
Who's the Author? Identifier soup - ORCID, ISNI, LC NACO and VIAF
39
Who's the Author? Identifier soup - ORCID, ISNI, LC NACO and VIAF Simeon Warner http ://orcid.org/0000-0002-7970-7855 CUL Career Development Days 2017, 2017-04-07
-
Upload
simeon-warner -
Category
Education
-
view
210 -
download
0
Transcript of Who's the Author? Identifier soup - ORCID, ISNI, LC NACO and VIAF

Who's the Author?
Identifier soup - ORCID, ISNI,
LC NACO and VIAF
Simeon Warner
http://orcid.org/0000-0002-7970-7855
CUL Career Development Days 2017, 2017-04-07

Promises and changes...
Identifiers, including ORCID, ISNI, LC NACO and
VIAF, are playing an increasing role in library
authority work.
We’ll describe changes to cataloging practices
to leverage identifiers.
We'll then tell a short story of the how and why
of ORCID identifiers for researchers, and
relationships with other person identifiers.
Finally, we'll discuss the use of identifiers as
part of moves toward linked data cataloging
being explored in Linked Data for Libraries
work (in the LD4L Labs and LD4P projects).
True
statemen
t
Sketchy
also LD4L
Labs part
This I
know well
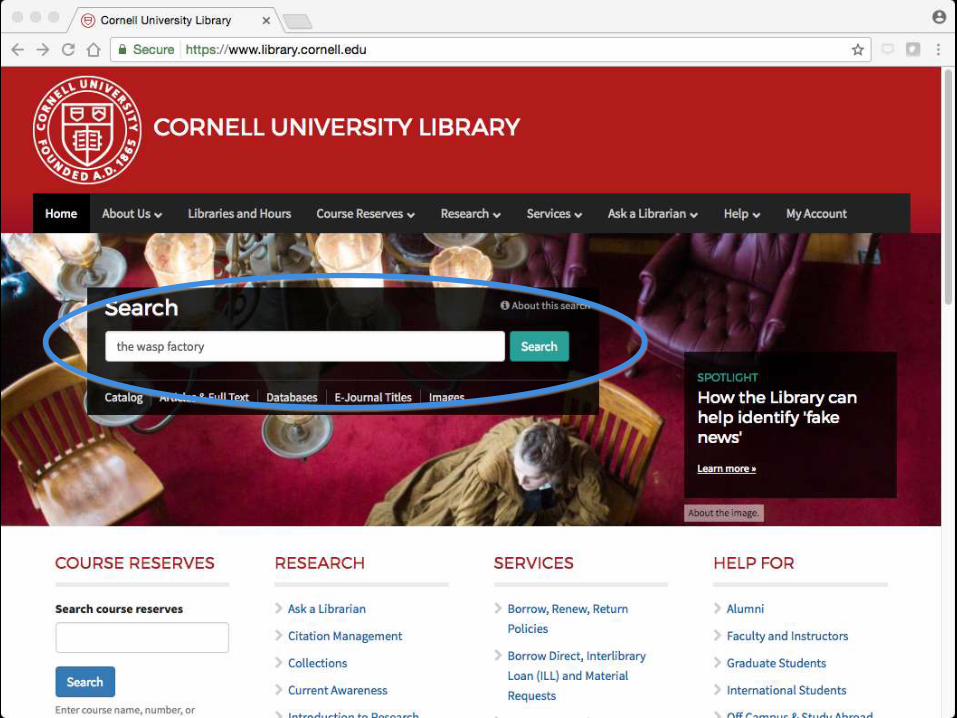

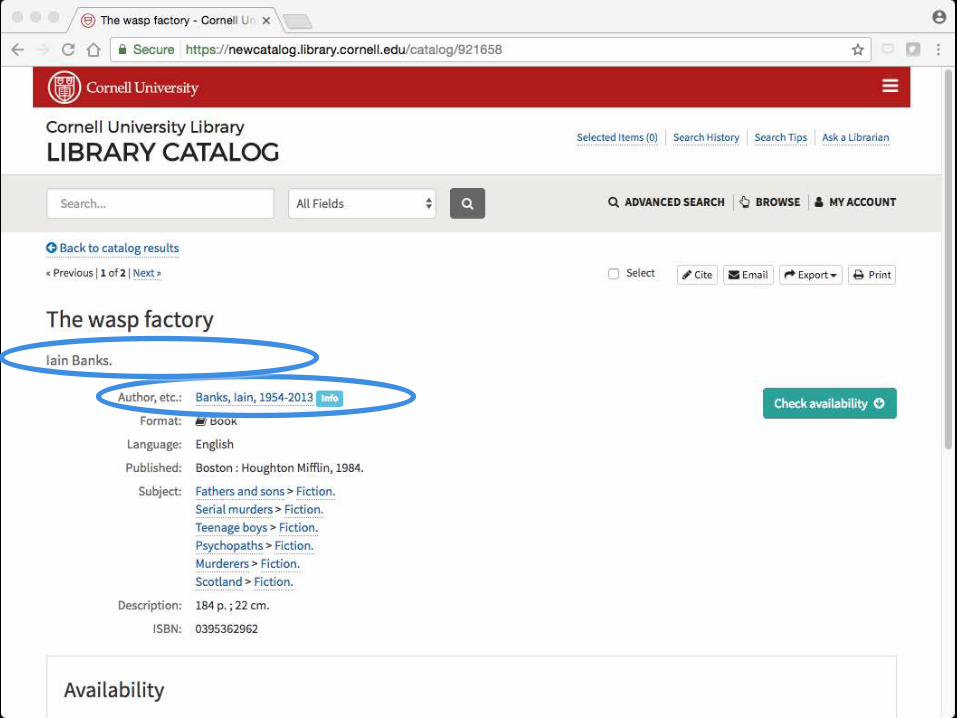
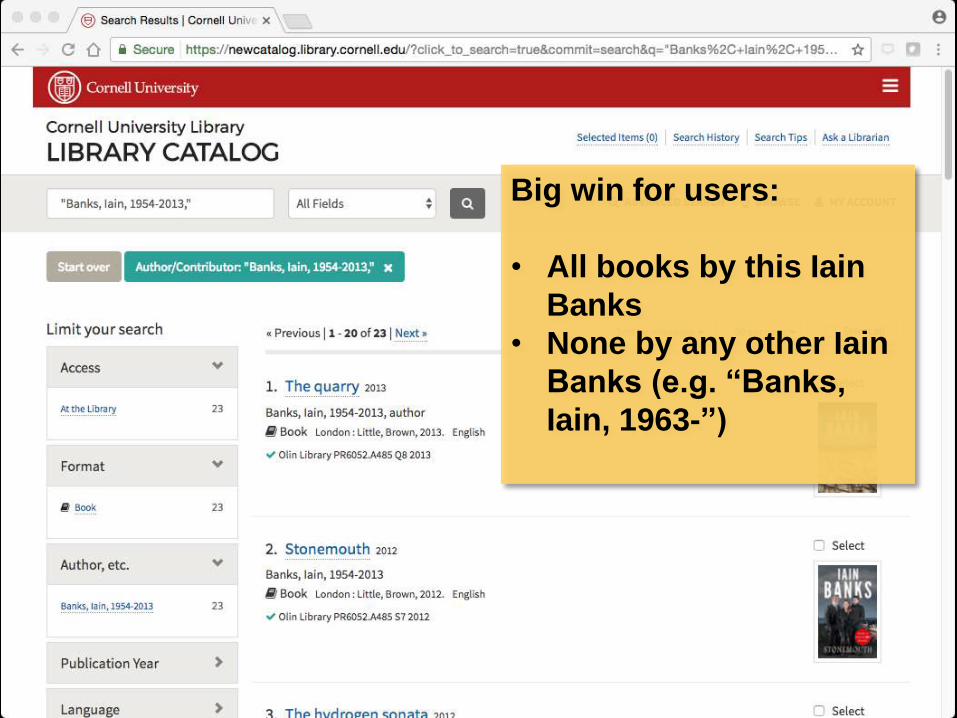
Big win for users:
• All books by this Iain
Banks
• None by any other Iain
Banks (e.g. “Banks,
Iain, 1963-”)

