 𝜎2 y las muestras
son pequeñas 𝑛1 y 𝑛2 < 30 y 𝜎12, se recurre a la distribución t.
Si el muestreo se lleva a cabo sobre poblaciones normales e independientes, con
varianzas iguales pero desconocidas 𝜎12 = 𝜎2
2= 𝜎2 , la variable aleatoria.
(Ŷ1 − Ŷ2) − (µ1 − µ2)
𝑆𝑃√1𝑛1
+ 1
𝑛2
= 𝑇
Se distribuye t con 𝑛1 + 𝑛2 – 2 grados de libertad. 𝑆𝑝2 Es un estimador combinado de la
varianza común 𝜎2 .
𝑆𝑝2 =
(𝑛1 − 1) 𝑆12+ (𝑛2 − 1)𝑆2
2
𝑛1 + 𝑛2 – 2
5.5.8 Intervalo de confianza para (µ𝟏 - µ𝟐) con muestras pequeñas y varianzas
iguales 𝝈𝟏𝟐 = 𝝈𝟐
𝟐 pero desconocidas. Dadas dos muestras aleatorias con tamaños 𝑛1 y
𝑛2 < 30 y medias muéstrales (Ŷ1 y Ŷ2) respectivamente, procedentes de dos poblaciones
normales e independientes con medias (µ1 y µ2) y varianzas desconocidas pero iguales
𝜎12 = 𝜎2
2 un intervalo de confianza para (µ1 - µ2) al (1-α) 100% de confiabilidad, viene
dado por:
(Ŷ1 − Ŷ2) − 𝑡1−𝛼
2,𝑣 𝑆𝑃 √
1
𝑛1+
1
𝑛2< (µ1 − µ2) < (Ŷ1 - Ŷ2) + 𝑡1−
𝛼
2 𝑆𝑃 √
1
𝑛1+
1
𝑛2
Donde 𝑡1−𝛼
2,𝑣es el valor de t con v= 𝑛1 + 𝑛2 − 2 grados de libertad y P[𝑇 ≤ 𝑡1−
𝛼
2,𝑣 =
1 −𝛼
2, 𝑆𝑝
2] Es un estimador combinado de la varianza común que se expresa como

276
𝑆𝑝2 =
(𝑛1 − 1) 𝑆12+ (𝑛2 − 1)𝑆2
2
𝑛1 + 𝑛2 – 2
El intervalo es bastante aceptable si las poblaciones de donde provienen las muestras
son aproximadamente normales.
Ejemplo 5.5.9: En una región con poca tradición en la ovina cultura se tomaron dos
muestras conformadas por 11 ejemplares machos, en dos fincas. En cada una de las
explotaciones se calcularon las respectivas medias y varianzas, para el variable peso a la
edad adulta, con los siguientes resultados:
Finca 1: 𝑛1 = 11
Ŷ1= 56,5 Kg
𝑆12= 146, 8 𝑘𝑔2
Finca 2: 𝑛2 = 11
Ŷ2= 57,8 Kg
𝑆22= 154, 2 𝑘𝑔2
Se pregunta, ¿Cuál es el intervalo de confianza para la diferencia de las dos medias?
Para responder este interrogante se aplica la expresión (5.5.12), donde será necesario
utilizar además (5.5.13) para obtener 𝑆𝑝2:
𝑆𝑝2 =
(11 − 1) 146,8+ (11 − 1)154,2
11 + 11 – 2= 150,5
𝑆𝑝= √𝑆𝑝2 = √150,5 = 12,27 𝐾𝑔
Como ya se dijo, el intervalo de confianza se calcula con (5.5.12):
-7,4 – 10,914 < (µ1 − µ2) < −7,4 + 10,914

277
-18,314 < (µ1 − µ2) < 3,514
Esto indica que (µ1 - µ2) puede tomar cualquier valor en (-18,314 a 3,514), y como cero
pertenece al intervalo, entonces (µ1 - µ2), es decir (µ1 - µ2), al 95 % de confiabilidad.
5.5.9 Intervalos de confianza para proporciones. Son útiles cuando se está interesado
en estimar la proporción de individuos de una población con una determinada
característica, como es el caso de establecer la proporción de animales vacunados contra
fiebre aftosa, que no se desarrollaron la enfermedad, las vacas positivas a cualquier
enfermedad los peces que sobreviven a una variación térmica brusca y en muchos
otros casos similares. Se debe recordar que p es la proporción de individuos poseedores
de cierta característica en una población de interés y un estimador de p es la proporción
muestral ��=𝑋
𝑛, donde X es el número de éxitos en n ensayos independientes, siempre y
cuando n sea grande y la variable sea aleatoria, entonces: es normal estándar.
�� − 𝑝
√𝑝(1 − 𝑝)𝑛
= 𝑍
5.5.9.1 intervalos de confianza para p con muestra grande. Sea �� la proporción
observada de éxitos en una muestra aleatoria de tamaño n, un intervalo de confianza
para p al (1-α) 100% de confiabilidad, viene dado por:
�� − 𝑍1−𝛼
2 √
𝑝(1−𝑝)
𝑛< 𝑝 < �� + 𝑍1−
𝛼
2 √
𝑝(1−𝑝)
𝑛
Donde 𝑍1−𝛼
2es tal que P[𝑍 ≤ 𝑧1−
𝛼
2] = 1 − 𝛼/2
El intervalo es confiable cuando n es grande y p y (1-p) no están demasiado cercanos a
1 o a 0. Generalmente se considera que estas condiciones se satisfacen si np y n (1-p)
son mayores que 5.

278
Ejemplo 5.5.10: en un estudio de prevalencia por muestreo, realizado con Colombia,
150 vacas de raza Guernesey resultaron positivas a brucelosis en un amuestra de 335
animales. ¿Cuál es el intervalo de confianza para la verdadera a proporción de animales
enfermos con un 1 –α= 0,95?
En primer lugar se debe calcular �� = 150
355= 0,42
Por lo tanto 1-p= q = 1- 0,42= 0,58
Para establecer el intervalo de confianza se aplica (5.5.15), por lo tanto:
0,42 − 1,96 √0,42(0,48)
355< 𝑝 < 0,42 + 1,96 √
0,42(0,48)
355
0,42 – 0,047 < p < 0,42 + 0,047
0,373 < p < 0,467
Por consiguiente, se puede asegurar que en la zona estudiada, la prevalencia se
encuentra entre 0,373 y 0,467. Estos valores, expresados en términos porcentuales
indican que las hembras positivas a brucelosis están entre 37,3 y 46,7%, afirmación que
se hace con el 95 % de confiabilidad.
5.5.9.2 tamaños de muestra para estimar p. El tamaño de muestra necesario para
estimar la proporción poblacional p a partir de la proporción muestral ��, con una
confiabilidad del (1-α) 100% y un error de estimación 𝔢 viene dado por:
n=𝑍
1−𝛼2
2 P(1−p)
𝑒2
Donde 𝑍1−∝/2 es el valor tabular de la normal estándar para un valor 1- α dado.
Z es la proporción de individuos con la característica de interés para el investigador. Α
es el error máximo admitido para la estimación del parámetro.

279
Como en el caso del tamaño de muestra para estimar la media, la confiabilidad 1-α y el
error de estimación 𝔢 son arbitrarios, y los fija el investigador dependiendo de los
alcances e implicaciones de sus resultados y conclusiones. Para proporciones, el error
máximo de estimación 𝔢 es una medida que indica la distancia entre la estimación y el
verdadero valor de la proporción |�� − 𝑝|.
Cuando p no se conoce, asume que p= 0,5 y de esta manera se obtendrá el máximo
valor de n.
Este valor proporciona el máximo tamaño muestral.
Si el tamaño de la población es relativamente pequeño y n > 0,05N, se puede utilizar el
factor de corrección para poblaciones finitas:
𝑛1 =𝑛
1 + 𝑛𝑁
Ejemplo 5.5.11: Un médico veterinario debe establecer la prevalencia de la neumonía
en zootica en una población de cerdos. Los registros de una entidad oficial indican que
total existen 2800 animales. Se asumen que la enfermedad ataca por igual a machos y
hembras de cualquier edad. No existe información previa sobre la proporción de
animales enfermos (��). La profesional pregunta: ¿Cuál es el tamaño de muestra para
estimar la prevalencia de la enfermedad, con una confiabilidad del 95 % y un error de
estimación del 5 %?
En primer lugar debe aplicarse (5.5.16), con p= 0,5 y α= 0,05:
n=𝑍
1−𝛼2
2 P(1−p)
𝑒2 = 1,962(0,5)(0,5)
0,052 = 0,9604
0,0025= 384,16
Debido a que no es posible muestrear fracciones de animales, es necesario aproximar el
tamaño de muestra requerido a 385 cerdos que se escogerán irrestrictamente al azar, lo
que indica que todos los individuos tienen la misma probabilidad de ser elegidos y
formar parte de la muestra.

280
Por otra parte, N x 0,05= 2800 x 0.05= 140 y n=384; estas cifras indican que el tamaño
inicial de muestra n es mayor que N (0,05); por lo tanto es necesario hacer la corrección
por tamaño finito, aplicando (5.5.17):
𝑛1(𝑡𝑎𝑚𝑎ñ𝑜 𝑓𝑖𝑛𝑎𝑙 𝑑𝑒 𝑙𝑎 𝑚𝑢𝑒𝑠𝑡𝑟𝑎) = 384
1 + 384
2800
= 384
113714= 337,69
En consecuencia, el veterinario deberá muestrear 338 animales.
Ejemplo 5.5.12: Con los mismos datos del Ejemplo 5.5.11, pero asumiendo que se
conoce un dato de prevalencia esperada del 20%, ¿Cuál será el tamaño de la muestra?
𝑛 =1,962(0,2)(0,8)
0,052 = 0,614656
0,0025= 245,86
𝑛1(𝑡𝑎𝑚𝑎ñ𝑜 𝑓𝑖𝑛𝑎𝑙 𝑑𝑒 𝑙𝑎 𝑚𝑢𝑒𝑠𝑡𝑟𝑎) = 246
1 + 246
2800
= 246
10878= 226,13
En este caso, la cantidad de animales a muestrear es 226
Ejemplo 5.5.13: Con los mismos datos del Ejemplo 5.5.12, pero con una confiabilidad
del 90% y error de estimación del 10%, ¿Cuál será el tamaño de la muestra?
𝑛 =1,642(0,2)(0,8)
0,12 =
0,430336
0,01= 43,034
5.5.9.3 Estimación de la diferencia entre dos proporciones. Muchas veces el
investigador está interesado en comparar dos proporciones provenientes de dos
poblaciones independientes, para establecer si estadísticamente son iguales o diferentes.

281
Así en el caso de probar la eficacia de dos tratamientos para el control de la saprolegnia
en truchas, cuando se utiliza yodo o azul de metileno, el interés se centra en estimar la
diferencia entre las proporciones de animales curados en cada uno de los tratamientos.
Para cumplir este objetivo se seleccionan dos muestras aleatorias independientes, de
tamaño 𝑛1 y 𝑛2` a partir de dos poblaciones binomiales, ya que los resultados son que
el animal se cure o no la enfermedad.
Un estimador 𝑃1 - 𝑃2 está dado por ��1 - ��2 DONDE ��1 =𝑋1
𝑛1 es la proporción muestral de
individuos que poseen la característica de interés en la primera población y ��2 =𝑋2
𝑛2 es la
proporción muestral en la segunda población.
Para muestras grandes 𝑛1 y 𝑛2` la distribución de ��1 - ��2 se aproxima a la normal, con
media 𝑃1 - 𝑃2 y varianza ��1(1−��1)
𝑛1 +
��2(1−��2)
𝑛2 es decir,
(𝑃1−𝑃2 )− (𝑃1−𝑃2)
√��1(1−��1)
𝑛1 +
��2(1−��2)
𝑛2
= 𝑍 (5.5.18)
5.5.9.4 Intervalo de confianza entre dos proporciones 𝑷𝟏 - 𝑷𝟐 con muestras
grandes. Sea ��1 la proporción de éxitos observados en un amuestra aleatoria de tamaño
𝑛1 procedente de una población con proporción de éxitos 𝑃1′ y sea ��2 la proporción de
éxitos observados de una muestra aleatoria independiente, de tamaño 𝑛2` procedente
de una población con proporción de éxitos 𝑃2 . Si los tamaños de muestras 𝑛1 y 𝑛2 son
grandes, un intervalo de confianza para 𝑃1 - 𝑃2 al (1-α) 100% de confiabilidad, viene
dado por:
(𝑃1 − 𝑃2 ) − 𝑍1−𝛼
2,√(
��1(1−��1)
𝑛1 +
��2(1−��2)
𝑛2 ) < (𝑃1 − 𝑃2) < (𝑃1 − 𝑃2 )+𝑍1−
𝛼
2,
√(��1(1−��1)
𝑛1 +
��2(1−��2)
𝑛2 )
1
𝑛2

282
(5.5.19)
Ejemplo 5.5.14: Un ingeniero en producción Acuícola utilizo dos tratamientos para el
control de la aspergillosis en molinesias, uno con sal marina y otro con formaldehido.
Para este propósito distribuyo los tratamientos en cinco acuarios, cada uno con 50
ejemplares afectados, es decir, en total fueron tratados 250 animales en cada grupo. Al
final del experimento se constató que la sal marina curo 96 peces y el formaldehido 103.
¿Cuál es el intervalo de confianza para la verdadera diferencia de las proporciones de
animales curados en cada tratamiento con confiabilidad del 95%?
En el primer lugar se calculan las proporciones de éxito en cada tratamiento, así:
��1=
96250
=0,384
��2=
103250
=0,412
De acuerdo con (5.5.19):
(0,384 − 0,412) − 1,96√(0,384(0,616)
250 +
0,412(0,588)
250 ) < (𝑃1 − 𝑃2) < (0,384 −
0,412)+1,96√(0,384(0,616)
250 +
0,412(0,588)
250)
-0,028 – 1,96(0,04376) < (𝑃1 − 𝑃2) < −0,028 + 1,96 (0,04376)
-0,1137696 < (𝑃1 − 𝑃2) < 0,0577696
5.5.10 Intervalos de confianza para la varianza. Es necesario recordar que si 𝑆2 =
⅀(𝑋1−𝑋) 2
𝑛−1 es la varianza de una muestra aleatoria de tamaño n, procedente de una
población normal con varianza 𝜎2, entonces, la distribución de muestreo (n-1)𝑆2
𝜎2 es chi-
cuadrado, con (n-1) grados de libertad.

