
Vector FPGA Acceleration of 1 -D DWT Computations … FPGA Acceleration of 1 -D DWT Computations...
16
Vector FPGA Acceleration of 1-D DWT Computations using Sparse Matrix Skeletons Sidharth Maheshwari, Gourav Modi, Siddhartha, Nachiket Kapre School of Computer Science and Engineering Nanyang Technological University
Transcript of Vector FPGA Acceleration of 1 -D DWT Computations … FPGA Acceleration of 1 -D DWT Computations...

VectorFPGAAccelerationof1-DDWTComputationsusingSparseMatrix
Skeletons
SidharthMaheshwari,GouravModi,Siddhartha,NachiketKapreSchoolofComputerScienceandEngineering
NanyangTechnologicalUniversity
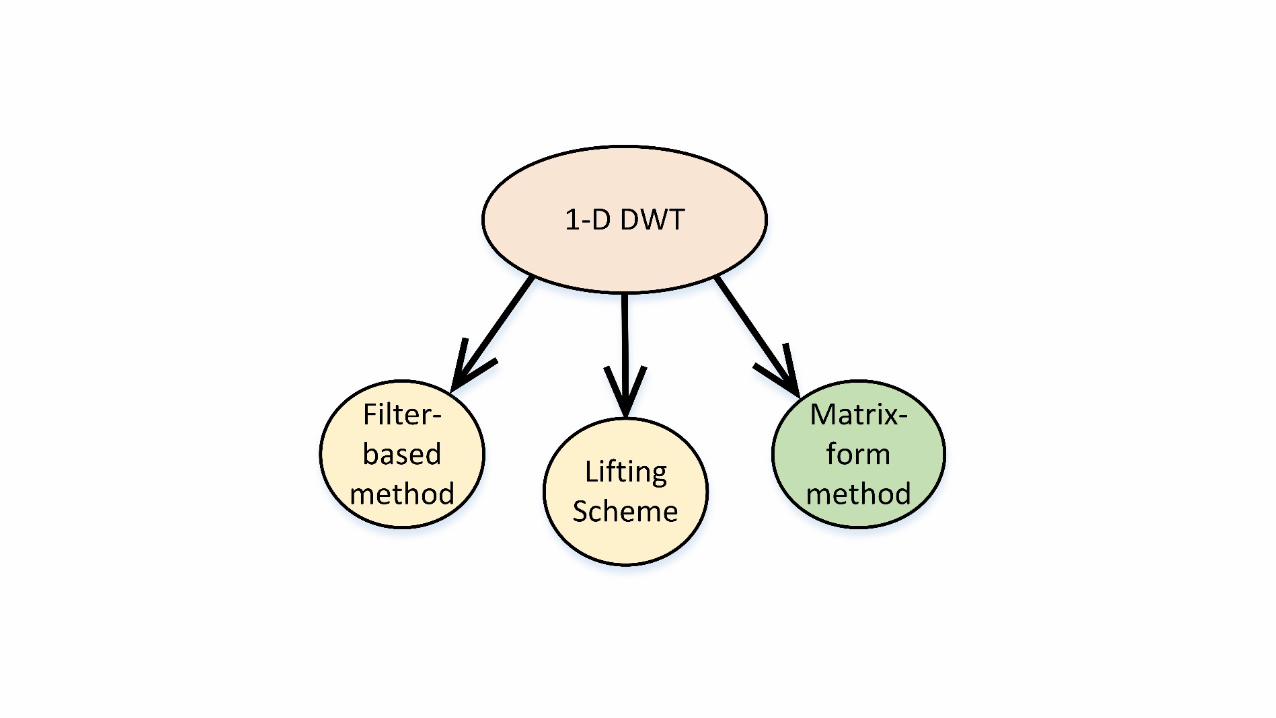

Matrix-Form1-DDWT
• Formulation:𝐶 = 𝑇𝑀 % 𝑋, where 𝑇𝑀 = ∏ 𝑇()
*)
• TMmatrixishighlysparseØLargenumberofmultiply-by-zerooperations
ØLargememoryfootprintconsistingofzeroes
• Goals:Ø SIMD-friendlyoperationsonnon-zerovaluesonly
Ø CustomizedDMAroutinesforefficientbandwidthutilization

Matrix-Form1-DDWT
• Formulation:𝐶 = 𝑇𝑀 % 𝑋, where 𝑇𝑀 = ∏ 𝑇()
*)
• TMmatrixishighlysparseØLargenumberofmultiply-by-zerooperations
ØLargememoryfootprintconsistingofzeroes
• Goals:Ø SIMD-friendlyoperationsonnon-zerovaluesonly
Ø CustomizedDMAroutinesforefficientbandwidthutilization

