
University of Michigan Electrical Engineering and Computer Science FLASH: Foresighted Latency-Aware...
52
University of Michigan Electrical Engineering and Computer Science FLASH: Foresighted Latency- Aware Scheduling Heuristic for Processors with Customized Datapaths Manjunath Kudlur, Kevin Fan, Michael Chu, Rajiv Ravindran, Nathan Clark, Scott Mahlke Advanced Computer Architecture Laboratory University of Michigan
-
date post
20-Dec-2015 -
Category
Documents
-
view
215 -
download
0
Transcript of University of Michigan Electrical Engineering and Computer Science FLASH: Foresighted Latency-Aware...

University of MichiganElectrical Engineering and Computer Science
FLASH: Foresighted Latency-Aware Scheduling Heuristic for Processors
with Customized Datapaths
Manjunath Kudlur, Kevin Fan, Michael Chu, Rajiv Ravindran, Nathan Clark, Scott Mahlke
Advanced Computer Architecture Laboratory
University of Michigan

University of MichiganElectrical Engineering and Computer Science
Introduction• Bypass network : Important
component of datapath• Allows for data forwarding to
reduce pipeline stalls• Full bypass: any FU can
bypass from any other FU and from any pipeline stage
• Cost of full bypass increases quadratically with number of FUs
# paths = (# FU)2 bypassable stages input ports per FU output ports per FU

University of MichiganElectrical Engineering and Computer Science
Case for Bypass Customization
• Only few bypasses are heavily utilized• The heavily utilized bypasses vary widely from
application to application
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Percent Utilization
No
rma
lize
d C
um
ula
tiv
e N
um
be
r o
f B
yp
as
se
s
Ind
ivid
ua
l B
yp
as
s P
ath
s
More
Less
Customize bypass network in an application specific processor by removing under-utilized paths

University of MichiganElectrical Engineering and Computer Science
Implications of Bypass Customization
Execute Stage Pipeline Latch
Memory Stage Pipeline Latch
Register File

University of MichiganElectrical Engineering and Computer Science
A
Implications of Bypass Customization
Execute Stage Pipeline Latch
Memory Stage Pipeline Latch
Register File
B
DFG

University of MichiganElectrical Engineering and Computer Science
A
Implications of Bypass Customization
• Latency depends on– Which FU the operation
is scheduled on– Which FU the operation’s
consumer is scheduled on
Execute Stage Pipeline Latch
Memory Stage Pipeline Latch
Register File
B
1 Cycle

University of MichiganElectrical Engineering and Computer Science
A
Implications of Bypass Customization
• Latency depends on– Which FU the operation
is scheduled on– Which FU the operation’s
consumer is scheduled on
Execute Stage Pipeline Latch
Memory Stage Pipeline Latch
Register File
B
2 Cycles

University of MichiganElectrical Engineering and Computer Science
A
Implications of Bypass Customization
• Latency depends on– Which FU the operation
is scheduled on– Which FU the operation’s
consumer is scheduled on
• Latency of an operation no longer constant– Varies per consumer
Execute Stage Pipeline Latch
Memory Stage Pipeline Latch
Register File
B
3 Cycles
Bypass Customization introduces non-uniform operation latencies

University of MichiganElectrical Engineering and Computer Science
Effects on List Scheduler (LS)
• Used widely in many compilation systems • Assign each operation to a free FU at the earliest time (Greedy!)• When more than one free FU available, pick one arbitrarily
WHILE (Readylist is non-empty)DO op Next unscheduled operation in priority order ; stime Earliest time when op can be scheduled ; WHILE (no free resource available to execute op at stime) DO stime stime + 1 ; END res Free resource capable of executing op; schedule (op, res, stime) ;END

University of MichiganElectrical Engineering and Computer Science
LS on Full Bypass Machine
A B C
Operations have 1-cycle latency. Machine with full bypass network.
1
2 3 4
5 6
DFG

University of MichiganElectrical Engineering and Computer Science
LS on Full Bypass Machine
1
2 3 4
5 6
Cycle A B C
0 1
1
2
A B C
Operations have 1-cycle latency. Machine with full bypass network.

