
Implementing a Data Warehouse with Microsoft SQL Server 2012
Upload
rizaldy-ignacioCategory
view
53download
2
Using the Power of Big SQL 3.0 to Build a Big Data-Ready Hybrid WarehouseIIH-5529Olivier Bernin & Rizaldy Ignacio October 30th
© 2014 IBM Corporation

Please Note• IBM’s statements regarding its plans, directions, and intent are subject to change or
withdrawal without notice at IBM’s sole discretion.
• Information regarding potential future products is intended to outline our general product direction and it should not be relied on in making a purchasing decision.
• The information mentioned regarding potential future products is not a commitment, promise, or legal obligation to deliver any material, code or functionality. Information about potential future products may not be incorporated into any contract.
• The development, release, and timing of any future features or functionality described for our products remains at our sole discretion.
Performance is based on measurements and projections using standard IBM benchmarks in a controlled environment. The actual throughput or performance that any user will experience will vary depending upon many factors, including considerations such as the amount of multiprogramming in the user’s job stream, the I/O configuration, the storage configuration, and the workload processed. Therefore, no assurance can be given that an individual user will achieve results similar to those stated here.
2

Agenda• Big Data & the Hybrid Data Warehouse
A quick recap on BigData The Hybrid Data Warehouse
• Big SQL 3.0 – SQL on Hadoop without compromises What is Big SQL ? Features
• Setting up an Hybrid Data Warehouse with Big SQL Federation Overview Configuration
3

Big Data & The Hybrid Warehouse
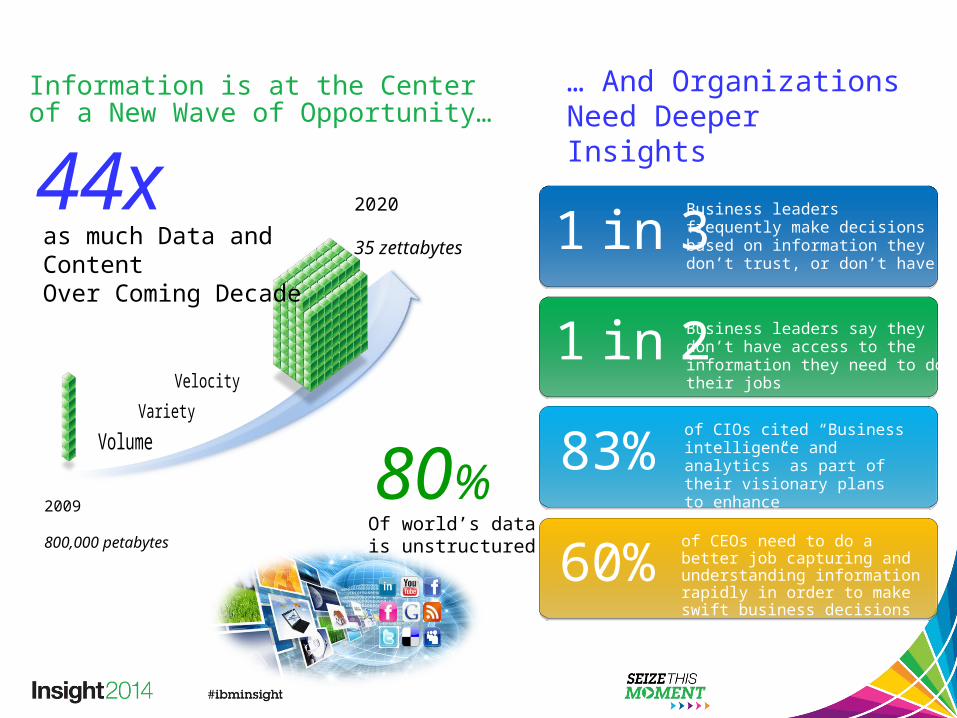
2009
800,000 petabytes
2020
35 zettabytesas much Data and ContentOver Coming Decade
44x Business leaders frequently make decisions based on information they don’t trust, or don’t have1 in 3
83%of CIOs cited “Business intelligence and analytics” as part of their visionary plansto enhance competitiveness
Business leaders say they don’t have access to the information they need to do their jobs
1 in 2
of CEOs need to do a better job capturing and understanding information rapidly in order to make swift business decisions
60%
… And Organizations Need Deeper Insights
Of world’s datais unstructured
80%
Information is at the Center of a New Wave of Opportunity…

Hadoop• Framework / ecosystem of component aimed at distributing work
across (very) big cluster for parallelizing …
• Components A distributed file system running on commodity hardware (HDFS) The MapReduce programming model & associated APIs Hive, HBase, Sqoop, etc ...
• Hadoop nodes store and process data Bringing the program to the data Easy scalability – just add more nodes
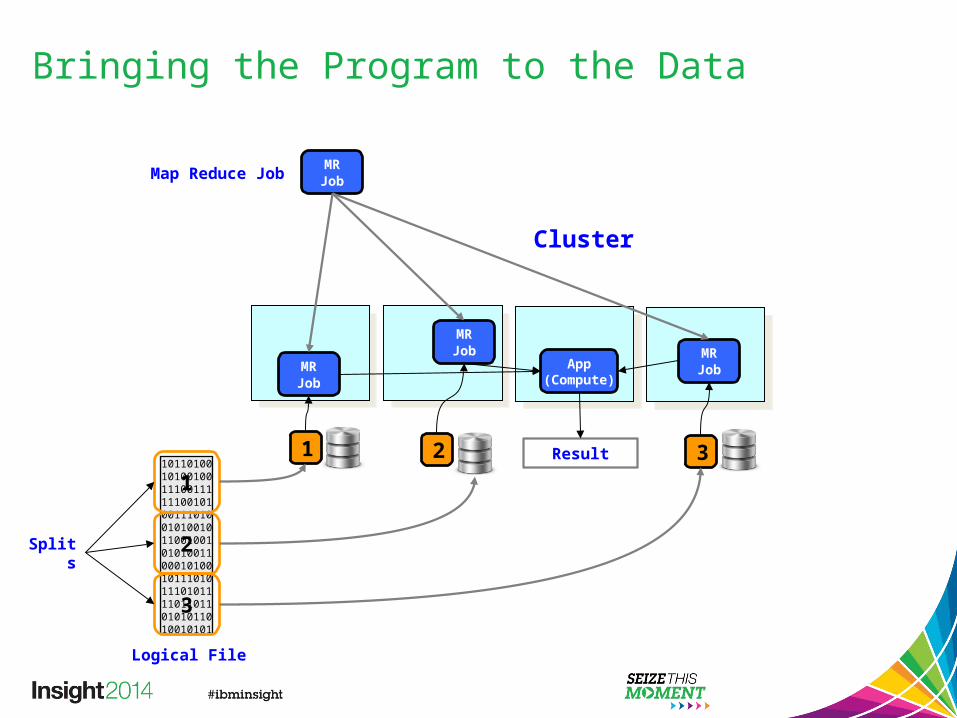
Bringing the Program to the Data
1
Cluster
32
MRJob
MRJob MR
JobApp(Compute)
MRJob
Result1011010010100100111001111110010100111010010100101100100101010011000101001011101011101011110110110101011010010101
1
2
3
Logical File
Splits
Map Reduce Job

