
UNIT V: CENTRAL PROCESSING UNIT -...
54
Transcript of UNIT V: CENTRAL PROCESSING UNIT -...


UNITV:CENTRALPROCESSINGUNIT

Agenda• BasicInstruc1onCycle&Sets• Addressing• Instruc1onFormat• ProcessorOrganiza1on• RegisterOrganiza1on• PipelineProcessors• Instruc1onPipelining• Co-Processors• RISCcomputersvs.CISCcomputers–Assignment2

AddressingModes• Immediate• Direct• Indirect• Register• Registerindirect• Displacement• Stack

ImmediateAddressing• Operandispartofinstruc1on• e.g.ADD5
— Add5tocontentsofaccumulator— 5isoperand
• Nomemoryreferencetofetchdata• Fast• Limitedrange
Operand Opcode
Instruction
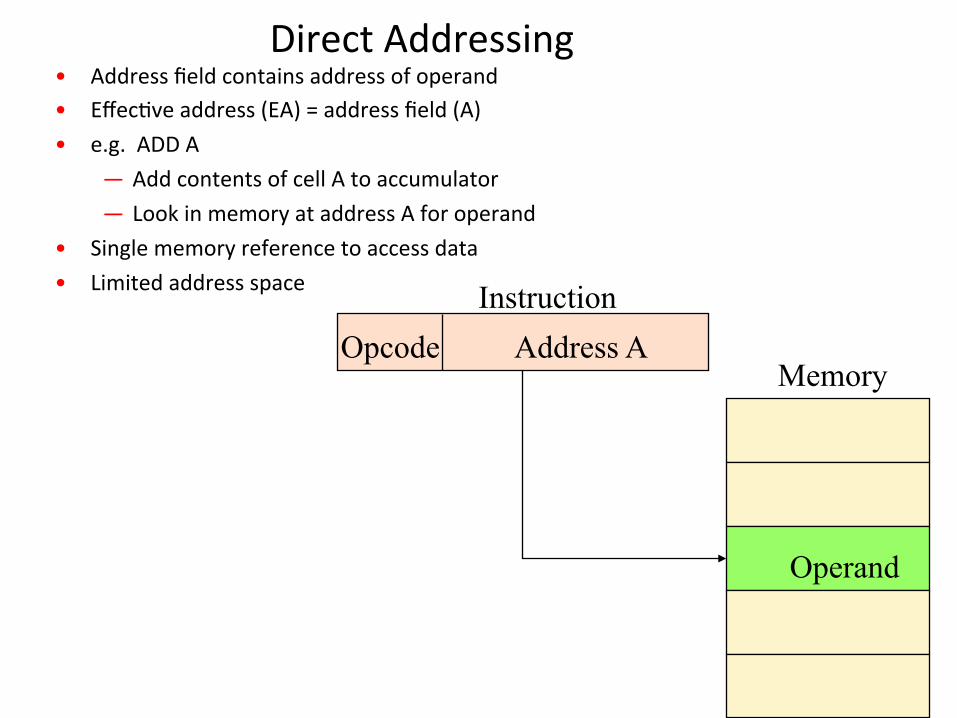
DirectAddressing• Addressfieldcontainsaddressofoperand• Effec1veaddress(EA)=addressfield(A)• e.g.ADDA
— AddcontentsofcellAtoaccumulator— LookinmemoryataddressAforoperand
• Singlememoryreferencetoaccessdata• Limitedaddressspace
Address A Opcode Instruction
Memory
Operand

IndirectAddressing• Memorycellpointedtobyaddressfieldcontainstheaddressof(pointer
to)theoperand
• e.g.ADD(A)— AddcontentsofcellpointedtobycontentsofAtoaccumulator
Address A Opcode Instruction
Memory
Operand
Pointer to operand

