
Voice Activation System
47
1 CHAPTER 1 SPEECH RECOGNITION 1.1INTRODUCTION The speech recognition process is performed by a software component known as the speech recognition engine. The primary function of the speech recognition engine is to pr ocess spoken inpu t and translate it into text that an application unde rstands. The app lication can then do one of two things: The application can int erpret the result of the recognition as a command. In this case, the application is a command and control application. An example of a command and control application is one in which the caller says ³check balance´, a nd the application returns the current balance of the caller¶s account. If an a pplication handles the recognized text simply as text, then it is considered a dictation application. In a dictation application, if you said ³c heck balance,´ the application would not interpret the result, but simply return the text ³check ba lance´. 1.2 TERMS AND CONCEPTS Following are a few of the basic terms and concepts that are fundamental to speech recognition. It is important to have a good understanding of these concepts. 1.2.1 UTTERANCES When the user says something, this is known as an utterance. An utterance is any stream of speech between two periods of silence. Utterances ar e sent to the speech engine to be processed. Silence, in s peech recognition, is almost as important as what is spoken, because silence delineates the start and end of an utterance. Here's how it works. The speech recognition engine is "listening" for speech input. When the engine detects audio input - in other words, a lack of silence -- the beginning of an utterance is sig nalled. Similarly, when the engine detects a certain amount of silence following the audio, the end of the utterance occurs.
-
Upload
ramyata-mahajan -
Category
Documents
-
view
226 -
download
0
Transcript of Voice Activation System

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 1/47
1
CHAPTER 1
SPEECH RECOGNITION
1.1INTRODUCTION
The speech recognition process is performed by a software component known as the speech
recognition engine. The primary function of the speech recognition engine is to process
spoken input and translate it into text that an application understands. The application can
then do one of two things:
� The application can interpret the result of the recognition as a command. In this case, theapplication is a command and control application. An example of a command and control
application is one in which the caller says ³check balance´, and the application returns the
current balance of the caller¶s account.
� If an application handles the recognized text simply as text, then it is considered a dictation
application. In a dictation application, if you said ³check balance,´ the application would not
interpret the result, but simply return the text ³check balance´.
1.2 TERMS AND CONCEPTS
Following are a few of the basic terms and concepts that are fundamental to speechrecognition. It is important to have a good understanding of these concepts.
1.2.1 UTTERANCES
When the user says something, this is known as an utterance. An utterance is any stream of
speech between two periods of silence. Utterances are sent to the speech engine to be
processed. Silence, in speech recognition, is almost as important as what is spoken, because
silence delineates the start and end of an utterance. Here's how it works. The speech
recognition engine is "listening" for speech input. When the engine detects audio input - in
other words, a lack of silence -- the beginning of an utterance is signalled. Similarly, when
the engine detects a certain amount of silence following the audio, the end of the utterance
occurs.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 2/47
2
Utterances are sent to the speech engine to be processed. If the user doesn¶t say anything, the
engine returns what is known as a silence timeout - an indication that there was no speech
detected within the expected timeframe, and the application takes an appropriate action, such
as reprompting the user for input.
An utterance can be a single word, or it can contain multiple words (a phrase or a sentence).
For example, ³checking´, ³checking account,´ or ³I¶d like to know the balance of my
checking account please´ are all examples of possible utterances. Whether these words and
phrases are valid at a particular point in a dialog is determined by which grammars is active
.Note that there are small snippets of silence between the words spoken within a phrase. If the
user pauses too long between the words of a phrase, the end of an utterance can be detected
too soon, and only a partial phrase will be processed by the engine.
1.2.2PRONOUNCIATION
The speech recognition engine uses all sorts of data, statistical models, and algorithms to
convert spoken input into text. One piece of information that the speech recognition engine
uses to process a word is its pronunciation, which represents what the speech engine thinks a
word should sound like.
Words can have multiple pronunciations associated with them. For example, the word ³the´
has at least two pronunciations in the U.S. English language: ³thee´ and ³thus.´
You can specify the valid words and phrases in a number of different ways. A grammar uses
a particular syntax, or set of rules, to define the words and phrases that can be recognized by
the engine. A grammar can be as simple as a list of words, or it can be flexible enough to
allow such variability in what can be said that it approaches natural language capability.
Grammars define the domain, or context, within which the recognition engine works. The
engine compares the current utterance against the words and phrases in the active grammars.
If the user says something that is not in the grammar, the speech engine will not be able to
decipher it correctly.
Let¶s look at a specific example:
� Accounts
� Account balances

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 3/47
3
� My account information
� Loans
� Loan balances
� My loan information
� Transfers
� Exit
� Help
In this grammar, you can see that there are multiple ways to say each command. You can
define a single grammar for your application, or you may have multiple grammars. Chances
are, you will have multiple grammars, and you will activate each grammar only when it is
needed.
1.3 SPEAKER DEPENDENCE VS. SPEAKER INDEPENDENCE
Speaker dependence describes the degree to which a speech recognition system requires
knowledge of a speaker¶s individual voice characteristics to successfully process speech. The
speech recognition engine can ³learn´ how you speak words and phrases; it can be trained to
your voice.
Speech recognition systems that require a user to train the system to his/her voice are known
as speaker-dependent systems. If you are familiar with desktop dictation systems, most are
speaker dependent. Because they operate on very large vocabularies, dictation systems
perform much better when the speaker has spent the time to train the system to his/her voice.
Speech recognition systems that do not require a user to train the system are known as
speaker-independent systems. Think of how many users (hundreds, maybe thousands) may be
calling into your web site. You cannot require that each caller train the system to his or her voice. The speech recognition system in a voice-enabled web application MUST successfully
process the speech of many different callers without having to understand the individual
voice characteristics of each caller.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 4/47
4
1.3.1 ACCURACY
The performance of a speech recognition system is measurable. Perhaps the most widely used
measurement is accuracy. It is typically a quantitative measurement and can be calculated in
several ways. Arguably the most important measurement of accuracy is whether the desired
end result occurred. This measurement is useful in validating application design. For
example, if the user said "yes," the engine returned "yes," and the "YES" action was
executed, it is clear that the desired end result was achieved. But what happens if the engine
returns text that does not exactly match the utterance? For example, what if the user said
"nope," the engine returned "no," yet the "NO" action was executed? Should that be
considered a successful dialog? The answer to that question is yes because the desired end
result was achieved.
Another measurement of recognition accuracy is whether the engine recognized the utterance
exactly as spoken. This measure of recognition accuracy is expressed as a percentage and
represents the number of utterances recognized correctly out of the total number of utterances
spoken. It is a useful measurement when validating grammar design. Using the previous
example, if the engine returned "nope" when the user said "no," this would be considered a
recognition error. Based on the accuracy measurement, you may want to analyze your
grammar to determine if there is anything you can do to improve accuracy. Recognition
accuracy is an important measure for all speech recognition applications. It is tied to grammar
design and to the acoustic environment of the user.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 5/47
5
Fig1.1: speech recognition in the car
1.3.2 HOW IT WORKS
Now that we've discussed some of the basic terms and concepts involved in speech
recognition, let's put them together and take a look at how the speech recognition process
works.
As you can probably imagine, the speech recognition engine has a rather complex task to
handle, that of taking raw audio input and translating it to recognized text that an application
understands. As shown in the diagram below, the major components we want to discuss are:
� Audio input
� Grammar(s)
� Acoustic Model
� Recognized text

