
Towards the Next Generation Intelligent BPM
42
Towards the Next Generation Intelligent BPM —— In the Era of Big Data Xiang Gao, China Mobile Communications Corporation
Transcript of Towards the Next Generation Intelligent BPM

Towards the Next Generation Intelligent BPM —— In the Era of Big Data
Xiang Gao, China Mobile Communications Corporation

Background
From BPM to iBPM
A Big Data Perspective on BPM
Embrace the Idea of Big Data
Outline
Conclusion and Future Work

Subscribers (million)
Over 1 million base
stations covering
99% of national
population, and
roaming service to
237 countries and
regions
Base stations
(thousand)
Brief Introduction of CMCC
As the leading Chinese telecommunication company, China Mobile Communications Corporation (CMCC) is also recognized as the world's largest mobile phone operator by subscribers with about 740 million. In 2012, the Company was once again selected as one of the "FT Global 500" by Financial Times and "The World's 2,000 Biggest Public Companies" by Forbes magazine.
Over 700 million
subscribers,
including over 100
million 3G
subscribers
1200TB
The world’s largest teleco BASS
data warehouse
over
The world’s largest daily signaling
data/billing data
100/10 TB over
The world’s largest teleco
business process repository
40000 processes over
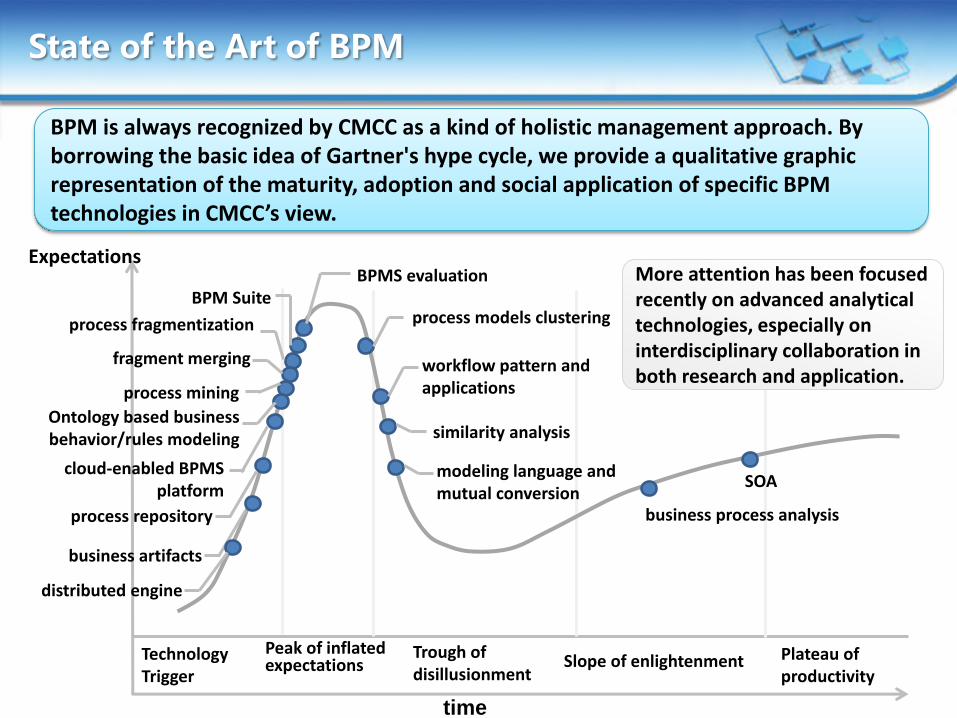
State of the Art of BPM
BPM is always recognized by CMCC as a kind of holistic management approach. By borrowing the basic idea of Gartner's hype cycle, we provide a qualitative graphic representation of the maturity, adoption and social application of specific BPM technologies in CMCC’s view.
time
Technology Trigger
Peak of inflated expectations
Trough of disillusionment
Slope of enlightenment Plateau of productivity
Expectations
business artifacts
process fragmentization
workflow pattern and applications
process repository
BPM Suite
modeling language and mutual conversion
process mining
similarity analysis
cloud-enabled BPMS platform
SOA
business process analysis
BPMS evaluation
fragment merging
process models clustering
Ontology based business behavior/rules modeling
distributed engine
More attention has been focused recently on advanced analytical technologies, especially on interdisciplinary collaboration in both research and application.

