
Unit 1 intro to bioinfo and biological databases student copy
83
Bioinformatics: Applications & Perspectives Naveen P Asst. Professor Dept. of Biotechnology & Bioinformatics Pad. Dr D.Y. Patil University India E-Mail: [email protected]
description
Courtesy: Naveen Sir
Transcript of Unit 1 intro to bioinfo and biological databases student copy

Bioinformatics: Applications & Perspectives
Naveen PAsst. Professor
Dept. of Biotechnology & BioinformaticsPad. Dr D.Y. Patil University
IndiaE-Mail: [email protected]

Today, my talk would focus on … Defining the trans-disciplinary area, i.e.,
Bioinformatics Necessity Landmarks Challenges Branches - Applications Selected Readings Acknowledgement Databases - Descriptive

Defining the term
** Source: Kristian Vlahovicek, 2004

Defining the term … contd. Paulien Hogeweg in the year 1979, coined
the term bioinformatics for the study of informatic processes in life systems.
** Source: Baxevanis et al.,Wiley, 2005
Bioinformatics is the field of science in which biology, computer science, and information technology merge to form a single discipline.
** Source: National Center for Biotechnology Information
So, what exactly is bioinformatics?
ACS National Meeting, San Francisco September 10-14, 2006
Biology
Statistics
Mathematics Computer Sc
Physics Chemistry

Why is it necessary? Tremendous increase in information Knowledge discovery Globalization of research and collaborative
works Data visualization Data interpretation Development of novel strategies for data
analysis

Landmarks …
“Starting with the small bacterium Haemophilus influenza, progressing to yeast and the more-complex multicellular organisms Caenorhabditis elegans and Drosophila melanogaster and ultimately, the draft sequence of the human genome”.
*** Source: Nature Genetics 33, 305 - 310 (2003)
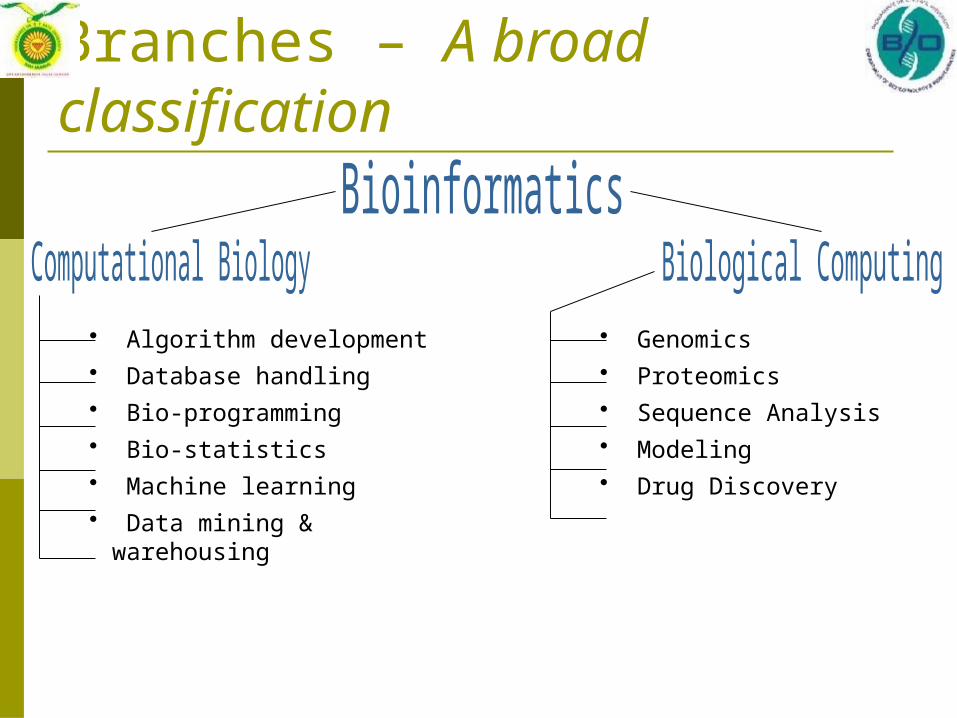
Branches – A broad classification
• Algorithm development• Database handling• Bio-programming• Bio-statistics• Machine learning• Data mining & warehousing
• Genomics • Proteomics• Sequence Analysis• Modeling• Drug Discovery

Branches – Algorithm development
*** Source: Hollard, 1975

Branches – Database handling
*** Source: KEGG

Branches – Bio-programming
*** Source: Anonymous

Branches – Bio-statistics
*** Source: Purdue University, Statistical Bioinformatics Center

Branches – Machine learning
*** Source: Anonymous

Branches – Data mining and warehousing
*** Source: Anonymous
Branches – Genomics
*** Source: Anonymous