Hadoop for Big Data ?
• Well suited for Big Data Distributed, parallel execution Cheap(er) per storage unit Flexible: no schema Highly available
• But … Data needs to be integrated to generate insights Prioritization of applications Capitalizing on investment
High priority / high performance SQL
applications
Semi-structured data applications
Low priority, low performance SQL
applications
Experimental applications
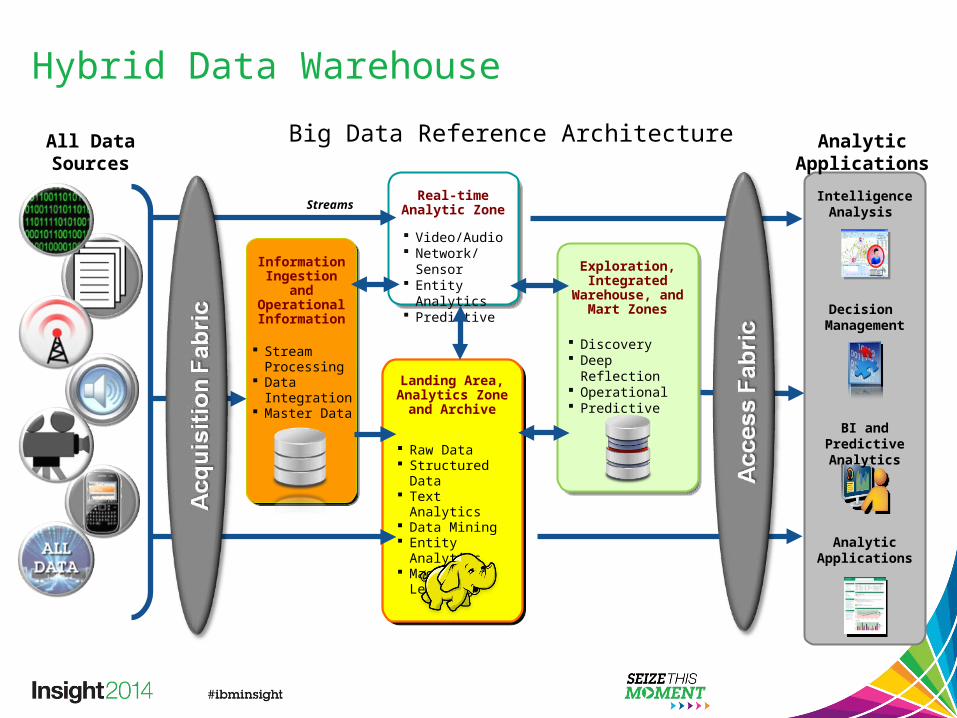
Hybrid Data Warehouse
Exploration,Integrated
Warehouse, and Mart Zones
Discovery Deep Reflection Operational Predictive
All Data Sources
Decision Management
BI and Predictive Analytics
Analytic Applications
IntelligenceAnalysis
Raw Data Structured Data Text Analytics Data Mining Entity Analytics Machine
Learning
Video/Audio Network/Sensor Entity Analytics Predictive
Stream Processing
Data Integration
Master Data
Streams
Analytic Applications
Real-time Analytic Zone
Landing Area, Analytics Zone
and Archive
Information Ingestion and Operational Information
Big Data Reference Architecture
Hybrid Data Warehouse
Exploration,Integrated
Warehouse, and Mart Zones
Discovery Deep Reflection Operational Predictive
All Data Sources
Decision Management
BI and Predictive Analytics
Analytic Applications
IntelligenceAnalysis
Raw Data Structured Data Text Analytics Data Mining Entity Analytics Machine
Learning
Video/Audio Network/Sensor Entity Analytics Predictive
Stream Processing
Data Integration
Master Data
Streams
Analytic Applications
Real-time Analytic Zone
Landing Area, Analytics Zone
and Archive
Information Ingestion and Operational Information
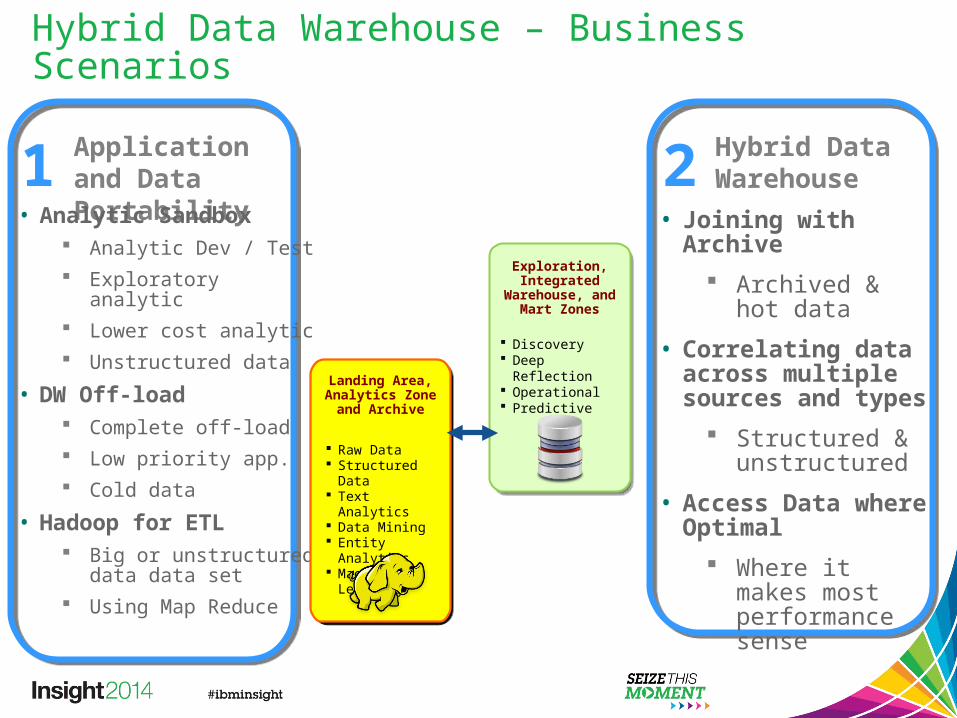
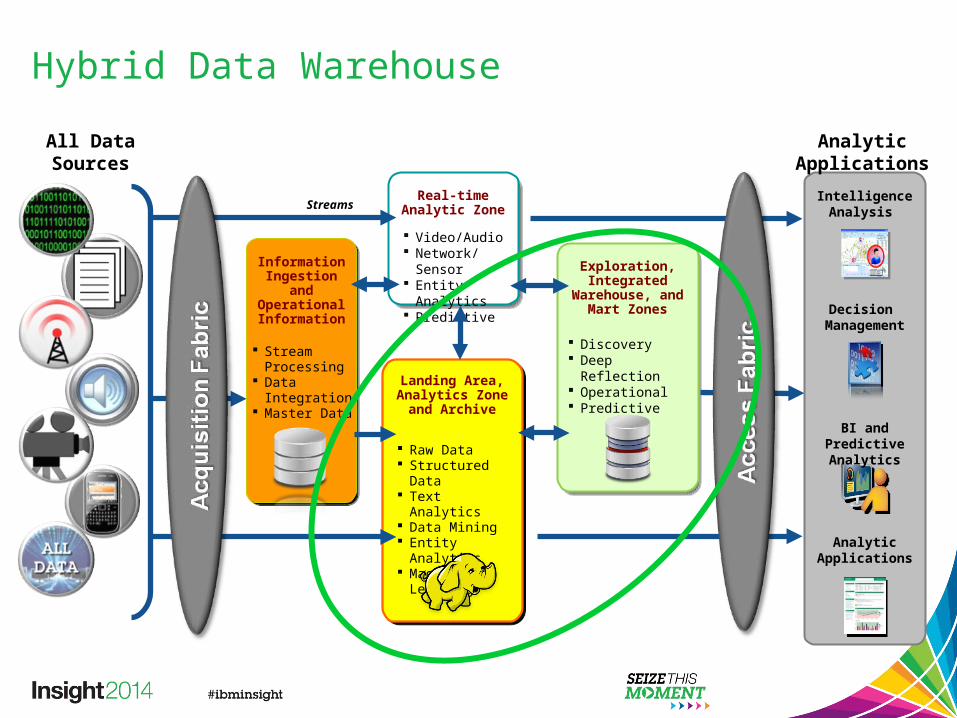
Hybrid Data Warehouse – Business Scenarios
Hybrid Data Warehouse2Application and
Data Portability1• Analytic Sandbox
Analytic Dev / Test Exploratory analytic Lower cost analytic Unstructured data
• DW Off-load Complete off-load Low priority app. Cold data
• Hadoop for ETL Big or unstructured
data data set Using Map Reduce
• Joining with Archive Archived & hot
data
• Correlating data across multiple sources and types
Structured & unstructured
• Access Data where Optimal
Where it makes most performance sense
Exploration,Integrated
Warehouse, and Mart Zones
Discovery Deep Reflection Operational Predictive
Raw Data Structured Data Text Analytics Data Mining Entity Analytics Machine
Learning
Landing Area, Analytics Zone
and Archive

