
Towards Unifying Stream Processing over Central and Near-the-edge Data Centers
85
Towards Unifying Stream Processing over Central and Near-the-Edge Data Centers Licentiate Seminar November 14, 2016, Kista, Sweden Hooman Peiro Sajjad [email protected]
-
Upload
hooman-peiro-sajjad -
Category
Presentations & Public Speaking
-
view
47 -
download
0
Transcript of Towards Unifying Stream Processing over Central and Near-the-edge Data Centers

Towards Unifying Stream Processing over Central and Near-the-Edge Data Centers
Licentiate SeminarNovember 14, 2016, Kista, Sweden
Hooman Peiro [email protected]

Outline
• Introduction and Research Objectives• Background• Contributions• Conclusions and Future Works
2

Introduction
3

Real-time Analytics
Examples: ● Server logs● User clicks● Social network
interactions
4
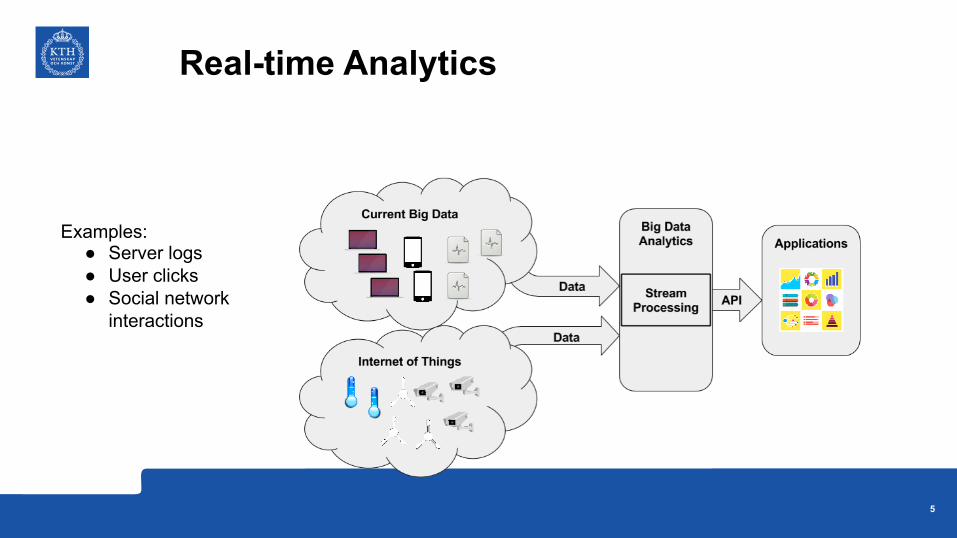
Real-time Analytics
Examples: ● Server logs● User clicks● Social network
interactions
5
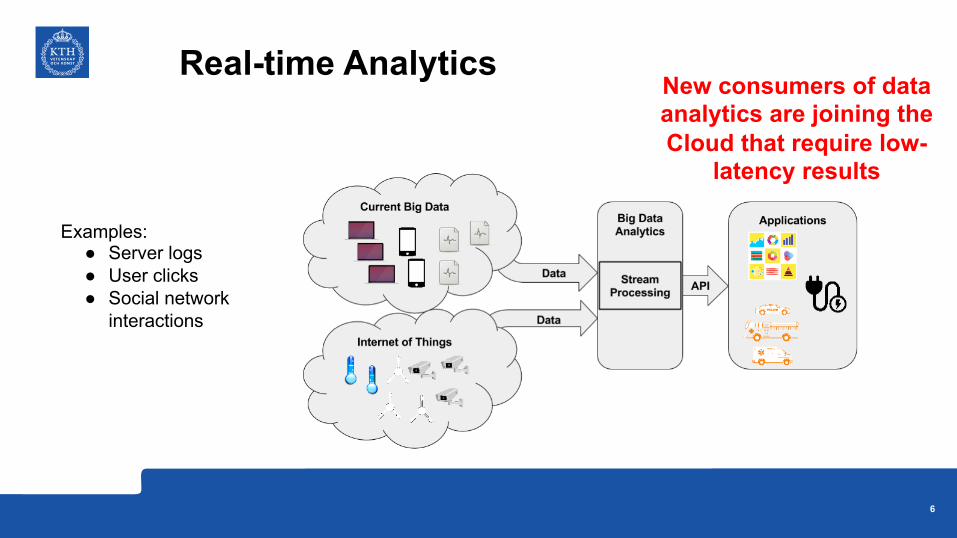
Examples: ● Server logs● User clicks● Social network
interactions
New consumers of data analytics are joining the Cloud that require low-
latency results
Real-time Analytics
6

Internet
Geo-Distributed Data
7
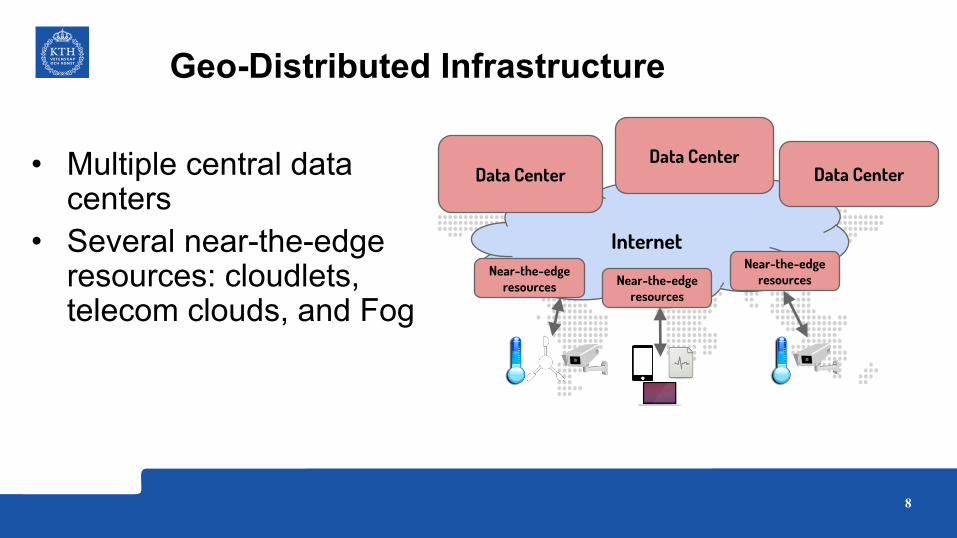
Geo-Distributed Infrastructure
• Multiple central data centers
• Several near-the-edge resources: cloudlets, telecom clouds, and Fog
Internet
Data CenterData Center
Data Center
Near-the-edge resources Near-the-edge
resources
Near-the-edge resources
8

Thesis Goal
To enable effective and efficient stream processing in geo-distributed settings Internet
Data CenterData Center
Data Center
Near-the-edge resources Near-the-edge
resources
Near-the-edge resources
9

Research Hypothesis
By placing stream processing applications closer to data sources and sinks, we can improve the response time and reduce the network overhead.
10

