
Web Services Discovery with QoS - Queen's University propose a simple model of reputation-enhanced...
102
Reputation-Enhanced Web Services Discovery with QoS by Ziqiang Xu A thesis submitted to the School of Computing in conformity with the requirements for the degree of Master of Science Queen’s University Kingston, Ontario, Canada August, 2006 Copyright © Ziqiang Xu, 2006
-
Upload
nguyenkiet -
Category
Documents
-
view
218 -
download
1
Transcript of Web Services Discovery with QoS - Queen's University propose a simple model of reputation-enhanced...

Reputation-Enhanced Web Services Discovery with QoS
by
Ziqiang Xu
A thesis submitted to the School of Computing
in conformity with the requirements for the degree of Master of Science
Queen’s University Kingston, Ontario, Canada
August, 2006
Copyright © Ziqiang Xu, 2006

Abstract
With an increasing number of Web services providing similar functionalities,
more emphasis is being placed on how to find the service that best fits the consumer’s
requirements. In order to find services that best meet their QoS requirements, the service
consumers and/or discovery agents need to know both the QoS information for the
services and the reliability of this information. The problem, however is that the current
UDDI registries do not provide a method for service providers to publish the QoS
information of their services, and the advertised QoS information of Web services is not
always trustworthy.
We propose a simple model of reputation-enhanced Web services discovery with
QoS. Advertised QoS information is expressed in XML style format and is stored using
tModels in a UDDI registry. Services that meet a customer’s functionality and QoS
requirements are ranked using the service reputation scores which are maintained by a
reputation management system. A service matching, ranking and selection algorithm is
presented and evaluated.
ii

Acknowledgments
I would like to extend my sincerest thanks to my supervisor, Patrick Martin, for
providing me with this opportunity. I would like to thank him for all his excellent
guidance, precious advice and endless support over the years during my graduate study
and research at Queen’s University.
I would also like to thank Wendy Powley for her excellent support and wonderful
advice.
I would like to acknowledge my lab mates, fellow students and friends who have
provided endless inspiration during my stay at Queen’s University.
I would like to extend my gratitude to the School of Computing at Queen’s
University for their support.
Finally, I would like to express my sincerest appreciation and love to my family
and my wife, Katie, for all their help and support during these past few years.
iii

Table of Contents
Abstract ii
Acknowledgements iii
Table of Contents iv
List of Tables vii
List of Figures viii
Glossary of Acronyms xi
Chapter 1 Introduction 1
1.1 Motivation 3
1.2 Problem 5
1.3 Research Statement 6
1.4 Thesis Organization 8
Chapter 2 Background and Related Work 9
2.1 Web Services Discovery 9
2.1.1 Discovery: Registry, Index and P2P Approaches 10
2.1.2 Manual versus Autonomous Discovery 11
2.2 The UDDI Registry 11
2.3 The Semantic Web and Ontology 12
2.4 QoS and Web Services Discovery 14
2.4.1 Storage of QoS Information in the UDDI Registry 15
2.4.2 Researches on Web Services Discovery with QoS 18
2.5 Web Services Reputation System 20
2.6 Reputation-enhanced Web Services Discovery with QoS 22
iv

Chapter 3 Reputation-Enhanced Service Discovery with QoS 24
3.1 UDDI Registry and QoS Information 25
3.1.1 Publishing QoS Information 25
3.1.2 Updating QoS Information 27
3.2 Discovery Agent 27
3.3 Reputation Manager 32
3.3.1 Reputation Collection 33
3.3.2 Storage of Service Ratings 33
3.3.3 Computation of Reputation Score 34
3.4 Dynamic Service Discovery 35
3.5 Service Matching, Ranking and Selection Algorithm 38
3.5.1 Service Matching, Ranking and Selection 38
3.5.2 Service Matching, Ranking and Selection Algorithm 41
Chapter 4 Evaluation 47
4.1 Evaluation of the Service Discovery Model 47
4.1.1 Experimental Environment 48
4.1.2 Test Scenarios 49
4.2 Evaluation of the Matching, Ranking and Selection Algorithm 51
4.2.1 Experimental Environment 52
4.2.2 Generation of Service Ratings and Execution of Discovery Requests 53
4.2.3 Selection of Inclusion Factor λ 54
4.2.4 Simulation 1: QoS and Reputation Requirements Help Find
Best Services 55
v

4.2.5 Simulation 2: Unstable Vs. Consistent QoS Performance 59
4.2.6 Simulation 3: Selection of Services with Unstable QoS Performance 64
4.2.7 Simulation 4: Effect of Inclusion Factor on Service Selection 67
4.2.8 Summary of the Evaluations 73
Chapter 5 Conclusions and Future Work 75
5.1 Thesis Contributions 75
5.2 Conclusions 77
5.3 Future Work 77
References 79
Appendix A: Service Matching, Ranking and Selection Algorithm 85
Appendix B: WSDL document of Web service XWebEmailValidation 90
vi

List of Tables
Table 3.1 Example Ratings for a Service 34
Table 4.1 Summary of QoS and reputation information of Services 56
Table 4.2 Service QoS information 56
Table 4.3 Service price information 56
Table 4.4 Service reputation information 56
Table 4.5 Summary of QoS and reputation requirements of consumers 57
Table 4.6 Price and QoS information of services 60
Table 4.7 Summary of QoS and reputation requirements of consumers 62
Table 4.8 Summary of QoS information of service 65
Table 4.9 Summary of QoS and reputation requirements of consumer 67
Table 4.10 Summary of QoS information of service 68
Table 4.11 Summary of QoS and reputation requirements of consumer 68
vii

List of Figures
Figure 1.1 Current Web services publish-find-bind model 2
Figure 1.2 Sample SOAP request message sent to XWebEmailValidation 2
Figure 1.3 Sample SOAP response message from XWebEmailValidation 3
Figure 2.1 UDDI core data structures 12
Figure 2.2 QoS Information on BindingTemplates 17
Figure 2.3 The tModel with the QoS Information 18
Figure 3.1 Model of Reputation-enhanced Web Services Discovery with QoS 24
Figure 3.2 The tModel with the QoS information 26
Figure 3.3 Service discovery request 28
Figure 3.4 Service discovery request with QoS and reputation requirements
using SOAP 31
Figure 3.5 Service discovery response using SOAP 32
Figure 3.6 Steps of Service Publish Process 36
Figure 3.7 Steps of Service QoS Information Update Process 36
Figure 3.8: Steps of Service Discovery Process 37
Figure 3.9: Flow chart of the service matching, ranking and selection algorithm 42
Figure 3.10 High level part of the service matching, ranking and selection
algorithm 42
Figure 3.11 Service QoS matching algorithm 43
Figure 3.12 Service QoS ranking algorithm 44
Figure 3.13 Service QoS and reputation ranking algorithm 45
Figure 3.14 Service selection algorithm 46
viii

Figure 4.1 Experiment of the service discovery model 49
Figure 4.2: Experimental environment for evaluation the matching,
ranking and selection algorithm 52
Figure 4.3: Effect of λ on the reputation score 55
Figure 4.4 Service selection result of simulation 1 59
Figure 4.5 Rating and reputation of service 1 in each group (Simulation 2) 60
Figure 4.6 Rating and reputation of service 2 in each group (Simulation 2) 61
Figure 4.7 Rating and reputation of service 3 in each group (Simulation 2) 61
Figure 4.8 Rating and reputation of service 4 in each group (Simulation 2) 61
Figure 4.9 Service selection for customer 1 (Experiment 1, Simulation 2) 63
Figure 4.10 Service selection for customer 2 (Experiment 1, Simulation 2) 63
Figure 4.11 Service selection for customer 3 (Experiment 1, Simulation 2) 64
Figure 4.12 Service selection for customer 4 (Experiment 1, Simulation 2) 64
Figure 4.13 Rating and reputation of service 1 (Simulation 3) 65
Figure 4.14 Rating and reputation of service 2 (Simulation 3) 66
Figure 4.15 Rating and reputation of service 3 (Simulation 3) 66
Figure 4.16 Rating and reputation of service 4 (Simulation 3) 66
Figure 4.17 Service selection for the customer (Simulation 3) 67
Figure 4.18 Rating and reputation of service 1 (Experiment 1, Simulation 4) 69
Figure 4.19 Rating and reputation of service 2 (Experiment 1, Simulation 4) 70
Figure 4.20 Rating and reputation of service 3 (Experiment 1, Simulation 4) 70
Figure 4.21 Rating and reputation of service 4 (Experiment 1, Simulation 4) 70
Figure 4.22 Rating and reputation of service 1 (Experiment 2, Simulation 4) 71
ix

Figure 4.23 Rating and reputation of service 2 (Experiment 2, Simulation 4) 71
Figure 4.24 Rating and reputation of service 3 (Experiment 2, Simulation 4) 71
Figure 4.25 Rating and reputation of service 4 (Experiment 2, Simulation 4) 72
Figure 4.26 Service selection for the customer (Experiment 1, Simulation 4) 73
Figure 4.27 Service selection for the customer (Experiment 2, Simulation 4) 73
x

Glossary of Acronyms
API Application Programming Interface
DAML DARPA Agent Markup Language
DARPA Defense Advanced Research Projects Agency
HTTP HyperText Transfer Protocol
OWL Ontology Web Language
QoS Quality of Service
P2P Peer-to-Peer
SOAP Simple Object Access Protocol
UDDI Universal Description, Discovery, and Integration
UBR UDDI Business Registry
WSAF Web Services Agent Framework
WSDL Web Service Description Language
WSLA Web Services Level Agreements
XML Extensible Markup Language
xi

Chapter 1
Introduction
What are Web services and why do we need them? Web services are application
components that communicate using open protocols such as HyperText Transfer Protocol
(HTTP), Extensible Markup Language (XML) and Simple Object Access Protocol
(SOAP). They are designed to support interoperable machine-to-machine interaction over
a network [40].
Many companies provide Web services to customers. For example, Google Web
APIs service [12] allows software developers to query billions of web pages directly from
their own computer programs. A developer can use his or her favorite programming
language, such as Java, Perl or Visual Studio .Net to develop applications that access the
Google Web services.
The current Web services architecture encompasses three roles: Web service
provider, Web service consumer and Universal Description, Discovery and Integration
(UDDI) registry [33], as shown in Figure 1.1. The Web service provider publishes a
description of the service in the UDDI registry, as well as details of how to use the
service. UDDI registries use Web Services Description Language (WSDL) [8], an XML-
based language, to describe a Web service, the location of the service and operations (or
methods) the service exposes. The Web service consumer uses the UDDI to discover
appropriate services that meet its requirements using the information provided by the
services, chooses one service, and invokes the service. The Web service publishing,
1
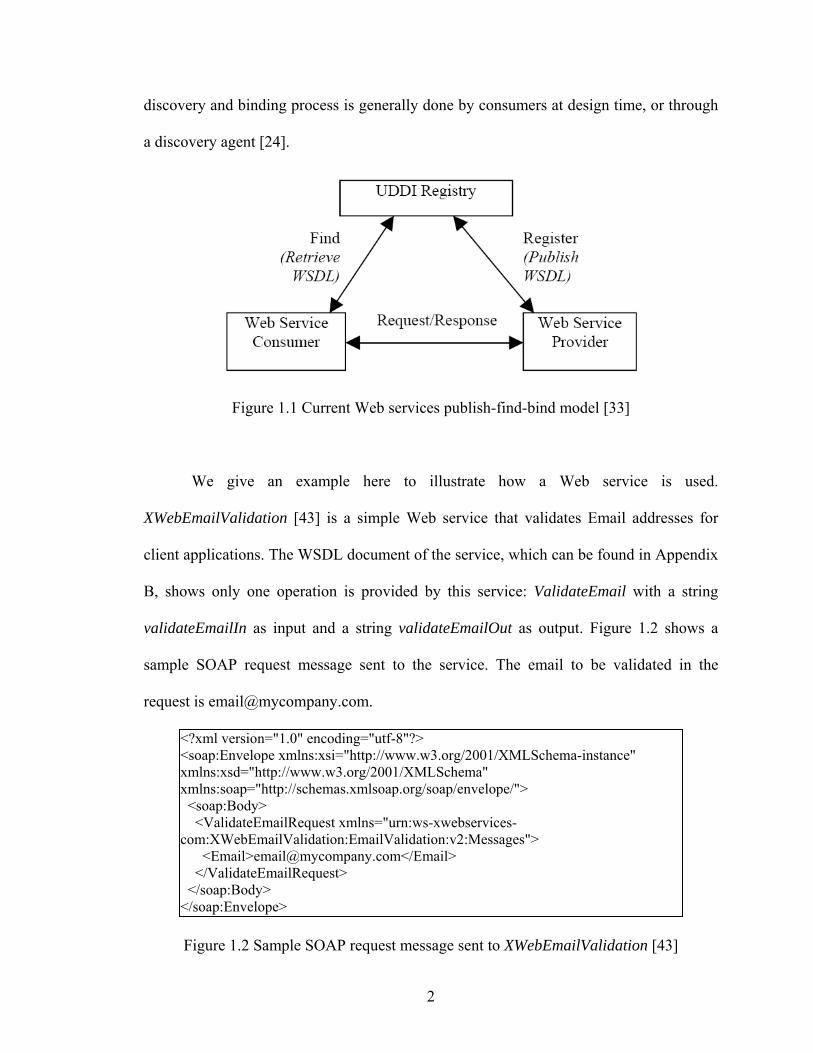
discovery and binding process is generally done by consumers at design time, or through
a discovery agent [24].
Figure 1.1 Current Web services publish-find-bind model [33]
We give an example here to illustrate how a Web service is used.
XWebEmailValidation [43] is a simple Web service that validates Email addresses for
client applications. The WSDL document of the service, which can be found in Appendix
B, shows only one operation is provided by this service: ValidateEmail with a string
validateEmailIn as input and a string validateEmailOut as output. Figure 1.2 shows a
sample SOAP request message sent to the service. The email to be validated in the
request is [email protected].
<?xml version="1.0" encoding="utf-8"?> <soap:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"> <soap:Body> <ValidateEmailRequest xmlns="urn:ws-xwebservices-com:XWebEmailValidation:EmailValidation:v2:Messages"> <Email>[email protected]</Email> </ValidateEmailRequest> </soap:Body> </soap:Envelope>
Figure 1.2 Sample SOAP request message sent to XWebEmailValidation [43]
2

Figure 1.3 shows a sample SOAP message from the service. The status of the
email is VALID.
<?xml version="1.0" encoding="utf-8"?> <soap:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"> <soap:Body> <ValidateEmailResponse xmlns="urn:ws-xwebservices-com:XWebEmailValidation:EmailValidation:v2:Messages"> <Status>VALID</Status> </ValidateEmailResponse> </soap:Body> </soap:Envelope>
Figure 1.3 Sample SOAP response message from XWebEmailValidation [43]
The current UDDI registries only support Web services discovery based on the
functional aspects of services [33]. However, customers are interested in not only the
functionalities of Web services, but also their quality of service (QoS), which is a set of
non-functional attributes (for example, response time and availability) that may have
impact on the quality of the service provided by Web services [19][33][39]. If there are
multiple Web services providing the same functionality in UDDI registries, the QoS
requirement can be used as a finer search constraint. We propose a model of reputation-
enhanced Web services discovery with QoS to help consumers find the services that best
meet their requirements. The following sections discuss the motivation, the problem and
the goal of the research.
1.1 Motivation
With an increasing number of Web services providing similar functionalities,
more emphasis is being placed on how to find the service that best fits the consumer’s
3

requirements. These are functional requirements, that is, what the service can do, and
non-functional requirements, such as the price and quality of service guaranteed by a
service.
For example, a financial company is looking for a Web service to obtain real time
stock quotes for its business management system. The target service must guarantee a
service availability of more than 98% (QoS requirement), and the cost of each transaction
should be no more than CAN $0.01 (price requirement). By manually searching the
major UDDI Business Registries (UBRs), such as those provided by IBM, Microsoft and
SAP, the company finds that there exist 20 Web services that provide real time stock
quotes. After contacting the service providers, it is found that only 10 services satisfy the
price requirement, and all of these 10 services claim that their service availability is
above 98%. Which service should be chosen? Assuming that the QoS claims made by
these service providers are trustworthy, the choice is simple, either the service with the
lowest price, or the service providing the highest availability.
The problem, however, is that the advertised QoS information of a Web service is
not always trustworthy. A service provider may publish inaccurate QoS information to
attract more customers, or the published QoS information may be out of date. Allowing
current customers to rate the QoS they receive from a Web service, and making these
ratings public, can provide new customers with valuable information on how to rank
services. Service QoS reputation can be considered as an aggregation of service ratings
for a service from consumers over a specific period of time. This provides a general and
overall estimate of the reliability of a service provider. With service reputation taken into
consideration, the probability of finding the best service for a customer can be increased.
4

1.2 Problem
As mentioned previously, service customers manually search UBRs to find Web
services that satisfy their functional requirements. If some suitable services are found, the
customer must contact the service providers to obtain the QoS information, since this
information is not provided in the UBRs. The customer manually selects from these
services the one that best matches both the functionality and the QoS requirements. To
achieve the goal of dynamic Web services discovery, which enables consumers to
discover services satisfying their requirements automatically at run time [24], this process
must be automated.
There are two major problems in dynamic Web services discovery with QoS. The
first involves the specification of QoS information. How should the QoS information be
expressed and/or stored? A standard format must be agreed upon and used in order for
the information to be exchanged and interpreted. The second problem is one of matching
the customer’s requirements with that of the provider. For example, if a customer is
looking for services that matches its QoS requirements of 2ms response time, 400Kbps
throughput and 99.9% availability, how can services be found whose QoS advertisement
satisfies these requirements?
Major efforts in this area include Web Services Level Agreements (WSLA)
[15][16][17] by IBM, Web Services Policy Framework (WS-Policy) [5] by BEA, IBM
and SAP, and the DARPA Agent Markup Language (DAML) Program [9]. These efforts
have considerable industrial support. Most of these efforts represent a complex
framework focusing not only on QoS specifications, but on a more complete set of
aspects relating to Web services. Modeling and management of service level agreements
5

(WSLA), service invocation policy (WS-policy specifications) and semantic annotation
(DAML-S specifications) are supported by these efforts [13].
Instead of using a complex framework, some researchers propose other simpler
models and approaches [22][26][38] for dynamic Web services discovery. However, all
of these efforts struggle with the same challenges related to QoS publishing and modeling,
and/or QoS matching.
In the current Web Services architecture, the UDDI registry stores descriptions
about Web services in a common XML format and functions like a "yellow pages" for
Web Services. However, the UDDI registry does not include QoS information. This
information can be added to the UDDI, but the challenge of how to express and match the
provider’s QoS advertisements and the consumer’s QoS requirements remains.
Additionally, how can reputation be expressed and used to facilitate service selection?
1.3 Research Statement
The goal of this research is to investigate how dynamic Web service discovery
can be realized to satisfy a customer’s QoS requirements using a new model that can be
accommodated within the basic Web service protocols. We propose a simple model of
reputation-enhanced Web services discovery with QoS. The motivation is to create a
simple model at the level of standards such as WSDL and UDDI as opposed to a more
complex model based on high-level WSLA or WS-Policy specifications.
The current UDDI registries support only keyword-based search [32][42] to find
Web services that satisfy a customer’s functional requirements. This process is typically
6

done at design time and choosing a Web service is static and does not change during run
time. Our interests lie not in the matching of functional requirements, but instead, in QoS
and reputation-based matching during dynamic service discovery process at run time.
We propose a Web services discovery model that contains a discovery agent and a
reputation management system. Based on the customer’s functional, QoS and reputation
requirements, the discovery agent contacts the UDDI registry to discover Web services
that match the given requirements. The agent then ranks the suggested services according
to their advertised QoS information and/or reputation scores, which are maintained by a
separate service reputation management system. The reputation management system is
responsible for collecting and processing ratings of services from consumers, then
updating the reputation score of the related service. We assume that the ratings are all
trustworthy.
We use technical models (tModels) [36], a current feature in UDDI registries, to
store advertised QoS information of services. A tModel consists of a key, a name, an
optional description and a Uniform Resource Locator (URL) which points to a place
where details about the actual concept represented by the tModel can be found. When a
business publishes a Web service, it creates and registers a tModel within a UDDI
registry. The QoS information of the Web service is represented in the tModel, which is
referenced in a binding template [35] that represents the Web service deployment.
We develop a service matching, ranking and selection algorithm that finds
services that match a consumer’s requirements, ranks the matches using their QoS
information and reputation scores and selects services based on the consumer’s
preference in the service discovery request.
7

