Week 1b. Principles, parameters, triggers, and subsets CAS LX 522A1 Topics in Linguistics: Language...
77
Week 1b. Principles, parameters, triggers, and subsets CAS LX 522A1 Topics in Linguistics: Language Acquisition
-
Upload
citlali-clowney -
Category
Documents
-
view
213 -
download
0
Transcript of Week 1b. Principles, parameters, triggers, and subsets CAS LX 522A1 Topics in Linguistics: Language...

Week 1b. Principles, parameters, triggers, and
subsets
CAS LX 522A1Topics in
Linguistics: Language
Acquisition

The proposed solution to the apparent paradox is to suppose that to a large extent all human languages are the same. The grammatical systems obey the same principles in all human languages.
UG Japanese
English
Principles and Parameters

Languages differ, but only in highly limited ways. In the order between the verb and the object. In whether the verb raises to tense …
UG Japanese
English
Principles and Parameters

This reduces the task for the child immensely—all that the kid needs to do is to determine from the input which setting each of the parameters needs to have for the language in his/her environment.
UG Japanese
English
Principles and Parameters

The standard picture
The way this is usually drawn schematically is like this. The Primary Linguistic Data (PLD) serves as input to a Language Acquisition Device (LAD), which makes use of this information to produce a grammar of the language being learned.
LADPLD grammar

The standard picture
This isolates the innately specified language faculty into a single component in the picture. The LAD contains (a specification for) all of the principles and the parameters, and has a procedure for going from PLD to parameter settings.
LADPLD grammar

We may be able to avoid confusion later, though, if we differentiate the innately provided system into its conceptual components.
This is my rendition of a way to think about UG, parameters, and LAD.
LAD
PLDUG
SubjacencyBinding Theory
Modeling human language capacity

UG provides the parameters and contains the grammatical system (including the principles, like Subjacency, Binding Theory, etc.) that makes use of them.
LAD sets the parameters based on the PLD. Responsible for getting language to kids.
LAD
PLDUG
SubjacencyBinding Theory
Modeling human language capacity

The idea behind this diagram is that UG is something like the shape of language knowledge. Knowledge of language can only take a certain,
innately pre-specified “shape”. A system with this “shape” has certain
properties, among them Binding Theory, Subjacency, … the Principles.
LAD
PLDUG
SubjacencyBinding Theory
Modeling human language capacity

The Parameters are different ways in which stored knowledge can conform to the “shape” of UG.
The LAD is a system which analyzes the PLD and sets the parameters.
LAD
PLDUG
SubjacencyBinding Theory
Modeling human language capacity

So two languages which differ with respect to one parameter setting might be represented kind of like this. This is of course a cartoon view of things,
but perhaps it might be useful later.
LanguageA Language
B
Principles and Parameters

Principles and Parameters
So what are the Principles and Parameters? Good question! —and that’s what
theoretical linguistics is all about. Since 1981, many principles and
parameters have been proposed. As our understanding of language grows, new evidence comes to light, and previous proposals are discarded in favor of better motivated ones. It’s hard to keep a current tally of “the principles we know of” because of the active nature of the field.

Principles and Parameters
Some of the (proposed) Parameters that have received a fair amount of press are: Bounding nodes for Subjacency Binding domain for anaphors and pronouns Verb-object order Overt verb movement (V moves to tense) Allowability of null subject (pro) in tensed
clauses
We’ll look at each of them in due course…

Verb-object orderThe parameter for verb-object order (more
generally, the “head parameter” setting out the order between X-theoretic head and complement) comes out as:
Japanese: Head-final (X follows complement)
English: Head-initial (X precedes complement).
Figuring out which type the target language is is often fairly straightforward. Kids can hear evidence for this quite easily. (Not trivial, though—consider German SOV-V2)

Principle A
22) Sam believes [that Harry overestimates himself]
23) Sam-wa [Harry-ga zibun-o tunet-ta to] it-ta]Sam-top Harry-nom self-acc pinch-past-that say-past‘Sam said that Harry pinched him(self).’

