
Tre linee di ricerca hanno portato alla scoperta che il...
93
Tre linee di ricerca hanno portato alla scoperta che il DNA è il materiale ereditario
-
Upload
phungquynh -
Category
Documents
-
view
217 -
download
0
Transcript of Tre linee di ricerca hanno portato alla scoperta che il...

Tre linee di ricerca hanno
portato alla scoperta che il
DNA è il materiale ereditario


Il principio trasformante (Griffith, 1928)


Figure. The general structure of
nucleotides. Left: computer model.
Right: a simplified representation.
Figure. The chemical structure of
pentose which contains five carbon
atoms, labeled as C1' to C5'. The
pentose is called ribose in RNA and
deoxyribose in DNA, because the
DNA's pentose lacks an oxygen
atom at C2'. Recalling that RNA
stands for "ribonucleic acid", and
DNA for "deoxyribonucleic acid".



Figure. Formation of the phosphodiester bond through
the condensation reaction.


Like peptide chains, a nucleic acid chain also has
orientation: its 5' end contains a free phosphate group
and 3' end contains a free hydroxyl group. Synthesis
of a nucleic acid chain always proceeds from 5' to
3'. Therefore, unless specified otherwise, the sequence
of a nucleic acid chain is written from 5' to 3' (left to
right).
Figure. A nucleic acid chain. Its 5' end
contains a free phosphate group. The 3'
end has a free hydroxyl group.
In DNA or RNA, a nucleic acid chain is also called a
strand. A DNA molecule typically contains two strands
whereas most RNA molecules contain a single strand.
The length of a nucleic acid chain is represented by the
number of bases. In the case of a double-stranded
nucleic acid, bases are paired between two
strands. Therefore, its length is given by the number of
base pairs (bp). 1 kb = 1000 bases or bp; 1 Mb = 1
million bases or bp. Oligonucleotides refer to short
nucleic acid chains (< 50 bases or bp) and
polynucleotides have longer chains.

The function of RNA
polymerases
Both RNA and DNA
polymerases can add
nucleotides to an existing
strand, extending its
length. However, there
is a major difference
between the two classes
of enzymes: RNA
polymerases can initiate
a new strand but DNA
polymerases
cannot. Therefore,
during DNA replication,
an oligonucleotide
(called primer) should
first be synthesized by a
different enzyme.
Figure. The chemical
reaction catalyzed by
RNA polymerases.

Figure. Computer model of base
pairing in DNA. In a normal DNA
molecule, adenine (A) is paired
with thymine (T), guanine (G) is
paired with cytosine (C). The
uracil (U) of RNA can also pair
with adenine (A), since U differs
from T by only a methyl group
located on the other side of
hydrogen bonding.
A DNA molecule has two
strands, held together by the
hydrogen bonding between
their bases.
As shown in the above figure, adenine can form two hydrogen bonds with thymine; cytosine
can form three hydrogen bonds with guanine. Although other base pairs [e.g., (G:T) and
(C:T) ] may also form hydrogen bonds, their strengths are not as strong as (C:G) and (A:T)
found in natural DNA molecules.

Schematic drawing of DNA's two
strands.
Due to the specific base pairing,
DNA's two strands are
complementary to each
other. Hence, the nucleotide
sequence of one strand determines
the sequence of another strand. For
example, in Figure 3-B-2, the
sequence of the two strands can be
written as
5' -ACT- 3'
3' -TGA- 5'
Note that they obey the (A:T) and
(C:G) pairing rule. If we know the
sequence of one strand, we can
deduce the sequence of another
strand. For this reason, a DNA
database needs to store only the
sequence of one strand. By
convention, the sequence in a DNA
database refers to the sequence of
the 5' to 3' strand (left to right).