1.4 Thesis Organization
The remainder of the dissertation is organized as follows. Chapter 2 outlines the
related research conducted in the area of Web services discovery, service QoS and
reputation. Chapter 3 describes the proposed reputation-enhanced Web service discovery
with QoS. Chapter 4 presents evaluations of our service discovery model and matching,
ranking and selection algorithm. It describes the simulations and then discusses a set of
experiments. The thesis is summarized and future work is discussed in Chapter 5.
8

Chapter 2
Background and Related Work
This section discusses work related to Web services discovery, and QoS and
reputation-based discovery. We give a brief introduction to Web service discovery in
Section 2.1 and the UDDI registry in Section 2.2. We present some previous work in the
area of Semantic Web and ontology in Section 2.3. Section 2.4 describes QoS of Web
services and related research on Web services discovery with QoS, while addressing how
our work looks to further the progress towards service QoS publishing and modeling.
Section 2.5 looks at work in the field of Web services reputation. Finally, Section 2.6
examines the issue of reputation-enhanced Web services discovery with QoS.
2.1 Web Services Discovery
Web services discovery is "the act of locating a machine-processable description
of a Web service that may have been previously unknown and that meets certain
functional criteria" [40]. The goal is to find appropriate Web services that match a set of
user requirements. A discovery service, which could be performed by either a consumer
agent or a provider agent, is needed to facilitate the discovery process. There are three
leading approaches [40] on how a discovery service should be designed: a registry, an
index, or a peer-to-peer (P2P) system. Their differences are discussed in the following
section.
9

2.1.1 Discovery: Registry, Index and P2P Approaches
A registry is an authoritative, centrally controlled repository of services
information. Service providers must publish the information of their services before they
are available to consumers. The registry owner decides who has the authority to publish
and update services information. A company is not able to publish or update the
information of services provided by another company. The registry owner decides what
information can be published in the registry. UDDI is an example of this approach.
Centralized registries are appropriate in static or controlled environments where
information does not change frequently.
An index is a collection of published information by the service providers. It is
not authoritative and the information is not centrally controlled. Anyone or any company
can create their own index, which collects information of services exposed on the web
usually using web spiders. The information in an index could be out of date but can be
verified before use. Google is an example of the index approach [40].
P2P computing provides a de-centralized alternative that allows Web services to
discover each other dynamically. Each Web service is a node in a network of peers. At
discovery time, a Web service queries its neighbors in search of a suitable Web service. If
any one of its neighboring peers matches its requirements, it replies and the query is
ended. Otherwise, the query is propagated through the network until a suitable Web
service is found or certain termination criteria are reached. P2P architecture is more
reliable than registry approach since it does not need a centralized registry, but introduces
more performance costs since most of time a node acts as a relayer of information.
10

2.1.2 Manual versus Autonomous Discovery
Depending on who is actually performing the discovery, service discovery could
be manual or autonomous. Manual discovery is typically done at design time and
involves a human service consumer that uses a discovery service to find services that
match its requirements. Autonomous discovery involves a discovery agent to perform this
task at design time or run time. One situation in which autonomous discovery is needed is
when a service consumer needs to switch to another service because the current service is
either no longer available or cannot satisfy its requirements anymore.
2.2 The UDDI Registry
The Universal Description, Discovery, and Integration, or UDDI, standard is the
most dominating among the Web services discovery mechanisms discussed above [11]. A
UDDI registry is a directory for storing information about Web services. A service
provider makes its services available to public users by publishing information about the
service in a UDDI registry. Individuals and businesses can then locate the services by
searching public and private registries. For example, airlines can publish their fare
services to a UDDI registry. Travel agencies then use the UDDI registry to locate Web
services provided by different airlines, and to communicate with the service that best
meets their requirements.
The information about Web services in a UDDI registry includes a description of
the business and organizations that provide the services, a description of a service’s
business function, and a description of the technical interfaces to access and manage
those services [35]. A UDDI registry consists of instances of four core data structures
11

including the businessEntity, the businessService, the bindingTemplate and the tModel.
The four core structures and their relationships are shown in Figure 2.1. This information
comprises everything a user needs to know to use a particular Web service. The
businessService is a description of a service’s business function, businessEntity describes
the information about the organization that published the service, bindingTemplate
describes the service’s technical details, including a reference to the service’s
programmatic interface or API, and tModel defines various other attributes or metadata
such as taxonomy and digital signatures [37].
Figure 2.1: UDDI core data structures [35]
2.3 The Semantic Web and Ontology
The current World Wide Web represents information using natural languages.
The information is intended for human readers but not machines. The Semantic Web is
“an extension of the current Web in which information is given well-defined meaning,
12

enabling computers and people to work in better cooperation” [2]. It is a mesh of
information that can be automatically processed and understood by machines. The
Semantic Web was devised by Tim Berners-Lee who invented the WWW, HTTP and
HTML.
The Resource Description Framework (RDF) [20] is a basic semantic markup
language for representing information about resources on the Web. It is used in situations
where the information needs to be processed by applications rather than humans. RDF
Schema (RDF-S) [6] is a language for describing RDF vocabulary. It is used to describe
the properties and classes of RDF resources. The Web Ontology Language (OWL) is
used to “publish and share sets of terms called ontologies, supporting advanced Web
search, software agents and knowledge management” [27]. It provides more vocabulary
for describing properties and classes of RDF resources than RDF-S. OWL-S, the Web
Ontology Language for Services [30], is an OWL based Web service ontology. It
provides a language to describe the properties and capabilities of Web services. OWL-S
can be used to automate Web service discovery, execution, composition and
interoperation.
WSDL is a XML document used to describe Web services [8]. It describes the
location of a Web service and the operations the service provides. It defines a protocol
and encoding independent way to describe interactions with Web services. One
shortcoming of the current technologies of Web services, such as WSDL, SOAP and
UDDI, is that they describe only the syntax but not semantics of services. By taking
advantage of the strengths of both OWL-S and WSDL, Web service providers can
describe their services in an unambiguous form that can be understood by computers [21].
13

Ontology is defined as “a specification of a conceptualization” [14]. It uses a
formal language, such as OWL, to describe the concepts and relationships in a domain.
The main reason to use ontologies in computing is that they facilitate interoperability and
machine reasoning [10]. A common ontology for Web services is the DAML-S ontology
[7], which aims to facilitate automatic Web service discovery, invocation and
composition. It describes properties and capabilities of Web services but does not provide
details about how to represent QoS descriptions. A DAML-QoS ontology [45] is
proposed as a complement for the DAML-S ontology. It describes QoS property
constraints and presents a matchmaking algorithm for QoS property constraints. Zhou et
al. [46] propose a QoS measurement framework based on the DAML-QoS ontology to
check the service provider’s compliance with the advertised QoS at run time.
Papaioannou et al. [31] develop a QoS ontology that aims to formally describe arbitrary
QoS parameters and support QoS-aware Web service provision. Maximilien and Singh
[24] propose a QoS ontology for their framework for dynamic Web services selection. A
QoS upper ontology that describes the basic characteristics of all qualities and a QoS
middle ontology that specifies domain-independent quality concepts are presented in the
paper.
2.4 QoS and Web Services Discovery
Quality of Service, or QoS, is “a combination of several qualities or properties of
a service” [29]. It is a set of non-functional attributes that may influence the quality of the
service provided by a Web service [39]. Some examples of the QoS attributes are given
below:
14

• Availability is the probability that system is up and can respond to consumer
requests. Generally it is slightly parallel to reliability and slightly opposite to
capability.
• Capacity is the limit of concurrent requests a service can handle. When the
number of concurrent requests exceeds the capacity of a service, its availability
and reliability decrease.
• Reliability is the ability of a service to perform its required functions under stated
conditions for a specific period of time.
• Performance is the measure of the speed to complete a service request. It is
measured by latency (the delay between the arrival and completion of a service
request), throughput (the number of requests completed over a period of time) and
response time (the delay from the request to getting a response from the service).
• Cost is the measure of the cost of requesting a service. It may be charged per the
number of service requests, or could be a flat rate charged for a period of time.
The QoS requirements for Web services are more important for both service
providers and consumers since the number of Web services providing similar
functionalities is increasing. Current Web service technologies such as WSDL and UDDI,
which are for publishing and discovering Web services, consider only customer
functionality requirements and support design time, or static service discovery. Non-
functional requirements, such as QoS, are not supported by current UDDI registries [24].
2.4.1 Storage of QoS Information in the UDDI Registry
15

As a current feature in the UDDI registry, the tModel is used to describe the
technical information for services. A tModel consists of a key, a name, an optional
description and a Uniform Resource Locator (URL) which points to a place where details
about the actual concept represented by the tModel can be found [36]. tModels play two
roles in the current UDDI registries. The primary role of a tModel is to represent a
technical specification that is used to describe the Web services. The other role of a
tModel is to register categorizations, which provides an extensible mechanism for adding
property information to a UDDI registry. Blum [3] [4] proposes that the categorization
tModels in UDDI registries can be used to provide QoS information on bindingTemplates.
In the proposal, a tModel for quality of service information for the binding template that
represents a Web service deployment is generated to represent quality of service
information. Each QoS metric, such as average response time or average throughput, is
represented by a keyedReference [36], that is a general-purpose structure for a name-
value pair, on the generated tModel.
Blum gives an example of the bindingTemplate reference to the tModel with the
QoS attribute categories, and an example of the QoS Information tModel, which contains
a categoryBag [36], which is a list of name-value pairs specifying QoS metrics. The two
examples are shown in Figures 2.2 and 2.3 respectively.
The example used in Figure 2.2 is one of a Stock Quote service. A tModel with
tModelKey "uddi:mycompany.com:StockQuoteService:PrimaryBinding:QoSInformation"
containing the QoS attribute categories is referenced in the bindingTemplate. In order to
retrieve more detailed management information, the location of a WSDL description is
stored in a keyed reference with tModelKey "uddi:mycompany.com:StockQuoteService
16

:PrimaryBinding:QoSDetail", which is not shown in the figure. Figure 2.3 shows the
tModel that is referenced in the bindingTemplate in Figure 2.2. This tModel contains a
categoryBag that specifies three QoS metrics of Average ResponseTime, Average
Throughput and Average Reliability. The tModelKey in each keyedReference is used as a
namespace which provides a uniform naming scheme.
<businessService serviceKey="uddi:mycompany.com:StockQuoteService" businessKey="uddi:mycompany.com:business> <name>Stock Quote Service</name> <bindingTemplates> <bindingTemplate bindingKey="uddi:mycompany.com:StockQuoteService:primaryBinding" serviceKey="uddi:mycompany.com:StockQuoteService"> <accessPoint URLType="http">
http://location/sample </accessPoint>
<tModelInstanceDetails> <tModelInstanceInfo tModelKey="uddi:mycompany.com:StockQuoteService:Primary Binding:QoSInformation"> <description xml:lang="en"> This is the reference to the tModel that will have all of the QOS related categories attached. </description> </tModelInstanceInfo> <tModelInstanceInfo tModelKey="uddi:mycompany.com:StockQuoteService:Primary Binding:QoSDetail"> <description xml:lang="en"> This points to the tModel that has the reference to the web service endpoint that allows detailed retrieval of information </description> </tModelInstanceInfo> </tModelInstanceDetails> </bindingTemplate> </bindingTemplates> </businessService
Figure 2.2: QoS Information on BindingTemplates [3]
17

<tModel tModelKey="mycompany.com:StockQuoteService: PrimaryBinding:QoSInformation"" > <name>QoS Information for Stock Quote Service</name> <overviewDoc> <overviewURL> http://<URL describing schema of QoS attributes> <overviewURL> <overviewDoc> <categoryBag> <keyedReference tModelKey="uddi:uddi.org:QoS:ResponseTime" keyName="Average ResponseTime" keyValue="fast" /> <keyedReference tModelKey="uddi:uddi.org:QoS:Throughput" keyName="Average Throughput" keyValue=">10Mbps" /> <keyedReference tModelKey="uddi:uddi.org:QoS:Reliability" keyName="Average Reliability" keyValue="99.9%" /> </categoryBag> </tModel>
Figure 2.3: The tModel with the QoS Information [3]
2.4.2 Research on Web Services Discovery with QoS
Many researchers work on how to take QoS information for Web services into
account in the service discovery process to find services that best meet a customer’s
requirements. Ran [33] proposes a model in which the traditional service discovery
model is extended with a new role called a Certifier, in addition to the existing three roles
of Service Provider, Service Consumer and UDDI Registry. The Certifier verifies the
advertised QoS of a Web service before its registration. The consumer can also verify the
advertised QoS with the Certifier before binding to a Web service. This system can
prevent service providers from publishing invalid QoS claims during the registration
phase, and help consumers to verify the QoS claims to assure satisfactory transactions
18

with the service providers. Although this model incorporates QoS into the UDDI, it does
not provide a matching and ranking algorithm, nor does it integrate consumer feedback
into service discovery process.
Gouscos et al. [13] propose a simple approach to dynamic Web services discovery
that models Web service management attributes such as QoS and price. They discuss how
this simple model can be accommodated and exploited within basic specification
standards such as WSDL. The key Web service quality and price attributes are identified
and categorized into two groups, static and dynamic. The Price, Promised Service
Response Time (SRT) and Promised Probability of Failure (PoF) are considered as static
in nature and could be accommodated in the UDDI registry. The actual QoS values that
are the actual SRT and PoF are subject to dynamic updates and could be stored either in
the UDDI registry or in the WSDL document, or could be inferred at run time through a
proposed information broker. The advantage of this model is its low complexity and
potential for straightforward implementation over existing standards such as WSLA and
WS-Policy specifications.
Maximilien and Singh [24] propose an agent framework and ontology for
dynamic Web services selection. Service quality can be determined collaboratively by
participating service consumers and agents via the agent framework. Service consumers
and providers are represented and service-based software applications are dynamically
configured by agents. QoS data about different services are collected from agents,
aggregated, and then shared by agents. This agent-based framework is implemented in
the Web Services Agent Framework (WSAF). A QoS ontology, which captures and
defines the most generic quality concepts, is proposed in their paper.
19

Zhou et al. [45] propose a DAML-QoS ontology as a complement for the DAML-
S ontology to provide a better QoS metrics model. QoS requirements and various
constraints can be specified explicitly and precisely using this novel ontology.
Although these works address some form of service discovery with QoS, none
considers feedback from consumers. The result of service discovery and selection is
based solely on advertised QoS, which may be invalid (in the one case though, advertised
QoS is verified by the Certifier in the model proposed by Ran).
2.5 Web Services Reputation System
QoS reputation can be considered as an aggregation of ratings for a service from
consumers for a specific period of time. It is a general and overall estimate of how
reliably a provider services its consumers. Compared to trust, which is the willingness to
depend on something or somebody in a given situation with a feeling of relative security
[28], reputation are public scores based on public information while trust are private
scores based on both private and public information.
Even if service consumers can obtain QoS advertisements from service providers
in a service registry, one cannot be assured that the services found in the discovery
process actually perform as advertised. However, with a reputation system, ratings of
services can be collected and processed, and reputation scores of services updated.
Services found to match a consumer’s requirements can be ranked according to their
reputation scores. This improves the possibility that the services that best meet user needs
are selected, and ensures that the selected services are reliable.
20

Majithia et al. [18] propose a framework for reputation-based semantic service
discovery. Ratings of services in different contexts, which either refer to particular
application domains, or particular types of users, are collected from service consumers by
a reputation management system. A coefficient (weight) is attached to each particular
context. The weight of each context reflects its importance to a particular set of users. A
damping function is used to model the reduction in the reputation score over time. This
function, however, only considers the time at which a reputation score is computed, and
ignores the time at which a service rating is made. This can result in a problem.
For example, consider two services, X and Y. Service X provides an increasing
quality of service over time, while the quality of service Y decreases. Assume the ratings
for service X are (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12), and for service Y are (12, 11, 10, 9,
8, 7, 6, 5, 4, 3, 2, 1), where each number represents the rating for one month and a higher
number is a better rating. Obviously service X should obtain a higher reputation score
because its performance is improving, while the performance of service Y is declining.
However, with the damping function used by Majithia et al., service X and Y obtain the
same reputation score.
Wishart et al. [41] present SuperstringRep, a new protocol for service reputation.
This protocol uses service reputation scores that reflect the overall quality of service in
order to rank the services found in the discovery process. An aging factor for the
reputation score is applied to each of the ratings for a service, thus newer ratings are more
significant than older ones. The value of the factor is examined in the paper and small
aging factors are found to be more responsive to changes in service activity while large
21

factors achieve relatively stable reputation scores. The value of the aging factor should
depend on the demands of the service consumers and the reputation management system.
Maximilien and Singh [23] propose a model of service reputation and
endorsement. The reputation of a service is the aggregation of the ratings of the service
by service consumers based on historic transaction records. New services that have no
historical data can be endorsed by trustworthy service providers or consumers even
before their reputation is established. No details are provided as to how the reputation
score of a service is computed based on the consumers’ ratings and endorsements.
Maximilien and Singh [25] also propose a multi-agent approach of service
selection based on user preferences and policies. A matching algorithm is presented to
match consumer policies to advertised provider service policies. Although reputation for
the QoS is mentioned in the algorithm, no details regarding how the reputation affects the
service selection process are provided.
2.6 Reputation-enhanced Web Services Discovery with
QoS
Although the approaches discussed previously pursue one or more aspects of Web
services discovery with QoS, none of them address the issues of where and how the
advertised QoS information is stored, and how it would be updated. If service discovery
agents need to contact service providers to obtain the latest QoS information each time a
discovery query is processed, then an extra burden is placed on service providers. If a
discovery agent chooses to keep a local copy of QoS information for the service
22

providers, the agent must periodically contact the service providers to update its local
QoS repository. In this case, it is unclear how the agent knows when the QoS information
should be updated.
In our proposed model, QoS information is stored in the UDDI registry and is
updated by providers whenever there are changes. Service discovery agents can obtain
the latest advertised QoS information directly from the UDDI registry without creating
additional workload for service providers. When experiencing a lower QoS performance
from a service than it expects, a consumer may send a service discovery request to the
discovery agent to find if there are other services available that meet its requirements.
Another critical issue that we examine is how the reputation of services affects the
matching process. Previous approaches either do not consider QoS reputation or they do
not provide details of how QoS reputation is specified in a customer’s requirement nor
how the reputation of services is used in the matching process. Our approach allows
consumers to specify requirements on both QoS (including price) and reputation. A
detailed service matching, ranking and selection algorithm is proposed that takes service
reputation into account in the ranking process.
23

