







Languages
Pages
Legal


BUILDING A
NOSQL“BIG DATA”
CLOUDOSCON’10
Krishna Sankar@ksankar
July 20, 2010
The future is an obsession ... an attraction ... an invention … an invitation

It does not matter where the train is going, what matters is it’s direction and your decision to get on …

A carchesion is a kind of swivel or universal joint.
“Give me a lever long enough & a fulcrum on which to place it, & I shall move the world.”

About me• Krishna Sankar, Distinguished Engineer
– Chief subordinate to Assistant to Chief of Staff to CTO to the CEO of Cisco
– Focusing on Cloud Computing & Data Clouds
• Co-chair : Workshop on Algorithms, Architectures and Applications for Big
Data Clouds & Modern Massive Datasets, held in conjunction with HiPC
2010 in Goa, India [http://nvdd.homeip.net/]
• MS Bioinformatics - John Hopkins Advanced Biotechnology Studies(tbd)
• Co-chair : DMTF Cloud Incubator
• Writing a Pragmatic BookShelf Book on Cloud Computing– “Building Clouds with Amazon Web Services”; Editor Michael Swaine
• Author : Enterprise Web 2.0 Fundamentals
– Written a few Java books. Don‟t buy them – they are very old
• Member: Scala Expert group on STM/July 2010
• Writing code for SNIA CDMI Ref Impl – File based Object Store SPI
• Lego Robotics : Technical Judge FLL World Festivals

The Prelude
GoalUnderstand & get a broader technology view of NOSQL eco system
A slice of the NOSQL eco system – explore further
Balance between discussion & hands-on (~80-20)
Tutorial, not a presentation
Which means broad as well as deep
How & What – Not Why Side step NOSQL vs NoSQL vs SQL
Not going to answer "Which NOSQL has the momentum?"
Try to keep the brand names out – just the facts
Assume no prior knowledge depth in this domain
No linear path through NOSQL – so there will be a few forward references, have minimized them
The road lies plain before me;--'tis a themeSingle and of determined bounds; …
- Wordsworth, The Prelude

Hands On work
Hands on with EC2 instances
Amazon has given us vouchers for $25 towards awsservices, valid until Dec 31,2010
Thanks to Jeff Barr & Jenny Kohr Chynoweth
Use the credits wisely
Prerequisites: Have an aws account
Apply the credits – voucher in the frontTutorial handout on-line http://doubleclix.wordpress.com/2010/07/13/oscon-nosql-training-ami/
We will follow the script for the hands on work

NOSQL Hands OnAs we have > 100 attendees, let us do this in a staggered way, linearly hashed by alphabetical order preserving LastName.startsWith
8:30 → *a,b,c] 8:40 → *d,e,f] 8:50 → *g,h,i] 9:00 → *j,k,l]
9:10 → *m,n,o] 9:20 → [p,q,r] 9:30 → *s,t,u] 9:40 → *v,w,x]
9:50 → *y,z]
Bring up EC2 AMI
Refer AWS Setup in handout http://doubleclix.wordpress.com/2010/07/13/oscon-nosql-training-ami/
I also have posted 3 preliminary chapters from my book to help you get started on aws[http://doubleclix.files.wordpress.com/2010/07/buildingclouds.pdf]
And, SSH into the instance

Homework !Today : Hands on with NOSQL document DB – MongoDB
The EC2 instance also has Cassandra
There is also some homework ideas
Hands on material is more than what we can do. NP, we will improvise
I am planning to augment the tutorials later - handout & EC2 image
3 node Cassandra, Neo4j, HBase (0.9 & beyond)
Will update script & EC2 AMI
Watch my readme.bloghttp://doubleclix.wordpress.com/2010/07/13/oscon-nosql-training-ami/

AgendaSession #1 – Opening Gambit
8:30-9:30 – NOSQL : Toil, Tears & Sweat !
Quick look at Data Clouds
NOSQL – An overview
NOSQL – Tales from the field
NOSQL – Themes
9:30-10:00 –Detour/Scenic Route : MongoDB [HandsOn]
10:00-10:30 – Real break !
Session #2 – The Pragmas10:30-11:15 – ABCs of NOSQL [ACID, BASE & CAP]
11:15-11:30 – Cassandra - Anatomy of a NOSQL Column Datastore
Session #3 – The Mechanics11:30-12:30 – NOSQL How do they do it ? Algorithmics & Mechanisms
End Game : Homework – NOSQL & BeerRead NOSQL papers
http://doubleclix.wordpress.com/2010/06/12/a-path-throug-nosql-summer-reading/
Explore more with the NOSQL AMI. Visit back for more hands on scripts
Referenced Links @ http://doubleclix.wordpress.com/2010/06/20/nosql-talk-references/

Thanks to …The giants whose shoulders I am standing on
Special Thanks to:Shirley BailesEd Dumbill

Data in the Cloud
vs. Data Cloud
Data in the Cloud = Syntax
Spatial Artifact
Data Cloud = Semantics
Architecture
devOps