A little additional
information
I do find 3 titles about this
Iain Banks
No links out
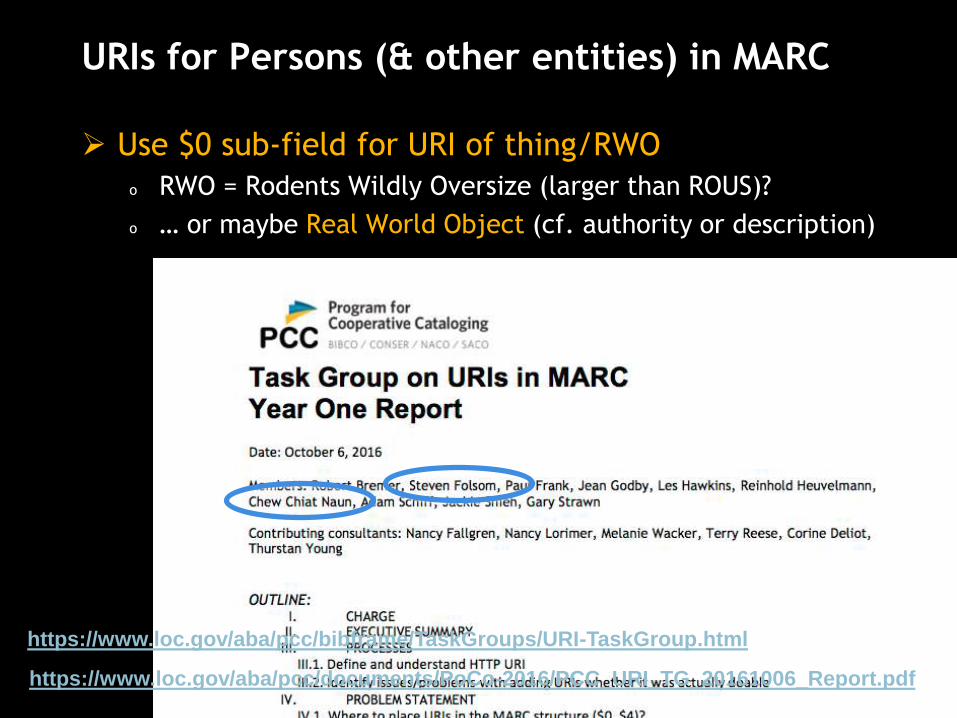
URIs for Persons (& other entities) in MARC
Use $0 sub-field for URI of thing/RWO
o RWO = Rodents Wildly Oversize (larger than ROUS)?
o … or maybe Real World Object (cf. authority or description)
https://www.loc.gov/aba/pcc/documents/PoCo-2016/PCC_URI_TG_20161006_Report.pdf
https://www.loc.gov/aba/pcc/bibframe/TaskGroups/URI-TaskGroup.html

~5k VIVO URIs in catalog
for committee members &
advisors of dissertations,
part of ETD process
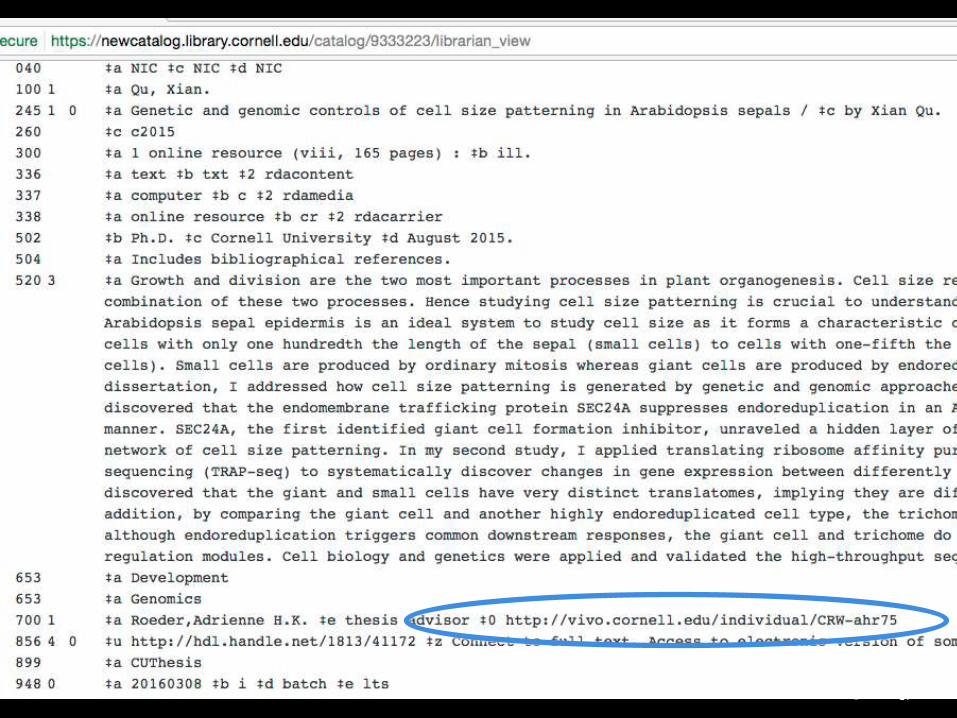
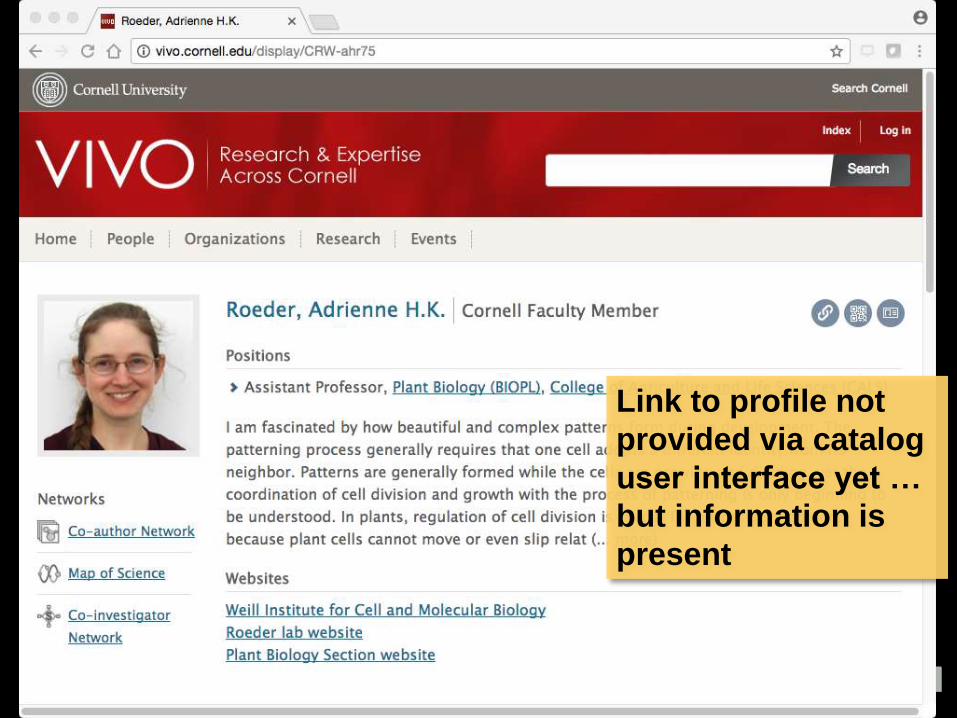
Link to profile not
provided via catalog
user interface yet …
but information is
present

