
Ubiquitous Computing Max Mühlhäuser, Iryna Gurevych (Editors) Part V : Ease-of-use Chapter 18:...
27
Ubiquitous Computing Max Mühlhäuser, Iryna Gurevych (Editors) Part V : Ease-of-use Chapter 18: Mouth-and-Ear Interaction Dirk Schnelle
-
Upload
lynette-brown -
Category
Documents
-
view
216 -
download
0
Transcript of Ubiquitous Computing Max Mühlhäuser, Iryna Gurevych (Editors) Part V : Ease-of-use Chapter 18:...

Ubiquitous Computing
Max Mühlhäuser, Iryna Gurevych (Editors)
Part V : Ease-of-useChapter 18: Mouth-and-Ear Interaction
Dirk Schnelle

2
UbiquitousComputing
Mouth-and-Ear Interaction:
Introduction
• Mobile workers– Need information to perform their task– Have their hands busy with their task– Look at what they are doing
• Problem– Hands & Eyes devices hinder them performing their task
• Solution– Audio channel
• Advantages of audio– Can be used without changing focus– Can be used in parallel– Still functional under extreme cases
• Darkness• Limited freedom of movement
– Can be used in addition to other modalities• Disadvantages of audio
– Unusable in noisy environments

3
UbiquitousComputing
Mouth-and-Ear Interaction:
Voice is a natural way of communication?
“Reports and theses in speech recognition often begin with a cliché, namely that speech is the most natural way for human beings to communicate with each other''
(Melvyn Hunt, 1992)
• Speech is one of the most important means of communication• Speech has been an efficient means of communication throughtout the
history of mankind
• Is this still valid for the computer as the counterpart?
• This vision requires active and passive communication competence of a human
• Advances in Natural Language Processing are first steps towards this vision
• Today– Still a vision– E.g. Banking companies observe a tend to graphical over voice based use of
their interfaces

4
UbiquitousComputing
Mouth-and-Ear Interaction:
Mixed Initiative
Dialog Strategies
• Main concepts of voice based interaction– Command & Control– Menu Hierarchy– Form based– Mixed Initiative
• Voice based interaction must be– Easy to learn– Easy to remember– Natural– Acoustically different
User Initiative
System Initiative

5
UbiquitousComputing
Mouth-and-Ear Interaction:
Definitions
• Voice User Interfaces (VUI)s are user interfaces using speech input through a speech recognizer and speech output through speech synthesis.
• Audio User Interfaces (AUI)s are an extension to VUIs, allowing also the use of sound as a means to communicate with the user.
• Today– The term VUI is used in the sense of AUI

6
UbiquitousComputing
Mouth-and-Ear Interaction:
Domain Specific Development
• Applications have to be integrated into the domain– Business context– Infrastructure
• Manual adaption is– Labor intensive– Requires heavy involvement of experts
• Vocabulary• Grammar• Semantic
High costs

7
UbiquitousComputing
Mouth-and-Ear Interaction:
Attempts to reduce costs
• Speech contexts– Modular solutions for handling specific tasks in the dialog– E.g. widgets for entering time and date for a recurring
appointment
– Can be used in RAD tools to develop applications

8
UbiquitousComputing
Mouth-and-Ear Interaction:
Speech Graffitti
• Universal Speech Interface by Carnegie Mellon University
• Main idea– Transfer the look&feel from the
world of graphical interfaces to audio
• Compromise of– Unconstrained NLU– Hand crafted menu hierarchieas as
they are used in todays telephony applications
• ExampleSystem: …movie is Titanic … theatre
is the Manor …User: What are the show times?
– „what are“ is standardized– „show times“ still domain specific
Speech Graffiti is not self contained

9
UbiquitousComputing
Mouth-and-Ear Interaction:
Size of vocabulary
• Application domain has a strong impact onto the size of the vocabulary
Domain Vocabulary size (words)
Dialog strategy
Alarm system(alarm command)
1 command & control
menu selection(Yes/No)
2 command & controlmenu hierarchy
Digits 10+x menu hierarchy
Control 20-200 command & control
Information Dialog 500-2,000 menu hierarchyform filling
Daily talk 8,000 - 20,000 mixed initiative
Dictation 20,000 - 50,000 n/a
German (no foreign words)
ca. 300,000 n/a

