
Joe Moxley Professor of English University of South Florida .
date post
21-Dec-2015Category
view
221download
0
Video Fingerprinting: Features for Duplicate and Similar Video Detection and Query-
based Video Retrieval
Anindya Sarkar, Pratim Ghosh, Emily Moxley and B. S. Manjunath
Presented by:
Anindya SarkarVision Research Lab,
Department of Electrical & Computer Engg,University of California, Santa Barbara
Januray 30, 2008

April 18, 2023
Problem Definition:• Duplicate video and similar video detection
– we represent a video compactly (fingerprint), for efficient storage and faster search without compromising the retrieval accuracy
• Query-based video retrieval – Input: short length (1-2% of big video length) query video– Output: actual “big” video from which the query is taken
–

April 18, 2023
Generation of Duplicate Videos
• Dataset: BBC rushes dataset, provided for the TRECVID-2007 task of video summarization
• Operations performed:– Image processing (per frame) based:
• Blurring using 3x3 and 5x5 window• Gamma correction by 20% and -20%• Gaussian noise addition at SNR of -20,0,10,20,30 and 40 dB• JPEG compression at QF=10,30,50,70 and 90
– Frame drop based errors:• frame drops of 20%, 40% and 60% of the original video for both
random and bursty case.

April 18, 2023
Interpretation of Similar videos
• Different takes of the same scene are considered as “similar” videos
• These videos are similar in content– However, due to human variability at both the cameraman
and actor level, (camera angles, cuts, and actor performance), videos may look similar but are still different
• BBC rushes dataset has unedited footage of the different retakes – hence, ideally suited for generation of similar videos

April 18, 2023
Keyframe based Video Fingerprint
Video Summarization
and key-frame extraction
N frames in the actual video
K key-frames K x d
Video Fingerprint
d-dimensional signature computed per key-frame
Features used for fingerprint creation:1. Compact Fourier Mellin Transform2. Scale Invariant Feature Transform
April 18, 2023
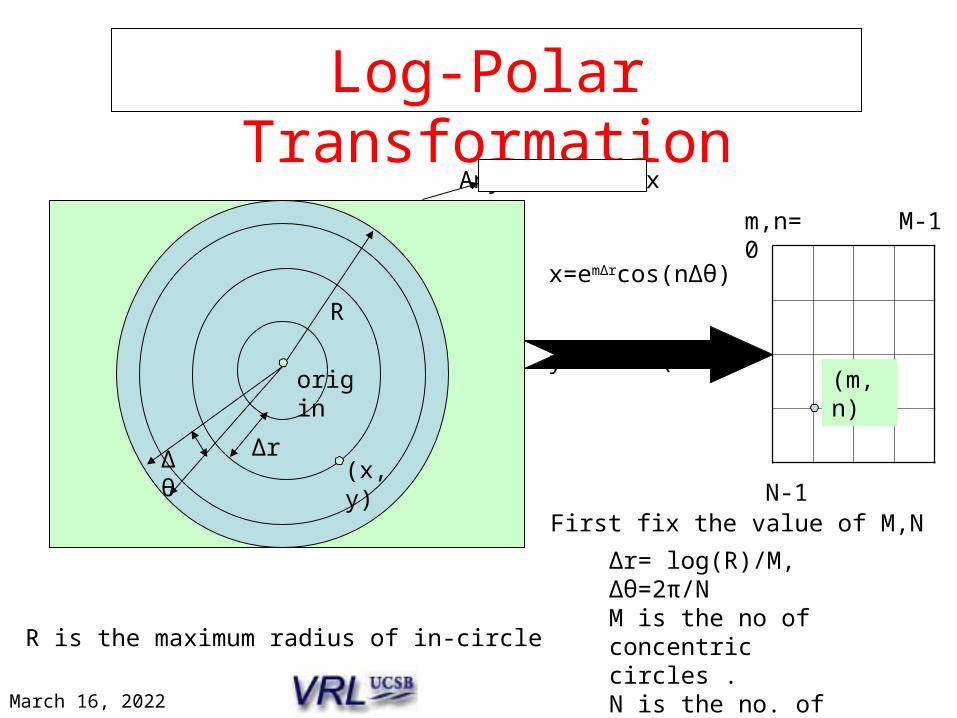
R
R is the maximum radius of in-circle
m,n=0 M-1
N-1
∆r∆θ
∆r= log(R)/M, ∆θ=2π/NM is the no of concentric circles .N is the no. of diverging radial lines .
x=em∆rcos(n∆θ) y=em∆rsin(n∆θ)
(x,y)
(m,n)
Log-Polar Transformation
First fix the value of M,N
origin
Any 2-D Matrix