NACO
NACO = Name Authority Cooperative Program of the PCC (Program
for Cooperative Cataloging)
“Through this program, participants contribute authority records
for personal, corporate, and jurisdictional names; uniform titles;
and series headings to the LC/NACO Authority File. Membership
in NACO is open to any institution willing to support their staff
through a process of training, review, and direct contributions of
records to the LC/NACO Name Authority File.”
(http://www.loc.gov/aba/pcc/naco/)
Collaborative construction of big centralized
name authority database that we use
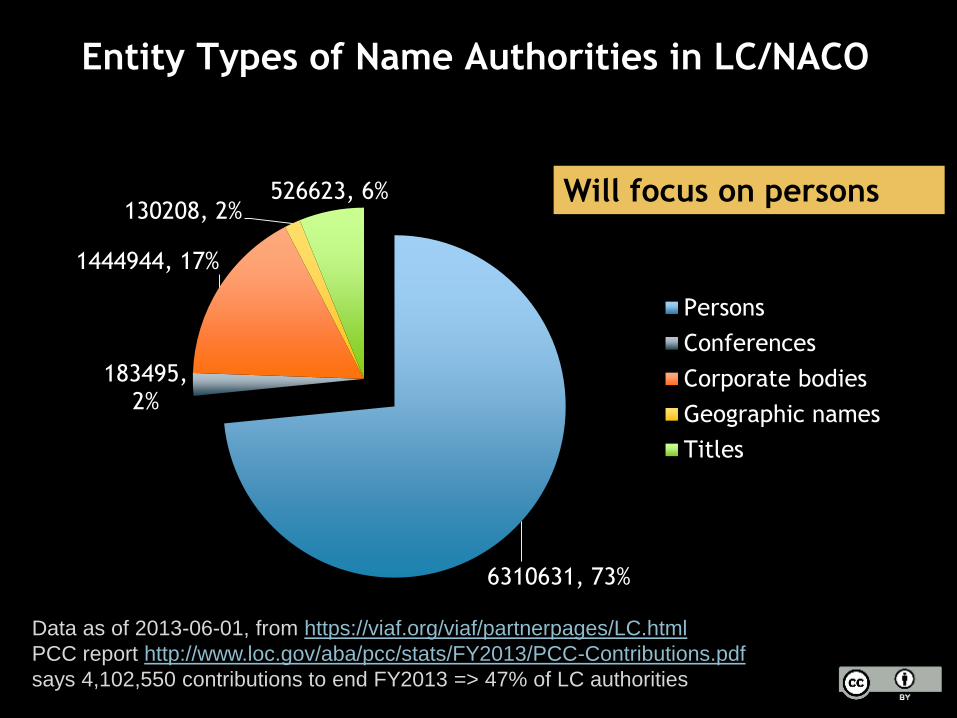
Entity Types of Name Authorities in LC/NACO
6310631, 73%
183495, 2%
1444944, 17%
130208, 2%526623, 6%
Persons
Conferences
Corporate bodies
Geographic names
Titles
Data as of 2013-06-01, from https://viaf.org/viaf/partnerpages/LC.html
PCC report http://www.loc.gov/aba/pcc/stats/FY2013/PCC-Contributions.pdf
says 4,102,550 contributions to end FY2013 => 47% of LC authorities
Will focus on persons