Research Objectives
1. Design decentralized methods for stream processing
2. Provide network-aware placement of distributed stream processing applications across geo-distributed infrastructures.
11

1. Decentralized MethodsIdentify limitations and
possible improvements in the existing systems and
algorithms
12

1. Decentralized MethodsIdentify limitations and
possible improvements in the existing systems and
algorithms
System
Apache Storm
13

1. Decentralized MethodsIdentify limitations and
possible improvements in the existing systems and
algorithms
System
Apache Storm
SpanEdge
14
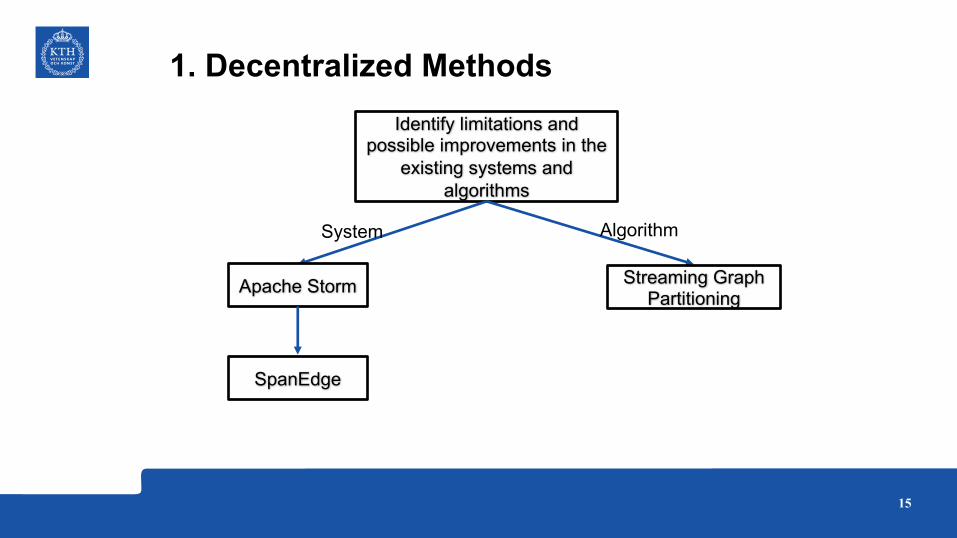
1. Decentralized MethodsIdentify limitations and
possible improvements in the existing systems and
algorithms
System Algorithm
Apache Storm Streaming Graph Partitioning
SpanEdge
15
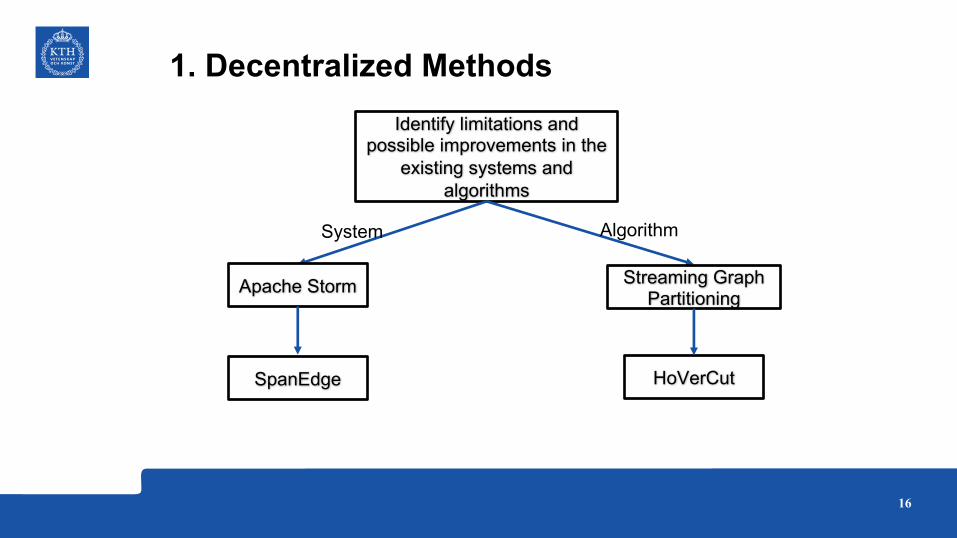
1. Decentralized MethodsIdentify limitations and
possible improvements in the existing systems and
algorithms
System Algorithm
Apache Storm Streaming Graph Partitioning
SpanEdge HoVerCut
16

2. Network-aware Placement
Utilize Network-awareness
17
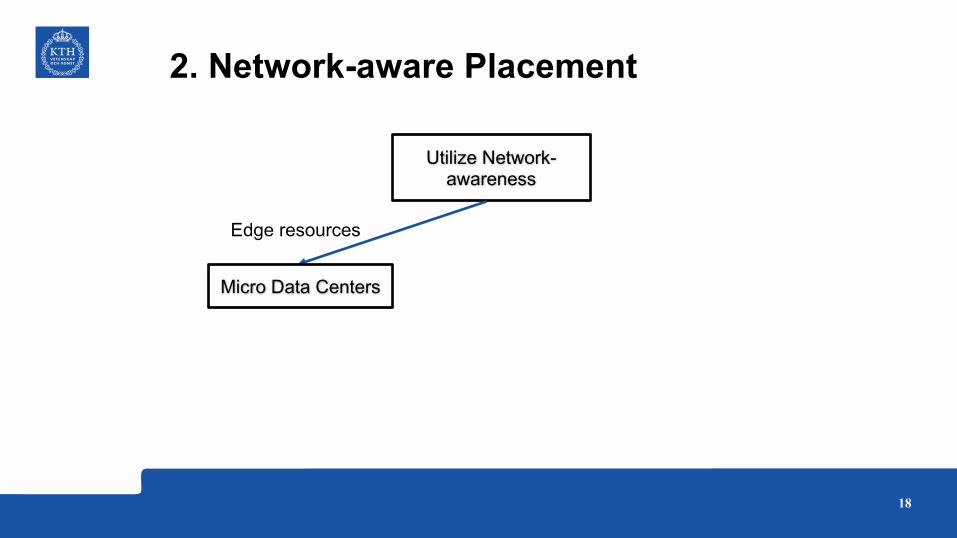
2. Network-aware Placement
Utilize Network-awareness
Edge resources
Micro Data Centers
18

2. Network-aware Placement
Utilize Network-awareness
Edge resources Central and micro data centers
Micro Data Centers SpanEdge
19

Thesis Contributions1. Stream Processing in Community Network Clouds
(FiCloud ’15)2. Smart Partitioning of Geo-Distributed Resources to
Improve Cloud Network Performance (CloudNet ‘15)3. Boosting Vertex-Cut Streaming Graph Partitioning
(BigData Congress ‘16), Best Paper Award4. SpanEdge: Towards Unifying Stream Processing
over Central and Near the Edge Data Centers (SEC ‘16)
20

