
UNIVERSIDAD PABLO DE OLAVIDE - eps.upo.eseps.upo.es/martinez/TFG/TFG_Luis_2015.pdf · 4.2. Minería...
97
UNIVERSIDAD PABLO DE OLAVIDE ESCUELA POLITÉCNICA SUPERIOR Grado en Ingeniería Informática en Sistemas de Información TRABAJO FIN DE GRADO Desarrollo de un algoritmo para la detección automática de patrones precursores de terremotos Autor: Luis Carlos Díaz Chamorro Tutor: Dr. Francisco Martínez Álvarez
Transcript of UNIVERSIDAD PABLO DE OLAVIDE - eps.upo.eseps.upo.es/martinez/TFG/TFG_Luis_2015.pdf · 4.2. Minería...

UNIVERSIDAD PABLO DE OLAVIDE
ESCUELA POLITÉCNICA SUPERIOR
Grado en Ingeniería Informática en Sistemas de Información
TRABAJO FIN DE GRADO
Desarrollo de un algoritmo para la detección automática de
patrones precursores de terremotos
Autor:
Luis Carlos Díaz Chamorro
Tutor:
Dr. Francisco Martínez Álvarez

1
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información

2
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Agradecimientos
Primeramente me gustaría decir que este año ha sido uno de los más difíciles de la
universidad, ya que no es tarea fácil llevar a cabo el proyecto fin de grado mientras estas
estudiando fuera de tu país, con otro idioma, otra cultura y otra forma de enseñanza. No
obstante esto no ha sido ningún impedimento para comunicarme con mi tutor, por ello
me gustaría empezar dándole las gracias a mi tutor Dr.Francisco Martínez Álvarez, por
su ayuda y dedicación durante el desarrollo de todo el proyecto y por ofrecerme esta
oportunidad de realizar un proyecto tan importante.
A continuación, me gustaría dedicarle mi sincero agradecimiento a Daniel Muñiz Amian
por su colaboración en el trabajo fin de grado. También me gustaría dedicarle mi sincero
agradecimiento a Aurelio López Fernández, puesto que gracias a él y a Daniel Muñiz
hemos formado un grupo de estudio increíble, con una coordinación inmejorable y una
motivación impresionante, sin olvidar siempre el buen humor, optimismo y amabilidad
que nos ha llevado a ser grandes amigos de forma incondicional.
A mi familia, por su apoyo incondicional y por animarme a entrar en la universidad, ya
que pude aprender de ellos que si quieres conseguir algo, solo tienes que confiar en ti
mismo y no rendirte nunca, no hay nada imposible.
A mis amigos, puesto que gracias a su comprensión y cariño, han sido el hombro donde
apoyarme cuando las cosas salían mal.
A los profesores de la universidad, por su dedicación en la enseñanza, que aprendí de
ellos que no importa lo difícil que sea una asignatura, porque con esfuerzo y
compañerismo se puede aprobar e incluso sacar matrícula de honor.
A todas las personas que han pasado por mi vida, puesto que gracias a ellos he aprendido
algo de cada uno que me ha hecho ser mejor persona de forma profesional y/o personal.
Gracias, de corazón, a todos vosotros.

3
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información

4
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Índice de contenido 1. Introducción ............................................................................................................. 7
1.1. Motivación ................................................................................................................... 7
1.2. Objetivos ...................................................................................................................... 8
2. Estado del arte ....................................................................................................... 10
2.1. Resumen ..................................................................................................................... 10
2.2. Introducción ............................................................................................................... 11
2.3. Modelos de procesos físicos ...................................................................................... 13
2.4. Modelos de sismicidad arreglados ........................................................................... 19
2.5. Conclusiones .............................................................................................................. 25
3. Descubrimiento de conocimiento a partir de grandes bases de datos (KDD).. 27
3.1. Introducción ............................................................................................................... 27
3.2. Adquisición de datos ................................................................................................. 29
3.3. Preprocesamiento y transformación ........................................................................ 30
3.4. Minería de datos ........................................................................................................ 31
3.5. Evaluación .................................................................................................................. 43
3.6. Interpretación ............................................................................................................ 44
4. Desarrollo de una metodología para la detección de patrones precursores de
terremotos...................................................................................................................... 45
4.1. Preprocesamiento y transformación ........................................................................ 45
4.1.1. Filtrado ............................................................................................................... 45
4.1.2. Clustering ........................................................................................................... 45
4.2. Minería de datos ........................................................................................................ 46
4.2.1. Filtrado ............................................................................................................... 47
4.2.2. Clustering ........................................................................................................... 50
4.2.3. Estadísticas ......................................................................................................... 51
5. Interfaz gráfica y resultados ................................................................................ 61
5.1. Interfaz gráfica .......................................................................................................... 61
5.1.1. Modo automático ............................................................................................... 61
5.1.2. Modo manual ..................................................................................................... 65
5.2. Resultados .................................................................................................................. 68
5.2.1. Resultados Talca ................................................................................................ 68
5.2.2. Resultados Pichilemu ........................................................................................ 69
5.2.3. Resultados Santiago .......................................................................................... 71
5.2.4. Resultados Valparaíso ....................................................................................... 72
6. Conclusión .............................................................................................................. 74

5
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
6.1. Conocimientos aplicados de las asignaturas ........................................................... 76
7. Referencias ............................................................................................................. 78

6
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Índice de Figuras
Figura 1: Proceso de negocio.......................................................................................... 46
Figura 2: Organización de los atributos del archivo ARFF ............................................ 47
Figura 3: Seleccionamos los atributos necesarios .......................................................... 48
Figura 4: Seleccionamos los datos necesarios y los agrupamos ..................................... 49
Figura 5: Archivo ARFF ya clusterizado ....................................................................... 51
Figura 6: Extraer resultados del archivo ARFF .............................................................. 52
Figura 7: [Combinación] aciertos / ocurrencias ........................................................ 52
Figura 8: Montar los árboles ........................................................................................... 53
Figura 9: Cálculo de valores (I) ...................................................................................... 53
Figura 10: Cálculo de valores (II) .................................................................................. 54
Figura 11: Elegir mejores nodos (I) ................................................................................ 54
Figura 12: Elegir mejores nodos (II) .............................................................................. 55
Figura 13: Conjunto de combinaciones de W seleccionado ........................................... 60
Figura 14: Elegir modo ................................................................................................... 61
Figura 15: Modo automático – parte 1 ........................................................................... 61
Figura 16: Modo automático – parte 2 ........................................................................... 62
Figura 17: Modo simple de visualizado ......................................................................... 63
Figura 18: Modo complejo de visualizado ..................................................................... 64
Figura 19: Modo complejo. Filtrado............................................................................... 65
Figura 20: Modo complejo. Clusterizado ....................................................................... 65
Figura 21: Modo complejo. Estadísticas ........................................................................ 66
Figura 22: Modo complejo. Predicciones ....................................................................... 67
Figura 23: Resultados Talca ........................................................................................... 68
Figura 24: Resultados Pichilemu .................................................................................... 69
Figura 25: Resultados Santiago ...................................................................................... 71
Figura 26: Resultados Valparaíso ................................................................................... 72
Índice de tablas
Tabla 1: Conocimientos aplicados de las asignaturas de primer curso .......................... 76
Tabla 2: Conocimientos aplicados de las asignaturas de segundo curso ........................ 76
Tabla 3: Conocimientos aplicados de las asignaturas de tercer curso ............................ 77
Tabla 4: Conocimientos aplicados de las asignaturas de cuarto curso ........................... 77

7
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
1. Introducción
La Real Academia de la Lengua Española (RAE) define literalmente a los terremotos
como “sacudida del terreno, ocasionada por fuerzas que actúan en lo interior del globo”
Esta definición aunque no es completa, pero define a grandes rasgos a tal sorprende
evento. El estudio de seísmo es muy antiguo y se han registrado durante años, pero que
se registre no quiere decir que se comprendieran.
Actualmente se utiliza estos datos registrados para comprender el comportamiento de los
terremotos y de esta forma poder predecir con casi total seguridad cuando va a ocurrir
uno y de que magnitud podría ser, gracias a esto se podría ahorrar muchas muertes por
seísmos ya que al anticiparnos nos permite tener un margen de tiempo para prepararnos.
Las consecuencias de los terremotos están asociadas a los grados de intensidad en la
escala de Richter. Cada año aproximadamente se producen 300000 seísmos en toda la
superficie con escalas entre 2 y 2,9 grados. Los terremotos de mayor intensidad de
aproximadamente 8 grados se producen en períodos que oscilan entre 5 y 10 años.
- Menos de 3,5 grados: terremoto que se pueden registrar, pero difícil de percibir,
en este caso no causa daño.
- 3,5 a 5,4 grados: el temblor se puede percibir, pero es poco probable que cause
destrucción.
- Menos de 6,0 grados: terremoto capaz de producir daños graves a los edificios
pequeños o edificios de pobre calidad y daños leves al resto de edificios.
- 6,1 a 6,9 grados: desprende una cantidad de energía que puede crear el caos y
daños en un área de 100 km alrededor del epicentro.
- 7 a 7,9 grados: energía de alto potencial en libertad que puede afectar a los
cimientos de edificios y causar grietas en la superficie, dañando los sistemas de
agua y alcantarillado que están bajo tierra y produciendo su ruptura.
- 8 a 8,5 grados: temblor grande de lo que se deriva una gran destrucción en los
edificios en general y puentes en ruinas donde casi ninguna construcción es capaz
de soportar la energía liberada.
- 9 grados: destrucción total.
- 12 grados: (hipotéticamente) podría romper la Tierra por la mitad.
1.1. Motivación
Debido a la gran cantidad de muertes y accidentes que provocan los desastres naturales,
me he centrado en los terremotos. En concreto, he seleccionado la zona de Chile puesto
que es uno de los países con mayor actividad sísmica a nivel mundial. Pero ¿por qué
sucede en Chile?
Esto es debido a que se encuentra sobre una placa relativamente joven, en donde es más
probable que se den movimientos fuertes como ahí se han dado, recordemos, que en Chile
es donde ha registrado el terremoto de mayor magnitud.

8
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Por este motivo he elegido a Francisco Martínez como tutor, ya que es la persona más
adecuada para orientarme y ayudarme a desarrollar este proyecto debido a su trayectoria
profesional en el campo de la minería de datos aplicada a la geofísica.
Debido a la gran cantidad de información que se puede obtener hoy en día de numerosas
bases de datos, resulta imprescindible la utilización de herramientas de procesado
automático de datos. En ese sentido, el desarrollo de algoritmos avanzados y complejos
ha sido siempre uno de los puntos que más me atraían del Grado en Ingeniería Informática
en Sistemas de Información que estoy cursando. La motivación, por tanto, es la de
desarrollar un algoritmo eficiente y eficaz para el procesado automático de datos de origen
sísmico.
1.2. Objetivos
Hoy en día, se cuenta con grandes cantidades de información almacenadas, pero ¿cómo
extraer alguna conclusión de esos datos? ¿Siguen algún patrón? ¿Es posible predecirlos?
Actualmente, debido a los avances científicos en todos los campos, se ha podido explicar
detalladamente el origen de estos sorprendentes fenómenos, los terremotos, registrando
todo tipo de información acerca de ellos.
Es en este punto donde se centra el objeto de este estudio. Con la ayudad de técnicas
estadísticas, inteligencia artificial e informática, se intentará dar una respuesta en este
campo.
Como se explicará más detalladamente más adelante, se va a seguir la metodología
Knowledge Discovery in Databases (KDD). Este proceso consiste en el descubrimiento
de existencia de información valiosa pero desconocida con anterioridad. Consta de varias
fases, como son la adquisición de datos, preprocesamiento y transformación, minería de
datos, evaluación e interpretación.
Se ha escogido Chile debido a que es considerado uno de los países más activos, en
términos sísmicos, debido en gran parte por su ubicación en el Cinturón de fuego del
Pacífico. Se le llama así por encontrarse el territorio continental junto a la zona de
subducción de la placa de Nazca, bajo la placa Sudamericana, mientras que al sur, la
subducción se produce por la placa Antártica que se mueve a menor velocidad.
Se han obtenido datos sobre las cuatro ciudades más activas y con más población en riesgo
de Chile, que son:
- Santiago.
- Valparaíso.
- Talca.
- Pichilemu.
Dichos datos son unos históricos que reúnen ciertas características sobre los terremotos
que han ocurrido a lo largo de un periodo.

9
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
El software que he desarrollado puede obtener información valiosa a partir de dichos
datos, pudiendo establecer un patrón y por consiguiente intentar predecir terremotos.
Dicho software se ha realizado con lenguaje de programación Java y la biblioteca gráfica
para java, llamada Swing. Swing incluye widgets para interfaz gráfica de usuario tales
como cajas de texto, botones, desplegables, tablas,… De este modo su uso es más fácil e
intuitivo.
Por tanto, los objetivos de este trabajo se pueden resumir en:
1. Desarrollo de un algoritmo eficiente y eficaz, capaz de descubrir patrones
precursores de terremotos.
2. Diseño de un software de fácil uso para diseminar la aplicación, que incluya una
interfaz gráfica amigable.
3. Aplicación de técnicas de minería de datos para la fácil interpretación y
evaluación de los resultados.

10
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
2. Estado del arte
2.1. Resumen
Los sistemas de terremotos de fallas interactúan sobre un amplio espectro de escalas
espaciales y temporales, y en años recientes, estudios sobre la sismicidad regional en una
gran variedad de regiones han producido un gran número de nuevas técnicas para la
predicción de seísmos basados en la sismicidad. A pesar de que una gran variedad de
supuestos físicos y aproximaciones científicas son incorporados en varias metodologías,
todos ellos se esfuerzan en replicar con precisión las estadísticas y propiedades de los
registros sísmicos históricos e instrumentales. Como resultado, los últimos diez años han
visto progresos significativos en el campo de la predicción de terremotos basados en la
sismicidad a medio y corto plazo. Estos incluyen acuerdos generales en la necesidad de
tests prospectivos e intentos de éxito para estandarizar los métodos de evaluación y la
apropiada hipótesis nula.
Aquí diferenciamos los enfoques predominantes en los modelos basados en técnicas para
identificar procesos físicos y aquellas que filtran o arreglan/suavizan la sismicidad. La
comparación de los métodos sugiere que mientras los modelos sísmicos
arreglados/suavizados proporcionan mejor capacidad de predicción en periodos de
tiempo más largos, se logra una mayor probabilidad durante periodos de tiempo más
cortos con métodos que integran técnicas estadísticas con el conocimiento de los procesos
físicos, tales como el modelo de secuencia de réplica de tipo epidémico (ETAS del inglés
epidemic-type aftershock sequence) o los relacionados con cambios en la variable b, por
ejemplo. En general, mientras ambas clases de predicción basados en sismicidad están
limitadas por el relativamente corto periodo de tiempo disponible para el catálogo
instrumental, se han hecho importantes avances en nuestra comprensión de las
limitaciones y el potencial de la predicción de terremotos basados en la sismicidad.
Existe un acuerdo general entre predicciones a corto plazo, entendiéndose esto como días
o semanas, y predicciones a largo plazo sobre periodos de entre 5 a 10 años. Este progreso
reciente sirve para iluminar la naturaleza crítica de las diferentes escalas temporales
intrínsecas al proceso de los terremotos y la importancia de datos sísmicos de alta calidad
para la correcta cuantificación del peligro sísmico en función del tiempo.

11
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
2.2. Introducción
El impacto que los grandes terremotos causan para la vida y la propiedad es
potencialmente catastrófico. En 2010, el seísmo de magnitud 7.0 en Haití, fue el quinto
más mortal registrado, matando a más de 200.000 personas y causando daños valorados
en unos 8 billones de dólares (Cavallo et al., 2010). El daño económico directo del
terremoto de magnitud 8.8 que sacudió Chile en febrero de 2010 alcanzó unos 30 billones
de dólares, o lo que es lo mismo, el 18% de la producción económica anual de Chile
(Kovacs, 2010). Como resultado del impacto regional y nacional de grandes terremotos,
las investigaciones en sus predicciones se han realizado desde hace casi 100 años, con
intervalos marcados por el optimismo, el escepticismo y el realismo (Geller et al., 1997;
Jordan, 2006; Kanamori, 1981; Wyss, 1997).
Hace más de diez años, esta controversia eclosionó en lo que ha llegado a ser conocido
en la comunidad como debates sobre la naturaleza (Main, 1999b).
Provocado en gran medida por la aparente falta de éxito del experimento predictivo de
Parkfield (Bakun et al., 2005), se centró en última instancia en la naturaleza de los propios
terremotos y si podrían ser intrínsecamente impredecibles. Si bien esta cuestión aún no
se ha decidido, marcó un punto de inflexión en el campo de la ciencia de los terremotos.
Tal es así que la predicción de seísmos hoy día, o la evaluación del peligro sísmico en
función del tiempo, con errores y probabilidades asociados, es ahora el estándar en la
investigación predictiva de terremotos.
Al mismo tiempo, una gran cantidad de datos sísmicos a niveles de magnitud
progresivamente más pequeños, han sido registrados durante los últimos 40 años. En parte
relacionado con el objetivo original de esfuerzos tales como el experimento de Parkfield
y en parte por el reconocimiento de que hay todavía mucho que aprender sobre el proceso
subyacente, particularmente después de que la predicción de Parkfield pasará sin ningún
terremoto (Bakun et al., 2005).
Si bien se ha reconocido desde hace tiempo que la agrupación temporal y espacial es
evidente en los datos sísmicos, muchas de las investigaciones asociadas con estos
patrones en los primeros años se centraron en una fracción relativamente pequeña de los
eventos principalmente en las magnitudes más grandes (Kanamori, 1981).
Aunque este cuerpo de la investigación representa importantes intentos para describir
estos patrones característicos usando funciones de densidad de probabilidad empírica, se
vio obstaculizado por las pobres estadísticas asociadas con el pequeño número de eventos
moderados a grandes, ya sea disponible o considerado para el análisis.
La disponibilidad de nuevos y más grandes conjuntos de datos junto con los avances
computacionales que facilitaban el análisis de complejas series temporales, incluyendo
simulaciones, pruebas estadísticos rigurosos y técnicas de filtrado innovadoras, dieron un
nuevo impulso a la predicción de terremotos cuando el campo fue aparentemente
polarizado por el tema (Nature Debates, Debate on earthquake forecasting,
http://www.nature.com/nature/debates/earthquake, Main, 1999b; Jordan, 2006).
En 2002, se publicó la primera predicción prospectiva usando datos de terremotos de baja
magnitud (Rundle et al., 2002). Este hecho fue seguido por un renovado interés en

12
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
metodologías basadas en la sismicidad y generaron nuevos esfuerzos para lograr una
mejor definición y pruebas de estas técnicas.
Iniciativas importantes en la validación y en el área de pruebas de la predicción de
terremotos incluyen el grupo de trabajo en modelos de probabilidad de seísmos regional
(RELM del inglés Regional Earthquake Likelihood Models) así como The Collaboratory
on the Study of Earthquake Predictability (CSEP) ambos fundados después del 2.000
(Field, 2007; Gerstenberger and Rhoades, 2010; Zechar et al., 2010).
Aunque una serie de fenómenos precursores potenciales existen además de los asociados
con cambios en la seismicidad, incluyendo precursores de inclinaciones y tensiones,
señales electromagnéticas, fenómenos hidrológicos y emisiones químicas (Scholz, 2002;
Turcotte, 1991), limitamos el análisis a las técnicas predominantes en la predicción
basadas en la seismicidad activamente investigada en los últimos 10 años.
Algunos métodos no analizados aquí incluyen técnicas de predicción asociadas con
interacciones de terremotos como las precursoras a los cambios de velocidad sísmica (por
ejemplo, Crampin and Gao, 2010) o estudios de transferencias de tensión (ver King et al.,
1994; Stein, 1999; y otros).
Aquí se revisa el estado actual de las metodologías de predicción basados en sismicidad
y el progreso realizado en el campo desde el debate de la naturaleza de 1999.
Para no alargar este trabajo en demasía, se limitará el análisis a las metodologías que
dependen del catálogo instrumental para su fuente de datos, el cual intenta producir
predicciones que son limitadas en tiempo y espacio de alguna manera cuantificable.
Como resultado, estos métodos principalmente producen predicciones a medio plazo, en
el sentido de años, aunque se incluye un pequeño subconjunto que se basa en estadísticas
de réplicas para generar predicciones a corto plazo del orden de días. Existen Debates
importantes en otra parte del estándar apropiado para suministrar una previsión de
terremotos comprobable (Jackson and Kagan, 2006; Jordan, 2006), así como la eficacia
de varias metodologías de pruebas de predicciones y su evaluación (por ejemplo, Field,
2007; Gerstenbergerand Rhoades, 2010; Schorlemmer et al., 2007; Vere-Jones, 1995;
Zechar, et al., 2010).
Si bien no hay ningún intento aquí para comprobar la fiabilidad de estas técnicas de
predicción entre ellas o contra una hipótesis nula en particular con estadísticas rigurosas,
en algunos casos se hacen intentos para comparar ya sea una hipótesis nula de Poisson o
una hipótesis nula que incluya la agrupación espacial y temporal como en el caso del
modelo de predicción de la intensidad relativa (RI del inglés relative intensity) (Holliday
et al., 2005) o el modelo de ETAS (por ejemplo Vere-Jones, 1995). Se discutirá
brevemente dichos esfuerzos o la falta de estos, particularmente en aquellos caso donde
el método no ha sido presentado formalmente para evaluaciones independientes.
Se han separado los métodos discutidos aquí en dos categorías diferentes, aunque hay
algunos solapamientos inevitables. Este trabajo comienza con una revisión del conjunto
de metodologías de predicción basadas en sismicidad, cada una asumiendo un mecanismo
físico en particular, que está asociado con la generación de grandes terremotos y sus
precursores y realiza un análisis detallado en el catálogo instrumental con el objetivo de

13
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
aislar dichos precursores. Se designan estos "modelos de proceso físicos". En este
subconjunto también se incluyen dos técnicas que caen ligeramente fuera de los
parámetros descritos anteriormente, la hipótesis de terremotos característica y la hipótesis
de liberación del momento acelerado (ARM del inglés accelerated moment release).
Si bien ambas usan un subconjunto relativamente pequeño de grandes eventos y no están
formulados de manera óptima para producir predicciones limitadas temporal y
espacialmente, su innegable impacto en la comunidad de predicción de terremotos obliga
a su inclusión aquí.
En la sección 2.4 se detalla la evolución y el estado actual de los modelos sísmicos
suavizados. Estos modelos principalmente se aplican a series de técnicas de filtrado,
normalmente basados en conocimientos o supuestos sobre estadísticas de terremotos o en
datos del catálogo sísmico con el objetivo de predecir en escalas de tiempo pequeñas y
medianas. Se concluye con un corto debate sobre las limitaciones y futuras perspectivas
de las herramientas de predicción basadas en la sismicidad.
2.3. Modelos de procesos físicos
Los modelos de procesos físicos son aquellos en los que el proceso preliminar se basa en
uno o más mecanismos o fenómenos físicos asociados con la generación de grandes
eventos. Un análisis detallado, normalmente pero no siempre estadístico, se lleva a cabo
en la sismicidad instrumental con el fin de aislar estos precursores.
Estas técnicas están basadas en las suposiciones de que la sismicidad actúa como un
sensor para el proceso físico subyacente y puede proporcionar información sobre la
naturaleza espacial y temporal del proceso. Cabe señalar que si bien la clasificación de
una fuente física y potencialmente verificable para el proceso de generación de un
terremoto es una característica atractiva de estas metodologías, diferenciar entre la fuente
y las variaciones sutiles de los fenómenos sísmicos es difícil. Como resultado, muchas de
estas técnicas se basan en reconocimiento de patrones o en metodologías estadísticas para
aislar la señal espacio-temporal. Una comprensión completa de sus éxitos y fracasos
relativos es a menudo oscurecida por la complicada naturaleza del análisis, las hipótesis
de simplificación del modelo físico y la heterogeneidad que existe en el mundo real.
Se discutirá estos modelos de proceso físicos que han tenido los mayores impactos en la
materia y son parte de las investigaciones sobre predicción actuales que emplean
catálogos de alta calidad de regiones sísmicas activas.
2.3.1. Liberación del momento de aceleración (AMR)
Las activaciones sísmicas precursoras, o también llamada actividad de sismos iniciales,
han sido observadas antes de un serie de grandes eventos por todo el mundo (Bakun et
al., 2005;Ellsworth et al., 1981; Jones and Molnar, 1979; Jordan and Jones, 2010;
Rikitake, 1976; Sykes and Jaumé, 1990). El método aplicado más extendido para analizar
estos aumentos de precursores en la sismicidad son conocidos como análisis de tiempo
hasta el fallo, liberación del momento sísmico de aceleración (ASMR del inglés

14
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
accelerating seismic moment release) o liberación del momento de aceleración (AMR del
inglés accelerating moment release) (Ben-Zion and Lyakhovsky, 2002;Bowman and
King, 2001; Bowman et al., 1998; Brehm and Braile, 1998; Bufe and Varnes, 1993; Jaumé
and Sykes, 1999; Mignan, 2008; Robinson, 2000; Turcotte et al., 2003; entre otros).Si
bien, en general, el ARM se encuentra fuera del alcance general de esta revisión debido
a que usa sólo una fracción relativamente pequeña del catálogo instrumental en sus
análisis, y su periodo de tiempo previsto está definido pobremente y normalmente a largo
plazo, es incluido aquí debido a la importante influencia que ha tenido en la disciplina así
como su potencial para la incorporación en metodologías de predicción en curso.
2.3.2. Terremotos característicos
A pesar de que la hipótesis de terremotos característico también se encuentra fuera de los
parámetros de estudio de esta revisión, como se ha resaltado antes, su amplio impacto de
propagación en la comunidad de predicción basado en sismicidad y los modelos de riesgo
en curso sobre los últimos 20 años merecen que se incluya aquí.
La duración de los terremotos característicos fue acuñada por Schwartz et al. (1981) y
detallado en Schwartz and Coppersmith (1984), pero el concepto es una extensión de los
primeros trabajos de Reid (1910). Como se ha señalado en la anterior sección, la teoría
de rebote elástico plantea la hipótesis de que un gran terremoto libera la mayoría de su
tensión acumulada en un segmento de una falla dada y que el siguiente seísmo ocurre
después de que la tensión se acumule hasta que es restaurada a un nivel que da como
resultado una ruptura de nuevo. Aquí, el modelo de terremotos característico supone que
las fallas tienden a generar seísmos del mismo tamaño sobre un rango muy estrecho de
magnitudes en las zonas de ruptura o segmentos que son similares en localización y
extensión espacial (Ellsworth and Cole, 1997; Parsons and Geist, 2009; Schwartz and
Coppersmith, 1984; Schwartz et al., 1981; Wesnousky, 1994). La hipótesis conduce a la
predicción de eventos específicos con un tamaño de dimensión de ruptura similar a los
terremotos más grandes (magnitudes entre 6.5 y 9). El modelo es atractivo porque ajusta
observaciones históricas y empíricas en los niveles más básicos, por ejemplo, los grandes
terremotos tienden a ocurrir donde han ocurrido en el pasado (Allen, 1968; Davison and
Scholz, 1985; Frankel et al., 2002; Kafka, 2002; Petersen et al., 2007). De nuevo, esto
método particular difiere de los principales métodos discutidos en otra parte en este
artículo en el que no se utilizan catálogos sísmicos recientes, incluyendo los eventos de
tamaño pequeño-mediano, para cuantificar peligros de sismicidad a medio plazo. En vez
de eso, se basa en eventos históricos de magnitudes entre 5 a 6 y superiores, y el evento
más grande desde los estudios paleosísmicos (Wesnousky, 1994). Los estudios
paleosísmicos (Anderson et al., 1989; Arrowsmith et al., 1997; Biasi and Weldon, 2006;
Biasi et al., 2002; Grant and Shearer, 2004; Grant and Sieh, 1994; Lienkaemper, 2001;
Lienkaemper and Prescott, 1989; Matsu'ura and Kase, 2010; Pantosti et al., 2008;
Rockwell et al., 2003; Sieh, 1984; Sieh et al., 1989;Weldon et al., 2004, entre otros)
proporcionan información detallada del desplazamiento, área de ruptura e intervalos de
recurrencia para la inclusión en el modelo de terremotos característico (Parsons and Geist,
2009; Schwartz and Coppersmith, 1984; Wallace, 1970; Wesnousky, 1994).