Principle A
Principle A. A reflexive pronoun must have a higher antecedent in its binding domain.
Parameter: Binding Domain Option (a): domain = smallest clause
containing the reflexive pronoun Option (b): domain = utterance
containing the reflexive pronoun

But how can you set this parameter?
Every sentence a kid learning English hears is consistent with both values of the parameter!
If a kid learning English decided to opt for the “utterance” version of the domain parameter, nothing would ever tell the kid s/he had made a mistake.
S/he would end up with non-English intuitions.

But how can you set this parameter?
A kid learning Japanese can tell right away that their domain is the sentence, since they’ll hear sentences where zibun refers to an antecedent outside the clause.

But how can you set this parameter?
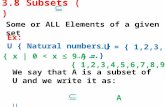
The set of sentences allowed in English is a subset of the set of sentences allowed in Japanese. If you started assuming the English value, you could learn the Japanese value, but not vice-versa.
Sentences allowed in Japanese (domain = utterance)
Sentences allowed in English (domain = clause)

Subset principle/defaults
Leads to: The acquisition device selects the most restrictive parametric value consistent with experience. (Subset principle)
That is, for the Principle A domain parameter, you (a LAD) start assuming you’re learning English and switch to Japanese only if presented with evidence.

What it takes to set a parameter
Binding domain parameter Option (a): Binding domain is clause. Option (b): Binding domain is
utterance.
English = option a, Japanese = option b.
EJ

What it takes to set a parameter
Binding domain parameter Kids should start under
the assumption that the parameter has the English setting.
If they hear only English sentences, they will stick with that setting.
If they hear Japanese sentences, they will have evidence to move to the Japanese setting.
EJ

What it takes to set a parameter
Null subject parameter Option (a): Null subjects are
permitted. Option (b): Null subjects are not
permitted.
Italian = option a, English = option b.
E
IVery sensible. Now, let’s consider another parameter of variation across languages.

What it takes to set a parameter
The Subset principle says that kids should start with the English setting and learn Italian if the evidence appears.
But even English kids are well-known to drop subjects early on in acquisition. As if had the Italian setting for this parameter.
E
I

Moreover…
English kids hear looks good and seems ok and stop that right now. Why don’t they end up speaking Italian? If they mis-set the parameter, how could they ever recover?
Italian kids hear subjectless sentences—why don’t they interpret them as imperatives or fragments (so as not to have to change the parameter from the default)?

Triggers
It seems like actual occurrence of null subjects isn’t a very good clue as to whether a subject is a null subject language or not.
Are there better clues? If a strapping young LAD were trying to set the null subject parameter, what should it look for?

Triggers Turns out: Only true subject-drop
languages allow null subjects in tensed embedded clauses.
24) *John knows that [— must go]. (English)
25) Juan sabe que [— debe ir].(Spanish)‘Juan knows that [he] must go.’
Perhaps the LAD “knows” this and looks for exactly this evidence. Null subjects in embedded tensed clauses would be a trigger for the (positive setting of the) null subject parameter.

Triggers A potential problem with the proposed
subject-drop trigger is that it requires complex sentences—you need to look at an embedded sentence to check for the trigger.
Such sentences might be too complicated for kids to process.
Degree-1 learnability: Triggers need look no lower than 1 level of embedding.
Degree-0 learnability: Triggers need look only at main clauses.

Triggers Many who work on learnability have
adopted the hypothesis that triggersneed to be degree-0 learnable.
Subjacency. *[wh … [a … [b … t … ] ]where a and b are bounding nodes.
Bounding node parameter for IP: Option (a): IP is a bounding node (English). Option (b): IP is not a bounding node (French,
Italian).
IP and TP are often
used inter-changeably

Triggers
Thus, a kid learning French couldn’t choose option (b) by hearing this…
28) Violà un liste de gens… ‘there is a list of people…’
[à qui on n’a pas encore trouvé [quoi envoyer t t ]]to whom one has not yet found [what to send]]
…since that’s a degree-2 trigger. But…

Triggers
29) Combien as- [IP tu vu [DP t de personnes]]?
How-many have you seen of people‘How many people did you see?’
If IP were a bounding node, this should be ungrammatical in French, so this can serve as (degree-0) evidence for option (b).