Background
21

Stream Processing
• Processing data as they are being streamed.
22

Stream Processing
• Processing data as they are being streamed.• Continuous flow of data items, i.e., tuples• Examples:
• temperature values• motion detection data• traffic information
23
Stream Processing
• Processing data as they are being streamed.• Continuous flow of data items, i.e., tuples• Examples:
• temperature values• motion detection data• traffic information
• Stream processing application: a graph of operators (e.g., aggregations or filters)
24
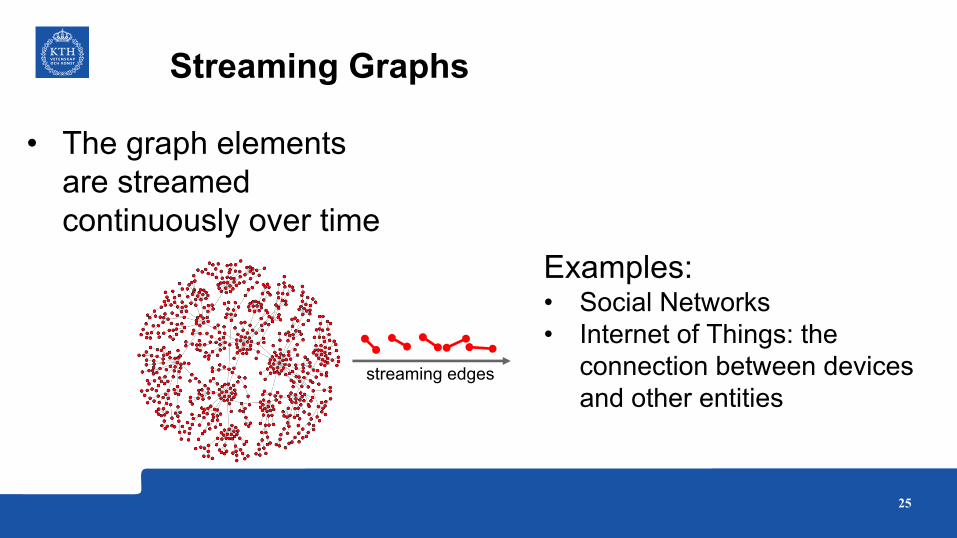
Streaming Graphs
streaming edges
Examples:• Social Networks• Internet of Things: the
connection between devices and other entities
• The graph elements are streamed continuously over time
25

• Partition large graphs for distributing them across disks, machines, or data centers
• Graph elements are assigned to partitions as they are being streamed
• No global knowledge
Partitioner
P1
P2
Pp
streaming edges
Streaming Graph Partitioning
26
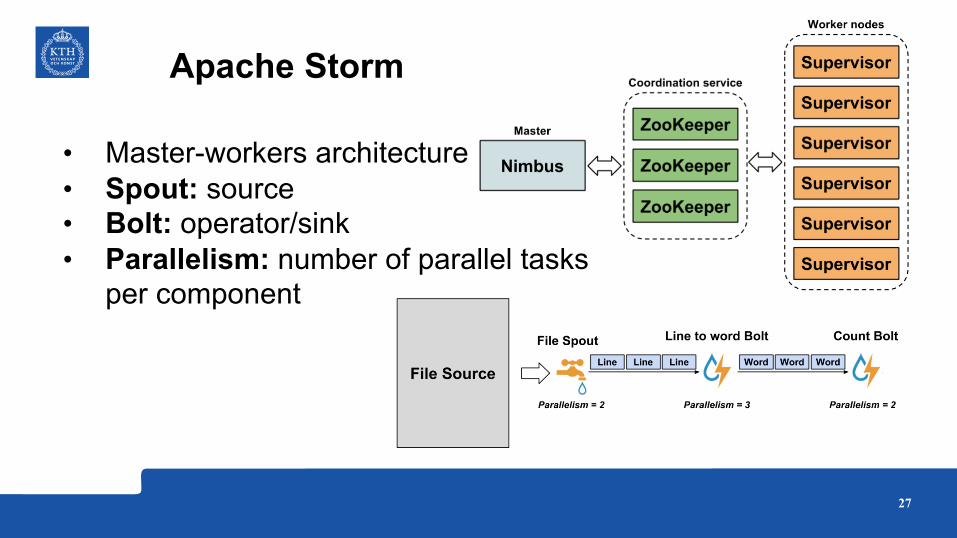
Apache Storm
• Master-workers architecture• Spout: source• Bolt: operator/sink• Parallelism: number of parallel tasks
per component
27

Contributions
28

Thesis Contributions1. Stream Processing in Community Network Clouds
(FiCloud ’15)2. Smart Partitioning of Geo-Distributed Resources to
Improve Cloud Network Performance (CloudNet ‘15)3. Boosting Vertex-Cut Streaming Graph Partitioning
(BigData Congress ‘16), Best Paper Award4. SpanEdge: Towards Unifying Stream Processing
over Central and Near the Edge Data Centers (SEC ‘16)
29

Contribution 1:
Stream Processing in Community Network Clouds
Ken Danniswara, Hooman Peiro Sajjad, Ahmad Al-Shishtawy, Vladimir Vlassov
3rd IEEE International Conference on Future Internet of Things and Cloud (FiCloud), 2015

Summary
• Objective: to find limitations of Storm for running in a geo-distributed environment
• We evaluate Apache Storm, a widely used open-source stream processing system
• We emulate a Community Network Cloud environment• The community network Cloud host applications on
the edge resources
31

Limitations of Storm
• Inefficient scheduling of stream processing applications across geo-distributed resources
• Network communication among Storm’s components:• Actual data streams
• Stream groupings: data transfer among tasks• Maintenance overhead (workers-manager):
• Scheduling time• Failure detection
32

Smart Partitioning of Geo-Distributed Resources to Improve Cloud Network Performance
Hooman Peiro Sajjad, Fatemeh Rahimian, Vladimir Vlassov
4th IEEE International Conference on Cloud Networking (CloudNet), 2015
Contribution 2:
33

Edge resources are connected through/co-located with the network devices, e.g., routers, base-stations, or the community network nodes.
Geo-Distributed Resources
34

Problem
• High variance in the network performance and the network cost:
• links heterogeneity• over-utilization of links• different number of hops between the
communicating nodes
• Their Network topology is not optimal for hosting distributed data-intensive applications
35

Problem Definition
Different placements of the application components on the resources affects the performance of the whole network.
36

Problem Definition
Different placements of the application components on the resources affects the performance of the whole network.
37

