







Languages
Pages
Legal


@Carnegie MellonDatabases
Improving Hash Join Performance Through Prefetching
Shimin Chen
Phillip B.
GibbonsTodd C. Mowry
Anastassia
Ailamaki‡
Carnegie Mellon University
Intel Research Pittsburgh
‡

- 2 -@Carnegie Mellon
Databases
Hash Join
Simple hash join: Build hash table on smaller (build) relation Probe hash table using larger (probe) relation
Random access patterns inherent in hashing
Excessive random I/Os If build relation and hash table cannot fit in
memory
Build Relation
Probe Relation
Hash Table

- 3 -@Carnegie Mellon
Databases
I/O Partitioning
Avoid excessive random disk accesses
Join pairs of build and probe partitions separately
Sequential I/O patterns for relations and partitions
Hash join is CPU-bound with reasonable I/O bandwidth
Build Probe

- 4 -@Carnegie Mellon
Databases
Partition: divides a 1GB relation into 800 partitions Join: 50MB build partition 100MB probe partition Detailed simulations based on Compaq ES40 system
Most of execution time is wasted on data cache misses
82% for partition, 73% for join Because of random access patterns in memory
Hash Join Cache Performance

- 5 -@Carnegie Mellon
Databases
Cache partitioning: generating cache-sized partitions
Effective in main-memory databases [Shatdal et al., 94], [Boncz et al., 99], [Manegold et al.,00]
Two limitations when used in commercial databases1) Usually need additional in-memory partitioning pass
Cache is much smaller than main memory 50% worse than our techniques
2) Sensitive to cache sharing by multiple activities
Employing Partitioning for Cache?
Main MemoryCPU
Cache
Build Partition
Hash Table

- 6 -@Carnegie Mellon
Databases
Our Approach: Cache Prefetching
Modern processors support: Multiple cache misses to be serviced simultaneously Prefetch assembly instructions for exploiting the parallelism
Overlap cache miss latency with computation Successfully applied to
Array-based programs [Mowry et al., 92] Pointer-based programs [Luk & Mowry, 96] Database B+-trees [Chen et al., 01]
Main MemoryCPUL2/L3CacheL1
Cache
pref 0(r2)pref 4(r7)pref 0(r3)pref 8(r9)

- 7 -@Carnegie Mellon
Databases
Challenges for Cache Prefetching
Difficult to obtain memory addresses early Randomness of hashing prohibits address prediction Data dependencies within the processing of a tuple Naïve approach does not work
Complexity of hash join code Ambiguous pointer references Multiple code paths Cannot apply compiler prefetching techniques

- 8 -@Carnegie Mellon
Databases
Our Solution
Dependencies are rare across subsequent tuples
Exploit inter-tuple parallelism Overlap cache misses of one tuple
with computation and cache misses of other tuples
We propose two prefetching techniques Group prefetching Software-pipelined prefetching

- 9 -@Carnegie Mellon
Databases
Outline
Overview
Our Proposed Techniques Simplified Probing Algorithm Naïve Prefetching Group Prefetching Software-Pipelined Prefetching Dealing with Complexities
Experimental Results
Conclusions

- 10 -@Carnegie Mellon
Databases
Simplified Probing Algorithm
foreach probe tuple{ (0)compute bucket number; (1)visit header; (2)visit cell array; (3)visit matching build tuple;}
HashBucket
Headers
Hash Cell (hash code, build tuple ptr)
BuildPartition

