
Using genome browsers
63
Using genome browsers Visualization and data repositories
-
Upload
xander-powers -
Category
Documents
-
view
43 -
download
0
description
Visualization and data repositories. Using genome browsers. Motivation. Aside from R, genome browsers are arguably the most important tool in computational genomics …but is not widely used in the experimental community - PowerPoint PPT Presentation
Transcript of Using genome browsers

Using genome browsers
Visualization and data repositories

Motivation
Aside from R, genome browsers are arguably the most important tool in computational genomics
…but is not widely used in the experimental community
The browser gives you an immediate edge - you can look at data, form hypothesis and up-and download data!

In this course
1: How to use the web interface; understanding the data types
2: How to download and upload data to the browser; interaction with R
3: How to make complex analyses between data types; Galaxy and R

Today's teaching:
• Lectures with genome browser examples
• Short discussions with your neighbour
• Exercises

Kick starting with a challenge• You are a major sequencing center• You have sequenced the killer whale
(Orca) genome - you have the whole genome as a stretch of ACGTs
• How do you make sense of this and show it to others? What value does the data have in itself?
• 2 minutes with your neighbour

Jim Kent, assembly-guru. Some profound words about
the genome sequence
“Well, it has a lot of G, C, A and Ts”

Genomes are worthless
• …without any annotation
• What type of annotations do we want to put on genomes?
• 2 minutes with your neighbour

Examples:
• 'DNA' annotation:– Known genes– Predicted genes– Repeats, transposons, CpG islands– Conservation across species
• 'Dynamic' annotation:– Known transcripts– Expression data– DNA modifications

How to present this data?
• Plain text files are useless..for most biologists
• Use the genome sequence as a frame, on which we map real data or predictions

The idea of the browser
• Based on the genome, we can– Zoom up and down, and scroll sideways– See the data in different representations– Select WHAT data we want to see (way to much
data to look at all at once)
• Important side-effect: if we map all interesting data, it means that all data is at one place, which means that we can download what we are interested in to do analysis!

The three browsers• UCSC genome browser
– http://genome.ucsc.edu– Updated often, simple but powerful interface. Very
simple underlying data formats
• ensEMBL– http://www.ensembl.org– More complex web interface, with multiple zoom
levels. Very complex underlying data formats
• The generic genome browser– http://www.gmod.org/GBrowse– Actually more a software development platform, so
that you can do your own. Resembles UCSC more than ensEMBL

In this course…
• We will only use the UCSC browser due to– Simplicity– Lecturer bias– The galaxy tool - a very nifty web-tool to do power
user analysis on UCSC data (more later)
• If you know this browser, other browsers are easy to understand

Basic concepts
• Zooming
• Data tracks
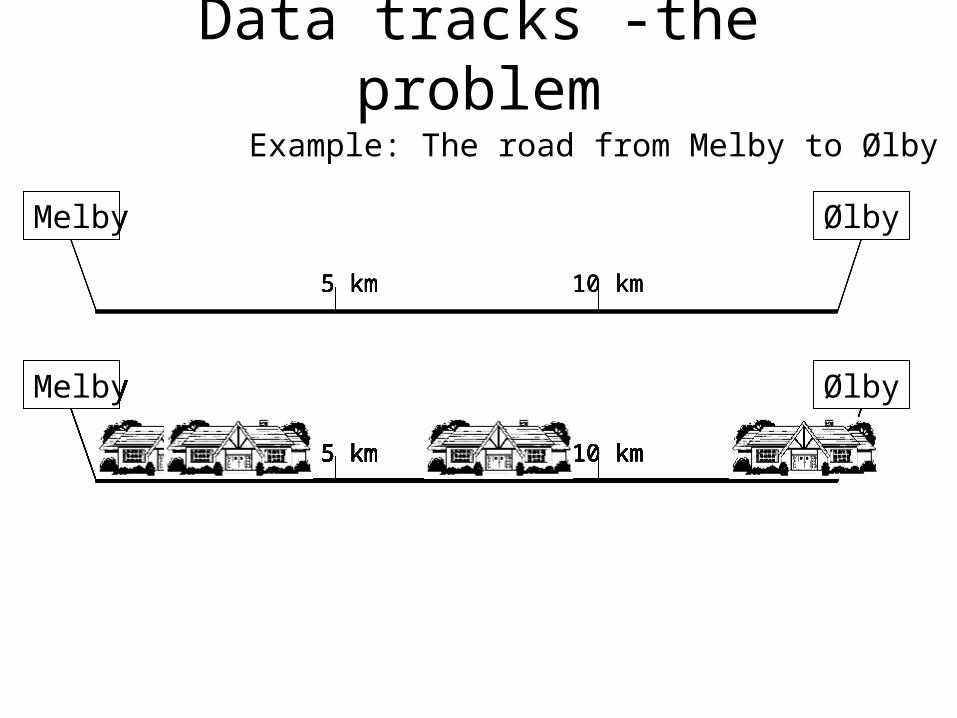
Data tracks -the problem
Example: The road from Melby to Ølby
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
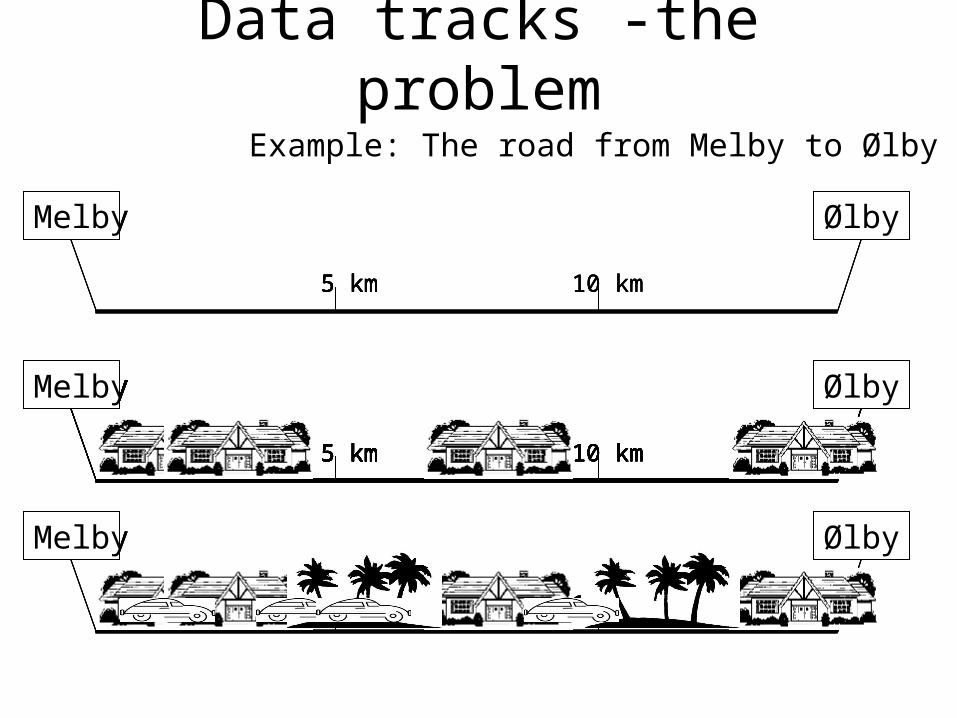
Example: The road from Melby to Ølby
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Data tracks -the problem

Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Melby Ølby
5 km5 km 10 km
Data tracks -the solution
5 km5 km5 km5 km5 km5 km
houses
trees
Monday
Sunday
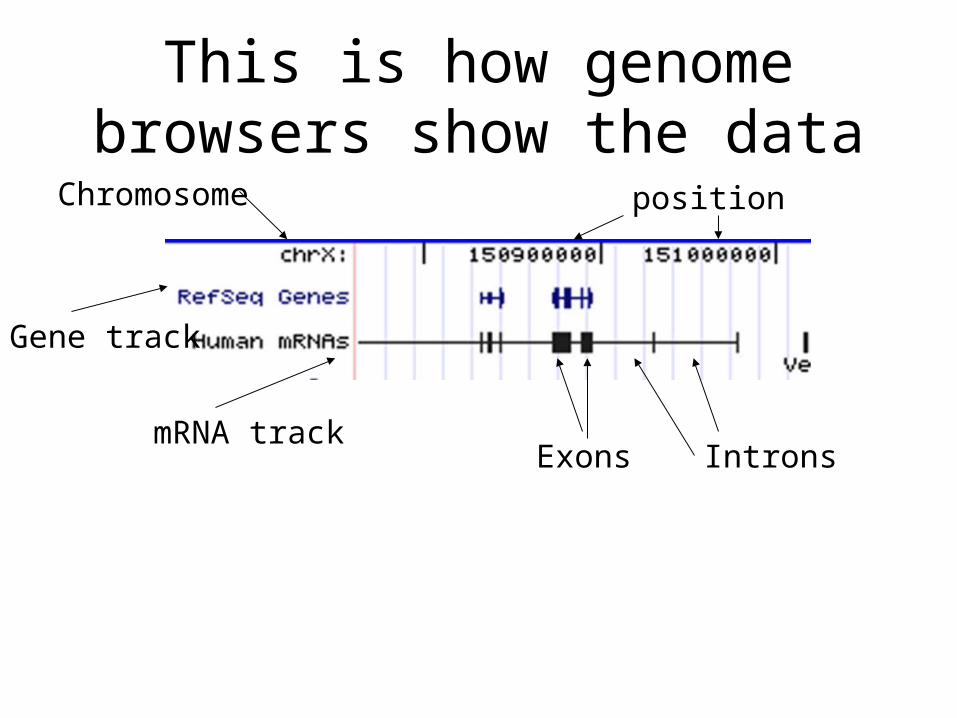
This is how genome browsers show the data
Chromosome position
Gene track
mRNA trackExons Introns

Annotation tracks
• A track is often one source of data, from a particular place, that is mapped to the genome
• Data can be viewed as “blocks” with a start and an end, expressed as chromosome coordinates
• It is important to know what the data is before trying to interpret it
• We will first look at the “human mRNA” track

Human mRNA track
• What the guys at UCSC did:– Take all the known mRNAs in Genbank,
and map these to the human genome using a software called BLAT (similar to blast). Everything that hits will be shown in this track.
– What is the pros and cons of this approach? What are the limitations? 2 minutes with your neighbour!