Great Challenges Arise from IT Consolidation
In the context of IT systems consolidation, such a large number of business processes must cause an extremely arduous task for maintaining and evolving. Accordingly, one must elaborately consider “business process consolidation” first.
business understanding & raw process reconstruction
During more than 10 years IT construction, a large number of business processes have been varied and updated for many times, and thus, have been biased from the original design. To achieve the objective of consolidation, great attention should be paid to deep understanding of business behavior and efficient process reconstruction.
Actually, business analysts have deep understanding of business but cannot design the process models independently without the support of IT staffs. It is really important to provide an efficient approach to assist flexible and agile design of process models for business analysts with the least IT efforts.
redundancy removal & process repository
flexible modeling based on business semantics
Different subsidiary organizations follow unified business specifications and design their own processes. Due to individual management requirements, their processes, even expressing the same business behavior, are usually not exactly the same while having a high degree of similarity. The technology to reduce duplications and make the differences between process models explicit is really important.
complex business logic & recessive rules
The current processes contain so many special and complex business logics, making the design and execution of processes extremely complicated. Formal design of these business logic should be of much consideration.

Example: OA Systems Consolidation
Office Automation (OA) is one of the most important management information systems for governments and enterprises in China, to process and communicate information for daily working of all the users. OA fundamentally refers to supporting document flow, approval, transfer, archive and other enterprise general management business processes.
The OA systems of CMCC have been independently built for more than 10 years by each subsidiary organizations.
more than 3 kinds of OS
more than 4 kinds of RAID
more than 5 kinds of middleware
more than 49 system integrators
more than 240 external interfaces
more than 1000 application modules
… …
more than 8190 business processes
These processes are described differently and each subsidiary may have its own description, mainly based on informal user-definition or natural-language text documents.
It is causing increased architecture heterogeneity, high integration complexity and especially high construction and maintenance cost.

Challenge I: Diversity of OA Process
Different subsidiary organizations follow unified business specifications and design their own processes. Due to individual management requirements, their processes, even expressing the same business behavior, are usually not exactly the same while having a high degree of similarity.
Statistics of OA Process Samples
Source: Jan Mendling. “Metrics for Process Models: Empirical Foundations of Verification, Error Prediction, and Guidelines for Correctness,” LNBIP 6, Springer, 2008
Let u1, u2, u3 express the normalized mean vectors of different subsidiaries, then the auto-correlation matrix R has the form
1 1 1 2 1 3
2 1 2 2 2 3
3 1 3 2 3 3
, , ,
, , ,
, , ,
1 0.9524 0.9909
0.9524 1 0.9337
0.9909 0.9337 1
R R R
R R R
R R R
u u u u u u
R u u u u u u
u u u u u u
where
T
,i j
i j
i j
R u u
u uu u
Within one subsidiary organization, different processes are highly different.
Processes belonging to different subsidiaries have high similarity.
high graph sparsity (edge density=0.07) high control-flow complexity (control-flow complexity = 16.41, when compared with number of tasks) weakly structured (structuredness = 0.61, include 5 arbitrary cycles) … …
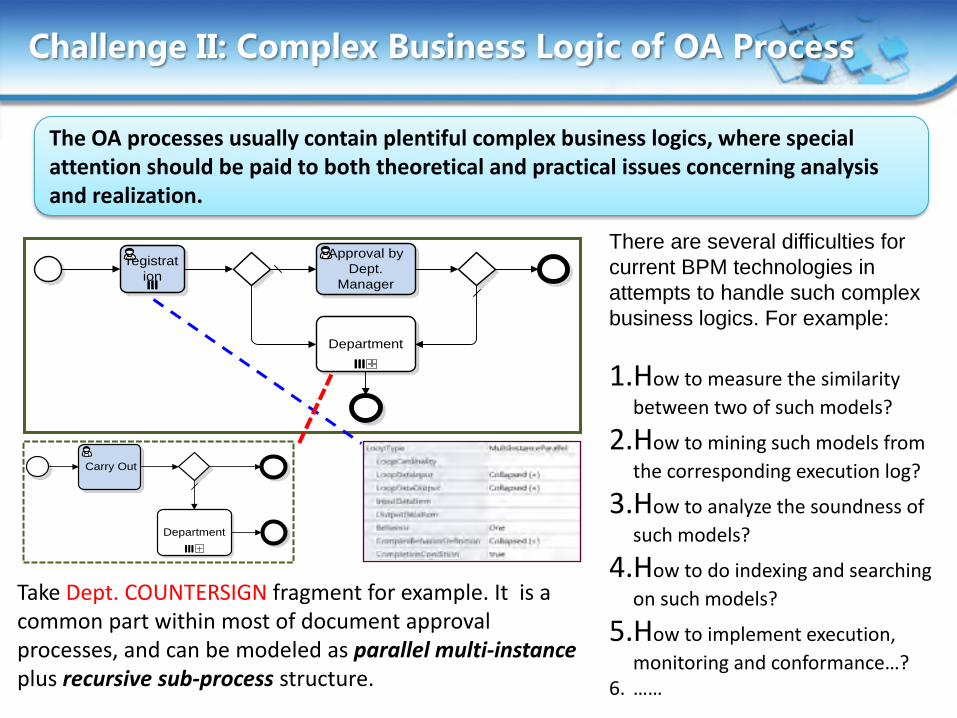
Challenge II: Complex Business Logic of OA Process
The OA processes usually contain plentiful complex business logics, where special attention should be paid to both theoretical and practical issues concerning analysis and realization.
registrat
ion
Approval by
Dept.
Manager
Department
Carry Out
Department
Take Dept. COUNTERSIGN fragment for example. It is a common part within most of document approval processes, and can be modeled as parallel multi-instance plus recursive sub-process structure.
There are several difficulties for
current BPM technologies in
attempts to handle such complex
business logics. For example:
1.How to measure the similarity
between two of such models?
2.How to mining such models from
the corresponding execution log?
3.How to analyze the soundness of
such models?
4.How to do indexing and searching
on such models?
5.How to implement execution,
monitoring and conformance…? 6. ……