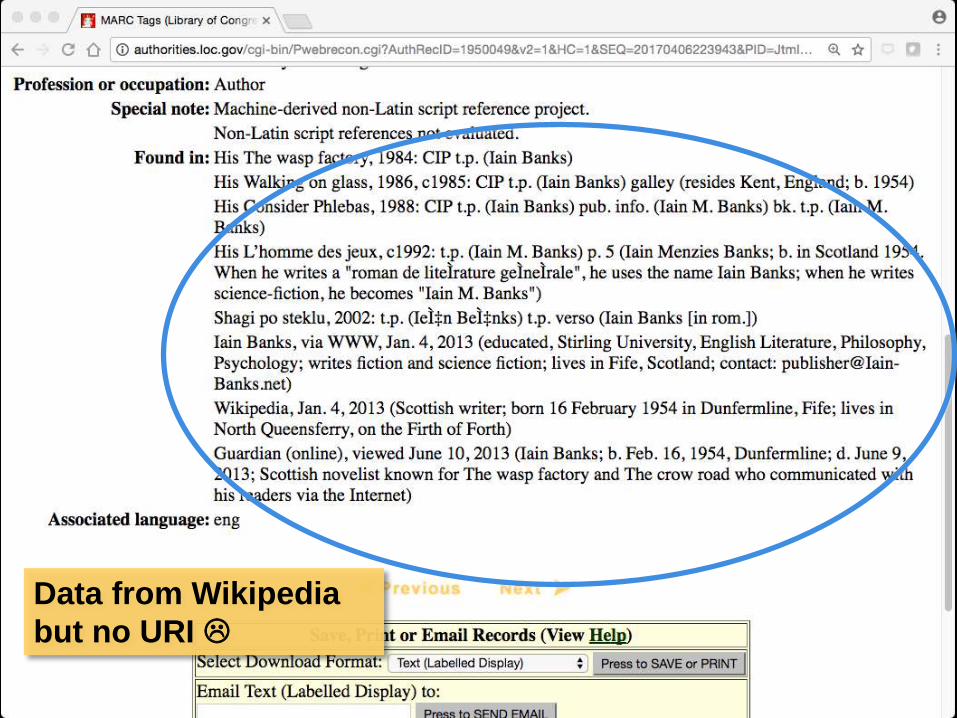
Data from Wikipedia
but no URI
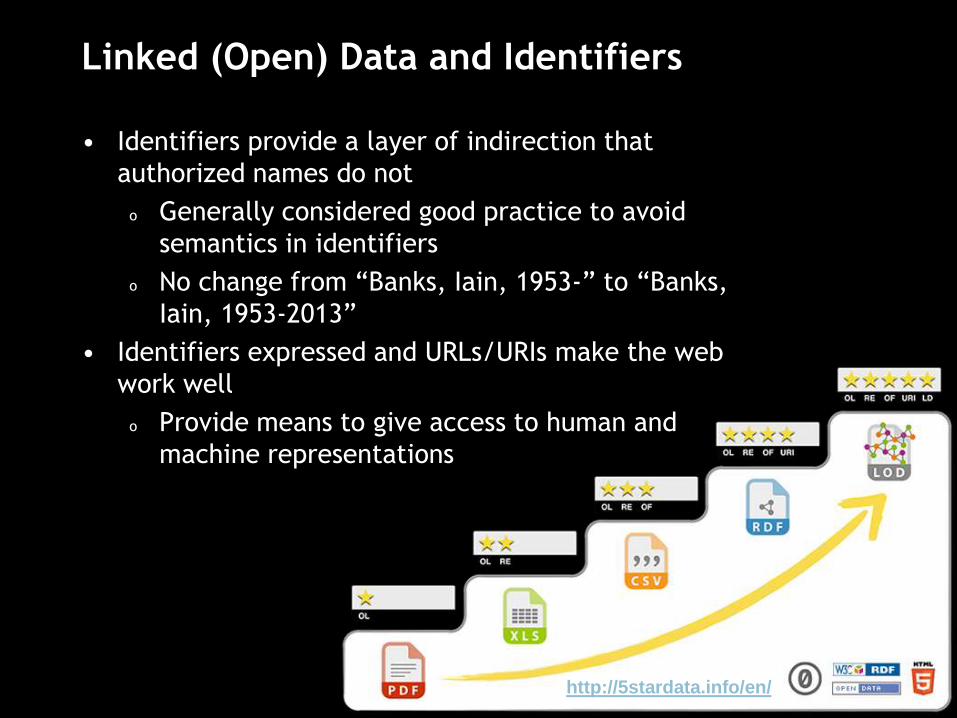
Linked (Open) Data and Identifiers
• Identifiers provide a layer of indirection that
authorized names do not
o Generally considered good practice to avoid
semantics in identifiers
o No change from “Banks, Iain, 1953-” to “Banks,
Iain, 1953-2013”
• Identifiers expressed and URLs/URIs make the web
work well
o Provide means to give access to human and
machine representations
http://5stardata.info/en/

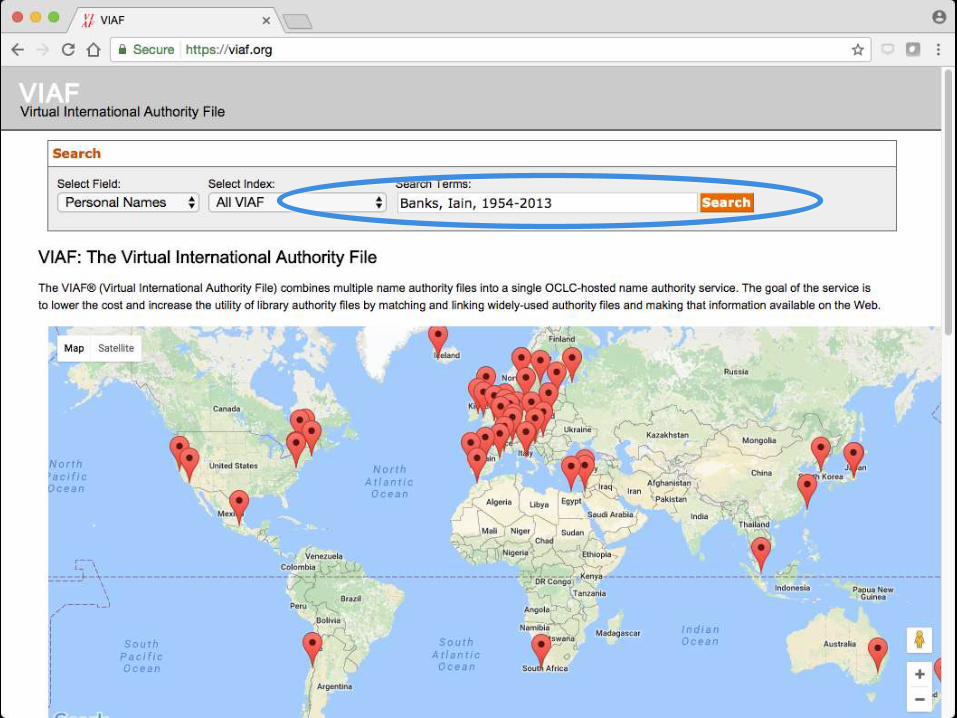
VIAF: The Virtual International Authority File
“The VIAF® (Virtual International Authority File) combines
multiple name authority files into a single OCLC-hosted name
authority service. The goal of the service is to lower the cost and
increase the utility of library authority files by matching and
linking widely-used authority files and making that information
available on the Web.” (https://viaf.org/)
Automated matching/clustering of authority data
from many sources (mostly national libraries) with
(resolvable) identifier
Access to greater internationalization than LC/NACO
More entries that LC/NACO, wider lookup
Changing data may merge / split / delete entries –
not yet policies and mechanisms to handle this
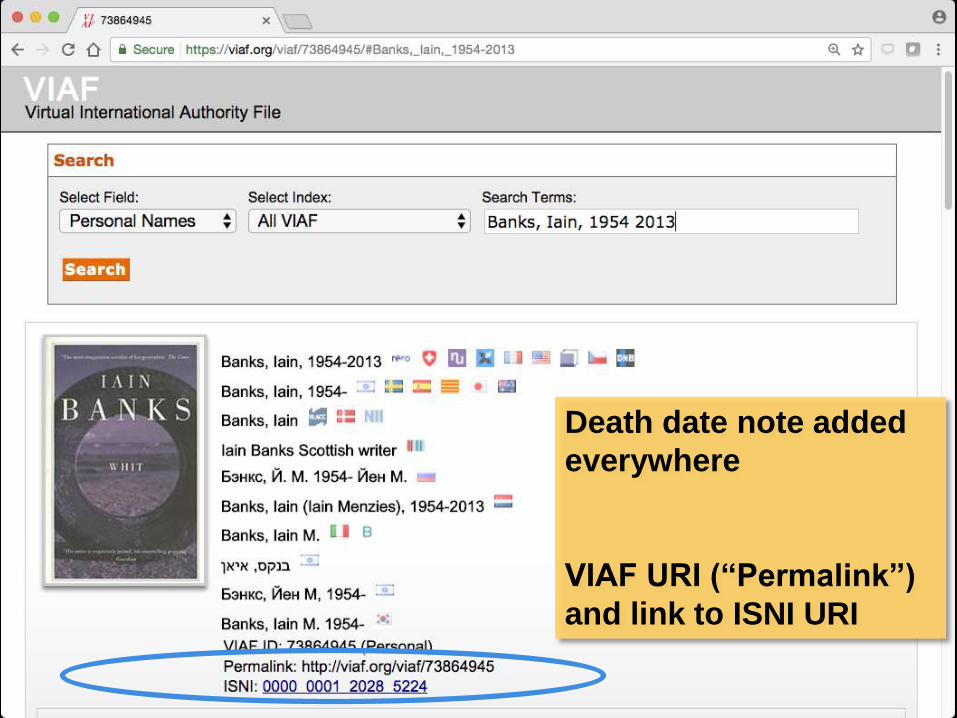
Death date note added
everywhere
VIAF URI (“Permalink”)
and link to ISNI URI