Example answers:
ProsSimple, and no filtering - leaving me to make interpretation
ConsNot real annotation - again, leaving me to make interpretationHeavily reliant on the data source qualityLimited by the extent of data

A short non-interactive tour
• We will use the browser extensively from now on
• But first, I will guide through a few key concepts - otherwise confusion ensues when trying the real thing

What version of the genome do you have?
• Genome sequences are based on many short sequenced reads, which then are assembled into a single sequence
• This is very tricky, and we get slightly updated genomes at regular intervals
• A version of the genome is called an assembly
• So, whenever you say that you are using a genome sequence to do something, you have to say what assembly you are working on!

More about assemblies
• The official naming system is– [species abbreviation][assembly number]
For instance hg17 (human nr 17), or mm8 (mus musculus 8)
There is an alternative way: the date of the release.
So, hg17 is also called “Human May 2004”

Even more about assembliesRules of thumb:
The newer an assembly, the “better”
Some older assemblies have more data mapped to them (because they have been around longer)
Some genomes are new, and unstable: updates come often, and big differences between updates. Some are more mature (like human)

Selecting species & assembly
Species
Assembly: the genome “version”.
Where on the genome
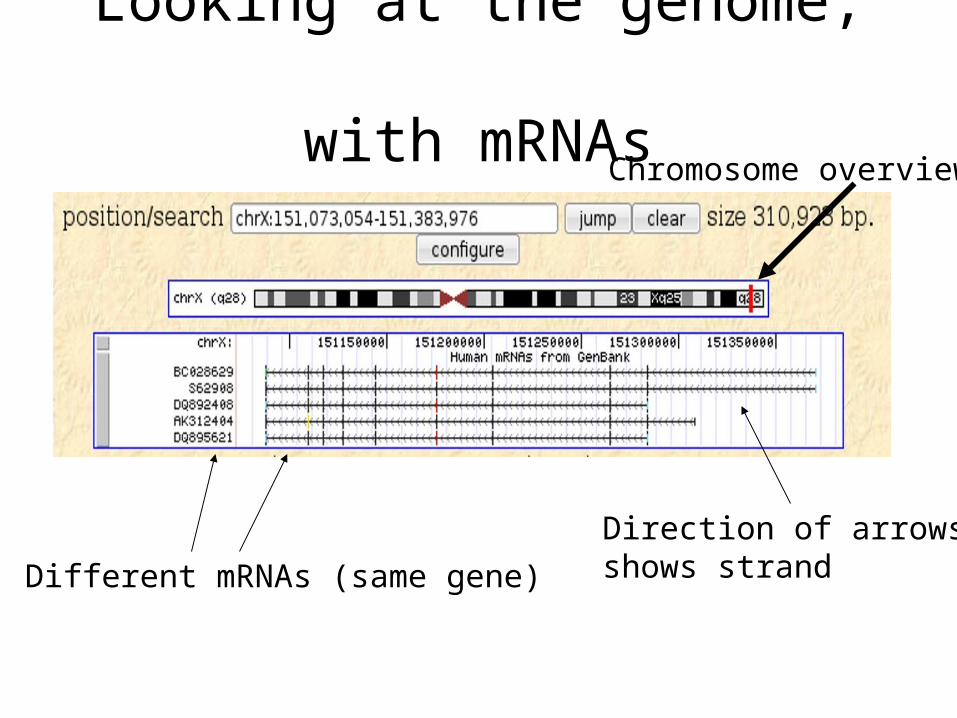
Looking at the genome, with mRNAs
Different mRNAs (same gene)
Direction of arrowsshows strand
Chromosome overview

Zooming in(We'll learn how later)

Some points:•Transcription, in this case, is right to left - transcription on the minus strand - shown by the arrows•Two of the mRNAs start here, the others start even further upstream. Probably alternative promoters•The fat, two-colored blocks are predicted to be protein-coding partsNote that•There are parts of mRNAs that are not translated - so called UTRs•There is one mRNA that is clearly non-coding (might have a stop-coding further upstream)

Zooming even further down - we see the actual DNA
Codons
Clicking on any of these mRNAs take you to the corresponding Genbank entry