SQL on Hadoop ?• Hadoop / HDFS great for storing lots of data cheaply• But …
Requires strong programming expertise Steep learning curve
• Yet, many, if not most, uses cases about structured data
• Why not use SQL in places its strength shine ? Familiar, widely used syntax Separation of what you want vs. how to get it Robust ecosystems of tools

Big SQL 3.0

Big SQL 3.0
• IBM BigInsights SQL-on-Hadoop solution BigInsights is IBM's enterprise ready Hadoop
distribution Big SQL is a standard component of BigInsights
• Integrates seamlessly with other components
• Big SQL applies SQL to your data in Hadoop Performant Rich SQL Compliance
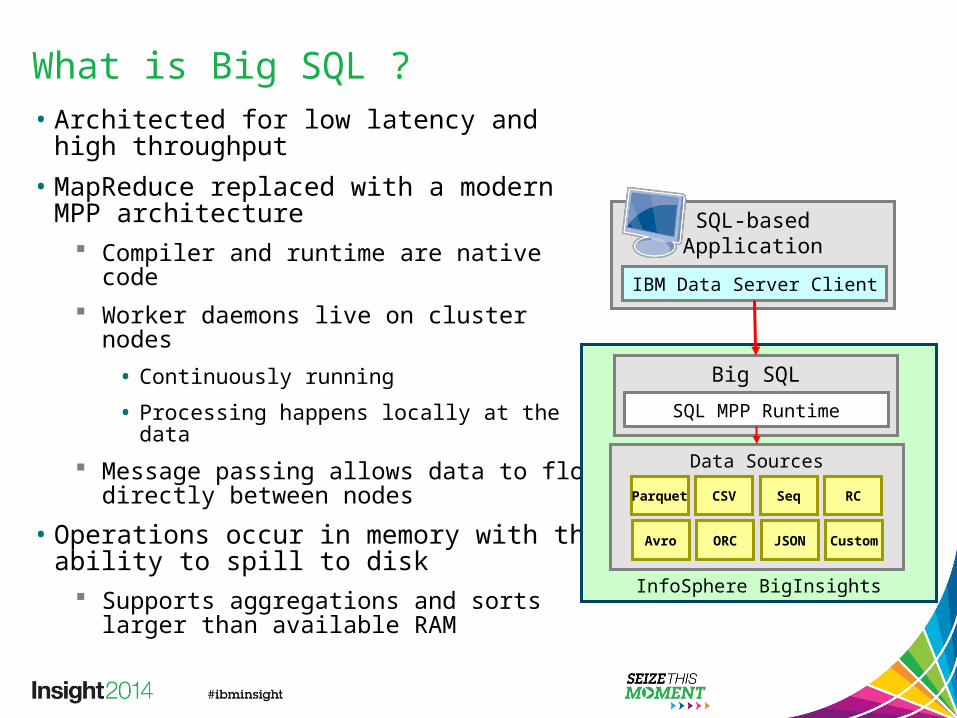
What is Big SQL ?• Architected for low latency and high
throughput• MapReduce replaced with a modern MPP
architecture Compiler and runtime are native code Worker daemons live on cluster nodes
• Continuously running
• Processing happens locally at the data Message passing allows data to flow
directly between nodes
• Operations occur in memory with the ability to spill to disk
Supports aggregations and sorts larger than available RAM
InfoSphere BigInsights
Big SQL
SQL MPP Runtime
Data Sources
Parquet CSV Seq RC
Avro ORC JSON Custom
SQL-basedApplication
IBM Data Server Client
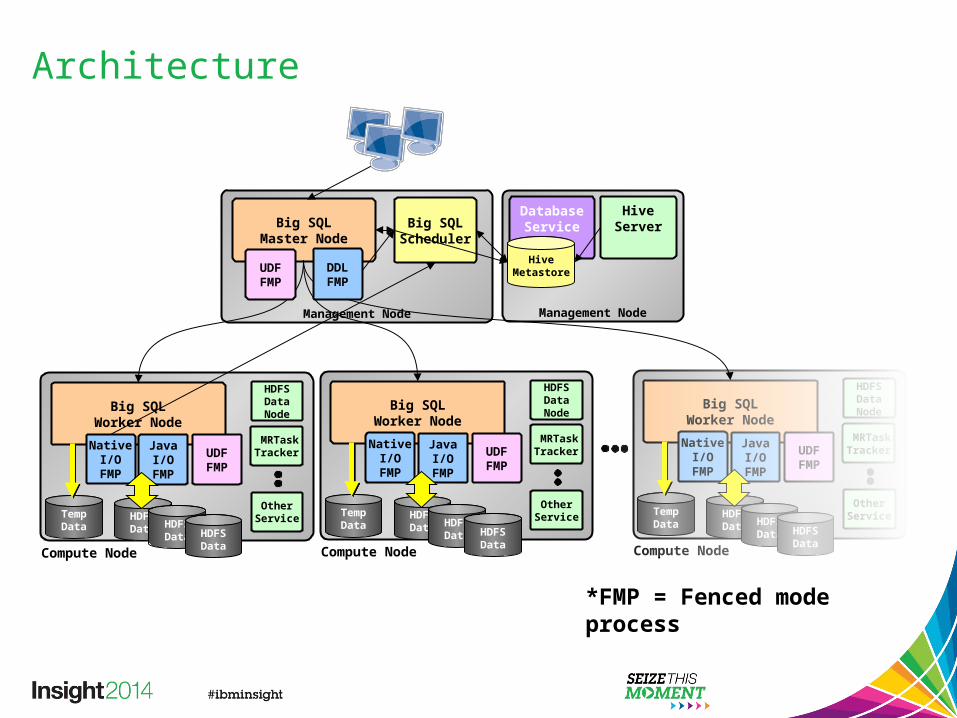
Architecture
Management Node
Big SQLMaster Node
Management Node
Big SQLScheduler
Big SQLWorker Node
JavaI/O
FMP
NativeI/O
FMP
HDFS Data Node
MRTask Tracker
Other ServiceHDFS
Data HDFSData HDFS
Data
TempData
UDF FMP
Compute Node
Database Service
Hive Metastore
Hive Server
Big SQLWorker Node
JavaI/O
FMP
NativeI/O
