RECOGNIZING FACIAL EXPRESSIONS THROUGH TRACKING Salih Burak Gokturk.
tracking and recognizing actions
13
Tracking and Recognizing Actions at a Distance Wei-Lwun Lu and James J. Little Department of Computer Science, University of British Columbia, Vancouver, BC V6T 1Z4, CANADA {vailen, little }@cs.ubc.ca Abstract. This paper presents a template-based algorithm to track and recognize athlete’s actions in an integrated system using only visual in- formation. Usually the two elements of tracking and action recognition are treated separately. In contrast, our algorithm emphasizes that track- ing and action recognition can be tightly coupled into a single framework, where tracking assists action recognition and vice versa. Moreover, this paper proposes to represent the athletes by the grids of Histograms of Oriented Gradient (HOG) descriptor. The using of the HOG descriptor not only improves the robustness of the tracker, but also centers the fig- ure in the tracking region. Therefore, no further stabilization techniques are needed. Empirical results on hockey and soccer sequences show the effectiveness of this algorithm. 1 Introduction Vision-based tracking and action recognition systems have gained more and more attention in the past few years because of their potential applications on smart surveillance systems, advanced human-computer in terfaces, and sport video anal- ysis. In the past decade, there has been intensive research and giant strides in designing algorithms for tracking humans and recognizing their actions [7]. In this paper, we develop a system that integrates visual tracking and action recognition, where tracking assists action recognition and vice versa. The first novelty of this paper is to represent the target by the HOG descriptor [5]. The HOG descriptor and its variants have been used in human detection [5] and object class recognition [15], and have been shown to be very distinctive and robust. This paper shows that the HOG descriptor can be also exploited in vi- sual tracking and action recognition as well. The second novelty of this paper is an algorithm that solves the tracking and action recognit ion problems together using learned templates. Given the examples of athletes’ appearances of differ- ent actions, we learn the templates and the transition between the templates offline. During the runtime, we use the templates and the transition matrix to classify the athlete’s actions and compute the most probable template sequence consistent with the visual observation. Moreover, the last template of the most probable sequence can be used for the visual tracking system to search for the next position and size of the athlete, which determines the next visual observa- tion of the athlete.
Transcript of tracking and recognizing actions

8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 1/12
Tracking and Recognizing Actions at a Distance
Wei-Lwun Lu and James J. Little
Department of Computer Science,University of British Columbia,
Vancouver, BC V6T 1Z4, CANADA{vailen, little}@cs.ubc.ca
Abstract. This paper presents a template-based algorithm to track andrecognize athlete’s actions in an integrated system using only visual in-formation. Usually the two elements of tracking and action recognitionare treated separately. In contrast, our algorithm emphasizes that track-ing and action recognition can be tightly coupled into a single framework,
where tracking assists action recognition and vice versa. Moreover, thispaper proposes to represent the athletes by the grids of Histograms of Oriented Gradient (HOG) descriptor. The using of the HOG descriptornot only improves the robustness of the tracker, but also centers the fig-ure in the tracking region. Therefore, no further stabilization techniquesare needed. Empirical results on hockey and soccer sequences show theeffectiveness of this algorithm.
1 Introduction
Vision-based tracking and action recognition systems have gained more and moreattention in the past few years because of their potential applications on smartsurveillance systems, advanced human-computer interfaces, and sport video anal-
ysis. In the past decade, there has been intensive research and giant strides indesigning algorithms for tracking humans and recognizing their actions [7].
