
UNIVERSIDADSIMONBOLIVAR …prof.usb.ve/gsanchez//tesis-gustavo sanchez.pdf · En primer lugar a la...
161
UNIVERSIDAD SIMON BOLIVAR DECANATO DE ESTUDIOS DE POST-GRADO DOCTORADO INTERDISCIPLINARIO EN CIENCIAS NUEVOS OPERADORES GENÉTICOS PARA EL DISEÑO DE CONTROLADORES CON MULTIPLES OBJETIVOS Y RESTRICCIONES NO-CONVEXAS Tesis Doctoral presentada ante la Universidad Simón Bolívar por Gustavo Adolfo Sánchez Hurtado como requisito parcial para optar al grado académico de DOCTOR EN CIENCIAS con la asesoría de la profesora Minaya Villasana Mayo, 2011
-
Upload
hoangquynh -
Category
Documents
-
view
213 -
download
0
Transcript of UNIVERSIDADSIMONBOLIVAR …prof.usb.ve/gsanchez//tesis-gustavo sanchez.pdf · En primer lugar a la...

UNIVERSIDAD SIMON BOLIVARDECANATO DE ESTUDIOS DE POST-GRADO
DOCTORADO INTERDISCIPLINARIO EN CIENCIAS
NUEVOS OPERADORES GENÉTICOS PARA EL DISEÑO DECONTROLADORES CON MULTIPLES OBJETIVOS Y RESTRICCIONES
NO-CONVEXAS
Tesis Doctoral presentada ante la Universidad Simón Bolívar por
Gustavo Adolfo Sánchez Hurtado
como requisito parcial para optar al grado académico de
DOCTOR EN CIENCIAS
con la asesoría de la profesora
Minaya Villasana
Mayo, 2011




v
AGRADECIMIENTOS
Quisiera manifestar mi agradecimiento a las personas que han colaborado para realizareste trabajo de investigación. En primer lugar a la profesora Minaya Villasana (USB)sin cuya valiosa asesoría hubiese sido imposible llevar a término el proyecto. En segundolugar a los profesores Miguel Strefezza y Ubaldo García Palomares (USB) por sus múltiplesrevisiones y comentarios. A los profesores Oliver Schüetze y Carlos Coello Coello por sucordial recibimiento y ayuda durante el tiempo en que estuvimos trabajando en conjuntoen las instalaciones del CINVESTAV, México. A los profesores Carlos González y OrlandoReyes (USB) por el apoyo recibido, tanto en el ámbito personal y profesional. Por último,a mi esposa, mis hijos, y a toda mi familia por el tiempo, la paciencia y la comprensiónque me han brindado.

vi
UNIVERSIDAD SIMON BOLIVARDECANATO DE ESTUDIOS DE POST-GRADO
DOCTORADO INTERDISCIPLINARIO EN CIENCIAS
NUEVOS OPERADORES GENÉTICOS PARA EL DISEÑO DECONTROLADORES CON MULTIPLES OBJETIVOS Y RESTRICCIONES
NO-CONVEXAS
Por: Gustavo Adolfo Sánchez HurtadoCarnet: 99-80737
Tutora: Prof. Minaya VillasanaFecha: Mayo, 2011
RESUMEN
En determinadas circunstancias, el diseño de un controlador automático debe ser for-mulado como un problema de optimización con múltiples objetivos y restricciones no-convexas. Desafortunadamente, no siempre estos problemas pueden resolverse mediantealgoritmos deterministas que garanticen la convergencia hacia una solución óptima. Enestos casos, los algoritmos aleatorios (y en particular los genéticos) pueden representaruna alternativa cuando se desea obtener mejores resultados. En efecto, la mayoría de losreportes publicados sobre el tema confirman de manera experimental la eficacia de estosalgoritmos para resolver problemas de diseño de controladores automáticos. No obstante,aún persisten en esta área de investigación numerosos aspectos por mejorar e importantesproblemas que considerar. En este contexto, la principal contribución del presente tra-bajo consiste en la propuesta y el análisis de nuevos operadores genéticos, especialmenteconcebidos para intentar obtener mejores aproximaciones de los Conjuntos de Pareto, encomparación con otros métodos competitivos citados frecuentemente en la literatura.
Palabras Claves: operadores de variación, diseño de controladores, optimización multi-objetivo, algoritmos genéticos, restricciones no convexas.

ÍNDICE GENERAL
APROBACIÓN DEL JURADO ii
AGRADECIMIENTOS v
RESUMEN vi
ÍNDICE DE TABLAS xi
ÍNDICE DE FIGURAS xiv
ÍNDICE DE ALGORITMOS xv
ÍNDICE DE SÍMBOLOS Y ABREVIATURAS xvi
1 INTRODUCCIÓN 1
1.1 Antecedentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Planteamiento del problema de investigación . . . . . . . . . . . . . . . . . 8
1.2.1 Consideración de las restricciones de diseño. . . . . . . . . . . . . . 8
1.2.2 Representación del espacio de búsqueda . . . . . . . . . . . . . . . . 9
1.2.3 Integración con operadores de búsqueda local . . . . . . . . . . . . 11
1.3 Estructura de la tesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2 SISTEMAS LINEALES REALIMENTADOS 15
2.1 Generalidades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2 Índices de desempeño . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2.1 Índices de estabilidad . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2.2 Índices de respuesta temporal . . . . . . . . . . . . . . . . . . . . . 19
2.2.3 Rechazo de perturbaciones . . . . . . . . . . . . . . . . . . . . . . . 21
2.2.4 Estabilidad robusta . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.3 Controladores PID . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.3.1 Método de Ziegler y Nichols . . . . . . . . . . . . . . . . . . . . . . 23
2.3.2 Método de Hohenbichler y Abel . . . . . . . . . . . . . . . . . . . . 24
2.4 Reubicación de polos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27

viii2.5 Diseño de controladores mediante LMIs . . . . . . . . . . . . . . . . . . . . 30
2.5.1 Problema H2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.5.2 Problema H∞ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.6 Resumen del capítulo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3 OPTIMIZACIÓN MULTI-OBJETIVO 36
3.1 Definiciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.2 Estrategias para resolver un problema multi-objetivo . . . . . . . . . . . . 39
3.2.1 Formulación de preferencias “a priori” . . . . . . . . . . . . . . . . 39
3.2.2 Formulación de preferencias de manera interactiva . . . . . . . . . . 41
3.2.3 Formulación de preferencias “a posteriori” . . . . . . . . . . . . . . 42
3.3 Algoritmos genéticos multi-objetivo . . . . . . . . . . . . . . . . . . . . . . 42
3.3.1 Operadores de variación . . . . . . . . . . . . . . . . . . . . . . . . 44
3.3.2 Esquemas de selección . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.3.3 Métodos de archivo . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.3.4 Tratamiento de las restricciones . . . . . . . . . . . . . . . . . . . . 48
3.3.5 Multi-Objective Genetic Algorithm (MOGA) . . . . . . . . . . . . . 49
3.3.6 Non-dominated Sorting Genetic Algorithm (NSGA-II) . . . . . . . 51
3.3.7 Strength Pareto Evolutionary Algorithm (SPEA2) . . . . . . . . . . 54
3.4 Evaluación de desempeño . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.4.1 Índices de desempeño . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.4.2 Pruebas estadísticas . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.5 Resumen del capítulo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4 DISEÑO DE CONTROLADORES PID MULTI-OBJETIVO 63
4.1 Antecedentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.2 Método de diseño basado en el cálculo exacto de la región de estabilidad . 64
4.3 Método de diseño basado en la aproximación la región de estabilidad . . . 75
4.4 Resumen del capítulo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
5 BÚSQUEDA MULTI-OBJETIVO LOCAL 82
5.1 Antecedentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5.2 Ascenso de Colina con Paso Lateral (ACPL) . . . . . . . . . . . . . . . . . 84
5.2.1 Caso sin información de gradientes . . . . . . . . . . . . . . . . . . 84
5.2.2 Caso con información de gradientes . . . . . . . . . . . . . . . . . . 89
5.2.3 Tratamiento de restricciones . . . . . . . . . . . . . . . . . . . . . . 90
5.3 Evaluación del operador ACPL . . . . . . . . . . . . . . . . . . . . . . . . 91

ix5.3.1 Problema convexo sin restricciones . . . . . . . . . . . . . . . . . . 91
5.3.2 Problema convexo con restricciones de intervalo . . . . . . . . . . . 95
5.3.3 Problema no convexo con restricciones de intervalo . . . . . . . . . 99
5.4 Sensibilidad del ACPL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
5.5 Integración SPEA2-ACPL . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
5.5.1 Problema convexo sin restricciones . . . . . . . . . . . . . . . . . . 106
5.5.2 Problema no convexo con restricciones de intervalo . . . . . . . . . 108
5.6 Resumen del capítulo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
6 PROBLEMA H2/H∞ 112
6.1 Formulación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
6.2 Antecedentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
6.3 Solución mediante LMIs . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
6.4 Método MOPPEA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
6.5 Resultados numéricos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
6.6 Resumen del capítulo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
7 CONCLUSIONES 129
APÉNDICE 133
REFERENCIAS 137

ÍNDICE DE TABLAS
1.1 Promedio y desviación standard del valor mínimo alcanzado por cada algo-
ritmo, calculados sobre un total de 100 ejecuciones. Problemas P1 y P2 . . 11
2.1 Frecuencias singulares y ecuaciones de las rectas que delimitan la región de
estabilidad para KP = −4.4, modelo (2.26) . . . . . . . . . . . . . . . . . . 26
3.1 Resumen de ventajas y desventajas de los algoritmos MOGA, NSGA-II y
SPEA2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.2 Resumen de indicadores de desempeño . . . . . . . . . . . . . . . . . . . . 60
3.3 Ejemplo de valores obtenidos para el indicador I correspondientes a 7 eje-
cuciones de los algoritmos A1 y A2 . . . . . . . . . . . . . . . . . . . . . . 60
4.1 Proporción de individuos factibles para distintos valores de L, L . . . . . . 66
4.2 Configuración utilizada para los algoritmos A1 y A2. Problema de diseño
PID . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.3 Resultados obtenidos para el indicador de cobertura. Algoritmos A1 y A2 . 73
4.4 Resultados de los indicadores ESS y DMAX. Algoritmos A1 y A2 . . . . . 73
4.5 P-valores correspondientes a las pruebas de Wilcoxon para determinar las
diferencias que son estadísticamente significativas. Algoritmos A1, A2 . . . 73
4.6 Configuración utilizada por SPEA2 durante la primera etapa del método
de aproximación de la región factible . . . . . . . . . . . . . . . . . . . . . 78
4.7 Resultados del indicador de cobertura. Algoritmos A1, A2 y A3 . . . . . . 80
4.8 Resultados de los indicadores N, ESS y DMAX. Algoritmos A1, A2 y A3 . 80
4.9 P-valores correspondientes a las pruebas de Wilcoxon para determinar las
diferencias que son estadísticamente significativas. Algoritmos A1, A2 y A3 80
5.1 Parámetros que deben ser definidos por el usuario en los casos con y sin
información de gradientes . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
5.2 Valores utilizados para los parámetros ACPL . . . . . . . . . . . . . . . . . 92
5.3 Valores utilizados para los parámetros ACPL. Problema P3 . . . . . . . . 100
5.4 Sensibilidad del operador ACPL1 ante variaciones en el vector r . . . . . . 101
5.5 Sensibilidad del operador ACPL1 ante variaciones en el vector Nnd . . . . 103

xi5.6 Configuración utilizada para resolver el problema P4 . . . . . . . . . . . . . 107
5.7 Indicadores GD/IGD obtenidos para el problema P4 . . . . . . . . . . . . 108
5.8 Configuración utilizada para las pruebas del problema P3 . . . . . . . . . . 108
5.9 Indicadores GD/IGD obtenidos para el problema P3 . . . . . . . . . . . . 109
5.10 Indicadores GD/IGD obtenidos para el problema P5 . . . . . . . . . . . . 109
6.1 Datos correspondientes a los problemas COMPleib . . . . . . . . . . . . . 122
6.2 Parámetros utilizados por SPEA2 y SPEA2-ACPL . . . . . . . . . . . . . 126
6.3 Resultados del indicador de cobertura . . . . . . . . . . . . . . . . . . . . . 127
6.4 Resultados de los indicadores ESS y DMAX . . . . . . . . . . . . . . . . . 127

ÍNDICE DE FIGURAS
1.1 Modelo a lazo cerrado en tiempo discreto. Controlador de dos grados de
libertad. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2 Sistema a lazo cerrado con controlador PID . . . . . . . . . . . . . . . . . 9
2.1 Sistema LTI a lazo abierto . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2 Interconexión Planta/Controlador (lazo cerrado) . . . . . . . . . . . . . . . 18
2.3 Diagrama de polos de un sistema con índices de estabilidad ns = 2, qa = 3 19
2.4 Diagrama de polos de un sistema con índices de estabilidad ns = 1, qa = 2 19
2.5 Indices de desempeño a partir de la respuesta ante un escalón unitario . . . 20
2.6 Lazo de realimentación con incertidumbre no estructurada ∆ . . . . . . . . 22
2.7 Lazo de control con PID ideal . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.8 Respuesta del sistema con los parámetros KD,KP , KI de acuerdo con las
fórmulas de Ziegler y Nichols . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.9 Límites de la región de estabilidad para KP = −4.4 para el modelo (2.26) . 27
2.10 Respuesta al escalón del sistema a lazo cerrado para el modelo (2.26) cor-
respondiente al controlador PID caracterizado por KP = −4.4, KI = 2.2 y
KD = −10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.11 Diagrama de polos (×) y ceros (◦) a lazo abierto para el modelo (2.26) . . 30
2.12 Respuesta al escalón del sistema a lazo cerrado, para el modelo (2.26).
Controlador diseñado mediante reubicación de polos. . . . . . . . . . . . . 30
3.1 Esquema general de un algoritmo genético . . . . . . . . . . . . . . . . . . 43
3.2 Operador discreto de cruce de un punto. El punto de cruce se encuentra en
la mitad del cromosoma. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.3 Operador discreto de cruce de dos puntos. . . . . . . . . . . . . . . . . . . 45
3.4 Ejemplo de cálculo de rango para el algoritmo MOGA . . . . . . . . . . . . 51
3.5 Ejemplo de cálculo de rango para el algoritmo NSGA-II . . . . . . . . . . . 52
3.6 Ejemplo de cálculo de crowding distance para el algoritmo NSGA-II . . . . 53
3.7 Ejemplo de cálculo de S y R para el algoritmo SPEA2 . . . . . . . . . . . 55
3.8 Ejemplo de cálculo de la distancia σ para el algoritmo SPEA2 . . . . . . . 56

xiii3.9 Ejemplo de dos aproximaciones con distintos valores para los indicadores
GD, IGD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.10 Ejemplo de cálculo para el indicador DMAX . . . . . . . . . . . . . . . . 59
3.11 Cálculo de los rangos para la prueba Wilcoxon . . . . . . . . . . . . . . . . 61
4.1 Espacio de controladores PID estabilizantes correspondiente al modeloG0(s)determinado mediante el método de Hohenbichler y Abel (2008) . . . . . . 66
4.2 Selección de un punto al azar en el interior de un polígono convexo . . . . 67
4.3 Lazo con controlador PID . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
4.4 Ejemplo de las aproximaciones obtenidas por A1 y A2 . . . . . . . . . . . . 71
4.5 Evolución de las aproximaciones de los frentes. Algoritmo A1. Ngen es el
número de generación. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.6 Evolución de las aproximaciones de los frentes. Algoritmo A2. Ngen es el
número de generación. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.7 Perturbación y ruido que actúan sobre el lazo . . . . . . . . . . . . . . . . 74
4.8 Salida del lazo de control, afectada por perturbación y ruido . . . . . . . . 74
4.9 Ejemplo de aproximación obtenida al final de la primera etapa . . . . . . . 78
4.10 Ejemplo de las aproximaciones que se obtienen mediante A1, A2 y A3 . . . 79
5.1 Situación que se presenta cuando el punto de prueba se encuentra lejos de
un COLP. Cono de descenso amplio (región sombreada). . . . . . . . . . . 85
5.2 Situación que se presenta cuando el punto de prueba se encuentra cerca de
un COLP. Cono de descenso estrecho (región sombreada). . . . . . . . . . . 85
5.3 Verdadero conjunto de Pareto para el problema P1 . . . . . . . . . . . . . . 92
5.4 Verdadero frente de Pareto para el problema P1 . . . . . . . . . . . . . . . 93
5.5 Aproximación del conjunto de Pareto generada por ACPL1. Problema P1 93
5.6 Aproximación del frente de Pareto generada por ACPL1. Problema P1 . . 94
5.7 Aproximación del conjunto de Pareto generada por ACPL2. Problema P1 94
5.8 Aproximación del frente de Pareto generada por ACPL2. Problema P1 . . 95
5.9 Verdadero conjunto de Pareto para el problema P2 . . . . . . . . . . . . . . 96
5.10 Verdadero frente de Pareto para el problema P2 . . . . . . . . . . . . . . . 96
5.11 Aproximación del conjunto de Pareto generada por ACPL1. Problema P2 97
5.12 Aproximación del frente de Pareto generada por ACPL1. Problema P2 . . 97
5.13 Aproximación del conjunto de Pareto generada por ACPL2. Problema P2 98
5.14 Aproximación del frente de Pareto generada por ACPL2. Problema P2 . . 98
5.15 Ejemplo de aproximaciones del frente de Pareto generadas por ACPL1 y
ACPL2. Problema P3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99

xiv5.16 Aproximación obtenida mediante ACPL2 con ε1=[0.01, 0.01] . . . . . . . . 101
5.17 Aproximación obtenida mediante ACPL2 con ε2=[0.1, 0.1] . . . . . . . . . 102
5.18 Aproximación obtenida mediante ACPL2 con ε3=[1, 1] . . . . . . . . . . . 102
5.19 Aproximación obtenida mediante ACPL2 con εP = 0.01 . . . . . . . . . . . 103
5.20 Aproximación obtenida mediante ACPL2 con εP = 0.1 . . . . . . . . . . . 104
5.21 Aproximación obtenida mediante ACPL2 con εP = 1 . . . . . . . . . . . . 104
5.22 Aproximaciones obtenidas por ACPL1 para distintos valores del parámetro
Tol . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
6.1 Modelo lineal a lazo cerrado . . . . . . . . . . . . . . . . . . . . . . . . . . 113
6.2 Representación genética propuesta. Método MOPPEA . . . . . . . . . . . 118
6.3 Ejemplo de las soluciones obtenidas por A1, A2 y A3. Problema AC1 . . . 123
6.4 Ejemplo de las soluciones obtenidas por A1, A2 y A3. Problema AC6 . . . 124
6.5 Ejemplo de las soluciones obtenidas por A1, A2 y A3. Problema NN10 . . 124
6.6 Ejemplo de las soluciones obtenidas por A1, A2 y A3. Problema WEC1 . . 125
6.7 Ejemplo de las soluciones obtenidas por A1, A2 y A3. Problema AC9 . . . 125

ÍNDICE DE ALGORITMOS
3.1 Extracción del sub-conjunto de soluciones no-dominadas . . . . . . . . . . . 42
3.2 Multi-Objective Genetic Algorithm (MOGA) . . . . . . . . . . . . . . . . . 50
3.3 Asignación de rango NSGA-II . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3.4 Non-Dominated Sorting Genetic Algorithm (NSGA-II) . . . . . . . . . . . 53
3.5 Strength Pareto Evolutionary Algorithm 2 . . . . . . . . . . . . . . . . . . 54
5.1 Operador ACPL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
5.2 Retorno a la región factible para el operador ACPL1 . . . . . . . . . . . . . 90
6.1 Generación de una aproximación del Frente de Pareto para el problema mixto
H2/H∞ mediante LMIs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
6.2 Generación de un vector de polos aleatorio . . . . . . . . . . . . . . . . . . . 121

ÍNDICE DE SÍMBOLOS Y ABREVIATURAS
LQR Linear Quadratic Regulator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
x(t) Vector de estados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
u(t) Vector de señales manipuladas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
H2 Norma 2 en el espacio de funciones complejas . . . . . . . . . . . . . . . . . . . . . . 3
H∞ Norma infinita en el espacio de funciones complejas . . . . . . . . . . . . . . . . 3
LMI Linear Matrix Inequalities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3
PID Proportional Integral Derivative . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
MOEA Multi-Objective Evolutionary Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . .8
MOGA Multi-Objective Genetic Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
G(s) Matriz o función de transferencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
SPEA2 Strength Pareto Evolutionary Algorithm 2 . . . . . . . . . . . . . . . . . . . . . . . . .5
MRCD Multi-objective Robust Control Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
NSGA− II Non-Dominated Sorting Genetic Algorithm . . . . . . . . . . . . . . . . . . . . . . . . 7
λ Vector de auto-valores de un sistema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
MOPSO Multiple Objective Particle Swarm Optimization . . . . . . . . . . . . . . . . . . .7
MOPPEA Multi-Objective Pole Placement with Evolutionary Algorithms . . . . 13
COMPleib COnstraint Matrix-optimization Problem library . . . . . . . . . . . . . . . . . .13
y(t) Vector de señales medidas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .15
w(t) Vector de señales exógenas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
z(t) Vector de señales controladas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .15
Ln2 [0,+∞) Espacio lineal de señales de energía finita . . . . . . . . . . . . . . . . . . . . . . . . . 15
R Conjunto de los números reales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .16
C Conjunto de los números complejos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .16
nu Dimensión del vector de señales manipuladas . . . . . . . . . . . . . . . . . . . . . 15
nw Dimensión del vector de señales exógenas . . . . . . . . . . . . . . . . . . . . . . . . . 15

xvii
ny Dimensión del vector de señales medidas . . . . . . . . . . . . . . . . . . . . . . . . . 15
nz Dimensión del vector de señales controladas . . . . . . . . . . . . . . . . . . . . . . 15
n Dimensión del vector de estados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
|X| Número de elementos del conjunto X . . . . . . . . . . . . . . . . . . . . . . . . . . . . .18
ncl Grado del sistema a lazo cerrado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
ns Número de polos estables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
qa Abscisa del polo que se encuentra más a la derecha . . . . . . . . . . . . . . . 18
ess Error en estado estacionario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .59
tr Tiempo de subida . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .20
ts Tiempo de asentamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
Mp Porcentaje de sobre-elongación máxima . . . . . . . . . . . . . . . . . . . . . . . . . . .20
R(s) Conjunto de funciones complejas racionales de coeficientes reales . . 21
KP Constante proporcional . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
KI Constante integral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
KD Constante derivativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
Tu Período de las oscilaciones críticas. Método de Ziegler-Nichols . . . . .24
Ku Ganancia de la cadena directa. Método de Ziegler-Nichols . . . . . . . . 24
POM Problema de optimización Multi-Objetivo . . . . . . . . . . . . . . . . . . . . . . . . 36
X Espacio factible de variables de decisión . . . . . . . . . . . . . . . . . . . . . . . . . . 36
n Número de variables de decisión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
M Número de funciones objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
x Vector de variables de decisión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
F Espacio Objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
z1 z2 z1 domina a z2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .37C(x,b) Cono de diversidad de tipo b en x . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
COGP Conjunto Óptimo Global de Pareto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .38
COLP Conjunto Óptimo Local de Pareto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .38
FOGP Frente Óptimo Global de Pareto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
FOLP Frente Óptimo Local de Pareto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .38
∇f Gradiente de f . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39

xviii
IWTP Interactive Weighted Tchebycheff Procedure . . . . . . . . . . . . . . . . . . . . . . 41
µs Número total de individuos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
λs Número de hijos generados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
GD Distancia generacional . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
IGD Distancia generacional inversa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .57
DMAX Distancia máxima . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .58
C Cobertura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
ESS Espaciado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
H0 Hipótesis nula . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
H1 Hipótesis alternativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
α Nivel de significancia de la prueba de Wilcoxon . . . . . . . . . . . . . . . . . . . 61
L,L Intervalo de variación para cada parámetro PID . . . . . . . . . . . . . . . . . . 65
Ns(L,L) Número de individuos factibles muestreados en L,L . . . . . . . . . . . . . .65
K Conjunto de controladores estabilizantes . . . . . . . . . . . . . . . . . . . . . . . . . .69
Vmax Volumen máximo del espacio de búsqueda . . . . . . . . . . . . . . . . . . . . . . . . 77
B(x0, r) Vecindario de definido alrededor de x0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
Nnd Vector de límites para el cálculo de direcciones de diversidad . . . . . . 88
ε Parámetros para calcular la longitud del paso lateral . . . . . . . . . . . . . .88
ab Dirección acumulada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
Niter Número de puntos muestreados en el vecindario del punto de origen 88
εP Tolerancia para decidir si un punto pertenece a P∗ . . . . . . . . . . . . . . . . .89
Tol Tolerancia para decidir si un punto es factible . . . . . . . . . . . . . . . . . . . . 90
rmax Cota para delimitar un semi-plano complejo . . . . . . . . . . . . . . . . . . . . . 120
imax Cota para delimitar un semi-plano complejo . . . . . . . . . . . . . . . . . . . . . 120
H2/H∞ Número de iteraciones del algoritmo basado en LMIs . . . . . . . . . . . . 122
∆γ2 Define el incremento en la cota de la inecuación H2 . . . . . . . . . . . . . . 122
∆γinf Define el incremento en la cota de la inecuación Hinf . . . . . . . . . . . . 122
γmin Define la mínima cota de la inecuación H2 . . . . . . . . . . . . . . . . . . . . . . .122γmax Define la máxima cota de la inecuación Hinf . . . . . . . . . . . . . . . . . . . . 122

CAPÍTULO I
INTRODUCCIÓN
El concepto de sistema es tal vez uno de los más fértiles en la historia de la ciencia y la
tecnología (Bertalanffy, 1950). Es posible definir un sistema real (compuesto por equipos,
maquinaria, objetos, etc) como una interconexión de componentes que intercambian infor-
mación, energía y materia, con la finalidad de lograr uno o varios objetivos. Un controlador
automático es un sistema que se interconecta con otro denominado planta, para intentar
que el conjunto se comporte de acuerdo a ciertas especificaciones establecidas previamente,
sin que sea necesario ningún tipo de intervención humana.
Los objetivos técnológicos que justifican la inversión económica que implica el proceso
de diseño, instalación y mantenimiento de un controlador automático pueden ser múltiples:
mejorar el funcionamiento, reducir costos, aumentar la seguridad, disminuir el consumo
de energía y/o la emisión de desechos, etc. Prácticamente todos los sistemas necesarios
para dar soporte a la vida humana moderna necesitan controladores automáticos para su
correcto funcionamiento (fábricas, máquinas, reactores, plantas de tratamiento de agua,
vehículos, turbinas, sistemas de bombeo, computadoras, equipos bio-médicos, etc). En
algunos casos resulta incluso imposible realizar las operaciones en modo manual (sin la
intervención de un controlador automático) debido a la complejidad de los procesos y la
necesidad de precisión y rapidez en la toma de decisiones.
1.1. Antecedentes
Hasta la segunda mitad del siglo XX, los métodos de análisis y diseño de contro-
ladores automáticos se basaban en la interpretación de diagramas y gráficos propuestos por
investigadores pioneros en el área tales como Bode, Evans, Nyquist y Nichols. De manera
sorprendente por su sencillez, estos métodos permitieron controlar sistemas de bajo orden,
de una sola entrada y una sola salida, obteniendo un desempeño aceptable para la época.

2A partir de 1960, la disponibilidad de equipos de computación cada vez más rápidos y
con mayor capacidad de memoria, hizo posible resolver problemas de mayor complejidad,
obteniendo al mismo tiempo mejor desempeño de los lazos de control. El diseño de un
controlador automático comienza a partir de entonces a formularse formalmente como un
problema de optimización con múltiples objetivos y restricciones. Es decir, se considera
que el proceso de diseño termina cuando se ha conseguido una solución que optimiza
un conjunto de funciones y satisface una serie de restricciones expresadas en forma de
desigualdades.
En este sentido, uno de los problemas de diseño multi-objetivo más conocidos es el
Linear Quadratic Regulator (LQR), el cual consiste en diseñar un controlador que estabilice
el sistema a lazo cerrado y que minimice al mismo tiempo dos cantidades: a) la norma
cuadrática de la desviación de los estados con respecto a su estado de reposo y b) la norma
cuadrática del esfuerzo de control (Kalman, 1960).
Considere por ejemplo un sistema lineal descrito por la ecuación de estado
•x(t) = Ax(t) + Bu(t) , x(0) = 0 (1.1)
que se supone controlable y observable. El problema LQR consiste en determinar el vector
de entrada u(t) en función del vector de estados x(t) de forma que la suma ponderada∫ ∞0 x(t)TQx(t)dt +
∫ ∞0 u(t)TRu(t)dt (1.2)
tenga el mínimo valor posible.
En esta formulación, las matrices Q y R juegan un papel importante ya que ayudan
a ponderar la influencia de cada término en el diseño final del controlador. De hecho,
considerar uno solo de estos términos a efectos de la determinación de una estrategia de
control, podría conducir a situaciones catastróficas.
Si se diseña una solución intentando minimizar la energía del vector de estados x(t), es
posible que aumente la energía de la señal de entrada u(t) de manera exagerada, lo cual
pudiera producir daños o al menos saturación de los actuadores.
Si por el contrario diseñamos el controlador intentando minimizar la energía de u(t),
entonces el tiempo de respuesta del sistema pudiera resultar demasiado lento y la acción
del controlador sería inocua. Es importante constatar que las dos cantidades que se desea

3minimizar se encuentran realmente en conflicto puesto que si se logra que una de ellas
disminuya, es probable que la otra aumente al mismo tiempo.
El ejemplo analizado en el párrafo anterior ilustra de manera sencilla la necesidad de
conseguir un compromiso entre diferentes criterios en conflicto, lo cual es un fenómeno am-
pliamente estudiado en ingeniería de control (rápidez vs precisión, desempeño vs robustez)
y en otras áreas tales como la economía (calidad vs costo, costo vs tiempo, etc).
De hecho, durante las últimas décadas se ha dedicado un enorme esfuerzo en el de-
sarrollo de métodos que permitan resolver problemas que involucran objetivos en conflicto,
en particular aquellos formulados en función de la normaH2 oH∞ de las matrices de trans-
ferencia características de un lazo (Apkarian et al, 2008; Boyd et al, 1994; Doyle et al,
1989; Scherer, 1997).
En este contexto, una de las estrategias que cuenta actualmente con mayor aceptación
consiste en reducir el problema (algunas veces al costo de obtener soluciones conservadoras)
a la determinación de la factibilidad de una inecuación matricial lineal (en inglés, LMI).
De acuerdo con el investigador Stephen Boyd (1994), la conexión entre el estudio de
las LMIs y los problemas de control fue establecida por primera vez aproximadamente
en 1892, año en que el matemático ruso Lyapunov demuestra en su tesis doctoral que el
sistema descrito por:
•x(t) = Ax(t) (1.3)
es estable, si y solo si existe una matriz S positiva definida tal que
ATS + SA < 0 (1.4)
Una de las principales ventajas de la formulación del problema de diseño en términos de
LMIs, es que existen herramientas de cómputo muy eficientes para decidir con respecto
a su factibilidad. De hecho, Boyd (1994) es catégorico al afirmar que “gracias a estas
herramientas, el problema teórico de control de sistemas lineales, tal como se planteaba
durante la etapa clásica, se encuentra definitivamente resuelto”.
No obstante, debido a diversas razones técnicas o económicas a menudo es nece-
sario adoptar una estructura pre-establecida para el controlador: Proporcional-Integral-
Derivativo (PID), compensador por adelanto/atraso, control decentralizado, etc. Tam-
bién puede ser necesario considerar índices de desempeño de muy variada naturaleza en

4diferentes canales de la planta (ver capítulo 2). Lo cual finalmente trae como consecuencia
que las funciones que intervienen en el problema de optimización sean no-convexas y que la
aproximación convexa (de tipo LMI por ejemplo) pueda resultar demasiado conservadora.
En estas circunstancias, una alternativa posible consiste en el empleo de algoritmos
aleatorios los cuales pueden ser aplicados para resolver el problema de diseño original,
sin necesidad de introducir aproximaciones conservadoras. De hecho, estos algoritmos
no exigen propiedades matemáticas tales como continuidad o convexidad, ni requieren
información sobre el gradiente de las funciones objetivo para su funcionamiento. Se basan
exclusivamente en el muestreo de un número determinado de puntos en el espacio de
búsqueda, acompañado de algún mecanismo que intenta guiar el proceso de búsqueda
hacia las regiones con mayor potencial para producir buenas soluciones.
En contrapartida, una importante desventaja de los algoritmos aleatorios es que en
general no garantizan convergencia hacia una solución óptima. De hecho, pueden producir
resultados diferentes (aunque bastante aproximados entre sí) cada vez que se ejecutan
a partir de las mismas condiciones iniciales: incertidumbre que genera serias dudas con
respecto a la confiabilidad en un entorno industrial, particularmente cuando se consideran
aplicaciones críticas y decisiones que deben tomarse en tiempo real.
A pesar de estos cuestionamientos, numerosos investigadores coinciden en que los algo-
ritmos aleatorios pueden representar una alternativa válida para intentar obtener mejores
resultados, cuando las soluciones obtenidas previamente por otros métodos no son com-
pletamente satisfactorias.
Dentro de este contexto, un algoritmo genético se define como un tipo de algoritmo
aleatorio que intenta simular el proceso de evolución biológica con el objeto de resolver
un problema de optimización. Desde hace más de una década se han utilizado para
resolver problemas en el área del control de procesos que involucran múltiples objetivos
en contradicción (Fleming, 2001). A continuación se presentan algunas referencias, con el
fin de dar una idea del trabajo desarrollado en esta área.
Uno de los primeros artículos fue presentado por Fonseca y Fleming (1994). Estos au-
tores describen una aplicación del algoritmo Multi-Objective Genetic Algorithm (MOGA)
para el diseño de un regulador lineal de segundo orden, parametrizado por su ganancia,

5sus polos y sus ceros, de la forma
C(s) = K(s + z1) (s + z2)(s + p1) (s + p2) (1.5)
La planta a lazo abierto estudiada tiene como función de transferencia
G(s) =−s + 4
s2 (s + 4)(1.6)
y consideran los siguientes objetivos de diseño:
1. Estabilidad del sistema a lazo cerrado
2. Valor medio cuadrático de la señal de control.
3. Valor medio cuadrático de la señal de salida.
4. Sensibilidad ante perturbaciones.
5. Sensibilidad ante incertidumbres en el modelo.
6. Estabilidad del controlador.
Los autores afirman que su método de diseño permite encontrar soluciones muy cer-
canas a las producidas resolviendo el problema LQR con distintos valores de las matrices
R y Q, pero considerando una estructura de control más sencilla.
Posteriormente, Fonseca (1995) publica su tesis de doctorado, en la cual presenta una
aplicación de MOGA para el control de una turbina de gas caracterizada por un sistema
de ecuaciones diferenciales no-lineales. Para este problema se propuso un controlador
parametrizado por 8 variables de decisión (ganancias) y 7 objetivos de diseño. Este autor
afirma que la presencia de múltiples discontinuidades y amplias mesetas en cada una de las
funciones objetivo, hace que los métodos que utilizan información de gradiente presenten
dificultades cuando se intentan aplicar a esta clase de problemas y justifica por ende el
enfoque genético.
Liu et al (1995) resuelven un problema de diseño con dos grados de libertad, tal como
es posible apreciar en la figura 1.1. El modelo de la planta a controlar viene dado en
tiempo discreto por
G(z) =b+(z)b−(z)
a+(z)a−(z)(1.7)

6
Figura 1.1: Modelo a lazo cerrado en tiempo discreto. Controlador de dos grados delibertad.
donde los polinomios b+(z) y a+(z) contienen los ceros y polos que el controlador puede
cancelar.
El problema consiste en diseñar las dos funciones de transferencia
C1(z) =g(z)a+(z)
(z − 1)d(z)b+(z)(1.8)
C2(z) = a0 +a1z
+a2z2 + . . . +
anzn (1.9)
donde los parametros ai , i ∈ {1, 2, . . . , n} y los coeficientes de los polinomios g(z) y d(z)
son las variables del problema de optimización.
El algoritmo genético que estos autores proponen es similar al Strength Pareto Evolu-
tionary Algorithm 2 (SPEA2) propuesto por Zitzler et al (2001). Comparan sus resultados
con respecto a los obtenidos mediante un método de optimización de tipo quasi-Newton
y en sus conclusiones afirman que logran disminuir los tiempos de subida, establecimiento
y sobre-elongación, utilizando para ello mayor energía en la señal de control.
En su tesis doctoral, Herreros (2000) presenta un estudio sobre el diseño de contro-
ladores robustos multi-objetivo por medio de algoritmos genéticos. Formula un problema
de tipo min-max que tiene como variables de decisión los coeficientes característicos de
la función de transferencia del controlador y del modelo de incertidumbre. Propone
un nuevo algoritmo llamado MRCD (Multi-Objective Robust Control Design) junto con
sus respectivos operadores. Para validar sus resultados, los compara con respecto a los
generados mediante LMIs. De acuerdo con el autor, el algoritmo genético produce mejores
aproximaciones (lo cual se ilustra gráficamente) aunque no presenta pruebas estadísticas
que sustenten esta afirmación.

