
Transactional Lee’s Algorithm 1 A Study of a Transactional Routing Algorithm Ian Watson, Chris...
21
Transactional Lee’s Algorithm 1 A Study of a Transactional Routing Algorithm Ian Watson, Chris Kirkham & Mikel Lujan School of Computer Science University of Manchester UK Supported by EPSRC Grant EP/E036368/1
-
Upload
sara-gilbert -
Category
Documents
-
view
220 -
download
0
Transcript of Transactional Lee’s Algorithm 1 A Study of a Transactional Routing Algorithm Ian Watson, Chris...

Transactional Lee’s Algorithm 1
A Study of a Transactional Routing Algorithm
Ian Watson, Chris Kirkham & Mikel Lujan
School of Computer Science
University of Manchester
UK
Supported by EPSRC Grant EP/E036368/1

Transactional Lee’s Algorithm 2
Aim of the Study
This paper is NOT about an implementation of a Transactional Memory system
It is about taking a ‘real’ application, expressing it in a transactional programming style and observing
– How easy it is to code
– What sort of performance can be achieved
– What transactional language facilities are needed to code it
The study was performed by running a real program but instrumenting it to gather data (read and write sets) to estimate the limits of performance on an idealized transactional system.

Transactional Lee’s Algorithm 3
Motivation
About 18 months ago, I became interested in TM as a programming model
Several of my colleagues were distinctly sceptical
I decided it was necessary to find a real application which
– Was useful, but easy to understand– Ought to have significant parallelism– Was difficult to parallelize using conventional techniques (locks etc.)– Was amenable to expression in a transactional style
So the initial motivation was to investigate the usefulness of TM but the study produced some interesting issues about the requirements of TM programming to achieve good performance.

Transactional Lee’s Algorithm 4
The Example
Lee’s Maze Routing Algorithm
Used for routing PCBs, FPGAs etc..
Guarantees to find minimum length connection between two points on a grid in the presence of arbitrary obstructions.
Real routing systems use complex sophisticated strategies and possibly multiple algorithms to achieve maximum connectivity
However, the essential principles can be understood and explored by a relatively simple implementation.
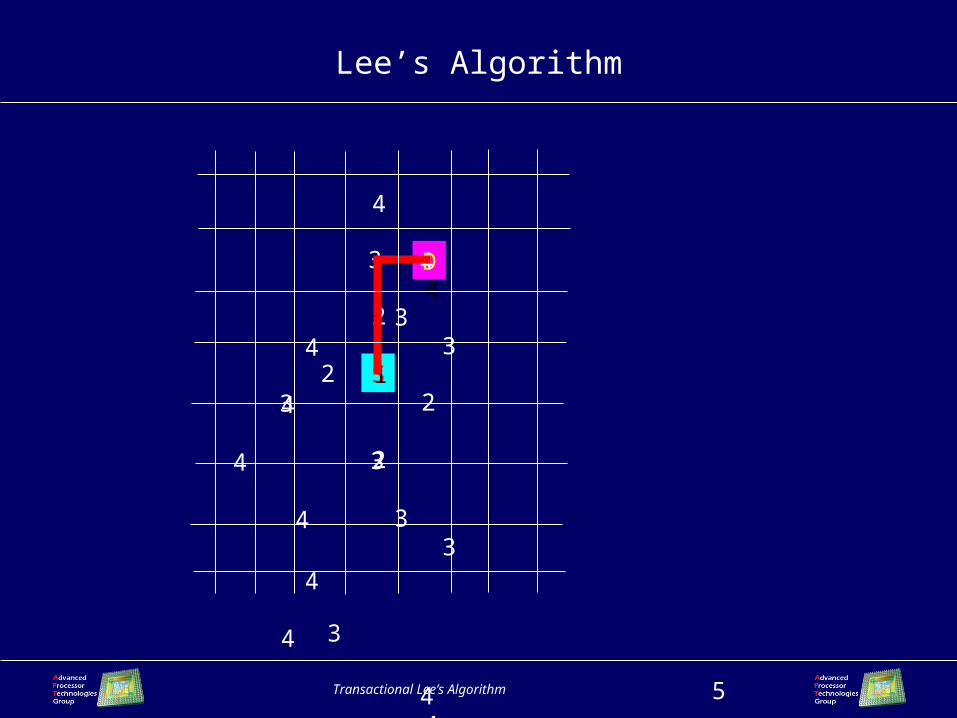
Transactional Lee’s Algorithm 5
D3
3 3
3 3
3 3
3
4
4 4
4 4
4 4
4 4
4 4
4
S
2
2 2
2
1
Lee’s Algorithm

Transactional Lee’s Algorithm 6
4 4
4
4 4
4 4
4 4
4
3
3 3
3 3
3
5
5 5
5 5
5
5
5
5
D
S2 2
2
1
Lee’s Algorithm – with Obstacle
6
6 6

Transactional Lee’s Algorithm 7
Parallelising Lee’s Algorithm
Uses grid to expand a ‘wavefront’
Wavefront expands around obstacles, other existing connections etc..
When wavefront reaches target a route is found by backtracking along any decreasing path of grid points.
Serial algorithm is fairly easy to write (simple version anyway)
Any real application has hundreds or thousands of interconnections. Should be highly parallel?
But connections are not independent.

