
Towards Coding for Human and Machine Vision: A Scalable ...
40
Towards Coding for Human and Machine Vision: A Scalable Image Coding Approach Yueyu Hu, Shuai Yang, Wenhan Yang, Ling-Yu Duan, Jiaying Liu Peking University IEEE ICME 2020
Transcript of Towards Coding for Human and Machine Vision: A Scalable ...

Towards Coding for Human and Machine Vision:
A Scalable Image Coding ApproachYueyu Hu, Shuai Yang, Wenhan Yang, Ling-Yu Duan, Jiaying Liu
Peking University
IEEE ICME 2020

IEEE ICME 20202
SCENE

3
WHAT HUMANS SEE
IEEE ICME 2020

4
MACHINE FEATURES
IEEE ICME 2020
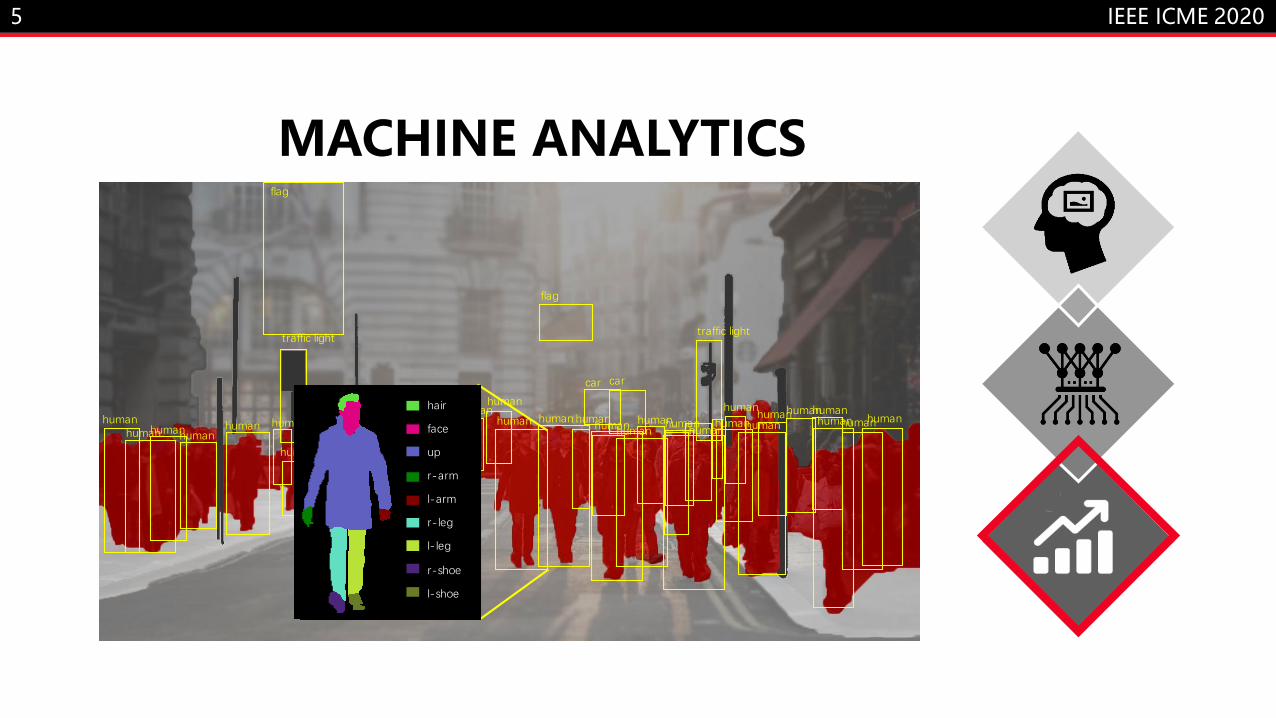
5
MACHINE ANALYTICS
human human human human
human human human
human
human
human human human human human
human human
human human human human human human human human human
human human human human
human human human human
car car
flag
flag
traffic light traffic light
hair
face
up
r-arm
l-arm
r-leg
l-leg
r-shoe
l-shoe
IEEE ICME 2020