10
UbiquitousComputing
Mouth-and-Ear Interaction:
STAIRS
• STAIRS– Structured Audio Information Retrieval System– Aims at delivering information to mobile workers
• Possible scenarios– Pick by voice– Musuem Guide– training@work
• Key features– Audio output– Use of contextual informaton– Command set

11
UbiquitousComputing
Mouth-and-Ear Interaction:
STAIRS - Audio Output
• Structuring information– no problem in visual media– Helps the user to stay oriented– Allows for fast and easy access to the desired information
• Structural meta data gets lost in audio
Structured audio• Background sounds• Auditory icons• Earcons
12
UbiquitousComputing
Mouth-and-Ear Interaction:
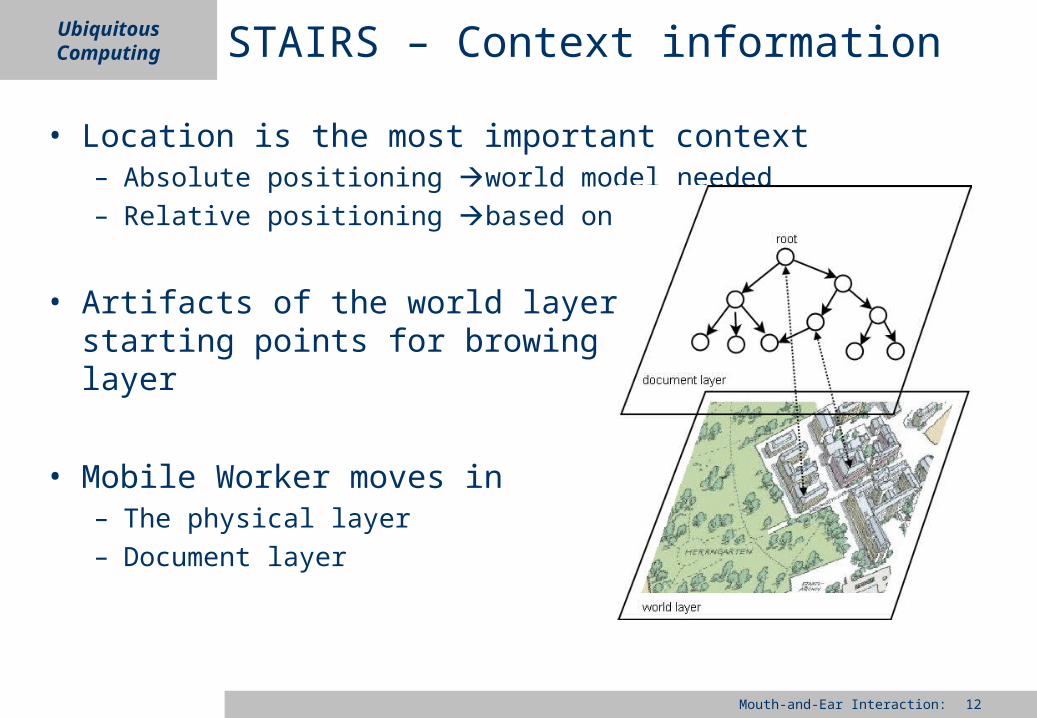
STAIRS – Context information
• Location is the most important context– Absolute positioning world model needed– Relative positioning based on tags
• Artifacts of the world layer are starting points for browing in the layer
• Mobile Worker moves in – The physical layer– Document layer