Chapter 3
Reputation-Enhanced Service Discovery with QoS
The traditional Web services publish and discovery model has three roles: service
provider, service consumer and UDDI registry. The UDDI registry is enhanced with QoS
information, and two new roles, discovery agent and reputation manger, are added in our
model as shown in Figure 1. The white boxes represent the existing roles in the current
Web services architecture, as shown in Figure 1.1. The shaded boxes/circles represent the
new roles in our model. The UDDI registry stores QoS information of services by using
tModels. The discovery agent acts as a broker between a service consumer, a UDDI
registry and a reputation manager to discover the Web services that satisfy the
consumer’s functional, QoS and reputation requirements. The reputation manager
Reputation Manager
Discovery Agent
Service Consumer
Reputation Scores
UDDI Registry
Ratings
Rating DB
Discovery Request/Result
QoS
QoS info.
Service Info.
Service Provider
Figure 3.1: Model of Reputation-enhanced Web Services Discovery with QoS
Request/Response
24

collects and processes service ratings from consumers, and provides service reputation
scores when requested by the discovery agent.
3.1 UDDI Registry and QoS Information
The tModel, a current feature of the UDDI registry, is used to store advertised
QoS information of Web services. When a provider publishes a service in a UDDI
registry, a tModel is created to represent the QoS information of the service. It is then
registered with the UDDI registry and related to the service deployment. When the
provider need update the QoS information of the service, it retrieves the registered
tModel from the UDDI registry, updates its content and saves it with the same tModel key.
rization tModels in UDDI registries to
represent QoS information in Chapter 2. W apply the same technique in our service
eates and registers a
tModel within a UDDI registry. The QoS inform
example, the default unit used for price is CAN$ per transaction, for response time is
nd for throughput is transaction per second.
3.1.1 Publishing QoS Information
We discussed how to use the catego
e
discovery model. When a business publishes a Web service, it cr
ation of the Web service is represented
in the tModel, which is referenced in the binding template that represents the Web service
deployment. Each QoS metric is represented by a keyedReference in the generated
tModel. The name of a QoS attribute is specified by the keyName, and its value is
specified by the keyValue. The units of QoS attributes are not represented in the tModel.
We assume default units are used for the values of QoS attributes in the tModel. For
second, for availability is percentage, a
25

For example a company publishes its Stock Quote service in a UDDI registry with
the following QoS information:
• Service price: CAN $0.01 per transaction
• Average response time: 0.05 second
• Availability: 99.99%
• Throughput: 500 transaction/second
Figure 3.2: The tModel with the QoS information
The company creates and registers a tModel that contains the QoS information for
this service before it publishes the service with the UDDI registry. An Application
<tModel tModelKey="somecompany.com:StockQuoteService:
<name>QoS Information for Stock Quote Service</name>
<overviewURL>
<overviewURL> <overviewDoc> <categoryBag> <keyedReference
PrimaryBinding:QoSInformation"" >
<overviewDoc>
http://<URL describing schema of QoS attributes>
keyValue=" 0.01" />
tModelKey="uddi:uddi.org:QoS:ResponseTime" e="Av age Re keyValue="0.05" /> uddi y" keyName=" Throughput" keyValue="500" /> </categoryBag> </tModel>
tModelKey="uddi:uddi.org:QoS:Price" keyName="Price Per Transaction"
<keyedReference
keyNam er sponseTime"
<keyedReference tModelKey="uddi: .org:QoS:Availabilit
keyName="Availability" keyValue="99.99" /> <keyedReference
tModelKey="uddi:uddi.org:QoS:Throughput"
26

Programming Interface (API) to the UDDI registry, such as UDDI4J [34], may be used to
an example of this tModel.
tModels in a UDDI registry,
find the services that match their QoS requirements by querying
details of this process are discussed in the following sections.
nformation
s providers to update the QoS
blishes a service and its
odify and update the QoS
ation of the services it
S information is accurate and up to date.
API to the UDDI registry, such as UDDI4J mentioned previously, may be
used to facilitate th publisher searches
the UDDI registry to find the tModel that contains QoS information for the service it
publish
3.2 Discovery Agent
nal,
oS, and reputation requirements can be specified in the discovery request. The detail of
facilitate the service publishing process. Figure 3.2 shows
With QoS information of Web services stored in
service consumers can
the UDDI registry. The
3.1.2 Updating QoS I
It is the right and responsibility of Web service
information in the UDDI registry. Only a service provider that pu
QoS information in a UDDI registry has the right to m
information. A service provider should also update the QoS inform
publishes frequently to ensure that the Qo
An
e process of updating QoS information. A service
ed before, updates the QoS information in the tModel, and then saves the tModel
with the same tModelKey assigned previously for the tModel to update the QoS
information of the service.
A discovery agent receives requests from service consumers, finds the services
that match their requirements and then returns the matches to the consumers. Functio
Q
27

how to specify functional, QoS and reputation requirements in the request, and how to
find ser
Figure 3.3: Service discovery request
Figure 3.3 shows the SOAP message for a discovery request in the general form.
The strings in bold are replaced by corresponding values of an actual discovery request.
Customers need not manually generate the SOAP messages for discovery requests.
Developers can specify QoS and reputation requirements in a Java program that
automatically generates required SOAP messages sent to the discovery agent. As Figure
3.3 shows, customers can specify the following in the discovery request:
• The maximum number of services to be returned by the discovery agent
• Functional requirements: keywords in service name and description
vices that match the requirements are discussed in this section.
<?xml version="1.0" encoding="UTF-8" ?>
<body> <find_service generic="1.0" xmlns="urn:uddi-org:api">
<functionalRequirement> Keywords in service name and description
<envelope xmlns="http://schemas.xmlsoap.org/soap/envelope/">
<QoS attribute 2>Value</QoS attribute 2>
……
</qualityRequirement>
</reputationRequirement> <maxNumberService>Value</maxNumberService>
</find_service>
</functionalRequirement> <qualityRequirement weight=QoS Weight>
<dominantQoS>Dominant QoS</dominantQoS> <QoS attribute 1>Value</QoS attribute 1>
<QoS attribute 3>Value</QoS attribute 3>
<QoS attribute n>Value</ QoS attribute n>
<reputationRequirement weight=Reputation Weight> <reputation>Reputation Score</reputation>
</body> </envelope>
28

• Service price: the maximum service price a customer is willing to pay
• Service nse time,
throughput, and availab
• Dominant QoS attribut
• Service reputation requiremen
• Weights for the QoS and reput
We assume that the sam re used
for QoS requirements in the one that
consumers consider as the most important and is used in the calculation of the QoS score
for each service candidate in the service matching process. Average response time is the
default dominant QoS attribute, if none is specified in the request. A consumer can
specify QoS requirements only or both QoS and reputation requirements in the request.
The weights for QoS and reputation requirements indicate their importance and they
range from zero to one, where zero means no requirement for QoS or reputation while
one means it is the only requirement on QoS or reputation. The weights must sum to one.
We allow consumers to specify a dominant QoS attribute instead of separate
weights for QoS attributes because we think it is more feasible and easier for customers
to choose the most important QoS attribute than to specify a separate weight for each of
the QoS attributes. As discussed in the research statement, we are proposing a simple
service discovery model at the level of standards such as WSDL and UDDI. The choice
of using the same weight for all QoS attributes will not affect the goal of the research and
will greatly simplify the calculation of QoS scores in the service ranking process.
performance and other QoS requirements such as respo
ility.
e
ts
ation requirements
e defau alt units as described earlier for the tModel
request. The dominant QoS attribute is the
29

After the agent receives the discovery request, it contacts the UDDI registry to
find functional requirements, and to obtain their QoS
info a he advertised QoS information
with the QoS requirements, finds the matched services, ranks the matches by QoS scores
and/or
•
he QoS
require
services that match the customer’s
rm tion stored in tModels. The agent then matches t
reputation scores and returns the result to the customer. The calculation of QoS
scores is described in the later section on the “Service Matching, Ranking and Selection
Algorithm”. The reputation scores are provided by the reputation manager, which is
described in the next section.
To illustrate, consider once again the company looking for a Stock Quote service
for its business information system. The company needs the service with the following
requirements:
• Service name and description: Stock Quote
• Service price: CAN $0.01 per transaction
Average response time: 0.1 second
• Availability: 99.9%
• Throughput: 400 transaction/second
• Reputation score: not less than 8
The company places more emphasis on reputation than on QoS of the service, so
it assigns a weight of 0.6 to the reputation requirement and a weight of 0.4 to t
ment in the discovery request. It also considers the availability of the service as
the most important QoS attribute so the availability is specified as the dominant QoS
30

attribute in the request. Figure 3.4 shows a service discovery request example with these
QoS and reputation requirements using SOAP.
Fig ery quest eputation requirements using SOAP.
<?xml version="1.0" encoding="UTF-8" ?>
<body> <find_service generic="1.0" xm
<envelope xmlns="http://schemas.xmlsoap.org/soap/envelope/">
lns="urn:uddi-org:api">
<dominantQoS>availability</dominantQoS> <price>0.01</price> <responseTime>0.1</responseTime >
0</throughput> <availability>99.9</availability>
/quali
8</reputation> eputa ent>
maxNumberService>
</body>
<functionalRequirement> Stock Quote </functionalRequirement> <qualityRequirement weight=0.4>
<throughput>40
< tyRequirement> <reputationRequirement weight=0.6>
<reputation></r tionRequirem<maxNumberService>1</
</find_service>
</envelope>
ure 3.4: Service discov re with QoS and r
The discovery agent finds two services that meet the requirements in the request,
ranks the services using their QoS scores and reputation scores, and returns one service to
the company since the request specifies the number of services to be returned is 1. A
service discovery response example using SOAP is shown in Figure 3.5. The next section
discusses the details of how the matched services are ranked and selected based on the
consumer’s requirements.
31

<?xml version="1.0" encoding="UTF-8" ?> <envelo
<body><servic false">
<servic
1-42e4-5ab0-1d87b8f1876a" -17ab-c2a32e6e1a27">
sponseTime > hput>
ility>99.99</availability>
eputationInformation>
</servic</servic
</body></envel
pe xmlns="http://schemas.xmlsoap.org/soap/envelope/">
eList generic="1.0" xmlns="urn:uddi-org:api" truncated="eInfos> <serviceInfo serviceKey="9521db61-eacbusinessKey="8e4a1bc28-afb7-32a9
<name>Stock Quote Canada</name> <qualityInformation>
<price>0.01</price> <responseTime>0.08 </re<throughput>800</throug<availab
</qualityInformation> <reputationInformation>9</r
</serviceInfo> eInfos>
eList>
ope>
Figure 3.5: Service discovery response using SOAP.
3.3
st service provider(s). A reputation manager is proposed in our
rvice discovery model based on the models by Majithia et al. [18] and Wishart et al.
[41]. A QoS reputation score is calculated based on feedback by service consumers. The
service reputation manager is responsible for collecting the data from service consumers,
processing the data, and then updating the reputation score for related service providers.
Reputation Manager
In the business world, a company chooses a supplier based on many criteria:
response time, availability, reputation, onsite inspection reports, transaction history and
recommendations. In Web services discovery, similar factors may be considered in
effectively choosing the be
se
32

3.3.1 Reputation Collection
We assume that service consumers provide a rating indicating the level of
satisfaction with a ser action with the service. A rating is simply an
integer ranging from 1 to 10 age
satisfaction and 1 means extreme diss
In order to encourage consumers to utation
manager, a bonus point system may be introd ir feedback.
The points might be used in se
The rat ires that the client perform an objective evaluation.
he scope of this paper. We do not deal with the lack of ratings nor invalid
ratings. We assume the ratings are available and valid.
.3.2 Storage of Service Ratings
s based on SuperstringRep, a protocol proposed
y Wishart et al. [41]. The ratings of services by consumers are stored in the reputation
manger’s local database. Each rating consists of service ID, consumer ID, rating value
and a timestamp. The service key in the UDDI registry of the service is used as the
service ID, and the IP address of the service consumer is used as the consumer ID.
Ratings for services are stored in a table. An example table is given in Table 3.1.
There are three services in Table 3.1 with Service ID “9021cb6e-e8c9-4fe3-9ea8-
3c99b1fa8bf3”, “74154900-f0b0-11d5-bca4-002035229c64” and “b6cb1cf0-3aaf-11d5-
80dc-002035229c64”, respectively. Each of the three services receives some ratings from
consumers. Only one rating for a service per consumer is stored in the table. New ratings
vice after each inter
, where 10 means extreme satisfaction, 5 means aver
atisfaction.
provide ratings of a service to the rep
uced to award consumers for the
rvice discovery to reduce the cost of the discovery.
ing of the services requ
This is beyond t
3
Our service rating storage system i
b
33

from repeat customers for the same service replace older ratings. The timestamp is used
to determine the aging factor of a particular service rating. This is further discussed in the
next section.
Service ID Consumer ID Rating Timestamp 9021cb6e-e8c9-4fe3-9ea8-3c99b1fa8bf3 30.15.6.210 8 2005-08-01 10:15:01 9021cb6e-e8c9-4fe3-9ea8-3c99b1fa8bf3 24.23.36.12 6 2005-08-11 12:25:02 9021cb6e-e8c9-4fe3-9ea8-3c99b1fa8bf3 69.36.87.10 5 2005-08-11 19:20:12 74154900-f0b0-11d5-bca4-002035229c64 24.23.3.22 6 2005-08-21 12:15:02 9021cb6e-e8c9-4fe3-9ea8-3c99b1fa8bf3 6.16.87.10 5 2005-08-21 09:20:22 74154900-f0b0-11d5-bca4-002035229c64 135.12.69.87 6 2005-08-29 09:20:22 b6cb1cf0-3aaf-11d5-80dc-002035229c64 46.22.109.12 7 2005-09-22 19:10:56 74154900-f0b0-11d5-bca4-002035229c64 87.26.5.120 6 2005-10-11 12:23:43 74154900-f0b0-11d5-bca4-002035229c64 52.36.102.36 8 2005-08-12 09:20:22
3.3.3 Computation of Reputation Score
The computation of reputation score in our model is based on the work by
Majithia et al. [18] and the work by Wishart et al. [41]. Majithia et al. propose a method
to calculate the reputation score as weighted sum of ratings for a service, where a
coefficient is the weight attached to a particular context. Wishart et al. propose an aging
function that applies a factor to each of the ratings regarding a service. In our model, the
reputation score (U) of a service is computed as the weighted average of all ratings the
service received from customers, where an inclusion factor is the weight attached to each
of the ratings for the service:
Table 3.1: Example ratings for services
∑
∑==
i
iiiS
U 1
γ
γ
id
=
N
i
N
1
where U is the reputation score for a service,
i λγ =
34

Si is the ith service rating,
γi is the aging factor for ith service rating,
λ is the inclusion factor, 0 < λ < 1,
d is th the days betwe e ti:
hen ion sco is com
rati service.
to sponsiveness of the reputation score
to the changes in service activity. When λ is set to 0, all ratings, except the ones that are
rovided by consumers on the same day as the reputation score is computed, have a
e computation. When λ is set to 1, all ratings
have e
3.4 Dynamic Service Discovery
that the provider has already registered at the UDDI registry and is
assigned a user id and a password. We also assume that it is the first time that the
provider publishes its services in the registry so it needs to create and save a business
i e number of en the two tim s tc and
tc is the current time w the reputat re puted,
ti is the time of the ith ng for the
The inclusion factor λ is used adjust the re
p
weight of 0 and are not be included in th
qual weight of 1 and used in the computation. A smaller λ means only recent
ratings are included and a larger λ means more ratings are included.
This section describes the steps of how a provider publishes its Web services with
QoS information, how to update service QoS information in the UDDI registry, and how
the discovery agent finds services that meet a customer’s functional, QoS and reputation
requirements.
The Figure 3.6 shows the detailed steps of the service publishing process for a
provider. We assume
entity in the UDDI registry.
35

Figure 3.6: Steps of Service Publish Process
The Figure 3.7 shows the detailed steps of service QoS inform
Get g user id and password registered at the UDDI registry Crea For
Create a tModel to represent the QoS information for the service, save it in the UDDI
Cre Cre ider is publishing
Set the reference to the bindingTemplate in the service entity
an authorization token by passin
te a business entity to represent the provider
each service to be published
registry
ate a bindingTemplate containing a reference to the tModel
ate a service entity to represent the service that the prov
Add the service entity to the business entity
Save the business entity in the UDDI registry, receive a business key and a list of service keys assigned by the UDDI registry
ation update
process for a provider. We assume that the provider has already registered at the UDDI
e also assume that the services have
been pu
Figure 3.7: Steps of Service QoS Information Update Process
registry and is assigned a user id and a password. W
blished in the UDDI registry so the provider has the business key and the service
keys that are needed to retrieve the business entities and service entities.
Get an authorization token by passing user id and password registered at the UDDI registry Fin
Find and update the tModel representing the QoS information for the service, save it in
d the business entity representing the provider with business key
For each service to be updated
Find the service entity representing the service that is to be updated with the service key
the UDDI registry with the same tModel key
36

Figure 3.8 shows the detailed steps of how the discovery agent finds services that
mee oS and reputation requirements. The details of the service
ranking an hing,
Ranking an
e use jUDDI [1], an open source Java implementation of the UDDI
specification for W
Web discovery model that
cons Process, the Service QoS Information Update Process and
the Service tion
scores) in e model by running a group of test
scenarios. The details of the implementation of evaluation are described in chapter 4.
t a customer’s functional, Q
d selection process are described in the next section “Service Matc
d Selection Algorithm”.
Figure 3.8: Steps of Service Discovery Process
Get an authorization token by passing user id and password registered at the UDDI registry
Functional matching Find serv irements
et the customer’s functional requirements
Find the service entity represent the service in the UDDI registry with the service key
Find the tMo Add the service key to the service candidate list if the service’s QoS information in the tModel meets the customer’s QoS requirements
// R
//ices that meet the customer’s functional requ
// QoS Matching For each of the services that me
del representing the QoS information for the service
anking and Selection Rank the services in the candidate list based on their QoS information and/or reputation scores, select and return the specified number of services based on the consumer’s requirement
W
eb Services, to set up our own UDDI registry and publish a group of
services for testing purposes. We implement the service
ists of the Service Publish
Discovery Process (without ranking services using QoS scores and reputa
Java using UDDI4J. We evaluate th
37

