
W3C WORKSHOP II Internationalizing Speech Synthesis Markup Language W3C Office in Heraklion, Crete,...
35
W3C WORKSHOP II Internationalizing Speech Synthesis Markup Language W3C Office in Heraklion, Crete, Greece, 30-31 May 2006
-
Upload
cory-skinner -
Category
Documents
-
view
244 -
download
0
Transcript of W3C WORKSHOP II Internationalizing Speech Synthesis Markup Language W3C Office in Heraklion, Crete,...

W3C WORKSHOP II
Internationalizing Speech Synthesis Markup Language
W3C Office in Heraklion, Crete, Greece, 30-31 May 2006

The Phonemic model from India for Bi-modal applications
Prof. R. K. Joshi• Visiting Design Specialist
Centre for Development of Advanced Computing
Mumbai (formerly NCST), India• Ex HOD,Professor IDC,IIT Mumbai.• Ex Chief Art Director,FCB-Ulka Advertising
-
Session 4: IPA/Phonetic Alphabets
W3C WORKSHOP II, Heraklion, Crete, Greece, 30th May 2006

Multilingual communication (textual/verbal)
< >
Oriya . P
unjabi . Sanskrit . S
anthali . Sindhi . T
amil . T
elugu . U
rdu .A
ssam
ese
. B
enga
li .
Bod
o .
Dog
ri .
Guj
arat
i . H
ind
i . K
anna
da .
Kashmiri . Konkani . Maithili . Malayalam . Manipuri . Marathi . Nepali .

Deshanagari – a common script for all Indian languages
Multilingual Happenings
< >
< >
Best wishes for the new year

Sound Poems
< >

Collaborative research on notation system for Indian music with Dr. Ashok Ranade
< >

Concrete text
< >

Indian oral tradition< >

Rigveda
Shakha Branches
Sanhita Text
Pratishakhya Phonetics
Shiksha Grammar
Lakshangrantha Brahman Aranyanka Upanishad Shroutasutra
Kaushitaki Ashvalayan Shankhayan Shakal Bashkal
Atharvaveda
Samaveda
Yajurveda Shukla - Madhyandina Kanva
Krishna -Taitariya Maitrayani
Shaunakiya Paipaladi
Jaiminiya Ranayaniya Kauthum
Rugveda Pratishakhya
Yajurveda Pratishakhya Taitariya Pratishakhya
Shaunakiya Chaturadhyayik Atharva Pratishakhya
Samaveda Pratishakhya Pushpasutra
Paniniya Apishali Audavraji Manduki Shodashashloki Yadnyavalka Naradiya etc.
< >
< >

Varna definitions
Varnamala/Matruka Brahmamatruka = 65 Varnas (13+8+25+4+4+4+4+3) Akshamatruka = 51 Varnas Rudramatruka = 43 Varnas Kulakramasiddha = 42 Varnas
Varnas (Phonemes) Swara Varna (Vowel phonemes)
Vyanjana Varna (Consonant phonemes)
< >

Taitariya Pratishakhya
Sadharanavidhi Samhitadhikarana Uccaranakalpa Formation of articulate sounds and mode of their production.
Varnakrama Shuddha, Swara, Matra, Anga Varnasarabhuta
Varnasara Bhutavarna Kramah1. Dhvani 2. Sthanam 3. Karnam 4. Prayatnah 5. Kalatah 6. Swarah7. Devata 8. Jati
SaraswatiSakaara Akaara Reph Akaara Sakaaradvitta Vakaara Akaara Takaara Iikaara
< >
< >
VedaLakshanam

Speech related issues
< >
< >

Spoken Utterances and written marks< >

< >
< >

< >
Brahmi script

< >
< >
Consonant sound + Vowel sound renderings in different Indian scripts
Consonant sound + consonant sound + vowel sound renderings in Devanagari script

Consonant sound + Vowel sound + accent marks renderings in Vedic Sanskrit
Consonant sound + Vowel sound + Samavedic intonation marks renderings in Vedic Sanskrit
< >
< >