Triggers
Principles are part of UG
Parameters are defined by UG
Triggers for parameter settings are defined as part of the LAD.

Navigating grammar spaces
Regardless of the technical details, the idea is that in the space of possible grammars, there is a restricted set that correspond to possible human grammars.
Kids must in some sense navigate that space until they reach the grammar that they’re hearing in the input data.

Learnability
So how do they do it? Where do they start? What kind of evidence do they need? How much evidence do they need?
Research on learnability in language acquisition has concentrated on these issues.

Are we there yet?
There are a lot of grammars to choose from, even if UG limits them to some finite number.
Kids have to try out many different grammars to see how well they fit what they’re hearing.
We don’t want to require that kids remember everything they’ve ever heard, and sit there and test their current grammar against the whole corpus of utterances—that’ a lot to remember.

Are we there yet?
We also want the kid, when they get to the right grammar, to stay there.
Error-driven learning Most theories of learnability rely on a
kind of error-detection. The kid hears something, it’s not
generable by their grammar, so they have to switch their hypothesis, to move to a new grammar.

Plasticity
Yet, particularly as the navigation progresses, we want them to be zeroing in on the right grammar.
Finding an error doesn’t mean that you (as a kid) should jump to some random other grammar in the space.
Generally, you want to move to a nearby grammar that improves your ability to generate the utterance you heard—move in baby steps.

Triggers
Gibson & Wexler (1994) looked at learning word order in terms of three parameters (head, spec, V2).
Their triggering learning algorithm says if you hear something you can’t produce, try switching one parameter and see if it helps. If so, that’s your new grammar. Otherwise, stick with the old grammar and hope you’ll get a better example.

Local maxima
A problem they encountered is that there are certain places in the grammar space where you end up more than one switch away from a grammar that will produce what you hear.
This is locally as good as it gets—nothing next to it in the grammar space is better—yet if you consider the whole grammar space, there is a better fit somewhere else, you just can’t get there with baby steps.

Local maxima
This is a point where any move you make is worse, so a conservative algorithm will never get you to the best place. Something a working learning algorithm needs to avoid. (And kids, after all, make it).

MLU
Kids’ linguistic development is often measured in terms of Mean Length of Utterance (MLU). Can be measured in various ways
(words, morphemes) Gives an idea of kids’ normal utterance
length Seems to correlate reasonably well with
other qualitative changes in kid productions

2-year olds
Around 2 years old Around MLU 1.75 Around 400 words in the vocabulary 1-3 word utterances Word order generally right Grammatical words (the, is)
generally missing

2 1/2 year olds
About 2 1/2 to 3 years About MLU 2.25 About 900 words in the vocabulary Some grammatical devices (past tense -
ed, verbal -ing). Over-regularization errors (He goed in the
house), indicating they’ve grasped the rule of past tense formation.
Single clause sentences

3 and 4 year olds
About 3 to 3 1/2 years, MLU about 2.75, about 1200 words, beginning to use syntactic transformations (Is Daddy mad? Where is he going?)
About 3 1/2 to 4 years, MLU about 3.5, about 1500 words, multi-clause sentences, still some over-regularization

4 and 5 year olds
4-5 years, MLU around 4, about 1900 words, using more conjunctions and temporal terms (before, after), gain some metalinguistic awareness.
After 5, MLU stays about the same (no longer predictive), sentences get more complex, vocabulary increases (more slowly), over-regularization decreases…

How do we describe multi-word utterances?
Syntactically, in the same terms as the adult grammar? (continuity)
Or discontinuously? (For some reason, people seem to think this is simpler…) Thematic (agent+action,
action+theme, …) Pivot (P1 + O, O + P2, O + O, O) “Limited scope formulas” (here+X,
want+X)

Syntactic approach
Continuity:
VP VP
V PP V PP
sit sit P NP P
NP on chairchair

Why 2 words? Maybe they omit words they don’t
know? Well, but they do omit words they
know. A kid who’s used hurt before,
documented as saying baby cheek to mean ‘baby hurt cheek.’
Pinker (1984): Processing bottleneck A 2-word utterance “filter” Kids “grow out” of this constraint. Still, kind of mysterious. What’s
easier?