15
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
2.3.3. Variaciones en el valor b
Debido a la relevancia que este valor tiene para el desarrollo del algoritmo propuesto en
este Trabajo Fin de Grado, se hará un poco más de hincapié en esta sección.
Variaciones en el valor b, o pendiente de la relación de distribución de magnitud y
frecuencia GR para terremotos, han sido estudiadas intensamente a lo largo de los últimos
20 años (Cao et al., 1996; Frohlich and Davis, 1993; Gerstenberger et al., 2001; Gutenberg
and Richter, 1944; Imoto, 1991; Imoto et al., 1990; Ogata and Katsura, 1993;
Schorlemmer et al., 2004a; Wiemer and Benoit, 1996; Wiemer and Schorlemmer, 2007;
Wiemer andWyss, 1997, 2002;Wiemer et al., 1998;Wyss andWiemer, 2000 entre otros)
Para una revisión más completa de los recientes investigaciones en la variaciones del
valor b, ver Wiemer andWyss (2002). En general, este trabajo demuestra que el valor b
es altamente heterogéneo en el espacio y en el tiempo y en una amplia variedad de escalas
(Schorlemmer etal., 2004a; Wiemer and Schorlemmer, 2007; Wiemer and Wyss, 2002).
Estas variaciones tienen importantes implicaciones para peligros sísmicos porque las
valoraciones de peligro sísmico probabilístico regional (PSHA del inglés probabilistic
seismic hazard assessment) son realizadas comúnmente usando la distribución de
frecuencia-magnitud de GR, particularmente en áreas de sismicidad dispersa (Field,
2007;Wiemer and Schorlemmer, 2007;Wiemer et al., 2009). Sin embargo, el principal
objetivo de este estudio será las implicaciones de cambios en el valor b, que están
asociados potencialmente con futuros grandes eventos, y la investigación asociada en la
predicción del valor b.
Algunos trabajos recientes basados en valores b regionales han dado como resultado dos
importantes conclusiones. La primera, que el valor de b varía con el mecanismo de falla.
El valor b para eventos de empuje es más pequeño (~ 0,7) mientras que la de los eventos
de desgarre es intermedia (~ 0,9) y es mayor para eventos normales (~ 1.1). Esta relación
es inversamente proporcional a la tensión media en cada régimen (Schorlemmer et al.,
2005; Gulia and Wiemer, 2010)confirmó este resultado para la sismicidad regional en
Italia. En segundo lugar, investigaciones relacionadas sugieren que los parches
bloqueados en fallas, o asperezas, se caracterizan por valores de b bajos, mientras que las
fallas de arrastre tienen mayores valores de b (Schorlemmer et al., 2004b; Wiemer and
Wyss, 1994, 1997, 2002). En su conjunto, esto sugiere que el cambio en el valor b puede
ser usado como un sensor de tensión, localizando áreas de acumulación de tensión grande
o baja, particularmente hacia el fin del ciclo sísmico, y cuantificable en un modelo de
predicción de terremotos regional (Gulia and Wiemer, 2010;Latchman et al., 2008;
Schorlemmer et al., 2005).Esta hipótesis es apoyada por los resultados en laboratorio para
emisiones acústicas. Estas mostraron que el valor de b es sensible tanto a la
heterogeneidad de la tensión (Scholz, 1968) como a la del material (Mogi, 1967) en
primera instancia, y a la intensidad de la tensión normalizada por la resistencia a la
fractura en segunda instancia (Sammonds et al., 1992). La intensidad de la tensión es
proporcional a la tensión efectiva (Sammonds et al., 1992) y la raíz cuadrada de la
longitud de formar un núcleo (nucleating) de la fractura, de tal manera que los materiales
heterogéneos tienden a estar juntos, confirmando la relación entre tensión, heterogeneidad
y el valor b.

16
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Muchas de las referencias anteriores debaten incrementos en el riesgo sísmico asociado
con valores de b bajos (por ejemplo Westerhaus et al., 2002) y formulan mapas de
variaciones del valor b para grandes eventos. Sin embargo, algunos trabajos recientes se
han centrado en formular predicciones probabilísticas predictivas usando variaciones del
valor b. Schorlemmer et al. (2005) estudió las variaciones del valor b a lo largo del
segmento de Parkfield de San Andrés, y produjo retrospectiva de periodos de 5 años por
la extrapolación de la distribución GR con valores de b variantes espacialmente sobre
pequeños volúmenes. Wiemer and Schorlemmer (2007) desarrolló el modelo de
probabilidad basado en aspereza (ALM del inglés asperity-based likelihood model) para
California y se lo pasó a la web de pruebas de predicciones RELM. En esta versión,
analizaban los catálogos sísmicos para California para la magnitud mínima de integridad
y una profundidad de 30 km. Debido a que los cálculos del valor b deben alcanzar de 5 a
20 km, dependiendo de la velocidad de actividad, se calculan dos modelos. El primero
es un modelo local, y el segundo es un modelo regional. El ajuste del valor b es calculado
desde una puntuación probable (Aki, 1965) y entonces los dos modelos son comparados
con el Criterio de información Akaike corregido, AIC (Akaike, 1974; Burnham and
Anderson, 2002; Kenneth et al., 2002). La puntuación más baja de AIC es el mejor
modelo. Se realiza una búsqueda variando el tamaño de regiones locales y comparándolas
con el valor AIC regional. La localización con los radios más pequeños donde el modelo
del valor b local puntúa un AIC más bajo es usado para computar la distribución para la
sismicidad en la región. Una vez que una distribución de magnitud-frecuencia es
determinada para cada localización, la tasa anual de eventos en cada magnitud encontrada
de 5.0≤M≤9.0 puede ser calculada para la predicción (Wiemer and Schorlemmer, 2007).
Gulia et al., 2010 proporcionó una predicción ALM para Italia en CSEP
(CSEP,www.cseptesting.org). La metodología fue similar a aquella de Wiemer and
Schorlemmer (2007), más arriba, excepto que la magnitud de valores de integridad fueron
arreglados usando un núcleo Gaussiano. Además, dos predicciones modificadas fueron
creados desde ALM: en el modelo ALM.IT, el catálogo de entrada es desagrupado para
M≥2 y un filtro Gaussiano es aplicado en una base de nodo antes del cálculo del valor de
a en la distribución magnitud-frecuencia.
En la versión HALM, el modelo fue modificado de modo que la región fue fraccionada
en ocho subregiones sobre provincias tectónicas, y esto fue usado para el modelo global,
dependiendo de la localización de cada nodo. Las investigaciones a largo plazo en las
estadísticas del valor b proporcionan fuertes evidencias de que ocurren variaciones
persistentes que están correlacionadas con el campo de tensión heterogéneo en zonas de
fallas principales. Los continuos esfuerzos han dado como resultado predicciones
testeables para ocurrencias sísmicas y proporcionan evidencia tranquilizadora de que los
precursores de sismicidad pueden ser traducidos a mapas de peligro dependientes del
tiempo.
2.3.4. La familia de algoritmos M8
El algoritmo M8 (Keilis-Borok and Kossobokov, 1990; Keilis-Borok et al., 1990;
Kossobokov, 2006a,b; Kossobokov et al., 1999, 2000, 2002; Latoussakis and
Kossobokov, 1990; Peresan et al., 2005 fue desarrollado aproximadamente hace 30 años
con el fin de localizar regiones de mayor probabilidad de ocurrencia de terremoto en el

17
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
espacio y el tiempo. Modificado en los años siguientes, el algoritmo actual calcula siete
series de tiempo, desde pequeños terremotos, ~ M4, para una región especifica de
investigación que es una función del tamaño del terremoto que va a ser pronosticado.
Los valores de estas series de tiempo son usados para tomar una decisión de si invocar
un "tiempo de probabilidad aumentada" o TIP (del inglés time of increased probability),
para un gran evento de aproximadamente M6,5-8 (Kossobokov et al., 1999).
2.3.5. RTL
El RTL es un método estadístico en el cual tres parámetros relacionados con terremotos
(tiempo, lugar y magnitud) son incluidos en un coeficiente ponderado (Sobolev and
Tyupkin, 1997, 1999). El algoritmo combina la distancia, tiempo y longitud de ruptura
de sismicidad agrupada en una medida combinada. La designación de Region-Time-
Lenght (RTL) surge por la región (en inglés Region) (distancia al epicentro), el intervalo
de tiempo (en inglés Time) y la longitud (en inglés Length) (tamaño de ruptura, por
ejemplo la magnitud). El algoritmo RTL es un método estadístico para investigar cambios
de sismicidad previos a grandes eventos. Estos cambios ocurren sobre regiones del orden
de 100 km, y unos pocos años antes de grandes eventos (Mignan and Di Giovambattista,
2008).
2.3.6. LURR
La tasa de respuesta de carga y descarga (LURR del inglés Load-Unload Response
Ration) originalmente fue propuesta para medir el cambio energético sísmico en los
meses y años anteriores a un gran evento de modo que podría ser usado como un
vaticinador de terremotos (Yin et al., 1995).
La idea física es que, cuando la corteza está cercana a la inestabilidad, más energía es
liberada en el periodo de carga que en el periodo de descarga. Si uno puede medir la tasa
entre periodos conocidos de carga y descarga, entonces puede ser derivada una medida
que determine con precisión tiempos y lugares de alta liberación de energía como un
precursor potencial. Aunque la fuerza de marea de capacidad de desencadenante de
terremoto sigue siendo controvertido, estudios en años recientes han sugerido que es un
efecto medible, al menos en ciertas regiones. Ciertamente, se espera que tensiones de
marea afecten a grandes cortezas terrestre (Cochran et al., 2004; Lockner and Beeler,
1999; Rydelek et al., 1992; Smith and Sammis, 2004; Tanaka, 2010; Tanaka et al., 2002;
Vidale et al., 1998, y otros). En el caso de LURR, la naturaleza cíclica de las tensiones de
marea se plantea como hipótesis para imponer carga y descarga en la corteza que
corresponde con valores positivos o negativos de la tensión de fallo Coulomb de marea
(CFS del inglés Coulomb Faiulure Stresses). En LURR periodos de carga y descarga son
identificados basados en la marea terrestre induciendo perturbaciones en el CFS de
manera óptima en fallas orientadas. (Feng et al., 2008; Mora et al., 2002; Peng et al.,
2006; Wang et al., 2004a,b; Yin and Mora, 2006; Yin et al., 1995, 2000, 2006, 2008a,b,
2010; Yu and Zhu, 2010; Yu et al., 2006; Zhang et al., 2004, 2006, 2010).

18
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
2.3.7. Índice informático de patrón
El índice PI (del inglés Pattern Informatics) es un método analítico para cuantificar los
cambios de tasa de sismicidad espacio-temporal en sismicidad histórica (Holliday et al.,
2006a; Rundle et al., 2002; Tiampo et al., 2002). Prácticamente, el método es una medida
objetiva en el cambio local en sismicidad relativo a la sismicidad de fondo a largo plazo
que ha sido usada para predecir grandes terremotos. El método identifica patrones
espacio-temporales de activación anómala o inactividad que sirve como proxys para
cambios en la tensión subyacente que puede preceder a grandes terremotos. Como
resultado, estas anomalías pueden estar relacionadas con la localización de grandes
terremotos que ocurren en los años siguientes a su formación (Tiampo et al., 2002,
2006a). De nuevo, la teoría sugiere que estas estructuras sísmicas están relacionadas con
cambios en los niveles de tensión subyacente (Dieterich, 1994; Dieterich et al., 2002;
Tiampo et al., 2006a; Toda et al., 2002).
El índice PI es calculado usando datos de catálogos instrumentales de áreas activas
sísmicamente. Debido a que la relación magnitud-frecuencia GR implica que, para un
volumen espacial V suficientemente grande y para un intervalo de tiempo suficientemente
largo, la frecuencia de terremotos sea constante para magnitudes m≥mc (Richter, 1958;
Turcotte, 1997), se calcula sobre una gran región con una tasa de fondo constante, o el
valor a de la relación GR. Mc es la magnitud de corte denotando la magnitud mínima de
integridad. Los datos sísmicos son mapeados por ubicación en recuadros. En California,
un tamaño de recuadro de la cuadrícula de 0,1º en latitud y longitud tuvo éxito, pero esto
podría variar con las áreas tectónicas. Las series de tiempo son creadas para cada una de
estas ubicaciones mapeadas. Una casilla de tiempo individual cuantifica el número total
de eventos en cada ubicación que ocurrió en ese intervalo de tiempo. Cada localización
se denota con xi, donde i oscila desde 1 hasta N localizaciones totales. La tasa de actividad
sísmica observada ψobs(xi,t) es el número de terremotos por unidad de tiempo, de
cualquier tamaño, en la casilla xi en el tiempo t.

19
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
2.4. Modelos de sismicidad arreglados
Los modelos de sismicidad arreglados son una clase más general de modelos de
predicción basados en sismicidad, los cuales definen las importantes características
físicas espacio-temporales de los procesos de terremotos, caracterizándose estas de una
manera matemática y/o probabilística, y calibrando el modelo basado en datos disponibles
de los catálogos sísmicos para regiones tectónicas particulares.
Originalmente desarrollado por Frankel (1995) el enfoque sísmico arreglado ha sido
extendido a muchos diferentes algoritmos y regiones por todo el mundo (ver, por ejemplo,
Helmstetter et al., 2006, 2007; Kafka, 2002; Kagan and Jackson, 1994, 2000; Kagan et
al., 2007; Nanjo, 2010; Rhoades and Evison, 2004; Stirling et al., 2002a, entre otros).
Aunque el algoritmo arreglado particular varía, el uso de una función Gaussiana
bidimensional en la cual la distancia es específica para cada región tectónica es todavía
la técnica implementada más extendida (Frankel et al., 1996; Petersen et al., 2008). Los
modelos arreglados pueden ser formulados para contar la agrupación que existe en la
sismicidad natural como resultado de las correlaciones espaciales y temporales entre
eventos que surgen debido a las interacciones de transferencia de tensión (King et al.,
1994). Además, a pesar de que los datos de catálogo de terremotos actuales a menudo son
limitados por los cortos periodos de tiempo disponibles para los datos registrados,
particularmente en magnitudes pequeñas, el arreglado espacial puede compensar esta
falta de datos así como para errores en los datos, tales como los de magnitud y localización
(Nanjo, 2010; Werner and Sornette, 2008). A lo largo de los últimos 10 años, se han hecho
significativos progresos en el desarrollo de métodos para caracterizar los procesos físicos
relacionados con la generación sísmica en esta clase de modelos. Señalar que un gran
número de técnicas han sido adaptadas a predicciones a corto plazo del orden de días, ya
sea como complemento o en lugar de predicciones a medio plazo.
Los modelos de sismicidad arreglados son intuitivamente atractivos porque concentran
peligros sísmicos en áreas que han tenido terremotos en el pasado, una propiedad de la
sismicidad que ha sido justificada por un gran número de investigadores (ver por ejemplo
Allen, 1968; Davison and Scholz, 1985; Frankel et al., 2002; Kafka, 2002; Petersen et al.,
2007). A pesar de que muchas versiones pueden ser bastante complicadas, la formulación
básica es relativamente sencilla y los resultados pueden ser fácilmente probados contra
estadísticas de catálogo instrumentales. Virtualmente todos los métodos pueden ser
comparados con hipótesis nulas tanto aleatorias como agrupadas de una manera
relativamente sencilla. Muchas también pueden evolucionar con el tiempo,
potencialmente monitorizando las dinámicas del sistema de fallas. Predicciones de
modelos de peligro proporcional (PHM del inglés proportional hazard model), por
ejemplo, son recalculados en la actualidad tanto en intervalos regulares como en grandes
eventos que se producen que modifican la naturaleza espacio-temporal en curso de la
sismicidad en la región (Faenza and Marzocchi, 2010). Sin embargo, errores o falta de
información en los catálogos instrumentales pueden dar como resultado grandes errores
en la predicción resultante, particularmente para grandes eventos que tienen escasas
estadísticas y aquellas áreas que han estado inactivas en los últimos tiempos (Werner and
Sornette, 2008).

20
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Aquí discutimos esos métodos, los cuales han tenido mayor impacto en el ámbito y son
un área en curso de investigación. En particular, un gran número de metodologías de
reconocimiento de patrones, aunque podrían mostrar una promesa significativa, son
omitidas porque son difíciles de implementar o no son aplicadas extensamente hasta la
fecha. Esto incluye técnicas de redes neuronales (Adeli and Panakkat, 2009; Alves, 2006;
Madahizadeh and Allamehzadeh, 2009; Sri Lakshmi and Tiwari, 2009), algoritmos de
reconocimiento de patrones tales como agrupamientos k-means (Morales-Esteban et al.,
2010), métodos de modelos de Markov ocultos (Ebel et al., 2007), y simulaciones de
autómatas celulares (Jiménez et al., 2008). La siguiente metodología lleva a cabo
investigaciones de predicción en curso en regiones sísmicas activas y con catálogos de
alta calidad.
2.4.1. EEPAS
El método conocido como “cada terremoto es un precursor acorde con la escala” (EEPAS
del inglés Every Earthquake is a Precursor According to Scale) está basado en el
fenómeno de incremento de escala precursora, donde incrementos sísmicos menores
ocurren antes y en la misma región que grandes eventos de la misma forma que las
réplicas. Como resultado, es tanto un modelo sísmico arreglado como basado en física,
pero es clasificado aquí como el segundo, porque la predicción generada está
intrínsecamente vinculada con las distribuciones asociadas con cada parámetro modelado.
Originalmente formulado en base a observaciones de nubes precursoras (Evison and
Rhoades, 1997, 1999), la idea fue extendida hasta la clase general de sismos previos para
identificar precursores localizados (Evison and Rhoades, 1999, 2002, 2004). El modelo
estocástico EEPAS fue formulado basándose en la simple idea de que cada terremoto es
un precursor, y su entrada en el modelo es escalado con su magnitud (Rhoades, 2010;
Rhoades and Evison, 2004).
2.4.2. Sismicidad arreglada dependiente del tiempo
En 1.994, Kagan y Jackson describieron por primera vez un método para desarrollar
modelos sísmicos arreglados extrapolando la información de catálogos sísmicos en
predicciones probabilísticas. Efectivamente, este es una predicción independiente del
tiempo en la cual las tasas de catálogos sísmicos históricos e instrumentales son
espacialmente prorrateadas para periodos de tiempo particulares. En los años siguientes,
este método particular ha sido aplicado en el noroeste y sudeste del pacífico (Jackson and
Kagan, 1999; Kagan and Jackson, 2000), California (Helmstetter et al., 2006; Kagan et
al., 2007), and Italy (Werner et al., 2010).
Aquí la tasa de densidad de terremoto, Λ(θ,ɸ,m,t), la probabilidad por unidad de área,
tiempo y magnitud, es asumido como constante en tiempo y es estimado como la suma
de contribuciones de todos los eventos a partir de una magnitud de corte prescrita. Como
en el caso con los modelos sísmicos más arreglados, pueden ser aplicados para cualquier
mínima magnitud de corte.

21
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
2.4.3. Metodologías ETAS
La hipótesis de secuencia de réplica de tipo epidémico original (ETAS del inglés
epidemic-type aftershock sequence) fue formulada por Ogata (1985a,b, 1987, 1988,
1989). No sólo es un modelo de secuencias de réplica, ETAS es fundamentalmente un
modelo de sismicidad interactiva desencadenante en la cual todos los eventos tienen roles
idénticos en el proceso de activación. De nuevo, es tanto un modelo basado en física como
un modelo de sismicidad arreglado, pero es clasificado aquí como lo segundo porque las
predicciones están intrínsecamente conectadas a las distribuciones asociadas con cada
parámetro. En este proceso cada terremoto se considera como desencadenante por eventos
anteriores y como un provocador potencial para seísmos subsecuentes, por ejemplo, cada
evento es una réplica potencial, sismo principal o sismo previo, con sus propias
consecuencias de réplica. Para sismicidad general un plazo de fondo con un componente
aleatorio es añadido a la formulación. En los años siguientes, el modelo ha sido usado en
muchos estudios para describir la distribución espacio-temporal y características de la
sismicidad actual Console and Murru, 2001; Console et al., 2003; Helmstetter and
Sornette, 2002, 2003a,b; Ma and Zhuang, 2001; Ogata, 1988, 1998, 1999, 2005; Ogata
and Zhuang, 2006; Saichev and Sornette, 2006; Vere-Jones, 2006; Zhuang et al., 2004,
2005 entre otros). Para una revisión más extensa de los primeros años de desarrollo y
aplicación de ETAS, ver Ogata (1999) and Helmstetter and Sornette (2002).
2.4.4. Método de intensidad relativa
El modelo de predicción RI (del inglés Relative Intensity) fue propuesto por primera vez
por Holliday et al. (2005), principalmente como una hipótesis nula mejor para testing
predictivo que un modelo de sismicidad no agrupado aleatorio. La idea es usar la tasa de
ocurrencia de terremotos en el pasado con el objetivo de predecir la localización de
futuros grandes seísmos, en el que futuros grandes eventos están considerados más
probable donde actividad sísmica mayor ocurrió en el pasado
El algoritmo RI es el más simple de los modelos de sismicidad arreglados y fue
originalmente formulado como una predicción binaria, aunque ha sido modificada de
diversas formas desde aquella vez. Inicialmente, la región estudiada es representada con
casillas cuadradas.
2.4.5. Triple S
El modelo de sismicidad suavizado simple (TripleS del inglés simple smoothed seismicity
model), fue desarrollado como una prueba de un modelo muy simple para predicción de
terremotos con un número mínimo de parámetros. En su forma más básica, aplica un filtro
suavizado Gaussiano a un conjunto de datos del catálogo y optimiza un sólo parámetro,
σ, el cual controla la extensión espacial de arreglo, contra predicciones retrospectivas
(Zechar and Jordan, 2010).

22
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
El método sísmico arreglado más simple es la técnica de predicción RI, como se detalla
anteriormente en este trabajo. En ese modelo, el arreglo es anisótropo y uniforme. TripleS
en vez de eso aplica un arreglo Gaussiano isotrópico bidimensional que usa una función
de origen continua que permitía una región más amplia de influencia.
2.4.6. Agrupamiento de terremotos con tasa de llegada no de Poisson
Como se destacó anteriormente, la mayoría de modelos de sismicidad alisados se basan
en la idea de que los terremotos tienden a ocurrir en el futuro donde han ocurrido ya en el
pasado (Allen, 1968; Davison and Scholz, 1985; Frankel et al., 2002; Kafka, 2002;
Petersen et al., 2007).
En el caso del modelo de agrupación de terremotos no de Poisson a corto plazo, un modelo
de predicción diario presentado al proyecto RELM por Ebel et al. (2007), se extiende la
suposición de que las propiedades estadísticas medias de las ocurrencias espaciales y
temporales de terremotos con M≥4.0 durante el periodo de predicción será la de los
últimos 70 o más años, incluyendo réplicas y sismos previos. La formulación espacial
inicial está basada en esta premisa.
Debido a que este es principalmente un algoritmo de predicción de réplicas, la tasa de
ocurrencia media es modelada usando la ley de Omori (Utsu et al., 1995), formando la
base para predecir actividad cerca del epicentro de un gran terremoto siguiendo
inmediatamente ese evento. Si un seísmo de M≥4.0 ocurre en algún lugar de la región, un
círculo de radio R es dibujado alrededor del epicentro, como definen Gardner and
Knopoff (1974). En el caso de California, la relación de Reasenberg and Jones (1989)
para la ley de Omori fue elegida para calcular la tasa esperada de terremotos de M≥4.0.
Además, la distribución de Poisson de tiempo entre los eventos es la distribución
estadística desde la cual son derivados predicciones a corto plazo de nuevos sismos
principales. La predicción asume que todos los eventos de magnitud más pequeña que el
sismo principal son réplicas. Si un nuevo evento tiene una magnitud mayor que el primer
evento, la predicción asume que el primer terremoto fue un sismo anterior. Cuando la tasa
de réplica/sismo previo predicha cae por debajo de la tasa de sismo principal de fondo
para cualquier localización dada, entonces la tasa del sismo principal de fondo es
sustituida. Finalmente, para esas localizaciones que están fuera de las zonas de réplica, la
tasa media de eventos M≥4 para un catálogo de terremoto desagrupado regional es
calculado y esta tasa media del sismo principal es distribuida a lo largo de toda el área
proporcionalmente a su distribución pasada (Ebel et al., 2007).
Ebel et al. (2007) detalla las varias elecciones de predicción para cualquier día dado y
como son combinados en predicciones a corto plazo. Destacar de nuevo que uno de los
beneficios de un mapa de sismicidad arreglado es que la discretización puede ser usada
para probar las limitaciones del algoritmo y los datos disponibles y, al menos en principio,
los errores asociados con ambos pueden también ser evaluados.