Challenge III: Big Gap between Business & IT Realization
There is always a big gap: business analysts have deep understanding of business but cannot design the process models independently without the support of IT staffs, even though notation based modeling language is exploited.
Provide business analysts numerous process templates and fragments templates with specific business semantics, automatically extracted from existing process models
Provide intelligent process models and log analysis capability, e.g., similarity, search, merging, mining and so forth
Provide statistics capability for all kinds of process data
Process template
Fragments templates
+
E-Form templates
Organizations and Role
Rules, external services …
Process models
An intelligent configuration tool for process models design is needed to assist business analysts with easy and flexible process models design.
+
+ ......
Scenario of Process Modeling by Business Analysts

Background
From BPM to iBPM
A Big Data Perspective on iBPM
Embrace the Idea of Big Data
Outline
Conclusion and Future Work

On the Way from BPM to Intelligent BPM
The IT systems consolidation highly depends on the consolidation of business processes first, where intelligent BPM (iBPM) has been given new impetus by integrating analytical technologies into orchestrated processes.
meet the ongoing need for process
agility, especially for regulatory changes
and more-dynamic exception handling
aim at leveraging the greater availability
of data from inside and outside the
enterprise as input into decision making
facilitate interactions and collaboration
in cross-boundary processes
iBPM
2012~ BPMS
Mid 2000s BPM
2000
Workflow
1990s
Evolution
Mobile Social Advanced
Analytics External Data
+ =
iBPMS
+ BPMS + Cloud
Platform

There are a thousand Hamlets in a thousand people’s eyes.——William Shakespeare
Definition of iBPM from an Industrial Point of View
Analytical
The most prominent feature of iBPM is the capability of advanced analytics. It
integrates with state-of-the-art analytic technologies, including both pre-
analytics and post-analytics.
process model based analysis, such as model decomposition, clone
detection, similarity search etc
historical log and other information based analysis, such as automatic
business process discovery (i.e., process mining), social analysis, intelligent
recommendation, prediction etc
Automatic
The enormous volumes of data require automated or semi-automated analysis
techniques to detect patterns, identify anomalies, and extract knowledge. Take
process consolidation for example. The iBPM should be designed to facilitate
the procedure that automatically reduces duplications and makes the
differences between process models explicit, instead of manual operation.
Like the famous definition of “Big Data” by the three Vs, from CMCC’s perspective, analytical, automatic, agile and adaptive may also constitute a comprehensive definition of iBPM, and they bust the myth that iBPM is only about analytics. In addition, each of the four As has its own ramifications for analytics.

SOCIAL
BLOG
SMART
METER
101100101001
001001101010
101011100101
010100100101
It is worth noticing that achieving of the “4As” features will be given new opportunities in the era of big data.
Agile
The iBPM is expected to simplify the procedure. For example, by
incorporating process fragments with business semantics into design
tool, the efficiency of modeling can be significantly improved and most
of the procedures can be implemented by business analysts with the
least IT efforts.
Adaptive
The dynamic changing of business processes and external data inside
and outside should be flexibly captured and responded by resorting to
not only the adaptive adjusting of the analysis algorithm parameters,
but also the on-demand selection of appropriate algorithms in a
configuration way.
Definition of iBPM from an Industrial Point of View

Background
From BPM to iBPM
A Big Data Perspective on iBPM
Embrace the Idea of Big Data
Outline
Conclusion and Future Work

