
Uma análise de algoritmos para extração de regras de ... · representam objetos, ... sendo sua...
8
Uma análise de algoritmos para extração de regras de associação usando Análise Formal de Conceitos Renato Vimieiro 1 e Newton José Vieira 1 1 Departamento de Ciência da Computação Universidade Federal de Minas Gerais {vimieiro,nvieira}@dcc.ufmg.br Abstract. This paper aims at presenting a performance evaluation of four re- presentative algorithms based on FCA for extracting association rules. The situations where each algorithm is less or more adequate will be discussed here. Resumo. Este artigo apresenta uma avaliação de desempenho de quatro algo- ritmos representativos baseados em AFC para extração de regras de associação. As situações em que cada algoritmo é mais, ou menos, adequado são discutidas aqui. 1. Introdução Este trabalho apresenta uma avaliação de desempenho de quatro algoritmos representati- vos baseados em Análise Formal de Conceitos (AFC) para extração de regras de associa- ção. A extração de regras de associação é um importante problema da área de mineração de dados que trata da descoberta de relacionamentos significativos, de natureza probabi- lística, entre itens de grandes bases de dados [Agrawal and Srikant 1994]. Já a AFC, é um arcabouço formal, baseado na teoria de reticulados [Davey and Priestley 2001], para a análise de dados [Ganter and Wille 1999]. A aplicação de AFC na extração de regras de associação é, de certa forma, natural, visto que, ao organizar os itens de dados em um reticulado, a AFC obtém uma malha de relacionamentos que pode servir de base para a mineração de associações significativas. Os quatro algoritmos avaliados são: AClose, Titanic, Frequent Next Neighbours (FNN) e Galicia.O AClose, proposto por Pasquier et al. [Pasquier et al. 1999], baseia- se no tradicional algoritmo para extração de regras de associação Apriori de Agrawal e Srikant [Agrawal and Srikant 1994]. O Titanic [Stumme et al. 2002], também tem inspira- ção no Apriori, porém o método difere do AClose por construir explicitamente reticulados conceituais. O FNN, proposto por Carpineto e Romano [Carpineto and Romano 2004], utiliza reticulados como guias para a extração de regras. O quarto algoritmo, Galicia, proposto por Valtchev et al. [Valtchev et al. 2002], é um método incremental que também usa reticulados, mas como forma de encontrar conjuntos de itens freqüentes. Os algoritmos foram implementados e submetidos a bases de dados sintéticas. As bases de dados foram geradas para avaliar a influência do tamanho (número de tuplas) e da densidade no tempo de execução dos algoritmos. Os experimentos realizados revelam comportamentos característicos para cada classe de algoritmo. Aqueles baseados no Apriori mostraram-se mais sensíveis a vari- ações na densidade das bases de dados. À medida que a densidade aumenta, os tempos de execução dos algoritmos também aumentam. Já para os algoritmos que usam diretamente III Workshop em Algoritmos e Aplicações de Mineração de Dados WAAMD 2007 31
Transcript of Uma análise de algoritmos para extração de regras de ... · representam objetos, ... sendo sua...

Uma análise de algoritmos para extração de regras deassociação usando Análise Formal de Conceitos
Renato Vimieiro1 e Newton José Vieira1
1Departamento de Ciência da ComputaçãoUniversidade Federal de Minas Gerais
{vimieiro,nvieira}@dcc.ufmg.br
Abstract. This paper aims at presenting a performance evaluation of four re-presentative algorithms based on FCA for extracting association rules. Thesituations where each algorithm is less or more adequate will be discussed here.
Resumo. Este artigo apresenta uma avaliação de desempenho de quatro algo-ritmos representativos baseados em AFC para extração de regras de associação.As situações em que cada algoritmo é mais, ou menos, adequado são discutidasaqui.
1. IntroduçãoEste trabalho apresenta uma avaliação de desempenho de quatro algoritmos representati-vos baseados em Análise Formal de Conceitos (AFC) para extração de regras de associa-ção. A extração de regras de associação é um importante problema da área de mineraçãode dados que trata da descoberta de relacionamentos significativos, de natureza probabi-lística, entre itens de grandes bases de dados [Agrawal and Srikant 1994]. Já a AFC, éum arcabouço formal, baseado na teoria de reticulados [Davey and Priestley 2001], paraa análise de dados [Ganter and Wille 1999]. A aplicação de AFC na extração de regrasde associação é, de certa forma, natural, visto que, ao organizar os itens de dados em umreticulado, a AFC obtém uma malha de relacionamentos que pode servir de base para amineração de associações significativas.