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 6/47
6
Fig1.2: speech recognition engine
The first thing we want to take a look at is the audio input coming into the recognition
engine. It is important to understand that this audio stream is rarely pristine. It contains not
only the speech data (what was said) but also background noise. This noise can interfere with
the recognition process, and the speech engine must handle (and possibly even adapt to) the
environment within which the audio is spoken.
As we've discussed, it is the job of the speech recognition engine to convert spoken input into
text. To do this, it employs all sorts of data, statistics, and software algorithms. Its first job is
to process the incoming audio signal and convert it into a format best suited for further
analysis. Once it identifies the most likely match for what was said, it returns what it
recognized as a text string.
Most speech engines try very hard to find a match, and are usually very "forgiving." But it is
important to note that the engine is always returning its best guess for what was said.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 7/47
7
1.3.3 ACCEPTANCE AND REJECTION
When the recognition engine processes an utterance, it returns a result. The result can be
either of two states: acceptance or rejection. An accepted utterance is one in which the engine
returns recognized text.
Whatever the caller says, the speech recognition engine tries very hard to match the utterance
to a word or phrase in the active grammar. Sometimes the match may be poor because the
caller said something that the application was not expecting, or the caller spoke indistinctly.
In these cases, the speech engine returns the closest match, which might be incorrect. Some
engines also return a confidence score along with the text to indicate the likelihood that the
returned text is correct.
Not all utterances that are processed by the speech engine are accepted. Acceptance or
rejection is flagged by the engine with each processed utterance .
1.4 SPEECH RECOGNITION IN THE TELEPHONY ENVIRONMENT
The quality of the audio stream is considerably degraded in the telephony environment, thus
making the recognition process more difficult. The telephony environment can also be quite
noisy, and the equipment is quite variable. Users may be calling from their homes, their offices, the mall, the airport, their cars - the possibilities are endless. They may also call from
cell phones, speaker phones, and regular phones. Imagine the challenge that is presented to
the speech recognition engine when a user calls from the cell phone in her car, driving down
the highway with the windows down and the radio blasting!
Another consideration is whether or not to support barge-in. Barge-in (also known as cut-
thru) refers to the ability of a caller to interrupt a prompt as it is playing, either by saying
something or by pressing a key on the phone keypad. This is often an important usability
feature for expert users looking for a ³fast path´ or in applications where prompts are
necessarily long.
When the caller barges in with speech, it is essential that the prompt is cut off immediately
(or, at least, perceived to be immediately by the caller). If there is any noticeable delay (>300
milliseconds) from when the user says something and when the prompt ends, then, quite

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 8/47

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 9/47
9
simple tasks is not a modern phenomenon, but one that goes back more than one hundred
years in history. By way of example, in 1881 Alexander Graham Bell, his cousin Chichester
Bell and Charles Sumner Tainted invented a recording device that used a rotating cylinder
with a wax coating on which up-and-down grooves could be cut by a stylus, which responded
to incoming sound pressure (in much the same way as a microphone that Bell invented earlier for use with the telephone). Based on this invention, Bell and Tainted formed the Volta
Graph phone Co. in 1888 in order to manufacture machines for the recording and
reproduction of sound in office environments. In 1907, Thomas Edison invented the
phonograph using a tinfoil based cylinder, which was subsequently adapted to wax, and
developed the ³Ediphone´ to compete directly with Columbia. The purpose of these products
was to record dictation of notes and letters for a secretary (likely in a large pool that offered
the service as shown in Figure 3) who would later type them out (offline), thereby
circumventing the need for costly stenographers. This turn-of-the-century concept of ³office
mechanization´ spawned a range of electric and electronic implements and improvements,
including the electric typewriter, which changed the face of office automation in the mid-part
of the twentieth century. It does not take much imagination to envision the obvious interest in
creating an ³automatic typewriter´ that could directly respond to and transcribe a human¶s
voice without having to deal with the annoyance of recording and handling the speech on
wax cylinders or other recording media.
A similar kind of automation took place a century later in the 1990¶s in the area of ³callcentres.´ A call centre is a concentration of agents or associates that handle telephone calls
from customers requesting assistance. Among the tasks of such call centres are routing the in-
coming calls to the proper department, where specific help is provided or where transactions
are carried out. One example of such a service was the AT&T Operator line which helped a
caller place calls, arrange payment methods, and conduct credit card transactions. The
number of agent positions (or stations) in a large call centre could reach several thousand.
Automatic speech recognition technologies provided the capability of automating these call
handling functions, thereby reducing the large operating cost of a call centre. By way of example, the AT&T Voice Recognition Call Processing (VRCP) service, which was
introduced into the AT&T Network in 1992, routinely handles about 1.2 billion voice
transactions with machines each year using automatic speech recognition technology to
appropriately route and handle the calls.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 10/47
10
Fig 1.3: An early 20th century transcribing pool at Sears, Roebuck and Co. The Women are
using cylinder dictation machines, and listening to the recordings with ear-tubes.
Speech recognition technology has also been a topic of great interest to a broad general
population since it became popularized in several blockbuster movies of the 1960¶s and
1970¶s, most notably Stanley Kubrick¶s acclaimed movie ³2001: A Space Odyssey´. In this
movie, an intelligent computer named ³HAL´ spoke in a natural sounding voice and was able
to recognize and understand fluently spoken speech, and respond accordingly. More recently
(in 1988), in the technology community, Apple Computer created a vision of speechtechnology and computers for the year 2011, ti tled ³Knowledge Navigator´, which defined
the concepts of a Speech User Interface (SUI) and a Multimodal User Interface (MUI) along
with the theme of intelligent voice-enabled agents. This video had a dramatic effect in the
technical community and focused technology efforts, especially in the area of visual talking
agents. Today speech technologies are commercially available for a limited but interesting
range of tasks. These technologies enable machines to respond correctly and reliably to
human voices, and provide useful and valuable services. While we are still far from having a
machine that converses with humans on any topic like another human, many important
scientific and technological advances have taken place, bringing us closer to the ³Holy Grail´
of machines that recognize and understand fluently spoken speech.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 11/47
11
1.5.2 FROM SPEECH PRODUCTION MODELS TO SPECTRAL
REPRESENTATION
Attempts to develop machines to mimic a human¶s speech communication capability appear
to have started in the 2nd half of the 18th century. The early interest was not on recognizingand understanding speech but instead on creating a speaking machine, perhaps due to the
readily available knowledge of acoustic resonance tubes which were used to approximate the
human vocal tract. In 1773, the Russian scientist Christian Kratzenstein, a professor of
physiology in Copenhagen, succeeded in producing vowel sounds using resonance tubes
connected to organ pipes. Later, Wolfgang von Kempelen in Vienna constructed an
³Acoustic-Mechanical Speech Machine´ (1791) and in the mid-1800's Charles Wheatstone
built a version of von Kempelen's speaking machine using resonators made of leather, the
configuration of which could be altered or controlled with a hand to produce different speech-like sounds.
1.5.3EARLY AUTOMATIC SPEECH RECOGNIZERS
Early attempts to design systems for automatic speech recognition were mostly guided by the
theory of acoustic-phonetics, which describes the phonetic elements of speech (the basic
sounds of the language) and tries to explain how they are acoustically realized in a spokenutterance. These elements include the phonemes and the corresponding place and manner of
articulation used to produce the sound in various phonetic contexts. For example, in order to
produce a steady vowel sound, the vocal cords need to vibrate (to excite the vocal tract), and
the air that propagates through the vocal tract results in sound with natural modes of
resonance similar to what occurs in an acoustic tube. These natural modes of resonance,
called the formants or formant frequencies, are manifested as major regions of energy
concentration in the speech power spectrum. In 1952, D avis, Biddulph, and Blazek of Bell
Laboratories built a system for isolated digit recognition for a single speaker, using theformant frequencies measured (or estimated) during vowel regions of each digit. In the
1960¶s, several Japanese laboratories demonstrated their capability of building special
purpose hardware to perform a speech recognition task. Most notable were the vowel.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 12/47
1 2
1.5.4 TECHNOLOGY DIRECTIIONS IN THE 1980¶S AND 1990¶S
Speech recognition research in the 1980¶s was characterized by a shift in methodology from
the more intuitive template-based approach (a straightforward pattern recognition paradigm)
towards a more rigorous statistical modelling framework. Although the basic idea of the
hidden Markov model (HMM) was known and understood early on in a few laboratories
(e.g., IBM and the Institute for D efence Analyses (I D A) ), the methodology was not complete
until the mid- 1980¶s and it wasn¶t until after widespread publication of the theory that the
hidden Markov model became the preferred method for speech recognition. The popularity
and use of the HMM as the main foundation for automatic speech recognition and
understanding systems has remained constant over the past two decades, especially because
of the steady stream of improvements and refinements of the technology.
The hidden Markov model, which is a doubly stochastic process, models the intrinsic
variability of the speech signal (and the resulting spectral features) as well as the structure of
spoken language in an integrated and consistent statistical modelling framework . As is well
known, a realistic speech signal is inherently highly variable (due to variations in
pronunciation and accent, as well as environmental factors such as reverberation and noise).
When people speak the same word, the acoustic signals are not identical (in fact they may
even be remarkably different), even though the underlying linguistic structure, in terms of the
pronunciation, syntax and grammar, may (or may not) remain the same. The formalism of the
HMM is a probability measure that uses a Markov chain to represent the linguistic structure
and a set of probability distributions to account for the variability in the acoustic realization
of the sounds in the utterance.
Given a set of known (text-labelled) utterances, representing a sufficient collection of the
variations of the words of interest (called a training set), one can use an efficient estimation
method, called the Baum-Welch algorithm , to obtain the ³best´ set of parameters that define
the corresponding model or models. The estimation of the parameters that define the model is
equivalent to training and learning. The resulting model is then used to provide an indication
of the likelihood (probability) that an unknown utterance is indeed a realization of the word
(or words) represented by the model. The HMM methodology represented a major step
forward from the simple pattern recognition and acoustic-phonetic methods used earlier in
automatic speech recognition systems.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 13/47
1 3
The idea of the hidden Markov model appears to have first come out in the late 1960¶s at the
Institute for D efence Analyses (I D A) in Princeton, N.J. Len Baum referred to an HMM as a
set of probabilistic functions of a Markov chain, which, by definition, involves two nested
distributions, one pertaining to the Markov chain and the other to a set of the probability
distributions, each associated with a state of the Markov chain, respectively. The HMMmodel attempts to address the characteristics of a probabilistic sequence of observations that
may not be a fixed function but instead changes according to a Markov chain. This doubly
stochastic process was found to be useful in a number of applications such as stock market
prediction and crypto-analysis of a rotary cipher, which was widely used during World War
II. Baum¶s modelling and estimation technique was first shown to work for discrete
observations (i.e., ones that assume values from a finite set and thus are governed by discrete
probability distributions) and then random observations that were well modelled using log-
concave probability density functions. The technique was powerful but limited. Leporine,
also of I D A, relaxed the log-concave density constraint to include an elliptical symmetric
density constraint (thereby including a Gaussian density and a Cauchy density), with help
from an old representation theorem by Fan . Baum¶s doubly stochastic process started to find
applications in the speech area, initially in speaker identification systems, in the late 1970¶s.
As more people attempted to use the HMM technique, it became clear that the constraint on
the form of the density functions imposed a limitation on the performance of the system,
particularly for speaker independent tasks where the speech parameter distribution was not
sufficiently well modelled by a simple log-concave or and symmetric density function. In the
early 1980¶s at Bell Laboratories, the theory of HMM was extended to mixture densities [30-
31] which have since proven vitally important in ensuring satisfactory recognition accuracy,
particularly for speaker independent, large vocabulary speech recognition tasks.
The HMM, being a probability measure, was amenable for incorporation in a larger speech
decoding framework which included a language model. The use of a finite-state grammar in
large vocabulary continuous speech recognition represented a consistent extension of the
Markov chain that the HMM utilized to account for the structure of the language, albeit at alevel that accounted for the interaction between articulation and pronunciation. Although
these structures (for various levels of the language constraints) were at best crude
approximations to the real speech phenomenon, they were computationally efficient and often
sufficient to yield reasonable (first order) performance results. The merger of the hidden
Markov model (with its advantage in statistical consistency, particularly in handling acoustic