April 18, 2023
CFMT FEATURE EXTRACTION
m, n=0 M-1
N-1
-(K-1) K-1
V-1
|FFT|
-(V-1)
Normalization&
vectorization
50% A.C.Energy
PCA
Quantization

April 18, 2023
SIFT Feature
• Generally used for object recognition – hence, can be used as an image similarity measure
• Distance between SIFT features – number of descriptor comparisons makes it computationally prohibitive
• Speed up – quantize descriptors to a finite vocabulary (consisting of words)– Each image is a weighted vector of the word frequencies
April 18, 2023
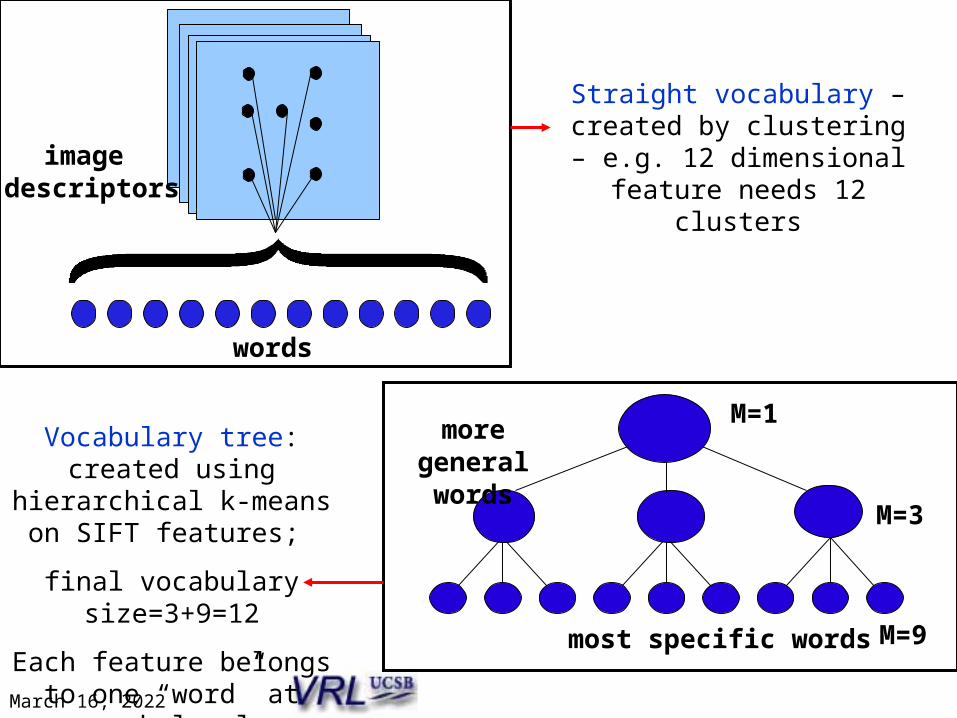
most specific words
M=1
M=3
more general words
words
image descriptors
Straight vocabulary – created by clustering – e.g. 12
dimensional feature needs 12 clusters
Vocabulary tree: created using hierarchical k-means
on SIFT features;
final vocabulary size=3+9=12
Each feature belongs to one “word” at each level
M=9