283
5.5.10.1 Intervalo de confianza para 𝝈𝟐. Si 𝑆2es la varianza de un amuestra aleatoria
de una población normal con media µ y varianza 𝜎2, un intervalo de confianza para
𝜎2al (1-α) 100% de confiabilidad viene dado por:
(𝑛 − 1)𝑆2
𝑋𝛼2,𝑛−1
2 < 𝜎2 < (𝑛 − 1)𝑆2
𝑋𝛼2,𝑛−1
2
Ejemplo 5.5.15: Con el fin de establecer un programa de producción piscícola con
Oreochromis sp, se midió el caudal de una fuente de agua durante un periodo de seis
meses, tomando una muestra semanal. Al final del periodo se estimó una varianza de
42𝐿2/𝑠𝑒𝑔. ¿Cuál es el intervalo de confianza para la varianza, con una confiabilidad del
95%?
Teniendo en cuenta que se tomaron 24 muestras, de acuerdo con (5.5.20):
(24 − 1)142
11,69 < 𝜎2 <
(24 − 1)142
38,08
42 – 27,44 < 𝜎2 < 42 + 27,44
14,56 < 𝜎2 < 69,44
Con el 95 % de confianza, el intervalo para la varianza esta entre 14,56 y 69,44 𝐿2
𝑠𝑒𝑔.
5.5.10.2 Intervalo de confianza para el cociente de dos varianzas. Muchas veces
surge la necesidad de comparar la variabilidad de dos procesos distintos, es decir, se
está interesado en comparar 𝜎12 y 𝜎2
2. Una manera de hacerlo es obtener su cociente 𝜎12
/ 𝜎22entonces, si las dos varianzas son iguales, dicho cociente será igual a 1.
Para la construcción de un intervalo de confianza para 𝜎12 /𝜎2
2es necesario
introducir la distribución F, donde, si 𝑆12 y 𝑆2
2 son las varianzas aleatorias
independientes de tamaños 𝑛1 y 𝑛2′ procedentes de dos poblaciones normales
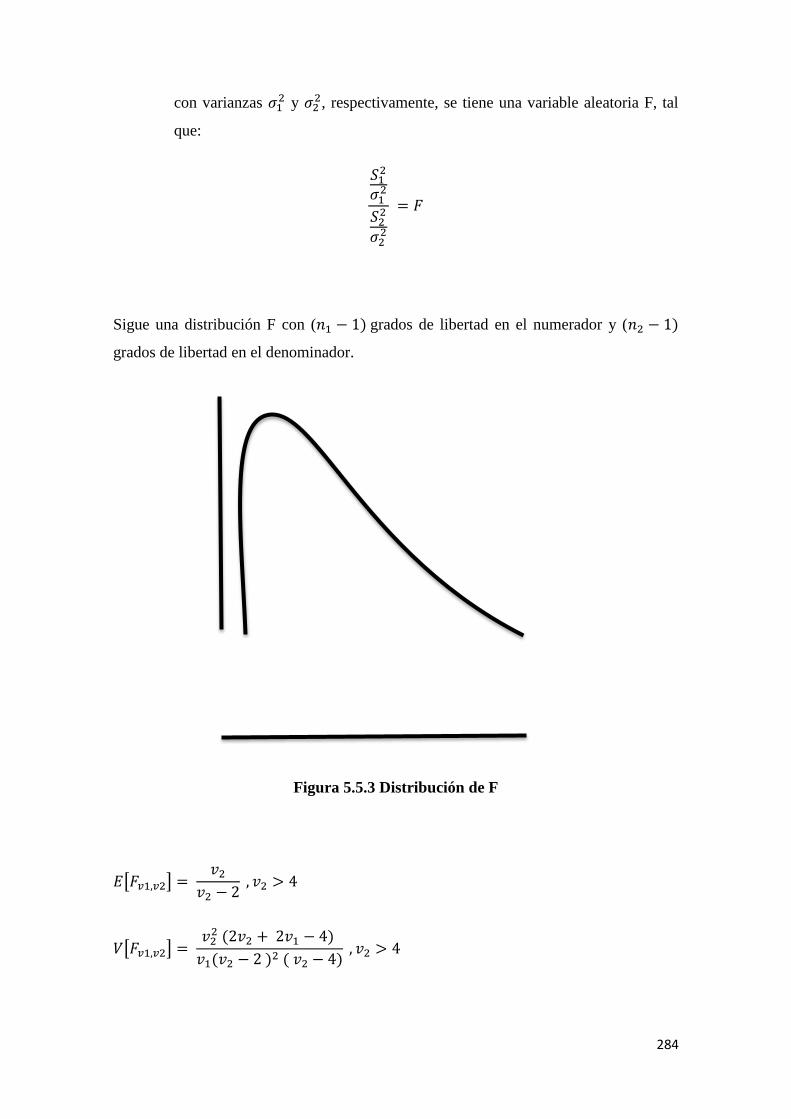
284
con varianzas 𝜎12 y 𝜎2
2, respectivamente, se tiene una variable aleatoria F, tal
que:
𝑆12
𝜎12
𝑆22
𝜎22
= 𝐹
Sigue una distribución F con (𝑛1 − 1) grados de libertad en el numerador y (𝑛2 − 1)
grados de libertad en el denominador.
Figura 5.5.3 Distribución de F
𝐸[𝐹𝑣1,𝑣2] = 𝑣2
𝑣2 − 2 , 𝑣2 > 4
𝑉[𝐹𝑣1,𝑣2] = 𝑣2
2 (2𝑣2 + 2𝑣1 − 4)
𝑣1(𝑣2 − 2 )2 ( 𝑣2 − 4) , 𝑣2 > 4
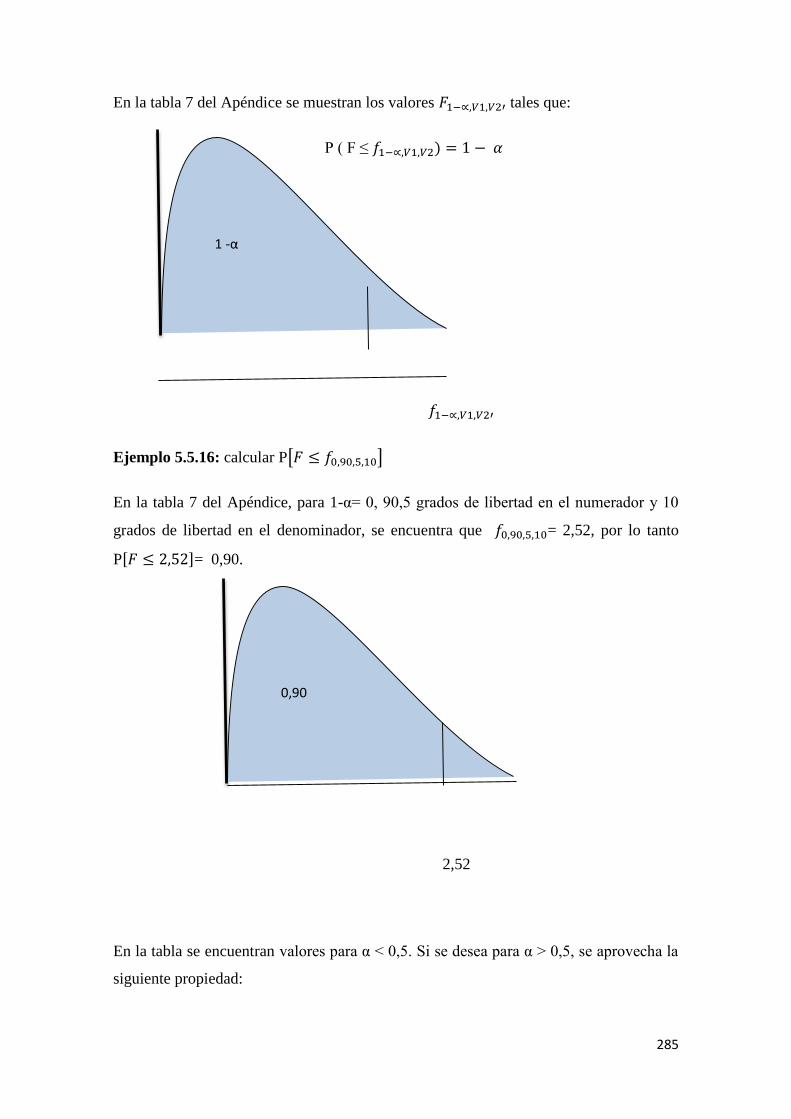
285
En la tabla 7 del Apéndice se muestran los valores 𝐹1−∝,𝑉1,𝑉2′ tales que:
P ( F ≤ 𝑓1−∝,𝑉1,𝑉2) = 1 − 𝛼
𝑓1−∝,𝑉1,𝑉2′
Ejemplo 5.5.16: calcular P[𝐹 ≤ 𝑓0,90,5,10]
En la tabla 7 del Apéndice, para 1-α= 0, 90,5 grados de libertad en el numerador y 10
grados de libertad en el denominador, se encuentra que 𝑓0,90,5,10= 2,52, por lo tanto
P[𝐹 ≤ 2,52]= 0,90.
2,52
En la tabla se encuentran valores para α < 0,5. Si se desea para α > 0,5, se aprovecha la
siguiente propiedad:
1 -α
0,90

286
𝑓∝,𝑉1,𝑉2 = 1
𝑓∝,𝑉1,𝑉2
En el siguiente caso:
P[𝐹 ≤ 𝑓0,10,10,5] =P[𝐹 ≤ 1
𝑓0,9,5,10]= P[𝐹 ≤
1
2,52]= P [𝐹 ≤ 0,3968] = 0,10
Los anteriores conceptos sirven como base para calcular el Intervalo de confianza para
el cociente de dos varianzas 𝜎12 /𝜎2
2. Cuando 𝑆12 y 𝑆2
2con las varianzas de dos muestras
aleatorias independientes de tamaños 𝑛12y 𝑛2respectivamente, procedentes de dos
poblaciones normales con varianzas 𝜎12 y 𝜎2
2, respectivamente, un intervalo de
confianza para 𝜎12 /𝜎2
2, al (1-α) x 100% de confiabilidad, viene dado por:
𝑆12
𝑆22 𝑋
1
[𝑓1−
𝛼2
;𝑣2;𝑣1]
< 𝜎1
2
𝜎22 <
𝑆12
𝑆22 𝑥 𝑓
1−𝛼2
;𝑣2;𝑣1
Donde 𝑓1−∝/2,𝑉1,𝑉2 Es un valor f con 𝑣1= 𝑛1- 1 y 𝑣2= 𝑛2 – 1 grados de libertad que
P[𝐹 ≤ 𝑓1−𝛼/2]= 1-α/2.
Ejemplo 5.5.17: En una población de Cavia porcellus, se estimó la varianza para el
peso al destete en 64,49 𝑔2, medida sobre 25 individuos de una línea mejorada y en otra
población, con 31 individuos, la varianza fue de 61,72 𝑔2. Se pide calcular el intervalo
de confianza para el cociente de varianzas, con 1-α= 0,90.
1 - α = 0,90
1 - 𝛼 2⁄ = 0,95
𝑓1−∝/2,24,30 = 1,89
𝑓1−∝/2,30,24 = 1,94
De acuerdo con (5.5.22) se tiene:

287
64,49
61,72 𝑋
1
1,94<
𝜎12
𝜎22 <
64,49
61,72 𝑥 1,89 = 0,5386 <
𝜎12
𝜎22 < 1,9784
De acuerdo con los resultados, el intervalo de confianza para el cociente de las dos
varianzas esta entre 0,5389 y 1,9748, con un 95 % de confiabilidad. Como 1 está en el
intervalo se puede afirmar que las os varianzas son iguales.

288
CAPÍTULO 6
Prueba de hipótesis
En el capítulo anterior se analizó la estimación puntual y por intervalo de un parámetro.
En este capítulo se considera otro enfoque de la inferencia estadística que se refiere a la
toma de decisiones sobre las poblaciones basada en el análisis de una muestra. Los dos
conceptos se fundamentan en la evidencia experimental que se obtiene a través de un
muestreo aleatorio. Muchas de estas decisiones tienen que ver con aceptar o rechazar
una afirmación sobre un parámetro o sobre la forma de la distribución de la población
de interés, las cuales se denominan hipótesis estadísticas y al procedimiento mediante el
cual se toma la decisión sobre la hipótesis se lo conoce como prueba o contraste de
hipótesis.
Ejemplos 6.0.1: Un procesador de leche afirma que el producto de su empresa contiene
en promedio 0.36 kilogramos de grasa por litro. Para verificar esta afirmación se toma
una muestra aleatoria de la leche procesada en la planta y se determina la cantidad de
grasa por litro, para luego generalizar este resultado muestral a toda la población, en
este caso, a toda la leche procesada en la planta.
Ejemplo 6.0.2: Un profesional tiene que definir, sobre la base de experimentos, la
efectividad del yodo y el azul de metileno en el control de saprolegnia en trucha arco
iris. Los animales afectados por el hongo se dividen en dos grupos al azar: el uno es
tratado con yodo y el otro con azul de metileno. Al terminar el ensayo es posible
establecer la proporción de animales curados en cada grupo y, mediante la prueba de
hipótesis, determinar si existen diferencias significativas entre dichas proporciones.
Para abordar este tema con mayor claridad es necesario recurrir a ciertas definiciones
como son: hipótesis nula, hipótesis alterna, región crítica, errores tipo I y tipo II, nivel
de significancia y potencia de la prueba.

289
En primer lugar se debe tener en cuenta que en el análisis de este tipo de problemas se
consideran dos clases de hipótesis estadísticas: la hipótesis nula (H0) y la hipótesis
alterna (H1).
La hipótesis nula es una afirmación o explicación tentativa sobre un fenómeno
particular, la cual debe ser comprobada. El rechazo de una hipótesis nula conduce a la
formulación de una hipótesis alternativa. Generalmente la hipótesis alternativa coincide
con la hipótesis planteada por el investigador y la hipótesis nula es la negación de la
hipótesis alternativa., de este modo, uno de los propósitos de todo experimento es decir
si la prueba de campo o laboratorio tiende a refutar o a apoyar la hipótesis nula,
aclarando que “rechazar una hipótesis significa concluir que es falsa”, mientras que
“aceptar una hipótesis significa no tener suficiente evidencia para rechazarla”.
En la mayoría de los casos es deseable que una hipótesis nula, referida a un parámetro
de la población, sea planteada de tal manera que se especifique un valor exacto del
parámetro, mientras que la hipótesis alternativa permite la posibilidad de contrastar
varios valores.
El en Ejemplo 6.0.1, la hipótesis nula sería:
H0: El contenido promedio de grasa por litro es de 0.36kg.
H0: µ=0.36
La hipótesis alternativa podría ser una de las siguientes:
H1: El contenido promedio de grasa por litro es mayor que 0.36 kg.
H1: El contenido promedio de grasa por litro es menor que 0.36 kg.
H1: El contenido promedio de grasa por litro es diferente de 0.36 kg.
Las hipótesis nula y alternativa podrían ser escritas como:
H0: µ=0.36
H1: µ>0.36

290
H0: µ=0.36
H1: µ<0.36
H0: µ=0.36
H1: µ≠0.36
Para el Ejemplo 6.0.2 la hipótesis nula se plantea como:
H0: La proporción de truchas curadas al recibir el tratamiento con yodo, es igual a la
proporción de truchas curadas al recibir un tratamiento con azul de metileno.
H0: Py= Pa
De la misma forma que en el caso anterior, las hipótesis nula y alternativa se podrían
plantear como:
H0: Py=Pa
H1: Py>Pa
H0: Py=Pa
H1: Py<Pa
H0: Py=Pa
H1: Py≠Pa
Después de platear las hipótesis nulas y alternativa y de recoger información muestral,
debe tomarse una decisión sobre la hipótesis nula. Las dos posibles decisiones respecto
a H0 son aceptarla o rechazarla y al tomar una de estas decisiones se pueden cometer
dos tipos de error.