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 14/47
1 4
variability) and the finite state network (with its search and computational efficiency,
particularly in handling word sequence hypotheses) was an important, although not
unexpected, technological development in the mid-1980. recognizer of Suzuki and Nakata at
the Radio Research Lab in Tokyo , the phoneme recognizer of Sakai and Toshiba at Kyoto
University ,and the digit recognizer of NEC Laboratories .
1.5.5Towards a Machine That Communicates
Most speech recognition research, up to the 1980¶s, considered the major research problem to
be one of converting a speech waveform (as an acoustic realization of a linguistic event) into
words (as a best-decoded sequence of linguistic units). Many researchers also believed that
the speech-to-text process was the necessary first step in the process that enabled a machine
to be able to understand and properly respond to human speech. In field evaluations of speech
recognition and understanding technology for a range of tasks, two important things were
learned about the speech communication process between humans and machines. First,
potential users of a speech recognition system tended to speak natural sentences that often did
not fully satisfy the grammatical constraints of the recognizer (e.g., by including out-of-
vocabulary (OOV) words, non-grammatical constructs, ill-formed sentences, etc.), and the
spoken utterances were also often corrupted by linguistically irrelevant ³noise´ components
such as ambient noise, extraneous acoustic sounds, interfering speech, etc. Second, as in
human-to-human speech communications, speech applications often required a dialog
between the user and the machine to reach some desired state of understanding. Such a dialog
often required such operations as query and confirmation, thus providing some allowance for
speech recognition and understanding errors. The keyword spotting method (and its
application in AT&T¶s Voice Recognition Call Processing (VRCP) System, as mentioned
earlier), was introduced in response to the first factor while the second factor focused the
attention of the research community on the area of dialog management.
Many applications and system demonstrations that recognized the importance of dialog
management over a system¶s raw word recognition accuracy were introduced in the early
1990¶s with the goal of eventually creating a machine that really mimicked the
communicating capabilities of a human.
Pegasus is a speech conversational system that provides information about the status of
airline flights over an ordinary telephone line. Jupiter is a similar system with a focus on

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 15/47
1 5
weather information access, both local and national. These systems epitomized the
effectiveness of dialog management. With properly designed dialog management, these
systems could guide the user to provide the required information to process a request, among
a small and implicit set of menu choices, without explicitly requesting details of the query,
e.g., such as by using the dialog management phrase ³please say morning, afternoon, or evening´ when time frame of the flight was solicited. D ialog management also often
incorporated imbedded confirmation of recognized phrases and soft error handling so as to
make the user react as if there was a real human agent rather than a machine on the other end
of the telephone line. The goal was to design a machine that communicated rather than
merely recognized the words in a spoken utterance.
The late 1990¶s was marked by the deployment of real speech-enabled applications, ranging
from AT&T¶s VRCP (automated handling of operator-assisted calls) and Universal Card
Service (customer service line) that were used daily (often by millions of people) in lieu of a
conventional voice response system with touch-tone input, to United Airlines¶ automatic
flight information system and AT&T¶s ³How May I Help You? (HMIHY)´ system for call
routing of consumer help line calls. Although automatic speech recognition and speech
understanding systems are far from perfect in terms of the word or task accuracy, properly
developed applications can still make good use of the existing technology to deliver real
value to the customer, as evidenced by the number and extent of such systems that are used
on a daily basis by millions of users.
1.5.6APPLICATIONS THAT USES ASR
There are two types of applications that use speech recognition:
1) Command and Control Applications: the application interprets the result of the
Recognition as a command. In this case, the application is a command and control
application. An example of a command and control application is one in which the caller says³check balance´, and the application returns the current balance of the caller¶s account;
2) D ictation Applications: if an application handles the recognized text simply as text, then it
is considered a dictation application. In a dictation application, if the user says ³check
balance,´ the application would not interpret the result, but simply return the text ³check
balance´ and use it in a more complex context, for instance, to feeding a dialogue session.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 16/47
1 6
Fig 1.4: Milestones in Speech Recognition and Understanding Technology over the Past 40
Years.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 17/47
1 7
CHAPTER 2
VOICE RECOGNITION
Fig 1.5: Voice verification
2.1 INTRODUCTION
Software is an essential business need today. But the question is: can we make it more user-
friendly, and simpler to use? The answer is ³YES´, and voice recognition is one important
answer. It allows a user to dictate text into a computer or control it by speaking certain
commands (such as open MS Word, pull down menus, save or delete work). Currently
voice/speech recognition applications allow a user to dictate text at up to 160 words per minute. Voice recognition uses a neural net to "learn" to recognize a user¶s voice. To achieve
this, the user is given some sample text to speak. In this way the software overcomes the
problem of different accents and inflections. With Voice Recognition software e-mails,
memos and reports can be input by dictation, and a user can tell the computer what to do.
Speaking into a microphone produces the same result as typing words manually with a