Wisdom & Insights from Werner• Properties of Data Clouds (occasionally paraphrasing Werner)
o Autonomy
o Asynchrony
o Decompose• Into well understood building blocks
• Employ Hierarchies & Functional Partitioning (mixing NOSQL & SQL)
o Don’t conceal heterogeneity
o Data distribution should be explicit to the application
o Cache near the edges
o Failure should be considered a common occurrence• Single failure should not interrupt the service
Ref : [41] Talk at InfoQ by WV
“Make progress locally under all circumstances, even if the world around you is burning ” (except, when there are real-time uncompensatable & unapologizable consequences![104])
“Make decisions based on local state – probabilistic techniques”


Agenda• Session #1 – Opening Gambit
– 8:30-9:30 – NOSQL : Toil,Tears & Sweat !
• Quick look at Data Clouds
NOSQL – An overview
• NOSQL – Tales from the field
• NOSQL – Themes
– 9:30-10:00 –Detour/Scenic Route : MongoDB [HandsOn]
– 10:00-10:30 – Real break !
• Session #2 – The Pragmas– 10:30-11:15 – ABCs of NOSQL [ACID, BASE & CAP]
– 11:15-11:30 – Cassandra - Anatomy of a NOSQL Column Datastore
• Session #3 – The Mechanics– 11:30-12:30 – NOSQL How do they do it ? Algorithmics & Mechanisms
• End Game : Homework – NOSQL & Beer– Read NOSQL papers
• http://doubleclix.wordpress.com/2010/06/12/a-path-throug-nosql-summer-reading/
– Explore more with the NOSQL AMI. Visit back for more hands on scripts
Referenced Links @ http://doubleclix.wordpress.com/2010/06/20/nosql-talk-references/

NOSQL – A Hitchhiker’s Guide

What is NOSQLAnyway ?
• NOSQL != NoSQL or NOSQL != (!SQL)
• NOSQL = Not Only SQL
• Can be traced back to Eric Evans[2]!
– You can ask him during the afternoon session!
• Unfortunate Name, but is stuck now
• Non Relational could have been better
• Usually Operational, Definitely Distributed
• NOSQL has certain semantics – need not stay that way

NOSQL – A Horseless Carriage ?[24-27]

NOSQL Bakers Dozen
1. They are not homogeneous, but as varied as NoC++
– Use cases rule
– The domain is still fragmented
– But many of the internals are similar (we will look at some later)
2. They are not a solution to world hunger
3. NOSQL is a feature set – now available in data stores like HBase, Cassandra,… but soon coming to a few databases near you !

NOSQL Bakers Dozen
4. You can't have them all (CAP)
5. They version using vector clocks
6. They gossip
7. They are usually append only, at runtime!
8. They use memory as primary storage

NOSQL Bakers Dozen
9. They are lazy & do only the essential work
10.They are very good procrastinators ! (do rebalance later or triggered)
11.They search patterns using bloom filters
12.They store "stuff" at random, but remember where they stored them and are excellent at retrieving them (unlike humans)

NOSQL Bakers Dozen
13.They are aware of data adjacency & locality (columns, super columns, the way they store)
14.They store in little chunks and retrieve in little chunks (so long as you tell them what chunks are)
15.They solve specific problems very well & general problems to a certain extent
^

NOSQL Bakers Dozen
16.Their power comes from optimization for one or related macro deployment/usage pattern
– Hadoop LZO at Twitter
17.Many of them are strangely Named –Voldemort listens to port 6666
18.Simpler, usually very less administrative overhead
19.No schema or Extensible schema
^

NOSQL Taxonomy• We can look by variety of ways
– Data Model[19], Client Interface, Persistent Model (BTree, memtable, on-disk linked list) , Distribution Model, ….
• Basic Categories
o key‐value
o Column
o Document
o Graph

A word about NOSQLtaxonomy
• Projects developed bottom-up based on need from the various companies
• There is some overlap
• But there are clear cut semantics as well
• Origins & Families tied to applications /use cases
• “ … think about the real-life concept you're trying to work with first, then find an appropriate model to digitize it, and finally pick the right project in that family according to your other constraints (scaling, partitioning, validations, previous experience, support available, etc.)”.
– Tim Anglade

Key Value Column Document Graph
Ref: [22,51,52]
NOSQL
Neo4j
FlockDB
InfiniteGraph
CouchDB
MongoDB
Lotus Domino
Riak
Google BigTable
HBase
Cassandra
HyperTable
In-memory
Disk Based
SimpleDB
Memcached
Redis
Tokyo Cabinet
Dynamo
Voldemort Azure TS

Agenda• Session #1 – Opening Gambit
– 8:30-9:30 – NOSQL : Toil,Tears & Sweat !
• Quick look at Data Clouds
• NOSQL – An overview
NOSQL – Tales from the field
• NOSQL – Themes
– 9:30-10:00 –Detour/Scenic Route : MongoDB [HandsOn]
– 10:00-10:30 – Real break !
• Session #2 – The Pragmas– 10:30-11:15 – ABCs of NOSQL [ACID, BASE & CAP]
– 11:15-11:30 – Cassandra - Anatomy of a NOSQL Column Datastore
• Session #3 – The Mechanics– 11:30-12:30 – NOSQL How do they do it ? Algorithmics & Mechanisms
• End Game : Homework – NOSQL & Beer– Read NOSQL papers
• http://doubleclix.wordpress.com/2010/06/12/a-path-throug-nosql-summer-reading/
– Explore more with the NOSQL AMI. Visit back for more hands on scripts
Referenced Links @ http://doubleclix.wordpress.com/2010/06/20/nosql-talk-references/