Branches – Proteomics
*** Source: Anonymous

Branches – Sequence Analysis
*** Source: Anonymous

Branches – Modeling
*** Source: Anonymous
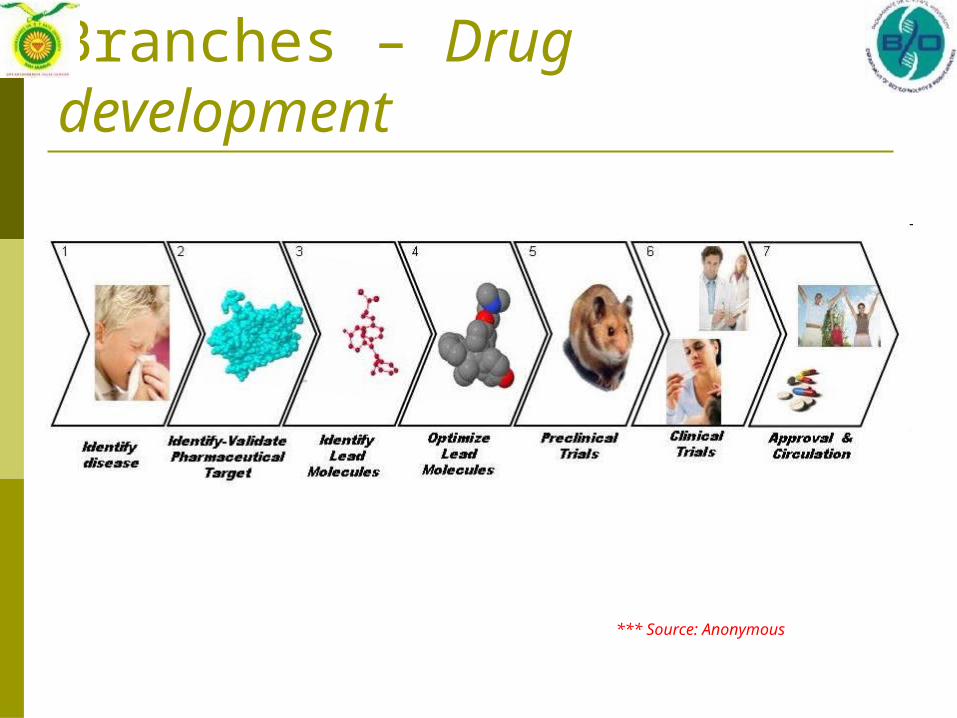
Branches – Drug development
*** Source: Anonymous

Selected Readings Supek, F. and Vlahovicek, K. (2004) “INCA: synonymous
codon usage analysis and clustering by means of self-organizing map”, Bioinformatics 20(14): 2329-2330.
Baxevanis, A.D. and Ouellette B.F.F. (Eds). (2005) “Bioinformatics: A Practical Guide to the Analysis of Genes and Proteins”, 3rd ed. John Wiley & Sons.
Kanehisa, M. and Bork, P. (2003) “Bioinformatics in the post-sequence era”, Nature Genetics 33: 305-310.
Tagore, S. (2010) “Issues in mining skills: Application to computational biology domain”, 1st ed. VDM Verlag.
Hollard, J.H. (1992) “Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence”, The MIT Press.

Introduction to Databases

What is a databaseA database is any organized collection of
data. Some examples of databases you may encounter in your daily life are: a telephone book T.V. Guide airline reservation system motor vehicle registration records papers in your filing cabinet. files on your computer hard drive.

Data vs. information:What is the difference? What is data?
Data can be defined in many ways. Information science defines data as unprocessed information.
What is information? Information is data
that have been organized and communicated in a coherent and meaningful manner.
Data is converted into information, and information is converted into knowledge.
Knowledge; information evaluated and organized so that it can be used purposefully.

Why do we need a database? Keep records of our:
Clients Staff Volunteers
To keep a record of activities and interventions;
Keep sales records; Develop reports; Perform research Longitudinal tracking

What is the ultimate purpose of a database management system?
Data Information Knowledge Action
Is to transform

More about database definitionWhat is a database? Quite simply, it’s an organized collection of
data. A database management system (DBMS)
such as Access, FileMaker, Lotus Notes, Oracle or SQL Server which provides you with the software tools you need to organize that data in a flexible manner.
It includes tools to add, modify or delete data from the database, ask questions (or queries) about the data stored in the database and produce reports summarizing selected contents.

Introduction to Biological Databases

How it started?

Human Genome Project, 1984-86
DOE, US was interested in genetic research regarding health effects from radiation and chemical exposure
NIH was interested in gene sequencing / mutations and their biomedical implications of genetic variation

Human Genome Project, 1990Five Year Plan Construct a high resolution genetic map
of the human genome Produce physical maps of all
chromosomes Determine genome sequence of human
and other model organisms Develop capabilities (technologies) for
collecting, storing, distributing and analyzing data

Human Genome Project, 1990Additional Goals Ethical, legal, social issues (ELSI)
Research training
Technology transfer
Human Genome Project began with a recommended budget of $200 million per year, adjusted for inflation 15 years, $3 billion

Draft Sequences, 2001 International Human Genome
Sequencing Consortium (‘public project’) Initial Sequencing and Analysis of the
Human Genome. Nature 409:860-921, 2001 Celera Genomics – Venter JC et al.
(‘private project’) The Sequence of the Human Genome.
Science 291:1304-1351, 2001.