Different data representations
Each data track has a selection 'box'Use this to :
-turn tracks on or off-change visualization
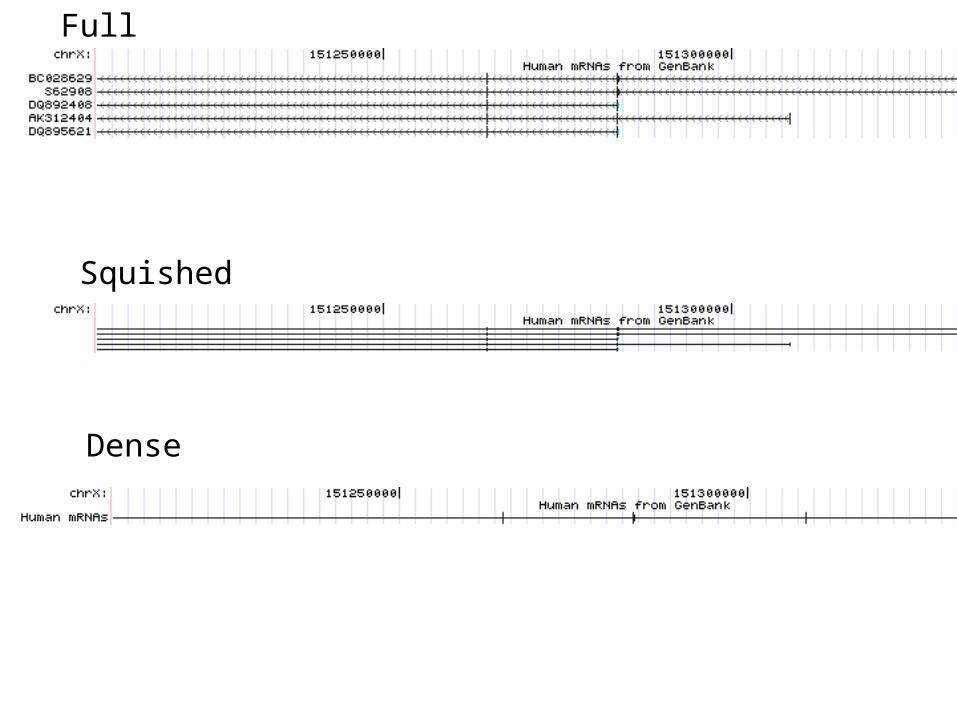
examplesFull
Squished
Dense

Time to try it out.. • Important: the genome browser shows many
tracks by default, some which are named in a confusing way
• Don’t let this throw you. We will walk them through!
• Goto http://genome.ucsc.edu/
• Click 'Genome browser' to the left
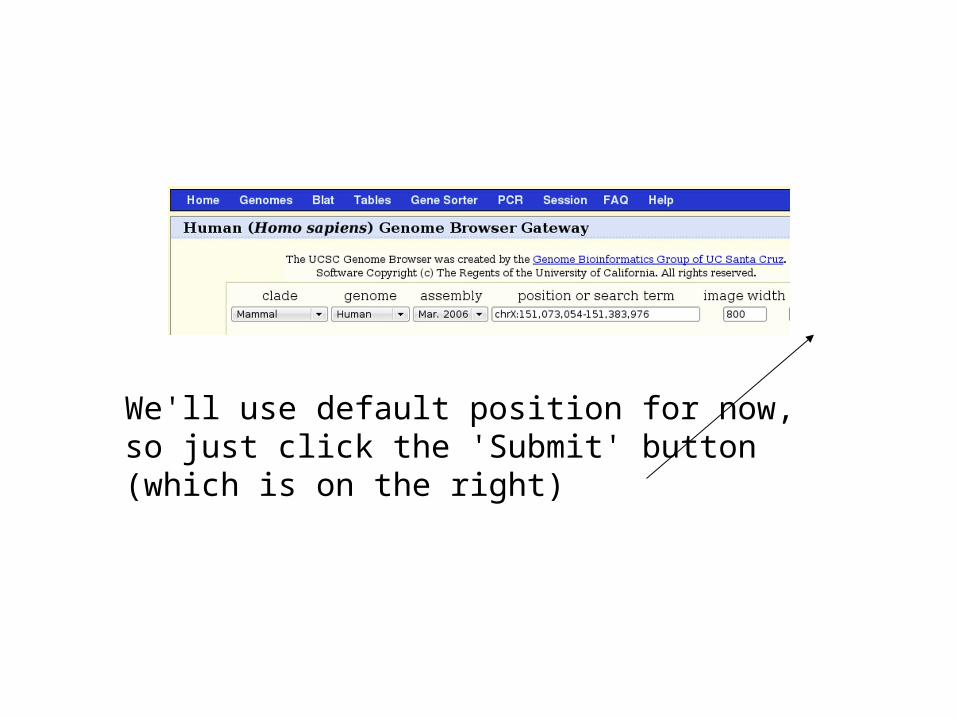
We'll use default position for now, so just click the 'Submit' button (which is on the right)

Overwhelmed? Many types of data! We will only use
some, others you can explore yourselves
Below the image, the data tracks are categorized for easier access:

Let’s look only at the Human mRNA track as before
Challenge:
Turn off all tracks, except “base position” and “human mRNA”!
(Expand/collapse the categories, then hide tracks.
Use 'refresh' to update the image.)

Challenge
Using the following buttons, and what we already went through, find out:
What is the DNA sequence of the first two codons of mRNA DQ892408?
What is the “gene name” of the mRNAs we are looking at?
Are the two longest RNAs starting at exactly the same place?
What are the neighboring genes?