So, do kids have syntactic categories?
There’s not really any clear way to know at the earliest (one word) stages.
One view is that the null hypothesis (which we adopt, lacking evidence to the contrary) should be that kids do have adult-like syntactic categories.
Continuity. Kids end up being adults with adult syntactic categories; if they initially categorize words differently, we need to explain how they change their categorization to the adult type.

Do kids at the one-word stage have/know
syntactic structure? Early attempt to answer the
question. Based on comprehension—kids
clearly understand more than they can produce.
de Villiers & de Villiers (1973), kids around MLU (mean length of utterance) 1 to 1.5 asked to act out the truck pushes the car, and got it right only about a third of the time.

Do kids at the one-word stage have/know
syntactic structure? Hirsh-Pasek & Golinkoff (1991),
preferential looking task. Less burdensome task. Significant preference for correct screen (word order & role).
Hey,Cookie Monster is tickling Big Bird.

Evidence for structure
Recall also the Hirsh-Pasek & Golinkoff (1991), preferential looking task.
Structure plays a crucial role in figuring out which screen to look at.
Hey,she’s kissing the keys.

One-substitution Anecdotal evidence:
nice [yellow pen], nice one (1;11)
Hamburger & Crain (1984): ‘Point to the first green ball. Ok. Now, point to the second one.’ Note: “Failure” wouldn’t tell us anything
here, since one could also legitimately mean ball—but if kids take one to mean green ball, that’s evidence that kids do have the syntactic sophistication to replace N with one.
Nevertheless, 42 / 50 kids interpreted it as green ball.

Some properties of kidspeak
Kids’ language differs from adult language in somewhat predictable ways. These can serve as clues to kids’ grammatical knowledge. Up to around 3 or so… Case errors for nouns Some word order errors Omitted subjects Verbs not (always) fully inflected

Word order errors? Languages vary with respect to word
order SVO English, French, Mandarin, … VSO Tagalog, Irish, … SOV Japanese, Korean, Turkish, … SOV+V2 German, …
Clahsen (1986) reports that German kids don’t manage to put the verb in second position until the finite/nonfinite distinction is “mastered.”
But at that point the change was immediate: Sentence-syntactic properties are stored separately from word’s category properties.

Word order errors? Surprisingly few—95% correct in English,
DP-internal order (*black the dog) may be at 100%.
Yet there are a number of things like: Doggy sew.
It appears that in these cases, it is theme+V without an expressed agent. When agent is expressed, themes are in their place.
Sounds like an unaccusative or a passive—perhaps they are treating the verb in these cases as unaccusatives? An attractive idea—but for the fact that young kids are bad at passives and unaccusatives.

Word order errors Occasionally, postverbal subjects occur—
but these seem to occur with likely unaccusatives with postverbal subjects on occasion: going it, come car, fall pants. (cf. adult Mandarin , or Italian, which would allow that).
Alternative approach to Doggy sew might be topicalization: Doggy, you sew—if kids actually can’t do passives and unaccusatives, then this might be the only explanation (short of pure performance error).

The Bennish optative Anecdote about Ben, from Sadock (1982)
SVO normally, but in optative (wish) constructions, he uses a weird word order.
Intransitives (subject follows verb) Fall down Daddy. ‘Daddy should fall down’ Eat Benny now. ‘Let Benny eat now.’ Sit down Maggie, Mommy.
‘Maggie should sit down, Mommy.’ Transitives (subject marked with for)
Pick up Benny for Daddy.‘Daddy should pick Ben up.’
Read a story for Mommy.‘Mommy should read a story.’

The Bennish optative He’s marking transitive subjects with for,
but leaving intransitive subjects and objects unmarked.
In the optative, Ben treats transitive subjects differently, and objects and intransitive subjects the same way.
This pattern is reflected in a type of adult language as well. Ergative languages mark subjects of transitives differently from both objects and intransitive subjects.
Accusative languages (like English) mark objects differently (I left, I bought cheese, Bill saw me).

