
Transfer Learning From Multiple Source Domains via Consensus Regularization Ping Luo, Fuzhen Zhuang,...
31
Transfer Learning From Multiple Source Domains via Consensus Regularization Ping Luo, Fuzhen Zhuang, Hui Xiong, Yuhong Xiong, Qing He
-
Upload
gabriella-greer -
Category
Documents
-
view
217 -
download
0
Transcript of Transfer Learning From Multiple Source Domains via Consensus Regularization Ping Luo, Fuzhen Zhuang,...

Transfer Learning From Multiple Source Domains via Consensus
Regularization
Ping Luo, Fuzhen Zhuang, Hui Xiong, Yuhong Xiong, Qing He

23/4/19 Ping Luo CIKM 08
OverviewIntroduction
• Preliminaries
• Consensus Regularization
• Experimental Evaluation
• Related Works
• Conclusions

23/4/19 Ping Luo CIKM 08
Research Motivation (1)Source
Domain 1
Source Domain 2
Source Domain 3
Target Domain
Knowledge Transfer
Source Domain
Target Domain
Knowledge Transfer
• How to exploit the distribution differences among multiple source domains to boost the learning performance in a target domain
• How to deal with the situation that the source domains are geographically separated with some privacy concerns

23/4/19 Ping Luo CIKM 08
Research Motivation (1)
• Motivating Examples– Web pages Classification
• Label Web pages from multiple different universities to find the course main page by text classification
• Different university with different terms to describe the course metadata
– Video concept detection• Generalize to models to detect semantic concepts from multiple source video data
Common Features
1.Multiple source
domains with different
data distributions
2.Separated source
domains

23/4/19 Ping Luo CIKM 08
Challenges and Contributions
• New Challenges
- How to make good use of the distribution mismatch among multiple source-domains to promote the prediction performance on target-domain
- Extend the consensus regularization to implement in a distributed manner, which modestly preserves privacy
• Contributions
- Propose a consensus regularization based algorithm for transfer learning from multiple source-domains
- Perform in a distributed and modest privacy-preserving manner

23/4/19 Ping Luo CIKM 08
Overview• Introduction
Preliminaries
• Consensus Regularization
• Experimental Evaluation
• Related Works
• Conclusions

23/4/19 Ping Luo CIKM 08
Consensus Measuring (1)
(1, 0, 0)
(1, 0, 0)
(1, 0, 0)
Average(1,0,0)
Entropy(1,0,0) 0eC E
• Example: three-class classification problem, three classifiers predict an
instance x
(1, 0, 0)
(0, 1, 0)
(0, 0, 1)
Average 1 1 1( , , )
3 3 3
Entropy 1 1 1( , , )3 3 3eC E
Minimal entropy, Maximal Consensus
Maximal entropy, Minimal Consensus

23/4/19 Ping Luo CIKM 08
Consensus Measuring (2)
1 2 2 2(1) (2) (1) (1) (1)( , , ) ( ) ( (1 )) (2 1)m
sC p p p p p p p
• Example: two-classes classification problem, three classifiers predict an
instance x
• Due to computing complexity in the entropy, for 2-entry probability distribution vectors, we can simplify the consensus measure as:
(0.75, 0.25)
(0.45, 0.55)
(0.9, 0.1)
Average(0.7,0.3)
Entropy2(0.7 0.3)sC

23/4/19 Ping Luo CIKM 08
Logistical Regression [Davie et al, 2000]
Logistic regression can be an approach to learn classification model for discrete outputs.•Given:
Training data set X, where X is any vector containing discrete or continuous random variables
Discrete outputs Y, where Y is discrete value
•Maximize the following formula to obtain Model w:
•Classification:1
1log .
1 exp( ) 2
NT
Ti i iy
w w
w x
1( 1| ; ) ( ) .
1 exp( )T
TP y y
y
x w w x
w x

23/4/19 Ping Luo CIKM 08
Overview• Introduction
• Preliminaries
Consensus Regularization
• Experimental Evaluation
• Related Works
• Conclusions

23/4/19 Ping Luo CIKM 08
Problem Formulation (1)
• Given: Let be m source-domains of labeled data,
and the l-th source-domain is represented by
The unlabeled target-domain is denoted by
Assume that are of different but closely related distributions
• Find: Train m classifiers
covers the knowledge from the i-th source domain achieve high degree of consensus on their
prediction results on the target domain
1{( , )} |ll l l n
s i i iyD x
1, , ms sD D
1{( )} |nt i iD x1, , ,ms s tD D D
1, , mh h
ih