Os quatro algoritmos avaliados são: AClose, Titanic, Frequent Next Neighbours(FNN) e Galicia. O AClose, proposto por Pasquier et al. [Pasquier et al. 1999], baseia-se no tradicional algoritmo para extração de regras de associação Apriori de Agrawal eSrikant [Agrawal and Srikant 1994]. O Titanic [Stumme et al. 2002], também tem inspira-ção no Apriori, porém o método difere do AClose por construir explicitamente reticuladosconceituais. O FNN, proposto por Carpineto e Romano [Carpineto and Romano 2004],utiliza reticulados como guias para a extração de regras. O quarto algoritmo, Galicia,proposto por Valtchev et al. [Valtchev et al. 2002], é um método incremental que tambémusa reticulados, mas como forma de encontrar conjuntos de itens freqüentes.
Os algoritmos foram implementados e submetidos a bases de dados sintéticas. Asbases de dados foram geradas para avaliar a influência do tamanho (número de tuplas) eda densidade no tempo de execução dos algoritmos.
Os experimentos realizados revelam comportamentos característicos para cadaclasse de algoritmo. Aqueles baseados no Apriori mostraram-se mais sensíveis a vari-ações na densidade das bases de dados. À medida que a densidade aumenta, os tempos deexecução dos algoritmos também aumentam. Já para os algoritmos que usam diretamente
III Workshop em Algoritmos e Aplicações de Mineração de DadosWAAMD 2007
31

Tabela 1. Exemplo de contexto formalAnimais aquático terrestre branquias pulmões pêlo pena mamífero razãopeixe × ×sapo × × × ×homem × × × × ×macaco × × × ×coruja × × ×tubarão × ×
o reticulado, esse comportamento não foi observado; o aumento da densidade não resul-tou no aumento do tempo de execução. Contudo, eles mostraram-se sensíveis ao aumentodo tamanho da base de dados. O aumento do tamanho da base resultou no aumento dotempo de execução desses algoritmos. Neste trabalho, as situações em que cada algoritmoadequa-se melhor serão discutidas.
O trabalho está organizado da seguinte forma: a próxima seção apresenta concei-tos básicos sobre AFC. A Seção 3 apresenta algumas definições sobre regras de associaçãoe mostra como a AFC pode ser usada para extração das mesmas. A Seção 4 apresenta osresultados das comparações dos algoritmos. Finalmente, a Seção 5 apresenta as conclu-sões e limites do trabalho e indica pesquisas futuras.
2. Análise formal de conceitosA AFC é um método proposto para a análise de dados estruturados como conceitos for-mais, entidades matemáticas que formalizam, simplificadamente, a concepção abstrata deconceito como manifestação do pensamento humano. Ela baseia-se na teoria de reticula-dos para construir hierarquias de conceitos, fundamentando-se em três entidades básicas:contextos formais, conceitos formais e reticulados conceituais.
Contextos formais são triplas (G, M, I) em que G é um conjunto de objetos, Mé um conjunto de atributos e I é uma relação binária, I ⊆ G ×M , chamada relação deincidência. A relação I indica se um objeto g ∈ G possui um atributo m ∈ M (gIm ou(g,m) ∈ I). Normalmente, contextos formais são representados por tabelas cujas linhasrepresentam objetos, colunas representam atributos e as interseções entre linhas e colunasindicam se objetos possuem ou não determinados atributos. A Tabela 1 apresenta umexemplo de contexto formal. Nela, os objetos são animais, os atributos são característicasdos animais e a relação de incidência indica, para cada animal, as características queele possui. Por exemplo, o fato de que o animal homem possui a característica razãoé indicado pelo sinal × na interseção entre a linha representando o homem e a colunarepresentando a razão.
Seja (G, M, I) um contexto formal e sejam A ⊆ G e B ⊆M conjuntos de objetose de atributos, respectivamente. Definem-se as seguintes funções, chamadas operadoresde derivação:
A↑ = {m ∈M | ∀g ∈ A gIm}, B↓ = {g ∈ G | ∀m ∈ B gIm}
A função ↑, aplicada a um conjunto de objetos A, retorna o conjunto dos atributos comunsaos objetos de A. Similarmente, a função ↓, aplicada a um conjunto de atributos B, retornao conjunto de objetos que possui os atributos de B em comum. Assim, para o exemploda Tabela 1, tem-se: {sapo, macaco}↑ = {terrestre, pulmões} e {terrestre, pulmões}↓ ={sapo, homem, macaco, coruja}. As funções ↑ e ↓ recebem a mesma notação (·)′, pormotivo de conveniência, como é comum em textos sobre AFC.
