
Transforming your Graph Analytics with GraphDB 8.1
78
GraphDB Fundamentals Ivelina Nikolova, PhD Ontotext Webinar May 11, 2017
Transcript of Transforming your Graph Analytics with GraphDB 8.1

GraphDB Fundamentals
Ivelina Nikolova, PhD
Ontotext Webinar May 11, 2017

Presentation Outline
• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Vizualizations#2

Presentation Outline
• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Vizualizations#3

Resource Description Framework (RDF) is a graph data model that
• Formally describes the semantics, or meaning, of information
• Represents metadata, i.e., data about data
RDF data model consists of triples
• That represent links (or edges) in an RDF graph
• Where the structure of each triple is Subject, Predicate, Object
Example triples:
‘br:’ refers to the namespace ‘http://bedrock/’ so that ‘br:Fred’ expands to <http://bedrock/Fred> a Universal Resource Identifier (URI).
What is RDF?
Subject Predicate Object
br:Fred br:hasSpouse br:Wilma .br:Fred br:hasAge 25 .
#4
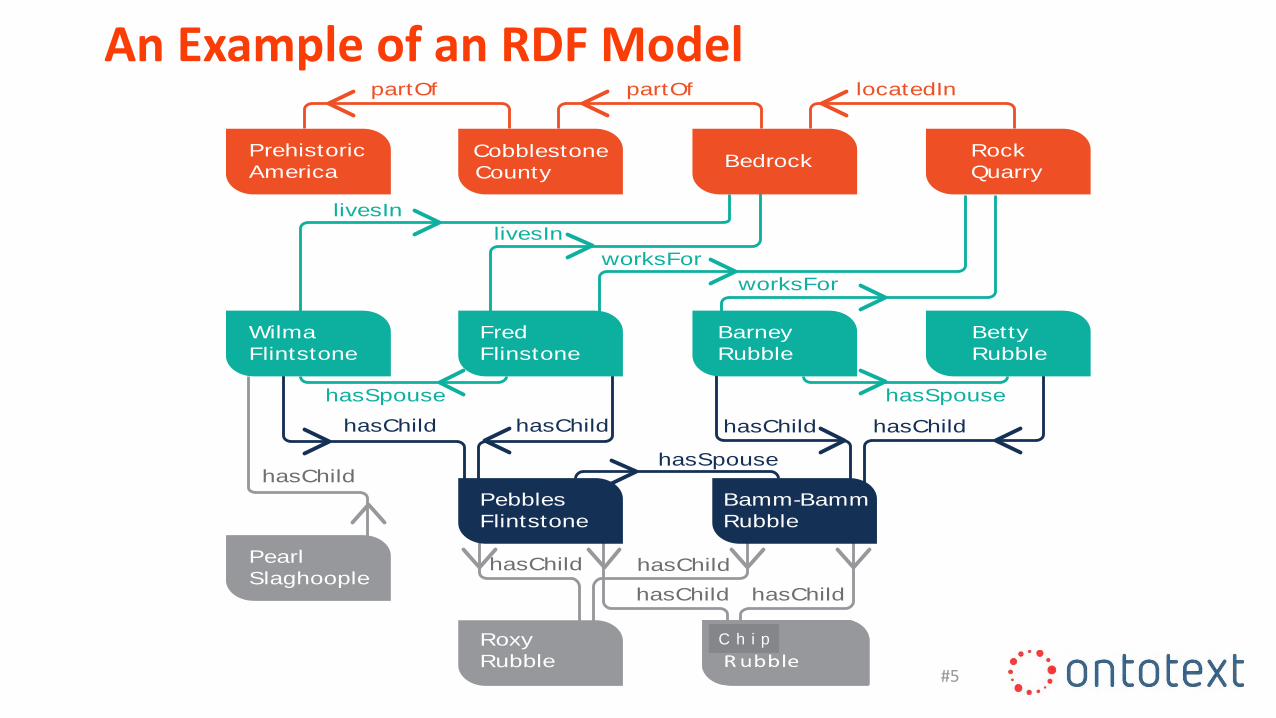
An Example of an RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
C h i p
#5

RDF Schema (RDFS)
• Adds
− Concepts such as Resource, Literal, Class, and Datatype
− Relationships such as subClassOf, subPropertyOf, domain, and range
• Provides the means to define
− Classes and properties
− Hierarchies of classes and properties
• Includes “entailment rules”, i.e., axioms to infer new triples from existing ones
What is RDFS?
#6