7En 2002, Liu et al publican una monografía que cubre buena parte de los conceptos
básicos en el área de control multi-objetivo. Como idea novedosa proponen una codificación
genética de los individuos de la forma
p = (λ, R, L) (1.10)
donde λ es el vector de auto-valores, R es la matriz de auto-vectores derechos y L es la
matriz de auto-vectores izquierdos de la matriz de estados a lazo cerrado. Estos autores
consideran como objetivos de diseño las sensibilidades individuales de cada auto-valor.
En (Takahashi et al., 2004) se propone un algoritmo genético que asegura la generación
de un conjunto de soluciones que cumple con las condiciones necesarias para ser un Con-
junto de Pareto. Este algoritmo se aplica al problema de diseño mixto H2/H∞, con-
siguiendo, de acuerdo con los autores, mejores soluciones que las obtenidas mediante LMIs.
Sin embargo estos autores tampoco presentan pruebas estadísticas que sustenten este he-
cho.
En (Tan et al., 2005) se presenta un estudio sobre optimización multi-objetivo evo-
lutiva, con aplicaciones para problemas de ingeniería tales como control de procesos y
programación de horarios. Se presenta además una interfaz de diseño en MATLAB R©llamada MOEA-Toolbox, la cual permite la formulación y ejecución de los programas de
manera amigable (Joos, 2002).
En (Pedersen, 2005) se proponen algunas variaciones del algoritmo Non-Dominated
Sorting Genetic Algorithm (NSGA-II) para adaptarlo al diseño de controladores de bajo
orden en el dominio frecuencial. Se analiza con detalle el problema del escalamiento de las
funciones objetivo y su efecto en la evolución del proceso de búsqueda y en la distribución
final de las soluciones.
En los últimos años se han reportado aplicaciones de diversos conceptos novedosos
relacionados con dominancia y evolución. Por ejemplo, Martinez et al (2006) proponen
una estrategia de optimización multi-objetivo llamada Programación Física (PF) para
resolver problemas de control robusto. Heo et al (2006) utilizan el algoritmo Multiple
Objective Particle Swarm Optimization (MOPSO) para diseñar el controlador de una
planta generadora de energía eléctrica. En (Gambier et al., 2006) se propone un nuevo
método de diseño basado en juegos dinámicos cooperativos. En (Dellino et al., 2007)
se propone una metodología híbrida para resolver problemas de alta complejidad en un

8contexto multi-disciplinario. Finalmente, en (Wang et al., 2009) se presenta un algoritmo
que intenta optimizar la posición de los polos del sistema a lazo cerrado utilizando MOPSO.
1.2. Planteamiento del problema de investigación
A partir del análisis de las referencias presentadas en la sección anterior, es posible
constatar que se ha desarrollado un importante trabajo en el área de la aplicación de
Multi-Objective Evolutionary Algorithms (MOEAs) para resolver problemas de control
automático. En líneas generales, se ha puesto mucho énfasis en ilustrar las ventajas de esta
metodología de forma experimental, mediante casos de estudio y aplicaciones prácticas.
El gran desafío en esta área de investigación, tal como lo plantean en su trabajo Fleming
y Purshouse (2002), consiste en “convencer a los escépticos de que estos nuevos métodos
merecen plena confianza en un entorno industrial”. No obstante, todavía persisten nu-
merosos aspectos prácticamente inexplorados en esta dirección, algunos de los cuales se
introducen brevemente en los siguientes párrafos.
1.2.1 Consideración de las restricciones de diseño.
La restricción de estabilidad, por sólo nombrar un ejemplo, es fundamental para
cualquier diseño. Un sistema inestable no debe funcionar en la práctica, puesto que pueden
producirse daños o incluso destrucción de sus componentes.
El enfoque tradicional para atacar los problemas de control automático mediante algo-
ritmos genéticos consiste en definir una función para penalizar fuertemente a los individuos
inestables, de forma que en el transcurso del proceso evolutivo se logre que la población esté
compuesta por una mayoría de individuos estables. Como ejemplo, considere la función
de penalidad propuesta por Herreros (2000)
f(K) =
0 si max [Re(λ(K))] < 0
max [Re(λ(K))] en caso contrario(1.11)
donde K representa la matriz de transferencia del controlador evaluado y λ es el vector
de autovalores del sistema a lazo cerrado. Con esta función se penalizan los individuos
inestables (no factibles) con una cantidad igual a la mayor abscisa de estabilidad del
sistema a lazo cerrado. Aunque esta estrategia tiene la ventaja de ser muy fácil de im-
plementar, en la práctica puede producir fenómenos indeseados tales como convergencia

9prematura de la población. El reto consiste en explorar métodos alternativos que permi-
tan un manejo más eficiente de las restricciones tales como la generación de individuos
estables por construcción y/o la reparación mediante operadores especiales (ver capítulo
4 y 6).
1.2.2 Representación del espacio de búsqueda
Es posible representar matemáticamente un controlador lineal e invariante en el
tiempo, de una entrada y una salida, de dos formas:
• Mediante una función de transferencia
K(s) =amsm + am−1sm−1 + . . . + a1s + a0sn + bn−1sn−1 + . . . + b1s + b0 (1.12)
• Mediante un par de ecuaciones matriciales de estado
xK(t) = AKxK(t) + BKy(t)
u(t) = CKxK(t) + DKy(t)(1.13)
La ventaja de estas dos representaciones es que son generales y por lo tanto permiten
imponer cualquier estructura deseada para el controlador. Su desventaja es que, desde el
punto de vista de la búsqueda genética, no es sencillo generar y mantener individuos que
satisfagan restricciones de estabilidad. Para ilustrar este fenómeno, considere el modelo
de planta propuesto por Fonseca y Fleming (1993):
G(s) =4− s
s2 (4 + s)(1.14)
Suponga que se desea diseñar un controlador PID ideal mediante un algoritmo genético
y se decide adoptar una representación de los individuos que consiste simplemente en un
vector que contiene los parámetros KD, KP y KI característicos del controlador (ver figura
1.2).
Suponga además que en alguna etapa del proceso de búsqueda se seleccionan los
siguientes padres factibles (estabilizantes)
p1 =(KD1 KP1 KI1 ) =
(3.5 1 2
)(1.15)
p2 =(KD2 KP2 KI2 ) =
(3.5 2 6
)(1.16)

10
Figura 1.2: Sistema a lazo cerrado con controlador PID
los cuales generan los siguientes vectores de polos a lazo cerrado
λp1 =
−0.1781 + 3.5024i
−0.1781− 3.5024i
−0.0719 + 0.8033i
−0.0719− 0.8033i
(1.17)
λp2 =
−0.1972 + 3.0607i
−0.1972− 3.0607i
−0.0528 + 1.5964i
−0.0528− 1.5964i
(1.18)
Mediante el operador de cruce uniforme, estos dos individuos generan el par de hijos
h1 =(
3.5 2 2)
(1.19)
h2 =(
3.5 1 6)
(1.20)
los cuales a su vez generan los siguientes vectores de polos a lazo cerrado
λh1 =
0.0163 + 3.3630i
0.0163− 3.3630i
−0.2663 + 0.7978i
−0.2663− 0.7978i
(1.21)

11
λh2 =
−0.4214 + 3.3099i
−0.4214 + 3.3099i
0.1714 + 1.4582i
0.1714− 1.4582i
(1.22)
Puesto que ninguno de los hijos generados produce un sistema a lazo cerrado estable,
el objetivo que se plantea en este caso consiste en desarrollar representaciones alternas
del espacio de controladores que permitan mejorar el proceso de generación de indi-
viduos factibles y la exploración del espacio de búsqueda mediante operadores de variación
genética especialmente adaptados (ver capítulo 6).
1.2.3 Integración con operadores de búsqueda local
Una de las principales desventajas de los algoritmos genéticos es que no existen
garantías con respecto a la precisión de las soluciones obtenidas. Considere por ejemplo
que se desea resolver el problema de minimización de la función de Rosenbrock (P1)P1 : x1, x2 ∈ [−10, 10]min100(x2 − x21)2 + (1− x1)2 (1.23)
En la tabla 1.1 se muestra un ejemplo de los resultados obtenidos luego de 100 ejecu-
ciones de un algoritmo genético simple (GS) y 100 ejecuciones del algoritmo determinista
BFGS, de tipo quasi-Newton (Broyden, 1970). Se presenta el promedio y la desviación es-
tandard del menor valor de la función objetivo encontrado durante la ejecución de cada al-
goritmo. Para las pruebas se utilizaron poblaciones iniciales aleatorias (en el caso genético)
y punto inicial aleatorio (en el caso BFGS). Note que el promedio de la mejor solución
obtenida por el algoritmo genético es aproximadamente 1000 veces mayor que el promedio
logrado por BFGS.
Tabla 1.1: Promedio y desviación standard del valor mínimo alcanzado por cada algo-ritmo, calculados sobre un total de 100 ejecuciones. Problemas P1 y P2
P1 P2Genético 5.4271(7.3176) 1.1762(0.6551)BFGS 0.0042(0.0151) 42.0898(41.7667)

12Considere ahora el siguiente problema (P2)
P2 : x1, x2 ∈ [−10, 10]min2 + x21 − cos(20πx1) + x22 − cos(20πx2) (1.24)
A partir de la misma configuración utilizada en el caso anterior, se obtienen los resultados
mostrados en la tabla 1.1. Note que ahora el promedio BFGS es aproximadamente 35 veces
mayor que el logrado por el genético, lo cual se explica considerando que el algoritmo
determinista queda “atrapado” en cualquiera de los mínimos locales característicos del
problema P2.Los anteriores ejemplos permiten ilustrar un fenómeno sobre el cual existe bastante
consenso dentro de la comunidad de investigadores en el área: los algoritmos genéticos
facilitan la exploración (búsqueda gruesa), pero presentan serias limitaciones para la ex-
plotación de las regiones (búsqueda fina).
Surge entonces la idea de combinar la capacidad de exploración del algoritmo genético
con la capacidad de explotación de un operador de búsqueda local, para intentar que las
zonas más prometedoras sean correctamente aprovechadas. En la literatura, este tipo de
algoritmos reciben el nombre de meméticos (Moscato, 1989), haciendo referencia a las
unidades de difusión cultural llamadas memes (Dawkins, 1976).
En la actualidad son pocas las publicaciones en las que se reportan aplicaciones de
algoritmos meméticos para problemas de control automático (Caponio et al, 2007; Shyr
et al 2002; Wanner et al, 2008). Un objetivo que se plantea en este trabajo consiste en
producir de manera eficiente mejores soluciones considerando un algoritmo memético (ver
capítulos 5 y 6) en comparación con el genético puro.
1.3. Estructura de la tesis
En los próximos capítulos se presenta un conjunto de operadores, representaciones
genéticas y adaptaciones algorítmicas, especialmente concebidos para intentar obtener
mejores aproximaciones de los Conjuntos de Pareto, en comparación con otros métodos
competitivos citados comúnmente en la literatura.
En el capítulo 2 se introducen conceptos básicos relacionados con el control de sistemas
lineales a lazo cerrado. Se presenta el problema general de control, haciendo énfasis en
su formulación como un problema multi-objetivo. Se describen algunos índices que usual-
mente se utilizan para especificar los requerimientos que debe cumplir un controlador.

13También se repasan algunos métodos clásicos de diseño incluyendo PIDs, reubicación de
polos y LMIs.
En el capítulo 3 se introducen conceptos generales relacionados con la optimización de
múltiples objetivos, conjuntos y frentes de Pareto. Se hace un breve recuento de las ideas
que pueden utilizarse para resolver problemas de esta naturaleza, tomando en cuenta el
archivo de las soluciones no-dominadas y el tratamiento de las restricciones. Seguidamente
se describe el funcionamiento de los algoritmos MOGA, NSGA-II y SPEA2, junto con los
índices de desempeño y las pruebas estadísticas que se han propuesto para su evaluación.
En el capítulo 4 se proponen nuevos operadores de variación para el diseño de con-
troladores PID, basados en la generación y mantenimiento de individuos estables durante
del proceso de búsqueda. Se utiliza el método propuesto en (Hohenbichler & Abel, 2008)
para generar los vértices de la región factible correspondiente al sistema a lazo cerrado.
Adicionalmente se propone un nuevo método para aproximar la geometría de la región
factible, basado en muestreo aleatorio uniforme (Calafiore & Dabbene, 2006). Los resulta-
dos de este capítulo fueron previamente publicados en (Sánchez et al., 2008a) y (Sánchez
et al., 2009).
En el capítulo 5 se presenta un nuevo operador de búsqueda local llamado Ascenso de
Colina con Paso Lateral (ACPL) especialmente diseñado para problemas multi-objetivo.
En caso de no encontrar soluciones dominantes (como en el ascenso de colina tradicional),
el operador utiliza la información recolectada para intentar moverse hacia algún cono de
diversidad (paso lateral). También se presenta un análisis de la sensibilidad del operador
con respecto a sus parámetros característicos. Por último se propone un esquema para
la integración del ACPL con el algoritmo SPEA2, dando como resultado un algoritmo
memético denominado SPEA2-ACPL, para el cual se presentan los resultados obtenidos
durante las pruebas que se realizaron en el caso de un problema convexo y uno no-convexo.
Estos resultados fueron previamente publicados en (Schütze et al., 2008) y (Lara et al.,
2010).
En el capítulo 6 se propone un nuevo método de diseño de controladores llamado Multi-
Objective Pole Placement with Evolutionary Algorithms (MOPPEA), utilizando como
base del proceso de búsqueda a los algoritmos SPEA2 y SPEA2-ACPL. Se presentan los
resultados obtenidos para el diseño mixto H2/H∞ en el caso de cinco modelos extraidos de
COMPleib (Leibfritz, 2004) y se comparan con respecto a los obtenidos mediante LMIs.

14Los resultados del capítulo fueron publicados en (Sánchez et al., 2007) y (Sánchez et al.,
2008b).
Por último, se presentan las conclusiones del trabajo y se describen algunas direcciones
para futuras investigaciones.

CAPÍTULO II
SISTEMAS LINEALES REALIMENTADOS
En este capítulo se introducen algunos conceptos básicos relacionados con el control
de sistemas lineales a lazo cerrado. Se presenta el problema general de control, haciendo
énfasis en su formulación como un problema multi-objetivo. Se definen los índices que
usualmente se incluyen como parte de las especificaciones que debe cumplir un controlador
automático. Por último se realiza un breve repaso de tres estrategias bien conocidas
que se han sido propuestas para resolver problemas de diseño de controladores lineales:
sintonización PID, reubicación de polos mediante realimentación de estados y LMIs.
2.1. Generalidades
Un sistema lineal e invariante (ver figura 2.1) puede definirse mediante las ecua-
ciones de estado
x(t) = Ax(t) + Bww(t) + Buu(t)
z(t) = Czx(t) + Dzww(t) + Dzuu(t)
y(t) = Cyx(t) + Dyww(t) + Dyuu(t)
(2.1)
donde u ∈ Lnu2 [0,+∞) es el vector de señales manipuladas, w ∈ Lnw2 [0,+∞) es el vector
de entradas exógenas (perturbaciones), y ∈ Lny2 [0,+∞) es el vector de señales medidas, z
∈ Lnz2 [0,+∞) es el vector de señales controladas y x ∈ Ln2 [0,+∞) es el vector de estado
(el espacio L2[0,+∞) es definido en el Apéndice).
Figura 2.1: Sistema LTI a lazo abierto

16Las matrices A ∈ Rn×n, Bw ∈ Rn×nw , Bu ∈ Rn×nu, Cz ∈ Rnz×n, Cy ∈ Rny×n, Dzw ∈
Rnz×nw , Dzu ∈ Rnz×nu , Dyw ∈ Rny×nw y Dyu ∈ Rny×nu se denominan matrices de estado
del sistema a lazo abierto.
Un sistema se dice estable en el sentido BIBO (Bounded Input Bounded Output) si
a cualquier entrada acotada, corresponde una salida acotada. Es posible demostrar que
el sistema (2.1) es estable en el sentido BIBO si y sólo si los autovalores de la matriz
A pertenecen a C− (semi-plano abierto complejo izquierdo). En este caso se dice que la
matriz de estado A es de tipo Hurwitz.
Los conceptos de controlabilidad y observabilidad (Kalman, 1963) juegan un papel
importante para el diseño de controladores. Se dice que un sistema es controlable si es
posible transferir un estado inicial a cualquier otro estado finito en un intervalo de tiempo
finito. Si todos los estados son controlables, se dice que el sistema es completamente
controlable.
Por otro lado, un sistema es completamente observable si es posible reconstruir la
información de cada variable de estado en función de las mediciones de las salidas y las
entradas.
De esta forma, el sistema (2.1) se dice completamente controlable y observable si y sólo
si las matrices (Bu ABu · · · An−1Bu ) (2.2)
(Cy CyA · · · CyAn−1 )T
(2.3)
son de rango completo.
La Transformada de Laplace (también definida en el Apéndice) de los vectores y(t) y
z(t) se escribe
Z(s) = Gzw(s)W (s) + Gzu(s)U(s) (2.4)
Y (s) = Gyw(s)W (s) + Gyu(s)U(s)
con
Gzw(s) = Cz(sI − A)−1Bw + Dzw (2.5)
Gzu(s) = Cz(sI − A)−1Bu + Dzu

17Gyw(s) = Cy(sI −A)−1Bw + DywGyu(s) = Cy(sI −A)−1Bu + Dyu
donde Gzw(s), Gzu(s), Gyw(s) y Gyu(s) se denominan matrices de transferencia a lazo
abierto.
La necesidad de interconectar el sistema a lazo abierto con un controlador automático
surge de los siguientes hechos:
• Existen perturbaciones (cuya acción es imposible evitar) que desplazan al sistema
del régimen de operación deseado.
• Es imposible conocer con exactitud la estructura y/o los parámetros del sistema real
(incertidumbre).
• Ante las perturbaciones y en presencia de incertidumbre, el sistema debe reaccionar
de una manera que sería imposible lograr mediante un sistema a lazo abierto (sin
realimentación).
Cuando se interconecta el sistema (2.1) con un controlador lineal (ver figura 2.2)
representado por
xK = AKxK + BKy
u = CKxK (2.6)
el sistema a lazo cerrado resultante se escribe
xcl = Aclxcl + Bclwz = Cclxcl + Dclw (2.7)
donde
Acl =
A BuCK
BKCy AK + BKDyuCK , Bcl =
Bw
BKDyw (2.8)
Ccl =(Cz DzuCK ) , Dcl = Dzw
Por su parte la matriz de transferencia a lazo cerrado puede escribirse como
Gzwcl(s) = Gzw(s) + Gzu(s)K(s)(I −Gyu(s)K(s))−1Gyw(s) (2.9)

18
Figura 2.2: Interconexión Planta/Controlador (lazo cerrado)
con
K(s) = CK(sI − AK)−1BK (2.10)
Es evidente, a partir de estas ecuaciones, que no es trivial la selección de matrices AK, BKy CK tales que el sistema a lazo cerrado sea estable y cumpla con una lista predeterminada
de requerimientos.
2.2. Índices de desempeño
A menudo se requiere que las salidas del sistema a lazo cerrado sigan cierta
dinámica en respuesta a las perturbaciones y en presencia de incertidumbre. En otras
palabras, se requiere dotar a la conexión (figura 2.2) de propiedades que el sistema a lazo
abierto (figura 2.1) no posee de manera aislada.
En el transcurso de las últimas décadas, se han propuesto numerosos criterios o índices
para medir el desempeño de un controlador automático, es decir, para cuantificar que tan
bien cumple con los objetivos para los cuales fue diseñado. A continuación se definen
algunos de los más comunes.
2.2.1 Índices de estabilidad
Sea ncl el grado y λ el vector de polos del sistema a lazo cerrado. Es posible
considerar como índice de estabilidad el número de polos estables
ns = |{λi/Re(λi) < 0}| (2.11)

19o a la abscisa del polo que se encuentre más a la derecha en el plano complejo, sea qa tal
que
qa = maxi Re(λi) (2.12)
En las figuras 2.3 y 2.4 se muestra un ejemplo del cálculo de estos índices para dos
configuraciones de polos distintas. Note que de acuerdo al índice ns el primer sistema
sería mejor que el segundo. Con respecto al índice qa la conclusión sería exactamente la
opuesta.
Figura 2.3: Diagrama de polos de un sistema con índices de estabilidad ns = 2, qa = 3
Figura 2.4: Diagrama de polos de un sistema con índices de estabilidad ns = 1, qa = 2
2.2.2 Índices de respuesta temporal
Cuando el sistema a lazo cerrado es estable, es posible definir índices en función de
su respuesta temporal ante señales de prueba en distintos canales de entrada. Considere
el caso de un sistema de tipo Single-Input Single-Output (SISO).

20Para una entrada de referencia r(t) en forma de escalón, es decir
r(t) =
0 para t < 0
R para t ≥ 0(2.13)
el error en estado estacionario ess se define como:
ess = limt→∞ |r(t)− y(t)| (2.14)
donde y(t) es la respuesta del sistema. Note que de manera similar es posible definir el
error en estado estacionario para entradas más complejas tales como rampas, senoidales,
triangulares, etc.
El tiempo de subida tr al 90%, el tiempo de asentamiento ts al 5% y el porcentaje de
sobre-elongación máxima Mp pueden definirse como se muestra a continuación (ver figura
2.5).
1
1.05
0.95
0.90
ess
t
y(t)
trts
Mp(%)
Figura 2.5: Indices de desempeño a partir de la respuesta ante un escalón unitario
tr(90%) =arg mint {t : y(t) = 0.9× limt→∞ y(t)
}(2.15)
ts(5%) =arg maxt {∣∣∣y(t)− limt→∞ y(t)∣∣∣ ≥ 0.05
}(2.16)
Mp =
‖y(t)‖∞− limt→∞ y(t)‖y(t)‖∞ × 100 si ‖y(t)‖∞ > limt→∞ y(t)
0 en caso contrario(2.17)

21Uno de los conflictos más comunes cuando se analiza la respuesta de un sistema a lazo
cerrado es el que existe entre el tiempo de subida tr y el porcentaje de sobre-elongación
máximaMp. En efecto, si se diseña el controlador para obtener el menor tiempo de subida,
es probable que se obtenga al mismo tiempo una mayor sobre-elongación.
Un problema de diseño multi-objetivo que hiciera intervenir los cuatro índices que se
acaban de definir más la restricción de estabilidad pudiera plantearse como
minK∈R(s)nu×ny ( ess(K) tr(K) ts(K) Mp(K))
sujeto a:
qa(K) < 0
(2.18)
2.2.3 Rechazo de perturbaciones
Sea w(t) una perturbación cuyo efecto sobre la salida z(t) es necesario rechazar y
Gzwcl(s) la matriz de transferencia definida en (2.9). El rechazo de la señal de perturbación
puede medirse en función de una norma (ver Apéndice A) tal como
‖W (s)Gzwcl(s,K)‖i (2.19)
donde i ∈ {1, 2,∞} y la matriz W (s) se incluye de manera arbitraria para ponderar la
importancia de las bandas de frecuencia en las cuales w(t) concentra su mayor energía.
Considere por ejemplo una perturbación en forma de impulso unitario w(t) = δ(t).
Para minimizar la energía de la señal de salida, se debe plantear un problema de la forma
minK∈R(s)nu×ny ‖W (s)Gzwcl(s,K)‖2sujeto a
qa(K) < 0
(2.20)
Si en lugar de minimizar la energía de la señal de salida se necesita minimizar su
máxima amplitud (por ejemplo para prevenir posibles situaciones peligrosas), se debe
entonces plantear el problema
minK∈R(s)nu×ny ‖W (s)Gzwcl(s,K)‖∞sujeto a
qa(K) < 0
(2.21)

222.2.4 Estabilidad robusta
Ningún modelo matemático puede predecir con absoluta certeza la respuesta de
un sistema en condiciones reales de funcionamiento. En consecuencia, cualquier método
de diseño de controladores debe considerar este hecho, introduciendo incertidumbre en el
modelo.
Considere por ejemplo el lazo mostrado en la figura 2.6. La matriz de transferencia
∆(s) representa una incertidumbre no estructurada que se adiciona al modelo de la planta
a lazo abierto G(s). Suponga que ∆(s) esté acotada de forma que se cumpla
‖∆(s)‖∞ ≤ 1 (2.22)
Entonces es posible demostrar que el sistema a lazo cerrado es estable si y sólo si se cumple∥∥K(s) (I + G(s)K(s))−1∥∥∞ < 1 (2.23)
Figura 2.6: Lazo de realimentación con incertidumbre no estructurada ∆
De manera general, se considera que mientras menor sea la norma que aparece en lado
izquierdo de la desigualdad (2.23) más robusto será el lazo de control con respecto las
incertidumbres sobre el modelo de la planta. Sin embargo, a medida que se mejora la
robustez del diseño, es posible que se degrade al mismo tiempo el desempeño del lazo
medido en términos de la norma de otro canal del modelo. De esta forma se constata
nuevamente la necesidad de adoptar un enfoque multi-objetivo en el tratamiento de los
problemas de diseño.
2.3. Controladores PID
De acuerdo con Åström y Hägglund (1995) cerca del 95% de los controladores
instalados en la industria son del tipo Proporcional-Integral-Derivativo (PID). Su principal

23ventaja en la práctica consiste en que vienen pre-programados en los equipos electrónicos
comerciales y por ende son bien conocidos tanto por los ingenieros como por los operadores
y responsables del mantenimiento de las plantas.
Desde un punto de vista teórico, un PID asegura un error en estado estacionario nulo
para una referencia en forma de escalón gracias a su efecto integrador. Por otro lado, la
acción derivativa interviene cuando hay cambios bruscos en el error (si el error cambia
lentamente, la contribución principal se debe a los modos proporcional e integral).
Considerando las ventajas expuestas anteriormente, se entiende la necesidad de veri-
ficar si es posible resolver un problema de diseño mediante una estructura PID (o alguna
adaptación de la misma) antes de considerar soluciones más complejas.
En la literatura es posible encontrar varias formas para expresar la función de trans-
ferencia de un controlador PID. La más simple es la conocida como forma ideal
KPID(s) =KDs2 + KPs + KI
s(2.24)
caracterizada por tres parámetros realesKD, KP , KI que deben ser ajustados por el diseñador
del sistema de control (ver figura 2.7).
Figura 2.7: Lazo de control con PID ideal
2.3.1 Método de Ziegler y Nichols
El investigador Aidan O’Dwyer (2006) ha contabilizado 408 reglas para el ajuste
de los parámetros PID, de las cuales 293 fueron propuestas después de 1992. Una de las
más importantes históricamente fue publicada por Ziegler y Nichols en 1942 y consiste
básicamente en las siguientes fórmulas
KP = 0.6Ku (2.25)
KI = 1.2KuTu
KD = 0.075KuTu

24donde Tu es el período de las oscilaciones que se obtienen a lazo cerrado cuando se in-
crementa progresivamente la ganancia de la cadena directa desde cero hasta el valor Ku.Considere el siguiente modelo a lazo abierto
G(s) =−0.5s4 − 7s3 − 2s + 1
(s + 1)(s + 2)(s + 3)(s + 4)(s2 + s + 1)(2.26)
Para este modelo, las oscilaciones críticas se obtienen para Ku = 6.2 y el período de
las oscilaciones es Tu = 4.2 lo cual, según las fórmulas de Ziegler y Nichols corresponde
a KP = 3.7, KI = 1.8 y KD = 1.95. La respuesta del sistema a lazo cerrado ante una
entrada de referencia en forma de escalón se muestra en la figura 2.8. Para este controlador,
los índices de respuesta temporal tienen los siguientes valores ess = 0, tr(90%) = 24.5,
ts(5%) = 30.9 y Mp = 0.
0 20 40 60 80 100−0.5
0
0.5
1
t
y(t)
Figura 2.8: Respuesta del sistema con los parámetros KD,KP , KI de acuerdo con lasfórmulas de Ziegler y Nichols
Aunque goza de mucha aceptación debido a su sencillez, el ámbito de aplicación del
método de Ziegler y Nichols, y de la mayoría de los métodos similares, es bastante limitado.
Por ejemplo, ninguno garantiza el logro de un compromiso satisfactorio entre un conjunto
de índices de desempeño, en relación con los problemas de diseño multi-objetivo formulados
en la sección anterior.
2.3.2 Método de Hohenbichler y Abel
Cuando se decide adoptar una estrategia de control PID, surge la duda acerca de
cuáles son los valores de los parámetrosKP ,KD, KI (si es que éstos existen) que garantizan
la estabilidad del sistema a lazo cerrado.