Big Data: Becoming Big Business
Source: Hilbert and Lopez, “The world’s technological capacity to store,
communicate, and compute information,” Science, 2011.
Global installed, optimally compressed, storage
Growth of global data
Trends of global data
Global installed computation to handle information
Source: Oracle, 2012
The birth and growth of big data was the defining characteristic of the 2000s. As obvious and ordinary as this might sound to us today, we are still unraveling the practical and inspirational potential of this new era.
Source: Cisco, 2011; Gartner 2009&2011; IDC, 2012

Network
Analysis
Pattern
Recognition
There is a need for ongoing innovation in techniques that will help individuals and organizations to analyze the growing torrent of big data. A wide variety of technologies has been developed and adapted to aggregate, manipulate, and analyze big data.
Big Data: Advanced Analytical Techniques
Association
Rule Learning Classification Clustering Crowd Sourcing Optimization
Data Fusion Machine Learning Ensemble
Learning
Genetic
Algorithms Neural
Networks
Spatial Analysis Natural Language
Processing Predictive
Modeling
Source: Big data: then next frontier for innovation, competition, and productivity, McKinsey Global Institute, June 2011
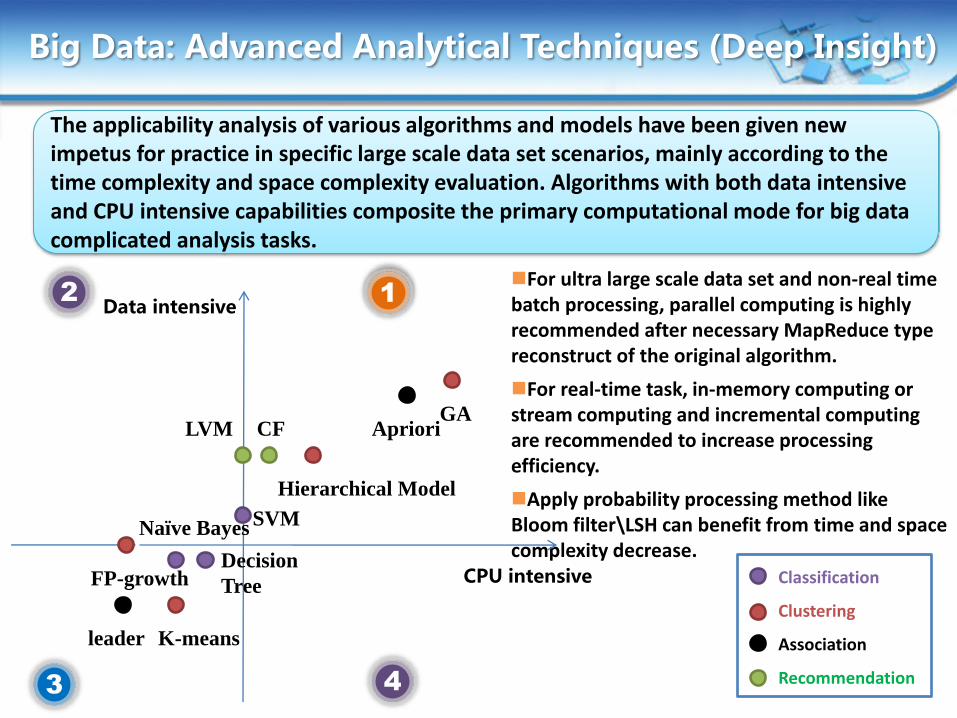
Classification
Clustering
Association
Recommendation
For ultra large scale data set and non-real time batch processing, parallel computing is highly recommended after necessary MapReduce type reconstruct of the original algorithm.
For real-time task, in-memory computing or stream computing and incremental computing are recommended to increase processing efficiency.
Apply probability processing method like Bloom filter\LSH can benefit from time and space complexity decrease.
The applicability analysis of various algorithms and models have been given new impetus for practice in specific large scale data set scenarios, mainly according to the time complexity and space complexity evaluation. Algorithms with both data intensive and CPU intensive capabilities composite the primary computational mode for big data complicated analysis tasks.
Big Data: Advanced Analytical Techniques (Deep Insight)
CPU intensive
Data intensive
leader K-means
FP-growth
Hierarchical Model
Apriori GA
CF
Decision
Tree
Naïve Bayes SVM
LVM

Mobile Social
External Data
Source: Big data, Analytics and the Path From Insights to
Value , MIT Sloan Management Review 2011
What does big data really mean in the evolution of BPM? Elegantly stated by the founding father and pioneer long before the introduction of the big data concept. In God we trust; all others must bring data. ——W. Edwards Deming.
Big Data——Catalyst for BPM Evolution
Driven by process data and other related data, it can be a new platform for the R &
D of intelligence based on big data, making Deming's maxims a reality for the operation of future iBPM systems.
Advanced
Analytics
New methods and tools to embed information into business
processes, are making insights
more understandable and actionable.