WHAT WORKS
Tales from the field
When I think of my own native land, In a moment I seem to be there;But, alas! recollection at hand
Soon hurries me back to despair.- Cowper, The Solitude Of Alexander SelKirk

• Designer Augmenting RDBMS with a Distributed key
Value Store[40 : A good talk by Geir]
• Invitation only designer brand sales
• Limited inventory sales – start at 12:00, members have
10 min to grab them. 500K mails every day
• Keeps brand value, hidden from search
• Interesting load properties
• Each item a row in DB-BUY NOW reserves it
– Can't order more
• Started out as a Rails app
– shared nothing
• Narrow peaks – half of revenue
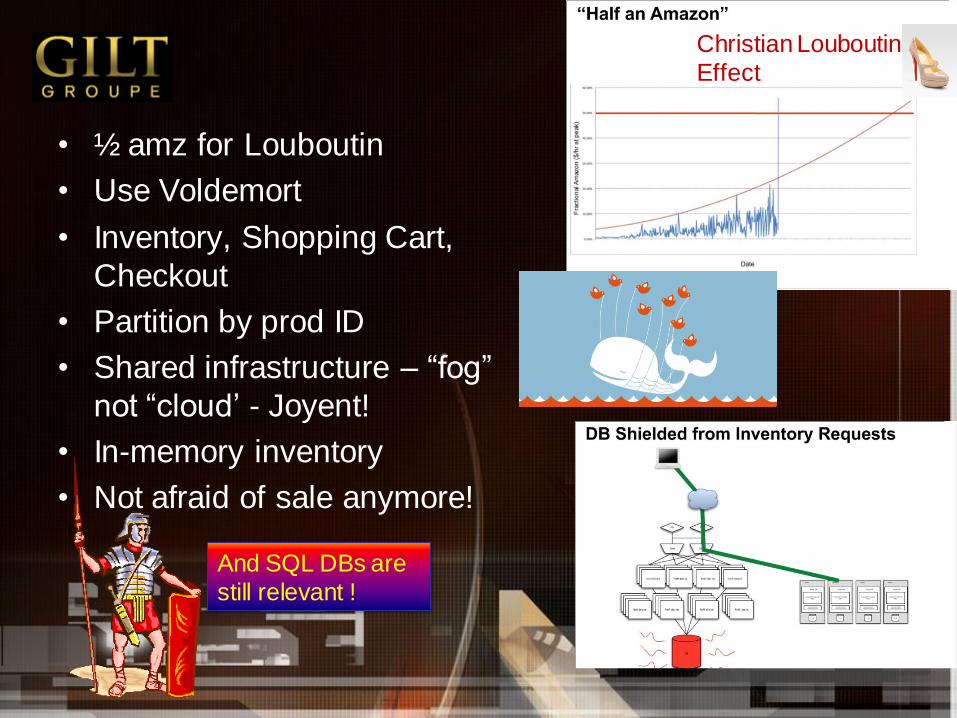
Christian Louboutin
Effect
• ½ amz for Louboutin
• Use Voldemort
• Inventory, Shopping Cart,
Checkout
• Partition by prod ID
• Shared infrastructure – “fog”
not “cloud‟ - Joyent!
• In-memory inventory
• Not afraid of sale anymore!
And SQL DBs are
still relevant !

Typical NOSQL Example Bit.ly
• Bit,ly URL shortening service, uses MongoDB
• User, title, URL, hash, labels[I-5], sort by time
• Scale – ~50M users, ~10K concurrent, ~1.25B shortens
per month
• Criteria:
– Simple, Zippy FAST, Very Flexible, Reasonable Durability, Low
cost of ownership
• Sharded by userid

• New kind of “dictionary” a word repository, GPS for
English – context, pronunciations, twitter … developer
API
• Characteristics[I-6,Tony Tam‟s presentation]
– RO-centric, 10,000 reads for every write
– Hit a wall with MySQL (4B rows)
– MongoDB read was so good that memcached layer was not
required
– MongoDB used 4 times MySQL storage
• Another example :
– Voldemort – Unified Communications, IPPhone data stored
keyed off of phone number. Data relatively stable

Large Hadron Collider@CERN
• DAS is part of giant data management
enterprise (cms)
– Polygot Persistence (SQL + NOSQL, Mongo, Couch,
memcache, HDFS, Luster, Oracle, mySQL, …)
• Data Aggregation System [I-1,I-2,I-3,I-4]
– Uses MongoDB
– Distributed Model, 2-6 pb data
– Combine info. from different metadata sources, query
without knowing their existence, user has domain
knowledge – but shouldn‟t deal with various formats,
interfaces and query semantics
– DAS aggregates, caches and presents data as JSON
documents – preserving security & integrity
And SQL DBs are
still relevant !