Applying RDFS To Infer New Triples
br:hasSpouse a rdf:Property;rdfs:domain br:Human ;rdfs:range br:Human .
br:Fred br:hasSpouse br:Wilma .
br:Human a rdf:Class;rdfs:subClassOf br:Mammal .
br:Fred a br:Human .br:Wilma a br:Human .
br:Fred a br:Mammal .br:Wilma a br:Mammal .
#7

Presentation Outline
• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Vizualizations#8

What is SPARQL?
SPARQL is a SQL-like query language forRDF graph data with the following querytypes:
• SELECT returns tabular results
• CONSTRUCT creates a new RDF graph based on query results
• ASK returns ‘yes’ if the query has a solution, otherwise ‘no’
• DESCRIBE returns RDF graph data about a resource; useful when the query client does not know the structure of the RDF data in the data source
• INSERT inserts triples into a graph
• DELETE deletes triples from a graph.
9

Using SPARQL to Insert TriplesTo create an RDF graph, perform these steps:
• Define prefixes to URIs with the PREFIX keyword
• Use INSERT DATA to signify you want to insert statements. Write the subject-predicate-object statements (triples).
• Execute this query.
:pebbles:bamm-bamm
:fred :wilma
:roxy :chip
:hasSpouse
:hasChild :hasChild
:hasChild :hasChild
PREFIX br: <http://bedrock/>INSERT DATA {
br:fred br:hasSpouse br:wilma .br:fred br:hasChild br:pebbles .br:wilma br:hasChild br:pebbles .br:pebbles br:hasSpouse br:bamm-bamm ;
br:hasChild br:roxy, br:chip .}
#10

Using SPARQL to Select TriplesTo access the RDF graph you just created, perform these steps:
• Define prefixes to URIs with the PREFIX keyword.
• Use SELECT to signify you want to select certain information, and WHERE to signify your conditions, restrictions and filters.
• Execute this query.
PREFIX br: <http://bedrock/>SELECT ?subject ?predicate ?object
WHERE {?subject ?predicate ?object}
Subject Predicate Object
br:fred br:hasChild br:pebblesbr:pebbles br:hasChild br:roxybr:pebbles br:hasChild br:chipbr:wilma br:hasChild br:pebbles
#11

Using SPARQL to Find Fred’s Grandchildren
To find Fred’s grandchildren, first find out if Fred has any grandchildren:
• Define prefixes to URIs with the PREFIX keyword
• Use ASK to discover whether Fred has a grandchild, and WHERE to signify your conditions.
YES
PREFIX br: <http://bedrock/>ASKWHERE {
br:fred br:hasChild ?child .?child br:hasChild ?grandChild .
}
#12

Using SPARQL to Find Fred’s Grandchildren
Now that we know he has at least one grandchild, perform these steps to find the grandchild(ren):
• Define prefixes to URIs with the PREFIX keyword
• Use SELECT to signify you want to select a grandchild, and WHERE to signify your conditions.
PREFIX br: <http://bedrock/>SELECT ?grandChild WHERE {
br:fred br:hasChild ?child .?child br:hasChild ?grandChild .
}
grandChild
1. br:roxy2. br:chip
#13
Presentation Outline• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Visualizations#14

What is OntologyAn ontology is a formal specification that provides sharable and reusable knowledge representation.
Examples of formal specifications include:
• Taxonomies
• Vocabularies
• Thesauri
• Topic Maps
• Logical Models
#15

What is in an Ontology?An ontology specification includes descriptions of
• Concepts and properties in a domain
• Relationships between concepts
• Constraints on how the relationships can be used
• Individuals as members of concepts
#16

The Benefits of an OntologyOntologies provide:
• A common understanding of information
• Explicit domain assumptions
These provisions are valuable because ontologies:
• Support data integration for analytics
• Apply domain knowledge to data
• Support interoperation of applications
• Enable model-driven applications
• Reduce the time and cost of application development
• Improve data quality, i.e., metadata and provenance#17

OWL Overview
The Web Ontology Language (OWL) adds more powerful ontologymodelling means to RDF/RDFS
• Providing− Consistency checks: Are there logical inconsistencies?− Satisfiability checks: Are there classes that cannot have instances?− Classification: What is the type of an instance?
• Adding identity equivalence and identity difference− Such as, sameAs, differentFrom, equivalentClass, equivalentProperty
• Offering more expressive class definitions, such as− Class intersection, union, complement, disjointness− Cardinality restrictions
• Offering more expressive property definitions such as,− Object and datatype properties− Transitive, functional, symmetric, inverse properties− Value restrictions
#18