On the Path from Insight to Action (Data) ——Finding the Needle in the Big Data BPM Haystack
Where is business process data?
From a special point of view, • the complete event log data • the process models in centralized repository • the process cases data • …… of a large corporation (e.g.,CMCC) can all be treated and analyzed as “big data” in the BPM field.
Traditionally, It is universally acknowledged that
While, from a generalized point of view, data describing a set of behavior or task with specific order can all be treated as “process”, such as user clicking on the web, searching …… Accordingly, a large number of such kind of data are all “big data” in the BPM field.
The biggest misnomer actually comes from the name itself — that is, that “big data” is about big data. When we talk about big data, we must put its size in relation to the available resources, the question asked, and the kind of data.

On the Path from Insight to Action (Analysis) —— Sparsity Vs. Redundancy
The widespread use of traditional data mining and artificial intelligence algorithms has usually exposed their limitations on data sparsity in large-scale data set or problems associated with high dimensionality. However, the large amount of process data always exhibits redundancy instead of sparsity.
For example, user-based collaborative filtering
systems have been very successful in the past,
but their weakness has been revealed for large,
sparse databases
Vs.
To deal with more than 8000 OA processes, the
technology to reduce duplications and make the
differences between process models explicit is
really important.
Identification of highly reusable fragments
approval process of province A
approval process of province B
reusable fragments (Draft & Approval)
Source: Analysis of Recommendation Algorithms for E-Commerce, Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl

On the Path from Insight to Action (Analysis) —— Sample Vs. Population
Take the process mining scenario for example, where the completeness of event log plays an extremely important role.
For limited event log (also recognized as sample), the global completeness needs to be evaluated by resorting to distribution fitting or at least bound estimation.
Sample based analysis is usually conducted to infer the whole behavior of population. However, in the age of big data, one turns to put emphasis on population but not sample, since collecting and processing large amount of data are feasible now.
For complete event log (also recognized as population), it seems the global completeness is definitely guaranteed. However, the data quality can also affect the efficiency of mining algorithms, while it suffers from data missing and noise infection for population data.
Therefore, one must pay more attention to unprecedented challenges when population based analysis was implemented, such as noise cancellation, redundancy removal, data quality improvement and so on.
Vs.
Arbitrary Jump
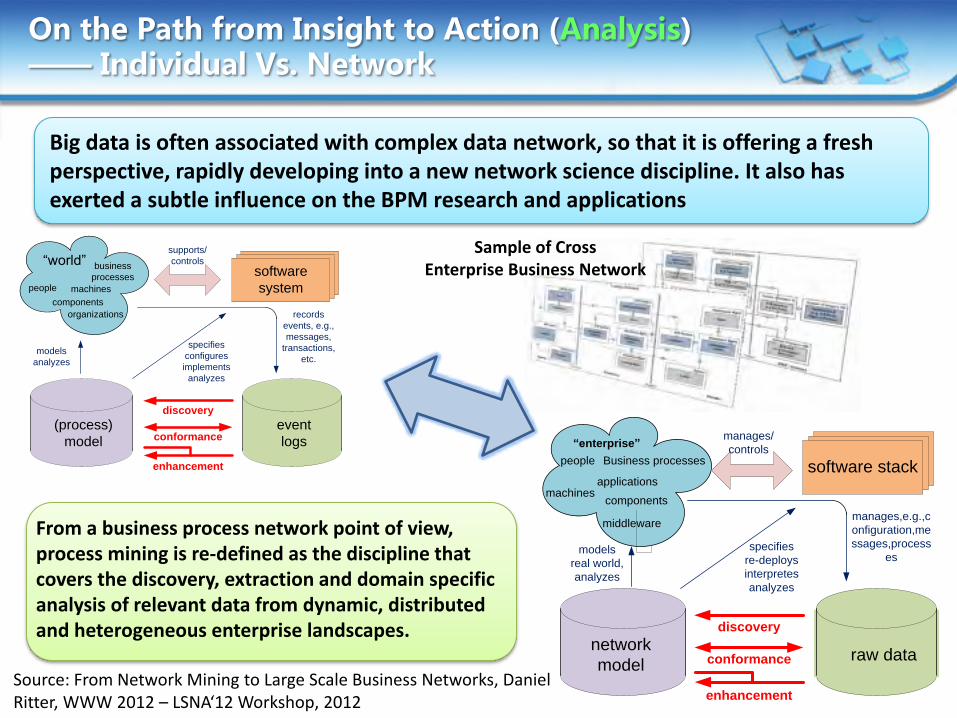
On the Path from Insight to Action (Analysis) —— Individual Vs. Network
Source: From Network Mining to Large Scale Business Networks, Daniel Ritter, WWW 2012 – LSNA‘12 Workshop, 2012
Sample of Cross Enterprise Business Network software
system
(process)
model
event
logs
models
analyzes
discovery
records
events, e.g.,
messages,
transactions,
etc.
specifies
configures
implements
analyzes
supports/
controls
enhancement
conformance
“world”
people machines
organizations
components
business
processes
applicationssoftware stack
network
modelraw data
models
real world,
analyzes
discovery
manages,e.g.,c
onfiguration,me
ssages,process
esspecifies
re-deploys
interpretes
analyzes
manages/
controls
enhancement
conformance
“enterprise”
people
machines
middleware
components
Business processes
Big data is often associated with complex data network, so that it is offering a fresh perspective, rapidly developing into a new network science discipline. It also has exerted a subtle influence on the BPM research and applications
From a business process network point of view, process mining is re-defined as the discipline that covers the discovery, extraction and domain specific analysis of relevant data from dynamic, distributed and heterogeneous enterprise landscapes.