University of MichiganElectrical Engineering and Computer Science
LS on Full Bypass Machine
1
2 3 4
5 6
Cycle A B C
0 1
1 2 3 4
2 5 6
Schedule length = 3 cycles
A B C
Operations have 1-cycle latency. Machine with full bypass network.

University of MichiganElectrical Engineering and Computer Science
LS on Full Bypass Machine
1
2 3 4
5 6
Cycle A B C
0 1
1 2 3 4
2 5 6
Schedule length = 3 cycles
A B C
Operations have 1-cycle latency. Machine with full bypass network.

University of MichiganElectrical Engineering and Computer Science
LS on Full Bypass Machine
1
2 3 4
5 6
Cycle A B C
0 1
1 2 3 4
2 5 6
Schedule length = 3 cycles
A B C
Operations have 1-cycle latency. Machine with full bypass network.

University of MichiganElectrical Engineering and Computer Science
LS on Full Bypass Machine
1
2 3 4
5 6
Cycle A B C
0 1
1 2 3 4
2 5 6
Schedule length = 3 cycles
Choice of FU does not affect schedulelength in a machine with full bypass.
A B C
Operations have 1-cycle latency. Machine with full bypass network.

University of MichiganElectrical Engineering and Computer Science
LS on Partial Bypass Machine
A B C
Operations have 1-cycle latency. Assume3 cycles required to transmit value via registerfile, if bypass path does not exist.
1
2 3 4
5 6
Cycle A B C
0 1
1 2
2
3 3 4
4 6 5
Schedule length = 5 cycles

University of MichiganElectrical Engineering and Computer Science
LS on Partial Bypass Machine
1
2 3 4
5 6
Cycle A B C
0 1
1 2 3 4
2 6 5
Schedule length = 3 cycles
A B C
Operations have 1-cycle latency. Assume3 cycles required to transmit value via registerfile, if bypass path does not exist.
University of MichiganElectrical Engineering and Computer Science
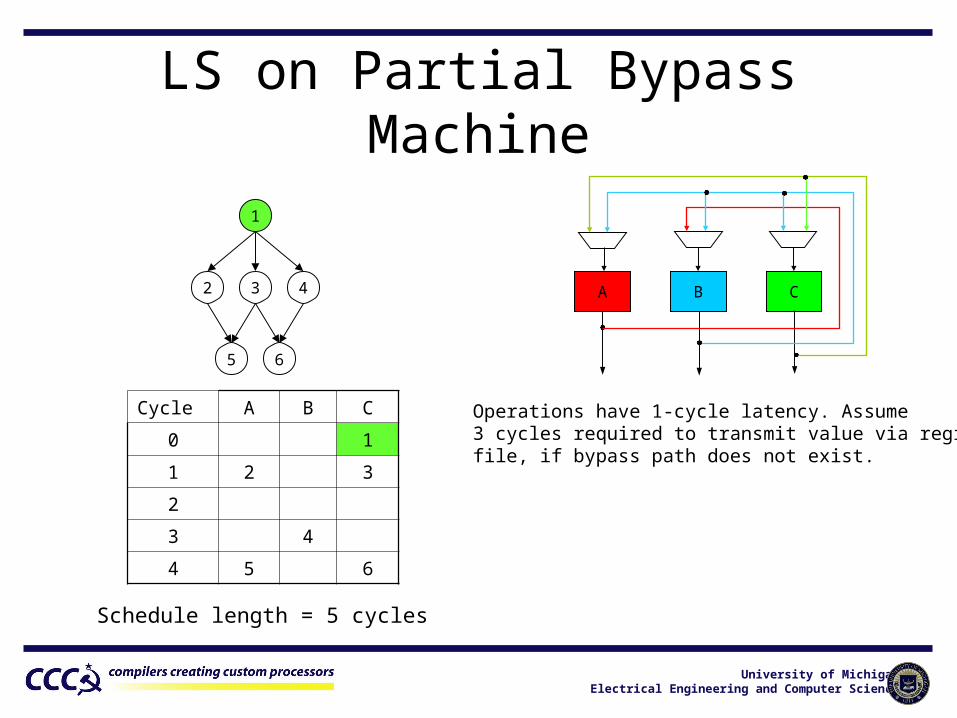
LS on Partial Bypass Machine
1
2 3 4
5 6
Cycle A B C
0 1
1 2 3
2
3 4
4 5 6
Schedule length = 5 cycles
A B C
Operations have 1-cycle latency. Assume3 cycles required to transmit value via registerfile, if bypass path does not exist.