ISNI: International Standard Name Identifier
“The mission of the ISNI International Authority (ISNI-IA) is to
assign to the public name(s) of a researcher, inventor, writer,
artist, performer, publisher, etc. a persistent unique identifying
number in order to resolve the problem of name ambiguity in
search and discovery; and diffuse each assigned ISNI across all
repertoires in the global supply chain so that every published
work can be unambiguously attributed to its creator wherever
that work is described.” (http://www.isni.org/)
The key driver was the need for accurate identities
for communication and payment associated with
rights

ISNI in libraries?
The mission of ISNI has expanded beyond rights, for example data
has been imported to create ISNI identifiers for PhD thesis authors
and from VIAF.
Restrictive terms of use: “All content provided on this Site and
any materials you download are provided for informational, non-
commercial purposes and you shall have no right to modify,
reproduce or redistribute any such content or materials”
(http://www.isni.org/terms-conditions)
Both VIAF and ISNI operated by OCLC so one can expect good
interoperability between them

ISNI URI stable and
managed
Includes Wikipedia &
Wikidata links

ORCID: Open Researcher and Contributor ID
“ORCID’s vision is a world where all who participate in research,
scholarship, and innovation are uniquely identified and connected
to their contributions across disciplines, borders, and time.”
“ORCID provides an identifier for individuals to use with their
name as they engage in research, scholarship, and innovation
activities. We provide open tools that enable transparent and
trustworthy connections between researchers, their
contributions, and affiliations. We provide this service to help
people find information and to simplify reporting and analysis.” (https://orcid.org/)
Research and scholarship focus
Expect use by individuals identified in workflows
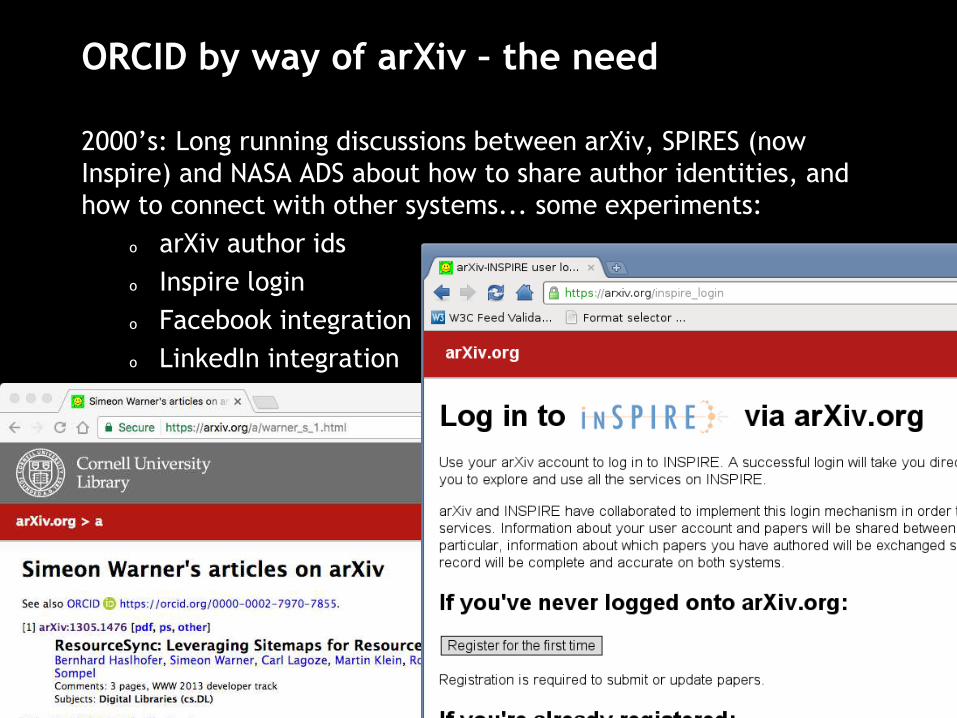
ORCID by way of arXiv – the need
2000’s: Long running discussions between arXiv, SPIRES (now
Inspire) and NASA ADS about how to share author identities, and
how to connect with other systems... some experiments:
o arXiv author ids
o Inspire login
o Facebook integration
o LinkedIn integration
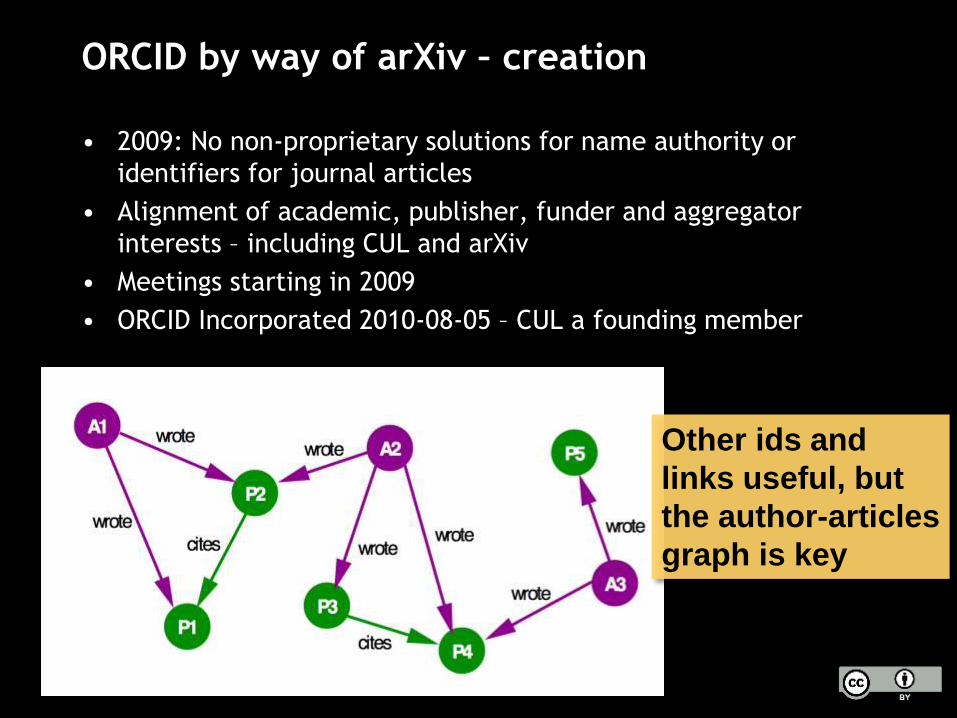
ORCID by way of arXiv – creation
• 2009: No non-proprietary solutions for name authority or
identifiers for journal articles
• Alignment of academic, publisher, funder and aggregator
interests – including CUL and arXiv
• Meetings starting in 2009
• ORCID Incorporated 2010-08-05 – CUL a founding member
Other ids and
links useful, but
the author-articles
graph is key