DNA polymerases can extend
nucleic acid strands only in the 5'
to 3' direction. However, in the
direction of a growing fork, only
one strand is from 5' to 3'. This
strand (the leading strand) can be
synthesized continuously. The
other strand (the lagging strand),
whose 5' to 3' direction is
opposite to the movement of a
growing fork, should be
synthesized discontinuously.
Figure.
(a) Comparison between the leading strand
and the lagging strand. (b) The primase first
synthesizes a new primer which is about 10
nucleotides in length. The distance between
two primers is about 1000-2000 nucleotides
in bacteria, and about 100-200 nucleotides in
eukaryotic cells. (c) DNA polymerase
elongates the new primer in the 5' to 3'
direction until it reaches the 5' end of a
neighboring primer. The newly synthesized
DNA is called an Okazaki fragment. (d) In
E. coli, DNA polymerase I has the 5' to 3'
exonuclease activity, which is used to
remove a primer. (e) DNA ligase joins
adjacent Okazaki fragments.
The whole lagging strand is synthesized by
repeating steps (b) to (e).

In a DNA molecule, the two strands are not
parallel, but intertwined with each other. Each
strand looks like a helix. The two strands
form a "double helix" structure, which was
first discovered by James D. Watson and
Francis Crick in 1953. In this structure, also
known as the B form, the helix makes a turn
every 3.4 nm, and the distance between two
neighboring base pairs is 0.34 nm. Hence,
there are about 10 pairs per turn. The
intertwined strands make two grooves of
different widths, referred to as the major
groove and the minor groove, which may
facilitate binding with specific proteins.
Figure. The normal right-handed "double
helix" structure of DNA, also known as the B
form.
In a solution with higher salt concentrations or with alcohol added, the DNA structure may
change to an A form, which is still right-handed, but every 2.3 nm makes a turn and there are
11 base pairs per turn.


Another DNA structure is called the Z form, because its bases seem to zigzag. Z
DNA is left-handed. One turn spans 4.6 nm, comprising 12 base pairs. The DNA
molecule with alternating G-C sequences in alcohol or high salt solution tends to
have such structure.
Figure. Comparison between B form and Z form.



Le proteine variano ampiamente in grandezza forma e funzione


Organismo Numero di
coppie di
basi
Lunghezza del
DNA (mm)
Dimesioni
dello spazio
cellulare (mm)
Numero di
cromosomi
Batteriofago 4.85 x 104 0,017 < 0,0001 1
Batterio
(Escherichia coli)
4,7 x 106 1,4 0,001 1
Lievito
(Saccharomyces
cervisiae)
1,25 x 107 4,6 0,005 16 (x 1 o 2)
Moscerino della
frutta (Drosophila
melanogaster)
1,65 x 108 56,0 0,010 4 (x 2)
Esseri umani
(Homo sapiens)
3 x 109 999,0 0,010 23 (x 2)
Il contenuto di DNA di varie specie

Organizzazione dei genomi a DNA
Genoma Forma Dimensioni (kb)
Eucarioti ds lineare da 104 a 106
Batteri ds circolare 103
Plasmidi ds circolare (alcuni ds lineari) 2-15
Virus a DNA dei
mammiferi
ss lineare, ds lineare, ds circolare 3-280
Batteriofagi ss circolare, ds lineare 50
DNA dei cloroplasti ds circolare 120-160
DNA mitocondriale ds circolare (alcuni ds lineari) Animali: 16,5
Piante: 100-2500



Genes
By definition, a gene includes the entire nucleic acid sequence necessary for the expression of its product (peptide or
RNA). Such sequence may be divided into regulatory region and transcriptional region. The regulatory region could
be near or far from the transcriptional region. In eucaryotic cells, the transcriptional region consists of exons and
introns. Exons encode a peptide or functional RNA. Introns will be removed after transcription.
As shown in the following figure, a typical DNA molecule consists of genes, pseudogenes and extragenic
region. Pseudogenes are nonfunctional genes. They often originate from mutation of duplicated genes. Because
duplicated genes have many copies, the organism can still survive even if a couple of them become nonfunctional
Figure. General organization of the DNA sequence. Only the exons encode a functional
peptide or RNA. The coding region accounts for about 3% of the total DNA in a human cell.