FMP
HDFS Data Node
MRTask Tracker
Other ServiceHDFS
Data HDFSData HDFS
Data
TempData
UDF FMP
Compute Node
Big SQLWorker Node
JavaI/O
FMP
NativeI/O
FMP
HDFS Data Node
MRTask Tracker
Other ServiceHDFS
Data HDFSData HDFS
Data
TempData
UDF FMP
Compute Node
DDLFMP
UDF FMP
*FMP = Fenced mode process
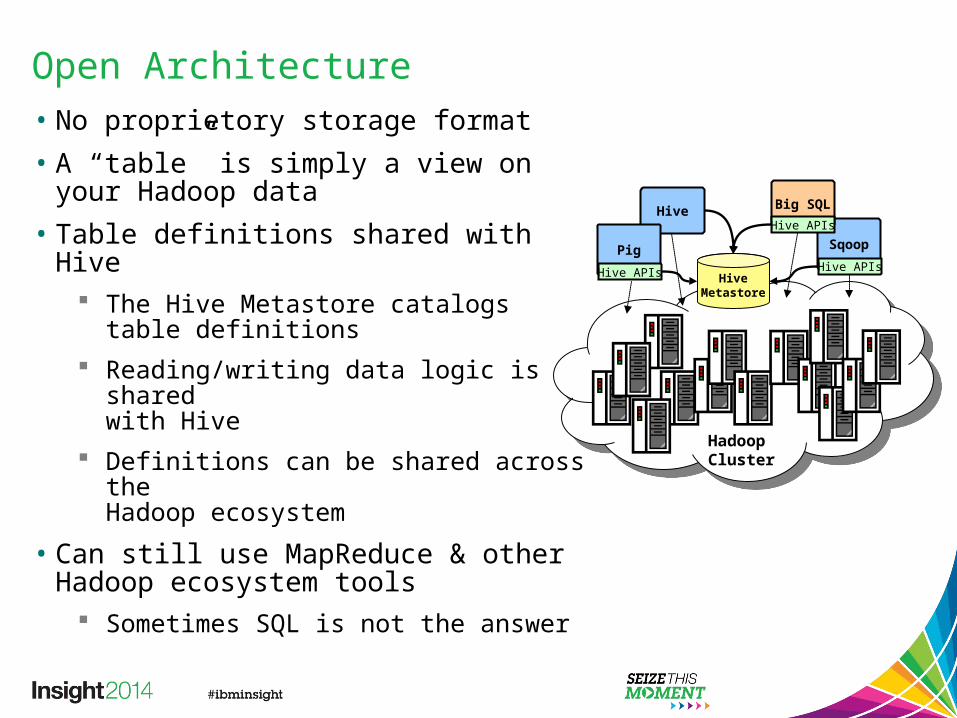
Open Architecture• No proprietory storage format• A “table” is simply a view on your
Hadoop data• Table definitions shared with Hive
The Hive Metastore catalogs table definitions
Reading/writing data logic is sharedwith Hive
Definitions can be shared across theHadoop ecosystem
• Can still use MapReduce & other Hadoop ecosystem tools
Sometimes SQL is not the answer
Hive
Hive Metastore
Hadoop Cluster
PigHive APIs
SqoopHive APIs
Big SQLHive APIs
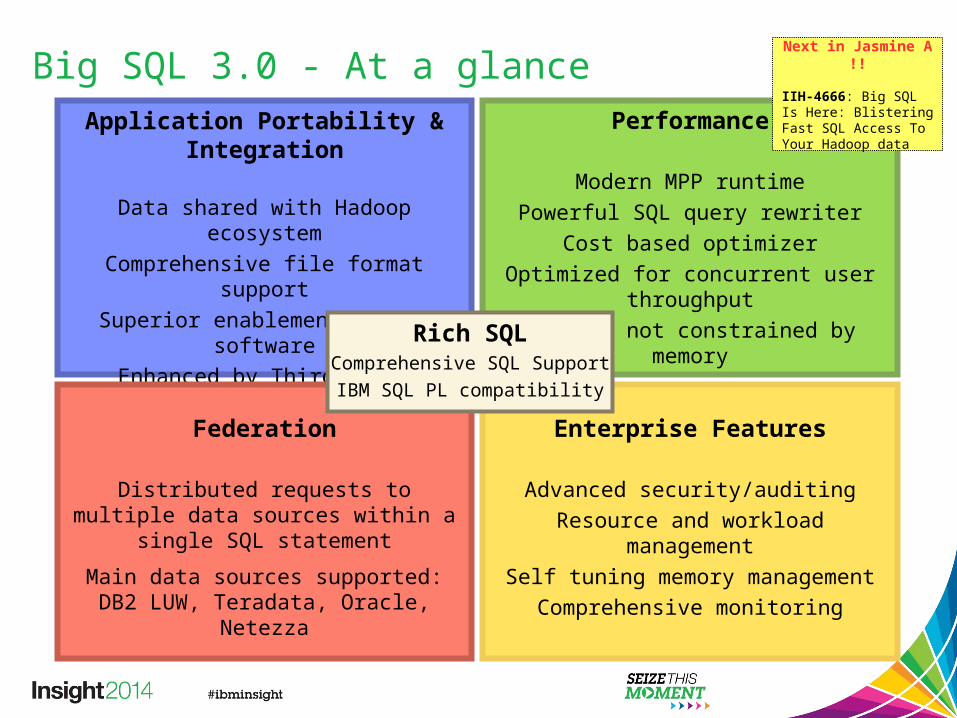
Big SQL 3.0 - At a glanceApplication Portability &
Integration
Data shared with Hadoop ecosystemComprehensive file format support
Superior enablement of IBM softwareEnhanced by Third Party software
Performance
Modern MPP runtimePowerful SQL query rewriter
Cost based optimizerOptimized for concurrent user throughput
Results not constrained by memory
Federation
Distributed requests to multiple data sources within a single SQL statement
Main data sources supported:DB2 LUW, Teradata, Oracle, Netezza
Enterprise Features
Advanced security/auditingResource and workload management
Self tuning memory managementComprehensive monitoring
Rich SQLComprehensive SQL Support
IBM SQL PL compatibility
Next in Jasmine A !!
IIH-4666: Big SQL Is Here: Blistering Fast SQL Access To Your Hadoop data

