







Languages
Pages
Legal



This is not a DB optimization talk
It’s a talk about how doing things in a specific way leads to getting way better results by default

“Preoptimization”
Don’t denormalize by defaultMaintenance is King (by default)1 Thread Performance != Parallel
PerformanceMyISAM vs InnoDBFast != Scalable

“Preoptimization”

I’ll just tune MySQL Parameters…
Will get you out of SOME trouble But not a good “default” solution, specially if
the base is flawed
Please do tune MySQLs defaults Not the theme for today


Start with your Schema
Your schema is probably the root cause of your “My DB doesn’t scale” problems The solution is not “have a loose/no schema”
How to fake a DB Design (Curtis Ovid Poe) https://www.youtube.com/watch?v=y1tcbhWLiUM

Data types: how (not) to bloat your DB
Selecting data types with a bit of care is very productive
It makes more data fit in less space Optimizes use of InnoDB Buffer Pool, MyISAM
Key Buffer, Join Buffer, Sort Buffer, Smaller indexes

Your new best friend
http://dev.mysql.com/doc/refman/5.6/en/storage-requirements.html
http://dev.mysql.com/doc/refman/5.5/en/storage-requirements.html
…

DataTypes: NULL vs NOT NULL
I don’t care about the NULL debate Saves Space Gives the DB hints
Use NULLs wisely

Data Types: Integers

DataTypes: Integers
INT(1) == INT(10) == 4 bytes
That’s it!

DataTypes: Integer family
TINYINT: 1 byte
SMALLINT: 2 bytes
MEDIUMINT: 3 bytes
INT
BIGINT:8 bytes
UNSIGNED: “double”
the range

INTS and surrogate keys
It’s good to have a surrogate key Just unique index the unique column
Why? InnoDB stores the PK on the leafs of all indexes Indexes bloat if they’re “big keys”

Id columns for your tables
INT by default for “things that can get big” Smaller INTs for smaller sets
Do you really need a BIGINT? The magnitude comparison trick:
Epochs in Unix have 4 bytes The epoch has been counting since 1970. Will run out in 2038
An INT can identify ONE THING HAPPENING EVERY SECOND for 68 YEARS!
Do you STILL need a BIGINT?

DataTypes: Integer family
TINYINT: 1 byte
SMALLINT: 2 bytes
MEDIUMINT: 3 bytes
INT
BIGINT:8 bytes
UNSIGNED: “double”
the range

DataTypes: Integer family
TINYINT: 1 byte
SMALLINT: 2 bytes
MEDIUMINT: 3 bytes
INT
BIGINT:8 bytes
UNSIGNED: “double”
the range

Data Types: Texts

DataTypes: Texts
Texts are strings of bytes with a charset and a collation
BINARY and VARBINARY
CHAR and VARCHAR

DataTypes: Texts
BINARY(10) == 10 bytes
CHAR(10) ==? 10 bytes

DataTypes: Texts
BINARY(10) == 10 bytes
CHAR(10) ==? 10 bytesCHAR(10) latin1: 10 bytesCHAR(19) utf-8: 30 bytes

DataTypes: Texts
BINARY(10) == 10 bytes
CHAR(10) ==? 10 bytesCHAR(10) latin1: 10 bytesCHAR(19) utf-8: 30 bytes
VARBINARY(10) == 1 to 11 bytes
VARCHAR(10) ==? 1 to 11 bytes

DataTypes: Texts
BINARY(10) == 10 bytes
CHAR(10) ==? 10 bytesCHAR(10) latin1: 10 bytesCHAR(10) utf-8: 30 bytes
VARBINARY(10) == 1 to 11 bytes
VARCHAR(10) ==? 1 to 11 bytesVARCHAR(10) latin 1: 1 to 11 bytesVARCHAR(10) utf-8: 1 to 31 bytes

So I’ll just go for VARCHAR(255) on all text columns
“After all… I’ll just consume the number of bytes + 1”

So I’ll just go for VARCHAR(255) on all text columns
“After all… I’ll just consume the number of bytes + 1”
When we need a temporary table
https://dev.mysql.com/doc/refman/5.6/en/memory-storage-engine.html
“MEMORY tables use a fixed-length row-storage format. Variable-length types such as VARCHAR are stored using a fixed length”


So I’ll just go for VARCHAR(255) on all text columns
Congrats! All your VARCHAR(255) are now CHAR(255) in memory
That’s 255 bytes latin-1. Or 765 bytes utf-8 O_o
Note: do the maths on VARCHAR(65535)

DataTypes: BLOBS
TEXT == BLOB == problems TEXT = BLOB + charset + collation TEXT fields are not unlimited!
TINYTEXT and TINYBLOB (up to 256 bytes == x chars)
TEXT / BLOB (up to 65KB == x chars)
MEDIUMBLOB / MEDIUMTEXT (up to 16MB == x chars)
LONGTEXT / LONGBLOB (up to 2GB == x chars)