Scaling Twitter
•

• Digg
– RDBMS places burden on reads than writes[I-8]
– Looked at NOSQL, selected Cassandra
• Colum oriented, so more structure than key-value
• Heard from noSQL
Boston[http://twitter.com/#search?q=%23nosqllive]
– Baidu: 120 node HyperTable cluster managing
600TB of data
– StumbleUpon uses HBase for Analytics
– Twitter‟s Current Cassandra cluster: 45 nodes

• Adob is a HBase shop[I-10,I-
11,2]
• Adobe SaaS Infrastructure –
tagging, content aggregation,
search, storage and so forth
• Dynamic schema & huge
number of records[I-5]
• 40 million records in 2008 to
1 billion with 50 ms response
• NOSQL not mature in 2008,
now good enough
• Prod Analytics:40 nodes,
largest has 100 nodes
• BBC is a CouchDB shop[I-
13]
• Sweet spot:
• Multi-master, multi
datacenter replication
• Interactive Mediums
• Old data to CouchDB
• Thus free up DB to do
work!

• Cloudkick is a Cassandra shop[I-12]
• Cloudkick offers cloud management services
• Store metrics data
• Linear scalability for write load
• Massive write performance
• Memory table & serial commit log
• Low operational costs
• Data Structure
– Metrics, Rolled-up data, Statuses at time slice : all indexed by
timestamp

• Guardian/UK
– Runs on Redis[I-14] !
– “Long-term The Guardian is looking
towards the adoption of a schema-free
database to sit alongside its Oracle
database and is investigating CouchDB.
… the relational database is now just a
component in the overall data
management story, alongside data
caching, data stores, search engines
etc.
– NOSQL can increase performance of
relational data by offloading specific
data and tasks
And SQL DBs are
still relevant !
"The evil that SQL
DBs do lives after
them; the good is
oft interred with
their bones...",

Agenda• Session #1 – Opening Gambit
– 8:30-9:30 – NOSQL : Toil,Tears & Sweat !
• Quick look at Data Clouds
• NOSQL – An overview
• NOSQL – Tales from the field
NOSQL – Themes
– 9:30-10:00 – Detour/Scenic Route : MongoDB [HandsOn]
– 10:00-10:30 – Real break !
• Session #2 – The Pragmas– 10:30-11:15 – ABCs of NOSQL [ACID, BASE & CAP]
– 11:15-11:30 – Cassandra - Anatomy of a NOSQL Column Datastore
• Session #3 – The Mechanics– 11:30-12:30 – NOSQL How do they do it ? Algorithmics & Mechanisms
• End Game : Homework – NOSQL & Beer– Read NOSQL papers
• http://doubleclix.wordpress.com/2010/06/12/a-path-throug-nosql-summer-reading/
– Explore more with the NOSQL AMI. Visit back for more hands on scripts
Referenced Links @ http://doubleclix.wordpress.com/2010/06/20/nosql-talk-references/


21 NOSQL Themes• Web Scale• Scale Incrementally/continuous growth• Oddly shaped & exponentially connected• Structure data as it will be used – i.e. read, query• Know your queries/updates in advance[96], but you can change
them later• Compute attributes at run time• Create a few large entities with optional parts
– Normalization creates many small entities
• Define Schemas in models (not in databases)• Avoid impedance mismatch• Narrow down & solve your core problem• Solve the right problem with the right tool
Ref: [I-8]

21 NOSQL Themes• Existing solutions are clunky[1] (in certain situations)
• Scale automatically, “becoming prohibitively costly (in terms of manpower) to operate” Twitter[I-9]
• Distribution & partitioning are built-in NOSQL
• RDBMS distribution & sharding not fun and is expensive
– Lose most functionality along the way
• Data at the center, Flexible schema, Less joins
• The value of NOSQL is in flexibility as much as it is in 'big data’

21 NOSQL Themes• Requirements[3]
– Data will not fit in one node• And so need data partition/distribution by the system
– Nodes will fail, but data needs to be safe – replication!– Low latency for real-time use
• Data Locality– Row based structures will need to read whole row,
even for a column– Column based structures need to scan for each row
• Solution : Column storage with Locality – Keep data that is read together, don’t read what you
don’t care• For example friends – other data
Ref: 3

Scenic DetourNOSQL Hands-on
Document datastore
MongoDB
CouchDBThanks to Nosh Petigara & Roger
Bodamer, both at 10gen, for their help
in creating this tutorial
If a problem has no solution, it is not a problem, but a fact, not to be solved but to be coped with, over time …
- Peres’s Law

MongoDB
• Document Oriented – JSON
• Map/Reduce for aggregation & processing
• GridFS
• Database & collections
• Capped Collections
• Geo
• Work from CLI
• JavaScript Shell!
• Good summary in reference list [72,73]

MongoDB[61]
• Master-slave replication (as opposed to
master-master in CouchDB for example)
• Query in JSON-style objects
– QBE + $modifiers - $gt‟ 15 et al// „$in‟:[2,3,4]
– april_1 = new Date(2010, 3, 1)
– db.posts.find({date: {$gt: april_1}})
– B-Tree indexes
• Highly scalable
– BoxedIce has 981,000,000 records in MongoDB![63]
in 48,000 collections, 396GB data, 241GB Index