23
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
2.4.7. Modelos potenciales de terremoto sísmico
El modelo potencial de terremoto sísmico, como propuso Ward (2007), es otra versión de
un modelo de sismicidad arreglado donde la teoría principal es que los terremotos son
probables de ocurrir en el futuro en la misma localización en los que ocurrieron en el
pasado. Las actuales localizaciones y dependencias de tiempo del evento son construidos
desde este principio basado en alguna combinación de las leyes aceptadas generalmente
de sismicidad, la distribución de magnitud frecuencia GR (Gutenberg and Richter, 1944),
la ley modificada de Omori (Utsu et al., 1995), y la ley de Bath (Båth, 1965). De nuevo
el requerimiento básico es un catálogo instrumental de localizaciones de terremoto,
fechas, y magnitudes y la magnitud mínima estimada de integridad, mc.
2.4.8. STEP
En 2.005, el modelo de probabilidad de terremotos a corto plazo (STEP del inglés short-
term earthquake probability) fue inaugurado en http://pasadena.wr.usgs.gov/step
(Gerstenberger et al.,2005). STEP es otro método que emplea una ley de sismicidad
universal (en este caso la ley de réplicas modificada de Omori) (Utsu et al., 1995) con
datos históricos e instrumentales con el objetivo de crear una predicción dependiente del
tiempo. Debido a que el modelo STEP está basado en la ley de Omori es una predicción
a corto plazo que produce predicciones en una escala de tiempo de días y cuya señal
principal está relacionada con secuencias de réplica, al igual que el modelo de agrupación
no de Poisson de Ebel et al. (2007).
El modelo STEP combina un modelo de ocurrencia independiente del tiempo de datos de
falla tectónica con modelos de agrupación estocásticos cuyos parámetros están derivados
de datos de catálogo recientes y a largo plazo. El modelo independiente del tiempo se
elabora de los mapas de riesgo a largo plazo de la U.S. Geological Survey de 1.996
(USGS) (Frankel et al., 1997). Tres modelos estocásticos son calculados para
incorporarse en el modelo de fondo: un modelo de agrupamiento genérico, un modelo
específico de secuencia, y un modelo heterogéneo espacial (Gerstenberger et al., 2005).
2.4.9. HAZGRIDX
HAZGRIDX, como propuso Akinci (2010), es otra versión de un modelo sísmico
arreglado donde el alisamiento es gobernado por la relación magnitud-frecuencia GR.
Comenzando con un catálogo sísmico para Italia el cual esta desagrupado, la magnitud
mínima de integridad es determinada. La sismicidad es entonces arreglada usando el
método sísmico alisado espacialmente (Frankel, 1995) y es calculada la siguiente
ecuación para la tasa arreglada de eventos en cada celda y es normalizada por la
sismicidad regional total usando la siguiente ecuación:
ñ =∑ 𝑛𝑗𝑒−Δ𝑔/𝑐2
𝑗:Δ𝑔≤3𝑐
∑ 𝑒−Δ𝑔/𝑐2𝑗:Δ𝑔≤3𝑐
(2.4.21)

24
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Donde Δij es la distancia entre el centrado de las celdas i y j de la cuadrícula y el parámetro
c la distancia de correlación. La suma es tomada sobre todas las celdas j dentro de una
distancia de 3c de la celda i.
Una predicción CSEP a cinco años para Italia fue creada por el arreglado sobre una
distancia de correlación, c, de 15 km y calculando tasas de actividad para cada casilla que
cumplía la relación de magnitud-frecuencia GR regional. Un modelo de Poisson
independiente del tiempo es empleado para calcular la tasa recurrente para cada evento.
Akinci (2010) destacó que, no sólo un catálogo integro tiene un efecto crucial en la
fiabilidad y la calidad de predicciones basadas en sismicidad potencial, sino que también
es crítico esa estimación exacta del valor b GR. En modelos tales como este, un valor b
bajo incrementará el valor de riesgo, mientras que una alta lo reduce.
Es necesario la adquisición de datos sísmicos de alta calidad sobre periodos de tiempo
largos con el objetivo de estimar con integridad valores b regionales y proporcionar
predicciones sísmicas arregladas más exactas.
2.4.10. Modelo de riesgo proporcional (PHM)
El Modelo de riesgo proporcional (PHM del inglés proportional hazard model) es un
método estadístico no paramétrico multivariante que caracteriza la dependencia temporal
de una función de riesgo que representa la probabilidad condicional instantánea de una
ocurrencia (Cox, 1972; Faenza et al., 2003, 2004; Kalbeisch and Prentice, 1980). El
modelo no asume a priori ninguna distribución estadística de los eventos y puede ser
usado para integrar simultáneamente diferentes tipos de información. En este caso,
permite análisis del proceso de ocurrencia de terremoto sin el requisito de asumir un
modelo tal como la distribución de seísmos característico. Además, permite probar el
impacto en la distribución de eventos de la integración de trozos individuales de
información física y a medida que se integran en el modelo probar su importancia relativa
(Faenza and Marzocchi, 2010).
El PHM fue aplicado en estudios de la distribución espacio temporal de terremotos
destructivos en Italia (Cinti et al., 2004; Faenza and Pierdominici;, 2007; Faenza et al.,
2003), terremotos de tamaño medio en Europa central (Faenza et al., 2009), y grandes
seísmos por todo el mundo (Faenza et al., 2008) la cual mostraba que agrupamientos
temporales de eventos del orden de unos pocos años ocurren como una señal precursora
previa a grandes eventos. Su escala espacial oscila entre decenas a cientos de kilómetros.

25
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
2.5. Conclusiones
Los recientes desarrollos en los campos de sismología estadística, en conjunción con la
disponibilidad de gran cantidad de datos sísmicos en pequeñas escalas y avances
computacionales, han mejorado significativamente nuestro entendimiento de los procesos
de terremotos dependientes del tiempo. Como resultado, los últimos diez años han visto
progresos significativos en el campo de la predicción de seísmos basados en sismicidad
a corto y medio plazo. Estas técnicas de predicción basadas en sismicidad pueden ser
diferenciadas de modelos basados en técnicas para identificar procesos físicos
particulares y de aquellos que filtran o arreglan la sismicidad.
Tales filtros están normalmente, aunque no siempre, basados en relaciones sísmicas bien
caracterizadas tales como la ley de Omori modificada. Exploraciones de la principal
diferencia entre estas dos clases de modelos reflejan su mayor fuerza y debilidad.
Mientras los modelos físicos generalmente tienen el potencial de proporcionar más
detalles en espacio y tiempo, la base para sus éxitos y fallos es normalmente oscurecido
por las simple estimaciones del modelo y las complicadas interacciones que existen en
el mundo real.
Por otra parte, mientras que los patrones de predicción y los éxitos o fracasos que resultan
son mejor entendidos en los modelos suavizados, la variación en el patrón espacial
resultante por los diferentes filtros es relativamente pequeña.
El progreso en la precisión y evaluación en las predicciones de terremotos basados en
sismicidad sobre los últimos 10 años ha llegado hasta el consenso general de que
proporcionan los caminos más prometedores para predicciones de terremotos
operacionales viables (ver por ejemplo Jordan and Jones, 2010). Técnicas de evaluación
actuales incluyen tests específicamente formulados para técnicas de predicción binaria,
así como aquellas que automáticamente generan ámbitos probabilísticos, tales como
modelos de sismicidad arreglados (www.cseptesting.org). Además, muchos progresos
han sido hechos en la modificación de un gran número de métodos, tales como M8, para
producir ámbitos de probabilidad. Sin embargo, otro gran número de técnicas no son
evaluadas regularmente, creando una importante y potencial diferencia en nuestra
habilidad de cuantificar la ganancia de probabilidad asociada con esos métodos, pero
también evitando ideas potenciales en el mecanismo y comportamientos que afectan a la
predicción de terremotos.
Aún quedan por hacer trabajos importantes, no solo en la evaluación de varios métodos
ya formulados para pruebas, sino también en determinar cuáles son los periodos de tiempo
de predicción óptimos y las precisiones para varios propósitos de predicción, y que nivel
de ganancia de probabilidad es razonable y probable para las regiones espaciales y
temporales de interés. Está claro que una diferencia existe entre predicciones que rinde
bien en el orden de días a semanas (modelos de predicción de réplicas) y aquellos que
rinden bien sobre periodos de tiempo de cinco a diez años. La pregunta sigue siendo si
predicciones fiables son posibles para periodos de tiempo de uno a dos años. Además ha
habido relativamente pequeña colaboración alrededor de varios métodos que intenta
tomar ventaja de la información científica y practica ganada desde su evaluación en curso.
Acuerdos sobre la hipótesis nula agrupada más aplicable podrían avanzar en este objetivo,
cambiando el fin de comparaciones entre modelos a evaluaciones contra un estándar.

26
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Ambos tipos de predicciones basadas en sismicidad están limitadas por la calidad de los
datos y el relativamente corto periodo de tiempo disponible para el catálogo instrumental,
subrayando la importancia de catálogos instrumentales de buena calidad derivados de
redes sísmicas densas. Errores de falta de información en los catálogos dan como
resultado grandes errores en la predicción resultante, particularmente para grandes
eventos, que tienen escasas estadísticas. Además, a diferencia de algunos modelos físicos,
los modelos sísmicos arreglados no pueden contar para regiones que han estado inactivas
en la historia reciente pero que podrían contener significativos terremotos potenciales en
escalas de tiempo más prolongadas. Quizás tan importante como el pequeño número de
grandes eventos que ocurrirán o bien en una región o por todo el mundo en un periodo
de tiempo próximo de treinta a cincuenta años, mucho menos en cinco o diez años, es
hacer evaluaciones estadísticas definitivas de todas estas técnicas extremadamente difícil
actualmente. Como resultado, estándares para rechazar hipótesis están todavía bajo
discusión. Esto sirve para enfatizar la importancia de entender las varias escalas de tiempo
asociadas con el proceso natural de terremotos y el hecho de que periodos de observación
más prolongados serán necesarios para evaluar apropiadamente la viabilidad y eficacia
de ambos tipos de modelos de predicción.
Un gran número de visiones importantes e interesantes se pueden extraer de una
exploración más minuciosa de las varias técnicas y su implementación.
Primero, muchas técnicas se centran principalmente en fenómenos particulares como
precursores específicos, y sin embargo, a menudo llegan a similares conclusiones con
respecto a la localización y el tiempo que las de eventos particulares. Por ejemplo, un
gran número de estudios identifican escalas de tiempo a corto plazo para activaciones e
inactividades precursoras alternativas del orden de varios años (ver por ejemplo, Evison
and Rhoades, 2002; Huang, 2004; Kossobokov, 2006a, 2006b; Tiampo et al., 2006a,b) .
Es más probable que en el futuro, observaciones más minuciosas y comparaciones de
varias técnicas proporcionen información importante de los procesos subyacentes que
identifican la física asociada.
En segundo lugar, la mayoría de las metodologías actuales se formulan de modo pueden
ser actualizadas para tener en cuenta la naturaleza cambiante del sistema de fallas de
terremotos. El desarrollo de técnicas de predicción de seísmos dependientes del tiempo
es una respuesta al reconocimiento de que el ámbito de tensión de evolución en un sistema
de falla regional es la fuerza motriz detrás de un sistema dinámico, si es lento. Como tal,
la sismicidad de magnitud pequeña y mediana está proporcionando información
importante en la evolución temporal y espacial en el ámbito de tensión local y regional.
Las técnicas de predicción basadas en sismicidad, incluso aquellas que son
independientes del tiempo (por ejemplo, Kagan et al., 2007) permiten actualizaciones
regulares tanto para sus predicciones como para predicciones revisadas después de la
ocurrencia de grandes eventos, teóricamente la captura de la dinámica del sistema.
Trabajos futuros probablemente incluirán análisis detallado de esta evolución temporal y
visiones importantes en la física de sistemas así como mayores avances en predicciones
de terremotos a corto y medio plazo.

27
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
3. Descubrimiento de conocimiento a partir de grandes bases
de datos (KDD)
3.1. Introducción
La revolución de la información global en la sociedad en la que vivimos ha producido
que se generen gran cantidad de datos a gran velocidad, creándose una necesidad de
aumento de las capacidades de almacenamiento que no pueden resolverse por métodos
manuales. En las últimas décadas la principal preocupación se ha centrado en cómo tratar
la información disponible de la forma más rápida y eficiente Se hace entonces necesario
encontrar técnicas y herramientas que ayuden en el análisis de dichas cantidades de datos,
que se encuentran normalmente infrautilizadas, ya que dicho volumen excede nuestra
habilidad para reducir y analizar los datos sin el uso de técnicas de análisis automatizadas.
La minería de datos (o data mining en su terminología inglesa) es una de las técnicas que
más se usan actualmente y que surgió como solución a este problema. Su misión no es
otra que la de analizar la información de las bases de datos. Apoyándose en distintas
disciplinas como la estadística, los sistemas para tomas de decisión o el aprendizaje
automático entre otros, permite extraer patrones, describir tendencias o predecir
comportamientos.
La minería de datos en resumen, no es más que una de las etapas más importantes del
descubrimiento de la información en bases de datos (KDD o Knowdledge discovery in
databases), entendiendo por descubrimiento la existencia de información valiosa
escondida y no conocida anteriormente. Definido en varias fases, este proceso se puede
entender entonces como el proceso completo de extracción de información, que se
encarga así mismo de la preparación de los datos y de la interpretación de los resultados
obtenidos.
En otras palabras, KDD se ha definido como “el proceso no trivial de identificación en
los datos de patrones válidos, nuevos, potencialmente útiles, finalmente comprensibles”
(Fayyad, U. et al., 1996)
El proceso de KDD incorpora distintas técnicas del aprendizaje automático, las bases de
datos, la estadística, la inteligencia artificial así como diversas áreas de la informática y
de la información en general.
Una de las causas que ha hecho que la minería de datos alcance gran popularidad ha sido
la difusión de herramientas y paquetes que implementan estas técnicas, tales como
MicroStrategy, Intelligent Miner de IBM o DM Suite (Darwin) de Oracle, siendo
conocidas como herramientas de Business Intelligence (BI).
Estos paquetes integrados o suites de BI los podemos definir como una colección de
herramientas y técnicas para la gestión de datos, análisis y sistemas de soporte a la
decisión o, de forma más amplia, como la combinación de arquitecturas, bases de datos,
herramientas de análisis, aplicaciones y metodologías para la recopilación,
almacenamiento, análisis, y acceso a los datos para mejorar el rendimiento del negocio y
ayudar a la toma de decisiones estratégicas.

28
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
La diversidad de disciplinas que contribuyen a la minería de datos da lugar a una gran
variedad de sistemas específicos para analizar los tipos de datos que se desean. Teniendo
en cuenta el modelo de datos que generan, los que minan, y la técnica o el tipo de
aplicación, se puede distinguir, citando a Hernández Orallo, (Hernández Orallo. J. (2004))
los siguientes tipos:
1. Tipo de base de dato minada. Partiendo de diferentes modelos de datos, existen
sistemas de minerías de datos relacionados y multidimensionales, entre otros. De
igual forma, teniendo en cuenta los tipos de datos usados se producen sistemas
textuales, multimedia, espaciales o web.
2. Tipo de conocimiento minado. Teniendo en cuenta los niveles de abstracción del
conocimiento minado se distinguen:
Conocimiento generalizado con alto nivel de abstracción.
Conocimiento a nivel primitivo, con filas de datos.
Conocimiento a múltiples niveles, de abstracción.
Además, se debe hacer la distinción entre los sistemas que buscan patrones, es decir,
regularidades, y los que buscan excepciones, irregularidades.
1. Tipo de funcionalidad (clasificación, agrupamiento) y de técnica, es decir,
métodos de análisis de los datos empleados.
2. Tipo de aplicación. En el que distinguimos dos tipos: los de propósito general y
los específicos. Sin pretender ser exhaustivos, se exponen seguidamente algunos
ejemplos de aplicaciones.
Medicina, básicamente para encontrar la probabilidad de una respuesta
satisfactoria a un tratamiento médico o la detección de pacientes con riesgo de
sufrir alguna patología (detección de carcinomas, pólipos...).
Mercadotecnia. Análisis de mercado, identificación de clientes asociados a
determinados productos, evaluaciones de campañas publicitarias,
estimaciones de costes o selección de empleados.
Manufacturas e industria: detección de fallas.
Telecomunicaciones. Determinación de niveles de audiencia, detección de
fraudes, etc.
Finanzas. Análisis de riesgos bancarios, determinación de gasto por parte de
los clientes, inversiones en bolsa y banca etc.
Climatología. Predicción de tormentas o de incendios forestales.
Comunicación. Análisis de niveles de audiencia y programación en los mass
media
Hacienda. Detección de fraude fiscal
Política. Diseño de campañas electorales, de la propaganda política, de
intención de voto, etc.
Como se viene comentando desde el principio del capítulo, los datos tal y como se
almacenan no suelen proporcionar beneficios directos. Su valor real reside en la
información que se pueda extraer de ellos, información que ayude a tomar decisiones o a
mejorar la comprensión de algún fenómeno que nos rodea.

29
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
En el caso que nos ocupa, la minería de datos es solo una fase de este proceso más amplio
cuya finalidad no es otra que el descubrimiento de conocimiento en bases de datos (KDD).
Con independencia de la técnica que se siga durante el proceso de extracción de datos,
los pasos a seguir son siempre los mismos:
1. Adquisición de datos
2. Preprocesamiento y transformación
3. Minería de datos
4. Evaluación
5. Interpretación
A continuación se detallan cada uno de estos pasos.
3.2. Adquisición de datos
En el proceso de minería de datos es muy importante comprender el dominio del
problema, por lo que resulta un paso clave definir claramente lo que se intenta abordar.
Se podría definir como la fase 0.
En un segundo momento se debe seleccionar el conjunto de datos sobre el que se desea
extraer información. Es decir, se localizan las fuentes de información y los datos
obtenidos se llevan a un formato común para poder trabajar de manera más adecuada con
ellos. Frecuentemente los datos necesarios para realizar un proceso de KDD pertenecen
a distintos departamentos u organizaciones, o incluso es posible que haya que buscar
datos complementarios de informaciones oficiales. Por tanto, es recomendable y
conveniente utilizar algún método automatizado para explorar dichos datos.
Se podría resumir entonces esta fase como una etapa de comprensión de los datos con una
colección de datos inicial y realización de actividades para familiarizarse con ellos. De
esta forma se podrá identificar más fácilmente problemas de calidad para descubrir las
características de los datos. Así mismo, se podrá detectar subconjuntos para realizar las
primeras hipótesis sobre la información oculta.
Entre las tareas que se realizan podemos distinguir:
Selección: de tablas, de atributos, registros y/o fuentes con las que comenzar a
trabajar.
Estudiar los datos: el mundo que nos rodea consiste de objetos que percibimos y lo
que interesa es descubrir las relaciones entre los objetos. Los objetos en sí tienen unas
características que son las que se van a analizar.
Establecer los metadatos que serán más tarde utilizados.
Establecer el tipo de variables: Generalmente se ha hecho la distinción en
cuantitativas o cualitativas. Las cuantitativas a su vez, se distinguen en discretas (por
ejemplo, el número de empleados de una empresa) o continuas (como el sueldo, días
de vacaciones…). Mientras que las cualitativas se distinguen entre nominales
(nombran el objeto al que se refieren, como el estado civil, género…) u ordinales (se
puede establecer un orden en sus valores, como alto, medio o bajo)

30
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Establecer la caducidad de cada dato, es decir, la vida de las variables, ya que las
medidas tienen un periodo de caducidad y se toman en unas circunstancias.
3.3. Preprocesamiento y transformación
En este apartado se detalla la fase de preparación de los datos así como su trasformación.
En esta etapa del KDD se engloban todas las actividades de construcción del conjunto
final de datos, los cuales servirán como datos de entrada en los futuros algoritmos de
minería de datos, desde el conjunto inicial de los datos.
Existe la posibilidad de que estas actividades se deban realizar múltiples veces y sin un
orden determinado.
Las tareas más importantes a realizar durante esta etapa son:
• Transformación de datos
• Limpieza de datos
El primer paso que hay que seguir dentro de esta fase es asegurar la calidad de los datos,
ya que estos pueden contener valores atípicos (outliers) o valores nulos. La recolección y
registro de los datos existentes no se hizo siguiendo un formato concreto, y menos aún
fueron recogidos para tareas de minería de datos. Es por ello que suelen caracterizarse
por ser datos pobres y/o inconsistentes, que en muchas ocasiones, y como se ha
comentado anteriormente, provienen de numerosas fuentes y diversos sistemas, cada uno
de ellos con su propio tipo de datos y su propia forma de tratarlos. Lo cual, en posteriores
análisis de minería de datos, podría llevar a formulación de modelos erróneos y/o muy
sesgados.
Se antoja entonces fundamental, realizar dos funciones básicas:
1. Revisión de los datos: debido a la gran cantidad de datos que pueden formar el
dominio del problema, se suelen utilizar métodos estadísticos y de visualización que
permitirán más fácilmente identificar aquellos valores no deseados. Si se trata de variables
categóricas, las técnicas más utilizadas para localizar dichos valores son la distribución
de variables, histogramas o gráficas circulares.
Mientras, para variables cualitativas, se aconseja el uso de media, varianza, moda,
diagrama de dispersión o diagrama de cajas
2. Tratamientos de valores nulos e información incompleta: los datos más
importantes a tratar son los valores atípicos (outliers) y los valores nulos. El tratamiento
de los primeros dependerá de su naturaleza y se podrán eliminar, si se considera necesario,
del proceso de carga en el data warehouse. Para el tratamiento de los valores nulos, no
existe una técnica perfecta, aunque las directrices mínimas que deben seguirse son
eliminar las observaciones con nulos, así como eliminar las variables con muchos nulos
y utilizar un modelo predictivo para ello.

31
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Una vez realizada esto, se conseguirá una visión integrada, consistente y consolidada de
los datos.
Toda vez que los datos han sido tratados, hay que refinarlos para que cumplan los
requisitos de entrada de los futuros algoritmos, para ello se deberá llevar a cabo tareas de
conversión de variables, reducción o adición de las mismas y una discretización o
generalización, dependiendo del conjunto de datos tratado.
3.4. Minería de datos
En este apartado se detallara más en profundidad acerca de la minería de datos y en la
técnica usada para este trabajo, clustering.
Al ser la minería de datos una técnica novedosa y cuyo concepto no resulta fácil de
declarar, no existe una única definición sobre esta. Como muestra, se exponen a
continuación algunas de las más conocidas:
Definición 1. Es el proceso no trivial de descubrir patrones válidos, nuevos,
potencialmente útiles y comprensibles dentro de un conjunto de datos,
Piatetski-Shapiro G., Frawley W. J., and Matheus C. J. (1991).
Definición 2. Es la aplicación de algoritmos específicos para extraer patrones
de datos,Fayyad U. M., Piatetski-Shapiro G., and Smith P. (1996),
entendiendo por datos un conjunto de hechos y por patrones una expresión en
algún lenguaje que describe un subconjunto de datos, siempre que sea más
sencilla que la simple enumeración de todos los hechos que componen.
Definición 3. Es la integración de un conjunto de áreas que tienen como
propósito la identificación de un conocimiento obtenido a partir de las bases
de datos que aporten un sesgo hacia la toma de decisión, Grossman R. L.,
Hornik M. F., and Meyer G. (2004).
Definición 4. Es el proceso de descubrimiento de conocimiento sobre
repositorios de datos complejos mediante la extracción oculta y
potencialmente útil en forma de patrones globales y relaciones estructurales
implícitas entre datos,Kopanakis I. and Theodoulidis B. (2003).
Definición 5. El proceso de extraer conocimiento útil y comprensible,
previamente desconocido, desde grandes cantidades de datos almacenados en
distintos formatos,Witten H. and Frank E. (2005).
Definición 6. La tarea fundamental de la minería de datos es encontrar
modelos inteligibles a partir de los datos,Hernández Orallo J., (2004).
En síntesis, Los objetivos que persigue la minería de datos se pueden resumir de esta
manera:
1. Identificación de patrones significativos o relevantes
2. Procesamiento automático de grandes cantidades de datos
3. Presentación de los patrones como conocimiento adecuado para satisfacer los
objetivos del usuario

32
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Cabe mencionar en este apartado que algunos autores distinguen dos tipos de minería de
datos,Fayyad U. M., Piatetski-Shapiro G., and Smith P. (1996).
1. Mdp o minería de datos predictiva. En otras palabras, predicción de datos,
básicamente técnicas estadísticas. La clasificación y la regresión son las tares
de datos que producen modelos predictivos.
Clasificación. Es la más usada. Cada registro de la base de datos pertenece
a una determinada clase o etiqueta discreta, que se indica mediante el
valor de un atributo o clase de la instancia. El objetivo no es otro que
predecir una clase, dados los valores de los atributos. Árboles de decisión,
sistemas de reglas o análisis de discriminantes son algunos ejemplos.
También podemos encontrar variantes de la tarea de clasificación como
rankings, aprendizaje de preferencias, etc…
Regresión o estimación. Es el aprendizaje de una función real que asigna
a cada instancia un valor real de tipo numérico. El objetivo es inducir un
modelo para poder predecir el valor de la clase dados los valores de los
atributos. Se usan, por ejemplo, árboles de regresión, redes neuronales
artificiales, regresión lineal, etc.
2. Mddc o minería de datos para el descubrimiento del conocimiento, usando
básicamente técnicas de ingeniería artificial. Las tareas que producen
modelos descriptivos son el agrupamiento (clustering), las reglas de
asociación secuenciales y el análisis correlacional, como se verá más delante.
Clustering o agrupamiento. Técnica descrita en este trabajo. Consiste en
la obtención de grupos, que tienen los elementos similares, a partir de los
datos. Estos elementos u objetos similares de un grupo son muy diferentes
a los objetos de otro grupo. Esta técnica de estudio por agrupamiento fue
ya utilizada a principios del siglo XX en otras áreas lingüísticas, como la
Semántica. Formando campos semánticos se estudia el léxico de un
idioma con sus particularidades.
Reglas de asociación. Su objetivo es identificar relaciones no explícitas
entre atributos categóricos. Una de las variantes de reglas de asociación
es la secuencial, que usa secuencias de datos.
Análisis correlacional. Utilizada para comprobar el grado de similitud de
los valores de dos variables numéricas.
El proceso de minería de datos cuenta con una serie de ventajas que se pueden sintetizar
en las siguientes:
Proporciona poder de decisión a los usuarios y es capaz de medir las acciones
y resultados de la mejor manera.
Contribuye a la toma de decisiones tácticas y estratégicas.
Supone un ahorro económico a las empresas y abre nuevas posibilidades de
negocio.
Es capaz de generar modelos prescriptivos y descriptivos.