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 18/47
1 8
keyboard. Voice recognition software applications are designed with an internal database or
grammar file of recognizable words or phrases. The program matches the audio signature of
speech with corresponding entries in the database or the grammar file. Turning speech into
text might sound easy, but it is in fact an extremely difficult task. The problem lies in
individual speech patterns and accents, compounded by the natural human tendency to runwords together.
2.2EVOLUTION OF VOICE RECOGNITION SYSTEM
The earliest computer speech recognition systems were hardware-based. Although these
systems provided a promising start, labour intensive ³training´ of the systems and
frustratingly low levels of accuracy hindered their widespread use. Before these speechrecognition systems could be used, the system had to be trained painstakingly to the unique
characteristics and vocabulary of each user. Such training usually took several hours and
required users to recite long lists of terms. Furthermore, because older systems rarely were
networked, users had to train the speech recognition systems on each computer they used.
Hardware-based systems also had difficulty adapting to temporary changes in a user¶s
voice²due to nasal congestion, for example²which limited accuracy and sometimes
required retraining. Surgical masks, fatigue and stress further affected the users¶ voices,
confusing the system and reducing accuracy.
Most of today¶s speech recognition systems are software-based solutions that are more
adaptive than their hardware-based forebears, leading to reductions in training time and
increases in accuracy. Speech recognition engine (SRE) software relies on complex
mathematical algorithms to assign to each sound an identifier, which enables the software to
distinguish voice sounds from background noise. New SREs perform ³context´ evaluations
during the communication process much as humans do. Context evaluations follow a series of
steps, according to Kaprielian1: ³listen for speech, identify the phonemes [basic units of
sound used to distinguish different words, match the phonemes to the words, and make an
educated guess as to the context.´ The adaptive nature of software-based speech recognition
allows most systems to achieve moderate levels of accuracy without prior training of the
system. For example, the customer support centres of some large companies now use voice

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 19/47
1 9
activated systems that listen and respond to spoken words or phrases rather than the number
tones produced by pressing a phone¶s keypad.
Once trained, speech recognition systems continue to ³learn´ by updating the user profile,
thus improving accuracy. Furthermore, because user profiles now can be stored on a network,
voice activated systems on all connected computers can be used after a single trainingsession, and multiple user profiles can be stored on a single network.
2.3 TYPES OF VOICE RECOGNITION SOFTWARE APPLICATION
2.3.1SPEAKER DEPENDENT SYSTEM
This type of system requires the user to ³train´ the software to recognize the particular stylized
patterns of speech which will be used. People commonly use such programs at home or at the office,
and Email, memos, letters, data and text can be input by speaking into a microphone .
2.3.2 DISCRETE SPEECH SYSTEM
This type of system requires the user to speak clearly and slowly and to separate words.
Continuous speech systems are designed to understand a more natural mode of speaking.
D iscrete speech voice recognition systems are typically used for customer service routing.
The system is speaker independent, but understands only a small pool of words or phrases.
The caller is given a question and then a choice of answers, usually ³yes´ or ³no.´ After
receiving an answer, the system escalates the caller to the next level. If the caller replies with
an answer that can't be recognized the automated response is usually, ³Sorry, I didn¶t
understand you; please try again,´ with a repeat of the question and available answers. This
type of voice recognition is also referred to as grammar constrained recognition.
2.4COMPONENTS OF VOICE RECOGNITION
Every speech recognition system uses four key operations to listen to and understand human
speech. They are:
a. Word separation - This is the process of identifying discreet portions of human speech.
Each portion can be as large as a phrase or as small as a single syllable or part of a word.
b. Vocabulary - This is the list of speech items that the speech engine can identify.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 20/47
2 0
c. Word matching - This is the method the speech system uses to look up a speech portion in
the system's vocabulary - the search engine part of the system.
d. Speaker dependence - This is the degree to which the speech engine is dependent on the
vocal tones and speaking patterns of individuals. To develop applications, one also needs to
look into the following concepts and technologies.
2.5. VOICE RECOGNITION ENGINES
Voice recognition engines are designed for specific applications, and can be categorized into
two types:
a. Command and Control Applications
b.D
ictation Applications
The first category application¶s recognizes the voice/speech of the user and executes it as a
command. Whereas, the second category application¶s will only turn the users voice/speech
into text.
2.5.1 GRAMMER FILE
The final ingredient in developing a voice recognition application is the Grammar file.
Grammar rules are used by the speech recognition application to analyze and identify human
speech input, process it, and attempt to understand what a itself using the grammar file and
this has been compared to kids in school who learn grammatical rules and having done so,
speak without thinking about those rules. There can be three different categories of grammar
files as follows:
a. Context Free Grammar:
Examples of rules in a context-free grammar are something like:
<Name Rule> = ALT ("Kevin", "Andy")
<SendMailRule> = ("Send Email to", <Name Rule>)
Context-free grammar has good flexibility when interpreting human speech.
b. D ictation Grammar:

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 21/47
2 1
D ictation grammar applications base their evaluations on vocabulary. They convert the
human speech into text as accurately as possible. To achieve this they need to have a very
rich vocabulary. The success of diction grammar systems depends upon the quality of the
vocabulary and most applications are used in a single subject or topic, for example legal or
medical.
c. Limited domain Grammar:
These applications use a combination of context-free grammar and dictation grammar
methods to achieve a limited domain grammar file which have the following elements:
a. Words - a list of words that are frequently used.
b. Groups - a set of related words that might be used.
This type of grammar file is very useful where the vocabulary of the system is small. For
example systems that use natural language to accept command statements, such as "How can
I open a new document?" or "Replace all instances of 'New York' with 'Los Angeles.'"
Limited domain grammars also work well for filling in forms or for simple text entry.
2.6FEATURES
The two main features of this application are Voice Activated D ialling [VA D ] and Messenger
Assistant [MA], a brief introduction to them follows. Through VA D , a user can dial into thesystem. Our application monitors the call and when the caller speaks, it recognizes the user
input as a command and performs the appropriate action. For example it might redirect the
call to a specific user or to an Interactive voice response [IVR] system. MA is integrated with
Microsoft Exchange Server and is used for reading emails. A user can dial into the
application and the system will read out his/her emails.
2.7HOW IS VOICE RECOGNITION PERFORMED?
The most common approaches to voice recognition can be divided into two classes: "template
matching" and "feature analysis". Template matching is the simplest technique and has the
highest accuracy when used properly, but it also suffers from the most limitations. As with
any approach to voice recognition, the first step is for the user to speak a word or phrase into
a microphone. The electrical signal from the microphone is digitized by an "analogue-to-
digital (A/ D ) converter", and is stored in memory. To determine the "meaning" of this voice

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 22/47
22
input, the computer attempts to match the input with a digitized voice sample, or template
that has a known meaning. This technique is a close analogy to the traditional command
inputs from a keyboard. The program contains the input template, and attempts to match this
template with the actual input using a simple conditional statement.
Since each person's voice is different, the program cannot possibly contain a template for
each potential user, so the program must first be "trained" with a new user's voice input
before that user's voice can be recognized by the program. D uring a training session, the
program displays a printed word or phrase, and the user speaks that word or phrase several
times into a microphone. The program computes a statistical average of the multiple samples
of the same word and stores the averaged sample as a template in a program data structure.
With this approach to voice recognition, the program has a "vocabulary" that is limited to the
words or phrases used in the training session, and its user base is also limited to those users
who have trained the program. This type of system is known as "speaker dependent." It can
have vocabularies on the order of a few hundred words and short phrases, and recognition
accuracy can be about 98 percent.
A more general form of voice recognition is available through feature analysis and this
technique usually leads to "speaker-independent" voice recognition. Instead of trying to find
an exact or near-exact match between the actual voice input and a previously stored voice
template, this method first processes the voice input using "Fourier transforms" or "linear
predictive coding (LPC)", then attempts to find characteristic similarities between the
expected inputs and the actual digitized voice input. These similarities will be present for a
wide range of speakers, and so the system need not be trained by each new user. The types of
speech differences that the speaker-independent method can deal with, but which pattern
matching would fail to handle, include accents, and varying speed of delivery, pitch, volume,
and inflection. Speaker-independent speech recognition has proven to be very difficult, with
some of the greatest hurdles being the variety of accents and inflections used by speakers of
different nationalities. Recognition accuracy for speaker-independent systems is somewhat
less than for speaker-dependent systems, usually between 90 and 95 percent.
Another way to differentiate between voice recognition systems is by determining if they can
handle only discrete words, connected words, or continuous speech. Most voice recognition
systems are discrete word systems, and these are easiest to implement. For this type of
system, the speaker must pause between words. This is fine for situations where the user is