Presentation Outline• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Visualizations#19

"Ontology Development 101" by Noy & McGuinness (2001) is a popular, practical seven-step methodology for developing an ontology.
• Step 1: Identify the domain and scope
• Step 2: Consider re-using existing ontologies
• Step 3: Enumerate important terms
• Step 4: Define the classes and class hierarchy
• Step 5: Define the properties of classes
• Step 6: Define property facets
• Step 7: Create instances
A Methodology for Ontologies
1
2
3
45
6
#20

To help identify the domain and scope of the ontology, answer these questions:
• What is the domain of the ontology?
• What is the purpose of the ontology?
• Who are the users and maintainers?
• What questions will the ontology answer?
Some say the last is most important (Competence Questions approach)
Step 1: Identify the Domain and Scope
#21

Ontologies are re-usable and extensible and there are a number of existing ontologies that you might consider:
• Your existing ontology
• Widely used ontologies
− such as: Dublin Core, FOAF, SKOS, Geo (WGS84)
• Upper Level Ontologies
− such as: Cyc, UMBEL, DOLCE, SUMO, PROTON
• Linked Open Data
• Specialized domain ontologies
Step 2: Consider Re-using Existing Ontology
#22

Terminology is useful for domain modeling. Start collecting terminology based on interviews and domain documentation.
Step 3: Enumerate Important Terms
#23

To help define the class and class hierarchy, determine which type of modeling to use.
Three types of modeling are:
• Top-down modeling
− Use it when the general domain concepts are known
• Bottom-up modeling
− Use it when there is a great variety of concepts and no clear overarching general concepts at the outset
• Hybrid modeling
− Use it when you need both top down and bottom up modeling, which is often the case
Step 4: Define Class and Class Hierarchy
Ontotext, AD and Keen Analytics, LLC. All Rights Reserved
#24

Define the properties of classes, such as:
• Intrinsic properties
− For example color, mass, density
• Extrinsic properties
− For example, name, location
• Parts
• Relationships to other individuals
Step 5: Define Properties of Classes
#25

Define property facets, such as:
• Property Type
− Is it symmetric? Is it transitive? Is it a datatype or an object property?
• Cardinality
− Is the property optional or essential? Is the property a one-to-many relationship?
• Domain
− From which classes does this property point?
• Range
− To which classes does this property point?
Step 6: Define Property Facets
#26

Create instances of classes
• For example, :Fred a :Human
Creating instances
• Tests the domain ontology
• May expose modeling issues
− which can be addressed by iterative refinement
Step 7: Create Instances
#27

Presentation Outline• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Visualizations#28

GraphDB™ Editions
• GraphDB™ Free
• GraphDB™ Standard
• GraphDB™ Cloud
• GraphDB™ as-a-Service (S4)
• GraphDB™ Enterprise
#29

GraphDB™ Editions
• GraphDB™ Free
• GraphDB™ Standard
• GraphDB™ Cloud
• GraphDB™ as-a-Service (S4)
• GraphDB™ Enterprise
#30

#31http://ontotext.com/products/graphdb/
GraphDB™ Free Installation

GraphDB™ Free Edition Installation Overview
#32
Step 1:
• On Windows - Download & run the GraphDB .exe file, follow the on-screen installer prompts.
• On Mac OS - Download & run the GraphDB .dmg file. Copy the program from the virtual disk to your hard disk applications folder.
• On Linux - Download the GraphDB .rmp or .deb file. Install the package with sudo rpm -i or sudo deb -i and the name of the downloaded package.
Step 2:
• Start the database by clicking the application icon. The GraphDB Server and Workbench open at http://localhost:7200/.

Create a new repository by:
• Launching the GraphDB™ Workbench
• Selecting “Setup”
• Selecting “Repositories”
• Configuring the new repository
GraphDB™ Free Edition Workbench New Repositoryhttp://localhost:7200
#33

GraphDB™ Free Edition Workbench New Repository
#34

Test the repository by
• Selecting “SPARQL”
• Submitting queries
GraphDB™ Workbench Execute Queries
2 Query
1 Insert Data
#35

Presentation Outline• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Visualizations#36

• All collections in all repositories are now using a single central chunk of memory.
• By default, the new cache takes 50% of the JVM heap size.
− if you start your database with -Xmx2GB (the maximum amount of memory for the JVM parameter), it will take 1GB for page caching.
• If you know that there won’t be that many group by queries to eat the other memory, you can easily change the parameter for the whole GraphDB instance with
-Dgraphdb.page.cache.size=<amount-of-memory-for-caching>
More about memory tuning can be found at: http://ontotext.com/new-caching-strategy-graphdb/
Performance Tuning: Memory
#37