291
El primero o error tipo I, consiste en rechazar H0, cuando en realidad ésta es verdadera.
El otro tipo de error es el denominado error tipo II que consiste en aceptar H0 cuando
en realidad ésta es falsa.
En la Tabla 6.0.1 se pueden apreciar los estados de la naturaleza y las decisiones sobre
la hipótesis nula.
Tabla 6.0.1 Estados de la naturaleza y decisiones sobre la hipótesis nula.
Decisiones sobre H0
Estados de la naturaleza
H0 es verdadera H0 es falsa
Aceptar H0 Decisión correcta Error tipo II
Rechazar H0 Error tipo I Decisión correcta
Como se mencionó anteriormente, la decisión de aceptar o rechazar una hipótesis
estadística se basa en una muestra, es decir es un proceso inferencial en el cual siempre
existirán riesgos de tomar una decisión falta, los que se expresan en términos
probabilísticos. Así, la probabilidad de rechazar H0, cuando Ho es verdadera, se define
como la probabilidad del error tipo I y se denota por α, donde 0≤α≤1.
P (rechazar H0/H0 es verdadera)=a
La probabilidad de aceptar H0, cuando Ho es falsa, se define como la probabilidad del
error tipo II y se denota por β, donde 0≤β≤1.
P (aceptar H0/H0 es falsa)=β
El valor que toma α se denomina nivel de significancia y entre más grande sea α mayor
será la probabilidad de rechazar H0 equivocadamente, es decir, existe mayor
probabilidad de cometer error tipo I.
Al verificar una prueba de hipótesis es difícil establecer la gravedad de los errores tipo I
y II, además, para un tamaño de muestra dado, una disminución del tamaño del error

292
tipo I o α, implica un aumento en el tamaño del error tipo II ό β, consiste en realizar
técnicamente el muestreo y utilizar el máximo tamaño de muestra.
En la práctica, lo que comúnmente se hace es fijar el máximo tamaño del error tipo I,
que puede tolerarse en una situación dada a criterio del investigador, dependiendo de los
alcances y de la gravedad de las recomendaciones., por ejemplo, si se trata de lanzar al
mercado un nuevo producto que potencialmente afecte la salud de los humanos, el valor
de α debe ser lo más pequeño posible. En la mayoría de los trabajos de investigación,
incluidos los de salud y producción animal, α oscila entre 1 y 5%.
Cuando se escoge un nivel de significancia α y se rechaza una hipótesis nula, se dice
que los resultados de la muestra son significativos al α*100%.
En revistas técnicas y libros especializados se utiliza el valor p para representar el
mínimo nivel de significancia α que permite, con los datos analizados, rechazar la
hipótesis nula. Por ejemplo, si en un ensayo de fertilización del Brachiaria decumbens,
se reporta que el rendimiento de materia verde por hectárea con dos niveles de fósforo,
no presento diferencias significativas, se reportará como (p>0.5); si por el contrario se
observaron diferencias estadísticas significativas en las medias de los rendimientos se
reportará como (p≤0.05).
6.1 REGIÓN CRÍTICA O REGIÓN DE RECHAZO
Como se mencionó anteriormente, al plantear una hipótesis el procedimiento mediante
el cual se toma la decisión de aceptarla o rechazarla es la prueba o contraste de
hipótesis., dicha decisión se basa en un estadístico de prueba definido como una
cantidad numérica calcula con la información obtenida de una muestra, teniendo en
cuenta el parámetro sobre el cual se hace la inferencia y la distribución muestral de los
estadístico correspondiente.
La hipótesis nula se rechaza para ciertos valores del estadístico de prueba, tales valores
constituyen lo que se conoce como región crítica o región de rechazo de la prueba., al
complemento se lo denomina zona de no rechazo o zona de aceptación.

293
Ejemplo 6.1.1 En el Ejemplo 6.0.1 el procesador de leche Afirma que su producto tiene
un contenido promedio de grasa por litro de 0.36 kg.
H0: µ=0.36
Para un tamaño de muestra dado, supóngase que se decide rechazar H0 si se obtiene un
promedio muestral Y‾ menor que 0.34.
En este ejemplo, Y‾ =0.34 es el valor crítico y el conjunto de valores menores que 0.34
constituyen la región crítica o región de rechazo de la prueba.
Para mostrarlo gráficamente se supone que el contenido de grasa por litro se distribuye
aproximadamente como una normal o que n es lo suficientemente grande, de tal manera
que la distribución de muestreo Y‾ se aproxime a una distribución normal.
En la Figura 6.1.1 se observa que la región crítica es la parte sombreada a la izquierda
del punto crítico y la región situada a la derecha de dicho punto es la región de
aceptación o no rechazo de H0. El área de la región crítica está dada por α que
constituye, como se ha indicado, el nivel de significancia de la prueba, es decir,
P [rechazar H0|µ=0.36]=α.
Por ejemplo, si α=0.05, entonces el tamaño de la región crítica es el 5.0% del área total
comprendida bajo la curva normal y P [Y‾<0.34|µ=0.36]=0.05 significa que hay
aproximadamente cinco ocasiones en 100 en que se rechazaría la hipótesis cuando en
realidad debería ser aceptada, es decir, que la confiabilidad es del 95% para tomar una
decisión adecuada. En este caso, se dice que la hipótesis ha sido rechazada al nivel de
significancia del 5.0%.

294
Figura 6.1.1 Regiones de aceptación y de rechazo de la hipótesis nula en
una distribución normal.
6.2 HIPÓTESIS UNILATERALES Y BILATERALES
En algunos problemas de pruebas de hipótesis se involucran hipótesis alternativas
unilaterales, también conocidas como pruebas de hipótesis a una cola, tal como se
indican a continuación:
H:0 θ=θ0 ό H0: θ=θ0
H1: θ>θ0 H1: θ<θ0
Se dice que H1 es una hipótesis alternativa unilateral, debido a que los posibles valores
de θ bajo a H1 se encuentran a un solo lado del valor propuesto bajo H0.
Si H1: θ> θ0, la región crítica se encuentra en la cola superior de la distribución del
estadístico de prueba mientras que si H1: θ< θ0, la región critica se encuentra en la cola
inferior de la distribución del estadístico de prueba. En cierto sentido, el símbolo de
desigualdad señala la dirección en la que se ubica la región crítica.
A una prueba de la forma.
H0: θ= θ0

295
H1: θ≠ θ0
Se la denomina prueba bilateral o de dos colas puesto que la región crítica está dividida
en dos partes iguales ubicadas en cada cola de la distribución del estadístico de prueba.
La hipótesis alterna H1: θ≠ θ0 implica que puedan presentarse dos situaciones, ya sea que
θ> θ0 ό que θ0.
Al realizar un procedimiento para probar hipótesis, la hipótesis nula siempre se plantea
como una igualdad, de tal manera que se especifica un solo valor para poder controlar la
probabilidad de error tipo I, mientras que la hipótesis alternativa puede ser unilateral o
bilateral, dependiendo del interés del investigador.
Resumiendo, una prueba o contraste de hipótesis consta, esquemáticamente, de los
siguientes pasos:
a) Identificación del parámetro de interés.
b) Planteamiento de la hipótesis nula y alternativa (H0 y H1).
c) Elección del nivel de significancia.
d) Definición del estadístico de prueba.
e) Establecimiento de las regiones de aceptación y de rechazo para el estadístico.
f) Cálculo del valor del estadístico de prueba a partir de una muestra aleatoria.
g) Decisión sobre el rechazo o aceptación de la hipótesis, dependiendo si el
estadístico de prueba se ubica en la región de rechazo o en la de aceptación.
6.3 CONTRASTES RELACIONADOS CON LA MEDIA µ
El objetivo fundamental de estas pruebas consiste en establecer si una media
poblacional µ es igual o diferente de cierto valor supuesto µ0, para lo cual se contrasta
una de las siguientes hipótesis respecto al parámetro µ:
H0:µ=µ0 H0:µ=µ0 H0:µ=µ0
H1:µ≠µ0 H1:µ>µ0 H1:µ<µ0

296
Los contrastes con respecto a µ varían en su procedimiento, dependiendo
fundamentalmente del conocimiento de σ2, en consecuencia, se pueden presentar las
situaciones que se describen a continuación.
6.3.1 Contraste de hipótesis para la media poblacional µ con varianza poblacional σ2
conocida. Sea Y‾ la media de una muestra aleatoria de tamaño n, procedente de una
población normal, con media µ y varianza σ2 conocida.
En este caso se pueden contrastar las siguientes hipótesis:
H0:µ=µ0
H1:µ≠µ0
Donde µo es un valor específico.
El contraste sobre la media poblacional tiene como estadístico de prueba la media
muestral Y‾, que por lo general se estandariza para utilizar un estadístico de prueba
basado en la distribución normal estándar. Bajo H0: µ = µ0 y por lo tanto la media
muestral Y‾ tiene una distribución normal con media µ0 y desviación estándar 𝛔
√𝒏 ; esto
es, la variable aleatoria.
𝑍Y‾ − µ0
σ/√𝒏
Donde (6.3.1) corresponde a una variable normal estándar.
La hipótesis nula H0:µ=µ0 se rechaza si la media muestral Y‾ es mayor o menor que el
valor postulado µ0 para la media poblacional µ. Por lo tanto, o se rechaza si se observa
un valor alto o un valor bajo para el estadístico de prueba (6.3.1).
Si α es la probabilidad de rechazar H0, cuando H0 es verdadera, la probabilidad de que Z
este ubicada en la región Z>Z1-α/2 o Z<Zα/2 es α.
Por lo tanto H0 se rechaza si: Z> Z1-α/2 ό z< Zα/2, donde Zα/2 y Z1-α/2 son los valores
cuantiles de la normal estándar.

297
Ejemplo 6.3.1: Un grupo investigador asegura que, mediante cruzamientos, ha logrado
obtener un híbrido de conejo, cuyo rendimiento promedio en canal es de 2.28 kg. Por
experiencia se sabe que σ=0.65kg. Un productor está interesado en adquirir ejemplares
del mencionado híbrido y para ello solicita a un profesional pecuario, un estudio que
confirme si efectivamente se alcanza el rendimiento indicado. El profesional toma una
muestra aleatoria de 25 animales y calcula un rendimiento promedio de 2.02kg. Con
base en esta información y utilizando un nivel de significancia de α=0.05, ¿se puede
afirmar que el rendimiento promedio es el indicado por los investigadores?
Siguiendo el esquema planteado en el numeral 6.2, para resolver este interrogante se
procede del siguiente modo:
a) El parámetro de interés es la media poblacional µ.
b) Las hipótesis nula y alternativa son:
H0:µ=2.28
H1:µ≠2.28
En este caso, la hipótesis alterna es bilateral, ya que se desea rechazar la H0 si la media
es significativamente mayor o menor que 2.28.
c) Se define α=0.05.
d) El estadístico de prueba es Y‾−μ0
σ/√𝒏𝑍
e) H0 se rechaza si: Z> Z1-α/2 = Z0.975=1.96 ό
Z<Zα/2 =Z0.025=-1.96

298
f) El valor del estadístico de prueba es:2.02−2.28
0.65/√25= −2
g) Decisión: Dado que Z=-2<-1.96, es decir, Z=-2 se ubica en la zona de
rechazo, por lo tanto H0: µ=2.28 debe rechazarse.
Para informar sobre los resultados de la prueba puede recurrirse a una explicación
planteada de la siguiente manera: con un nivel de significancia del 5% se asegura que el
rendimiento promedio en canal de los híbridos de conejo es diferente de 2.28kg.
En realidad, los datos proporcionan evidencia suficiente para asegurar que existe un
rendimiento promedio menor de 2.28kg, tal como se puede apreciar en la figura
siguiente, donde se observa que el valor crítico cae en la región donde se encuentran
valores negativos:
Por otra parte, es necesario recordar que el valor p es el mínimo nivel de significancia α,
para el cual los datos observados indiquen la necesidad de rechazar la hipótesis nula. En
este caso, el mínimo valor α con el cual se rechaza la hipótesis H0: µ=2.28kg, viene
dado por la probabilidad de encontrar un Z< -2, es decir, P(Z<-2)=0.0228; como el
contraste es a dos colas α/2=0.0228, por lo tanto, α=0.0456. Esto significa que si la
hipótesis nula fuera cierta, la probabilidad de encontrar una media muestral alejada de
2.28kg es 0.0456.
6.3.2 Relación entre contraste de hipótesis en intervalo de confianza. Para las
hipótesis H0:µ=µ0 y H1: µ≠ µ0, los puntos críticos son:
𝑎 = µ0 − Z1−α/2𝜎
√𝑛 y
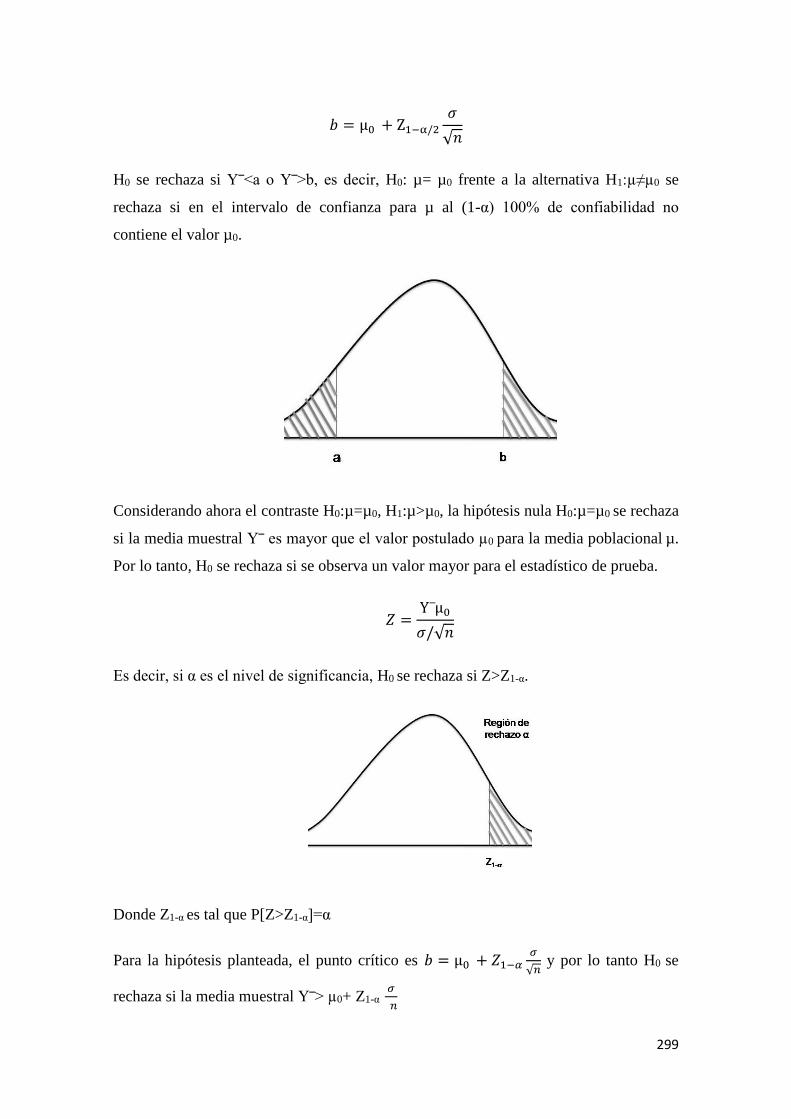
299
𝑏 = µ0 + Z1−α/2
𝜎
√𝑛
H0 se rechaza si Y‾<a o Y‾>b, es decir, H0: µ= µ0 frente a la alternativa H1:µ≠µ0 se
rechaza si en el intervalo de confianza para µ al (1-α) 100% de confiabilidad no
contiene el valor µ0.
Considerando ahora el contraste H0:µ=µ0, H1:µ>µ0, la hipótesis nula H0:µ=µ0 se rechaza
si la media muestral Y‾ es mayor que el valor postulado µ0 para la media poblacional µ.
Por lo tanto, H0 se rechaza si se observa un valor mayor para el estadístico de prueba.
𝑍 =Y‾µ0
𝜎/√𝑛
Es decir, si α es el nivel de significancia, H0 se rechaza si Z>Z1-α.
Donde Z1-α es tal que P[Z>Z1-α]=α
Para la hipótesis planteada, el punto crítico es 𝑏 = µ0 + 𝑍1−𝛼𝜎
√𝑛 y por lo tanto H0 se
rechaza si la media muestral Y‾> µ0+ Z1-α 𝜎
𝑛

300
De la misma forma, para contrastar H0:µ=µ0, H1:µ<µ0
H0 se rechaza si se observa un valor menor para el estadístico de prueba
𝑍 =Y‾ − µ0
𝜎√𝑛⁄
Si α es el nivel de significancia, H0 se rechaza si Z<Zα.
Donde P [Z<Zα]=α
De manera equivalente H0 se rechaza si Y‾ < µ0 + 𝑍1−𝛼𝜎
√𝑛
En el Ejemplo 6.3.1 se dijo que existe una fuerte evidencia de que el rendimiento
promedio en canal de los híbridos de conejo es menor que 2.28kg, dado que el valor
crítico se ubicó en la región de la curva con valores negativos.
Para afianzar esa afirmación se debe contrastar la hipótesis:
H0:µ=2.28
H1:µ<2.28

301
Siguiendo el esquema planteado en el numeral 6.2, se tiene:
a) El parámetro de interés es la media poblacional µ.
b) Las hipótesis son:
H0:µ=2.28
H1:µ<2.28
c) α=0.05
d) el estadístico de prueba es: 𝑍 =Y‾−μ0𝜎
√𝑛⁄
e) H0 se rechaza si Z< Zα=Z0.05=-1.65
f) El valor de este estadístico de prueba es:
2.02 − 2.28
0.65/√25− 2
g) Dado que Z=-2<Z0.05=-1.65, como se muestra en la siguiente figura, H0 se
rechaza, es decir, con un nivel de significancia de 5% se concluye que el
rendimiento promedio en canal de los conejos híbridos es menor de 2.28kg.
Es importante que, por lo general, cuando se hacen pruebas de hipótesis relacionadas
con variables productivas, se asume que la variable sigue una distribución normal y, si
bien, esta afirmación es confirmada por múltiples trabajos de investigación, es
conveniente analizar los datos de cada caso particular para confirmar la normalidad de
las variables analizadas. En caso de encontrarse una desviación marcada de la
normalidad en los datos, los procedimientos indicados para las pruebas de hipótesis no
serían los más adecuados.