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 23/47
23
required to give only one word responses or commands, but is very unnatural for multiple
word inputs. In a connected word voice recognition system, the user is allowed to speak in
multiple word phrases, but he or she must still be careful to articulate each word and not slur
the end of one word into the beginning of the next word. Totally natural, continuous speech
includes a great deal of "co-articulation", where adjacent words run together without pausesor any other apparent division between words. A speech recognition system that handles
continuous speech is the most difficult to implement. While designing our project we need to
consider all these aspects in deciding which type of voice recognition we will need.
So far as it stands we only need a discreet word system, or maybe a connected word
recognition system. Also, we plan on having the user-recognition software be good for a
myriad of users without having to train the system for each different user.
2.8VOICE RECOGNITION GADGETS MAKE LIFE EASIER
Have you ever wished that your home electronics would do what you told them to? Most
everyone has at some point or another screamed and yelled at their TV, only to get no
response. That is about to change, as the not so distant future of voice recognition looks very
bright. So bright, that soon enough you will be able to give orders to all of your favorite
gadgets. In the not so distant future, they may even be able to talk back! There are a few
kinks here and there that voice recognition specialists are going to need to smooth out before
the technology is flawless, but they are working on it. There is a great D ynamic-Living article
talks about the current problems with this technology, ³The biggest problem with voice
activation and voice recognition is the ability for the computer chip to distinguish speech
from all the other noise in the environment. The program must also recognize all the
variances of the human speech, from accents to dialects to speech impediments.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 24/47
24
Fig1.6: Voice recognition gadgets
Excitingly enough, this technology that at one point was only a vision of the future is starting
to appear in all sorts of cool gadgets in the market that are sure to make your life easier.
Voice activation technology is being integrated into many different aspects of the home.
Following are a few cool voice activated gadgets that are out on the market.
2.8.1VOICE ACTIVATED CHRISTMAS TREE LIGHT
If everything in the future is going to be voice automated, why not Christmas tree lights
right? Wouldn¶t it be easier to just say ³Christmas lights on´ rather than have to climb under
the tree to light up your Christmas tree? This little gadget is a great example of how peopleare starting to implement voice recognition technology into every product possible. The Intel
Voice D immer is a system that allows you to program a controller with different phrases to
control whether the lights are turned on and off, as well as how did you would like the lights
to be. Even life during Christmas is getting easier.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 25/47
25
Once the technology has reached this level, it is just a matter of time before our home gadgets
are working with this kind of voice recognition. It also begs the question of whether or not
household robots will be further introduced to the market, as that is one application of voice
recognition that will be evolutionary and exciting. Who knows what developments will come
next, but one thing is for sure- in the future we can all be a lot lazier.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 26/47
26
CHAPTER 3
VOICE ACTIVATION SYSTEM
3.1INTRODUCTION
Voice Activation is a system that reduces the amount of computer work you have to do.
Voice Activation is a system that is voice activated and does is controlled by the sound of
your voice. There are many types of voice activation systems, such as voice activated
lightening, air condition system, and computer\ technological systems. Voice activation is a
user-friendly and cost effective way to increase clinical productivity.
For e.g.: - D ragon Naturally speaking it is one of the computer\ technological systems.
D ragon Naturally Speaking is a system that is speech recognition system.
3.2 WHAT IS DRAGON NATURAL SPEAKING?
D ragon Naturally Speaking is a important piece of technology because it is a quicker way for
us to type papers, write blogs, and present presentations. It turns your voice into text three
times faster than the average person can type. D ragon Naturally Speaking is basically
software that decreases the amount of time that you spend typing. By talking into the
microphone the words you say will run through the computer onto your document. Using
D ragon Naturally Speaking or any voice activated system you will decrease the amount of
time you stress about typing papers or projects and presentations.
3. 2.1HOW IT WILL AFFECT OUR CULTURE?
D ragon Naturally Speaking will affect our culture by decreasing the time that we spend
working on projects, papers, and blogs. It helps us decrease time, and focus on other tasks. It
is a speech recognition system that is activated by the sound of your voice. D ragon Naturally
Speaking is used worldwide. A lot of people use the computer for office work such as typing
and documenting works.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 27/47
27
3.2.2HOW IT WILL IMPACT OUR GOVERENMENT AND POLICIES?
D ragon Naturally Speaking helps our government and politics; by decreasing the amount of
files and paperwork they would have to type. It helps the government and politics by
managing their time, and helps them with the office work .

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 28/47
28
CHAPTER 4
APPLICATIONS OF VOICE ACTIVATION SYSTEM
4.1VOICE ACTIVATED REMOTE CONTROL
The Voice Activated Remote Control will address the need of people who do not like to
search for the remote control or do not have the energy to walk up to the television or any
device which makes use of a remote control. This project will aim to create a device which
can accept audio input and will send a corresponding signal to another device atop the
instrument wishing to be controlled to perform the required task. We will develop an
application which will run inside a device, such as a computer or P D A, which will send the
signal to a set-top device which we will create. By creating a separate set-top box, we will be
able to enable the product to be compatible to future devices which may integrate Bluetooth.
4.1.1INTRODUCTION
In a voice-activated remote control, it entails putting together a device that will be able to
control a television set using voice commands. Instead of the traditional infrared remotecontrol, we are planning on extending it¶s transmit range by adding a set of Bluetooth
receiver/transmitter to the system. Some type of processor, either that of a P D A or a D SP,
will be used to analyze the voice commands given by the user. It will then send the command
via its attached Bluetooth transmitter. At the other end, by the television there will be a
customized Bluetooth receiver to receive the signal. Finally it converts the RF signal into
compatible infrared signal to be sent on a modified remote control.
One example is a voice activated garage door opener. The driver will no longer have to take
his/her eye off the road to press a button to open his garage door. Another application would
be a voice-activated VCR programmer, just to name a few. Currently, the group aims to
develop a prototype using two laptops connected via Bluetooth. We will develop an interface
for users to speak to and use a program to analyze the voice. The command will then transfer
to a module on the TV, which then converts the command to infrared. After a working
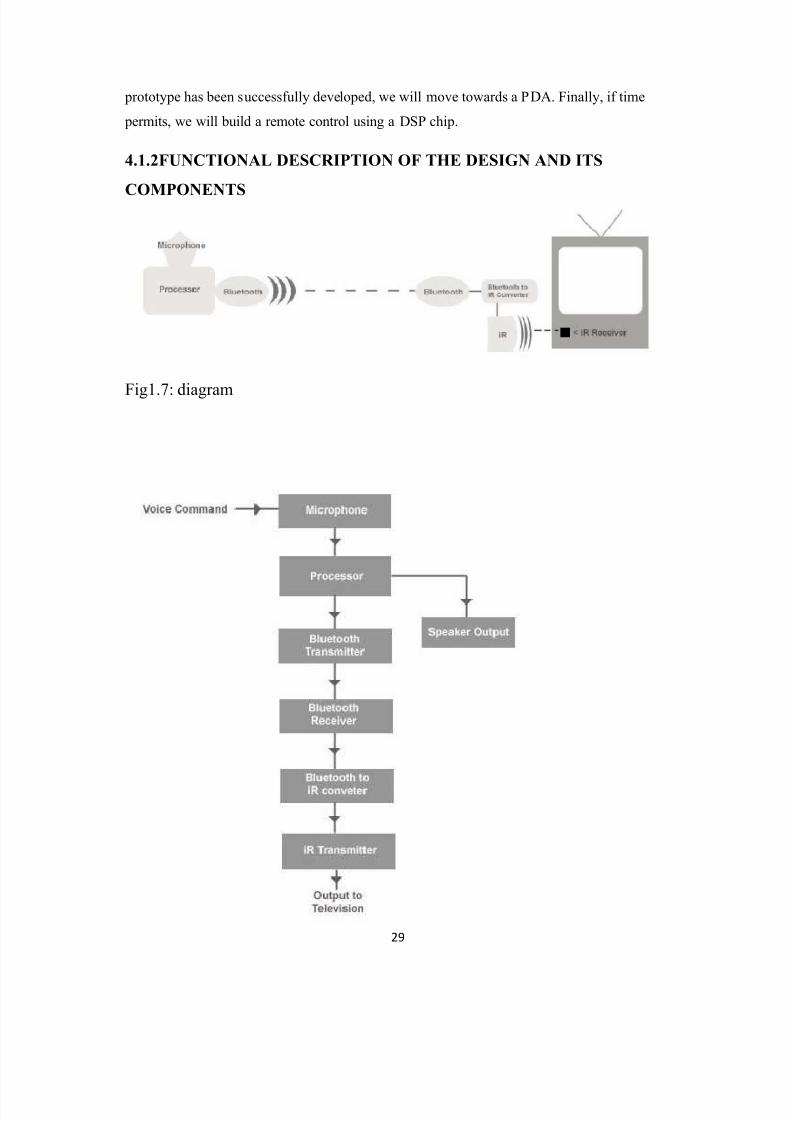
8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 29/47
29
prototype has been successfully developed, we will move towards a P D A. Finally, if time
permits, we will build a remote control using a D SP chip.
4.1.2FUNCTIONAL DESCRIPTION OF THE DESIGN AND ITS
COMPONENTS
Fig1.7: diagram

