

Troubleshooting: A High-Value Asset For The Service-Provider Discipline
25
Sagi Brody, CTO @webairsagi Troubleshooting: A High Value Asset for The Service Provider Discipline
-
Upload
sagi-brody -
Category
Internet
-
view
25 -
download
1
Transcript of Troubleshooting: A High-Value Asset For The Service-Provider Discipline

Sagi Brody, CTO@webairsagi
Troubleshooting:A High Value Asset for The Service Provider
Discipline

Background
• 17+ Years experience as a service provider.• MSP - We own your infrastructure stack.• Managed Public, Private, and Hybrid Cloud.• High Touch - Monitoring, Managing, Securing
all layers (app/db/fw/nw/cdn)• Mix of Open Source, Commercial, and
Proprietary Software.• Context of an MSP but applicable to all IT.

The Art of Troubleshooting
• Troubleshooting is a standalone skill - Must be Taught, Trained, Documented, Reviewed.
• Technical skills are important but soft skills cannot be forgotten.
• Big buzz around hyped technologies in DevOps.
• Other important soft skills - Resourcefulness, Communication, Technical Documentation, Mentoring.

Why Care?
• We're already doing it, internally or customer facing.
• We're trusted to do it well.• We’re judged how we act during crisis. • Technology agnostic skill. Never become obsolete
and only becomes more important as systems become more complex.
• Applicable to infrastructure & software development.
• Allows us to scale - It's how we manage many complex environments with small teams.
• Reduce downtime & Save lives!! 4

Brief History
• Hardware & Software Systems traditionally monolithic in nature.
• Flat topology without abstraction.
• Mostly physical infrastructure.
• Perpetual configurations .
• No automation.• Easier
Troubleshooting. 5
Today
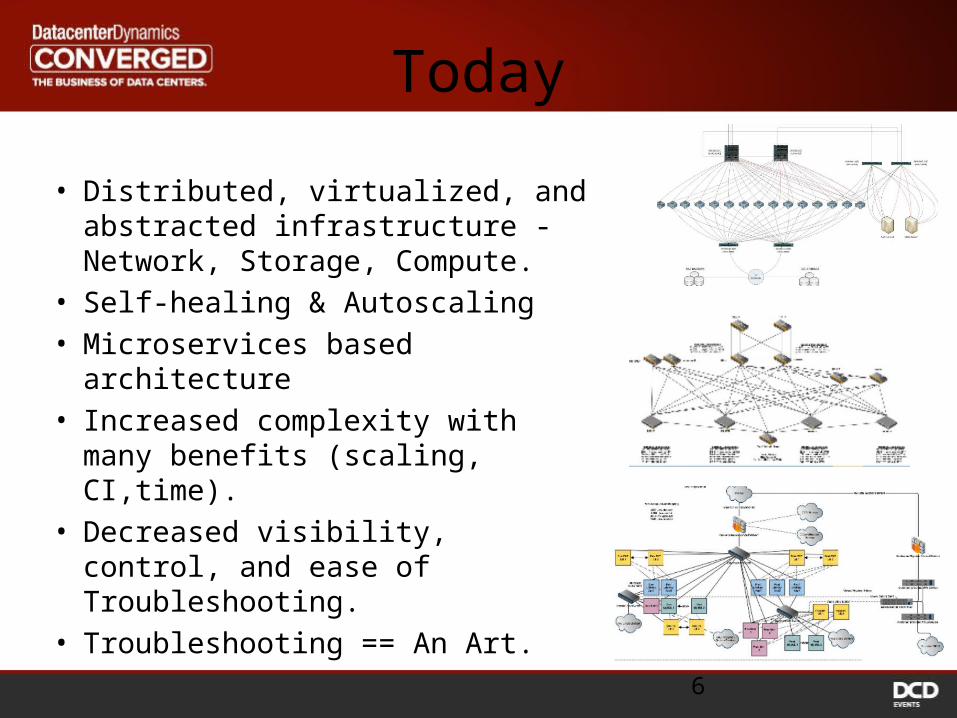
• Distributed, virtualized, and abstracted infrastructure - Network, Storage, Compute.
• Self-healing & Autoscaling• Microservices based
architecture• Increased complexity with
many benefits (scaling, CI,time).
• Decreased visibility, control, and ease of Troubleshooting.
• Troubleshooting == An Art.6