International Human Genome Sequencing Consortium Collaboration would be open to centers
from any nation 20 centers from 6 countries- US, UK, China, France, Germany, Japan
Rapid and unrestricted data release - Assembled sequences >2 kb were deposited
within 24 hours of assembly

Challenges Data were generated in labs all over the
world Organism is diploid, extremely large
genome Large proportion of the human genome
consists of repetitive and duplicated sequences
Cloning bias (under-representation of some region of the genome)
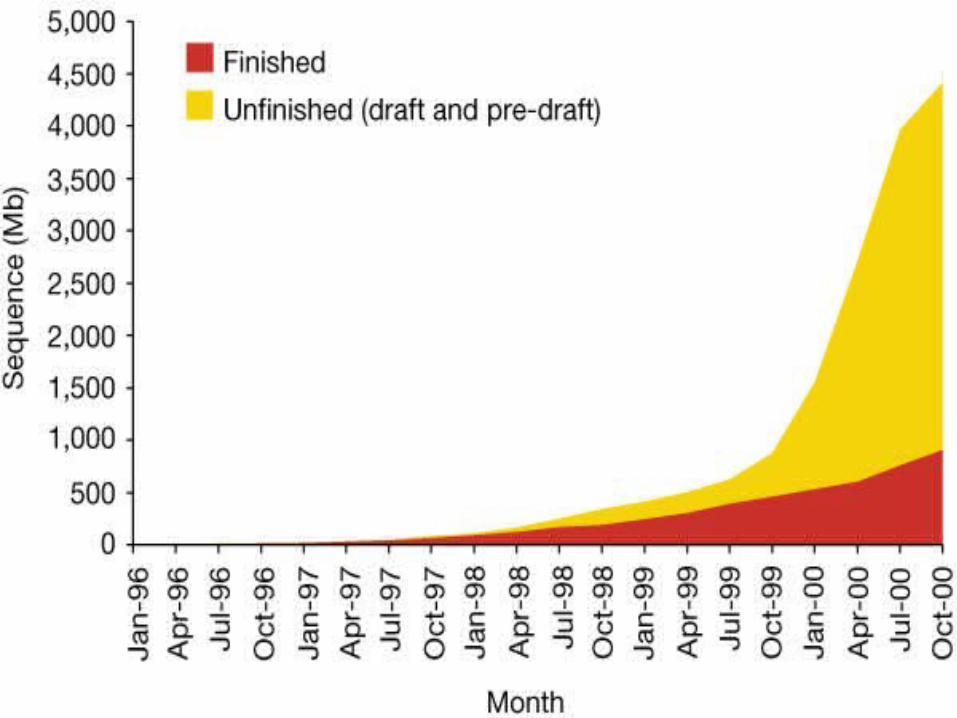

1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003
Year
Minimum estimated values are represented
Cumulative Pace of Gene Discovery 1981-20031

Number of Genes Number of genes only ~ 35,000
<2% of genome encode genes Fruit fly has 13,000 genes Mustard weed has 26,000
Proteome is complex Alternative splicing
- Variation in gene regulation- Post transcription modification
Hundreds of genes appear to have come from bacteria

Number of GenesEstimated from:
- Comparisons with other genomes- Comparisons with identified genes
(protein motifs, pseudogenes)- Presence of initiator, promoter or
enhancer / silencer sequences- Evidence of alternative splicing- Known expressed sequence tags

In the US Senate,February 27, 2003 Concurrent Resolutions Designating
- April, 2003 as “Human Genome Month”- IHGSC placed complete human genome sequence
in public databases- Celera database was offered for purchase- NHGRI unveils new plan for the future of
genomics- April 25 as “DNA Day”
- Marks the 50th anniversary of the description of the double helix by Watson and Crick

Bioinformatics… Bioinformatics is the application of Information
technology to store, organize and analyze the vast amount of biological data which is available in the form of sequences and structures of proteins.
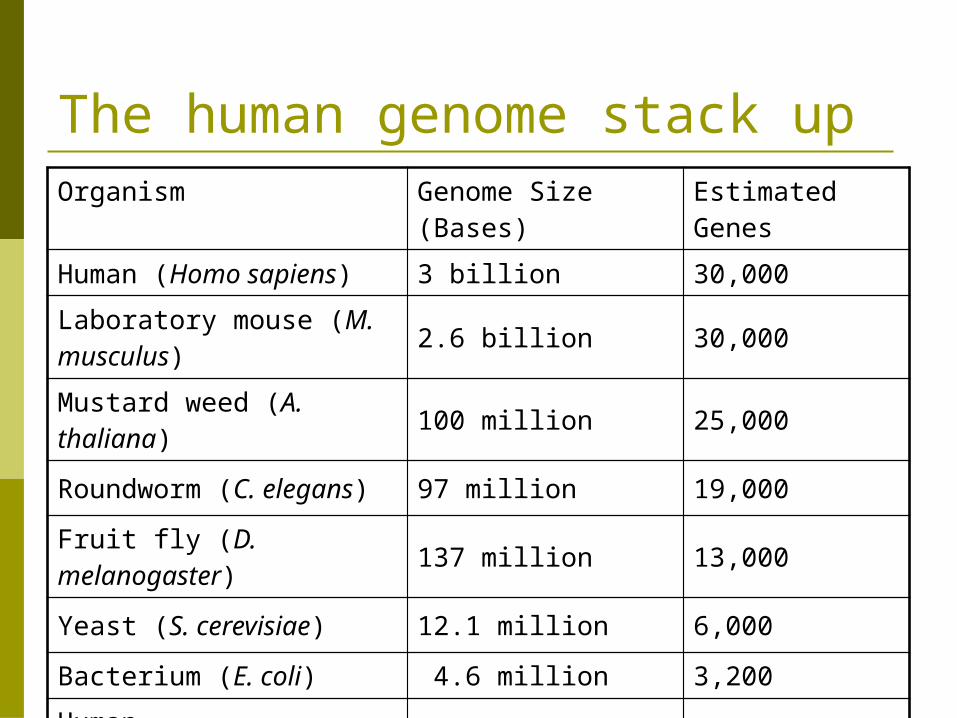
The human genome stack upOrganism Genome Size (Bases) Estimated Genes
Human (Homo sapiens) 3 billion 30,000Laboratory mouse (M. musculus) 2.6 billion 30,000
Mustard weed (A. thaliana) 100 million 25,000
Roundworm (C. elegans) 97 million 19,000
Fruit fly (D. melanogaster) 137 million 13,000
Yeast (S. cerevisiae) 12.1 million 6,000
Bacterium (E. coli) 4.6 million 3,200Human immunodeficiency virus (HIV) 9700 9