Network-aware grouping of geo-
distributed resources into a set
of computing clusters, each
called a micro data center.
Our Solution: Micro Data Centers
38
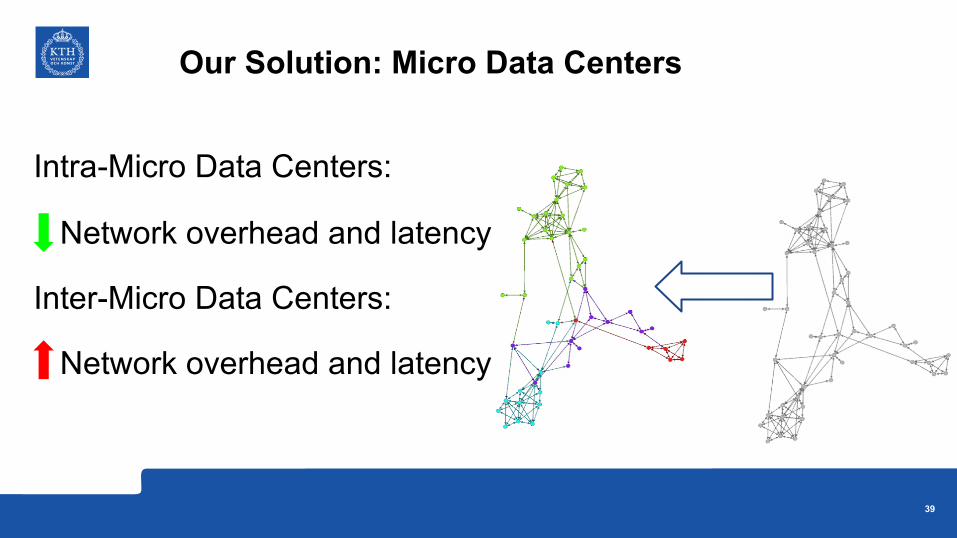
Intra-Micro Data Centers:
Network overhead and latency
Inter-Micro Data Centers:
Network overhead and latency
Our Solution: Micro Data Centers
39

• Based on Random Walk
• Decentralized
• No global knowledge of the topology
• High quality results
Diffusion Based Community Detection
40

● Geolocation based (KMeans)
● Modularity based community detection (Centralized)
● Diffusion based community detection(Decentralized)
● Real data set from community network: 52 nodes and
224 links
Evaluation: Clustering Methods
41
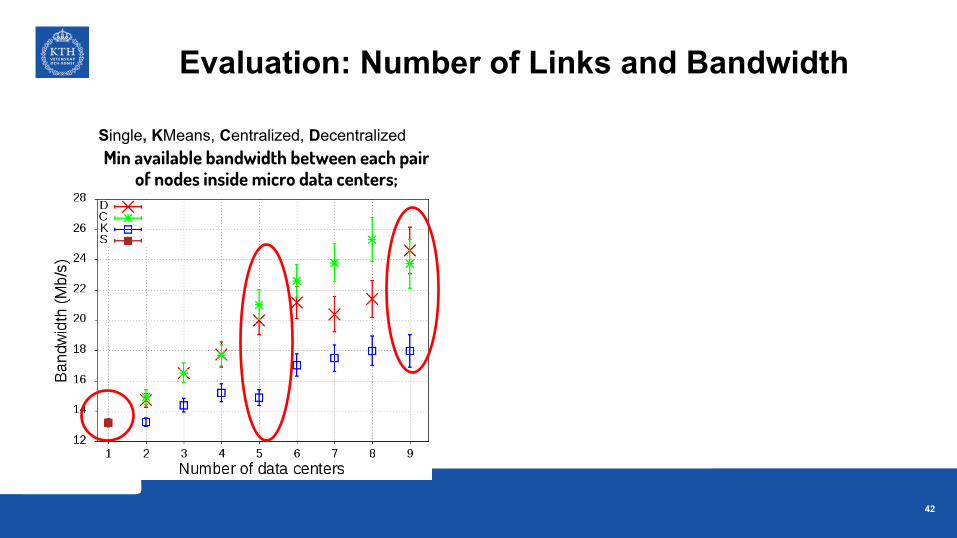
Single, KMeans, Centralized, Decentralized
Evaluation: Number of Links and Bandwidth
Min available bandwidth between each pair of nodes inside micro data centers;
42
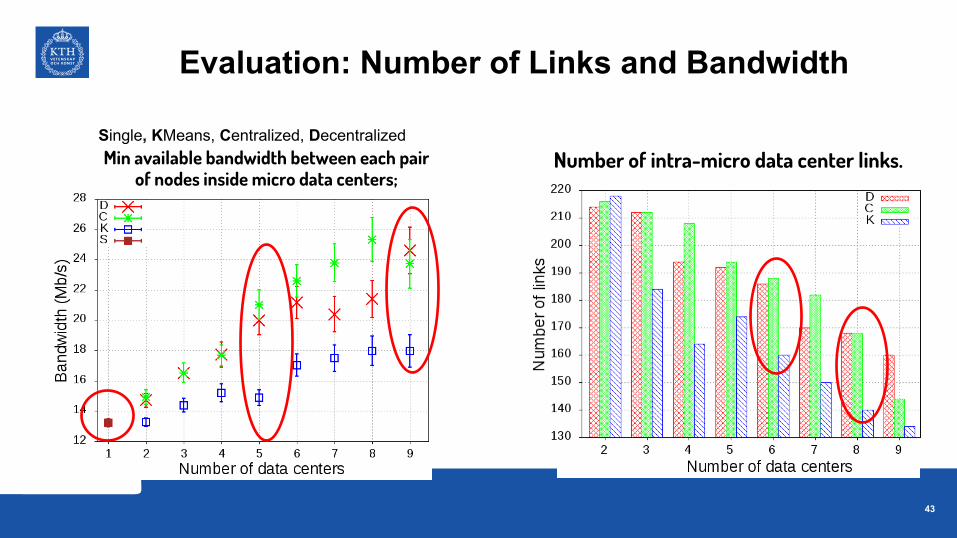
Number of intra-micro data center links.Single, KMeans, Centralized, Decentralized
Evaluation: Number of Links and Bandwidth
Min available bandwidth between each pair of nodes inside micro data centers;
43
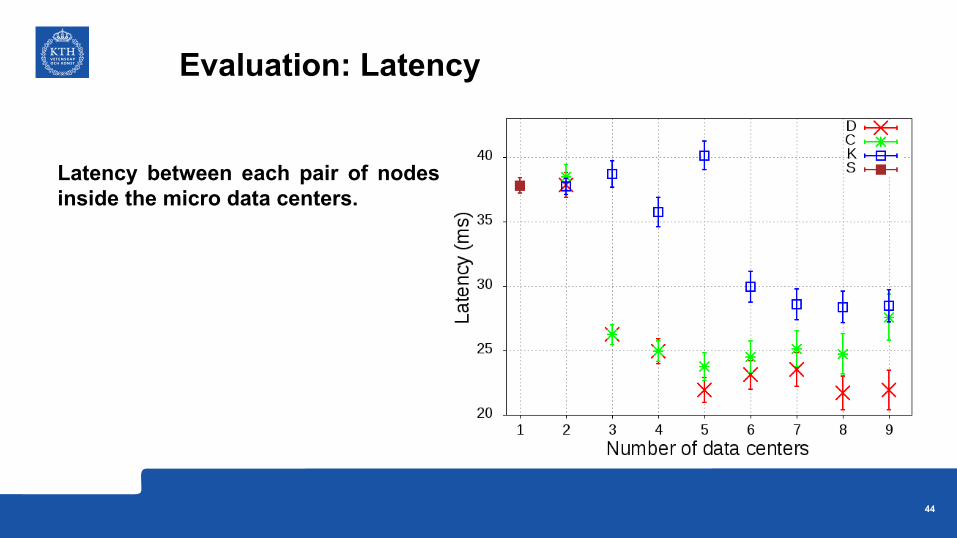
Latency between each pair of nodesinside the micro data centers.
Evaluation: Latency
44