Rich SQL Support• Modern SQL capabilities• All standard join operations
Standard and ANSI join syntax - inner, outer, and full outer joins Equality, non-equality, cross join support Multi-value join (WHERE (c1, c2) = …) UNION, INTERSECT, EXCEPT
• Full support for subqueries In SELECT, FROM, WHERE and HAVING Correlated and uncorrelated Equality, non-equality subqueries EXISTS, NOT EXISTS, IN, ANY, SOME, etc.
• SQL Procedures, Flow of Control, etc ...

Drivers & Tooling Support
• Big SQL 3.0 adopts IBM's standard Data Server Client Drivers Robust, standards compliant ODBC, JDBC, and .NET drivers Same driver used for DB2 LUW, DB2/z and Informix Expands support to numerous languages (Python, Ruby, Perl, etc.)
• Together with rich SQL support, provides application portability Allows interaction with external Information Management tools
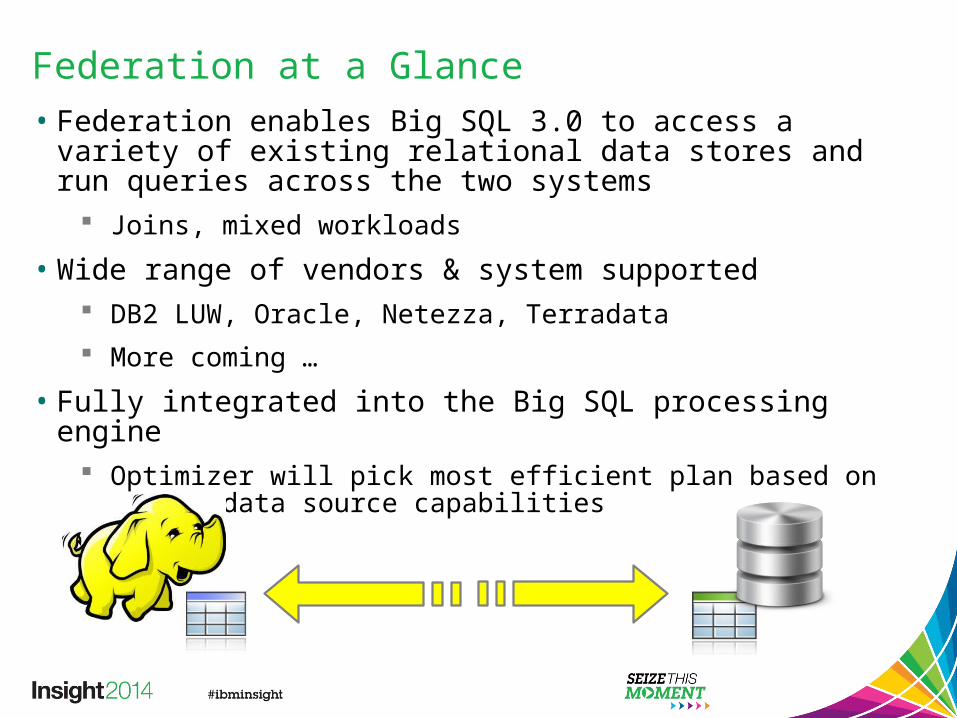
Federation at a Glance• Federation enables Big SQL 3.0 to access a variety of existing
relational data stores and run queries across the two systems Joins, mixed workloads
• Wide range of vendors & system supported DB2 LUW, Oracle, Netezza, Terradata More coming …
• Fully integrated into the Big SQL processing engine Optimizer will pick most efficient plan based on remote data source
capabilities

Using Federation to set up an Hybrid Data Warehouse

Federation – A Closer Look
• Server: A remote data source.• Wrapper: Library handling communication between engine &
remote database client. • Nickname: A local name representing an object (Table, View,
etc…) in the remote data source.• User mapping: An association between a local and a remote
authorization ID.

The Wrapper• A library to access a particular type of data sources
Typically one wrapper for each external vendor and / or version
• One wrapper to be registered for each data source type, regardless of the number of data sources of that type
• Implemented by means of a library of routines called wrapper module
Performs remote query execution using remote system client APIs
• Register in federated database using CREATE WRAPPER statement

The Server• Defines the properties and options of a specific data source
Type and version of data source Database name for the data source Access parameters & other metadata specific to the data source
• Server is defined using CREATE SERVER statement• A wrapper for this type of data source must have been previously
registered to the federated server• Multiple servers can be defined for the same remote data source
instance• e.g. Multiple servers may be defined for two different databases
from remote Oracle instance