Why we need a database ? A biological database is a collection of data that is
organized so that its contents can easily be accessed, managed, and updated. The activity of preparing a database can be divided in to:
Collection of data in a form which can be easily accessed.
Making it available to a multi-user system (always available for the user).

Data Access
Experiments
Organization of data
Host/Server
Network/online access
UsersDatabases

Biological Databases The biological data bases are classified
into two types Nucleotide sequence data bases. EMBL, Genbank (NCBI) , DDBJ,
Unigene,SGD genome, EBI genomes, Ensemble.
Protein sequence databases SWISS-PROT & TrEMBL, PIR, PROSITE,
PFAM, PDB, SCOP, CATH

NCBI Derivative Sequence Data
ATTGACTA
TTGACA
CGTGAATTGACTA
TATA
GCCG
ACGTGC
ACGTGCACGT
GC
TTGACA
TTGACA
TTGACA
CGTG
A CGTGA
CGTG
A
ATTG
ACTA
ATTGACTA ATTGACTA
ATTGACTATATAGCCG
TATAGCCGTA
TAGC
CGTATAGCCG
GenBank
TATAGCCG TATAGCCGTATAGCCGTATAGCCG
ATGA
CATT
GAGA
ATTATTC
C GAGA
ATTC
CGAGA
ATTC GAGA
ATTC
GAGA
ATTC
C GAGA
ATTC
C
UniGene
RefSeq
GenomeAssembly
Labs
Curators
Algorithms
TATAGCCGAGCTCCGATACCGATGACAA
Users

Protein resourcesPrimary Sequence VLKLMQHP
Secondary Motif [AS]-[IL]2-x[DE]-K
Tertiary domain folding units
Primary DatabaseSecondary DatabaseStructure Database

Nucleotide sequence Databases Primary Nucleotide sequence Databases. The data bases EMBL, Genebank(NCBI) and DDBJ
are the three primary nucleotide sequence databases. They include sequences submitted directly by
scientists and genome sequencing group, and sequences taken from literature and patents.
There is comparatively little error checking and there is a fair amount of redundancy.

EMBL Database URL: www.ebi.ac.uk/embl/ The European Bioinformatics institute (EBI)
in Cambridge,UK, maintains the EMBl nucleotide sequence database.
It contained 10,378,022 records with a total of 11,302,156,937 bases.

Genebank Database URL: www.ncbi.nlm.nih.gov/Genbank/ The Genbank nucleotide database is
maintained by national Center for Biotechnology Information, which is part of National Institute of Health (NIH), a federal agency of US government

DDBJ Database URL: www.ddbj.nig.ac.jp The DNA Data Bank of Japan began as
collaboration with EMBL and Genbank. It is run by the National Institute of
Genetics.

UniGene Database URL: www.ncbi.nlm.nih.gov/UniGene/ The UniGene system attempts to process
the Genbank sequence data into a non-redundant set of gene-oriented clusters.
Each UniGene cluster contains sequences that represent a unique gene, as well as related information such as the tissue types in which the gene has been expressed and map location.

SCD database URL: www.staford.edu/Saccharomyces/ The Saccharomyces Genome Database
(SGD) is a scientific database of the molecular biology and genetics of the yeast Saccharomyces cerevisiae.

EBI Genomes Database URL: www.ebi.ac.uk/genomes/ This web site provides access and
statistics for the completed genomes and information about ongoing projects.

Ensemble Database URL: www.ensemble.org Ensemble is a joint project between EMBL-
EBI and the Sanger Center to develop a software system which produces and maintains automatic annotation of eucaryotic genomes.

Protein databases These are further divided into three types. Primary structure d/b Swiss-Prot & TrEMBL and PIR. Secondary structure d/b PROSITE & Pfam Tertiary structure d/b PDB, SCOP & CATH

SWISS-PROT URL: www.expasy.ch/sprot/, www.ebi.ac.uk/swissprot/ Features: It was established in 1986 by Department of Medical
Biochemistry at University Of Geneva. But now ,it is maintained by SIB and EBI.
It is a protein sequence database, which provides a high level of annotations ( such as functions of proteins, its domain structures, post translational modification, variants , etc.,).
It maintains minimal level of redundancy. It has high level of integration with other databases. The current SwissProt database contains 123,945 entries.

TrEMBL URL: www.ebi.ac.uk/trembl/ Features: It is a computer-annotated supplement of Swiss Prot
database. It cont5ains all the translations of EMBL nucleotide
sequence entries. It is also maintained by SIB and EBI. It contains 830,525 entries. Restrictions: These databases has some legal restrictions The entries are copyrighted, but freely accessible and
usable by academic researchers. Commercial companies must pay a license fee for SIB to use
SWISSPROT.