6
IMAGE CODING FOR WHOM?
HUMAN VISION
AMOUNT OF INFORMATION
1) Feature Extraction• DegradedHigh-Quality • Enhanced Information
2) Guided Reconstruction• Feature Image• Information Generation
MACHINE VISION
1) Feature Extraction• Redundant Compact• Compressed Information
2) Regression• Feature Label• Further Compressed
?HIGH-LEVEL FEATURESFOR MACHINE VISION
RECONSTRUCTED IMAGESFOR HUMAN VISION
IEEE ICME 2020
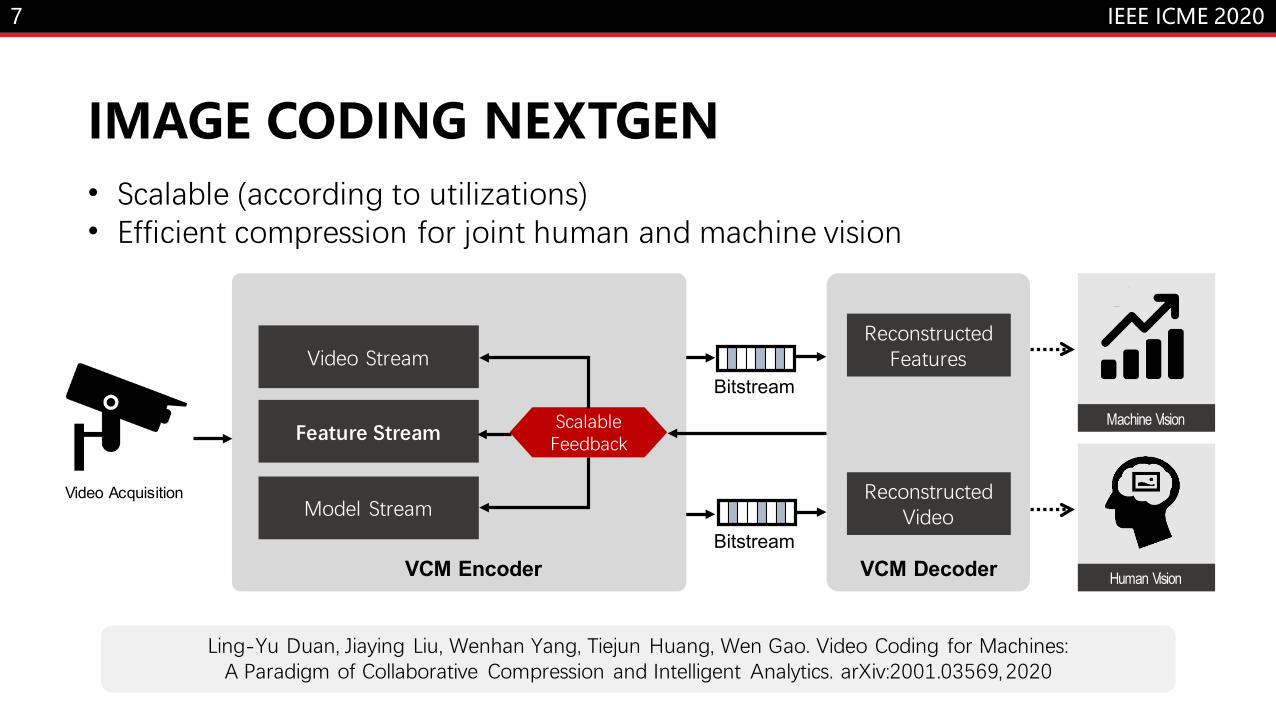
7
IMAGE CODING NEXTGEN
Ling-Yu Duan, Jiaying Liu, Wenhan Yang, Tiejun Huang, Wen Gao. Video Coding for Machines: A Paradigm of Collaborative Compression and Intelligent Analytics. arXiv:2001.03569, 2020
Video Acquisition
VCM EncoderBitstream
Bitstream
VCM Decoder
Machine Vision
Human Vision
• Scalable (according to utilizations)• Efficient compression for joint human and machine vision
Reconstructed Video
Reconstructed FeaturesVideo Stream
Feature Stream
Model Stream
ScalableFeedback
IEEE ICME 2020
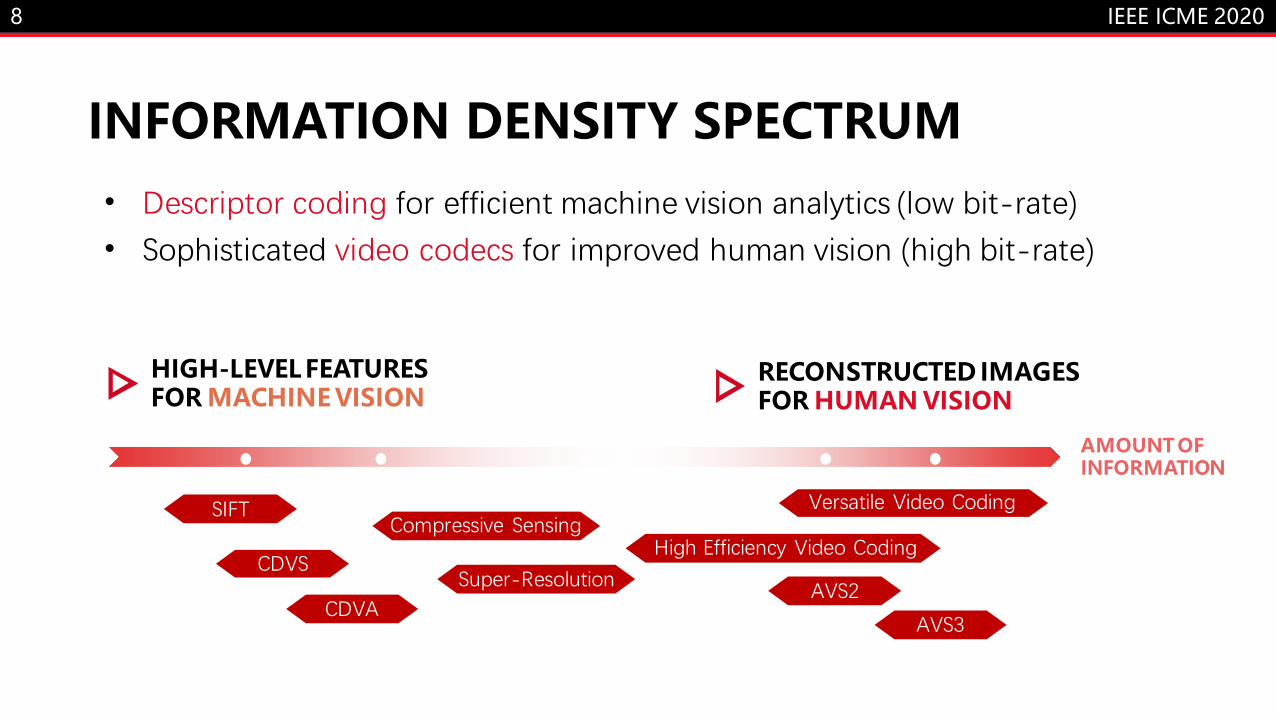
8
INFORMATION DENSITY SPECTRUM
High Efficiency Video Coding
SIFT
CDVS
CDVA
Compressive Sensing
Super-Resolution
AVS3
AVS2
Versatile Video Coding
HIGH-LEVEL FEATURESFOR MACHINE VISION
RECONSTRUCTED IMAGESFOR HUMAN VISION
AMOUNT OF INFORMATION
• Descriptor coding for efficient machine vision analytics (low bit-rate)• Sophisticated video codecs for improved human vision (high bit-rate)
IEEE ICME 2020

9
EDGES• Efficient for structural information
• Maintain scalability
• Sparse and light-weight
• Supports smooth scaling
PROS
• Inefficient for details in images
• Ambiguous in color
CONS
IMAGE REPRESENTATIONS
IEEE ICME 2020

