
Chapter 2 When Worlds Collide Chapter 2 When Worlds Collide.
Upload
edina-university-of-edinburghCategory
view
334download
0
Where data and journal content collide
what does it mean to ‘publish your data’?
Peter Burnhill,EDINA, Information Services
University of Edinburgh
09:40 – 10:00
#ReCon_15 : Beyond the paper: publishing data, software and more. Edinburgh, 19 June 2015

OverviewTime-served data person reverts to being a PI-cum-
researcher, & having to ask: What data should be shared, when and how?
1. Propose 3 categories of dataA: Databases used [how the data came about]
B: The assembled Datasets [what I analysed]
C: Data behind the graph [what is part of my statement]
2. Report on 2 case studies to illustrate this• Each of relevance to scholarly communication

1. Scottish Education Data Archive, 1979 - mid ‘80s– Survey statistician: school leavers, YTS & 16-19 cohort surveys
• In Centre for Educational Sociology
2. Edinburgh University Data Library,1984 & on– Manager: set-up and development– President of IASSIST, 2000 – 2004 : social science data professionals
3. Graduate School, Faculty of Social Science, 1987 – 1997– Senior Lecturer, teaching quantitative/survey methods
• In Research Centre for Social Sciences
4. ESRC Regional Research Laboratory for Scotland, 1986/90– Co-director: early days of Geographical Information Systems (GIS)
• With University’s Department of Geography; Honorary Fellow, Royal Scottish Geographical Society, 2015
5. EDINA, 1995/6 to present - main focus as day job– Director: set-up and continuous development– Jisc-designated centre for service delivery & digital expertise
6. Digital Curation Centre, 2004/05– Director for set-up & definition of ‘data curation + digital preservation’
• With University’s School of Informatics
a time-served data person (at U of Ed)

Two ‘case studies’ to illustrate
① Project funded by Andrew Mellon Foundation
• No mandate on data deposit but encourage OA for tools/application developed as part of the project
② ‘Ongoing project’: statistical statement using data from operation of two Jisc services
• with no direct mandate (& could have passed undetected)
Both case studies have findings about threats to the integrity of the scholarly record.

① Reference Rot ② E-Journal Archiving
Study Measure the extent of what we now call
Reference Rot = Link Rot + Content Drift
• Identify intervention opportunities to stop the rot
• Devise sustainable solutions with maximal reach
Project Hiberlink
Andrew Mellon Foundation
EDINA & Language Technology Group, School of Informatics (Claire Grover & colleagues )
jointly with the Research Library, Los Alamos National Laboratory
(Herbert Van de Sompel & colleagues).
hiberlink.org

Link Rot
‘Link Rot’

+ Content Drift: What is at end of URI has changed, or gone!
http://dl00.org
2000
http://dl00.org
2004
http://dl00.org
2005
http://dl00.org
2008
(a) Dynamic contentas values on webpage changes over time
(b) Static contentbut very different (often unrelated) web pages

① Reference Rot ② E-Journal Archiving
Study status of references to the web-at-large (in e-theses)
Project Hiberlink
FindingsEmpirical statements
Made as:
i) WORK-IN-PROGRESS
in preparation for
ii) PUBLICATION
Analysis of of 7,000 e-theses revealed thatReference Rot occurs in over 36% of the embedded URIs
Routine web archiving delivers less than a 50:50 chance that content is being kept safe
circa 1 in 5 of referenced content is probably lost for ever
+ Use of 3 very large corpus of journal articles demonstrated very significant reference rot => ‘rotten articles for sale’‘

Scholarly Articles increasingly link to Web Resources, not just back to other Articles

Findings: Status of Referenced URIs, PMC corpus
Klein M, Van de Sompel H, Sanderson R, Shankar H, Balakireva L, et al. (2014) Scholarly Context Not Found: One in Five Articles Suffers from Reference Rot. PLoS ONE 9(12): e115253. doi:10.1371/journal.pone.0115253http://127.0.0.1:8081/plosone/article?id=info:doi/10.1371/journal.pone.0115253
6 publicly accessible web archives for lookup: Internet Archive, archive.is (archive.today), Archive-It, BL Web Archive, UK National Archives Web Archive & Icelandic National Archive

Klein M, Van de Sompel H, Sanderson R, Shankar H, Balakireva L, et al. (2014) Scholarly Context Not Found: One in Five Articles Suffers from Reference Rot. PLoS ONE 9(12): e115253. doi:10.1371/journal.pone.0115253http://127.0.0.1:8081/plosone/article?id=info:doi/10.1371/journal.pone.0115253
Findings: Status of Referenced URIs, Elsevier corpus
6 publicly accessible web archives for lookup: Internet Archive, archive.is (archive.today), Archive-It, BL Web Archive, UK National Archives Web Archive & Icelandic National Archive