RegisterAddressing• Operandisheldinregisternamedinaddressfiled• EA=R• Limitednumberofregisters
Register Address R Opcode
Instruction
Registers
Operand
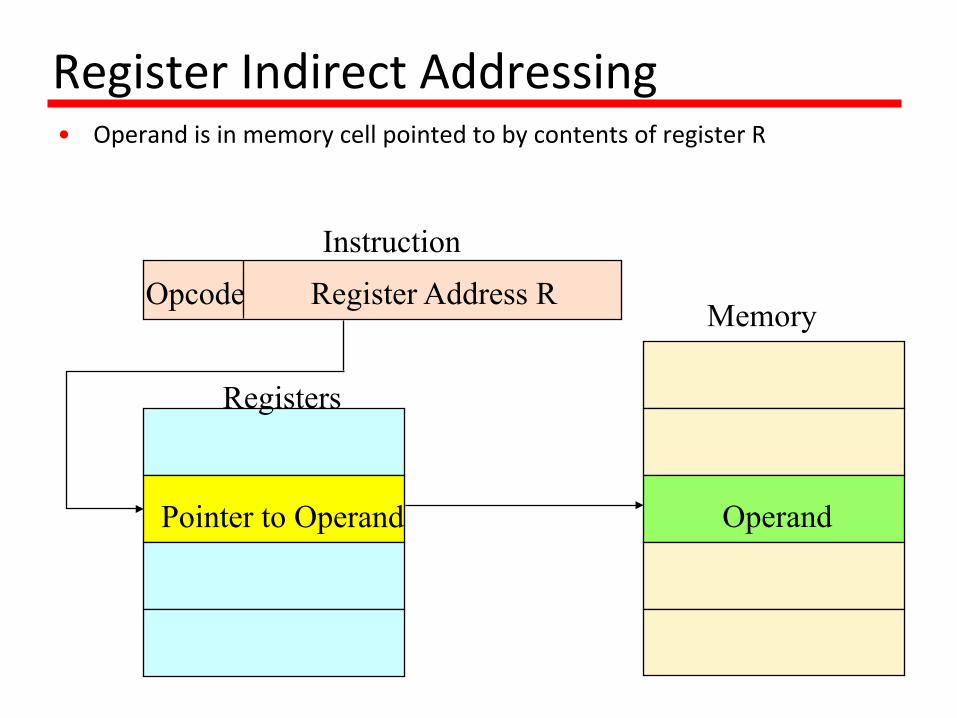
RegisterIndirectAddressing• OperandisinmemorycellpointedtobycontentsofregisterR
Register Address R Opcode Instruction
Memory
Operand Pointer to Operand
Registers