13
UbiquitousComputing
Mouth-and-Ear Interaction:
STAIRS – Command Set
• Problem– Embedded devices allow only
few commands
• Observation– Only few commands are needed
to control a browser– Allows to handle complex
applications
transfer this concept to audio
14
UbiquitousComputing
Mouth-and-Ear Interaction:
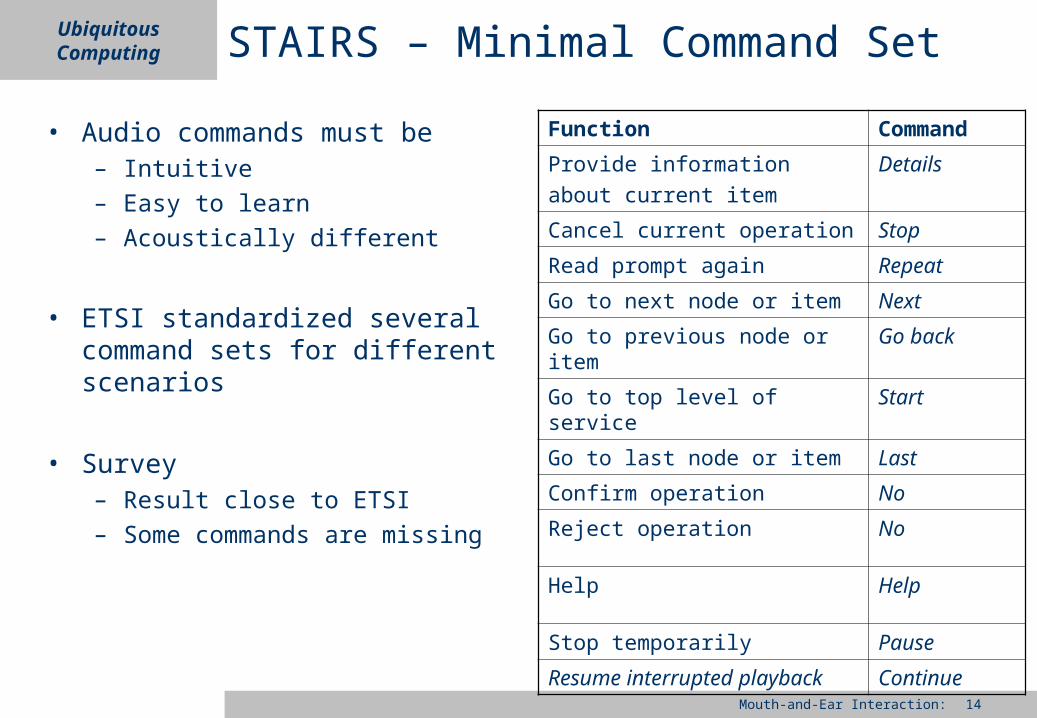
STAIRS – Minimal Command Set
• Audio commands must be– Intuitive– Easy to learn– Acoustically different
• ETSI standardized several command sets for different scenarios
• Survey– Result close to ETSI– Some commands are missing
Function Command
Provide information about current item
Details
Cancel current operation Stop
Read prompt again Repeat
Go to next node or item Next
Go to previous node or item Go back
Go to top level of service Start
Go to last node or item Last
Confirm operation No
Reject operation No
Help Help
Stop temporarily Pause
Resume interrupted playback
Continue

15
UbiquitousComputing
Mouth-and-Ear Interaction:
Additional Challenges with UC
Inherent to audio
Technical problems
Challenges with audio
Speech recognition performanceSpeech Synthesis qualityRecognition: Flexibility vs. AccuracySpeech is transientInvisibilityAssymetryOne-dimensionalityConversationPrivacyService Availability

16
UbiquitousComputing
Mouth-and-Ear Interaction:
Speech Recognition Performance
• Speech is not recognized with an accuracy of 100%(even humans can‘t do that)
• People are used to graphical user interfaces with a recognition rate of 100%
• Sentences are NOT only sequences of words and words being sequences of phonemes
Plain text
Spontaneous speech
Spontaneous speech without interpunctuation
Contiuous speech
Variances
Articulator slurring
Channel problems
Cocktail party effect

17
UbiquitousComputing
Mouth-and-Ear Interaction:
Speech is…
• Continuous• Flexible
– Inherent to the audio channel– Acoustic problems
• Complex• Ambiguous

18
UbiquitousComputing
Mouth-and-Ear Interaction:
Speech synthesis quality
• Quality of modern speech synthesizers is still low• In general people prefer to listen to prerecorded audio
Conflict• Texts have to be known in advance
• Texts must be prerecorded
• But: Not all texts are known in advance
Current solutions• Audio snippets are prerecorded and pasted together as needed• Professional speakers are able to produce voice with a similar
pitch• Humans are very sensitive in listening and are able to hear small
differences