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 30/47
3 0
Figure1.8: Block D iagram of Project
4.1.3TECHNICAL DESCRIPTION OF THE DESIGN AND ITS
COMPONENTS
The Microphone that we will use will be a miniature microphone based on one by Radio
Shack, specifically Catalogue number 33-3026. The microphone will be connected to the
processor by a standard RCA jack, (or directly to the board we¶re working with), which will
be connected to the appropriate pins or inputs that are connected to the processor. The
microprocessor chip will be simply placed inside the socket or will be connected so as to
make replacement easier in case the chip is damaged. We plan to utilize a P D A, as our
processor at first, and if successful we plan to upgrade to a standalone D SP chip andmicroprocessor combination. The general outlook of the D SP will be like something pictured
below. The P D A we plan to use is a Toshiba e740 and it is also picture below.
Figure1.9: Example of a D SP

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 31/47
3 1
Figure2.0: PD
A to be used
An example of some D SP¶s that we are planning on using is TI¶s TMS320C54x line. The
D SP will be programmed to do voice recognition after which it will output to a
microcontroller which in turn will convert the interpreted command into a Bluetooth signal
using the appropriate protocol options. There will also be a speaker connected to the
microcontroller to allow communication with the end user. Essentially, this is a standard
computer speaker. This was chosen because it is very cheap and meets the objectives of beingan effective communication medium with the end user. The two wires from the speakers will
be directly soldered to the microcontroller socket to reduce the size of the housing for the
speaker, microphone, D SP, its socket, and the Bluetooth transmitter, which will all be
assembled on a perforated board.
Before we implement this setup we will have an intermediate step, where we will utilize a
PD A, running a pocket PC operating system. This will serve exactly the same function as the
D SP connected to a microcontroller and a Bluetooth module. The P D A will serve as a sort of
simulation type environment for the actual D SP. And if that approach works better we will
leave the solution as is. This P D A will be Bluetooth enabled and will automatically transmit
to the receiver.
On the receiving end, another Bluetooth transmitter will be used, however it will be set to
receive the signal from the transmitter. The transmitter will be directly connected to the

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 32/47

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 33/47
33
The speech recognizer should recognize the user's voice properly at least 90% of the time.
� It should recognize commands from users that have strong accents.
� It should recognize the commands despite relatively low level of noise coming from the
background and the TV itself. Note: In order to lower the relative level of noise, the user canspeak louder or closer to the microphone.
� 99% of the time when the signal is transmitted from the Bluetooth base, receiver should
receive the proper signal to send to the TV. That is, once the D SP/P D A has the voice
interpreted properly, the TV or device being controlled should receive the proper signal 99%
of the time.
� The D /A converter must properly interpret the signal from Bluetooth 100% of the time
� The time between the issuance of a command to the execution of the command should
appear instantaneous to the user. In the worst case, the user should not have to wait more than
1 second for the command to be executed.
4.2ADVANCED HUMAN COMPUTER PROCESSING AND
APPLICATION IN SPACE
Much interest already exists in the electronics research community for developing and
integrating speech technology to a variety of applications, ranging from voice-activated
systems to automatic telephone transactions. This interest is particularly true in the field of
aerospace where the training and operational demands on the crew have significantly
increased with the proliferation of technology. Indeed, with advances in vehicular and robot
automation, the role of the human operator has evolved from that of pilot/driver and manual
controller to supervisor and decision maker. Lately, some effort has been expended to
implement alternative modes of system control, but automatic speech recognition (ASR) and
human-computer interaction (HCI) research have only recently extended to civilian aviation
and space applications. The purpose of this paper is to present the particularities of operator-computer interaction in the unique conditions found in space. The potential for voice control
applications inside spacecraft is outlined and methods of integrating spoken-language
interfaces onto operational space systems are suggested .

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 34/47
34
4.2.1INTRODUCTION
For more than three decades, space programs internationally have been synonymous with the
frontier of technological developments. Since 1957, NASA alone has launched an impressive
series of earth orbiting satellites, exploration missions and manned vehicles. Mission
complexity has increased tremendously as instrumentation and scientific objectives have
become more sophisticated. Recent developments in robotics and machine intelligence have
led to striking changes in the way systems are monitored, controlled, and operated. In the
past, individual subsystems were managed by operators in complete supervisory and directing
mode. Now the decision speed and complexity of many aerospace systems call for a new
approach based on advanced computer and software technology. In this context, the
importance of the human computer interface cannot be underestimated. Astronauts will come
to depend on the system interface for all aspects of space life including the control of theonboard environment and life support system, the conduct of experiments, the
communication among the crew and with the ground, and the execution of emergency
procedures.
4.2.2THE WORKPLACE: SPACE
Any space flight represents some degree of risk and working in space, as in aviation,
comports some hazards. Suddenly, at any time during a mission, a situation may occur that
will threaten the life of the astronauts or radically alter the flight plan. Thus, critical to the
success of the mission and security of the crew is the complex process of interaction between
astronauts and their spacecraft, not only in routine operation, but also in unforeseen,
unplanned, and life-threatening situations.
4.2.3ENVIRONMENTAL FACTORS
The environment outside spacecraft is unforgiving. With surface temperatures ranging from -
180 C in darkness and 440 C in sunlight, high radiation and no atmosphere, lower earth orbit
is hostile to life. Yet, astronauts work in this environment, under high workload and high
stress, sheltered inside protective vehicles or dressed in bulky spacesuits. To limit the risks of
space walks, the ability to perform physical actions remotely is crucial. All the above
considerations impose restrictions and introduce severe design requirements as follows :

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 35/47
35
� Safety: security is a paramount consideration aboard any spacecraft. Every procedure and
piece of equipment undergoes thorough review before being rated flight eligible. For
example, all critical shuttle controls, such as an emergency stop switch, are required to meet
very stringent layout requirements. No floating object or particle may inadvertently activate
or damage a sensitive system.
� Reliability/Accuracy/Redundancy: high tolerance to failure is a condition to safety.
Operative systems in space must be at least two fault-tolerant, if not more in the ease of
critical systems such as flight controls or environmental control and life support systems
(ECLSS). Where applicable, error correction mechanisms must be implemented.
� Accessibility: the crew's ability to execute tasks safely and efficiently is notably improved if
controls are ergonomically placed, clearly marked, and readily available. Indirect
accessibility is also crucial, particularly where overriding of automated functions is required.
4.2.4AUTOMATIC SPEECH IN SPACE
Automatic recognition and understanding of speech is one of the very promising application
of advanced information technology. As the most natural communication means for humans,
speech is often argued as being the ultimate medium for human-machine interaction. On the
other hand, with its hesitations and complexity of intention, spoken language is often thoughtas being inadequate and unsafe for accurate control and time critical tasks. Unconvinced of
the reliability of speech processing as a control technology, pilots and astronauts have
traditionally been reluctant to accept voice interfaces. Yet within a domain-limited command
vocabulary, voice control has already been identified as a likely choice for controlling
multifunction systems, displays and control panels in a variety of environments. Requiring
minimal training, information transfer via voice control offers the basis for more effective
information processing, particularly in situations where speakers are already busy performing
some other tasks.
4.2.5BENEFITS OF SPEECH TECHNOLOGY
Motivations for using ASR in space are numerous. Traditionally, space operations have been
accomplished via hardware devices, dedicated system switches, keyboards and display
interfaces. In such context, ASR is seen as a complement to existing controls that should be