SELECT * IS YOUR FRIEND?
IF a SELECT contains a BLOB/TEXT columnTemporary tables go DIRECTLY to DISK


SELECT * IS YOUR FRIEND?
IF a SELECT contains a BLOB/TEXT columnTemporary tables go DIRECTLY to DISK
Note: “Big” columns belong on a filesystem or an object store

DataTypes: Small Sets
ENUM One value out of the possibilities (‘big’, ‘small’)
SET A set of possible values (‘pool’,’terrace’,’fence’)
SETS are NOT good for finding stuff FIND_IN_SET is a function. No indexes Default to a separate table + relation

DataTypes: Dates
YEAR = 1 byte (range from 1901 to 2155) DATE = 3 bytes TIME = 3 bytes DATETIME = 8 bytes TIMESTAMP = 4 bytes
Timestamp is an epoch. Ideal for “things that happen now” (sold time, renewal date, etc)

Masked Data

Masked Types
An IP Address
234.34.123.92CHAR(15)? VARCHAR(15)?

Masked Types

INT

INSERT INTO table (col) VALUES (INET_ATON(’10.10.10.10’));
SELECT INET_NTOA(col) FROM table;

Masked Types
MD5("The quick brown fox jumps over the lazy cat") 71bd588d5ad9b6abe87b831b45f8fa95 CHAR(32)
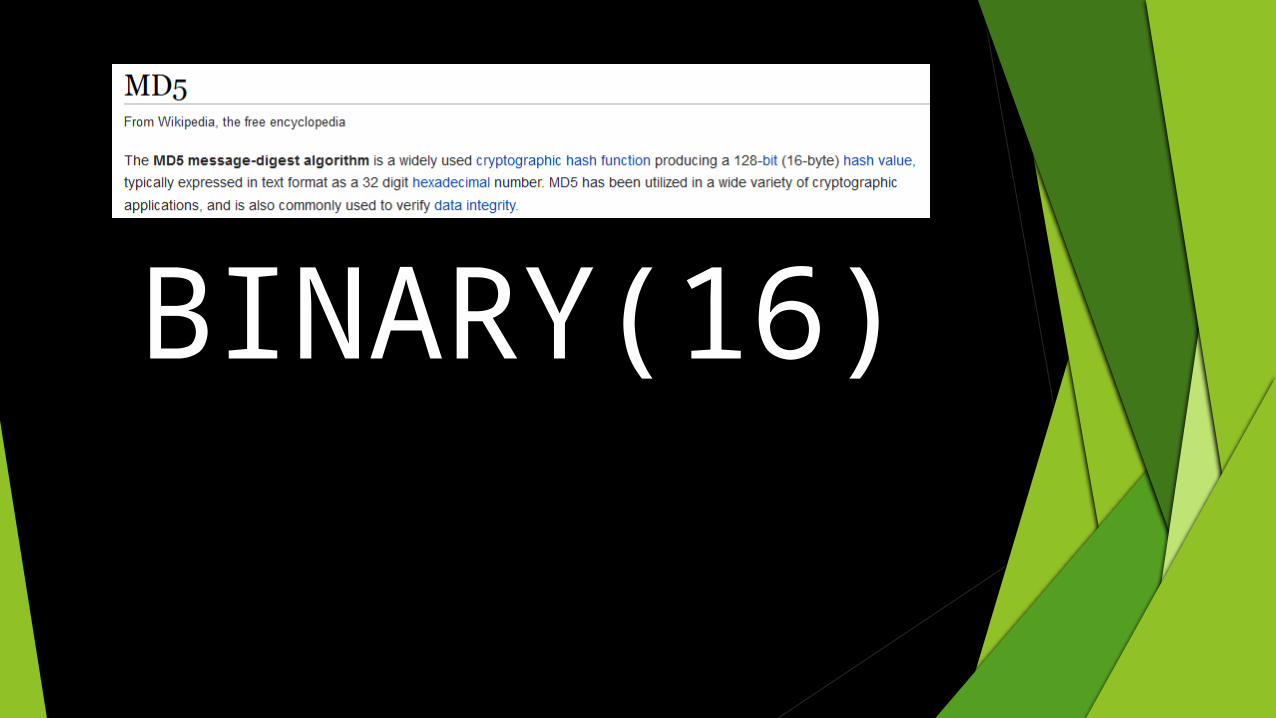
BINARY(16)

Masked Types
UUIDsHASH functionsNetwork masks

Indexes for starters

Indexes for starters

Index the two sides of relations
PK

Index the two sides of relations
Index this guy too!

Index the two sides of relations
Index this guy too!
And this guy!