Nicknames & Mappings• Nickname
A nickname “maps” a remote table or view in Big SQL Once declared, can be used transparently by the application
• Mappings Possible to map other obects from remote data source locally
• User ID
• Data Types
• Functions
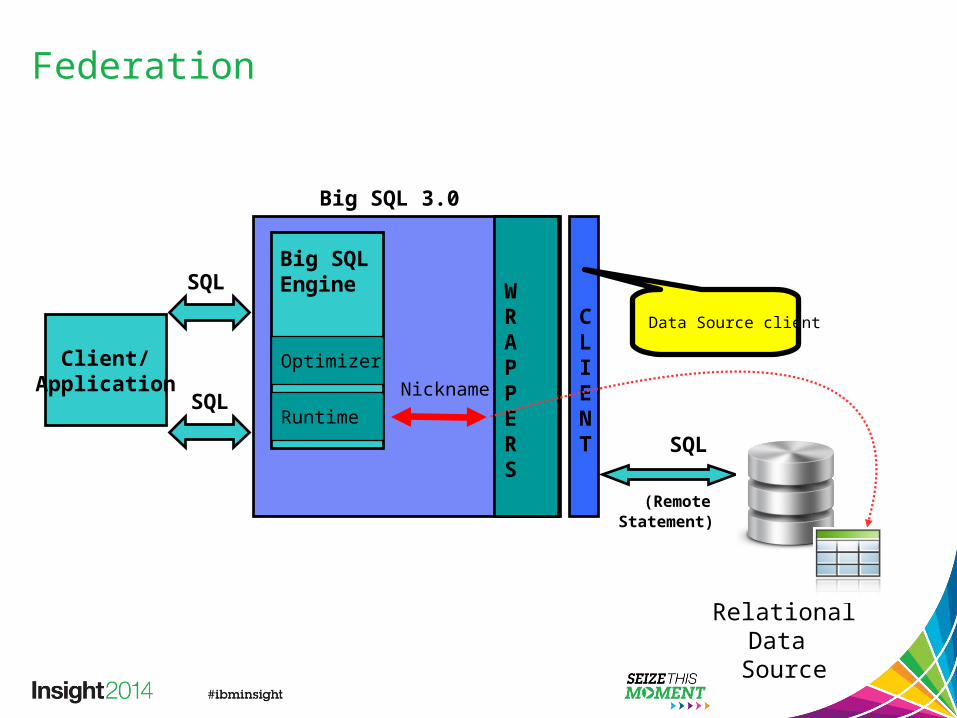
Federation
Big SQL 3.0
SQL
SQL
SQL
(Remote Statement)
Client/Application
Relational Data Source
Big SQL Engine W
RAPPERS
NicknameOptimizer
Runtime
CLIENT
Data Source client
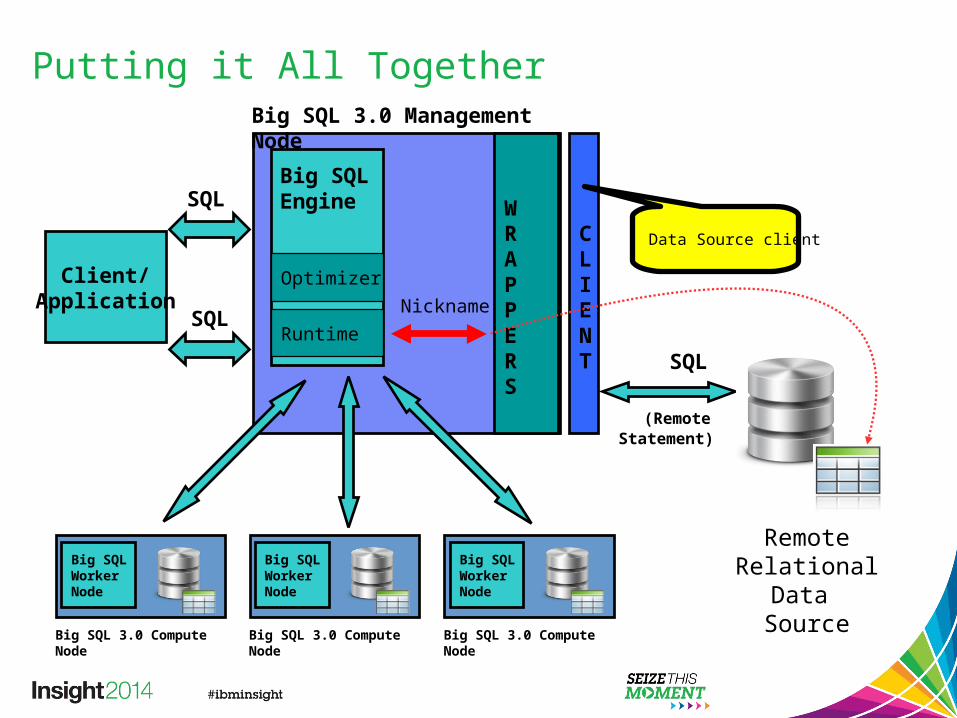
Putting it All TogetherBig SQL 3.0 Management Node
Big SQL Engine W
RAPPERS
NicknameOptimizer
RuntimeSQL
SQLCLIENT
Data Source client
SQL
(Remote Statement)
Client/Application
Remote Relational Data
Source
Big SQL Worker Node
Big SQL 3.0 Compute Node
Big SQL Worker Node
Big SQL 3.0 Compute Node
Big SQL Worker Node
Big SQL 3.0 Compute Node
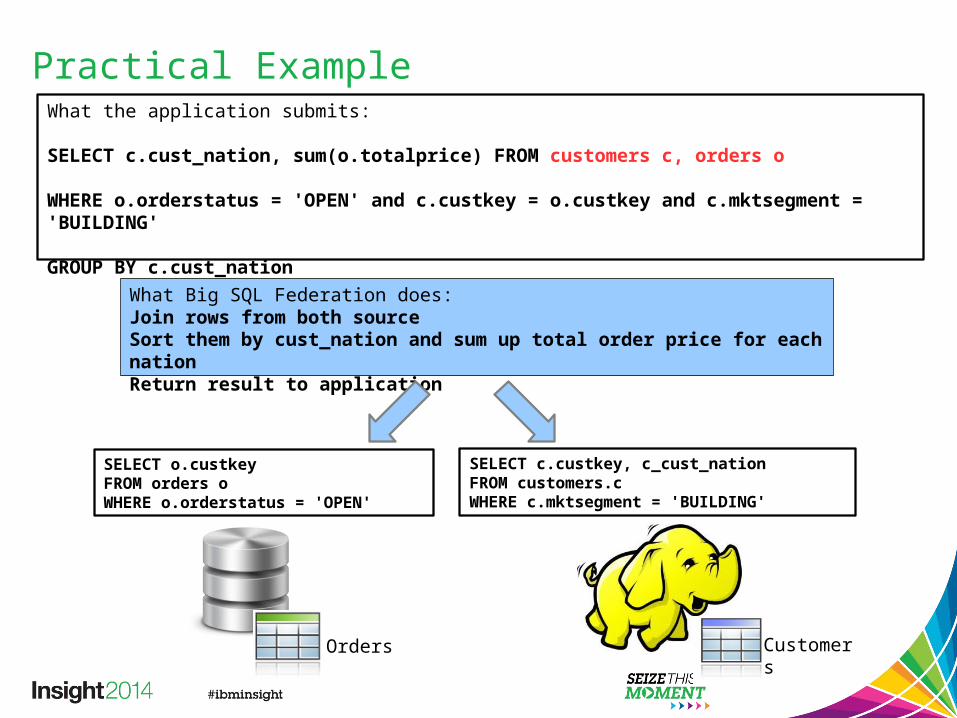
Practical ExampleWhat the application submits:
SELECT c.cust_nation, sum(o.totalprice) FROM customers c, orders o
WHERE o.orderstatus = 'OPEN' and c.custkey = o.custkey and c.mktsegment = 'BUILDING'
GROUP BY c.cust_nation
SELECT o.custkeyFROM orders oWHERE o.orderstatus = 'OPEN'
SELECT c.custkey, c_cust_nationFROM customers.cWHERE c.mktsegment = 'BUILDING'
What Big SQL Federation does:Join rows from both sourceSort them by cust_nation and sum up total order price for each nationReturn result to application
Orders Customers
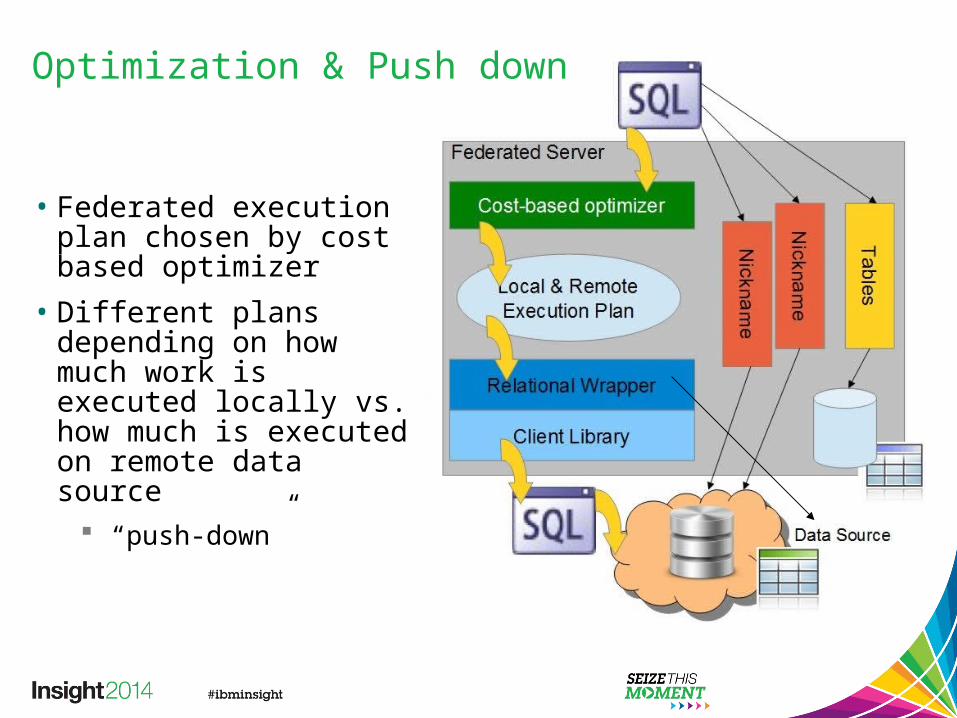
Optimization & Push down
• Federated execution plan chosen by cost based optimizer
• Different plans depending on how much work is executed locally vs. how much is executed on remote data source
“push-down”