10
• Avoid color ambiguity
• Sparse and compact
• Related to visual fidelity
PROS
• Usually randomly distributed
• Inefficient for further compress
CONS
COLOR
IMAGE REPRESENTATIONS
DARK BLUE
LIGHT BLUE BLUE
IEEE ICME 2020
✔✘

IEEE ICME 202011
HUMAN FACES
Faces are naturally salient area in images we are looking at.
Machine vision systems to analysis faces have been widely developed.
It is the reflection of humanity in technology.
Analytics of Faces
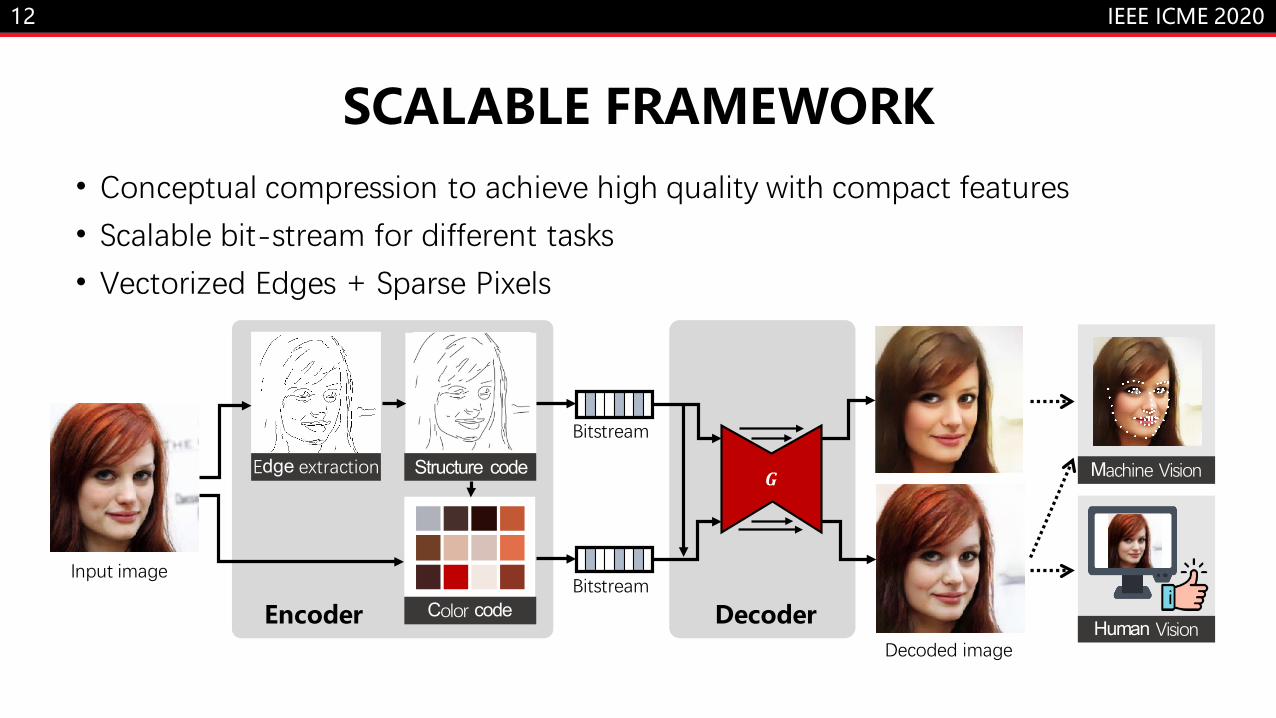
12
Input image
Decoded image
Edge extraction Structure code
Color code EncoderBitstream
Bitstream
G
Decoder
Machine Vision
Human Vision
• Conceptual compression to achieve high quality with compact features• Scalable bit-stream for different tasks• Vectorized Edges + Sparse Pixels
SCALABLE FRAMEWORK
IEEE ICME 2020

13
Input image
Decoded image
Edge extraction Structure code
Color code EncoderBitstream
Bitstream
G
Decoder
Machine Vision
Human Vision
ENCODER · EDGE• Edge detection via structured forests
P. Dollar and C. L. Zitnick. Structured forests for fast edge detection. ICCV, 2013.
IEEE ICME 2020