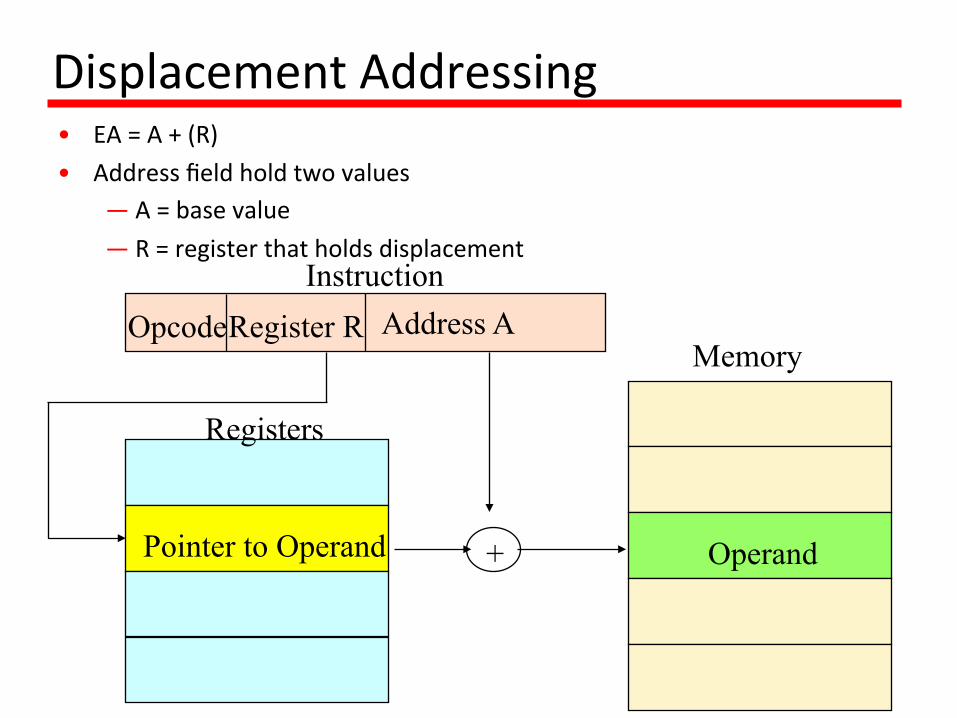
DisplacementAddressing• EA=A+(R)• Addressfieldholdtwovalues
— A=basevalue— R=registerthatholdsdisplacement
Register R Opcode Instruction
Memory
Operand Pointer to Operand
Registers
Address A
+
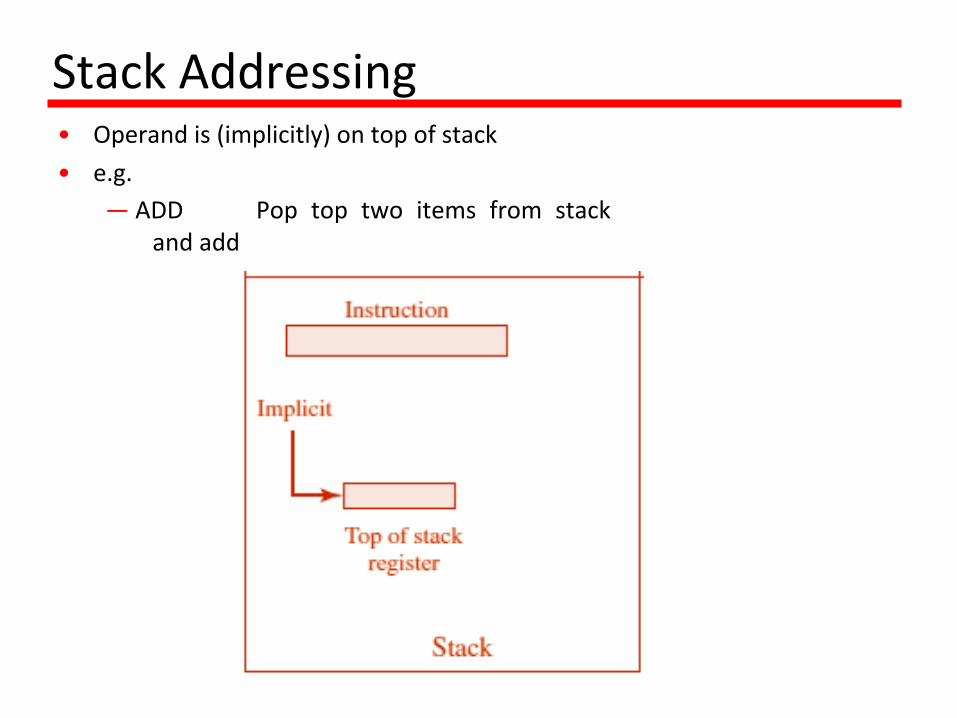
StackAddressing• Operandis(implicitly)ontopofstack• e.g.
— ADD Pop top two items from stack andadd