302
6.3.3 Contraste de hipótesis para la media poblacional µ con muestras grandes (n≥30)
y varianza σ2 desconocida. En la mayoría de situaciones prácticas no se conoce σ2, pero
por lo general, si el tamaño de muestra es grande (n≥30), el teorema central del límite
permite concluir que la distribución de la media muestral es aproximadamente normal y,
por lo tanto, se pueden utilizar los mismos procedimientos de contraste desarrollados
para el caso en que σ2 es conocida, para lo cual se debe sustituir σ2 por S2.
Ejemplo 6.3.2: Un investigador asegura que un rebaño selecto de vacas Holstein, cuyo
promedio de producción es 34L/día, podría llegar a producir 41L/día siempre y cuando
se incorpore en la dieta proteínas de origen animal y vitaminas liposolubles, en las
cantidades que él sugiere. Con una muestra aleatoria de 50 vacas, sometidas a una dieta
como la indicada, se calculó un promedio de producción de 39 L, con una desviación
estándar de 6,0 litros. Se pregunta ¿existen razones suficientes para creer que el
promedio producción es menos de 41 L? Esta pregunta se puede responder
desarrollando el procedimiento para prueba de hipótesis. Como ợ2 es desconocida y el
tamaño de muestra es mayor de 30, se aplica el mismo proceso general, así:
a) El parámetro de interés es la media µ.
b) Ho: µ= 41
Ho: µ < 41
c) ∝= 0,05
d) El estadístico de prueba es ��− μ0
𝜎/√𝑛= 𝑍, donde ợ≅ 𝑆
e) Ho se rechaza si Z < 𝑍∝ = 𝑍0,05 = −1,65
f) El valor del estadístico de prueba es: 39−42
6 /√50= −2,36
g) Decisión: Dado queZ = −2,36 < −1,65, como se muestra en la figura
siguiente:

303
-2,36 -1,65
Ho se rechaza y, por lo tanto, se concluye que el promedio de producción de las vacas
que se sometieron a dicha dieta es menor que 41 L, afirmación que se hace con un nivel
de significancia del 5%.
6.3.4 Contraste de hipótesis para la media poblacional µ con muestras pequeñas (µ
<30) y ớ2 desconocida. Sean 𝑌 y S la media y la desviación estándar, respectivamente,
de una muestra aleatoria de tamaño n, procedente de una población normal, con media
µ y varianza ớ2 desconocida, el contraste de hipótesis bilateral:
Ho: µ= µ0
Ho: µ ≠µ0
𝑇 = �� − µ0
𝑆
√𝑛
El cual tiene una distribución t con n-1 grados de libertad. Usando el mismo
procedimiento general de prueba de hipótesis anteriormente indicado, Ho se rechaza así:
𝑇 > 𝑡1− ∝/(2,𝑛−1)
𝑇 < 𝑡∝/(2,𝑛−1)
Para el contraste de hipótesis:

304
Ho: µ=µ0
Ho: µ > µ0
Ho se rechaza si 𝑇 > 𝑡1−∝,𝑛−1
Para el contraste de hipótesis:
Ho: µ=µ0
Ho: µ < µ0
Ho se rechaza si 𝑇 < 𝑡𝜇,𝑛−1
6.6.3: Una compañía dedicada a la comercialización de camarón congelado, imprime las
etiquetas de las bandejas “contiene 12 oz”. Con una muestra de 22 bandejas se calculó
una media de ��= 11,84 onzas y una desviación estándar (S) de 0,5 onzas. Si se supone
que los pesos de las bandejas siguen en forma adecuada una distribución normal, con un
nivel de significancia del 5,0% ¿aseguraría que la afirmación del productor es correcta?.
Al igual que en los ejemplos anteriores, debe seguirse el procedimiento general de
prueba de hipótesis:
a) El parámetro que en los ejemplos anteriores, debe seguirse el procedimiento
general de prueba de hipótesis:
b) Se plantea la hipótesis
Ho: µ=12
Ho: µ < 12 (a una cola)
c) ∞= 0,05
d) El estadístico de prueba es: ��− μ0
𝑆
√𝑛
e) Ho: se rechaza si T < t∞ n-1 = t 0,95,21 = -1,712
f) El valor del estadístico de prueba: 11,84−12
0,5
12
= −1,5
g) Decisión
Dado que T = -1,5 > t0,05, 21 = -1,712, es decir, t= -1,5, cae en zona de aceptación
como se muestra en la figura siguiente, en cuyo caso, Ho no se rechaza y por lo

305
tanto µ= 12 onzas, y la afirmación sobre el contenido de los envases (12 onzas)
es correcta.
-1,712 -1,5
6.4 CONTRASTES RELACIONADOS CON LA DIFERENCIA DE MEDIAS
El objetivo fundamental de estos contrastes consiste en establecer si existe diferencia
entre dos medias µ1 y µ2 de dos poblaciones independientes, para ellos se recurre a uno
de los siguientes contrastes:
Ho: µ1 = µ2 Ho: µ1 = µ2 Ho: µ1 = µ2
Ho: µ1≠µ2 Ho: µ1> µ2 Ho: µ1< µ2
A veces es de interés analizar si la diferencia µ1 - µ2 es igual, mayor o menor que un
número real cualquiera δ, es decir, se analizan los siguientes contrastes:
Ho: µ1 - µ2 = δ Ho: µ1 - µ2 = δHo: µ1 - µ2 = δ
Ho: µ1−µ2 ≠δHo: µ1 - µ2 >δHo: µ1 - µ2<δ
6.4.1 Contraste de hipótesis para la diferencia de medias con varianzas 𝝈𝟏𝟐 y 𝝈𝟐
𝟐
conocidas. Sean dos muestras aleatorias con tamaños n1 y n2 y con medias muestrales
��1 y ��2, respectivamente, procedentes de dos poblaciones normales e independientes,
con medias µ1 y µ2 y varianzas 𝜎12 y 𝜎2
2 conocidas. En casos como este, la mayoría de

306
veces el investigador puede establecer la igualdad o diferencia de las medias, para lo
cual se recurre a realizar la correspondiente prueba de hipótesis que se basa en el
siguiente estadístico de prueba:
𝑍 =(�� − 𝑌2) − (𝜇1 − 𝜇2)
√𝜎1
2
𝑛1+
𝜎22
𝑛2
En (6.4.1) Z tiene una distribución normal estándar y los contrastes de hipótesis se
apoyan en este resultado.
En el contraste bilateral:
Ho: µ1 = µ2
Ho: µ1≠ µ2
El estadística de prueba indicado en (6.4.1) se puede expresar del siguiente modo:
𝑍 =(�� − 𝑌2)
√𝜎1
2
𝑛1+
𝜎22
𝑛2
La regla de decisión consiste en rechazar Ho si 𝑍 > 𝑍1−∝/(2) ó 𝑍 < 𝑍∝
2
Para constatar la hipótesis alternativa unilateral:
Ho: µ1 = µ2
Ho: µ1> µ2
La regla de decisión consiste en rechazar Ho cuando 𝑍 > 𝑍 1−∝
Para la otra hipótesis unilateral:
Ho: µ1 = µ2
Ho: µ1< µ2

307
Ho se rechaza cuando 𝑍 < 𝑍∝
Es muy común en producción y salud animal el uso de la prueba de hipótesis para
establecer la igualdad de dos medias, ya que por dos motivos de costos sólo se pueden
comparar dos tratamientos o probar la efectividad de dos sistemas de producción, y
muchos casos similares.
Ejemplo 6.4.1: En los peces de la tribu tilapinae, se recurre a la técnica de triploidía
inducida, cuyo objetivo consiste en producir animales con un juego cromosómico
adicional que en muchas ocasiones presentan un rendimiento medio superior a los
diploides normales y como ventaja adicional no se reproducen. En un experimento
donde se conocían previamente las varianzas, se comparó el peso final de los diploides
normales y los triploides, encontrándose los siguientes resultados:
Diploides: 𝑛1 = 60; ��= 0,320 kg 𝜎12= 0,86 kg2
Triploides: 𝑛2= 60, 𝑌2 = 0,360, 𝜎22= 0,94 kg2
Con base en los anteriores datos, con ∝ = 0,05 se debe decidir si las medidas de los dos
grupos son iguales o diferentes.
a) El parámetro de interés es la diferencia de medias µ1 - µ2
b) Las hipótesis son:
Ho: µ1 = µ2
Ho: µ1≠ µ2
c) ∝= 0.05
d) El estadístico de prueba es:
𝑍 =(�� − 𝑌2)
√𝜎1
2
𝑛1+
𝜎22
𝑛2
e) Ho se rechaza así: 𝑍 > 𝑍1−∝
2= 𝑍0,975 = 1,96 ó
𝑍 < 𝑍∝2
= 𝑍0,025 = −1,96
f) El valor del estadístico de prueba es:

308
0,320 − 0,360
√0,8660 + √0,94
60
= −0,04
√0,03=
−0,04
0,1732= −0,23
g) Decisión: Dado que 𝑍 = −0,23 > 𝑍∝
2= −1,96
-1,96 -0,23
Ho no se rechaza; por lo tanto, con un nivel de significancia del 5% se asegura que las
medas son iguales.
6.4.2 Contraste de hipótesis para la diferencia de medias con muestras grandes (n1 y
n2 ≥ 𝟑𝟎) y 𝝈𝟏𝟐, 𝝈𝟐
𝟐 desconocidas. Si los tamaños de muestras n1 y n2 son grandes, el
teorema central del límite garantiza que la distribución de la diferencia de medias
muestrales es aproximadamente normal y, en consecuencia, se puede utilizar el
procedimiento empleado cuando σ12, σ2
2 se conocen, reemplazando 𝑆12 por σ1
2 y 𝑆22 por
σ22.
Ejemplo 6.4.2: En las razas bovinas para leche, luego de muchos años de
investigación, se aprobó la aplicación de hormona del crecimiento (GH) como factor
importante para el incremento de la producción láctea. En un experimento se comparó la
producción promedio de dos hatos de vacas Guernesey de segundo parto, uno que no
recibió ningún tratamiento y otro tratado con GH. Al final de la lactancia se encontraron
los siguientes resultados:
Grupo Control (sin tratamiento): 𝑛1 = 43, 𝑌1 = 3.200 𝑘𝑔, 𝑆12 = 126.000 𝑘𝑔2.

309
Grupo experimental (con tratamiento): 𝑛1 = 48, 𝑌2 = 3.260 𝑘𝑔, 𝑆22 =
109.000 𝑘𝑔2.
Con base en los anteriores datos muestrales debe decidirse si se justifica el uso de GH, e
igualmente debe recurrirse a una prueba de hipótesis, con ∞ =0,05.
a) El parámetro de interés es 𝜇1 − 𝜇2.
b) Ho: 𝜇1 = 𝜇2.
H1: 𝜇1 < 𝜇2. (La producción promedio sin tratamiento es menor que la
producción promedio con tratamiento)
c) ∝ =0,05
d) El estadístico de prueba es: 𝑍 = 𝑌1 − 𝑌2
√𝑆1
2
𝑛1+
𝑆22
𝑛2
e) Ho se rechaza si 𝑍 < 𝑍∝ = 𝑍 0,05 = −1,65
f) El valor del estadístico de prueba es
𝑍 = 3.200 − 3.260
√126.00043 +
109.00048
= −60
√5.201=
−60
72,12= −0,83
g) Decisión: Dado que 𝑍 = −0,83 > 𝑍∝ = −1,65
-1,65 -0,83
Ho no se rechaza, es decir, la producción promedio de los dos grupos es igual, lo
que conduce a no recomendar la aplicación de la hormona del crecimiento (GH).
6.4.3 Contraste de hipótesis para la diferencia de medias con muestras pequeñas
(𝒏𝟏 𝒚 𝒏𝟐 < 30) y varianzas desconocidas pero iguales (𝝈𝟏𝟐 = 𝝈𝟐
𝟐). Dadas dos muestras
aleatorias con tamaños 𝑛1, 𝑛2 < 30 y medias muestrales 𝑋1 𝑦 𝑋2
, respectivamente,

310
procedentes de dos poblaciones normales e independientes con medias 𝜇1 𝑦 𝜇2 y
varianzas 𝜎12 𝑦 𝜎2
2 desconocidas pero que se suponen iguales 𝜎12 = 𝜎2
2 = 𝜎2.
Si las varianzas muestrales son 𝑆12 𝑦 𝑆2
2, un estimador de la varianza común𝜎2 es:
𝑆𝑝2 =
(𝑛1 − 1)𝑆12 + (𝑛2 − 1)𝑆2
2
𝑛1 + 𝑛2 − 2
Bajo estas condiciones, en el capítulo anterior se vio que la variable aleatoria
𝑇 = (𝑋1 − 𝑋2) − (𝜇1 − 𝜇2)
𝑆𝑝√1
𝑛1+ √
1𝑛1
Tiene una distribución 𝑡 𝑐𝑜𝑛 𝑛1 + 𝑛2 − 2 grados de libertad. Este es el estadístico de
prueba en el cual se apoya el contraste de hipótesis.
El contraste bilateral
𝐻𝑜: 𝜇1 = 𝜇2
𝐻𝑜: 𝜇1 ≠ 𝜇2
Tiene como estadístico de prueba
𝑌1 − 𝑌2
𝑆𝑝 √
1𝑛1
+ 1
𝑛2
Y la regla de decisión es rechazar Ho si:
𝐻𝑜 ∶ 𝜇1 = 𝜇2
𝐻𝑜 ∶ 𝜇1 > 𝜇2
La regla de decisión es rechazar Ho si:
𝑇 > 𝑡1−∝/2;(𝑛1+ 𝑛2)−2ó
𝑇 > 𝑡∝/2;(𝑛1+ 𝑛2)−2

311
Donde 𝑡1−∝/2 es el valor de 𝑡 𝑐𝑜𝑛 (𝑛1 + 𝑛2) − 2 grados de libertad y 𝑃 (𝑇 ≤
𝑡1−∝/2) = 1−∝/2
Para el contraste unilateral:
𝐻𝑜: 𝜇1 = 𝜇2
𝐻𝑜: 𝜇1 > 𝜇2
La regla de decisión es rechazar 𝐻𝑜: 𝑠𝑖 𝑇 > 𝑡1−∝(𝑛1+𝑛2)
Para el otro contraste unilateral:
𝐻𝑜: 𝜇1 = 𝜇2
𝐻𝑜: 𝜇1 < 𝜇2
La regla de decisión es rechazar 𝐻𝑜: 𝑠𝑖 𝑇 < 𝑡𝑎,(𝑛1+ 𝑛2)−2
Ejemplo 6.4.3: En el Prochilodus magdalenae (bocachico), como en todas las especies
ícticas, el diámetro de los huevos es un indicador de mucha importancia ya que él
depende en buena medida el tamaño de las larvas y, por consiguiente, su capacidad de
adaptación al medio, mejorando así la supervivencia. La utilización de hormonas
estimulantes de la maduración gonadal, además de producir mayor cantidad de ovocitos,
incrementan el tamaño de los huevos; por esta razón se planteó un experimento
consistente en probar el efecto del extracto pituitaria de carpa (Cyprinuscarpio) (EPC) y
la hormona coriónica humana (HCG) en el tamaño de los huevos de la especie en
mención, midiendo el diámetro en mm, los resultados del citado experimento fueron los
siguientes:
EPC HCG EPC HCG
1,5 1,3 1,6 1,4
1,2 1,0 1,5 1,5
1,8 1,6 1,8 1,5