Duplicated Genes
Most proteins do not need duplicated genes, because the mRNA molecule transcribed from one gene can
be translated into many copies of its protein product. However, rRNA and tRNA are the final gene
products. In order to accelerate the production process, all species contain an array of tandemly repeated
RNA genes. The number of repeats ranges from tens to 24,000.
Number of RNA genes
*The X chromosome of fruit fly contains 250 copies of Pre-rRNAs, Y chromosome contains 150 copies.
There are four types of rRNA in mammalian cells: 28S, 5.8S, 5S and 18S. In the human genome, 28S, 5.8S and 18S are
clustered together. They form a single transcription unit which will be separated by specific enzymes after transcription. "
Pre-rRNA" refers to their precursor. In humans, a repeat unit for the pre-rRNA has about 40 kb in length, including a 13-
kb transcription unit and a 27-kb untranscribed spacer region. The transcription unit contains three spacers: ETS, ITS1 and
ITS2. They will be removed during RNA processing.

b globin gene
Figure. Graphic view of the b
globin gene, which consists of
three exons and two introns, with
a total length of 1.6 kb. This
figure was obtained from NCBI.
Gene family
"Gene family" refers to a set of genes with homologous sequences. For example, H2A, H2B,
H3 and H4 are in the same histone gene family. Their products have similar structures and
functions. Another example is the b-globin gene family located on the chromosome 11.
Figure. The b-
globin gene
family includes
b, d, Ag, Gg
and e. Y is a
pseudogene. H
S1 to HS4 are
regulatory
elements.


Caratteristiche delle sequenze genomiche degli eucarioti
E’ possibile distinguere la frequenza di ripetizione di sequenze
genomiche dalle cinetiche di riassociazione del DNA di un genoma
denaturato.
Dalle cinetiche di riassociazione si individuano due tipi di
sequenze genomiche:
Il DNA non ripetitivo consiste di sequenze uniche di cui ce
ne è una sola copia per genoma aploide.
Il DNA ripetitivo consiste di sequenze presenti in più di una
copia per genoma.
•Le proteine sono in genere codificate da sequenze di DNA
non ripetute.


Soltanto lo 0,1% del genoma umano differisce da una persona
all’altra. Ad eccezione della regione codificante gli antigeni
leucocitari umani (HLA) la variazione genetica è modesta nel
DNA codificante.
Meno del 40% del genoma umano è costituito da geni e da
sequenze correlate a geni.
Il DNA intergenico consiste di: 1) sequenze uniche od in basso
numero di copie; 2) sequenze moderatamente od altamente
ripetitive.
Le sequenze moderatamente od altamente ripetitive si possono
suddividere in due classi principali: (1) elementi sparsi; (2)
sequenze ripetute in tandem.

• Il DNA ripetitivo può essere suddiviso in due categorie
generali:
DNA moderatamente ripetitivo, costituito da sequenze
relativamente corte ripetute nel genoma in genere da 10 a 1000
volte. Sono sequenze disperse nel genoma.
DNA altamente ripetitivo, consiste di sequenze molto corte
(in genere meno di 100 bp) ripetute molte migliaia di volte nel
genoma e spesso organizzate come lunghe ripetizioni in
tandem.
• Nessuna delle due classi si trova nelle regioni codificanti.
• Nello stesso gruppo tassonomico i genomi più grandi non
contengono più geni, ma solo una maggiore quantità di DNA
ripetitivo.

Le proporzioni delle
diverse componenti
di sequenza variano
nei genomi
eucariotici

Elementi dispersi nel genoma
Sono ripetizioni presenti in tutto il genoma che sono trasposoni
(elementi instabili del DNA che si possono spostare in parti
diverse del genoma) o meglio copie degenerate di trasposoni.
Le ripetizioni non sono raggruppate, ma sono sparse in numerose
posizioni all’interno del genoma. Possono essere suddivisi in due
categorie in base alla loro lunghezza:
Sequenze più corte di 500 bp - SINE (short interspersed
nuclear elements); elementi Alu (SINE attivi nell’uomo).
Sequenze più lunghe di 500 bp – LINE (long interspersed
nuclear elements); elementi L1 (LINE attivi nell’uomo).