33
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Nos centraremos ahora en la técnica usada para este trabajo, clustering, como se ha
mencionado en apartados anteriores.
Clustering no es más que agrupar un conjunto de objetos abstractos o físicos en clases
similares. Por lo tanto un clúster se puede definir como una colección de datos parecidos
entre ellos y diferentes de los datos que pertenecen a otro clúster. Así mismo, un clúster
de datos puede ser tratado colectivamente como un único grupo.
Sabiendo esto, las técnicas de clustering se pueden definir como técnicas de clasificación
no supervisada de patrones en conjuntos denominados clúster.
Aunque el problema de clustering ha sido planteado por una gran cantidad de disciplinas
y es aplicable a también gran número de contextos, sigue siendo un problema complejo y
su desarrollo es más lento que el esperado.
Se pasará ahora a ofrecer una visión global de los distintos métodos de clustering así
como las distintas aplicaciones de conceptos relacionados con este entorno.
El análisis de clúster es una importante actividad humana. Ya desde temprana edad, el ser
humano aprende a distinguir entre hombre y mujer, o entre oriental u occidental, mediante
una mejora continua de los esquemas de clasificación.
Las técnicas de clustering han sido ampliamente utilizadas en múltiples aplicaciones tales
como reconocimiento de patrones, análisis de datos, procesado de imágenes o estudios de
mercado. Gracias al clustering se pueden identificar regiones tanto pobladas como
dispersas y, por consiguiente, descubrir patrones de distribución general y correlaciones
interesantes entre los atributos de los datos. En el área de los negocios, el clustering puede
ayudar a descubrir distintos grupos en los hábitos de sus clientes y así, caracterizarlo en
grupos basados en patrones de compra. En el ámbito de la biología puede utilizarse, por
ejemplo, para derivar taxonomías animales y vegetales o descubrir genes con
funcionalidades similares.
De igual manera, el clustering puede ayudar a identificar áreas en las que la composición
de la tierra se parece y, más concretamente, en teledetección se pueden detectar zonas
quemadas, superpobladas o desérticas. En internet se puede utilizar para clasificar
documentos y descubrir información relevante de ellos.
El análisis de clústeres se puede usar para hacerse una idea de la distribución de los datos,
para observar las características de cada clúster y para centrarse en un conjunto particular
de datos para futuros análisis.
El clustering de datos es una disciplina científica que cuenta con multitud de estudios y
artículos en diferentes ámbitos. Debido a la enorme cantidad de datos contenidos en las
bases de datos, el clustering se ha convertido en un tema muy activo en las investigaciones
de la minería de datos. Como rama de la estadística, el análisis de clústeres ha sido objeto
de estudio durante muchos años, centrándose principalmente en los las técnicas basadas
en la medida de distancias.
En lo referente al aprendizaje automático, el clustering suele venir referido como
aprendizaje no supervisado.

34
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
A diferencia de la clasificación, el clustering no depende de clases previamente definidas
ni en ejemplos de entrenamientos etiquetados a priori. Por esta razón, se trata de una
forma de aprendizaje por observación en vez de aprendizaje por ejemplos. En el clustering
conceptual un grupo de objetos forma una clase sólo si puede ser descrito mediante un
concepto.
El clustering conceptual consiste en dos componentes:
1. Descubre las clases apropiadas.
2. Forma descripciones para cada clase, tal y como sucede en la clasificación.
El clustering es, hoy en día, un campo de investigación en el que sus aplicaciones
potenciales plantean sus propios requerimientos específicos. Dichos requerimientos se
pueden resumir en:
1. Escalabilidad. Aplicar clustering sobre una muestra de una gran base de datos
dada puede arrojar resultados parciales. El reto está en desarrollar algoritmos
de clustering que sean altamente escalables en grandes bases de datos.
2. Capacidad para tratar con diferentes tipos de atributos. Muchos algoritmos se
diseñan para clústeres de datos numéricos. Sin embargo, multitud de
aplicaciones pueden requerir clústeres de otro.
3. Descubrir clústeres de forma arbitraria. Muchos algoritmos de clustering
determinan clústeres basándose en medidas de distancia de Manhattan o
euclídeas. Tales algoritmos tienden a encontrar clústeres esféricos con
tamaños y densidades similares. Sin embargo, un clúster puede tener
cualquier tipo de forma. Es por ello que es importante desarrollar algoritmos
capaces de detectar clústeres de forma arbitraria.
4. Requisitos mínimos para determinar los parámetros de entrada. Muchos
algoritmos requieren que los usuarios introduzcan ciertos parámetros en el
análisis de clústeres (como puede ser el número de clústeres deseado).El
clustering es muy sensible a dichos parámetros. Este hecho no sólo preocupa
a los usuarios sino que también hace que la calidad del clustering sea difícil
de controlar.
5. Capacidad para enfrentarse a datos ruidosos. La mayor parte de las bases de
datos reales contienen datos de tipo outliers o datos ausentes, desconocidos o
erróneos. Algunos algoritmos de clustering son sensibles a este tipo de datos
lo que puede acarrear una baja calidad en los clústeres obtenidos.
6. Insensibilidad al orden de los registros de entrada. Determinados algoritmos
son sensibles al orden de los datos de entrada, pudiendo el mismo conjunto
de datos presentados en diferente orden generar clústeres extremadamente
diferentes. Se hace necesario desarrollar algoritmos que sean insensibles al
orden de la entrada.
7. Alta dimensionalidad. Una base de datos puede contener varias dimensiones
o atributos. Muchos algoritmos de clustering son buenos cuando manejan
datos de baja dimensión (dos o tres dimensiones). El ojo humano es adecuado
para medir la calidad del clustering hasta tres dimensiones.

35
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Es un reto agrupar objetos en un espacio de alta dimensión, especialmente
considerando que en dicho espacio los datos pueden estar altamente
esparcidos y distorsionados.
8. Clustering basado en restricciones. Las aplicaciones del mundo real pueden
necesitar realizar clustering bajo ciertos tipos de restricciones.
9. Interpretabilidad y usabilidad. Los usuarios esperan que los resultados
proporcionados por el clustering sean interpretables, comprensibles y útiles.
Esto es, el clustering puede necesitar ser relacionado con interpretaciones
semánticas específicas. Así, es importante estudiar cómo el objetivo buscado
por una aplicación puede influir en la selección de los métodos de clustering.
Dados los requerimientos anteriormente mencionados, el estudio del análisis de clústeres
se hará como sigue.
En primer lugar se estudian los diferentes tipos de datos y cómo pueden
influir los métodos de clustering.
En segunda instancia se presentan una categorización general de los
anteriormente citados métodos.
Posteriormente se estudiará cada método en detalle, incluyendo los métodos
de particionado, jerárquico, basados en densidad, basados en rejilla, y
basados en modelos.
Los pasos de una tarea de clustering típica se pueden resumir en los cinco siguientes, A.
K. Jain and R. C. Dubes (1988), divididos por los que realizan el agrupamiento de los
datos en clústeres frente a los que se refieren a la utilización de la salida.
Agrupamiento de los datos:
1. Representación del patrón (opcionalmente incluyendo características de la
extracción y/o selección).
2. Definición de una medida de la proximidad de patrones apropiada para el
dominio de los datos.
3. Clustering propiamente dicho (agrupamiento de los patrones).
Utilización de la salida:
4. Abstracción de los datos (si es necesario).
5. Evaluación de la salida (si es necesario).
La representación del patrón se refiere al número de clases, el número de patrones
disponible, y el número, tipo, y escala de las características disponibles para el algoritmo
de clustering. La selección de características es el proceso de identificar el subconjunto
más apropiado de características dentro del conjunto original para utilizarlo en el proceso
de agrupamiento. La extracción de características es el uso de una o más transformaciones
de las características de la entrada para producir nuevas características de salida. La
proximidad de patrones se mide generalmente según una función de distancia definida
para pares de patrones. Existen gran variedad de funciones de distancias que han sido
utilizadas por diversos autores y que serán descritas más adelante.

36
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
El paso de agrupamiento o clustering propiamente dicho puede ser realizado de diversas
formas. El clustering de salida puede ser hard (duro) o fuzzy (difuso).
El primero realiza una partición de los datos en grupos y en el segundo cada patrón tiene
un grado variable de calidad en cada uno de los clústeres de salida. Los algoritmos de
clustering jerárquicos son una serie jerarquizada de particiones basadas en un criterio de
combinación o división de clústeres según su semejanza. Los algoritmos de clustering
particionales identifican la partición que optimiza un criterio de agrupamiento. Todas las
técnicas se detallarán más adelante.
Es difícil evaluar si la salida de un algoritmo de clustering ha obtenido clústeres válidos
o útiles para el contexto concreto en el que se aplica. Hay que tener en cuenta la cantidad
y calidad de recursos de que se dispone, así como las restricciones tiempo y espacio
establecidos. Debido a estas razones es posible que haya que realizar un análisis previo
de la información que se desea procesar.
El análisis de validez de clústeres consiste en la evaluación de la salida obtenida por el
algoritmo de clustering. Este análisis utiliza a menudo un criterio específico; sin embargo,
estos criterios llegan a ser generalmente subjetivos. Así, existen pocos estándares en
clustering excepto en subdominios bien predefinidos.
Los análisis de validez deben ser objetivos,Dubes R. C. (1993), y se realizan para
determinar si la salida es significativa. Cuando se utiliza aproximaciones de tipo
estadístico en clustering, la validación se logra aplicando cuidadosamente métodos
estadísticos e hipótesis de prueba. Hay tres tipos de estudios de la validación:
1. La evaluación externa de la validez compara la estructura obtenida con una
estructura a priori.
2. La evaluación interna intenta determinar si una estructura es intrínsecamente
apropiada para los datos.
3. La evaluación relativa compara dos estructuras y mide la calidad relativa de
ambas.
Así, la medida de la distancia es un aspecto clave en multitud de técnicas de minería de
datos. Puesto que la semejanza entre patrones es fundamental a la hora de definir un
clúster, es necesario establecer una forma de medir esta semejanza. La gran variedad de
tipos de atributos hace que la medida (o medidas) de semejanza debe ser elegida
cuidadosamente. Lo más común es calcular el concepto contrario, es decir, la diferencia
o disimilitud entre dos patrones usando la medida de la distancia en un espacio de
características. Existen unos cuantos métodos para definir la distancia entre objetos. La
medida de distancia más popular es la distancia euclídea que se define como:
𝑑(𝑖, 𝑗) = √|𝑥𝑖1 − 𝑥𝑗1|2 + |𝑥𝑖2 − 𝑥𝑗2|2 + ⋯ + |𝑥𝑖𝑝 − 𝑥𝑗𝑝|2 (3.4.1)
Donde i = (xi1, xi2, · · · , xip) y j = (xj1, xj2, · · · , xjp) son dos objetos de p dimensiones.
La distancia euclídea nos da una medida intuitiva de la distancia entre dos puntos en un
espacio de dos o tres dimensiones. Esto puede ser útil cuando los clústeres son
compactos,Mao J. and Jain A. (1996).

37
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Otra métrica utilizada es la distancia Manhattan, definida por:
𝑑(𝑖, 𝑗) = |𝑥𝑖1 − 𝑥𝑗1| + |𝑥𝑖2 − 𝑥𝑗2| + ⋯ + |𝑥𝑖𝑝 − 𝑥𝑗𝑝| (3.4.2)
Tanto la distancia euclídea como la distancia Manhattan satisfacen los siguientes
requisitos matemáticos para una función de distancia:
1. d(i, j) >= 0. Esto es, la distancia es un número no negativo.
2. d(i, i) = 0. Es decir, la distancia de un objeto a él mismo es cero.
3. d(i, j) = d(j, i). La distancia es una función simétrica.
4. d(i, j) =<d(i, h) + d(h, j). Se trata de una desigualdad triangular que afirma
que ir directamente desde un punto i hasta un punto j nunca es más largo que
pasando por un punto intermedio h.
Finalmente, la distancia Minkowski es una generalización de las distancias Manhattan y
euclídea. Se define por:
𝑑(𝑖, 𝑗) = (|𝑥𝑖1 − 𝑥𝑗1|𝑞
+ |𝑥𝑖2 − 𝑥𝑗2|𝑞
+ ⋯ + |𝑥𝑖𝑝 − 𝑥𝑗𝑝|𝑞
)1/𝑞 (3.4.3)
Donde q es un entero positivo. Representa a la distancia Manhattan cuandoq = 1 y a la
euclídea cuando q = 2. El inconveniente que presenta dicha medida de la distancia es la
tendencia de los atributos de mayor magnitud a dominar al resto. Para solucionar esta
desventaja se puede normalizar los valores de los atributos continuos, de forma que todos
tomen valores dentro de un mismo rango. Por otro lado, la correlación entre los distintos
atributos puede influir negativamente en el cálculo de la distancia. Para dar solución a
este problema se usa la distancia cuadrática de Mahalanibis:
𝑑𝑀(𝑥𝑖 , 𝑥𝑗) = (𝑥𝑖, 𝑥𝑗) ∑ (𝑥𝑖, 𝑥𝑗)𝑇−1 (3.4.4)
Donde xi y xj son vectores fila y P es la matriz de covarianza de los patrones. La distancia
asigna diferentes pesos a cada característica basándose en la varianza y en la correlación
lineal de los pares. Si a cada variable se le asigna un peso de acuerdo con su importancia,
la nueva distancia euclídea ponderada se puede calcular de la siguiente manera:
𝑑(𝑖, 𝑗) = √𝑤1|𝑥𝑖1 − 𝑥𝑗1|2 + 𝑤2|𝑥𝑖2 − 𝑥𝑗2|2 + ⋯ + 𝑤𝑝|𝑥𝑖𝑝 − 𝑥𝑗𝑝|2 (3.4.5)
Este escalado es también aplicable a las distancias Manhattan y Minkowski.
Las medidas de los coeficientes de similitud o disimilitud pueden ser utilizadas para
evaluar la calidad del clúster. En general la disimilitud d(i, j) es un número positivo
cercano a cero cuando i y j están próximos el uno del otro y se hace grande cuando son
más diferentes.
Las disimilitudes se pueden obtener mediante una simple clasificación subjetiva, hecha
por un grupo de observadores o expertos, de cuánto difieren determinados objetos unos
de otros.
Por ejemplo, en ciencias sociales se puede clasificar lo cercano que un sujeto está de otro,
así como en matemáticas, biología o física.

38
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Alternativamente, las disimilitudes se pueden calcular con coeficientes de correlación.
Dados n objetos para clasificar la correlación producto-momento de Pearson entre dos
variables f y g se define en (3.4.5), donde f y g son variables que describen los objetos,
mf y mg son los valores medios de f y g respectivamente y xif es el valor de f para el objeto
i−ésimo, equivalentemente xig es el valor de g para el objeto i−ésimo.
𝑅(𝑓, 𝑔) =∑ (𝑥𝑖𝑓−𝑚𝑓)(𝑥𝑖𝑔−𝑚𝑔)𝑛
𝑖=1
√∑ (𝑥𝑖𝑓−𝑚𝑓)2𝑛𝑖=1 √∑ (𝑥𝑖𝑔−𝑚𝑔)2𝑛
𝑖=1
(3.4.6)
La fórmula de conversión (3.4.6) se usa para calcular los coeficientes de disimilitud d(f,
g) tanto para coeficientes de correlación paramétricos como para coeficientes de
correlación no paramétricos.
𝑑(𝑓, 𝑔) =1−𝑅(𝑓,𝑔)
2 (3.4.7)
El tener variables con valores de correlación altos y positivos implica que el coeficiente
de disimilitud está cercano a cero. Por el contrario, aquellas variables que tengan una
correlación alta negativa tendrán un coeficiente de disimilitud cercano a uno, es decir, las
variables son muy diferentes.
En determinadas aplicaciones los usuarios pueden preferir usar la fórmula de conversión
(3.4.7) donde las variables con valores de correlación altos (tanto positivos como
negativos) tienen asignadas el mismo valor de similitud.
d(f, g) = 1− | R(f, g) | (3.4.8)
Igualmente, hay quien puede querer usar coeficientes de similitud s(i, j) en vez del
coeficiente de disimilitud. La fórmula (3.4.8) puede usarse para relacionar ambos
coeficientes.
s(i, j) = 1 − d(i, j) (3.4.9)
Nótese que no todas las variables deberían estar incluidas en el análisis de clustering.
Incluir una variable que no aporte significado a un clustering dado puede hacer que la
información útil proporcionada por otras variables quede enmascarada.
Por ejemplo, en el caso de que se quisiera hacer clustering de un grupo de personas de
acuerdo con sus características físicas, incluir el atributo número de teléfono resultaría
altamente ineficiente y, por tanto, este tipo de variables basura deben se excluidas del
proceso de clustering.
A continuación se expone los tipos de datos que aparecen con frecuencia en el clustering
y cómo se preprocesan los mismos. Supóngase que el conjunto de los datos objetivo
contiene n objetos que pueden representar personas, casas, o cualquier otra variable que
pueda imaginar. Los principales algoritmos de clustering basados en memoria operan
normalmente en una de las dos siguientes estructuras de datos.
1. Matriz de datos. Ésta representa n objetos, como pueden ser n personas, con
p variables (también llamadas atributos), como pueden ser edad, altura o
peso. La estructura tiene forma de tabla relacional o de matriz de dimensión
n × p (n objetos por p variables), se muestra en (3.4.10).

39
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
[
𝑥11 𝑥22 ⋯ 𝑥1𝑝
𝑥21 𝑥22 ⋯ 𝑥2𝑝
⋯ ⋯ ⋱ ⋯𝑥𝑛1 𝑥𝑛2 ⋯ 𝑥𝑛𝑝
] (3.4.10)
2. Matriz de disimilitud. Almacena la colección de distancias disponibles para
todos los pares de n objetos. Se suele representar como una tabla n × n, tal y
como se muestra a continuación.
[
0 0 ⋯ 0𝑑(2,1) 0 ⋯ 0
⋯ ⋯ ⋱ ⋯𝑑(𝑛, 1) 𝑑(𝑛, 2) ⋯ 0
] (3.4.11)
Donde d(i, j) es la distancia medida entre los objetos i y j. Ya que d(i, j) =d(j, i) y que d(i,
i) = 0 tenemos la matriz mostrada en (3.4.11). Las medidas de similitud serán discutidas
en este apartado.
La matriz de datos suele llamarse matriz de dos modos, mientras que la matriz de
disimilitud se llama matriz de un modo ya que las filas y columnas de la primera
representan entidades diferentes, mientras que las de la segunda representan la misma
entidad. Muchos algoritmos de clustering trabajan con la matriz de disimilitud. Si la
entrada se presenta como una matriz de datos, se deben transformar en una matriz de
disimilitud antes de aplicar dichos algoritmos.
Se comentarán a continuación las distintas técnicas de clustering existentes.
Existen un gran número de algoritmos de clustering en la actualidad. La elección de una
técnica u otra dependerá tanto del tipo de datos disponibles como del propósito de la
aplicación. Si se utiliza el análisis de clustering como una herramienta descriptiva o
exploratoria, es posible que se prueben distintos algoritmos sobre los mismos datos con
el fin de ver cuál es el método que mejor se ajusta al problema.
En general, los métodos de clústeres se pueden agrupar en las siguientes categorías:
1. Métodos particionales. Dada una base de datos con n objetos, un método
particional construye k grupos de los datos, donde cada partición representa
a un clúster y k ≤n. Esto es, clasifica a los datos en k grupos que satisfacen
los siguientes requisitos:
Cada grupo debe contener, al menos, un elemento.
Cada elemento debe pertenecer únicamente a un grupo.
Nótese que el segundo requerimiento se relaja en ciertas técnicas
particionales difusas.
Dado k, el número de particiones que se deben construir, los métodos
particionales realizan una partición inicial. A continuación, utilizan una
técnica iterativa de recolocación que intenta mejorar la partición moviendo
los objetos de un grupo a otro. El criterio general para decidir si una partición

40
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
es buena es que los objetos pertenecientes al mismo clúster estén cerca
mientras que los objetos pertenecientes a los clústeres restantes estén lejos de
ellos.
Conseguir una optimización global de un clustering basado en particiones
requeriría una enumeración exhaustiva de todas las posibles particiones.
Por el contrario, la mayoría de las aplicaciones adoptan una de las dos
heurísticas más populares:
Algoritmo K-means, donde cada clúster se representa por medio de
los objetos en el clúster. Existen algunas variaciones de este método
como el Expectation Maximization.
Algoritmo K-medianas, donde cada clúster se representa por uno de
los objetos situados cerca del centro del clúster.
Estas heurísticas funcionan bien para bases de datos pequeñas o medianas
que tengan una forma esférica. Para encontrar clústeres con formas más
complejas y en bases de datos más grandes, se debe recurrir a extensiones de
los mismos.
2. Métodos jerárquicos. Estos métodos crean una descomposición jerárquica del
conjunto de datos objeto de estudio. Un método jerárquico puede ser
clasificado como aglomerativo o divisivo:
Aglomerativo: comienza con cada patrón en un clúster distinto y combina
sucesivamente clústeres próximos hasta un que se satisface un criterio
preestablecido.
Divisivo: comienza con todos los patrones en un único clúster y se
realizan particiones de éste, creando así nuevos clústeres hasta satisfacer
un criterio predeterminado.
Los métodos jerárquicos presentan un pequeño inconveniente y es que una
vez que un paso se realiza (unión o división de datos), éste no puede
deshacerse. Esta falta de flexibilidad es tanto la clave de su éxito, ya que
arroja un tiempo de computación muy bajo, como su mayor problema puesto
que no es capaz de corregir errores.
Si se usa primero el algoritmo aglomerativo jerárquico y después la
recolocación iterativa se puede sacar más provecho de estas técnicas. Existen,
de hecho, ciertos algoritmos como BIRCH, Zhang T, Ramakrishnan R., and
Livny M. (1996), y CURE,Guha S., Rastogi R., and Shim K. (1998), que han
sido desarrollados basándose en esta solución integrada.
3. Métodos basados en densidad. La mayoría de los métodos particionales sólo
pueden encontrar clústeres de forma esférica. Para paliar este efecto, se han
desarrollado técnicas de clustering basados en la noción de densidad. La idea
subyacente es continuar aumentando el tamaño del clúster hasta que la
densidad (número de objetos o datos) en su vecindad exceda de un
determinado umbral, es decir, para cada dato perteneciente a un clúster, la
vecindad de un radio dado debe contener al menos un mínimo de número de
puntos. Este método se puede usar para eliminar ruido (outliers) y para
descubrir clústeres de forma arbitraria. El DBSCAN es un método métodos
típicamente basado en densidad.

41
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Existen otros tipos de técnicas de clustering, métodos basados en rejilla y métodos
basados en modelos, que dada su escaso peso en las aplicaciones que se estudian en este
documento no serán detallados con profundidad.
Mención aparte merecen los fuzzy (difusos) clustering y su estudio se realiza en sucesivos
apartados.
Se comentará ahora los distintos tipos de algoritmos particionales, como son el algoritmo
K-means (K-medias), el algoritmo Expectation Maximization (EM) y el algoritmo K-
mediods (K-medianas).
Algoritmo K-means (K-medias)
El algoritmo K-means fue propuesto por MacQueen en el año
1968,MacQueen J. (1968). Este algoritmo coge el parámetro de entrada, k, y
particiona el conjunto de n datos en los k clústeres de tal manera que la
similitud intra-clúster es elevada mientras que la inter-clúster es baja. Dicha
similitud se mide en relación al valor medio de los objetos en el clúster, lo
que puede ser visto como si fuera su centro de gravedad.
El algoritmo procede como sigue. En primer lugar, escoge aleatoriamente k
objetos haciendo que éstos representen el centro del clúster. Cada uno de los
objetos restantes se va asignando al clúster que sea más similar basándose en
la distancia del objeto a la media del clúster. Entonces computa la nueva
media de cada clúster y el proceso sigue iterando hasta que se consigue la
convergencia (se minimiza el error cuadrático medio).
El método es relativamente escalable y eficiente para el procesado de
conjuntos de datos grandes ya que la complejidad computacional del
algoritmo es O(nkt), donde n es el número de objetos, k el número de clústeres
y t el número de iteraciones. Normalmente k << n y t << N, produciéndose
un óptimo local.
El K-means se puede aplicar sólo cuando la media de un clúster puede ser
definida, esto es, no es de aplicación en los casos en que los atributos sean
categóricos. Otro inconveniente es su sensibilidad al ruido y a los outliers.
Además, la necesidad de dar el valor de k a priori resulta uno de sus mayores
puntos débiles.
Algoritmo Expectation Maximization (EM)
Este algoritmo es una variante del K-means y fue propuesto por Lauritzen en
1995, MacQueen J. (1995). Se trata de obtener la FDP (función de densidad
de probabilidad) desconocida a la que pertenecen el conjunto completo de
datos. Esta FDP se puede aproximar mediante una combinación lineal de NC
componentes, definidas a falta de una serie de parámetros𝜃 =∪ 𝜃𝑗∀𝑗=
1. . 𝑁𝐶, que son los que hay que averiguar,
𝑃(𝑥) = ∑ 𝜋𝑗𝑝(𝑥; 𝜃𝑗)𝑁𝐶𝑗=1 (3.4.11)
con
∑ 𝜋𝑗𝑁𝐶𝑗=1 = 1 (3.4.12)
Donde𝜋𝑗 son las probabilidades a priori de cada clúster cuya suma debe ser
1, que también forman parte de la solución buscada, 𝑃(𝑥)denota la FDP
arbitraria y 𝑝(𝑥; 𝜃𝑗) la función de densidad del componente j. Cada clúster se

42
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
corresponde con las respectivas muestras de datos que pertenecen a cada una
de las densidades que se mezclan. Se pueden estimar FDP de formas
arbitrarias, utilizándose FDP normales n-dimensionales, t-Student, Bernoulli,
Poisson, y log-normales. El ajuste de los parámetros del modelo requiere
alguna medida de su bondad, es decir, cómo de bien encajan los datos sobre
la distribución que los representa. Este valor de bondad se conoce como el
likelihood de los datos. Se trataría entonces de estimar los parámetros
buscados 𝜃, maximizando este likelihood (este criterio se conoce como ML-
Maximun Likelihood). Normalmente, lo que se calcula es el logaritmo de este
likelihood, conocido como log-likelihood, ya que es más fácil de calcular de
forma analítica. La solución obtenida es la misma gracias a la propiedad de
monotonicidad del logaritmo. La forma de esta función log-likelihood es:
𝐿(𝜃, 𝜋) = 𝑙𝑜𝑔Π𝑛=1𝑁𝐼 𝑃(𝑥𝑛) (3.4.13)
Donde NI es el número de instancias, que suponemos independientes entre
sí.
El algoritmo EM, procede en dos pasos que se repiten de forma iterativa:
1. Expectation. Utiliza los valores de los parámetros iniciales o
proporcionados por el paso Maximization de la iteración anterior,
obteniendo diferentes formas de la FDP buscada.
2. Maximization. Obtiene nuevos valores de los parámetros a partir de
los datos proporcionados por el paso anterior.
Después de una serie de iteraciones, el algoritmo EM tiende a un máximo
local de la función L. Finalmente se obtendrá un conjunto de clústeres que
agrupan el conjunto de proyectos original. Cada uno de estos clúster estará
definido por los parámetros de una distribución normal.
Algoritmo K-mediods (K-medianas)
Como se comentó anteriormente, el algoritmo K-means es sensible a los
outliers ya que un objeto con un valor extremadamente elevado puede
distorsionar la distribución de los datos. En lugar de coger el valor medio de
los objetos de un clúster como punto de referencia, se podría tomar un objeto
representativo del clúster, llamado mediod, Kaufman L. and Rousseeuw P.
J., (1990), que sería el punto situado más al centro del clúster.
Así, el método particional puede ser aplicado bajo el principio de minimizar
la suma de las disimilitudes entre cada objeto y con su correspondiente punto
de referencia.
El algoritmo trata, pues, de determinar k particiones para n objetos. Tras una
selección inicial de los kmediods, el algoritmo trata de hacer una elección
mejor de los mediods repetidamente. Para ello analiza todos los posibles
pares de objetos tales que un objeto sea el mediod y el otro no. La medida de
calidad del clustering se calcula para cada una de estas combinaciones. La
mejor opción de puntos en una iteración se escoge como los mediods para la
siguiente iteración.
El coste computacional de cada iteración es de O(k(n − 𝑘)2), por lo que
para valores altos de k y n el coste se podría disparar.