25En este sentido, Hohenbichler y Abel (2008) propusieron un método para calcular
los límites de la región de controladores PID estabilizantes en el espacio (KP , KD,KI).
Dado un modelo de planta G(s) a lazo abierto, estos autores demostraron que es posible
determinar los intervalos de la ganancia proporcional KP tales que exista al menos un
plano (KD, KI) estabilizante. La única limitación para este resultado es que el sistema a
lazo abierto no posea ceros en el eje imaginario.
La idea básica de dicho método se fundamenta en el teorema propuesto en (Ackermann
& Kaesbauer, 2003), el cual afirma que las regiones estabilizantes en el planoKI−KD para
unKP fijo, están formadas por polígonos convexos cuyos vértices pueden ser determinados.
Considere una función de transferencia a lazo abierto expresada como:
G(s) =A(s)
R(s), B(s) = sR(s) (2.27)
con
A(s) = amsm + am−1sm−1 + . . . + a1s + a0, am = 0 (2.28)
B(s) = bnsn + bn−1sn−1 + . . . + b1s, bn = 0
y para un valor s = jω, denote:
RA(ω) = Re [A(jω)] , RB(ω) = Re [B(jω)] (2.29)
IA(ω) = Im [A(jω)] , IB(ω) = Im [B(jω)]
Suponga que se interconecta G(s) con un controlador PID ideal de manera que la ecuación
característica del lazo cerrado se escriba como (ver figura 2.7):
P (s) =(KDs2 + KP s + KI)A(s) + B(s) = 0 (2.30)
Ackermann y Kaesbauer (2003) demostraron el siguiente resultado: Para un valor fijo
de KP , la región de estabilidad del polinomio P (s) en el plano KI −KD está compuesta
por polígonos convexos, cuyos vertices se definen mediante la intersección de las siguientes
rectas:
KI = 0 (2.31)
KD =
0 si n < m + 2
− bnam , si n = m+ 2
∞, si n > m+ 2
(2.32)

26
KI = KDω2 − RA(ω)RB(ω) + IA(ω)IB(ω)
R2A(ω) + I2A(ω)(2.33)
donde ω > 0 (denominada frecuencia singular) es solución real de la ecuación
ω =IA(ω)RB(ω)−RA(ω)IB(ω)
KP (R2A(ω) + I2A(ω))(2.34)
Considere la función de transferencia propuesta anteriormente en (2.26). Para KP =
−4.4 las rectas que delimitan la región de estabilidad en el plano KI −KD , junto con sus
respectivas frecuencias singulares, se muestran en la tabla 2.1. En la figura 2.9 se grafican
dichas rectas, de manera que es posible observar los límites de la región de estabilidad
para este valor particular de KP .La respuesta al escalón del sistema a lazo cerrado correspondiente a los valores KP =
−4.4, KI = 2.2 y KD = −10 se muestra en la figura 2.10. En este caso los índices
de respuesta temporal tienen los siguientes valores ess = 0, tr(90%) = 15.9, ts(5%) =
32.6 y Mp = 17%. Note que a diferencia del lazo diseñado mediante Ziegler-Nichols,
esta respuesta presenta mayor sobre-elongación pero en contrapartida presenta un menor
tiempo de subida. Queda claro entonces que el valor de los índices de desempeño del
sistema a lazo cerrado dependen de la posición del vector de parámetros KP ,KI , KD en
el espacio de controladores estabilizantes.
Tabla 2.1: Frecuencias singulares y ecuaciones de las rectas que delimitan la región deestabilidad para KP = −4.4, modelo (2.26)
ω KI −KD- KI = 0- KD = ∞
0.32 KI = 0.1KD + 6.83.65 KI = 24KD − 88.8

27
−70 −60 −50 −40 −30 −20 −10 0
−4
−2
0
2
4
6
8
KD
KI
Figura 2.9: Límites de la región de estabilidad para KP = −4.4 para el modelo (2.26)
2.4. Reubicación de polos
En esta sección suponga que se desea diseñar un controlador para el sistema lineal
x(t) = Ax(t) + Bu(t)
y(t) = Cx(t) + Du(t)(2.35)
que se supone controlable y observable. Considere el cambio de variables de estado definido
mediante
x = Tx, u = Ru+ Fx (2.36)
donde T y R son matrices invertibles. Se obtiene de esta forma una representación
equivalente del sistema a lazo abierto:
·x= (T−1AT + T−1BF )x + (T−1BR)u
y = (CT + DF )x + DRu(2.37)
Por otra parte, si el vector de estados se encuentra disponible y se realimenta mediante
una matriz estática K ∈ Rnu×n de la forma
u = Kx, u = R−1(KT − F )x = Kx (2.38)
tendremos dos representaciones equivalentes a lazo cerrado
x = (A + BK)x
y = (C + DK)x⇔
·x= (A + BK)x
y = (C + DK)x(2.39)

28
10 20 30 40 50 60 70 80 90 100
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
t
y(t
)
Figura 2.10: Respuesta al escalón del sistema a lazo cerrado para el modelo (2.26)correspondiente al controlador PID caracterizado por KP = −4.4, KI = 2.2 y KD = −10
con
A = T−1AT + T−1BF,B = T−1BR (2.40)
C = (CT + DF ), D = DR (2.41)
y además
A + BK = T−1(A + BK)T (2.42)
En el caso de sistemas de una sola entrada y una sola salida, la transformación definida
por
T =(V V A . . . V An−1 )−1 , R = 1, F = −V AnT (2.43)
donde V es un vector tal que
V Ak−1B = 0, ∀k < n− 1, V An−1B = 1 (2.44)
produce el par(A,B)en la forma controlable
A =
0 1 0 0 . . . 0
0 0 1 0 . . . 0...
......
. . . . . . 0
0 0 0 0 1 0
0 0 0 0 0 0
, B =
0
0...
0
1
(2.45)

29En particular, si se desea que el sistema a lazo cerrado esté caracterizado por el poli-
nomio
p(s) = sn + pn−1sn−1 + pn−2sn−2 + . . . + p1s + p0 (2.46)
basta con seleccionar
K = −(p0 p1 . . . pn−1 ) (2.47)
de donde es posible deducir
K = (RK + F )T−1 (2.48)
Si el vector de estados no se encuentra disponible, es posible realimentar un observador
de la forma ·x= Ax+ Bu+ L(Cx− y) (2.49)
donde (Cx − y) es el término de corrección y L ∈ Rn×ny es la matriz de ganancias del
observador, la cual debe ser calculada de forma que los autovalores de la matriz A + LC
pertenezcan todos a C−. La representación completa en espacio de estados del controlador
diseñado se expresa como
·x= (A + BK + LC)x− Ly
u = Kx(2.50)
Considere el sistema a lazo abierto definido por la función de transferencia (2.26). Para
asegurar un error en estado estacionario nulo ante una entrada de referencia en forma de
escalón unitario, se incluye un polo en el origen en el modelo a lazo abierto. El diagrama
de polos y ceros correspondiente se muestra en la figura 2.11. Suponga que se desea aplicar
el método explicado en esta sección de manera que a lazo cerrado se tenga el siguiente
vector de polos
λK =(−1 −2 −3 −4 −5 −0.5 + 0.866i −0.5− 0.866i
)(2.51)
Es posible verificar que este objetivo se logra mediante el vector de realimentación de
estados
K = −(
10 13.75 14.37 14.84 17.03 11.56 15)
Para completar el diseño es necesario calcular el vector de ganancias del observador L.
Suponga que se desea obtener el vector de polos para el observador λL = λK, lo cual se
logra mediante el vector de ganancias
L = −(
0 0 0 0 0 0 40)T
(2.52)

30La respuesta al escalón del sistema a lazo cerrado se muestra en la figura 2.12. En este caso
los índices de respuesta temporal tienen los siguientes valores ess = 0, tr(90%) = 2.85,
ts(5%) = 10.65 y Mp = 13%, los cuales son bastante mejores que los obtenidos mediante
los controladores PID presentados en la sección anterior. En contrapartida, la complejidad
de este controlador es mucho mayor que la de un PID.
−14 −12 −10 −8 −6 −4 −2 0
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
Figura 2.11: Diagrama de polos (×) y ceros (◦) a lazo abierto para el modelo (2.26)
0 5 10 15−1.5
−1
−0.5
0
0.5
1
1.5
t
y(t
)
Figura 2.12: Respuesta al escalón del sistema a lazo cerrado, para el modelo (2.26).Controlador diseñado mediante reubicación de polos.
2.5. Diseño de controladores mediante LMIs
Una LMI es una inecuación matricial lineal de la forma:
F (x) = F0 +m∑i=1 xiFi > 0 (2.53)

31donde cada xi ∈ R es una variable escalar real y cada Fi ∈ Rn×n es una matriz simétrica
constante. El símbolo de desigualdad en la ecuación (2.53) significa que la matriz F debe
ser positiva definida.
En numerosos problemas de diseño de controladores, las variables de decisión que deben
ser ajustadas son matrices simétricas. Considere por ejemplo la inecuación de Lyapunov
ATX + XA < 0 (2.54)
donde
X =
x1 x2
x2 x3 , A =
a11 a12
a21 a22 (2.55)
la cual puede reescribirse como en (2.53) definiendo F0 = 0 y
−x1F1 − x2F2 − x3F3 > 0 (2.56)
F1 =
2a11 a12
a12 0
(2.57)
F2 =
2a21 a11 + a22
a11 + a22 2a12 (2.58)
F3 =
0 a21
a21 2a22 (2.59)
De esta manera, resolver la inecuación (2.54) equivale a determinar una matriz X
tal que la matriz ATX + XA sea negativa semi-definida. En las próximas secciones se
formulan los problemas de diseño H2 y H∞, de amplia importancia en el área de sistemas
automáticos, los cuales pueden ser resueltos determinando la factibilidad de una LMI.
2.5.1 Problema H2En esta sección se considera el siguiente modelo lineal a lazo abierto:
·x
zjy
=
A Bj B
Cj Dj EjC Fj 0
x
wju
(2.60)

32y un controlador lineal K representado mediante:
·xcu
=
AK BK
CK DK xKy
(2.61)
de forma que a lazo cerrado se tiene
zj = Tjwj =
Aclj Bclj
Cclj Dclj wj (2.62)
con
Acl =
A + BDKC BCK
AK BKC (2.63)
Bclj =
Bj + DKFj
BKFj (2.64)
Cclj =(Cj + EjDKC EjCK ) (2.65)
Dclj = Dj + EjDKFj (2.66)
El problema H2 consiste en diseñar un controlador tal que
‖Tj(s)‖2 ≤ γ2j (2.67)
donde γ2j es el valor deseado para la norma de la matriz de transferencia a lazo cerrado,
el cual debe ser fijado por el diseñador.
Es posible demostrar (Scherer et al., 1997) que la desigualdad (2.67) se cumple si y
sólo si existen matrices X > 0, Y > 0, A, B, C, D tales que:
AX + XAT + BC +(BC)T
AT + A + BDC Bj + BDFj(AT + A + BDC
)TAY + Y AT + BC +
(BC)T
Y Bj + BFj(Bj + BDFj)T (
Y Bj + BFj)T−I
< 0
(2.68)
X I(CjX + EjC)T
I Y(Cj + EjDC)T
CjX + EjC Cj + EjDC Q
> 0 (2.69)

33
traza(Q) < γ2j (2.70)
Dj + EjDFj = 0 (2.71)
Si estas inecuaciones se cumplen, las matrices del controlador correspondiente se cal-
culan mediante las fórmulas:
MNT = I −XY (2.72)
DK = D
CK = (C − DCX)M−TBK = N−1(B − Y BD)
AK = N−1(A−NBcCX − Y BCcMT − Y (A + BDcC)X)M−TConsidere el siguiente modelo a lazo abierto, propuesto en (Scherer et al., 1997):
A B1 B
C1 D1 E1C F1 0
=
0 10 2
−1 1 0
0 2 −5
1
0
1
0
1
0
0 1 0
0 0 1
0
0
0
0
0 1 0 2 0
(2.73)
Para verificar si el anterior conjunto de inecuaciones es o no factible es posible utilizar
la instrucción feasp de MATLAB R©. En este caso, fijando γ21 = 10 las LMIs resultan
factibles y se obtienen los siguientes resultados
X =
473.7130 −24.7516 −6.9934
−24.7516 3.6762 −0.0953
−6.9934 −0.0953 4.2502
(2.74)
Y =
0.9540 1.5255 −4.2185
1.5255 11.8585 −20.8031
−4.2185 −20.8031 115.0885
(2.75)

34
‖T1(s)‖2 = 3.1748 ≤ γ21 (2.76)
y la función de transferencia del controlador correspondiente es
K2(s) = 1206.314(s + 5.008)(s + 1.365)
(s + 460.4)(s + 5.16)(s + 0.6827)(2.77)
2.5.2 Problema H∞De manera análoga a lo planteado en la sección anterior, el problema H∞ consiste
en diseñar K tal que
‖Tj(s)‖∞ ≤ γ∞j (2.78)
lo cual se cumple si y sólo si existen matrices X,Y, A, B, C, D tales que:
AX + XAT + BC +(BC)T
∗ ∗ ∗
(AT + A + BDC)T AY + Y AT + BC +(BC)T
∗ ∗
(Bj + BDFj)T (Y Bj + BFj)T −γ∞jI ∗
CjX + EjC Cj + EjDC Dj + EjDFj −γ∞jI< 0
(2.79)
Con γ∞1 = 10, las LMIs resultan factibles y se obtienen los siguientes resultados
X =
391.3011 −36.2150 −8.0631
−36.2150 56.4724 −4.3847
−8.0631 −4.3847 48.2515
(2.80)
Y =
1.2249 2.2637 −2.5332
2.2637 15.3622 −12.9829
−2.5332 −12.9829 75.7149
(2.81)
‖T1(s)‖∞ = 3.2448 ≤ γ∞1 (2.82)
y el controlador correspondiente es
K∞(s) = 1.225(s− 46.14)(s + 4.799)(s + 2.718)
(s + 13.94)(s + 5.707)(s + 2.351)(2.83)

352.6. Resumen del capítulo
En este capítulo se introdujeron algunos conceptos básicos relacionados con el
control de sistemas lineales a lazo cerrado. Se presentó un breve repaso de tres métodos
que han sido propuestos para el control de sistemas lineales: PID, reubicación de polos
y factibilidad de LMIs. La ventaja de la estructura PID consiste en su sencillez y bajo
orden. Además, la región de estabilidad está perfectamente definida y puede calcularse
a partir del método propuesto por Hohenbichler y Abel (2008). La reubicación de polos
permite, en el caso SISO, seleccionar la posición de los polos a lazo cerrado, lo cual permite
al menos asegurar la estabilidad de la interconexión Modelo Nominal / Controlador. Las
herramientas que permiten resolver LMIs se han convertido en una de las mejores opciones
disponibles en el área del diseño de controladores lineales. En este capítulo se presentó un
conjunto de LMIs que deben ser satisfechas para que las normas H2 y H∞ de una matriz
de transferencia sean acotadas.
También se definieron indicadores de desempeño que pueden adoptarse como medida
de la calidad de una interconexión Planta/Controlador, de tal forma que el diseño puede
a partir de este punto plantearse como la búsqueda de soluciones que representen un buen
compromiso entre distintos indicadores en conflicto, problema que se analiza de manera
detallada en el próximo capítulo.

CAPÍTULO III
OPTIMIZACIÓN MULTI-OBJETIVO
En este capítulo se analizan algunos conceptos relacionados con los problemas de opti-
mización de múltiples objetivos y con las estrategias que pueden plantearse para resolver-
los. Se introduce brevemente el tema de los mecanismos para el archivo de las soluciones
no-dominadas y el tema de las restricciones. Seguidamente se describe el funcionamiento
de tres algoritmos genéticos en particular, a saber: MOGA, NSGA-II y SPEA2. Por úl-
timo, se introduce el tema de la evaluación del desempeño estadístico de estos algoritmos.
3.1. Definiciones
Resolver un problema de optimización multi-objetivo (POM) consiste en mini-
mizar de manera simultánea un conjunto de funciones de la forma
minx∈X f1(x) (3.1)
minx∈X f2(x)
...
minx∈X fM(x)
donde x representa el vector de decisión, X ⊂ Rn el espacio de búsqueda y n ∈ N, n > 0,
el número de variables de decisión (Roy, 1971).
En general, la reducción del valor de una de las funciones objetivo conduce al incre-
mento de otra, por lo cual no existe un x∗ ∈ X que sea mínimo de todas simultaneamente.
Para Osyczka (1985) el símbolo “min” debe ser interpretado en el caso multi-objetivo como
la búsqueda de un conjunto de soluciones que produzcan valores aceptables para todos los
objetivos.
Muchos métodos que se han propuesto para resolver este problema se basan en una
transformación escalar del vector objetivo, de la forma
U : RM → R (3.2)

37con el fin de replantear el problema de optimización en forma escalar, como
minz1,z2,...,zM U(z1, z2, . . . , zM) (3.3)
sujeto a : zi = fi(x) , 1 ≤ i ≤M , x ∈ X
Kalianmoy Deb (2001) considera que reducir el problema vectorial a uno escalar, im-
plica en general alguna pérdida en la calidad de las soluciones que pueden obtenerse. Los
algoritmos que producen una sola solución deben ejecutarse en repetidas ocasiones para
identificar los mejores compromisos, utilizando conocimiento previo sobre el problema para
definir prioridades entre los objetivos.
Un enfoque alternativo consiste en la búsqueda de soluciones especiales llamadas no-
dominadas, de acuerdo con los conceptos que se definen a continuación . Dado el problema
planteado en (3.1), se denomina Espacio Objetivo y se denota F al conjunto definido por
z ∈F ⇐⇒ ∃x ∈ X : z = F(x) =(f1(x) f2(x) ... fM(x)
)T(3.4)
Sean z1 y z2 dos vectores pertenecientes a F . Se dice que z2 es dominado por z1 y se
denota z1 z2 si y solo si
z1i ≤ z2i , i = 1, 2, ...,M (3.5)
∃i ∈ {1, ..,M} : z1i < z2iSi todas las componentes de z1 son estrictamente menores que las de z2 , es decir, si se
cumple
z1i < z2i , i = 1, 2, ...,M (3.6)
se dice entonces que z2 es estrictamente dominado por z1 y se denota z1 ≺ z2. También
puede suceder que los vectores z1 y z2 sean no dominados mutuamente, es decir, tales que
z1 � z2 ∧ z2 � z1 (3.7)
En este caso se dice que z1 y z2 son incomparables y se denota
z1 ‖ z2 (3.8)
Sea BM el conjunto de números binarios de M dígitos tales que
b ∈ BM ⇐⇒
b = bMbM−1 . . . b2b1, bi ∈ {0, 1}, i = 1, 2, . . . ,M
b = 00 . . . 000, b = 11 . . . 111(3.9)

38Se denomina cono de diversidad de tipo b definido en el punto x al conjunto C(x, b) definido
por
y ∈ C(x, b) ⇐⇒
fi(y) ≤ fi(x) si bi = 0
fi(y) > fi(x) si bi = 1para i = 1, 2, . . . ,M (3.10)
Note que el número de conos de diversidad es igual a 2M − 2. Como ejemplo, x1 ∈C(x0, 110) si y sólo si
f1(x1) ≤ f1(x0) (3.11)
f2(x1) > f2(x0)f3(x1) > f3(x0)
Se denomina Conjunto Óptimo Global de Pareto (COGP) y se denota P∗ al conjunto
para el cual se cumple
x∗ ∈ P∗ ⇔ ∄x ∈ X , F(x) F(x∗) (3.12)
De manera similar, se denomina Conjunto Óptimo Local de Pareto (COLP) y se denota
P∗L a cualquier conjunto para el cual se cumple
x∗ ∈ P∗L ⇔ ∄x ∈ XL , F(x) F(x∗) (3.13)
donde XL es un sub-conjunto de X .
Se denomina Frente Óptimo Global de Pareto (FOGP) y se denota PF∗ al conjunto
para el cual se cumple
z∗ ∈ PF∗ ⇔ ∃x∗ ∈ X , z∗ = F(x∗) (3.14)
Se denomina Frente Óptimo Local de Pareto (FOLP) y se denota PF∗L al conjunto para
el cual se cumple
z∗ ∈ PF∗L ⇔ ∃x∗ ∈ XL , z∗ = F(x∗) (3.15)
Note que si todas las funciones objetivo son continuas y derivables, una condición
necesaria para x∗ ∈ P∗ es que se cumpla
∇fi(x∗)Td ≥ 0,∀i ∈ {1, ..,M},∀d ∈ RM (3.16)
De hecho, es posible calcular una dirección de descenso para todas las funciones objetivo
(3.1) a partir de la información sobre los gradientes ∇fi(x), i ∈ {1, ..,M}.

39En efecto, sea x ∈ X y sea d ∈ Rn, d = 0, definida mediante
d = −M∑i=1 α∗i∇fi(x) (3.17)
donde α∗ ∈ RM es solución del problema
minα∈RM ∥∥∥∑Mi=1αi∇fi(x)∥∥∥22
sujeto aM∑i=1αi = 1,αi ≥ 0
(3.18)
entonces Schäffler et al (2002) demostraron que si d es distinto de 0, entonces d es una
dirección de descenso para todas las funciones f1, f2, . . . , fM3.2. Estrategias para resolver un problema multi-objetivo
Una gran cantidad de estrategias se han propuesto para resolver problemas que
involucran objetivos en conflicto. Las preferencias del diseñador pueden ser consideradas
antes, durante o después del proceso de búsqueda. De esta forma es posible establecer la
siguiente clasificación.
3.2.1 Formulación de preferencias “a priori”
El rasgo común a este tipo de métodos es que el diseñador define sus preferencias
antes de ejecutar el algoritmo, ya sea mediante coeficientes de ponderación, metas mínimas
a alcanzar, orden lexicográfico, etc.
Método min-max Consiste en plantear el problema de la forma:
minx∈X maxi∈{1,2,...,M}
c1 (f1(x)− γ1)c2 (f2(x)− γ2)∗
∗
cM (fM(x)− γM)
(3.19)
En esta formulación los ci, γi se eligen para normalizar los valores de las funciones objetivo
y en general se utilizan las fórmulas:

40
ci =1
fimax − fimin (3.20)
γi = fimindonde
fimax = maxx∈X fi(x), i ∈ {1, 2, ...,M} (3.21)
fimin = minx∈X (x), i ∈ {1, 2, ...,M}
Note que de igual forma podría plantearse la minimización de cualquier otra norma para
medir la magnitud del vector de funciones objetivo.
Método de suma ponderada El problema se plantea de la forma
minx∈X M∑i=1 wici (fi(x)− γi) (3.22)
donde los wi son coeficientes que se eligen para ponderar la importancia relativa de cada
función objetivo. La desventaja de este enfoque es que no es sencillo seleccionar los valores
de wi, por lo cual en general se requieren varios intentos de ensayo y error para ajustarlos.
Los parámetros ci, γi se calculan de la misma forma que en el método anterior.
Método de restricción ε Este método se conoce igualmente como método de las de-
sigualdades (Zakian & Al-Naib, 1973). Consiste en resolver el siguiente problema escalar
minx∈X f1(x)
sujeto a:
fi(x) ≤ εi , i ∈ {2, 3, ...,M}
(3.23)
En este caso es necesario experimentar sucesivamente con distintos valores del vector ε,
relajando las restricciones que sean más dificiles de satisfacer, hasta conseguir una solución
satisfactoria.
Programación de metas Consiste en resolver el siguiente problema escalar
minx∈X M∑i=1wipisujeto a:
fi(x)− pi = ti, i ∈ {1, 2, 3, ...,M}
pi ≥ 0
(3.24)

41donde los wi, ti, i ∈ {1, 2, 3, ...,M} son parámetros que deben ser definidos por el diseñador.
Método de optimización lexicográfica En este método se establece un orden de
preferencia (lexicográfico) entre los objetivos. Se resuelve en primer lugar el problema
escalar
minx∈X f1(x) (3.25)
con α1 valor mínimo de f1. En una segunda etapa se intenta resolver el problema
minx∈X f2(x)
sujeto a:
f1(x) = α1 (3.26)
y así sucesivamente.
Por ejemplo, en una tercera etapa se intentaría resolver
minx∈X f3(x)
sujeto a:
f1(x) = α1f2(x) = α2 (3.27)
3.2.2 Formulación de preferencias de manera interactiva
Un ejemplo de este tipo de métodos es el Interactive Weighted Tchebycheff Pro-
cedure (IWTP), el cual consiste en resolver una secuencia de problemas escalares del tipo
minα α
sujeto a:
α ≥ wTF(x)
x ∈ X
(3.28)
Durante el proceso, el diseñador debe interactuar con el algoritmo, proporcionando el
vector de pesos w más adecuado, con el fin de explorar las zonas del espacio objetivo que
sean más interesantes a su criterio.

423.2.3 Formulación de preferencias “a posteriori”
Estos métodos generan un conjunto de potenciales soluciones al problema hasta
que se cumpla alguna condición de parada. Al finalizar la ejecución, el diseñador debe
seleccionar la solución definitiva entre las no-dominadas que se generaron durante el pro-
ceso de búsqueda. Un ejemplo sencillo consiste en generar vectores al azar, uniformemente
distribuidos en el espacio de variables y luego filtrarlos para extraer el sub-conjunto de
soluciones no-dominadas (ver algoritmo 3.1).
Otro ejemplo que puede ser incluido dentro de esta categoría son los llamados algorit-
mos genéticos multi-objetivo, los cuales se describen en la siguiente sección.
Entradas : P : Población generada por un algoritmo de optimizaciónSalidas : A : Conjunto de soluciones no-dominadas extraídas de Pi = 1;1j = 1;2Mientras i ≤ |P | hacer3
p1 ← Pi;4flag ← false;5Mientras (j ≤ |P |) ∧ (flag = false) hacer6
p2 ← Pj;7Si p2 p1 entonces8
flag ← true;9finsi10j = j + 1;11
Fin12Si flag = false entonces13
Incluir p1 en A;14finsi15i = i + 1;16
Fin17Algoritmo 3.1 : Extracción del sub-conjunto de soluciones no-dominadas
3.3. Algoritmos genéticos multi-objetivo
Los Algoritmos Genéticos (AG) ejecutan operaciones aleatorias sobre una población
de individuos, semejantes a las que se realizan durante el proceso de la evolución biológica
(mutaciones y recombinaciones). De manera similar a lo que ocurre en la naturaleza, los
individuos más adaptados tienen mayor probabilidad para sobrevivir y reproducirse con
respecto a los menos aptos. Jimenez y Sánchez (2002) identifican los siguientes elementos

43
Figura 3.1: Esquema general de un algoritmo genético
característicos de un AG (ver figura 3.1):
• Una representación del espacio de soluciones.
• Un método para crear nuevos individuos.
• Un criterio para comparar individuos entre sí, usualmente expresado mediante una
función de adaptación.
• Un método para seleccionar los individuos más adaptados.
• Un conjunto de operadores de variación.
• Un conjunto de parámetros que guían la evolución del algoritmo: tamaño de la
población, número de iteraciones, probabilidades de aplicación de los operadores,
etc.
• Un criterio de parada.
Tradicionalmente se considera que los AG realizan de manera adecuada la búsqueda
global (exploración) pero no son eficientes para la explotación de las soluciones (Hart,
1994). Otra importante desventaja de estos algoritmos es que no existen reglas precisas
para ajustar los parámetros que controlan la dinámica del algoritmo, ni para decidir el
tipo de operador que conviene utilizar (Eiben & Smith, 2003).
No obstante, numerosos autores han publicado reportes en los que afirman que este tipo
de herramientas han permitido resolver problemas de optimización de alta complejidad,
especialmente en aplicaciones de control automático (Fleming & Purshouse, 2002).

443.3.1 Operadores de variación
A continuación se describen algunos operadores de variación que transforman uno
o más vectores reales en otro u otros vectores reales. Cada operador se aplica sobre uno o
varios individuos con una probabilidad, denotada pc en el caso de los operadores de cruce
y pm en el caso de los operadores de mutación.
La terminología que se adopta en este capítulo fue propuesta en (Eiben & Smith, 2003).
En particular, se denomina cromosoma a la estructura que contiene la información genética
de un individuo, la cual puede venir expresada en diversos formatos alfa-numéricos. Cada
cromosoma está compuesto por diversos genes, los cuales se asocian con las variables de
decisión del problema de optimización.
Operadores de cruce
Los operadores de cruce generan nuevos individuos (hijos) a partir de la informa-
ción de dos o más padres. De acuerdo con la naturaleza de la operación que llevan a cabo,
es posible identificar dos tipos:
• Operadores discretos, caracterizados por uno, dos o más puntos de cruce, tal
como se muestra en las figuras 3.2 y 3.3. Cada punto de cruce define una sección de
cromosoma que será heredada por uno de los hijos. En el caso extremo, si cada gen
se elige aleatoriamente a partir del cromosoma de uno de los padres, el operador de
cruce se denomina uniforme.
• Operadores continuos, entre los cuales es posible mencionar el operador arit-
mético. Sean x1 y x2 los cromosomas correspondientes a dos individuos pertenecientes
a la población. El operador de cruce aritmético genera dos nuevos individuos x1 y
x2 mediante
x1 = αx1 + (1− α)x2 (3.29)
x2 = (1− α)x1 + αx2donde α es un escalar aleatorio uniformente distribudo en el intervalo [0, 1]. Note
que si la región factible es convexa y los padres x1,x2 son factibles, los hijos x1,x2generados por este operador son igualmente factibles.

45
Figura 3.2: Operador discreto de cruce de un punto. El punto de cruce se encuentra enla mitad del cromosoma.
Figura 3.3: Operador discreto de cruce de dos puntos.
Un operador continuo citado frecuentemente en la literatura es el Simulated Binary
Cross-Over (SBX) propuesto en (Deb & Agrawal, 1995). Este operador produce dos hijos
a partir de dos padres mediante las ecuaciones :
x1i =1
2(1 + βi)x1i +
1
2(1− βi)x2i (3.30)
x2i =1
2(1− βi)x1i +
1
2(1 + βi)x2i
con
βi =
(2ri) 1ηc+1 , si ri ≤ 12( 12(1−ri)) 1ηc+1 (3.31)
donde ri es una variable aleatoria distribuida uniformemente en el intervalo [0, 1] y ηc es
un coeficiente que regula la distancia entre los cromosomas de los padres y los hijos. Un
valor ηc ≫ 1 produce hijos que con alta probabilidad se encuentran muy cerca de sus
padres en el espacio de variables.

46Operadores de mutación
En el mundo natural, una mutación es un fenómeno poco común. En mamíferos
la tasa de mutación es de 1 en 2.2×109 bases nucleotídicas (Kumar & Subramanian, 2002)
mientras que en los virus es del orden de 1 en 100 (Malpica et al., 2002). En la mayoría de
los casos las mutaciones son letales para los organismos (los mutantes no suelen alcanzar
la edad reproductiva) pero a lo largo del proceso evolutivo, contribuyen a incrementar la
diversidad genética de la especie.
De cualquier forma, el operador de mutación se aplica únicamente a un porcentaje
reducido de los genes totales de la población. Este porcentaje se puede seleccionar de
dos maneras: de forma fija, especificando el mismo porcentaje de mutación en todas
las generaciones del algoritmo genético y de forma variable, por ejemplo reduciendo el
porcentaje de una generación a otra. De esta manera, se intenta realizar una búsqueda
más amplia al principio del algoritmo y más restringida en las generaciones finales.
Un operador de mutación puede ser representado de la forma
〈x1,x2, . . . ,xn〉 → 〈x1,x2, . . . ,xn〉 (3.32)
donde el vector x representa al individuo original y x representa al mutante. Un tipo
común de mutación es la perturbación aletoria, definida mediante
xi = xi + δi , ∀i ∈ {1, 2, . . . , n} (3.33)
donde cada δ es un vector aleatorio de distribución uniforme, gaussiana u otra.
3.3.2 Esquemas de selección
Por convención, se denota µs al número de padres que conforman la población
actual, a partir de los cuales se generan λs hijos. En un algoritmo de tipo (µs, λs) los hijos
son directamente seleccionados para ser parte de la próxima generación (sin competencia
en contra de sus padres). Si λs < µs es necesario completar a partir de los antiguos padres.
Si λs > µs es posible eliminar los peores hijos hasta que queden exactamente µs.Por el contrario, en un algoritmo de tipo (µs + λs) se establece una competencia entre
padres e hijos para seleccionar los µs sobrevivientes.