NOSQL Hands On
• Bring up EC2 AMI
– Refer AWS Setup in handout
– I also have posted 3 preliminary chapters from my book to help you
get started on aws
[http://doubleclix.files.wordpress.com/2010/07/buildingclouds.pdf]
• And, SSH into the instance
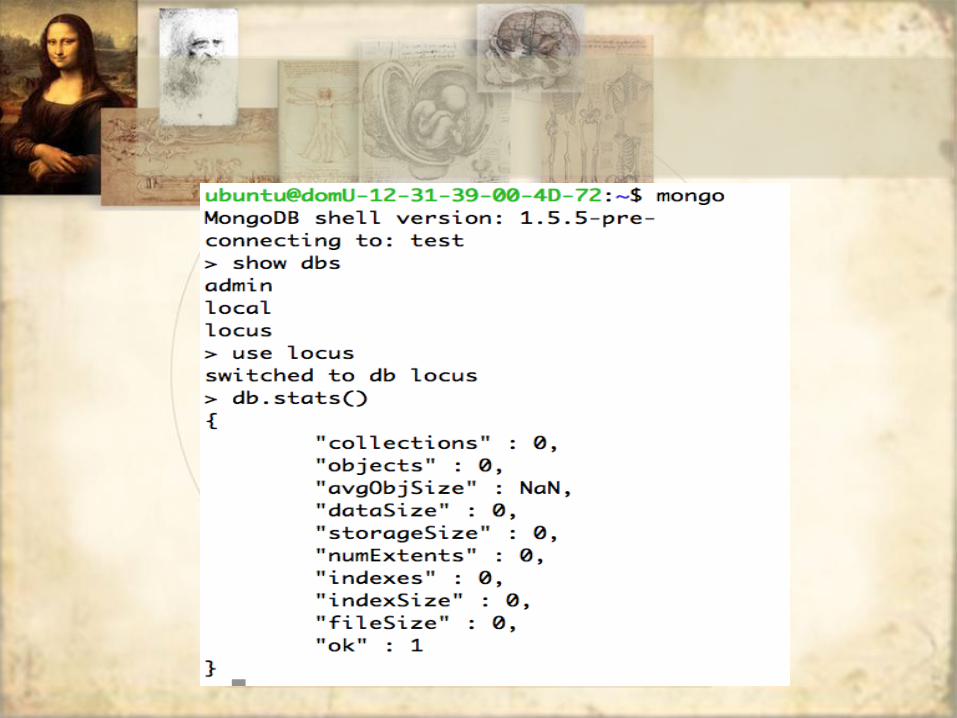

• The CLI is a full JavaScript interpreter
• Type any JavaScript commands
function loopTest() {
for (i=0;i<10;i++) {
print(i);
}
}

• See how the shell understands editing, multi-line and end of function
• loopTest will show the code
• loopTest() will run the function
• Other commands to try
– show dbs, use <dbname>, show collections, db,.help(), db.collections.help(), db.stats(), db.version()

Create & Insert a document
Use test
person = {“name”,”aname1”,”phone”:”555-1212”}
db.persons.insert(person)
db.persons.find()
db.persons.help()
db.persons.count()
Create 2 more documents
db.persons.insert({“name”,”aname2”,”phone”:”555-1313”})
db.persons.insert({“name”,”aname3”,”phone”:”555-1414”})

A word about _id
• Present in all documents
• Unique among collections
• Auto generated or you can generate your own
0 1 2 3 4 5 6 7 8 9 0 1Time Stamp m/c ID Process ID Counter

Embedded nested Documents
address = {“street”:”123,somestreet”,”City”:”Portland”,”state”:”WA”,”tags”:[“home”,”WA”]}
db.persons.update({“name”:”aname1”},address) – will replace
Need to use update modifier
db.persons.update({“name”:”aname2”},
{$set : address}) to add address

Embedded Nested Docs
• Discussion:
– Embedded docs are very versatile
– For example the collider could add more
data from another source with nested docs
and added metadata
– As mongo understands json structure, it can
index inside embedded docs. For example
address.state to update keys in embedded
docs

Interesting operations
• Upsert - Interesting feature (no need for find, create if !exists and
then update)
– db.persons.update({“name”:”xyz”},{“$inc”:{“checkins”:1}}) <- won‟t add
– db.runCommand({getLastError:1})
– { "err" : null, "updatedExisting" : false, "n" : 0, "ok" : 1 }
– db.persons.update({“name”:”xyz”}, {“$inc”:{“checkins”:1}},{“upsert”:
“true”}) <-will add
– db.runCommand({getLastError:1})
– {
– "err" : null,
– "updatedExisting" : false,
– "upserted" : ObjectId("4c44d8c0c7f562d8c720e33d"),
– "n" : 1,
– "ok" : 1
– }

Interesting operations
• Add a new field/update schema
– db.persons.update({},{“$set”:{“insertDate”:new Date()}})
– db.runCommand({getLastError:1})
-> { "err" : null, "updatedExisting" : true, "n" : 1, "ok" : 1 }
– db.persons.update({},{“$set”:{“insertDate”:new
Date()}},{“upsert”:”false”},{”multi”:”true”})
– db.runCommand({getLastError:1)
– { "err" : null, "updatedExisting" : true, "n" : 4, "ok" : 1 }