43
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
El algoritmo K − mediods es más robusto que el K − means frente a la
presencia del ruido y de los outliers ya que la mediana es menos influenciable
por un outlier, u otro valor extremo, que la media. Sin embargo, su procesado
es mucho más costoso y además necesita también que el usuario le
proporcione el valor de k.
3.5. Evaluación
Una vez se ha aplicado la técnica o técnicas de minería de datos elegidas, y se han
obtenido el o los modelos de conocimientos que representan patrones de comportamiento
observados en los valores, es necesario validarlos para comprobar que las resultados que
se obtienen son, efectivamente, válidos y lo suficiente satisfactorios. En el caso de que
sea hayan obtenido más de un modelo se deben comparar para buscar el que se ajuste
mejor al problema.
Si resultara que ninguno de los modelos obtiene los resultados esperados, debe volverse
a alguno de los pasos anteriores y alterarlos para generar nuevos modelos.
Por otra parte, si el modelo final no pasará la evaluación, el proceso se podría repetirse
desde el comienzo o a partir de los pasos anteriores, sopesando el incluir otros datos, otros
algoritmos, otras metas u otras estrategias. Se puede considerar este paso como crucial,
en donde se requiere tener conocimiento del dominio.
De otro lado, si el modelo es validado y resulta ser aceptable, es decir, que proporciona
salidas adecuadas y ofrece márgenes de error admisibles, se puede entonces considerar
listo para su explotación e interpretación.
Pero antes de comenzar con la evaluación del modelo es necesario contar con una serie
de parámetros de calidad.
Nos centraremos en los más usados, contando con los indicadores previos que
necesitamos usar:
Verdaderos positivos, TP (del inglés true positive). Es definido como el número de
veces que el clasificador asigna un 1 a la instancia que está clasificando, y éste,
efectivamente, ocurre durante los siguientes cinco días. (Predice la ocurrencia del
evento analizado)
Verdaderos negativos, TN (del inglés true negative). Se define como el número de
veces que se ha predicho que no ocurrirá el evento analizado durante los cinco
próximos días, y verdaderamente, éste no ocurre. (Predice la no ocurrencia del evento
analizado)
Falso positivo, FP (del inglés false positive). Es definido como el número de veces
que se detecta de forma errónea que sucederá el evento analizado en los próximos
cinco días. En otras palabras, indica el número de veces que el clasificador asignó
una etiqueta con valor 1 cuando en realidad debía asignar un 0. (Predice la ocurrencia
del evento analizado, y este no ocurre)

44
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Falso negativo, FN (del inglés, false negative). Se define como el número de veces
que se ha predicho que no ocurrirá el evento analizado durante los próximos cinco
días, y sin embargo, éste ocurre. (Predice la no ocurrencia del evento analizado, y en
realidad ocurre)
A partir de los indicadores anteriores, se calculan los parámetros de calidad propiamente
dichos. En particular:
Sensibilidad, S: Se define como la proporción de eventos identificados
correctamente, sobre el total de los mismos, sin tener en cuenta los FP. De forma
matemática se expresa como: S = TP / (TP + FN). Estadísticamente indica la
capacidad del estimador elegido para identificar como casos positivos los que de
verdad lo son, o puede verse también como la proporción de eventos correctamente
identificados.
Especificidad, E: Es definido como el ratio de negativos identificados de forma
correcta. De forma matemática se expresa como: E= TN / (TN+FP). Estadísticamente
indica la capacidad del estimador para dar como casos negativos los que realmente
lo son, o puede verse también como la proporción de eventos negativos
correctamente identificados.
3.6. Interpretación
Una vez el modelo ha sido validado, se tiene que pasar a interpretar los resultados
obtenidos. Para ello se hace imprescindible tener un buen conocimiento del dominio
tratado y así poder interpretar correctamente los patrones obtenidos, de esta forma podrá
ser traducido y explicado en términos que puedan entender usuarios no expertos en la
materia.
El fin de la interpretación no es más que, en base a los modelos o patrones conseguidos,
llegar a una conclusión que lleve a reafirmar la hipótesis que se tenía o la desmientan y
lleven a otra hipótesis e interpretación de los resultados, para así llegar a una hipótesis
final.

45
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
4. Desarrollo de una metodología para la detección de patrones
precursores de terremotos
Siguiendo con la metodología de KDD explicada anteriormente de forma teórica vamos
a aplicarla a la práctica en el proyecto que he realizado.
4.1. Preprocesamiento y transformación
En este apartado se detalla la fase de preparación de los datos así como su trasformación.
4.1.1. Filtrado
En esta etapa podemos ver que las tareas más importantes a realizar durante esta etapa
son:
Establecer el valor de la magnitud (M).
Establecer el número de agrupaciones.
Una vez cargado el archivo podemos obtener un rango de magnitudes con la que dicho
archivo ha trabajado, por lo que debemos establecer el valor de la magnitud mínima que
queremos predecir dentro de dicho rango.
También tenemos que establecer el número de agrupaciones que deseamos obtener, de
este modo se puede elegir una agrupación de uno, en el caso de que no se deseen agrupar
los registros/filas del archivo que se ha cargado previamente para no perder valor sobre
los datos. Aunque es posible que el archivo sea excesivamente grande y deseemos
acortarlo realizando agrupaciones de los diferentes registros/filas que contiene dicho
archivo.
Esta etapa es la encargada de cargar los datos (.arff) y realiza una transformación del
fichero dependiendo de los parámetros que se le indique. Se debe realizar antes de avanzar
hacia la siguiente etapa.
4.1.2. Clustering
Una vez que los datos se encuentren previamente filtrados, entonces podremos avanzar
hasta la etapa de Clustering, donde gracias a la ayuda de la API de Weka se puede realizar
un clusterizado al archivo con el algoritmo “SimpleKMeans” indicando previamente el
valor de “K”, es decir, indicando el número de cluster que se van a formar. Las
posibilidades establecidas son desde 2 hasta 5 números de cluster, donde el usuario es el
que decide.
Una vez decidido se iniciará a realizar dicho algoritmo de clustering, donde los datos
resultantes serán guardados en otro archivo (.arff), preparándolo ya para la siguiente
etapa.
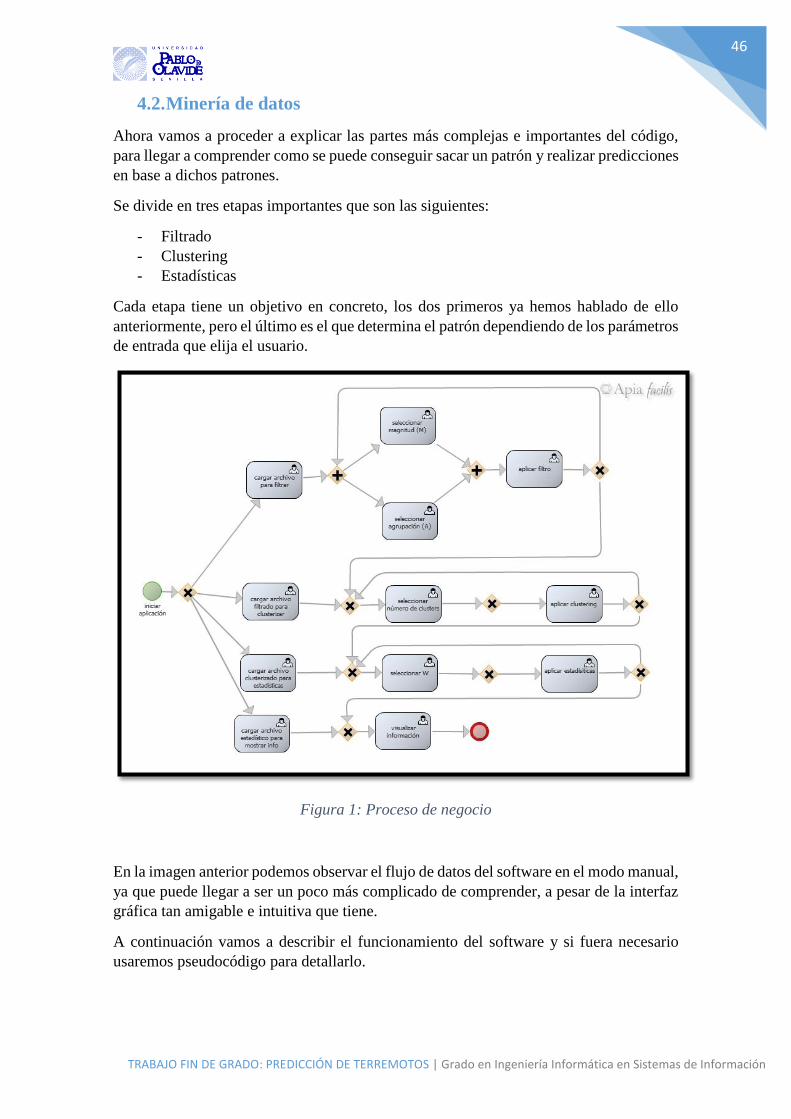
46
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
4.2. Minería de datos
Ahora vamos a proceder a explicar las partes más complejas e importantes del código,
para llegar a comprender como se puede conseguir sacar un patrón y realizar predicciones
en base a dichos patrones.
Se divide en tres etapas importantes que son las siguientes:
- Filtrado
- Clustering
- Estadísticas
Cada etapa tiene un objetivo en concreto, los dos primeros ya hemos hablado de ello
anteriormente, pero el último es el que determina el patrón dependiendo de los parámetros
de entrada que elija el usuario.
Figura 1: Proceso de negocio
En la imagen anterior podemos observar el flujo de datos del software en el modo manual,
ya que puede llegar a ser un poco más complicado de comprender, a pesar de la interfaz
gráfica tan amigable e intuitiva que tiene.
A continuación vamos a describir el funcionamiento del software y si fuera necesario
usaremos pseudocódigo para detallarlo.

47
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
4.2.1. Filtrado
1º PASO:
Abrir archivo y guardar la información de manera ordenada.
- Guardamos todas las línea de atributos (ej: “@attribute continuousClass
numeric”) en una lista de String.
- Como podemos en el ejemplo de la siguiente imagen, los datos están guardados
de modo que una línea/registro contiene valores (separados por coma), el número
de valores se corresponde con el número de atributos. Por lo tanto se necesita una
lista de lista de String, donde la lista contendrá listas (líneas/registros) y en cada
lista contendrá un valor (dicho valor hace referencia al valor de un atributo).
Figura 2: Organización de los atributos del archivo ARFF
2ºPASO:
Filtrar y exportar a un archivo.
- Filtrar y exportar atributos:
Al filtrar tenemos que indicar una M (ejemplo: 3.5), por tanto no hay que exportar
aquellos atributos que hagan referencia a otras M, como podemos observar en la
siguiente imagen.

48
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Figura 3: Seleccionamos los atributos necesarios
Mientras vamos exportando los atributos necesarios, guardamos en un Array la
posición de aquellos atributos que SI se exportan, porque luego nos será útil para
el filtro de datos. Ya que el orden de los atributos es el mismo orden que el de los
valores.
- Filtrar y exportar datos:
A la hora de manejar los datos solo se trata de localizar las posiciones de los
atributos que SI son exportados y ver cuáles son sus correspondientes datos,
realizando la agrupación indicada por el usuario.
Podemos ver en la siguiente imagen un ejemplo de cómo serían las agrupaciones
(agrupación = 2) y las selecciones de los datos para luego ser exportados a otro
archivo.

49
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Figura 4: Seleccionamos los datos necesarios y los agrupamos
En el caso de que se desee observar más detenidamente, tenemos a continuación
el pseudocodigo que lo explica de manera más detallada como se filtra y exporta
los datos.
Inicio
listaAtributos // lista de atributos (aunque aquí lo trataremos como array en vez de lista)
listaValores // lista de lista de valores (aunque aquí lo trataremos como array de array en vez de lista de lista)
agrupacion // número que indica agrupación que se ha seleccionado al filtrar
arrayAtribSelect // array que contiene los números de las posiciones de los atributos que SI se han exportado
Para i0 hasta tam(listaValores) en ii+agrupacion hacer
Para j0 hasta tam(arrayAtribSelect) en jj+1 hacer
exportarArchivo(agruparValores(arrayAtribSelect[j],i))
Fin
Fin
Fin
Programa agruparValores(posicion, línea)
Var res
Si listaAtributos[posicion] contiene “x” o “T” Entonces
ressacarUltimoMenosPrimero(posicion,línea)
Si no, Si listaAtributos[posicion] contiene "@attribute continuousClass numeric"
Entonces
ressacarMaximo(posicion,línea)
Si no
ressacarPromedio(posicion,línea)
FinSi
Devuelve res
FinPrograma

50
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Programa sacarUltimoMenosPrimero(posicion,línea)
Var primero listaValores[linea][posicion]
Var ultimo, res
Var entra false
Para k1 hasta k >= agrupacion OR línea+k >= tam(listaValores) en kk+1 hacer
entratrue
ultimo listaValores[línea+k][posicion]
Fin
Si entra = true Entonces
res ultimo-primero
Sino
res primero
FinSi
Devuelve res
FinPrograma
Programa sacarMaximo(posicion,línea)
Var res listaValores[linea][posicion]
Var maximo
Para k1 hasta k >= agrupacion OR línea+k >= tam(listaValores) en kk+1 hacer
maximo listaValores[línea+k][posicion]
Si res < maximo Entonces
resmaximo
FinSi
Fin
Devuelve res
FinPrograma
Programa sacarPromedio(posicion,línea)
Var res0
Para k0 hasta k >= agrupacion OR línea+k >= tam(listaValores) en kk+1 hacer
res res + listaValores[línea+k][posicion]
Fin
resres / k
Devuelve res
FinPrograma
4.2.2. Clustering
1º PASO:
Con la ayuda de la librería de Weka carga el archivo que queremos clusterizar, crea una
instancia, crea el algoritmo a aplicar, en este caso el algoritmo SimpleKMeans, le
asignamos el número de cluster a realizar y luego se realiza el clustering.

51
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
2º PASO:
Una vez realizado solo queda exportarlo a un archivo.
Para ello tenemos que pasar todos los atributos más el atributo del cluster (ejemplo:
“@attribute cluster {0,1,2}”). Luego añadimos los datos línea a línea, y por cada línea
agregamos al final de la misma el número del cluster que se ha generado en el paso previo.
En la siguiente imagen podemos observar un fragmento de un archivo arff una vez ya
clusterizado.
Figura 5: Archivo ARFF ya clusterizado
4.2.3. Estadísticas
Hay dos formas diferentes de realizar las estadísticas de un fichero “arff” que se encuentra
ya filtrado y clusterizado por el programa. A continuación se detalla el funcionamiento
de cada una, dependiendo si desea mostrar la mejor estadística o estadísticas con una W
fija.
4.2.3.1. Con tamaño de W estático
PASO 1:
Con un bucle vamos tratando línea a línea, de tal forma que solamente necesitamos los
dos últimos valores correspondientes a los atributos “ContinuousClass” y “Cluster”. Al
ser la W fija se hacen grupos del tamaño elegido en la W, siendo la combinación de W
los clusters que se encuentran dentro del grupo, y el ContinuousClass elegido es el último
del grupo y una vez obtenido los datos realizamos el paso 2, esto se repite hasta que
termina el bucle. Por ejemplo, podemos ver en la siguiente imagen que con una W de 3,
cogemos los valores del atributo “cluster” de la primera, segunda y tercera fila (en ese
orden), siendo esto la combinación de W, y también cogemos el valor del atributo

52
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
“ContinuousClass” de la tercera fila, de esta forma, se va repitiendo con todos los
registros/líneas del fichero ARFF.
Figura 6: Extraer resultados del archivo ARFF
PASO 2:
Una vez que tenemos la combinación de W y el ContinuousClass, tenemos que guardarlo.
Para ello necesitamos una lista donde se irá guardando las diferentes combinaciones,
cuantas veces se repiten en el archivo (ocurrencias) y de estas ocurrencias, cuantas veces
el valor del ContinuousClass supera o no a la M seleccionada en la fase de filtrado
(aciertos).
Figura 7: [Combinación] aciertos / ocurrencias
PASO 3:
Una vez hecho el paso 1 (y por lo tanto el paso 2, ya que está incluido en el paso 1)
tendremos una lista con las diferentes combinaciones de W que contiene el archivo,
solamente tendremos que ordenarlas, para ello el orden es según la siguiente fórmula:
𝑟𝑒𝑠𝑢𝑙𝑡𝑎𝑑𝑜 = 𝑎𝑐𝑖𝑒𝑟𝑡𝑜𝑠
𝑜𝑐𝑢𝑟𝑟𝑒𝑛𝑐𝑖𝑎𝑠
De tal forma que el orden debe ser decreciente según el resultado.

53
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
4.2.3.2. Con tamaño de W dinámico
Para esto necesitaremos un array de árboles, dicho array será del tamaño del número de
clusters que se haya indicado en cuando se realizó el clustering.
PASO 1:
Primero, tenemos que montar los árboles, es decir, crear tantos árboles como clusters
haya, y después cada árbol debe estar completado con las diferentes combinaciones
posibles, tal y como podemos ver en la siguiente imagen, suponiendo que el número de
cluster es 2.
Figura 8: Montar los árboles
Como podemos ver en la imagen anterior cada nodo contiene la combinación W y el
número de aciertos y de ocurrencias (aciertos/ocurrencias), hablaremos posteriormente
sobre esto.
PASO 2:
Segundo, tenemos que calcular los valores de los árboles, es decir, completar los aciertos
y ocurrencias de cada combinación de W. Para realizar este paso tenemos que tratar cada
nodo y buscar cuantas veces se encuentra la combinación de W en el archivo ARFF,
entonces si se encuentra hay que incrementar la ocurrencia y si la M (continuousClass)
supera la M indicada en el filtrado, también se incrementa el acierto.
Figura 9: Cálculo de valores (I)

54
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Como podemos ver en el ejemplo de la imagen anterior, en el archivo ARFF se ha
encontrado 4 veces la combinación de W [101] y de estas 4, solo 3 han superado la M en
el filtrado, por lo tanto se guardará que dicha combinación de W tiene 3 aciertos y 4
ocurrencias.
Una vez hagamos esto con todos los nodos de todos los árboles, tendremos algo similar a
la siguiente imagen.
Figura 10: Cálculo de valores (II)
PASO 3:
A continuación debemos elegir el mejor nodo de cada árbol, que serán aquellos que
tengan el número más alto al dividir los aciertos entre las ocurrencias.
Para ello recorremos el árbol de forma Preorder (padre, hijo izquierda, hijo derecha),
obteniendo los mejores nodos, tal y como podemos ver en el ejemplo de la siguiente
imagen.
Figura 11: Elegir mejores nodos (I)

55
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
PASO 4:
Luego de haber seleccionado los mejores nodos hay que comprobar que una combinación
no exista dentro de otra. En este ejemplo que estamos realizando la combinación [00] se
encuentra dentro de la combinación [100], por lo tanto se elimina el nodo con la
combinación [100] y se vuelve al paso 3 para elegir mejores nodos otra vez, así hasta que
al final no exista ninguna combinación dentro de otra.
Figura 12: Elegir mejores nodos (II)
Una vez hecho esto, tendremos una lista de las diferentes combinaciones de W que
contiene el archivo, solamente tendremos que ordenarlas, para ello el orden es según la
siguiente fórmula:
𝑟𝑒𝑠𝑢𝑙𝑡𝑎𝑑𝑜 = 𝑎𝑐𝑖𝑒𝑟𝑡𝑜𝑠
𝑜𝑐𝑢𝑟𝑟𝑒𝑛𝑐𝑖𝑎𝑠
De tal forma que el orden debe ser decreciente según el resultado.
En el caso de que se desee observar más detenidamente, tenemos a continuación el
pseudocodigo que lo explica de manera más detallada como se extraen las estadísticas del
archivo ARFF ya filtrado y clusterizado.

56
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Inicio
contador // contador especial cuya secuencia depende del número de cluster (ejemplo: nº cluster=3, secuencia:
0,1,2,00,01,02,10,11,12,20,21,22,000,001,002,…,222)
arrayArboles // array de árboles, cada posición del array contiene un árbol, el tamaño del array depende del número de cluster
numeroCluster // número de cluster que tiene el archivo
listaValores // lista de lista de valores (aunque aquí lo trataremos como array de array en vez de lista de lista)
listaResultado // lista de datos que contiene todos los datos de combinacionW (aunque aquí lo trataremos como array de datos
en vez de lista de datos)
valorM // valor de M predefinida en la fase del filtrado
montarArboles(numeroCluster)
calcularValoresDeArboles(valorM)
Var existe true
Mientras existe=true hacer
elegirMejoresNodos()
existe existeSecuenciaDentroDeOtra()
FinMientras
Fin

57
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Programa montarArboles(numeroCluster)
Var combinacionW, numero, arbol, nodoNuevo, nodoPadre, datoPadre
Mientras puedoIncrementar(contador) hacer
Contador.incremento()
combinacionWcontador.DevolverCombinacion()
numeroPrimerCaracter(combinacionW)
Si longitud(combinacionW) = 1 Entonces
nodoNuevo crearNodo(crearDato(combinacionW))
arrayArboles[numero] crearArbol(nodoNuevo)
Sino
arbolarrayArboles[numero]
nodoNuevocrearNodo(crearDato(combinacionW))
datoPadrecrearDato(todoMenosUltimoCaracter(combinacionW))
nodoPadreencontrarNodo(arbol,datoPadre)
anadirNodo(nodoPadre,nodoNuevo) // añade nodoNuevo como hijo del nodoPadre
FinSi
FinMientras
FinPrograma
Programa calcularValoresDeArboles(valorM)
Var listaNodos
Para i0 hasta tam(arrayArbol) en ii+1 hacer
listaNodosconvertirArbolEnLista(arrayArbol[i])
Para j0 hasta tam(listaNodos) en jj+1 hacer
rellenarDatosDelNodo(devolverDatoDelNodo(nodo),valorM)
Fin
Fin
FinPrograma

58
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Programa rellenarDatosDelNodo(dato,valorM)
Recorre toda la lista de lista de valores (llamada: listaValores) en busca de la combinación de W
que contenga el dato, y si lo encuentra, comprueba si supera el valor de M indicado como
parámetro de entrada, en caso de que lo supere o iguale se apunta en el dato que ha habido una
ocurrencia y un acierto, sino solo se apunta en el dato que ha habido una ocurrencia.
Una vez que termine el bucle tendremos en el dato guardado cuantas veces se ha repetido esa
combinación de W y cuantas han superado o igualado el valor de M indicado.
FinPrograma
Programa elegirMejoresNodos()
vaciar(listaResultado)
Var averageMejor,averageAux
Var datoMejor,datoAux
Var listaNodos
Var listaDatos
Para i0 hasta tam(arrayArboles) en ii+1 hacer
averageMejor0
datoMejornull
listaNodosconvertirArbolEnLista(arraArboles[i])
Para j0 hasta tam(listaNodos) en jj+1 hacer
datoAuxsacarDatoDelNodo(listaNodos[j])
vaciar(listaElegida)
agregarDatoALista(listaElegida,datoAux)
averageAuxcalcularAverage(listaElegida)
Si averageAux>averageMejor Entonces
datoMejordatoAux
averageMejoraverageAux
FinSi
Fin
agregarDatoALista(listaResultado,datoMejor)
Fin
FinPrograma

59
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Programa existeSecuenciaDentroDeOtra()
Var existefalse
Var datoA,datoB
Var nodo,nodoPadre
Para i0 hasta tam(listaResultado) OR existe=true en ii+1 hasta
datoAlistaResultado[i]
Para ji+1 hasta tam(listaResultado) OR existe=true en jj+1 hasta
datoBlistaResultado[j]
Si contiene(datoA,datoB) Entonces // si datoA contiene a datoB
existetrue
nodoencontrar(arrayArboles[i],datoA) // devuelve el nodo que
contenga ese dato en el árbol indicado
nodoPadrepadreDelNodo(nodo)
eliminarNodoHijoDelPadre(nodoPadre,nodo) // elimina el nodo del
nodo padre
Sino, Si contiene(datoB,datoA) Entonces // si datoB contiene a datoA
existetrue
nodoencontrar(arrayArboles[j],datoB)
nodoPadrepadreDelNodo(nodo)
eliminarNodoHijoDelPadre(nodoPadre,nodo)
FinSi
Fin
Fin
FinPrograma

60
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
4.2.3.3. Calcular mejor resultado
Una vez obtenido las diferentes combinaciones de W tendremos que averiguar cuál
combinación o conjunto de combinaciones es mejor. Para ello disponemos de
combinaciones de m elementos tomados de n en n (m ≥ n) a todas las agrupaciones
posibles que pueden hacerse con los m elementos de forma que:
- No entran todos los elementos.
- No importa el orden.
- No se repiten los elementos.
También podemos calcular las combinaciones mediante factoriales:
Gracias a esta combinación matemática la usaremos para realizar todas las posibles
combinaciones en la lista de las diferentes combinaciones de W que se ha debido
almacenar previamente.
Con esto conseguiremos obtener la mejor combinación de W o un conjunto de
combinaciones de W.
Figura 13: Conjunto de combinaciones de W seleccionado
En la imagen anterior podemos ver la lista de las diferentes combinaciones de W y
podemos observar que se encuentran seleccionados solamente aquellos cuyo conjunto
proporciona la mejor media, en este ejemplo la mejor media es 0.65, también podemos
ver otros cálculos de dicho conjunto, como por ejemplo la sensibilidad, especificidad,
PPV, NPV, TP, TN, FP, FN.