Remedy: Create Snapshots of Referenced Resources
Snapshots can be created at various stages. The closer to the moment of referencing, the better the image captured.
Stage Actor Snapshot Quality
Preparation Author/reference tool best
Submission/Issue
Editor/manuscript system
good
Access (post-publication)
Aggregator/publisher platform
so-so
Shelving Librarian/IR, journal archive
better than nothing

Prototypes of pro-active approaches to support the archiving of web references for scholarly
communicationsRichard Wincewicz1, Peter Burnhill1
& Herbert Van de Sompel21EDINA, University of Edinburgh, 2Los Alamos National Laboratory
http://hiberlink.org #hiberlink

Authoring - Zotero Plugin Demonstrator
Richard Wincewicz (2014) Prototype Hiberlink plugin for Zotero for pro-active archiving and temporal referenceshttps://www.youtube.com/v/ZYmi_Ydr65M%26vq

① Reference
Rot
② E-Journal Archiving
Study Extent to which scholarly record is at risk of loss: who is looking after your e-journal content?
Project] Keepers+
‘Unfunded’ (Jisc / UoEd)
EDINA in collaboration internationally with archiving organisations & research libraries
thekeepers.org
http://thekeepers.blogs.edina.ac.uk

That Article in the Scholarly Record is not in the custody of Libraries, nor yet on their digital shelves.
Picture credit: http://somanybooksblog.com/2009/03/27/library-tour/

thekeepers.org as Global Monitor
… to discover who is looking after what

① Reference Rot
② E-Journal Archiving
Study status of references to the web-at-large in e-theses.
scholarly record at risk of loss: who is looking after e-journal content?
Project Hiberlink Keepers+
Key FindingsEmpirical statements
Made as:
i) WORK-IN-PROGRESS
in preparation for
ii) PUBLICATION
Two thirds (68%) of what was consulted online (108 UK universities) in 2012 is at risk of loss.
Missing Volumes & Issues
Only 22% to 28% of Title Lists of 3 US research libraries (Columbia, Cornell & Duke) were being archived when checked in 2011/12
We need to update these findings annually
Libraries don’t have e-collections of serials (only e-connections)
So we all need to know what scholarly content is being kept safe somewhere!
(SafeNet Project just statted)

Two Key Statistics
‘Ingest Ratio’ = titles ingested by one or more Keeper / ‘online serials’ in ISSN Register
= 28,103 / 165,949 [as of June 2015]
=> 17%‘KeepSafe Ratio’ = titles being ingested by 3+
Keepers / ‘online serials’ in ISSN Register
= 9,836 / 165,949
=> 6%

with usage logs for the UK OpenURL Router*• 8.5m full text requests in UK during 2012
=> 53,311 online titles requested Analysis in 2013:
‘Ingest Ratio’ = 32% (16,985/53,311)
=> over two thirds 68% (36,326 titles) held by none!
Archival Status of e-Serials Requested
* As reported in Keepers Registry Blog, OpenURL Router passes ‘discovery’ requests to commercial OpenURL resolver services; developed & delivered by EDINA as part of Jisc support for UK universities & colleges

with usage logs for the UK OpenURL Router*• 8.5m full text requests in UK during 2012
53,311 online titles requested
Analysis carried out again in 2015:
‘Ingest Ratio’ = 36% (19,231/53,311) ; up by 2,246 (4%)
=> but still, 64% (34,080 titles) held by none!
‘KeepSafe Ratio’ = 20% (10,847/53,311) ; up by 2,985 (5%)
Archival Status of Requested e-Serials: Update

Archival Status of Online Continuing Resources assigned ISSN, by Country, June 2015

very many ‘at risk’ e-journals from many small publishers
BIG publishers
act early but incompletely
Priority: find economic way to
archive content from …

Cannot ignore the focus on Publication
re-visiting an article now being cited again:
On measuring the relation between social science research activity and
research publication.
Research Evaluation 4.3 130-152 doi: 10.1093/rev/4.3.130
P. Burnhill & M. Tubby-Hille (1994)
& What the Funder sees

STUDY
DATA, other working capital & references to work of others
FINDINGS
Taken from: Figure 1 in P. Burnhill & M. Tubby-Hille (1994) On measuring the relation between social science research activity and research publication.
Research Evaluation 4.3 130-152. doi: 10.1093/rev/4.3.130