String Comparison • Things to consider when comparing string types
Collation sequence - A > B ? Blank sensitivity - “ABC” = “ABC ” ? Empty string as NULL - “” = NULL ?
• Big SQL uses BINARY collation Byte for byte comparison of the data – Hive behaviour Blank sensitive, empty string are not NULL
• More String operation processing can be pushed on remote server if the collations are compatible
Use the COLLATING_SEQUENCE parameter to indicate compatibility with the BINARY collation
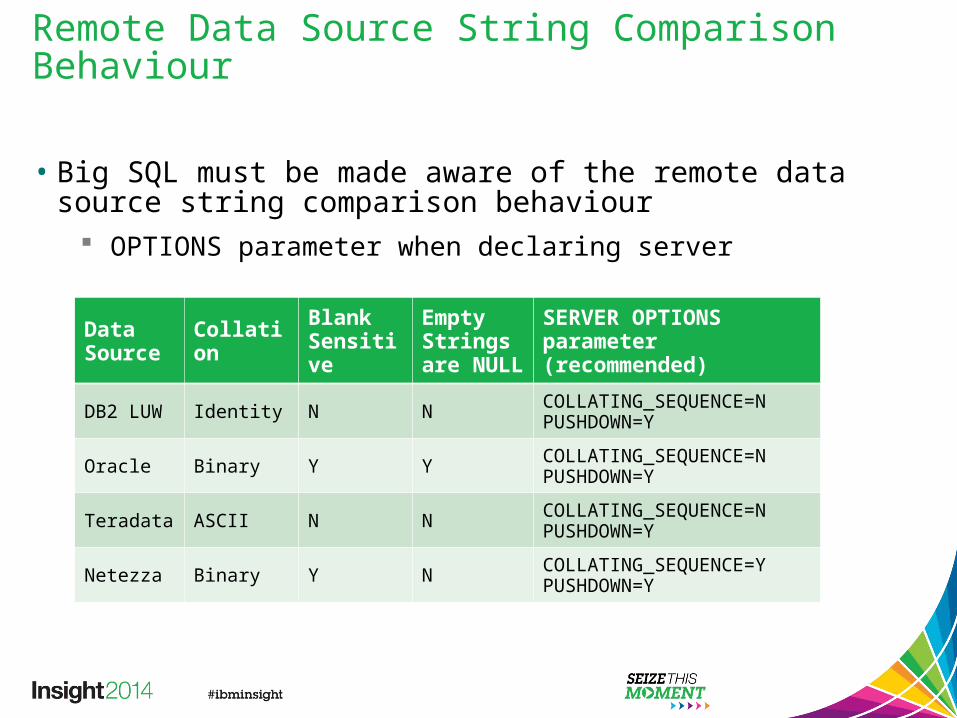
Remote Data Source String Comparison Behaviour
• Big SQL must be made aware of the remote data source string comparison behaviour
OPTIONS parameter when declaring server
Data Source Collation Blank
SensitiveEmpty Strings are NULL
SERVER OPTIONS parameter (recommended)
DB2 LUW Identity N N COLLATING_SEQUENCE=NPUSHDOWN=Y
Oracle Binary Y Y COLLATING_SEQUENCE=NPUSHDOWN=Y
Teradata ASCII N N COLLATING_SEQUENCE=NPUSHDOWN=Y
Netezza Binary Y N COLLATING_SEQUENCE=YPUSHDOWN=Y

Federation - Installation & Support• Available out of the box
Setup by BigInsights installation Wrappers available for following RDBMs: DB2, Teradata, Oracle,
Netezza
• Version supported
RDBM Version Wrapper Library
DB2 LUW 9.7, 9.8, 10.1, 10.5 libdb2drda.so
Teradata 12, 13 libdb2teradata.so
Oracle 11g, 11gR1, 11gR2 libdb2net8.so
Netezza 4.6, 5.0, 6.0, 7.1, 7.2 libdb2rcodbc.so