The concept of InPho Phonemic Model from India for Bi-modal applications
< >

InPho
• To identify the total range of InPho: vowel phonemes, consonant phonemes, modifiers, tonal marks and other signs with phonetic and orthographic definitions.
• To evolve standardized codes for InPho.
• To document bi-modal models: written and spoken.
Bases: 1. Vedic Sanskrit 2. Manak Hindi 3. International Phonetic Alphabet
is an attempt to identify and realize strong Indian oral tradition with the phonemic root base of Indian languages and to explore the correlation between verbal and written expressions.
(Phonemic model from India for Bi-modal applications - Bharatiya Varna Samamnaya)
< >
< >
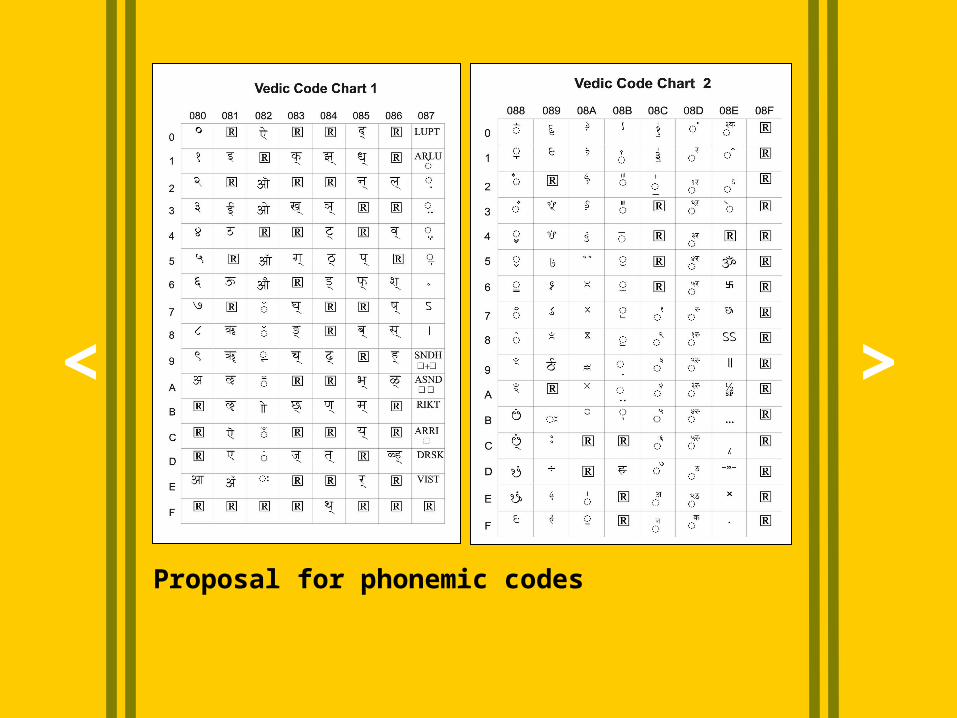
Proposal for phonemic codes
< >

Testing of Vedic Sanskrit, A part from "Naradiya Siksa“ Bhandarkar Oriental Research Institute, Poona 411 004, INDIA
How codes work
0831 080A Glyph FullKa
0831 0814 Glyph Ku
0831 0823 08AE Glyph KOUdatta
< >
< >
Syllables of consonant sound K
Samavedic syllabic text output from phonemic input
V
VV
VC
CV
CCC….V
Vm
Vm Vm
Vm C
Cm V
Cm Cm Cm ...Vm
m - modifierV – Vowel C - Consonant
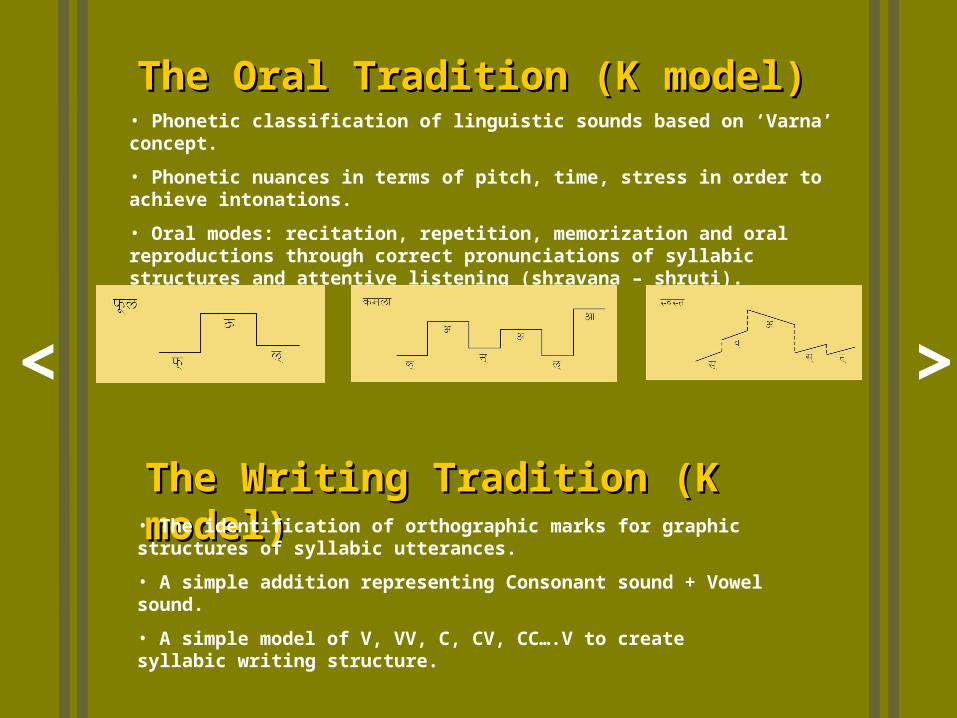
The Oral Tradition (K model)The Oral Tradition (K model)
The Writing Tradition (K model)The Writing Tradition (K model)
• Phonetic classification of linguistic sounds based on ‘Varna’ concept.
• Phonetic nuances in terms of pitch, time, stress in order to achieve intonations.
• Oral modes: recitation, repetition, memorization and oral reproductions through correct pronunciations of syllabic structures and attentive listening (shravana – shruti).
• The identification of orthographic marks for graphic structures of syllabic utterances.
• A simple addition representing Consonant sound + Vowel sound.
• A simple model of V, VV, C, CV, CC….V to create syllabic writing structure.
< >