- 11 -@Carnegie Mellon
Databases
Naïve Prefetching
foreach probe tuple{ (0)compute bucket number;
prefetch header;
(1)visit header; prefetch cell array;
(2)visit cell array; prefetch matching build tuple;
(3)visit matching build tuple;}
0
1
2
30
1
2
30
1
2
3
tim
e
Cache miss latency
Data dependencies make it difficult to obtain addresses early
- 12 -@Carnegie Mellon
Databases
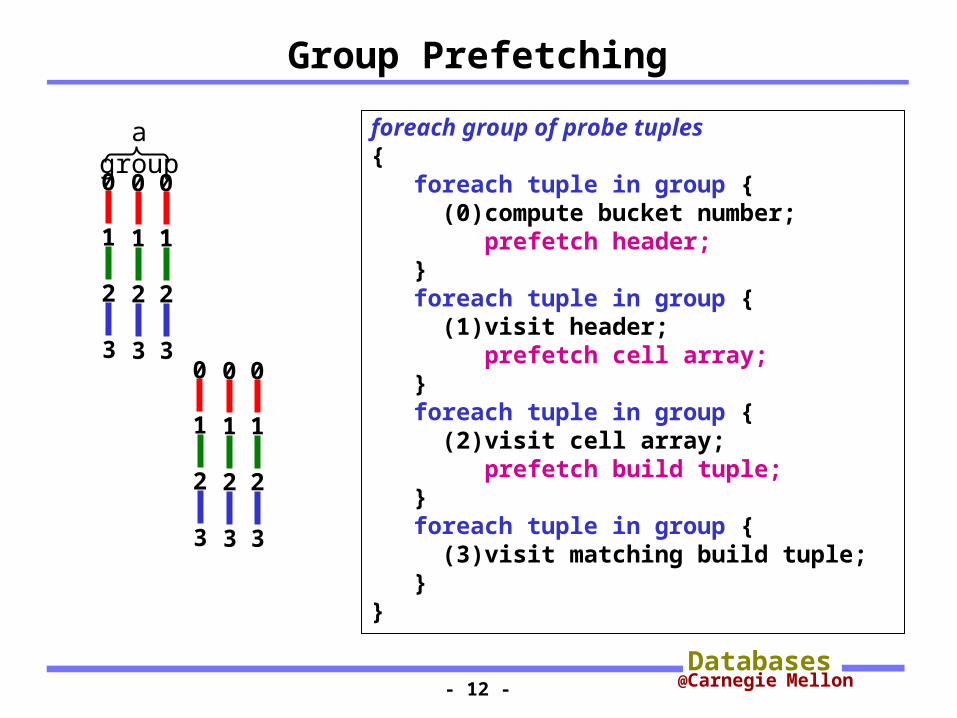
Group Prefetching
foreach group of probe tuples { foreach tuple in group { (0)compute bucket number; prefetch header; } foreach tuple in group { (1)visit header; prefetch cell array; } foreach tuple in group { (2)visit cell array; prefetch build tuple; } foreach tuple in group { (3)visit matching build tuple; }}
0
1
2
3
0
1
2
3
0
1
2
30
1
2
3
0
1
2
3
0
1
2
3
a group
- 13 -@Carnegie Mellon
Databases
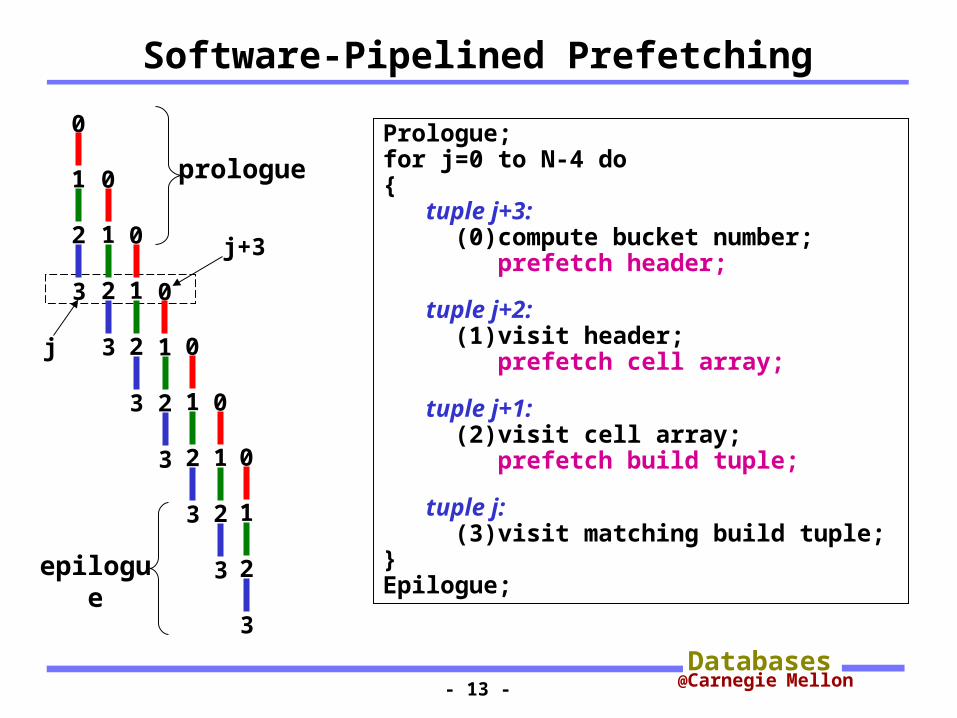
Software-Pipelined Prefetching
Prologue;for j=0 to N-4 do{ tuple j+3: (0)compute bucket number; prefetch header;
tuple j+2: (1)visit header; prefetch cell array;
tuple j+1: (2)visit cell array; prefetch build tuple;
tuple j: (3)visit matching build tuple;}Epilogue;
prologue
epilogue
j
j+3
0
1
2
3
0
1
2
3
0
1
2
3
0
1
2
3
0
1
2
3
0
1
2
3
0
1
2
3
- 14 -@Carnegie Mellon
Databases
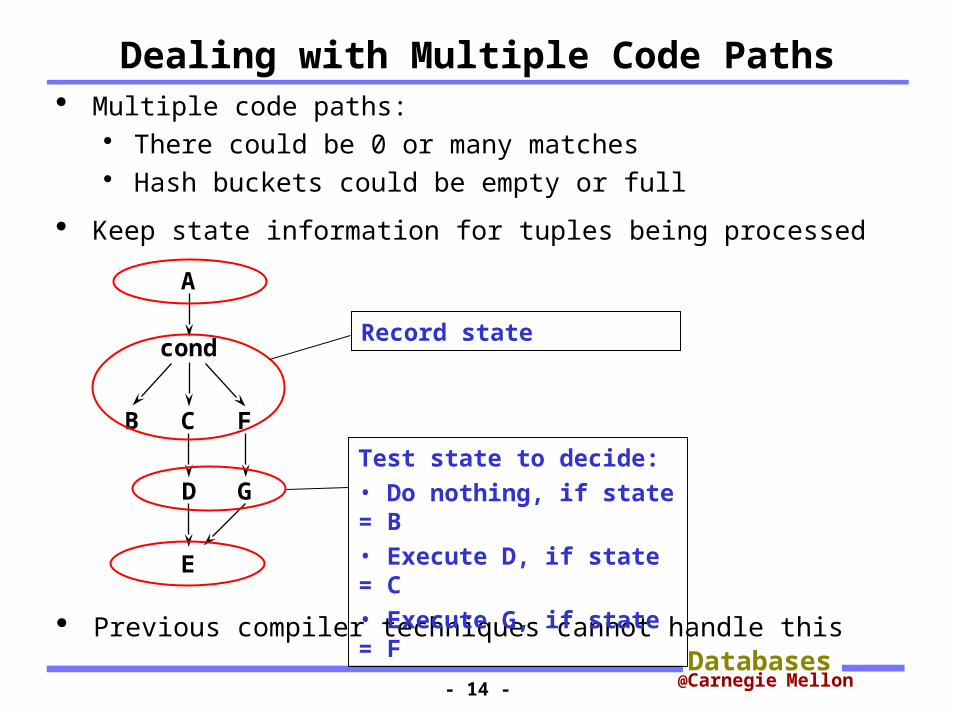
Dealing with Multiple Code Paths
Previous compiler techniques cannot handle this
A
B C F
D G
E
cond
Multiple code paths: There could be 0 or many matches Hash buckets could be empty or full
Keep state information for tuples being processed
Record state
Test state to decide:• Do nothing, if state = B• Execute D, if state = C• Execute G, if state = F