Classi di elementi trasponibili
Classe Intermedio di trasposizione Esempi
Classe I
Retrotrasposoni LTR RNA Lievito: elementi Ty;
Esseri umani: Retrovirus endogeni
umani (HERV);
Topo: particella A intracisternali
(AP).
Retrotrasposoni non LTR
LINE (autonomi)
SINE (non autonomi)
RNA Esseri umani:
Elementi L1
Elementi Alu
Classe II
Trasposoni di DNA DNA Batteri:
Sequenze di inserzione
Batteriofago Mu
Trasposoni (batterifago Tn7).
Drosophila:
Elementi P.
Mais:
Elementi Ac e Ds.
Invertebrati e vertebrati:
Superfamiglia Tc1/mariner

ITR: ripetizioni terminali invertite; DR: brevi ripetizioni dirette; ORF: modulo di
lettura aperto; LTR, lunghe ripetizioni terminali; HERV, retrovirus endogeni umani;
gag, antigene gruppo specifico; prt, proteasi; Pol, polimerasi; env, involucro; RT,
trascriptasi inversa; EN, endonucleasi; TSD, duplicazioni del sito di bersaglio; UTR,
regione terminale non trascritta.


Sequenze ripetute in tandem
• Le ripetizioni in tandem costituiscono approssimativamente il 10% del
genoma e si dividono in tre classi in base alla lunghezza:
Satelliti: sono costituiti da DNA altamente ripetitivo con una lunghezza
di ripetizione che va da una a parecchie migliaia di coppie di basi.
Queste sequenze sono organizzate in grandi gruppi nelle regioni di
eterocromatina dei cromosomi, vicino ai centromeri ed ai telomeri, e
sono abbondanti anche nel cromosoma Y.
Minisatelliti: loci di ripetizioni in tandem a numero variabile (VNTR),
sono composti da motivi di sequenza che vanno da circa 15 a 50 bp. La
lunghezza totale delle ripetizioni in tandem va da 500 bp a 20 kb.
Microsatelliti o brevi ripetizioni in tandem (STR): l’unità ripetuta va da
2 a 6 bp per una lunghezza totale che varia fra 50 e 500 bp. Le
sequenze STR più comuni sono ripetizioni dinucleotidiche.

• La variazione genetica da individuo ad individuo nei
minisatelliti e STR (polimorfismi) è dovuta soprattutto al
numero di elementi ripetitivi disposti in tandem, ma ci possono
essere piccole differenze anche nella sequenza.
• Queste regioni variabili sono particolarmente utili per la
genetica legale perché si possono usare per generare un profilo
del DNA di un individuo, pur non dando alcuna informazione
sui tratti fenotipici dello stesso.