Matrix-Form1-DDWT
• Formulation:𝐶 = 𝑇𝑀 % 𝑋, where 𝑇𝑀 = ∏ 𝑇()
*)
• TMmatrixishighlysparseØLargenumberofmultiply-by-zerooperations
ØLargememoryfootprintconsistingofzeroes
• Goals:Ø SIMD-friendlyoperationsonnon-zerovaluesonly
Ø CustomizedDMAroutinesforefficientbandwidthutilization

SparseMatrixSkeleton
• Removemultiply-by-zerooperations• ReductioninmemoryfootprintofTM.
36
8
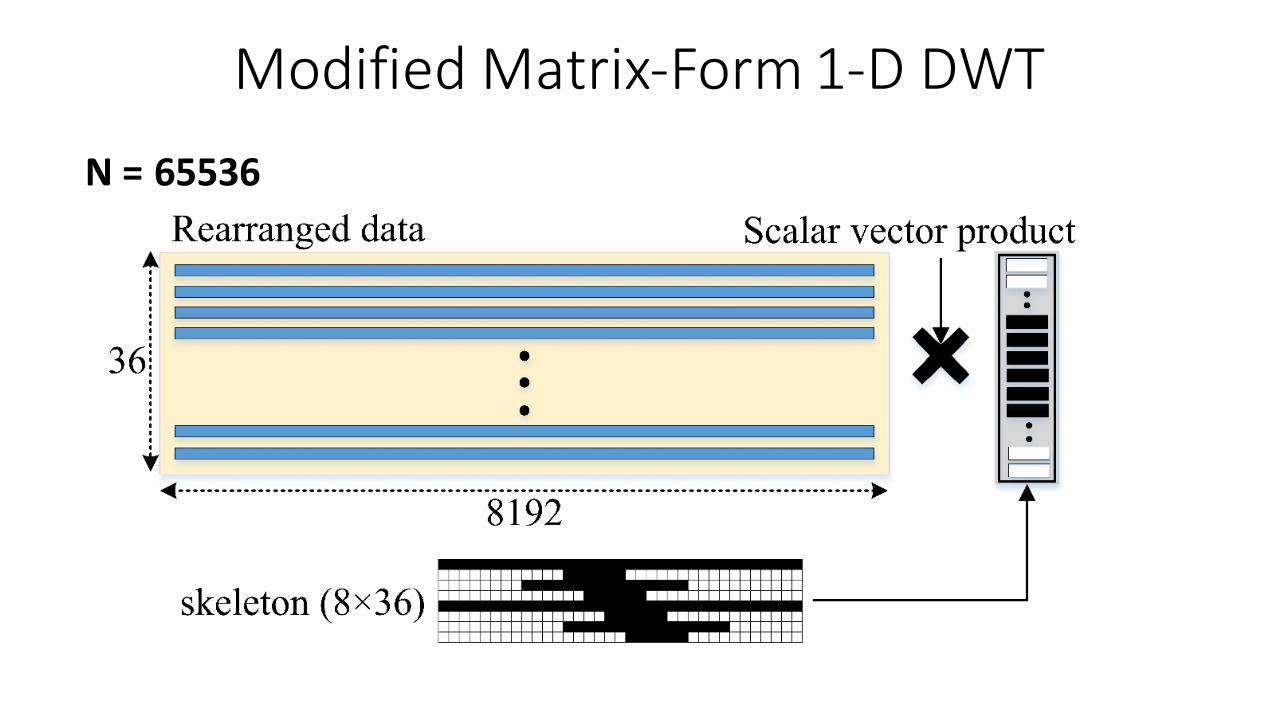
ModifiedMatrix-Form1-DDWTN=65536