Study / Project / Data / Findings / Publication
STUDY/ Activity [Purpose] Large-scale experiment /Exploratory investigation
PROJECT [Grant] FunderRef ; GrantID
Databases consulted / used
Source / Origination
Using extant databases
(Generating new data)
Dataset(s)
Assembled & Analysed
Extracted data ; derived variables; multiple versions
FINDINGS i) Work-in-progress
ii) PUBLICATION
Empirical Statement(s)
i) Presentations etc
ii) Formal report of the results of research
DATA as resultsto be shared?
DATA as working capital

Study / Project / Data / Findings / Publication
Study Large-scale experiment /Exploratory investigation
Project
Data Source / Origination‘database(s)’
Using extant databases
(Generating new data)
Who has custody of new data?
‘Assembled datasets’’Dataset(s)’ Analysed
Extracted data; derived variables; multiple versions
‘Data behind the graph’ Supplementary data which enhance the publication of the results reported.
Do publishers want to hand responsibility to subject & institutional repositories?
Key Findingsi) Work-in-progress ii) Publication
Empirical Statement(s)
What Data should beshared?
DataType C
DataType B
DataType A
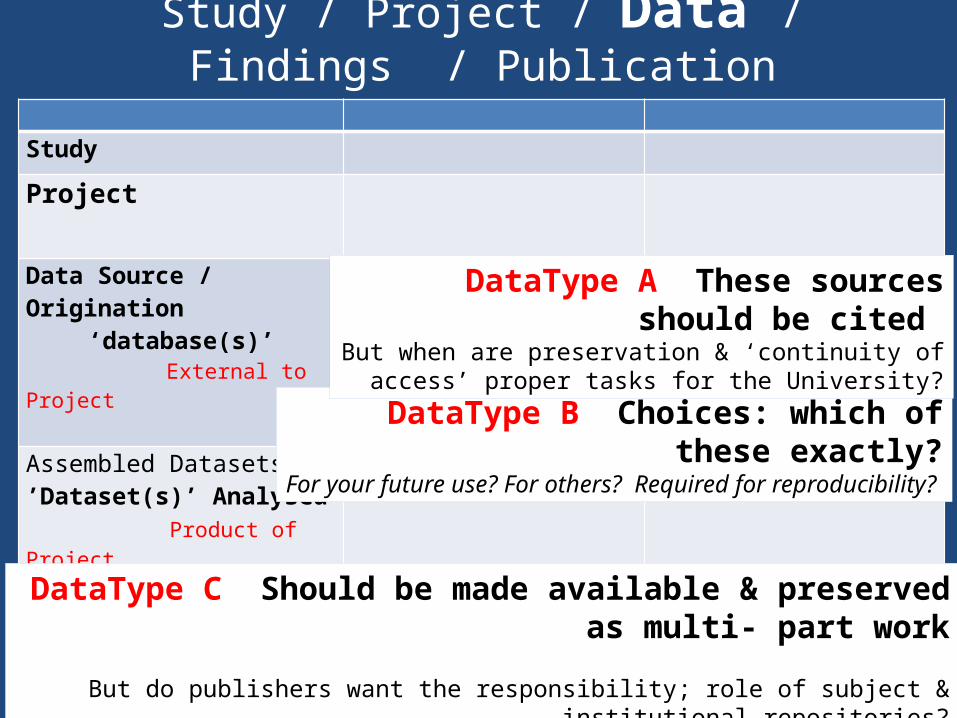
Study / Project / Data / Findings / Publication
Study
Project
Data Source / Origination‘database(s)’
External to Project
Generating new data Using extant databases
Assembled Datasets’Dataset(s)’ Analysed Product of Project
multiple versions
‘Data behind the graph’ Supplementary data
Key Findingsi) Work-in-progress ii) Publication
Empirical Statement(s) DataType C: Should be made available & preserved as multi- part work
But do publishers want the responsibility; role of subject & institutional repositories?
DataType B: Choices: which of these exactly?For your future use? For others? Required for reproducibility?
DataType A: These sources should be cited But when are preservation & ‘continuity of access’ proper
tasks for the University?