In this paper, we develop a system that integrates visual tracking and actionrecognition, where tracking assists action recognition and vice versa. The firstnovelty of this paper is to represent the target by the HOG descriptor [5]. TheHOG descriptor and its variants have been used in human detection [5] andobject class recognition [15], and have been shown to be very distinctive androbust. This paper shows that the HOG descriptor can be also exploited in vi-sual tracking and action recognition as well. The second novelty of this paper isan algorithm that solves the tracking and action recognition problems togetherusing learned templates. Given the examples of athletes’ appearances of differ-ent actions, we learn the templates and the transition between the templatesoffline. During the runtime, we use the templates and the transition matrix to
classify the athlete’s actions and compute the most probable template sequenceconsistent with the visual observation. Moreover, the last template of the mostprobable sequence can be used for the visual tracking system to search for thenext position and size of the athlete, which determines the next visual observa-tion of the athlete.

8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 2/12
2
This paper is organized as follows: In Section 2, we review some related workin visual tracking and action recognition. In Section 3, we introduce the HOGdescriptor representation. Section 4 details our tracking and action recognitionalgorithms. The experimental results in hockey and soccer sequences are shownin Section 5. Section 6 concludes this paper.
2 Previous Work
The task of vision-based action recognition can be described as follows: givena sequence of consecutive images containing a single person, our task is to de-termine the action of the person. Therefore, the vision-based action recognitionproblem is indeed a classification problem of which the input is a set of images,and the output is a finite set of labels.
The input of a vision-based action recognition system is usually a set of
stabilized images: figure-centric images containing the whole body of a singleperson (including the limbs). Fig. 3 provides some examples of the stabilizedimages. In order to obtain the stabilized images, vision-based action recognitionsystems usually run visual tracking and stabilization algorithms prior to theaction recognition [6][22]. Then, the systems will extract relevant features suchas pixel intensities, edges, optical flow from the images. These features are fedinto a classification algorithm to determine the action of the person. For example,Yamato et al. [24] transform a sequence of stabilized images to mesh features,and use a Hidden Markov Model classifier to recognize the actions. Efros et al. [6]transform the images to novel motion descriptors computed by decomposing theoptical flow of images into four channels. Then, a nearest-neighbor algorithm isperformed to determine the person’s actions. In order to tackle the stabilizationproblem, Wu [22] develops an algorithm to automatically extract figure-centric
stabilized images from the tracking system. He also proposes to use DecomposedImage Gradients (DIG), which can be computed by decomposing the imagegradients into four channels, to classify the person’s actions.
The task of visual tracking can be defined as follows: given the initial state(usually the position and size) of a person in the first frame of a video sequence,the tracking systems will continuously update the person’s state given the succes-sive frames. During the tracking algorithm, relevant features should be extractedfrom the images. Some systems use intensities or color information [2][20], someuse shape information [8][10], and some use both [1][23]. The tracking problemcan be solved either deterministically [2][4][11] or probabilistically [1][10][23]. Inorder to improve the performance and robustness of the tracker, many systemsalso combine the tracking system with other systems such as object detection[1][19] and object recognition [12].
In order to simplify the tracking problem, many trackers use a fixed targetappearance [4][19][20]. However, having a fixed target appearance is optimisticin the real world because the view point and the illumination conditions maychange, and the person constantly changes his poses. In order to tackle thisproblem, [9][13] project the images of the person to a linear subspace and in-

8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 3/12
3
crementally update the subspace based on the new images. These systems areefficient; however, they have difficulties recovering from drift because the linearsubspace also accumulates the information obtained from the images contain-ing only the background. Jepson et al. [11] propose the WSL tracker of whichthe appearance model is dominated by either the stable (S), wandering (W), orlost (L) components. They use an online EM algorithm to update the parame-ters of the stable component, and therefore the tracker is robust under smoothappearance changes.
The tracking systems that most resemble ours are Giebel et al. [8] and Leeet al. [12]. Giebel et al. [8] learn the templates of the targets and the transitionmatrix between the templates from examples. However, they do not divide thetemplates into different actions. During tracking, they use particle filtering [20]to infer both the next template, and the position and size of the target. Lee et
al. [12] introduce a system that combines face tracking and recognition. Theyalso learn templates of faces and the transition matrix between the templates
from examples, and partition the templates into different groups according tothe identity of the face. During the runtime, they first recognize the identity of the face based on the history of the tracking results. Knowing the identity of theface, the target template used by the tracker can be more accurately estimated,and thus improve the robustness of the tracker.
