







Languages
Pages
Legal


26 Trillion App Recommendation using100 Lines of Spark Code
Ayman Farahat

●Motivation
●Spark Implementation
○ Collabrative Filtering
○ Data Frames
○ BLAS-3
●Results and lessons learnt.
Overview

●App discovery is a challenging problem due to the exponential
growth in number of apps
●Over 1.5 million apps available through both market places (i.e.
Itunes and Google Play store)
●Develop app recommendation engine using various user
behavior signals
○Explicit Signal (App rating)
○Implicit Signal (frequency/duration of app usage)
Motivation

●Data available through Flurry SDK is rich in both coverage
and depth
●Collected session length for Apps used on IOS platform in
period between Sept 1-15 2015 .
●Restricted analysis to Apps used by 100 or more users
○~496 million Users
○~53,793 Apps
Flurry Data and Summary

●User Count : 496,508,312
●App Count : 153,773
●App 100+ : 53,793
●Train time : 52 minutes
●Predict time : 8 minutes
Data Summary

●Utilize a collaborative filtering based App recommendation
●Run collaborative filtering that works at scale to generate:
○Low dimension user features
○Low dimension App features
○Compute user x App rating for all possible
combinations (26.7 Trillion)
●Used spark framework to efficiently train and recommend.
Our Approach
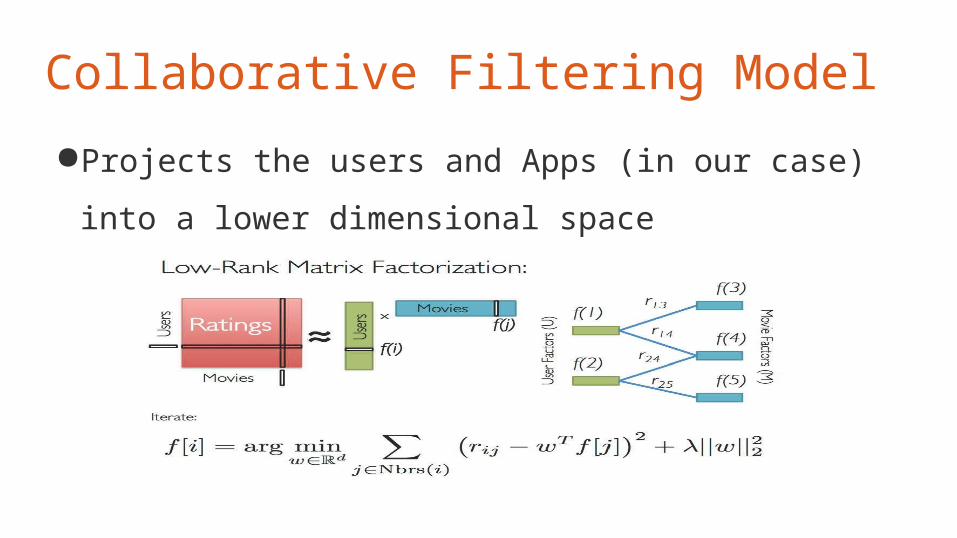
●Projects the users and Apps (in our case) into a lower
dimensional space
Collaborative Filtering Model

●Used out of sample prediction accuracy on 20+ Apps Users
●The MSE was minimum with number of factors fixed at 60
Model Fitting and Parameter Optimization

●Join operation can greatly benefit from caching.
●Filter out Apps that have less than 100 userscleandata = allapps.join(cleanapps)
●Do a replicated join in Spark #only keep the apps that had 100 or more usercleanapps = myapps.filter(lambda x :x[1] > MAXAPPS).map(lambda x: int(x[0]))#persist the apps dataapps = sc.broadcast(set(cleanapps.collect()))# filter by the data set: I have simulated a replicated join cleandata = allapps.filter(lambda x: x[1] in apps.value)
Data Frames

●In spark you can use a dataframe directly Record = Row("userId", "iuserId", "appId", "value")MAXAPPS = 100#transform allapps to a df allappsdf = allapps.map(lambda x: Record(*x)).toDF()
# register the DF and issue SQL queriessqlContext.registerDataFrameAsTable(allappdf, "table1")#here I am grouing by the AppIDdf2 = sqlContext.sql("SELECT appId as appId2, avg(value), count(*) from table1 group by appId")topappsdf = df2.filter(df2.c2 >MAXAPPS)
#DF joincleandata = allappsdf.join(topappsdf, allapps.appId == topappdf.appId2)
Data Frames

●The number of possible user x App combinations is very large
Default prediction : PredictAll○predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2]))
○Prediction is simply matrix multiplication of user “i” and App “j”
●Never completes and most of time spent on reshuffle.
●The users are not partioned so can be on all Nodes.
●The Apps are not partioned so can be on all Nodes.
●Reshuffle is extremely slow.
BLAS 3

●The key is that the Number of Apps << Number of users
●Exploit the low number of Apps to optimize the prediction time
BLAS 3