3.5
service discovery request to the discovery agent,
which then contacts the UDDI er’s
requ are found to match both the functional and QoS requirements,
and reputation requirements have also been specified, then the discovery agent contacts
the candidate services and
ranks the services based on the customer’s QoS and reputation requirements.
3.5.1 Service Matching, Ranking and Selection
QoS
requirements. A service is a “match” if it satisfies the customer’s functional requireme
and its QoS informat the customer’s QoS
requirements, including price and other QoS attributes. If no matched service is found by
the mat
sed
Service Matching, Ranking and Selection
Algorithm
A service consumer sends a
registry to find services that meet the custom
irements. If services
reputation manager to obtain the reputation scores for the
The matching process is based on the customer’s functional and
nts
ion stored in the UDDI registry matches all of
ching process, the discovery agent returns an empty result to the customer.
If no reputation requirement is specified in the discovery request and only one
match is found, the agent returns this service identifier the customer. In the event that
multiple services match the functional and QoS requirements, the discovery agent
calculates a QoS score for each matched service based on the dominant QoS attribute
specified by the customer, or on the default dominant attribute, average response time.
The best service is assigned a score of 1, and the other services are assigned scores ba
38

on the value of the dominant QoS attribute. The details of calculating QoS scores are
r of services to
be returned as specified by the customer) with the highest QoS scores are returned to the
custom ecified, one service is randomly selected from those services
whose
If the customer specifies a reputation requirement in the discovery request, the
ion score is either unavailable or below
the spe
justed
reputat
given in next section. The top M services (M being the maximum numbe
er. If M is not sp
QoS score is greater than LowLimit, the predefined lower limit of acceptable
scores ranging from 0 to 1. For example, if LowLimit is 0.9, it means all services whose
QoS score is greater than 0.9 will be considered in the random selection. The random
selection prevents the service that has the highest QoS score from being selected
exclusively, and helps to achieve workload balance among the services that provide the
same functionality and similar quality of service.
agent removes the matched services whose reputat
cified requirement. If only one service remains, it is returned to the customer
without further processing since it is the only service that matches the customer’s QoS
and reputation requirements. Otherwise, the agent calculates the QoS score for the
remaining matched services in the same way as described previously. Reputation scores
of the remaining matched services are then adjusted using a factor f so that ad
ion scores range from 0.1 to 1, the same as QoS scores. Assuming the highest
reputation score in the remaining services is h, then f = 1/h. All original reputation scores
are multiplied by the factor f so the score of the service with the best reputation is
adjusted to 1, and the other services’ scores are adjusted based on their original reputation
scores. Finally, the agent calculates an overall score, which is a weighted sum of the QoS
score and the adjusted reputation score, for all services based on the weights of the QoS
39

and reputation requirements specified by the customer in the discovery request. A
number of services are then selected according to the maximum number, M, of services
to be returned in the request as described earlier. If M is greater than 1, the top M services
with the highest overall scores are returned to the customer. Otherwise, one service is
randomly selected from those whose overall score is greater than LowLimit.
The calculation of QoS scores of services is performed by the equation below:
QoSScore i = BestDominantQoS DominantQoS i if dominant QoS attribute is monotonically increasing
BestDominantQoS if dominant QoS attribute is monotonically decreasing DominantQoS i
{
where QoSScore i is the QoS score of service i,
i is the position of the service in the list of matched services,
DominantQoS i is the value of the dominant QoS attribute of service i,
BestDominantQoS is the highest/lowest value of the dominant QoS attribute of the matched services when the dominant attribute is monotonically increasing/decreasing. A QoS attribute is monotonically increasing means increases in the value reflects improvements in the quality, while monotonically decreasing means decreases in the value reflects improvements in the quality.
The calculation of adjusted reputation scores of services is given by the equation
below:
where AdjRepuScore is the adjusted reputation score of service i,
AdjRepuScore = iRepuScore i
h
i
40

i is the position of the service in the list of matched services,
RepuScore i is the original reputation score of service i,
h is the highest original reputation scores of the matched services.
The calculation of overall scores of services is given by the equation below:
QoSWeight is the weight of QoS requirement specified by consumers,
AdjRepuScore is the adjusted reputation score of service i,
RepuWeight is the weight of reputation requirement specified by consumers.
We assume QoSScore and AdjRepuScore are in the same magnitude.
3.5.2 S
ing
algorith
ing of this work, namely how the reputation scores affect the service selection.
lgorith ion hm can be found in appendix A.
Figure 3.10 shows the high level part of the algorithm. It comprises the following
OverallS i i i
core = QoSScore × QoSWeight + AdjRepuScore × RepuWeight
where OverallScore i is the overall score of service i,
i is the position of the service in the list of matched services,
QoSScore i is the QoS score of service i,
i
i i
ervice Matching, Ranking and Selection Algorithm
ur service matching, ranking and selection algorithm is based on the matchO
m proposed by Maximilien and Singh [25]. Our algorithm addresses a
shortcom
Figure 3.9 shows a flow chart and Figures 3.10~3.14 shows a simplified version of our
a m. A complete vers of the algorit
methods:
41
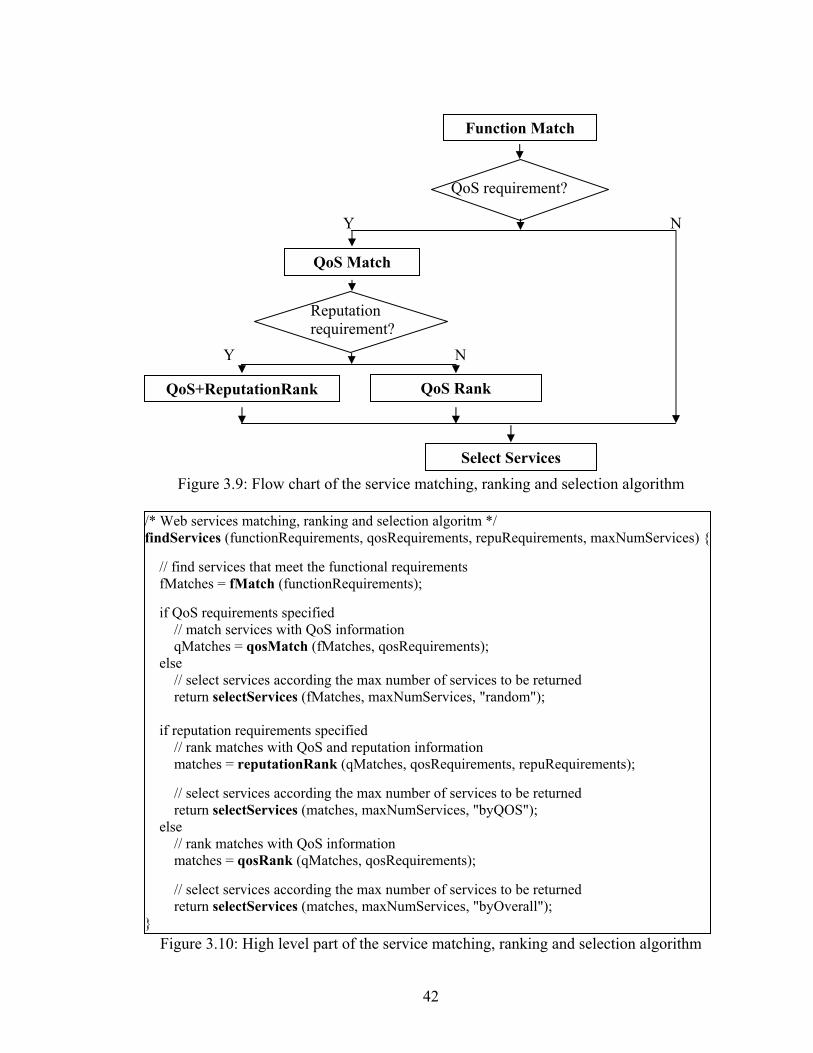
Fi rithm
Figure 3.10: High level part of the service matching, ranking and selection algorithm
Function Match
gure 3.9: Flow chart of the service matching, ranking and selection algo
/* Web findServices (functionRequirements, qosRequirements, repuRequirements, maxNumServices) { // find fMat if QoS requirements specified
atch services with QoS information
// select ret
// rank matches with QoS and reputation information
matches = qosRank (qMatches, qosRequirements); // select
selectServices (matches, maxNumServices, "byOverall");
services matching, ranking and selection algoritm */
services that meet the functional requirements ches = fMatch (functionRequirements);
// m qMatches = qosMatch (fMatches, qosRequirements); else
services according the max number of services to be returned urn selectServices (fMatches, maxNumServices, "random");
if reputation requirements specified
matches = reputationRank (qMatches, qosRequirements, repuRequirements); // select services according the max number of services to be returned return selectServices (matches, maxNumServices, "byQOS"); else // rank matches with QoS information
services according the max number of services to be returned return}
QoS Match
Select Services
QoS+ReputationRank QoS Rank
QoS requirement?
Reputation requirement?
Y N
Y N
42

fMa
tch returns a list of services that meet the functional requirement.
f the
following methods:
rtisements of a service satisfies the QoS
qosMatch returns the services that meet the QoS requirements.
qosRank calculates QoS scores for the service returned by the method qosMatch and
returns a list of services sorted by the QoS score in descending order.
reputationRank removes services whose reputation scores are below the reputation
requirement from those returned by method qosMatch, calculates QoS, reputation and
then overall scores for remaining services and returns a list of services sorted by the
overall score in descending order.
selectServices returns a list of services according to the maximum number of services to
be returned in the discovery request.
Figure 3.11 shows the details of QoS matching algorithm. It is comprised o
getServiceQoS finds the QoS advertisements of a service in a UDDI registry.
qosMatchAdvert finds if the QoS adve
requirements.
// find services that match QoS requirements qosMatch (services, qosReqt) {
atches = Service []; m for each s in services // get QoS info from UDDI qosAds = getServiceQoS (s); // if QoS info available and satisfies QoS requirements if qosAds != null && qosMatchAdvert (qosAds, qosReqt)
matches.add(s); end for
return matches; }
Figure 3.11: Service QoS matching algorithm
43

Figure 3.12 shows the details of QoS ranking algorithm. It is comprised of the
Figure 3.12: Service QoS ranking algorithm
e following methods:
s for the services that meet both the QoS and
lculates adjusted reputation scores for the services that
ents. The reputation score of the most
ices are adjusted accordingly.
ls of how the reputation scores are adjusted can be found in the method
nScore in appendix A.
following methods:
calculateQoSScore calculates QoS scores for the services that meet the QoS
requirements.
sortByQoSScore returns a list of services sorted by the QoS score in descending order.
// rank matches with QoS information
services = calculateQoSScore (serv
qosRank (services, qosReqt) {
// calculate QoS scores ices, qosReqt);
}
// sort the result by QoS score in descending order services = sortByQoSScore (services); return services;
Figure 3.13 shows the details of QoS and reputation ranking algorithm. It is
comprised of th
calculateQoSScore calculates QoS score
reputation requirements.
calculateReputationScore ca
meet both the QoS and reputation requirem
reputable service is adjusted to 1 and the scores of other serv
The detai
calculateReputatio
44

calOve
nts. An overall score is a weighted sum of the QoS score and the
e customer in the discovery request.
g
nd reputation ranking algorithm
rallScore calculates the overall scores for the services that meet both the QoS and
reputation requireme
adjusted reputation score based on the weights of the QoS and reputation requirements
specified by th
sortByOverallScore returns a list of services sorted by the overall score in descendin
order.
Figure 3.13: Service QoS a
// rank services with reputation information reputationRank (services, qosReqt, repuReqt) { for each s in services // get reputatio r = getReputat
n mark for each service from reputation manager ion (s);
// remove services whose reputation score is not available or below requirement if r != null and r >= repuReqt.reputationScore s.reputationScore else
services.remove(s); end for // calculate QoS scores
s, qosReqt);
for services services = calOverallScore (services, qosReqt.weight, repuReqt.weight)
// sort the result by overall score in descending order
= r;
services = calculateQoSScore (service // calculate adjusted reputation scores services = calculateReputationScore (services); // calculate overall scores
services = sortByOverallScore (services);
return services; }
45

Figure 3.14 shows the details of the service selection algorithm. If the
maxNumServices, that is the maximum number of services to be returned by discovery
agent, is greater than 1, then the top maxNumServices services are returned if the option
is “random”, or the top maxNumServices services with the highest QoS or overall scores
is randomly selected if the option is “random”, or from those whose QoS or
verall score is greater than LowLimit if the option is “byQoS” or “byOverall”.
if the option is “byQoS” or “byOverall”, are returned to the customer. Otherwise, one
service
o
// select services according the max number of services to be returned maxNumServices, option) {
i = 0;
on == "random" candidate = matches;
if option == "byQoS"
selectServices (matches, selection = service []; if maxNumServices > 1 while i < maxNumServices && I < matches.size() selection.add(matches[i]); i++; else candidate = service []; if opti else for each s in matches if s.QoSScore >= LowLimit candidate.add(s); else if s.overallScore >= LowLimit candidate.add(s); end for pickNum = random (0, candidate.size() ); selection.add(candidate[pickNum]); return selection; }
Figure 3.14: Service selection algorithm
46

Cha
publish
rvices with QoS information and update the service QoS information in the UDDI
functional and QoS
discovery agent.
atching, ranking
cuss the experimental results. The goal of the evaluations
ithm Web services that best meet a customer’s
ments have more chance to be selected than those that do not
iscovery model is implemented and the result of
describe the experimental environment for the
anking and selection algorithm, present and discuss the
4 simulations of the algorithm in section 4.2.
.1 Evaluation of the Service Discovery Model
In this section we describ st scenarios with an
implementation of the service discovery model. The goal is to demonstrate that by using
pter 4
Evaluation
In this section we first describe the implementation of the proposed service
discovery model, and present the result of the evaluation that consists of three test
scenarios to demonstrate that the model works as expected: providers can
se
registry, and consumers can find services that meet their
requirements through a
We also present a set of experiments designed to evaluate our m
and selection algorithm, and dis
is to demonstrate that by using the algor
QoS and reputation require
meet these requirements.
We describe how the service d
three test scenarios in section 4.1. We
evaluation of the matching, r
expected and actual experimental results of
4
e the results of three te
47

our service discovery model, providers can publish services with QoS information and
update the service QoS information in the UDDI registry, and consumers can find
ents through a discovery agent. Only
one QoS attribute, response time, is used in the scenarios of service publishing, QoS
update
UDDI
imulate a service consumer using a Java program running on
the thir
e providers publishes an Online DVD Rental service with QoS information in the
ce (different
response time).
services that meet their functional and QoS requirem
and service discovery. Service reputation score is not used in order to simplify the
implementation of service matching process.
4.1.1 Experimental Environment
The four components run on four separate machines in the experiments, as shown
in Figure 4.1:
Registry: We use jUDDI (Version 0.9rc4) to set up our own UDDI registry on the
first machine, which connects to a local MySQL (Version 4.1.13) database.
Discovery Agent: We implement the agent as a Web service running on the second
machine, which runs TomCat 5.5 and AXIS 1.3.
Service Consumer: We s
d machine. The consumer program can send service discovery request to the Web
service for discovery agent to find services that meet its requirements.
Service Providers: We simulate the service publishing process and QoS update process
for three service providers using Java programs that run on the fourth machine. Each of
th
UDDI registry. The services provide different level of quality of servi
48

Discovery Agent UDDI Registry (Web Service) (jUDDI) UDDI Database (MySQL) Find Publish
Service Consumer Service Provider
Figure 4.1 Experiment of the service discovery model
The four machines we use are IBM ThinkCentre (8183-36U) PC Desktops with
the Windows XP operating system. Each desktop is equipped with one 2.8 GHz Pentium
4 processor and 1 GB of RAM. The four machines are networked by a SAMSUNG
SS6208 SmartEther 10/100M Dual Speed Switch.
4.1.2 Test Scenarios
There are three test scenarios in this evaluation.
Test Scenario 1: Service Publishing with QoS
The first test scenario demonstrates that service providers can publish services
with QoS information in the UDDI registry. Each of the three service providers described
earlier publishes an Online DVD Rental service in the UDDI registry. The first provider’s
Discover
49

service provides a short response time, while the second provides an intermediate and the
running the service provider program, a
separate Java program is used to tModel using the
service key assigned by the UDDI registry u e pub to check
the content of the QoS atches the
publish
Test Scenario 2: Service QoS Update
The second test scenario demonstrates that service providers can update the QoS
informa iders
described earlier upda r updates the
QoS tModel for its service with a long response time, and the third provider updates the
QoS tModel for its service with a short response time.
After each of the two providers updates the QoS information for its service by
running the QoS update program, a separate Java program is used to find the updated
service and QoS tModel using the service key assigned by the UDDI registry during the
publishing process, and to check the content of the QoS tModel. The QoS tModel is
found and its content reflects the changes made during the QoS update process.
Test Scenario 3: Service Discovery
The last test scenario demonstrates that service consumers can find services that
meet their functional and QoS requirements through a discovery agent. The consumer in
third provides a long response time.
After each service is published by
find the published service and QoS
d th lishing process, andring
tModel. The QoS tModel is found and its content m
ed QoS information.
tion for the services it published in the UDDI registry. Two of the three prov
te QoS information for their services. The first provide
50

the experiment looks for Online DVD Rental Web services that provide intermediate
response time. We run the consumer program to send a discovery request to the
Discov
service key of this service is added to a vector, which is
turned to the consumer after all matched services are checked.
ds a discovery request to the discovery agent, it
receive
anking and Selection
signed to
valuate the algorithm, and discuss the experimental results. We demonstrate that the
best meets a customer’s requirements is improved
by usi
ery Agent Web service. The agent queries the UDDI registry to find services that
meet the customer’s functional requirements (“Online DVD Rental”), retrieves the QoS
tModel for each of the matched services, and checks if the advertised response time in the
tModel matches the QoS requirement (“intermediate response time”) in the discovery
request. If they match, the
re
After the consumer program sen
s the result of the discovery: the service keys of the service publish by the first
provider (intermediate response time) and the service published by the third provider
(short response time). This is exactly the same as we expect.
4.2 Evaluation of the Matching, R
Algorithm
In this section we first describe the experimental environment, the generation of
service ratings and the execution of discovery requests. The selection of inclusion factor
for each experiment is then discussed. At last we present a set of experiments de
e
probability of selecting a service that
ng the algorithm. We show that services that do not provide stable QoS
performance are less likely to be selected than those that provide consistent QoS
51

performance to customers. We demonstrate that if the QoS performance of a service is
unstable, it is selected by the discovery agent only at times when its performance is good.
We demonstrate that an appropriate inclusion factor can lessen the effect of anomalies in
reputation scores.
4.2.1 Experimental Environment
and writes them to a text file. A reputation manager program reads ratings from the text
rvice Se QoS Info. Reputation Mgr.
ReputationScore
Figure 4.2: Experimental environment for evaluation the matching, ranking and selection
algorithm
Figure 4.2 shows the components in the experimental environment for this
evaluation. A customer program simulates consumers with different QoS and reputation
requirements, services with different QoS performance and reputation. The service QoS
information is stored in a text file. A rating generator program produces service ratings
Rating
Rating
Discovery Request
Discovery Agent
QoS info.
Service Ratings
Rating Generator
Consumer
52