University of MichiganElectrical Engineering and Computer Science
LS on Partial Bypass Machine
1
2 3 4
5 6
Cycle A B C
0 1
1 2 3
2
3 4
4 5 6
Schedule length = 5 cycles
Choice of FU affects schedulelength drastically in a machine with partial bypass.Arbitrary choice no good!
A B C
Operations have 1-cycle latency. Assume3 cycles required to transmit value via registerfile, if bypass path does not exist.

University of MichiganElectrical Engineering and Computer Science
Greediness of LS
A B C
Operations have 1-cycle latency. Assume3 cycles required to transmit value via registerfile, if bypass path does not exist.
1
2 3 4
Partial DFG
Cycle A B C
i
i+1
i+2
i+3
i+4
Consider Scheduling Op1
Earliest Time

University of MichiganElectrical Engineering and Computer Science
Greediness of LS
A B C
Operations have 1-cycle latency. Assume3 cycles required to transmit value via registerfile, if bypass path does not exist.
1
2 3 4
Cycle A B C
i
i+1 1
i+2 2
i+3
i+4 3 4
Greedily scheduling op 1at cycle i+1 delays ops 3 and 4

University of MichiganElectrical Engineering and Computer Science
Greediness of LS
A B C
Operations have 1-cycle latency. Assume3 cycles required to transmit value via registerfile, if bypass path does not exist.
1
2 3 4
Cycle A B C
i
i+1 1
i+2 2 3
i+3
i+4 4
Greedily scheduling op 1 at cycle i+1 delays op 4

University of MichiganElectrical Engineering and Computer Science
Greediness of LS
A B C
Operations have 1-cycle latency. Assume3 cycles required to transmit value via registerfile, if bypass path does not exist.
1
2 3 4
Cycle A B C
i
i+1
i+2 1
i+3 2 3 4Delayed 1 cycle
Delaying ops could improve schedule.Being Greedy no good!

University of MichiganElectrical Engineering and Computer Science
FLASH : Goals
• Keep the List Scheduling framework, it is fast and widely used
• Effectively deal with non-uniform latencies– Intelligently select from among multiple co-
equal choices– Avoid greedy choices by delaying schedule
slots

University of MichiganElectrical Engineering and Computer Science
Observation I
A
B
Consider FU choices for operation A :