III Workshop em Algoritmos e Aplicações de Mineração de DadosWAAMD 2007
32

Figura 1. Diagrama de linha do contexto formal da Tabela 1.
A partir de contextos formais, pode-se extrair conceitos formais. Um conceito for-mal é constituído por um conjunto de objetos denominado extensão, e por um conjuntode atributos denominado intensão. Todo objeto da extensão possui todos os atributos daintensão e todo atributo da intensão é comum a todos os objetos da extensão. Ou seja, umconceito formal é um par (A, B), em que A ⊆ G e B ⊆ M , tal que A′ = B e B′ = A;A é a extensão e B a intensão do conceito. O par ({homem, macaco}, {terrestre, pul-mões, pêlo, mamífero}) é um exemplo de conceito formal obtido do contexto formal daTabela 1.
Os conceitos formais podem ser ordenados criando-se um reticulado conceitual.Os conceitos são ordenados pela inclusão de conjuntos sobre as extensões e pela ordeminversa de inclusão sobre as intensões. Sejam (A1, B1), (A2, B2) dois conceitos formais.Então (A1, B1) ≤ (A2, B2) se, e somente se, A1 ⊆ A2 e B2 ⊆ B1 [Ganter and Wille1999].
Um reticulado conceitual pode ser representado graficamente através de um dia-grama de linhas. Os conceitos formais são representados no diagrama através de círculos,sendo sua extensão desenhada abaixo e sua intensão acima do círculo. A relação de or-dem estabelecida entre os conceitos formais é explicitada apenas para conceitos formaisvizinhos imediatos, por meio de uma linha conectando os círculos que os representam. AFigura 1 apresenta o diagrama de linhas dos conceitos do contexto formal da Tabela 1. Aextensão e intensão dos conceitos formais são exibidas de forma reduzida. Nesse caso,um objeto g é desenhado somente na extensão do menor conceito formal (A, B) tal queg ∈ A. Similarmente, um atributo m é desenhado na intensão do maior conceito formal(A, B) tal que m ∈ B.
O reticulado conceitual torna explicítos os relacionamentos entre atributos, forne-cendo uma base para extração de regras em geral e, em particular, de regras de associação.Exemplificando, dos conceitos formais com rótulo pêlo e mamífero, e terrestre e pulmõesno reticulado conceitual da Figura 1, pode-se extrair a seguinte regra, dentre outras: para50% dos animais, se um animal tem o atributo terrestre, então ele tem pêlo. Observeque nem todo animal terrestre possui pêlo; a coruja, por exemplo, é terrestre e não pos-sui pêlos. Regras desse tipo ilustram regras de associação que são definidas na próximaseção.
3. Regras de associação e AFCRegras de associação são relacionamentos entre atributos, válidos para grupos de objetosem uma base de dados. Considerando uma base de dados representada por um contextoformal, pode-se enunciar formalmente regras de associação como quadrúplas (A, B, s, c)em que A é um conjunto de atributos, chamado de antecedente da regra, B é um conjuntode atributos, chamado de conseqüente da regra, s ∈ [0, 1] é o suporte e c ∈ [0, 1] éa confiança da regra. O suporte de uma regra de associação revela a probabilidade dos
III Workshop em Algoritmos e Aplicações de Mineração de DadosWAAMD 2007
33

objetos da base de dados possuírem os atributos envolvidos na regra. Já a confiançarevela a proporção de objetos que possuem os atributos do antecedente e do conseqüente.Normalmente, a regra (A, B, s, c) é exibida por meio da notação A → B(s,c). Sejam(G, M, I) um contexto formal e A→ B(s,c) uma regra de associação em que A, B ⊆ M .O suporte s e a confiança c da regra são obtidos assim:
s =|(A ∪B)′||G|
, c =|(A ∪B)′||A′|
É comum, ao extrair regras de associação de uma base de dados, definir o suportemínimo e a confiança mínima das regras a serem extraídas. Esses parâmetros funcionamcomo uma espécie de filtro e o usuário é quem os define.
