Workflow Engines for Hadoop
39
Workflow Engines for Hadoop Joe Crobak @joecrobak NYC Data Engineering Meetup September 5, 2013 1
-
Upload
joe-crobak -
Category
Technology
-
view
7.280 -
download
5
description
Building a reliable pipeline of data ingress, batch computation, and data egress with Hadoop can be a major challenge. Most folks start out with cron to manage workflows, but soon discover that doesn't scale past a handful of jobs. There are a number of open-source workflow engines with support for Hadoop, including Azkaban (from LinkedIn), Luigi (from Spotify), and Apache Oozie. Having deployed all three of these systems in production, Joe will talk about what features and qualities are important for a workflow system.
Transcript of Workflow Engines for Hadoop

Workflow Engines for Hadoop
Joe Crobak@joecrobak
NYC Data Engineering MeetupSeptember 5, 2013
1

Intro
2

Background
• Devops/Infra for Hadoop
• ~4 years with Hadoop
• Have done two migrations from EMR to the colo.
• Formerly Data/Analytics Infrastructure @
• worked with Apache Oozie and Luigi
• Before that, Hadoop @
• worked with Azkaban 1.0
Disclosure: I’ve contributed to Luigi and Azkaban 1.0
3

What is Apache Hadoop?
4

What is a workflow?
5

What is a workflow engine?
6

Two Example Use-Cases
7

Analytics / Data Warehousing
• logs -> fact table(s).
• database backups -> dimension tables.
• Compute rollups/cubes.
• Load data into a low-latency store (e.g. Redshift, Vertica, HBase).
• Dashboarding & BI tools hit database.
8

Analytics / Data Warehousing
9

Analytics / Data Warehousing
• What happens if there’s a failure?
• rebuild the failed day
• ... and any downstream datasets
10

Hadoop-Driven Features
• People You May Know
• Amazon-style “People that buy this often by that”
• SPAM detection
• logs, databases -> machine learning / collaborative filtering
• derivative datasets -> production database (often k/v store)
11

Hadoop-Driven Features
12

Hadoop-Driven Features
• What happens if there’s a failure?
• possibly OK to skip a day.
• Workflow tends to be self-contained, so you don’t need to rerun downstream.
• Sanity check your data before pushing to production.
13

Workflow Engine Evolution
• Usually start with cron
• at 01:00 import data
• at 02:00 run really expensive query A
• at 03:00 run query B, C, D
• ...
• This goes on until you have ~10 jobs or so.
• It’s hard to debug and rerun.
• Doesn’t scale to many people.
14

Workflow Engine Evolution
• Two possibilities:
1. “a workflow engine can’t be too hard, let’s write our own”
2. spend weeks evaluating all the options out there. Try to shoehorn your workflow into each one.
15

Workflow Engine Considerations
How do I...
• Deploy and Upgrade
• workflows and the workflow engine
• Test
• Detect Failure
• Debug/find logs
• Rebuild/backfill datasets
• Load data to/from a RDBMS
• Manage a set of similar tasks
16

Oozie - architecture
18

Oozie - the good• Great community support
• Integrated with HUE, Cloudera Manager, Apache Ambari
• HCatalog integration
• SLA alerts (new in Oozie 4)
• Ecosystem support: Pig, Hive, Sqoop, etc.
• Very detailed documentation
• Launcher jobs as map tasks
19

Oozie - the bad
• Launcher jobs as map tasks.
• UI - but HUE, oozie-web (and good API)
• Confusing object model (bundles, coordinators, workflows) - high barrier to entry.
• Setup - extjs, hadoop proxy user, RDBMS.
• XML!
20

Oozie - the bad
• Hello World in Oozie
21

http://azkaban.github.io/azkaban2/
22

Azkaban - architecture
Source: http://azkaban.github.io/azkaban2/overview.html
23