Study / Project / Data / Findings / Publication
① Reference Rot Study ② E-Journal Archiving
Study status of references to the web-at-large [in e-theses]
scholarly record at risk of loss: who is looking after e-journal content?
Project Hiberlink Keepers+
‘database(s)’
Data Source / Origination
DataType AExternal to Project
• Full text of c.7,500 doctoral theses, as downloaded from 5 university repositories
• Networked Digital Library of Theses and Dissertations metadata
•Logs of requests from UK universities (c.10m pa) via Jisc OpenURL Router
• Aggregation of archival actions’ for online serials via the Keepers Registry
‘Assembled datasets’
’Dataset(s)’ Analysed
‘Data behind the graph’

Study / Project / Data = Findings / Publication① Reference Rot Study ② E-Journal Archiving
Study status of references to the web-at-large (in e-theses)
scholarly record at risk of loss: who is looking after e-journal content?
Project Hiberlink Keepers+
‘database(s)’Data Source / Origination
DataType A
• Full text of c.7,500 doctoral theses, as downloaded from 5 university repositories
• Networked Digital Library of Theses and Dissertations metadata
•Logs of requests from UK universities (c.10m pa) via Jisc OpenURL Router
• Aggregation of archival actions’ for online serials via the Keepers Registry
Datasets AssembledDataset(s) Analysed
DataType BProduct of Project
c.46,000 URIs extracted from 7,000 eTheses
& 3 other very large corpus tested for status, recording live/not, archived/not & other attributes
c.53,000 online serial titles cross checked against the reports in Keepers Registry
* This could be the first of a regular (annual) series of datasets recording what is being archived and what is not

• why should we publish our data?
• what data should be shared, when and how?
& what about the new Web-resident research statements?

Data as scholarship: a cultural shift?
Preserve or Perish
“You are not finished until you have done the research, published the results, and published the data, receiving formal credit for everything.”
Mark A. Parsons (2006)International Polar Year
“A scholar’s positive contribution is measured by the sum of the original data that he contributes. Hypotheses come and go but data remain.”
in Advice to a Young Investigator (1897) Santiago Ramón y Cajal (Nobel Prize winner, 1906)

A more practical set of questions?• why should we publish our data?
• what data should be shared, when &how?

The What• why should we publish our data?
• what data should be shared, when and how?
DataType B: Data = Findings• The dataset(s) on which we based our research
statements, or …• The dataset(s) that were assembled, upon which
others can base their research

STUDY
DATA, other working capital & references to work of others
FINDINGS
Taken from: Figure 1 in P. Burnhill & M. Tubby-Hille (1994) On measuring the relation between social science research activity and research publication.
Research Evaluation 4.3 130-152. doi: 10.1093/rev/4.3.130
DATA as FINDINGS

http://www.restfulliving.com/wp-content/uploads/2013/12/Time-1024x861.jpg
Preserving the integrity of the scholarly
recordWhen?

STUDY
DATA, other working capital & references to work of others
FINDINGS
When Findings are reported in Publications?

STUDY
DATA, other working capital & references to work of others
FINDINGS
This last stage can take a very long time!
Temporal Rot

• why should we publish our data?
• what data should be shared, when and how?– What?
• The dataset(s) on which we based our research statements, or better still the datasets we assembled
– When?: Start early … with documentation & deposit (with embargo?)
– How? • We are about to learn that first-hand
– with a little help from a friend in the Data Library
• maybe we might publish one of those new Web-resident research statements
Time to use Datashare …
The When & How

Jisc-funded DataShare Project: Edinburgh, LSE, Oxford, Southampton (DISC-UK)
from informal storage and sharing
to formal institutional arrangement

Side Note on Web-resident research objects
Web as dominant means to make & access scholarly statement
• The Web enables rich aggregations of linked content, with data intrinsic to the statement
– research objects, composite digital objects, ‘multi-part works’
• As scholarly statement has become digital, it becomes malleable & lacking in ‘fixity’
• Notions of fixity may conflict with demands for usability:
– a record of activity, and thus be immutable?
– made available with secondary analysis by a third party in mind?
• What should it be cited? Role of Linked Data?
• Need to avoid Reference Rot for this ‘rich content’

DataShare2
from formal institutional arrangement
formal publishing into In Llinked) Data infrastructure

① Reference Rot ② E-Journal Archiving
Study Investigation into status of references in scholarly statement to the web-at-large
Monitoring extent the scholarly record is at risk of loss: who is looking after e-journal content?
Project Hiberlink
Andrew Mellon Foundation
with Language Technology Group & the Research Library at Los Alamos
National Laboratory
Keepers+
‘Unfunded’ (Jisc / UoEd)
in collaboration internationally with archiving organisations & research libraries
http://thekeepers.blogs.edina.ac.uk
hiberlink.org thekeepers.org
Thank You! [email protected]


