3 The HOG Descriptor Representation
In this paper we propose to use the grids of Histograms of Oriented Gradient(HOG) descriptor [5] to represent the athletes. The HOG representation is in-spired by the SIFT descriptor proposed by Lowe [14], and it can be computedby first dividing the tracking regions into non-overlapping grids, and then com-
puting the orientation histograms of the image gradient of each grid (Fig. 1).The HOG descriptor is originally designed for human detection [5]. In this
paper, we will show that the HOG/SIFT representation can be also used inobject tracking and action recognition as well. Using the HOG/SIFT represen-tation has several advantages. Firstly, since the HOG/SIFT representation isbased on edge , the rectangular tracking region can contain the entire body of the athlete (including the limbs) without sacrificing the discrimination betweenthe foreground and background. This is especially the case in tracking athletesin sports such as hockey and soccer because the background is usually homo-geneous. Another attractive property of the HOG/SIFT representation is thatit is insensitive to the changes of athlete’s uniform. This enables the tracker tofocus on the shape of the athletes but not the colors or textures of the uni-form. Secondly, the HOG/SIFT representation improves the robustness of the
tracker because it is robust to small misalignments and illumination changes[5][16]. Thirdly, the HOG/SIFT representation implicitly centers the figure inthe tracking region because it preserves some spatial arrangement by dividingthe tracking region into non-overlapping grids. In other words, no further sta-bilization techniques [22] need to be used to center the figure in the tracking

8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 4/12
4
region. This helps integrate tracking and action recognition into a single frame-work. Fig. 1 gives an example of the grids of HOG descriptor with a 2 × 2 gridand 8 orientation bins.
(a) (b)
Fig. 1. Examples of the HOG descriptor: (a) The image gradient. (b) The HOGdescriptor with a 2 × 2 grid and 8 orientation bins.
4 Tracking and Action Recognition
The probabilistic graphical model of our system (Fig. 2) is a hybrid HiddenMarkov Model with two first-order Markov processes. The first Markov process,{E t; t ∈ N}, contains discrete random variable E t denoting the template at timet. The second Markov process, {X t; t ∈ N}, contains continuous random variable
X t denoting the position, velocity, and size of a single athlete at time t. Therandom variable {I t; t ∈ N} denote the frame of the video at time t, and theparameter αt denote the action of the athlete at time t. The joint distributionof the entire system is given by:
p(X ,E , I |α) = p(X 0) p(E 0)t
p(I t|X t, E t, αt)·
t
p(E t|E t−1, αt)t
p(X t|X t−1)(1)
The transition distribution p(E t|E t−1, αt) is defined as:
p(E t = j | E t−1 = i, αt = a) = Aaij (2)
where Aaij is the transition distribution between templates i and j of action a.
The continuous random variable X t is defined as X t = {xt, yt, vxt , vyt , wt}T ,
where (xt, yt) denotes the center of the athlete, wt denotes the width of the rect-angular tracking region (we currently fix the aspect ratio of the tracking region),

8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 5/12

8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 6/12
6
Since computing the exact posterior distribution of Eq. (4) is intractable, we useparticle filtering [10][19][20] to approximate Eq. (4). Assume that we have a set
of N particles {X
(i)
t }i=1...N . In each time step, we sample candidate particlesfrom an proposal distribution:
X (i)
t ∼ q (X t | X 0:t−1, I 1:t, E 0:t, α1:t) (5)
and weight these particles according to the following importance ratio
ω(i)t = ω
(i)t−1
p(I t|X (i)
t , E t, αt) p( X (i)
t |X (i)t−1)
q ( X (i)
t |X (i)0:t−1, I 1:t, E 0:t, α1:t)
(6)
In this paper, we set the proposal distribution by:
q (X t | X 0:t−1, I 1:t, E 0:t, α1:t) = p(X t|X t−1) (7)
and thus Eq. 6 becomes ω(i)t = ω
(i)t−1 p(I t|X
(i)
t , E t, αt). We re-sample the par-
ticles using their importance weights to generate an unweighted approximation p(X t|I 1:t, E 0:t, α1:t).