23/4/19 Ping Luo CIKM 08
Problem Formulation (2)• Formulation:
Adapt supervised learning framework with consensus regularization
Output m models , which maximize:
( , , | )l mtConsensus h h D
1, , mh h
( | )l lsP h D
1Maximum Consensus
Maximum A Posteriori
( | ) ( , , | )m
l l l ms t
l
P h D Consensus h h D
lhlsD
where is the probability of the hypotheses given the
observed data set .
is the consensus degree of the prediction results of these classifiers on the target domain

23/4/19 Ping Luo CIKM 08
Why Consensus Regularization (1)
In this study we focus on binary classification problems with the labels 1 and -1, and the number of classifiers m = 3.
•
( | ) 1/ 2 or ( | ) 1/ 2P h u Y u P h u Y u The non-trivial classifier can be restated as:
•

23/4/19 Ping Luo CIKM 08
Why Consensus Regularization (2)
•
Thus, minimizing the disagreement means to decrease the classification error.

23/4/19 Ping Luo CIKM 08
Consensus Regularization by Logistic Regression (1)• The proposed consensus regularization framework
outputs m logistic models , which minimize:1, , mw w
For binary classification problem, the entropy based consensus measure Ce can be equivalent with Cs. Thus, the objective function can be rewritten as

23/4/19 Ping Luo CIKM 08
• The partial differential of objective is,sg
where
A function of a local classifier and the data from the corresponding source domain. Thus, this function can be computed locally on each source domain.
A function of all the local classifiers and the data from the target domain. Thus, this function can be computed on the target domain with all the classifiers.
Consensus Regularization by Logistic Regression (2)

23/4/19 Ping Luo CIKM 08
Distributed Implementation of Consensus Regularization (1)
In the distributed setting, the data notes contain source-domain data are used as slave nodes, denoted by , and the node contains target-domain is used as master node, called .
1, , msn snmn
mn
sn1 snm
1 1( , )snw
1 ( )sgw
( , )m msnw
( )m sgw

23/4/19 Ping Luo CIKM 08
Overview• Introduction
• Preliminaries
• Consensus Regularization
Experimental Evaluation
• Related Works
• Conclusions

23/4/19 Ping Luo CIKM 08
Experimental Preparation (1)• Data Preparation
– Three source domains (A1, B1) (A2, B2) (A3, B3), one target domain (A4, B4)
– 96 ( ) problem instances can be constructed for the experimental evaluation
• Baseline Algorithms– Distributed approach: Distributed Ensemble (DE),
Distributed Consensus Regularization (CCR3)– Centralized approach: Centralized Training (CT),
Centralized Consensus Regularization (CCR) (eg. CCR1 means m = 1), CoCC [Dai et al., KDD’07], TSVM [Joachims, ICML’99], SGT [Joachims, ICML’03]
444 P
A1
sci.crypt
A2
sic.electronics
A3
sci.med
A4
sci.space
B1
talk.guns
B2
talk.mideast
B3
talk.misc
B4
talk.religion

23/4/19 Ping Luo CIKM 08
Experimental Parameters and Metrics• Note that, when parameterθ= 0, DE is
equivalent to DCR, and CT is equivalent to CCR1.
• Parameter setting– The range ofθis [0,0.25]– The parameters of CoCC, TSVM, SGT are the same
as [Dai ea al., KDD’07]• Experimental metrics
Accuracy Convergence