University of MichiganElectrical Engineering and Computer Science
Observation I
A
B
No Good!
Consider FU choices for operation A :
3 cycle delay
University of MichiganElectrical Engineering and Computer Science
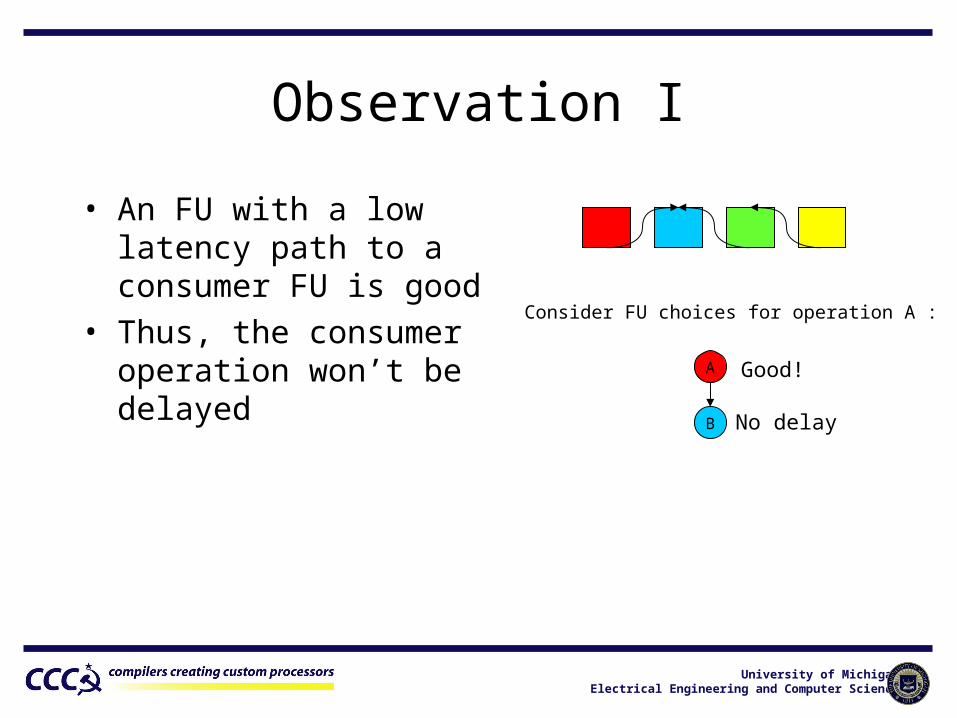
Observation I
A
B
Good!
Consider FU choices for operation A :
• An FU with a low latency path to a consumer FU is good
• Thus, the consumer operation won’t be delayed
No delay

University of MichiganElectrical Engineering and Computer Science
Observation I
A
B
C
Good ???
Consider FU choices for operation A :
• An FU with a low latency path to a consumer FU is good
• Thus, the consumer operation won’t be delayed
No Delay
3 cycle delay

University of MichiganElectrical Engineering and Computer Science
Observation I
A
B
C
Better!
Consider FU choices for operation A :
• An FU with a low latency path to a consumer FU is good
• Thus, the consumer operation won’t be delayed
• Same observation extends to consumer’s consumer, and so on
No Delay
No Delay
An FU which does not delay the consumers is a good choice

University of MichiganElectrical Engineering and Computer Science
Observation II
Consider FU choices for operation A :
A
BC
D
Slack 1 Slack 0

University of MichiganElectrical Engineering and Computer Science
Observation II
Consider FU choices for operation A :
A
BC
D
Good ???
• All consumers are not equal
No Delay 3 cycle delay

University of MichiganElectrical Engineering and Computer Science
Observation II
• All consumers are not equal
• Its better to delay a non-critical consumer
• Criticality
Consider FU choices for operation A :
A
BC
D
Better!
An FU which does not delay acritical chain of consumers is a good choice
No Delay
No Delay
3 cycle delay
1
SLACK

University of MichiganElectrical Engineering and Computer Science
The FLASH Technique
• Compute the merit (FLASH_RANK) of each FU choice for an operation
• FLASH_RANK - weighted estimate of schedule lengths of the dependence chains of an operation
• Schedule the operation on the FU with the best FLASH_RANK
• Avoid greediness by delaying schedule slot, if necessary
FLASH_RANK(op, FU) = MAXc
Estimated schedule length of c
where c is a dependence chain of op
1
Slack(c) + 1X

University of MichiganElectrical Engineering and Computer Science
FLASH_RANK Example
A
BC
D
Slack 1 Slack 0
FLASH_RANK(op, FU) = MAXc
Estimated schedule length of c
where c is a dependence chain of op
1
Slack(c) + 1X

University of MichiganElectrical Engineering and Computer Science
FLASH_RANK Example
A
BC
D
Slack 1 Slack 0
FLASH_RANK(A, Green FU) = ?
FLASH_RANK(op, FU) = MAXc
Estimated schedule length of c
where c is a dependence chain of op
1
Slack(c) + 1X