312
1,1 0,9 1,9 1,7
1,4 0,7 1,6 1,4
1,0 0,9 1,6 1,4
1,6 1,4 1,7 1,5
1,6 1,4
Con base en los datos, se pide decidir cuál de los dos tratamientos es más recomendable
para incrementar el tamaño de las ovas.
El procedimiento para realizar una recomendación técnicamente formulada consiste en
efectuar una prueba de hipótesis.
a) El parámetro de interés de 𝜇𝐸𝑃𝐶 − 𝜇𝐻𝐶𝐺
b) 𝐻𝑜: 𝜇𝐸𝑃𝐶 = 𝜇𝐻𝐶𝐺
𝐻1: 𝜇𝐸𝑃𝐶 ≠ 𝜇𝐻𝐶𝐺
Esto indica que en Ho se asegura que el diámetro medio de las ovas es igual en
los dos tratamientos, mientras que en H1 se plantea que el diámetro medio es
diferente.
c) ∝ = 0,05
d) Se asume que las varianzas son iguales (efectivamente lo son), así que el
estadístico de prueba es:
𝑌1 + 𝑌2
𝑆𝑝√1𝑛1
+ 1
𝑛2
= 𝑇 𝐷𝑜𝑛𝑑𝑒 𝑆𝑝 = √(𝑛1 − 1)𝑆1
2 + (𝑛2 − 1)𝑆22
𝑛1 + 𝑛2 − 2
e) Ho se rechaza si:
𝑇 > 𝑡1−∝/2,𝑛1+𝑛2−2= 𝑡0,975,28 = 2,05 ó
𝑇 < 𝑡∝/2,𝑛1+ 𝑛2−2= 𝑡0,025,28 = −2,05
f) Para calcular el estadístico de prueba, en primer lugar se calculan los
estadígrafos más importantes, así:

313
𝑆𝑝 = √(15 − 1)0,0664 + (15 − 1)0,0849
28= √
1,1182
28= √0,7565
= 0,2750
√1
𝑛1+
1
𝑛2= √
1
15+
1
15= 0,3651
El estadístico de prueba es:
𝑇 = 𝑌1 − 𝑌2
𝑆𝑝√1𝑛1
+ 1
𝑛2
= 1,526 − 1,306
0,2750 × 0,3651= 2,19
g) Dado que 𝑇 = 2,19 > 𝑡0,975,28 = 2,05
EPC HCG
N 15 15
Media 1,5260 1,3060
Varianza 0,0664 0,0849
Desviación
estándar
0,2576 0,2915

314
2,05 2,19
Ho se rechaza y se concluye que las medias son diferentes, razón por la cual se puede
decir que hay suficiente evidencia para recomendar el extracto pituitario de carpa (EPC)
como tratamiento para incrementar el tamaño de ovas.
Ejemplo 6.4.4: Algunos autores aseguran que el selenio es uno de los principales
oligoelementos para una adecuada producción de la avena forrajera (Avena sativa). En
un experimento se evaluó el efecto de la adición de este mineral en los programas de
fertilización midiendo la producción de materia seca por hectárea (Tn /Ha) con el
objetivo de recomendar su adición en las prácticas culturales. Los resultados al final del
trabajo de investigación fueron los siguientes:
Con selenio: 𝑛1 = 9, 𝑌1 = 9,69 𝑇𝑛, 𝑆12 = 0,336 𝑇𝑛2
Sin selenio: 𝑛2 = 10, 𝑌2 = 7,33 𝑇𝑛, 𝑆22 = 1,073 𝑇𝑛2
Con base en estos resultados se debe recomendar la incorporación del selenio en los
programa de fertilización.
a) 𝐻𝑜 : 𝜇 𝑐𝑜𝑛 𝑠𝑒𝑙𝑒𝑛𝑖𝑜 = 𝜇 sin 𝑠𝑒𝑙𝑒𝑛𝑖𝑜
𝐻1 : 𝜇 𝑐𝑜𝑛 𝑠𝑒𝑙𝑒𝑛𝑖𝑜 > 𝜇 sin 𝑠𝑒𝑙𝑒𝑛𝑖𝑜
b) ∝ = 0,05
c) Si se supone que las varianzas son iguales, el estadístico de prueba es como en
(6.4.4):
𝑇 = 𝑌1 − ��2
𝑆 √1
𝑛1+
1𝑛2

315
d) Ho se calcula si 𝑇 > 𝑡1−∝,𝑛−1+𝑛2−2 = 𝑡0,975,17 = 1,74
e) Se calcula el estadístico de prueba:
𝑆𝑝 = √(9 − 1)0,336 + (10 − 1)1,073
17= √0,7262 = 0,8522
√1
𝑛1+
1
𝑛2= √
1
15+
1
15= 0,3651
𝑇 = 9,69 − 7,33
0,8522 × 0,4595= 6,03
f) Dado que 𝑇 = 6,03 > 𝑡0,95;17 = 1,74 Ho se rechaza y por lo tanto se puede
concluir que el rendimiento medio de materia seca por hectárea cuando se utiliza
selenio es mayor que cuando no se utiliza.
Cuando las varianzas 𝜎12 𝑦 𝜎2
2 son diferentes, el estadístico de prueba se calcula de la
siguiente manera:
𝑇´ = 𝑌1 − 𝑌2
√𝑆2
1
𝑛1+
𝑆22
𝑛2
(6.4.5)
Se utiliza para indicar que el estadístico de prueba no se distribuye exactamente como
una t de Student, sino en una forma suficiente aproximada a ésta, con 𝜗grados de
libertad, donde 𝜗 se calcula como:
𝜗 =[𝑆1
2
𝑛1+
𝑆22
𝑛2]
2
[𝑆1
2
𝑛1⁄ ]
2
𝑛1 + 1 +[𝑆2
2
𝑛2⁄ ]
2
𝑛2 + 1
(6.4.6)

316
Ejemplo 6.4.5: Los carbohidratos son la fuente más importante de energía y de los
principales precursores de grasa y lactosa en la leche de las vacas. Un experimento tuvo
como objetivo evaluar dos dietas con diferentes fuentes de maíz, con el propósito de
recomendar la que produjera mayor contenido graso en la leche (kg/L) de vacas jersey
de segundo parto. Los resultados al final de experimento fueron los siguientes:
Dieta con trigo: 𝑛1 = 12, 𝑌1 = 0,31𝑘𝑔, 𝑆1 2 = 0,001454 𝑘𝑔2
Dieta con maíz: 𝑛2 = 12, 𝑌2 = 0,26𝑘𝑔, 𝑆2 2 = 0,001159 𝑘𝑔2
Con estos valores se debe decidir cuál de las dos fuentes de carbohidratos es la más
recomendable y para ello se realiza una prueba de hipótesis, asumiendo que las
varianzas son diferentes.
De acuerdo con los datos parece que la dieta con trigo produce un promedio mayor en el
contenido graso de la leche, entonces contrastamos esta hipótesis.
a) 𝐻𝑜: 𝜇1 = 𝜇2
𝐻𝑜: 𝜇1 > 𝜇2 (La dieta con trigo produce mayor contenido graso en la leche)
b) ∝= 0,05
c) Si las varianzas son diferentes, el estadístico de prueba es como en (6.4.5):
𝑇´ = 𝑌1 − 𝑌2
√𝑆1
2
𝑛1+
𝑆22
𝑛2
d) Ho: se rechaza su 𝑇´ > 𝑡1−∝,𝜗
e) Se calcula el estadístico de prueba con (6.4.5):
𝑇´ = 0,31 − 0,26
√0.00145412 +
0,01150912
= 1,521
Se calculan los grados de libertad con (6.4.6):
𝜗 =[𝑆1
2
𝑛1+
𝑆22
𝑛2]
2
[𝑆1
2
𝑛1⁄ ]
2
𝑛1 + 1 +[𝑆2
2
𝑛2⁄ ]
2
𝑛2 + 1
=(0,0010802)2
0,000000084956= 13,73 ≈ 14

317
Entonces se encuentra el valor t de la tabla:
𝑡1−∝;𝜗 = 𝑡0,95;14 = 1,761
f) Dando que 𝑇´ = 1,521 < 𝑡0,95 = 1,761
Ho no se rechaza, es decir, la producción media de grasa cuando se utiliza trigo en la
dieta no es mayor que cuando se utiliza maíz. Por consiguiente se recomienda
cualquiera de las dos dietas y se deben evaluar otros factores tales como el costo o la
disponibilidad de la materia prima en la zona.
1,54 1,761
6.4.4 Contraste de hipótesis para la diferencia de medias: datos pareados. En los
contrastes de hipótesis con respecto a la diferencia de medias, se asumió que las
muestras son independientes. En ocasiones se presentan casos en los que las muestras
no son independientes; esto, por lo general, sucede cuando las observaciones de las dos
muestras se asocian por pares, por ejemplo, cuando los mismos individuos escogidos al
azar se comparan antes y después de haber recibido algún tratamiento o cuando los
grupos control y experimental deban aparearse considerando alguna característica de
interés.
El objetivo de la asociación por pares es hacer que las unidades experimentales dentro
de cada nivel o grupo sean, en lo posible, lo más homogéneas, de tal manera que las

318
CAPÍTULO 7
Principios básicos de las relaciones entre variables
7.1 ASPECTOS GENERALES
En la producción y en la salud animal, establecer si dos o más variables tienen algún
tipo de relación ayuda a tomar determinaciones técnicas importantes. Por ejemplo, al

319
planear el manejo alimenticio de un hato debe establecerse si el consumo de alimento en
materia seca o verde está determinado por el peso vivo de los animales, el contenido
graso o de fibra de las reacciones; en el mejoramiento genético de las especies
productivas es fundamental saber si dos o más rangos de importancia en la producción
están o no relacionados, es el caso de la grasa y la proteína de la leche, en nutrición
animal es importante determinar si la calidad nutritiva de un forraje depende de la edad
al corte del pasto; en las explotaciones porcinas es fundamental establecer si la
composición de la dieta afecta el espesor de la grasa dorsal de los animales destinados al
sacrificio; en la administración de medicamentos es imprescindible conocer si la dosis
aplicada de un determinad fármaco afecta la composición del producto final, como
carne o leche e incluso el volumen de producción; en la alimentación animal debe
comprobarse si la conversión alimenticia está influenciada por la edad del animal; en el
manejo reproductivo el peso de la hembra al primer servicio puede ser una variable que
influya en el peso de la crías o el tamaño de la camada, lo mismo puede suceder con la
edad de los parentales; en piscicultura el peso y la talla son variables que guardan algún
tipo de relación y, como las anteriores, podrían citarse múltiples situaciones similares.
A continuación se presentan los procedimientos estadísticos que permiten confirmar o
no la pertenencia de la relación funcional entre variables y el tipo de dicha relación
7.1.1. Relaciones funcionales de dependencia. En este caso específico se trata de
establecer si una variable aleatoria, que en adelante se denominara Y, tiene una
relación funcional de dependencia con una o más variables, que en adelante se
denominaran X. El objetivo de los análisis de esta naturaleza consiste en desarrollar una
ecuación que permita estimar el valor medio de Y, conociendo los valores de X. Cuando
el interés se centra en este tipo de problemas se hace referencia a la regresión.
En los análisis de regresión, pueden presentarse varias situaciones, la primera que se
menciona en este texto se refiere al cambio observado en una variable aleatoria Y por
efecto o influencia de una variable X, caso en el que se utilizan los análisis de regresión
simple, pero además, el cambio de Y puede ser lineal, exponencial, potencial, etc.
Cuando el cambio observado en Y se explica por el efecto de una sola variable X, se
hablara de regresión simple.

320
7.1.2 Regresión lineal simple. Cuando el cambio observado en Y por efecto el cambio
X se explica de una forma tal que se puede representar en una línea recta se habla de
regresión lineal. Para encontrar la ecuación que relacione las variables, por lo general,
se inicia con la recolección de los datos que toma Y cuando varían los valores de X,
luego se marcan los puntos X, Y sobre un sistema de coordenadas y se obtiene lo que en
estadística se llama nube de puntos o diagramas de dispersión (figura 7.1.1). A partir
de esta figura es posible observar una curva denominada aproximante, que sugiere el
tipo de relación existente. Como ilustración se presenta el diagrama de dispersión
correspondiente a la variación observada en el consumo de forraje (expresado en
gramos por día) en cuyes (cavita porcellus) por efecto de la variación en la edad de los
animales, expresada en días, según el estudio realizado por Lagos y Velasco(2005), en
la tabla 7.1.1
Días Consumo (g/ animal/ día )
1 10
2 15
3 34
4 45
5 40
6 69
7 120
8 100
9 160
10 200
Tabla 7.1.1 consumo de forraje (g/ animal/día) en cuyes (cavia porcellus)

321
Como se aprecia, la nube de puntos sugiere una relación lineal entre las variables X; Y
el trazado de una línea confirma con mayor claridad este hecho.
Una vez establecida la existencia de dependencia lineal se procede a encontrar una
ecuación que describa el comportamiento de Y por efecto de la acción de X; para
alcanzar este objetivo debe estimarse dos parámetros denominadosᵦ₀ y ᵦr
El primer término representa el intercepto, es decir el punto de corte con el eje Y,
mientras que el segundo indica la pendiente de la recta. Para efectos de conclusiones y
recomendaciones prácticasᵦ₀ indica el valor medio de Y cuando X tiene un valor igual a
cero., valor que no siempre tendrá explicación biológicas y ᵦ₁ deberá interpretarse como
el cambio promedio de Y, por cada aumento de una unidad en X. definidos los dos
parámetros anteriores, ahora es posible describir el valor de Y con la siguiente ecuación.
𝑌𝑖=ᵦ0+ ᵦ₁Xi
Dónde:
0
100
200
300
400
0 5 10 15Y c
on
sum
o g
X (dias )
Consumo (g/ animal/ día )
11 254
12 296
13 300
14 310
Grafico 7.1.1 diagrama de dispersión de los datos de la Tabla 7.1.1

322
𝑌𝑖 Valor que toma la variable aleatoria en estudio o también denominada variable
dependiente
ᵦ₀ y ᵦ₁parámetros cuyo significado ya fue explicado
Xi = Valor que toma X, variable no aleatoria, denominada variable independiente,
predictoria o regresora.
Con respecto a los valores de la variable independiente X, es conveniente advertir que
estos pueden seleccionarse antes de desarrollar la ecuación, como en el caso donde la
temperatura se fija en intervalos de 2°C, para observar el consumo de alimento en un
plantel avícola, de tal modo que el primer valor de X es de 20°C y luego se incrementan
a 22,24,26 °C etc., hasta llegar al máximo biológico establecido por el investigador, de
acuerdo con el comportamiento típico de la especie.
En este caso es claro que el estudio de la regresión es controlado, pero cuando los
valores de X se escogen entre una gama de posibles valores, el estudio de la regresión es
observacional, como en el caso de los análisis bromatológicos, donde los valores que
toma X pueden ser las cifras de humedad de una planta cuando esta se recolecta para
llevar acabo los análisis.
Así los estudios sean controlados u observacionales, el propósito de los estudios de
regresión lineal simple será idéntico en los dos casos es decir encontrar la recta que
mejor ajuste el comportamiento de las observaciones X, Y.
Para mayor claridad de los procedimientos que se indicaran más adelante conviene
hacer las siguientes precisiones: Al observar los puntos trazados en la figura 7.1.1, es
fácil notar que no todos los puntos “caen” exactamente sobre la recta, algunos tienen un
desvió positivo, otros negativos y otros cero, pero en todo caso a cada punto (Xi Yi) le
corresponde un valor ɛ₁˴, ɛ₂˴, ɛ₃˴…ɛɳˏ. Estas desviaciones en adelante se denominaran
error o residuo, aclarando que los ɛᵢ son aleatorios.
Una medida que podría indicar la calidad del ajuste de la curva es la sumatoria de los ɛᵢ
al cuadrado Σ ɛᵢ₂ ya que entre más pequeño sea este valor, mejor será el ajuste, así que
en la práctica, lo que realmente se busca es que esta expresión sea mínima para obtener
los mejores estimadores de ᵦ₀ y ᵦ₁. Una recta que ajuste los datos, con la condición

323
antes citada se denomina recta de mínimos cuadrados. Para mayor claridad se presenta a
continuación algunos aspectos importantes, para la estimación de los citados
parámetros:
a) Considerar el módulo de la regresión lineal simples:
𝑌𝑖=ᵦ0+ ᵦ₁Xi
b) Como ya se dijo, las Xi se conocen a priori, ᵦ₀ y ᵦ₁ son parámetros
desconocidos. Se mencionó que la ecuación (7.1.1), expresa el valor medio de
Y, así que podría ser expresado de esta manera.
𝐸(𝑌𝑖)=ᵦ0+ ᵦ₁Xi
c) Si se consideran los desvíos ɛᵢ como valores aleatorios N(0,o², es posible escribir
esta expresión
𝑌₁ = ᵦ0+ ᵦ₁𝑥₁+ ɛ₁
𝑌₁ = ᵦ0+ ᵦ₁𝑥₂+ ɛ₂
d) Se dijo que esta es una expresión válida para cada valor de Y, así que si se
considera todos los valores de Y, incluidos en el análisis se tendrá:
𝑌₁ = ᵦ0+ ᵦ₁𝑥₁+ ɛ₁
𝑌₁ = ᵦ0+ ᵦ₁𝑥₂+ ɛ₂
De cada una de las anteriores expresiones despeje ɛ
ɛᵢ = 𝑌𝑖− ᵦ0− ᵦ1x1ᵢ=1,2,…,n
La suma de los cuadrados de las desviaciones de las observaciones son respecto a la
recta es
𝑄 = 𝛴ɛᵢ² = 𝛴(𝑌𝑖−ᵦ0 − ᵦ₁𝑥₁)
Esta es una función de los parámetros desconocidos ᵦ0 − ᵦ₁. Los estimadores de
mínimos cuadrados ᵦ0 y ᵦ₁respectivamente, se obtienen mediante la diferenciación de
(7.1.5) con respecto a ᵦ0 y ᵦ₁ y después al igualar cada derivada parcial a cero.