Why must ORCID be different?
• How many people should have ORCID iDs?
o UNESCO 2013 estimate: 7.8 million researchers
o OECD 2014 estimate: 25.5 million researchers
o Far more than person records in LC NACO, and rapidly
changing
• Around 2 million journal articles published per year
(https://arxiv.org/abs/1402.4578)
Only partial overlapping with other kinds of
publication
“Sort it all out with manual effort” solution not
practical
Solve with researcher engagement and use in
publication workflows
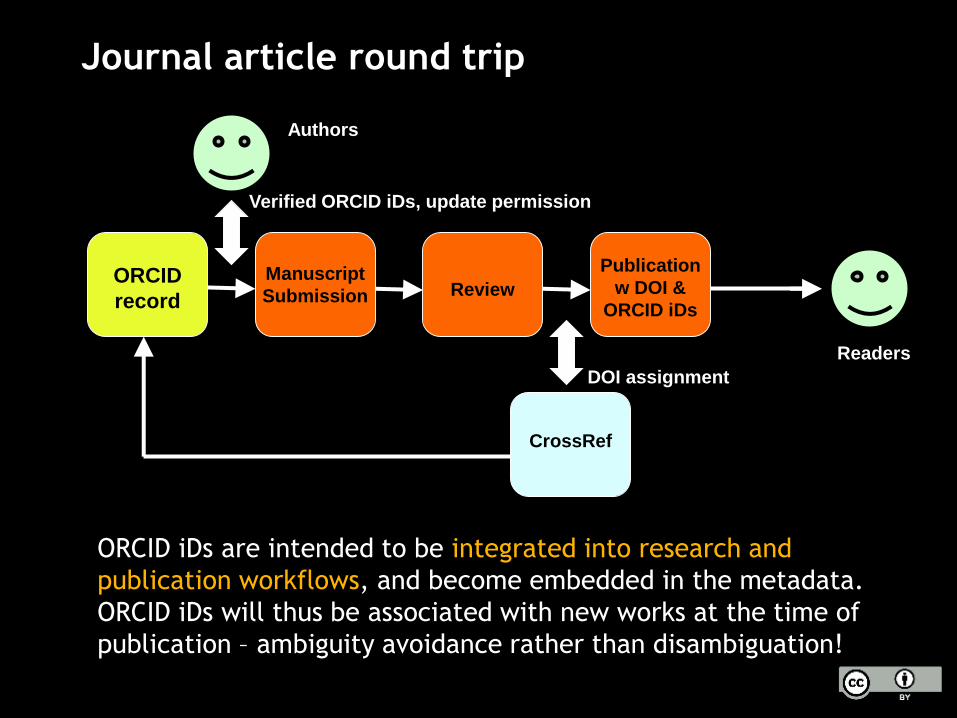
Journal article round trip
ORCID iDs are intended to be integrated into research and
publication workflows, and become embedded in the metadata.
ORCID iDs will thus be associated with new works at the time of
publication – ambiguity avoidance rather than disambiguation!
ORCID
record
Manuscript
SubmissionORCID
record
ORCID
recordReview
Publication
w DOI &
ORCID iDs
CrossRef
DOI assignment
Verified ORCID iDs, update permission
Readers
Authors
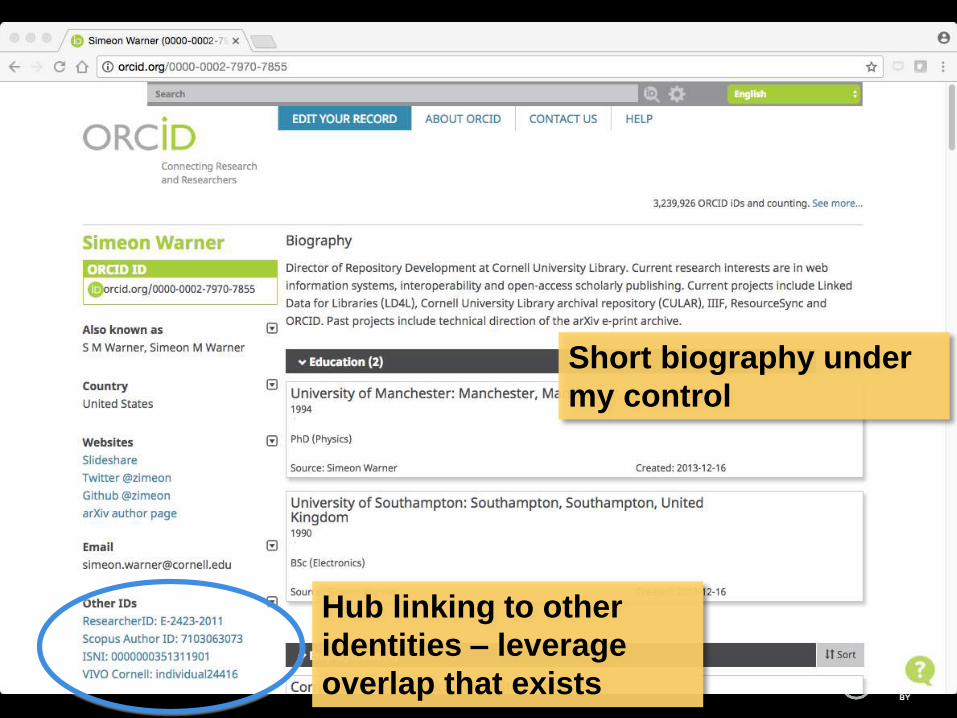
Hub linking to other
identities – leverage
overlap that exists
Short biography under
my control
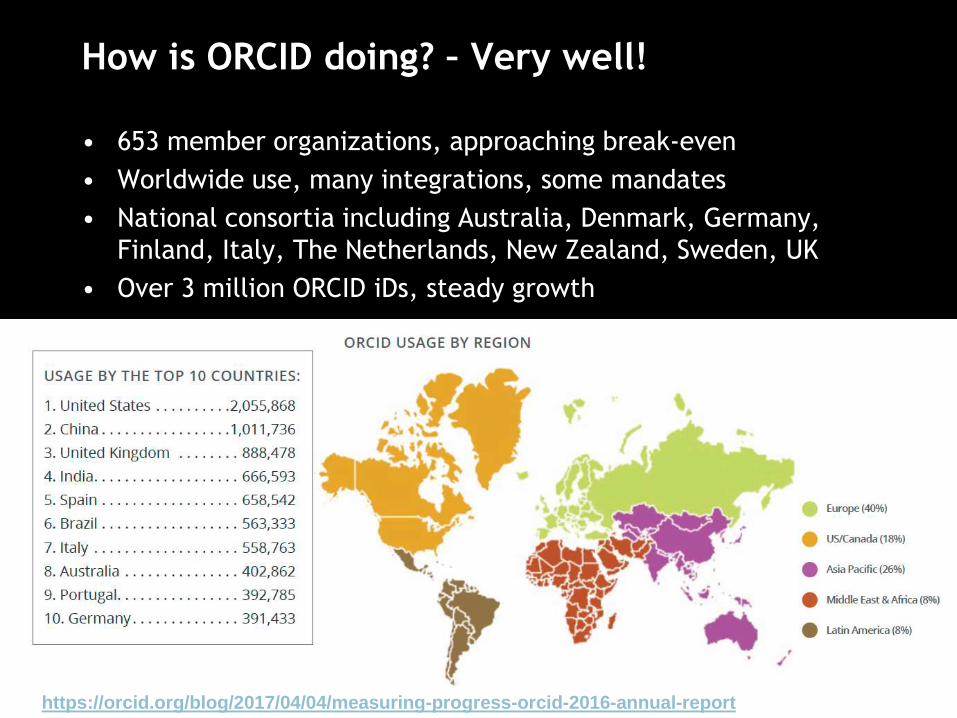
How is ORCID doing? – Very well!
• 653 member organizations, approaching break-even
• Worldwide use, many integrations, some mandates
• National consortia including Australia, Denmark, Germany,
Finland, Italy, The Netherlands, New Zealand, Sweden, UK
• Over 3 million ORCID iDs, steady growth
https://orcid.org/blog/2017/04/04/measuring-progress-orcid-2016-annual-report