53
ent in the request, the agent contacts the reputation manager, which
calculates and returns the reputation scores to the agent. The agent ranks the matched
ion scores of the services, selects services that best
e
ter the same functionalities. We assume all consumers request the
same functional requirements which are sati ese services. In the following
mulations, the QoS infor ation of a service includes service price, response time,
vailability and throughput. We treat serv e
arameter te parameter to es
nce every customer is sensitive to pric
parame rs used in the following simulation are for simulation only and are not intended
to refle real level of quality of service of current W
he simulation programs are implemented in Java and run on an IBM
desktop is equipped with one 3.00 GHz processor and 512 MB of RAM.
file and calculates reputation scores when requested. When the discovery agent program
receives a request from a customer, it retrieves the QoS information directly from the
Service QoS Info. file and runs the matching algorithm. If the customer specifies a
reputation requirem
service based on the QoS and reputat
meets the customer’s requirements, and returns them to the customer.
We assume that in the following simulations all services present the sam
in face, and provide
sfied by th
si m
a ice price in the sam way as other QoS
p s. However, service price is used as a separa categorize servic
si e. The values of the price and other QoS
te
ct the eb services.
T
ThinkCentre (8171-2EU) PC Desktop with the Windows XP operating system. The
Pentium 4
4.2.2 Generation of Service Ratings and Execution of Discovery Requests
In each experiment in this evaluation, a rating generator dynamically produces
one rating for each service per day, and each consumer sends one discovery request to the

discovery agent per day after new ratings are generated and written to the Service Ratings
file. Therefore, the reputation score of a service may be changing because a new rating is
possibly different from previous ones.
At the beginning of each experiment, there is only one rating for each service. As
the simulation progresses, a new rating is generated by the rating generator for each
service on each day. So each service has two ratings on the second day, three ratings on
the third day, …… , and so on.
selection algorithm
describ
ng 50
tings, each of which is produced by the rating generator per day. When the inclusion
reputation
scores.
In the first simulation, a service discovery request is run 50 times, which is
adequate to demonstrate the influence of non-functional requirements on the selection of
services with unchanging reputation scores. In each of the next three simulations, a
discovery request is run 100 times for every experiment in order to ensure all variations
of service reputation scores are considered.
4.2.3 Selection of Inclusion Factor λ
The inclusion factor λ is used to adjust the responsiveness of the reputation score
to the changes in service activity in the service matching, ranking and
ed in the previous chapter. The effect of λ on the reputation score is examined and
the result is shown in Figure 4.3. The reputation score of a service is plotted as a function
of the number of ratings provided by service consumers. The test was conducted usi
ra
factor is set to 0.15, only the recent ratings are taken into the calculation of
On the other hand, when the factor is set to 0.95, more ratings are taken into
account. A large inclusion factor close to 1 makes the reputation score become stable but
54
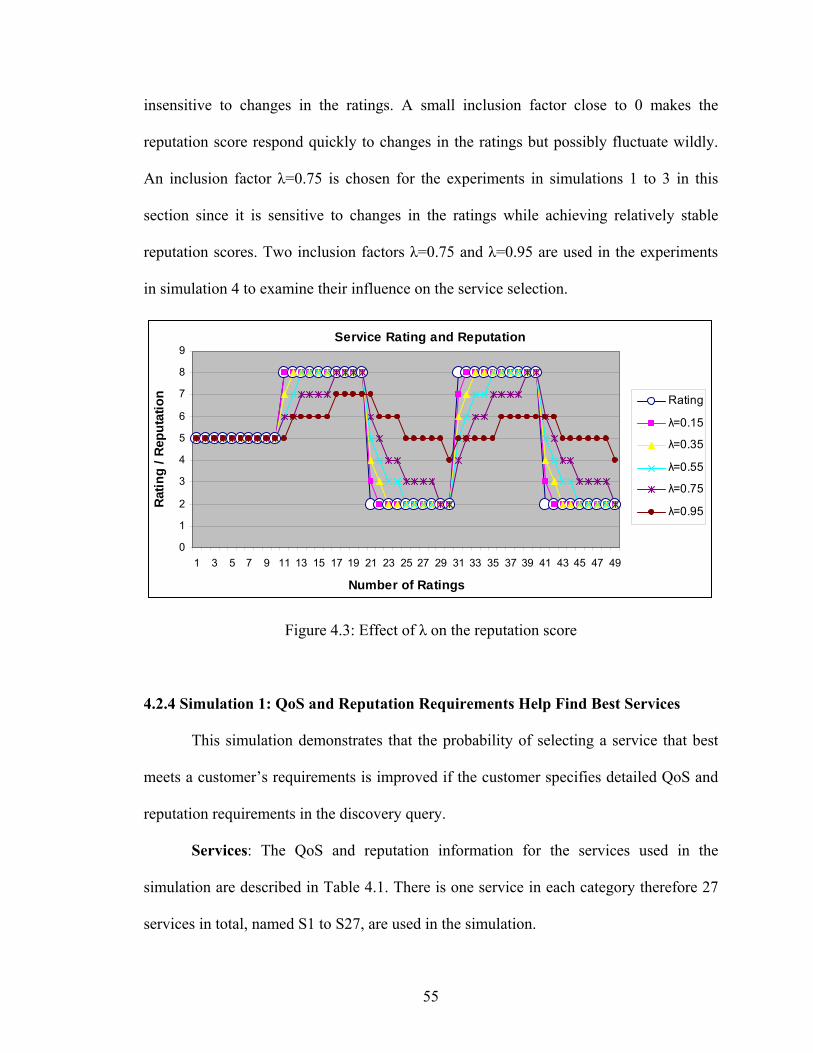
insensitive to changes in the ratings. A small inclusion factor close to 0 makes the
reputation score respond quickly to changes in the ratings but possibly fluctuate wildly.
An inclusion factor λ=0.75 is chosen for the experiments in simulations 1 to 3 in this
section since it is sensitive to changes in the ratings while achieving relatively stable
reputation scores. Two inclusion factors λ=0.75 and λ=0.95 are used in the experiments
in simulation 4 to examine their influence on the service selection.
Service Rating and Reputation
0
1
2
3
4
5
7
Ra
ng /
Rep
utio
n
6
8
9
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
r of Ratings
tita
Rating
λ=0.15
λ=0.35
λ=0.55
λ=0.75
λ=0.95
Numbe
Figure 4.3: Effect of λ on the reputation score
4.2.4 Simulation 1: QoS and Reputation Requirements Help Find Best Services
This simulation demonstrates that the probability of selecting a service that best
meets a customer’s requirements is improved if the customer specifies detailed QoS and
reputation requirements in the discovery query.
Services: The QoS and reputation information for the services used in the
simulation are described in Table 4.1. There is one service in each category therefore 27
services in total, named S1 to S27, are used in the simulation.
55
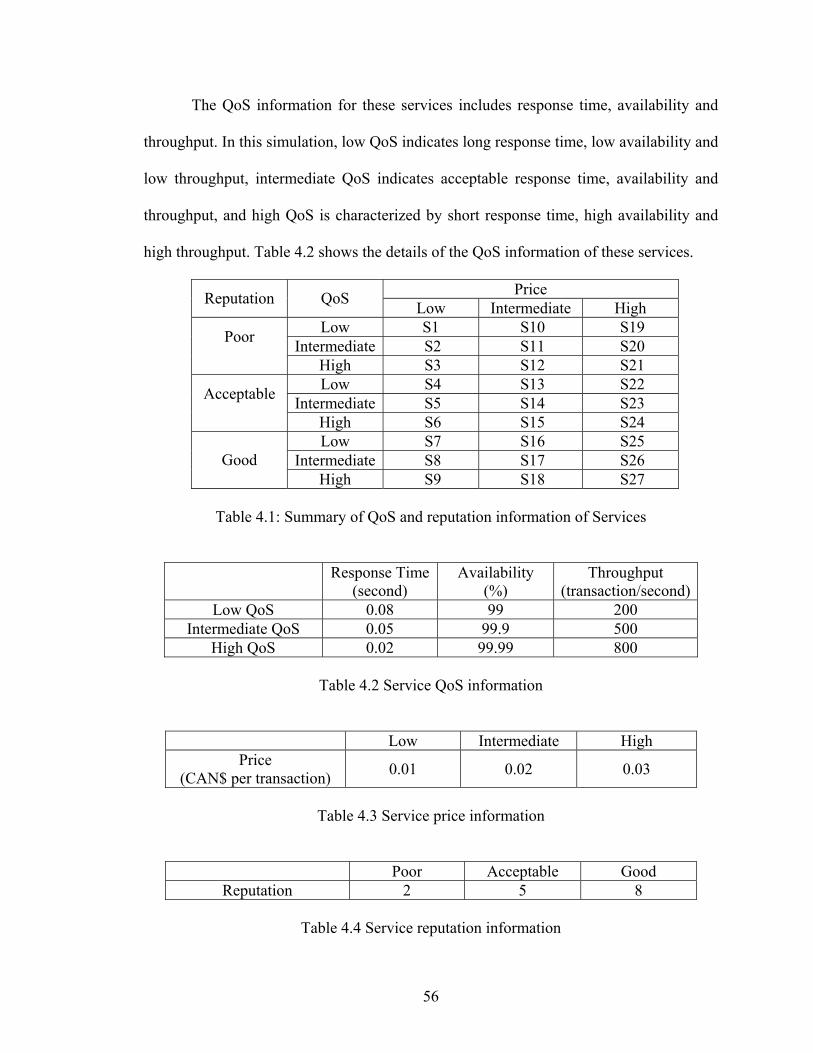
The QoS information for these services includes response time, availability and
throughput. In this simulation, low QoS indicates long response time, low availability and
low throughput, intermediate QoS indicates acceptable response time, availability and
throughput, and high QoS is characterized by short response time, high availability and
high throughput. Table 4.2 shows the details of the QoS information of these services.
Price Reputation QoS Low Intermediate High Low S1 S10 S19
Intermediate S2 S11 S20 Poor High S3 S12 S21
Low S4 S13 S22 Intermediate S5 S14 S23 Acceptable
High S6 S15 S24 Low S7 S16 S25
Intermediate S8 S17 S26 Good High S9 S18 S27
Table 4.1: Summary of QoS and reputation information of Services
Response Time (second)
Availability (%)
Throughput (transaction/second)
Low QoS 0.08 99 200 Intermediate Q 500 oS 0.05 99.9
High QoS 0.02 99.99 800
Table 4.2 Service QoS information
Low Intermediate High Price
(CAN$ per transaction) 0.01 0.02 0.03
e information
Poor Acceptable Good
Table 4.3 Service pric
Reputation 2 5 8
n
Table 4.4 Service reputation informatio
56

Table 4.3 shows the details of the price information for these services. Table 4.4
shows the details of the reputation information for these services. The reputation scores
of the services are static during the simulation.
C serv nsumers are used in thi lation. Each has different
QoS and reputation requirements. Their QoS (including price) and reputation
requirements are summarized in Table 4.5. The dominant QoS attribute in the QoS
requirem u C4 sponse tim he weigh QoS and
reputation requirements are 0.5. All co ers speci t the maxi
services to b ned i
Requirements
onsumers: 4 ice co s simu
ents of cons mers C3 and is re e. T ts for
both nsum fy tha mum number of
e retur s one.
Consumer Price (CAN$ per transa
P oS , T tationction) Response ti
erformance Qme, Availability hroughput Repu
C1 No e Non No C No 2 0.01 NoneC 0.03 sec, 99.95%, 700 trans/sec No 3 0.01C4 0.01 0.03 sec, 99.95%, 700 trans/sec 8
Table 4.5: Summ ts of consumers
As Table 4.5 shows, C1 is a “functionality o
the fu , C2, C3 and C4, on the other hand, specify QoS and/or
tion requirements in ice. C2 is a “price only”
consumer whose only interest is the price of a service. C3 is a “QoS only” consumer who
is concerned with the price and the performance of a se -all”
ary of QoS and reputation requiremen
nly” consumer who cares only about
nctionality of a service
reputa addition to functionality of a serv
rvice, while C4 is a “care
57

consum r who is concerned with the price, the performance and the reputation of a
service
e the following results:
• C1: a service will be randomly selected from the 27 services for consumer C1 given
that
umer C3 who specifies price and performance preference
in the QoS requirement.
• gh QoS and good reputation service group, will
always be selected for consumer ding p and
performance) and reputation requirements in the discovery request.
F once per
day, and the service selected for each run was noted. The actual service selection results
were as expected. Figure 4.4 shows the results.
e
.
Experimental Result: We expect to observ
no requirements are specified.
• C2: a service from S1 to S9, which are in the low price service group will be
randomly selected for consumer C2 who specifies only a price preference in the QoS
requirement.
• C3: S3, S6 or S9, which are in the low price and high QoS service group, will be
randomly selected for cons
C4: S9, which is in the low price, hi
C4 who specifies both QoS (inclu rice
or each consumer, the same service discovery request was run 50 times,
58
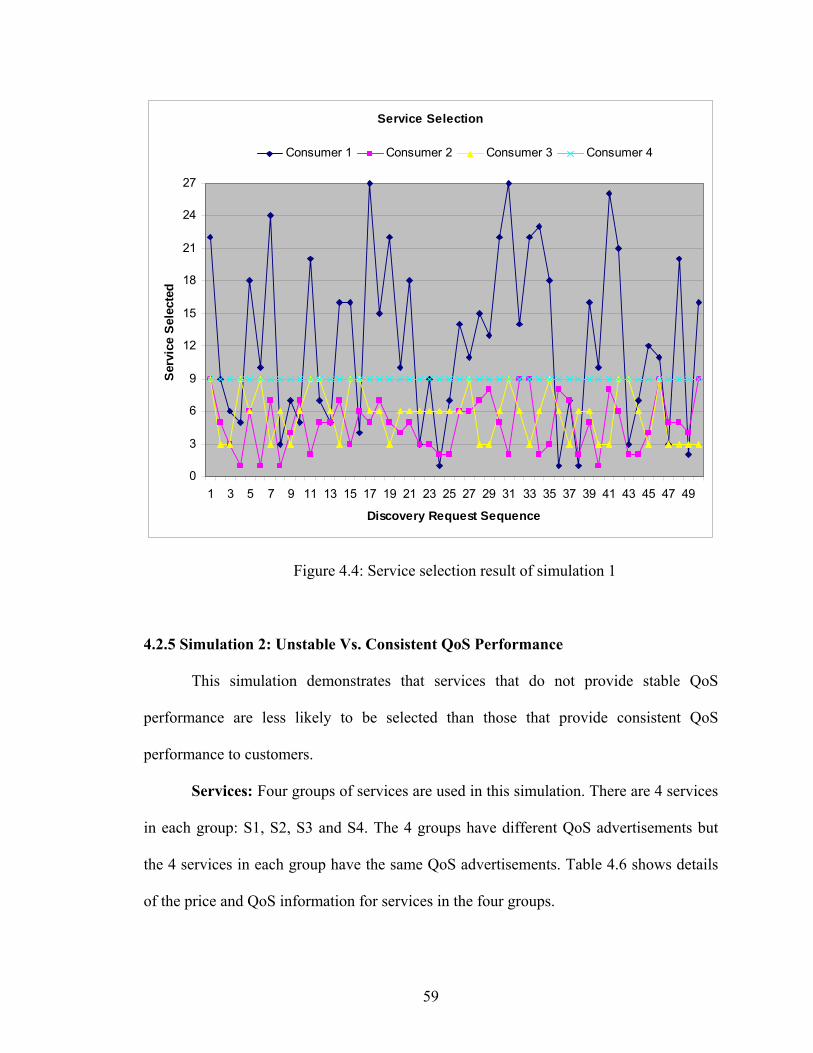
Service Selection
Consumer 1 Consumer 2 Consumer 3 Consumer 4
0
3
6
9
12
15
27
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
Discovery Request Sequence
Ser
vice
Sel
ecte
d
24
18
21
Figure 4.4: Service selection result of simulation 1
4.2.5 Simulation 2: Unstable Vs. Consistent QoS Performance
This simulation demonstrates that services that do not provide stable QoS
performance are less likely to be selected than those that provide consistent QoS
performance to customers.
Services: Four groups of services are used in this simulation. There are 4 services
in each group: S1, S2, S3 and S4. The 4 groups have different QoS advertisements but
the 4 services in each group have the same QoS advertisements. Table 4.6 shows details
of the price and QoS information for services in the four groups.
59
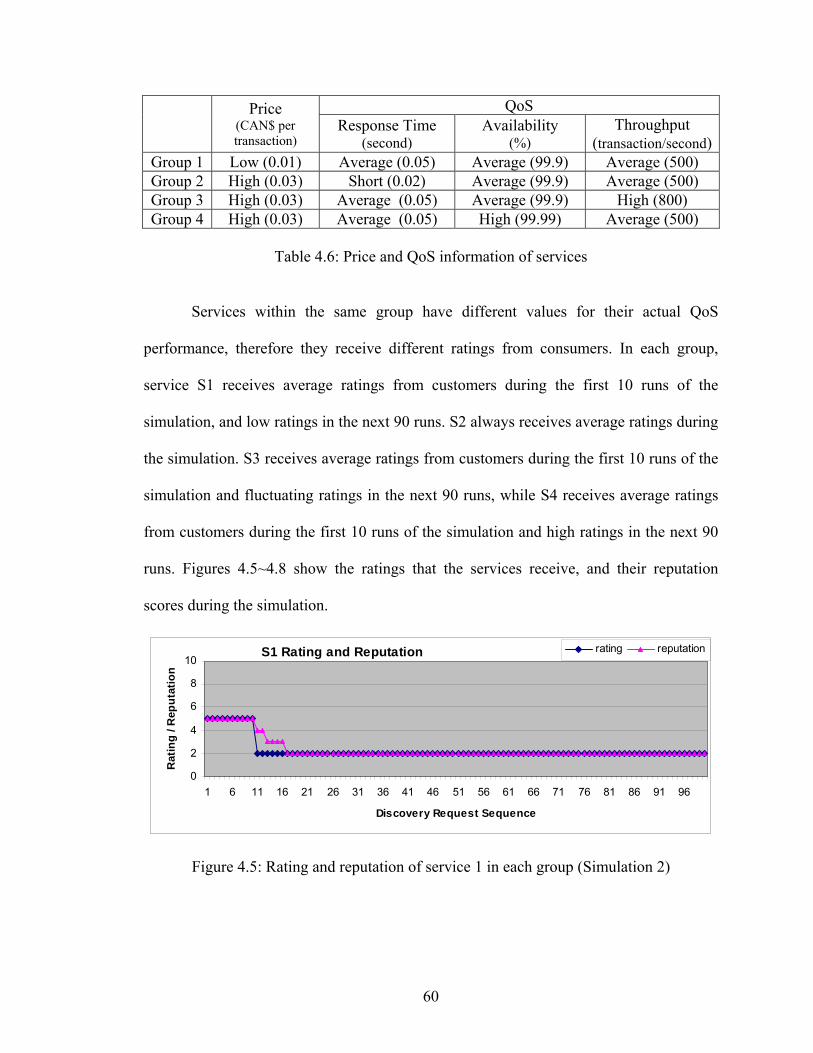
QoS
Price (CAN$ per transaction)
Response Time (second)
Availability (%)
Throughput (transaction/second)
Group 1 Low (0.01) Average (0.05) Average (99.9) Average (500) Group 2 High (0.03) Short (0.02) Average (99.9) Average (500) Group 3 High (0.03) Average (0.05) Average (99.9) High (800) Group 4 High (0.03) Average (0.05) High (99.99) Average (500)
Table 4.6: Price and QoS information of services
Services within the same group have different values for their actual QoS
performance, therefore they receive different ratings from consumers. In each group,
service S1 receives average ratings from customers during the first 10 runs of the
simulation, and low ratings in the next 90 runs. S2 always receives average ratings during
the simulation. S3 receives average ratings from customers during the first 10 runs of the
simulation and fluctuating ratings in the next 90 runs, while S4 receives average ratings
from customers during the first 10 runs of the simulation and high ratings in the next 90
runs. Figures 4.5~4.8 eir reputation
scores during the simulation.
show the ratings that the services receive, and th
rating reputationS1 Rating and Reputation
0
10
Discovery Request Sequence
g /
tatio
n
2
4
6
8
Rat
in R
epu
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Figure 4.5: Rating and reputation of service 1 in each group (Simulation 2)
60
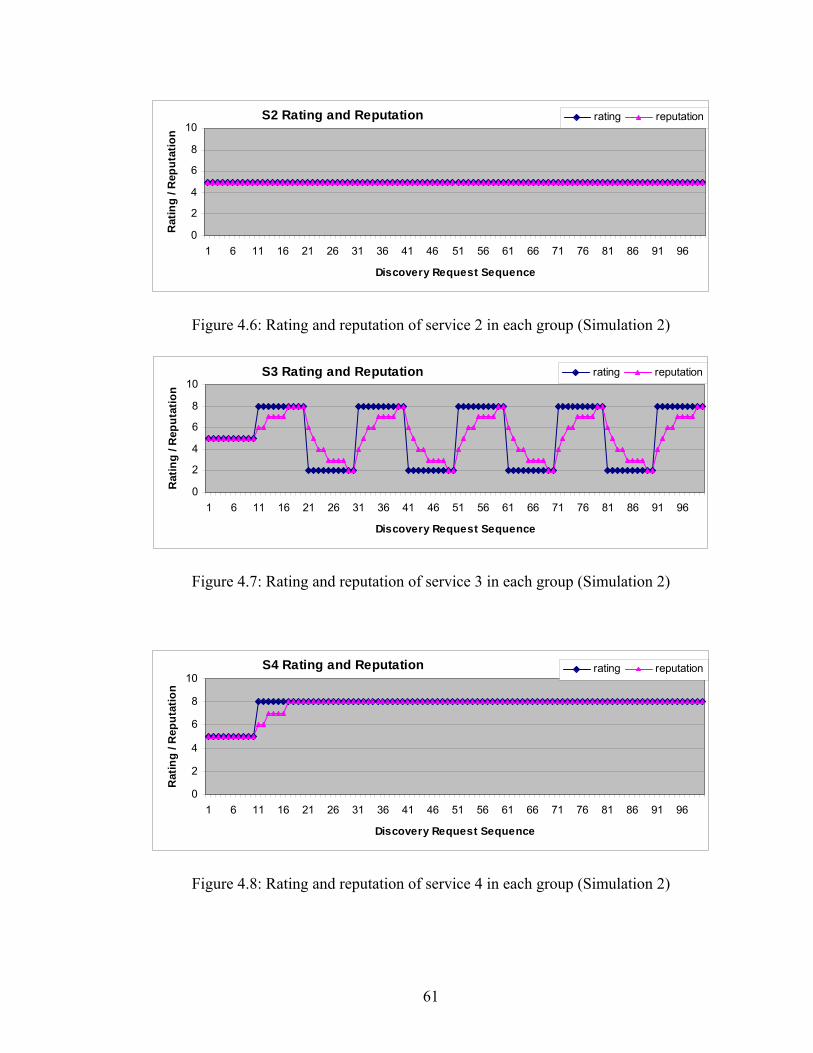
S2 Rating a
0
10
1 6 11 81 86 91 96
Discovery Request Sequence
on
nd Reputation
2
Rat
i
4
ng /
6 R
e
8
puta
ti
rating reputation
16 21 26 31 36 41 46 51 56 61 66 71 76
Figure 4.6: Rating and reputation of service 2 in each group (Simulation 2)
S3 Rating and Reputation
0
2
4
6
10
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
Rng
/ep
uta
on
8
ati
Rti
rating reputation
Figure 4.7: Rating and reputation of service 3 in each group (Simulation 2)
S4 Rating and Reputation
0
2
4
6
8
10
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
Rat
ing
/ Rep
utat
ion
rating reputation
Figure 4.8: Rating and reputation of service 4 in each group (Simulation 2)
61