61
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
5. Interfaz gráfica y resultados
5.1. Interfaz gráfica
A continuación vamos a describir los pasos para saber cómo usar el programa.
Primeramente tenemos que saber que hay dos modalidades, modo manual y automático,
en el caso de que el usuario quiera obtener los mejores resultados del archivo cargado
seleccionaría el modo automático, por otro lado, en el caso de que el usuario quiera
observar el resultado con unos parámetros en concreto, debe usar el modo manual.
Para cambiar de modo solamente nos tenemos que dirigir a la barra de herramientas y
seleccionar en “modo”, después podemos elegir que modo deseamos, tal y como podemos
ver en la siguiente imagen.
Figura 14: Elegir modo
5.1.1. Modo automático
Al ejecutar el programa aparece la siguiente pantalla correspondiente al modo automático.
Figura 15: Modo automático – parte 1
Como podemos ver en la imagen anterior lo primero que debemos hacer es seleccionar el
archivo (.arff) para cargarlo, después de esto seleccionamos el número de los mejores
resultados que quieres mostrar (1-24 resultados diferentes), lo recomendado es establecer

62
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
24, de esta forma podrá ver las diferentes mejores opciones que puede ofrecer el
programa, de modo que el usuario puede visualizar cada una de ellas.
Una vez elegido el número de resultados a mostrar pulsamos sobre el botón “Mostrar
estadísticas” y esperamos un tiempo mientras que realiza el filtrado, clusterizado y extrae
las estadísticas.
Figura 16: Modo automático – parte 2
Como podemos ver en la imagen anterior una vez que realice las estadísticas mostrará la
ruta de los diferentes resultados y su media de probabilidad.
Para ver cada archivo se puede realizar de dos formas diferentes:

63
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
FORMA SIMPLE:
Puedes pulsar sobre el botón “Seleccione un archivo estadístico” y seleccionad dicho
archivo, para después visualizarlo, tal y como se puede ver en la siguiente imagen con un
archivo de ejemplo.
Figura 17: Modo simple de visualizado

64
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
FORMA COMPLEJA:
Para visualizar el archivo en modo complejo debemos cambiar al modo manual e irnos a
la pestaña “Predicciones” y por último seleccionar el botón “Seleccione un archivo
estadístico”, donde cargara los datos, mostrándonos más información sobre dicho
archivo.
En la imagen de abajo podemos observar que a la izquierda se encuentra los diferentes
registros/líneas donde cada uno hace referencia a una secuencia y en dicha secuencia
podemos saber cuántas veces se repite y cuantas veces sobrepasa la magnitud (M)
indicada en el filtrado. Y al seleccionar algunos de ellos y pulsar sobre el botón “Calcular”
nos mostrará la información de aquellos registros/líneas que hayamos seleccionado.
Figura 18: Modo complejo de visualizado

65
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
5.1.2. Modo manual
Ahora mostraremos los pasos a ejecutar en el caso del modo manual. Este modo es más
complejo pero también podemos obtener los resultados con unos parámetros en concreto.
1º FILTRADO DATOS
Figura 19: Modo complejo. Filtrado
En primer lugar seleccionaremos el archivo (.arff) que deseemos cargar en el programa.
En segundo lugar se cargarán las diferentes magnitudes (M) con las que trata el archivo,
donde tenemos que seleccionar la magnitud mínima que deseemos predecir, también
tenemos que decidir el número de agrupaciones, desde 1 hasta 7(si elegimos 1 no habrá
agrupaciones).
Por último, una vez decididos los parámetros de entrada pulsaremos sobre el botón
“Aplicar Filtro”, donde se aplicará el filtro y pasaremos automáticamente al siguiente
paso, al igual que automáticamente se mostrará cargado el archivo (.arff) que se ha
generado al filtrarlo.
2º CLUSTERIZAR DATOS
Figura 20: Modo complejo. Clusterizado

66
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Primeramente seleccionaremos el archivo (.arff) ya filtrado para cargarlo, solo en el caso
de que no se encuentre cargado, pulsando sobre el botón “Seleccione un archivo filtrado”.
Segundo elegiremos el número de cluster que deseemos para aplicárselo al algoritmo
“SimpleKMeans”. Después de elegir el parámetro de entrada pulsamos sobre el botón
“Aplicar Clustering”. Y pasaremos automáticamente al siguiente paso, al igual que
automáticamente se mostrará cargado el archivo (.arff) que se ha generado al
clusterizarlo.
3º ESTADÍSTICAS DE LOS DATOS
Figura 21: Modo complejo. Estadísticas
Para comenzar seleccionaremos el archivo para cargarlo pulsando sobre el botón
“Seleccione un archivo clusterizado”, en el caso de que no se encuentre ya cargado,
teniendo en cuenta que dicho archivo debe estar previamente filtrado y clusterizado.
A continuación elegimos el tamaño fijo de W, teniendo en cuenta que la W hace
referencia al tamaño de la secuencia (ejemplo: W= 3, secuencia [X, X, X], siendo X
cualquier número), pudiendo ser entre 1 y 7 el tamaño de la W.
También podemos elegir la opción “mejor” del tamaño de la W, al seleccionarlo
estaríamos buscando las mejores combinaciones sin establecer un número fijo del tamaño
de W.
Una vez elegido el parámetro de entrada, pulsamos sobre el botón “Mostrar Estadísticas”.
Y pasaremos automáticamente al siguiente paso, al igual que automáticamente se
mostrará cargado el archivo (.txt) que se ha generado al aplicar las estadísticas.

67
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
4º PREDICCIONES
En esta etapa veremos detalladamente las secuencias escogidas y la mejor selección que
se ha aplicado de entre las secuencias para obtener la mejor media.
Figura 22: Modo complejo. Predicciones
Como podemos ver en la imagen anterior, lo primero que hay que hacer es seleccionar el
archivo para cargarlo pulsando sobre el botón “Seleccione un archivo estadístico”, en el
caso de que no se encuentre ya cargado, teniendo en cuenta que dicho archivo (.txt) debe
contener los datos estadísticos que se realizó en la pestaña previa.
Una vez cargado dicho archivo mostrará a la izquierda las diferentes secuencias y estará
seleccionado por defecto la mejor combinación de entre dichas secuencias mostrando su
respectivo cálculo, no obstante si el usuario lo desea puede cambiar dicha selección y
luego pulsar sobre el botón “Calcular” para ver los resultados del mismo.

68
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
5.2. Resultados
A continuación vamos a mostrar una imagen por cada ciudad con la que se ha trabajado
y una breve descripción, dicha imagen contendrá los mejores resultados que se pueda
obtener, es decir, aquellos que tengan la mejor media.
5.2.1. Resultados Talca
A continuación se mostrará en la siguiente imagen los mejores resultados obtenidos con
los datos de la ciudad de Talca.
Figura 23: Resultados Talca
Como podemos ver en la imagen anterior, se muestra uno de los mejores resultados que
se han obtenido al ejecutar el software en modo automático con el archivo que contiene
datos de la ciudad de Talca, por lo que debemos tener en cuenta que en este resultado
tenemos una agrupación de 6 registros (A=6), el exigir un mínimo de magnitud de 4.8
(M=4.8), realizar un clustering con 5 clusters (K=5) y un tamaño de W no fijo (W=0), de
ese modo se obtiene la mejor combinación sin importar el tamaño de W.
Para empezar podemos observar que tenemos 19 ocurrencias, esto quiere decir que
existen 19 registros en el archivo que se ha tratado, después de haberse filtrado. También
podemos observar que solamente existen 2 aciertos, por lo tanto sabemos que solamente
2 de estos registros superan o igualan a la magnitud que se ha aplicado en el filtrado
(M=4.8).
Al observar la parte lateral izquierda de la imagen podemos ver una lista de
combinaciones de W con sus aciertos y ocurrencias de cada una de ellas.
La combinación de W es uno o varios registros sucedidos en el tiempo que dan lugar a
una secuencia determinada, gracias a esta secuencia tenemos un patrón, por lo tanto
podemos decir que una combinación de W es un patrón.

69
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Una vez que ya tenemos los diferentes patrones (por ejemplo: [0] [00] [01] [02] [1] [10]
[11] [12] [2] [20] [21] [22]) solamente tenemos que averiguar cuantas veces se repite cada
patrón en el archivo ARFF que debe estar previamente filtrado y clusterizado.
Las ocurrencias son el número de veces que aparece dicho patrón en el archivo ARFF y
los aciertos son el número de veces que dicho patrón tiene una magnitud (M) igual o
superior a la magnitud establecida en el filtrado (M=4.8), por lo tanto podemos decir que
dicho patrón se ha repetido m veces (ocurrencias) y de estas hemos acertado n veces
(aciertos).
También podemos observar que en la lista de combinaciones de W que se ha encontrado,
hemos seleccionado dentro de la misma la mejor combinación de W o el mejor conjunto
de combinaciones de W. Para realizar esta selección hemos realizado unas combinaciones
matemáticas de m elementos tomados de n en n (m ≥ n) a todas las agrupaciones posibles
que pueden hacerse con los m elementos, teniendo en cuenta que se han realizado todas
las combinaciones posibles con la n=1 hasta n=m-1 para obtener el mejor conjunto de
combinaciones de W.
Con cada grupo que se formaba (n) se realizaba unos cálculos sobre estos (TP, TN, FP,
FN, especificidad, sensibilidad, PPV, NPV) que daban lugar a la media, a través de la
cual se averiguaba si dicho grupo es el mejor conjunto de combinaciones de W.
Gracias a dicha interfaz gráfica establecida en el modo manual podemos seleccionar las
combinaciones de W que deseemos para posteriormente pulsar sobre el botón Calcular y
mostrar todos sus cálculos, de ese modo el usuario puede comprobar que la selección que
aparece por defecto es el mejor conjunto de combinaciones de W.
5.2.2. Resultados Pichilemu
A continuación se mostrará en la siguiente imagen los mejores resultados obtenidos con
los datos de la ciudad de Pichilemu.
Figura 24: Resultados Pichilemu

70
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Como podemos ver en la imagen anterior, se muestra uno de los mejores resultados que
se han obtenido al ejecutar el software en modo automático con el archivo que contiene
datos de la ciudad de Pichilemu, por lo que debemos tener en cuenta que en este resultado
tenemos una agrupación de 5 registros (A=5), el exigir un mínimo de magnitud de 3.8
(M=3.8), realizar un clustering con 3 clusters (K=3) y un tamaño de W no fijo (W=0), de
ese modo se obtiene la mejor combinación sin importar el tamaño de W.
Para empezar podemos observar que tenemos 22 ocurrencias, esto quiere decir que
existen 22 registros en el archivo que se ha tratado, después de haberse filtrado. También
podemos observar que solamente existen 9 aciertos, por lo tanto sabemos que solamente
9 de estos registros superan o igualan a la magnitud que se ha aplicado en el filtrado
(M=3.8).
Al observar la parte lateral izquierda de la imagen podemos ver una lista de
combinaciones de W con sus aciertos y ocurrencias de cada una de ellas.
La combinación de W es uno o varios registros sucedidos en el tiempo que dan lugar a
una secuencia determinada, gracias a esta secuencia tenemos un patrón, por lo tanto
podemos decir que una combinación de W es un patrón.
Una vez que ya tenemos los diferentes patrones (por ejemplo: [0] [00] [01] [02] [1] [10]
[11] [12] [2] [20] [21] [22]) solamente tenemos que averiguar cuantas veces se repite cada
patrón en el archivo ARFF que debe estar previamente filtrado y clusterizado.
Las ocurrencias son el número de veces que aparece dicho patrón en el archivo ARFF y
los aciertos son el número de veces que dicho patrón tiene una magnitud (M) igual o
superior a la magnitud establecida en el filtrado (M=3.8), por lo tanto podemos decir que
dicho patrón se ha repetido m veces (ocurrencias) y de estas hemos acertado n veces
(aciertos).
También podemos observar que en la lista de combinaciones de W que se ha encontrado,
hemos seleccionado dentro de la misma la mejor combinación de W o el mejor conjunto
de combinaciones de W. Para realizar esta selección hemos realizado unas combinaciones
matemáticas de m elementos tomados de n en n (m ≥ n) a todas las agrupaciones posibles
que pueden hacerse con los m elementos, teniendo en cuenta que se han realizado todas
las combinaciones posibles con la n=1 hasta n=m-1 para obtener el mejor conjunto de
combinaciones de W.
Con cada grupo que se formaba (n) se realizaba unos cálculos sobre estos (TP, TN, FP,
FN, especificidad, sensibilidad, PPV, NPV) que daban lugar a la media, a través de la
cual se averiguaba si dicho grupo es el mejor conjunto de combinaciones de W.
Gracias a dicha interfaz gráfica establecida en el modo manual podemos seleccionar las
combinaciones de W que deseemos para posteriormente pulsar sobre el botón Calcular y
mostrar todos sus cálculos, de ese modo el usuario puede comprobar que la selección que
aparece por defecto es el mejor conjunto de combinaciones de W.

71
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
5.2.3. Resultados Santiago
A continuación se mostrará en la siguiente imagen los mejores resultados obtenidos con
los datos de la ciudad de Santiago.
Figura 25: Resultados Santiago
Como podemos ver en la imagen anterior, se muestra uno de los mejores resultados que
se han obtenido al ejecutar el software en modo automático con el archivo que contiene
datos de la ciudad de Santiago, por lo que debemos tener en cuenta que en este resultado
tenemos una agrupación de 5 registros (A=5), el exigir un mínimo de magnitud de 3.9
(M=3.9), realizar un clustering con 5 clusters (K=5) y un tamaño de W no fijo (W=0), de
ese modo se obtiene la mejor combinación sin importar el tamaño de W.
Para empezar podemos observar que tenemos 28 ocurrencias, esto quiere decir que
existen 28 registros en el archivo que se ha tratado, después de haberse filtrado. También
podemos observar que solamente existen 9 aciertos, por lo tanto sabemos que solamente
9 de estos registros superan o igualan a la magnitud que se ha aplicado en el filtrado
(M=3.9).
Al observar la parte lateral izquierda de la imagen podemos ver una lista de
combinaciones de W con sus aciertos y ocurrencias de cada una de ellas.
La combinación de W es uno o varios registros sucedidos en el tiempo que dan lugar a
una secuencia determinada, gracias a esta secuencia tenemos un patrón, por lo tanto
podemos decir que una combinación de W es un patrón.
Una vez que ya tenemos los diferentes patrones (por ejemplo: [0] [00] [01] [02] [1] [10]
[11] [12] [2] [20] [21] [22]) solamente tenemos que averiguar cuantas veces se repite cada
patrón en el archivo ARFF que debe estar previamente filtrado y clusterizado.
Las ocurrencias son el número de veces que aparece dicho patrón en el archivo ARFF y
los aciertos son el número de veces que dicho patrón tiene una magnitud (M) igual o

72
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
superior a la magnitud establecida en el filtrado (M=3.9), por lo tanto podemos decir que
dicho patrón se ha repetido m veces (ocurrencias) y de estas hemos acertado n veces
(aciertos).
También podemos observar que en la lista de combinaciones de W que se ha encontrado,
hemos seleccionado dentro de la misma la mejor combinación de W o el mejor conjunto
de combinaciones de W. Para realizar esta selección hemos realizado unas combinaciones
matemáticas de m elementos tomados de n en n (m ≥ n) a todas las agrupaciones posibles
que pueden hacerse con los m elementos, teniendo en cuenta que se han realizado todas
las combinaciones posibles con la n=1 hasta n=m-1 para obtener el mejor conjunto de
combinaciones de W.
Con cada grupo que se formaba (n) se realizaba unos cálculos sobre estos (TP, TN, FP,
FN, especificidad, sensibilidad, PPV, NPV) que daban lugar a la media, a través de la
cual se averiguaba si dicho grupo es el mejor conjunto de combinaciones de W.
Gracias a dicha interfaz gráfica establecida en el modo manual podemos seleccionar las
combinaciones de W que deseemos para posteriormente pulsar sobre el botón Calcular y
mostrar todos sus cálculos, de ese modo el usuario puede comprobar que la selección que
aparece por defecto es el mejor conjunto de combinaciones de W.
5.2.4. Resultados Valparaíso
A continuación se mostrará en la siguiente imagen los mejores resultados obtenidos con
los datos de la ciudad de Valparaíso.
Figura 26: Resultados Valparaíso
Como podemos ver en la imagen anterior, se muestra uno de los mejores resultados que
se han obtenido al ejecutar el software en modo automático con el archivo que contiene

73
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
datos de la ciudad de Valparaíso, por lo que debemos tener en cuenta que en este resultado
tenemos una agrupación de 3 registros (A=3), el exigir un mínimo de magnitud de 4.2
(M=4.2), realizar un clustering con 4 clusters (K=4) y un tamaño de W no fijo (W=0), de
ese modo se obtiene la mejor combinación sin importar el tamaño de W.
Para empezar podemos observar que tenemos 54 ocurrencias, esto quiere decir que
existen 54 registros en el archivo que se ha tratado, después de haberse filtrado. También
podemos observar que solamente existen 14 aciertos, por lo tanto sabemos que solamente
14 de estos registros superan o igualan a la magnitud que se ha aplicado en el filtrado
(M=4.2).
Al observar la parte lateral izquierda de la imagen podemos ver una lista de
combinaciones de W con sus aciertos y ocurrencias de cada una de ellas.
La combinación de W es uno o varios registros sucedidos en el tiempo que dan lugar a
una secuencia determinada, gracias a esta secuencia tenemos un patrón, por lo tanto
podemos decir que una combinación de W es un patrón.
Una vez que ya tenemos los diferentes patrones (por ejemplo: [0] [00] [01] [02] [1] [10]
[11] [12] [2] [20] [21] [22]) solamente tenemos que averiguar cuantas veces se repite cada
patrón en el archivo ARFF que debe estar previamente filtrado y clusterizado.
Las ocurrencias son el número de veces que aparece dicho patrón en el archivo ARFF y
los aciertos son el número de veces que dicho patrón tiene una magnitud (M) igual o
superior a la magnitud establecida en el filtrado (M=4.2), por lo tanto podemos decir que
dicho patrón se ha repetido m veces (ocurrencias) y de estas hemos acertado n veces
(aciertos).
También podemos observar que en la lista de combinaciones de W que se ha encontrado,
hemos seleccionado dentro de la misma la mejor combinación de W o el mejor conjunto
de combinaciones de W. Para realizar esta selección hemos realizado unas combinaciones
matemáticas de m elementos tomados de n en n (m ≥ n) a todas las agrupaciones posibles
que pueden hacerse con los m elementos, teniendo en cuenta que se han realizado todas
las combinaciones posibles con la n=1 hasta n=m-1 para obtener el mejor conjunto de
combinaciones de W.
Con cada grupo que se formaba (n) se realizaba unos cálculos sobre estos (TP, TN, FP,
FN, especificidad, sensibilidad, PPV, NPV) que daban lugar a la media, a través de la
cual se averiguaba si dicho grupo es el mejor conjunto de combinaciones de W.
Gracias a dicha interfaz gráfica establecida en el modo manual podemos seleccionar las
combinaciones de W que deseemos para posteriormente pulsar sobre el botón Calcular y
mostrar todos sus cálculos, de ese modo el usuario puede comprobar que la selección que
aparece por defecto es el mejor conjunto de combinaciones de W.

74
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
6. Conclusión
Se ha desarrollado una metaheurística con el objetivo de obtener información valiosa para
predecir terremotos. Este método heurístico resuelve el problema computacional usando
los parámetros dados por el usuario, con la ayuda de procedimientos genéricos.
La metaheurística es aplicada a problemas que disponen de una heurística determinada
que tenga una respuesta satisfactoria.
Para realizar este software que predice terremotos nos hemos centrado en uno de los
países que suele haber más seísmos y de grandes magnitudes, como es el caso de Chile,
concretamente en cuatro ciudades, que son las siguientes:
- Santiago
- Valparaíso
- Talca
- Pichilemu
Para ello tenemos cuatro archivos ARFF, uno por cada ciudad, donde hay tanta cantidad
de datos que es imposible obtener una información valiosa de dichos datos. Por ello es
necesario el uso del software que se ha desarrollado con la interfaz gráfica de Java, que
es una interfaz gráfica sencilla, amigable e intuitiva para que el usuario pueda manipularlo
fácilmente.
Para extraer información valiosa de dichos datos, estos datos deben pasar por un
procedimiento, donde primero se realizará un preprocesado, después se le aplicará un
algoritmo y por última se extraerá la información para finalmente el usuario pueda
visualizarla y manipular dicha información.
PASO 1: Preprocesamiento
Se selecciona a partir de qué magnitud se desea predecir, puesto que lo realmente
importante es predecir terremotos de gran magnitud. También se selecciona la agrupación
que se desea hacer, es decir, se agrupará los registros para que de este modo sea concentrar
varios registros en uno solo y tener una menor cantidad de registros que manipular
después sin llegar a perder información importante.
También hay que tener en cuenta que al seleccionar la magnitud, los datos referentes a
otras magnitudes se eliminarán, por lo tanto se eliminarán muchos atributos que no son
necesarios para el paso posterior.
PASO 2: Algoritmo
Se realizará el algoritmo Simple K-means que se encuentra en la librería Weka, siendo la
variable K, aquella que seleccione el usuario (Entre 2 y 5) de ese modo el número de
clusters es el número de K.
Una vez aplicado el algoritmo, se guardará dichos resultados como un atributo más del
archivo de modo que pueda ser utilizado en el siguiente paso.

75
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
PASO 3: Estadísticas
Una vez ya preprocesado y clusterizado los datos, es hora de interpretar el contenido del
archivo, para ello es necesario especificar una W. La W es la combinación o secuencia
del cluster donde se encuentra uno o varios registros, dicha combinación o secuencia es
considerado un patrón, también junto con este patrón viene dado la magnitud del
terremoto registrado, donde solamente nos interesa saber la magnitud del último registro
de la combinación.
Si seleccionamos un número de la W, estamos seleccionando un tamaño estático de la
combinación, es decir, si seleccionamos 3, solamente obtendrá las combinaciones de 3 en
3.
Sin embargo, si seleccionamos mejor se creará tantos árboles n-arios como clusters haya,
y en cada árbol se creará todas las posibles opciones de combinación (por ejemplo: [0]
[00] [01] [02] [1] [10] [11] [12] [2] [20] [21] [22]) siendo de 3 el tamaño máximo de
dichas combinaciones, para que de ese modo el árbol no sea demasiado grande. Una vez
creado solo tenemos que mirar cuantas veces se repite cada combinación en el archivo
(que se encuentra previamente filtrado y clusterizado) y de entre esas veces que se repita
(ocurrencias) tendremos que saber si la magnitud que se obtiene supera o no a la magnitud
seleccionada en el filtrado que se habrá hecho anteriormente (acierto).
Cuando se haya realizado esto con cada combinación se procederá a elegir la mejor
combinación de cada árbol, que será aquella que tenga el resultado mayor a la hora de
realizar la siguiente operación:
𝑟𝑒𝑠𝑢𝑙𝑡𝑎𝑑𝑜 = 𝑎𝑐𝑖𝑒𝑟𝑡𝑜𝑠
𝑜𝑐𝑢𝑟𝑟𝑒𝑛𝑐𝑖𝑎𝑠
Por último tendremos una lista con las mejores combinaciones de cada árbol para después
ser tratada en el último paso.
PASO 4: Predicción
Una vez que ya hemos obtenido la información valiosa, es decir, la lista de
combinaciones, hay que averiguar de entre ellas cuales darán mejores resultados, es decir,
se realizarán cálculos (sensibilidad, especificidad, PPV, NPV, TP, TN, FP, FN) y la media
de la sensibilidad, especificidad, PPV, NPV indicará cuales son los mejores de la lista.
Para ello debemos probar todos con todos, es decir, debemos realizar unas combinaciones
matemáticas de m elementos tomados de n en n (m ≥ n) a todas las agrupaciones posibles
que pueden hacerse con los m elementos, teniendo en cuenta que se debe realizar todas
las combinaciones posibles con la n=1 hasta n=m-1 para obtener el mejor conjunto de
combinaciones de W, dicho conjunto puede estar formado por una combinación, por dos
combinaciones o por todas las combinaciones que hay en la lista de combinaciones.
Con cada grupo que se forma (n) se realiza unos cálculos sobre estos (TP, TN, FP, FN,
especificidad, sensibilidad, PPV, NPV) que darán lugar a la media, a través de la cual se
averiguaba si dicho grupo es el mejor conjunto de combinaciones de W.

76
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Una vez obtenido cuales combinaciones son las mejores de la lista de combinaciones,
entonces serán estos los elegidos los patrones para que pueda llegar a realizar predicciones
con una probabilidad, que será aquella que indique la media de los cálculos.
6.1. Conocimientos aplicados de las asignaturas
Se ha detallado los conocimientos aprendidos que se han aplicado en la realización de
este software y la asignatura a la cual corresponde cada conocimiento.
Tabla 1: Conocimientos aplicados de las asignaturas de primer curso
Primer curso
Fundamentos de la programación Bases de la programación estructurada, como por
ejemplo puede ser bucles, sentencias, variables,
constantes,…
Estadísticas Cálculos estadísticos del software, como puede
ser la combinación de m elementos tomados de n
en n
Programación orientada a objeto Lenguaje de programación Java con el que se
desarrollado el software
Tabla 2: Conocimientos aplicados de las asignaturas de segundo curso
Segundo curso
Algorítmica I Capacidad de desarrollar un algoritmo lo más
eficiente y eficaz posible, de forma que se pueda
reducir su complejidad lo máximo posible
Estructura de datos Conocimientos sobre listas, pilas, colas, árboles y
grafos
Ingeniería del software I Interfaz de Java, llamada Swing y los posibles
patrones que se pueden usar
Algorítmica II Conocimientos en profundidad sobre listas, pilas,
colas, árboles y grafos
Ingeniería del software II Conocimientos sobre cómo realizar el software
antes de iniciar el desarrollo, realizando un
documento explicando lo que se va a realizar y
como se va a realizar, con ayuda de casos de usos,
diagramas, patrones de diseño, arquitectura, …
Sistemas operativos Conocimientos sobre hilos de ejecución y como
se gestionan

77
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Tabla 3: Conocimientos aplicados de las asignaturas de tercer curso
Tercer curso
Sistemas distribuidos Conocimientos en profundidad sobre hilos de
ejecución, sincronización y su correcta
manipulación
Ingeniería de proyecto Conocimientos sobre cómo realizar una
documentación previa al desarrollo para saber lo
que se va a realizar y como se realizará, los
documentos son plan de proyecto, análisis y
diseño
Bioinformática Tratamientos de archivos ARFF que contiene un
microarray, donde debemos extraer información
importante sobre dicho microarray
Minería de datos Tratamiento de archivos ARFF, introducción a
weka, correcto preprocesamiento, tratamiento de
algoritmos como clustering, clasificación,… Por
última extraer la información importante una vez
que se ha ejecutado el/los algoritmo/s
Tabla 4: Conocimientos aplicados de las asignaturas de cuarto curso
Cuarto curso
Calidad Conocimientos a la hora de desarrollar para que
el código sea limpio, claro, sencillo y funcional,
gracias a las tareas de refactorización, pruebas
unitarias, pruebas de integración, inspección de
códigos y métricas usadas
Planificación de proyecto Conocimientos sobre cómo realizar una
documentación para planificar, controlar y
monitorizar un proyecto
Inteligencia artificial Realización de algoritmos que pueden predecir el
futuro basándose en datos obtenidos del pasado,
realizando búsquedas sobre dichos datos
Inteligencia de negocio Conocimientos sobre procesos ETL, minería de
datos, creación de ideas, integración de
información

78
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
7. Referencias
Adeli, H., Panakkat, A., 2009. A probabilistic neural network for earthquake magnitude
prediction. Neural Networks 22, 1018–1024. Akaike, H., 1974. New look at statistical-
model identification. IEEE Transactions on Automatic Control 6, 716–723 AC19.
Aki, K., 1965. Maximum likelihood estimate of b in the formula logN=a−bM and its
confidence limits. Bulletin of the Earthquake Research Institute 43, 237–239.
Akinci, A., 2010.HAZGRIDX: earthquake forecasting model forML≥ 5.0 earthquakes in
Italy based on spatially smoothed seismicity. Annals of Geophysics 53.doi:10.4401/ag-
4811.
Allen, C.R., 1968. The tectonic environments of seismically active and inactive areas
along the San Andreas fault system. In: Dickinson, W.R., Grantz, A. (Eds.), Proceedings
of the Conference on Geologic Problems of the San Andreas Fault System. Geol. Sci.,
11. Stanford Univ. Publ, pp. 70–82.
Alves, E.I., 2006. Earthquake forecasting using neural nets.Nonlinear Dynamics 44.
doi:10.1007/s11071-006-2018-1.Co.
Anderson, J.G., Rockwell, T.K., Agnew, D.C., 1989.Past and possible future earthquakes
of significance to the San Diego region. Earthquake Spectra 5, 299–335.
Arrowsmith, R., McNally, K., Davis, J., 1997. Potential for earthquake rupture and M 7
earthquakes along the Parkfield, Cholame, and Carrizo segments of the San Andreas
Fault. Seismological Research Letters 68, 902–916.
Bakun, W.H., King, G.C.P., Cockerham, R.S., 1986. Seismic slip, aseismic slip, and the
mechanics of repeating earthquakes on the Calaveras fault, California, in Earthquake
Source Mechanics. In: Das, S., Boatwright, J., Schlotz, C.H. (Eds.), Geophys.
Monogr.Ser., vol. 37. AGU, Washington, D.C, pp. 195–208.
R.M., Reasenberg, P.A., Reichle, M.S., Roeloffs, E.A., Shakal, A., Simpson, R.W.,
Waldhauser, F., 2005. Implications for prediction and hazard assessment from the 2004
Parkfield earthquake. Nature 437, 969–974.
Båth, M., 1965. Lateral inhomogeneities in the upper mantle. Tectonophysics 2, 483–514.
Ben-Zion, Y., Lyakhovsky, V., 2002.Accelerated seismic release and related aspects of
seismicity patterns on earthquake faults.Pure and Applied Geophysics 159, 2385–2412.
Biasi, G., Weldon II, R.J., 2006. Estimating surface rupture length and magnitude of
paleoearthquakes from point measurements of rupture displacement. Bulletin of the
Seismological Society of America 96, 1612. doi:10.1785/0120040172.
Biasi, G.P., Weldon II, R.J., Fumal, T.E., Seitz, G.G., 2002. Paleoseismic event dating
and the conditional probability of large earthquakes on the southern San Andreas fault,
California. Bulletin of the Seismological Society of America 92, 2761–2781.
Bowman, D.D., King, G.C.P., 2001.Accelerating seismicity and stress accumulation
before large earthquakes.Geophysical Research Letters 28, 4039–4042.