19
UbiquitousComputing
Mouth-and-Ear Interaction:
Flexibility vs. accuracy
• Speech can have many faces for the same issue• Natural language interfaces must serve them all
Example task: Enter a date• Flexible interface
– Allow the user to enter the date in any format• „March 2nd“, „Yesterday“, „2nd of March 2004“, …
requires more work by the recognition softwareerror pronepreferred by users
• Restrictive interface– Prompt the user individually for each component of the date
• „Say the year“, „Say the month“,…less work required from the recognition softwareless error prone

20
UbiquitousComputing
Mouth-and-Ear Interaction:
Medium inherent challenges
• One dimensionality– Eye is an active organ, but the ear is passiveThe ear cannot browse a set of recordings as the eye can browse a se of
documents
• Transience– Listening is controlled by the STM (short term memory)– Users forget what was said in the beginningAudio is not ideal to deliver large amounts of dataUsers get lost in VUIs (lost in space problem)
• Invisibilty– VUIs must indicate the user what to say and what actions to performLeave the impression of not being in controlAdvantage: Audio can be received without the need to switch context
• Assymetrie– People speek faster than they type but listen more slowly than they can
readCan be exploited in multi-modal scenarios

21
UbiquitousComputing
Mouth-and-Ear Interaction:
Challenges for UC
• Conversation– Scenario: User speaks to another person– Risk of triggering unwanted commands is higher than in noisy
environments
• Privacy– Audio input and output should be hidden from others– Impossible to avoid– Only solution: Do not deliver critical or confidental information
• Service availability– Speech dependent service may become unavailable while the
user is on the movemay have an impact on the vocabulary that can be used– User has to be notified about the change

22
UbiquitousComputing
Mouth-and-Ear Interaction:
Error Handling
• Possible causes for errors– Use of an out-of vocabulary word– Use of a word that cannot be used in the current context– Recognition error– Background noise– Incorrect pronounciation (e.g. no native speaker)
• Applications may detect errors but without knowing the source
• Ways to deal with errors– Do nothing and let the user find and correct the error– Prevent the user from continuing– Complain and warn the user using a feedback mechanism– Correct it automatically without user interaction– Initiate a procedure to correct the error with the user‘s help through
Users will refrain from working with the applicationbetter error prevention

23
UbiquitousComputing
Mouth-and-Ear Interaction:
Error prevention
• Reduce the probability of misrecognized words– Limit background noise (Noise cancelling head sets)– Allow the user to turn off the device (push-to-talk)

24
UbiquitousComputing
Mouth-and-Ear Interaction:
Lost in space
• A user gets lost in space if she does not know where in the graph she is
Possible Solutions to avoid lost in space• Calling
– Someone calls you from somewhere and you can head in the direction to find her
• Telling– Someone next to you gives you directions
• Landmarks– You hear a familiar sound and you can use it to orient yourself
and work out where to head

25
UbiquitousComputing
Mouth-and-Ear Interaction:
General solutions
• Guidelines– Try to capture design knowledge
into small rules
• Guidelines have disadvantages– Often too simplistic or too abstract– Often have authority issues
concerning their validity– Can be conflicting– Can be difficult to select– Can be difficult to interpret
Top 10 VUI No-No’s• Don't use open ended prompts• Make sure that you don't have
endless loops• Don't use text-to-speech unless you
have to• Don't mix voice and text-to-speech• Don't put into your prompt
something that your grammar can't handle
• Don't repeat the same prompt over and over again
• Don't force callers to listen to long prompts
• Don’t switch modes on the caller• Don’t go quiet for more than 3
seconds• Don’t listen for short words
http://www.angel.com/services/vui-design/vui-nonos.jsp

26
UbiquitousComputing
Mouth-and-Ear Interaction:
VUI pattern language
• Patterns– Capture design knowledge
• Form• Context• Solution
• Structure– Preconditions– Postconditions
• Current trend– Transfer guidelines into patterns

27
UbiquitousComputing
Mouth-and-Ear Interaction:
Future research directions
• Challenges about audio are still not completely soved• Current solutions
– Guidelines– Patterns
• Patterns seem to be more promising
• More pattern mining needed• Tools to apply the patterns• Use patterns in code generators from modality
independent UI languages (e.g. XForms)


