Where to Start?
• Fast resolution starts with absolute understanding of the issue.
• Is this the cause or a symptom?• Was it brought to us pre-diagnosed?• What is the context? • Why is this a problem? Why is it important?• No tunnel vision. Look at the big picture.• Examples: 'Email Issue' , 'Wifi/Speed' ,
'DDoS & API'
7

Observe
• Can you have a clear understanding of the issue without seeing it for yourself?
• Before attempting resolution, be sure you can reproduce.
• Gain perspective using tools - remote logins, screen shares, screen shots.
• Understand expected behavior vs fault.• Software development & Debugging tools. • Supplement lack of perspective with solid
communication.8

Localize
• Drill Down - Peel back the layers of the onion.• Process of elimination to localize the issue.• Examples: static content vs dynamic content,
local storage vs shared/network storage, directly test and bypass layers, rule out network
• Follow the flow of data and test each step.• Major Outages - localize to commonality - What
do the effected services have in common?• Use monitoring tools or SPOTs to localize.• Don't assume anything - NIH (Not invented
here).9

Resolve and Test
• Scientific Method: Question -> Hypothesis –> Experiment -> Observation ->Analysis -> Conclusion
• Make small incremental changes.• Use sandboxes where possible.• Document each test and result, and
change.• Use ability to reproduce and observe to
confirm resolution.
10

Monitor for Success
• Fast resolution starts with a solid monitoring strategy.
• Empower DevOps to create layered alerts.
• Create simple interfaces, scripts, APIs to allow for easy additions of monitoring to standardized systems.
• Make it part of development & build process.
• Monitor the Big and the Small:
• Big - The finished product. Look for expected result via end user interface to ensure all services are properly functioning.
• Small - Every layer! OK/FAIL monitoring for multi-dimensional services and 3rd party providers.
• If setup properly, big and small alerts should trigger simultaneously allowing instant localization.
11

High level Context
12
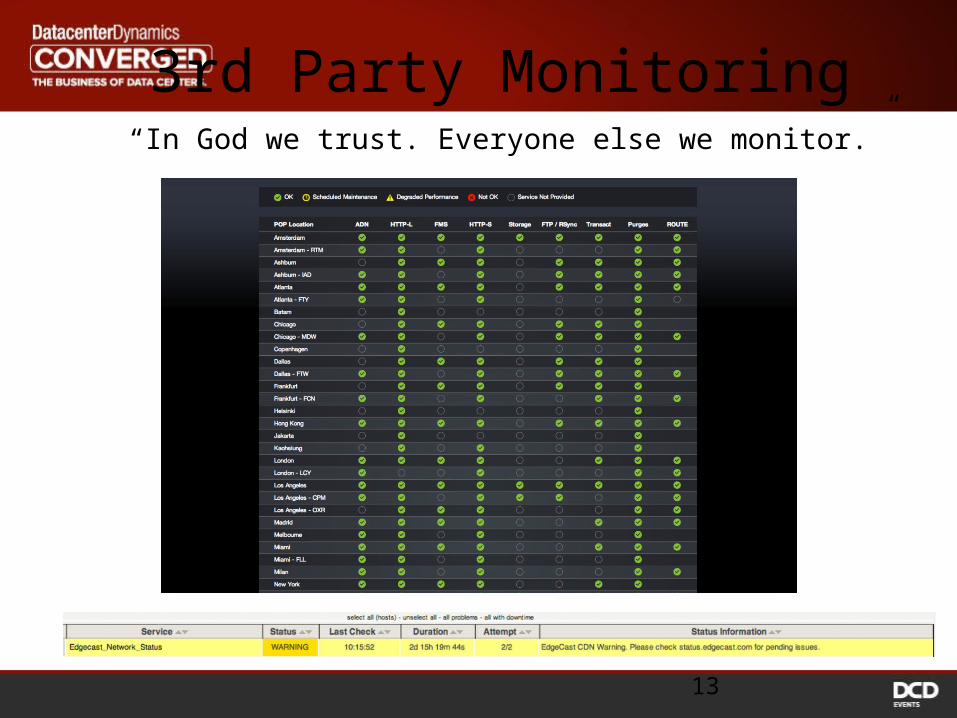
3rd Party Monitoring“In God we trust. Everyone else we monitor.”
13