14
Input image
Decoded image
Edge extraction Structure code
Color code EncoderBitstream
Bitstream
G
Decoder
Machine Vision
Human Vision
ENCODER · EDGE• Edge detection via structured forests
• AutoTrace to convert edge pixels to vectorized representations
• Represented by lines and curves• Short and trivial edges are screened
• Prediction for Partial Matching (PPM)to losslessly compress vectors
M.Weber. AutoTrace: a program for converting bitmap to vector graphic. 1998. http://autotrace.sourceforge.net/
IEEE ICME 2020
15
Input image
Decoded image
Edge extraction Structure code
Color code EncoderBitstream
Bitstream
G
Decoder
Machine Vision
Human Vision
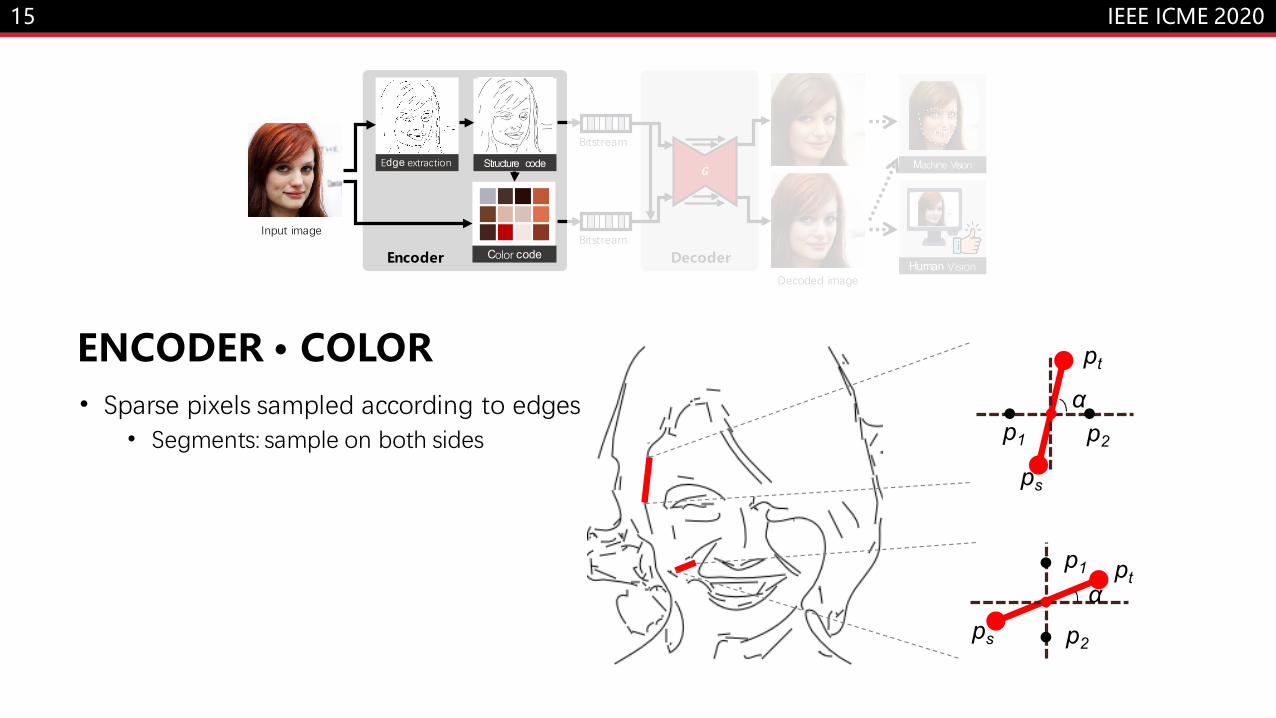
ENCODER · COLOR• Sparse pixels sampled according to edges
• Segments: sample on both sides
α
αp1 p2
p1
p2
ps
ps
pt
pt
IEEE ICME 2020

16
Input image
Decoded image
Edge extraction Structure code
Color code EncoderBitstream
Bitstream
G
Decoder
Machine Vision
Human Vision
pa
ps pt
pb
p1
ENCODER · COLOR• Sparse pixels sampled according to edges
• Segments: sample on both sizes• Curves: sample on areas with steepest