79
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Brehm, D.J., Braile, L.W., 1998. Intermediate-term earthquake prediction using
precursory events in the New Madrid Seismic Zone. Bulletin of the Seismological Society
of America 88, 564–580.
Bufe, C.G., Varnes, D.J., 1993. Predictive modeling of the seismic cycle of the greater
San Francisco Bay region.Journal of Geophysical Research 98, 9871–9883.
Burnham, K.P., Anderson, D.R., 2002. Model Selection and Multimodel Inference: A
Practical Information-Theoretic Approach. Springer, New York.
Cao, T.Q., Bryant, W.A., Rowshandel, B., Branum, D., Wills, C.J., 2003. The Revised
2002 California Probabilistic Seismic Hazard
Maps.www.conservation.ca.gov/CGS/rghm/psha/fault_parameters/pdf/2002_CA_Hazar
d_Maps.pdf2003.
Cao, T.Q., Petersen, M.D., Frankel, A.D., 2005. Model uncertainties of the 2002 update
of California seismic hazard maps. Bulletin of the Seismological Society of America
95,2040–2057.
Cavallo, E., Powell, A., Becerra, O., 2010. Estimating the direct economic damage of the
earthquake in Haiti. Inter-American Development Bank working paper series, No. IDB-
WP-163.
Cochran, E.S., Vidale, J.E., Tanaka, S., 2004. Earth tides can trigger shallow thrust fault
earthquakes. Science 306, 1164–1166.
Console, R., Murru, M., 2001.A simple and testable model for earthquake clustering.
Journal of Geophysical Research 106, 8,699–8,711.
Console, R., Murru, M., Lombardi, A.M., 2003.Refining earthquake clustering
models.Journal of Geophysical Research 108, 2468.doi:10.1029/2002JB002130.
Console, R., Murru, M., Catalli, F., 2006a.Physical and stochastic models of earthquake
clustering. Tectonophysics 417, 141–153.
Console, R., Rhoades, D.A., Murru, M., Evison, F.F., Papadimitriou, E.E., Karakostas,
V.G., 2006b. Comparative performance of timeinvariant, long-range and short-range
forecasting models on the earthquake catalogue of Greece.Journal of Geophysical
Research 111, B09304.doi:10.1029/2005JB004113.
Cox, D.R., 1972.Regression models and life tables with discussion. Journal of the Royal
Statistical Society, Series B 34, 187–220.
Crampin, S., Gao, Y., 2010. Earthquakes can be stress-forecast. Geophysical Journal
International 180, 1124–1127. doi:10.1111/j.1365-246X.2009.04475.x.
CSEP, d. www.cseptesting.org.
Davison, F., Scholz, C.H., 1985. Frequency-moment distribution of earthquakes in the
Aleutian Arc: a test of the characteristic earthquake model. Bulletin of the Seismological
Society of America 75, 1349–1362.
Dieterich, J., 1994. A constitutive law for rate of earthquake production and its application
to earthquake clustering.Journal of Geophysical Research 99, 2601–2618.

80
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Dieterich, J.H., Cayol, V., Okubo, P., 2002. The use of earthquake rate changes as a stress
meter at Kilauea volcano. Nature 408, 457–460.
DubesR. C. (1993). Handbook of Pattern Recognition and Computer Vision - Cluster
Analysis and Related Issues. World Scientific Publishing Co.
Ebel, J.E., Chambers, D.W., Kafka, A.L., Baglivo, J.A., 2007. Non-Poissonian
earthquake clustering and the hidden Markov model as bases for earthquake forecasting
in California. Seismological Research Letters 78, 57–65.
Ellsworth, W.I., Cole, A.T., 1997. A test of the characteristic earthquake hypothesis for
the San Andreas Fault in central California.Seismological Research Letters 68, 298.
Eneva,M., Ben-Zion, Y., 1997. Techniques and parameters to analyze seismicity patterns
associated with large earthquakes. Journal of Geophysical Research 102, 17,785–17,795.
Evison, F.F., 1977. The precursory earthquake swarm. Physics of the Earth and Planetary
Interiors 15, 19–23.
Evison, F.F., Rhoades, D.A., 1997. The precursory earthquake swarm in New Zealand:
hypothesis tests II. New Zealand Journal of Geology and Geophysics 40, 537–547.
Evison, F.F., Rhoades, D.A., 1999. The precursory earthquake swarm and the inferred
precursory quarm. New Zealand Journal of Geology and Geophysics 42, 229–236.
Evison, F.F., Rhoades, D.A., 2001. Model of long-term seismogenesis.Annali di
Geofisica 44, 81–93.
Evison, F.F., Rhoades, D.A., 2002. Precursory scale increase and long-term
seismogenesis in California and Northern Mexico. Annals of Geophysics 45, 479–495.
Evison, F.F., Rhoades, D.A., 2004. Demarcation and scaling of long-term seismogenesis.
Pure and Applied Geophysics 161, 21–45.
Faenza, L., 2005. Analysis of the spatio-temporal distribution of large earthquakes, Ph.
D. Thesis, Università degli Studi di Bologna, Alma Mater Studiorum, Bologna, Italy
available at: http://hdl.handle.net/2122/.
Faenza, L., Marzocchi, W., 2010. The Proportional Hazard Model as applied to the CSEP
forcasting area in Italy. Annals of Geophysics 53.doi:10.4401/ag-4759.
Faenza, L., Pierdominici, S., 2007.Statistical occurrence analysis and spatio-temporal
distribution of earthquakes in the Apennines Italy. Tectonophysics 439, 13–31.
Faenza, L., Marzocchi, W., Boschi, E., 2003. A nonparametric hazard model to
characterize the spatio-temporal occurrence of large earthquakes; an application to the
Italian catalogue.Geophysical Journal International 155, 521. doi:10.1046/j.1365-
246X.2003.02068.x.
Faenza, L., Marzocchi, W., Lombardi, A.M., Console, R., 2004.Some insights into the
time clustering of large earthquakes in Italy. Annals of Geophysics 47, 1635–1640.
Faenza, L., Marzocchi, W., Serretti, P., Boschi, E., 2008. On the spatio-temporal
distribution of M70.+ worldwide seismicity. Tectonophysics 449, 97–104.

81
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Faenza, L., Hainzl, S., Scherbaum, F., 2009.Statistical analysis of the central-Europe
seismicity. Tectonophysics 470, 195–204.
Fayyad, U. et al. (1996). Advanced in Knowledge Discovery and Data Mining, MIT
Press, MA.
Fayyad U. M., Piatetski-Shapiro G., and Smith P. (1996).From data mining to knowledge
discovery.AAAI-MIT Press.
Field, E.H., 2007. Overview of the Working Group for the Development of Regional
Earthquake Likelihood Models (RELM). Seismological Research Letters 78, 7–16.
Frankel, A., 1995. Mapping seismic hazard in the central and eastern United States.
Seismological Research Letters 66, 8–21.
Frankel, A., Mueller, C., Barnard, T., Perkins, D., Leyendecker, E.V., Dickman, N.,
Hanson, S., Hopper, M., 1996. National seismic-hazard maps; documentation June 1996:
U.S. Geological Survey Open-File Report 96–532, 110 pp.
Frankel, A., Mueller, C., Barnard, T., Perkins, D., Leyendecker, E.V., Dickman, N.,
Hanson, S., Hopper, M., 1997. Seismic hazard maps for Califonia, Nevada and Western
Arizona/Utah. USGS Open-File Report 97–130.
Frankel, A.D., Petersen, M.D., Mueller, C.S., Haller, K.M., Wheeler, R.L., Leyendecker,
E.V., Wesson, R.L., Harmsen, S.C., Cramer, C.H., Perkins, D.M., Rukstales, K.S., 2002.
Documentation for the 2002 update of the national seismic hazard maps.U.S. Geol.
Surv.Open-File Rept. OFR-02-420, 33 pp.
Frohlich, C., Davis, S., 1993. Teleseismic b-values: Or, much ado about 1.0. Journal of
Geophysical Research 98, 631–644.
Gardner, J.K., Knopoff, L., 1974. Is the sequence of earthquakes in southern California
with aftershocks removed Poissonian? Bulletin of the Seismological Society of America
64, 1363–1367.
Geller, R.J., Jackson, D.D., Kagan, Y.Y., Mulargia, F., 1997. Enhanced: earthquakes
cannot be predicted. Science 275, 49–70.
Gerstenberger, M.C., Rhoades, D.A., 2010. New Zealand Earthquake Forecast Testing
Centre. Pure and Applied Geophysics 167, 877–892.
Gerstenberger, M., Wiemer, S., Giardini, D., 2001.A systematic test of the hypothesis that
the b value varies with depth in California. Geophysical Research Letters 28, 57–60.
Gerstenberger, M.C., Wiemer, S., Jones, L.M., Reasenberg, P.A., 2005. Real-time
forecasts of tomorrow's earthquakes in California. Nature 435, 328–331.
Gerstenberger, M.C., Jones, L.M., Wiemer, S., 2007. Short-term aftershock probabilities:
case studies in California. Seismological Research Letters 78, 66–77.
Gibowitz, S. J. (1974). Frequency–magnitude depth and time relations for earthquakes in
Island Arc: North Island, New Zealand. Tectonophysics, 3(3), 283–297.

82
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Grant, L.B., Shearer, P.M., 2004. Activity of the offshore Newport–Inglewood Rose
Canyon Fault Zone, coastal southern California, from relocated microseismicity. Bulletin
of the Seismological Society of America 94, 747–752.
Grant, L.B., Sieh, K., 1994. Paleoseismic evidence of clustered earthquakes on the San
Andreas fault in the Carrizo Plain, California. Journal of Geophysical Research 99, 6819–
6841.
Grossman R. L., HornikM. F., and MeyerG.(2004). Data mining standards initiatives.
Communications of ACM, 45(8):59–61.
Guha S., Rastogi R., and Shim K. (1998). Cure: an efficient data clusteringmethod for
very large databases. ACM-SIGMOD Proceedings of the InternationalConference
Management of Data, pages 73–84.
Gulia, L., Wiemer, S., 2010. The influence of tectonic regimes on the earthquake size
distribution: a case study for Italy. Geophysical Research Letters 37,
L10305.doi:10.1029/2010GL043066.
Gulia, L., Wiemer, S., Schorlemmer, D., 2010. Asperity-based earthquake likelihood
models for Italy. Annals of Geophysics 53.doi:10.4401/ag-4843.
Gutenberg, B., & Richter, C. F. (1942).Earthquake magnitude, intensity, energy and
acceleration. Bulletin of the Seismological Society of America, 2(3), 163–191.
Gutenberg, B., Richter, C.F., 1944. Frequency of earthquakes in California. Bulletin of
the Seismological Society of America 34, 185–188.
Gutenberg, B., & Richter, C. F. (1954).Seismicity of the Earth.Princeton University.
Helmstetter, A., Sornette, D., 2002. Subcritical and supercritical regimes in epidemic
models of earthquake aftershocks.Journal of Geophysical Research
107.doi:10.1029/2001JB001580.
Helmstetter, A., Sornette, D., 2003a. Importance of direct and indirect triggered
seismicity in the ETAS model of seismicity.Geophysical Research Letters 30,
1576.doi:10.1029/2003GL017670.
Helmstetter, A., Sornette, D., 2003b. Predictability in the epidemic-type aftershock
sequence model of interacting triggered seismicity. Journal of Geophysical Research 108,
2482.doi:10.1029/2003JB002485.
Helmstetter, A., Kagan, Y.Y., Jackson, D.D., 2005. Importance of small earthquakes for
stress transfers and earthquake triggering.Journal of Geophysical Research
110.doi:10.1029/2004JB003286.
Helmstetter, A., Kagan, Y.Y., Jackson, D.D., 2006. Comparison of short-term and
timeindependent earthquake forecast models for southern California. Bulletin of the
Seismological Society of America 96, 90–106.
Helmstetter, A., Kagan, Y.Y., Jackson, D.D., 2007. High-resolution time-independent
grid-based forecast for M≥5 earthquakes in California.Seismological Research Letters 78,
78–86.

83
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Hernández Orallo J., (2004). Introducción a la minería de datos. Prentice-Hall.
Holliday, J.R., Nanjo, K.Z., Tiampo, K.F., Rundle, J.B., Turcotte, D.L., 2005. Earthquake
forecasting and its verification.Nonlinear Processes in Geophysics 12.doi:10.5194/npg-
12-965-2005.
Holliday, J.R., Rundle, J.B., Tiampo, K.F., Klein, W., Donnellan, A., 2006a. Systematic
procedural and sensitivity analysis of the Pattern Informatics method for forecasting large
MN5 earthquake events in southern California. Pure and Applied Geophysics
doi:10.1007/s00024-006-0131-1.
Holliday, J.R., Rundle, J.B., Tiampo, K.F., Turcotte, D., 2006b. Using earthquake
intensities to forecast earthquake occurrence times.Nonlinear Processes inGeophysics 13,
585–593.
Holliday, J.R., Rundle, J.B., Tiampo, Turcotte, D., Klein, W., Tiampo, K.F., Donnellan,
A., 2006c. Space-time clustering and correlations ofmajor earthquakes.Physical Review
Letters 97 238501.
Huang, Q., 2004. Seismicity changes associated with the 2000 earthquake swarm in the
Izu Island region. Journal of Asian Earth Sciences 26, 509–517.
Imoto, M., 1991.Changes in the magnitude frequency b-value prior to large M-
greaterthan-or-equal-to-6.0 earthquakes in Japan. Tectonophysics 193, 311–325.
Imoto, M., Hurukawa, N., Ogata, Y., 1990.Three-dimensional spatial variations of bvalue
in the Kanto area, Japan. Zishin 43, 321–326.
Ishimoto, M., & Iida, K. (1939). Observations sur les seismes enregistres par le
microsismographe construit derniereme. Bulletin Earthquake Research Institute, 17, 443–
478.
Jackson, D.D., Kagan, Y.Y., 1999. Testable earthquake forecasts for 1999. Seismological
Research Letters 70, 393–403.
Jackson, D.D., Kagan, Y.Y., 2006. The 2004 Parkfield earthquake, the 1985 prediction,
and characteristic earthquakes: lessons for the future. Bulletin of the Seismological
Society of America 96.doi:10.1785/012005082.
Jaumé, S.C., Sykes, L.R., 1999.Evolving towards a critical point: a review of accelerating
seismic moment/energy release prior to large and great earthquakes. Pure and Applied
Geophysics 155, 279–306.
Jiménez, A., Tiampo, K.F., Levin, S., Posadas, A., 2005. Testing the persistence in
earthquake catalogs: the Iberian Peninsula. Europhysics Letters. doi:10.1209/epl/i2005-
10383-8.
Jiménez, A., Posadas, A., Tiampo, K.F., 2008. Describing seismic pattern dynamics by
means of Ising cellular automata, nonlinear time series analysis in the
geosciences.Lecture Notes in Earth Sciences. Springer, Berlin, pp. 273–290.
doi:10.1007/978-3- 540-78938-3_12.

84
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Jones, L.M., Molnar, P., 1979. Some characteristics of foreshocks and their possible
relationship to earthquake prediction and premonitory slip on faults.Journal of
Geophysical Research 84.
Jordan, T.H., 2006. Earthquake predictability, brick by brick. Seismological Research
Letters 77, 3–6.
Jordan, T.H., Jones, L.M., 2010. Operational earthquake forecasting: some thoughts on
why and how. Seismological Research Letters 81.
Kafka, A., 2002. Statistical analysis of the hypothesis that seismicity delineates areas
where future large earthquakes are likely to occur in the central and eastern United
States.Seismological Research Letters 73, 990–1001.
Kagan, Y.Y., 1997. Are earthquakes predictable? Geophysical Journal International 131,
505–525.
Kagan, Y.Y., 2002. Aftershock zone scaling.Bulletin of the Seismological Society
ofAmerica 922, 641–655.doi:10.1785/0120010172.
Kagan, Y., 2005. Combined Provisional Southern California Earthquake
Catalog.http://scec.ess.ucla.edu/~ykagan/relm_index.html 2005.
Kagan, Y.Y., Jackson, D.D., 1994. Long-term probabilistic forecasting of earthquakes.
Journal of Geophysical Research 99, 13,685–13,700.
Kagan, Y.Y., Jackson, D.D., 1995. New seismic gap hypothesis: five years after. Journal
of Geophysical Research 100, 3943–3959.
Kagan, Y.Y., Jackson, D.D., 2000. Probabilistic forecasting of earthquakes. Geophysical
Journal International 143, 438–453.
Kalbeisch, J.D., Prentice, R.L., 1980. The Statistical Analysis of Failure Time Data.New-
York, 336 pp.
Kanamori, H., 1981. The nature of seismicity patterns before large earthquakes.
Earthquake Prediction: An International Review, AGU Monograph. AGU, Washington,
D.C, pp. 1–19.
Kanamori, H., Anderson, D.L., 1975. Theoretical basis of some empirical relation in
seismology. Bulletin of the Seismological Society of America 65, 1073–1096.
Kaufman L. and RousseeuwP. J., (1990). Finding groups in Data: an Introduction to
Cluster Analysis. Wiley.
Keilis-Borok, V.I., Shebalin, P.N., Zaliapin, I.V., 2002. Premonitory patterns of
seismicity months before a large earthquake: five case histories in Southern California.
PNAS 99, 16,562–16,567.
Kenneth, P., Burnhaman, K.P., Anderson, D.R., 2002. Model Selection and Multimodel
Inference: A Practical Information–Theoretic Approach. Springer, New York.
King, G.C.P., Bowman, D.D., 2003. The evolution of regional seismicity between large
earthquakes.Journal of Geophysical Research 108.doi:10.1029/2001JB000783.

85
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
King, G.C.P., Stein, R.S., Lin, J., 1994. Static stress changes and the triggering of
earthquakes. Bulletin of the Seismological Society of America 84, 935–953.
Kopanakis I. and Theodoulidis B. (2003).Visual data mining modeling techniquesfor the
visualization of mining outcomes. Journal of Visual Languagesand Computing,
14(6):543–589.
Kossobokov, V.G., 2006a. Quantitative earthquake prediction on global and regional
scales. In: Ismail-Zadosh (Ed.), Recent Geodynamics, Geortsk and Sustainable
Development in the Black Sea to Caspian Sea Region: Proceedings of the International
Workshop, pp. 32–50.
Kossobokov, V.G., 2006b. Testing earthquake prediction methods: the West Pacific
short-term forecast of earthquakes with magnitude MwHRV≥5.8. Tectonophysics 413,
25–31.
Kossobokov,V.G.,Romashkova, L.L., Keilis-Borok,V.I., 1999.
Testingearthquakepredictionalgorithms: statistically significant advance prediction of the
largest earthquakes in the Circum-Pacific, 1992–1997. Physics of the Earth and Planetary
Interiors 111, 187–196.
Kossobokov, V.G., Keilis-Borok, V.I., Turcotte, D.L., Malamud, B.D., 2000.
Implications of a statistical physics approach for earthquake hazard assessment and
forecasting. Pure and Applied Geophysics 157, 2323–2349.
Kossobokov,V.G., Romashkova, L.L., Panza,G.F., Peresan, A., 2002. Stabilizing
intermediateterm middle-range earthquake predictions.Journal of Seismology and
Earthquake Engineering 8, 11–19.
Kovacs, P., 2010. Reducing the risk of earthquake damage in Canada: lessons from Haiti
and Chile.ICLR Research Paper Series, 49.
Latchman, J.L., Morgan, F.D.O., Aspinall, W.P., 2008. Temporal changes in the
cumulative piecewise gradient of a variant of the Gutenberg–Richter relationship, and the
imminence of extreme events. Earth-Science Reviews 87, 94–112.
Latoussakis, J., Kossobokov, V.G., 1990. Intermediate term earthquake prediction in the
area of Greece—application of the algorithm M8. Pure and Applied Geophysics 134,
261–282.
Lee, K., & Yang, W. S. (2006). Historical seismicity of Korea. Bulletin of the
Seismological Society of America, 71(3), 846–855.
Lienkaemper, J.J., 2001. 1857 slip on the San Andreas fault southeast of Cholame,
California. Bulletin of the Seismological Society of America 91, 1659–1672.
Lienkaemper, J.J., Prescott, W.H., 1989. Historic surface slip along the San Andreas Fault
near Parkfield, California. Journal of Geophysical Research 94, 17,647–17,670.
Lockner, D.A., Beeler, N.M., 1999.Premonitory slip and tidal triggering of
earthquakes.Journal of Geophysical Research 104.doi:10.1029/1999JB900205.

86
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Lombardi, A.M., Marzocchi, W., 2010a. A double-branching model applied to longterm
forecasting of Italian seismicity (ML≥5.0) within the CSEP project. Annals of
Geophysics 53.doi:10.4401/ag-4762.
Lombardi, A.M., Marzocchi, W., 2010b. The ETAS model for daily forecasting of Italian
seismicity in the CSEP experiment. Annals of Geophysics 53.doi:10.4401/ag-4848.
Macqueen, J. B. (1968). Some methods for classification and analysis of multivariate
observations.In Proceedings of the 5th Berkeley symposium on mathematical statistics
and probability (pp. 281–297).
MacQueen J. (1995). The em algorithm for graphical association models withmissing
data. Computational Statistics and Data Analysis, 19:191–201.
Madahizadeh, R., Allamehzadeh, M., 2009.Prediction of aftershocks distribution using
artificial neural networks and its application on the May 12, 2008 Sichuan
earthquake.Journal of Seismology and Earthquake Engineering 12 (n. 10).
Main, I., 1999a. Applicability of the time-to-failure analysis to accelerated strain before
earthquakes and volcanic eruptions. Geophysical Journal International 139, F1–F6.
Main, I. (moderator), 1999b. Is the reliable prediction of individual earthquakes a realistic
scientific goal?, Debate in Nature,
www.nature.com/nature/debates/earthquake/equake_frameset.html.
Martinez-Alvarez, F., Troncoso, A., Morales-Esteban, A., Riquelme, J. C. 2011.
Computational intelligence techniques for predicting earthquakes. Lecture Notes in
Artificial Intelligence, Vol. 6679, No. 2, pages 287-294.
Martínez-Álvarez, F., Troncoso A., Riquelme, J. C., Aguilar-Ruiz, J. S.. 2011. Lecture
Notes in Artificial Intelligence, Vol. 6679, No. 2, pages 287-294.
Martínez-Álvarez, F., Troncoso, A., Riquelme, J. M., Riquelme, J. C., 2007. Discovering
Patterns in Electricity Price Using Clustering Techniques. Proceedings of the
International Conference on Renewable Energies and Power Quality, 67-68.
Marzocchi, W., Lombardi, A.M., 2008. A double-branching model for earthquake
occurrence.Journal of Geophysical Research 113, B08317.doi:10.1029/2007JB005472.
Marzocchi, W., Sandri, L., Boschi, E., 2003. On the validation of earthquake-forecasting
models: the case of pattern recognition algorithms. Bulletin of the Seismological Society
of America 935, 1994–2004.
Matsu'ura, T., Kase, Y., 2010.Late Quaternary and coseismic crustal deformation across
the focal area of the 2008 Iwate–Miyagi Nairiku earthquake. Tectonophysics 487,13–21.
Mao J. and Jain A.(1996). A self-organizing network for hyperellipsoidal clustering
(hec). IEEE Transactions on Neural Networks, 7:381–389.
Mignan, A., 2008. The Non-Critical Precursory Accelerating Seismicity Theory (NC
PAST) and limits of the power-law fit methodology. Tectonophysics 452.
doi:10.1016/j.tecto.2008.02.010.