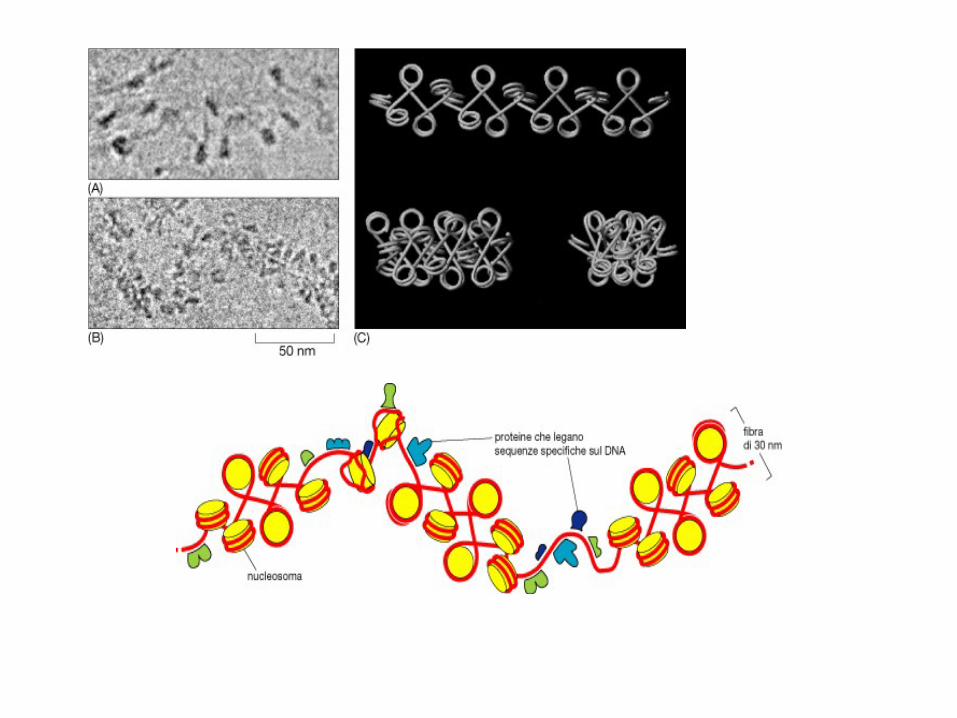
Chromatin is the substance
which becomes visible
chromosomes during cell
division. Its basic unit is
nucleosome, composed of
146 bp DNA and eight
histone proteins. The
structure of chromatin is
dynamically changing, at least
in part, depending on the need
of transcription . In the
metaphase of cell division,
the chromatin is condensed
into the visible
chromosome. At other times,
the chromatin is less
condensed, with some regions
in a "Beads-On-a-String"
conformation.
Figure. The condensed structure of chromatin.
(a) The 30 nm chromatin fiber is associated with scaffold proteins (notably
topoisomerase II) to form loops. Each loop contains about 75 kb
DNA. Scaffold proteins are attached to DNA at specific regions called scaffold
attachment regions (SARs), which are rich in adenine and thymine.
(b) The chromatin fiber and associated scaffold proteins coil into a helical
structure which may be observed as a chromosome. G bands are rich in A-T
nucleotide pairs while R bands are rich in G-C nucleotide pairs.
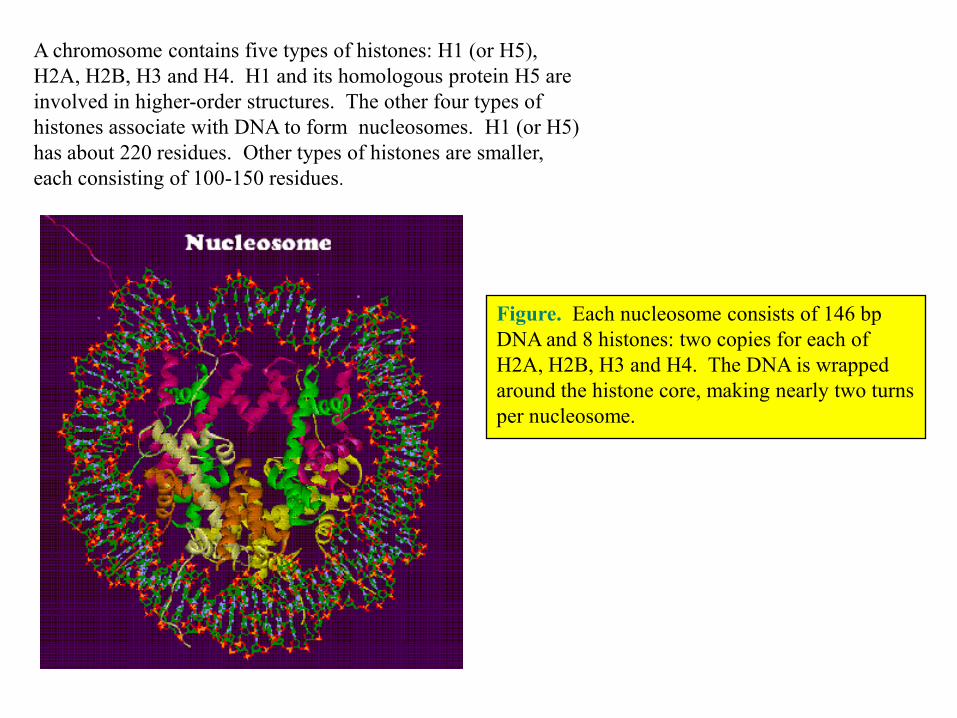
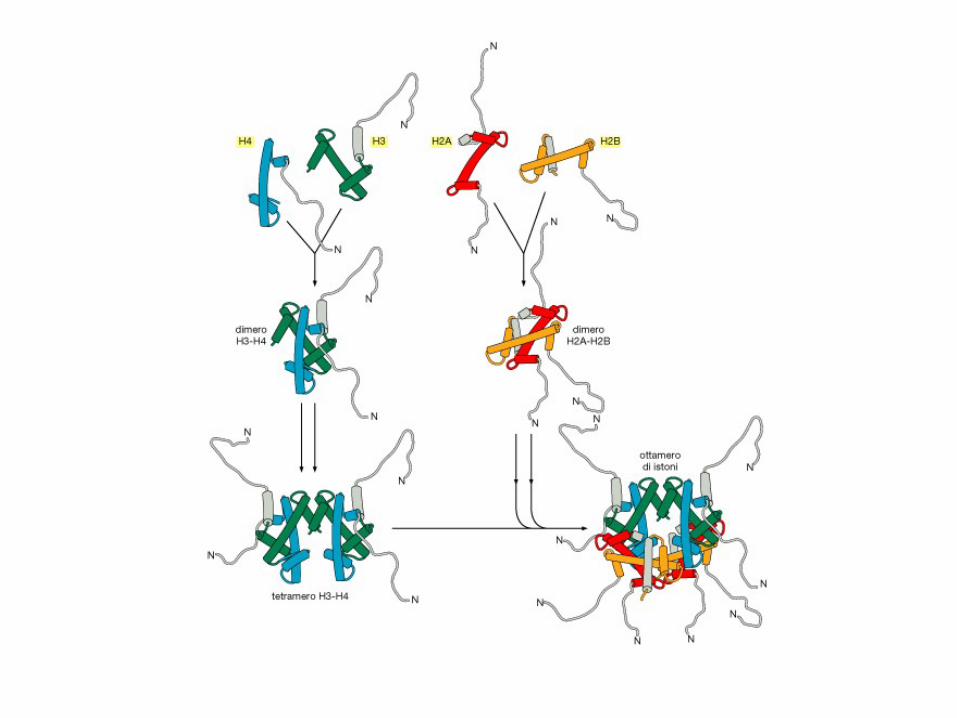
A chromosome contains five types of histones: H1 (or H5),
H2A, H2B, H3 and H4. H1 and its homologous protein H5 are
involved in higher-order structures. The other four types of
histones associate with DNA to form nucleosomes. H1 (or H5)
has about 220 residues. Other types of histones are smaller,
each consisting of 100-150 residues.
Figure. Each nucleosome consists of 146 bp
DNA and 8 histones: two copies for each of
H2A, H2B, H3 and H4. The DNA is wrapped
around the histone core, making nearly two turns
per nucleosome.