23/4/19 Ping Luo CIKM 08
Experimental Results (1)
max max3 1 and CCR CCR
• Comparison of CCR3, CCR1, DE and CT
• are the best performance whenθis sampled in [0, 0.25]
23/4/19 Ping Luo CIKM 08
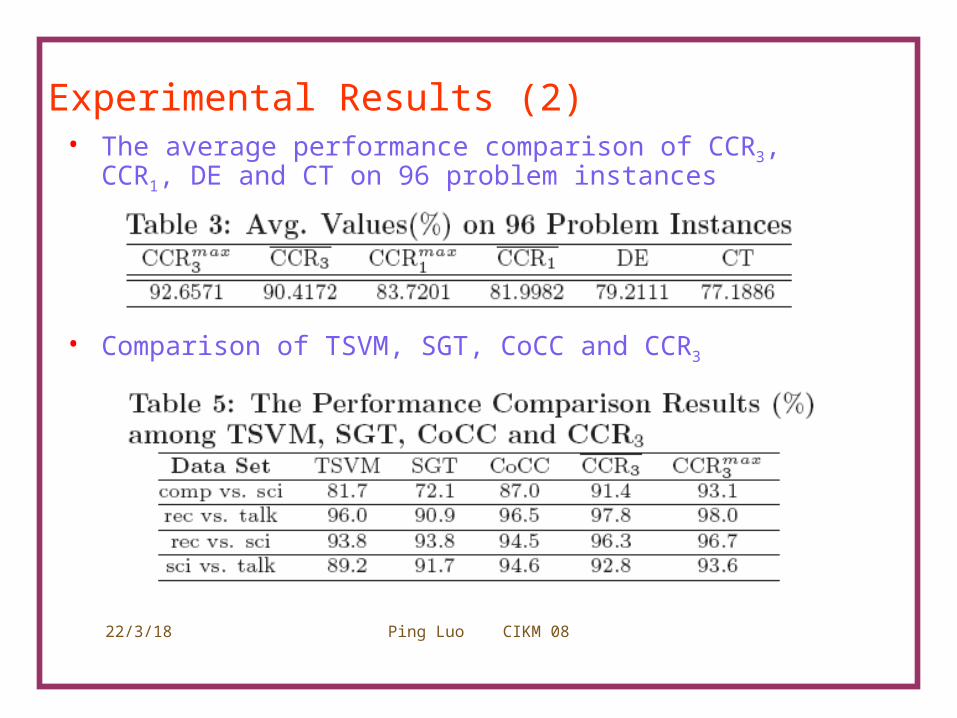
Experimental Results (2)• The average performance comparison of CCR3, CCR1,
DE and CT on 96 problem instances
• Comparison of TSVM, SGT, CoCC and CCR3

23/4/19 Ping Luo CIKM 08
Experimental Results on Algorithm Convergence
• The algorithm almost converges after 20 iterations, which indicates that our algorithm owns a good property of convergence.

23/4/19 Ping Luo CIKM 08
More experiments (1)
• Note that, the original source-domains have much large distribution mismatch, but after merging, the distribution mismatch is greatly alleviated.
Domain 1
Domain 2
Domain 3
Source Domain
Merge
SDomain 1
SDomain 2
SDomain 3
Random sampling without
replacement

23/4/19 Ping Luo CIKM 08
More experiments (2)
• The experiments on image classification are also very promising

23/4/19 Ping Luo CIKM 08
Overview• Introduction
• Preliminaries
• Consensus Regularization
• Experimental Evaluation
Related Works
• Conclusions

23/4/19 Ping Luo CIKM 08
Related Work (1)
• Transfer Learning
Solve the fundamental problem of different distributions between the training and testing data.
– Assume there are some labeled data from the target domain data
Estimation of mismatch degree by Liao et al.[ICML’05] Boosting based learning by Dai et al.[ICML’07] Building generative classifiers by Smith et al.[KDD’07] Constructing information priors from source-domain and
then encoding it to the model built by Raina et al.[ICML’06]
– The data in target-domain are totally unlabeled Co-clustering based Classification by Dai et al.[KDD’07] Transductive Bridged-Refinement by Xing et al.
[PKDD’07]

23/4/19 Ping Luo CIKM 08
Related Work (2)
• Self-Taught Learning Use a large amount of unlabeled data to improve
performance of given classification task– Apply sparse coding to construct higher-level features
using the unlabeled data by Raina et al.[ICML’07]• Semi-supervised Classification
– Entropy minimization by Grandvalet et al.[NIPS’05], which is a special case of our regularization framework when m = 1
• Multi-View Learning– Co-training by Blum et al.[COLT’98]– Boosting mixture models by Grandvalet et al.
[ICANN’01]– Co-regularization by Sindhwani et al.[ICML’05],
which focus on two views only and does not have the effect of entropy minimization

23/4/19 Ping Luo CIKM 08
Overview
• Introduction
• Preliminaries
• Consensus Regularization
• Experimental Evaluation
• Related Works
Conclusions

23/4/19 Ping Luo CIKM 08
Conclusions
Propose a consensus regularization framework for transfer learning by learning from multiple source-domains
Maximize the likelihood of each model on its corresponding source domain Maximize the consensus degree of all the trained models
Extend the algorithm to a distributed implementation Only some statistical values are shared between the source-domains and the target-domain, so it can modestly alleviate the privacy concerns
Experiments on real-world text data sets show the effectiveness of our consensus regularization approach

23/4/19 Ping Luo CIKM 08
Q. & A.
Acknowledgement


