• Placing distributed applications inside micro data centersreduces the network overhead and the network latency.
• Our proposed decentralized community detectionsolution finds clusters with qualities competitive to thecentralized community detection method.
Summary
45

Boosting Vertex-Cut Partitioning For Streaming Graphs
Hooman Peiro Sajjad, Amir H. Payberah, Fatemeh Rahimian, Vladimir Vlassov, and Seif Haridi
5th IEEE International Congress on Big Data (IEEE BigData Congress), 2016
Contribution 3:
46
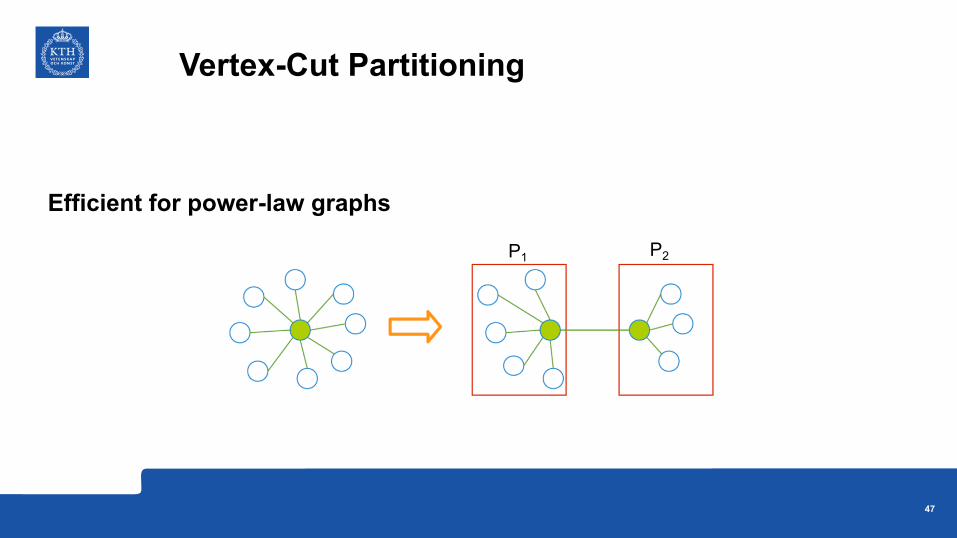
Vertex-Cut Partitioning
P1 P2
Efficient for power-law graphs
47

• Low replication factor: the average number of replicas for each vertex
• Balanced partitions with respect to the number of edges
A Good Vertex-Cut Partitioning
48

Slow partitioning timeLow replication factor
Centralized partitioner Distributed partitioner
Fast partitioning timeHigh replication factor
HoVerCut
Partitioning Time vs. Partition Quality
49

• Streaming Vertex-Cut partitioner• Parallel and Distributed• Multiple streaming data sources• Scales without degrading the quality of partitions• Employs different partitioning policies
HoVerCut ...
50
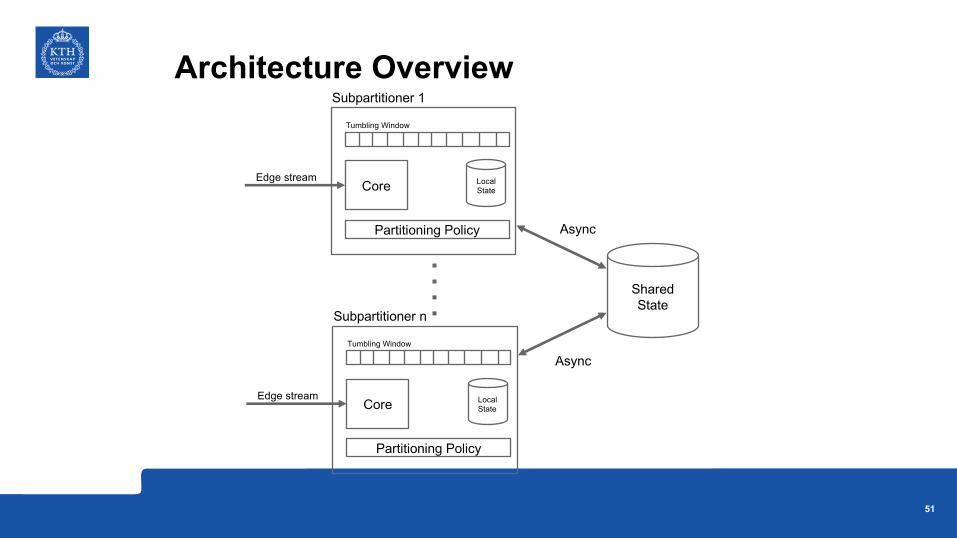
Core
Partitioning Policy
Tumbling Window
Local State
Subpartitioner 1
Edge stream
Core
Partitioning Policy
Tumbling Window
Local State
Subpartitioner n
Edge stream
Shared State
Async
Async
Architecture Overview
51

Core
Partitioning Policy
Tumbling Window
Local
State
Subpartitioner 1
Core
Partitioning Policy
Tumbling Window
Local State
Subpartitioner n
Edge stream
Async
Async
• Input graphs are streamed by their edges
• Each subpartitioner receives an exclusive subset of the edges
Shared State
Architecture: Input
52

Partitioning Policy
Local State
Subpartitioner 1
Edge stream
Core
Partitioning Policy
Tumbling Window
Local State
Subpartitioner n
Edge stream
Async
Async
Subpartitioners collect a number of incoming edges in a window of a certain size
Tumbling Window
Core
Shared State
Architecture: Configurable Window
53

Local State
Subpartitioner 1
Edge stream
Core
Partitioning Policy
Tumbling Window
Local State
Subpartitioner n
Edge stream
Async
Async
Each subpartitioner assigns the edges to the partitions based on a given policy
Partitioning Policy
Tumbling Window
Shared State
Core
Architecture: Partitioning Policy
54

Each subpartitioner has a local state, which includes information about the edges processed locally
Partitioning Policy
Subpartitioner 1
Edge stream
Core
Partitioning Policy
Tumbling Window
Local State
Subpartitioner n
Edge stream
Async
Async
Local State
Tumbling Window
Shared State
Core
Architecture: Local State
55