On the Path from Insight to Action (Analysis) —— Causality Vs. Correlation
A major issue of concern in big data research is that correlation plays much more important role than causality. Google's founding philosophy is that we don't know why this page is better than that one: If the statistics of incoming links say it is, that's good enough. No semantic or causal analysis is required. However, we would like to mention that causality and correlation are equally important in BPM field.
Process mining is strongly based on the rigorous deduction of activity causality from event log.
Similarity analysis and clustering based technologies are typical correlation taken into consideration.
Clustering
Similarity

Background
From BPM to iBPM
A Big Data Perspective on iBPM
Embrace the Idea of Big Data
Outline
Conclusion and Future Work

Embrace the Idea of Big Data
• OA Processes Consolidation
• Social Network Analysis
• Intelligent Recommendation & Matching
• Test & Application of Distributed Cloud Storage
Outline

OA Process Consolidation Procedure
Fragment Repository
Raw Process Repository
Fragmentatization Tool
Process mining Tool
Process Template
Repository
Fragment Analysis
Tool
Process designer
BPMN 2.0 Specification
Temporary Fragment
Reopsitory
Legacy Process Asset
XLS Event Log
Process models
Raw process level process fragment level Refined process level
I. Mining Processes with Particular Business Logic
Algorithms: improved alpha++ Process Modeling Language: standard BPMN 2.0 Implementation: tailor made tool (to be shown in the video)
II. Fragmentization and Reuse
Algorithms: clone detection based on RPST Process Modeling Language: standard BPMN 2.0 Implementation: tailor made tool (to be shown in the video)
VI. Ontology based Rule Modeling
Process Modeling Language: standard BPMN 2.0, OWL Implementation: tailor made tool (to be shown in the video) External Tools: protégé 4.1
business understanding & raw process reconstruction
redundancy removal & process repository
flexible modeling based on business semantics
Complex business logic & recessive rules
IV. Merging
Algorithms: based on SPL (Software Product Line) Process Modeling Language: standard BPMN 2.0 Implementation: tailor made tool (to be shown in the video)
III. Similarity & Clustering
Algorithms: clone detection, hierarchical clustering, SSDT-matrix based behavioral similarity Process Modeling Language: standard BPMN 2.0, Newick format Implementation: tailor made tool (to be shown in the video) External Tools: Figtree, bpcd
V. Differentiation based on change operations
Process Modeling Language: standard BPMN 2.0 Implementation: tailor made tool (to be shown in the video)

Fragment Repository
Raw Process Repository
Fragmentatization Tool
Process mining Tool
Process Template
Repository
Fragment Analysis
Tool
Process designer
BPMN 2.0 Specification
Temporary Fragment
Reopsitory
Legacy Process Asset
XLS Event Log
Process models
Raw process level process fragment level Refined process level
II. Fragmentization and Reuse
Source: Vanhatalo J, Völzer H, Koehler J. The refined process structure tree[M]//Business Process Management. Springer Berlin Heidelberg, 2008: 100-115.
Motivation
Fragments reuse can reduce duplications between processes.
Fragment based process modeling significantly improves the process design efficiency. By testing, the average duration for modeling a process can be reduced by 20% to 60%, when compared to the common approach without fragments
Fragment with specific business semantic can assist business analysts directly design processes with least IT efforts.
Based on clone detection and RPST, a procedure is proposed for process model decomposition, and thus, obtains highly reusable fragments.
Decompose process models into fragments that are suitable for reuse.
Select fragments that are frequently used. The selection can be made manually by experienced business analysts or automatically by thresholds (e.g., size of fragments), according to specific scenario.
Fragmentization of “sending document” process model
Uba R, Dumas M, García-Bañuelos L, et al. Clone detection in repositories of business process models[M]//Business Process Management. Springer Berlin Heidelberg, 2011: 248-264. Gao X., Chen Y., Ding Z., et.al, Process Model Fragmentization, Clustering and Merging: An Empirical Study

