







Languages
Pages
Legal


Granular, Precached, & Under Budget
Alex Russell Software Engineer

Reliable Performance Matters

Arrivals
Loading...
4The need for mobile speed
Loading...
How fast should mobile sites be?People need mobile speed every day.
Imagine you’ve just landed at the airport in a new city for an important business meeting. Hurrying
through the terminal, you’re looking at your phone for a restaurant recommendation to take your client
to dinner. From baggage claim to the taxi line, only two pages load. What are you going to do?
Closing out slow-loading sites is something most people know well. The world’s fastest cars can go
from 0-60 in less than three seconds,4 but the majority of mobile sites don’t load that quickly.
Chapter 1
1 out of 2 people expect a page to load in less than 2 seconds6
4. Autosaur, “Fastest Car In The World: The Ultimate Guide” March, 20165. Google Data, Aggregated, anonymized Google Analytics data from a sample of mWeb sites opted into sharing benchmark data, n=3.7K, Global, March 20166. Akamai Technologies, “Consumer Web Performance Expectations Survey”, 2014
53% of visits are abandoned if a mobile site takes more than three seconds to load5

60%goo.gl/fDkY1g
almost
of mobile is 2G
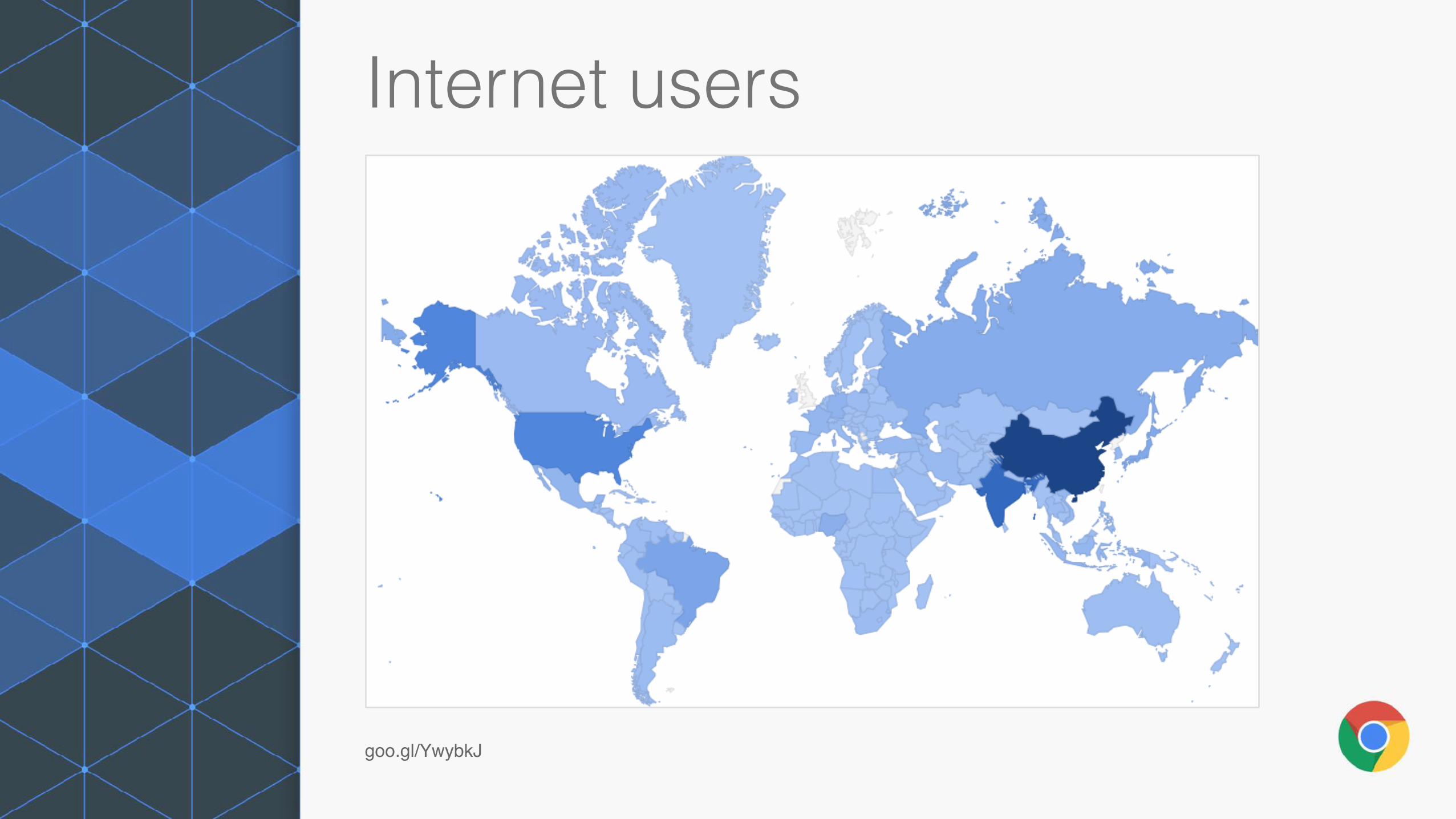
Internet users
goo.gl/YwybkJ
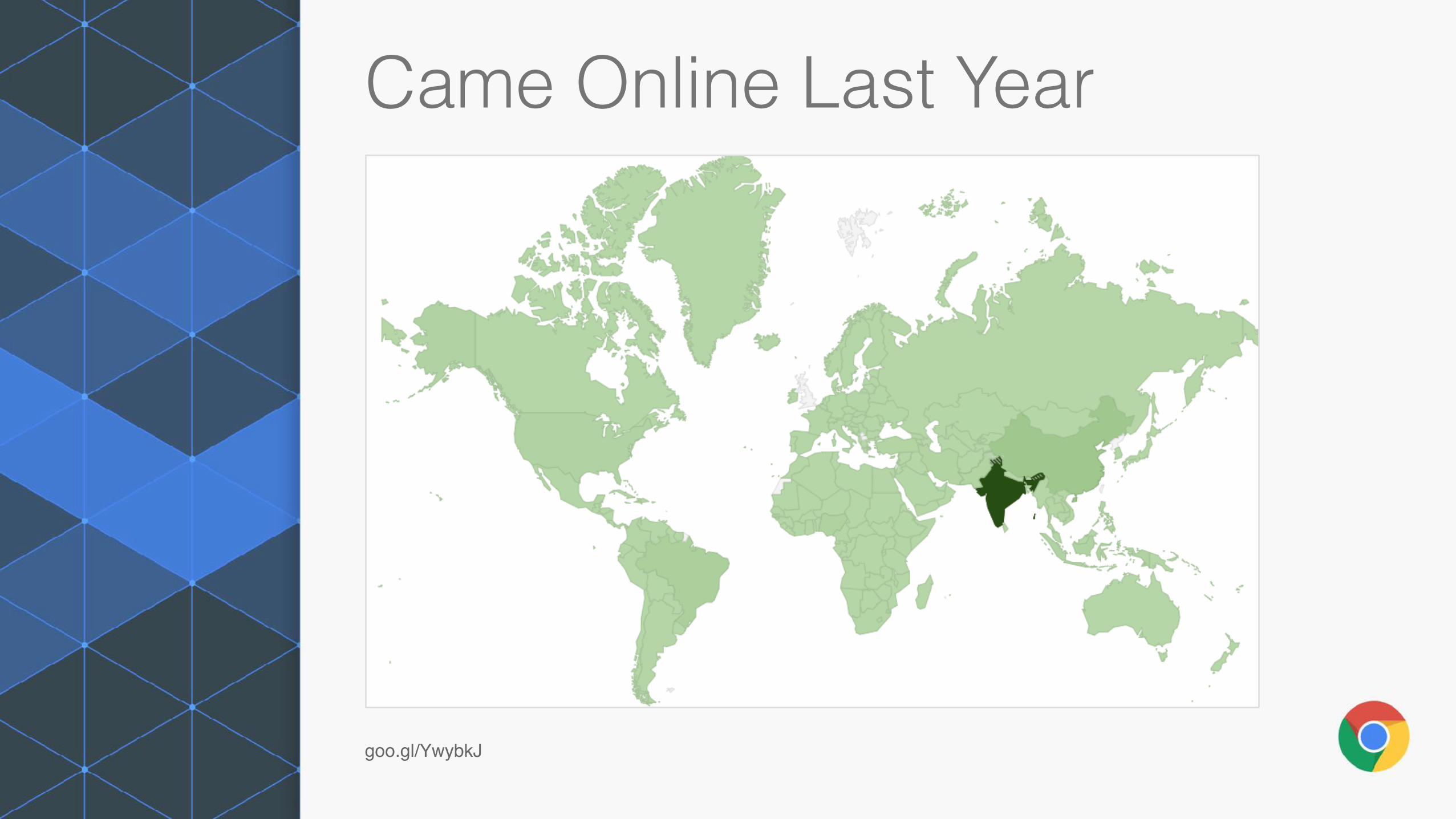
Came Online Last Year
goo.gl/YwybkJ
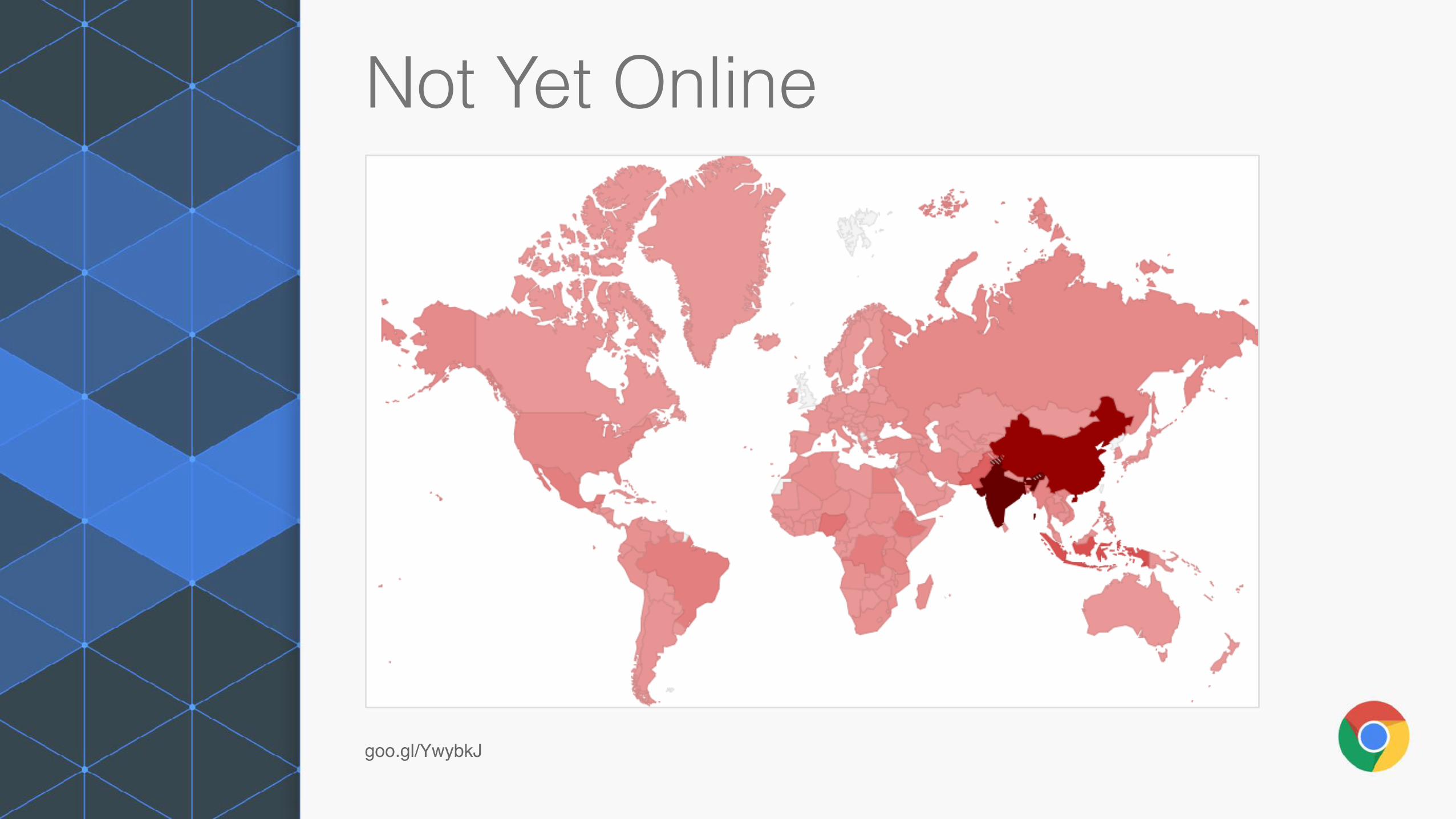
Not Yet Online
goo.gl/YwybkJ