O problema da extração de regras de associação é dividido em duas etapas: (1)descobrir conjuntos de atributos freqüentes, daqui para frente denominados conjuntos deitens freqüentes, como na literatura relativa a regras de associação, e (2) extrair regras comconfiança mínima a partir de cada conjunto de itens freqüente. Os algoritmos baseadosem AFC são úteis principalmente na primeira etapa.
A primeira etapa da extração de regras de associação consiste em descobrir, emum contexto formal (G, M, I), o conjunto CIF = {X ⊆M |s(X) ≥ supmin}. A funçãos : ℘(M)→ [0, 1] dá o suporte de cada conjunto de atributos; ou seja, s(X) = |X ′|/|G|.O parâmetro supmin é o suporte mínimo. Este problema é computacionalmente caro,já que o espaço de soluções é o conjunto de todos os subconjuntos de atributos de M .Felizmente, o espaço de busca pode ser reduzido, pois, segundo Agrawal et al. [Agrawaland Srikant 1994], os conjuntos de itens freqüentes podem ser obtidos dos conjuntos deitens freqüentes máximos.
Um conceito formal (X, Y ) é freqüente, se s(Y ) ≥ supmin. Como o suporte deum conjunto de atributos é dado em função do número de objetos que possuem os atribu-tos do conjunto, o suporte de Y é |X|/|G|. Portanto, (X, Y ) é freqüente, se |X|/|G| ≥supmin. O conjunto de conceitos formais freqüentes é definido por: CCF = {(X, Y ) ∈B(G, M, I)|s(Y ) ≥ supmin} em que B(G, M, I) é o reticulado conceitual em questão.
Definido o conjunto dos conceitos formais freqüentes, pode-se definir o conjuntodos conceitos formais freqüentes mínimos, como:
CCFM = {(X, Y ) ∈ CCF | ∀(X1, Y1) ∈ CCF [(X1, Y1) ≤ (X, Y )→ (X1, Y1) = (X, Y )]}.
Este conjunto é importante, pois dá origem ao conjunto das máximas intensões devido àrelação de ordem definida sobre os conceitos formais. O conjunto das máximas intensõesé, por sua vez, importante, pois ele é igual à família dos conjuntos de itens freqüentesmáximos [Pasquier et al. 1999].
Como o conjunto das intensões máximas é igual à família dos conjuntos de itensfreqüentes máximos, o reticulado conceitual pode ser usado para a identificação de con-juntos de itens freqüentes.
4. Comparando os algoritmosNesta seção, será discutido o uso de quatro algoritmos baseados em AFC para extraçãode regras: AClose, Titanic, Frequent Next Neighbours e Galicia.
III Workshop em Algoritmos e Aplicações de Mineração de DadosWAAMD 2007
34

O AClose, proposto por Pasquier et al. [Pasquier et al. 1999], foi o primeiro al-goritmo baseado em AFC para extração de regras de associação. Ele foi inspirado noApriori [Agrawal and Srikant 1994]. O AClose identifica itens freqüentes através de con-ceitos freqüentes. Ele encontra os conceitos freqüentes gradualmente, usando a idéia degeradores. Esses geradores são os menores conjuntos de atributos que dão origem a umaintensão através da aplicação da composição dos operadores de derivação (·)′′. Por exem-plo, o conjunto de atributos {aquático} na Tabela 1 é um gerador para a intensão do con-ceito formal ({peixe, sapo, tubarão}, {aquático, branquias}). Durante a i-ésima etapa,o AClose avalia os geradores com i atributos e determina suas intensões. Ele armazenaapenas as intensões freqüentes. Para descobrir os geradores de tamanho i + 1, o ACloseusa apenas as intensões freqüentes. O algoritmo repete esse ciclo (encontrar intensões egeradores de tamanho i + 1) até que não haja mais geradores a serem avaliados.
O Titanic foi proposto por Stumme et al. [Stumme et al. 2002] e também foi inspi-rado no Apriori, porém sua abordagem é distinta. Ele constrói um reticulado iceberg, queé um reticulado conceitual dos conceitos freqüentes, para encontrar os conjuntos de itensfreqüentes. A construção do reticulado iceberg baseia-se nas idéias de geradores usadospelo Apriori e AClose. No entanto, ao invés de aplicar os operadores de derivação para ob-ter uma intensão, o Titanic usa uma função de peso cuja aplicação é computacionalmentemais barata que a aplicação dos operadores de derivação. Outra diferença apresentadapelo Titanic é que ele particiona o conjunto de geradores em classes de equivalência nasquais todos os elementos de uma classe dão origem a uma mesma intensão. Isso evita quedois geradores sejam avaliados para a computação de uma mesma intensão.