PIR URL: http://pir.georgetown.edu Features: It is a protein sequence database developed at National
Biomedical Research Foundation (NBRF) in US in early 1960.
It is involved in collaboration with Munich Information Center for Protein Sequences (MIPS) and the Japanese International Protein Sequence Database (JIPID).
It contains 198,801 entries. It provides comprehensive, well organized, accurate and
consistently annotated data.

PROSITE URL: www.expasy.ch/prosite/ Features: It is a database of protein families and domains. It consists of biologically significant sites, patterns and
profiles that help to reliably identify to which known family a new sequence belongs.
It was started by Amos Bairoch and is maintained in the same way as SWISSPROT.
This site is used to search by keyword or text in the entries, to search for a pattern in a sequence, To search for proteins in SWIS-PROT that match a pattern.

PDB Url: www.rcsb.org/pdb/ Features: It is a main primary databases for 3D structures of biological
macromolecules determined by X-ray crystallography and NMR. It was established in 1970 at Brookhaven Lab on Long Island, New
York State, US. In 1999 the management was moved to Research Collaboratory for Structural Bioinformatics (RCSB).
As of now the PDB contains 20747 structures. The PDB entries contain the atomic coordinates and some structural
parameters connected with the atoms. They also contain some annotation but it is not as comprehensive as SWISS-PROT.
There are no legal restriction for the uses of the data in the PDB.

Nucleic Acid DatabasesGenBank

Outline
I.GenBank Sequence Database
II.Text Term Searching: The Entrez System

GenBank Sequence Database The GenBank sequence database is the NIH
genetic sequence database, an annotated collection of all publicly available nucleotide sequences and their protein translations.
International collaboration of sequence databases GenBank European Molecular Biology Laboratory (EMBL) DNA Database of Japan (DDBJ)
Submissions to GenBank Direct submissions (using BankIt or Sequin) Batch submissions (EST, STS, and GSS
sequences) FTP accounts (HTGS, WGS, etc.)

http://www.ncbi.nlm.nih.gov/Genbank/index.html

GenBank DivisionNCBI-GenBank Flat File Release 154.0 (June 15 2006) Organismal divisions
PRI - primate sequences (30) ROD - rodent sequences (24) MAM - other mammalian sequences (2) VRT - other vertebrate sequences (11) INV - invertebrate sequences (9) PLN - plant, fungal, and algal sequences (18) BCT - bacterial sequences (15) VRL - viral sequences (6) PHG - bacteriophage sequences (1) SYN - synthetic sequences (1) UNA - unannotated sequences (1)
ftp://ftp.ncbi.nih.gov/genbank/gbrel.txt

Technology-based divisions EST - expressed sequence tags
(528) PAT - patent sequences (24) STS - sequence tagged sites (14) GSS - genome survey sequences
(177) HTG - high throughput genomic sequences
(83) HTC - high throughput cDNA sequences
(10) ENV - Environmental sampling sequences(3)
GenBank DivisionNCBI-GenBank Flat File Release 154.0 (June 15 2006)
ftp://ftp.ncbi.nih.gov/genbank/gbrel.txt

File Formats of the Sequence Databases
GenBank and GenPept flatfiles
FASTA GenBank ASN.1 INSDSet structured XML TinySeq XML

GenBank Flat File FormatLOCUS OSU37133 3921 bp DNA linear PLN 14-DEC-1995DEFINITION Oryza sativa receptor kinase-like protein (Xa21) gene, complete cds.ACCESSION U37133VERSION U37133.1 GI:1122442KEYWORDS .SOURCE Oryza sativa (indica cultivar-group) ORGANISM Oryza sativa (indica cultivar-group) Eukaryota; Viridiplantae; Streptophyta; Embryophyta; Tracheophyta; Spermatophyta; Magnoliophyta; Liliopsida; Poales; Poaceae; BEP clade; Ehrhartoideae; Oryzeae; Oryza.REFERENCE 1 (bases 1 to 3921) AUTHORS Song,W.-Y., Wang,G.-L., Chen,L.-L., Kim,H.-S., Pi,L.-Y., Holsten,T., Wang,G.B., Zhai,W.-X., Zhu,L.-H., Fauquet,C. and Ronald,P. TITLE A receptor kinase-like protein encoded by the rice disease resistance gene, Xa21 JOURNAL Science 270 (5243), 1804-1806 (1995) PUBMED 8525370REFERENCE 2 (bases 1 to 3921) AUTHORS Ronald,P., Song,W.-Y., Wang,G.-L., Kim,H.-S. and Pi,L.-Y. TITLE Direct Submission JOURNAL Submitted (26-SEP-1995) Pamela Ronald, Plant Pathology, UC Davis, Hutchison Hall, Davis, CA 95616, USA