The problem of Eq. (6) is that E t and αt are unknown. Assuming that theappearance of the athletes changes smoothly, we approximate the current tem-plate and action by the previous ones, i.e., E t = E t−1, αt = αt−1. Following[4][20][19], we define the sensor distribution p(I t|X t, E t, αt) as:
p(I t|X t, E t = i, αt = a) ∝ exp(−λ ξ 2(H t,Π ai )) (8)
where H t is the HOG descriptor of the image I t given the state X t, Π ai isthe HOG descriptor of the template i of the action a, and λ is a constant. Thesimilarity measure ξ 2(·, ·) is the Bhattacharyya similarity coefficient [4][20][19]defined as:
ξ (H ,Π ) =
1 −
N kk=1
hkπk
1/2(9)
where H = {h1 . . .hN k}, Π = {π1 . . .πN k}, and N k denotes the dimensionalityof the HOG descriptor.
4.2 Action Recognition
Knowing the position and size of the athlete, the current HOG descriptor H t of the tracking region can be computed. Assuming that the previous T observationsare generated by the same action, we use a Hidden Markov Model classifier [21][24] to determine the athlete’s current action based on the previous T observa-tions. Let s = t−T + 1 denote the time of first observation we use to classify theathlete’s action, the likelihood of the previous T observations can be defined as:
p(H s:t|αt) =E t
p(H s:t, E t|αt) (10)
p(H s:t, E t|αt) = p(H t|E t, αt)E t−1
p(H s:(t−1), E t−1|αt) p(E t|E t−1, αt) (11)

8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 7/12
7
The sensor distribution p(H t|E t, αt) is defined as a Gaussian distribution:
p(H t | E t = i, αt = a) = N (H t | Π ai , Σ ai ) (12)
where Π ai and Σ ai are the mean and covariance of the HOG descriptor of thetemplate i in action a.
The optimal action of the athlete at time t can be computed by
α∗t = argmaxαt
p(H s:t | αt) (13)
Note that Eq. (10), (11), and (13) can be efficiently computed using the forward-backward algorithm [21]. The parameters of the Hidden Markov Model, i.e. Aa
ij ,Π
ai , Σ
ai , and the initial distribution, can be learned using the Baum-Welch (EM)
algorithm [21].
4.3 Template Updating
Knowing the current action α∗t , we compute the most probable template sequencefrom time s to t given the observations represented by the HOG descriptors:
E ∗s:t = argmaxE s:t
p(E s:t | H s:t, α∗t ) (14)
We can use the Viterbi algorithm [21] to compute the most probable templatesequence E ∗s:t.
To update the current template E t, we simply set E t = E ∗t . In other words,we use the last template of the most probable sequence as the template of timet.
5 Experimental Results
We tested our algorithm in soccer sequences [6] and hockey sequences [19]. Forboth sequences, we first manually crop a set of stabilized images and partitionthem into different groups according to the action of the player. These imageswill be used to learn the parameters of the Hidden Markov Model of each action.Fig. 3 shows some of the training images of both the hockey and soccer sequences.
Fig. 3. Examples of the training images.