Shared-state is the global state accessible by all subpartitioners Partitioning Policy
Subpartitioner 1
Edge stream
Core
Partitioning Policy
Tumbling Window
Local State
Subpartitioner n
Edge stream
Async
Async
Local State
Tumbling Window
Shared State
Core
Architecture: Local State
56
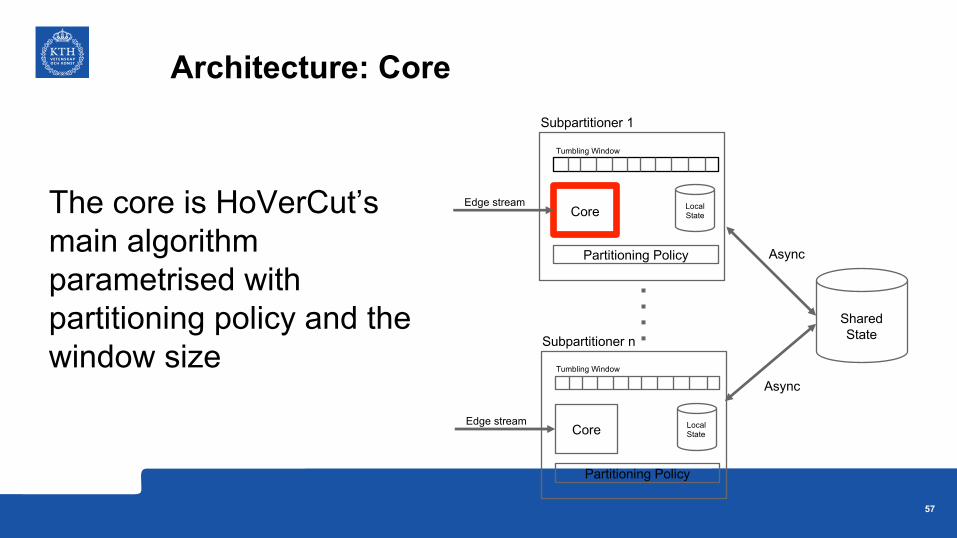
Partitioning Policy
Local State
Subpartitioner 1
Edge stream
Core
Partitioning Policy
Tumbling Window
Local State
Subpartitioner n
Edge stream
Async
Async
The core is HoVerCut’s main algorithm parametrised with partitioning policy and the window size
Core
Shared State
Tumbling Window
Architecture: Core
57
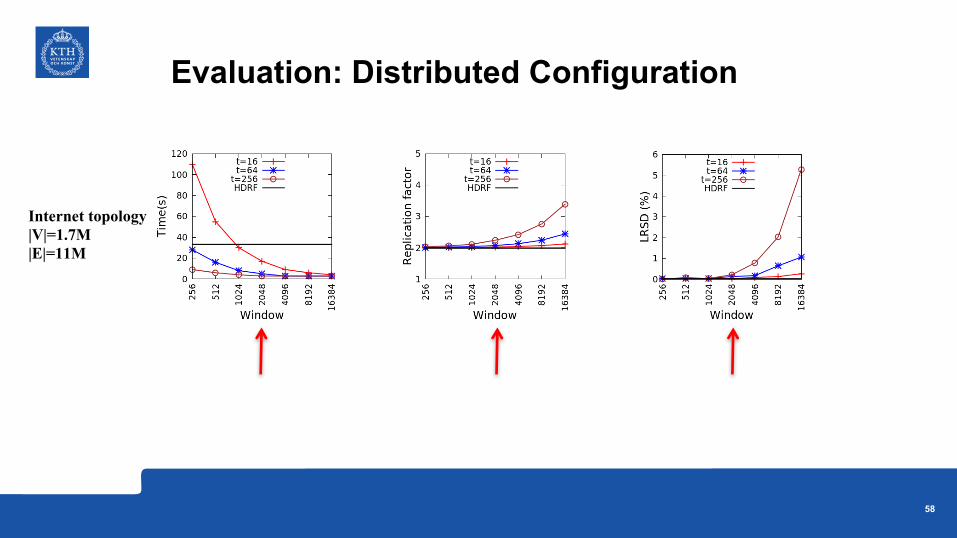
Evaluation: Distributed Configuration
Internet topology|V|=1.7M|E|=11M
58

Evaluation: Distributed ConfigurationInternet topology|V|=1.7M|E|=11M
Orkut Social Network|V|=3.1M|E|=117M
59

• HoVerCut is a parallel and distributed partitioner
• We can employ different partitioning policies in a scalable fashion
• We can scale HoVerCut to partition larger graphs without degrading the quality of partitions
• https://github.com/shps/HoVerCut
Conclusion
60

SpanEdge: Towards Unifying Stream Processing over Central and Near-the-
Edge Data CentersHooman Peiro Sajjad, Ken Danniswara, Ahmad Al-Shishtawy, and Vladimir Vlassov
The First IEEE/ACM Symposium on Edge Computing (SEC), 2016
Contribution 4:
61

How to enable and achieve an effective and efficient stream processing given the following:• Multiple central and near-the-edge DCs• Multiple data sources and sinks• Multiple stream processing applications
Problem Definition
Internet
Data CenterData Center Data Center
Micro Data Center Micro Data
Center
Micro Data Center
62

How to enable and achieve an effective and efficient stream processing given the following:• Multiple central and near-the-edge DCs• Multiple data sources and sinks• Multiple stream processing applications
Problem Definition
Internet
Data CenterData Center Data Center
Micro Data Center Micro Data
Center
Micro Data Center
And:• Data is streamed from sources to their closest near-the-edge DC• DCs are connected with heterogeneous network
63
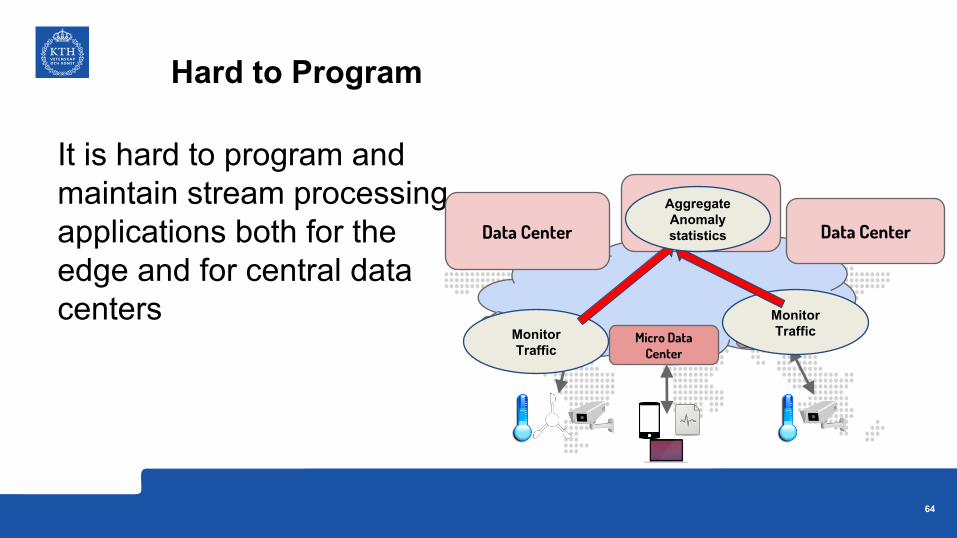
It is hard to program and maintain stream processing applications both for the edge and for central data centers
Data CenterData Center
Data Center
Micro Data Center
Micro Data CenterMonitor
Traffic
Monitor Traffic
Aggregate Anomaly statistics
Hard to Program
64