Before we go any further…
What are all these data? What can we use them for?
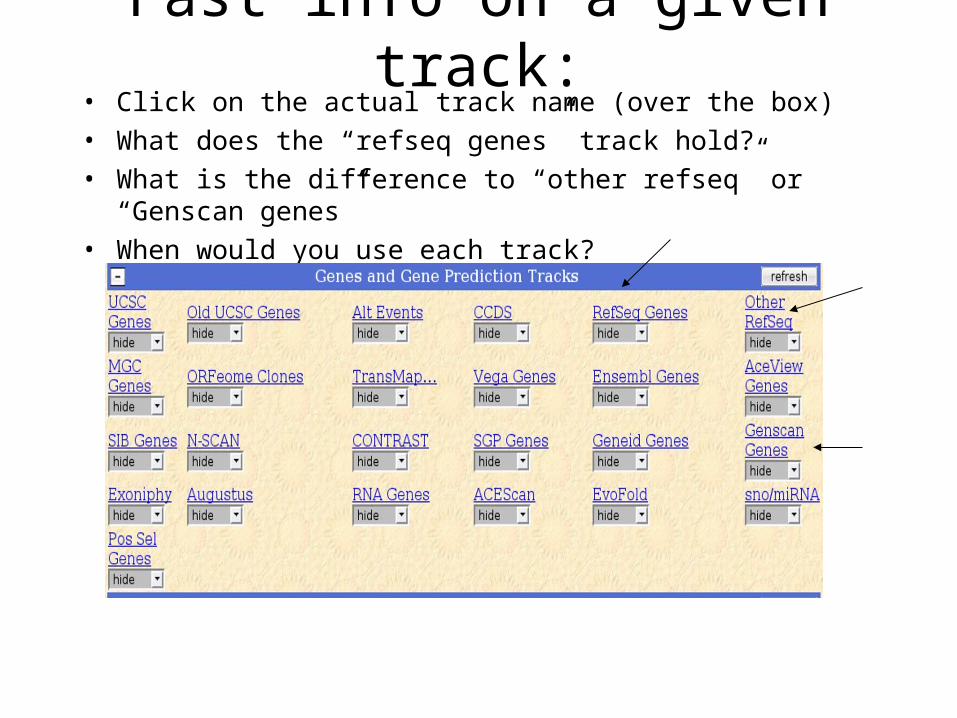
Fast info on a given track:• Click on the actual track name (over the box)• What does the “refseq genes” track hold?• What is the difference to “other refseq” or “Genscan genes”• When would you use each track?

• It is not realistic to go through all tracks in this course
• …and not meaningful, because new tracks are added over time
• We will go over the main types of tracks, and the relevant experimental methods for producing the tracks
• Understanding what we are looking is very necessary for meaningful interpretation

Big groups of things, summarized
• Sequence features– CpG islands– Repeats
• Transcripts or part of transcripts– mRNA, ESTs
• The so-called genes (predicted or experimental)• Tiling array expression data• Chip-Chip• Variation within species (SNPs)• Conservation and alignments between species
– net alignments, Phastcons scores, • The ENCODE dataset
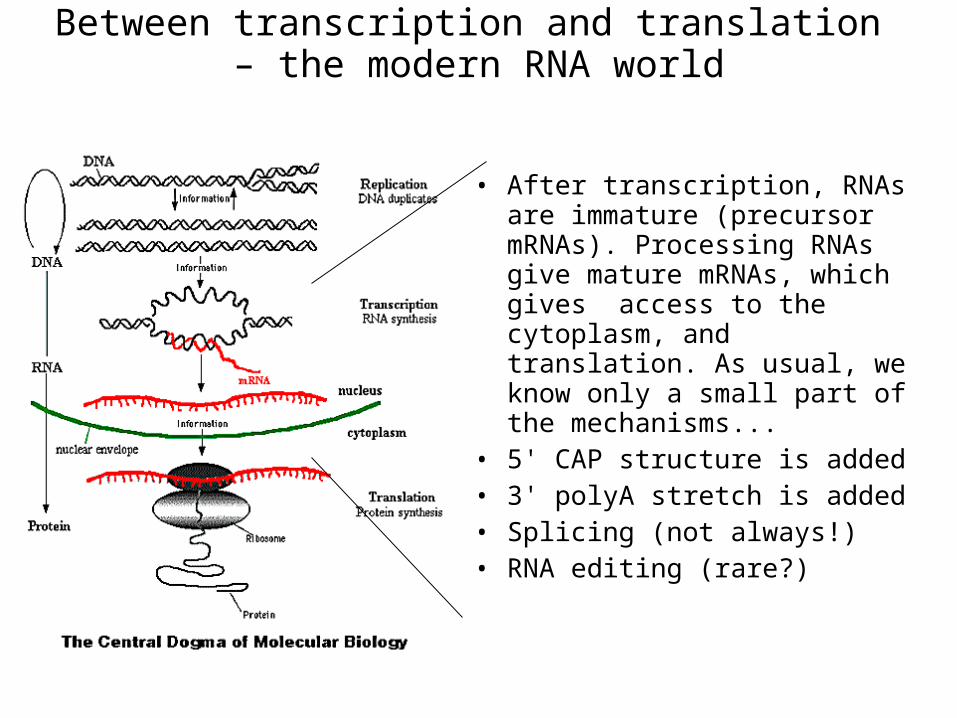
Between transcription and translation – the modern RNA world
• After transcription, RNAs are immature (precursor mRNAs). Processing RNAs give mature mRNAs, which gives access to the cytoplasm, and translation. As usual, we know only a small part of the mechanisms...
• 5' CAP structure is added• 3' polyA stretch is added• Splicing (not always!)• RNA editing (rare?)
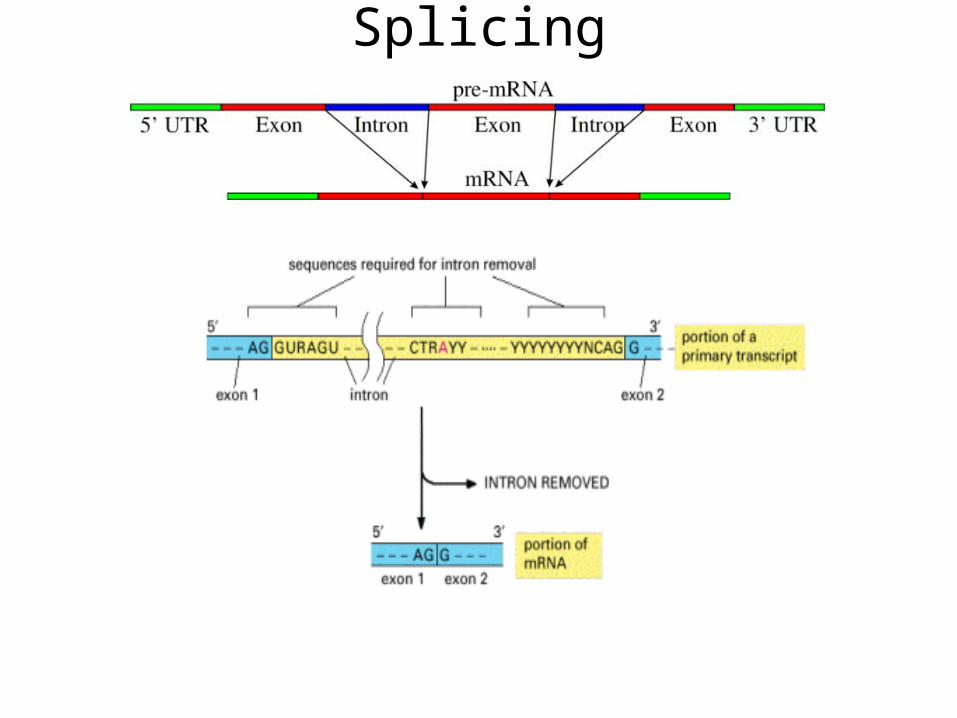
Splicing