Locus!
• Goal is to develop location based/geospatial capability :
– Allow users to 'check in' at places
– Based on the location, recommend near-by
attractions
– Allow users to leave tips about places
– Do a few aggregate map-reduce operations like
“How many people are checked in at a place?” and
“List who is there” …
• But for this demo, we will implement a small slice :
Ability to checkin & show nearby soccer attractions
using a Java program

geoHashing[66]
• MongoDB implements geoHashing capability,
so that we can fine near-by places
– From an algorithmic perspective, geoHash is
implemented as grid index[66]
• Other ways are r-tree and quadtree [Homework!]
– Closer locations appear as close hashes[67]
– Longer a shared prefix is, the closer the places
are[68]
– The index is 2D
– Let us see hands on how this works …

• A quick DataModel
– Database : locus
– Collections:
• places – state, city, stadium, latlong
• checkin – name, when, latlong






• Quick walkthrough the Java Programs
– TestMongo1.java
– CheckIn.Java

MapReduce
• MapReduce
– Cron jobs on data stores
– Run them in background and query in real
time or run them on a slave (use -- slave --
master switch to start the slave)
– Faceted search
– Map reduce with verbose : true[70] & [71] & [74] have
good intro
– Reduce must be associative & idempotent

TERMINATE THE INSTANCE!
10:00

The Afterhours (NOSQL +
Beer) HomeWork !
• Add social graph based inference mechanisms
- MyNearby Friends
– When you check-in show if your friends are here
(either add friends to this site or based on their
facebook page using the OpenGraph API)
• We were here
– Show if their friends were here or nearby places the
friends visited
– Show pictures taken by friends when they were here

Break !10:00-10:30

ABCs of NOSQL -
ACID, BASE& CAP
The woods are lovely, dark, and deep, But I have promises to keep, And miles to go before I sleep, And miles to go before I sleep.
-Frost

ABCs of NOSQL
• ACID
o Atomicity, Consistency, Isolation & Durability – fundamental properties of SQL DBMS
• BASE[35,39]
o Basically Available Soft state(Scalable) Eventually Consistent
• CAP[36,39]
o Consistency, Availability & Partitioning
o This C is ~A+C• i.e. Atomic Consistency[36]

ACID
• Atomicity
o All or nothing
• Consistent
o From one consistent state to another• e.g. Referential Integrity
o But it is also application dependent on • e.g. min account balance
• Predicates, invariants,…
• Isolation
• Durability

CAP Pragmas
• Preconditionso The domain is scalable web apps
o Low Latency For real time use
o A small sub-set of SQL Functionality
o Horizontal Scaling
• Pritchett[35] talks about relaxing consistency across functional groups than within functional groups
• Idempotency to consider
o Updates inc/dec are rarely idempotent
o Order preserving trx are not idempotent either
o MVCC is an answer for this (CouchDB)

Consistency
• Strict Consistency
o Any read on Data X will return the most recent write on X[42]
• Sequential Consistency
oMaintains sequential order from multiple processes (No mention of time)
• Linearizability
o Add timestamp from loosely synchronized processes

Consistency
• Write availability, not read availability[44]
• Even load distribution is easier in eventually consistent systems
• Multi-data center support is easier in eventually consistent systems
• Some problems are not solvable with eventually consistent systems
• Code is sometimes simpler to write in strongly consistent systems

CAP Essentials – 1 of 3
• “CAP Principle → Strong Consistency, High Availability, Partition-resilience: Pick at most 2”[37]
• Which feature to discard depends on the nature of your system[41]
• C-A No P → Single DB server, no network partition
• C-P No A → Block transaction in case of partition failure
• A-P No C → Expiration based caching, voting majority

CAP Essentials – 2 of 3
• Yield vs. Harvest[37]
o Yield → Probability of completing a request
o Harvest → Fraction of data reflected in the response
• Some systems tolerate < 100% harvest (e.g search i.e. approximate answers OK) others need 100% harvest (e.g. Trx i.e. correct behavior = single well defined response)
• For sub-systems that tolerate harvest degradation, CAP makes sense

CAP Essentials – 3 of 3
• Trading Harvest for yield – AP
• Application decomposition & use NOSQL in appropriate sub-systems that has state management and data semantics that match the operational feature & impedance
o Hence NotOnly SQL not No SQL
o Intelligent homing to tolerate partition failures[44]
o Multi zones in a region (150 miles - 5 ms)
o Twitter tweets in Cassandra & MySQL
o BBC using MongoDB for offloading DBMS
o Polygot persistence at LHC@CERN

CAP Essentials – 3 of 3
• Trading Harvest for yield – AP
• Application decomposition & use NOSQL in appropriate sub-systems that has state management and data semantics that match the operational feature & impedance
o Hence NotOnly SQL not No SQL
o Intelligent homing to tolerate partition failures[44]
o Multi zones in a region (150 miles - 5 ms)
o Twitter tweets in Cassandra and MySQL
o BBC using MongoDB for offloading DBMS
o Polygot persistence at LHC@CERN
Most important
point in the whole
presentation

Eventual Consistency & AMZ
• Distribution Transparency[38]
• Larger distributed systems, network partitions are given
• Consistency Models
o Strong
o Weak
• Has an inconsistency window before update and guaranteed view
o Eventual
• If no new updates, all will see the value, eventually

Eventual Consistency & AMZ
• Guarantee variations[38]
o Read-Your-writes
o Session consistency
oMonotonic Read consistency
• Access will not return previous value
oMonotonic Write consistency
• Serialize write by the same process
• Guarantee order (vector clocks, mvcc)o Example : Amz Cart merger (let cart add even with partial
failure)

Eventual Consistency & AMZ - SimpleDB• SimpleDB strong consistency
semantics [49,50]
o Until Feb 2010, SimpleDB only supported eventual consistency i.e. GetAttributes after PutAttributesmight not be the same for some time (1 second)
oOn Feb 24, AWS Added ConsistentRead=True attribute for read
o Read will reflect all writes that got 200OK till that time!