GraphDB™ Enterprise edition provides scalability
• Replication / High Availability cluster
• Improved concurrent querying and scalability
• Resilience for failover
Scalability: GraphDB™ Enterprise
#38

Presentation Outline• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Visualizations#39

GraphDB™ Workbench is a web-based administration tool. It is similar to RDF4J Workbench, but
• Has more features
• Is more intuitive and easier to use
GraphDB™ Workbench functions Include
• Managing GraphDB™ repositories
• Loading and exporting data
• Monitoring query execution
• Managing connectors and users
GraphDB™ Workbench and RDF4J
#40

On the following slide is an example of the GraphDB™ Workbench screen.
• Access the GraphDB™ Workbench from a browser.
• The splash page provides a summary of the installed GraphDB™ Workbench.
GraphDB™ Workbench
#41
• The Workbench has a side menu bar with convenient drop down menus organized under “Import”, “Explore”, “SPARQL”, “Monitor”, “Setup” and “Help”.
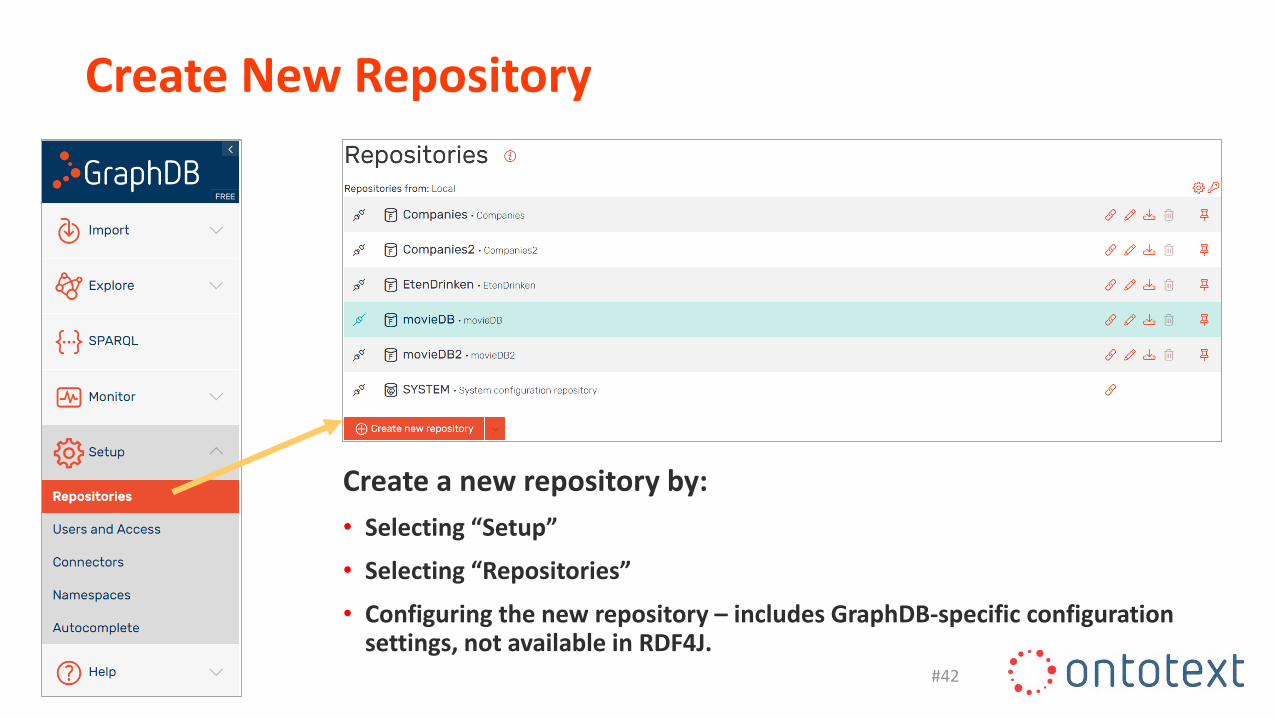
Create New Repository
#42
Create a new repository by:
• Selecting “Setup”
• Selecting “Repositories”
• Configuring the new repository – includes GraphDB-specific configuration settings, not available in RDF4J.