47Se han propuesto numerosos métodos para la selección de un sub-conjunto de indi-
viduos a partir de una población inicial. La mayoría se basa en la definición de una
función de adaptación (fitness) Fit(i) ≥ 0 para cada individuo i, lo cual permite realizar
comparaciones.
Por ejemplo, el torneo binario consiste en seleccionar al azar (con probabilidad uni-
forme) dos individuos pertenecientes a la población. Sean Fit(i) y Fit(j) los valores de la
función de adaptación correspondientes a los individuos i, j. El torneo binario selecciona
el individuo i si y sólo si se cumple Fit(i) ≥ Fit(j) (se dice en este caso que i está más
adaptado que j). En caso contrario se selecciona el individuo j.
Otro método consiste en asignar a cada individuo i una probablidad de selección pro-
porcional a su función de adaptación de la forma
pi =Fit(i)∑µsi=1 Fit(i) (3.34)
Sin embargo, el método descrito en el párrafo anterior presenta desventajas debido a
que suele conducir a dos situaciones extremas: convergencia prematura o convergencia
lenta. Por esta razón, Eiben y Smith (2003) recomiendan una alternativa basada en el
ordenamiento de la población en valores decrecientes de la función de adaptación y la
asignación de la probabilidad de selección mediante la fórmula
pi =2− s
µs +2(µs − r(i) + 1)(s− 1)
µs(µs + 1)(3.35)
donde r(i) es el rango del individuo en la lista ordenada y s ∈ [1, 2] es un parámetro que
controla la presión de selección. Cuando s se acerca a 2, mayor presión se ejerce para
seleccionar los mejores individuos. Por el contrario, cuando s se acerca a 1, todos los
individuos tienen idéntica probabilidad de selección.
3.3.3 Métodos de archivo
El problema de la gestión de archivo se presenta de manera natural cuando se
intenta generar una aproximación finita, lo más cercana y bien distribuida posible con
respecto al verdadero frente de Pareto. La idea básica para la gestión del archivo consiste
en comparar la solución actual con respecto a las que ya existen en el archivo, para
posteriormente decidir si es conveniente o no incluir la nueva, eliminando las soluciones
dominadas por esta última.

48Para comprobar si una solución pertenece o no al archivo es posible considerar un
criterio de similitud, ya sea en el espacio objetivo o en el espacio de variables. El objetivo
consiste en evitar que se archiven soluciones duplicadas o muy similares, de tal manera
que se preserve la diversidad genética y se mejore la distribución de las soluciones.
También es posible considerar cualquier otro criterio que se estime conveniente para
favorecer el tipo de soluciones que se desea archivar, o utilizar conceptos especiales de
dominancia, que incluyan las preferencias del diseñador. Cuando el archivo sobrepasa
su capacidad máxima es necesario eliminar algunas soluciones, tomando en cuenta por
ejemplo una medida de densidad, para favorecer a las soluciones pertenecientes a las
regiones menos pobladas.
3.3.4 Tratamiento de las restricciones
Un problema de optimización multi-objetivo con restricciones puede plantearse
como sujeto a
minx∈X ( f1(x) f2(x) . . . fM(x))T
sujeto a:
g1(x) ≤ 0
g2(x) ≤ 0...
gR(x) ≤ 0
(3.36)
Una estrategia frecuentemente considerada consiste en transformar el problema en uno
sin restricciones mediante la incorporación de una función de penalidad por cada objetivo,
de la forma
minx∈X f1(x) + p1(x) (3.37)
minx∈X f2(x) + p2(x)
...
minx∈X fM(x) + pM(x)
donde usualmente se toma
pi(x) =R∑j=1 wij [max (0, gj(x))] , i = 1, 2, . . .M (3.38)

49y los parámetros wij son pesos que deben ser ajustados para ponderar el efecto de cada
restricción sobre cada función objetivo. Precisamente, una desventaja de este enfoque es
que puede ser difícil seleccionar estos pesos de manera que el algoritmo explore la región
factible de manera eficiente (Coello et al., 2007).
Algunos investigadores han propuesto transformar las restricciones del problema en R
nuevos objetivos, de manera que el problema se reformula como
minx∈X f1(x) minx∈X g1(x) (3.39)
minx∈X f2(x) minx∈X g2(x)
......
minx∈X fM(x) minx∈X gR(x)
Otra forma de atacar el problema de las restricciones consiste en modificar los esquemas
de selección de individuos, para dar prioridad a los individuos factibles con respecto a los
no factibles. También es posible utilizar operadores de reparación los cuales utilizan algún
mecanismo para transformar un individuo no factible en factible.
En general se recomienda no eliminar por completo a todos los individuos no factibles,
con el objeto de permitir la captura de las regiones del conjunto de Pareto que pertenezcan
a las fronteras de la región de factibilidad.
A continuación se presentan tres algoritmos frecuentemente citados en la literatura y
que, con numerosas variantes y mejoras, conforman el estado del arte en el área de la
optimización genética multi-objetivo.
3.3.5 Multi-Objective Genetic Algorithm (MOGA)
Propuesto originalmente por Fonseca (1995), este algoritmo ha sido utilizado en
numerosas aplicaciones de control (Chipperfield & Fleming, 1996; Chipperfield et al, 1998;
Duarte et al, 2000). Por ejemplo, en (Griffin et al., 2000) se utilizó para resolver un pro-
blema de diseño caracterizado por 10 objetivos y 12 variables de decisión. En (Adra et al.,
2005a) se propuso una versión híbrida para optimizar el sistema de control de una aeronave.
También en (Silva et al., 2008) se utilizó para diseñar el controlador H∞ de una turbina
de gas. Estos autores redujeron los tiempos de simulación mediante aproximaciones del
proceso no-lineal.

50El funcionamiento de MOGA se explica a continuación (ver algoritmo 3.2). A cada
individuo se le asigna un rango rMOGA de acuerdo al número de otros individuos que lo
dominan.
Entradas :P0 : Población inicial N : Número máximo de generacionesµs número de padres que conforman la poblaciónλs número de hijos a ser generadospc probabilidad de crucepm probabilidad de mutaciónσshare : Tamaño deseado para cada sub-poblaciónSalidas : P : Aproximación del Conjunto de Paretok = 1;1Mientras k ≤ N hacer2
Pk = Pk−1;3Calcular la función de adaptación para cada individuo de Pk de acuerdo con la4ecuación 3.41;Seleccionar los padres;5Aplicar los operadores de variación para generar los hijos;6Calcular la función de adaptación para cada individuo de Pk incluyendo a los7hijos generados en el paso anterior;Seleccionar los sobrevivientes y almacenarlos en Pk;8k = k + 1;9
Fin10Algoritmo 3.2 : Multi-Objective Genetic Algorithm (MOGA)
De esta forma, el rango rMOGA de un individuo i ∈ {1, 2, . . . µs} viene dado por:
rMOGA(i) = 1 + psup(i) (3.40)
donde psup(i) es el número de individuos que dominan a i (los no-dominados tendrán rango
1). En la figura 3.4 se muestra un ejemplo del rango correspondiente a una población de
7 individuos, en un problema de dos objetivos.
Para seleccionar los mejores individuos, MOGA adopta un mecanismo llamado fitness
sharing que consiste en calcular la función de adaptación de cada individuo mediante la
fórmula
Fit(i) =µs − rMOGA(i) + 1
µs µs∑j=1 Φ(dij) (3.41)
Φ(dij) =
1−( dijσshare)2 , si dij ≤ σshare
0, si dij > σshare (3.42)

51
Figura 3.4: Ejemplo de cálculo de rango para el algoritmo MOGA
donde
dij =∥∥Fi − Fj∥∥2 (3.43)
F es el vector de funciones objetivo y σshare representa la distancia mínima deseada (en
el espacio objetivo) entre dos soluciones pertenecientes a la aproximación final del Frente
de Pareto.
Este mecanismo penaliza a los individuos que habitan en zonas densamente pobladas,
intentando conservar la diversidad genética y mejorar la distribución.
3.3.6 Non-dominated Sorting Genetic Algorithm (NSGA-II)
Este algoritmo (Deb et al., 2000) es uno de los más ampliamente citados en la
literatura. En cuanto a las aplicaciones de control, en su tesis de doctorado Lagunas
(2004) lo utiliza para sintonizar los parámetros de un controlador PID de dos grados de
libertad. Por su parte, Dupuis et al (2004) presentan el diseño de un controlador PID
cuyos objetivos se plantean en función de las diferencias entre los índices deseados y los
índices simulados. También, Reyes et al (2009) presentan el diseño multi-objetivo de un
controlador difuso caracterizado por 50 variables de decisión.
El NSGA-II asigna un rango rNSGA−II(i) a cada individuo i ∈ {1, 2, . . . µs}, calculadocomo se explica a continuación. En cada iteración j (ver algoritmo 3.4) se determinan los
individuos no-dominados y se les asigna rango j. Seguidamente se eliminan los individuos
no-dominados de la sub-población actual y se comienza una nueva iteración (ver algoritmo
3.3). En la figura 3.5 se muestra un ejemplo de los rangos correspondientes a la misma
población presentada en la figura 3.4.

52
Entradas : P0 : Población inicialSalidas : rNSGA−II : Vector de rangos correspondiente a P0j = 1;1Mientras |Pj| > 0 hacer2
Generar el conjunto Qj de vectores no-dominados pertenecientes a Pj;3Actualizar el vector rNSGA−II asignando rango j a los individuos pertenecientes4a Qj;Pj+1 = Pj/Qj;5j = j + 1;6
Fin7Algoritmo 3.3 : Asignación de rango NSGA-II
Rango 1
Rango 2Rango 3
Figura 3.5: Ejemplo de cálculo de rango para el algoritmo NSGA-II
La preservación de diversidad de NSGA-II se basa en calcular para cada individuo una
cantidad llamada crowding distance, calculada como se explica a continuación (ver figura
3.6). En primer lugar se seleccionan los individuos que tengan el mismo rango. Luego se
ordenan estos individuos en valores crecientes con respecto al objetivo i ∈ {1, 2, . . .M}.
Sea ki el índice que corresponde a un individuo cualquiera en la lista ordenada con respecto
al objetivo i, de forma que sus vecinos más cercanos tengan índices ki − 1 y ki + 1.

53
Entradas :P0 : Población inicial N : Número máximo de generacionesµs número de padres que conforman la poblaciónλs número de hijos a ser generadospc probabilidad de crucepm probabilidad de mutaciónSalidas : P : Aproximación del Conjunto de Paretok = 1;1Mientras k ≤ N hacer2
Pk = Pk−1;3Calcular el vector de rangos y crowding distance para cada individuo en Pk;4Seleccionar los padres mediante torneo binario modificado;5Aplicar operadores de variación;6Calcular el vector de rangos y crowding distance para cada individuo en Pk7incluyendo los hijos generados en el paso anterior;Seleccionar los sobrevivientes mediante torneo binario modificado y8almacenarlos en Pk;k = k + 1;9
Fin10Algoritmo 3.4 : Non-Dominated Sorting Genetic Algorithm (NSGA-II)
d1
d2
crowding distance =
d1 + d2
crowding distance =∞
crowding distance =∞
Figura 3.6: Ejemplo de cálculo de crowding distance para el algoritmo NSGA-II

54El valor del crowding distance se calcula mediante la fórmula:
crowding distance =M∑i=1 Fki+1i − Fki−1i (3.44)
El mecanismo de selección utilizado por NSGA-II es un torneo binario modificado:
entre dos individuos se prefiere al que tenga menor rango. Si los rangos son iguales,
entonces se prefiere al que tenga el mayor valor de crowding distance.
3.3.7 Strength Pareto Evolutionary Algorithm (SPEA2)
Este algoritmo fue propuesto en (Zitzler et al., 2001) como una versión mejorada
del algoritmo SPEA (Zitzler, 1999). Pocas aplicaciones se han publicado en el área de
sistemas de control. Una de ellas fue presentada por Wang et al (2008) en la cual describen
el diseño de un controlador robusto para un sistema de calentamiento a base de vapor.
El SPEA2 utiliza un archivo externo A para almacenar los individuos no dominados
(ver algoritmo 3.5) generados durante el proceso de búsqueda.
Entradas :P0 : Población inicial N : Número máximo de generacionesµs número de padres que conforman la poblaciónλs número de hijos a ser generadospc probabilidad de crucepm probabilidad de mutaciónSalidas : Ak = 1;1Mientras k ≤ N hacer2
Calcular la función de adaptación Fit(i) para los individuos pertenecientes a Pk3y A;Seleccionar los padres mediante torneo binario modificado;4Aplicar operadores de variación;5Calcular la función de adaptación Fit(i) para los individuos pertenecientes a Pk6, A y los hijos generados en el paso anterior;Actualizar el archivo A;7Seleccionar los sobrevivientes mediante torneo binario modificado y8almacenarlos en Pk;k = k + 1;9
Fin10Algoritmo 3.5 : Strength Pareto Evolutionary Algorithm 2

55A cada individuo i se le asigna un valor S(i) llamado fuerza (del inglés, strength) que
se calcula como:
S(i) =∣∣{j : j ∈ P ∪A ∧Fi Fj}∣∣ (3.45)
es decir es el número de individuos que son dominados por i en el conjunto unión de P
y A. Posteriormente se calcula la suma de las fuerzas de los individuos que dominan a i
obteniendo
R(i) =∑j∈P∪P,zj zi S(j) (3.46)
En la figura 3.7 se presenta un ejemplo del cálculo de estos valores.
S=2
R=0
S=3
R=0S=2
R=0
S=3
R=0
S=1
R=2
S=1
R=6
S=1
R=8
S=0
R=13
Figura 3.7: Ejemplo de cálculo de S y R para el algoritmo SPEA2
Por otra parte se calcula un valor de densidad D(i) para cada individuo, definida como:
D(i) =1
2 + σi (3.47)
donde σi corresponde a la distancia entre el individuo i y su k-ésimo vecino más cercano
(ver figura 3.8). El valor de k se toma como el entero más cercano a√|P |+ |A|.
Finalmente, la función de adaptación Fit(i) de cada individuo se obtiene como
Fit(i) =1
R(i) + D(i)(3.48)
Para seleccionar los padres selecionan todos los individuos cuyo Fit(i) sea mayor que 1 (no-
dominados). Si este número es menor que λs, se completa con individuos cuyo Fit(i) sea
el mayor posible. En caso contrario se utiliza un mecanismo para eliminar los individuos
que habiten en las zonas de más alta densidad.

56
k-ésimo vecino más
cercano 1
2
3
σ
Población de 9 individuos → k = 3
distancia
Figura 3.8: Ejemplo de cálculo de la distancia σ para el algoritmo SPEA2
Para finalizar esta sección, en la tabla 3.1 se presenta un resumen de las ventajas y
desventajas de los tres algoritmos descritos anteriormente.
Tabla 3.1: Resumen de ventajas y desventajas de los algoritmos MOGA, NSGA-II ySPEA2
Algoritmo Ventajas DesventajasMOGA Utiliza un mecanismo
de asignación de rangosencillo
El usuario necesita es-pecificar el parámetroσshare
NSGA-II Utiliza un mecanismorápido para laasignación de rango.No necesita especi-ficar parámetrosadicionales
No integra la gestiónde un archivo externopara las soluciones no-dominadas
SPEA2 Utiliza un archivoexterno para alma-cenar las solucionesno dominadas. Nonecesita especi-ficar parámetrosadicionales
Es más lento com-parado con MOGA YNSGA-II

573.4. Evaluación de desempeño
El tema de la evaluación del desempeño de algoritmos multi-objetivo se encuentra
todavía en desarrollo. En esta sección se presentan en primer lugar los indicadores que
serán utilizados en los próximos capítulos. Luego se describe brevemente la prueba de
Wilcoxon, la cual permite la comprobación de hipótesis relacionadas con las medianas de
dos conjuntos de datos.
3.4.1 Índices de desempeño
Básicamente, son tres los aspectos que se miden mediante los índices que se han
propuesto (Coello et al., 2007):
• Cantidad de soluciones no-dominadas.
• Distancia entre las soluciones no-dominadas y las soluciones del COGP.
• Distribución de las soluciones no-dominadas: se desea obtener una distribución lo
más uniforme y completa que sea posible (que cubra la mayor parte del COGP).
Es interesante notar que la evaluación de las aproximaciones es también un problema
de naturaleza multi-objetivo. Por ello, los expertos recomiendan usar varios indicadores
para evaluar los distintos aspectos del desempeño de un algoritmo. En lo que sigue se
denota P a una aproximación cualquiera de P∗ y PF a la aproximación correspondiente
de PF∗.Distancia generacional
Este indicador, denotadoGD, mide la distancia promedio de las soluciones pertenecientes
a la aproximación PF con respecto a PF∗.GD =
1
|PF|
√√√√|PF|∑i=1 |di|2 (3.49)
di = minzk∈PF∗ ∥∥zi − zk∥∥ (3.50)
De igual forma es posible evaluar la Distancia Generacional Inversa (IGD) mediante la
fórmula
IGD =1
|PF∗|√√√√|PF∗|∑i=1 |di|2 (3.51)

58di = minzk∈PF ∥∥zi − zk∥∥ (3.52)
Mientras menores sean ambas medidas, mejor será la aproximación correspondiente.
Sin embargo, estos indicadores no son necesariamente compatibles: si uno tiene un valor
cercano a cero, esto no implica que el otro también lo tenga. En la figura 3.9 se muestran
dos ejemplos para ilustrar esta situación. La gráfica de la izquierda corresponde a un caso
en cual se tendría un valor bajo para GD y alto para IGD. La gráfica de la izquierda
muestra un ejemplo de la situación inversa.
f1
f2
GD ↓ IGD ↑
f1
f2
GD ↑ IGD ↓ Caso:
Caso:
Figura 3.9: Ejemplo de dos aproximaciones con distintos valores para los indicadoresGD, IGD
Distancia máxima
Es la distancia máxima medida entre dos soluciones cualesquiera pertenecientes a
la aproximación. En otras palabras, este indicador mide la extensión de la aproximación
del frente de Pareto (ver figura 3.10).
DMAX = maxzi,zk∈PF ∥∥zi − zk∥∥ (3.53)
Cobertura
Este indicador binario fue propuesto en (Zitzler, 1999), para comparar dos aproximaciones
PF1 y PF2, sin necesidad de conocer el COGP. Se define como sigue a continuación:
C (PF1,PF2) =|{z2 ∈ PF2 tales que ∃z1 ∈ PF1 : z1 z2}|
|PF2| (3.54)

59
f1
f2
DMAX
Figura 3.10: Ejemplo de cálculo para el indicador DMAX
Mide la proporción de elementos de PF2 que son dominados por al menos un elemento
de PF1. Por ejemplo, C(PF1,PF2) = 1 implica que todos los elementos de PF2 son
dominados por al menos un elemento de PF1.Espaciado
Propuesto en (Schott, 1995), este indicador mide la desviación de las distancias
entre los vecinos más cercanos en el espacio objetivo. Se define como sigue a continuación:
ESS =1
|PF|
√√√√|PF|∑i=1 ∣∣di − d
∣∣2 (3.55)
di = minzk∈PF,k �=i ∥∥zi − zk∥∥ , d =1
|PF|
|PF|∑i=1 di (3.56)
En la tabla 3.2 se muestra un resumen de los diferentes indicadores junto con el valor
ideal para cada uno de ellos. El símbolo ∞ significa que mientras más grande es el valor,
mejor es la aproximación con respecto al indicador correspondiente.

60Tabla 3.2: Resumen de indicadores de desempeño
Indicador Símbolo Valor IdealDistancia generacional GD 0
Distancia generacional inversa IGD 0Distancia máxima DMAX ∞
Cobertura C 1Espaciado ESS 0
3.4.2 Pruebas estadísticas
Los algoritmos genéticos pueden ser considerados fundamentalmente como pro-
cesos estocásticos. El mismo algoritmo, partiendo de las mismas condiciones iniciales,
produce resultados distintos cada vez que se ejecuta, lo cual justifica el empleo de me-
didas y pruebas estadísticas para comparar los resultados producidos por dos algoritmos
cualesquiera.
En particular, la prueba de Wilcoxon utiliza como estadístico de decisión W la suma
de los rangos de cada observación, siendo el rango el número que le corresponde a cada
observación cuando se ordenan todas en orden ascendente.
Suponga que se realizan siete ejecuciones de dos algoritmos, A1 y A2, comenzando a
partir de la misma población inicial. Posteriormente se calculan los valores correspondientes
a un indicador de desempeño I obteniendo los resultados de la tabla 3.3.
Tabla 3.3: Ejemplo de valores obtenidos para el indicador I correspondientes a 7 ejecu-ciones de los algoritmos A1 y A2
I A1 A21 0.44 0.502 0.55 0.483 0.61 0.584 0.53 0.525 0.56 0.596 0.45 0.657 0.54 0.70
Promedio 0.52 0.57
La prueba consiste en formular una hipótesis nula de la forma
H0 : IA1 = IA2 (3.57)

61y una hipótesis alternativa
H1 : IA1 = IA2 (3.58)
con un nivel de significancia α, donde IA1 y IA2 son las medianas de cada proceso estocás-
tico. En la figura 3.11 se muestra el cálculo de los estadísticos WA1, WA2 para el ejemplo
de la tabla 3.3.
Figura 3.11: Cálculo de los rangos para la prueba Wilcoxon
Si el p-valor correspondiente a la prueba es menor que α entonces se rechaza la hipótesis
H0. Este valor puede obtenerse mediante la instrucción ranksum de MATLAB R© y es igual
a 0.3829 para este caso, por lo cual no existe evidencia estadística para rechazar la hipótesis
H0 con un nivel de significancia α = 0.05.
3.5. Resumen del capítulo
En este capítulo se definieron algunos conceptos básicos relacionados con el área
de optimización multi-objetivo y algoritmos genéticos, tales como conjunto y frente de
Pareto, dominancia, direcciones de descenso, conos de diversidad, operadores de variación
y esquemas de selección.
Se realizó un breve repaso de las estrategias que pueden ser utilizadas para resolver un
problema de esta naturaleza, las cuales pueden ser agrupadas en 3 categorías:
• Formulación de preferencias a priori
• Formulación de preferencias de manera interactiva
• Formulación de preferencias a posteriori

62Con respecto a esta última categoría, se presentó un breve análisis de los algoritmos
MOGA, NSGA-II y SPEA2, los cuales son los más citados en la literatura y constituyen
el estado del arte en esta área.
Un punto importante para la evaluación del desempeño de estos algoritmos consiste
en la definición de índices para medir la calidad de las aproximaciones generadas. En este
capítulo se definieron índices tales como la distancia generacional, distancia generacional
inversa, cobertura, espaciamiento, etc.
Puesto que el proceso de búsqueda es fundamentalmente estocástico, se hace im-
prescindible el uso de pruebas estadísticas para la correcta evaluación de los resultados.
La prueba de Wilcoxon presentada permite la comprobación de hipótesis relacionadas
con las medianas de dos conjuntos de datos, sin necesidad de conocer las distribuciones
probabilísticas asociadas. Esta prueba será utilizada en los próximos capítulos para evaluar
el desempeño de los algoritmos propuestos.

CAPÍTULO IV
DISEÑO DE CONTROLADORES PID MULTI-OBJETIVO
En este capítulo se proponen nuevos operadores de variación, especialmente conce-
bidos para el diseño de controladores PID mediante algoritmos genéticos. La idea principal
consiste en garantizar la generación y el mantenimiento de una alta proporción de indi-
viduos factibles durante todo el proceso de búsqueda.
En primer lugar se utiliza el método propuesto en (Hohenbichler & Abel, 2008) para
generar los vértices de la región factible correspondiente al sistema a lazo cerrado. Poste-
riormente se propone un nuevo método para aproximar la geometría de la región factible,
basado en muestreo aleatorio uniforme (Calafiore & Dabbene, 2006).
Parte de los resultados presentados en este capítulo fueron previamente incluidos como
parte de las publicaciones (Sánchez et al., 2008a) y (Sánchez et al., 2009).
4.1. Antecedentes
Es posible encontrar en la literatura numerosas referencias de trabajos previos
relacionados con el problema que se intenta resolver en este capítulo, basados tanto en
algoritmos deterministas como aleatorios.
Con respecto a los primeros, Åström et al (1998) utilizaron el algoritmo de Newton-
Raphson para minimizar la energía de la señal de error en un lazo de control PID sujeto
a la acción de una perturbación de salida. Estos autores señalan que el resultado de la
optimización depende fundamentalmente del punto de inicio seleccionado.
Hwang & Hsiao (2002) resuelven el problema no-convexo de la siguiente forma: parten
de un valor arbitrario para la constante derivativa y a partir de allí resuelven el problema
de dos variables (proporcional/integral) incluyendo restricciones para asegurar estabilidad.

64Granado et al (2007) presentan el diseño de un controlador PID multivariable robusto,
el cual garantiza la estabilidad a lazo cerrado de sistemas lineales sujetos a incertidum-
bre poliédrica. El algoritmo de diseño se basa en resolver un conjunto de BMIs (Bilinear
Matrix Inequalities) de manera iterativa. Tal como se mencionó en la introducción, la
desventaja de este tipo de enfoques es que las soluciones encontradas pueden ser en oca-
siones demasiado conservadoras y por otra parte únicamente consiguen una solución en
cada ejecución (ver capítulo 6).
Con respecto al empleo de algoritmos aleatorios, Herreros (2000) propuso dos nuevos
algoritmos en su tesis de doctorado, a saber MRCD y MRCD-min-max. Este autor diseñó
controladores PIDs para los sistemas de ensayo de bajo órden propuestos en (Astrom et
al., 1998), consiguiendo mejores soluciones que las obtenidas mediante LMIs.
En (Dupuis et al., 2004) se reporta el diseño de un PID para controlar la velocidad
de giro de un motor de corriente continua, utilizando el algoritmo NSGA-II. Los obje-
tivos fueron planteados en función de la diferencia entre la dinámica obtenida durante
la simulación y la dinámica deseada. Se tomó en cuenta el criterio de estabilidad de
Routh-Hurwitz a efectos de generar individuos estables.
Por último, en su tesis doctoral Lagunas (2004) utilizó el NSGA-II para diseñar contro-
ladores PIDs en el caso de los sistemas de ensayo SISO propuestos en (Astrom et al., 1998).
Se consideraron los siguientes objetivos: seguimiento de la señal de referencia, rechazo de
perturbación en la carga, atenuación de ruido en la medición, robustez ante variaciones de
los parámetros de la planta y acotamiento de la señal de control.
4.2. Método de diseño basado en el cálculo exacto de la región deestabilidad
Los algoritmos genéticos operan en el interior de un espacio de búsqueda finito,
generalmente definido por el diseñador, el cual debe incluir la región factible para que el
proceso de búsqueda sea capaz de conseguir soluciones válidas.
Típicamente, la población inicial es generada mediante muestreo aleatorio uniforme en
el espacio de búsqueda. Esto significa que cada cromosoma xi, i = 1, 2, . . . µs, es generado
mediante la fórmula
xij = Lj + rj (Lj − Lj) , j = 1, 2, . . . n (4.1)

65donde L,L ∈ Rn son vectores que definen el intervalo de búsqueda para cada variable de
decisión y cada ri es una variable aleatoria distribuida uniformemente en [0, 1].
Sin embargo, este método puede resultar bastante ineficiente para producir una alta
proporción de individuos factibles, en aplicaciones de diseño de controladores. Para ilustrar
este hecho, suponga que se desea generar de manera aleatoria un conjunto de controladores
PID, caracterizados por su función de transferencia
KPID(s) =KDs2 + KPs + KI
s(4.2)
para estabilizar el modelo (Ackermann & Kaesbauer, 2003):
G0(s) =A(s)
B(s)=
−0.5s4 − 7s3 − 2s + 1
(s + 1)(s + 2)(s + 3)(s + 4)(s2 + s + 1)(4.3)
el cual posee una complejidad superior a los que típicamente se han analizado en trabajos
previos (órden 6 y fase no-mínima).
Sean L,L ∈ R3 los vectores que definen el intervalo de variación para cada parámetro
PID, de forma que
KP ∈ [L1, L1] (4.4)
KI ∈ [L2, L2]KD ∈ [L3, L3]
Suponga que se toman N muestras en el interior del volumen definido por L,L y sea
Ns(L,L) el número de individuos factibles correspondiente, es decir:
Ns(L,L) =N∑i=1 St(KPIDi) (4.5)
con
St(KPID) =
0 si max {Re [λ(KPID)]} ≥ −ε
1 en caso contrario(4.6)
donde ε > 0 es un parámetro que define la tolerancia considerada para la región de
estabilidad y λ(KPID) denota el vector de raices de la ecuación
B(s) + KPID(s)A(s) = 0 (4.7)
La tabla 4.1 muestra el promedio de la proporción de individuos factibles NsN para distintos
valores de L,L, calculada para N = 1000, ε = 0.01 y repitiendo el experimento un total

66de 100 veces. Note que la mejor proporción (≈ 40%) se logra en el caso L = [−1,−1,−1]
y L = [1, 1, 1] (el valor mostrado entre paréntesis corresponde a la desviación standard del
cociente NsN ).
Tabla 4.1: Proporción de individuos factibles para distintos valores de L, L
L L NsN[−0.1,−0.1,−0.1] [0.1, 0.1, 0.1] 0(0)
[−1,−1,−1] [1, 1, 1] 0.3871(0.0155)[−10,−10,−10] [10, 10, 10] 0.1440(0.0130)
[−100,−100,−100] [100, 100, 100] 0(0)[−1000,−1000,−1000] [1000, 1000, 1000] 0(0)
Es posible concluir a partir de estos resultados que definir el espacio de búsqueda
de manera arbitraria puede ser muy ineficiente. Precisamente con el objeto de evitar
esta situación, se propone a continuación un método alternativo que permite resolver el
problema de diseño en dos etapas consecutivas.
Figura 4.1: Espacio de controladores PID estabilizantes correspondiente al modelo G0(s)determinado mediante el método de Hohenbichler y Abel (2008)
Durante la primera se determinan los límites de la región de controladores PID esta-
bilizantes (ver figura 4.1) utilizando el método de Hohenbichler y Abel (2008) presentado
en el capítulo 2.

67Durante la segunda etapa se genera una distribución uniforme de individuos en el
interior de los polígonos determinados por los límites calculados durante la etapa anterior,
utilizando el método que se explica a continuación.
La información de base son los vértices de los polígonos de estabilidad. Suponga que
para un polígono de V vértices se ordena esta información de la forma
v1v2...
vV
(4.8)
donde v1 está conectado con v2 y vV , v2 está conectado con v1,v3 y así sucesivamente.
En primer lugar se seleccionan dos aristas del polígono al azar. A su vez, en cada arista
se selecciona un punto al azar, sean xa y xb. Posteriormente se selecciona un punto xcperteneciente al segmento que une xa con xb (ver figura 4.2) mediante la fórmula
xc = αxa + (1− α)xb (4.9)
donde α es un escalar aleatorio perteneciente al intervalo [0, 1].
En el caso de la región estabilizante correspondiente a G0(s) se determinaron 25 polí-
gonos de estabilidad y se generaron 2 individuos al interior de cada uno de ellos, para
obtener una población inicial de 50 individuos.
Figura 4.2: Selección de un punto al azar en el interior de un polígono convexo
En cuanto a los operadores de variación, note que aunque para un mismo valor de KPla región factible es convexa, es posible que al cruzar dos individuos con distinto valor de

68KP se produzcan hijos no factibles. En este caso se propone utilizar el siguiente mecanismo
de reparación:
• Suponga que se conocen los dos padres x1y x2, a partir de los cuales se generan los
descendientes x1 y x2 mediante el operador de cruce aritmético de la forma:
x1 = αx1 + (1− α)x2 (4.10)
x2 = (1− α)x1 + αx2donde α es un escalar aleatorio perteneciente al intervalo [0,1].
• Si cualquiera de los descendientes no es factible, entonces se disminuye α a la mitad
y se genera un nuevo par de hijos.
• La mutación se realiza de forma similar, fijando α = 1 y a partir de un individuo
factible x se genera una mutación mediante
x = x + αδ (4.11)
donde δ es un vector aleatorio de distribución gaussiana. Si el individuo resultante
no es factible entonces se disminuye α a la mitad y se genera una nueva mutación.
Considere el lazo de control mostrado en la figura 4.3. Los bloques Wn(s) y Wd(s)
corresponden a funciones arbitrarias de ponderación en frecuencia. Las variables que
intervienen en el lazo son r(s), d(s) y n(s) como señales de referencia, perturbación y
ruido respectivamente.
Figura 4.3: Lazo con controlador PID

69Tradicionalmente, para el problema de regulación se considera r(s) = 0 y por lo tanto
a lazo cerrado se tiene:
y(s) = −KPID(s)G(s)
1 + KPID(s)G(s)Wn(s)n(s) (4.12)
+1
1 + KPID(s)G(s)Wd(s)d(s) (4.13)
= −T (s)Wn(s)n(s) + S(s)Wd(s)d(s) (4.14)
con
T (s) =KPID(s)G(s)
1 + KPID(s)G(s)(4.15)
S(s) =1
1 + KPID(s)G(s)(4.16)
La función de transferencia S(s) se conoce como función de sensibilidad, mientras
que T (s) se conoce como función de sensibilidad complementaria. Note que siempre
se cumple
S(s) + T (s) = 1 (4.17)
A partir de la ecuación (4.12) se concluye que para compensar los efectos de la perturbación
y del ruido, es necesario diseñar el controlador para que las normas de S(s) y T (s) tengan
el menor valor posible. Sin embargo, la ecuación (4.17) implica que no se puede disminuir
ambas normas simultaneamente.
El modelo de planta a lazo abierto es G0 (ver ecuación 4.3) y los filtros Wn y Wd se
definen como:
Wn(s) = 1, Wd(s) =1
s + 1(4.18)
El problema que se desea resolver se plantea como
minKPID∈K f1(KPID) (4.19)
minKPID∈K f2(KPID) (4.20)
con
f1(KPID) = ‖Wd(s)S(s)‖2 (4.21)
f2(KPID) = ‖Wn(s)T (s)‖2donde K es el conjunto de controladores estabilizantes.