Eventual Consistency & AMZ - SimpleDB
• SimpleDB strong consistency semantics [49,50]
o Also added conditional put/delete
o Put attribute has a specified value (Expected.1.Value=) or (Expected.1.Exists = true/false)
o Same conditional check capability for delete also
o Only on one attribute !

Eventual Consistency & AMZ – S3• S3 is an eventual consistency system
o Versioning
o “S3 PUT & COPY synchronously store data across multiple facilities before returning SUCCESS”
o Repair Lost redundancy, repair bit-rot
o Reduced Redundancy option for data that can be reproduced (99.999999999% vs. 99.99%)
• Approx 1/3rd less
o CloudFront for caching

!SQL ?
• “We conclude that the current RDBMS code lines, while attempting to be a “one size fits all” solution, in fact, excel at nothing. Hence, they are 25 year old legacy code lines that should be retired in favor of a collection of “from scratch” specialized engines.”[43]
• “Current systems were built in an era where resources were incredibly expensive, and every computing system was watched over by a collection of wizards in white lab coats, responsible for the care, feeding, tuning and optimization of the system. In that era, computers were expensive and people were cheap”
• “The 1970 - 1985 period was a time of intense debate, a myriad of ideas, & considerable upheaval. We predict the next fifteen years will have the same feel “

Further deliberation
• Daniel Abadi[45],Mike Stonebreaker[46], James Hamilton[47], Pat Hilland[48] are all good read for further deliberations

Cassandra
I AM monarch of all I survey;My right there is none to dispute;From the centre all round to the sea
I am lord of the fowl and the brute- Cowper, The Solitude Of Alexander SelKirk

Cassandra
• Started from facebook
• Now an Apache top Level project
• Very popular NOSQL
• Facebook, Twitter, Digg, Rackspace, SimpleGeo, …
• Distributed
• Symmetric
• “Always Writable”
• Value: Reliable & simple scale, large datasets
• Value : High Write Throughput– MySQL : ~300ms W, ~350ms R
– Cassandra : ~0.12ms W, ~15ms R
– But No Joins, No referential integrity

Cassandra
• Written in Java
• Client API
– Thrift
– Avro (Being worked on)
• Largest Cluster – 100 TB, 150 nodes[95]

Data Model• Of all the things, the data model is a little
confusing.
– But folks[78],[78a],[75],[79],[80],[100],[101],[102]&[103] have done a good
job explaining the concepts
• Cluster, KeySpaces, Column Family, Super
Column Family, Column
• In essence it is a 4 layered nested map/key-
value
– For example SuperColumn is nothing but a map of
columns with the key = column name[100]
• This nested key-value structure gives data
adjacency & data affinity properties which in the
SQL world requires joins, group by & so forth[102]

Cluster
Keyspace
Column
Family
Name
Value
TimeStamp
Column
Application~ Database
Record Collection/Nested Map(Separate file)
Attribute CollectionNested MapKey Column Column
Tuple or Attribute List
KeySuper Column
Column Column Column
Name Super Column
Column Column Column
Name
Server Cassandra –Data Model

Data Model
• “The columnfamily model shared by Cassandra
& HBase is inspired by the one described by
Google’s Bigtable paper, section 2“
• “Cassandra drops historical versions, and adds
supercolumns “
• “In both systems, you have rows & columns like
you are used to seeing, but the rows are sparse:
each row can have as many or as few columns
as desired, & columns do not need to be defined
ahead of time “[19]

Amazon Dynamo
•Consistent Hashing
•Partitioning
•Replication
Google BigTable
•Column Families
•Memtable
•SStables
• Eventual Consistency
• Knobs to tune tradeoff between consistency, durability and latency
• N – Number of Replicas
• W/R – Agree for success
• CL.Options– Zero
– Any
– One
– Quorum ((N/2)+1)
– All
Ref:[53]

Tunable Consistency Knobs
• Write
– W=0, asyncwrite (pray)
– W=1, wait for 1 write
– W=N, wait for all writes
• Read
– R=1, wait for one
– R=N, wait for all
• Quorum
• R/W = (N/2)+1
• R+W > N
W=2R=2
N=3• Prod Catalog et al
– R=1 (fast read)
– W=N (max replicas, reliable write)
• N – Number of Replicas
• W/R – Agree for success

NOSQL Internals & Algorithmics

Caveats• A representative subset of the mechanics and
mechanisms used in the NOSQL world
• Being refined & newer ones are being tried
• At a system level – to show how the techniques play a part to deliver a capability
• The NOSQL Papers and other references for further deliberation
• Even if we don’t cover fully, it is OK. I want to introduce some of the concepts so that you get an appreciation …