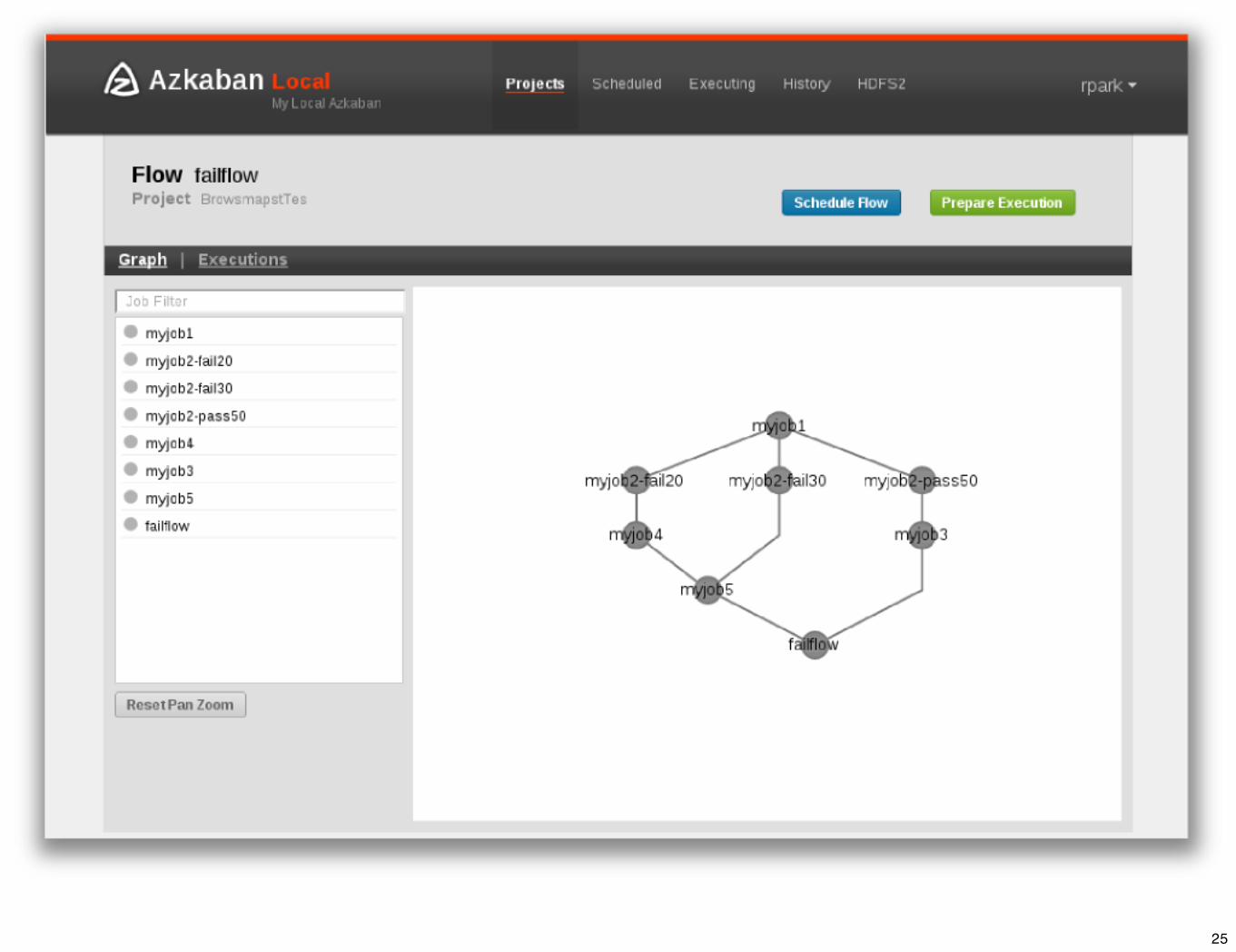
Azkaban - the good• Great UI
• DAG visualization
• Task history
• Easy access to log files
• Plugin architecture
• Pig, Hive, etc. Also, voldemort “build and push” integration
• SLA Alerting
• HDFS Browser
• User Authentication/Authorization and auditing.
• Reportal: https://github.com/azkaban/azkaban-plugins/pull/6
24
25

Azkaban - the bad
• Representing data dependencies
• i.e. run job X when dataset Y is available.
• Executors run on separate workers, can be under-utilized (YARN anyone?).
• Community - mostly just LinkedIn, and they rewrote it in isolation.
• mailing list responsiveness is good.
26

Azkaban - good and bad
• Job definitions as java properties
• Web uploads/deploy
• Running jobs, scheduling jobs.
• nearly impossible to integrate with configuration management
27

https://github.com/spotify/luigi
28

Luigi - architecture
29

Luigi - the good• Task definitions are code.
• Tasks are idempotent.
• Workflow defines data (and task) dependencies.
• Growing community.
• Easy to hack on the codebase (<6k LoC).
• Postgres integration
• Foursquare got this working with Redshift and Vertica.
30

Luigi - the bad
• Missing some key features, e.g. Pig support
• but this is easy to add
• Deploy situation is confusing (but easy to automate)
• visualizer scaling
• no persistent backing
• JVM overhead
31

Comparison matrix - part 1
LangCode
ComplexityFrameworks Logs Community Docs
oozie java high - 105kpig, hive, sqoop,
mapreducedecentralized,
map tasksGood - ASF in many distros
excellent
azkaban java moderate - 26kpig, hive,
mapreduceUI-accessible
few users, responsive on
MLsgood
luigi python simple - 5.9khive, postgres,
scalding, python streaming
decentral-ized on workers
few users, responsive on github and MLs
good
32

Comparison matrix - part 2
property configuration
RerunsCustomizat
ion (new job type)
Testing User Auth
ooziecommand-line,
properties file, xml defaults
oozie job -rerun
difficult MiniOozieKerberos, simple,
custom
azkabanbundled inside
workflow zip, system defaults
partial reruns in UI
plugin architecture
?xml-based,
custom
luigicommand-line, python ini file
remove output,
idempotency
subclass luigi.Task
python unittests
linux-based
33

Other workflow engines
• Chronos
• EMR
• Mortar
• Qubole
• general purpose:
• kettle, spring batch
34

Qualities I like in a workflow engine
• scripting language
• you end up writing scripts to run your job anyway
• custom logic, e.g. representing a dep on 7-days of data or run only every week
• Less property propagation
• Idempotency
• WYSIWYG
• It shouldn't be hard to take my existing job and move it to the workflow engine (it should just work).
• Easy to hack on
35

Less important
• High availability (cold failover with manual intervention is OK)
• Multiple cluster support
• Security
36

Best Practices
• Version datasets
• Backfilling datasets
• Monitor the absence of a job running
• Continuous deploy?
37

Resources
• Azkaban talk at Hadoop User Group: http://www.youtube.com/watch?v=rIUlh33uKMU
• PyData talk on Luigi: http://vimeo.com/63435580
• Oozie talk at Hadoop user Group: http://www.slideshare.net/mislam77/oozie-hug-may12
38

Thanks!
• Questions?
• shameless plug: Subscribe to my newsletter: http://hadoopweekly.com
39