Instruc1onFormats• Layoutofbitsinaninstruc1on• Includesopcode• Includes(implicitorexplicit)operand(s)• Usuallymorethanoneinstruc1onformatinaninstruc1onset

Instruc1onLength• Affectedbyandaffects:
— Memorysize— Memoryorganiza1on— Busstructure— CPUcomplexity— CPUspeed

Alloca1onofBits• Numberofaddressingmodes• Numberofoperands• Registerversusmemory• Numberofregistersets• Addressrange• Addressgranularity

Example:PDP-10Instruc1onFormat

Example:PDP-11Instruc1onFormat

Instruc1onCycle• Fetch:Readthenextinstruc1onfrommemoryintotheprocessor.• Execute:Interprettheopcodeandperformtheindicatedopera1on.• Interrupt: If interrupts are enabled and an interrupt has occurred, save
thecurrentprocessstateandservicetheinterrupt.

Instruc1onCyclewithInterrupts
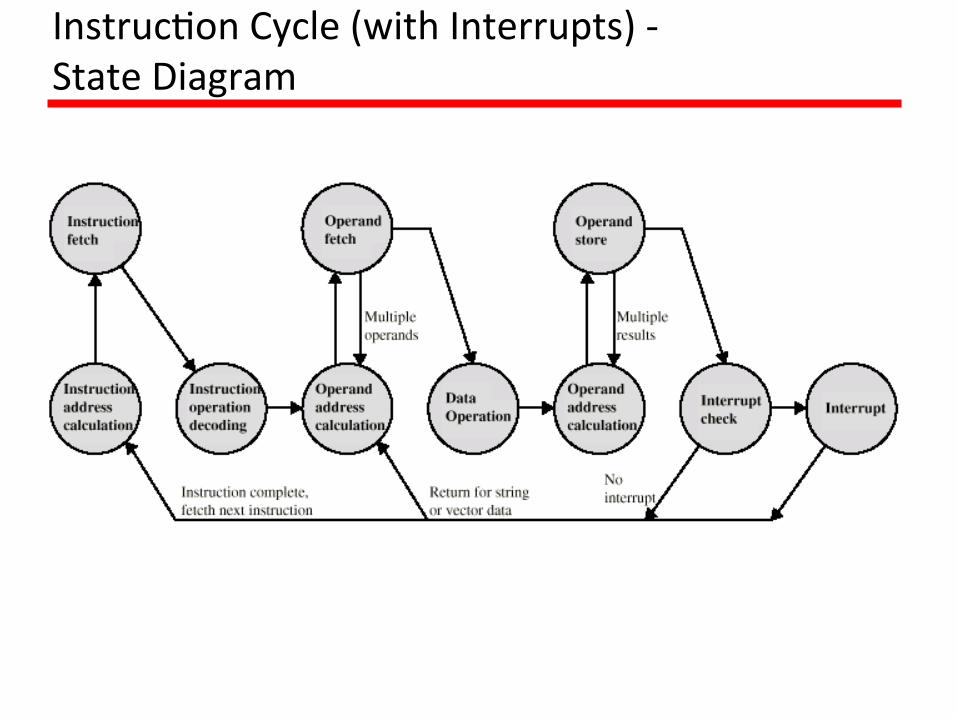
Instruc1onCycle(withInterrupts)-StateDiagram

IndirectCycle• The main line of ac1vity consists of alterna1ng instruc1on fetch and
instruc1onexecu1onac1vi1es.• A]eraninstruc1onisfetched,itisexaminedtodetermineifanyindirect
addressing is involved. If so, the required operands are fetched usingindirectaddressing.Followingexecu1on,an interruptmaybeprocessedbeforethenextinstruc1onfetch.

Instruc1onCycleStateDiagram

DataFlow(Instruc1onFetch)
PC Contains address of the next instruction
Address moved to MAR
Add
ress
Control Unit requests Memory read
Res
ult
PC incremented by1
Result copied
1
2
3
5
6
7
4
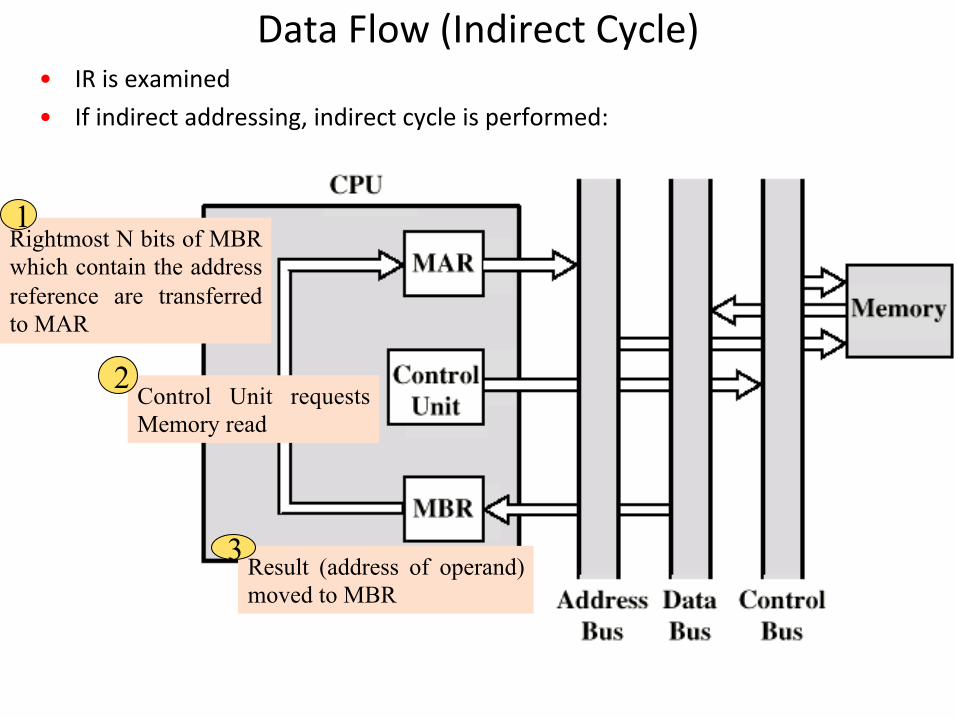
DataFlow(IndirectCycle)• IRisexamined• Ifindirectaddressing,indirectcycleisperformed:
Rightmost N bits of MBR which contain the address reference are transferred to MAR
1
Control Unit requests Memory read
2
Result (address of operand) moved to MBR
3