InPho and IPA< >
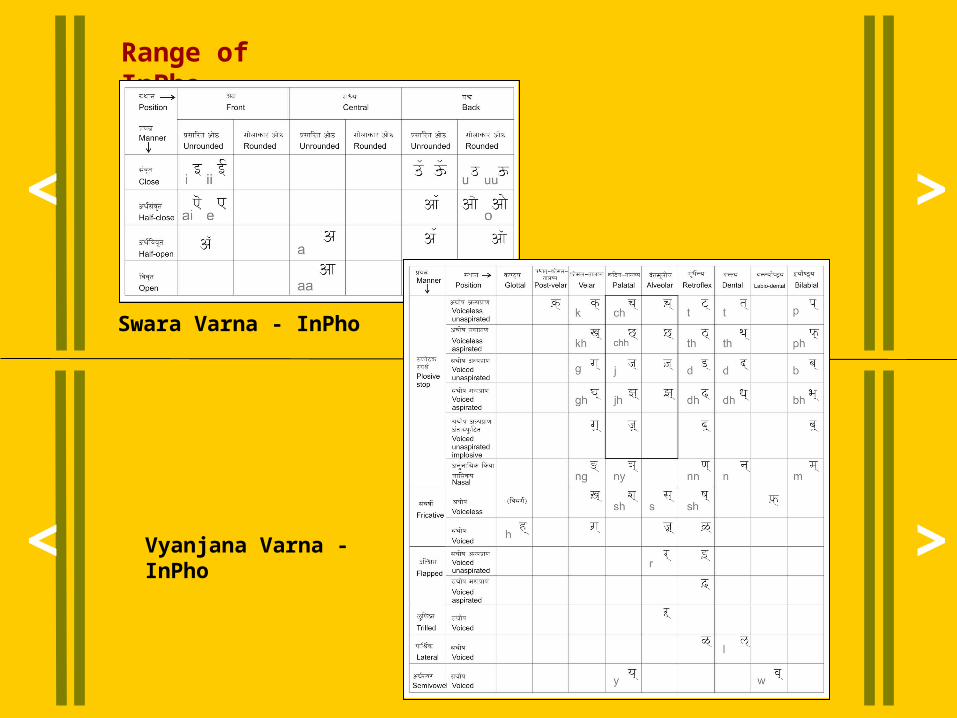
Range of InPho
Vyanjana Varna - InPho
Swara Varna - InPho
< >
< >