Figure. The sequence of
H4 from a cow. Lysine
residues (red color) at the
N terminus play a major
role in the regulation of
gene transcription.
An important feature about histones is that they contain a few lysine (K) residues at the N
terminus. Under normal cellular conditions, the R group of lysine is positively charged,
which can interact with the negatively charged phosphates in DNA. The positive R group of
lysine may be neutralized by acetylation, reducing the binding force between histones and
DNA. Such mechanism has been demonstrated to play a major role in the regulation of gene
transcription.






Istone acetiltransferasi (HAT); istone metiltransferasi (HMT); istone chinasi;
istone deacetilasi (HDAC); istone demetilasi; istone fosfatasi.


Atomic Force Microscopy
of Chromatin Fiber



Most cellular RNA molecules are single stranded. They may form secondary structures such
as stem-loop and hairpin.

mRNA is transcribed from DNA, carrying information for protein synthesis. Three
consecutive nucleotides in mRNA encode an amino acid or a stop signal for protein
synthesis. The trinucleotide is know as a codon
Figure. The sequence relationship of DNA, mRNA and the encoded peptide . The sequence
of mRNA is complementary to DNA's template strand, and thus the same as DNA's coding
strand, except that T is replaced by U.

Figure. The
secondary
structure of
tRNA. Blue
color indicates
modified
nucleotides,
with "m"
representing
"methylated". A
nticodon is the
trinucleotides
complementary
to a codon on
mRNA.