DataFlow(Execute)• Maytakemanyforms• Dependsoninstruc1onbeingexecuted• Mayinclude
— Memoryread/write— Input/Output— Registertransfers— ALUopera1ons
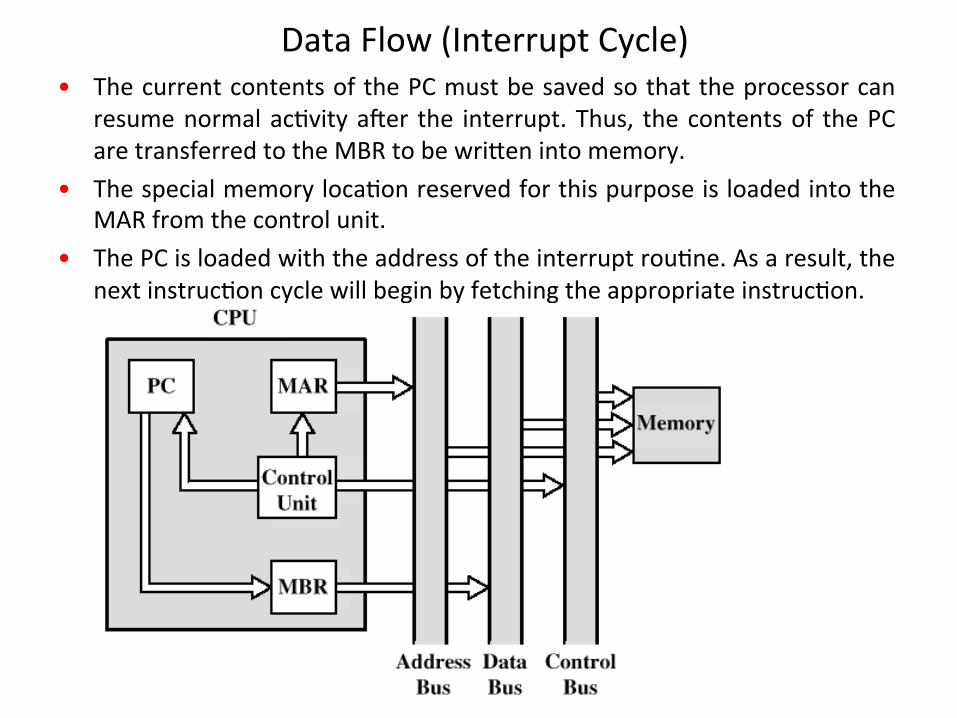
DataFlow(InterruptCycle)• ThecurrentcontentsofthePCmustbesavedsothattheprocessorcan
resumenormalac1vitya]er the interrupt.Thus, thecontentsof thePCaretransferredtotheMBRtobewri`enintomemory.
• Thespecialmemoryloca1onreservedforthispurposeisloadedintotheMARfromthecontrolunit.
• ThePCisloadedwiththeaddressoftheinterruptrou1ne.Asaresult,thenextinstruc1oncyclewillbeginbyfetchingtheappropriateinstruc1on.

ProcessorOrganiza1on• CPUmust:
— Fetch instruc=on: The processor reads an instruc1on frommemory(register,cache,mainmemory).
— Interpret instruc=on:The instruc1on is decoded to determinewhatac1onisrequired.
— Fetchdata:Theexecu1onofaninstruc1onmayrequirereadingdatafrommemoryoranI/Omodule.
— Processdata:Theexecu1onofaninstruc1onmayrequireperformingsomearithme1corlogicalopera1onondata.
— Writedata:The resultsof anexecu1onmay requirewri1ngdata tomemoryoranI/Omodule.

CPUWithSystemsBus

CPUInternalStructure

RegisterOrganiza1on• User-visible registers: Enable the machine- or assembly language
programmer tominimizemainmemory referencesbyop1mizinguseofregisters.
• Control and status registers: Used by the control unit to control theopera1onoftheprocessorandbyprivileged,opera1ngsystemprogramstocontroltheexecu1onofprograms.