GenBank Flat File Format, cont.FEATURES Location/Qualifiers source 1..3921 /organism="Oryza sativa (indica cultivar-group)" /mol_type="genomic DNA" /strain="IRBB21" /db_xref="taxon:39946" /chromosome="11" /map="11q, RG103" gene 1..3921 /gene="Xa21" CDS join(1..2677,3521..3921) /gene="Xa21" /note="Xa21 disease resistance gene" /codon_start=1 /product="receptor kinase-like protein" /protein_id="AAC49123.1" /db_xref="GI:1122443" /translation="MISLPLLLFVLLFSALLLCPSSSDDDGDAAGDELALLSFKSSLL YQGGQSLASWNTSGHGQHCTWVGVVCGRRRRRHPHRVVKLLLRSSNLSGIISPSLGNL SFLRELDLGDNYLSGEIPPELSRLSRLQLLELSDNSIQGSIPAAIGACTKLTSLDLSH NQLRGMIPREIGASLKHLSNLYLYKNGLSGEIPSALGNLTSLQEFDLSFNRLSGAIPS SLGQLSSLLTMNLGQNNLSGMIPNSIWNLSSLRAFSVRENKLGGMIPTNAFKTLHLLE VIDMGTNRFHGKIPASVANASHLTVIQIYGNLFSGIITSGFGRLRNLTELYLWRNLFQ TREQDDWGFISDLTNCSKLQTLNLGENNLGGVLPNSFSNLSTSLSFLALELNKITGSI PKDIGNLIGLQHLYLCNNNFRGSLPSSLGRLKNLGILLAYENNLSGSIPLAIGNLTEL

GenBank Flat File Format, cont. NILLLGTNKFSGWIPYTLSNLTNLLSLGLSTNNLSGPIPSELFNIQTLSIMINVSKNN LEGSIPQEIGHLKNLVEFHAESNRLSGKIPNTLGDCQLLRYLYLQNNLLSGSIPSALG QLKGLETLDLSSNNLSGQIPTSLADITMLHSLNLSFNSFVGEVPTIGAFAAASGISIQ GNAKLCGGIPDLHLPRCCPLLENRKHFPVLPISVSLAAALAILSSLYLLITWHKRTKK GAPSRTSMKGHPLVSYSQLVKATDGFAPTNLLGSGSFGSVYKGKLNIQDHVAVKVLKL ENPKALKSFTAECEALRNMRHRNLVKIVTICSSIDNRGNDFKAIVYDFMPNGSLEDWI HPETNDQADQRHLNLHRRVTILLDVACALDYLHRHGPEPVVHCDIKSSNVLLDSDMVA HVGDFGLARILVDGTSLIQQSTSSMGFIGTIGYAAPEYGVGLIASTHGDIYSYGILVL EIVTGKRPTDSTFRPDLGLRQYVELGLHGRVTDVVDTKLILDSENWLNSTNNSPCRRI TECIVWLLRLGLSCSQELPSSRTPTGDIIDELNAIKQNLSGLFPVCEGGSLEF" exon 1..2677 /gene="Xa21" /number=1 intron 2678..3520 /gene="Xa21" exon 3521..3921 /gene="Xa21" /number=2ORIGIN 1 atgatatcac tcccattatt gctcttcgtc ctgttgttct ctgcgctgct gctctgccct 61 tcaagcagtg acgacgatgg tgatgctgcc ggcgacgaac tcgcgctgct ctctttcaag <sequence omitted>
3841 atcatcgacg aactgaatgc catcaaacag aatctctccg gattgtttcc agtgtgtgaa 3901 ggtgggagcc ttgaattctg a//
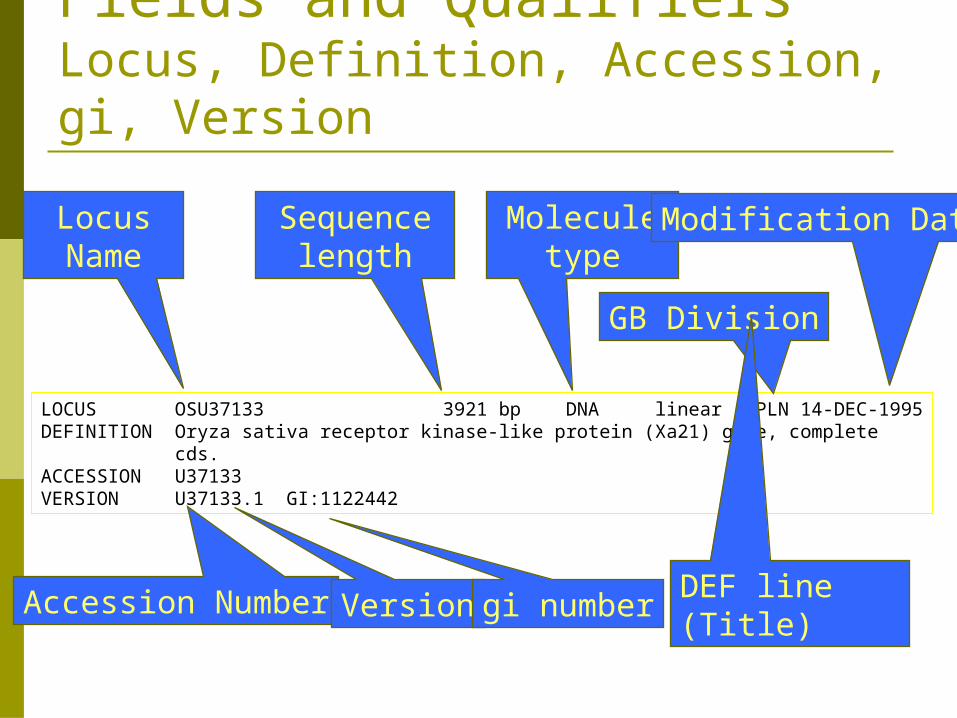
Fields and QualifiersLocus, Definition, Accession, gi, Version
LOCUS OSU37133 3921 bp DNA linear PLN 14-DEC-1995DEFINITION Oryza sativa receptor kinase-like protein (Xa21) gene, complete cds.ACCESSION U37133VERSION U37133.1 GI:1122442
Locus Name
Sequencelength
Moleculetype
GB Division
Modification Date
Accession Number Version gi number DEF line (Title)