70El problema de diseño que involucra exclusivamente normas H2 en los distintos canales
de la función de transferencia a lazo cerrado, puede ser resuelto de manera eficiente medi-
ante métodos de programación convexa, en caso de que no se imponga ninguna estructura
especial del controlador.
Por ejemplo, Khargonekar y Rotea (1991) resolvieron este problema asumiendo una
estructura de orden completo para los controladores y considerando un único objetivo en
términos de la suma convexa de las normas cuadráticas, de la forma
minαK∈R1×n f1(K) + (1− α)f2(K) (4.22)
donde para cada valor α ∈ [0, 1] se obtiene una solución perteneciente al frente de Pareto
del problema multi-objetivo.
En el presente caso, la dificultad radica en que se desea obtener controladores con una
estructura seleccionada a priori de tipo PID, lo cual dificulta el planteamiento en términos
de programación convexa.
Como base del proceso evolutivo se adopta el algoritmo SPEA2 (ver capítulo 3) con-
siderando que:
• Permite seleccionar la cantidad máxima y las características de las soluciones de la
aproximación, gracias a un manejo adecuado del archivo externo.
• Optimiza la distribución de las soluciones en el frente, sin necesidad de ajustar
parámetros dependientes de su geometría.
• Su desventaja con respecto al NSGA-II y al MOGA es que su tiempo de ejecución,
para un mismo problema, es relativamente más lento. Sin embargo, para el tipo de
problemas que se consideran en este trabajo, la velocidad de cómputo no se considera
una variable determinante.
En concreto, se presentan a continuación los resultados obtenidos a partir de dos ver-
siones de SPEA2:
• A1: El cual opera en un espacio de búsqueda definido de manera arbitraria como
−10 ≤ KP ,KI , KD ≤ 10 (4.23)
y utiliza una función de penalidad en cada objetivo para manejar la restricción de
estabilidad.
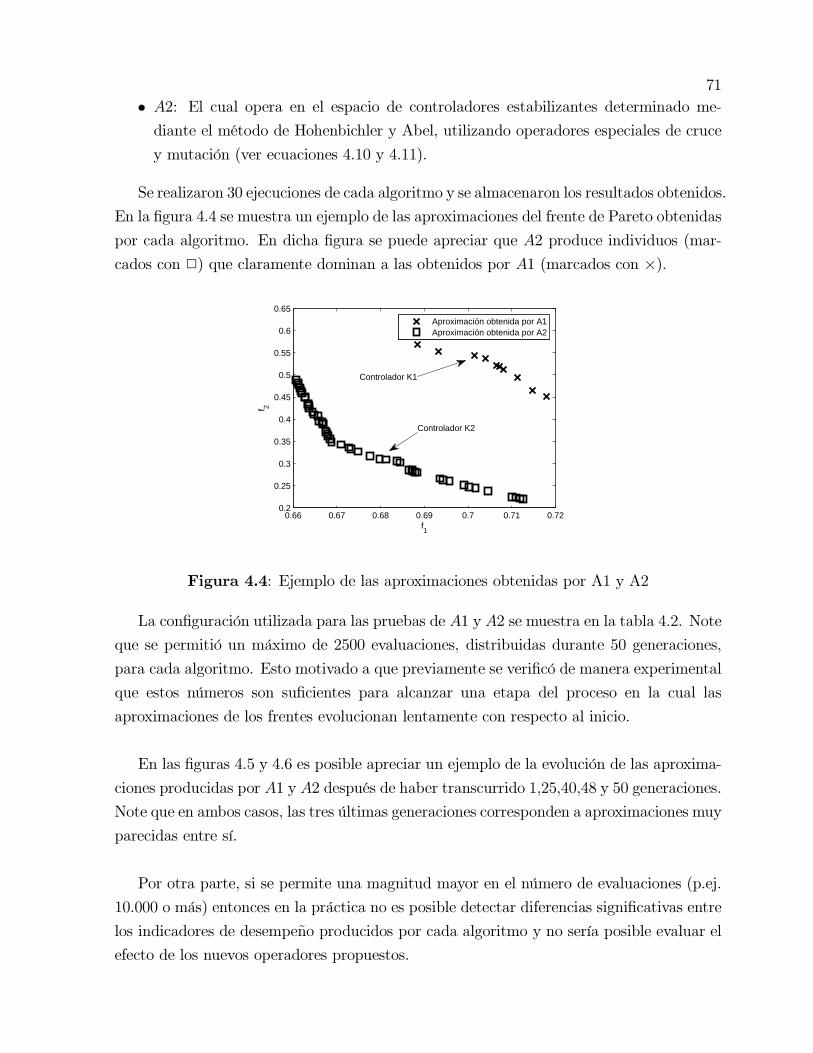
71• A2: El cual opera en el espacio de controladores estabilizantes determinado me-
diante el método de Hohenbichler y Abel, utilizando operadores especiales de cruce
y mutación (ver ecuaciones 4.10 y 4.11).
Se realizaron 30 ejecuciones de cada algoritmo y se almacenaron los resultados obtenidos.
En la figura 4.4 se muestra un ejemplo de las aproximaciones del frente de Pareto obtenidas
por cada algoritmo. En dicha figura se puede apreciar que A2 produce individuos (mar-
cados con �) que claramente dominan a las obtenidos por A1 (marcados con ×).
0.66 0.67 0.68 0.69 0.7 0.71 0.720.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
0.6
0.65
f1
f 2
Aproximación obtenida por A1Aproximación obtenida por A2
Controlador K1
Controlador K2
Figura 4.4: Ejemplo de las aproximaciones obtenidas por A1 y A2
La configuración utilizada para las pruebas de A1 y A2 se muestra en la tabla 4.2. Note
que se permitió un máximo de 2500 evaluaciones, distribuidas durante 50 generaciones,
para cada algoritmo. Esto motivado a que previamente se verificó de manera experimental
que estos números son suficientes para alcanzar una etapa del proceso en la cual las
aproximaciones de los frentes evolucionan lentamente con respecto al inicio.
En las figuras 4.5 y 4.6 es posible apreciar un ejemplo de la evolución de las aproxima-
ciones producidas por A1 y A2 después de haber transcurrido 1,25,40,48 y 50 generaciones.
Note que en ambos casos, las tres últimas generaciones corresponden a aproximaciones muy
parecidas entre sí.
Por otra parte, si se permite una magnitud mayor en el número de evaluaciones (p.ej.
10.000 o más) entonces en la práctica no es posible detectar diferencias significativas entre
los indicadores de desempeño producidos por cada algoritmo y no sería posible evaluar el
efecto de los nuevos operadores propuestos.

72
0.68 0.7 0.72 0.74 0.76 0.78
0.8
0.9
1
1.1
1.2
1.3
1.4
1.5
1.6
1.7
f1
f 2
Ngen = 1Ngen = 25Ngen = 40Ngen = 48Ngen = 50
Figura 4.5: Evolución de las aproximaciones de los frentes. Algoritmo A1. Ngen es elnúmero de generación.
Tabla 4.2: Configuración utilizada para los algoritmos A1 y A2. Problema de diseño PIDParámetro Valor
Representación Números realesOperador de cruce Aritmético (A1) y Aritmético con retorno (A2)
Probabilidad de cruce 0.9Operador de mutación Perturbación gaussiana con retorno a la región factible
Probabilidad de mutación 0.1Condición de parada 50 generaciones
Número máximo de evaluaciones 2500Tamaño máximo del archivo externo 50
Esquema de selección (50+50)
0.65 0.7 0.75
0.25
0.3
0.35
0.4
0.45
0.5
0.55
0.6
f1
f 2
Ngen = 1Ngen = 25Ngen = 40Ngen = 48Ngen = 50
Figura 4.6: Evolución de las aproximaciones de los frentes. Algoritmo A2. Ngen es elnúmero de generación.

73Los resultados obtenidos para los indicadores C,N,DMAX y ESS (definidos en el
capítulo 3) se muestran en las tablas 4.3 y 4.4.
Tabla 4.3: Resultados obtenidos para el indicador de cobertura. Algoritmos A1 y A2C(Ai, Aj) A1 A2
A1 − 0.2043(0.3103)A2 0.5946(0.4552)∗ −
Tabla 4.4: Resultados de los indicadores ESS y DMAX. Algoritmos A1 y A2N DMAX ESS
A1 15.4667(15.1128) 0.1767(0.1559) 0.0118(0.0224)A2 36.5333(14.0804)∗ 0.3692(0.1629)∗ 0.0080(0.0082)
Tabla 4.5: P-valores correspondientes a las pruebas de Wilcoxon para determinar lasdiferencias que son estadísticamente significativas. Algoritmos A1, A2
Hipótesis Nula p− valor ConclusiónC(A1, A2) = C(A2, A1) 7.7540e− 004 Rechazar
N(A1) = N(A2) 1.9066e− 006 RechazarDMAX(A1) = DMAX(A2) 2.4321e− 005 Rechazar
ESS(A1) = ESS(A2) 0.4118 No Rechazar
El indicador N representa simplemente la cantidad de individuos almacenados en el
archivo de soluciones no-dominadas al finalizar la ejecución del algoritmo. El asterisco
corresponde al indicador que es significativamente mejor de acuerdo a la prueba deWilcoxon,
para un nivel de significancia α = 0.05. En la tabla 4.5 se presentan los p-valores cor-
respondientes a la prueba de Wilcoxon, los cuales nos permiten identificar las diferencias
entre los promedios que son significativas desde el punto de vista estadístico. Note que A2
obtiene mejores valores que A1 con respecto a los indicadores C,N y DMAX.
Estos resultados podrían haberse anticipado, puesto que A2 utiliza información especial
para mantener a la población dentro de la región factible durante todo el proceso de
búsqueda. Con respecto al espaciamiento de las soluciones, el indicador ESS no permite
identificar mayores diferencias, lo cual puede constatarse de manera gráfica observando la
figura 4.4.
Para ilustrar lo que representa la diferencia entre las aproximaciones obtenidas por A1
y A2 en términos prácticos, en la figura 4.8 se presenta una simulación del efecto de dos
controladores K1 y K2 (ver figura 4.4) ante la acción de las señales de perturbación y ruido
mostradas en la figura 4.7. En particular, es posible observar una reducción significativa
de los picos de la señal de salida.

74
0 10 20 30 40 50 60 70 80 90
−0.2
0
0.2
0.4
0.6
0.8
1
t
y(t)
Perturbación p(t)Ruido n(t)
Figura 4.7: Perturbación y ruido que actúan sobre el lazo
0 20 40 60 80 100−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
t
y(t)
Respuesta del lazo con controlador K1Respuesta del lazo con controlador K2
Figura 4.8: Salida del lazo de control, afectada por perturbación y ruido

754.3. Método de diseño basado en la aproximación la región de
estabilidad
Tal como hemos visto en las sección anterior, la restricción de estabilidad es fun-
damental para el diseño de controladores automáticos. Cuando se intenta resolver el
problema mediante algoritmos genéticos, es posible utilizar una función auxiliar para pe-
nalizar los individuos inestables (no factibles) y tratar de guiar a la población hacia la
región estabilizante.
Sin embargo, esta estrategia puede conducir a fenómenos no deseados tales como con-
vergencia prematura en caso de que sea difícil encontrar soluciones factibles. Ante esta
situación, los investigadores han planteado dos tipos de enfoque:
• Utilizar un algoritmo que opere en un espacio de búsqueda con límites dinámicos,
que puedan adaptarse para no quedar atrapado dentro de una región no factible.
• Utilizar algun método para obtener información acerca de la geometría de las regiones
factibles.
Varios investigadores han propuesto espacios de búsqueda con límites dinámicos. De
hecho el algoritmo Multi-Objective Robust Control Design (MRCD) propuesto en (Her-
reros, 2000) utiliza límites dinámicos para el espacio de búsqueda y una división de la
población en islotes distribuidos.
En (Arakawa et al., 1998) se propone el algoritmo Adaptive Range Genetic Algorithm
(ARange GA) en el cual se adopta un espacio de búsqueda adaptivo que no necesita
especificar el rango para la población inicial.
En (Khor et al., 2002) se utiliza un enfoque de aprendizaje inductivo/deductivo para di-
rigir a la población hacia zonas que se encuentran fuera de los límites iniciales de búsqueda.
Los autores afirman que su método es capaz de adaptar la precisión de la representación
genética con el fin de mejorar las soluciones.
Otro algoritmo que puede citarse dentro de esta categoría es el Adaptive Range Multi-
Objective Genetic Algorithm (ARMOGA) propuesto en (Sasaki et al., 2002). Este algo-
ritmo calcula estadísticas en función de las muestras que se han tomado para decidir los
límites del espacio de búsqueda que se utilizarán en la siguiente iteración. Los autores

76afirman que su método permite reducir el número de evaluaciones necesarias para obtener
la aproximación de Pareto.
En otro orden de ideas, los métodos aleatorios han ganado aceptación para el estudio
de sistemas inciertos y una cantidad considerable de resultados han sido publicados en la
literatura (Calafiore & Dabbene, 2006). La idea básica consiste en considerar los parámet-
ros inciertos como variables aleatorias, lo que conduce a evaluar su desempeño en términos
de probabilidades. De manera recíproca, la síntesis probabilística consiste en determinar
los valores de los parámetros para que la probabilidad de obtener un buen desempeño sea
alta.
A continuación se propone un método de diseño que intenta determinar una aproxi-
mación de la geometría de la región factible mediante muestreo aleatorio puro. Es necesario
aclarar que el objetivo no es el cálculo de la región estabilizante como tal, ya que en este
caso el algoritmo de Hohenbichler y Abel permite determinarla de manera eficiente como
se mostró anteriormente. El objetivo que se persigue es mostrar que en algunos casos
es posible obtener aproximaciones que permiten mejorar la calidad de los diseños finales
obtenidos por el algoritmo genético.
Durante la primera etapa del método propuesto se resuelve un sub-problema que con-
siste en estimar los vértices del espacio de búsqueda que maximizan simultaneamente el
volumen y la proporción de individuos factibles, muestreados aleatoria y uniformemente.
Durante la segunda etapa se selecciona un conjunto de vértices en particular con el fin de
continuar la búsqueda evolutiva considerando los objetivos de diseño del problema original
y enfocándose en la región seleccionada.
Sea n el número de variables de decisión del problema (4.19) y L,L ∈ Rn vectores
reales que definen el intervalo de variación para cada una de las variables. En el caso del
diseño PID hemos visto que se tiene n = 3 y además
KP ∈ [L1, L1] (4.24)
KI ∈ [L2, L2]KD ∈ [L3, L3]
Consideremos el siguiente sub-problema:
minL,L∈Rn g1(L,L)
g2(L,L)
(4.25)

77con
g1(L,L) = 1−Ns(L,L)
N(4.26)
g2(L,L) =
Vmax − n∏i=1(Li − Li)Vmax (4.27)
y donde Ns es el número de individuos factibles obtenidos mediante muestreo aleatorio
en el interior del volumen definido mediante L,L, ver ecuación (4.5). El número N de
elementos del conjunto de muestreo puede ser estimada mediante la fórmula de Chernoff:
N =1
2ǫ2 ln2
δ(4.28)
y entonces se cumple:
Prob{∣∣∣∣p−
NsN
∣∣∣∣ ≤ ǫ
}≥ 1− δ (4.29)
donde
p = Prob{St(KPID) = 1} (4.30)
con ǫ, δ cantidades positivas que deben ser ajustadas en función de la precisión deseada.
Por otra parte, en la ecuación (4.27) la cantidad Vmax es el volumen máximo del espacio
de búsqueda, calculado como
Vmax = maxL,L∈Rn n∏i=1(Li − Li) (4.31)
Para la pruebas se seleccionaron los valores ǫ = δ = 0.1 lo cual conlleva a un muestreo
de 100 individuos por cada sub-región. Se consideró el mismo modelo a lazo abierto
estudiado en la sección anterior (ver figura 4.3) con Vmax = 20× 20× 20.
En la tabla 4.6 se muestra la configuración utilizada para la ejecución del SPEA2
durante esta primera etapa. Note que para este problema se permitió un total de 1000
evaluaciones de las funciones g1 y g2, lo cual es suficiente para seleccionar una aproximación
de la región factible.
La figura 4.9 permite apreciar un ejemplo del frente obtenido al finalizar esta etapa.
En dicha figura también es posible apreciar los intervalos PID correspondientes a las dos
soluciones extremas del frente de Pareto. Note el conflicto agudo entre los objetivos g1 y
g2, en el cual practicamente no existe solución de compromiso.

78Tabla 4.6: Configuración utilizada por SPEA2 durante la primera etapa del método deaproximación de la región factible
Parámetro ValorRepresentación Números reales
Operador de cruce Aritmético con reparaciónProbabilidad de cruce 0.9Operador de mutación Perturbación gaussiana con reparación
Probabilidad de mutación 0.1Condición de parada 20 generaciones
Número máximo de evaluaciones 1000Tamaño máximo del archivo externo 50
Esquema de selección (50+50)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
0
0.2
0.4
0.6
0.8
1
1.2
g1
g 2
KP∈ [−4.9,2.4]
KI∈ [0.19,6.24]
KI∈ [−5.9,3.2]
KP∈ [−20,20]
KI∈ [−20,20]
KI∈ [−20,20]
Figura 4.9: Ejemplo de aproximación obtenida al final de la primera etapa
Con respecto a los operadores de variación, a lo largo de esta primera etapa es necesario
utilizar un mecanismo de reparación para corregir los individuos que no correspondan
a un conjunto válido de vértices. Esta reparación consiste simplemente en ordenar la
información contenida en los cromosomas para asegurar que aparezcan en forma ordenada.
Una vez culminada la primera etapa, se selecciona un conjunto de vértices en particular
con el fin de continuar el proceso de búsqueda considerando el problema de diseño original
y enfocándose en la región delimitada por los vértices seleccionados.
A continuación se presentan los resultados obtenidos mediante los siguientes algoritmos:
• A1: que opera en un espacio de búsqueda definido por
KP ,KI , KD ∈ [−10, 10] (4.32)

79• A2: que opera en el espacio de controladores estabilizantes determinado mediante el
método de Hohenbichler y Abel, junto con operadores especiales de variación.
• A3: correspondiente al método de diseño en dos etapas presentado en esta sección,
utilizando los límites
KP ∈ [−4.95, 2.43] (4.33)
KI ∈ [0.19, 6.24]
KD ∈ [−5.97, 3.25]
que corresponden a g1 = 0 y g2 = 0.99 (ver figura 4.9). Estos valores indican que
se le da más importancia al objetivo g1, relacionado con la proporción de individuos
factibles muestreados.
La configuración utilizada para A1, A2 y A3 es idéntica a la mostrada anteriormente
en la tabla 4.2. En la figura 4.10 se puede observar un ejemplo de las aproximaciones que
se obtiene mediante cada uno de los algoritmos. En las tablas 4.7 y 4.8 se presentan los
valores promedios y las desviaciones correspondientes a los indicadores C,N,DMAX y
ESS.
0.66 0.67 0.68 0.69 0.7 0.71 0.720.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
0.6
0.65
f1
f 2
Aproximación obtenida por A1Aproximación obtenida por A2Aproximación obtenida por A3
Figura 4.10: Ejemplo de las aproximaciones que se obtienen mediante A1, A2 y A3
Como era de esperarse, el algoritmo A2 produce los mejores indicadores en cuanto
al indicador de cobertura, para el cual A1 y A3 son estadísticamente equivalentes. Sin
embargo, A3 produce mejores indicadores que A1, lo cual ilustra la eficacia del método de
aproximación de la región factible para el problema propuesto. En la tabla 4.9 se presentan
los p-valores correspondientes a las pruebas de Wilcoxon para determinar las diferencias
que son estadísticamente significativas.

80
Tabla 4.7: Resultados del indicador de cobertura. Algoritmos A1, A2 y A3C(Ai, Aj) A1 A2 A3
A1 − 0.2043(0.3103) 0.0580(0.1790)A2 0.5946(0.4552)∗ − 0.6074(0.2898)∗A3 0.6483(0.4228) 0.0723(0.1680) −
Tabla 4.8: Resultados de los indicadores N, ESS y DMAX. Algoritmos A1, A2 y A3N DMAX ESS
A1 15.4667(15.1128) 0.1767(0.1559) 0.0118(0.0224)A2 36.5333(14.0804)∗ 0.3692(0.1629)∗ 0.0080(0.0082)A3 26.5333(14.7712) 0.2423(0.1050) 0.0074(0.0076)
Tabla 4.9: P-valores correspondientes a las pruebas de Wilcoxon para determinar lasdiferencias que son estadísticamente significativas. Algoritmos A1, A2 y A3
Hipótesis Nula p− valor ConclusiónC(A1, A2) = C(A2, A1) 7.7540e− 004 RechazarC(A1, A3) = C(A3, A1) 6.0177e− 008 RechazarC(A2, A3) = C(A3, A2) 2.4955e− 009 Rechazar
N(A1) = N(A2) 1.9066e− 006 RechazarN(A1) = N(A3) 9.5896e− 004 RechazarN(A2) = N(A3) 0.0096 Rechazar
DMAX(A1) = DMAX(A2) 2.4321e− 005 RechazarDMAX(A1) = DMAX(A3) 0.0199 RechazarDMAX(A2) = DMAX(A3) 0.0025 Rechazar
ESS(A1) = ESS(A2) 0.4118 No RechazarESS(A1) = ESS(A3) 0.4917 No RechazarESS(A3) = ESS(A2) 0.9352 No Rechazar

814.4. Resumen del capítulo
En este capítulo se presentaron dos nuevos métodos de diseño PID multi-objetivo
que utilizan resultados de la teoría de control y algoritmos genéticos para resolver el
problema de optimización. El primer método determina los límites de la región de contro-
ladores PID estabilizantes utilizando el método propuesto por Hohenbichler y Abel (2008).
Posteriormente genera la población inicial y utiliza operadores especiales de variación para
mantenerse en el interior de la región factible.
El segundo método determina una aproximación de los límites resolviendo previamente
un primer sub-problema: se intenta maximizar simultaneamente el volumen y el número
de individuos factibles muestreados aleatoria y uniformemente.
A continuación se selecciona un conjunto de vértices en particular con el fin de continuar
el proceso de búsqueda considerando los objetivos originales y enfocándose en la región
delimitada por el conjunto de vértices seleccionados.
Las pruebas estadísticas muestran que, en el caso del problema de diseño bajo estudio,
ambos métodos permiten obtener mejores valores de los indicadores de desempeño con
respecto al método tradicional.

CAPÍTULO V
BÚSQUEDA MULTI-OBJETIVO LOCAL
En este capítulo se presenta un nuevo operador genético específicamente diseñado para
la búsqueda local multi-objetivo, llamado Ascenso de Colina con Paso Lateral (ACPL).
En caso de no encontrar soluciones dominantes el operador utiliza la información recolec-
tada para intentar moverse hacia algún cono de diversidad (paso lateral). Se propone un
esquema para la integración del ACPL con el algoritmo SPEA2, generando de esta forma
un algoritmo híbrido (memético) denominado SPEA2-ACPL. Se presentan los resultados
obtenidos cuando se utiliza el operador propuesto para resolver problemas que involucran
funciones convexas y no-convexas.
Parte de los resultados presentados en este capítulo fueron previamente incluidos como
parte de las publicaciones (Schütze et al., 2008) y (Lara et al., 2010).
5.1. Antecedentes
Algunos algoritmos de optimización se caracterizan por lograr buenas propiedades
de convergencia local, lo cual viene asociado al costo de la información sobre las derivadas
de la función objetivo. Por otra parte, los algoritmos genéticos (y muchos otros similares)
permiten explorar el espacio de búsqueda para intentar aproximarse a los mínimos globales.
Los algoritmos meméticos (Moscato, 1989) intentan combinar las ventajas de un al-
goritmo genético y un algoritmo de búsqueda local. Una de las primeras referencias en
el caso multi-objetivo fue presentada por Ishibuchi & Murata (1996) con el nombre de
Multi-Objective Genetic Local Search (MOGLS). Este autor propuso utilizar una función
escalar de ponderación con pesos aleatorios para seleccionar los padres a partir de los
cuales se debe realizar la búsqueda local.
Otro memético importante desde el punto de vista histórico es el M-PAES propuesto
en (Knowles & Corne, 2000). Este algoritmo utiliza dos archivos de almacenamiento:

83uno para las soluciones no-dominadas globales (que funciona de la misma manera que
en el SPEA2 por ejemplo) y el otro para soluciones no-dominadas locales que se emplea
únicamente para decidir si se acepta el individuo producido por la búsqueda local.
En (Murata et al., 2003) se propuso un operador que utiliza una regla generalizada de
dominancia, basada en el número de objetivos que se ven mejorados al aplicar el operador.
Típicamente la estrategia más utilizada consiste en reemplazar el individuo actual por otro
que lo domina en todos los objetivos.
Una de las primeras referencias en el caso de funciones definidas para un rango continuo
es el artículo (Goel & Deb, 2002), en el que un operador de búsqueda local fue combinado
con el NSGA-II. En las primeras pruebas el operador se aplicó al finalizar la ejecución
del NSGA-II (de manera que realmente no hay interacción entre el operador de búsqueda
local y los operadores genéticos). Posteriormente se aplicó el operador de búsqueda local
en cada generación. Los autores encontraron que el operador local mejoraba la calidad de
las soluciones obtenidas, pero aumentando considerablemente el número de evaluaciones
del vector objetivo.
En (Sharma et al., 2007) se combinó una búsqueda local de tipo Sequential Quadratic
Programming (SQP) con los algoritmos NSGA-II y SPEA2 para resolver un conjunto
de problemas benchmark. Los autores afirman que si no hay frentes de Pareto locales,
el algoritmo híbrido converge más rápido hacia un COGP sin perder diversidad en las
soluciones.
En (Adra et al., 2005b) tres métodos de búsqueda local fueron hibridizados conMOGA:
Recocido Simulado, Ascenso de Colina y Búsqueda Tabú. Los tres híbridos fueron com-
parados contra el MOGA tomando en cuenta el mismo número de evaluaciones. Los
autores afirman que el híbrido MOGA - Ascenso de Colina produjo los mejores resulta-
dos. También observaron que el proceso de búsqueda local puede provocar el fenómeno de
convergencia prematura si no se incorpora un mecanismo de preservación de la diversidad.
En (Wanner et al., 2006) el operador de búsqueda local utiliza aproximaciones cuadráti-
cas de todas las funciones objetivo, utilizando la información obtenida a partir del punto
seleccionado. Se presentan los resultados obtenidos mediante la hibridización con el algo-
ritmo SPEA2.

845.2. Ascenso de Colina con Paso Lateral (ACPL)
Sea xk ∈ X a un punto factible a partir del cual se desea llevar a cabo el proceso de
búsqueda local y xk+1 el nuevo punto generado por el operador. En el caso multi-objetivo
sería deseable que esta operación verifique las siguientes propiedades:
1. Si xk se encuentra “lejos” de un COLP, entonces xk+1 debería ser tal que xk+1 xk(descenso en todos los objetivos).
2. En caso contrario, xk+1 debería ser tal que xk+1 ‖ xk, lo cual puede contribuir a la
exploración del COLP.
3. Por otra parte el operador debe ser capaz de utilizar información de gradiente, tomar
en cuenta las restricciones del problema e interactuar fácilmente con un algoritmo
de búsqueda global.
En esta sección se presenta el operador ACPL, especialmente diseñado para proble-
mas multi-objetivo intentando cumplir en la medida de lo posible con las propiedades
antes enumeradas. En caso de no encontrar soluciones dominantes, el operador utiliza la
información recolectada para intentar generar soluciones que pertenezcan a los conos de
diversidad (paso lateral).
La idea principal se inspira en el análisis geométrico realizado por Brown y Smith
(2005). Cuando un punto se encuentra “lejos” de un COLP, los conos de ascenso, descenso
y diversidad presentan aproximadamente el mismo ángulo (ver figura 5.1). Si por el
contrario, el punto se encuentra “cerca” de un COLP, los ángulos de ascenso y descenso
se hacen menores (ver figura 5.2) y como consecuencia es menos probable seleccionar al
azar una dirección en estos conos.
5.2.1 Caso sin información de gradientes
A continuación se describe el funcionamiento del operador, asumiendo que no se
dispone de la información del gradiente de ninguna función objetivo (ver algoritmo 5.1).
Sea x0 ∈ X (con X ⊂ Rn) un punto factible a partir del cual se comienza la búsqueda
local con el objetivo de generar un conjunto Xnd de nuevos puntos factibles no dominados
con respecto a x0.

85
Figura 5.1: Situación que se presenta cuando el punto de prueba se encuentra lejos deun COLP. Cono de descenso amplio (región sombreada).
Figura 5.2: Situación que se presenta cuando el punto de prueba se encuentra cerca deun COLP. Cono de descenso estrecho (región sombreada).