UserVisibleRegisters• GeneralPurposeRegisters:Maybeusedfordataoraddressing• Dataregisters:Usedonlytoholddata• Address registers:Devoted to a par1cular addressingmode. Examples-
Indexregisters,Stackpointer• Condi=on codes: Bits set by the processor hardware as the result of
opera1ons.— For example, an arithme1c opera1on may produce a posi1ve,
nega1ve,zero,oroverflowresult.Inaddi1ontotheresultitselfbeingstoredinaregisterormemory,acondi1oncodeisalsoset.Thecodemaysubsequentlybetestedaspartofacondi1onalbranchopera1on.
— Canberead(implicitly)byprograms–e.g.Jumpifzero

Control&StatusRegisters• Program counter (PC): Contains the address of an instruc1on to be
fetched• Instruc=onregister(IR):Containstheinstruc1onmostrecentlyfetched• Memory address register (MAR):Contains the address of a loca1on in
memory• Memorybufferregister(MBR):Containsawordofdatatobewri`ento
memoryorthewordmostrecentlyread

ProgramStatusWord• Sign:Containsthesignbitoftheresultofthelastarithme1copera1on.• Zero:Setwhentheresultis0.• Carry: Set if an opera1on resulted in a carry (addi1on) into or borrow
(subtrac1on) out of a high-order bit. Used for mul1word arithme1copera1ons.
• Equal:Setifalogicalcompareresultisequality.• Overflow:Usedtoindicatearithme1coverflow.• InterruptEnable/Disable:Usedtoenableordisableinterrupts.• Supervisor:Indicateswhethertheprocessorisexecu1nginsupervisoror
user mode. Certain privileged instruc1ons can be executed only insupervisormode, and certain areas ofmemory canbe accessedonly insupervisormode.

ExampleRegisterOrganiza1ons

PipelineProcessor• Pipelining: A means of introducing parallelism into the essen1ally
sequen1alnatureofamachineinstruc1onprogram.• Example:Instruc1onPipelining• A processor which works on the property of parallelism is known as
pipelineprocessor.

Pipelining• Twostages:fetchinstruc1onandexecuteinstruc1on.• The first stage fetches an instruc1on and buffers it. When the second
stage is free, thefirststagepasses it thebuffered instruc1on.Whilethesecondstageisexecu1ngtheinstruc1on,thefirststagetakesadvantageof any unusedmemory cycles to fetch and buffer the next instruc1on.Thisiscalledinstruc(onprefetchorfetchoverlap.
• Advantage:— This process will speed up instruc1on execu1on. If the fetch and
execute stages were of equal dura1on, the instruc1on cycle 1mewouldbehalved.