April 18, 2023
Straight Vocabulary vs Vocabulary Tree
• Straight vocabulary:
– Does not consider relationship between words• That is, ignores that certain words are closer to each other than other
words.– At very coarse level (dictionary size ~10-20), additional
words are more descriptive than the relationship among words. Therefore, outperforms vocabulary tree.
• In our experiments, low-dimensional SIFT features, obtained using straight vocabulary, perform much better as “fingerprints” than tree-based features

April 18, 2023
Non-keyframe based Video Fingerprint
N frames
P=N/K frames, where each window has P frames
P frames
P frames
Video Fingerprint
K x 125Video Fingerprint Extraction
for each of K windows
Computing the 125-dim YCbCr Histogramin YCbCr Space using P ConsecutiveFrames and thus avoiding Key FramesExtraction. Whole color space is quantizedinto 125 bins (5 bins for each of Y, Cb and Cr).
Features used for fingerprint creation:YCbCr histogram based feature

April 18, 2023
Signature Distance Computation
• For two (K x d) fingerprints, X and Y,
where X(i) = ith feature vector of X
• Properties of this distance function:
• Such a distance relation is called a “quasi-distance”
d(X ;Y ) =KX
i=1
½min
1· j · KjjX (i) ¡ Y (j )jj1
¾
d(X ;Y ) = 0; is possible even if X 6= Y
d(X ;Y ) 6= d(Y;X )

April 18, 2023
Motivation Behind Distance Function
This closest-overlap based distance is robust to:
Frame reordering:
For 2 signatures, temporal sequence may not be maintained between them – e.g. a video consisting of a reordering of scenes from the same video is still regarded as a duplicate
Frame drops:
If frame drops occur or some video frames are corrupted by noise, distance between duplicate videos should still be small

April 18, 2023
Experiments and Results
• We present precision-recall plots for both similarity and duplicate detection, over 3888 videos– CFMT for dimensions 36/24/20/12/4– SIFT for dimensions 781/341/33/21/12– CFMT vs best performing SIFT for duplicate detection– SIFT vs best performing CFMT for similarity detection
• CFMT performs better for duplicate detection
• SIFT performs better for similarity detection

April 18, 2023
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
RECALL
PR
EC
ISIO
NCFMT Signature Exact Retrieval on 3888 videos (Bursty Error)
362420124
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
RECALL
PR
EC
ISIO
N
CFMT Signature Similar Retrieval on 3888 videos (Bursty Error)
362420124
Precision-recall curves for different dimensional CFMT for
duplicate detection
Precision-recall curves for different dimensional CFMT for
similarity detection