8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 8/12
8
For the hockey sequences, we partition the training images into 6 actions:skating left, skate right, skate in, skate out, skate left 45, and skate right 45.Note that the action of the player can not be determined by only the positionand velocity of the tracking region because the camera is not stationary; often theplayer of interest remains centered in the image by the tracking camera. Then,we transform the training images to the HOG descriptors. To compute the HOGdescriptors, we first convolve the images by a 5×5 low-pass Gaussian filter withσ = 5.0, and then divide the image into 5 × 5 grids. For each grid, we computethe 8 bins orientation histograms of the image gradient. Next, we perform theBaum-Welch algorithm to learn the parameters of the Hidden Markov Model of each actions, i.e., Aa
ij, Π aij, Σ aij, and the initial distribution. For each action,we assume that there are 10 possible templates, and we classify the action of player based on the previous 7 observations (T = 7). Tracking will start with amanually initialized tracking region and with 60 particles in our experiments.
We implement the entire system using Matlab. The processing time of thehockey sequence is about 2 seconds for each frame (320 × 240 gray image). Fig.4 and Fig. 5 show the experimental results of two hockey sequences. The upperpart of these images shows the entire frame while the lower part of the imagesshows the previous tracking regions used to determine the player’s action. In Fig.4, the player first moves inward, turns left, moves outward, and finally turn aright. Since the camera is following the tracked player, the velocity of the trackingregion is not consistent with the action of the player. However, our system canstill track the entire body of the player and recognize his action based on thevisual information. Fig. 5 gives an example when there is significant illuminationchanges (flashes) and partial occlusion. We can observe that our system is notinfluenced by the illumination changes because we rely on the shape information.Moreover, the system also works well under partial occlusion because it maintains
an accurate appearance model of the tracked player. However, when two playerscross over and one completely occludes the other, further techniques such as [3]are needed to solve the data association problem. In Fig. 4 frame 198, we canobserve that the action recognizer make a mistake when the player moves towardthe camera. This is because the contours of a person moving toward and awayfrom the camera are very difficult to distinguish (even by human beings).
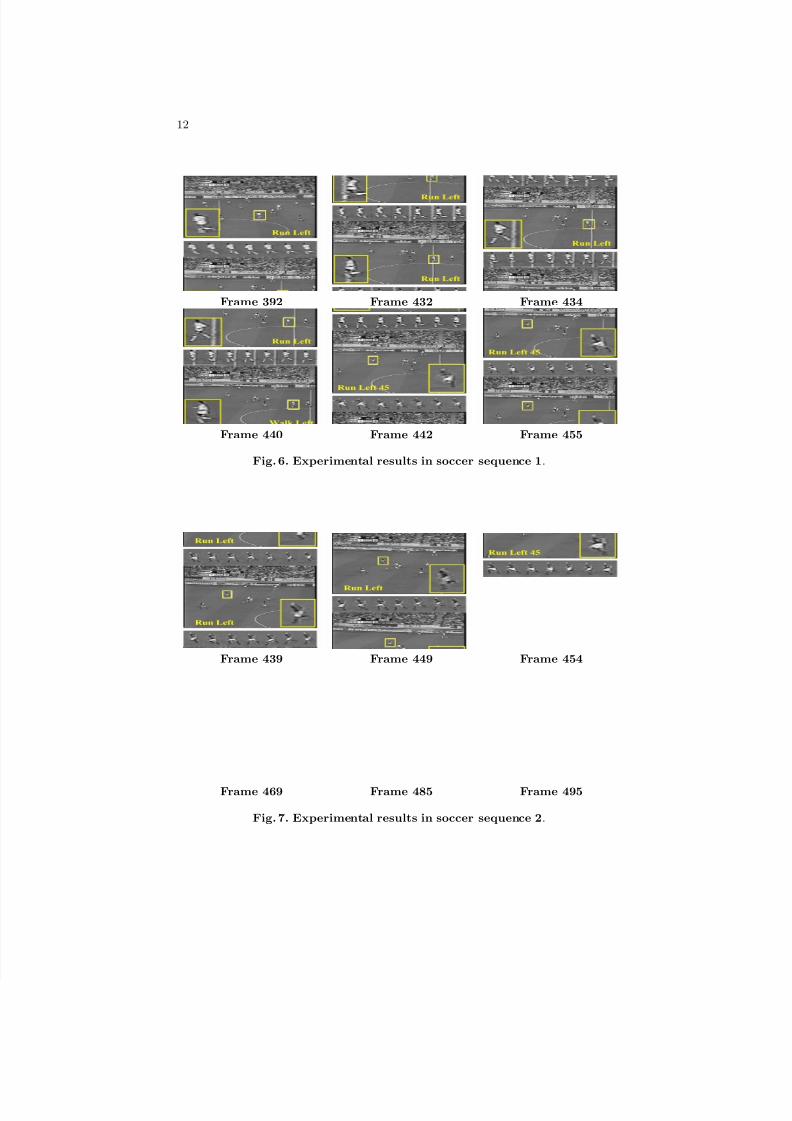
For the soccer sequences, we partition the training images into 8 actions: runin/out, run left, run right, run left 45, run right 45, walk in/out, walk right, andwalk left (the categories are the same as [6]). We use the same way to computethe HOG descriptors. We also assume that there are 10 possible templates, andclassify the player’s action based on the previous 7 observations (T = 7).