Pipelining• Disadvantage:
— 1.Theexecu1on1mewillgenerallybelongerthanthefetch1me.Execu1onwill involve reading and storing operands and the performance of someopera1on.Thus,thefetchstagemayhavetowaitforsome1mebeforeitcanemptyitsbuffer.
— 2.Acondi1onalbranchinstruc1onmakestheaddressofthenextinstruc1ontobefetchedunknown.Thus,thefetchstagemustwaitun1l itreceivesthenextinstruc1onaddressfromtheexecutestage.Theexecutestagemaythenhavetowaitwhilethenextinstruc1onisfetched.
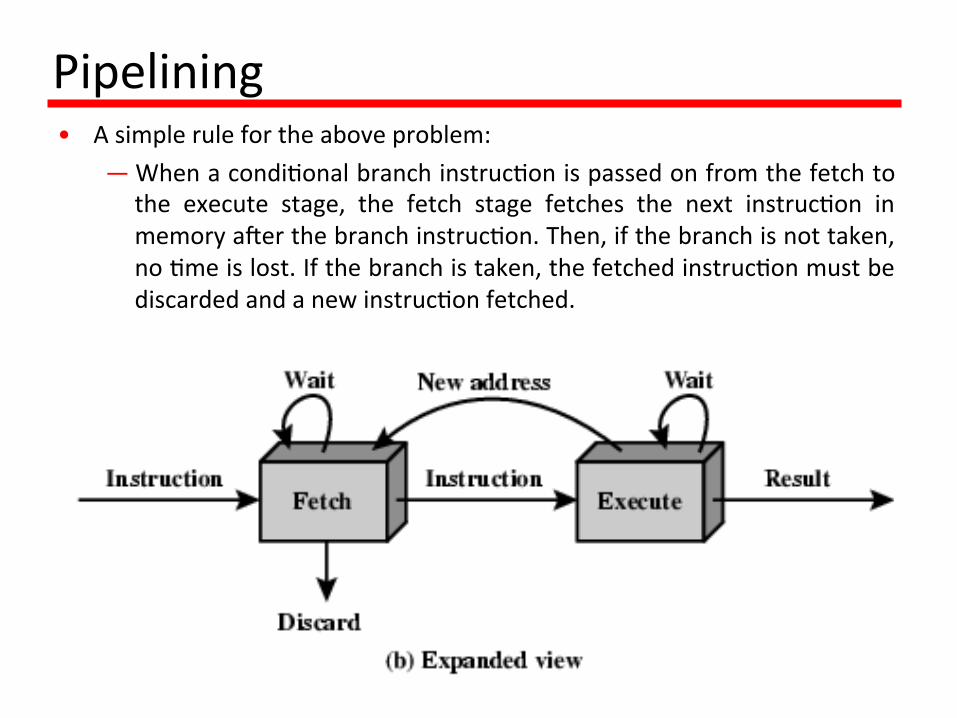
Pipelining• Asimplerulefortheaboveproblem:
— Whenacondi1onalbranchinstruc1onispassedonfromthefetchtothe execute stage, the fetch stage fetches the next instruc1on inmemorya]erthebranchinstruc1on.Then,ifthebranchisnottaken,no1meislost.Ifthebranchistaken,thefetchedinstruc1onmustbediscardedandanewinstruc1onfetched.

Pipelining• Fetchinstruc=on(FI):Readthenextexpectedinstruc1onintoabuffer.• Decode instruc=on (DI): Determine the opcode and the operand
specifiers.• Calculateoperands (CO):Calculate theeffec1veaddressof each source
operand.• Fetchoperands(FO):Fetcheachoperandfrommemory.• Execute instruc=on (EI):Perform the indicated opera1on and store the
result,ifany,inthespecifieddes1na1onoperandloca1on.• Writeoperand(WO):Storetheresultinmemory.

TimingDiagram:Instruc1onPipelineOpera1on
Six-stagepipelinecanreducetheexecu1on1mefor9instruc1onsfrom541meunitsto141meunits.(Assump1on:Allstagestakesequaldura1on)

Pipelining:example(condi1onalbranch)• Assumethatinstruc1on3isacondi1onalbranchtoinstruc1on15.• Un1l the instruc1on is executed, there is no way of knowing which
instruc1onwillcomenext.• The pipeline, in this example, simply loads the next instruc1on in
sequence(instruc1on4)andproceeds.• This is not determined un1l the end of 1me unit 7. At this point, the
pipelinemustbeclearedofinstruc1onsthatarenotuseful.• During1meunit8,instruc1on15entersthepipeline.• No instruc1ons complete during 1me units 9 through 12; this is the
performance penalty incurred because we could not an1cipate thebranch.
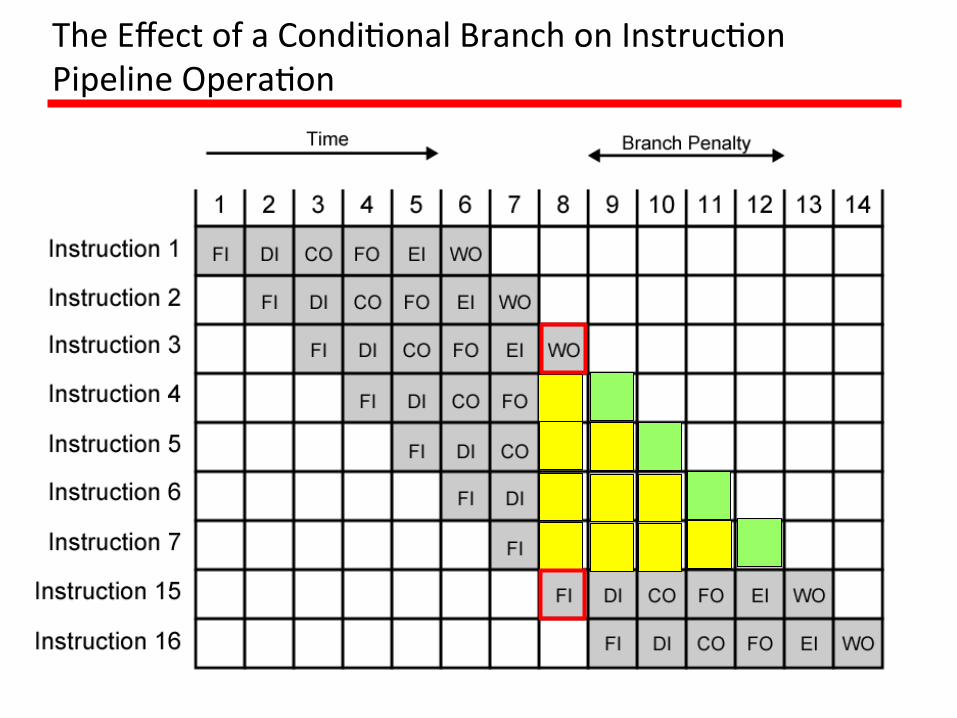
TheEffectofaCondi1onalBranchonInstruc1onPipelineOpera1on