O Frequent Next Neighbours(FNN), proposto por Carpineto e Romano [Carpinetoand Romano 2004], assemelha-se ao Titanic, por construir um reticulado conceitual deconceitos freqüentes. A construção do reticulado conceitual, entretanto, é feita atravésde uma adaptação do algoritmo de Bordat [Bordat 1986]. O algoritmo encontra os con-ceitos formais por níveis, sendo que, em cada nível, apenas os conceitos freqüentes sãoarmazenados e usados para encontrar os conceitos freqüentes do próximo nível. Tendo en-contrado o reticulado conceitual dos conceitos freqüentes, o algoritmo executa uma buscaem largura no reticulado conceitual à procura das regras de associação, iniciando pelomaior conceito do reticulado. As regras são geradas considerando-se apenas um conceitoe seus vizinhos imediatos.
O Galicia foi proposto por Valtchev et al. [Valtchev et al. 2002]. Assim como oTitanic e o FNN, o Galicia constrói um reticulado conceitual para identificar os conjuntosde itens freqüentes. Contudo, ele constrói o reticulado de forma incremental. Inicial-mente, considera-se um contexto formal sem objetos, mas com o conjunto de atributosdefinido. O conjunto de atributos de cada objeto, por si só, é uma intensão de um con-ceito formal. Assim, a cada iteração, o algoritmo simula a inclusão de um novo objetoao contexto e verifica as modificações necessárias para que a estrutura do reticulado sejapreservada. Ao contrário dos demais, o Galicia armazena todos os conceitos formais,mesmo os não-freqüentes, pois, após sucessivas inclusões de objetos, alguns conceitosfreqüentes podem tornar-se não-freqüentes e vice-versa.
Os algoritmos foram escritos em Java e executados em uma máquina virtual Java,versão 1.4.2 para Windows XP, em um computador Pentium 3 com 440MB de memó-ria principal. Não houve qualquer providência para eliminar os overheads desse sistema
III Workshop em Algoritmos e Aplicações de Mineração de DadosWAAMD 2007
35
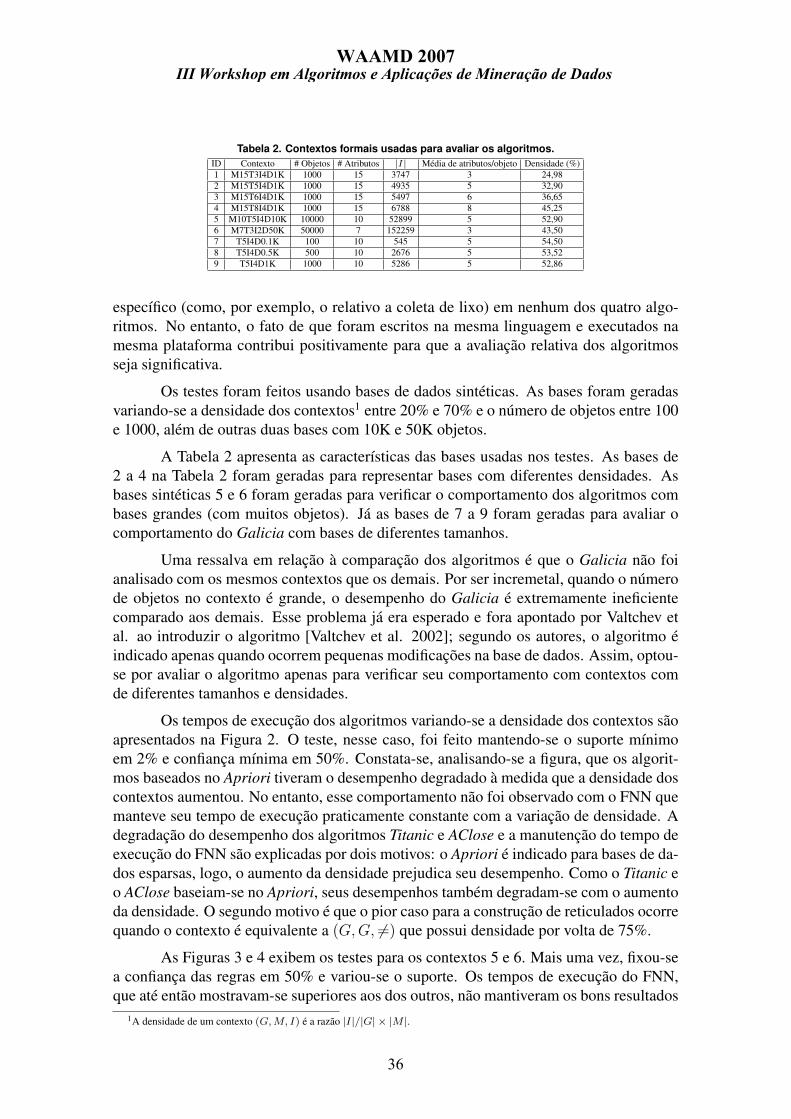
Tabela 2. Contextos formais usadas para avaliar os algoritmos.ID Contexto # Objetos # Atributos |I| Média de atributos/objeto Densidade (%)1 M15T3I4D1K 1000 15 3747 3 24,982 M15T5I4D1K 1000 15 4935 5 32,903 M15T6I4D1K 1000 15 5497 6 36,654 M15T8I4D1K 1000 15 6788 8 45,255 M10T5I4D10K 10000 10 52899 5 52,906 M7T3I2D50K 50000 7 152259 3 43,507 T5I4D0.1K 100 10 545 5 54,508 T5I4D0.5K 500 10 2676 5 53,529 T5I4D1K 1000 10 5286 5 52,86
específico (como, por exemplo, o relativo a coleta de lixo) em nenhum dos quatro algo-ritmos. No entanto, o fato de que foram escritos na mesma linguagem e executados namesma plataforma contribui positivamente para que a avaliação relativa dos algoritmosseja significativa.