The processing time of the soccer sequence is about 3 seconds for each frame
(720× 480 gray image) due to the larger image size (we pre-compute the imagegradients of the entire image and quantize them into orientation bins). Fig. 6and Fig. 7 show the experimental results of two soccer sequences. Fig. 6 shows asoccer player running across a line on the field, and Fig. 7 shows a soccer playerof very low resolution. In both cases, our tracker and action recognizer work well.

8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 9/12
9
6 Conclusions and Future Works
This paper presents a system that tightly couples tracking and action recognitioninto an integrated system. In addition, the HOG descriptor representation notonly provides robust and distinctive input features, but also implicitly centersthe figure in the tracking region. Therefore, no further stabilization techniquesneed to be used. Experimental results in hockey and soccer sequences show thatthis system can track a single athlete and recognize his/her actions effectively.
6.1 Future Works
In the future, we plan to extend the current system to the following three di-rections. Firstly, the feature size of the HOG descriptor can be reduced us-ing dimensionality reduction techniques such as Principal Component Analysis(PCA). The advantages of reducing the feature size are two-folds: (1) it can pos-
sibly increase the processing speed without loss of accuracy. (2) the number of training examples can be reduced because of the small feature vector. Secondly,it is possible to use a more sophisticated graphical model such as a hybrid Hier-archical Hidden Markov Model [17] instead of the current one. For example, wecan treat the action as a random variable instead of a parameter. We can alsointroduce dependencies between the current action and the previous action, anddependencies between the action and the state of the tracker. Then, the actionof the player will not only determined by the appearance/pose of the player, butalso by the velocity and position of the player. Furthermore, after registeringthe player onto the hockey rink [18] or the soccer field, the action of the playercan help to predict the velocity and position of the player. Finally, the actioncan be used as an additional cue in multi-target tracking when players occludeeach other. Imagine that one player is moving left and another is moving right
and they cross over. Since we know the action and the appearance change of theplayers, we can possibly accurately predict the next appearance of the player.Thus, the probability that two tracking windows get stuck into a single playercan be reduced and the data association problem could be solved.
7 Acknowledgments
This work has been supported by grants from NSERC, the GEOIDE Networkof Centres of Excellence and Honeywell Video Systems.
References
1. S. Avidan. Ensemble tracking. In CVPR, 2005.2. M.J. Black and A.D. Jepson. EigenTracking: Robust Matching and Tracking of
Articulated Objects Using a View-Based Representation. IJCV , 26(1):63–84, 1998.3. Y. Cai, N. de Freitas, and J.J Little. Robust visual tracking for multiple targets.
In ECCV, to be appeared , 2006.