!Respond: 100ms !Animate: 8ms !Idle work: 50ms chunks !Load: 1000ms to interactive

mobile and desktop web usage

Appears in the Proceedings of the 38th International Symposium on Computer Architecture (ISCA ’11)
Dark Silicon and the End of Multicore Scaling
Hadi Esmaeilzadeh† Emily Blem‡ Renée St. Amant§ Karthikeyan Sankaralingam‡ Doug Burger⇧†University of Washington ‡University of Wisconsin-Madison§The University of Texas at Austin ⇧Microsoft Research
[email protected] [email protected] [email protected] [email protected] [email protected]
ABSTRACTSince 2005, processor designers have increased core counts to ex-ploit Moore’s Law scaling, rather than focusing on single-core per-formance. The failure of Dennard scaling, to which the shift to mul-ticore parts is partially a response, may soon limit multicore scalingjust as single-core scaling has been curtailed. This paper modelsmulticore scaling limits by combining device scaling, single-corescaling, and multicore scaling to measure the speedup potential fora set of parallel workloads for the next five technology generations.For device scaling, we use both the ITRS projections and a setof more conservative device scaling parameters. To model single-core scaling, we combine measurements from over 150 processorsto derive Pareto-optimal frontiers for area/performance and pow-er/performance. Finally, to model multicore scaling, we build a de-tailed performance model of upper-bound performance and lower-bound core power. The multicore designs we study include single-threaded CPU-like and massively threaded GPU-like multicore chiporganizations with symmetric, asymmetric, dynamic, and composedtopologies. The study shows that regardless of chip organizationand topology, multicore scaling is power limited to a degree notwidely appreciated by the computing community. Even at 22 nm(just one year from now), 21% of a fixed-size chip must be poweredo↵, and at 8 nm, this number grows to more than 50%. Through2024, only 7.9⇥ average speedup is possible across commonly usedparallel workloads, leaving a nearly 24-fold gap from a target ofdoubled performance per generation.Categories and Subject Descriptors: C.0 [Computer Systems Or-ganization] General — Modeling of computer architecture; C.0[Computer Systems Organization] General — System architecturesGeneral Terms: Design, Measurement, PerformanceKeywords: Dark Silicon, Modeling, Power, Technology Scaling,Multicore
1. INTRODUCTIONMoore’s Law [24] (the doubling of transistors on chip every 18
months) has been a fundamental driver of computing. For the pastthree decades, through device, circuit, microarchitecture, architec-
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.ISCA’11, June 4–8, 2011, San Jose, California, USA.Copyright 2011 ACM 978-1-4503-0472-6/11/06 ...$10.00.
ture, and compiler advances, Moore’s Law, coupled with Dennardscaling [11], has resulted in commensurate exponential performanceincreases. The recent shift to multicore designs has aimed to in-crease the number of cores along with transistor count increases,and continue the proportional scaling of performance. As a re-sult, architecture researchers have started focusing on 100-core and1000-core chips and related research topics and called for changesto the undergraduate curriculum to solve the parallel programmingchallenge for multicore designs at these scales.
With the failure of Dennard scaling–and thus slowed supply volt-age scaling–core count scaling may be in jeopardy, which wouldleave the community with no clear scaling path to exploit contin-ued transistor count increases. Since future designs will be powerlimited, higher core counts must provide performance gains despitethe worsening energy and speed scaling of transistors, and giventhe available parallelism in applications. By studying these charac-teristics together, it is possible to predict for how many additionaltechnology generations multicore scaling will provide a clear ben-efit. Since the energy e�ciency of devices is not scaling along withintegration capacity, and since few applications (even from emerg-ing domains such as recognition, mining, and synthesis [5]) haveparallelism levels that can e�ciently use a 100-core or 1000-corechip, it is critical to understand how good multicore performancewill be in the long term. In 2024, will processors have 32 times theperformance of processors from 2008, exploiting five generationsof core doubling?
Such a study must consider devices, core microarchitectures,chip organizations, and benchmark characteristics, applying areaand power limits at each technology node. This paper consid-ers all those factors together, projecting upper-bound performanceachievable through multicore scaling, and measuring the e↵ects ofnon-ideal device scaling, including the percentage of “dark silicon”(transistor under-utilization) on future multicore chips. Additionalprojections include best core organization, best chip-level topology,and optimal number of cores.
We consider technology scaling projections, single-core designscaling, multicore design choices, actual application behavior, andmicroarchitectural features together. Previous studies have alsoanalyzed these features in various combinations, but not all to-gether [8, 9, 10, 15, 16, 21, 23, 28, 29]. This study builds andcombines three models to project performance and fraction of “darksilicon” on fixed-size and fixed-power chips as listed below:
• Device scaling model (DevM): area, frequency, and powerrequirements at future technology nodes through 2024.• Core scaling model (CorM): power/performance and area/
performance single core Pareto frontiers derived from a largeset of diverse microprocessor designs.• Multicore scaling model (CmpM): area, power and perfor-