Os testes foram feitos usando bases de dados sintéticas. As bases foram geradasvariando-se a densidade dos contextos1 entre 20% e 70% e o número de objetos entre 100e 1000, além de outras duas bases com 10K e 50K objetos.
A Tabela 2 apresenta as características das bases usadas nos testes. As bases de2 a 4 na Tabela 2 foram geradas para representar bases com diferentes densidades. Asbases sintéticas 5 e 6 foram geradas para verificar o comportamento dos algoritmos combases grandes (com muitos objetos). Já as bases de 7 a 9 foram geradas para avaliar ocomportamento do Galicia com bases de diferentes tamanhos.
Uma ressalva em relação à comparação dos algoritmos é que o Galicia não foianalisado com os mesmos contextos que os demais. Por ser incremetal, quando o númerode objetos no contexto é grande, o desempenho do Galicia é extremamente ineficientecomparado aos demais. Esse problema já era esperado e fora apontado por Valtchev etal. ao introduzir o algoritmo [Valtchev et al. 2002]; segundo os autores, o algoritmo éindicado apenas quando ocorrem pequenas modificações na base de dados. Assim, optou-se por avaliar o algoritmo apenas para verificar seu comportamento com contextos comde diferentes tamanhos e densidades.
Os tempos de execução dos algoritmos variando-se a densidade dos contextos sãoapresentados na Figura 2. O teste, nesse caso, foi feito mantendo-se o suporte mínimoem 2% e confiança mínima em 50%. Constata-se, analisando-se a figura, que os algorit-mos baseados no Apriori tiveram o desempenho degradado à medida que a densidade doscontextos aumentou. No entanto, esse comportamento não foi observado com o FNN quemanteve seu tempo de execução praticamente constante com a variação de densidade. Adegradação do desempenho dos algoritmos Titanic e AClose e a manutenção do tempo deexecução do FNN são explicadas por dois motivos: o Apriori é indicado para bases de da-dos esparsas, logo, o aumento da densidade prejudica seu desempenho. Como o Titanic eo AClose baseiam-se no Apriori, seus desempenhos também degradam-se com o aumentoda densidade. O segundo motivo é que o pior caso para a construção de reticulados ocorrequando o contexto é equivalente a (G, G, 6=) que possui densidade por volta de 75%.
As Figuras 3 e 4 exibem os testes para os contextos 5 e 6. Mais uma vez, fixou-sea confiança das regras em 50% e variou-se o suporte. Os tempos de execução do FNN,que até então mostravam-se superiores aos dos outros, não mantiveram os bons resultados
1A densidade de um contexto (G, M, I) é a razão |I|/|G| × |M |.