87
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Mignan, A., 2011. Retrospective on the Accelerating Seismic Release (ASR) hypothesis:
controversy and new horizons. Tectonophysics 505, 1–16.
Mignan, A., Di Giovambattista, R., 2008. Relationship between accelerating seismicity
and quiescence, two precursors to large earthquakes. Geophysical Research Letters 35,
L15306. doi:10.1029/2008GL035024.
Mignan, A., Tiampo, K.F., 2010. Testing the Pattern Informatics index on synthetic
seismicity catalogues based on the Non-Critical PAST. Tectonophysics 483, 255–
268.doi:10.1016/j.tecto.2009.10.023.
Mignan, A., Bowman, D.D., King, G.C.P., 2006a. An observational test of the origin of
Accelerating Moment Release before large earthquakes.Journal of Geophysical Research
111, B11304.doi:10.1029/2006JB004374.
Mignan, A., King,G.C.P., Bowman,D.D., Lacassin, R.,Dmowska, R., 2006b. Seismic
activity in the Sumatra–Java region prior to the December 26, 2004Mw=9.0–9.3 and
March 28, 2005 Mw=8.7 earthquakes. Earth and Planetary Science Letters 244, 639–654.
Mignan, A., King, G.C.P., Bowman, D.D., 2007. A mathematical formulation of
accelerating moment release based on the Stress Accumulation model. Journal of
Geophysical Research 112, B07308. doi:10.1029/2006JB004671.
Mogi, K., 1967. Regional variations in magnitude–frequency relation of earthquakes.
Bulletin of the Earthquake Research Institute, Tokyo University 5, 67–86.
Mogi, K., 1969. Some features of recent seismic activity in and near Japan 2, Activity
before and after large earthquakes. Bulletin of the Earthquake Research Institute, Tokyo
University 47, 395–417.
Mora, P., Wang, Y.C., Yin, C., Place, D., Yin, X.C., 2002. Simulation of the load–unload
response ratio and critical sensitivity in the lattice solid model. Pure and Applied
Geophysics 159, 2525–2536.
Morales-Esteban, A., Martinez-Alvarez, F., Troncoso, A., Justlo, J.L., Rubio-Escudero,
C., 2010.Pattern recognition to forecast seismic time series. Expert Systems with
Applications 37, 8333–8342.
Morales-Esteban, A., Martinez-Alvarez, F., Reyes, J., 2013. Earthquake prediction in
seismogenic areas of the Iberian Peninsula based on computational intelligence.
Tectonophysics 593, 121-134.
Nanjo, K.Z., 2010. Earthquake forecast models for Italy based on the RI algorithm.
Annals of Geophysics 53, 3.doi:10.4401/ag-4810.
Nanjo, K., Nagahama, H., Satomura, M., 1998. Rates of aftershock decay and the fractal
structure of active fault systems. Tectonophysics 287, 173–186.
Nanjo, K.Z., Rundle, J.B., Holliday, J.R., Turcotte, D.L., 2006b. Pattern informatics and
its application for optimal forecasting of large earthquakes in Japan.Pure and Applied
Geophysics 163.doi:10.1007/s00024-006-0130-2.

88
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Nuannin, P., Kulhanek, O., & Persson, L. (2005).Spatial and temporal b-value anomalies
preceding the devastating off coast of NW Sumatra earthquake of December 26,
2004.Geophysical Research Letters, 32.
Ogata, Y., 1983. Estimation of the Parameters in the Modified Omori Formula for
Aftershock Frequencies by the Maximum Likelihood Procedure. Journal of Physics of
the Earth 31, 115–124.
Ogata, Y., 1985a. Statistical models for earthquake occurrences and residual analysis for
point processes. Res. Memo. Tech. Rep., 288. Inst. of Stat. Math, Tokyo.
Ogata, Y., 1985b. Statistical models for earthquake occurrences and residual analysis for
point processes. Res. Memo. Tech. Rep., 288. Inst. of Stat. Math, Tokyo.
Ogata, Y., 1987. Long-term dependence of earthquake occurrences and statistical models
for standard seismic activity in Japanese. In: Saito, M. (Ed.), Mathematical Seismology,
vol. II. Inst. of Stat. Math, Tokyo, pp. 115–125.
Ogata, Y., 1988. Statistical models for earthquake occurrence and residual analysis for
point process. Journal of the American Statistical Association 83, 9–27.
Ogata, Y., 1989. Statistical model for standard seismicity and detection of anomalies by
residual analysis. Tectonophysics 169, 159–174.
Ogata, Y., 1998. Space-time point-process models for earthquake occurrences. Annals of
the Institute of Statistical Mathematics 50, 379–402.
Ogata, Y., 1999. Seismicity analysis through point-process modeling: a review. Pure and
Applied Geophysics 155, 471–507.
Ogata, Y., 2005. Synchronous seismicity changes in and around the northern Japan
preceding the 2003 Tokachi-oki earthquake of M8.0. Journal of Geophysical Research
110.doi:10.1029/2004JB003323 B08305.
Ogata, Y., Katsura, K., 1993. Analysis of temporal and spatial heterogeneity of magnitude
frequency distribution inferred from earthquake catalogues. Geophysical Journal
International 113, 727–738.
Ogata, Y., Zhuang, J., 2006. Space-time ETAS models and an improved extension.
Tectonophysics 413, 13–23.
Pantosti, D., Pucci, S., Palyvos, N., DeMartini, P.N., D'Addezio, G., Collins, P.E.F.,
Zabci, C., 2008. Paleoearthquakes of the Duzce fault North Anatolian Fault Zone: insights
for large surface faulting earthquake recurrence. Journal of Geophysical Research
113.doi:10.1029/2006JB004679.
Parsons, T., 2004.Recalculated probability of M≥7 earthquakes beneath the Sea of
Marmara, Turkey.Journal of Geophysical Research 109,
B05304.doi:10.1029/2003JB002667.
Parsons, T., Geist, E.L., 2009. Is there a basis for preferring characteristic earthquakes
over a Gutenberg–Richter distribution in probabilistic earthquake forecasting? Bulletin
of the Seismological Society of America 99, 2012–2019. doi:10.1785/0120080069.

89
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Peng, K.Y., Yin, X.C., Zhang, L.P., 2006. A statistical investigation of the earthquake
predictions using LURR.Pure and Applied Geophysics 163, 2353–2362.
Peresan, A., Kossobokov, V., Romashkova, L., Panza, G.F., 2005. Intermediate-term
middle-range earthquake predictions in Italy: a review. Earth-Science Reviews 69, 97–
132.
Petersen, M.D., Cao, T., Campbell, K.W., Frankel, A.D., 2007. Time-independent and
time-dependent seismic hazard assessment for the state of California: uniform California
earthquake rupture forecast model. Seismological Research Letters 78.
doi:10.1785/gssrl.78.1.99.
Petersen, M.D., Frankel, A.D., Harmsen, S.C., Mueller, C.S., Haller, K.M., Wheeler,
R.L., Wesson, R.L., Zeng, Y., Boyd, O.S., Perkins, D.M., Luco, N., Field, E.H., Wills,
C.J., Rukstales, K.S., 2008. Documentation for the 2008 Update of the United States
National Seismic Hazard Maps, U.S. Geological Survey Open-File Report 1128, 61 pp.
Piatetski-Shapiro G., Frawley W. J., and Matheus C. J. (1991).Knowledge discovery in
databases: an overview. AAAI-MIT Press.
Press, F., Allen, C., 1995. Patterns of seismic release in the southern California
region.Journal of Geophysical Research 100, 6421–6430.
R Development Core Team, 2006. R: a language and environment for statistical
computing. Vienna, R Foundation for Statistical Computing. www.R-project.org 2006.
Ranalli, G. (1969). A statistical study of aftershock sequences. Annali di Geofisica, 22,
359–397.
Reasenberg, P.A., Jones, L.M., 1989. Earthquake hazard after a mainshock in California.
Science 243, 1,173–1,176.
Reasenberg, P.A., Jones, L.M., 1994. Earthquake aftershocks: update. Science 265,
1,251–1,252.
Reid, H.F., 1910. The mechanics of the earthquake, the California earthquake of April
18, 1906.Report State Investig.Comm., vol. 2. Carnegie Inst., Washington.
Reyes, J., Morales-Esteban, A., Martínez-Álvarez, F., 2013. Neural networks to
predict earthquakes in Chile. Applied Soft Computing. 13(2), 1314-1328.
Rhoades, D.A., 2007. Application of the EEPAS model to forecasting earthquakes of
moderate magnitude in Southern California. Seismological Research Letters 78, 110–115.
Rhoades, D.A., 2010. Lessons and questions from thirty years of testing the precursory
swarm hypothesis. Pure and Applied Geophysics 167, 629–644.
Rhoades, D.A., Evison, F.F., 2004. Long-range earthquake forecasting with every
earthquake a precursor according to scale. Pure and Applied Geophysics 161, 47–71.
Rhoades, D.A., Evison, F.F., 2005. Test of the EEPAS forecasting model on the Japan
earthquake catalogue. Pure and Applied Geophysics 162, 1271–1290.

90
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Rhoades, D.A., Gerstenberger, M.C., 2009. Mixture models for improved short-term
earthquake forecasting. Bulletin of the Seismological Society of America 99,636–646.
doi:10.1785/0120080063.
Richter, C.F., 1958. Elementary Seismology. Freeman, San Francisco.
Rikitake, T., 1976.Earthquake Prediction. Elsevier, Amsterdam, Netherlands, pp. 7–26.
Robinson, R., 2000. A test of the precursory accelerating moment release model on some
recent New Zealand earthquakes. Geophysical Journal International 140, 568–576.
Rockwell, T.K., Young, J., Seitz, G., Meltzner, A., Verdugo, D., Khatib, F., Ragona, D.,
Altangerel, O., West, J., 2003. 3,000 years of groundrupturing earthquakes in the Anza
Seismic Gap, San Jacinto fault, southern California: time to shake it up? Seismological
Research Letters 74, 236.
Romachkova, L.L., Kossobokov, V.G., Panza, G.F., Costa, G., 1998. Intermediate-term
predictions of earthquakes in Italy: algorithm M8. Pure and Applied Geophysics 152, 37–
55. doi:10.1007/s000240050140.
Romanowicz, B., Rundle, J.B., 1993. On scaling relations for large earthquakes. Bulletin
of the Seismological Society of America 83, 1294–1297.
Ruina, A., 1983. Slip instability and state variable friction laws. Journal of Geophysical
Research 88, 10,359–10,370.
Rundle, J.B., 1989. Derivation of the complete Gutenberg–Richter magnitude–frequency
relation using the principle of scale invariance. Journal of Geophysical Research 94,
12,337–12,342.
Rundle, J.B., Tiampo, K.F., Klein, W., Sá Martins, J., 2002. Self-organization in leaky
threshold systems: the influence of near mean field dynamics& its implications for
earthquakes, neurobiology and forecasting. PNAS 99 (Suppl. 1), 2463.
Rundle, J.B., Turcotte, D.L., Shcherbakov, R., Klein, W., Sammis, C., 2003. Statistical
physics approach to understanding the multiscale dynamics of earthquake fault systems.
Review of Geophysics 41, 1019.
Rydelek, P.A., Sacks, I.S., Scarpa, R., 1992. On tidal triggering of earthquakes at Campi
Flegrei, Italy. Geophysical Journal International 109, 125–137.
Saichev, A., Sornette, D., 2006. Renormalization of branching models of triggered
seismicity from total to observable seismicity. European Physical Journal B: Condensed
Matter and Complex Systems 51, 443–459. doi:10.1140/epjb/e2006-00242-6.
Sammonds, P.R., Meredith, P.G., Main, I.G., 1992. Role of pore fluids in the generation
of seismic precursors to shear fracture. Nature 359, 228–230.
Scholz, C.H., 1968. The frequency–magnitude relation ofmicrofracturing in rock and its
relation to earthquakes. Bulletin of the Seismological Society of America 58, 399–415.
Scholz, C.H., 2002. The Mechanics of Earthquakes and Faulting, 2nd edition. Cambridge
Univ. Press, Cambridge.

91
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Schorlemmer, D., Gerstenberger, M.C., 2007. RELM Testing Center. Seismological
Research Letters 78, 30–36.
Schorlemmer,D.,Wiemer,S.,Wyss,M., 2004a.EarthquakestatisticsatParkfield: 1.
Stationarity of b values.Journal of Geophysical Research
109.doi:10.1029/2004JB003234 B12307.
Schorlemmer, D., Wiemer, S., Wyss, M., Jackson, D.D., 2004b. Earthquake statistics at
Parkfield: 2. Probabilistic forecasting and testing. Journal of Geophysical Research,
Solid Earth 109.doi:10.1029/2004JB003235 B12308.
Schorlemmer, D., Wiemer, S., Wyss, M., 2005.Variations in earthquake-size distribution
across different stress regimes. Nature 437, 539–542. doi:10.1038/nature04094.
Schorlemmer, D., Gerstenberger, M.C., Wiemer, S., Jackson, D.D., Rhoades, D.A., 2007.
Earthquake likelihood model testing. Seismological Research Letters 78, 17–29.
Schwartz, D.P., Coppersmith, K.J., 1984. Fault behavior and characteristic earthquakes:
examples from Wasatch and San Andreas fault zones. Journal of Geophysical Research
89, 5681–5698.
Shcherbakov, R., Turcotte, D.L., Rundle, J.B., Tiampo, K.F., Holliday, J.R., 2010.
Forecasting the locations of future large earthquakes: an analysis and verification. Pure
and Applied Geophysics 167, 743–749.
Shi, Y., & Bolt, B. A. (1982).The standard error of the magnitude–frequency b-value.
Bulletin of the Seismological Society of America, 72(5), 1677–1687.
Sieh, K.E., 1984. Lateral offsets and revised dates of large earthquakes at Pallett Creek,
California. Journal of Geophysical Research 89, 7641–7670.
Sieh, K., Stuiver, M., Brillinger, D., 1989. A more precise chronology of earthquakes
produced by the San Andreas fault in southern California. Journal of Geophysical
Research 94, 603–623.
Smith, S.W., Sammis, C.G., 2004. Revisiting the tidal activation of seismicity with a
damage mechanics and friction point of view.Pure and Applied Geophysics 161, 2393–
2404.doi:10.1007/s00024-004-2571-9.
Sri Lakshmi, S., Tiwari, R.K., 2009. Model dissection from earthquake time series: a
comparative analysis using modern non-linear forecasting and artificial neuralnetwork
approache. Computers & Geosciences 35, 191–204.
Seismological Research Letters 76, 432–436.
Stirling,M.W.,Wesnousky, S.G., 1997. Do historical rates of seismicity in southern
California require the occurrence of earthquakemagnitudes greater thanwould be
predicted from fault length? Bulletin of the Seismological Society of America 87, 1662–
1666.

92
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Stirling, M.W., McVerry, G.H., Berryman, K.R., 2002a. A new seismic hazard model for
New Zealand. Bulletin of the Seismological Society of America 92, 1878–1903.
Stirling, M., Rhoades, D., Berryman, K., 2002b. Comparison of earthquake scaling
relations derived from data of the instrumental and preinstrumental era. Bulletin of the
Seismological Society of America 92, 812–830.
Sykes, L.R., 1971. Aftershock zones of great earthquakes, seismicity gaps, and
earthquake prediction for Alaska and the Aleutians. Journal of Geophysical Research 76,
8021–8041.
Sykes, L.R., Jaumé, S.C., 1990.Seismic activity on neighbouring faults as a long-term
precursor to large earthquakes in the San Francisco Bay area. Nature 348, 595–599.
Tanaka, S., 2010. Tidal triggering of earthquakes precursory to the recent Sumatra
megathrust earthquakes of 26 December 2004 Mw 9.0, 28 March 2005 Mw 8.6,and 12
September 2007 Mw 8.5. Geophysical Research Letters 37.doi:10.1029/2009GL041581
L02301.
Tanaka, S., Ohtake, M., Sato, H., 2002.Evidence for tidal triggering of earthquakes as
revealed from statistical analysis of global data.Journal of Geophysical Research
107.doi:10.1029/2001JB001577.
Tiampo, K.F., Rundle, J.B., McGinnis, S., Gross, S., Klein, W., 2002. Mean-field
threshold systems and phase dynamics: an application to earthquake fault systems. Eur.
Phys. Lett. 60, 481–487.
Tiampo, K.F., Rundle, J.B., Klein, W., 2006a. Premonitory seismicity changes prior to
the Parkfield and Coalinga earthquakes in southern California. Tectonophysics 413, 77–
86.
Tiampo, K.F., Rundle, Klein,W., 2006b. Stress shadows determined from a phase
dynamicalmeasure of historic seismicity. Pure and Applied
Geophysics.doi:10.1007/200024-006-0134-y.
Tiampo, K.F., Rundle, J.B., Klein, W., Holliday, J., 2006c. Forecasting rupture dimension
using the pattern informatics technique. Tectonophysics 424, 367–376.
Tiampo, K.F., Bowman, D.D., Colella, H., Rundle, J.B., 2008. The Stress Accumulation
Method and the Pattern Informatics Index: complementary approaches to earthquake
forecasting. Pure and Applied Geophysics 165, 693–709. doi:10.1007/s00024-008-0329-
5.
Turcotte, D.L., 1991. Earthquake prediction. Annual Review of Earth and Planetary
Sciences 19, 263–281.
Turcotte, D.L., 1997. Fractals and Chaos in Geology and Geophysics. Cambridge
University Press, Cambridge.
Utsu, T. (1965). A method for determining the value of b in a formula log n = a-bm
showing the magnitude–frequency relation for earthquakes. Geophysical bulletin of
Hokkaido University, 13, 99–103.

93
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Vere-Jones, D., 1995. Forecasting earthquakes and earthquake risk. International Journal
of Forecasting 11, 503–538.
Vere-Jones, D., 2006. The development of statistical seismology: a personal experience.
Tectonophysics 413, 5–12.
Vidale, J.E., Agnew, D.C., Johnston, M.J.S., Oppenheimer, D.H., 1998. Absence of
earthquake correlation with earth tides: an indication of high preseismic fault stress rate.
Journal of Geophysical Research 103, 24,567–24,572.
Wallace, R.E., 1970. Earthquake recurrence intervals on the San Andreas
Fault.Geological Society of America Bulletin 81, 2875–2890.
Wang, Y.C., Yin, C., Mora, P., Yin, X.C., Peng, K.Y., 2004a. Spatio-temporal scanning
and statistical test of the Accelerating Moment Release (AMR) model using Australian
earthquake data.Pure and Applied Geophysics 161, 2281–2293.
Wang, Y.C., Mora, P., Yin, C., Place, D., 2004b. Statistical tests of load–unload response
ratio signals by lattice solid model: Implication to tidal triggering and earthquake
prediction. Pure and Applied Geophysics 161, 1829–1839.
Ward, S.N., 2007. Methods for evaluating earthquake potential and likelihood in and
around California. Seismological Research Letters 78, 121–133.
Weldon, R., Scharer, K., Fumal, T., Biasi, G., 2004. Wrightwood and the earthquake
cycle: what a long recurrence record tells us about how faults work. GSA Today 14, 4–
10.
Werner, M.J., Sornette, D., 2008. Magnitude uncertainties impact seismic rate estimates,
forecasts and predictability experiments. Journal of Geophysical
Research113.doi:10.1029/2007JB005427.
Werner, M.J., Helmstetter, A., Jackson, D.D., Kagan, Y.Y., Wiermer, S.,
2010.Adaptively smoothed seismicity earthquake forecasts for Italy.Annals of
Geophysics 53.doi:10.4401/ag-4839.
Wesnousky, S., 1994. The Gutenberg–Richter or characteristic earthquake distribution,
which is it? Bulletin of the Seismological Society of America 84,1940–1959.
Wiemer, S., Benoit, J., 1996.Mapping the b-value anomaly at 100 km depth in the Alaska
and New Zealand subduction zones. Geophysical Research Letters 23,1557–1560.
Wiemer, S., Schorlemmer, D., 2007. ALM: an asperity-based likelihood model for
California. Seismological Research Letters 78, 134–140.
Wiemer, S., Wyss, M., 1994. Seismic quiescence before the Landers M=7.5 and Big Bear
M=6.5 1992 earthquakes. Bulletin of the Seismological Society of America 84, 900–916.
Wiemer, S., Wyss, M., 1997. Mapping the frequency–magnitude distribution in
asperities: an improved technique to calculate recurrence times? Journal of Geophysical
Research 102, 15,115–15,128.
Wiemer, S., Wyss, M., 2002.Mapping spatial variability of the frequency–magnitude
distribution of earthquakes. Advances in Geophysics 45, 259–302.

94
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Wiemer, S., McNutt, S.R., Wyss, M., 1998.Temporal and three-dimensional spatial
analysis of the frequency–magnitude distribution. Geophysical Journal International 134,
409–421.
Wiemer, S., Giardini, D., Fäh, D., Deichmann, N., Sellami, S., 2009. Probabilistic seismic
hazard assessment of Switzerland: best estimates and uncertainties. Journal of
Seismology 13, 449–478. doi:10.1007/s10950-008-9138-7.
Witten H. and Frank E. (2005). Data mining: Practical Machine Learning Toolsand
Techniques. Morgan Kaufmann Publishers.
Working Group on California Earthquake Probabilities WG02, 2002. Earthquake
probabilities in the San Francisco Bay region: 2002–2031. U.S. Geol. Surv.Circular 1189.
Working Group on California Earthquake Probabilities WGCEP, 1988. Probabilities of
large earthquakes occurring in California on the San Andreas fault. U.S. Geol.
Surv.Open-File Rept. 62 pp.
Working Group on California Earthquake Probabilities WGCEP, 1990.Probabilities of
large earthquakes in the San Francisco Bay Region, California, U.S. Geol. Surv.Circ. 51
pp.
Working Group on California Earthquake Probabilities WGCEP, 1995. Seismic hazards
in Southern California: probable earthquakes, 1994 to 2024. Bulletin of the Seismological
Society of America 85, 379–439.
Working Group on California Earthquake Probabilities WGCEP, 2003. Earthquake
probabilities in the San Francisco Bay region: 2002 to 2031. U.S. Geol. Surv. Open-File
Rept. 03–214.
Working Group on California Earthquake Probabilities WGCEP, 2008. The uniform
California earthquake rupture forecast, version 2 UCERF 2, U.S. Geol. Surv. Open-File
Rept. 2007–1437.California Geological Survey Special Report, 203
http://pubs.usgs.gov/of/2007/1437/.104 pp.
Wyss, M., 1997. Cannot earthquakes be predicted? Science 278, 487–490.
Wyss, M., Wiemer, S., 2000. Change in the probability for earthquakes in Southern
California due to the Landers magnitude 7.3 earthquake. Science 290, 1,334–1,338.
Wyss, M., Shimaziki, K., Urabe, T., 1996.Quantitative mapping of a precursory seismic
quiescence to the Izu-Oshima 1990 M6.5 earthquake, Japan. Geophysical Journal
International 127, 735–743.
Yin, C., Mora, P., 2006. Stress reorientation and LURR: implication for earthquake
prediction using LURR. Pure and Applied Geophysics 163, 2363–2373.
Yin, X.C., Wang, Y., Peng, K., Bai, Y., Wang, H., Yin, X.F., 2000. Development of a
new approach to earthquake prediction: load/Unload Response Ratio (LURR) theory.
Pure and Applied Geophysics 157, 2365–2383.

95
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Yin, X.C., Zhang, L.P., Zhang, H.H., Yin, C., Wang, Y.C., Zhang, Y.X., Peng, K.Y.,
Wang, H.T., Song, Z.P., Yu, H.Z., Zhaung, J.C., 2006. LURR's twenty years and its
perspective. Pure and Applied Geophysics 163, 2317–2341.
Yin, C., Xing, H.L., Mora, P., Xu, H.H., 2008a.Earthquake trend around Sumatra
indicated by a new implementation of LURR method. Pure and Applied Geophysics 165,
723–736.
Yin, X.C., Zhang, L.P., Zhang, Y.X., Peng, K.Y., Wang, H.T., Song, Z.P., Yu, H.Z.,
Zhang, H.H.,
Yin, C., Wang, Y.C., 2008b. The newest developments of load–unload response ratio
(LURR). Pure and Applied Geophysics 165, 711–722.
Yin, X.C., Zhang, L.P., Zhang, Y.X., Peng, K.Y., Wang, H.T., Song, Z.P., Zhang, X.T.,
Yuan, S.A., 2010. The peak point of LURR and its significance. Concurrency and
Computation 22, 1549–1558.
Yu, H.Z., Zhu, Q.Y., 2010. A probabilistic approach for earthquake potential evaluation
based on the load/unload response ratio method. Concurrency and Computation 22,
1520–1533.
Yu, H.Z., Shen, Z.K., Wan, Y.G., Zhu, Q.Y., Yin, X.C., 2006. Increasing critical
sensitivity of the Load/Unload Response Ratio before large earthquakes with identified
stress acclumulation pattern. Tectonophysics 428, 87–94.
Zechar, J.D., Jordan, T.H., 2008. Testing alarm-based earthquake predictions.
Geophysical Journal International 172, 715–724. doi:10.1111/j.1365-
246X.2007.03676.x.
Zechar, J.D., Jordan, T.H., 2010. Simple smoothed seismicity earthquake forecasts for
Italy. Annals of Geophysics 53.doi:10.4401/ag-4845.
Zechar, J.D., Zhuang, J., 2010. Risk and return: evaluating Reverse Tracing of Precursors
earthquake predictions. Geophysical Journal International 182, 1319–1326. doi:10.1111/
j.1365-246X.2010.04666.x.
Zechar, J.D., Schorlemmer, D., Liukis, M., Yu, J., Euchner, F., Maechling, P., Jordan, J.,
2010.The collaboratory for the study of earthquake predictability perspective on
computational earthquake science. Concurrency and Computation 22, 1836–1847.
Zhang T, Ramakrishnan R., and Livny M. (1996). Birch: an efficient data clustering
method for very large databases. ACM-SIGMOD Proceedings of the International
Conference Management of Data, pages 103–114.
Zhang, Y.X., Yin, X.C., Peng, K.Y., 2004. Spatial and temporal variation of LURR and
its implication for the tendency of earthquake occurrence in Southern California.Pure and
Applied Geophysics 161, 2359–2367.
Zhang, X.T., Zhang, Y.X., Yin, X.C., 2009. Study on the earthquake potential regions in
north and northeast China by Pattern Informatics method. Proceeding of the 2009 2nd
International Conference on Biomedical Engineering and Informatics, v. 1–4, pp. 2266–
2270.

96
TRABAJO FIN DE GRADO: PREDICCIÓN DE TERREMOTOS | Grado en Ingeniería Informática en Sistemas de Información
Zhang, L.P., Yin,X.C., Liang, N.G., 2010. Relationship between load/unload response
ratio and damage variable and its application. Concurrency and Computation 22, 1534–
1548.
Zhuang, J., Ogata, Y., Vere-Jones, D., 2004. Analyzing earthquake clustering features by
using stochastic reconstruction.Journal of Geophysical Research 109,
B05301.doi:10.1029/2003JB002879.
Zollo, A., Marzocchi, W., Capuano, P., Lomaz, A., & Iannaccone, G. (2002). Space and
time behavior of seismic activity at Mt. Vesuvius volcano, outhern Italy. Bulletin of the
Seismological Society of America, 92(2), 625–640.
http://earthquaketrack.com/p/chile/recent
http://moho.ess.ucla.edu/~kagan/GJI_1997.pdf
http://www.escuelapedia.com/consecuencias-de-terremotos/
http://docs.oracle.com/javase/7/docs/api/
http://weka.sourceforge.net/doc.stable/
https://github.com/vivin/GenericTree
https://github.com/adiazc26/gitadiazc26ed/blob/master/ArturoDed/src/febrero/Dispositi
voContador.java
https://github.com/jarroba/ThreadsJarroba
https://github.com/mgamallo/SwingWorkerEjemplo/tree/master/BarraProgresoEjemplo
http://www.vitutor.com/pro/1/a_r.html
http://es.slideshare.net/lissetsuarez/modelos-de-datos-y-procesos
http://www.justdocument.com/download/97223903893/problemas-universales-ante-
terremotos-moderadamente-fuerte-de-aceleracion-momento-de-lanzamiento/
http://portalweb.sgm.gob.mx/museo/es/riesgos/sismos
http://www.ingenieria.peru-v.com/sismos/esfuerzos_para_predecir_sismos.html
https://github.com/adiazc26/gitadiazc26ed/blob/master/ArturoDed/src/febrero/DispositivoContador.java


