Problem:We want to know what mRNA look like... but RNA is unstable, can't be sequenced directly
Solution: Turn them into cDNA first.
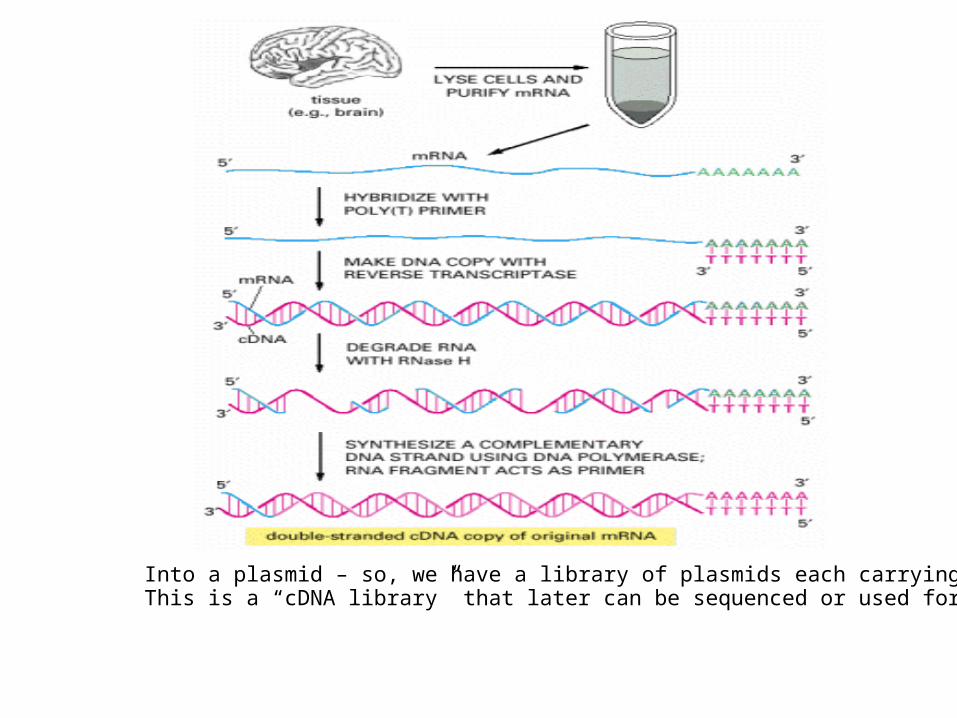
Into a plasmid – so, we have a library of plasmids each carrying one cDNAThis is a “cDNA library” that later can be sequenced or used for other things

General problems with cDNA sequencing:
• Reverse transcriptase falls off• Hard to sequence long transcripts• Many cDNAs are identical
– Very expensive if you want to sequence all unique molecules

Solving the problem
Only sequence parts of cDNAs - these are called ESTs(more in a few slides)
Semi-recent development: sequencing of full-length cDNAs, using– Cap-trapping– PolyA primers– subtraction