III Workshop em Algoritmos e Aplicações de Mineração de DadosWAAMD 2007
36
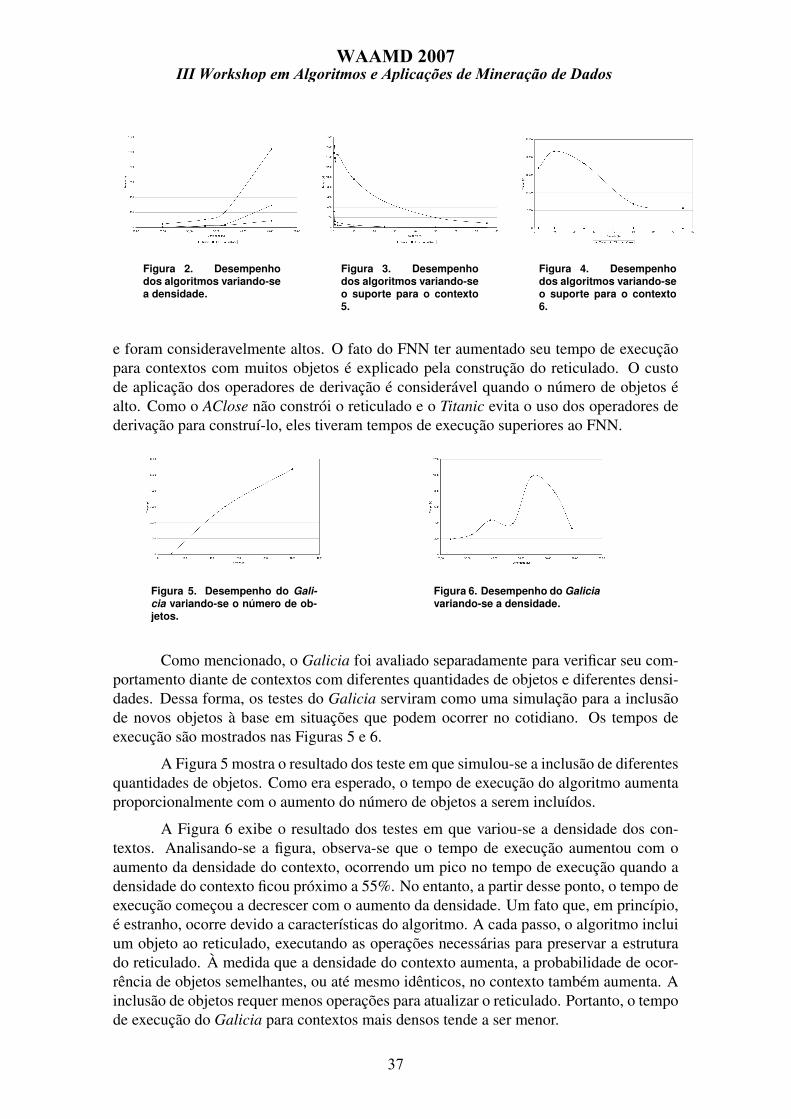
Figura 2. Desempenhodos algoritmos variando-sea densidade.
Figura 3. Desempenhodos algoritmos variando-seo suporte para o contexto5.
Figura 4. Desempenhodos algoritmos variando-seo suporte para o contexto6.
e foram consideravelmente altos. O fato do FNN ter aumentado seu tempo de execuçãopara contextos com muitos objetos é explicado pela construção do reticulado. O custode aplicação dos operadores de derivação é considerável quando o número de objetos éalto. Como o AClose não constrói o reticulado e o Titanic evita o uso dos operadores dederivação para construí-lo, eles tiveram tempos de execução superiores ao FNN.
Figura 5. Desempenho do Gali-cia variando-se o número de ob-jetos.
Figura 6. Desempenho do Galiciavariando-se a densidade.
Como mencionado, o Galicia foi avaliado separadamente para verificar seu com-portamento diante de contextos com diferentes quantidades de objetos e diferentes densi-dades. Dessa forma, os testes do Galicia serviram como uma simulação para a inclusãode novos objetos à base em situações que podem ocorrer no cotidiano. Os tempos deexecução são mostrados nas Figuras 5 e 6.
A Figura 5 mostra o resultado dos teste em que simulou-se a inclusão de diferentesquantidades de objetos. Como era esperado, o tempo de execução do algoritmo aumentaproporcionalmente com o aumento do número de objetos a serem incluídos.