University of MichiganElectrical Engineering and Computer Science
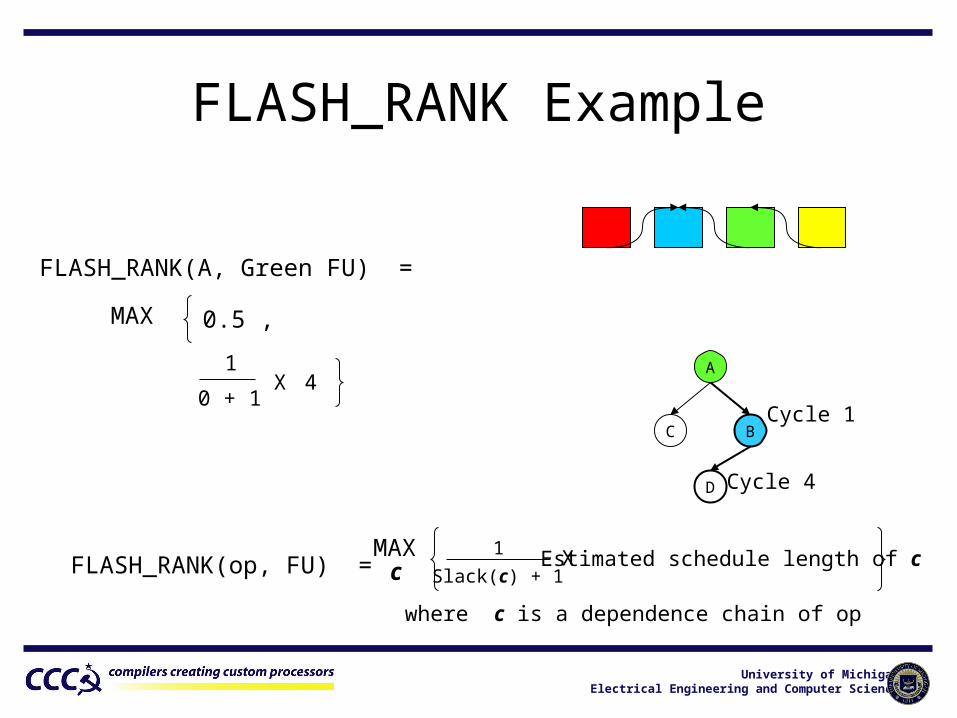
FLASH_RANK Example
A
BC
D
Cycle 1
FLASH_RANK(A, Green FU) =
MAX 1
1 + 1X 1
FLASH_RANK(op, FU) = MAXc
Estimated schedule length of c
where c is a dependence chain of op
1
Slack(c) + 1X
University of MichiganElectrical Engineering and Computer Science
FLASH_RANK Example
A
BC
D
FLASH_RANK(A, Green FU) =
MAX 0.5 ,
1
0 + 1X
Cycle 1
Cycle 4
4
FLASH_RANK(op, FU) = MAXc
Estimated schedule length of c
where c is a dependence chain of op
1
Slack(c) + 1X

University of MichiganElectrical Engineering and Computer Science
FLASH_RANK Example
A
BC
D
FLASH_RANK(A, Green FU) =
MAX 0.5 , 4 = 4
FLASH_RANK(op, FU) = MAXc
Estimated schedule length of c
where c is a dependence chain of op
1
Slack(c) + 1X

University of MichiganElectrical Engineering and Computer Science
FLASH_RANK Example
A
BC
D
Slack 1 Slack 0
FLASH_RANK(A, Yellow FU) = ?
FLASH_RANK(op, FU) = MAXc
Estimated schedule length of c
where c is a dependence chain of op
1
Slack(c) + 1X

University of MichiganElectrical Engineering and Computer Science
FLASH_RANK Example
A
BC
D
Cycle 1
FLASH_RANK(A, Yellow FU) =
MAX 1
1 + 1X 1
FLASH_RANK(op, FU) = MAXc
Estimated schedule length of c
where c is a dependence chain of op
1
Slack(c) + 1X

University of MichiganElectrical Engineering and Computer Science
FLASH_RANK Example
A
BC
D
FLASH_RANK(A, Yellow FU) =
MAX 0.5 ,
1
0 + 1X
Cycle 1
Cycle 2
2
FLASH_RANK(op, FU) = MAXc
Estimated schedule length of c
where c is a dependence chain of op
1
Slack(c) + 1X