Subtraction: how to only get RNAs you have not seen yet
• Simple concept:
• For a cDNA sample, we add an excess of abundant RNAs. These will hybridize
• Then, we remove everything which hybridized
• …and sequence the rest
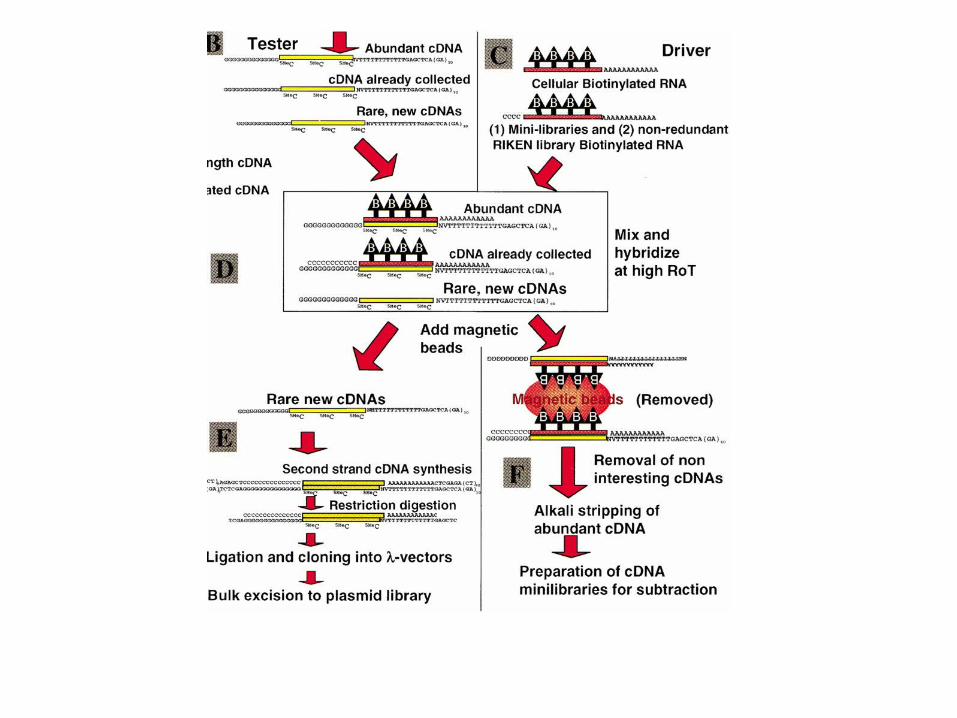

Discuss with your neighbour (2 min)
Say that we have two cDNA libraries - one is subtracted, one is not
What are they good for?
Expression (how many transcripts of a certain gene)?
Annotation and gene discovery?

Visualizing and annotating cDNAs in the genome browser
• The genome is actually needed to make sense of cDNAs, especially if it is not protein-coding
• A general approach is to map your cDNA to the genome using an alignment algorithms
• Here, we will use BLAT and the UCSC browser• Should be straight-forward, but...lets try it out: See the
course page for 3 mouse sequences in the blat_seqs file – I will do one in real-time
• Assume these are new sequences that you must say whether they are good enough to be part of the genome browser

Bottom line
• cDNA <->genome is sometimes trivial, but can become very tricky. Bear this in mind when you look at genome mappings – this is the process they are annotated with!
• cDNAs are often good quality, but always be sceptical unless there are multiple lines of evidence
• Biological knowledge helps here – sanity checks become easier

More on the problem of sequencing cDNAs
Hard to sequence full-length cDNAs…and expensive to sequence many
If we cannot sequence the whole cDNAs…Only sequence parts of cDNAs - these are
called expressed sequence tags: ESTs
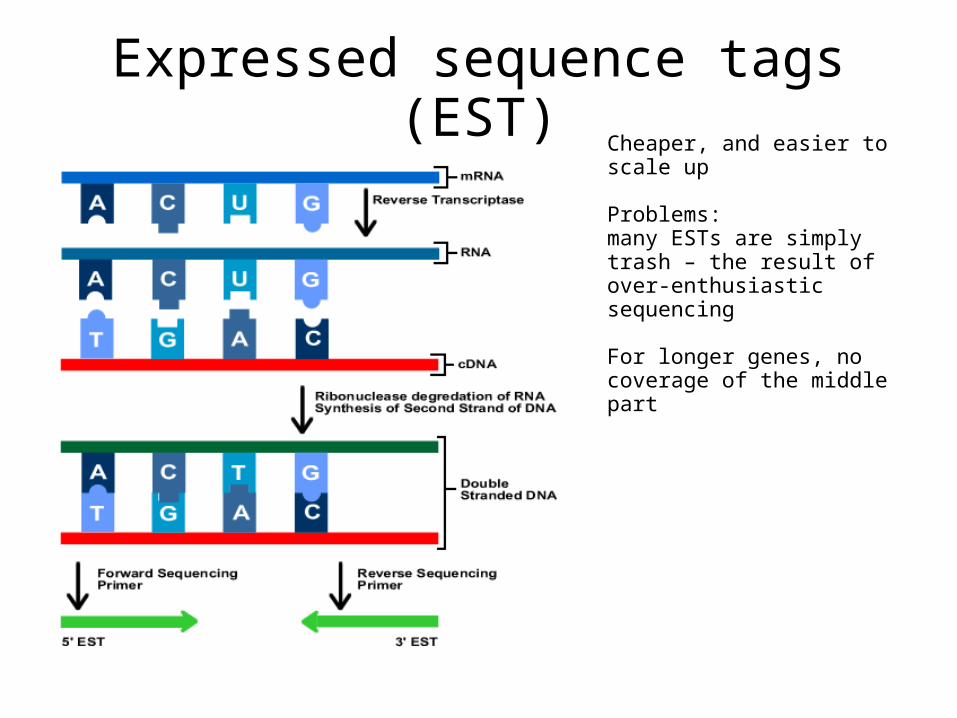
Expressed sequence tags (EST)Cheaper, and easier to scale up
Problems: many ESTs are simply trash – the result of over-enthusiastic sequencing
For longer genes, no coverage of the middle part