- 15 -@Carnegie Mellon
Databases
Dealing with Read-write Conflicts
Use busy flag in bucket header to detect conflicts
Postpone hashing 2nd tuple until finish processing 1st
Compiler cannot perform this transformation
HashBucket
Headers
BuildTuples
In hash table building:

- 16 -@Carnegie Mellon
Databases
More Details In Paper
General group prefetching algorithm
General software-pipelined prefetching algorithm
Analytical models
Discussion of important parameters: group size, prefetching distance
Implementation details

- 17 -@Carnegie Mellon
Databases
Outline
Overview
Our Proposed Techniques
Experimental Results Setup Performance of Our Techniques Comparison with Cache Partitioning
Conclusions

- 18 -@Carnegie Mellon
Databases
Experimental Setup Relation schema: 4-byte join attribute + fixed length payload
No selection, no projection
50MB memory available for the join phase
Detailed cycle-by-cycle simulations 1GHz superscalar processor Memory hierarchy is based on Compaq ES40

- 19 -@Carnegie Mellon
Databases
Joining a Pair of Build and Probe Partitions
Our techniques achieve 2.1-2.9X speedups over original hash join
•A 50MB build partition joins a 100MB probe partition
•1:2 matching
•Number of tuples decreases as tuple size increases

- 20 -@Carnegie Mellon
Databases
Varying Memory Latency
0
1000
2000
3000
4000
5000
6000
150 cycles 1000 cycles
Baseline
Group Pref
SP Pref
processor to memory latency
exec
uti
on t
ime
(M c
ycle
s)•A 50MB build partition joins a 100MB probe partition
•1:2 matching
•100 B tuples
150 cycles: default parameter
1000 cycles: memory latency in future
Our techniques achieve 9X speedups over baseline at 1000 cycles
Absolute performances of our techniques are very close

- 21 -@Carnegie Mellon
Databases
Comparison with Cache Partitioning
Cache partitioning: generating cache sized partitions [Shatdal et al., 94], [Boncz et al., 99], [Manegold et al.,00]
Additional in-memory partition step after I/O partitioning
At least 50% worse than our prefetching schemes
•A 200MB build relation joins a 400MB probe relation
•1:2 matching
•Partitioning + join

- 22 -@Carnegie Mellon
Databases
Robustness: Impact of Cache Interference
Cache partitioning relies on exclusive use of cache
Periodically flush cache: worst case interference
Self normalized to execution time when no flush
Cache partitioning degrades 8-38%
Our prefetching schemes are very robust

- 23 -@Carnegie Mellon
Databases
Conclusions
Exploited inter-tuple parallelism
Proposed group prefetching and software-pipelined prefetching Prior prefetching techniques cannot handle code complexity
Our techniques achieve dramatically better performance 2.1-2.9X speedups for join phase 1.4-2.6X speedups for partition phase
9X speedups at 1000 cycle memory latency in future Absolute performances are close to that at 150 cycles
Robust against cache interference Unlike cache partitioning
Our prefetching techniques are effective for hash joins

- 24 -@Carnegie Mellon
Databases
Thank you !
Top Related