gradients
IEEE ICME 2020

17
Input image
Decoded image
Edge extraction Structure code
Color code EncoderBitstream
Bitstream
G
Decoder
Machine Vision
Human Vision
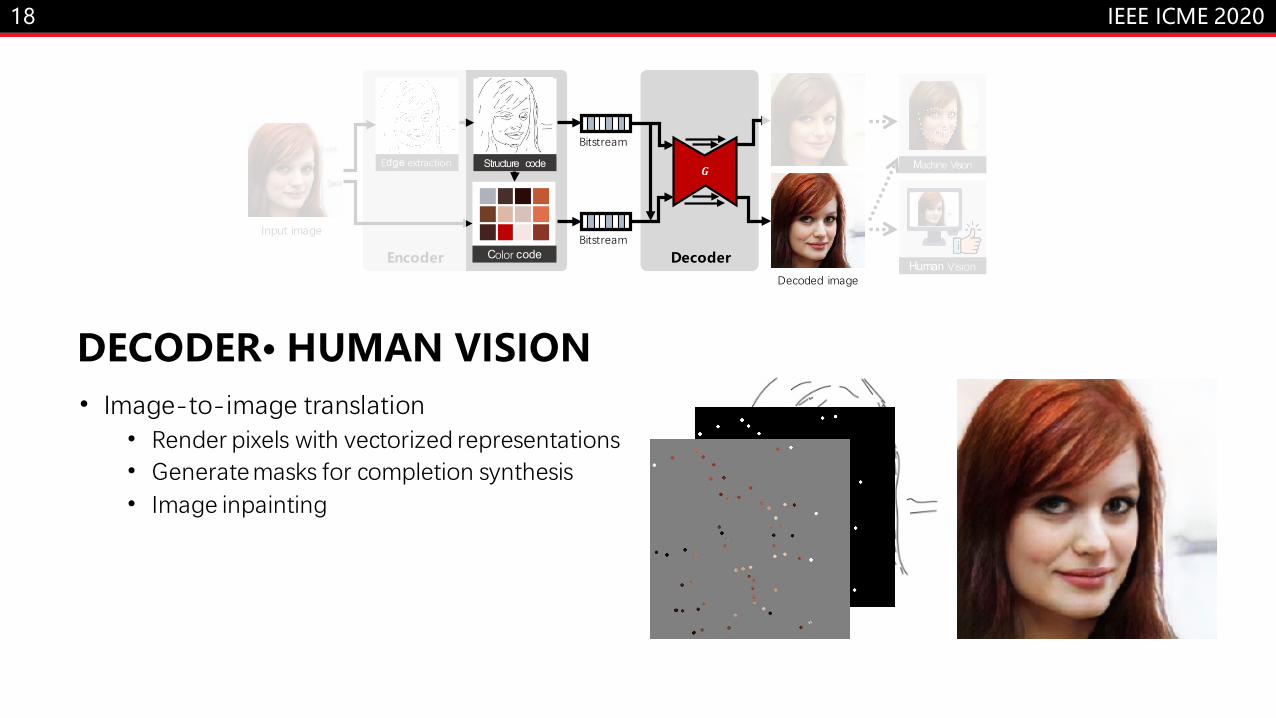
DECODER· MACHINE VISION• Image-to-image translation
• Render pixels with vectorized representations• Edge-to-RGB translation
IEEE ICME 2020
18
Input image
Decoded image
Edge extraction Structure code
Color code EncoderBitstream
Bitstream
G
Decoder
Machine Vision
Human Vision
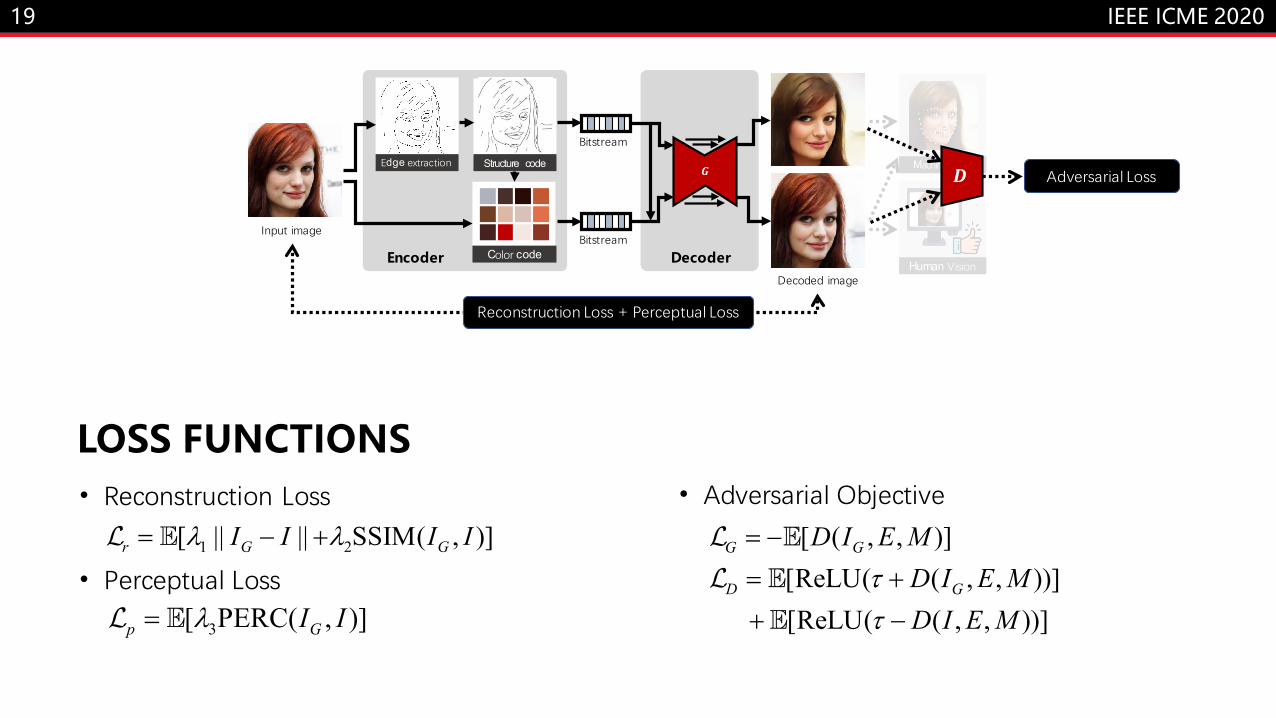
DECODER· HUMAN VISION• Image-to-image translation
• Render pixels with vectorized representations• Generate masks for completion synthesis• Image inpainting
IEEE ICME 2020
19
Input image
Decoded image
Edge extraction Structure code
Color code EncoderBitstream
Bitstream
G
Decoder
Machine Vision
Human Vision
LOSS FUNCTIONS• Reconstruction Loss
• Perceptual Loss1 2|| || SSIM( , )][r G GI I I Iλ λ= − +
3PERC( , )][p GI Iλ=
D
Reconstruction Loss + Perceptual Loss
Adversarial Loss
• Adversarial Objective
]
, , )],
[ ([ReLU( ([ReLU( ( ,
, ))] , ))
G G
D G
DM
ID ID I E M
E MEτ
τ −
= −=+
+
IEEE ICME 2020