Fields and QualifiersKeywords, Source-organism
KEYWORDS .SOURCE Oryza sativa (indica cultivar-group) ORGANISM Oryza sativa (indica cultivar-group) Eukaryota; Viridiplantae; Streptophyta; Embryophyta; Tracheophyta; Spermatophyta; Magnoliophyta; Liliopsida; Poales; Poaceae; BEP clade; Ehrhartoideae; Oryzeae; Oryza.
Legacy fieldException:EST, STS, GSS, HTG, etc.
Taxonomic lineage according to GenBank

Fields and QualifiersFeature Table
FEATURES Location/Qualifiers source 1..3921 /organism="Oryza sativa (indica cultivar-group)" /mol_type="genomic DNA" /strain="IRBB21" /db_xref="taxon:39946" /chromosome="11" /map="11q, RG103" gene 1..3921 /gene="Xa21" CDS join(1..2677,3521..3921) /gene="Xa21" /note="Xa21 disease resistance gene" /codon_start=1 /product="receptor kinase-like protein" /protein_id="AAC49123.1" /db_xref="GI:1122443" /translation="MISLPLLLFVLLFSALLLCPSSSDDDGDAAGDELALLSFKSSLL YQGGQSLASWNTSGHGQHCTWVGVVCGRRRRRHPHRVVKLLLRSSNLSGIISPSLGNL SFLRELDLGDNYLSGEIPPELSRLSRLQLLELSDNSIQGSIPAAIGACTKLTSLDLSH NQLRGMIPREIGASLKHLSNLYLYKNGLSGEIPSALGNLTSLQEFDLSFNRLSGAIPS SLGQLSSLLTMNLGQNNLSGMIPNSIWNLSSLRAFSVRENKLGGMIPTNAFKTLHLLE
Coding sequence GenPept Identifiers
Base span of the biological feature

FASTA Format>gi|1122442|gb|U37133.1|OSU37133 Oryza sativa receptor kinase-like protein (Xa21) gene, complete cdsATGATATCACTCCCATTATTGCTCTTCGTCCTGTTGTTCTCTGCGCTGCTGCTCTGCCCTTCAAGCAGTGACGACGATGGTGATGCTGCCGGCGACGAACTCGCGCTGCTCTCTTTCAAGTCATCCCTGCTATACCAGGGGGGCCAGTCGCTGGCATCTTGGAACACGTCCGGCCACGGCCAGCACTGCACATGGGTGGGTGTTGTGTGCGGCCGCCGCCGCCGCCGGCACCCACACAGGGTGGTGAAGCTGCTGCTGCGCTCCTCCAACCTGTCCGGGATCATCTCGCCGTCGCTCGGCAACCTGTCCTTCCTCAGGGAGCTGGACCTCGGCGACAACTACCTCTCCGGCGAGATACCACCGGAGCTCAGCCGTCTCAGCAGGCTTCAGCTGCTGGAGCTGAGCGATAACTCCATCCAAGGGAGCATCCCCGCGGCCATTGGAGCATGCACCAAGTTGACATCGCTAGACCTCAGCCACAACCAACTGCGAGGTATGATCCCACGTGAGATTGGTGCCAGCTTGAAACATCTCTCGAATTTGTACCTTTACAAAAATGGTTTGTCAGGAGAGATTCCATCCGCTTTGGGCAATCTCACTAGCCTCCAGGAGTTTGATTTGAGCTTCAACAGATTATCAGGAGCTATACCTTCATCACTGGGGCAGCTCAGCAGTCTATTGACTATGAATTTGGGACAGAACAATCTAAGTGGGATGATCCCCAATTCTATCTGGAACCTTTCGTCTCTAAGAGCGTTTAGTGTCAGAGAAAACAAGCTAGGTGGTATGATCCCTACAAATGCATTCAAAACCCTTCACCTCCTCGAGGTGATAGATATGGGCACTAACCGTTTCCATGGCAAAATCCCTGCCTCAGTTGCTAATGCTTCTCATTTGACAGTGATTCAGATTTATGGCAACTTGTTCAGTGGAATTATCACCTCGGGGTTTGGAAGGTTAAGAAATCTCACAGAACTGTATCTCTGGAGAAATTTGTTTCAAACTAGAGAACAAGATGATTGGGGGTTCATTTCTGACCTAACAAATTGCTCCAAATTACAAACATTGAACTTGGGAGAAAATAACCTGGGGGGAGTTCTTCCTAATTCGTTTTCCAATCTTTCCACTTCGCTTAGTTTTCTTGCACTTGAATTGAATAAGATCACAGGAAGCATTCCGAAGGATATTGGCAATCTTATTGGCTTACAACATCTCTATCTCTGCAACAACAATTTCAGAGGGTCTCTTCCATCATCGTTG
FASTA Definition Line>gi|1122442|gb|U37133.1|OSU37133
gi numberDatabase Identifiersgb GenBankemb EMBLdbj DDBJsp SWISS-PROTpdb Protein Databankpir PIRref RefSeq
Accession number
Locus Name