By selecting the SPARQL menu, the SPARQL query editor displays and
• Allows you to render your query results as Table, Pivot Table, or Google Analytic Charts
Execute Queries With GraphDB™ Workbench
#43

GraphDB™ Workbench Query Editor
#44

Query Monitoring: Abort Query
#45
GraphDB™ allows you to abort long queries that are executing.
E.g. you create a query that is long running, and you would like to halt it, and perhaps modify it and resubmit it and not wait until it completes.
From the side menu panel select Monitor, then Queries.

Presentation Outline• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Visualizations#46

Loading data may be accomplished by using
• GraphDB™ Workbench
− To upload individual files
− To upload bulk data from a directory
• LoadRDF Parallel Loader
Loading Data
#47

Loading Data
Supported File Formats
#48

Loading data through the GraphDB Workbench
To load a local file:
#49
• Select Import -> RDF.• Open the Local files tab and click the Select files icon to choose the file you want to upload.• Click the Import button.• Enter the import settings in the pop-up window

Loading Local Files
#50

Loading a database server file
#51
• Create a folder named graphdb-import in your user home directory.• Copy all data files you want to load into the GraphDB database to this folder.• Go to the GraphDB Workbench.• Select Data -> Import.• Open the Server files tab.• Select the files you want to import.• Click the Import button.

The LoadRDF Parallel Bulk Loader
• Features fast loading of large datasets into new repositories
• Is not intended for updating existing repositories
• Is easy to use:
− Enter loadrdf <config.ttl> <serial|parallel> <files...>
▪ For example “./loadrdf.sh config.ttl parallel example.ttl”
− The “Serial Load” option pipelines the parse, entity resolution, and load tasks.
− The “Parallel Load” batch processes the parse, entity resolution, and load tasks.
LoadRDF Parallel Bulk Loader
#52

Other ways to load data
#53
By pasting data in the Text area tab
of the Import page.
By pasting a data URL in the
Remote content tab of the Import page.
By executing an INSERT query in the
SPARQL -> SPARQL Query page.

Loading tabular data using OntoRefine
#54

Loading tabular data using OntoRefine
#55

Presentation Outline• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Visualizations#56

Reasoning Strategies:
• Forward Chaining
− Inferences pre-computed
− Faster query performance
− Slower load times
− More memory/disk space required
− Updates are expensive (truth maintenance is non-trivial)
• Backward Chaining
− Inferences performed as needed at query time
− Slower query performance
− Faster load times
• Hybrid Reasoning
− Partial forward chaining at data loading time + partial backward chaining at query time
Reasoning Strategies
#57

− Fast (incremental) inserts (assertions) and deletes (retractions)
− Most triplestores perform an expensive full re-compute on updates
• Reasoning on insert: forward chaining optimization− Rule sets compiled to fast Java code
− Every statement is passed through all rules. First check is in-memory, reducing need for lookups
• Delete Optimization: smooth (incremental) delete− Truth maintenance minimizes the re-compute but the required dependency tracking is expensive
− GraphDB optimizes deletes by using backward chaining to derive delete dependencies dynamically
− This backward search stops at axioms or ontology triples (see onto:schemaTransaction to control it)
− Inferred triples without alternative support are retracted. Recursively
GraphDB™ Reasoning Optimizations
#58

owl:sameAs optimisation• sameAs is useful in semantic data integration
− Often independent agencies mint different URLs for the same entity
− sameAs, an equivalence relation, declares them the same (“smushing”)
− All statements of URL X in equivalence cluster are “copied” to all Y in the same cluster
− Such inference causes combinatorial explosion of statements
− If unchecked, decreases memory and query time performance
• sameAs Optimisation− Compact representation: statements are made against clusters, not against individual URLs
− Backward chaining finds all solutions across cluster
− Query results compacted by picking one representative from cluster (option disableSameAs=true)
− disableSameAs=false = “Expand results over equivalent URIs”
#59

A Rule Set Consists of
• Prefixes (namespace prefixes)
• Axiomatic triples
• Custom rules
Pre-Defined Rule Sets are
• empty: no reasoning, GraphDB™ operates as a plain RDF store;
• rdfs: standard RDFS semantics;
• owl-horst: RDFS + D-Entailment + Some OWL – Tractable
• owl-max: RDFS with most of OWL Lite
• owl2-rl: Conformant OWL2 RL profile except for D-Entailment (types)
• owl2-ql: Reasoning over large volumes of data
Rule Sets
#60

Presentation Outline• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Visualizations#61