Consumers: 4 service consumers are used in this simulation. Each has different
QoS and reputation requirements. Their QoS (including price) and reputation
requirements are summarized in Table 4.7. The dominant QoS attribute in the QoS
requirements of consumer C3 and C4 is response time. The weights for QoS and
reputation requirements are both 0.5. All consumers specify that the maximum number of
services to be returned is one.
Requirements
Consumer Price (CAN$ per transaction)
Performance QoS Response time, Availability, Throughput Reputation
C1 No None No C2 0.03 None No C3 0.03 0.05 sec, 99.9%, 500 trans/sec No C4 0.03 0.05 sec, 99.9%, 500 trans/sec 8
Table 4.7: Summary of QoS and reputation requirements of consumers
Experimental Result:
We expect that a service will be randomly selected for customers C1, C2 and C3
from service S1, S2, S3 and S4, since the four services all meet the QoS and/or reputation
requirements of the three customers. We expect that S4 will be selected most of time for
C4 because it provides stable QoS performance, receives good ratings from consumers,
and meets the QoS and reputation requirements of C4. S3 should be occasionally selected
for C4 because it meets the QoS requirements of C4 and its fluctuating reputation score
occasionally meets C4’s reputation requirement.
This simulation consists of 4 experiments which use the same consumers (C1~4
but different groups of services
ely. In each experiment and for each consumer,
)
as described earlier. Experiment 1, 2, 3 and 4 use the
services of group 1, 2, 3, and 4, respectiv
62
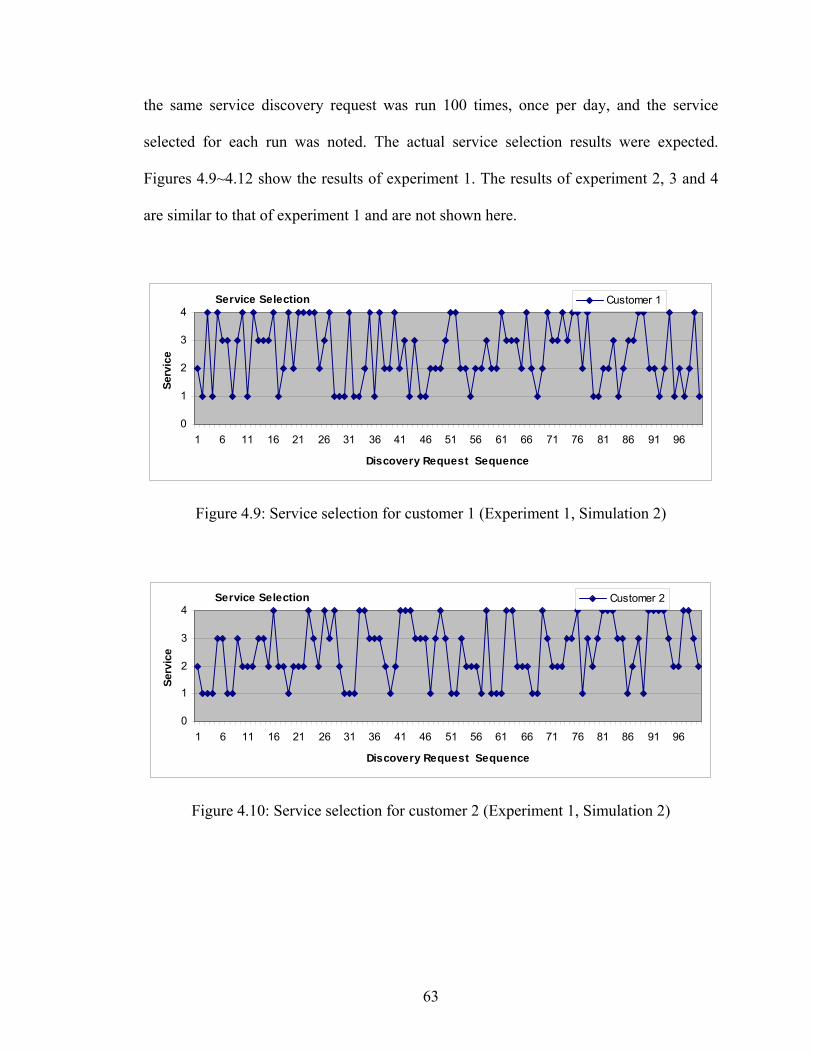
the same service discovery request was run 100 times, once per day, and the service
selected for each run was noted. The actual service selection results were expected.
Figures 4.9~4.12 show the results of experiment 1. The results of experiment 2, 3 and 4
are similar to that of experiment 1 and are not shown here.
Service Selection
01
1
3
4
6 11 16 26 31 36 41 46 51 66 71 76 81 86 6
Disc
ice
2
Serv
21 56 61 91 9
overy Request Sequence
Customer 1
F
igure 4.9: Service selection for customer 1 (Experiment 1, Simulation 2)
Service Selection
0
2
3
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
Serv
ie
1
4
c
Customer 2
Figure 4.10: Service selection for customer 2 (Experiment 1, Simulation 2)
63
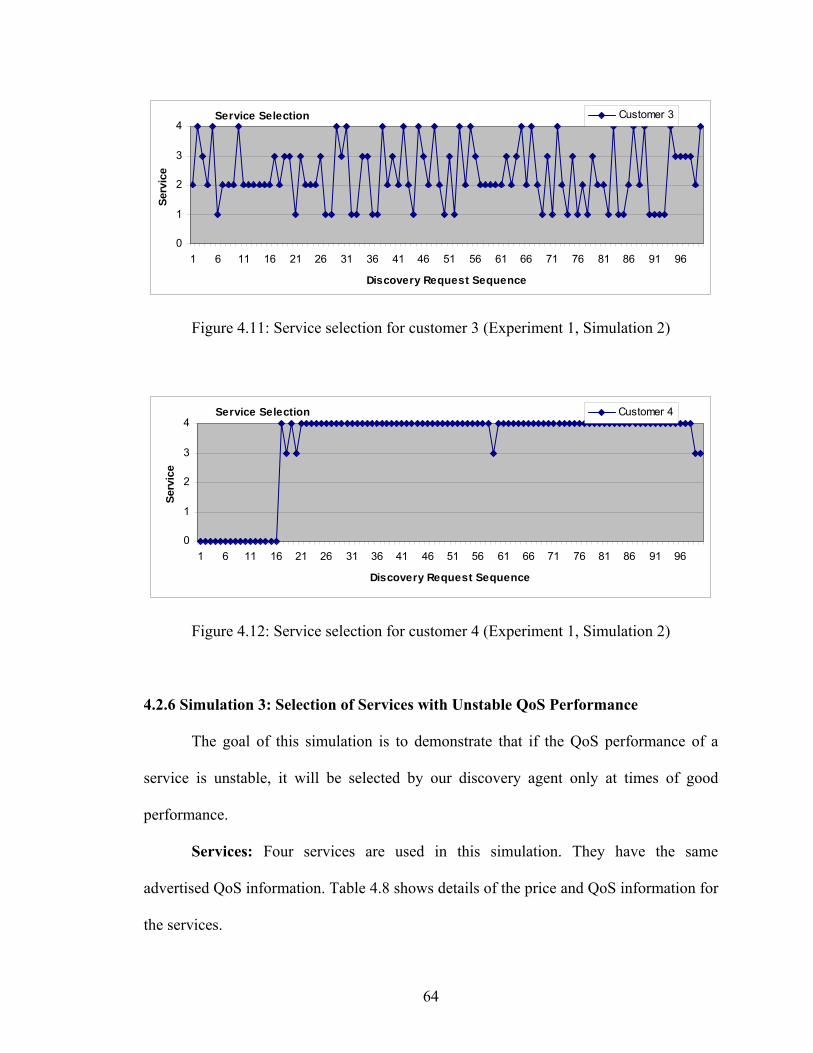
Service Selection
0
1
2rvic
e3
4
6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
Se
Customer 3
1
Figure 4.11: Service selection for customer 3 (Experiment 1, Simulation 2)
Service Selection
0
1
2
3
4
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
Serv
ice
Customer 4
Figure 4.12: Service selection for customer 4 (Experiment 1, Simulation 2)
4.2.6 Simulation 3: Selection of Services with Unstable QoS Performance
The goal of this simulation is to demonstrate that if the QoS performance of a
service is unstable, it will be selected by our discovery agent only at times of good
perform
Services: Four services are used in this simulation. They have the same
advertised QoS information. Table 4.8 shows details of the price and QoS information for
the services.
ance.
64

QoS Price
(CAN$ per transaction) Response Time (second)
Availability (%)
Throughput (transaction/second)
0.03 0.05 99.9 500
Table 4.8: Summary of QoS information of service
The difference between the services is their actual QoS performance, therefore
they re atings
from customers during the simulation, S2 receives average ratings during the first 10 runs
of the simulation and low ratings in the next 90 runs, while S3 and S4 receive average
ratings from customers during the first 10 runs of the simulation and fluctuating ratings in
the next 90 runs. Figures 4.13~4.16 show the ratings that S1, S2, S3 and S4 receive, and
their reputation scores during the simulation.
ceive different ratings from consumers. Service S1 always receives average r
S1 Rating and Reputation
01 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77 81 85
R
2
4
10
89 93 97
atin
g / R
eput
atio
n
rating reputation
6
8
Discovery Request Sequence
Figure 4.13: Rating and reputation of service 1 (Simulation 3)
65
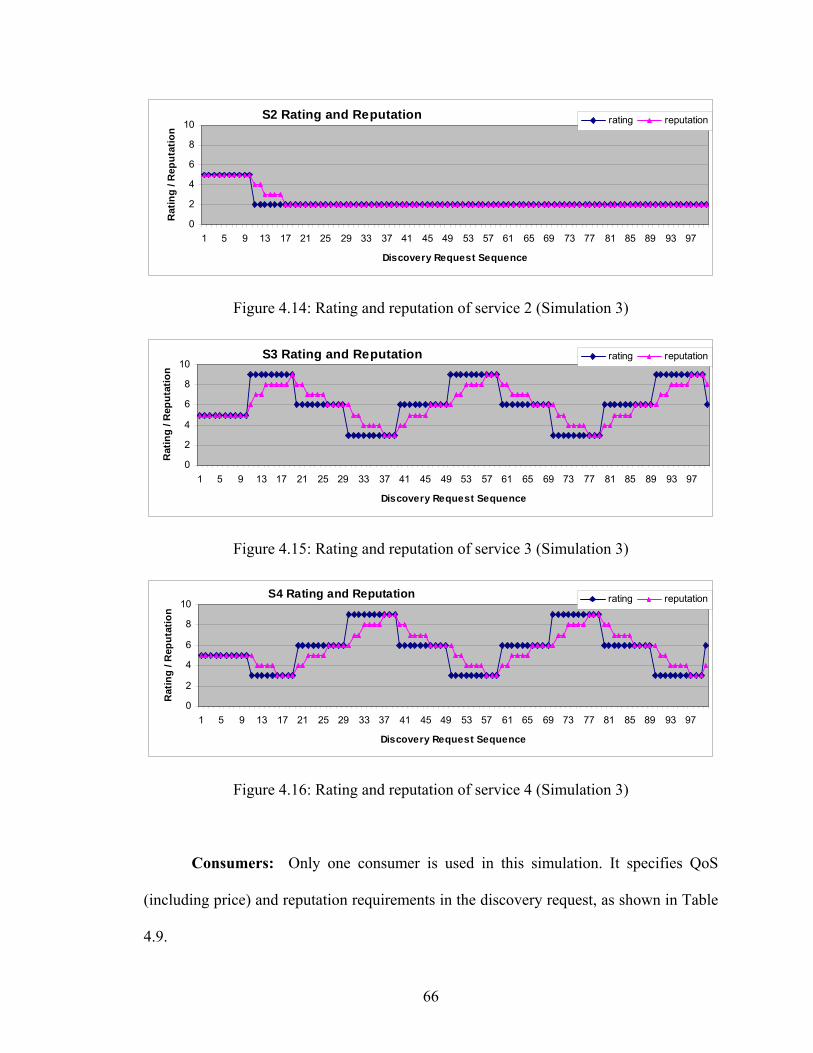
S2 Rating and Reputation
0
2
4
6
8
10
1 5 9 1 81 85 89 93 97
Discovery equest Sequence
Rat
ing
/ Rep
utat
ion
rating reputation
3 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77
R
Figure 4.14: Rating and reputation of service 2 (Simulation 3)
S3 Rating and Reputation
0
2
4
6
10
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77 81 85 89 93 97
Discovery R
atin
g /
eput
aon
8
equest Sequence
R R
ti
rating reputation
Figure 4.15: Rating and reputation of service 3 (Simulation 3)
S4 Rating and Reputation
0
2
4
6
8
10
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77 81 85 89 93 97
Discovery Request Sequence
Rat
ing
/ Rep
utat
ion
rating reputation
Figure 4.16: Rating and reputation of service 4 (Simulation 3)
Consumers: Only one consumer is used in this simulation. It specifies QoS
(including price) and reputation requirements in the discovery request, as shown in Table
4.9.
66

Requirements Price
(CAN$ per transaction)
Performance QoS Response time, Availability, Throughput Reputation
$0.03 0.05 sec, 99.9%, 500 trans/sec 6
Table 4.9: Summary of QoS and reputation requirements of consumer
Experimental Result:
We ex only during
periods of good performance since their reputation scores can meet the customer’s
requirement during periods when they continuously receive good ratings. The length of
these periods is affected by the inclusion factor λ as described earlier in section 4.1.2. We
expect that service S1 and S2 will not be selected for the customer since their reputation
scores cannot meet the customer’s requirement.
The same service discovery request was run 100 times, once per day, and the
service selected for each run was noted. The e as
expected. Figure 4.17 shows the results.
pect that service S3 or S4 will be selected for the customer
actual service selection results wer
Service Selection
0
1
2
3
4
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77 81 85 89 93 97
Customer 1
Serv
ice
Discovery Request Sequence
Figure 4.17: Service selection for the customer (Simulation 3)
4.2.7 Simulation 4: Effect of Inclusion Factor on Service Selection
67