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 36/47
36
used in conjunction with other interaction devices bounded in terms of previously defined
needs and capabilities. Interest in voice command and automatic speech recognition
interfaces for space stems from the benefits it may bring to the demanding operational
environment:
� Hands free control
� Alternate control (redundancy)
� Extension capabilities
� Task adaptability
� Consistency of interface
� Commonality of usage
� Generic input/output function without requiring diversion of visual attention from
monitoring tasks .
4.2.6DISADVANTAGES AND CONCERN
The technical constraints and environmental factors impose significant implementation
requirements on the use of ASR and voice technology in space. Other issues to be consideredrange from the technical choices (isolated word vs. continuous speech, single vs. multiple
speakers, word based vs. phoneme based), the recognizer training update and maintenance
requirements, the magnitude of changes in voice characteristics while in microgravity, and
the effect of the space suit (0.3 atmosphere, pure oxygen) upon maintenance of highly
accurate recognition. Without a doubt, ASR system will require a very high recognition
accuracy rate, possibly 99evaluations performed at NASA that astronauts will switch to
habitual controls if latency, reliability and efficiency criteria are not met. Also, safety and
requirements will necessitate a high level of recognition feedback to the users, with
interactive error correction and user query functions. Finally, on the international Space
Station, the diversity of languages and accents may make ASR an even more difficult
challenge to meet.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 37/47
37
4.3IN THE WAREHOUSE
4.3.1 INTRODUCTION
Voice activated technology is gaining greater prominence in the warehousing industry. It is
seen by some as the source of a new generation of operational improvements in thewarehouse, especially for activities like picking. The robustness and maturity of the
technology is now beyond question, it having been proven in numerous installations around
the world. Understanding the benefits is crucial in ensuring the technology is successful in
any particular installation. There can be some confusion as to what can be expected from the
technology. D ifferent starting points mean different degrees of improvement and, as a
consequence, different pay back periods. This is important because it tells us how to set
appropriate levels of expectation of the technology.
4.3.2 VOICE TECHNOLOGY-THE CONCEPT
The key feature of voice technology is the user interface. It is based upon speech synthesis
and recognition and operates through a head-set worn by the user. This allows the user to
work in a µhands free, eyes free¶ fashion. At the heart of the technology is the voice terminal,
worn by the user on a belt, which communicates a host control system, typically a warehouse
management system (WMS), via radio frequency (RF) links. Therein lay the two key features
of voice;
1. The hands free, eyes free operation of the voice interface and
2. The real-time validation of RF control from the WMS.
In essence, hands free, eyes free yields productivity benefits, whilst real-time validation
yields accuracy benefits. This concept is illustrated in Figure 12.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 38/47
38
Figure2.1: D imensions of operational improvement
The µbase case¶ represents an operation without any technological support. An example of
this is the traditional paper-based picking method, where the picker follows a printed pick list
or sheets of stickers. This method has no special consideration for accuracy or productivity
and so yields little in either dimension. Benefits in accuracy and productivity can be gained
by support from an appropriate technology.
4.3.3 ACCURACY BENEFITS THROUGH REAL TIME VALIDATION
Real-time validation allows the host WMS to validate the operation as it proceeds. For
example, a picker uses an RF terminal to scan bar codes or enter check digits on products and
locations so that the WMS can verify that the correct product is being picked. If a mistake is
made, then this is detected immediately and a correction can be made before proceeding
further. Eliminating errors at this stage carries virtually no cost and is the primary
justification for using RF terminals in the warehouse. Of course, there are also some
improvements in productivity which are gained indirectly as a result of the improvements in
accuracy. Accurate picking, for example, means that stock levels in pick slots are known
correctly and can be replenished when required. This will lead to fewer instances of pickers
encountering stock outs in locations from which they are picking. There are also productivity
benefits from real-time control in general. For example, issuing instructions through an RF
terminal means that the picker does not have to return to the warehouse office to get the next

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 39/47
39
pick list to work on. The administrative task of confirming a picked pick list back to the host
system can also be eliminated. A sophisticated WMS will also have the necessary
functionality to manage unforeseen problems with the minimal impact on the picker ±
keeping the picker working as much as possible. This support is provided through the RF
terminal.
4.3.4VOICE TECHNOLOGY-THE IMPLICATIONS
So, what does all this mean? It is very important to understand these fundamental concepts
because they underpin what benefits are derived from implementing voice technology.
Therefore they are vital for building a reliable business case and for calculating an accurate
return on investment. The type of technology used currently in an operation determines how
much incremental benefit can be derived from implementing voice technology. This is
illustrated by Figure 13, which is a revised version of Figure 12 but with the migration path
options shown. An operation currently using paper-based picking will gain a two-dimensional
improvement by implementing voice. An operation already using hand-held RF terminals
will already have realised accuracy benefits and will gain in the productivity dimension by
upgrading. These benefits are still considerable, but the expectations should be different from
the start.
Figure2.2: D imensions of picking improvement

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 40/47
4 0
4.4VOICE RECOGNITION FOR BLIND COMPUTER USERS
Many people with no usable vision, who would need screen reading software to use a
computer, are attracted to the idea of operating their computer by voice (known as voice in-
voice out). However, the keyboard is still the most efficient way of inputting data into your
computer. Providing there is no physical difficulty that makes the use of a keyboard
impossible, we would recommend learning to touch type, before trying solutions involving
using screen readers and voice recognition together. There is still no system offering easy and
intelligent verbal interaction between man and machine (as seen on science fiction
programmes), but rather complex solutions that work quite well if set up and used correctly.
4.4.1 VOICE RECOGNITION
One way to communicate with your computer is to speak to it. With voice recognitionsoftware, the right hardware, and some time and patience, you can train your computer to
recognise text you dictate and commands that you issue. Success in using this software
depends upon suitable hardware, training and technique.
4.4.2 SPPECH OUTPUT
You do not need to be able to see the screen to use a computer. Software called a screen-
reader can intelligently send all information to a voice synthesiser - such as what you are
typing, what you have typed, and menu options.
4.4.3 COMBINING THE TWO...VOICE IN/VOICE OUT
Using both systems together involves two main areas:
D ictating and correcting text
Controlling your programs
At any time this will include the voice recognition program, your screen reader and the
program you are using. When issuing commands or correcting dictated text, it is vital to be
confident that what you say is correctly recognised. If you manage to correct every mistake
the recognition rate will improve, otherwise it may be actually get worse. Ideally anything
you say (word, phrase or command followed by a pause) should be automatically echoed