Transactional Lee’s Algorithm 8
Parallelising Lee’s Algorithm (cont)
Possible routes for a connection may depend on any that have been previously decided.
OK if they are physically disjoint but ….
A backtracking connection may
Invalidate expansion of another
Unless routes are far apart, it is
Impossible to predict
How can we deal with this?

Transactional Lee’s Algorithm 9
A Locking Version?
Can we use locking?
Can allow parallel expansion but lock whole grid for each backtrack– If any expansion is touched by a backtrack it must be restarted– Parallelism will be reduced significantly
Lock individual grid points either for expansion or backtrack– Can prevent valid backtracks unnecessarily– Again will impact parallelism– May still require restarting
Other locking solutions? Are they.– Simple– Efficient (still parallel)– Correct?

Transactional Lee’s Algorithm 10
Serial Code
Core of the serial program is very simple
while more_connections {
Expand until target is hit;
Backtrack until source reached;
Reset grid points used in expansion;
}
This assumes a single global grid which is used for both the expansion and the backtracking.
This is the standard way of implementing the algorithm

Transactional Lee’s Algorithm 11
Transactional version
for all connections {Start transaction
Expand until target is hit;
Backtrack until source reached;
Reset grid points used in expansion;End transaction
}
A complete route will succeed and commit as long as no other route has changed the grid points it has used.
The parallelisation is almost trivial – but does it work?

Transactional Lee’s Algorithm 12
A serial Java based implementation of Lee’s Algorithm (available on the web) was produced to route a real PCB layout
Experimental Framework 1
Algorithm refined to do 2 layer routing and constrain to X&Y layers
Approx 1500 routes
Board taken from an original layout description
Is real, plenty of potential for inter route interference

Transactional Lee’s Algorithm 13
Experimental Framework 2
Serial program was instrumented to collect read & (committed) write sets for each route
Routes were sorted in length (common technique) and run serially
If the read set of a route appeared in the write set of a previous route, it was abandoned else it committed
When all routes had been attempted, unsuccessful routes were re-sorted and attempted in a further batched iteration
This was repeated until all routes had completed successfully.
Idealised transactional system – except for lockstep batches

Transactional Lee’s Algorithm 14
Results
For 1506 routes
Total Iterations 305
Successful commits in 1st iteration 70
Total transactions attempted 89534
Average parallelism (1506 / 305) 4.9
Excess work factor (89534/1506) 59.5
I.e. we do 60x more work to get a parallel speedup of 5
Not a very encouraging result

Transactional Lee’s Algorithm 15
Privatisation
But this was a very naïve translation into transactions
The structure used for the expansion is logically private to each route. Making them all share the global grid was stupid
for all connections {Take copy of grid;
Start transaction
Expand until target is hit; // using copy of grid
Backtrack until source reached;
End transaction
}

Transactional Lee’s Algorithm 16
Results
For 1506 routes
Total Iterations 227
Successful commits in 1st iteration 118
Total transactions attempted 53838
Average parallelism (1506 / 227) 6.6
Excess work factor (53838/1506) 35.7
I.e. we do 36x more work to get a parallel speedup of 6.6
Still not a very encouraging result!

Transactional Lee’s Algorithm 17
What is going wrong?
During the expansion we must look at each square in the global grid to see if it is blocked before expanding into it
S
DSo any route which commits within the wavefront will write a global value which is in the read set of the expansion and thus cause the expanding route to abort.
However, in many cases the aborted route would not have wanted to use those cells and could have committed its route quite happily.
The intersection of read and write sets is too crude – it depends on the properties of the algorithm.

Transactional Lee’s Algorithm 18
Insight into the Algorithm
The important insight is that a grid point, found blocked during expansion, is only relevant if the route will later use it during backtracking.
So, the only relevant members of the read set during expansion are those which will later be in the write set of the backtracking
In practice therefore, we can use the intersection of the write sets to determine whether to abort

Transactional Lee’s Algorithm 19
Results
For 1506 routes
Total Iterations 14 (was 305 or 227)
Successful commits in 1st iteration 697
Total transactions attempted 3774
Average parallelism (1506 / 14) 107.6
Excess work factor (3774/1506) 2.5 (was 59.5 or 39.7)
I.e. we do 2.5x more work to get a parallel speedup of 108
A dramatic improvement!

Transactional Lee’s Algorithm 20
Limited Batch Size – e.g. equivalent to 64 cores
For 1506 routes
Total Iterations 40
Successful commits in 1st iteration 64
Total transactions attempted 2270
Average parallelism (1506 / 40) 37.7
Excess work factor (2270/1506) 1.51
Note that the overall core usage is 2270/40 = 56.8 or 56.8/64 = 89%
So some wastage of resources for excess work and when the parallelism drops towards the end – but significant performance.

Transactional Lee’s Algorithm 21
Conclusions
TM appears to really work ! (for this example anyway)
But …– It wasn’t as simple as enclosing a serial program with ‘atomic’
– We needed to understand the algorithm to optimise
– We needed to prune the read set• Correctness !• Conflict model ?• How & when to prune ?• How to express in language ?
Does this result extend to other algorithms ?


