April 18, 2023
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
RECALL
PR
EC
ISIO
NExact Retrieval on 3888 videos (Bursty Error) for SIFT dim 11111 to 12
1111178134133312112
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
RECALL
PR
EC
ISIO
N
Similar Retrieval on 3888 videos (Bursty Error) for SIFT dimensions 11111 to 12
1111178133312112
Precision-recall curves for different dimensional SIFT for
duplicate detection
Precision-recall curves for different dimensional SIFT for
similarity detection
April 18, 20230.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
RECALL
PR
EC
ISIO
N
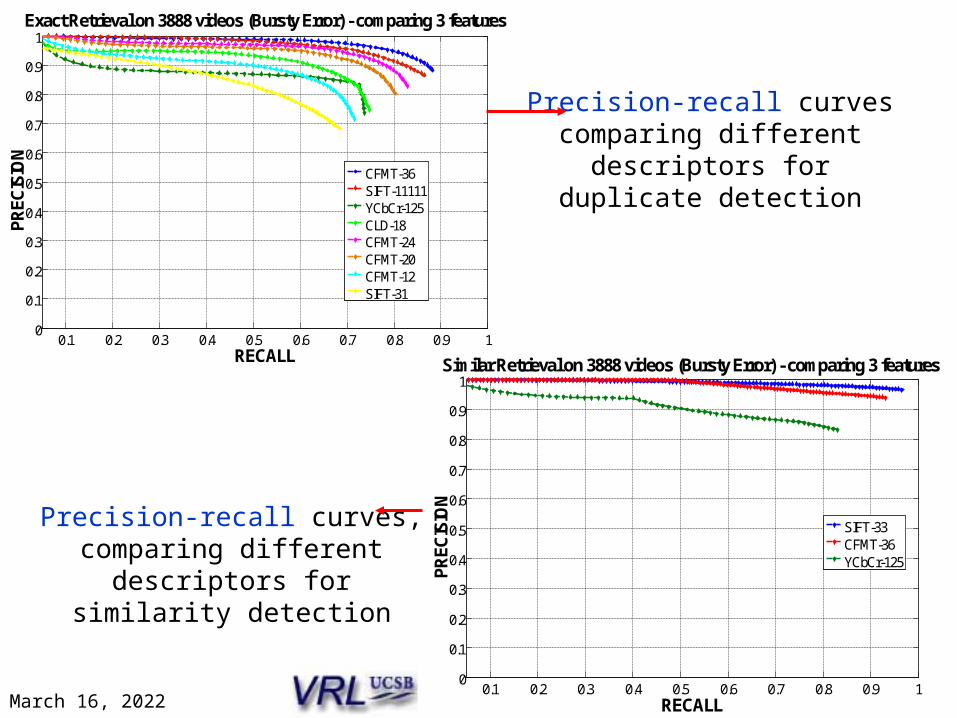
Similar Retrieval on 3888 videos (Bursty Error) - comparing 3 features
SIFT-33CFMT-36YCbCr-125
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
RECALL
PR
EC
ISIO
NExact Retrieval on 3888 videos (Bursty Error) - comparing 3 features
CFMT-36SIFT-11111YCbCr-125CLD-18CFMT-24CFMT-20CFMT-12SIFT-31
Precision-recall curves, comparing different descriptors
for similarity detection
Precision-recall curves comparing different descriptors
for duplicate detection

April 18, 2023
Full-length Video Retrieval with Clip Querying
• Generation of the small-length query:
– We put together 4 different scenes from a full length video to create our input query:
– Each individual scene is represented by 8 keyframes– For a single query, we have 4x8=32 keyframes– We experiment with different features for query
representation
• Repository is of full-length video signature (65 videos):– Number of keyframes used to create the signature size for
“large video” is varied from 1%-4% of video length

April 18, 2023
Algorithm
• Step 1: Input query signature Xquery is a (32 x d) matrix
• Step 2: Its distance from all the stored “large video” signatures (Xlarge) is computed, as shown below:
• Step 3: The best matched video is returned
¢ (i) = minj
jjX query(i) ¡ X large(j )jj1; 1 · i · 32 (1)
D(X query;X large) =32X
i=1
¢ (i)=32 (2)

April 18, 2023
Video name
CFMT-36
CFMT-20
CFMT-12
YCbCr-125
SIFT-781
SIFT-31
SIFT-21
Query 1 1.00 1.01 1.00 7.92 1.01 3.83 13.26
Query 2 1.00 1.01 1.00 1.60 1.00 2.67 1.49
Query 3 1.03 1.36 1.03 1.71 1.00 1.00 2.15
Query 4 1.00 1.00 1.00 1.92 1.00 1.00 1.00
Video name
CFMT-36
CFMT-20
CFMT-12
YCbCr-125
SIFT-781
SIFT-31
SIFT-21
Query 1 1.00 1.09 1.23 1.78 1.00 2.52 3.94
Query 2 1.00 1.00 1.00 2.11 1.00 1.00 1.45
Query 3 1.00 1.21 1.59 4.70 1.00 1.41 8.44
Query 4 1.00 1.00 1.47 1.99 1.00 1.00 1.00
Retrieval results for 1% summary lengths for “large” videos
Retrieval results for 4% summary lengths for “large” videos

April 18, 2023
Conclusions• CFMT features provide quick/accurate retrieval for
duplicate videos
• SIFT features perform better for similar video detection
• Future work – expanding the domain of “similar” videos (non-retakes yet
still similar ?)– Importance of an efficient summary to create video signature
(strategic keyframes vs random keyframes ?)

April 18, 2023
Thanks for your patience.
Questions?


