324
𝜕𝑄
𝜕𝛽₁= 2𝛴(𝛾ᵢ − ᵦ0 − ᵦ𝑋ᵢ)(−1)
𝜕𝑄
𝜕𝛽₁= 2𝛴(𝛾ᵢ − ᵦ0 − ᵦ𝑋ᵢ)(−1)
Después de simplificar se obtiene:
ɳᵦ0+ ᵦ1𝛴𝑥ᵢ = 𝛴𝑌ᵢ
ᵦ1𝛴𝑋ᵢ + ᵦ1𝛴𝑋ᵢ₂= 𝛴𝑋ᵢ𝑌ᵢ
Estas ecuaciones reciben el nombre de ecuaciones normales de mínimos cuadrados.
Resolviendo el sistema de ecuaciones, se obtiene:
ᵦ0 = ��-ᵦ₁ ��= 𝛴 𝑌ᵢ
𝑛 - ᵦ₁
𝛴 𝑌ᵢ
𝑛
ᵦ₁=𝛴(𝑋ᵢ− �� )(𝑌ᵢ− �� )
𝛴(𝑋ᵢ− ��)²=
𝛴𝑋ᵢ𝑌ᵢ−(𝛴𝑋ᵢ)(𝛴𝑌ᵢ)
𝑛
𝛴𝑋ᵢ²−
(𝛴 𝑋ᵢ)²
𝑛
Por lo tanto la ecuación de regresión estimada para el modulo (7.1.3) es :
�� = ᵦ0 + ᵦ₁ 𝑋
Ejemplo 7.1.1.: Un investigador en nutrición animal está interesado en establecer si el
contenido de fibra de la dieta, expresado en kg/100kg de alimento, afecta el consumo
voluntario en consejos nueva Zelanda. Para alcanzar su objetivo prepara diferentes
dietas con diversos contenidos de fibra y suministra a varios grupos de conejos,
homogéneos en cuanto a edad, sexo, raza, y peso las diferentes raciones, encontrando
los siguientes resultados.
7.1.9
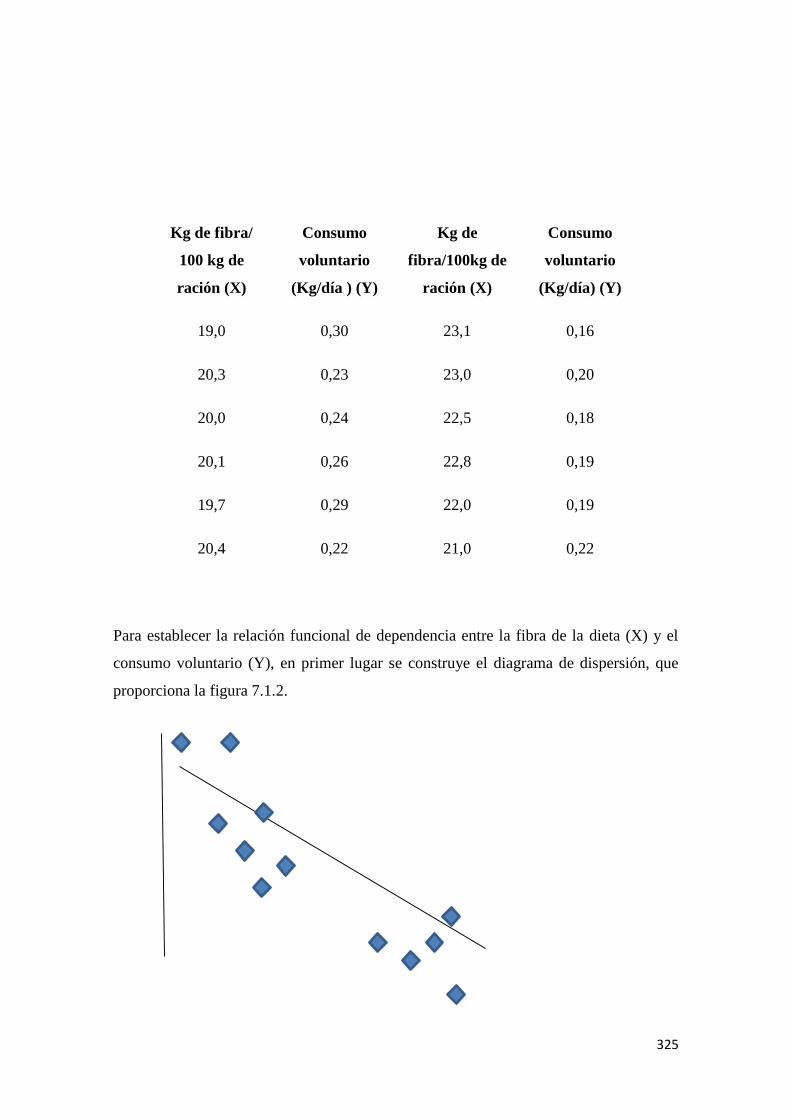
325
Kg de fibra/
100 kg de
ración (X)
Consumo
voluntario
(Kg/día ) (Y)
Kg de
fibra/100kg de
ración (X)
Consumo
voluntario
(Kg/día) (Y)
19,0 0,30 23,1 0,16
20,3 0,23 23,0 0,20
20,0 0,24 22,5 0,18
20,1 0,26 22,8 0,19
19,7 0,29 22,0 0,19
20,4 0,22 21,0 0,22
Para establecer la relación funcional de dependencia entre la fibra de la dieta (X) y el
consumo voluntario (Y), en primer lugar se construye el diagrama de dispersión, que
proporciona la figura 7.1.2.

326
Puesto que la figura 7.1.2 sugiere una relación lineal se procede a establecer la recta de
mejor ajuste y para esto se necesitara estimar los valores de β₀ y β₁.
Las cifras necesarias para su cálculo se obtienen de la siguiente manera:
Xᵢ Yᵢ Xᵢ Yᵢ 𝑿ᵢ𝟐 𝒀ᵢ
𝟐
19,0 0,30 5,700 361,00 0,0900
20,3 0,23 4,669 412,09 0,0529
20,0 0,24 4,800 400,00 0,0576
20,1 0,26 5,226 404,01 00676
19,7 0,29 5,713 388,09 0,0841
20,4 0,22 4,488 416,16 0,0484
23,1 0,16 3,696 533,61 0,0256
23,0 0,20 4,600 529,00 0,0400
22,5 0,18 4,050 506,25 0,0324
22,8 0,19 4,332 519,84 0,0361
22,0 0,19 4,180 484,00 0,0361
21,0 0,22 4,620 441,00 0,0484
253,9 2,68 56,074 5395,05 0,06192
Se puede apreciar que:
Figura 7.1.2 diagrama de dispersión de las variables fibra de
la dieta (X) y consumo voluntario (Y)

327
∑ 𝑋ᵢ = 253,9
12
ᵢ=1
∑ 𝑌ᵢ = 2,68
12
ᵢ=1
∑ 𝑋ᵢ𝑌ᵢ = 56,074
12
ᵢ=1
∑ 𝑋ᵢ2 = 5395,05
12
ᵢ=1
∑ �i�2 =12ᵢ=1 0, 6192
Con las anteriores cantidades es posible calcular los estimadores de los parámetros,
como en (7.1.7) y (7.1.8) así:
ᵦ₁=𝛴𝑋ᵢ𝑌ᵢ−
(𝛴𝑋ᵢ)(𝛴𝑌ᵢ)
𝑛
𝛴𝑋ᵢ²−
(𝛴 𝑋ᵢ)²
𝑛
=56,074−
253,9𝑥 2,68
12
5395,05−(253,9)²
12
= -0,02745
ᵦ0 = ��-ᵦ₁ ��= 2,68
12-(− 0,02745 ×
253,9
12)= 0,804
ᵦ₁ En la recta representa la pendiente, la interpretación aplicada de este valor indica que
el consumo de alimento en los consejos Nueva Zelanda, en promedio disminuye en
0,02745 kg por cada aumento de un kilo de fibra en la dieta.
ᵦ0 Representa el punto de corte o intercepto con el eje Y. podría interpretarse como el
valor del consumo cuando la dieta no tiene fibra, que en este caso si tiene lógica desde
el punto de vista aplicado.
Conocidos los valores de los estimadores, ahora es posible hacer uso de una las
importantes propiedades de la regresión, consiste en predecir el valor medio de Y para
cualquier valor de X, siempre y cuando este se encuentre en el rango de valores
utilizados para calcular los estimadores de los parámetros. Así si se desea estimar el

328
valor medio de Y cuándo la dieta de la fibra se fije en 20,5 kg basta con aplicar el
siguiente procedimiento.
�� = ᵦ₀+ ᵦ₁𝛽 X₁ = 0.804+ (-0,02745X 20,5) = 0,242
Se puede concluir que el consumo medio de alimento será de 0,242 kg, para la cantidad
de fibra indicada. No se podrá utilizar la ecuación de predicción para valores de fibra
menores de 19 o mayores de 23,1 kg.
El paso siguiente consiste en llevar acabo la prueba de hipótesis para la regresión. El
procedimiento general de la prueba de hipótesis no varía en referencia al indicado para
la prueba de medias o proporciones con algunas particularidades específicas. El
propósito de la prueba pretende generalizar el comportamiento de las variables deducido
con los datos de la muestra, para la población de donde se extrajo esa muestra
Para ellos es necesario hacer una consideración previa, antes de realizar el análisis de
varianza. En la figura 7.1.3, ara cada punto observado Yᵢ se verifica que:
Y₁
��ᵢ ��= ᵦ₀+ ᵦ₁ X
��
Figura 7.1.3. Ecuación de regresión lineal con
verificación en los puntos de intersección

329
(𝑌ᵢ − ��)= (��ᵢ-��)+ (Yᵢ- ��ᵢ)
Siendo ��ᵢ
El valor estimado de Y en dicha observación y �� la media muestral de la variable Y, se
demuestra que:
𝛴(𝑌ᵢ − ��)²= 𝛴(��ᵢ − ��)² + 𝛴(𝑌ᵢ − ��ᵢ)²
DONDE:
𝛴(𝑌ᵢ − ��)²= se denomina suma total de cuadrados (SCT), y representa la variación total
de las observaciones respecto a su media.
𝜮(��ᵢ − ��)².- se denomina suma de cuadrados debido a la regresión (SCR), y representa
la variación de las observaciones que es atribuible al efecto de X sobre Y.
𝛴(𝑌ᵢ − ��ᵢ)².- Se le denomina suma de cuadrados debido al error (SCE) y representa la
variación de las observaciones con respecto a la recta de regresión estimada.
Reemplazando en (7.1.10), se tiene que:
SCT= SCR+SCE
SCT= 𝛴(𝑌ᵢ − ��)= 𝛴�i�2-(𝛴𝑌ᵢ)²
𝑁
SCR= 𝜮(��ᵢ − ��)²= (ᵦ1)²(𝜮(𝑿ᵢ − ��)² = ᵦ² [𝜮𝑿𝟏𝟐 −
(𝛴 𝑋ᵢ)²
𝑛]
7.1.3. Prueba de hipótesis sobre la significación del modelo de regresión.- Permite
tomar una decisión global con respecto a la aceptación o rechazo del modelo. Para esto
puede utilizarse el análisis de varianza.
Las hipótesis se plantean del siguiente modo
Ho: β₁= 0 X e Y no estarán relacionadas linealmente

330
H₁: β₁≠0 X e Y están relacionadas linealmente
La tabla de análisis de varianza (ANAVA) para la regresión lineal simple es la
siguiente:
Fuentes de
variación GL
Suma de
cuadrados
Cuadrado
medio Fc Ft
Regresión 1 SCR 𝑆𝐶𝑅
1
𝐶𝑀𝑅
𝐶𝑀𝐸
Error n-2 SCE CMR=𝑆𝐶𝐸
𝑛−2
total n-1 SCT
DONDE:
CMR se denomina cuadrado medio de la regresión
CME se denomina cuadrado medio del error
𝐶𝑀𝑅
𝐶𝑀𝐸= Fc
Tiene una distribución F con 1 y n-2 grados de libertad (GL)
Ho se rechaza si Fc ≥Ft es decir si Fc ≥ 𝑓1−∞;1,𝑛−2
EJEMPLO 7.1.2: a continuación se presenta el resultado del análisis para los datos del
ejemplo 7.1.1
Fuentes de GL SC CM Fc Ft

331
variación
Regresión 1 0,01731 0,01731 51,51 10,04*
Error 10 0,00336 0,000336
Total 11 0,02067
SCT= 𝛴�i�2 − (𝛴𝑌ᵢ)²
𝑁= 0, 6192-
(2,68)2
12= 0,02067
SCR= (ᵦ1)² [𝜮𝑿𝟏𝟐 −
(𝛴 𝑋ᵢ)²
𝑛]= (-0, 02742)²[5395,05 −
(253,9)²
12]= 0, 02067
SCE = SCT-SCR= 0,000336
CMR=𝑆𝐶𝑅
1= 0, 01731
CME= 𝑆𝐶𝐸
10= 0,000336
Fc= 𝐶𝑀𝑅
𝐶𝑀𝐸=
0,01731
0,000336= 51,51
SI ∞ = 0,01, entonces 𝑓1−∞;1,𝑛−2= 𝑓0,99;1,10= 10,04
Dado que Fc = 51,51 es mayor que Ft= 10,04 se rechaza Ho y se concluye con el 99%
de confiabilidad que hay relación lineal entre la fibra de la dieta y el consumo de
alimento.
Otra medida que es necesario calcular al realizar análisis de regresión es el coeficiente
de determinación R² que es una medida relativa del grado de asociación lineal entre las
dos variables tanto para X como para , Y el cual viene dado por:
R²=𝑠𝑢𝑚𝑎 𝑐𝑢𝑎𝑑𝑟𝑎𝑑𝑜 𝑑𝑒 𝑙𝑎 𝑟𝑒𝑔𝑟𝑒𝑠𝑖𝑜𝑛 (𝑆𝐶𝑅)
𝑠𝑖𝑚𝑎 𝑐𝑢𝑎𝑑𝑟𝑎𝑑𝑜 𝑡𝑜𝑡𝑎𝑙(𝑆𝐶𝑇)
Ejemplo 7.1.3. PARA EL EJEMPLO 7.1.2 SE TIENE QUE