Remove Roadblocks
14
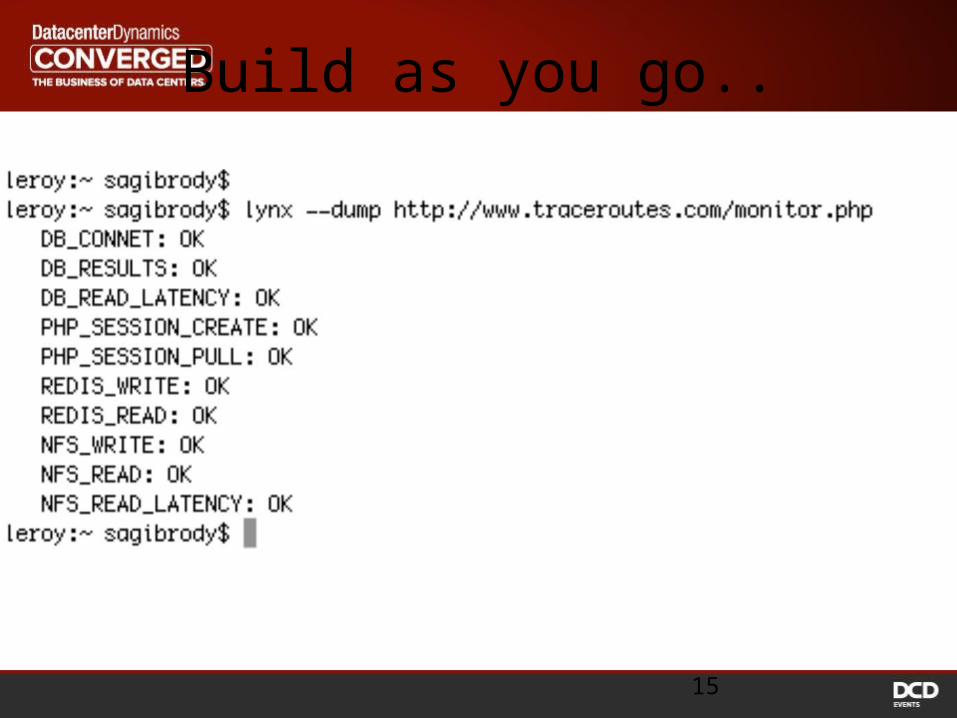
Build as you go..
15

Automated Troubleshooting
• Trigger action based on logging events (syslog, splunk, logstash).
• Scan configuration files for dangerous conditions.
• Pipe events to software designed to diagnose and take action.
• Actions: disable interfaces, line cards, services, servers, notify operations.
• Platform that allows easy addition of new tests based on experience.
16