University of MichiganElectrical Engineering and Computer Science
FLASH_RANK Example
A
BC
D
FLASH_RANK(A, Yellow FU) =
MAX 0.5 , 2 = 2
Choose Yellow FU for op A
FLASH_RANK(op, FU) = MAXc
Estimated schedule length of c
where c is a dependence chain of op
1
Slack(c) + 1X

University of MichiganElectrical Engineering and Computer Science
Some Practical Considerations
• Impractical to estimate schedule length of entire dependence chain (few 10s of operations)– Truncate dependence chains to manageable depths, say 2
or 3 (Look Ahead depth)
• Impractical to calculate schedule lengths of all dependence chains together – Many dependence chains originate from an operation– Consider dependence chains independently– Ignore resource constraint between dependence chains

University of MichiganElectrical Engineering and Computer Science
Experiments
• Implemented in TRIMARAN compiler framework
• Evaluated MediaBench and SPECint2000• Machine is a 9 wide VLIW (4I, 2F, 2M, 1B)• Application specific bypass network [Fan ’03]
– 30% cost of a full bypass network

University of MichiganElectrical Engineering and Computer Science
Comparisons
• Baseline is the performance achieved by the traditional list scheduler
• Global Resource Preference (GRP) algorithm [Fan ’03]– Global pre-scheduling phase assigns FU
preferences to operations based on Bottom-Up Greedy (BUG) schedule estimates
– List scheduler uses these preferences as hints while scheduling
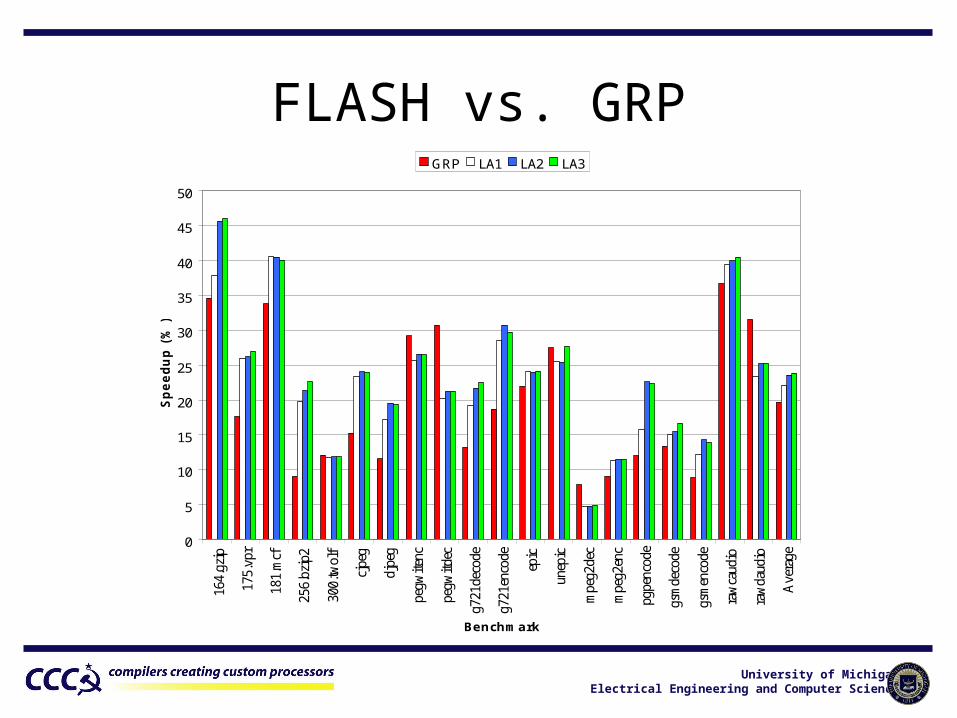
University of MichiganElectrical Engineering and Computer Science
FLASH vs. GRP
0
5
10
15
20
25
30
35
40
45
50
164.
gzip
175.
vpr
181.
mcf
256.
bzip
2
300.
twol
f
cjpe
g
djpe
g
pegw
iten
c
pegw
itde
c
g721
deco
de
g721
enco
de
epic
unep
ic
mpe
g2de
c
mpe
g2en
c
pgpe
ncod
e
gsm
deco
de
gsm
enco
de
raw
caud
io
raw
daud
io
Ave
rage
Benchmark
Speedup (
%)
GRP LA1 LA2 LA3