A multi-data center stream processing solution that provides:• an expressive programming model to unify programming on a geo-
distributed infrastructure.• a run-time system to manage (schedule and execute) stream
processing applications across the DCs.
SpanEdge
65
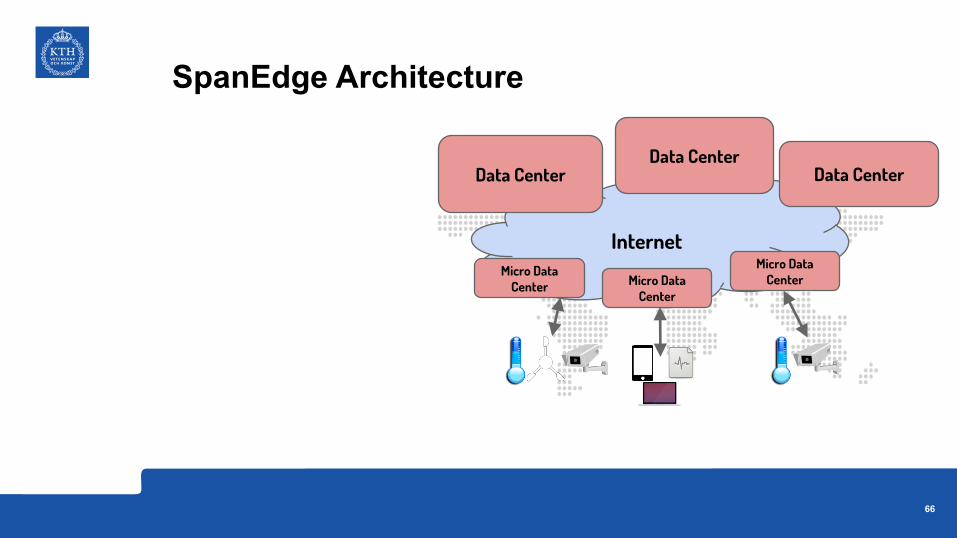
Internet
Data CenterData Center
Data Center
Micro Data Center Micro Data
Center
Micro Data Center
SpanEdge Architecture
66
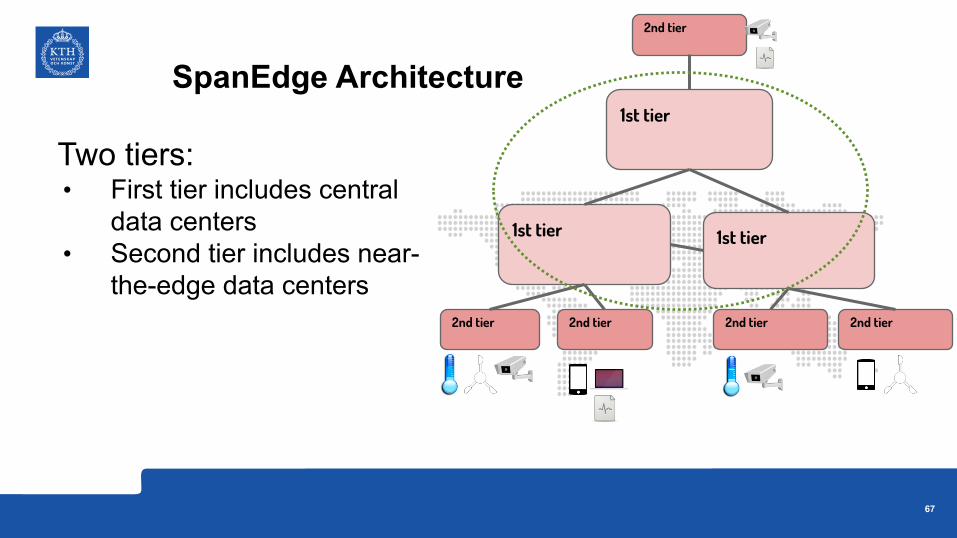
Two tiers:• First tier includes central
data centers• Second tier includes near-
the-edge data centers
1st tier
1st tier
1st tier
2nd tier 2nd tier
2nd tier
2nd tier 2nd tier
SpanEdge Architecture
67

Two types of workers:• Hub-worker• Spoke-worker
1st tier
1st tier
1st tier
2nd tier 2nd tier
2nd tier
2nd tier 2nd tier
Hub-Worker Hub-Worker
Spoke-Worker Spoke-Worker Spoke-Worker Spoke-Worker
Spoke-Worker
Hub-Worker
Manager
SpanEdge Architecture
68

1st tier
1st tier
1st tier
2nd tier 2nd tier
2nd tier
2nd tier 2nd tier
Hub-Worker Hub-Worker
Spoke-Worker Spoke-Worker Spoke-Worker Spoke-Worker
Spoke-Worker
Hub-Worker
SpanEdge Architecture
Manager
69

1st tier
1st tier
1st tier
2nd tier 2nd tier
2nd tier
2nd tier 2nd tier
Hub-Worker Hub-Worker
Spoke-Worker Spoke-Worker Spoke-Worker Spoke-Worker
Spoke-Worker
Hub-Worker
SpanEdge Architecture
Manager
70

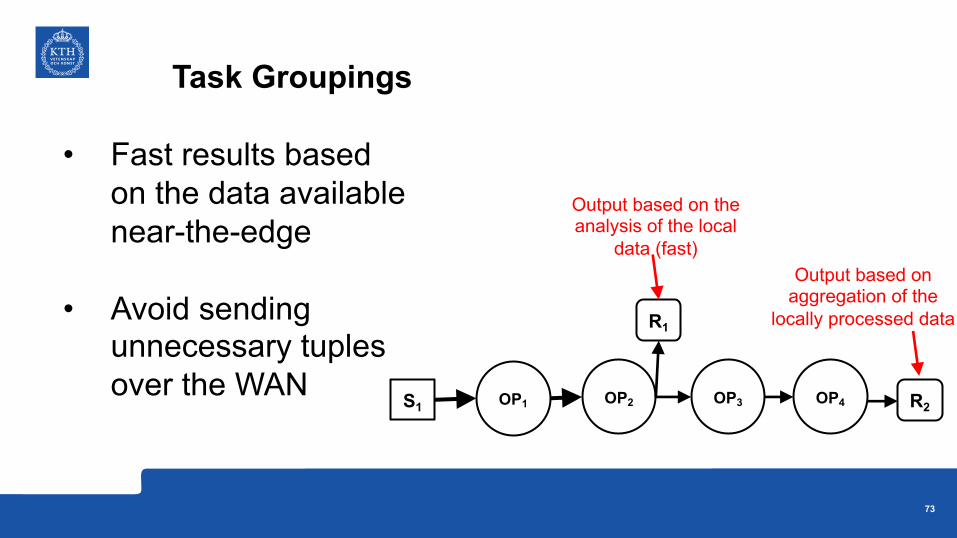
Task Groupings
71

S1 OP1 OP2 OP3
R1
OP4 R2
Output based on aggregation of the
locally processed data
Output based on the analysis of the local
data (fast)
Task Groupings
72
S1 OP1 OP2 OP3
R1
OP4 R2
Output based on aggregation of the
locally processed data
Output based on the analysis of the local
data (fast)
• Fast results based on the data available near-the-edge
• Avoid sending unnecessary tuples over the WAN
Task Groupings
73