28nm, FML

medium.com/reloading/javascript-start-up-performance-69200f43b201


mobile.httparchive.org/trends.php?s=Top1000



twitter.com/notwaldorf/status/778248810371747840

Nexus 5X
SOC, Memory, Radio

CPU is UNDERNEATH the memory module
Nexus 5X
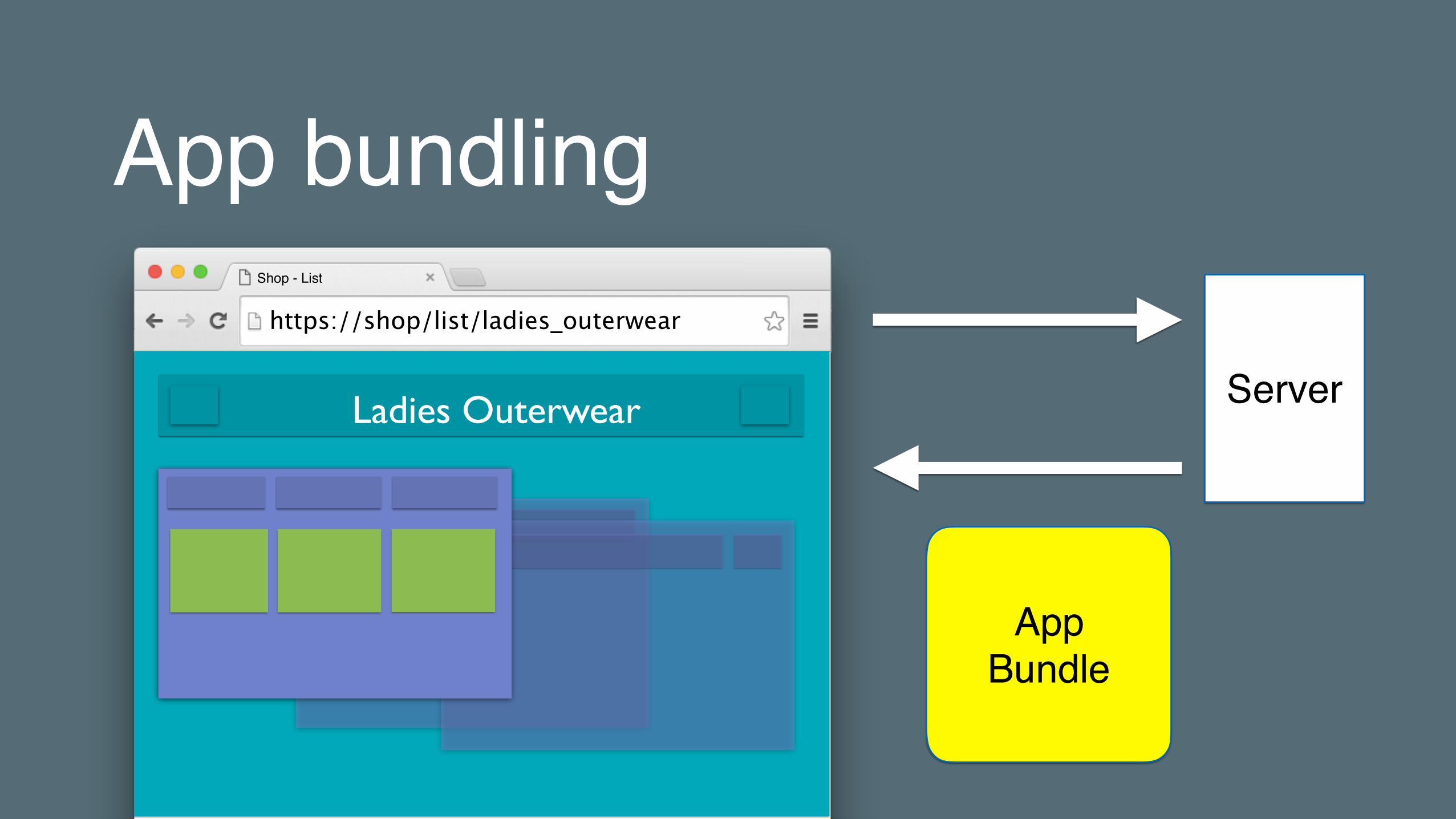
App bundling
AppBundle
https://shop/list/ladies_outerwear
Shop - List
Ladies Outerwear Server