A Figura 6 exibe o resultado dos testes em que variou-se a densidade dos con-textos. Analisando-se a figura, observa-se que o tempo de execução aumentou com oaumento da densidade do contexto, ocorrendo um pico no tempo de execução quando adensidade do contexto ficou próximo a 55%. No entanto, a partir desse ponto, o tempo deexecução começou a decrescer com o aumento da densidade. Um fato que, em princípio,é estranho, ocorre devido a características do algoritmo. A cada passo, o algoritmo incluium objeto ao reticulado, executando as operações necessárias para preservar a estruturado reticulado. À medida que a densidade do contexto aumenta, a probabilidade de ocor-rência de objetos semelhantes, ou até mesmo idênticos, no contexto também aumenta. Ainclusão de objetos requer menos operações para atualizar o reticulado. Portanto, o tempode execução do Galicia para contextos mais densos tende a ser menor.
III Workshop em Algoritmos e Aplicações de Mineração de DadosWAAMD 2007
37

5. ConclusãoA avaliação dos algoritmos baseados em AFC para extração de regras de associação mos-trou que eles são uma boa alternativa para extração de regras. Os algoritmos mostraram-seadequados a situações distintas. Em resumo, os algoritmos que usam diretamente reticu-lados para extração de regras mostraram-se mais eficazes para contextos com alta den-sidade. Enquanto os algoritmos baseados no Apriori mostraram-se mais eficazes paracontextos esparsos com muitos objetos. Existe, ainda, a situação em que o algoritmo éadequado para pequenas atualizações, como o Galicia.
Este trabalho tenta suprir deficiências constatadas na literatura no que diz respeitoà definição de critérios para escolha de bases de dados para comparação de métodos ba-seados em AFC para extração de regras de associação. No entanto, este trabalho aindaapresenta deficiências que deverão ser sanadas em trabalhos futuros.
O primeiro ponto a ser considerado é a escolha da linguagem de programaçãopara implementação dos algoritmos. Em trabalhos futuros, deve-se considerar implemen-tações ótimas (ou as melhores possíveis) dos métodos. Assim, deve-se fazer análises deestruturas de dados eficientes para implementação dos algoritmos. Esse ponto é crucialjá que a maioria dos autores, ao apresentarem seus algoritmos, não discutem aspectos deimplementação. O segundo ponto é a escolha de bases de dados mais realistas. As basesde dados têm grande influência no desempenho dos algoritmos. Dessa forma, a escolhade bases de dados que retratem com maior confiança situações reais é extremamente im-portante. O terceiro e último ponto diz respeito à comparação dos algoritmos baseadosem AFC com algoritmos tradicionais para extração de regras de associação.
Esses pontos serão considerados em trabalhos futuros e, portanto, será possívelfazer análises mais conclusivas sobre a adequação de cada método a cada situação real.
ReferênciasAgrawal, R. and Srikant, R. (1994). Fast algorithms for mining association rules. In
Proceedings of the 20th Very Large Data Bases Conference, pages 487–499.
Bordat, J. P. (1986). Calcul pratique du treillis de Galois d’une correspondance. Mathé-matiques et Sciences Humaines, (96):31–47.
Carpineto, C. and Romano, G. (2004). Concept Data Analysis: Theory and Applications.John Wiley & Sons, England.
Davey, B. A. and Priestley, H. A. (2001). Introduction to Lattices and Order. CambridgeMathematical Textbooks, England, 2nd edition.
Ganter, B. and Wille, R. (1999). Formal Concept Analysis: Mathematical Foundations.Springer-Verlag.
Pasquier, N., Bastide, Y., Taouil, R., and Lakhal, L. (1999). Efficient mining of associationrules using closed itemset lattices. Information Systems, 24(1):25–46.
Stumme, G., Taouil, R., Bastide, Y., Pasquier, N., and Lakhal, L. (2002). Computingiceberg concept lattices with TITANIC. Data Knowledge Engineering, 42(2):189–222.
Valtchev, P., Missaoui, R., Godin, R., and Meridji, M. (2002). Generating frequent item-sets incrementally: two novel approaches based on Galois lattice theory. Journal ofExperimental and Theoretical Artificial Intelligence, 14(2–3):115–142.
III Workshop em Algoritmos e Aplicações de Mineração de DadosWAAMD 2007
38


