IV. Merging
Fragment Repository
Raw Process Repository
Fragmentatization Tool
Process mining Tool
Process Template
Repository
Fragment Analysis
Tool
Process designer
BPMN 2.0 Specification
Temporary Fragment
Reopsitory
Legacy Process Asset
XLS Event Log
Process models
Raw process level process fragment level Refined process level
The merging operation converts a set of similar fragments into one merged fragment (also referred as master fragment), by borrowing some basic ideas from the software product line (SPL).
Variation points in the merged diagrams represent locations where the input models disagree in their behavior. That is, a variation point occurs when several alternative flows that belong to different input processes go out from a common activity.
Action
Blocking
Activating
HidingBlocking
Blocking and hiding are the essential concepts of configuration.
Configurable Process Model
Subtraction
Addition: Process Fragment Weaving

Fragment Repository
Raw Process Repository
Fragmentatization Tool
Process mining Tool
Process Template
Repository
Fragment Analysis
Tool
Process designer
BPMN 2.0 Specification
Temporary Fragment
Reopsitory
Legacy Process Asset
XLS Event Log
Process models
Raw process level process fragment level Refined process level
V. Differentiation based on Change Operations
identifying change operations between models
Match nodes between two models (one to one match).
Delete nodes from the original model. These nodes do not have a matching node in the target model.
Objectives
Always get a sound model from a sound model by change operations. The correctness of OA process models/fragments changing and maintenance can be naturally guaranteed
More syntactical meanings and much less than change primitives. Make sure that changing operation can be structured recorded.
Model A
Model B
Compute the (minimal) movements. These movements that are operated on the original model, to match the relationship between matching nodes of models.
Insert nodes into the original model (at the right place). These nodes are in the target model but do not have a matching node in the original model.
Model A1
Model A2
typeset Archive
typeset Archive
Model A3=Model B
typeset Archive
1. Delete (A, Typeset) 2. Delete (A, Archive) 3. Move (A, Assign ID, Check Document,
Distribution 4. Insert (A, print, Distribute, end)
Source: Li C, Reichert M, Wombacher A. On measuring process model similarity based on high-level change operations[M]//Conceptual Modeling-ER 2008. Springer Berlin Heidelberg, 2008: 248-264.

Fragment Repository
Raw Process Repository
Fragmentatization Tool
Process mining Tool
Process Template
Repository
Fragment Analysis
Tool
Process designer
BPMN 2.0 Specification
Temporary Fragment
Reopsitory
Legacy Process Asset
XLS Event Log
Process models
Raw process level process fragment level Refined process level
VI. Ontology based Rule Modeling
Motivation
Business processes are always influenced by legal and regulatory constraints according to managerial requirements. These kinds of constraints are always recessive.
Ontology based rule modeling can avoid redundancy and keep consistency
Ontology based rule modeling can make information sharable and exchangeable
Implementation
ontology is designed to allow modeling of external and internal regulations as guidelines and constraints on the interaction between entities and on states of process template.
Standard specification of a given language is provided as a descriptive facility and OWL is adopted to describe business rules.

Prototype Show
In the context of OA consolidation, a specialized configuration tool has been built, which integrates all the aforementioned algorithms as well as tools, aiming at providing flexible and efficient process modeling capability for both the business analysts and IT staffs.
Integrative modeling tool
User friendly interface
Open source based
Pluggable modules
intelligent analysis
Complete statistics
Snapshot of the fragment based process configuration tool
A short video

Embrace the Idea of Big Data
• OA Processes Consolidation
• Social Network Analysis
• Intelligent Recommendation
• Test & Application of Distributed Cloud Storage

Enterprise Social Network Analysis (continued)
We have gathered about 20 million user and 1.2 billion microblogs. By using our SNA models, we achieved useful tools for enterprise management, such as public opinion tracing, VIP discovery, satisfaction survey and novel CRM.
Mining public topics and opinions from one billion micro-blogs
Method: Text Mining, Spam-trim,TDT,
Public Opinion Tracing
Opinion leader and VIP discovery
Satisfaction survey
Novel CRM
National-wide, 100 thousand user satisfaction survey
Method: Sentiment analysis, NLP
Discovery 244 opinion leader and VIPs out of 100 thousand users.
Method: Graph Clustering, Spam detection
Based on user ‘s satisfaction and his influence, we draw a user-care map
Method: Sentiment analysis, NLP, Social influence

Embrace the Idea of Big Data
• OA Processes Consolidation
• Social Network Analysis
• Intelligent Recommendation
• Test & Application of Distributed Cloud Storage