SixStageInstruc1onPipeline

Alterna1vePipelineDepic1on
Figb:Thepipeline is fullat1mes6and7.At1me7, instruc1on3 is intheexecutestageandexecutesabranchtoinstruc1on15.Atthispoint,instruc1onsI4throughI7areflushedfromthepipeline,sothatat1me8,onlytwoinstruc1onsareinthepipeline,I3andI15.

SpeedupFactorswithInstruc1onPipelining

PipelineHazards• A pipeline hazard occurs when the pipeline, or some por1on of the
pipeline, must stall because condi1ons do not permit con1nuedexecu1on. Such a pipeline stall is also referred to as apipeline bubble.Therearethreetypesofhazards:
Resource Hazards
Data Hazards
Control Hazards

ResourceHazard• A resource hazard occurs when two (or more) instruc1ons that are
already in the pipeline need the same resource. The result is that theinstruc1onsmustbeexecuted inserial ratherthanparallel forapor1onofthepipeline.

ResourceHazard:Example
Assumethatthesourceoperandfor instruc1on I1 is in memory,ratherthanaregister.Therefore,thefetchinstruc1onstageofthepipelinemust idle for one cyclebeforebeginning the instruc1onfetchforinstruc1onI3.Assume that all other operandsareinregisters.
Now assume that main memory has a single port. In this case, an operand read to or write from memory cannot be performed in parallel with an instruction fetch.

DataHazard• Adatahazardoccurswhenthereisaconflictintheaccessofanoperand
loca1on. In general terms, we can state the hazard in this form: Twoinstruc1onsinaprogramaretobeexecutedinsequenceandbothaccessapar1cularmemoryorregisteroperand.
• If the two instruc1ons are executed in strict sequence, no problemoccurs.However, if the instruc1onsareexecuted inapipeline,then it ispossiblefortheoperandvaluetobeupdatedinsuchawayastoproducea different result than would occur with strict sequen1al execu1on. Inotherwords,theprogramproducesanincorrectresultbecauseoftheuseofpipelining.

DataHazard:Example• Asanexample,considerthefollowingx86machineinstruc1onsequence:
ADDEAX,EBX/*EAX=EAX+EBXSUBECX,EAX/*ECX=ECX-EAX
• TheADDinstruc1ondoesnotupdateregisterEAXun1ltheendofstage5,whichoccursatclockcycle5.
• But the SUB instruc1on needs that value at the beginning of its stage 2,whichoccursatclockcycle4.
• Tomaintaincorrectopera1on,thepipelinemuststallfortwoclockscycles.• Thus,adatahazardresultsininefficientpipelineusage.

DataHazard:Types
WAR
WAW

DataHazard:Types

ControlHazards• A control hazard, also known as a branch hazard, occurs when the
pipelinemakesthewrongdecisiononabranchpredic1onandthereforebringsinstruc1onsintothepipelinethatmustsubsequentlybediscarded.

Co-Processors• Acoprocessorisacomputerprocessorusedtosupplementthefunc1ons
of the primary processor (the CPU). Opera1ons performed by thecoprocessormaybefloa1ngpointarithme1c,graphics,signalprocessing,stringprocessing,encryp1onorI/OInterfacingwithperipheraldevices.



