II.Text Term Searching: The Entrez System

Entrez Cross Database Search Engine http://www.ncbi.nlm.nih.gov/gquery/gquery.fcgi
xa21


The Nucleotide database is divided into three subsets: CoreNucleotide
contains all Nucleotide records that are not in the other subsets.
EST contains Expressed Sequence Tag records only.
GSS contains Genome Survey Sequence records only

Details explains how Entrez interpreted your query, and provides details about error messages.
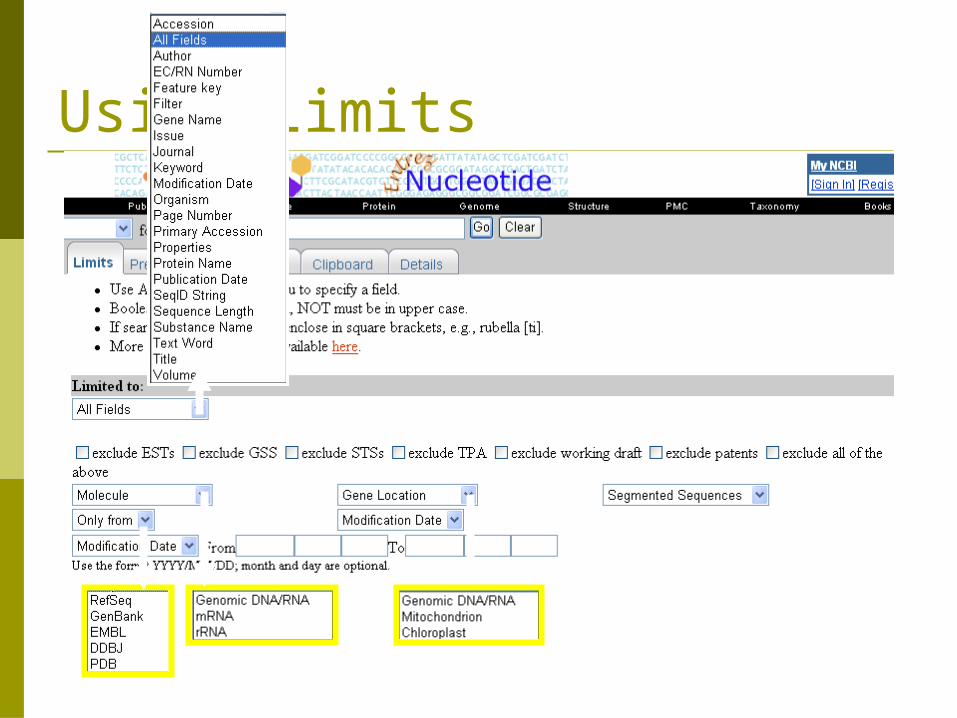
Using Limits

Using Preview/Index
xa21
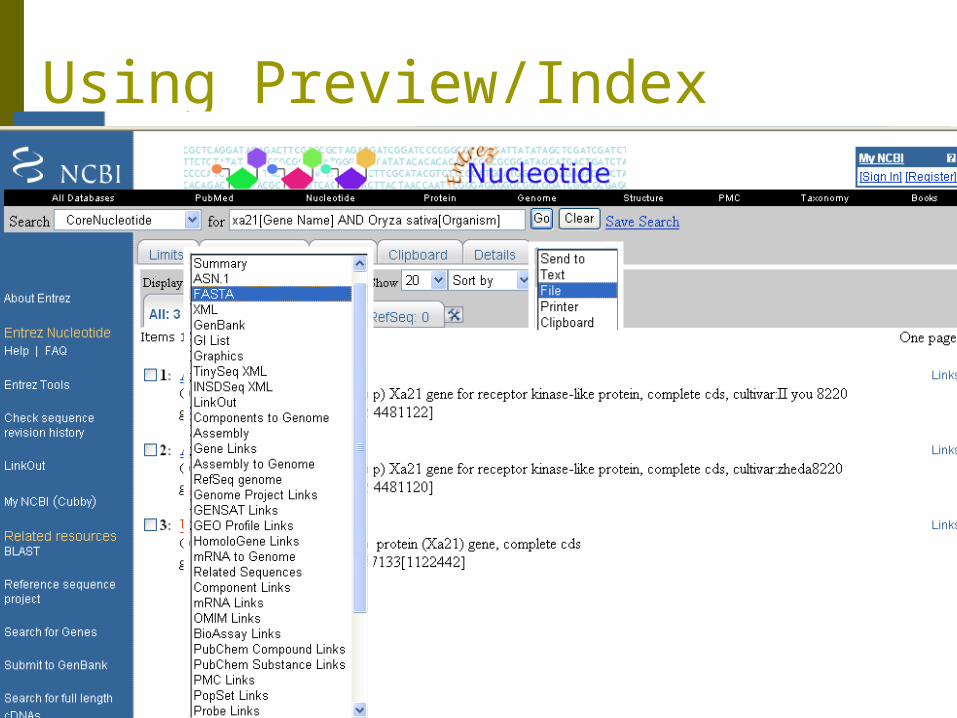
Using Preview/Index

The Entrez search rules and syntax for using Boolean operators Boolean operators AND, OR, NOT must be entered
in UPPERCASE. Entrez processes all Boolean operators in a left-to-
right sequence. The terms inside the parentheses are processed
first as a unit and then incorporated into the overall strategy.
Click on the Details button to see how Entrez translated and executed your search strategy.


