LD4L Labs and LD4P (2016-2018)
Follow-ons from LD4L 2014-2016
LD4L Labs –Linked Data for Libraries Labs - https://ld4l.org/ld4l-labs/
(Cornell, Harvard, Stanford, Iowa)
o advance the use and usefulness of linked data in libraries
o create and assemble tools, ontologies, services
o pilot tools and services with a view to solutions in 3-5 years
o develop tools and provide support for LD4P projects
LD4P – Linked Data for Production – https://ld4l.org/ld4p
(Columbia, Cornell, Harvard, LC, Princeton, Stanford)
o pilot transition of technical services workflows to a linked
data environment
o “production” means creation of catalog records, not
production-ready
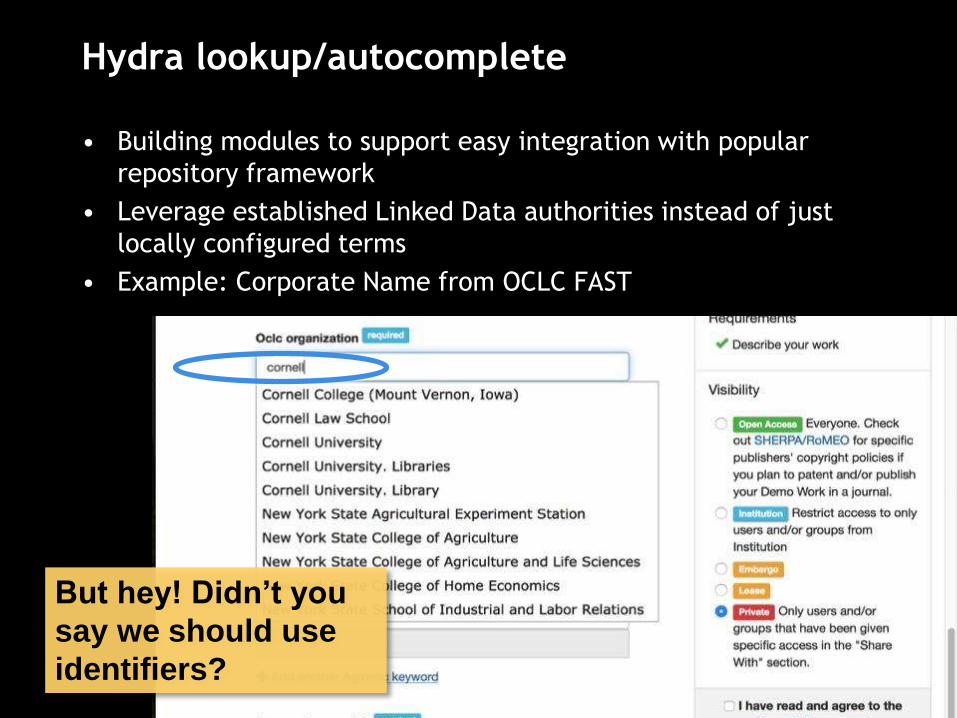
Hydra lookup/autocomplete
• Building modules to support easy integration with popular
repository framework
• Leverage established Linked Data authorities instead of just
locally configured terms
• Example: Corporate Name from OCLC FAST
But hey! Didn’t you
say we should use
identifiers?
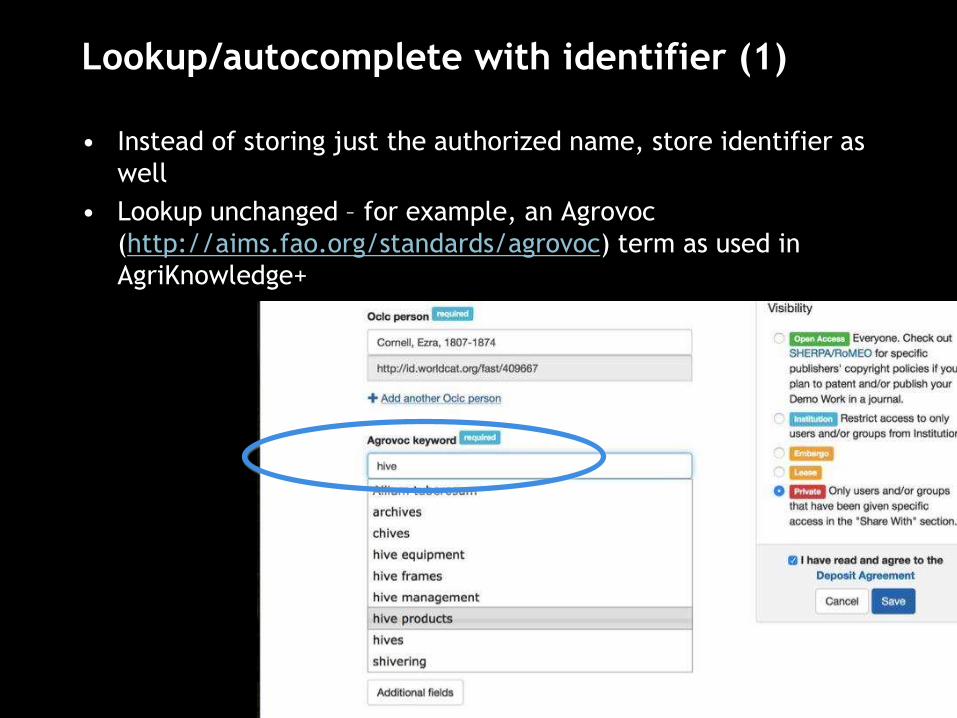
Lookup/autocomplete with identifier (1)
• Instead of storing just the authorized name, store identifier as
well
• Lookup unchanged – for example, an Agrovoc
(http://aims.fao.org/standards/agrovoc) term as used in
AgriKnowledge+
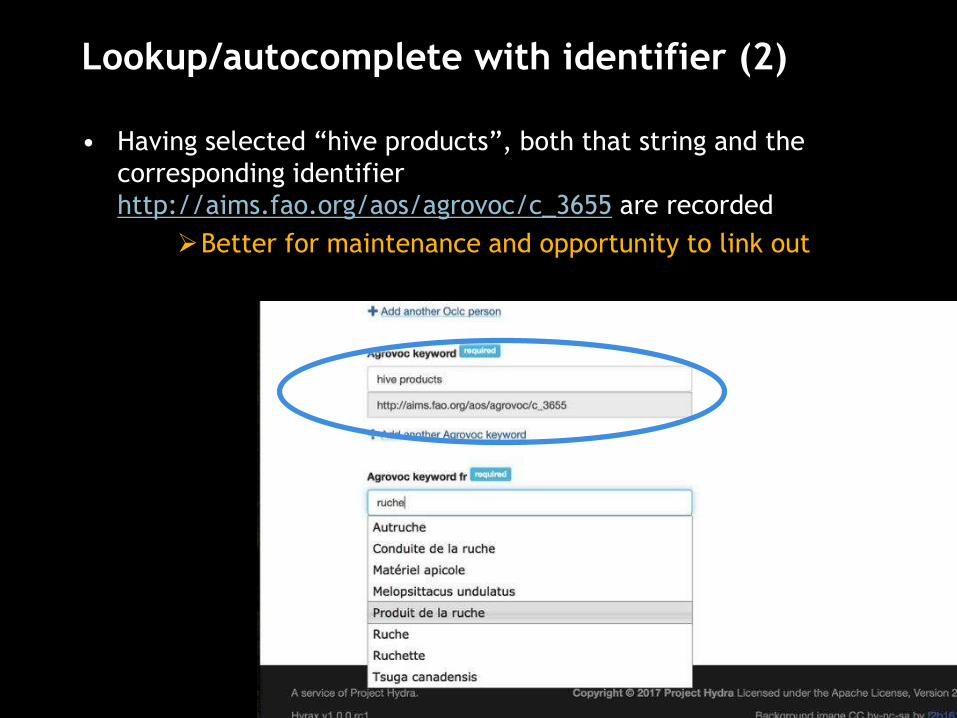
Lookup/autocomplete with identifier (2)
• Having selected “hive products”, both that string and the
corresponding identifier
http://aims.fao.org/aos/agrovoc/c_3655 are recorded
Better for maintenance and opportunity to link out
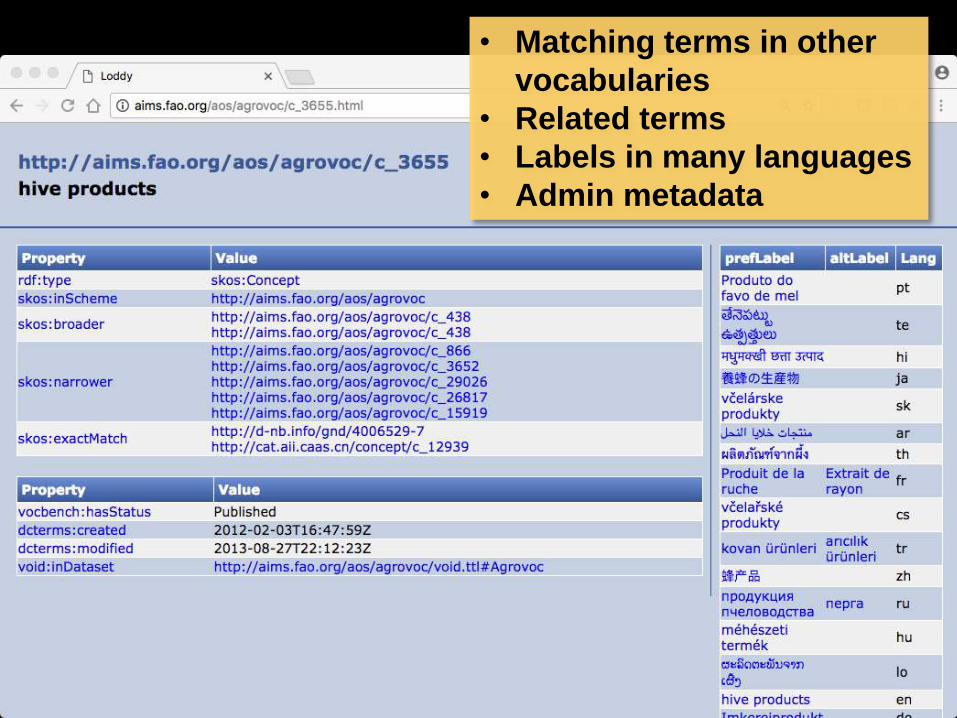
• Matching terms in other
vocabularies
• Related terms
• Labels in many languages
• Admin metadata