86
Entradas : x0, r,Nnd, ε,NiterSalidas : Xnk = 1;1ab = 0,∀b ∈ BM ;2nb = 0, ∀b ∈ BM ;3Mientras k ≤ Niter hacer4
Seleccionar x1∈B(x0, r);5Si f(x1) f(x0) entonces6
d = x1 − x0;7Calcular t de acuerdo a (5.4);8x2 = x0 + td;9Xnd = Archivar(x2);10ab = 0, ∀b ∈ BM ;11nb = 0, ∀b ∈ BM ;12x0 = x2;1314
sino si f(x0) f(x1) entonces15d = x0 − x1;16Calcular t de acuerdo a (5.4);17x2 = x0 + td;18Xnd = Archivar(x2);19ab = 0, ∀b ∈ BM ;20nb = 0, ∀b ∈ BM ;21x0 = x2;2223
sino24b = tipo de cono de diversidad de x1 con respecto a x0;25nb = nb + 1;26ab = ab + x1−x0‖x1−x0‖ ;27
finsi28k = k + 1;29
Fin30k = 1;31Mientras k ≤M hacer32
Si nb = r,Nndb entonces33Calcular tb de acuerdo a (5.10);34x2 = x0 + tbab);35Xn = Archivar(x2)36
finsi37k = k + 1;38
Fin39Algoritmo 5.1 : Operador ACPL

87En primer lugar se selecciona de manera aleatoria un punto de prueba x1 perteneciente
al vecindario B(x0, r) definido por
B(x0, r) ={x ∈ X : x0i − ri ≤ xi ≤ x0i + ri, i = 1, 2, . . . , n
}(5.1)
En este punto existen varias posibilidades. Si se cumple f(x1) f(x0) entonces se define
la dirección de búsqueda como
d = x1 − x0 (5.2)
Si por el contrario se cumple la condición f(x0) f(x1) entonces es posible realizar la
búsqueda en la dirección inversa d = x0 − x1.El siguiente paso consiste en llevar a cabo una búsqueda lineal multi-objetivo en la
dirección d, resolviendo M sub-problemas de la forma
mintj∈R fj(x0 + tjd), j = 1, 2, . . . ,M (5.3)
para obtener un conjunto de soluciones {t∗1, t∗2, . . . , t∗M}, a partir de las cuales se debe
seleccionar la longitud del paso t (Dennis & Schnabel, 1983). Para intentar garantizar
el descenso de todas las funciones objetivo generalmente la estrategia más conservadora
consiste en seleccionar
t = min {t∗1, t∗2, . . . , t∗M} (5.4)
A continuación se describe un método aproximado con el fin de resolver los sub-
problemas escalares (5.3). Sea f : R → R la función que se desea minimizar. Como
datos de entrada se tienen dos valores t0 < t1 tales que f(t0) < f(t1). Defina
∆ = t1 − t0 (5.5)
tl = t0tm = t1tr = t0 + 2∆
En primer lugar se comprueba la condición de curvatura
f(tm)− f(tl)tm − tl <
f(tr)− f(tm)
tr − tm (5.6)
Si esta condición se cumple, entonces es posible aproximar a f por un polinomio de la
forma
p(t) = at2 + bt + c (5.7)

88cuyos coeficientes a, b, y c pueden ser calculados a partir de los valores p(tl) = f(tl),p(tm) = f(tm) y p(tr) = f(tr). En particular, el mínimo de p(t) se alcanza para
t∗ = −b
2a(5.8)
cantidad que puede servir como estimado de la solución del problema (5.3) para cada
función objetivo.
Si la condición de curvatura (5.6) no se cumple, entonces se puede conjeturar que
todavía es posible dar un paso más grande fijando tl = tm, tm = tr y tr = 2tr. Este
procedimiento puede realizarse tantas veces como sea necesario, aumentando progresiva-
mente la longitud del paso hasta que se cumpla la condición (5.6) o hasta que se llegue a
un punto fuera de la región factible (ver sección de tratamiento de las restricciones más
adelante).
Suponga ahora que x0 y x1 resulten incomparables. El operador ACPL identifica
el tipo de cono de diversidad al cual pertenece x1 con respecto a x0 y almacena esta
información. Seguidamente se selecciona un nuevo punto de prueba x2 en B(x0, r) y se
repite el procedimiento descrito anteriormente para el procesamiento de x1.Si durante este proceso se recolectan nb ≥ Nndb puntos pertenecientes a C(x0, b) en-
tonces se intenta realizar movimientos laterales utilizando las direcciones acumuladas:
ab =1
nb nb∑j∈{índices de los puntos pertenecientes a C(x0,b)} xj − x0‖xj − x0‖ (5.9)
donde los xj que intervienen en la expresión anterior corresponden a la secuencia de puntos
pertenecientes a C(x0, b). El vector Nnd debe ser definido por el usuario, en función del
presupuesto disponible para el número de evaluaciones de las funciones objetivo.
La longitud del paso lateral tb en la dirección ab puede ser calculada mediante la
ecuación
tb =εb
‖ab‖∞ (5.10)
donde ε es un vector de parámetros que regulan la distancia entre dos soluciones vecinas
del conjunto de Pareto, para cada cono de diversidad.
Todo el proceso descrito en los párrafos anteriores se ejecuta la cantidad de Niter veces:
mientras mayor sea este parámetro, mayor número de puntos serán muestreados en el
vecindario del punto de origen.

895.2.2 Caso con información de gradientes
Cuando se tiene acceso a todos los gradientes de las funciones objetivo, es posible
calcular la dirección de descenso propuesta en el capítulo 3 (ver ecuación 3.17). Poste-
riormente se puede calcular la longitud del paso mediante el método que se describió en
la sección anterior o preferiblemente mediante una búsqueda inexacta intentando que se
satisfagan las condiciones de Wolfe para todas las funciones objetivo (Dennis & Schnabel,
1983).
Con respecto al movimiento lateral, en cuanto se detecta la condición
∥∥∥∥∥
M∑i=1 α∗i∇fi(x∗)∥∥∥∥∥22 ≤ εP (5.11)
donde εP > 0 es una cantidad pequeña a definir, se puede conjeturar que el punto actual
se encuentra cerca de un COLP.
En este sentido, un método para intentar obtener puntos incomparables pertenecientes
a un vecindario de x∗ fue propuesto en (Hillermeier, 2001). En primer lugar se determinan
los vectores qi ∈ Rn, i = 1, 2, ...,M − 1 extraídos de las primeras n filas de las M − 1
columnas que conforman la matriz QK ∈ R(M+n)×(M−1), obtenida a su vez a partir de la
factorización ortogonal QR[QN QK ] ∗R = (M ′(x∗,α∗))T (5.12)
donde M ′ ∈ R(M+n)×(M+n) es la matriz jacobiana de
M(x,α) =
∑Mi=1αi∇fi(x)∑Mi=1αi − 1
(5.13)
Note que los vectores qi forman una base ortonormal de un hiperplano de dimensión
M − 1 tangente al COLP en x∗ y por lo tanto pueden ser utilizados (así como cualquier
combinación lineal) como potencial dirección de diversidad. La longitud del paso lateral
se determina como
tb =εb
‖qb‖∞ (5.14)
donde ε es el vector que se introdujo previamente en la ecuación (5.10).

905.2.3 Tratamiento de restricciones
Para el manejo de las restricciones, en el caso en que no se maneja información de
gradientes, se propone adoptar un mecanismo de retorno a la región factible. Suponiendo
que el punto de origen es factible, se realiza una búsqueda lineal multi-objetivo en la
dirección de descenso, tal como se explicó en las secciones anteriores. Si el resultado no
es factible, se ejecuta el algoritmo 5.2, basado en el método de bisección hasta alcanzar la
precisión deseada, especificada mediante el parámetro Tol.
Entradas : x0 ∈ X , x1 /∈ X , TolSalidas : x ∈ x0x1 ∩ X con miny∈∂X ‖y − x‖ ≤ Tolin0 = x0;1out0 = x1;2i = 0;3Mientras ‖outi − ini‖ ≥ Tol hacer4
mi = ini + 12(outi − ini);5Si mi ∈ X entonces6
ini+1 = mi;7outi+1 = outi;8
sino9ini+1 = ini;10outi+1 = mi;11
i = i + 1;12Fin13Algoritmo 5.2 : Retorno a la región factible para el operador ACPL1
Con respecto al caso en que se maneja información de gradiente, al momento en que
se redacta este documento todavía no se cuenta con una versión del operador que tome en
cuenta el gradiente de las funciones de restricción de manera eficiente. No obstante, para
las restricciones de intervalo sobre las variables, del tipo
ximin ≤ xi ≤ ximax (5.15)
se propone utilizar un mecanismo sencillo de proyección a la región factible de la forma
xpi =
xi si ximin ≤ xi ≤ ximaxximin si ximin > xiximax si ximax < xi (5.16)
donde xp es el vector proyectado. Este método tiene como ventaja que no se necesita
especificar ningún parámetro adicional desde el punto de vista del funcionamiento del
operador.

91En la tabla 5.1 se muestra un resumen de los parámetros a ser fijados para el correcto
funcionamiento del operador, en los casos con o sin información de gradiente.
Tabla 5.1: Parámetros que deben ser definidos por el usuario en los casos con y sininformación de gradientes
Parámetro Sin ∇fi(x) Con ∇fi(x)r ∈Rn+ Si No
Nnd ∈N2M−2+ Si Noε ∈R2M−2+ Si SiNiter ∈N+ Si SiεP ∈R+ No SiTol ∈ R+ Si Si
5.3. Evaluación del operador ACPL
5.3.1 Problema convexo sin restricciones
En esta sección considere el siguiente problema
P1 :minx∈R2 (x1 − 1)4 + (x2 − 1)2(x1 + 1)2 + (x2 + 1)2 (5.17)
Las figuras 5.3 y 5.4 muestran el verdadero conjunto y frente de Pareto, obtenidos re-
solviendo el problema escalar
P ′1 :minx∈R2 α [(x1 − 1)4 + (x2 − 1)2]+ (1− α)[(x1 + 1)2 + (x2 + 1)2]
para 1000 valores de α distribuidos uniformemente entre 0 y 1.
A continuación se presentan los resultados obtenidos al aplicar el operador ACPL
sucesivamente a partir de un punto de origen. Para verificar si el operador es capaz de
generar todo el frente, la prueba se divide en tres etapas.
En primer lugar se aplica el operador hasta que se detecta el primer paso lateral.
Inmediatamente se modifica el funcionamiento del operador para aceptar únicamente las
soluciones que mejoren un objetivo, por ejemplo f1. Durante la tercera etapa se aceptan
únicamente las soluciones que mejoren el otro objetivo, por ejemplo f2.Se realizaron pruebas utilizando las dos modalidades del operador: sin información de
gradiente (denotado ACPL1) y con información de gradiente (denotado ACPL2). Para la

92
−1 −0.5 0 0.5 1−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x1
x 2
Figura 5.3: Verdadero conjunto de Pareto para el problema P1prueba de ambas versiones se utilizó el mismo punto de inicio x0 = [5, 5]. Los valores de
los parámetros característicos del operador se muestran en la tabla 5.2.
Tabla 5.2: Valores utilizados para los parámetros ACPLParámetro Valor
ε [0.1, 0.1]εP 0.01r [0.01, 0.01]
Niter 10Nnd [5, 5]Tol 10−4
En las figuras 5.5 y 5.6 se muestra un ejemplo de apróximación generada por ACPL1,
en el espacio de objetivos y en el espacio de variables respectivamente. En total, ACPL1
requirió 925 evaluaciones de las funciones objetivo y ACPL2 únicamente 143. Sin embargo
ACPL2 empleó 50 evaluaciones de la matriz jacobiana y 50 evaluaciones de las matrices
hessianas. Note que la aproximación producida por ACPL2 es prácticamente idéntica al
frente de Pareto generado mediante escalarización, tal como es posible apreciar en las
figuras 5.7 y 5.8.

93
0 5 10 15 200
1
2
3
4
5
6
7
8
f1
f 2
Figura 5.4: Verdadero frente de Pareto para el problema P1
−1 −0.5 0 0.5 1−1.5
−1
−0.5
0
0.5
1
1.5
x1
x2
Verdadero Conjunto de ParetoAproximación obtenida mediante ACPL1
Figura 5.5: Aproximación del conjunto de Pareto generada por ACPL1. Problema P1

94
0 2 4 6 8 10 12 14 16 180
1
2
3
4
5
6
7
f1
f 2
Verdadero frente de ParetoAproximación obtenida mediante ACPL1
Figura 5.6: Aproximación del frente de Pareto generada por ACPL1. Problema P1
−1 −0.5 0 0.5 1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x1
x2
Verdadero Conjunto de Pareto
Aproximación obtenidamediante ACPL2
Figura 5.7: Aproximación del conjunto de Pareto generada por ACPL2. Problema P1

95
0 5 10 15 20 250
1
2
3
4
5
6
7
8
f1
f 2
Verdadero frente de ParetoAproximación obtenida mediante ACPL2
Figura 5.8: Aproximación del frente de Pareto generada por ACPL2. Problema P1
5.3.2 Problema convexo con restricciones de intervalo
En esta sección considere el siguiente problema
P2 : minx∈[0.5,1]×[1,2] (x1 − 1)4 + (x2 − 1)2(x1 + 1)2 + (x2 + 1)2 (5.18)
Las figuras 5.9 y 5.10 muestran el verdadero conjunto y frente de Pareto, obtenidos re-
solviendo el problema escalar
P ′2 : minx∈[0.5,1]×[1,2] α [(x1 − 1)4 + (x2 − 1)2]+ (1− α)[(x1 + 1)2 + (x2 + 1)2]
para 1000 valores de α distribuidos uniformemente entre 0 y 1.
Para la prueba de ambas versiones del algoritmo se utilizó el mismo punto de inicio
factible x0 = [1, 2] con los mismos valores de los parámetros mostrados en la tabla 5.2. En
las figuras 5.11 y 5.12 se puede observar un ejemplo del tipo de apróximación que puede
generar ACPL1 en el caso con restricciones. En las figuras 5.13 y 5.14 se observan las
correspondientes a ACPL2. En total, ACPL1 utilizó 2021 evaluaciones de las funciones
objetivo. ACPL2 requirió 103 evaluaciones de las funciones objetivo, 50 evaluaciones de
la matriz jacobiana y 50 evaluaciones de las matrices hessianas.

96
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1
0.75
0.8
0.85
0.9
0.95
1
1.05
1.1
1.15
1.2
1.25
x1
x 2
Figura 5.9: Verdadero conjunto de Pareto para el problema P2
0 0.01 0.02 0.03 0.04 0.05 0.06
6.4
6.6
6.8
7
7.2
7.4
7.6
7.8
8
8.2
f1
f 2
Figura 5.10: Verdadero frente de Pareto para el problema P2

97
0.5 0.6 0.7 0.8 0.9 10.97
0.98
0.99
1
1.01
1.02
1.03
x1
x 2
Verdadero Conjunto de ParetoAproximación obtenida mediante ACPL1
Figura 5.11: Aproximación del conjunto de Pareto generada por ACPL1. Problema P2
0 0.01 0.02 0.03 0.04 0.05
6.4
6.6
6.8
7
7.2
7.4
7.6
7.8
8
8.2
f1
f 2
Verdadero frente de ParetoAproximación obtenida mediante ACPL1
Figura 5.12: Aproximación del frente de Pareto generada por ACPL1. Problema P2

98
0.5 0.6 0.7 0.8 0.9 1
0.99
0.992
0.994
0.996
0.998
1
1.002
1.004
1.006
1.008
1.01
x1
x 2
Verdadero Conjunto de ParetoAproximación generada popr ACPL2
Figura 5.13: Aproximación del conjunto de Pareto generada por ACPL2. Problema P2
0 0.01 0.02 0.03 0.04 0.05 0.06
6.4
6.6
6.8
7
7.2
7.4
7.6
7.8
8
8.2
f1
f 2
Verdadero Frente de ParetoAproximación generada por ACPL2
Figura 5.14: Aproximación del frente de Pareto generada por ACPL2. Problema P2

995.3.3 Problema no convexo con restricciones de intervalo
En esta sección considere el siguiente problema no convexo propuesto en (Zitzler
et al., 1999)
P3 : min
xi ∈ [−5, 5] , i = 2, 3, . . . , 20
x1 ∈ [0, 1]
x1g(x)
(1−√ x1g(x)) (5.19)
con g(x) = 191 +20∑i=2 (x2i − 10 cos(4πxi))
Este problema posee 2119 frentes locales y el frente global, para el cual g(x) = 1, se obtiene
con xi = 0, i = 2, 3, . . . , 20. Se realizaron pruebas con ambas versiones del operador,
iniciando la búsqueda a partir del punto
x0 =(
0.5 3 3 . . . 3)
(5.20)
En la figura 5.15 se muestra un ejemplo de las aproximaciones que pueden obtenerse
mediante cada versión del operador.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
0
50
100
150
200
250
Aproximación ACPL2Verdadero frente de ParetoAproximación ACPL1
Figura 5.15: Ejemplo de aproximaciones del frente de Pareto generadas por ACPL1 yACPL2. Problema P3

100Los valores de los parámetros empleados se muestran en la tabla 5.3. Como era de
esperar, ambas versiones del operador producen aproximaciones que se encuentran com-
pletamente alejadas del verdadero frente, esto motivado por el gran número de frentes
locales característicos de este problema.
Tabla 5.3: Valores utilizados para los parámetros ACPL. Problema P3Parámetro Valor
ε [0.05, 0.05]εP 1r
(0.01 0.1 0.1 . . . 0.1
)
Niter 20Nnd [5, 5]Tol 10−4
5.4. Sensibilidad del ACPL
El comportamiento del operador ACPL depende de los valores seleccionados para
sus parámetros. En esta sección se considera de nuevo el problema P1 formulado en la
sección anterior.
La influencia del vector r ∈Rn+ se manifiesta en el número de evaluaciones de las
funciones objetivo necesarias para alcanzar el Frente de Pareto. En la tabla 5.4 se presenta
un ejemplo del número de evaluaciones que emplea ACPL1 antes de que se produzca el
primer intento de paso lateral. Note que este número disminuye cuando aumenta ‖r‖.
Mientras menor sea esta norma, menor será el tamaño de los pasos que ejecuta el operador
y en consecuencia se requieren más pasos para cubrir la misma distancia.
Cuando ‖r‖ aumenta a partir de cierto punto, el operador se hace demasiado impreciso,
de manera que se hace muy difícil conseguir direcciones de descenso. En consecuencia, el
número de evaluaciones de las funciones objetivo necesarios para alcanzar el frente de
Pareto aumenta de manera exponencial.

101Tabla 5.4: Sensibilidad del operador ACPL1 ante variaciones en el vector r
r Evaluaciones de las funciones objetivo[0.001, 0.001] 895[0.01, 0.01] 135[0.1, 0.1] 74
[1, 1] 7269
Como se ha visto previamente, el vector ε ∈R2M−2+ regula la distancia entre dos solu-
ciones vecinas del conjunto de Pareto, para cada cono de diversidad. En las figuras 5.16,
5.17 y 5.18 se muestran las aproximaciones obtenidas por ACPL2 a partir de tres valores
del vector ε. En las mismas es posible apreciar que el espaciamiento entre las soluciones
es regulado mediante los valores especificados en el vector ε ∈R2M−2+ .
El valor del parámetro Niter debe ser ajustado en función del número de evaluaciones
que es posible invertir durante la ejecución del operador. Mientras más grande sea Niter,mayor cantidad de puntos vecinos serán muestreados en busca de direcciones de descenso
o de diversidad. Como regla general, esta cantidad debe ser mayor que la mayor de las
cantidades especificadas en el vector Nnd, para permitir que pueda ocurrir al menos un
paso lateral en cualquier cono de diversidad.
Por su parte, la influencia del vector Nnd se manifiesta en el número de pasos laterales
ejecutados por ACPL1 para intentar cubrir el frente de Pareto. En la tabla 5.5 se presenta
el número de pasos laterales que son efectivamente ejecutados para diferentes valores del
vector Nnd, fijando Niter = 20.
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8
−1.5
−1
−0.5
0
0.5
1
1.5
x1
x2
Verdadero conunto de ParetoAproximación generada por ACPL2
Figura 5.16: Aproximación obtenida mediante ACPL2 con ε1=[0.01, 0.01]

102
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8
−1
−0.5
0
0.5
1
x1
x2
Verdadero conunto de ParetoAproximación generada por ACPL2
Figura 5.17: Aproximación obtenida mediante ACPL2 con ε2=[0.1, 0.1]
−1 −0.5 0 0.5 1−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x1
x 2
Verdadero conjunto de Pareto
Aproximación obtenida mediante ACPL2
Figura 5.18: Aproximación obtenida mediante ACPL2 con ε3=[1, 1]

103Note que mientras menos pasos laterales se ejecutan, menos evaluaciones de las fun-
ciones objetivo se invierten en el funcionamiento del operador y la aproximación de la
dirección de diversidad es más precisa (se promedian más vectores). La contraparte de
esto es que la longitud del frente que se cubre es menor. En efecto, note que en el caso
extremo, cuando Nnd = [20, 20], no se ejecuta ningún paso lateral.
Tabla 5.5: Sensibilidad del operador ACPL1 ante variaciones en el vector NndNnd Número de pasos laterales N◦ de evaluaciones[2, 2] 202 25024[5, 5] 45 5591
[10, 10] 30 3919[20, 20] 0 2000
Las figuras 5.19, 5.20 y 5.21 permiten observar la influencia del parámetro εP en el fun-
cionamiento del operador ACPL2 (la versión que maneja información de gradientes). En
general se aprecia que mientras menor sea el valor de εP , más precisa será la aproximación
del Conjunto de Pareto, pero por otra parte se invertirá un mayor número de evaluaciones
de las funciones objetivo para generarla.
−1 −0.5 0 0.5 1−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x1
x 2
Verdadero Conjunto de ParetoAproximación generadapor ACPL2
Figura 5.19: Aproximación obtenida mediante ACPL2 con εP = 0.01
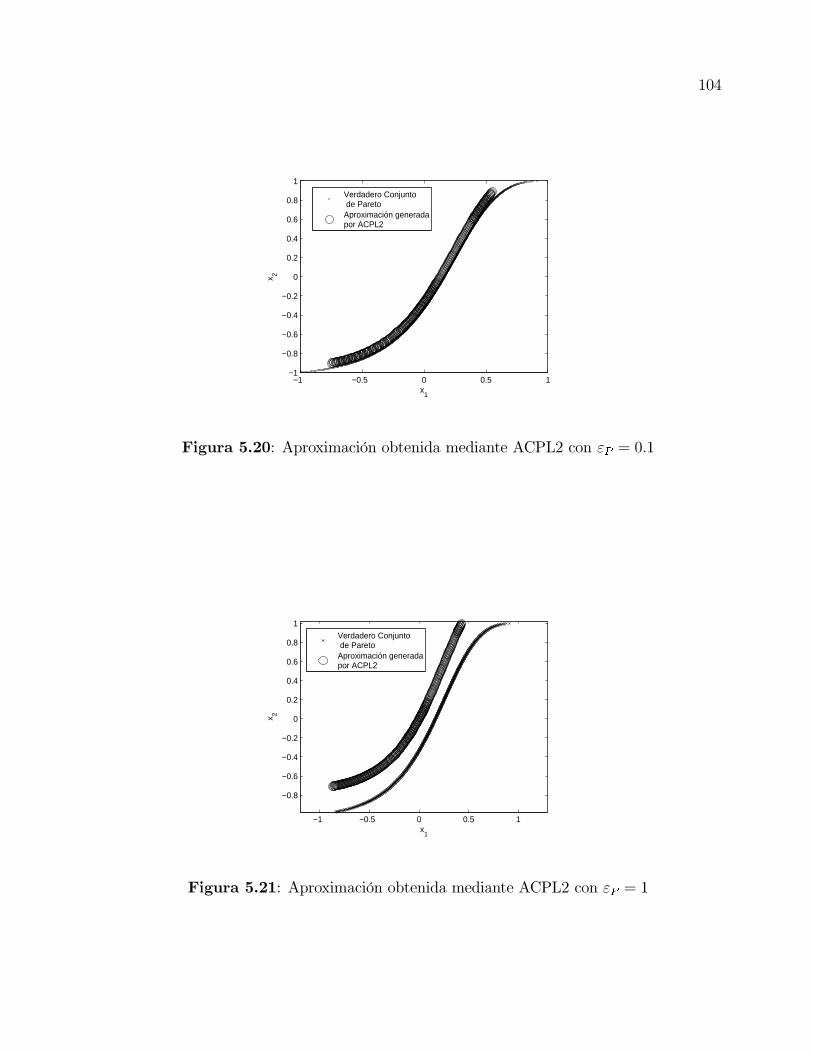
104
−1 −0.5 0 0.5 1−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x1
x 2
Verdadero Conjunto de ParetoAproximación generadapor ACPL2
Figura 5.20: Aproximación obtenida mediante ACPL2 con εP = 0.1
−1 −0.5 0 0.5 1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x1
x 2
Verdadero Conjunto de ParetoAproximación generadapor ACPL2
Figura 5.21: Aproximación obtenida mediante ACPL2 con εP = 1

105Para finalizar esta sección, considere el problema de optimización con restricciones P2.
La influencia del parámetro Tol se manifiesta en la distancia tolerada para las soluciones
de la aproximación con respecto con respecto al borde de la región factible (ver figura
5.22).
0.5 0.6 0.7 0.8 0.9 1 1.1 1.20.99
1
1.01
1.02
1.03
1.04
1.05
1.06
1.07
1.08
Aproximación obtenidacon ACPL1 para Tol = 0.01
Aproximación obtenidacon ACPL1 para Tol = 0.1
Figura 5.22: Aproximaciones obtenidas por ACPL1 para distintos valores del parámetroTol
5.5. Integración SPEA2-ACPL
Tal como se expuso en la sección anterior, los algoritmos meméticos intentan
combinar las ventajas de un algoritmo genético con las de un algoritmo de búsqueda local.
Sin embargo, no existe en la actualidad un consenso con respecto a la mejor forma de
realizar esta integración. Entre los elementos que deben tomarse en cuenta se encuentran:
• A cuántos y a cuales individuos debe aplicarse el operador?
• En qué momento? Con qué frecuencia? Durante cuántas generaciones?
De acuerdo con la investigación que se ha realizado, estas preguntas no han sido respon-
didas de manera satisfactoria. El compromiso entre búsqueda local vs búsqueda global es
similar al que existe entre individualismo y colectivismo. En efecto, cuando es necesario
asignar recursos limitados a una población, se debe decidir entre si se quiere lograr mejorar
mucho la condición de pocos individuos, o bien mejorar poco la condición de muchos.
En este trabajo, se propone utilizar el operador ACPL como un operador de mutación
especial, el cual se aplica únicamente a los individuos pertenecientes al archivo externo

106actualizado por SPEA2. En lo que sigue se denota SPEA2-ACPL1 a la versión híbrida
correspondiente al SPEA2 en conjunto con ACPL1 (operador que no utiliza información
de gradiente). De forma similar, se denota SPEA2-ACPL2 a la versión híbrida correspon-
diente al SPEA2 en conjunto con ACPL2 (operador que utiliza información de gradiente).
En particular se propone evaluar tres estrategias de integración:
• E1: Aplicar el operador en todas las generaciones con probabilidad pACPL a partir
de la primera generación.
• E2: Aplicar el operador de manera intermitente, una de cada NACPL generaciones,
con probabilidad pACPL.• E3: Aplicar el operador con probabilidad pACPL cuando se haya consumido el 50%
de la cantidad total de evaluaciones disponibles.
Para todas las pruebas que se presentan a continuación se consideró un presupuesto
fijo de 20.000 evaluaciones del vector objetivo. Por una parte esta cantidad de evalua-
ciones permite que las 30 ejecuciones del algoritmo genético no excedan el tiempo máximo
permitido (≈24 horas). Por otra parte esta cantidad de evaluaciones es suficiente para
alcanzar una etapa del proceso en la cual las aproximaciones de los frentes evolucionan
lentamente con respecto al inicio.
5.5.1 Problema convexo sin restricciones
En esta sección considere el siguiente problema convexo
P4 : minx∈R30 (x1 − 1)4 +30∑i=2(xi − 1)230∑i=1(xi + 1)2
(5.21)
el cual involucra 30 variables de decisión. El verdadero frente de Pareto puede ser obtenido
resolviendo el problema escalar
P ′4 : minx∈R30 α[(x1 − 1)4 +30∑i=2 (xi − 1)2] + (1− α)
[ 30∑i=1 (xi + 1)2] (5.22)
con 100 valores de α distribuidos uniformemente entre 0 y 1.

107La configuración utilizada para la ejecución de las pruebas se muestra en la tabla
5.6. En la tabla 5.7 se presenta el valor medio y la desviación estándar calculada para
los indicadores GD, IGD evaluados a partir de 30 ejecuciones de cada algoritmo. El
valor resaltado con un asterisco corresponde al algoritmo que consigue estadísticamente
los mejores valores, de acuerdo con la prueba de Wilcoxon, con un nivel de significancia α
= 0.05.
Note que las versiones híbridas permiten, cualquiera sea la estrategia de integración,
obtener mejores aproximaciones considerando ambos indicadores. Por otra parte, la es-
trategia E1, la cual consiste en aplicar el operador a partir de la primera iteración, es
la que consigue los mejores resultados. Por lo tanto es posible concluir que para este
problema, la mejor opción consiste en utilizar la información de gradiente lo más pronto
posible.
Tabla 5.6: Configuración utilizada para resolver el problema P4Parámetros ValorRepresentación Números reales
Operador de cruce SBXProbabilidad de cruce 0.9Operador de mutación Perturbación gaussiana
Probabilidad de mutación 0.1Probabilidad de aplicación del ACPL 0.5
NACPL 10ε [0.1, 0.1]εP 0.1r [0.01, 0.01]
Niter 20Nnd [10, 3]Tol 10−4
Condición de parada 200 generacionesNúmero máximo de evaluaciones 20.000
Tamaño máximo del archivo externo 100Esquema de selección (100 + 100)

108Tabla 5.7: Indicadores GD/IGD obtenidos para el problema P4
GD IGDSPEA2 10.5563(5.4469) 16.1034(6.6455)
SPEA2-ACPL1E1 : 3.2782(0.3388)∗E2 : 5.8222(1.4305)E3 : 4.6148(0.5481)
E1 : 6.7728(1.8759)∗E2 : 11.6404(3.3716)E3 : 11.0787(2.2915)
SPEA2-ACPL2E1 : 0.6797(0.0284)∗E2 : 0.7679(0.0722)E3 : 0.6645(0.0306)∗ E1 : 0.5350(0.0479)∗
E2 : 2.2375(2.7337)E3 : 0.9584(0.7102)
5.5.2 Problema no convexo con restricciones de intervalo
En esta sección se retoma el problema P3 anteriormente formulado. La configu-
ración utilizada para estas pruebas se muestra en la tabla 5.8. En la tabla 5.9 se presenta
el valor medio y la desviación estándar calculada para los indicadores GD, IGD evaluados
a partir de 30 ejecuciones de cada algoritmo.
Tabla 5.8: Configuración utilizada para las pruebas del problema P3Parámetros ValorRepresentación Números reales
Operador de cruce SBXProbabilidad de cruce 0.9Operador de mutación Perturbación gaussiana
Probabilidad de mutación 0.1Probabilidad de aplicación del ACPL 0.1
NACPL 10ε [0.1, 0.1]εP 0.1r [0.01, 0.01]
Niter 10Nnd [5, 2]Tol 10−4
Condición de parada 200 generacionesNúmero máximo de evaluaciones 20.000
Tamaño máximo del archivo externo 100Esquema de selección (100 + 100)

109Tabla 5.9: Indicadores GD/IGD obtenidos para el problema P3
GD IGDSPEA2 3.6011(1.1629) 3.2091(0.9735)
SPEA2-ACPL1E1 : 3.7380(1.2520)E2 : 3.7443(1.1807)E3 : 3.7047(1.1083)
E1 : 3.2947(1.0338)E2 : 3.3384(0.9472)E3 : 3.3347(0.8820)
SPEA2-ACPL2E1 : 3.1866(0.9524)E2 : 3.6439(1.0985)E3 : 3.3079(1.0496)
E1 : 2.9530(0.8846)E2 : 3.3188(0.9771)E3 : 3.0206(0.9099)
Las pruebas estadísticas indican que no existen diferencias significativas entre los re-
sultados obtenidos por los diferentes algoritmos, independientemente de la estrategia de
evolución que se adopte. Esto se explica por la gran cantidad de frentes locales, lo cual
aumenta la probabilidad de que los operadores de búsqueda local queden atrapados.
Ahora se considera una variación del problema P3 tal como se muestra a continuación
P5 : min
xi ∈ [−5, 5] , i = 2, 3, . . . , 20
x1 ∈ [0, 1]
x1g(x)
(1−√ x1g(x)) (5.23)
con g(x) = 191 +20∑i=2 (x2i − 10 cos(πxi))
Este problema posee 519 frentes locales y el frente global, para el cual g(x) = 1, se
sigue obteniendo con xi = 0, i = 2, 3, . . . , 20. Los resultados se muestran en la tabla 5.10.
Tabla 5.10: Indicadores GD/IGD obtenidos para el problema P5GD IGD
SPEA2 0.0401(0.0099) 0.0503(0.0062)
SPEA2-ACPL1E1 : 0.0443(0.0103)E2 : 0.0430(0.0076)E3 : 0.0426(0.0096)
E1 : 0.0534(0.0063)E2 : 0.0513(0.0052)E3 : 0.0534(0.0054)
SPEA2-ACPL2E1 : 0.0146(0.0080)∗E2 : 0.0272(0.0081)E3 : 0.0375(0.0102)
E1 : 0.0412(0.0035)∗E2 : 0.0460(0.0052)E3 : 0.0509(0.0056)

110Note que para esta variación el algoritmo SPEA2-ACPL2, utilizando la estrategia
de integración E1, es nuevamente capaz de obtener mejores valores de los indicadores
GD/IGD con respecto al SPEA2, a pesar de la gran cantidad de frentes locales.
5.6. Resumen del capítulo
En este capítulo se presentó un nuevo operador local, denominado ACPL, específi-
camente diseñado para la búsqueda multi-objetivo. Las principales bondades del operador
son las siguientes:
1. Si el punto de prueba se encuentra “lejos” de un COLP, entonces se intenta conseguir
una dirección de descenso en todos los objetivos.
2. Si el punto de prueba se encuentra “cerca” de un COLP, entonces se intenta conseguir
una dirección de diversidad, para intentar mejorar la aproximación del frente.
3. El operador es capaz de utilizar la información de gradiente, en caso de que esta se
encuentre disponible.
4. El operador es capaz de tomar en en cuenta las restricciones del problema y de
interactuar fácilmente con un algoritmo de búsqueda global.
Se consideraron dos versiones del operador ACPL1 (la cual no utiliza información
de gradiente) y ACPL2 (que si utiliza esta información). Se presentaron los resultados
obtenidos cuando se utiliza el operador, en sus dos versiones, de manera aislada o integrada
con un algoritmo de búsqueda global para resolver problemas convexos y no convexos.
Se evaluaron tres estrategias de integración que consisten en
• E1: Aplicar el operador en todas las generaciones con probabilidad pACPL a partir
de la primera generación.
• E2: Aplicar el operador de manera intermitente, una de cada NACPL generaciones,
con probabilidad pACPL.• E3: Aplicar el operador con probabilidad pACPL cuando se haya consumido el 50%
de la cantidad total de evaluaciones disponibles.
En el caso del problema convexo P4, ambas versiones del algoritmo híbrido son capaces
de obtener mejores valores para los indicadores GD/IGD con respecto a los obtenidos por

111el SPEA2 de manera aislada, cualquiera sea la estrategia de integración utilizada. No
obstante la estrategia E1 es la que obtiene los mejores resultados.
En el caso del problema P3 con 2119 frentes locales, ninguna versión del algoritmo
híbrido es capaz de mejorar los resultados obtenidos por SPEA2. En el caso del problema
P5 caracterizado por 519 frentes locales, únicamente la versión SPEA2-ACPL2, utilizando
la estrategia E1, logra mejorar los resultados del SPEA2.