Range of IPA
< >

IPA issues
1. Based on extended (Manak Hindi) and phonemic structure of Sanskrit, InPho with the combinations of 52 consonant phonemes and 22 vowel phonemes (CV), provides a basic bi-modal common K model for writing as well as speech in Indian languages. The model has a possibility of extension with the provision of tonal marks.
2. Vedic tonal marks and other intonation signs can have multipurpose usage for present linguistic and dialectal scene of India
InPho issues
1. Based on Latin script, IPA has 516 code points in Unicode. Majority of code description is of graphic nature. No equivalences are marked for Asian/Indian languages.
2. 19 variations of lower case ‘a’ and 16 variations of capital ‘A’ are provided without phonetic description.
3. IPA has its own coding scheme and is being used at higher scholarly level for transliteration purpose.
< >
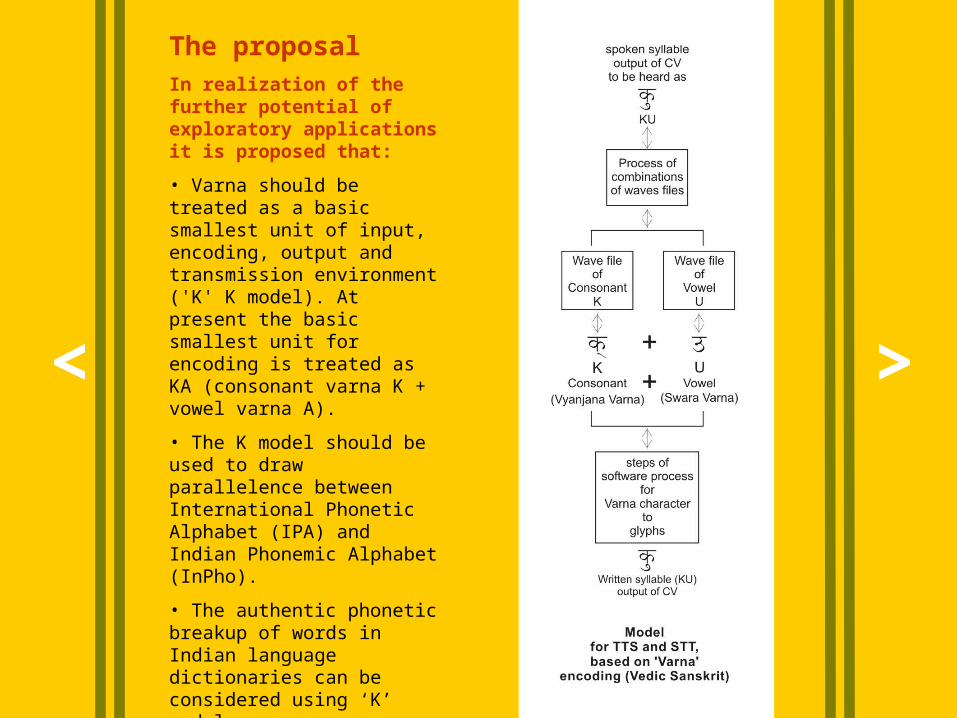
The proposalIn realization of the further potential of exploratory applications it is proposed that:
• Varna should be treated as a basic smallest unit of input, encoding, output and transmission environment ('K' K model). At present the basic smallest unit for encoding is treated as KA (consonant varna K + vowel varna A).
• The K model should be used to draw parallelence between International Phonetic Alphabet (IPA) and Indian Phonemic Alphabet (InPho).
• The authentic phonetic breakup of words in Indian language dictionaries can be considered using ‘K’ model.
• To adopt ‘K' model for Indian Languages for bi-modal applications to realize <phoneme> element as part of SSML
< >