Ontotext GraphDB Connectors
#62
• Provides extremely fast full text, range, faceted search, and aggregations
• Utilize an external engine like Lucene, Solr or Elasticsearch
• Flexible schema mapping: index only what you need
• Real-time synchronization of data in GraphDB and the external engine
• Connector management via SPARQL
• Data querying & update via SPARQL
• Based on the GraphDB plug-in architecture

Interface
• All interaction via SPARQL queries − INSERT for creating connectors
− SELECT for getting connector configuration parameters− INSERT/SELECT/DELETE for managing & querying RDF data
#64

Connectors – Primary Features
• Maintaining an index that is always in sync with the data stored in GraphDB
• Multiple independent instances per repository
• The entities for synchronization are defined by:
− a list of fields (on the Lucene side) and property chains (on the GraphDB side) whose values will be synchronised
− a list of rdf:type's of the entities for synchronisation
− a list of languages for synchronisation (the default is all languages)
− additional filtering by property and value
• Full-text search using native Lucene queries
#65

Connectors – Primary Features
• Snippet extraction: highlighting of search terms in the search result
• Faceted search, e.g. Europeana Food and Drink
• Sorting by any preconfigured field
• Paging of results using offset and limit
• Custom mapping of RDF types to Lucene types
• Specifying which Lucene analyzer to use (the default is Lucene'sStandardAnalyzer)
• Boosting an entity by the [numeric] value of one or more predicates
• Custom scoring expressions at query time to evaluate score based on Lucene #66

TinkerPop Blueprints Support
• Blueprints (Apache TinkerPop, aka Gremlin) is a popular API for accessing graph databases
• It is supported by Hadoop, Neo4j, Titan, etc
• GraphDB supports Blueprints since 7.0 for accessing RDF databases
• It represents RDF as a simplified version of the Property Graph model
• In this way you can use graph programming frameworks, or use ready graph exploration software like Linkurious
#67

RDF Rank is a GraphDB™ extension that
• Is similar to PageRank and it identifies “important” nodes in an RDF graph based on their interconnectedness
• Is accessed using the rank:hasRDFRank system predicate
• Incremental RDF Rank is useful for frequently changing data
For Example, to select the top 100 important nodes in the RDF graph:
RDF Rank
PREFIX rank: <http://www.ontotext.com/owlim/RDFRank#>SELECT ?n WHERE {?n rank:hasRDFRank ?r }ORDER BY DESC(?r)LIMIT 100

GeoSPARQL Support
#69
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium, using the Geography Markup Language
• A small topological ontology in RDFS/OWLfor representation
• Simple Features, RCC8, and DE-9IM (a.k.a. Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
• A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning

Presentation Outline• Welcome
• RDF and RDFS Overviews
• SPARQL Overview
• Ontology Overview
• Ontology Modeling
• GraphDB™ Installation
• Performance Tuning and Scalability
• GraphDB™ Workbench and RDF4J
• Loading Data
• Rule Sets and Reasoning Strategies
• Extensions
• Visualizations#70

Explore Your Data Graph
• Navigate to Explore -> Visual graph. You see a search input to choose a resource as a starting point for graph exploration.
#71

#72
Visualize the graph of Sofia

Info about the Resource
#73

Visualize the graph of Sofia
#74

Teaching time is 9 + 1 hours
including:
• Pre-class assignments
(recorded sessions);
• Live Class Sessions;
• Individual Consultation
(optional).

GraphDB™ Devops Training
• Product editions and features
• Quick start
• Product APIs
• Connect to GraphDB
• Advanced SPARQL
• Reasoning
• Connectors
• Administration and monitoring
76

Support and FAQ’s
Additional resources:
Ontotext:Community Forum and Evaluation Support: http://stackoverflow.com/questions/tagged/graphdbGraphDB Website and Documentation: http://graphdb.ontotext.comWhitepapers, Fundamentals: http://ontotext.com/knowledge-hub/fundamentals/
SPARQL, OWL, and RDF:RDF: http://www.w3.org/TR/rdf11-concepts/RDFS: http://www.w3.org/TR/rdf-schema/SPARQL Overview: http://www.w3.org/TR/sparql11-overview/SPARQL Query: http://www.w3.org/TR/sparql11-query/SPARQL Update: http://www.w3.org/TR/sparql11-update
77

For Further Information
• Peio Popov, North America Sales and Business Development
−1.929.239.0659
• Ilian Uzunov, Europe Sales and Business Development
−359.888.772.248
#78

The End


