VectorBloxMXP
• Lanes: 16-32• Scratchpad: 64-128 KB• DMA bandwidth: 4-32 B/cycle
𝑁 = 2-., 𝐿 = 6𝑎𝑛𝑑𝑘 = 3
Results- Speedup
05
1015202530354045505560
MXP−DE2 MXP−DE4 MXP−ZedBoard
Speedup Baseline CPU
Raspberry PiZedboardBeagleBone Black
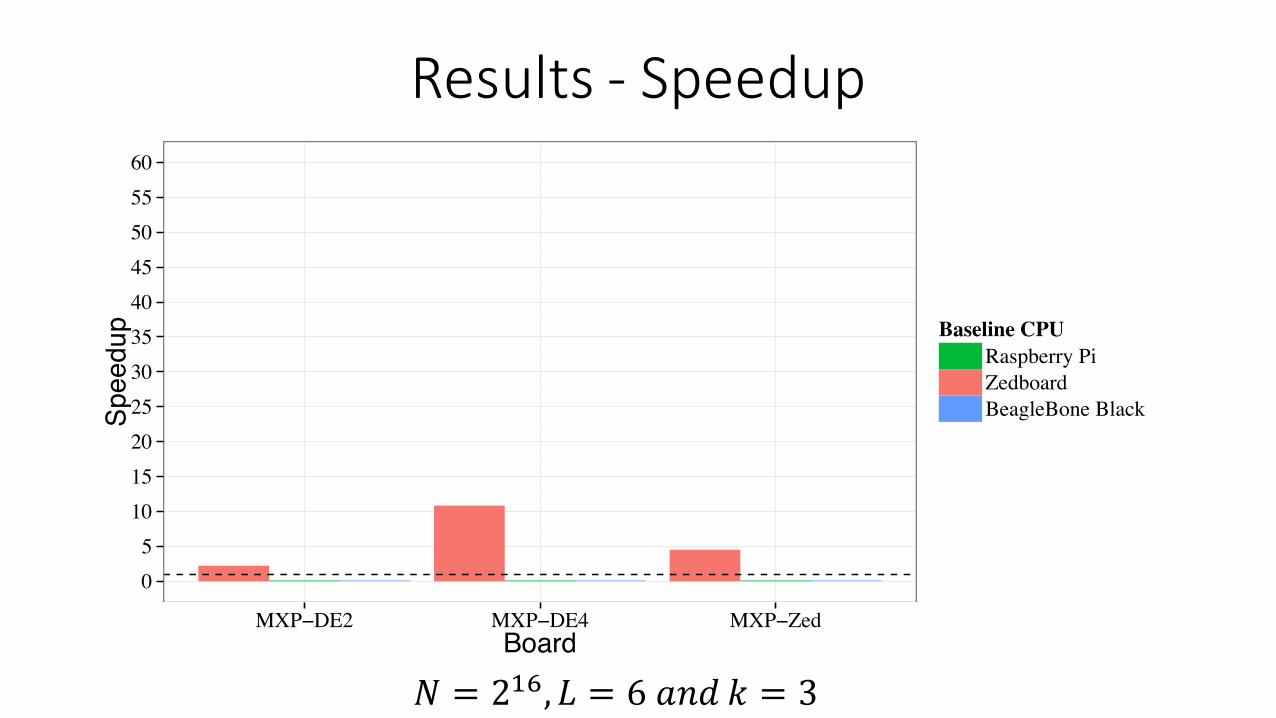
𝑁 = 2-., 𝐿 = 6𝑎𝑛𝑑𝑘 = 3
Results- Speedup
05
1015202530354045505560
MXP−DE2 MXP−DE4 MXP−ZedBoard
Speedup Baseline CPU
Raspberry PiZedboardBeagleBone Black

𝑁 = 2-., 𝐿 = 6𝑎𝑛𝑑𝑘 = 3
Results- Speedup
05
1015202530354045505560
MXP−DE2 MXP−DE4 MXP−ZedBoard
Speedup Baseline CPU
Raspberry PiZedboardBeagleBone Black

Summary
• We propose a Modified Matrix-Form scheme to unlock inherentparallelism in 1-D DWT
• We exploit the sparsity pattern in TM to reduce complexity fromO(𝑛8) to O(𝑛) using :
Ø Skeletons to avoid wastefulmultiply-by-zero operationsØ Rearrangement of input samples
• Speedups of 12-103x over state-of-the-art in-built signal libraryin Octave (dwt function)

ExperimentalSetupMatrix-form1-DDWT
SparseMatrixSkeletons
CPU- OptimizedOpenBLASroutinesinOctaveandC(compiledwith–O3)- PerformancemeasuredusingPAPIv5.4.3- 32bARMv7onBeagleboneBlack,Zedboard,andARMv6onRaspberryPi
CPU+MXP- CustomizedDMAroutinesfordatatransferbetweenhostandMXP- 16-32vectorlanes- 64-128KBscratchpadmemory- PerformancemeasuredusingMXPTimingAPI- AlteraDE2/DE4andZedboard

Results- Throughput
𝑁 = 2-., 𝐿 = 6𝑎𝑛𝑑𝑘 = 3
●
●●
20
40
60
80
0.1 1.0Throughput (GOps/S)
Ener
gy (m
J)●
●●
ARM (Beagl.)
ARM (Rasp.)
ARM (Zedb.)
MXP−DE2
MXP−DE4
MXP−Zed

CHALLENGES:• Largevolumeofdata• Strictreal-timeprocessingconstraints• Highaccuracydemands• Energyconstraints,especiallyinembedded systems

ModifiedMatrix-Form1-DDWTRearrangement


