Federation – Set up Overview• Set-up the environment• Set-up the data source client
Environment variable and/or entries in $HOME/sqllib/cfg/db2dj.ini If db2dj.ini modified, reload the db2profile
• Create the wrapper• Define the server object on Big SQL• Create the nicknames• Create the user & data type mappings
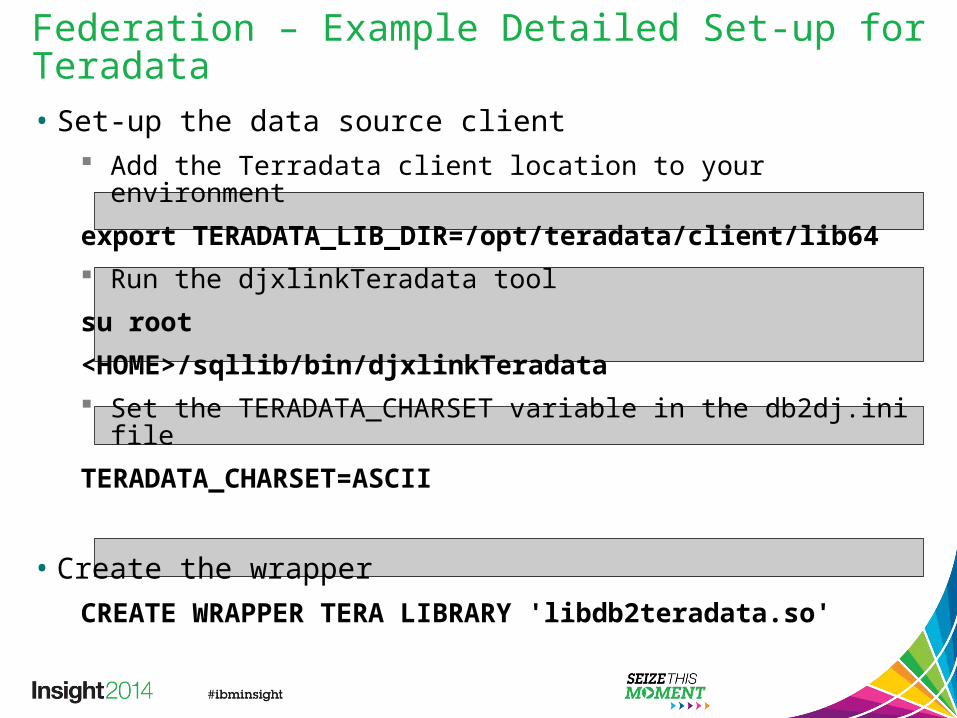
Federation – Example Detailed Set-up for Teradata• Set-up the data source client
Add the Terradata client location to your environment
export TERADATA_LIB_DIR=/opt/teradata/client/lib64 Run the djxlinkTeradata tool
su root<HOME>/sqllib/bin/djxlinkTeradata Set the TERADATA_CHARSET variable in the db2dj.ini file
TERADATA_CHARSET=ASCII
• Create the wrapperCREATE WRAPPER TERA LIBRARY 'libdb2teradata.so'

Federation – Example Detailed Set-up for Teradata• Define the server object on Big SQL
CREATE SERVER TERASERV TYPE TERADATAVERSION 13 WRAPPER TERA AUTHORIZATION 'terauser' PASSWORD 'terapwd' OPTIONS (NODE 'teranode.ibm.com', PUSHDOWN 'Y', COLLATING_SEQUENCE 'N')
• Create the user & data type mappingsCREATE USER MAPPING FOR dbuser SERVER TERASERV OPTIONS (REMOTE_AUTHID 'terauser', REMOTE_PASSWORD 'terapwd')
• Create the NicknameCREATE NICKNAME TD_CUSTOMERSFOR TERARVER.SALES.CUSTOMERS

Federation – Example Detailed Set-up for Teradata• Run a query involving the remote table through the nickname
SELECT * FROM TD_CUSTOMERS

Conclusion
• Big Data offers new opportunities & potential for competitive advantages
• Hadoop is the solution, but must be integrated with existing data management infrastructure
• Big SQL 3.0 offers a performant, rich SQL on Hadoop solution, with a powerful federation capabilities, on which to build your hybrid data warehouse

Reference
• IBM InfoSphere BigInsights 3.0 Knowledge Center• IBM Big SQL 3.0• Set up and use federation in InfoSphere BigInsights Big SQL V3.0
• Try it for yourself at the drop-in lab LCI-6260: Federating Big SQL 3.0 with a Relational Data Store
• Coming next in this room ! IIH-4666: Big SQL Is Here: Blistering Fast SQL Access To Your
Hadoop data

• Get it BigInsights Quick Start Edition VM
• ibm.co/quickstart Analytics for Hadoop Service
• bluemix.net Big SQL Tech Preview
• bigsql.imdemocloud.com• Learn it
Follow online tutorials• ibm.biz/tutorial
Enroll in online classes • BigDataUniversity.com
• HadoopDev Links all available Watch video demos, read articles, etc. https://developer.ibm.com/hadoop
Want to Learn More ?

We Value Your Feedback!• Don’t forget to submit your Insight session and speaker feedback!
Your feedback is very important to us – we use it to continually improve the conference.
• Access the Insight Conference Connect tool to quickly submit your surveys from your smartphone, laptop or conference kiosk.
41

Acknowledgements and Disclaimers Availability. References in this presentation to IBM products, programs, or services do not imply that they will be available in all countries in which IBM operates.
The workshops, sessions and materials have been prepared by IBM or the session speakers and reflect their own views. They are provided for informational purposes only, and are neither intended to, nor shall have the effect of being, legal or other guidance or advice to any participant. While efforts were made to verify the completeness and accuracy of the information contained in this presentation, it is provided AS-IS without warranty of any kind, express or implied. IBM shall not be responsible for any damages arising out of the use of, or otherwise related to, this presentation or any other materials. Nothing contained in this presentation is intended to, nor shall have the effect of, creating any warranties or representations from IBM or its suppliers or licensors, or altering the terms and conditions of the applicable license agreement governing the use of IBM software.
All customer examples described are presented as illustrations of how those customers have used IBM products and the results they may have achieved. Actual environmental costs and performance characteristics may vary by customer. Nothing contained in these materials is intended to, nor shall have the effect of, stating or implying that any activities undertaken by you will result in any specific sales, revenue growth or other results.
© Copyright IBM Corporation 2014. All rights reserved. — U.S. Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract
with IBM Corp.
IBM, the IBM logo, ibm.com, Information Management and InfoSphere BigInsights are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. If these and other IBM trademarked terms are marked on their first occurrence in this information with a trademark symbol (® or TM), these symbols indicate U.S. registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered or common law trademarks in other countries. A current list of IBM trademarks is available on the Web at
•“Copyright and trademark information” at www.ibm.com/legal/copytrade.shtml
•Other company, product, or service names may be trademarks or service marks of others.
42

Thank You !


