VitroLib – A experimental cataloging tool
• Using Vitro (the platform behind VIVO), customized for library
metadata as an editing environment – VitroLib
• Usability studies to understand how to build systems that will
work for cataloging
Early days, long journey!
“Let’s imagine you are creating
an entirely new record”
“But I never create an entirely
new record!”
“Oh, and BTW, we shouldn’t say
record”

Why move from authorities to identifiers?
• Reduce maintenance and copy/paste work in library
environment
• Bridge between library catalog world and rest-of-world
o Journal literature
o Popular web
o Profiling services
• Better services to users
o More links to related sources
o Better localization options (maybe some users don’t want
the romanized names?)
o Better discovery (leverage structured data from other
sources)

That’s all folks…
• Thanks to Huda Khan and Nick Cappadona for VitroLib
prototype screenshot
• Thanks to Lynette Rayle for screenshots of Hydra “Questioning
Authority” work
• Thanks to Christina Harlow for finding examples in the catalog!
• Thanks to Cornell LD4L Labs and LD4P teams, including: Dean
Krafft, Lynette Rayle, Rebecca Younes, Jim Blake, Muhammad
Javed, Huda Khan, Nick Cappadona, Sandy Payette, Chew Chiat
Naun, Steven Folsom, Jason Kovari and Christina Harlow


