332
R²= 𝑆𝐶𝑅
𝑆𝐶𝑇=
0,01731
0,02067= 0,8374
Expresándolo como porcentaje: R² = 83,74%
Esto significa que el 83,74% de la variación observada con el consumo se explica por la
variación en el contenido de fibra de la dieta
También es conveniente expresar el valor de Sβ₁ como un límite de confianza, tal como
se indicó en los casos de la media y la proporción. El procedimiento es básicamente
igual, solo que en el caso de la regresión se debe calcular la expresión S ᵦ₁ O error
estándar de β1 cuyo cálculo se obtiene así:
𝑆𝛽12 =
𝐶𝑀𝐸
Σ(𝑋𝑖 − ��)2
Un intervalo de confianza para β1 al (1- 𝛼) 100% de confiabilidad viene dado por:
β1 ± Sβ1 t1- 𝛼/2, n-2
Ejemplo 7.1.4: Para el Ejemplo 7.1.3, un intervalo de confianza para β1 al 95% de
confiabilidad viene dado por:
β1 ± Sβ1 t0.957, 10
𝑆𝛽1 = √𝐶𝑀𝐸
Σ(Xi − ��)2= √
0,000336
22,9492= 0,00302
T0, 975, 10 =2,228
Reemplazando se obtiene: -0,02745 ± 0,00382*2,228
En consecuencia se tiene que β1 Está comprendido entre -0,035 y – 0,019, con una
confiabilidad del 95%.
Es de interés construir un intervalo de confianza a partir de la respuesta media e un
valor especifico de X1 por ejemplo Xp.
Un intervalo de confianza al (1−∝)100% de confiabilidad alrededor de la respuesta
media E (Yp) viene dado por:
𝑌𝑝 ± 𝑡1−∝/2;𝑛−2 𝑆(𝑌𝑝)

333
Donde 𝑌𝑝se lo calcula a partir del modelo de regresión ajustado 𝑌𝑝 = 𝛽0 + 𝛽1𝑋 y
𝑆2(𝑌𝑃) = 𝐶𝑀𝐸 [1
𝑛+
(𝑋𝑝−��)2
Σ(𝑋1−��)2]
Ejemplo 7.1.5: En el Ejemplo 7.1.3, que se viene analizando, se supone que se desea
construir un intervalo de confianza al 95% de confiabilidad para la media de 𝑌𝑝𝑒𝑛 𝑋𝑝 =
20,5 kg.
El valor estimado es 𝑌𝑝= 0,804 + (-0,02745 x 20,5) = 0,242 y la desviación estándar
estimada es:
𝑆2(𝑌𝑝) = {0,000336 [1
12+
(20,5 − 21,158)2
22,9492]}
1/2
= 0,005859
Y 𝑡1−𝛼
2,𝑛−2 = 𝑡0.975,10 = 2,228
Por lo tanto, un intervalo de confianza para la media de 𝑌𝑝′ 𝐸(𝑌𝑝) es
0,242 ± 2,228 x 0,005859 = (0,229, 0,2550).
Un intervalo de confianza de E(Yp) se ¡refiere a la verdadera respuesta promedio en
𝑋 = 𝑋𝑝 (esto es, el parámetro de la población)y no a observaciones futuras.
Una aplicación importante en un modelo de regresión es la predicción de observaciones
nuevas o futura de Y, si X0 es el valor que se quiere pronosticar, entonces:
𝑌0 = 𝛽0 + 𝛽1𝑋0
Es el estimador puntual del valor futuro de la respuesta 𝑌0.
Un intervalo de predicción para una observación futura 𝑌0 en el valor 𝑋0 al
(1−∝)100% de confiabilidad, está dado por:
𝑌0 ± 𝑡1−
∝2
,𝑛−2𝑆(𝑌0)

334
Dónde: 𝑆2(𝑌0) = 𝐶𝑀𝐸 [1 +1
𝑛+
(𝑋0−��)2
Σ(𝑋𝑖−��)2]
Ejemplo 7.1.5: En el mismo Ejemplo 7.1.3, se quiere construir un intervalo de
predicción al 95% de confiabilidad para la predicción 𝑌0 en el valor 𝑋0 = 20,5kg.
El valor estimado es 𝑌0 = 0,804 + (-0,02745x 20,5) = 0,242
𝑆2(𝑌𝑝) = {0,000336 [1
12+
(20,5 − 21,158)2
22,9492]}
1/2
= 0,005859
𝑡1−𝛼
2,𝑛−2 = 𝑡0.975,10 = 2,228 , por tanto el intervalo es 0,242 ± 2,228 x 0,0192
(0,199 a 0,285)
Con una confiabilidad del 95%, el pronóstico 𝑌𝑥=020.5 para X = 20,5 está comprendido
entre (0,199 y 0,285).
7.2 CORRELACIÓN LINEAL
Cuando dos o más variables de interés son aleatorias y ninguna de ellas se considera
dependiente de la otra el análisis de correlación permite establecer si las variables en
cuestión están o no correlacionadas.

335
Si se analizan únicamente dos variables la correlación será simple y cuando se involucra
a más de dos variables el estudio es de correlación será múltiple. El grado de asociación
lineal entre dos o más variables está determinado por el coeficiente de correlación de
Pearson o correlación producto momento y su forma de cálculo se expresa así:
𝜌 =
Σ(𝑋𝑖 − 𝜇𝑥)(𝑌𝑖 − 𝜇𝑦)𝑁
√Σ(𝑋𝑖 − 𝜇𝑥)2
𝑁 . √Σ(𝑋𝑖 − 𝜇𝑥)2
𝑁
=𝐶𝑜 𝑣𝑎𝑟𝑖𝑎𝑛𝑧𝑎 (𝑋, 𝑌)
√𝑉𝑎𝑟𝑖𝑎𝑛𝑧𝑎 𝑋. √𝑉𝑎𝑟𝑖𝑎𝑛𝑧𝑎 𝑌
=Σ(𝑋𝑖 − 𝜇𝑥)(𝑌𝑖 − 𝜇𝑦)
√Σ(𝑋𝑖 − 𝜇𝑥)2. √Σ(𝑌𝑖 − 𝜇𝑦)2
El estadígrafo se denota por la letra r y se calcula del mismo modo, sólo que en lugar de
los parámetros 𝜇 𝑦 𝜎 se utilizan los estadígrafos correspondientes.
El coeficiente de correlación puede tomar valores entre -1 y 1 incluyendo el cero. Un
valor negativo indica asociación en un modo tal que mientras una variable aumenta la
otra disminuye; un valor de cero indica que las dos variables son independientes, no
están asociadas linealmente o no existe correlación lineal, y un valor positivo sugiere
que cuando una variable aumenta la otra también lo hace.
Establecer si dos o más variables están correlacionadas es un factor importante en
muchos aspectos de la producción animal, especialmente en los programas de
mejoramiento genético puesto que si se decide mejorar por selección una característica
de importancia económica se debe conocer si al mejorar un rasgo se desmejora otra,
caso en el cual la selección no tendría un efecto positivo. En cambio cuando dos rasgos
tienen correlación positiva al mejorar uno también de modo simultáneo, se mejora el
otro, logrando así un impacto positivo en los planes de mejora.

336
Ejemplo 7.2.1 A continuación se presenta un ejemplo con datos reales medidos en
1.999 y utilizados por Cerón, et al (2.003), donde se presentan las cifras de producción
de leche por lactancia ajustada a 305 días, expresada en kilogramos y el puntaje total
por tipo (tabla 7.2.1). El objetivo del análisis consiste en establecer sí estas dos variables
aleatorias están correlacionadas.
En los planes de mejoramiento de los bovinos lecheros se ha discutido ampliamente si
la morfología de los animales es un aspecto relevante para alcanzar los objetivos de
producción. Uno de los aspectos importantes para dirimir la discusión consiste en
establecer matemáticamente si hay relación funcional de asociación entre el puntaje y la
producción. Sí esta es positiva, podría diseñarse un plan de mejoramiento que busque
mejorar simultáneamente los dos rasgos.
Las cantidades necesarias para calcular el coeficiente de correlación muestral 𝑟 son las
siguientes:
𝑟 =Σ(𝑌1 − ��1)(𝑌2 − ��2)
√Σ(𝑌1 − ��1)22. √Σ(𝑌2 − ��2)2
=Σ𝑋𝑖𝑌𝑖 −
(Σ𝑋𝑖)(Σ𝑌𝑖)𝑛
√ΣX𝑖2 −
(Σ𝑋𝑖)2
𝑛 . √ΣY𝑖2 −
(Σ𝑌𝑖)2
𝑛
Σ(𝑌1 − ��1)2 = 666,08 Σ(𝑌2 − ��2)2 = 5,499003 × 107
Σ(𝑌1 − ��1)(𝑌2 − ��2) = −6546,8
De acuerdo con los anteriores valores el coeficiente de correlación se calcula de la
siguiente manera:

337
𝑟 =−646,8
√666,08√5,499003 × 107= −0,00337
Una prueba de hipótesis especial respecto al coeficiente de correlación poblacional 𝜌se
plantea como:
𝐻0:𝜌 = 0
𝐻1:𝜌 ≠ 0
La estadística de prueba es: 𝑇 =𝑟√𝑛−2
√1−𝑟2
Y tiene una distribución t con n-1 grados de libertad.
𝐻0 Se rechaza sí:
𝑇 > 𝑡1−
𝛼2
;𝑛−2𝑜 𝑇 < 𝑡𝛼
2;𝑛−2
En este ejemplo, la prueba de hipótesis se plantea como:
𝐻0:𝜌 = 0 El puntaje por tipo y la producción de leche no están correlacionados
linealmente.
𝐻1:𝜌 ≠ 0 El puntaje por tipo y la producción de leche están correlacionados
linealmente.

338
La estadística de prueba es:
𝑇𝑐 =𝑟√𝑛 − 2
√1 − 𝑟2=
−0,00337√48
√1 − (−0,00337)2= −0,0233
Para α = 0.05 se tiene que 𝑡𝛼
2,𝑛−2 = 𝑇0.025.48 = −2.0 como -0.0233 no es menor que 2.0
entonces, H0 no se rechaza.
7.3 REGRESIÓN LINEAL SIMPLE CON NOTACIÓN Y OPERACIONES
MATRICIALES
Tomando nuevamente los datos del Ejemplo 7.1.1, el problema puede resolverse con
notación matricial. En primer lugar se escribe el modelo de la siguiente forma:
𝑌 = 𝑋𝛽 + 𝜀
-2.0 -0.0233

339
Donde Y representa el vector de observaciones, X es una matriz de parámetros
observables, β es un vector de parámetros desconocidos y 𝜀 es un vector de errores
aleatorios.
El procedimiento para obtener los valores de las incógnitas, es decir los valores betas o
estimadores de los parámetros que ajustan la línea de regresión es el de mínimos
cuadrados, de tal manera que 𝛽= (𝑋`𝑌)−1𝑋`𝑌
𝑋`𝑌 = [𝑛 ∑𝑋1
∑𝑋1 ∑𝑋12] , 𝑋`𝑌 = [
∑𝑋1
∑𝑋1𝑌1] , 𝛽 = [
𝛽0
𝛽1]
Reemplazando las expresiones por los valores obtenidos con los datos de la tabla 7.2.1
se tiene:
𝑋`𝑌 = [12 253.9
253.9 5395.05] , 𝑋`𝑌 = [
2.6856.074
] , 𝛽 = [𝛽0
𝛽1]
[𝛽0
𝛽1] = [
19.59058063 −0.9219652129−0.9219652129 0.04357456697
] [2.68
56.074] = [
0.8044787392−0.02746650205
]
Como puede observarse, para encontrar los estimadores de los beta basta con invertir
X`X y luego multiplicar dicha inversa por el vector X`Y.
Para llevar a cabo el análisis de varianza se construye una tabla tal como se hizo en el
ejemplo anterior, solo que los cálculos en forma matricial son diferentes.
Tabla 7.3.1 análisis de varianza de la regresión lineal simple con notación matricial

340
F.V GL SC CM Fc Ft
Regresión K Β`X`Y-FC SCR/GLR CMR/CME
Error n-1-k (YY-FC)-( Β`X`Y-FC) SCE/GLE
Total n-1 YY-FC
a) Se debe calcular el factor de corrección así: FC=∑𝑌2
𝑛= 𝑛��2
b) Calcular la suma cuadrado total: SCT =YY-FC = ∑𝛾2-FC
c) Calcular la suma cuadrado de la regresión: SCR=β`X´Y-FC
SCE = SC total corregida – SC de la regresión corregida
Al reemplazar las expresiones indicadas en la tabla por sus correspondientes valores se
tiene:
Fc = 0.5985
Y`Y = 0.6192 – Fc = 0.0207
β`X`Y= [0.8044787392 − 0.027466502] [2.68
56.074] = 0.6158463851 − 𝐹𝑐 =
0.017346.
SCE= 0.027 – 0.017346= 0.0003354
Estos valores coinciden con los datos del ejemplo 7.1.1 y lógicamente las conclusiones
son las mismas, ya que lo único que se ha variado es la forma de cálculo.
Para llevar a cabo las pruebas de hipótesis utilizando procedimientos matriciales es
necesario calcular la matriz de varianzas y covarianzas para esto basta con multiplicar la
matriz (𝑋`𝑌)−1 por el cuadrado medio del error. Para el ejemplo se tiene:

341
[19.59058063 −0.9219652129
−0.9219652129 0.04357456697] 𝐶𝑀𝐸
Para facilitar los cálculos posteriores, la matriz de (𝑋`𝑌)−1 se denominara en adelante,
matriz de coeficientes y se denotara por C.
𝐶 = [𝐶00 𝐶01
𝐶10 𝐶11]
Para llevar a cabo la prueba de hipótesis para 𝛽0se procede así:
𝐻0:𝛽 = 0
𝐻1:𝛽 ≠ 0
Como ya se mencionó, esta prueba no tiene mayor importancia, la hipótesis nula indica
que el punto de corte de los ejes es cero y la hipótesis alterna indica lo contrario.
Para probar la hipótesis se contrasta el valor T calculado con el valor T de la tabla.
𝑇𝑐 =𝛽0
√𝐶00 − 𝐶𝑀𝐸=
0.804478
√(19.59058)(0.0003354)=
0.804478
0.081= 9.93
El valor tabular para una confiabilidad del 95% y 10 grados de libertad en el error es
2.306, por lo que se rechaza la hipótesis nula.
Para β, el valor:
𝑇𝑐 =𝛽1
√𝐶11 − 𝐶𝑀𝐸=
−0.02746
√(0.04357)(0.0003354)=
−0.02746
0.003822= 7.184

342
Tal como se había probado, en este caso se rechaza la hipótesis nula y se concluye que
hay dependencia lineal entre consumo y fibra.
Los intervalos de confianza para los estimadores de los parámetros se calculan de la
siguiente manera;
𝐼𝐶𝛽𝑖 = 𝛽𝑖 ± √𝐶ü 𝐶𝑀𝐸 𝑇∝ 2⁄ , 𝑛−2
En el ejemplo el intervalo de confianza para β1, sería:
ICβ1 = -0,02746± (0,003822 x 2,228) = -0,02746 ± 0,0085
El coeficiente de determinación se calcula del siguiente modo:
𝑅2 =𝐵´𝑋´𝑌 − 𝐹𝐶
𝑌´𝑌 − 𝐹𝐶=
0,017346
0,207= 0,837
La interpretación de esta cifra se indicó en el desarrollo anterior del mismo ejemplo sin
uso de la notación matricial.
7.4 ANÁLISIS DE REGRESIÓN NO LINEAL
El modelo de regresión de la línea recta es el más simple y más comúnmente usado
entre las expresiones matemáticas con las que se representa la relación entre dos
variables. En ocasiones, este modelo es inapropiado, porque la ecuación que se ajusta al
conjunto de puntos puede ser no lineal. La no linealidad se determina visualmente a
partir del diagrama de dispersión, en otras ocasiones, el conocimiento teórico del
problema o la experiencia sugieren que el modelo no es lineal. Existe un gran número
de modelos no lineales que cumplen dicha función en el caso en que la línea recta no
sea la apropiada.