CAPÍTULO VI
PROBLEMA H2/H∞El proceso de diseño de un sistema de control tiene como objetivo dotar a la inter-
conexión de propiedades que la planta no posee de manera aislada. En el capítulo 2 se
definieron algunos índices de desempeño que pueden utilizarse para expresar matemática-
mente y verificar en la práctica el cumplimiento de dichas propiedades. Por ejemplo, para
un sistema SISO, la norma H2 mide la energía de la señal de respuesta del sistema ante
un impulso unitario, mientras que la norma H∞ se relaciona con la amplitud máxima de
la misma señal.
En este capítulo se propone un nuevo método de diseño llamado Multi-Objective
Pole Placement with Evolutionary Algorithms (MOPPEA) y se presentan los resultados
obtenidos cuando se aplica dicho método para resolver el problema mixto H2/H∞ en el
caso de cinco modelos extraídos de la biblioteca COMPleib (Leibfritz, 2004). Como base
del proceso de búsqueda se utilizan los algoritmos SPEA2 y SPEA2-ACPL (ver capítulo
4) y se comparan los resultados con respecto a los obtenidos mediante una secuencia de
problemas de factibilidad LMI. Parte de los resultados presentados en este capítulo fueron
previamente publicados en (Sánchez et al., 2007) y (Sánchez et al., 2008b).
6.1. Formulación
Se asume que el modelo de la planta a controlar (ver figura 6.1) es el siguiente:
x = Ax + Iw + Bu
z1 = y = Cx
z2 = Ax
(6.1)
el cual fue propuesto originalmente por Herreros (2000) en su tesis de doctorado, para
comparar los resultados obtenidos por un algoritmo genético con respecto a la solución
calculada mediante LMIs. Una ventaja de este modelo es que únicamente necesita las

113matrices A,B y C para estar completamente definido, sin perder por ello complejidad en
su estructura.
Figura 6.1: Modelo lineal a lazo cerrado
Con el fin de analizar el conflicto entre los objetivos de robustez y desempeño del lazo,
el problema de diseño mixto PH2/H∞ es formulado en este capítulo como:
PH2/H∞ : minKc∈R(s)nu×ny ‖G1(Kc)‖2‖G2(Kc)‖∞ (6.2)
donde G1 y G2 son las funciones de transferencia a lazo cerrado desde w hacia z1 y z2respectivamente.
6.2. Antecedentes
Uno de los primeros artículos en los que se propone un intento de solución para
el problema que nos interesa en este capítulo fue publicado por Khargonekar y Rotea en
1991. Estos autores propusieron un enfoque basado en ecuaciones algebraicas de Riccati
para el problema planteado de la forma
minK∈Rnu×nx ‖G1(K)‖2sujeto a
‖G2(K)‖∞ ≤ γ
(6.3)
donde γ es un escalar positivo.
Doyle et al (1994) formularon las condiciones suficientes y necesarias para la existencia
de soluciones, proporcionando expresiones matriciales explícitas para la determinación de

114los controladores, en el caso de un problema formulado de la forma
minK∈Rnu×ny ‖G1(K)‖2 + γ ‖G2(K)‖∞ (6.4)
donde γ es un escalar positivo.
Posiblemente uno de los artículos que ha tenido más influencia en el campo de las
aplicaciones de LMIs al problema H2/H∞ fue publicado por Carsten W. Scherer en 1995,
el cual de hecho fue previamente mencionado en el capítulo 2. Este artículo ha inspirado
y servido de base para muchos otros (Clement, 2001; Hassibi et al, 1999; Hindi et al, 1998;
Miyamoto 1997).
En cuanto a las soluciones del problema H2/H∞ basadas en algoritmos genéticos,
diversos autores han publicado artículos relacionados con este tema.
En su tesis doctoral, Herreros (2000) presenta un estudio sobre el diseño de contro-
ladores robustos multi-objetivo por medio de algoritmos genéticos. Propone el algoritmo
MRCD, junto con sus respectivos operadores y demuestra de manera gráfica que sus re-
sultados son mejores con respecto a los producidos mediante LMIs.
Como ya se ha mencionado, fue precisamente Herreros quien propuso la estructura
que se presenta en la figura 6.1. De hecho, propone tres diferentes representaciones del
espacio de controladores, con el fin de estudiar la influencia en la convergencia: la forma
canónica controlable, la forma canónica diagonal y una forma canónica balanceada. En sus
conclusiones, afirma que la forma controlable es la más adecuada para la representación del
espacio de controladores ya que tiene más posibilidades de explorar el espacio de búsqueda.
Molina-Cristobal (2005) y Popov (2005) utilizan el algoritmo MOGA para reducir el
orden de los controladores y mejorar las soluciones con respecto a las obtenidas mediante
LMIs. El primero utiliza una representación de los controladores en tiempo discreto, en
forma de ceros y polos:
K(z) = K(z + z1) (z + z2) . . . (z + znz)
(z + p1) (z + p2) . . . (z + pnp)(6.5)
y el segundo una representación polinomial en tiempo continuo
K(s) = Kb0snz + b1snz−1 + . . . + bnz−1s + bnzsnp + a1snp−1 + . . . + anp−1s + anp (6.6)

115Ambos autores señalan que estas representaciones son ineficaces para generar soluciones
factibles, lo cual los obliga a aumentar el tamaño de las poblaciones y en consecuencia el
número de evaluaciones de las funciones objetivo.
Takahashi et al (2004) proponen un algoritmo genético que asegura la generación de
aproximaciones consistentes del Conjunto de Pareto y lo aplican al problema de diseño
H2/H∞. Estos autores se ocupan del problema de la realimentación estática de estados y
proponen una representación de los controladores de la forma
K =(k1 k2 . . . kn ) (6.7)
lo cual les permite utilizar como población inicial la aproximación del Conjunto de Pareto
generada mediante LMIs.
6.3. Solución mediante LMIs
Una posible solución del problema PH2/H∞ consiste en utilizar los resultados del
trabajo de Scherer (1995) para resolver el problema mixto como una secuencia de proble-
mas de factibilidad H2 y H∞, de la manera que se describe en el algoritmo 6.1.
La idea básica consiste en disminuir linealmente el límite superior de una de las
restricciones, aumentando al mismo tiempo el límite de la otra. Note que aunque en
este trabajo se plantea una evolución lineal para el ajuste, bien pudiera utilizarse un poli-
nomio de orden superior u otras funciones monótonas decrecientes y crecientes. En el caso
que nos ocupa, antes de ejecutar el algoritmo 6.1 es necesario seleccionar los valores de los
parámetros NH2/H∞,∆γ2, ∆γ∞, γmin y γmax.El paso más importante consiste en determinar un controlador Kc que satisfaga las
condiciones
‖G1(Kc)‖2 ≤ γ2 (6.8)
‖G2(Kc)‖∞ ≤ γ∞lo cual puede lograrse resolviendo un conjunto de LMIs, tal como fue mostrado en el
capítulo 2.
Para resolver el conjunto de LMIs es necesario igualar las matrices de decisión correspon-
dientes a cada norma, razón por la cual el propio Scherer (1995) reconoce que este en-
foque genera diseños conservadores. Sin embargo argumenta que “el método posee méritos

116
Entradas :G1 : Función de transferencia entre w y z1G2 : Función de transferencia entre w y z2NH2/H∞ : Número de iteraciones∆γ2 : Distancia deseada entre dos soluciones vecinas. Norma H2∆γ∞ : Distancia deseada entre dos soluciones vecinas. Norma H∞γmin : Mínimo valor deseado para la norma H2γmax : Máximo valor permitido para la norma H∞Salidas : Pk = 1;1Mientras k ≤ NH2/H∞ hacer2
Calcule Kkc solución del sub-problema3∥∥G2(Kkc )
∥∥2 ≤ γmin + k∆γ2∥∥G1(Kkc )
∥∥∞ ≤ γmax − k∆γ∞Pk = ActualizarArchivo(Kkc , Pk−1);4k = k + 1;5
Fin6Algoritmo 6.1 : Generación de una aproximación del Frente de Pareto para elproblema mixto H2/H∞ mediante LMIs
valiosos con respecto a las alternativas disponibles, puesto que conduce a problemas que
pueden ser resueltos numéricamente de manera eficiente”.
Dado que las soluciones obtenidas al resolver la secuencia de problemas de factibilidad
LMI no son necesariamente consistentes con una aproximación del Frente de Pareto, se
propone utilizar un mecanismo para archivar las soluciones no-dominadas (ver capítulo
3) lo cual permite introducir en el proceso de búsqueda cualquier requerimiento que se
desee con respecto a la distribución o diversidad deseada en la aproximación del frente.
Es importante resaltar que en la investigación bibliográfica que se ha realizado, no ha
sido posible encontrar referencias previas del empleo de un algoritmo del tipo que aquí se
propone para resolver el problema PH2/H∞.
6.4. Método MOPPEA
Usualmente la representación genética del espacio de controladores se realiza en
formato de función de transferencia
Kc(s) = x1 s2 + x2s + x3s3 + x4s2 + x5s + x6 (6.9)

117o de matrices de estado (forma controlable u otra)
Kc =
Ac Bc
Cc Dc =
x1 x2 x31 0 0
0 1 0
1
0
0
x4 x5 x6 0
(6.10)
donde x1, x2, . . . , x6 ∈ R son las variables de decisión (Cesareo, 1997).
Sin embargo, también se han propuesto representaciones más elaboradas, con el objeto
de hacer el proceso de búsqueda más eficiente. Por ejemplo, Sánchez y Ferrer (2004) pro-
pusieron una representación basada en la parametrización de controladores estabilizantes
de Youla, la cual permite eliminar la restricción de estabilidad en la formulación del prob-
lema de optimización.
Liu et al (2002) incluyen en la representación genética la información correspondiente
a los auto-valores y auto-vectores de la matriz de transferencia a lazo cerrado, de la forma
p = (λ, R, L) (6.11)
donde λ es el vector de auto-valores, R es la matriz de auto-vectores derechos y L es la
matriz de auto-vectores izquierdos de la matriz de estados a lazo cerrado.
Zavala et al (2002) proponen utilizar como variables de decisión la posición de las raices
de los polinomios R(s), S(s) que intervienen en la ecuación diofantina característica de un
lazo, de la forma
F (s) = A(s)S(s) + B(s)R(s) (6.12)
Existen aplicaciones que exigen representaciones muy particulares. Por ejemplo, en
(Andres et al., 2004) se propuso un algoritmo llamado Variable Interval Multi-Objective
(VIM) en el cual se codifica directamente la duración y la amplitud de los intervalos de la
señal de control. También en (Villasana & Ochoa, 2003) se utiliza una representación de
la señal de control basada en intervalos de duración variable.
A continuación se propone un método de diseño, llamado Multi-Objective Pole Place-
ment with Evolutionary Algorithms (MOPPEA) cuya idea principal consiste en asignar

118una estructura de “Observación + Realimentación de Estados” (ver capítulo 2) a cada
individuo, de la forma:
·x= (A + BK + LC)x− Ly
u = Kx(6.13)
donde x es la estimación del vector de estado, K es la matriz de realimentación de esta-
dos y L la matriz de observación. De manera que el problema de diseño PH2/H∞ puede
replantearse como:
minK∈Rnu×n,L∈Rn×ny ‖G1(K,L)‖2‖G2(K,L)‖∞ (6.14)
y por lo tanto la restricción de estabilidad desaparece del problema de optimización: esto
constituye la principal ventaja del método propuesto con respecto a los trabajos de Her-
reros (2000), Molina-Cristobal (2005) y Takahashi et al (2004).
La representación genética propuesta consiste en concatenar las filas de las matrices K
y L correspondientes a cada individuo en un vector de valores reales. De esta manera, el
número total de variables de decisión se calcula mediante la fórmula
nMOPPEA = n× (nu + ny) (6.15)
donde n es el grado, nu el número de entradas y ny el número de salidas del sistema a lazo
abierto (ver figura 6.2).
Figura 6.2: Representación genética propuesta. Método MOPPEA
Esta representación genética permite utilizar los operadores de variación descritos en
el capítulo 3 y el operador de búsqueda local ACPL propuesto en el capítulo 4. Se propone
en particular utilizar el operador de cruce aritmético. Si los padres seleccionados para el
cruce pertenecen a la región de factibilidad, los hijos producidos por este operador son
igualmente factibles.

119Sean (K1, L1) y (K2, L2) las matrices correspondientes a dos individuos estabilizantes,
es decir, tales que
A + BK1 < 0, A + L1C < 0 (6.16)
A + BK2 < 0, A + L2C < 0
Entonces, se cumple que los hijos(K1, L1) y
(K2, L2) generados mediante el operador
aritmético son ambos igualmente estabilizantes.
En efecto, sean(K1, L1) y (K2, L2) las matrices que representan a los hijos generados
a partir de (K1, L1) y (K2, L2), a saber
K1 = αK1 + (1− α)K2 (6.17)
K2 = (1− α)K1 + αK2L1 = αL1 + (1− α)L2L2 = (1− α)L1 + αL2
donde α es un escalar perteneciente al intervalo [0,1]. Posteriormente se multiplican las
ecuaciones (6.16) por α y (1− α) de manera que se obtiene
αA + αBK1 < 0, αA + αL1C < 0 (6.18)
(1− α)A + (1− α)BK2 < 0, (1− α)A + (1− α)L2C < 0
(1− α)A + (1− α)BK1 < 0, (1− α)A + (1− α)L1C < 0
αA + αBK2 < 0, αA + αL2C < 0
las cuales se cumplen si α = 0, α = 1. Note que en los casos α = 0 o α = 1 los hijos son
idénticos a los padres.
Ahora se adicionan las ecuaciones (6.18) para obtener
αA + αBK1 + (1− α)A + (1− α)BK2 < 0 (6.19)
(1− α)A + (1− α)BK1 + αA + αBK2 < 0
αA + αL1C + (1− α)A + (1− α)L2C < 0
(1− α)A + (1− α)L1C + αA + αL2C < 0
lo cual puede reescribirse como
A + BK1 < 0, A + L1C < 0 (6.20)
A + BK2 < 0, A + L2C < 0

120de donde se se deduce que los hijos generados de esta forma son ambos estabilizantes.
En cuanto al operador de mutación, se propone utilizar un esquema similar al presen-
tado en el capítulo 4. La mutación se realiza fijando α = 1 y a partir de un individuo
factible x se genera una mutación mediante
x = x + αδ (6.21)
donde δ es un vector aleatorio de distribución gaussiana. Si el individuo resultante no es
factible entonces se disminuye α a la mitad y se genera una nueva mutación hasta que el
resultado sea factible.
La generación de la población inicial de MOPPEA se basa en el algoritmo recursivo
6.2. Sean pk ∈ Cn , pl ∈ Cn los autovalores de A + BK , A + LC respectivamente. Para
asegurar la condición de estabilidad a lazo cerrado, las matrices K y L deben calcularse
de tal forma que pk y pl pertenezcan al semi-plano C−, lo cual puede lograrse mediante el
método presentado en el capítulo 2, sección 2.4.
La idea principal es decidir al azar si se genera un polo real o un par de polos conjuga-
dos y a partir de allí formular la recursividad. El objetivo consiste en generar individuos
factibles, distribuidos uniformemente en la zona del semi-plano complejo izquierdo delimi-
tada por dos cotas denotadas rmax , imax que deben ser ajustadas en función de la posición
de los polos del sistema a lazo abierto. Dado que en general se recomienda perturbar lo
menos posible las coordenadas de los polos a lazo abierto, es posible calcular las cotas rmax, imax a partir de dichas coordenadas, dejando sin embargo un cierto márgen para que sea
posible la reubicación en caso de que se estime necesario.
Una vez generada la población inicial, la fase de exploración puede realizarse mediante
cualquier algoritmo genético que permita la búsqueda multi-objetivo. En este trabajo se
propone comparar los resultados obtenidos por SPEA2 y SPEA2 - ACPL con respecto al
método basado en factibilidad LMI, tal como se presenta en la próxima sección.
6.5. Resultados numéricos
Los modelos que se estudian en esta sección fueron extraidos de COMPleib, libr-ería que contiene más de 120 sistemas LTI en formato MATLAB R© (Leibfritz, 2004). Una
justificación para esta selección, es que los modelos estudiados previamente por Herreros,

121
Entradas :n : grado del polinomio caracerístico del sistema a lazo cerradormax : cota superior de los polos en el eje realimax : cota superior de los polos en el eje imaginarioSalidas : pSi n = 1 entonces1
p = −rand ∗ rmax;2sino3
Si n = 2 entonces4Si rand < 0.5 entonces5
p1 = −rand ∗ rmax;6p2 = −rand ∗ rmax;7
sino8p1 = −rmax ∗ rand + i ∗ imax ∗ rand;9p2 = −rmax ∗ rand− i ∗ imax ∗ rand;10
finsi11sino12
Si rand < 0.5 entonces13p = [−rmax ∗ rand, genpol(n− 1, rmax, imax)];14
sino15p1 = −rmax ∗ rand + i ∗ imax ∗ rand ;16p2 = −rmax ∗ rand− i ∗ imax ∗ rand;17p = [p1, p2, genpol(n− 2, rmax, imax)]18
finsi19finsi20
finsi21Algoritmo 6.2 : Generación de un vector de polos aleatorio
Molina-Cristobal y Takahashi corresponden a sistemas SISO de bajo orden, más adaptados
a la evaluación de controladores PID, para lo cual de hecho fueron propuestos (Astrom et
al., 1998).
Dado que originalmente COMPleib fue propuesta para la evaluación de soluciones al
problema H∞, para adaptar los modelos al caso H2/H∞ que se estudia en este capítulo, se
propone extraer únicamente las matrices A, B y C, conservando la estructura que aparece
en la ecuación (6.1).
Se propone en concreto evaluar el funcionamiento de tres algoritmos para resolver el
problema PH2/H∞:

122• A1: que corresponde al algoritmo SPEA2 utilizando el método MOPPEA para la
generación y el mantenimiento de individuos estabilizantes.
• A2: que corresponde al algoritmo memético SPEA2-ACPL-E1 (ver capítulo 5) uti-
lizando el método MOPPEA para la generación y el mantenimiento de individuos
estabilizantes.
• A3: que corresponde al algoritmo basado en factibilidad de LMIs (algoritmo 6.1).
En la tabla 6.1 se presentan los datos correspondientes a los modelos seleccionados para
las pruebas. Cada modelo COMPleib se caracteriza por una nomenclatura específica. Para
este trabajo se consideran cinco en particular, a saber: AC1, AC6, NN10, WEC1 y AC9.
Note que los mismos fueron seleccionados de forma que el número de variables de
decisión oscile entre 30 y 90, con el fin de analizar la influencia de esta cantidad sobre los
resultados obtenidos por cada algoritmo.
También se muestran en la tabla 6.1 los valores de los parámetros NH2/H∞,∆γ2, ∆γ∞,
γmin y γmax correspondientes a la configuración del algoritmo basado en LMIs. Los mismos
fueron ajustados mediante ensayo y error tomando en cuenta las soluciones extremas que
se obtienen considerando cada objetivo de manera aislada, utilizando los comandos h2syn
y hinfsyn de MATLAB R©.
Los parámetros rmax , imax que también aparecen en la tabla 6.1 corresponden a las
cotas utilizadas para la generación de la población inicial de MOPPEA, calculadas para
incluir los polos de cada modelo a lazo abierto.
Tabla 6.1: Datos correspondientes a los problemas COMPleibCOMPleib n nu ny nMOPPEA NH2/H∞ ∆γ2 ∆γ∞ γmin γmax rmax imax
AC1 5 3 3 30 100 0.01 0.01 1.5 5.5 10 10AC6 7 2 4 42 100 0.1 1 1 110 20 20NN10 8 3 3 48 100 0.01 0.02 3 15 10 10WEC1 10 3 4 70 100 0.05 1 2 200 100 100AC9 10 4 5 90 100 0.1 0.1 50 100 100 100

123Es importante resaltar que adicionalmente a los algoritmos A1, A2 y A3 antes men-
cionados se realizaron pruebas utilizando la representación tradicional en forma polino-
mial y en espacio de estados. Sin embargo, no fue posible conseguir individuos estables
utilizando estos formatos, por lo cual no se incluyen en los resultados que se presentan a
continuación.
Se realizaron 30 ejecuciones de cada algoritmo. En las figuras 6.3, 6.4, 6.5, 6.6 y 6.7 se
puede apreciar un ejemplo de las aproximaciones obtenidas mediante cada uno.
0.8 1 1.2 1.4 1.6 1.8 21.6
1.7
1.8
1.9
2
2.1
2.2
2.3
2.4
2.5
H2
H∞
Ejemplo de aproximación obtenida con A1Ejemplo de aproximación obtenida con A2Ejemplo de aproximación obtenida con A3
Figura 6.3: Ejemplo de las soluciones obtenidas por A1, A2 y A3. Problema AC1

124
2 3 4 5 6 7 820
40
60
80
100
120
140
160
H2
H∞
Ejemplo de aproximación obtenida con A1Ejemplo de aproximación obtenida con A2Ejemplo de aproximación obtenida con A3
Figura 6.4: Ejemplo de las soluciones obtenidas por A1, A2 y A3. Problema AC6
2.5 3 3.5 4 4.5 58
10
12
14
16
18
20
H2
H∞
Ejemplo de aproximación obtenida por A1Ejemplo de aproximación obtenida por A2Ejemplo de aproximación obtenida por A3
Figura 6.5: Ejemplo de las soluciones obtenidas por A1, A2 y A3. Problema NN10
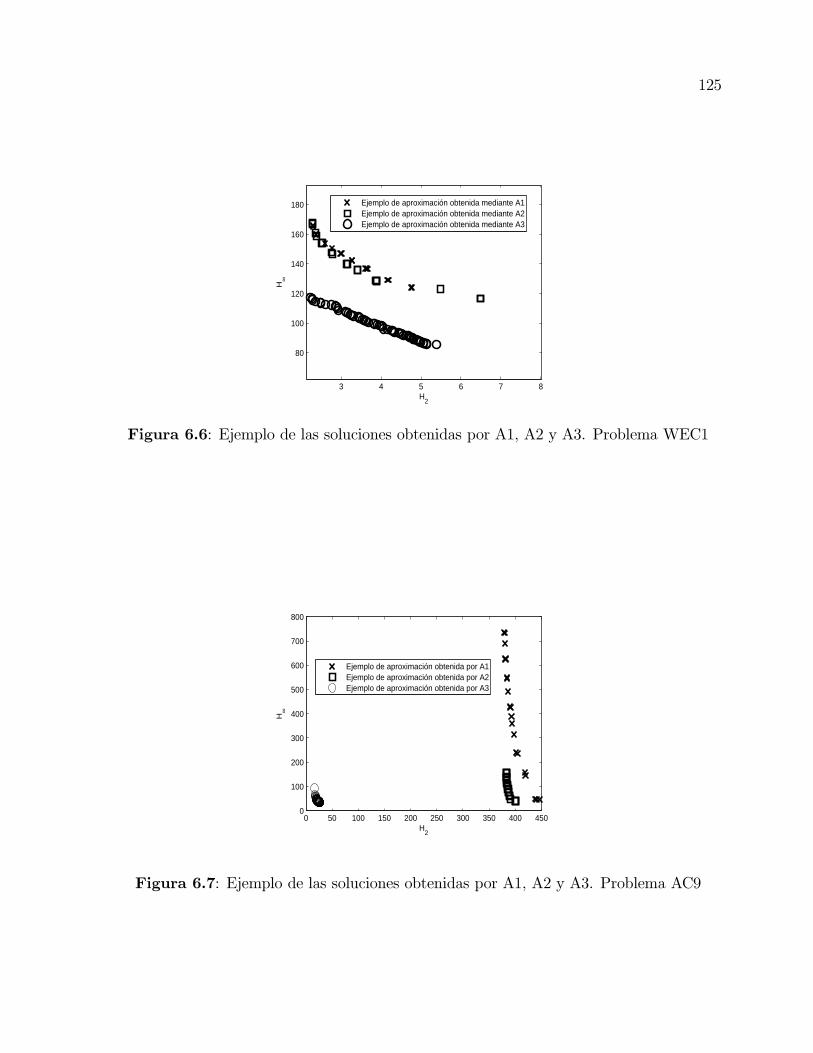
125
3 4 5 6 7 8
80
100
120
140
160
180
H2
H∞
Ejemplo de aproximación obtenida mediante A1Ejemplo de aproximación obtenida mediante A2Ejemplo de aproximación obtenida mediante A3
Figura 6.6: Ejemplo de las soluciones obtenidas por A1, A2 y A3. Problema WEC1
0 50 100 150 200 250 300 350 400 4500
100
200
300
400
500
600
700
800
H2
H∞
Ejemplo de aproximación obtenida por A1Ejemplo de aproximación obtenida por A2Ejemplo de aproximación obtenida por A3
Figura 6.7: Ejemplo de las soluciones obtenidas por A1, A2 y A3. Problema AC9

126En estas figuras es posible apreciar que entodos los casos A2 produce individuos que
en su mayoría dominan a los de A1. Para el problema AC1 (30 variables), se aprecia
que A2 mejora los resultados de A3. En el caso de AC6, las soluciones de A2 y A3 son
mutuamente no-dominadas.
En los casos NN10, WEC1 y AC9 los resultados del algoritmo basado en LMIs mejoran
claramente los resultados del genético, considerando un presupuesto fijo de 20.000 evalua-
ciones del vector objetivo. Esta cantidad de evaluaciones permite que las 30 ejecuciones
del algoritmo genético no excedan el tiempo máximo permitido para completar el proceso
de diseño (≈24 horas).
La configuración utilizada para la ejecución de las pruebas se muestra en la tabla
6.2. Los resultados obtenidos para los indicadores C,DMAX y ESS se muestran en las
tablas 6.3 y 6.4. Independientemente del problema, es posible observar que los resultados
obtenidos por A2 son mejores que los de A1 con respecto al operador de cobertura, lo cual
ilustra la utilidad del operador ACPL para la búsqueda local en estos casos.
Por otra parte, el algoritmo A2 logra mejorar las soluciones de A3 en el caso del
problema AC1 e igualar en el caso AC6, con respecto al operador de cobertura. En los
otros dos casos, el algoritmo basado en LMIs es claramente superior, tal como fue posible
constatar de manera gráfica.
Tabla 6.2: Parámetros utilizados por SPEA2 y SPEA2-ACPL
Parámetros ValorRepresentación K+L
Operador de cruce AritméticoProbabilidad de cruce 0.9Operador de mutación Gaussiana
Probabilidad de mutación 0.1Probabilidad de aplicación del ACPL 0.25
ε [0.1, 0.1]r [0.1, 0.1]
Niter 10Nnd [5, 5]Tol 10−4
Condición de parada 200 generacionesNúmero máximo de evaluaciones 20.000
Tamaño máximo del archivo externo 20Esquema de selección (100 + 100)

127
Tabla 6.3: Resultados del indicador de cobertura
C(Ai, Aj) A1 A2 A3
A1 −
AC1:0.0200(0.0535)AC6:0.0217(0.0773)NN10:0.3650(0.3996)WEC1:0.2500(0.2603)AC9:0.2978(0.3548)
AC1:0.8619(0.1326)AC6:0(0)NN10:0(0)WEC1:0(0)AC9:0(0)
A2
AC1:0.8517(0.1850)AC6:0.6750(0.2589)NN10:0.4600(0.4438)WEC1:0.3867(0.2846)AC9:0.4850(0.4329)
−
AC1:0.9810(0.0494)AC6:0(0)NN10:0(0)WEC1:0(0)AC9:0(0)
A3
AC1:0(0)AC6:0(0)NN10:1(0)WEC1:1(0)AC9:1(0)
AC1:0(0)AC6:0(0)NN10:1(0)WEC1:1(0)AC9:1(0)
−
Tabla 6.4: Resultados de los indicadores ESS y DMAXDMAX ESS
A1
AC1:0.7589(0.0535)AC6:120.4263(67.0600)NN10:3.5940(0.7046)WEC1:45.3320(7.7541)AC9:564.2026(190.4456)
AC1:0.0190(0.0069)AC6:3.5698(4.0164)NN10:0.1026(0.0407)WEC1:1.0784(0.4881)AC9:21.5037(17.8440)
A2
AC1:0.9638(0.3524)AC6:73.0991(15.1735)NN10:3.7460(0.6381)WEC1:44.4208(6.2985)AC9:261.0278(169.0322)
AC1:0.0253(0.0121)AC6:1.7792(0.5986)NN10:0.0998(0.0298)WEC1:1.0812(0.3809)AC9:14.7817(19.8238)
A3
AC1:0.1618(0)AC6:2.8065(0)NN10:1.0200(0)WEC1:36.0976(0)AC9:59.2017(0)
AC1:0.0122(0)AC6:0.0152(0)NN10:0.0188(0)WEC1:0.1540AC9:3.3800(0)

128De igual forma, con respecto al indicador ESS, el algoritmo A3 logra mejorar los
resultados obtenidos por los otros dos, lo cual se explica por el caracter determinista del
algoritmo basado en LMIs, el cual intenta producir una distribución uniforme en el frente,
caracterizada por los parámetros ∆γ2, ∆γ∞.
En relación con el índice DMAX no se aprecian claras diferencias entre A1 y A2,
aunque ambos algoritmos producen frentes mucho más amplios que A3, para todos los
problemas. Tampoco con respecto a ESS se aprecian notables diferencias entre A1 y A2.
6.6. Resumen del capítulo
En este capítulo se propuso un nuevo método de diseño de controladores multi-
objetivo llamado MOPPEA, que consiste fundamentalmente en:
1. Asignar a cada individuo una representación de la forma (K,L), donde K es la
matriz de realimentación y L es la matriz de observación de estados.
2. Utilizar un algoritmo recursivo para generar la población inicial de individuos factibles.
3. Utilizar un operador de cruce aritmético que permite mantener a la población dentro
de la región factible y un algoritmo genético multi-objetivo para llevar a cabo el
proceso de búsqueda.
En particular se presentó una comparación entre los resultados obtenidos por SPEA2
y SPEA2 - ACPL con respecto al método basado en factibilidad LMI, cuando se intenta
resolver el problema mixto H2/H∞ en el caso de cinco modelos de COMPleib.Las pruebas estadísticas realizadas permiten afirmar que, considerando un presupuesto
fijo de 20.000 evaluaciones, el enfoque genético es eficiente únicamente para los problemas
AC1 y AC6 caracterizados por 30 y 42 variables de decisión respectivamente. Por el
contrario, en el caso de los pro-blemas NN10, WEC1 y AC9 (con 48, 70 y 90 variables)
las soluciones obtenidas mediante LMIs dominan a las producidas por SPEA2 y SPEA2 -
ACPL.
Por otra parte, en todas las pruebas realizadas, los valores del indicador de cobertura
obtenidos por el algoritmo memético SPEA2-ACPL superan a los obtenidos por el SPEA2,
lo cual confirma la conveniencia de utilizar el operador de búsqueda local en esta clase de
problemas.