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 41/47
4 1
back to you. If the solution does not support this, then thorough reviewing of the text for
mistakes is necessary.
4.4.4 HANDS FREE-USE
If the programs can be used without keyboard or mouse they are said to work µhands-free¶.
Voice recognition packages range from complete hands-free use to some that require varying
amounts of keyboard or mouse input. The different screen-reader functions such as µsay line¶
or µspell word¶, which would usually involve a key combination, are accessed by verbal
commands that may or may not already be set up for you.
4.4.5 DIFFICULTIES WITH VOICE IN/VOICE OUT
Many problems are inherent in using voice recognition with speech output. Not least is that
hearing words or phrases echoed back is often NOT BE ENOUGH for the user to be sure that
there are no errors in the recognition or formatting of the text. For example, hearing the
correct echoing back of your dictated phrase "I will write to Mrs Wright right now" will not
tell you whether each of the three words that sound the same have been correctly recognised,
capitalised and are grammatically correct. Other examples might be "there", "their" and
"they're", "here" and "hear´, and even "youth in Asia" and "euthanasia", and 1,000 other
examples which all sound very similar. Whilst the software's knowledge of grammar might
get these correct most of the time, it is impossible to know unless painstaking reviewing is
carried out.
It is also very easy to become disorientated when a command you have just issued is not
recognised and you are suddenly taken somewhere unexpected. This can be at best
frustrating, and at worst, disastrous. These difficulties can be at their worst when first starting
to use your system - when the software is learning how you speak and you are still learning
how to use the software.
Another consideration is cost. Modern voice recognition software requires a relatively highspecification PC to work well ± we would suggest a minimum of a PIII 700Mhz processor
with 512MB RAM. Then there is the cost of both the voice recognition and screen reading
software to consider.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 42/47
42
4.5CELL PHONES
Remember the unused ³speech recognition´ feature on your cell phone? For
Almost as many years as cell phones have existed, manufacturers have tortured their
customers with stone-age ³voice tag´ speech recognition systems allowing you to call 10 or
20 people by name by voice, after a training session. These systems would work if you
mimicked the way you said each name during training, but the systems tended to fail in noisy
environments or anywhere unlike where you trained the phone. The acoustic matching
technology used (dynamic programming) was an algorithm well suited to the primitive
acoustic models available in the early days of automatic speech recognition, but it was
effective nor efficient in doing the job at hand ± dialling the phone by name. Speech
recognition technology has advanced substantially since those early systems were designed.
You can call a voice activated assistant on the phone for banking, travel, ordering, and many
other activities.
A new technology is phonetic embedded speech recognition. You can find it in speech
activated dialling in some cell phones, P D As, and other handheld devices. New telephone
services are emerging which will make small devices into powerful communication
assistants, and a competent speech interface will make these services easy to use and possible
to remember.
D uring the last year, algorithms based on modern embedded speech recognition have become
available on many cell phones. They allow phone dialling by name or by number using your
voice, and often allow voice activation of other cell phone functions. In these new
applications, it is no longer necessary to ³train´ the system to your voice. The application
understands how names, numbers, and other words sound in a particular language, and can
match your utterance to a name, number or command in the phone. Users have found this
new functionality straightforward to use and easy to remember.
There are more than 10 million phones that include these modern embedded speech
applications. They work very well at calling the numbers listed by name from your phone
book, at allowing you to dial your phone by saying the phone number, and at letting you look
up a contact entry, launch a browser, start a game, and more. It is interesting to look at some
of the history of this new technology and the associated emerging market forces, and then to
speculate about its future.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 43/47
43
4.5.1WHO NEEDS VOICE DIALLING?
The only remaining issue is whether or not people want voice dialling. For this discussion,
we need only look at the local cell phone store to see what is happening to the technology of
cell phones themselves.
Figure 13 shows several cell phone styles. Newer phones tend to be small. In fact,
They are becoming so small that it is difficult to successfully dial a number using the keypad.
For dome form factors, the keypads have all but disappeared. In the Samsung i700, a
PD A/phone combination, the only numeric keypad is a touch screen that mimics a dialling
touch pad. While it is possible to use and see that screen, one handed or no handed use is all
but impossible. The voice interface is a substantial improvement. In the recent Xelebi line by
Siemens, one of the phones (the Xelibre 3) has only one button! While it was possible to dial
a number with that button, the user interface can best be described as baroque. The speech
recognition system became a requirement for any kind of usability.
Finally, in many states and several countries, it is illegal to hold your cell phone while
driving. Since the majority of cell phone calls in the United States are made from an
automobile, some form of hands free dialling will be essential.
Figure 2.3: Some cell phones supporting Voice D ialing. The i700 is the second from the top.

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 44/47

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 45/47
45
short, today¶s pilot has become more of a ³systems operator´ and frequently spends more
time manipulating his flight management system than he does actually manipulating the
aircraft controls and looking out the window. This increased cockpit workload can ultimately
distract from his real-time situational awareness. Such distraction has proven to be a
significant factor in Controlled Flight into Terrain (CFIT) incidents.
4.6.2BENEFITS OF A VOICE ACTIVATED COCKPIT
Generally speaking, a pilot has three bidirectional channels for information flow ± visual,
manual, and auditory. He typically receives cockpit-generated information visually and
responds/commands manually. His auditory channel is usually reserved for communications
with his co-pilot and passengers. Under stressful flight conditions (e.g., abnormal or
emergency flight situations, shooting an instrument approach or looking for traffic) while his
manual channel is moderately to heavily loaded, depending on the degree to which he is
manually flying the aircraft or having to reprogram his FMS and/or instrumentation for
rapidly-changing flight conditions. D uring all of this, his auditory channel is usually only
lightly loaded. D ata entry is a particular problem in a fast-moving vehicle like an aircraft.
Keypads and keyboards common, are relatively easy to use, and are familiar to the generation
that has grown up in the computer age. However, any type of keyboard is susceptible to input
error and the keyboards and keypads typically found in an aircraft cockpit are smaller and
more compressed than the full size keyboard found on an office desktop. D ials and switches
are excellent quick, sequential data entry methods, but there are rather few data types that can
be entered more efficiently using dials than with a keyboard. Just as keyboard entry requires
close attention and hinders situational awareness, knobs and dials require even closer
attention while sequencing through numbers or letters. Even relatively straightforward tasks
in general aviation require a number of appropriately- sequenced actions in order to execute
them. For instance, to talk to a specific control tower, a GA pilot must divert his/her scan
from traffic and instruments and at least one hand from the controls, find the appropriate
frequency for that location either by spotting it buried somewhere on a paper chart or search
for it in an FMS or GPS database, then dial the frequency into the radio, press the appropriate
button to make it current, depress his PTT button, and ± finally ± speak. One means of safely
making cockpit interactions more efficient is obviously to exploit the pilot¶s lightly-loaded
auditory channel. Voice communication is very efficient. Suppose that a pilot could
communicate with his cockpit like he does with his co-pilot. A simple ³Google´ internet

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 46/47
46
search for ³cockpit speech (or voice) recognition´ will produce thousands of results, many of
which are detailed studies about whether speech recognition might be a beneficial means for
pilots to interact with aircraft systems. These studies go back more than twenty years, and
with very few exceptions agree that if speech recognition were robust enough to deal with the
challenging environment of an aircraft cockpit, then the technology would indeed bebeneficial from both a safety and efficiency perspective.
A Voice-Activated Cockpit (VAC) could provide direct access to most system functions,
even as the pilot maintains hands-on control of the aircraft. By ³cutting out the middlemen´
of button pushes and interpreting visual representations, the following safety and efficiency
benefits now become possible:
y
D irect Aircraft Systems Queries ± Rather than step through menus to query specific
aircraft systems or scan a specific instrument, a pilot could simply ask the aircraft
what he wants to know, much as he would a co-pilot or flight engineer. For instance,
³say remaining fuel´ would cause a synthetic voice to report the fuel state.
y
D ata Entry for FMS, Autopilot, Radio Frequencies ± Updating the flight profile in
flight now becomes easier and safer, as there is far less likelihood of the wrong
lat/long or radio frequency than there is in inputting the incorrect data.
y
Glass Cockpit Configuration ± Today¶s glass cockpits offer almost limit
configurations. A well-designed VAC would allow each pilot to configure the cockpit
quickly to his or her preference by simply announcing himself when he took the left
seat. Furthermore, different configurations could be defined for each flight modality
and initiated as required via voice commands, e.g., the pilot
y
Prefer a different cockpit configuration in cruise than he would on an IFR approach.
y
Checklist Assistant ± Here there are two application possibilities:
1) A single pilot aircraft operator might read through the checklist as the aircraft
executes and confirms his instructions, or
2) The synthetic speech system leads the pilot through the checklist without the need
to refer to its printed version. As the pilot reports compliance, the checklist assistant
automatically moves to the next item.
Again, these features would provide significant benefit in emergency situations and abnormal
flight conditions. Looking at the modern aircraft cockpit, it is easy to see how a pilot can be

8/7/2019 Voice Activation System
http://slidepdf.com/reader/full/voice-activation-system 47/47
distracted by the task of ³systems management´. The Airbus A380, for example, has a
multitude of LC D displays, numerous gauges, desk space for full size computer keyboards
and hundreds of buttons, dials, switches and knobs, some of which are rarely used.
Fig 2.4: Airbus A380 Cockpit
Human factors specialists working on new aircraft cockpits such as the A380 are trying to
produce interfaces that are intuitive and easy to use. But the sheer number of tasks that may
be executed by the flight crew combined with the restricted amount of cockpit real estate
available to display the information, as well as the criticality of aircraft weight as part of the
aircraft design criteria, will always result in a cockpit environment that is suboptimal (human
factors wise) and promotes more and more heads-down activity. An aircraft in which the
flight crew can concentrate on flying the aircraft and ensure that the pilots gain and maintainsituational awareness will always be a safer aircraft. Many hundreds of millions of dollars are
being and will continue to be spent on ASR R& D , thereby ensuring that the performance of
the VAC system will continue to improve at an exponential rate we believe that talking to


