343
Aquí sólo se hace referencia a tres de los tipos más usados de estos modelos: La
recíproca, la exponencial y la parabólica.
Suponiendo que los estimadores 𝛽1, 𝛽2 𝑦 𝛽2 sean iguales a, b y c respectivamente.
El modelo recíproco es: 𝑌 = 𝑎 +𝑏
𝑥
Este modelo, mediante la transformación 𝑍 =1
𝑋 se lo expresa como una línea recta 𝑌 =
𝑎 + 𝑏𝑍.
El modelo exponencial es 𝑌 = 𝑎𝑏𝑥

344
En este caso, utilizando logaritmos:
Log 𝑌 = Log 𝑎 + 𝑋(Log 𝑏) (7.4.1)
Haciendo la transformación W = Log Y, g= Log a y h= Log b, el modelo se lo expresa
como una recta:
𝑊 = 𝑔 + ℎ𝑋 (7.4.2)
Ejemplo 7.4.l: Los siguientes datos corresponden al número de bacterias por unidad de
volumen presentes en un cultivo de Salmonella sp, durante seis horas.
En el diagrama de dispersión se puede apreciar que el crecimiento de las bacterias es
exponencial.
6
0
275
4
5
32
47
65
92
132
190
3
2
Número de horas xNúmero de bacterias Por
unidad de volumen
1

345
Se ajusta un modelo 𝑌 = 𝑎𝑏𝑥
Tomando logaritmos se tiene: Log Y = log a + X (log b).
Si W= log Y, g = Log a y h= log b, el modelo se expresa como una línea recta:
W= g + h X
Y se resuelve de la misma manera que el modelo de línea recta, teniendo en cuenta los
datos:
Los valores de los estimadores h y g se calculan como:
ℎ =Σ𝑋𝑖𝑊𝑖 −
(Σ𝑋𝑖)(Σ𝑊𝑖)𝑛
Σ𝑋𝑖2 −
(Σ𝑋𝑖)2
𝑛
= 0,154
𝑔 = �� − ℎ�� = 1,507
Por lo tanto, el modelo se expresa como: W = 1,507 + 0,154X
Teniendo en cuenta las transformaciones, se tiene que:
X W= log y
0 1,505
1 1,672
2 1,813
3 1,964
4 2,121
5 2,279
6 2,439

346
Log a= g, entonces a = 10g = 101,507 = 32,137
Log b = h, entonces b = 10h,= 100,154 = 1,426
Y el modelo exponencial se expresa como: 𝑌 = 𝑎𝑏𝑥 = 32,137(1,426)𝑋
Así por ejemplo, para X = 6 el pronóstico bajo este modelo es:
𝑌 = 32,137(1,426)6 = 270
Este valor está bastante cercano del valor observado: Y = 275, para X = 6
El modelo parabólico Y = a + bX + cX2
Para hallar los valores de los estimadores a, b y c resuelve el sistema:
∑𝑌𝑖 = 𝑛𝑎 + 𝑏 ∑𝑋𝑖 + 𝑐∑𝑋𝑖2
∑𝑋𝑖𝑌𝑖 = 𝑎∑𝑋𝑖 + 𝑏 ∑𝑋𝑖2 + 𝑐∑𝑋𝑖3
∑𝑋𝑖2𝑌𝑖 = 𝑎∑𝑋𝑖2 + 𝑏 ∑𝑋𝑖3 + 𝑐∑𝑋𝑖4
b>0, c>0
b>0, c<0
b<0,c<0
b>0, c<0
b<0, c<0

347
Ejemplo 7.4.2: en la tabla 7.4.1 se presentan los datos de producción láctea de búfalas
en el Brasil (Cerón 2001), donde X son los días de lactancia, Y es la producción en
litros. Con esta información se pretende establecer un modelo que explique la
producción en función de los días de lactancias.
El diagrama de dispersión es el siguiente
Se ajusta un modelo parabólico de segundo orden:
𝑌 = 𝑎 + 𝑏𝑋 + 𝑐𝑋2
Para esto se resuelve el sistema:
82.521 = 41ª + 10.822b + 3.397.468c
23.959.748= 10.822ª + 3.397.468b + 1.204.890.664c
7.715.665.498= 3.397.468ª + 1.204.890.664b + 468.431.174.152c
Al resolverlo se tiene que:
A= -1.198,11 b= 22,16 c=-0.032
Por lo tanto, el modelo es Y= -1.198,11 + 22,16X – 0.32𝑋2

348
7.5 ANÁLISIS DE RESIDUALES: VALIDACIÓN DEL MODELO
Otra estrategia para evaluar cuanto el ajuste de la recta de regresión de mínimos
cuadrados, a los datos observados en la muestra utilizada, consiste en construir un
gráfico de dispersión de los residuos, contra los valores predichos de la variable �� o
contra X.
Se debe recordar que el i-esimo residuo 𝑒𝑖 es la diferencia entre el valor observado Yi y
el correspondiente valor estimado ��𝑖
𝑒𝑖 = Yi - ��𝑖 para todo i = 1, 2,3……, n
A las cantidades 𝑑𝑖 =𝑒𝑖
𝑆=
𝑒𝑖
√𝐶𝑀𝐸 para todo i=1, 2, 3….., n
Se les denomina residuales estandarizadas
Si el modelo de regresión lineal simple es correcto, los residuales estandarizados tienen
una distribución normal estándar, por lo que los residuales estarán aleatoriamente
distribuidos (sin mostrar ningún patrón) alrededor del intervalo (-2; 2) como se muestra
en la figura.
Las gráficas residuales con aspecto similar al de la Figura 7.5.1 indica que el modelo es
inadecuado, es decir, que es necesario añadir al modelo términos de orden superior( no
solo lineal) para poder expresar la relación entre X e Y.
7.6 REGRESIÓN LINEAL MÚLTIPLE
La notación matricial indicada para la regresión simple se puede extender al caso donde
el interés se centra en establecer la relación funcional de dependencia entre una variable
Y con dos o más variables independientes X. como se sabe el consumo de alimento no
depende únicamente del contenido de fibra de la ración, sino también de otros factores
tales como el peso vivo del animal, la temperatura del galpón, la densidad de
alojamiento y muchas otras variables.
Las operaciones matriciales indicadas en el numeral anterior son de mucha utilidad para
afrontar estudios de esta naturaleza. Las pruebas de hipótesis y los conceptos que deben
manejarse son básicamente extensiones de análisis simple.

349
Ejemplo 7.6.1: para establecer la relación de dependencia lineal del consumo (Y) con
respecto al peso corporal 𝑋1, la temperatura del galpón 𝑋2 y el diámetro de las
partículas del alimento 𝑋3 en gallinas ponedoras Isabrown, se recopilaron los datos
consignados en la tabla 7.6.1
El modelo lineal para estos datos se puede expresar con la siguiente ecuación.
𝑌𝑖= 𝛽0 + 𝛽1𝑋1 + 𝛽2𝑋2 + 𝛽3𝑋3
Este modelo teóricamente se puede extender a cualquier número de variables
independientes:
𝑌𝑖= 𝛽0 + 𝛽1𝑋1 + 𝛽2𝑋2 + … . 𝛽𝑘𝑋𝑘 En este caso se indica que las X varían de 1 a K
En forma matricial, el modelo es el mismo para cualquier número de variables
independientes solo que el tamaño de las matrices que contiene las ecuaciones normales
aumentan a medida que se incluyen más variables en los análisis, así para una variable
independiente, el tamaño de X´X es 2*2 y el XY es 2*1; para dos variables
independientes.
En general las matrices anteriores se pueden identificar de la siguiente forma para k
variables independientes.
Los modelos de la regresión lineal múltiple generan matrices de rango completo, por lo
tanto la matriz X´X tiene inversa que al multiplicarla por el vector XÝ dará como
resultado la estimación de los parámetros.
La tabla de análisis de varianza, las pruebas de hipótesis, el cálculo de los intervalos de
confianza y del coeficiente de determinación se hacen del modo indicado en el numeral.
Para mayor claridad a continuación se desarrolla el procedimiento para los datos de la
tabla 7.6.1
En primer lugar se organiza la información y se lleva a cabo los cálculos necesarios para
facilitar la posterior construcción de las matrices. Las expresiones necesarias son las
indicadas a continuación.

350
Variable ∑𝑌𝑖 ∑𝑌𝑖2 ∑𝑌𝑋1𝐼 ∑𝑌𝑋2𝐼
Consumo 990.52 22888.1 1641.57 25225.1
Variable ∑𝑋1𝐼 ∑𝑋𝑖2 ∑𝑋1𝑖𝑋2𝐼 ∑𝑋1𝑖𝑋3𝐼
Peso Corporal 69.73 114.19 1775.24 245.588
Variable ∑𝑋2𝐼 ∑𝑋2𝑖2 ∑𝑋2𝑖𝑋1𝐼 ∑𝑋2𝑖𝑋3𝐼
Temperatura 1095.9 28067.5 1775.24 3891.44
Variable ∑𝑋3𝐼 ∑𝑋3𝑖2 ∑𝑋2𝑖𝑋3𝐼 ∑𝑋3𝑖𝑋2𝐼
Granulometría 152.7 546.73 245.588 3891.44
Con las cifras anteriores se construyen las matrices correspondientes a las ecuaciones
normales.
𝑋´𝑋 [43 69.73 1095.9
69.73 114.19 1775.241095.9 1775.24 28067.5
152.7 245.588 3891.44
] , 𝑋`𝑌 [990.52
1614.5725225.1
], 𝛽 = [
𝛽0
𝛽1
𝛽2
]
Para obtener los estimadores de los parámetros β se invierte X´X y se multiplica ese
resultado por X`Y
(𝑋´𝑋)−1 = [90.91042 −23.0053 −0.5271−23.0053 6.3571 0.09393−0.5271 0.09393 0.0086701
−11.30503
2.901080.04332
]
(𝑋´𝑋)−1. 𝑋`𝑌 = 𝛽 = [18.723285.67754
−0.064048]
De acuerdo con los anteriores resultados los valores del vector solución β se interpretan
del siguiente modo

351
𝛽0 18.72328477 punto de corte del eje Y con los ejes 𝑋1𝑋2𝑋3 Valor del consumo
cuando el peso corporal, la temperatura del galpón y el tamaño de las partículas del
alimento valen cero.
𝛽1 5.677543238 incremento promedio en el consumo por cada aumento de un kg en el
peso vivo de las aves.
𝛽2 -0.06404879725 disminución promedio del consumo por cada aumento de un grado
centígrado en la temperatura del ambiente del galpón.
𝛽3 -0.9186985828 disminución promedio del consumo por cada aumento de un mm en
el tamaño de las partículas de alimento.
De acuerdo con las anteriores cifras se puede observar que a mayor peso vivo mayor
consumo, mientras que a mayor temperatura y diámetro de las partículas el consumo
disminuye.
El paso siguiente consiste en realizar las pruebas de hipótesis para cada uno de los
parámetros así que deben realizarse los cálculos necesarios de las sumas de los
cuadrados, las que luego se descomponen en las diferentes fuentes de variación. Las
cifras necesarias son las siguientes.
𝐹𝑐 =(∑𝑌𝑖)
2
𝑛=
(990.52)2
43= 22816.97373 = 𝑛��2 = 43 ∗ (90.10232558)2
SC total = Y`Y – FC = 22884.1 – 22816.97373 = 67.1627
SC regresión = β XY-FC= 2.287978788 *104-22816.97373=62.81415
La SC del error se obtiene por diferencia de la SC total corregida menos SC regresión
corregida.
Lo más práctico es construir la tabla de análisis de varianza donde se indican las
respectivas sumas de cuadrados para cada fuente de variación.
FV GL SC CM Fc Ft
Regresión 3 62.81415 20.9380500 187.78 2.84

352
Error 39 4.34855 0.1115012
Total 42 67.16270
Como el Fc es mayor que el Ft se concluye con 95% de confiabilidad que por lo menos
una de las variables independientes X influye sobre el consumo, es decir que el
consumo depende linealmente de por lo menos una de las variables independientes. Para
establecer si solo es una o son más variables independientes las que presentan esta
influencia deben efectuarse las pruebas de hipótesis específicas para cada una de las
variables, utilizando la distribución de probabilidad T de Student.
La regla general para obtener el T calculando (Tc) es la siguiente:
𝑇𝑐 = 𝛽𝑖
√𝐶𝑖𝑖𝐶𝑀𝐸 𝐷𝑂𝑁𝐷𝐸 𝐼 = 1,2 … . . , 𝑘
𝐶𝑖𝑖 = Jesimo coeficiente de la diagonal de la matriz de coeficientes.
Los coeficientes de la matriz C se obtienen de la matriz inversa X`X.
𝑇𝑐 = 𝛽𝑖
√𝐶𝑖𝑖𝐶𝑀𝐸=
5.677543238
√ 6.35717012 ∗ 0.1115012=
5.677543238
0.8419216691= 6.74
El Tt para 39 Gl con α del 5% es 2.021, así que se deben rechazar la hipótesis nula y
concluir que el consumo depende linealmente del peso vivo de las gallinas, puesto que
|6.74| es mayor que el valor de la tabla.
𝑇𝑐 = −0.06404879725
√0.008670169059 ∗ 0.1115012=
−0.06404879725
0.03109235041= −2.06
Como |−2.061| es mayor que 2.021 se rechaza la hipótesis nula y se concluye que el
consumo depende linealmente de la temperatura del galpón.
𝑇𝑐 = −0.9186985828
√1.547773715 ∗ 0.1115012=
−0.9186985828
0.4154258376= 2.21

353
Ya que |2.21| es mayor que 2.021, se rechaza la hipótesis nula y la conclusión es que el
consumo depende del tamaño de las partículas del alimento.
7.7 PREDICCIÓN DE RESPUESTAS FUTURAS
La predicción de la respuesta promedio Ῠ= X β, donde X = [1 X1 X2……Xk]
Ejemplo 7.7.1: la predicción Ῠ para el punto X1= 28, X2=28 y X3=3.3 viene dado por:
Ῠ = [1 1.9 28 3.3] [
18.725.68
−0.064−0.92
]
= (1*18.72)+ (1.9*5.68)-(28*0.64)-(3.3*0.92)=24.684
Un intervalo de confianza al 95% de confiabilidad para la respuesta promedio Ῠ=
24.684.
Ῠ𝒑 ± 𝒕𝟎.𝟗𝟕𝟓.𝟑𝟗𝑺Ῠp
𝑆ῨP2 = 𝐶𝑀𝐸 [𝑋`𝑝(𝑋`𝑋)−1]𝑋𝑝
= [1 1.9 28 3.3 ] [90.910 −23.005 −0.527
−23.005 6.357 0.094−0.527 0.094 0.009
−11.3052.9010.043
] 1
1.928
= 0.555
Por lo tanto
𝑆ῨP = √0.1115012 ∗ 0.555 = 0.248763
Ῠ𝒑 ± 𝒕𝟎.𝟗𝟕𝟓.𝟑𝟗 ≈ 2.021
Y el intervalo de confianza es: 24.684 ± 2.021 * 0.248763 = (24.18 25.19)
Un intervalo de predicción al (1-α) 100% de confiabilidad para una observación futura
Ῠ𝟎 en el valor 𝑿𝟏𝑿𝟐……..𝑿𝒌 viene dada por:

354
Ῠ𝒑 ± 𝒕𝟏−
𝜶𝟐
;𝒏−𝒌−𝟏𝑺Ῠ0
Donde
Ῠ𝟎 ±𝑿𝟎��
𝑿𝟎 = 𝟏 𝑿𝟏 𝑿𝟐 … … 𝑿𝒌
𝑆Ῠ02 =CME [1 + 𝑋0(𝑋`𝑋)−1𝑋0]
En el ejemplo, un intervalo de predicción para el punto 𝑿𝟏 = 𝟏. 𝟗, 𝑿𝟏 = 𝟐𝟖 𝒚 𝑿𝟑 = 𝟑. 𝟑
al 95% de confiabilidad, viene dado por:
24.684 ± 2.021 ∗ √0.1115012(1 + +0.555)
24.684 ± 2.021 ∗ 0.4164
24.684 ± 0.8416
(23.84 a 25.53)
Top Related