The Bennish optative
Perhaps Ben’s language is ergative in the optative mood. (An option for adult languages, though clearly not in his parents’ language)
Further evidence: Ergative case marker is often
homophonous with marker for possessive (cf. Inuktitut -up used for both), and Ben uses for (his ERG marker) in possessive constructions as well.
That’s a nose for Maggie ‘That’s Maggie’s nose.’

The Bennish optative
Further evidence: Ergative languages are almost invariably split
often along semantic lines. Sadock takes the optative restriction to be of this type (cf. Georgian, nominative-accusative most of the time, except in the subjunctive and aorist, where it is ergative-absolutive)
Ben’s not really making word order errors, exactly—he just thinks he’s speaking Georgian. His errors come from among the options.

Pre-subject negation
Kids will say things like: No I see truck Not Fraser read it No lamb have a chair either.
Anaphoric no? ‘No, I see the truck.’ Often distinguishable from context,
and they are not all anaphoric.

Pre-subject negation
Déprez & Pierce 1993 looked at these, and proposed that not Fraser read it comes from a failure to raise the subject out of SpecVP to SpecIP. That is, here, Fraser is still in its VP-internal subject position.
Some believe this, some don’t, but it’s a well-known analysis.

Case errors
English pronouns exhibit Case Nom: I, he, she, they Acc: me, him, her, them Gen: my, his, her, their
Kids seem to make errors until at least 2. me got bean her do that me eye
In general, it is often overgeneralization of Acc.

Overuse of accusative
Default case: Acc in adult English (Schütze 1997) Me too. What, me cheat?! Never! Me, I like pizza. It’s me. —Who did this? —Me.
So, “overuse of accusative” may well be just using a default form for nouns which don’t have case.

Default Case
Russian (Babyonyshev 1993): Default case appears to be Nom.
Russian kids make basically no errors in subject case.
…but they overuse Nom in other positions (e.g., Nom instead of Acc on an object).

Default Case
German (Schütze 1995): Default case also appears to be Nom: Was? Ich dich betrügen? Nie!
‘What? I cheat on you? Never!’ Der, den habe ich gesehen.
‘He, him I saw.’
Object case errors are more common than subject case errors, and usually involve overgeneralization of Nom.

Determiners
Kids will also often leave out determiners. Hayley draw boat. Turn page. Reading book. Want duck. Wayne in garden Daddy want golf ball.

Subject drop
Even in languages which don’t allow null subjects, kids will often leave subjects out. No turn. Ate meat. Touch milk.
Dropping the subject is quite common—dropping other things (e.g., object) is quite rare.

Subject vs. object drop
0
10
20
30
40
50
60
70
Adam Eve Sarah
Percentage of Missing subjects and Objects from Obligatory Contexts
Subjects
Objects
A E S
Subject
57 61 43
Object 8 7 15

Root infinitives
Another, fairly recently-noticed aspect of kid speech is that they will use infinitive verbs sometimes when adults would use finite verbs. In lots of languages.
French: Pas manger la
poupéenot eat[inf] the doll
Michel dormirMichel sleep[inf]
German: Zahne putzen
teeth brush[inf] Thorstn das haben
Thorsten that have[inf].
Dutch: Ik ook lezen
I also read[inf.]

Root infinitives
English kids do this too, it turns out, but this wasn’t noticed for a long time. It only write on the pad (Eve 2;0) He bite me (Sarah 2;9) Horse go (Adam 2;3)
It looks like what’s happening is kids are leaving off the -s.
Taking the crosslinguistic facts into account, we now think those are nonfinite forms (i.e. to write, to bite, to go).

Root infinitives
However, children learning some languages seem to show very few root infinitives or none at all. Italian, for example.
Often these languages with very few root infinitives Allow null subjects Have fairly complex agreement
morphology

Pulling it all together
Kids sometimes use nonfinite verbs. Kids sometimes leave out the
subject. Kids sometimes use the wrong Case
on the subject (looks like a default Case).
Kids sometimes get the word order wrong (specifically, with respect to negation and for V2).
Kids generally leave out determiners.

Kid grammars
A major research industry arose trying to explain how these properties of child speech come about (and how they relate to each other) in terms of the grammatical and/or performance abilities of children.