The tertiary structure of tRNA. PDB ID = 1TN2

Struttura terziaria del RNA
• I grandi RNA sono composti da domini strutturali.
• Dispositivi per il ripiegamento del RNA: legami ad idrogeno
ed impilamento delle basi.
• I domini preformati con struttura secondaria del RNA
interagiscono per formare la struttura terziaria.
• Interazione del RNA con proteine basiche ed attacco di ioni
metallici mono e/o bivalenti per neutralizzare le cariche
negative del RNA.
• Motivi più comuni: pseudonodo, motivo ad A-minore,
tetranse, cerniere lampo di ribosio, pieghe K.

Motivo a pseudonodo

Motivo A-minore (rRNA)

Motivo a tetraansa

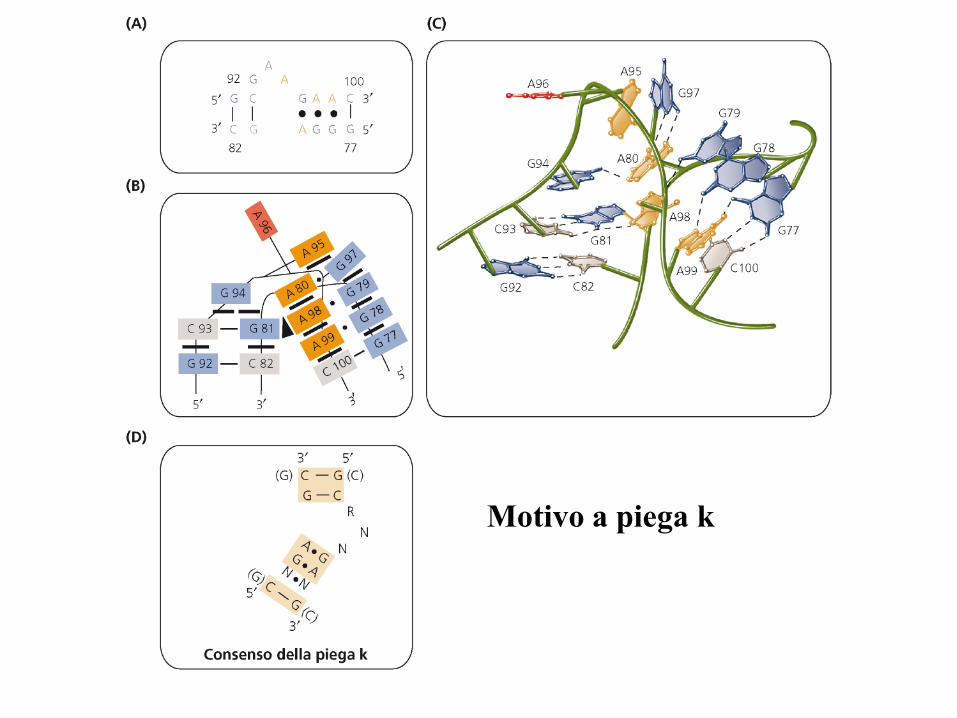
Motivo a piega k

Ripiegamento del
RNA mediato da
proteine


Versatilità della funzione dell’RNA
• Interazione tra molecole di RNA e con DNA a singolo filamento.
• Associazione con proteine, con formazione di complessi RNA-proteine
particelle ribonucleoproteiche od RNP.
• RNA come “impalcatura” particella di riconoscimento del segnale
(SRP).
• RNA della RNP influenza l’attività catalitica della proteina
telomerasi.
• RNA catalitico ribozimi.
• Piccoli RNA che controllano direttamente l’espressione genica
miRNA.
• RNA come materiale ereditario genomi dei virus ad RNA.

In prokaryotes, the
ribosomal RNA (rRNA)
has three types: 23S, 5S,
and 16S. In mammals,
four types of rRNA have
been found : 28S, 5.8S, 5S
and 18S. After rRNA
molecules are produced in
the nucleus, they are
transported to the
cytoplasm, where they
combine with tens of
specific proteins to form a
ribosome. In prokaryotes,
the size of a ribosome is
70S, consisting of two
subunits: 50S and
30S. The size of a
mammalian ribosome is
80S, comprising a 60S and
a 40S subunit. Proteins in
the larger subunit are
designated as L1, L2, L3,
etc. (L = large). In the
smaller subunit, proteins
are denoted by S1, S2, S3,
etc.