• Local-Task: close to the data source on spoke-workers
• Global-Task: for processing data generated from local-tasks, placed on a hub-worker
S1 OP1 OP2 OP3
R1
OP4 R2
Output based on aggregation of the
locally processed data
Output based on the analysis of the local
data (fast)
L1
G1
Task Groupings
74

Converts a stream processing graph to an execution graph and assigns the created tasks to workers.
1st tier
1st tier
1st tier
2nd tier 2nd tier
2nd tier
2nd tier 2nd tier
Hub-Worker Hub-Worker
Spoke-Worker Spoke-Worker Spoke-Worker Spoke-Worker
Spoke-Worker
Hub-Worker
Manager
The manager runs the scheduler.Scheduler
75
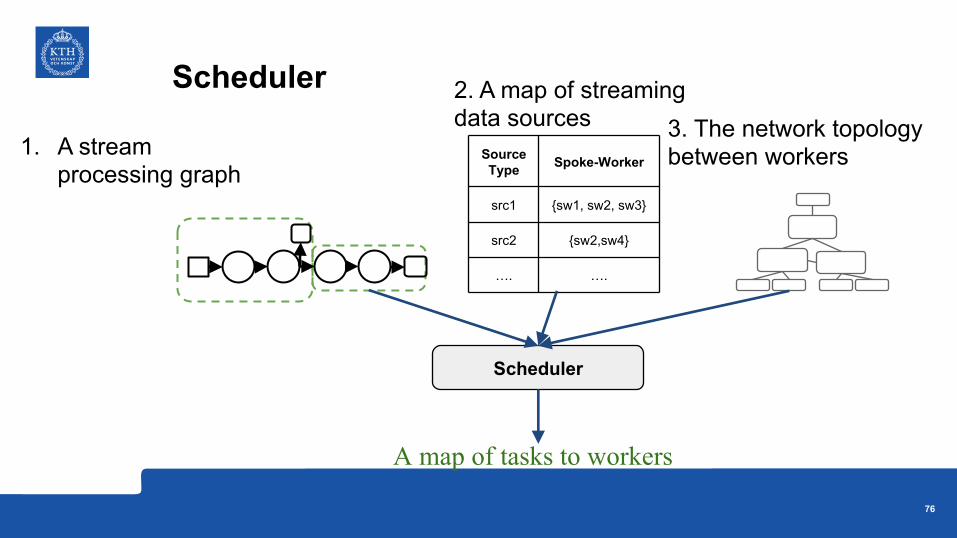
2. A map of streaming data sources
1. A stream processing graph
3. The network topology between workers
Scheduler
Source Type Spoke-Worker
src1 {sw1, sw2, sw3}
src2 {sw2,sw4}
…. ….
A map of tasks to workers
Scheduler
76
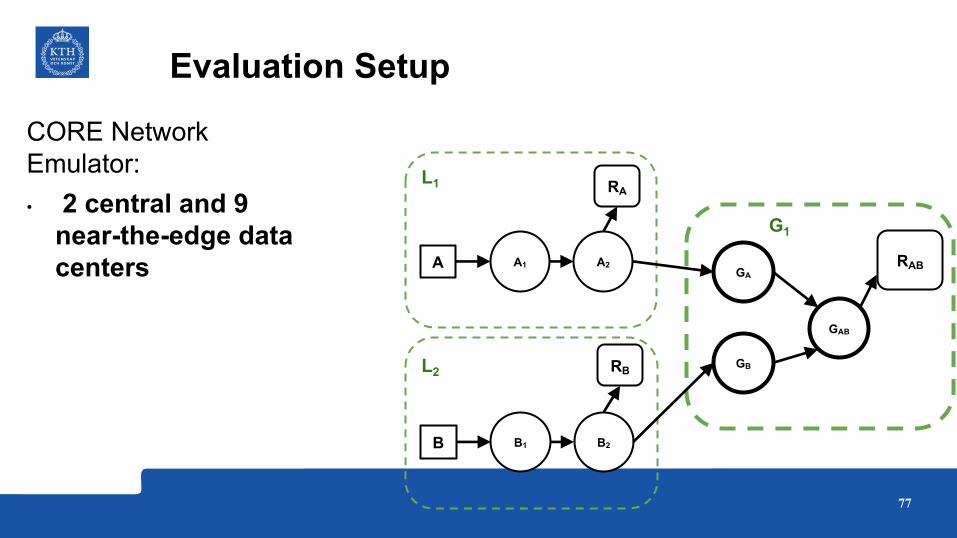
Evaluation Setup
CORE Network Emulator: • 2 central and 9
near-the-edge data centers A A1 A2
GA
GAB
L1
G1
B B1 B2
L2
RA
RB GB
RAB
77

Bandwidth Consumption
Evaluation: Bandwidth
78

Partial results Aggregated results
Evaluation: Latency
79

SpanEdge:• facilitates programming on a geo-distributed
infrastructure including central and near-the-edge data centers
• provides a run-time system to manage streamprocessing applications across the DCs
• https://github.com/Telolets/StormOnEdge
Conclusions
80

Conclusions and Future Work
81

ConclusionsTo enable effective and efficient stream processing in geo-distributed settings, we proposed solutions both on system level and algorithm to fill the gaps for:
• A multi-data center stream processing system that utilizes both central and near-the-edge data centers
• Network-aware placement of stream processing components and network-aware structuring of edge resources
• Efficient state-sharing in distributed streaming graph partitioning
82

Scheduling of stream processing applications with respect to:
• Dynamic network conditions• Resource heterogeneity on the edge• Mission-critical applications and applications with different
priorities
Reducing the latency for:• Scheduling• Failure detection and failure recovery
Potential Future Work
83

Acknowledgements
CLOMMUNITY FP-7 EU-Project http://clommunity-project.euE2E Clouds Research Project http://e2e-clouds.org
My advisor, Vladimir VlassovMy secondary advisors, Fatemeh Rahimian, and Seif HaridiMy co-authorsMy colleagues at KTH and SICS
84

Thank You!
85


