●The App features being smaller in size can be stored in
primary memory (BLAS 3)
●We broadcast the Apps to all executors, which reduces the
overall reshuffling of data
●use BLAS-3 matrix multiplication available within numpy which
is highly optimized
BLAS 3

Basic linear algbera system for solving problems of the form
D = a A * b B + c C
Highly optimized for matrix multiplication.
BLAS 3

import numpy
from numpy import *
myModel=MatrixFactorizationModel.load(sc, "BingBong”)
m1 = myModel.productFeatures()
m2 = m1.map(lambda (product,feature) : feature).collect()
m3 = matrix(m2).transpose()
pf = sc.broadcast(m3)
uf = myModel.userFeatures().coalesce(100)
#get predictions on all user
f1 = uf.map(lambda (userID, features): (userID, squeeze(asarray(matrix(array(features)) * pf.value))))
BLAS 3

Evaluation :Predicted Score
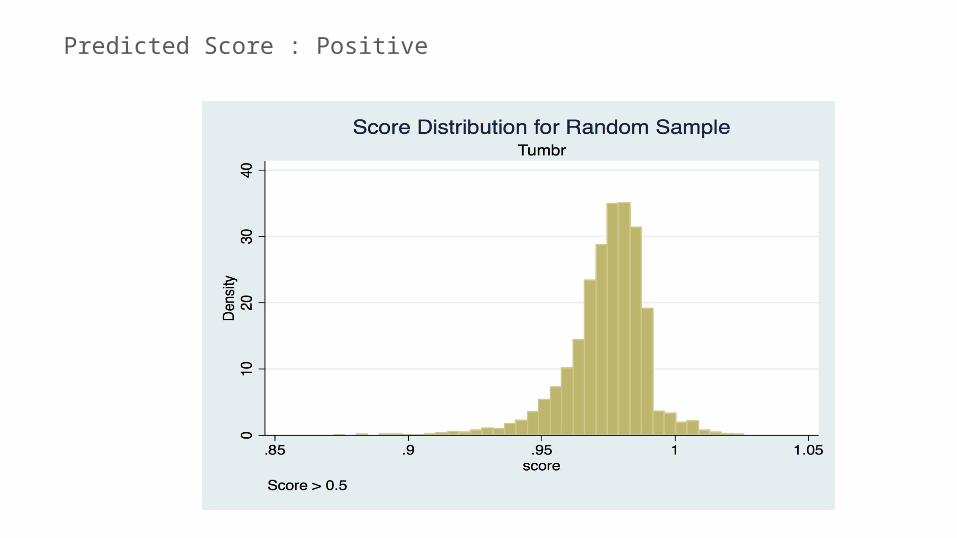
Predicted Score : Positive
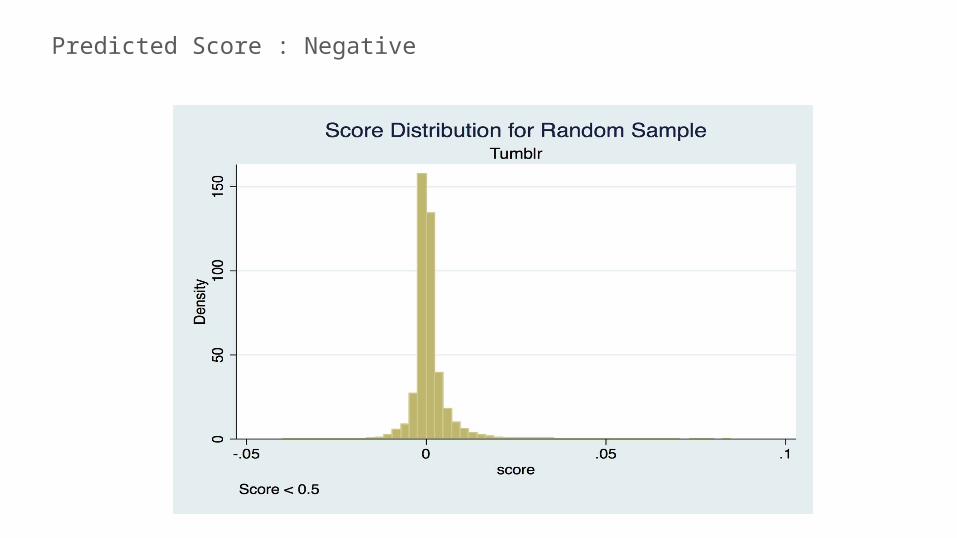
Predicted Score : Negative

Evaluation of Recommendation● Identify users with high(low) scores
● Design of experiment :
● High score x Recommendation
● High score x Placebo
● Low score x Recommendation
● High score x Placebo

Future Work● Spark econometrics library (std. error, robust std. errors.. )
● Online experiments to measure value of recommendation .
● Experiments with various implicit ratings :
● number of sessions
● days used
● Log of days used

Top Related