This simulation demonstrate tation of a service that generally
receives go ccasio if th factor is
appropriately selected in our p
Se the same
advertised QoS information. Table 4.10 shows the details of the price and QoS
information for the services.
QoS
s that the repu
od, but o nally bad, ratings is not affected e inclusion
roposed discovery model.
rvices: Four services are used in this simulation. All services have
Price (CAN$ per Response Time
(second) Throughput (trans/sec) transaction) Availability (%)
0.03 0.05 99.9 500
Table 4.10: Summary of QoS information of service
For each service, the actual QoS performance is different and therefore each
receives dif
runs, S3 receives average ratings during the
first 10 runs of the simulation and general low, but occasional high, ratings in the next 90
runs. S4 receives average ratings during the first 10 runs of the simulation and general
high, but occasional low, ratings in the next 90 runs.
Consumers: Only one consumer is used in this simulation. It specifies QoS
(including price) and reputation requirements in the discovery request, as shown in Table
4.11.
ferent ratings from consumers. Service S1 always receives average ratings
from customers during the simulation, S2 receives average ratings during first 10 runs of
the simulation and low ratings in the next 90
Requirements Price
(CAN$ per transaction)
Performance QoS Response time, Availability, Throughput Reputation
$0.03 0.05 sec, 99.9%, 500 trans/sec 7
Table 4.11: Summary of QoS and reputation requirements of consumer
68
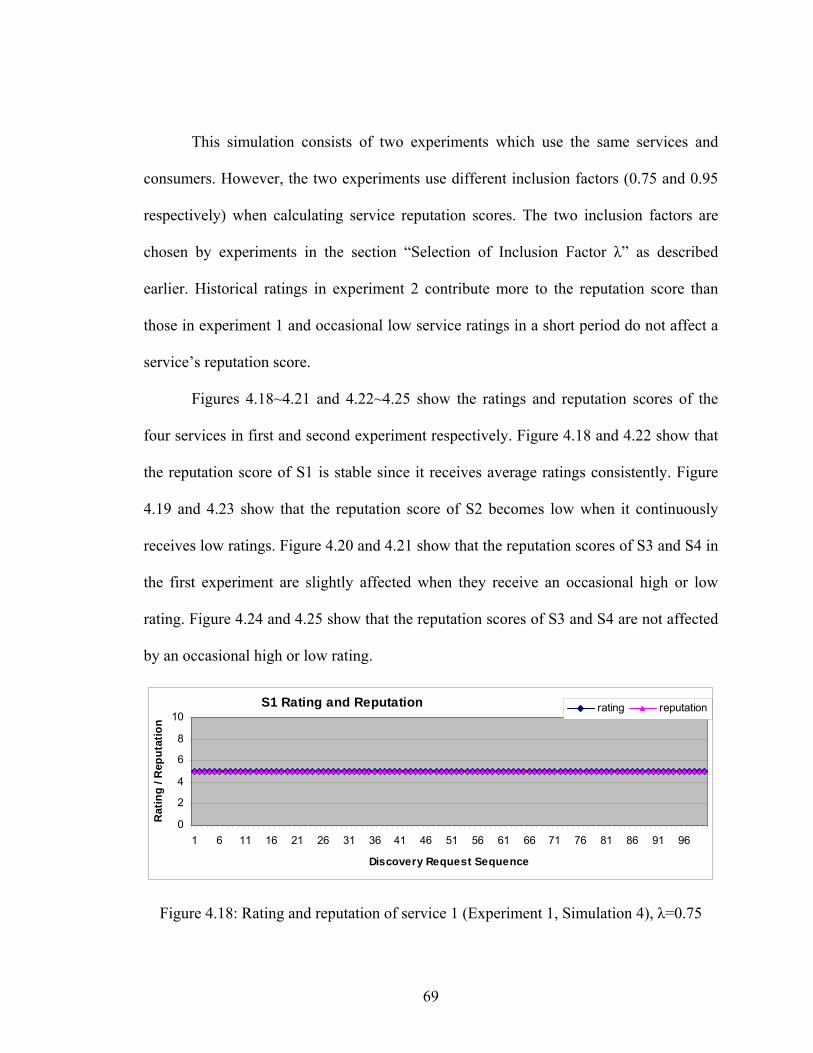
inclusion factors (0.75 and 0.95
respect
xperiment 2 contribute more to the reputation score than
those in exp 1 and occasional low service ratings in a short period do not affect a
service’s r ore.
Figures 4.18~4.21 and 4.22~4.25 show the ratings and reputation scores of the
four services in first and second experiment respectively. Figure 4.18 and 4.22 show that
the rep
This simulation consists of two experiments which use the same services and
consumers. However, the two experiments use different
ively) when calculating service reputation scores. The two inclusion factors are
chosen by experiments in the section “Selection of Inclusion Factor λ” as described
earlier. Historical ratings in e
eriment
eputation sc
utation score of S1 is stable since it receives average ratings consistently. Figure
4.19 and 4.23 show that the reputation score of S2 becomes low when it continuously
receives low ratings. Figure 4.20 and 4.21 show that the reputation scores of S3 and S4 in
the first experiment are slightly affected when they receive an occasional high or low
rating. Figure 4.24 and 4.25 show that the reputation scores of S3 and S4 are not affected
by an occasional high or low rating.
S1 Rating and Reputation
0
8
10
1 6 11 16 21 26 31 36 61 66 71 76 81 86 91 96
D uence
g /
tatio
n
rating reputation
2
4
6
Rat
in R
epu
41 46 51 56
iscovery Request Seq
Figure 4.1 g and rep ulation 4), λ=0.75 8: Ratin utation of service 1 (Experiment 1, Sim
69
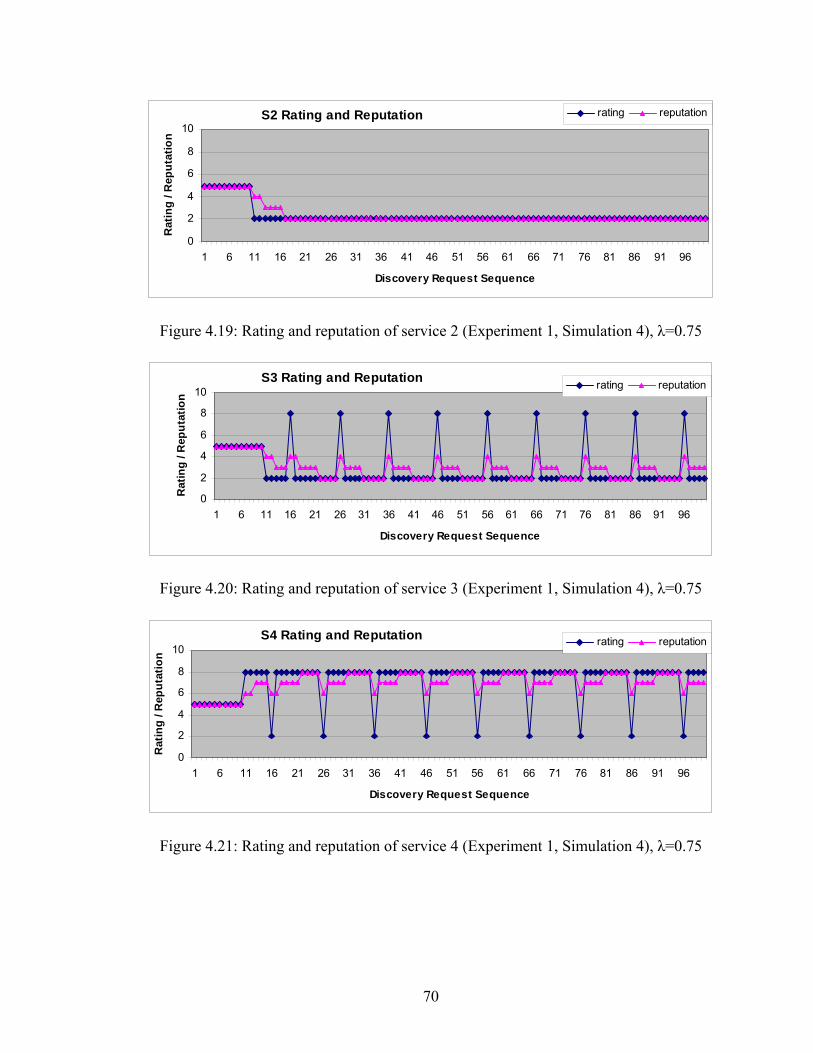
S2 Rating and Reputation rating reputation
0
2
6
8
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
atin
g R
epu
4
10
R /
tatio
n
Figure 4.19: Rating and reputation of service 2 (Experiment 1, Simulation 4), λ=0.75
S3 Rating and Reputation
0
2
6
10
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
ting
/ep
u
4
8
Ra
Rta
tion
rating reputation
Figure 4.20: Rating and reputation of service 3 (Experiment 1, Simulation 4), λ=0.75
S4 Rating and Reputation
0
2
4
6
8
rating reputation10
on
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
Rat
ing
/ Rep
utat
i
Figure 4.21: Rating and reputation of service 4 (Experiment 1, Simulation 4), λ=0.75
70
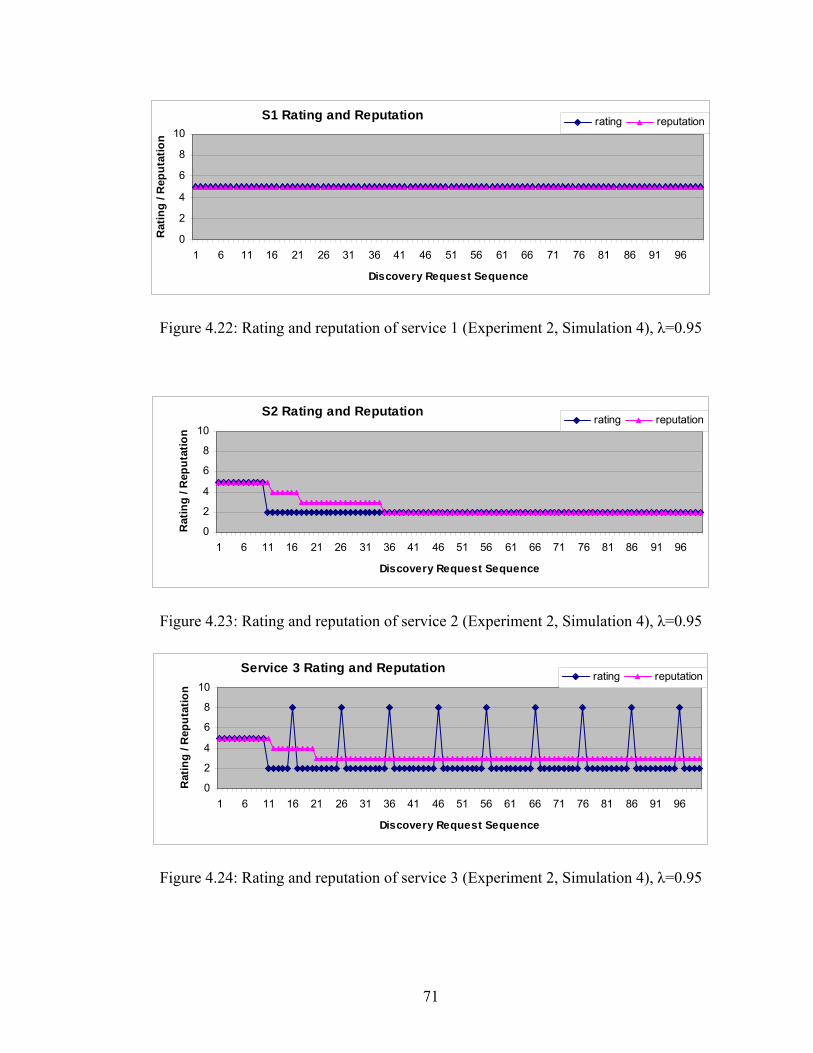
S1 Rating and Reputation
0
2
4
6
8
10
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
Rat
ing
/ Rep
utat
ion
rating reputation
Figure 4.22: Rating and reputation of service 1 (Experiment 2, Simulation 4), λ=0.95
S2 Rating and Reputation
0
2
4
6
8
10
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
Rat
ing
/ Rep
utat
ion
rating reputation
Figure 4.23: Rating and reputation of service 2 (Experiment 2, Simulation 4), λ=0.95
Service 3 Rating and Reputation
0
2
4
6
8
10
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
Rat
ing
/ Rep
utat
ion
rating reputation
Figure 4.24: Rating and reputation of service 3 (Experiment 2, Simulation 4), λ=0.95
71
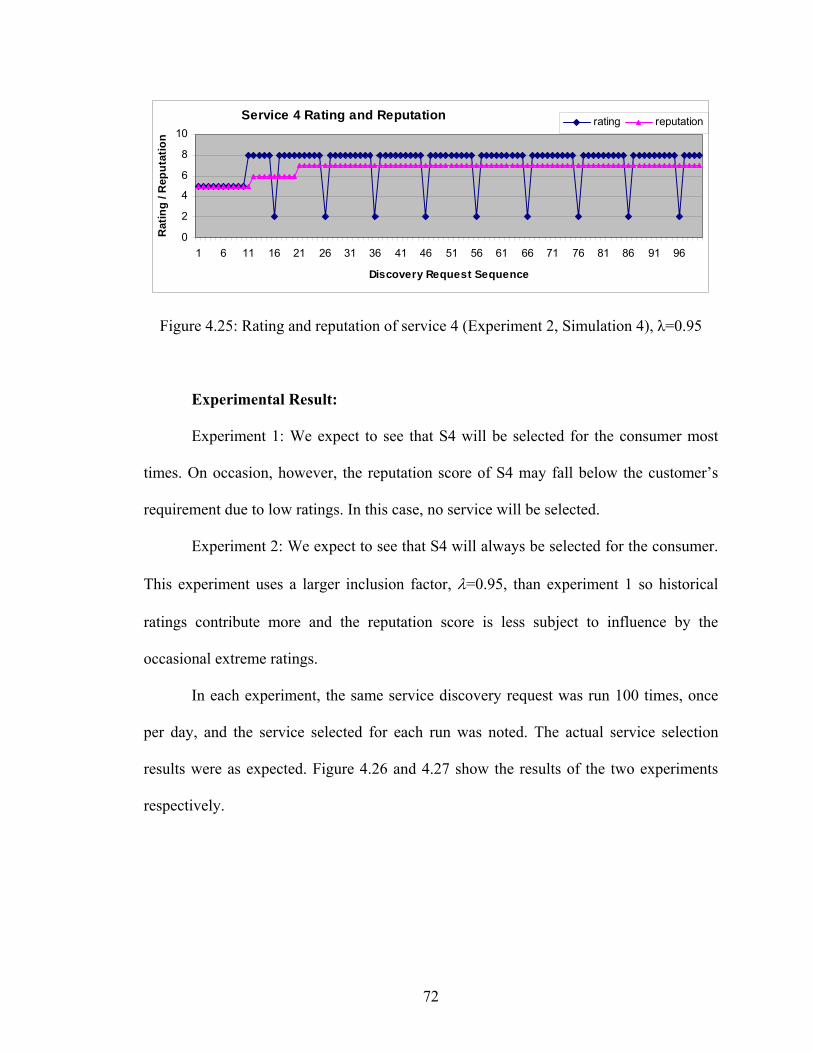
Service 4 Rating and Reputation
0
2
4
6
8
10
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
Rat
ing
/ Rep
utat
ion
rating reputation
Figure 4.25: Rating and reputation of service 4 (Experiment 2, Simulation 4), λ=0.95
Experimental Result:
Experiment 1: We expect to see that S4 will be selected for the consumer most
times. On occasion, however, the reputation score of S4 may fall below the customer’s
requirement due to low ratings. In this case, no service will be selected.
Experiment 2: We expect to see that S4 will always be selected for the consumer.
This experiment uses a larger inclusion factor, λ=0.95, than experiment 1 so historical
ra e
occasional extreme ratings.
In each experiment, the same service discovery request was run 100 times, once
per day, and the service selected for each run was noted. The actual service selection
results were as expected. Figure 4.26 and 4.27 show the results of the two experiments
respectively.
tings contribute more and the reputation score is less subject to influence by th
72
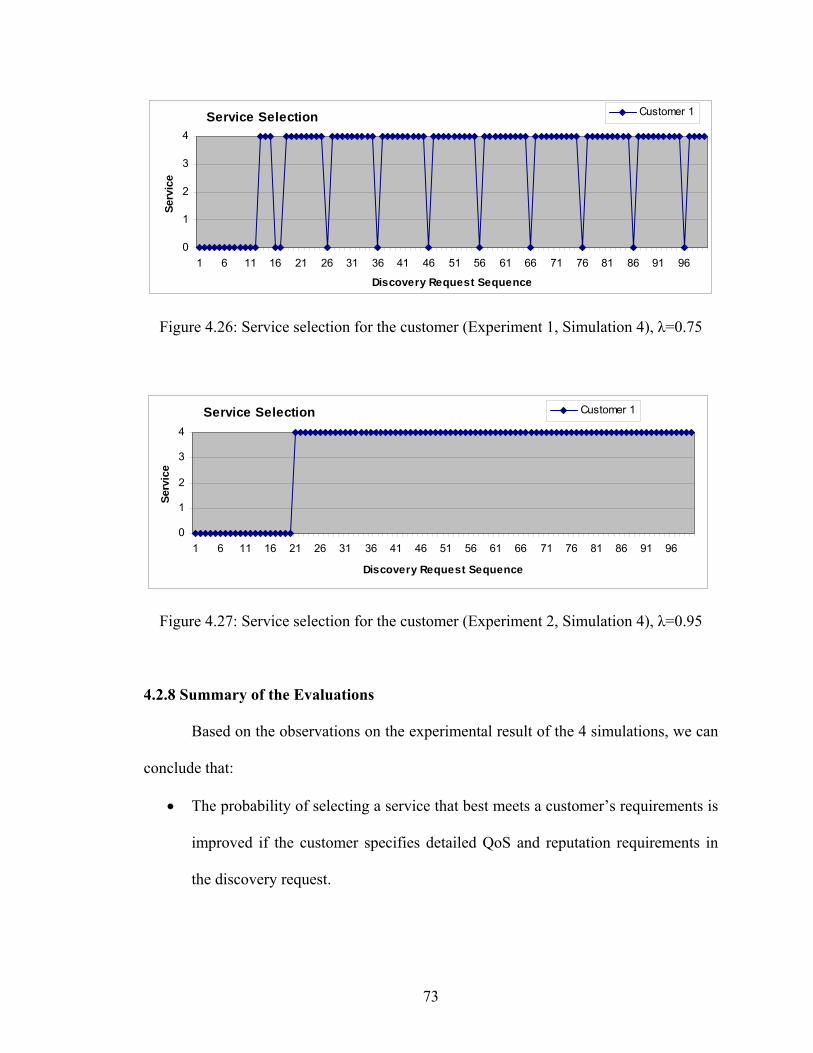
Service Selection
0
1
2
3
4
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Discovery Request Sequence
Serv
ice
Customer 1
Figure 4.26: Service selection for the customer (Experiment 1, Simulation 4), λ=0.75
Service Selection
0
Customer 1
1
2
Sevi
ce
3
4
Discovery Request Sequence
r
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
Figure 4.27: Service selection for the customer (Experiment 2, Simulation 4), λ=0.95
4.2.8 S
bability of selecting a service that best meets a customer’s requirements is
proved if the customer specifies detailed QoS and reputation requirements in
the discovery request.
ummary of the Evaluations
Based on the observations on the experimental result of the 4 simulations, we can
conclude that:
• The pro
im
73

• Services that do not provide stable QoS performance are less likely to be selected
than those that provide consistent QoS performance to customers.
• If the QoS performance of a service is unstable, it is selected by the discovery
agent only at times when its performance is good.
• An appropriate inclusion factor can lessen the effect of anomalies in reputation
scores.
74