NOSQL Mechanics• Horizontal Scalability
– Gossip (Cluster membership)
– Failure Detection
– Consistent Hashing
– Replication Techniques
• Hinted Handoff
• Merkle Trees
– Sharding MongoDB
– Regions in HBase
• Performance
– SStables/memtables
– LSM w/Bloom Filter
• Integrity/Version reconciliation
– Timestamps
– Vector Clocks
– MVCC
– Semantic vs. syntactic reconciliation

Consistent Hashing• Origin: web caching “To decrease ‘hot
spots’
• Three goals[87]
– Smooth evolution
• When a new machine joins, minimum rebalance work and impact
– Spread
• Objects assigned to a min number of nodes
– Load
• # of distinct objects assigned to a node is small

Consistent Hashing• Hash Keyspace/Token is divided into partitions/ranges• Cassandra – choice
– OrderPreserving partitioner – key = token (for range queries)– Also saw a CollatingOrderPreservingPartitioner
• Partitions assigned to nodes that are logically arranged in a circle topology
• Amz (dynamo) – assign sets of (random) multiple points to different machines depending on load
• Cassandra – monitor load & distribute
• Specific join & leave protocols• Replication – next 3 consecutive• Cassandra – Rack-aware,
Datacenter-aware

Consistent Hashing - Hinted-handoff• What happens when a node is not available ?
– May be under load
– May be network partition
• Sloppy Quorum & Hinted-handoff
• R/W performed on the 1st n healthy nodes
• Replica sent to a host node with hint in metadata & then transferred when the actual node is up
• Burdens neighboring nodes
• Cassandra 0.6.2 default is disabled (I think)

Consistent Hashing - Replication• What happens when a new node
joins ?
– It gets one or more partitions
– Dynamo : Copy the whole partition
– Cassandra : Replicate keyset
– Cassandra : working on a bit torrent type protocol to copy from replicas

Anti-entropy• Merge and reconciliation operations
– Operate on two states and return a new state[86]
• Merkle Trees
– Dynamo use of Merkle trees to detect inconsistencies between replicas
– AntiEntropy in Cassandra exchanges Merkle trees and if they disagree, range repair via compaction[91,92]
– Cassandra uses the Scuttlebutt Reconciliation[86]

Gossip• Membership & Failure detection
• Based on emergence without rigidity –pulse coupled oscillators, biological systems like fireflies ![90]
• Also used for state propagation
– Used in Dynamo/Cassandra

Gossip• Cassandra exchanges heartbeat state, application state
and so forth
• Every second, random live node, random unreachable node and exchanges key-value structures
• Some nodes play the part of seeds
• Seed /initial contact points in static conf file storage.conf file
• Could also come from a configuration service like zookeeper
• To guard against node flap, explicit membership join and leave – now you know why hinted handoff was added

Membership & Failure detection• Consensus & Atomic Broadcast - impossible to
solve in a distributed system[88,89]
– Cannot differentiate between an slow system and a crashed system
• Completeness
– Every system that crashed will be eventually detected
• Correctness
– A correct process is never suspected
• In short, if you are dead somebody will notice it and if you are alive, nobody will mistake you for dead !

Ø Accrual Failure Detector• Not Boolean value but a probabilistic number that “accrues” over
an exponential scale
• Captures the degree of confidence that a corresponding monitored process has crashed[94]
– Suspicion Level
– Ø = 1 -> prob(error) 10%
– Ø = 2 -> prob(error) 1%
– Ø = 3 -> prob(error) 0.1%
• If process is dead,
– Ø is monotonically increasing & Ø→α as t →α
• If process is alive and kicking, Ø=0
• Account for lost messages, network latency and actual crash of system/process
• Well known heartbeat period Δi, then network latency Δtr can be
tracked by inter-arrival time modeling

Write/Read Mechanisms• Read & Write to a random node
(StorageProxy)
• Proxy coordinates the read and write strategy (R/W = any, quorum et al)
• Memtables/SSTables from big table
• Bloom Filter/Index
• LSM Trees

BF
Index
BF
Index
BF
Index
Commit Logs
MemTable
SSTable•Immutable•Compaction•Maintain Index & Bloom Filter
Node
Node
Flushing
Read
Write
Memory
Disk
Hbase – WAL, Memstore, HDFS File system

How… does HBase work again?
http://www.larsgeorge.com/2010/01/hbase-architecture-101-write-ahead-log.html
http://hbaseblog.com/2010/07/04/hug11-hbase-0-90-preview-wrap-up/

Bloom Filter• The BloomFilter answers the question
• “Might there be data for this key in this SSTable?” [Ref: Cassandra/Hbasemailer]
– “Maybe" or
– “Definitely not“
– When the BloomFilter says "maybe" we have to go to disk to check out the content of the SSTable
• Depends on implementation
– Redone in Cassandra
– Hbase 0.20.x removed, will be back in 0.90 with a “jazzy” implementation

Was it a vision, or a waking dream?Fled is that music:—do I wake or sleep?
-Keats, Ode to a Nightingale
Top Related