Tools & Integration
• Use Single Point of truth (ie collins).• Integrate 3rd party best in breed to SPOT
(Nagios, MRTG, ManageEngine, Vmware, Xen, ScienceLogic)
• Combine communication, monitoring, and culture
• We've connected: Nagios, Phone calls, LiveChats, Ticket updates, WO updates, Ansible deployments, Network alerts, Network capacity alerts, Physical data center alerts, DDoS attacks, Confluence.
• Make documentation & diagram management easier. "If its not documented, it didnt happen"
17
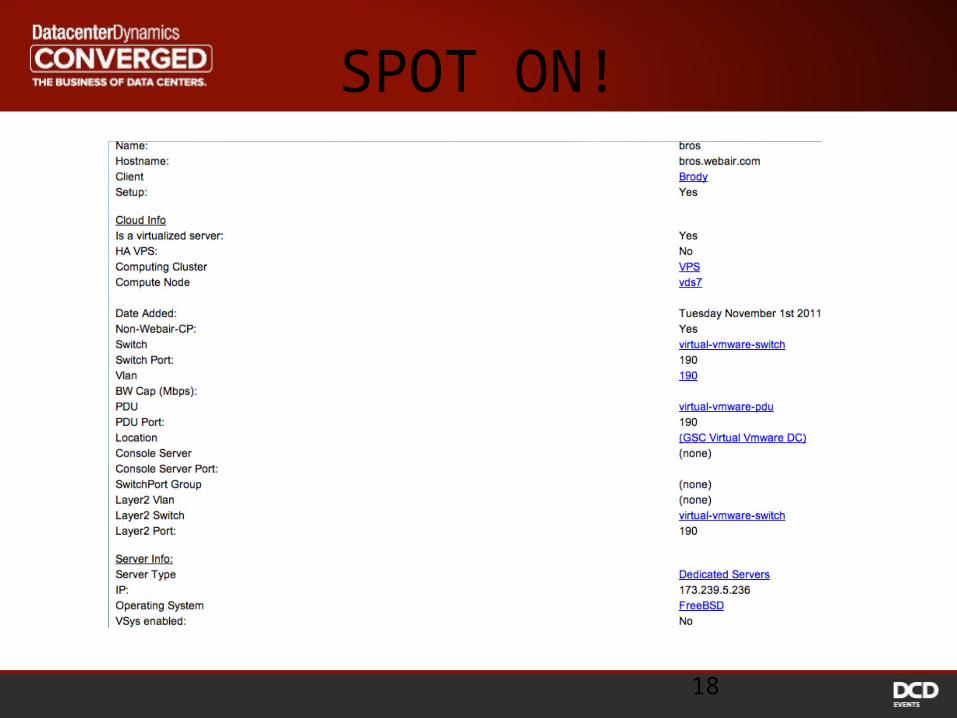
SPOT ON!
18
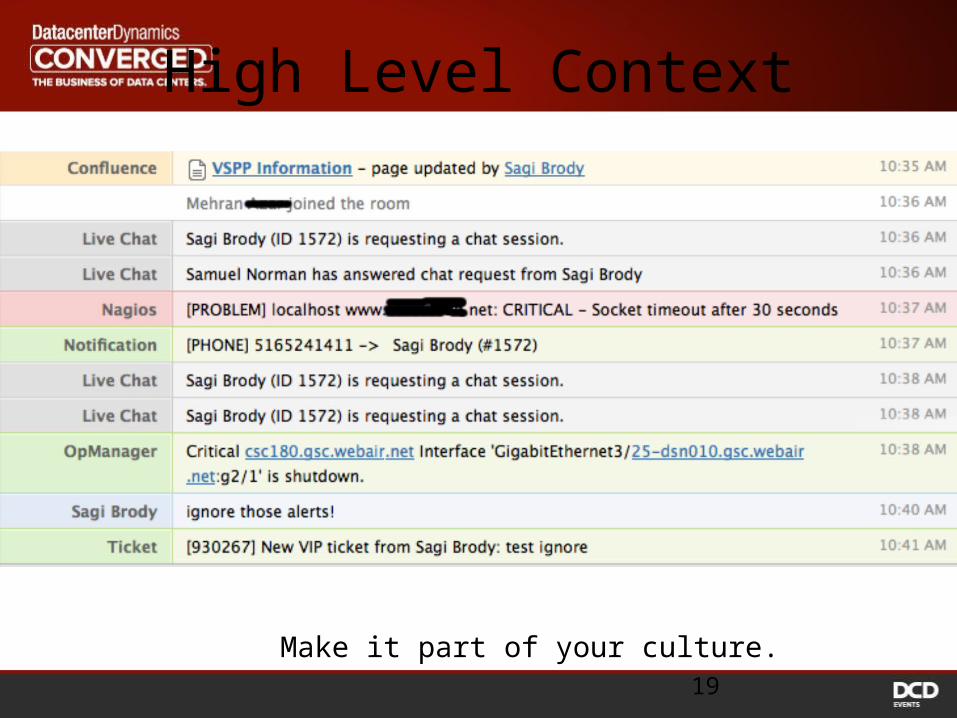
High Level Context
Make it part of your culture.19

Historical Data a Must
• Establish baselines.• Am I looking at a
preexisting condition?
• What changed and when?
• Data Aggregation• 3rd party: DataDog,
ScienceLogic, GroundWorks, NewRelic 20
Aggregated Statistics
21
Cluster Wide
CPU
Network
Memory
Disk
Aggregated Statistics
22
Network by Host
Host 1
Host 2
Host 3
Host 4
Aggregated Statistics
23
Network by VM (Host 1)
VM 1
VM 2
VM 3
VM 4

People Factor• Why is it not taught alongside technical skill?• Becomes part of the interview process.• Adopt approach used by the medical field -
Bed Side Clinics. Use your superstars.• Make it part of your culture and develop a
reward system around it.• Collapse silos, broaden context for everyone.
24


