C a
C n
more e is being placed on how to find the service that best fits the consumer’s
requirements. In order to find services that best meet their QoS requirements, the service
consumers and/or discovery agents need to know both the QoS information for the
services and the reliability of this information. The problem, however is that the current
UDDI registries do not provide a method for service providers to publish the QoS
information of their services, and the advertised QoS information of Web services is not
always trustworthy. We propose a simple model of reputation-enhanced Web services
discovery with QoS. Advertised QoS information is expressed in XML style format and
is stored using tModels in a UDDI registry. Services that meet a customer’s functionality
and QoS requirements are ranked using the service reputation scores which are
maintained by a reputation management system. A service matching, ranking and
selection algorithm is presented and evaluated.
5.1 Thesis Contributions
This thesis examines some major problems in dynamic Web services discovery
with QoS. We identify that the publishing of service QoS information, the matching of
QoS requirements and advertisements and the ranking of services using reputation scores
are key challenges. As a solution, we propose a model of reputation-enhanced Web
h pter 5
o clusions and Future Work
With an increasing number of Web services providing similar functionalities,
mphasis
75

services discovery with QoS. We use the service matching, ranking and selection
algorithm of this model to address the service ranking problem to test the model’s
We develop a service discovery model that contains a discovery agent and a
reputat
er’s
reference in the service discovery request.
iscovery model and evaluate the model by
experiments. We evaluate the service matching, ranking and selection algorithm by
simulations using several groups of services with different QoS advertisements and
reputations scores and consumers with different requirements. We present the
validity.
ion management system. The discovery agent finds services that best meet a
consumer’s QoS and reputation requirements that are specified in a discovery request.
The reputation management system collects feedback from consumers and provides
reputation scores to the discovery agent to rank services that meet a customer’s QoS
requirements.
We use tModels, a current feature in UDDI registries, to store advertised QoS
information of services. When a business publishes a Web service, it creates and registers
a tModel within a UDDI registry. The QoS information of the Web service is represented
in the tModel, which is referenced in a binding template that represents the Web service
deployment.
We develop a service matching, ranking and selection algorithm that finds
services that match a consumer’s requirements, ranks the matches using their QoS
information and reputation scores and selects services based on the consum
p
We implement the service d
76

experimental results to demonstrate that our service discovery model can find services
that best meet a customer’s requirements.
5.2 C
Based on our research, we can conclude that:
• The reputation-enhanced Web services discovery with QoS model proposed in
this work provides a solution to dynamic Web service discovery at run time that
can be accommodated within the basic Web service protocols, that is, a low-
complexity model at the level of standards such as WSDL and UDDI as opposed
to one based on high-level WSLA or WS-Policy specifications.
• A reputation management system provides a method to assist a service discovery
agent to improve the possibility to find services that provide consistently stable
QoS performance and that match a consumer’s QoS and reputation requirements.
• The processing of historical service ratings is critical in finding the services that
best meet a consumer’s requirements. The inclusion factor used in our service
matching, ranking and selection algorithm plays an important role in adjusting the
responsiveness of service reputation scores to changes in ratings from consumers.
The exact value depends on the demands of the environment in which the model
operates.
onclusions
5.3 Future Work
77

There are a number of interesting avenues of future research suggested by this
work. Some of the most interesting are:
• Extending the service discovery model. Future work would look at expanding the
stomers to specify a reputation preference that can be used to
fine tune the ranking process. For example, a customer may specify the preference
on the history and trend of service reputation scores in order to find services that
whose reputation scores are consistently stable and have never dropped below a
specific value. Moreover, QoS information that is in tModels in the UDDI registry
or in the service discovery requests is assumed to use default measurement units.
Future work may look at the possibility of using QoS ontology to allow different
units to be converted automatically [31].
• Refining the reputation management system. Future work may look at the
accountability of those providing ratings. We assume the service ratings are all
trustworthy, however, in the real world, ratings of a service could be from its
competitors and trade partners, or even the service itself [23]. A possible solution
is to allow the raters themselves to be rated [44].
• Extending the reputation management system. A new “stability score” may be
introduced to measure how stable a service is. A service that always provides
good quality of service as its advertised QoS information will be assigned a high
stability score while a service that cannot provide stable quality of service as its
QoS advertisement will receive a low stability score, which will help to remove
ervice selection process.
model to allow cu
unstable services in s
78

Refe
[1] Apache Software Foundation. (2005). "Welcome to jUDDI". Retrieved May 23, 2006
from http://ws.apache.org/juddi/
[2] Berners-Lee, T., Miller, E. (2002). "The Semantic Web lifts off". ERCIM News, No.
51, October 2002. Retrieved May 21, 2006 from
http://www.ercim.org/publication/Ercim_News/enw51/berners-lee.html
[3] Blum, A. (2004). “UDDI as an Extended Web Services Registry: Versioning, quality
of service, and more”. Retrieved April 20, 2006 from http://www.sys-
con.com/story/?storyid=45102&DE=1
[4] Blum, A. (2004). “Extending UDDI with Robust Web Services Information”.
Retrieved April 20, 2006 from
http://searchwebservices.techtarget.com/originalContent/0,289142,sid26_gci952129,0
0.html
[5] Bajaj, S. et al. (2006) “Web Services Policy Framework (WSPolicy)”. Retrieved
April 30, 2006 from
http://download.boulder.ibm.com/ibmdl/pub/software/dw/specs/ws-polfram/ws-
policy-2006-03-01.pdf
[6] Brickley, D., Guha, R.V. (2004). "Rdf vocabulary language description 1.0: Rdf
schema". Retrieved May 21, 2006 from http://www.w3.org/TR/rdf-schema/
[7] Burstein, M. H., Hobbs, J. R., Lassila, O., Martin, D., McDermott, D. V., McIlraith, S.
A., Narayanan, S., Paolucci, M., Payne, T. R., Sycara, K. P. (2002). "DAML-S: Web
Service Description for the Semantic Web". Proceedings of the First International
Semantic Web Conference on The Semantic Web, p.348-363, June 09-12, 2002
rences
79

[8] Christensen, E., Curbera, F., Meredith, G., and Weerawarana, S. (2001). "Web
Services Description Language (WSDL) 1.1". Retrieved April 30, 2006 from
http://www.w3.org/TR/2001/NOTE-wsdl-20010315.
[9] DAML Coalition. (2003). "About the DAML Language". Retrieved May 21, 2006
from http://www.daml.org/about.html
[10] Dobson, G., Lock, R., Sommerville, I. (2005). "QoSOnt: a QoS Ontology for
Service-Centric Systems". 31st EUROMICRO Conference on Software Engineering
and Advanced Applications, 2005.
[11] Garofalakis, J., Panagis, Y., Sakkopoulos, E., Tsakalidis, A. (2004). "Web Service
Discovery Mechanisms: Looking for a Needle in a Haystack?". International
Workshop on Web Engi-neering, Santa Cruz, 2004.
[12] Google Corporation (2006). “Google Web APIs”. Retrieved April 30, 2006 from
http://www.google.com/apis/
[13] Gouscos, D., Kalikakis, M., and Georgiadis, P. (2003). “An Approach to
Modeling Web Service QoS and Provision Price”. Proceedings. of the 1st
International Web Services Quality Workshop - WQW 2003 at WISE 2003, Rome,
Italy, pp.1-10, 2003
[14] Gruber, T. R. (1993). "A translation approach to portable ontologies". Knowledge
Acquisition, 5(2):199-220, 1993
[15] IBM Corporation (2003). “Web Service Level Agreement (WSLA) Language
Specification Version 1.0”. Retrieved April 30, 2006 from
http://www.research.ibm.com/wsla/WSLASpecV1-20030128.pdf
80

[16] Keller, A. & Ludwig, H. (2003). “The WSLA Framework: Specifying and
Monitoring Service Level Agreements for Web Services”. Journal of Network and
Systems Management, vol. 11, no.1, March 2003.
[17] Ludwig, H., Keller A., Dan, A. & King, R. (2003). “A Service Level Agreement
Language for Dynamic Electronic Services”. Electronic Commerce Research, 3, 2003,
[18]
”. Proceedings of the 13th IEEE International
[19] ing quality of service for Web
library/ws-quality.html
[21]
Web Services using OWL-S and WSDL". Retrieved May 21,
[22] M.P. (2002). "Conceptual Model of Web Services
ep
[23]
pp.43-59.
Majithia, S., Shaikhali, A., Rana, O., and Walker, D.W. (2004). “Reputation-
based Semantic Service Discovery
Workshops on Enabling Technologies: Infrastructure for Collaborative Enterprises
(WET ICE’04), Italy, June 2004.
Mani, A., Nagarajan, A. (2002). "Understand
services". Retrieved May 15, 2006, from http://www-
128.ibm.com/developerworks/
[20] Manola, F., Miller, E. (2004). "Rdf primer". Retrieved May 21, 2006, from
http://www.w3.org/TR/rdf-primer.
Martin, D., Burstein, M., Lassila, O., Paolucci, M., Payne, T., and McIlraith, S.
(2004). "Describing
2006, from http://www.daml.org/services/owl-s/1.1/owl-s-wsdl.html
Maximilien, E.M. & Singh,
R utation". ACM SIGMOD Record, 31(4):36-41, 2002
Maximilien, E.M. & Singh, M.P. (2002). “Reputation and Endorsement for Web
Services”. ACM SIGecom Exchanges, 3(1):24–31, 2002.
81

[24] Maximilien, E.M. & Singh, M.P. (2004). “A Framework and Ontology for
Dynamic Web Services Selection”. IEEE Internet Computing, 8(5):84-93, 2004.
Maximilien, E.M. & Singh, M.P. (2004). “T[25] oward Autonomic Web Services
[26] ilien, E.M. & Singh, M.P. (2005). "Self-Adjusting Trust and Selection for
[27]
6, from http://www.w3.org/TR/owl-features/
[31] , M. (2006). “A
Applications (AINA 2006),
[32] . (2004). "Enhancing Web
services Description and Discovery to Facilitate Composition". Proceedings of the 1st
Trust and Selection”. Proceedings of the 2nd international conference on Service
Oriented Computing, pp.212-221, New York City, NY, USA, 2004
Maxim
Web Services". Extended Proceedings of 2nd IEEE International Conference on
Autonomic Computing (ICAC 2005), pp.385-386, 2005
McGuinness, D. L., Harmelen, F. V. (2004) "Owl web ontology language
overview". Retrieved May 21, 200
[28] McKnight, D.H., Chervany, N.L. (1996) “The Meanings of Trust”. Technical
Report MISRC Working Paper Series 96-04, University of Minnesota, Management
Information Systems Reseach Center, 1996
[29] Menascé, D. A. (2002). "QoS Issues in Web Services", IEEE Internet Computing,
6(6):72-75, 2002
[30] OWL-S Coalition. (2004). "OWL-S: Semantic Markup for Web Services".
Retrieved May 21, 2006, from http://www.daml.org/services/owl-s/1.1/overview/
Papaioannou, I., Tsesmetzis, D., Roussaki, I., and Anagnostou
QoS Ontology Language for Web-Services”. Proceedings of 20th International
Conference on Advanced Information Networking and
Vienna, Austria, 2006
Rajasekaran, P., Miller, J., Verma, K. and Sheth, A
82

International Workshop on Semantic Web services and Web Process Composition,
San Diego, California, USA, July 2004
[33] Ran, S. (2004). "A Model for Web Services Discovery with QoS". SIGEcom
Exchanges, vol. 4, no. 1, 2004, pp. 1–10.
SourceForge.net (2005). “Introduction”. Retrieved April [34] 30, 2006 from
[35]
[38] K. (2005). “QoS-based service selection
operative Information Systems (CoopIS 2005)
/kr-
[40]
http://uddi4j.sourceforge.net/
UDDI.org, “UDDI Technical White Paper”, Retrieved April 30, 2006 from
http://uddi.org/pubs/uddi-tech-wp.pdf
[36] UDDI.org, “UDDI Version 2.03 Data Structure Reference”, Retrieved April 30,
2006 from http://uddi.org/pubs/DataStructure-V2.03-Published-20020719.htm
[37] UDDI.org, “UDDI Version 3.0.2”, Retrieved April 30, 2006 from
http://uddi.org/pubs/uddi-v3.0.2-20041019.htm
Vu, L.H., Hauswirth, M., and Aberer,
and ranking with trust and reputation management”. Proceedings of the International
Conference on Co
[39] W3C Working Group (2003). "QoS for Web Services: Requirements and Possible
Approaches". Retrieved May 15, 2006, from http://www.w3c.or.kr
office/TR/2003/NOTE-ws-qos-20031125/
W3C Working Group (2004). “Web Services Architecture, W3C Working Group
Note 11 February 2004”. Retrieved April 30, 2006 from http://www.w3.org/TR/ws-
arch
83

[41]
ery”. Proceedings of the Twenty-eighth
[42] -based Web Service Matchmaking".
2006 from
[44] tation
an
t 1, Bologna, Italy, 294–301, 2002
Wishart, R., Robinson, R., Indulska, J., and Josang, A. (2005). “SuperstringRep:
Reputation-enhanced Service Discov
Australasian conference on Computer Science, Vol. 38: 49-57, 2005
Wu, J. and Wu, Z. (2005). "Similarity
Proceedings of 2005 IEEE International Conference on Services Computing (SCC05),
Vol. 1: 287-294, 2005
[43] XWebServices Inc. (2006). “Email Address Validation Web Service”. Retrieved
April 30,
http://www.xwebservices.com/Web_Services/XWebEmailValidation
Yu, B. and Singh, M.P. (2002). “An evidential model of distributed repu
m agement”. Proc. Proceedings of the first international joint conference on
Autonomous agents and multiagent systems: par
[45] Zhou, C. and Chia, L.T. and Lee, B.S. (2004). “DAML-QoS Ontology for Web
Services”. Proceedings. IEEE International Conference on Web Services, 472-479,
2004.
[46] Zhou, C., Chia, L.-T., & Lee, B.-S. (2005). "QoS Measurement Issues with
DAML-QoS Ontology," icebe, pp. 395-403, IEEE International Conference on e-
Business Engineering (ICEBE'05), 2005.
84

Appendix A
Service Matching, Ranking and Selection Algorithm
/* Web services matching, ranking and selection algoritm */ findmaxNumServices) { // find services that meet the functional requirements
i // match services with QoS information else
return selectServices (fMatches, maxNumServices, "random"); if reputation requirements specified matches = reputationRank (qMatches, qosRequirements, repuRequirements);
return selectServices (matches, maxNumServices, "byQOS"); e // rank matches with QoS information es = qosRank (qMatches, qosRequirements); // select services according the max number of services to be returned
} // fiqosMatch (services, qosReqt) {
matches = Service []; for each s in services // get QoS info from UDDI qosAds = getServiceQoS (s); // if QoS info available and satisfies QoS requirements if qosAds != null && qosMatchAdvert (qosAds, qosReqt) matches.add(s); end for
Services (functionRequirements, qosRequirements, repuRequirements,
fMatches = fMatch (functionRequirements);
f QoS requirements specified
qMatches = qosMatch (fMatches, qosRequirements);
// select services according the max number of services to be returned
// rank matches with QoS and reputation information
// select services according the max number of services to be returned
lse
match
return selectServices (matches, maxNumServices, "byOverall");
nd services that match QoS requirements
85

return matches; }
for each q1 in reqt
1, q2) == true isMatch = true;
return false;
ckQoS (q1, q2) {
eckMonoDecreasing (q1,q2)
return true if QoS advertisement q1 satisfies QoS requirement q2
and q1.monoIncreasing and 1.QoSValue>=q2.QoSValue
t q1 satisfies QoS requirement q2
return q2.type.monoDecreasing and q1.monoDecreasing and
// return true if QoS advertisements match QoS requirements qosMatchAdvert (ads, reqt) {
isMatch = flase; for each q2 in ads if checkQoS (q break; if isMatch == flase; end for return true; } // return true if QoS q1 matches QoS q2 che if q1.type != q2.type return false; if q1.unit != q2.unit convertUnit (q1, q2); return checkMonoIncreasing (q1,q2) or ch return true; else return false; } //checkMonoIncreasing (q1,q2) { return q2.type.monoIncreasingq} // return true if QoS advertisemencheckMonoDecreasing (q1,q2) { q1.QoSValue<=q2.QoSValue }
86

// rank matches with QoS information , qosReqt) {
// calculate QoS scores
QoS score in descending order SScore (services);
S scores: 0~1)
// find the highest dominant QoS value ue = findBestDominantQoS (services);
if qosReqt.domiQoS.type.monoIncreasing
ces domiQoS.value * adjustFactor;
adjustFactor = bestQoSValue; es
tFactor / s.domiQoS.value;
rank services with reputation information
ach service from reputation manager r = getReputation (s);
low requirement reputationScore
services.remove(s); end for
qosRank (services services = calculateQoSScore (services, qosReqt); // sort the result by services = sortByQo return services; } // calculate QoS score (QocalculateQoSScore (services, qosReqt) { bestQoSVal adjustFactor = 1 / bestQoSValue; for each s in servi s.QoSScore = s. else for each s in servic s.QoSScore = adjus return services; } //reputationRank (services, qosReqt, repuReqt) { for each s in services // get reputation mark for e // remove services whose reputation score is not available or be if r != null and r >= repuReqt. s.reputationScore = r; else
87

// calculate QoS scores services = calculateQoSScore (services, qosReqt);
tation scores
sReqt.weight, repuReqt.weight)
by overall score in descending order services = sortByOverallScore (services);
calculate adjusted reputation scores (reputation scores: 0~1)
on score
putationScore / bestRepu;
calculate overall scores Weight) {
s.overallScore = s.QoSScore * qosWeight + s.reputationScore * repuWeight;
umServices, option) { n = service [];
while i < maxNumServices && I < matches.size()
// calculate adjusted repu services = calculateReputationScore (services); // calculate overall scores for services services = calOverallScore (services, qo // sort the result return services; } //calculateReputationScore (services) { // find the highest reputati bestRepu = findBestReputation (services); for each s in services s.reputationScore = s.re end for return services; } //calOverallScore (services, qosWeight, repu for each s in services end for return services; } // select services according the max number of services to be returned selectServices (matches, maxN selectio if maxNumServices > 1 i = 0;
88

selection.add(matches[i]);
else
candidate = matches;
if option == "byQoS"
else erallScore >= LowLimit
candidate.add(s); end for
pickNum = random (0, candidate.size() ); selection.add(candidate[pickNum]);
i++; candidate = service []; if option == "random" else for each s in matches if s.QoSScore >= LowLimit candidate.add(s); if s.ov
return selection; }
89

Appendix B
WSDL document of Web service XWebEmailValidation
- <d /www.w3.org/2001/XMLSchema" es-
idation:v2" ap.org/wsdl/soap/"
services-tion:v2:Messages" s-
ailValidation:v2" name="XWebEmailValidation" xmlns= /schemas.xmlsoap.org/wsdl/">
-
efinitions xmlns:xsd="http:/xmlns:tns="urn:ws-xwebserviccom:XWebEmailValidation:EmailVal
.xmlsoxmlns:soap="http://schemas="urn:ws-xwebxmlns:import0
com:XWebEmailValidation:EmailValidatargetNamespace="urn:ws-xwebservicecom:XWebEmailValidation:Em
"http:/ <t-
ypes> <x <xsd:import schemaLocation="XWebEmailValidation.xsd" namespace="urn:ws-
:XWebEmailValidation:EmailValidation:v2:Messages" /> types>
-
sd:schema>
xwebservices-comxsd:schema></
</ <message name="validateEmailIn"> <part name="messagePart" element="import0:ValidateEmailRequest" /> </message>
- <message name="validateEmailOut"> <part name="messagePart" element="import0:ValidateEmailResponse" /> </message>
- <portType name="XWebEmailValidationInterface">- <operation name="ValidateEmail"> <input message="tns:validateEmailIn" /> <output message="tns:validateEmailOut" /> </operation> </portType>
- <binding name="XWebEmailValidation" type="tns:XWebEmailValidationInterface">
<soap:binding transport="http://schemas.xmlsoap.org/soap/http" style="document" />
- <operation name="ValidateEmail"> <soap:operation soapAction="urn:ws-xwebservices-
com:XWebEmailValidation:EmailValidation:v2:validateEmailIn" style="document" />
- <input> <soap:body use="literal" /> </input>
- <output> <soap:body use="literal" /> </output> </operation> </binding>
90

- <s ation">-
ervice name="EmailValid <p on" binding="tns:XWebEmailValidation"> <soap:address
location="http://ws.xwebservices.com/XWebEmailValidation/V2/EmailValid
</service>
ort name="EmailValidati
ation.asmx" /> </port>
</definitions>
91


