Background and Targets
• Daily generated log data is up to
50GB now , resulting to a more than
20TB annual accumulation
• However, the data growth speed is
still rising
More than 200,000,000 users
More than 150,000 apps
More than 1,500,000 audios
More than 1,800,000 videos
More than 50,000 books
More than 60,000 comics
More than 100,000,000 PVs per day
More than 10,000,000 downloads per day
Truly massive data Severe information overload
Poor download rate
Very hard for users to choose items of their
interest
Very hard for developers to promote
products effectively
Targets of Intelligent Recommendation
To Realize tripartite win of the users,
developers and operators of MM
• For users: better user experience
• For developers: equitable opportunity to
promote products efficiently
• For operators: improving operational income
MM (Mobile Market) of CMCC is similar to Apple App Store, which provides not only more than 150,000 mobile apps, but also a huge number of other digital commodities. “Information overload“ problem of MM is becoming more and more challenging.

System Architecture
Run Hadoop Mapreduce on top of MongoDB cluster, achieving better performance
Complete all offline computing based on 12 months data in 5 hours
Every recommendation costs less than 10ms under concurrent PV up to 3000 per second
Data Storage
MM
Business Sys User
Intelligent Rec Engine
MM Log Sys
MM
UI
Results Optimization
ETL & Modeling Intelligent
Recommendation
System
Architecture
Hybrid CF
ALS-LFM
P-FP
Pluggable recommendation algorithms
Support customized algorithm parameter sets for different scenes
Three algorithms integrated now: Hybrid-CF(Hybrid Collaborative Filtering)、P-FP(Association rule mining)、ALS-LFM
We built the intelligent recommendation system for MM with open source big data tools, such as Hadoop, MongoDB, Mahout, etc.
Feature & Performance

Reciprocal Recommendation
Scenario 1 : Online Dating Scenario 2 : Social Networking
Scenario 3 : Job-Hunting Scenario 4 : Stable Roommates
Dealing with SMP(Stable Marriage Problem),to find a stable pair between two sets of elements representing men and women. Matching models such as Gale–Shapley algorithm are applied.
Recommending people on social networking sites. To help people to create social and personal connections, to expand friend lists. IBM Beehive using “Content-plus-Link” model to recommend new colleagues.
Known as Roommate Finder, Roommate matching Networks. To help students to find their satisfied roommates. Similar to the stable marriage problem, but differs in that all participants belong to a single pool.
Motivated by the matching between medical students and hospitals in the US, currently known as NRMP (National Resident Matching Program). A bilateral recommendation approach in matching people and jobs.
Traditional recommenders is to provide a USER with recommendations of ITEMS likely to be of interest to the user, such as books, movies, mobile APPs and pharmacy products. Apart from this, we also focus on another important class of recommendations named Reciprocal Recommender, where both the USER and the ITEM models represent people. The two sides have similar standing and both have preferences to be satisfied.

Embrace the Idea of Big Data
• OA Processes Consolidation
• Social Network Analysis
• Intelligent Recommendation
• Test & Application of Distributed Cloud Storage

Test terms Test content MySQL Cassandra Mongo
DB HBase
Basic function
Data definition, data operation, control, manage & maintain, function and interface
Basic performance
System performance with full-read
System performance with full plug-in
System performance with upgrade
System performance with frequent read
System performance with frequent update
elastic System expansion with stable frequent read
System expansion with stable frequent update
flexibility ability of dynamic node extension with online service
High availability
group influence with failed manage node
Group influence with failed data node
Group influence with failed router node
Group influence with failed distributed node
Consistency group node synchronies time, estimate system consistency
Metrics and Evaluation of NoSQL Database
CM-CBF aims to test the suitability of cloud storages for different scenarios, in order to benchmark the performance, CM-CBF includes six aspects: basic function test, basic performance test, elastic test, flexibility test, high availability test, consistency test.

Background
From BPM to iBPM
A Big Data Perspective on iBPM
Embrace the Idea of Big Data
Outline
Conclusion and Future Work

The best way to predict the future is to create it. ——Peter F. Drucker
Conclusions and Future Work
social network analysis
machine learning
semantic web
data visualization
distributed cloud storage
Open R & D Ecosystem
Platform & Commercialization
Multi-discipline collaboration
build cloud enabled iBPM platform and provide on-demand analytical service
integrate various advanced technologies and tools into process engine and accelerate the evolution to iBPM
build open and harmony environments for both academia and industry
promote and encourage open source tools and prototypes for technology innovation and incubation
We sincerely hope to promote the relationship with academia, share our idea, devote ourselves to the advanced researches as well as their realization.

Thanks for your attentions


