20
EXPERIMENTAL RESULTS
HUMAN VISION
Subjective preference survey.
Measuring fidelity and Aesthetics.
MACHINE VISION
Evaluate facial landmark detection.
Measuring information preservation.
IEEE ICME 2020

HUMAN VISION
21
SCALABLE OUTPUT
MACHINE VISION INPUT IMAGE
0.114 bpp 0.172 bpp
0.157 bpp 0.249 bpp
IEEE ICME 2020

22
HUMAN PERCEPTION
Input image JPEG 0.266 bpp
IEEE ICME 2020

23
HUMAN PERCEPTION
Input image Ours 0.249 bpp
IEEE ICME 2020

24
HUMAN PERCEPTION
Input image JPEG 0.208 bpp
IEEE ICME 2020

25
HUMAN PERCEPTION
Input image Ours 0.198 bpp
IEEE ICME 2020

26
HUMAN PERCEPTION
Input image JPEG 0.178 bpp
IEEE ICME 2020

27
HUMAN PERCEPTION
Input image Ours 0.177 bpp
IEEE ICME 2020
28
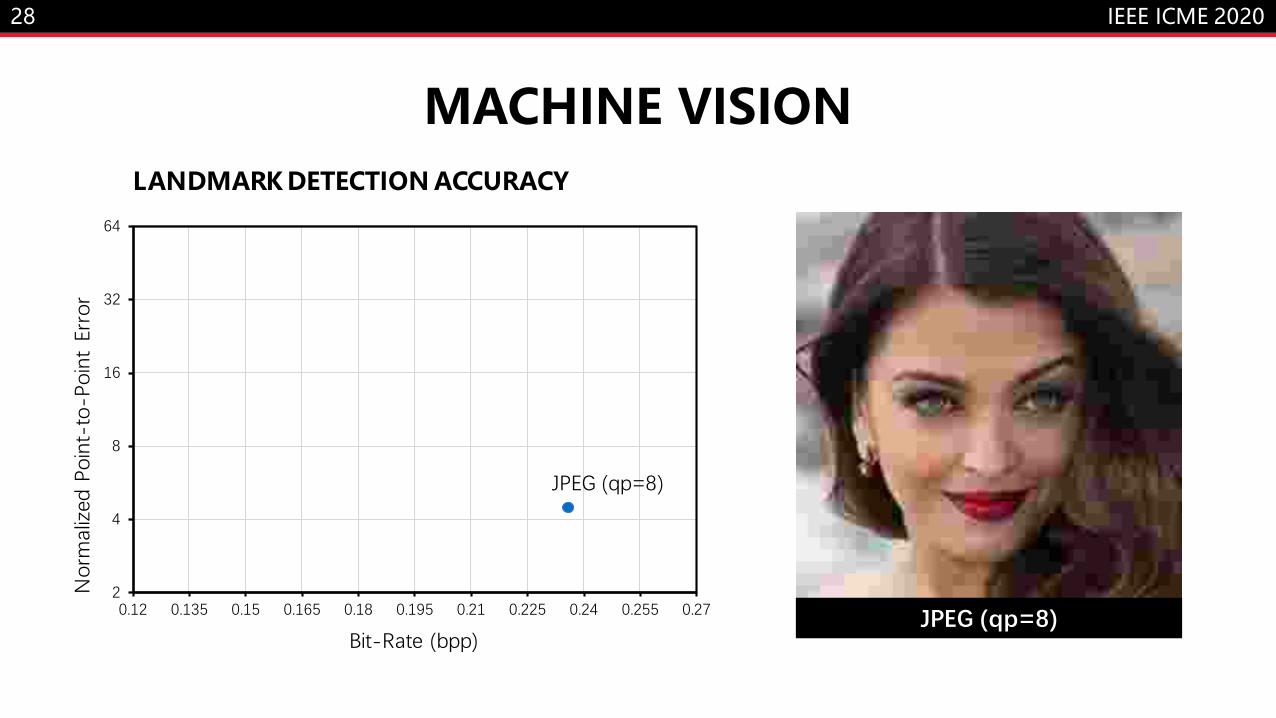
MACHINE VISION
2
4
8
16
32
64
0.12 0.135 0.15 0.165 0.18 0.195 0.21 0.225 0.24 0.255 0.27
Nor
mal
ized
Poi
nt-t
o-Po
int
Erro
r
Bit-Rate (bpp)
JPEG (qp=8)
JPEG (qp=8)
LANDMARK DETECTION ACCURACY
IEEE ICME 2020
29
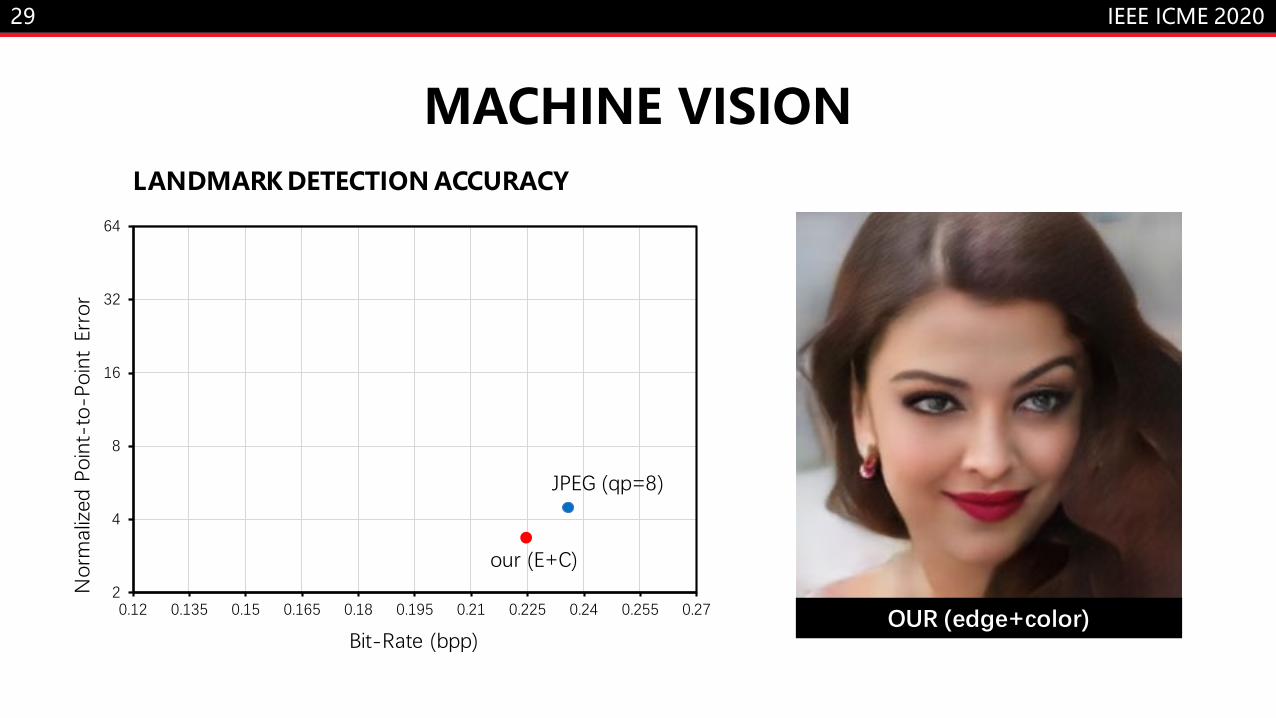
MACHINE VISION
2
4
8
16
32
64
0.12 0.135 0.15 0.165 0.18 0.195 0.21 0.225 0.24 0.255 0.27
Nor
mal
ized
Poi
nt-t
o-Po
int
Erro
r
Bit-Rate (bpp)
JPEG (qp=8)
our (E+C)
OUR (edge+color)
LANDMARK DETECTION ACCURACY
IEEE ICME 2020