University of MichiganElectrical Engineering and Computer Science
Bypass Utilization
0
0.5
1
1.5
2
2.5
3
3.5
164.g
zip
175.v
pr
181.m
cf
256.b
zip
2
300.tw
olf
cjp
eg
djp
eg
pegw
itenc
pegw
itdec
g721decode
g721encode
epic
unepic
mpeg2dec
mpeg2enc
pgpdecode
pgpencode
gsm
decode
gsm
encode
raw
caudio
raw
daudio
Harm
onic
Mean
Benchmark
Uti
lizati
on (
#bypasses/cycle
)Original Utilization FLASH Utilization

University of MichiganElectrical Engineering and Computer Science
Conclusion
• Developed a effective scheduling heuristic for machines with customized bypass interconnect– Intelligent FU choice– Avoid greediness
• Average performance improvement of 25% over baseline– Bypass paths utilized better
• Could be applied to other cases of non-uniform latencies

University of MichiganElectrical Engineering and Computer Science
Questions
University of MichiganElectrical Engineering and Computer Science
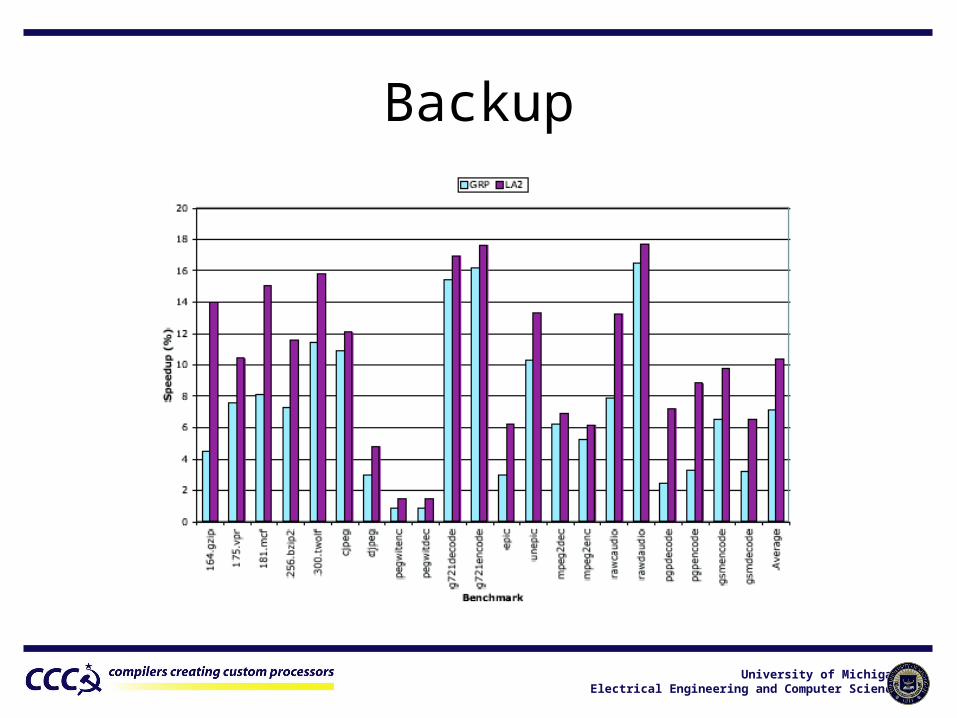
Backup

University of MichiganElectrical Engineering and Computer Science
Backup

University of MichiganElectrical Engineering and Computer Science
Backup














![Informed [Heuristic] Search - University of Delawaredecker/courses/681s07/pdfs/04-Heuristic...Informed [Heuristic] Search Heuristic: “A rule of thumb, simplification, or educated](https://static.fdocuments.us/doc/165x107/5aa1e13c7f8b9a84398c48b6/informed-heuristic-search-university-of-delaware-deckercourses681s07pdfs04-heuristicinformed.jpg)