During protein synthesis, the
ribosome binds to mRNA and
tRNA as shown in the following
figure. Only the tRNA
containing the anticodon which
matches mRNA's codon may
join the complex.
The mRNA-ribosome-tRNA complex formed
during protein synthesis.

Figure. The standard genetic code. Synthesis of a peptide always starts from methionine (Met), coded
by AUG. The stop codon (UAA, UAG or UGA) signals the end of a peptide. This table applies to
mRNA sequences. For DNA, U (uracil) should be replaced by T (thymine). In a DNA molecule, the
sequence from an initiating codon (ATG) to a stop codon (TAA, TAG or TGA) is called an open reading
frame (ORF), which is likely (but not always) to encode a protein or polypeptide.

Figure. An approach used by Marshall Nirenberg and his colleagues to crack the genetic code.
(i) Synthesize a trinucleotide (e.g. UUU) which mimics a codon in mRNA.
(ii) Prepare various types of aminoacyl-tRNA, e.g., Thr-tRNA, Phe-tRNA, Lys-tRNA, etc.
(iii) Radioactively label an aminoacyl-tRNA (e.g. Phe-tRNA) which might contain the anticodon for
the synthesized trinucleotide.
(iv) Place the trinucleotide, aminoacyl-tRNA and ribosome on a nitrocellulose filter.
Individual trinucleotide and aminoacyl-
tRNA can pass through the filter, but the
ribosome is too big to pass
through. Therefore, if the labeled
aminoacyl-tRNA contains the anticodon
for the trinucleotide, it will bind to the
trinucleotide and ribosome on the
filter. In this case, the radioactivity can
be detected on the filter and the amino
acid in the labeled aminoacyl-tRNA is
likely to be encoded by the
trinucleotide. If no radioactivity was
detected, the trinucleotide is unlikely to
be the codon of the amino acid. Most of
the 64 possible codons can be determined
by repeating this procedure for different
trinucleotides and labellings.

The genetic code is not randomly assigned. If an amino acid is coded by several codons, they often
share the same sequence in the first two positions and differ in the third position. Such assignment is
accomplished by the design of wobble position, but "the evolutionary dynamic that shaped the code
remains a mystery".

Translation is a process by which the nucleotide sequence of mRNA is converted
Translation is carried out by tRNA through the relationship between its anticodon and the associated
amino acid. When a tRNA is brought to the ribosome by the pairing between its anticodon and the
mRNA's codon, the amino acid attached at its 3' end will be added to the growing peptide. In bacteria,
there are 30-40 tRNAs with different anticodons. In animal and plant cells, about 50 different tRNAs are
found. However, there are 61 codons coded for amino acids. Suppose each codon can pair with only a
unique anticodon, then 61 tRNAs would be needed.
Figure. Pairing between tRNA's anticodon and mRNA's codon. The left figure defines the wobble
position where base pairing does not obey the standard rule. The right tables show all possible base
pairings at the wobble position. For example, guanine (G) can pair with both cytosine (C) and uracil
(U) ; inosine (I) can pair with cytosine, adenine and uracil.

In most cases, frameshift involves the insertion or deletion of a single nucleotide in
mRNA. Theoretically, it could involve more than one nucleotide, as long as the number is
not a multiple of 3. When a nucleotide is added to or deleted from the mRNA, the
subsequent sequence will produce an entirely different peptide.
Figure. Illustration of the frameshift. mRNA(a) and mRNA(b) differ by only one
nucleotide: mRNA(b) has an additional nucleotide "G" at the third position in this
figure. Note that the translated amino acids are entirely different after the insertion point.

Wobble pairing

The standard genetic code applies to most, but not all, cases. Exceptions have been found
in the mitochondrial DNA of many organisms and in the nuclear DNA of a few lower
organisms. Some examples are given in the following table.


