30
MACHINE VISION
2
4
8
16
32
64
0.12 0.135 0.15 0.165 0.18 0.195 0.21 0.225 0.24 0.255 0.27
Nor
mal
ized
Poi
nt-t
o-Po
int
Erro
r
Bit-Rate (bpp)
JPEG (qp=7)
JPEG (qp=8)
our (E+C)
JPEG (qp=7)
LANDMARK DETECTION ACCURACY
IEEE ICME 2020
2
4
8
16
32
64
0.12 0.135 0.15 0.165 0.18 0.195 0.21 0.225 0.24 0.255 0.27
Nor
mal
ized
Poi
nt-t
o-Po
int
Erro
r
Bit-Rate (bpp)
31
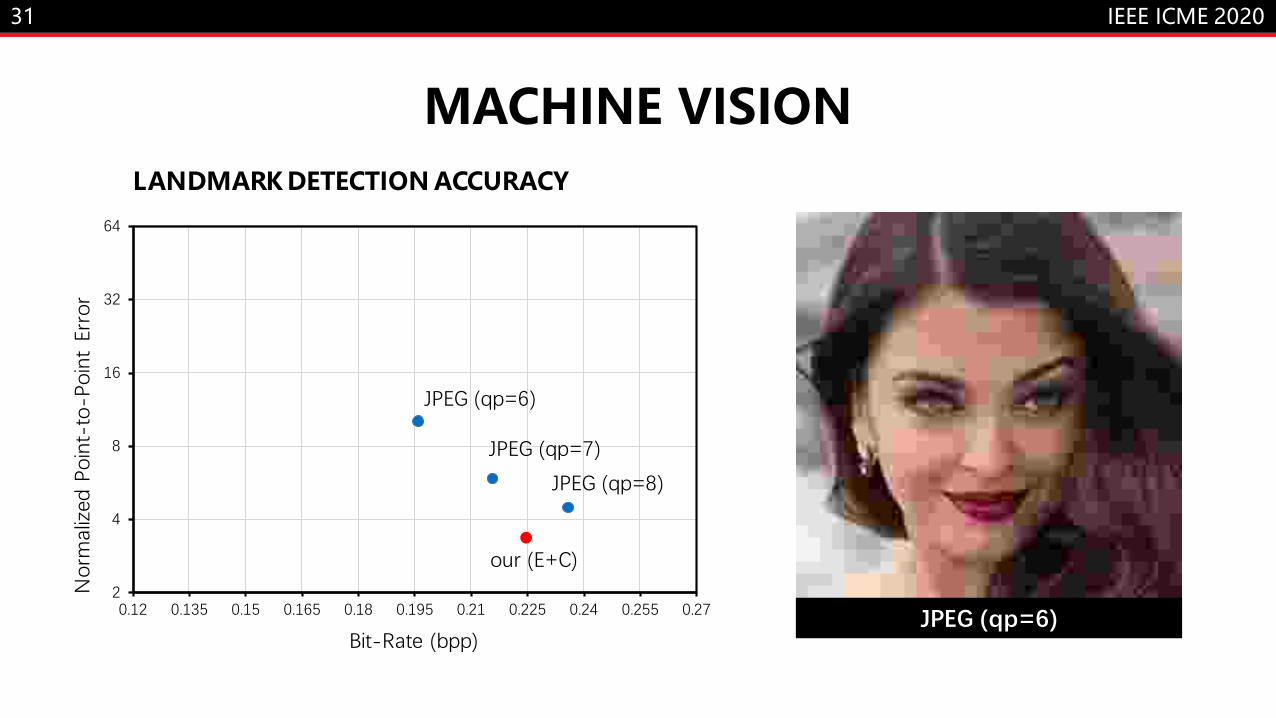
MACHINE VISION
JPEG (qp=6)
JPEG (qp=7)
JPEG (qp=8)
our (E+C)
JPEG (qp=6)
LANDMARK DETECTION ACCURACY
IEEE ICME 2020
32
MACHINE VISION
2
4
8
16
32
64
0.12 0.135 0.15 0.165 0.18 0.195 0.21 0.225 0.24 0.255 0.27
Nor
mal
ized
Poi
nt-t
o-Po
int
Erro
r
Bit-Rate (bpp)
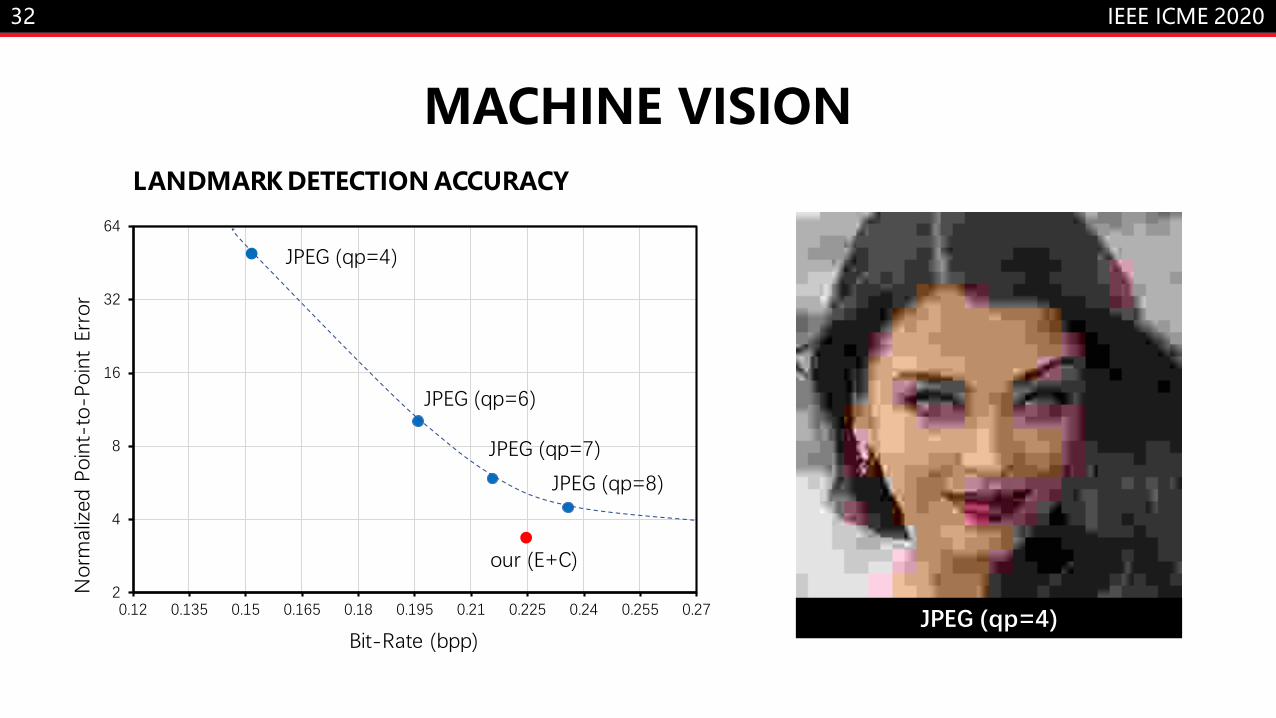
JPEG (qp=4)
JPEG (qp=6)
JPEG (qp=7)
JPEG (qp=8)
our (E+C)
JPEG (qp=4)
LANDMARK DETECTION ACCURACY
IEEE ICME 2020