Position Statement – Prof R. K. Joshi
Writing was a means of recording speech. Writing as an art was practiced by calligraphers under calligraphy. Text printing was a means of spreading writing. Text planning as an art was practiced by Typographers under typography. Computing is a means of processing digital data of multi-modal linguistic/graphic expressions (writing, speech and graphics). Computing is an art practiced by compugraphers under compugraphy.
Compugraphy should aim at a new idiom of writing - writing with graphic elemental changes. a new idiom of printing - dynamically changing printed text in time. a new idiom of processing - multi-modal conversions through natural language processing for cross cultural exchange.
< >From pen to print (Analog era) Processing of spoken utterances and/or written marks was carried out internally by human brain/mind/intelligence.
From print to processing (Digital era) Processing of spoken utterances and/or written marks is carried out externally by standardized processing mechanism with artificial intelligence.
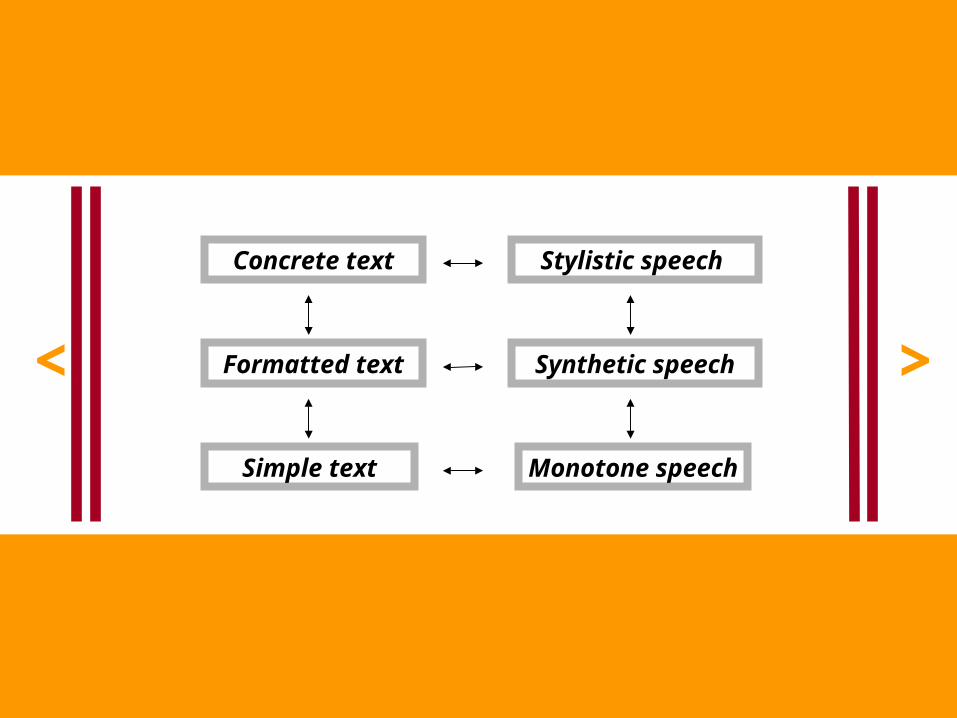
< >
Simple text
Formatted text
Concrete text
Monotone speech
Synthetic speech
Stylistic speech

< >

Concrete text
< >

ConclusionConclusion• The multitude of Indian language and dialects are written using different scripts. These scripts have been allotted distinct code pages in the Unicode scheme.
• Bi-modal rendering and processing of Indian languages is complex and mandates distinctly different techniques than Latin script.
• InPho scheme caters standards to both writing and speech and is based on Indian oral and written tradition.
• InPho scheme is well suited for other processing tasks such as transliteration, sorting, searching, speech synthesis, speech recognition etc.
• InPho scheme with its K model to be propagated as a ‘new media’ standard for Indian language Information Interchange.
< >

References• Kelkar A.R. 1989. Transliteration of South Asian languages, a brief review and a proposal for a standard. Centre of advanced study in linguistics, Deccan College, Pune.
• Handbook of the International Phonetic Association. 1999. Cambridge University Press.
• Naravane V.D. 1961. Bharatiya Vyavahar Kosh. Triveni Sangam.
• Peter Ladefoged, 2001, Vowels and Consonants. Blackwell publishers, UK.
• Prabodh Primer, Department of official languages, Ministry of home affairs, Govt. of India.
• R. K. Joshi, Prague 2003, A unified phonemic code based scheme for effective processing of Indian languages. 23rd Internationalization and Unicode.
• R. K. Joshi. October 2002, Vedic Code, a draft, Vishwabharat No. 7.
• R. Shama Sastri, K. Rangacharya, 1985 reprint, The Taittiriya Pratishakhya, Motilal Banarasidas, Delhi.
• Shrinath Shanbaug, Durgesh Rau, R. K. Joshi 2002, An intelligent multi-layered input scheme for phonetic scripts. ACM International conference proceeding series, Hawthorne, New York.
• Unicode 4.1 - The Unicode Consortium 2004. The Unicode standard is the universal character-encoding scheme for written characters and text. It defines a consistent way of encoding multilingual text through software.
• Vinod Kumar, 2005, IndiX information leaflet, C-DAC Mumbai.
• W.S. Allen, 1961, Phonetics in Ancient India, London, Oxford University Press.
• Gajendragadakar S. N., 1972, Bhasha Va Bhashashastra, Venus Prakashan, Pune, November 1972.
Acknowledgements
• Executive Director, Director Admin, C-DAC Mumbai.
• IndiX technology team.
• IndiX design team: Jui Mhatre, Supriya Kharkar.
• Vaidik Samshodhan Mandal, Pune.
• Bharati Sanskrut Niketanam, Mumbai/Lonavala.
< >
< >

http://staff.cdacmumbai.in/rkjoshi
designer
calligraphertype designer
revivalist
poet
academician
typographer
compugrapher

< / THANK YOU >


