8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 10/12
10
4. D. Comaniciu, V. Ramesh, and P. Meer. Kernel-Based Object Tracking. PAMI ,25(5):564–575, 2003.
5. N. Dalal and B. Triggs. Histograms of Oriented Gradients for Human Detection.
In CVPR, 2005.6. A.A. Efros, C. Breg, G. Mori, and J. Malik. Recognizing Action at a Distance. In
ICCV , 2003.7. D.M. Gavrila. The Visual Analysis of Human Movement: A Survey. CVIU ,
73(1):82–98, 1999.8. J. Giebel, D.M. Gavrila, and C. Schnorr. A Bayesian Framework for Multi-cue 3D
Object Tracking. In ECCV , 2004.9. J. Ho, K.C. Lee, M.H. Yang, and D. Kriegman. Visual Tracking Using Learned
Linear Subspaces. In CVPR, 2004.10. M. Isard and A. Blake. CONDENSATION–Conditional Density Propagation for
Visual Tracking. IJCV , 29(1):5–28, 1998.11. A.D. Jepson, D.J. Fleet, and T.F. El-Maraghi. Robust online appearance models
for visual tracking. PAMI , 25(10):1296–1311, 2003.12. K.C. Lee, J. Ho, M.H. Yang, and D. Kriegman. Visual tracking and recognition
using probabilistic appearance manifolds. CVIU , 99:303–331, 2005.13. J. Lim, D. Ross, R.S. Lin, and M.H. Yang. Incremental Learning for Visual Track-
ing. In NIPS , 2004.14. D. Lowe. Distinctive Image Features from Scale-Invariant Keypoints. IJCV ,
60(2):91–110, 2004.15. K. Mikolajczyk, B. Leibe, and B. Schiele. Local features for object class recognition.
In ICCV , 2005.16. K. Mikolajczyk and C. Schmid. A Performance Evaluation of Local Descriptors.
PAMI , 27(10):1615–1630, 2005.17. K.P. Murphy. Dynamic Bayesian Networks: Representation, Inference and Learn-
ing . PhD thesis, University of California, Berkeley, 2002.18. K. Okuma, J.J. Little, and D.G. Lowe. Automatic rectification of long image
sequences. In Proc. Asian Conference on Computer Vision (ACCV’04) , 2004.19. K. Okuma, A. Taleghani, N. de Freitas, J.J. Little, and D.G. Lowe. A Boosted
Particle Filter: Multitarget Detection and Tracking. In ECCV , pages 28–39, 2004.20. P. Perez, C. Hue, J. Vermaak, and M. Gangnet. Color-Based Probabilistic Track-
ing. In ECCV , 2002.21. L.R. Rabiner. A Tutorial on Hidden Markov Models and Selected Applications in
Speech Recognition. Proc. of the IEEE , 77(2):257–286, 1989.22. X. Wu. Templated-based Action Recognition: Classifying Hockey Players’ Move-
ment. Master’s thesis, The University of British Columbia, 2005.23. Y. Wu and T.S. Huang. Robust visual tracking by integrating multiple cues based
on co-inference learning. IJCV , 58(1):55–71, 2004.24. J. Yamato, J. Ohya, and K. Ishii. Recognizing Human Action in Time-Sequential
Images using Hidden Markov Model. In CVPR, 1992.

8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 11/12
11
Frame 198 Frame 213 Frame 233
Frame 273 Frame 303 Frame 312
Fig. 4. Experimental results in hockey sequence 1.
Frame 1715 Frame 1735 Frame 1800
Frame 1804 Frame 1809 Frame 1819
Fig. 5. Experimental results in hockey sequence 2.
8/12/2019 tracking and recognizing actions
http://slidepdf.com/reader/full/tracking-and-recognizing-actions 12/12
12
Frame 392 Frame 432 Frame 434
Frame 440 Frame 442 Frame 455
Fig. 6. Experimental results in soccer sequence 1.
Frame 439 Frame 449 Frame 454
Frame 469 Frame 485 Frame 495
Fig. 7. Experimental results in soccer sequence 2.