Complementary information to cDNAs
• Can be used for expression studies (more later)
• Many MORE of them than full-length cDNAs - higher coverage
• If you only have ONE cDNA for a given isoform, ESTs can help to “validate it”

So-called “gene” tracks
• We have now seen that often a “gene” have many mRNAs - forming a “transcription unit”
• If you have many mRNAs, it is good to have summary tracks of genes or transcription units
• The UCSC browser has (at least) two of these:– The RefSeq track– The “Known genes” track

Refseq• Refseq is actually database with high-quality
cDNAs, from NCBI. So, a Refseq sequence always has at least one identical cDNA in GenBank.
• Good, because some individual cDNAs are trash, and we get a more manageble dataset
• Bad, because the criteria used are somewhat arnitrary. For example, “long cDNAs are better than short”

Known Genes
A track made by the UCSC people, which uses multiple databases (Refseq, uniprot, etc)
Horrible name - easy to misunderstand it - it is NOT all known genes!
If clicking on individual genes, you get very nice summaries, sometimes with expression information

Searching by gene name
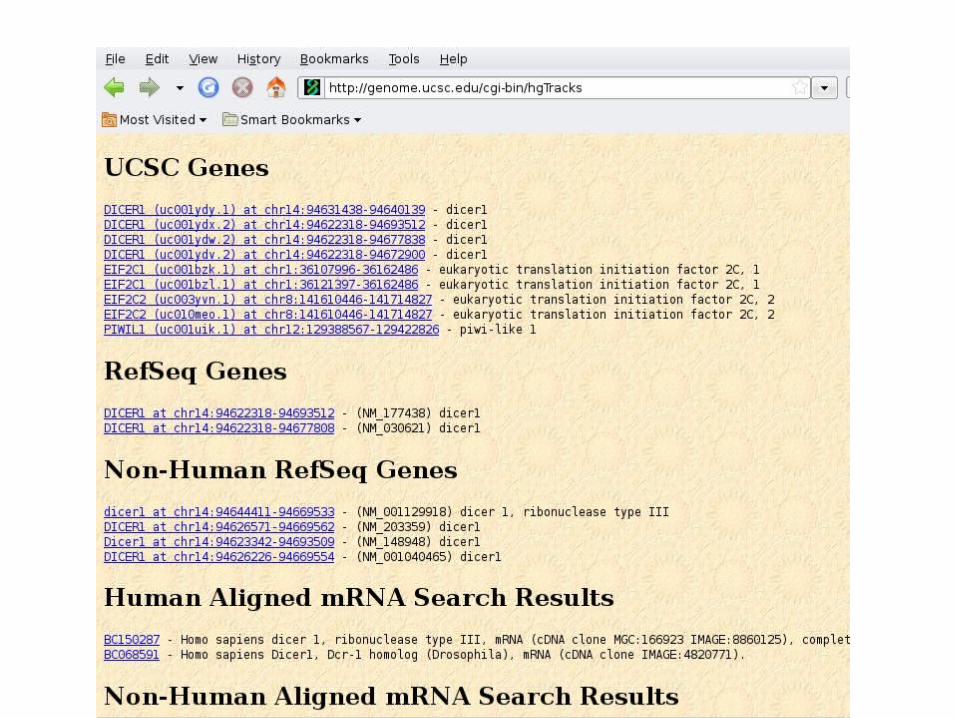
• If you put in a gene name, or an accession number in the coordinate box, the browser will search the mRNA, Refseq and Known Genes tracks (and some more) for this name, and give you a list if you get more than one hit
• Is usually easy: here is an example: the Dicer1 gene (an important RNAse)

CpG islandsA CpG dinucleotide is simply a C followed by a G
CpGs are uncommon (1%) in vertebrate genomes, due to that the C in the CG is easily methylated and then deaminated into a T
However, there are stretches of CpG rich dinucleotides, called CpG islands
These are correlated with promoters - around 50% of promoters have a CpG island. Function is unclear!
In the UCSC browser, this is simply called the CpG island track

Repeats
Large portions of the genomes are “repeats”, classified into two main types:1)Tandem repeats
Two or more nucleotides are repeated, directly after each other
ATTCGATTCGATTCG(number of repeats are used in crime forensics
and parentage tests)2) Interspersed repeats
Results of RNA-mediated transposition (not in this course)

Repeats, cont
• Generally, repeats are considered “uninformative”, and presents problems when aligning things to the genome
• However, there are clear cases of functional repeats
• In the UCSC browser, all repeats can be turned on in the repeat track

Lets look at these things• 5 minutes with your neighbour:• Look at the RPS9 gene, and turn on Refseqs,
known genes, human mRNAs, ESTs, CpG islands and repeats
• How well does refseqs, ESTs and Known genes correlate
• Are there any CpGs or repeats - where are they located? What type of repeats are there?


