33
MACHINE VISION
2
4
8
16
32
64
0.12 0.135 0.15 0.165 0.18 0.195 0.21 0.225 0.24 0.255 0.27
Nor
mal
ized
Poi
nt-t
o-Po
int
Erro
r
Bit-Rate (bpp)
JPEG (qp=4)
JPEG (qp=6)
JPEG (qp=7)
JPEG (qp=8)
our (E+C)our (E)
OUR (edge)
LANDMARK DETECTION ACCURACY
IEEE ICME 2020

34
MACHINE VISIONLANDMARK DETECTION ACCURACY
• Quantitatively evaluate the accuracy
of facial landmark detection on the
reconstructed images.
• Results show statistically improved
accuracy at a lower bit-rate.
• While the basic layer maintain a high
accuracy, the enhancing layer provide
more fidelity.
IEEE ICME 2020

35
MACHINE VISIONLANDMARK DETECTION RESULTS
JPEG 0.131 bpp Ours 0.115 bpp
IEEE ICME 2020

36
MACHINE VISIONLANDMARK DETECTION RESULTS
JPEG 0.138 bpp Ours 0.114 bpp
IEEE ICME 2020

37
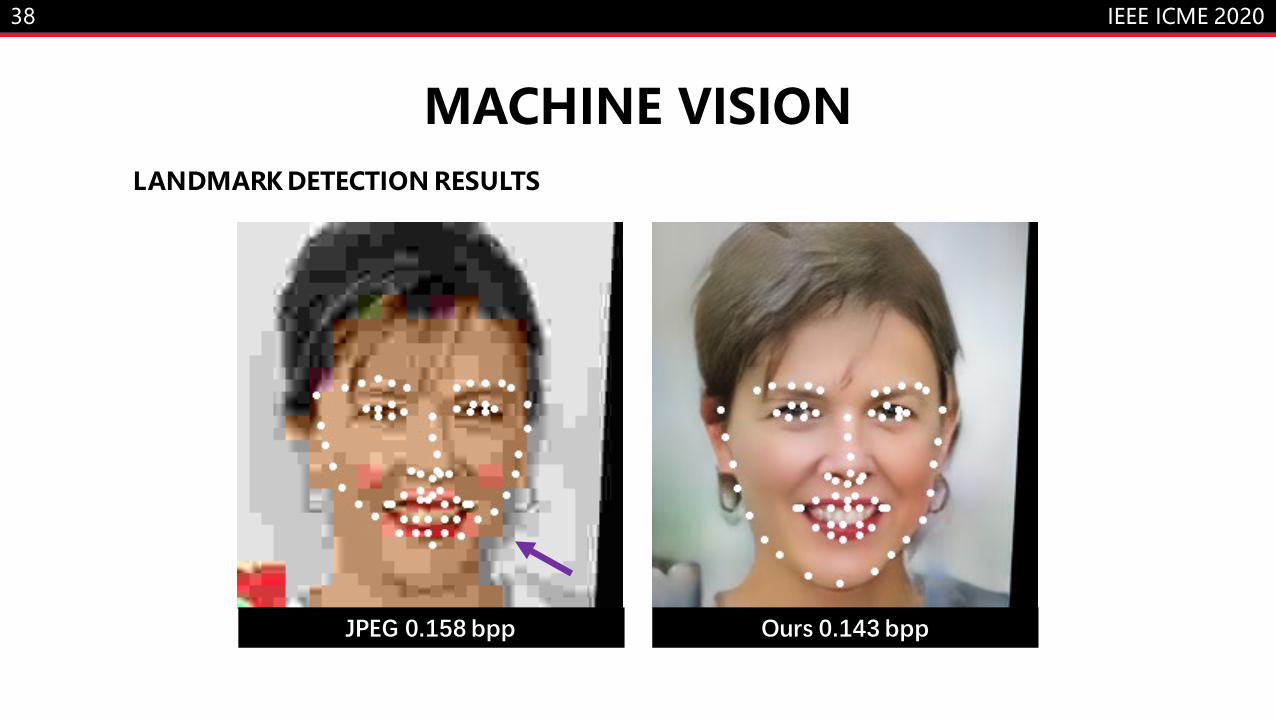
MACHINE VISIONLANDMARK DETECTION RESULTS
JPEG 0.145 bpp Ours 0.108 bpp
IEEE ICME 2020
38
MACHINE VISIONLANDMARK DETECTION RESULTS
JPEG 0.158 bpp Ours 0.143 bpp
IEEE ICME 2020
39
CONCLUSION
APPROACH TO COLLABORATIVE CODING• Edge + sparse pixels, vectorized representation• Generative adversarial reconstruction
• Human-machine collaborative feature extraction
INFORMATION SCALABLE FRAMEWORK• Base layer Semantically accurate
• Enhanced layer Visually faithful• Efficient feature adaptation
FUTURE DIRECTIONS• Self-learned feature adaptation• Multi-task collaborative inference
• Theoretical analysis on collaborative coding
IEEE ICME 2020

IEEE ICME 2020
PROJECT
Towards Coding for Human and Machine Vision: A Scalable Image Coding Approach
PAPER ID 818
Thank You!CODE


