CAPÍTULO VII
CONCLUSIONES
La principal contribución de este trabajo consiste en la propuesta y el análisis de
nuevos operadores, especialmente concebidos para intentar mejorar el proceso de diseño
de controladores automáticos lineales mediante algoritmos genéticos.
Sin embargo, algunas estrategias pueden ser extrapoladas para resolver problemas de
ingeniería en otras áreas tales como identificación de sistemas y análisis de señales. Por
ejemplo, el operador ACPL puede ser adaptado para intentar resolver otros problemas de
optimización multi-objetivo, previa adecuación de sus parámetros y escalamiento de vari-
ables. En este sentido, se presentaron evidencias que permiten concluir que para problemas
que no poseen muchos frentes locales, la utilización del ACPL conduce a mejoras estadísti-
camente significativas del indicador de cobertura, con respecto al algoritmo genético puro.
Este resultado confirma las conclusiones obtenidas por otros autores en trabajos previos
similares.
También con respecto al operador ACPL, es importante destacar que la codificación
binaria propuesta para la identificación de los conos de diversidad y el cálculo de la di-
rección correspondiente a cada cono son aspectos sobre los cuales no se han conseguido
referencias previas en la revisión bibliográfica realizada. Por otra parte, aunque los mecan-
ismos de integración entre el algoritmo genético y el operador de búsqueda local explorados
en el transcurso de esta investigación fueron muy sencillos, los resultados obtenidos son
prometedores y alientan la continuación en esta línea de investigación.
El método propuesto para el diseño PID basado en el cálculo exacto de la región
estabilizante produjo resultados satisfactorios en un caso de estudio basado en un modelo a
lazo abierto de orden seis y de fase no-mínima, de una complejidad superior a los analizados
por otros autores. Es posible que su aplicación se justifique en un caso práctico, puesto que
permitiría mejorar considerablemente la calidad de las soluciones y disminuir el tiempo del
proceso de diseño. Una extensión posible consiste en evaluar el método en aplicaciones en

130línea (auto-tuning y control adaptivo), puesto que es posible asegurar que los controladores
obtenidos son al menos estabilizantes y por ende no pondrían en riesgo la integridad de la
planta controlada.
El tema de la inestabilidad es un punto sobre el cual se hizo mucho énfasis en este
trabajo. Es curioso que ninguno de los investigadores que adoptaron previamente la
metodología genética para resolver problemas de control haya tomado en cuenta este as-
pecto tan fundamental con mayor interés, optando en la mayoría de los casos por un
enfoque basado en una función de penalidad.
En este sentido, el método MOPPEA permite generar y mantener una población com-
puesta exclusivamente por individuos estabilizantes: algo que, de acuerdo con la revisión
de la literatura realizada, ningún otro algoritmo genético había garantizado plenamente.
Y esto gracias a las ventajas de la representación matricial (K,L) para la exploración del
espacio de controladores estabilizantes, con respecto a la representación polinomial o en
espacio de estados utilizada por otros autores. Las pruebas realizadas confirmaron que en
efecto estas últimas no son nada eficientes en el caso de sistemas MIMO de alto orden.
La representación (K,L) propuesta en este trabajo es preferible ya que toma en cuenta
de manera intrínseca la restricción de estabilidad. Es posible afirmar, a partir de los resul-
tados obtenidos, que la representación genética de los controladores en forma polinomial o
en forma controlable únicamente se justifica si el sistema a lazo abierto es SISO y de bajo
orden.
En nuestro conocimiento, ninguno de los investigadores dedicados previamente al problema
mixto H2/H∞ ha publicado información relacionada con los límites de la eficiencia de los
algoritmos genéticos con respecto a las soluciones LMI. En este trabajo se abordó este
tema a partir de casos de estudio en los cuales el número de variables de decisión oscila
entre 30 y 90, considerando un presupuesto fijo de 20.000 evaluaciones.
Se pudo concluir que MOPPEA es capaz de mejorar las soluciones LMI en el caso del
problema de 30 variables y de igualarlas en el caso de 42 variables. Para un mayor número
mayor de variables las soluciones LMI son claramente superiores, tomando en cuenta el
presupuesto limitado de evaluaciones del vector objetivo.

131Estos resultados confirman que, como era de esperarse, mientras más grande es el
número de variables de decisión, menos competitivo se hace el enfoque genético con
respecto a las LMIs. Queda como punto pendiente analizar lo que sucede si se aumenta
el presupuesto de evaluaciones, para lo cual se requiere la disponibilidad de equipos con
mayor capacidad de cómputo, de manera que se pueda obtener resultados en un tiempo
adecuado. Esto se debe a que es necesario repetir las pruebas tantas veces como sea
posible, con el fin de obtener medidas estadísticamente significativas.
Otro punto de investigación que queda abierto consiste en lograr una formulación
del problema LMI en términos de las matrices K y L de la estructura “Observación
+ Realimentación de Estados”. Esta formulación facilitaría una interacción que podría
conducir a mejores soluciones con respecto a cada método de diseño considerado de manera
aislada.
Una innovación interesante de MOPPEA consiste en el algoritmo recursivo para la
generación de la población inicial. En su versión actual este algoritmo permite generar
lazos cerrados cuyos polos pertenecen a una región rectangular delimitada por dos cotas.
Sin embargo, en el futuro es posible adaptar el algoritmo para que los polos se distribuyan
en otras regiones del plano complejo, tales como discos o conos.
También es importante señalar que aunque los indicadores de desempeño utilizados a
lo largo del trabajo (Cobertura, Distancia Máxima y Espaciado) son ampliamente cono-
cidos por los investigadores en el área de algoritmos genéticos multi-objetivo, tampoco
ha sido posible conseguir referencias previas relacionadas con el cálculo de indicadores de
desempeño y pruebas estadísticas similares a las presentadas en este trabajo, en el caso
de problemas de diseño de controladores. Es recomendable que los procedimientos de
evaluación de las soluciones multi-objetivo se conviertan en un estándar para este tipo de
aplicaciones, ya que permite la comparación entre los resultados obtenidos por diversos
autores.
A lo largo del trabajo se puso mucho énfasis en la generación de la población inicial.
De hecho, en este sentido se propusieron tres novedosos métodos con esta finalidad: el
método exacto que calcula los vértices de la región estabilizante en el caso PID, el método
que calcula una aproximación mediante muestreo aleatorio y el método recursivo para la
generación de individuos factibles (MOPPEA). Es interesante notar que estos métodos
se inspiran de diversas fuentes tales como la teoría clásica de control, la programación

132matemática, la geometría, la topología y los algoritmos genéticos. Cada disciplina fue
abordada intentando obtener lo mejor de cada una para alcanzar el objetivo final, el cual
no es otro que conseguir las mejores soluciones posibles para los problemas de diseño.
De esta forma se ha confirmado la necesidad de incorporar conocimiento específico en las
aplicaciones de los algoritmos genéticos, como consecuencia del famoso teorema “No free
lunch” (Wolpert & Macready, 1997).
Muchos puntos quedan sin embargo por abordar, entre los cuales es posible mencionar
los siguientes:
• Implementar algoritmos genéticos adaptivos, para disminuir la necesidad de ajustes
de parámetros por parte del diseñador.
• Continuar el estudio sobre la interacción de los operadores de búsqueda local con los
operadores de búsqueda global (explotación vs exploración).
• Considerar conceptos novedosos de dominancia, para permitir la inclusión de las
preferencias del diseñador, antes o después del proceso de búsqueda.
• Mejorar las interfaces con el usuario y del proceso de selección de soluciones (toma
de decisiones).
• Desarrollo de métodos multi-objetivo de optimización estructural y mixto-entera.
• Continuar el estudio sobre representaciones del espacio de controladores, principal-
mente en el caso no-lineal de múltiples entradas y salidas.
• Consideración de problemas de modelaje e identificación de la planta en el contexto
del diseño multi-objetivo.
• Resolver problemas de control que necesiten optimización multi-objetivo en línea,
considerando las dificultades tecnológicas que ello implica.

133
APÉNDICE
Se denomina señal a cualquier función f : R → Cn que represente una magnitud
física o lógica variable en el tiempo. A continuación se presentan algunos resultados
teóricos relacionados con señales, operadores y normas en diversos espacios de interés para
el análisis de sistemas dinámicos.
Se denota Ln2(−∞,∞) al espacio lineal compuesto por las señales f : R→ Cn continuas
y deterministas, tales que: +∞∫−∞ f ∗(t)f(t)dt <∞ (7.1)
La función ‖·‖2 : Ln2(−∞,∞) → R+0 tal que
‖f‖2 =
√√√√√+∞∫−∞ f ∗(t)f(t)dt, ∀f ∈ Ln2 (7.2)
define una norma sobre Ln2(−∞,∞). Esta cantidad puede ser interpretada como la energía
total contenida en f .
Se denota C+ al semi-plano complejo abierto derecho y C+
al semi-plano complejo
cerrado derecho, esto es
C+ ≡ {c ∈ C; Re(c) > 0}
C+
≡ {c ∈ C; Re(c) ≥ 0}
Se denota Ln2(jR) al espacio de Hilbert compuesto por las funciones matriciales
f : jR→ Cn (7.3)
dotado del producto interno
⟨f1, f2⟩ =
+∞∫−∞ f ∗1 (jω)f2(jω)dω (7.4)

134El operador lineal acotado Γ : Lp×m2 (−∞,∞) → Ln2(jC) definido por
Γ(f) = f(jω) =
+∞∫−∞ f(t)e−jωtdt (7.5)
se denomina Transformada de Fourier. Γ es un operador unitario e invertible, esto es, Γ
define un isomorfismo entre Ln2(−∞,∞) y Ln2(jC).
Se denota Hp×m2 al espacio de funciones matriciales complejas
f : C+→ Cp×m
tales que:
• f es analítica en C+.
• Para cualquier ω ∈ R , excepto en un conjunto finito {ω1, ω2, ...ωN} , se cumple:
f(jω) = limσ→0+ f(σ + jω) (7.6)
• La siguiente cantidad es finita
supσ≥0 +∞∫−∞ traza[f∗(σ + jω)f(σ + jω)]dω (7.7)
La función ‖·‖2 : Hp×m2 → R+0 tal que
∥∥∥f∥∥∥2 =
√√√√√supσ≥0 1
2π
+∞∫−∞ traza[f ∗(σ + jω)f(σ + jω)]dω (7.8)
∀f ∈ Hp×m2 , define una norma sobre Hp×m2 , denotada H2.Una función matricial f : C
+→ Cp×m se denomina real racional, si cada uno de sus
elementos fij(s) es de la forma:
fij(s) =bnusnu + bnu−1snu−1 + .. + b1s + b0snd + and−1snu−1 + .. + a1s + a0 =
Nij(s)Dij(s) (7.9)
donde todos los coeficientes de los polinomios Nij(s) y Dij(s) son reales.

135El conjunto de funciones matriciales f : C
+→ Cp×m reales racionales se denota
R(s)p×m. Si ∀fij(s), nd ≥ nu , f es llamada propia. Si ∀fij(s), nd > nu , f es lla-
mada estrictamente propia. Para cualquier fij(s), se denomina “polo” a cualquier p ∈ C+
tal que∣∣∣fij(s)∣∣∣ → ∞, cuando s → p. Una función real racional f pertenece a Hp×m2 si y
solo si es estrictamente propia y no posee polos en C+. Se denota RHp×m2 al sub-espacio
de funciones matriciales reales racionales pertenecientes a Hp×m2 .
El operador lineal acotado Λ : Ln2 [0,∞) → Hn2 definido por:
Λ(f) = f(s) =
+∞∫0 f(t)e−stdt (7.10)
se denomina Transformada Unilateral de Laplace. Λ define un isomorfismo entre Ln2 [0,∞)
y Hn2 .Se denota Ln∞(−∞,∞) al espacio lineal de señales continuas y determinísticas, com-
puesto por las funciones f : R+0 → Cn tales que:
ess supt∈(−∞,∞)√f ∗(t)f(t) <∞ (7.11)
La función ‖·‖∞ : Ln∞(−∞,∞) → R+0 tal que
‖f‖∞ = ess supt∈(−∞,∞)√f∗(t)f(t) (7.12)
∀f ∈ Ln∞ define una norma sobre Ln∞(−∞,∞) que puede ser interpretada como el módulo
máximo de la señal f para t ∈ (−∞,∞).
Se denota Hp×m∞ al espacio de funciones matriciales G : C+→ Cp×m tales que:
• G es analítica en C+.
• Para cualquier ω ∈ R , excepto en un conjunto finito {ω1, ω2, ...ωN}, se cumple:
G(jω) = limσ→0+ G(σ + jω) (7.13)
• La siguiente cantidad es finita:
ess sups∈C+ σ[G(s)] (7.14)

136donde σ representa el máximo valor singular de la matriz G(s), es decir,
σ[G(s)] =maxi √λi[G(s)∗G(s)] (7.15)
con,
λi[G(s)∗G(s)] ≡ i-ésimo autovalor de G(s)∗G(s)
La función ‖·‖∞ : Hp×m∞ → R+0 tal que∥∥∥G∥∥∥∞ =supω∈R σ[G(jω)], ∀G ∈ Hp×m∞ (7.16)
define una norma sobre Hp×m∞ denotada H∞. De hecho suponga u ∈ Hnu2 . Entonces, G
∈ Hny×nu∞ se comporta como un operador lineal multiplicativo, esto es, y = Gu ∈ H
ny2 . El
operador G es comunmente llamado “matriz de transferencia” desde u hacia y. Además,
mediante el operador Transformada de Laplace, la matriz G ∈ Hp×m∞ define un operador
lineal acotado y causal G de Lm2 [0,∞) → Lp2[0,∞), de la forma:
G = Λ−1GΛ (7.17)
Una función racional G ∈ R(s)p×m , pertenece a Hp×m∞ si y solo si G es propia y no posee
polos en C+. El conjunto de funciones matriciales racionales pertenecientes a Hp×m∞ se
denota RHp×m∞ .

REFERENCIAS
Ackermann, J. & Kaesbauer, D. (2003). Stable polyhedra in parameter space. Automat-ica, (39):937—943.
Adra, S. ; Amody, A. ; Griffin, I. & Fleming, P. (2005a). A hybrid multi-objectiveevolutionary algorithm using an inverse neural network for aircraft control systemdesign. In Proceedings of the IEEE Congress on Evolutionary Computation, pp 1—8.
Adra, S. ; Griffin, I. & Fleming, P. (2005b). Hybrid multi-objective genetic algorithmwith a new adaptive local search process. In Hans-Georg-Beyer et al. editor, Geneticand Evolutionary Computation Conference GECCO’2005, volume 1, pp 1009—1010.
Andres, B. ; Jiron, J. ; Fernandez, P. ; Lopez, J. & Besada, E. (2004). Multiobjectiveoptimization and multivariable control of the beer fermentation process with the useof evolutionary algorithms. Journal of Zhejiang University - Science, pp 378—389.
Apkarian, P. ; Noll, D. & Rondepierre, A. (2008). Mixed H2/H∞ control via nonsmoothoptimization. SIAM Journal on Control and Optimization, 47(3):1516—1546.
Arakawa, M. ; Nakayama, H. ; Hagiwara, I. & Yamakawa, H. (1998). Multi-objectiveoptimization using adaptive range genetic algorithms with data envelopment analy-sis. In A Collection of Technical Papers of the 7th Symposium on MultidisciplinaryAnalysis and Optimization, pp 2074—2082.
Astrom, K. & Hagglund, T. (1995). PID controllers: theory, design and tuning. Instru-ments Society of America.
Astrom, K. ; Panagopoulos, H. & Hagglund, T. (1998). Design of PI controllers basedon non-convex optimization. Automatica, 34(5):585—601.
Bertalanffy, L. (1950). An outline of general systems theory. British Journal for thePhilosophy of Science, 1(2).
Boyd, S. ; El-Ghaoui, L. ; Feron, E. & Balakrishnan, V. (1994). Linear matrix in-equalities in system and control theory. SIAM Studies in Applied Mathematics.
Brown, M. & Smith, R. (2005). Directed multi-objective optimization. InternationalJournal on Computers, Systems and Signals, 6(1):3—17.
Broyden, C. (1970). The Convergence of a Class of Double-rank Minimization Algo-rithms. Journal of the Institute of Mathematics and Its Applications, 6:76—90.
Calafiore, G. & Dabbene, F. (2006). Probabilistic and randomized methods for designunder uncertainty. Springer-Verlag, London.

138Caponio, A. ; Cascella, G. ; Neri, F. ; Salvatore, N. & Sumner, M. (2007). A fast adap-
tive memetic algorithm for online and offline control design of PMSM drives. IEEETransactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 37(1):28—41.
Cesareo, J. (1997). Estrategias evolutivas y su aplicación en la síntesis de controladores.PhD thesis, Universidad de Vigo. Dpto. de Ingeniería de Sistemas.
Chipperfield, A. ; Bica, B. & Fleming, P. (1998). Fuzzy scheduling control of a gasturbine aero-engine: a multi-objective approach. IEEE Transactions on IndustrialElectronics, 49(3):536—548.
Chipperfield, A. & Fleming, P. (1996). Multi-objective gas turbine engine controllerdesing using genetic algorithms. IEEE Transactions on Industrial Electronics,43(5):583—587.
Clement, B. (2001). Synthese multiobjectifs et sequencement de gains: Application aupilotage d’un lanceur spatial. PhD thesis, Service Automatique de SUPELEC - Gifsur Yvette, France.
Coello, C. ; Lamont, G. & Van-Veldhuizen, D. (2007). Evolutionary algorithms forsolving multi-objective problems. Springer. Genetic and Evolutionary ComputationSeries. Second Edition.
Dawkins, R. (1976). The selfish gene. Oxford University Press.
Deb, K. (2001). Multiobjective optimization using evolutionary algorithms. Jhon Wileyand Sons Ltd.
Deb, K. & Agrawal, R. (1995). Simulated binary crossover for continuous search space.Complex Systems, 9(2):115—148.
Deb, K. ; Agrawal, S. ; Pratab, A. & Meyarivan, T. (2000). A fast elitist non-dominatedsorting genetic algorithm for multi-objective optimization: NSGA-II. In Proceedingsof the Parallel Problem Solving from Nature VI Conference, pp 849—858.
Dellino, G. ; Lino, P. ; Meloni, C. & Rizzo, A. (2007). Enhanced evolutionary algo-rithms for multidisciplinary design optimization: a control engineering perspective.In Hybrid Evolutionary Algorithms - Studies in Computational Intelligence, pp 173—216. Springer Berlin / Heidelberg.
Dennis, J. & Schnabel, R. (1983). Numerical methods for unconstrained optimizationand nonlinear equations. Prentice-Hall. New York.
Doyle, J. ; Glover, K. ; Khargonekar, P. & Francis, B. (1989). State-space solutions tostandard H2 and H∞ control problems. IEEE Transactions on Automatic Control,34(8):831—847.
Duarte, N. ; Ruano, A. ; Fonseca, C. & Fleming, P. J. (2000). Accelerating multi-objective control system design using a neuro-genetic approach. Proceedings of the8th IFAC Symposium on Computer Aided Control Systems Design. University ofSalford, U.K.
Dupuis, A. ; Ghribi, M. & Kaddouri, A. (2004). Multi-loop PI tuning using a multiob-jective genetic algorithm. In Proceedings of the IEEE International Conference on

139Industrial Technology, pp 1505—1510.
Eiben, A. & Smith, J. (2003). Introduction to evolutionary computing. Springer-Verlag.
Fleming, P. (2001). Genetic Algorithms in Control System Engineering. Technical re-port, No. 789. University of Sheffield. UK.
Fleming, P. J. & Purshouse, R. (2002). Evolutionary algorithms in control systemsengineering: a survey. Control Engineering Practice (10), pp 1223—1241.
Fonseca, C. (1995). Multi-objective genetic algorithms with application to control en-gineering problems. PhD thesis, Departement of Automatic Control and SystemsEngineering. University of Sheffield.
Fonseca, C. & Fleming, P. (1994). Multiobjective optimal controller design with geneticalgorithms. In Proc. IEE Control International Conference, volume 1, Warwick,U.K, pp 745—749.
Gambier, A. ; Wellenreuthera, A. & Badreddin, E. (2006). A new approach to designmulti-loop control systems with multiple controllers. In Proceedings of the 45th IEEEConference on Decision and Control. San Diego, CA, USA, pp 416—423.
Goel, T. & Deb, K. (2002). Hybrid methods for multi-objective evolutionary algorithms.In Proceedings of the 4th Asia-Pacific conference on Simulated Evolution and Learn-ing, pp 188—192.
Granado, E. ; Colmenares, W. & Perez, O. (2007). Diseño de PID multivariable usandoLMI iterativas. Revista de la Fac. Ing. UCV, 22(3):5—12.
Griffin, I. ; Schroder, P. ; Chipperfield, A. & Fleming, P. (2000). Multi-objective Opti-mization Approach to the Alstom Gasifier Problem. In Proceedings of the I MECHE Part I Journal of Systems and Control Engineering, pp 453—468.
Hart, W. (1994). Adaptive Global Optimization with Local Search. PhD thesis, Universityof California, San Diego. USA.
Hassibi, A. ; Howy, J. & Boyd, S. (1999). Low-Authority Controller Design via ConvexOptimization. AIAA Journal of Guidance, Control and Dynamics, 22(6):862—872.
Heo, J. ; Lee, K. & Garduno-Ramirez, R. (2006). Multiobjective control of power plantsusing particle swarm optimization techniques. IEEE Transactions on Energy Con-version, 21(2):552—561.
Herreros, A. (2000). Diseño de controladores robustos multiobjetivo por medio de algo-ritmos genéticos. Tesis Doctoral. Departamento de Ingenieria de Sistemas y Auto-matica. Universidad de Valladolid, España.
Hillermeier, C. (2001). Nonlinear multiobjective optimization - A generalized homotopyapproach. Birkhauser.
Hindi, H. A. ; Hassibi, B. & Boyd, S. P. (1998). Multi-objective H2/H∞ optimal con-trol via finite dimensional Q-parametrization and linear matrix inequalities. In Pro-ceedings of the American Control Conference, pp 3244—3249.

140Hohenbichler, N. & Abel, D. (2008). Calculating all KP admitting stability of a PID
control loop. In Proceedings of the 17th World IFAC Congress. Seoul, Korea, July6-11, pp 5802—5807.
Hwang, C. & Hsiao, C.-Y. (2002). Solution of a non-convexoptimization arising in PI-PID control design. Automatica 38, pp 1895—1904.
Ishibuchi, H. & Murata, T. (1996). Multi-objective genetic local search algorithm. InProc. of the IEEE Int. Conf. on Evol. Computation, Nagoya, Japan, pp 119—124.
Joos, H. (2002). A multi-objective optimisation-based software environment for controlsystems design. In Proceedings of the IEEE International Symposium on ComputerAided Control System Design, pp 7—14.
Kalman, R. (1960). Contributions to the Theory of Optimal Control. Boletín de laSociedad Matemática Mexicana, (5):102—119.
Kalman, R. (1963). Mathematical Description of Linear Dynamical Systems. SIAMJournal on Control, 1(2):152—192.
Khor, E. ; Tan, K. & Lee, T. (2002). Learning the search range for evolutionary optimiza-tion in dynamic environments. Knowledge and Information Systems, 4(2):228—255.
Knowles, J. & Corne, D. (2000). M-PAES: a memetic algorithm for multiobjectiveoptimization. In Proceedings of the IEEE Congress on Evolutionary Computation,pp 325—332.
Kumar, S. & Subramanian, S. (2002). Mutation rates in mammalian genomes. In Pro-ceedings of the National Academy of Sciences of the United States of America, pp803—808.
Lagunas, J. (2004). Sintonización de controladores PID mediante un algoritmo genéticomulti-objetivo (NSGA-II). PhD thesis, Departamento de Control Automático. Cen-tro de Investigación y de Estudios Avanzados. México.
Lara, A. ; Sánchez, G. ; Coello-Coello, C. & Schüetze, O. (2010). HCS: A New LocalSearch Strategy for Memetic Multiobjective Evolutionary Algorithms. IEEE Trans-actions on Evolutionary Computation, 14(1):112—132.
Leibfritz, F. (2004). COMPlib - Constrained Matrix-optimization Problem Library.Technical report, University of Trier. Department of Mathematics, Germany.
Liu, G. ; Yang, J. & Whidborne, J. (2002). Multiobjective optimisation and control.Research Studies Press, Baldock, UK.
Liu, T.-K. ; Ishihara, T. & Inooka, H. (1995). Multiobjective Control Systems Design byGenetic Algorithms. In Proceedings of the 34th SICE annual conference. Hokkaido,Japan, pp 1521—1526.
Lyapunov, A. (1892). The general problem of stability motion. PhD thesis, Universityof Kharkov, Russia.
Malpica, J. M. ; Fraile, A. ; Moreno, I. ; Obies, C. I. ; Drakec, J. W. & García-Arenal,F. (2002). The Rate and Character of Spontaneous Mutation in an RNA Virus.

141Genetics, 162:1505—1511.
Martinez, M. ; Sanchis, J. & Blasco, X. (2006). Algoritmos genéticos aplicados al diseñode controladores robustos. Revista Iberoamericana de Automática e Informática In-dustrial, 3(1):39—51.
Miyamoto, S. (1997). Robust control design - a coprime factorization and LMI approach.PhD thesis, University of Cambridge.
Molina-Cristobal, A. (2005). Multi-objective control: linear matrix inequality techniquesand genetic algorithms approach. PhD thesis, University of Sheffield, UK.
Moscato, P. (1989). On evolution, search, optimization, genetic algorithms and martialarts: toward memetic algorithms. Technical report, Caltech Concurrent Computa-tion Program.
Murata, T. ; S.Kaige & Ishibuchi, H. (2003). Generalization of Dominance RelationBased Replacement Rules for Memetic EMO Algorithms. In Proceedings of the Ge-netic and Evolutionay Computation Conference, pp 1234—1245.
O’Dwyer, A. (2006). PI and PID controller tuning rules: an overview and personalperspective. In Proceedings of the IET Irish Signals and Systems Conference, pp161—166.
Osyczka, A. (1985). Multicriteria optimization for engineering design. Academic Press,Cambridge, MA.
Pareto, V. (1906). Manuale di economia politica. Societa Editrice Libraria, Milan, Italy.
Pedersen, G. (2005). Towards Automatic Controller Design using Multi-Objective Evo-lutionary Algorithms. PhD thesis, Department of Control Engineering. Aalborg Uni-versity, Denmark.
Popov, A. ; Farag, A. & Werner, H. (2005). Less Conservative Mixed H2/Hinf Con-trollerDesign UsingMulti-Objective Optimization. Technical report, Technische Uni-versitat Hamburg-Harburg.
Reyes, O. ; Sánchez, G. & Strefezza, M. (2009). Multiobjective GA fuzzy logic controller.In Proceedings of the ICINCO 2009 Conference. Milan, Italy, pp 384—389.
Rotea, M. & Khargonekar, P. (1991). H2-optimal Control with an Hinf-constraint: TheState Feedback Case. Automatica, 27(2):307—316.
Roy, B. (1971). Problems and methods with multiple objective functions. MathematicalProgramming, 1(2):239—266.
Sánchez, G. & Ferrer, J. (2004). A new approach for approximating the free transferfunction in Q-parametrization. In Proceedings of the IEEE Conference ComputerAided Control Systems Design.Taipei,Taiwan, pp 339—343.
Sánchez, G. ; Reyes, O. & Gonzalez, G. (2008a). Diseño de controladores PID multi-objetivo mediante algoritmos genéticos incluyendo el cálculo de los límites de laregión de controladores estabilizantes. In XIII Congreso Latinoamericano de ControlAutomático. 25-28 de Noviembre. Mérida. Venezuela.

142Sánchez, G. ; Reyes, O. & Strefezza, M. (2009). A Muti-objective Approach to Ap-
proximate the Stabilizing Region for Linear Control Systems. In Proceedings of theICINCO 2009 Conference. Milan, Italy, pp 153—158.
Sánchez, G. ; Villasana, M. & Strefezza, M. (2007). Multi-Objective Pole Placementwith Evolutionary Algorithms. Springer-Verlag. Berlin. Series: Lecture Notes inComputer Science, 4403:417—427.
Sánchez, G. ; Villasana, M. & Strefezza, M. (2008b). Solving Multi-Objective LinearControl Design Problems Using Genetic Algorithms. In Proceedings of the 17th IFACWorld Conference, pp 12324—12329.
Sasaki, D. ; Obayashi, S. & Nakahashi, K. (2002). Navier-Stokes optimization of super-sonics wings with four objectives using evolutionary algorithms. Journal of Aircraft,39(4):621—629.
Scherer, C. ; Gahinet, P. & Chilali, M. (1997). Multi-objective output-feedback controlvia LMI optimization. IEEE Transactions on Automatic Control, 42(7):896—910.
Schäffler, S. ; Schultz, R. & Weinzierl, K. (2002). A stochastic method for the solutionof unconstrained vector optimization problems. J. Optimization Theory Applicat.,114(1):209—222.
Schott, J. (1995). Fault tolerant design using single and multicriteria genetic algorithmoptimization. Master’s thesis, Department of Aeronautics and Astronautics, MIT.Cambridge, MA. USA.
Schütze, O. ; Sánchez, G. & Coello, C. A. C. (2008). A New Memetic Strategy forthe Numerical Treatment of Multi-Objective Optimization Problems. Genetic andEvolutionary Computation Conference. July 12-16 ,Atlanta, Georgia, USA.
Sharma, D. ; Kumar, A. ; Deb, K. & Sindhya, K. (2007). Hybridization of SBX basedNSGA-II and sequential quadratic programming for solving multi-objective opti-mization problems. In Proceedings of the IEEE Congress on Evolutionary Computa-tion, Singapore, pp 3003—3010.
Shyr, W.-J. ; Wang, B.-W. ; Yeh, Y.-Y. & Su, T.-J. (2002). Design of optimal PIDcontrollers using memetic algorithm. In Proceedings of the American Control Con-ference, pp 2130—2131.
Silva, V. ; Fleming, P. ; Sugimoto, J. & R.Yokoyama (2008). Multiobjective optimiza-tion using variable complexity modelling for control system design. Applied SoftComputing 8, pp 392—401.
Takahashi, R. ; Palhares, R. ; Dutra, D. & Goncalves, L. (2004). Estimation of Paretosets in the mixed H2/H∞ control problem. International Journal of System Science,35(1):55—67.
Tan, K. ; Khor, E. & Lee, T. (2005). Multiobjective evolutionary algorithms and appli-cations. Springer-Verlag.
Villasana, M. & Ochoa, G. (2003). Heuristic Design of Cancer Chemotherapies. IEEETransactions on Evolutionary Computation, Vol. 8, No. 6.

143Wang, J. ; Brackett, B. T. & Harley, R. G. (2009). Particle Swarm-Assisted State
Feedback Control: From Pole Selection to State Estimation. In Proceedings of theAmerican Control Conference.St. Louis, MO, USA. June 10-12, pp 1493—1498.
Wang, J. ; Wang, S. ; Wang, Z.-P. ; Tao, L. & Chen, J.-J. (2008). Robust controllerdesign for a main steam pressure based on SPEA2. Journal of Zhengzhou University.
Wanner, E. ; Guimaraes, F. ; Takahashi, H. & Fleming, P. (2006). A QuadraticApproximation-Based Local Search Procedure for Multiobjective Genetic Algo-rithms. In IEEE Congress on Evolutionary Computation. Vancouver, BC, Canada,pp 3361—3368.
Wanner, E. ; Guimaraes, F. ; Takahashi, R. & Fleming, P. (2008). Local search withquadratic approximations into memetic algorithms for optimization with multiplecriteria. Evolutionary Computation, 16(2):185—224.
Wolpert, D. & Macready, W. (1997). No free lunch theorems for optimization. IEEETransactions on Evolutinoary Computation, 1(1):67—82.
Zakian, V. & Al-Naib, V. (1973). Design of dynamical and control Systems by themethod of inequalities. Proceedings of the Institution of Electrical Engineers, pp1421—1427.
Zavala, J. ; Stewart, P. & Fleming, P. (2002). Multiobjective automotive drive by wirecontroller design. In Proceedings of the International Conference on Computer aidedControl System Design, Glasgow, Scotland, pp 69—73.
Ziegler, J. & Nichols, N. (1942). Optimum settings for automatic controllers. Transac-tions of ASME, pp 759—768.
Zitzler, E. (1999). Evolutionary algorithms for multiobjective optimization: methods andapplications. PhD thesis, Swiss Federal Institute of Technology. Zurich, Switzerland.
Zitzler, E. ; Deb, K. & Thiele, L. (1999). Comparison of Multiobjective EvolutionaryAlgorithms on Test Functions of Different Difficulty. In Wu, A. S., editor, Proceed-ings of the 1999 Genetic and Evolutionary Computation Conference, pp 121—122,Orlando, Florida.
Zitzler, E. ; Laumanns, M. & Thiele, L. (2001). SPEA2: improving the Strength ParetoEvolutionary Algorithm. Technical report, Computer Engineering and NetworksLaboratory - TIK,ETH Zurich.










![[prof.usb.ve]prof.usb.ve/jaller/CT6311/white_and_woodson.pdf2008-12-23 · [prof.usb.ve]](https://static.fdocuments.us/doc/165x107/5b1a95757f8b9a23258dbc91/profusbveprofusbvejallerct6311whiteand-profusbve.jpg)