Per-route bundlinghttps://shop/list/ladies_outerwear
Shop - List
Ladies Outerwear Server
list
button
tabs
Optimal /list bundle

https://shop/cart
Shop - Cart
Per-route bundling
Server
list
button
icon-button
Shopping Cart
Optimal /cart bundle
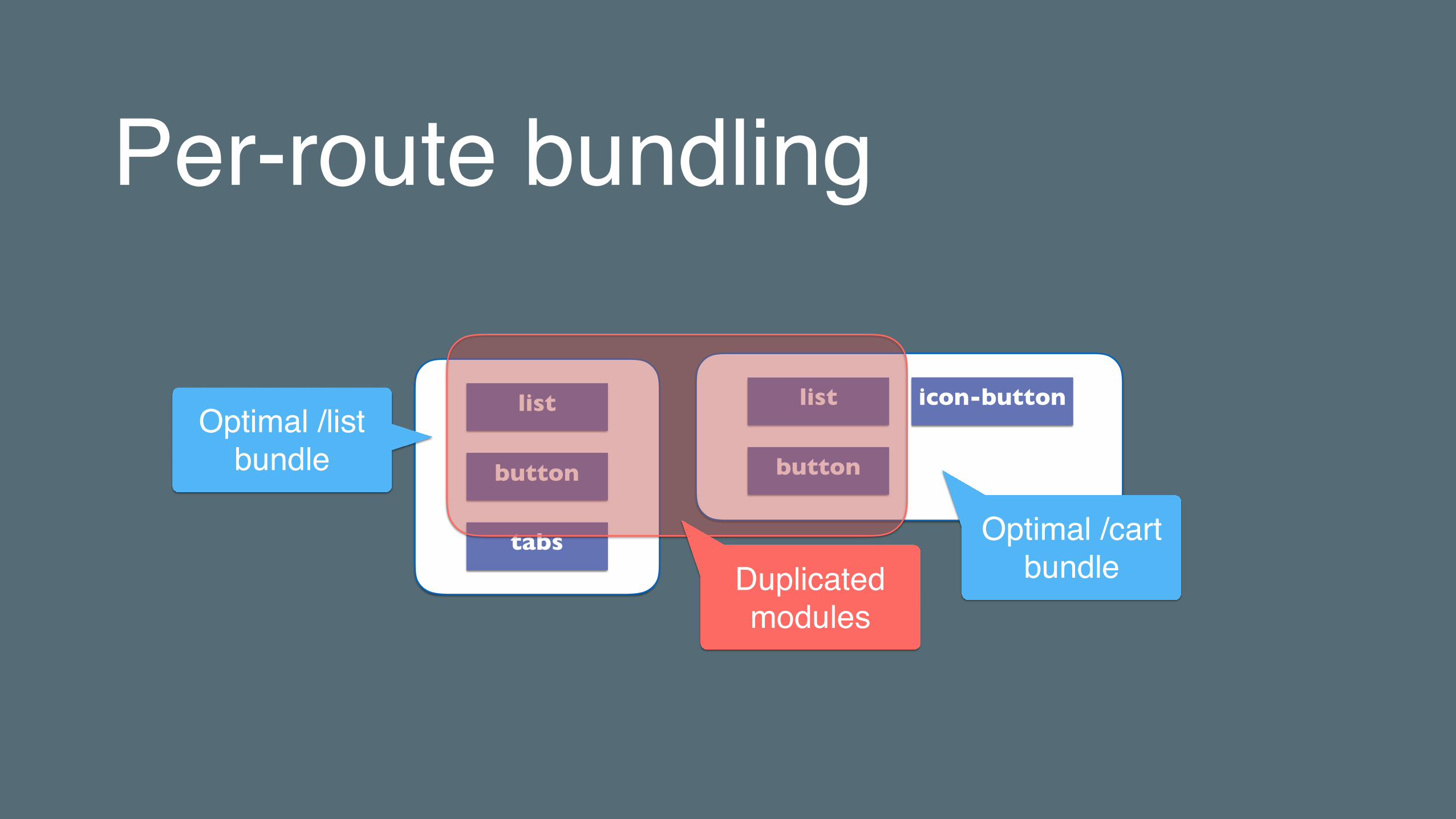
Per-route bundling
list
button
icon-button
Optimal /cart bundle
list
button
tabs
Optimal /list bundle
Duplicated modules
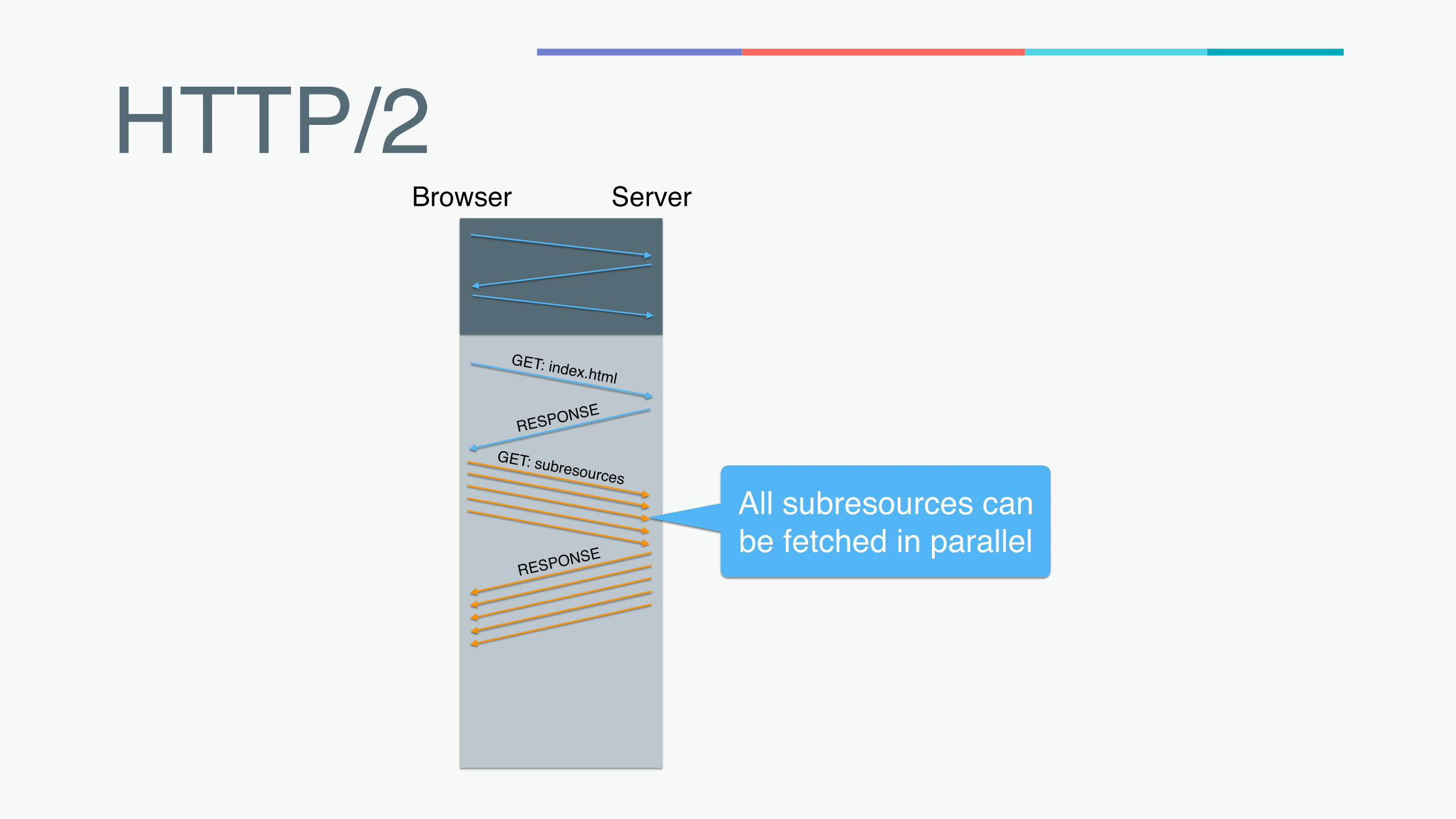
Browser Server
All subresources can be fetched in parallel
RESPONSE
GET: index.html
GET: subresources
RESPONSE
HTTP/2