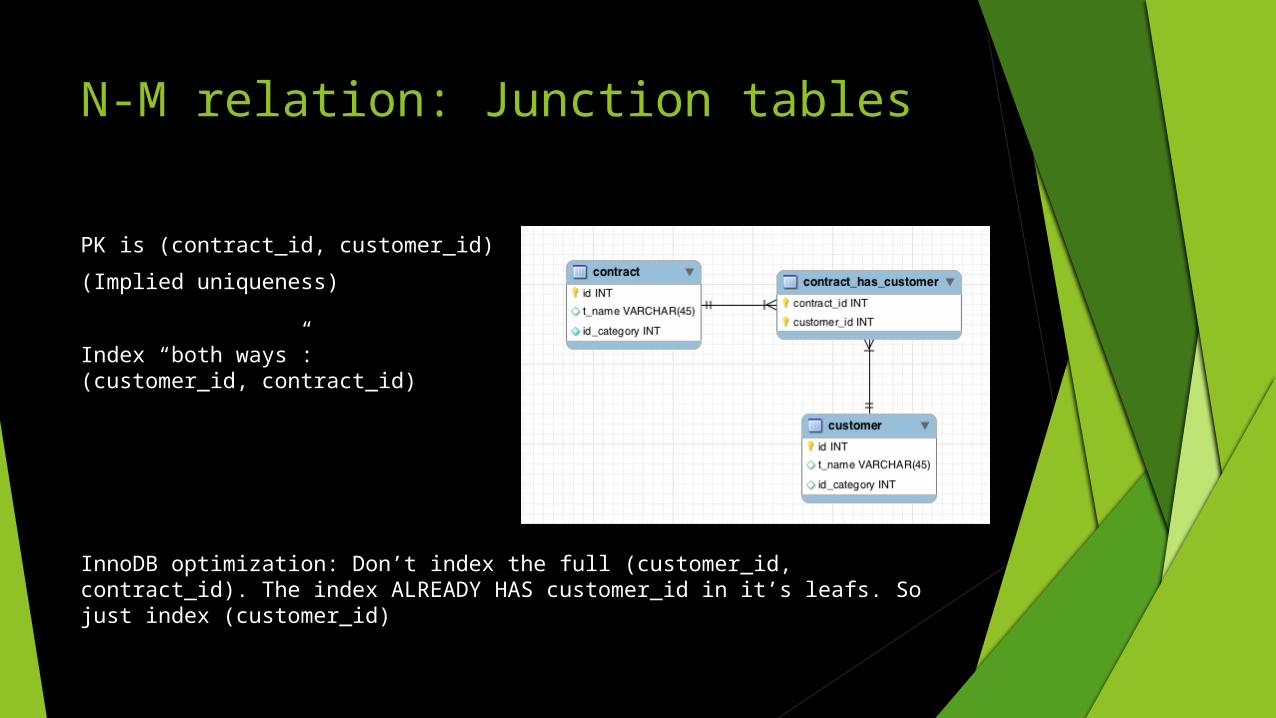
PK is (contract_id, customer_id)
(Implied uniqueness)
Index “both ways”: (customer_id, contract_id)
InnoDB optimization: Don’t index the full (customer_id, contract_id). The index ALREADY HAS customer_id in it’s leafs. So just index (customer_id)
N-M relation: Junction tables


Don’t operate on fields
Because they can’t use indexes
WHERE column = ‘x’WHERE column > 2000WHERE column LIKE ‘prefix%’
WHERE column + 2000 > 2013WHERE FIND_IN_SET(column)WHERE CONCAT(f1,f2) = “xxxx.com”WHERE YEAR(date) = 2015WHERE column LIKE ‘%.com’

Polish your maths: Algebra
Doesn’t use indexWHERE column + 2000 > 2013
WHERE FIND_IN_SET(‘pool’,column)
WHERE CONCAT(f1,’.’,f2) = “xxxx.com”
WHERE YEAR(date) = 2015
WHERE column LIKE ‘%.com’
Uses indexWHERE column > 13
?
WHERE f1 = ‘xxxx’ AND f2 = ‘com’
WHERE date BETWEEN ’01-01-2015’ and ’31-12-2015’
?

The old switcheroo…
Doesn’t use indexWHERE column + 2000 > 2013
WHERE FIND_IN_SET(‘pool’,column)
WHERE CONCAT(f1,’.’,f2) = “xxxx.com”
WHERE YEAR(date) = 2015
WHERE column LIKE ‘%.com’
Uses index
WHERE has_pool = 1
WHERE column_rev LIKE ‘moc.%’

The old switcheroo…
Doesn’t use indexWHERE column + 2000 > 2013
WHERE FIND_IN_SET(‘pool’,column)
WHERE CONCAT(f1,’.’,f2) = “xxxx.com”
WHERE YEAR(date) = 2015
WHERE column LIKE ‘%.com’
Uses index
WHERE has_pool = 1
UPDATE t SET has_pool = FIND_IN_SET(‘pool’,column);
WHERE column_rev LIKE ‘moc.%’
UPDATE t SET column_rev=REVERSE(column)


CAT IS HERE

Wrap up
SchemaData Types
How to select themMasked Types
IndexesRelationsUsing them

Wrap up
Smaller is better
VS


cpsd.es/SRE-job-team
Top Related