RESPONSE
GET: index.html
Browser Server
GET: subresources
RESPONSETransitive dependencies discovered & requested
RESPONSE
GET: subresources
HTTP/2

GET: index.html
Browser Server
RESPONSE
Transitive dependencies preemptively pushed
HTTP/2 + Server Push
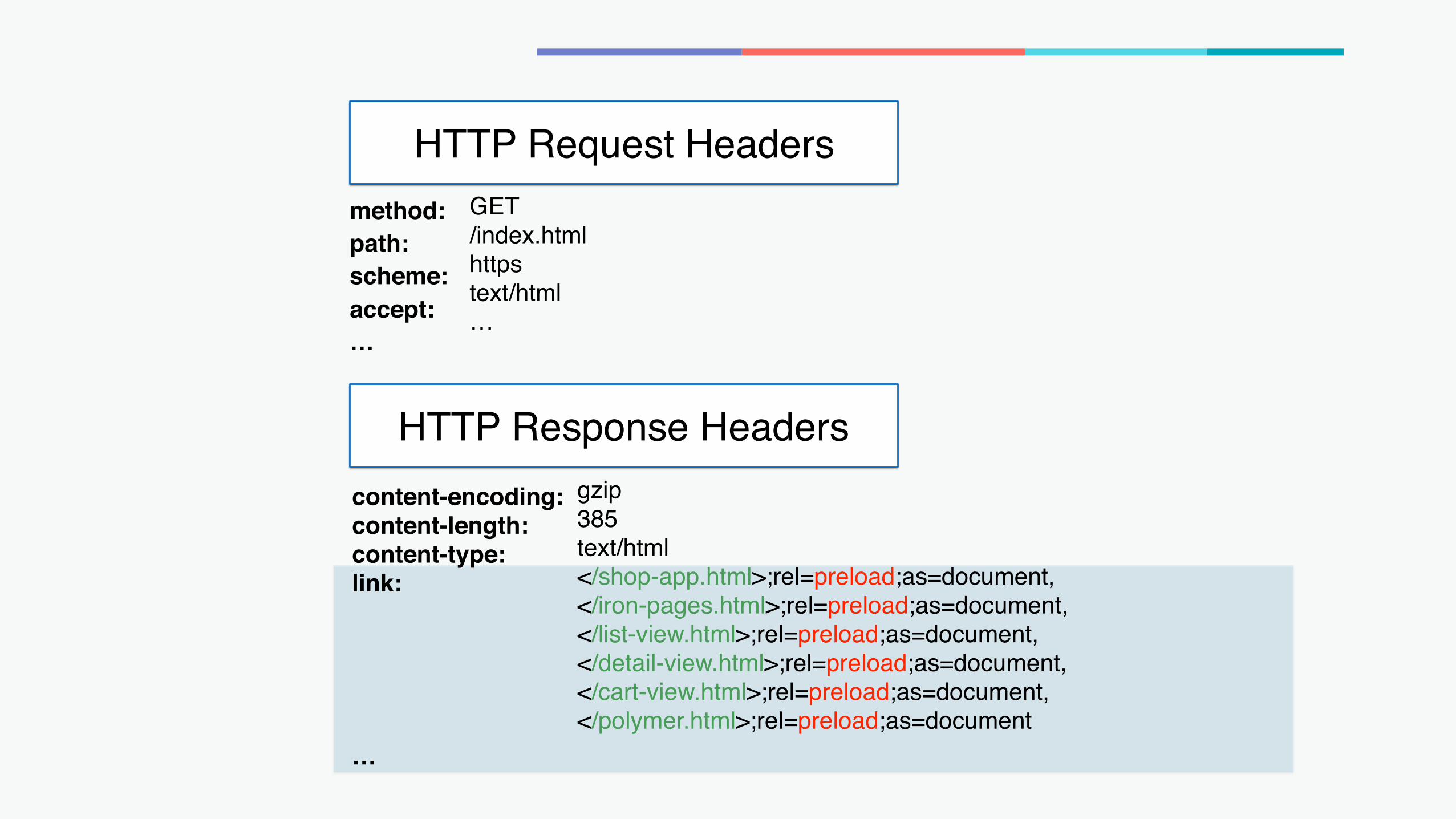
Response Headers:
content-encoding:content-length:content-type:link:
…
gzip385text/html</shop-app.html>;rel=preload;as=document,</iron-pages.html>;rel=preload;as=document,</list-view.html>;rel=preload;as=document,</detail-view.html>;rel=preload;as=document,</cart-view.html>;rel=preload;as=document,</polymer.html>;rel=preload;as=document
method:path:scheme:accept:…
GET/index.htmlhttpstext/html…
HTTP Request Headers
HTTP Response Headers
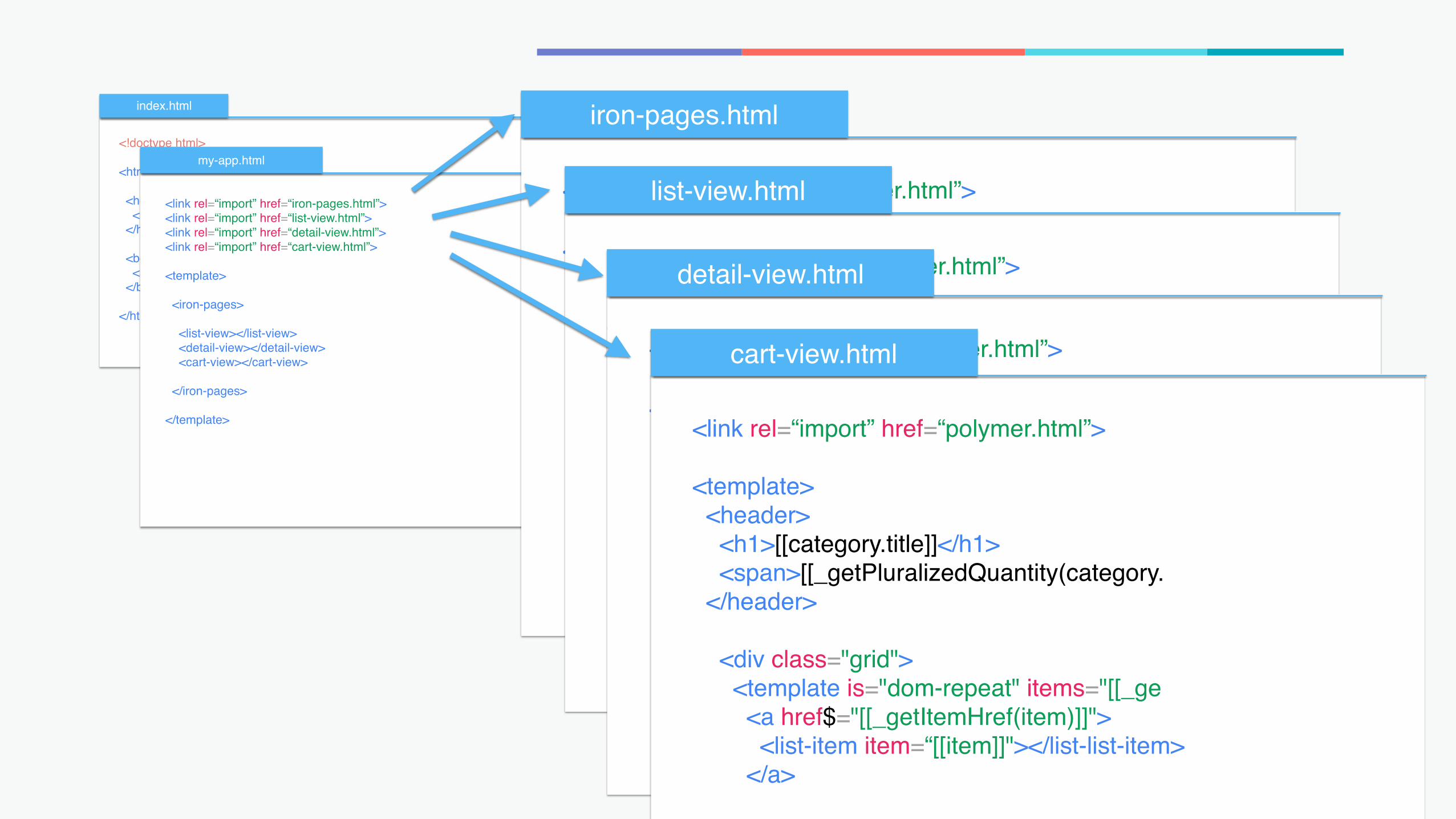
<link rel=“import” href=“polymer.html”>
<link rel=“import” href=“iron-pages.html”><link rel=“import” href=“list-view.html”><link rel=“import” href=“detail-view.html”><link rel=“import” href=“cart-view.html”>
<link rel=“import” href=“shop-app.html”>
index.html
<!doctype html>
<html>
<head> <link rel=“import” href=“shop-app.html”> </head>
<body> <shop-app></shop-app> </body>
</html>
my-app.html
<link rel=“import” href=“iron-pages.html”><link rel=“import” href=“list-view.html”><link rel=“import” href=“detail-view.html”><link rel=“import” href=“cart-view.html”>
<template>
<iron-pages>
<list-view></list-view> <detail-view></detail-view> <cart-view></cart-view>
</iron-pages>
</template>
iron-pages.html
<link rel=“import” href=“polymer.html”>
<template>
list-view.html
<link rel=“import” href=“polymer.html”>
<template>
detail-view.html
<link rel=“import” href=“polymer.html”>
<template>
cart-view.html
<link rel=“import” href=“polymer.html”>
<template> <header> <h1>[[category.title]]</h1> <span>[[_getPluralizedQuantity(category. </header>
<div class="grid"> <template is="dom-repeat" items="[[_ge <a href$="[[_getItemHref(item)]]"> <list-item item=“[[item]]"></list-list-item> </a>

<link rel=“import” href=“iron-pages.html”><link rel=“import” href=“list-view.html”><link rel=“import” href=“detail-view.html”><link rel=“import” href=“cart-view.html”>
<link rel=“import” href=“shop-app.html”>
<link rel=“import” href=“polymer.html”>
Response Headers:
link: </shop-app.html>;rel=preload;as=document,</iron-pages.html>;rel=preload;as=document,</list-view.html>;rel=preload;as=document,</detail-view.html>;rel=preload;as=document,</cart-view.html>;rel=preload;as=document,</polymer.html>;rel=preload;as=document

tabs
button
list…
Cold cache:Only load code
critical for /list route
icon-buttoniconheaderdrawer
1. Push components for initial route
https://shop/list
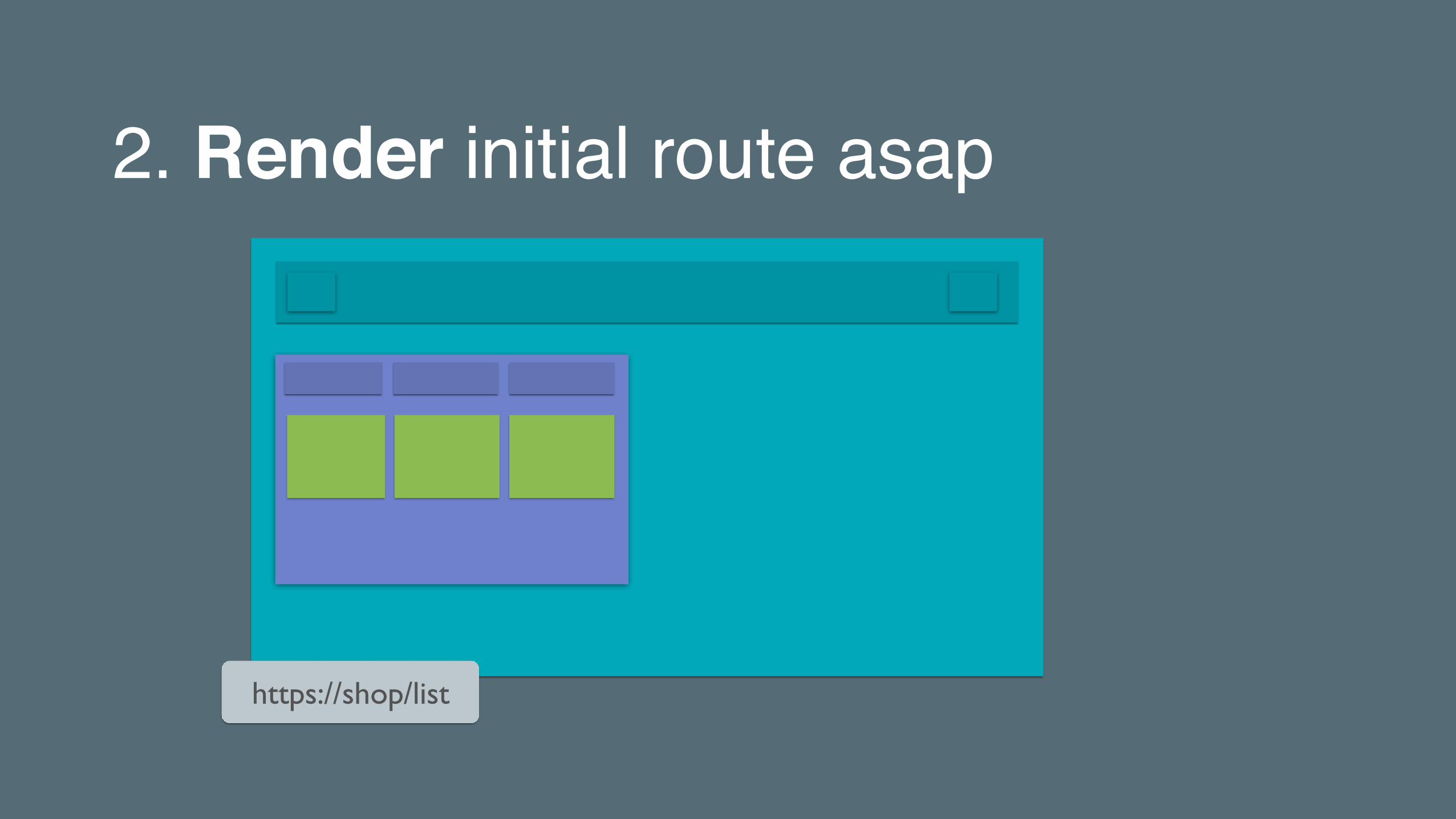
2. Render initial route asap
https://shop/list

3. Pre-cache remaining components
……
Code for secondary routes pre-cached
lazily
https://shop/list

4. Lazy load & create secondary route
https://shop/cart

PushRender
Pre-cacheLazy-load
resources for initial routethe initial route asap
code for remaining routes& create next routes on-demand
The PRPL Pattern

Ok, So What’s New?



Automated Code Splitting!

Thank You!+AlexRussell @slightlylate

Top Related