
Tous droits réservés © 2005 CRIM The CRIM Systems for the NIST 2008 SRE Patrick Kenny, Najim...
27
ous droits réservés © 2005 CRIM The CRIM Systems for The CRIM Systems for the NIST 2008 SRE the NIST 2008 SRE rick Kenny, Najim Dehak and Pierre Ouellet Centre de recherche informatique de Montreal (CRIM)
-
date post
22-Dec-2015 -
Category
Documents
-
view
217 -
download
3
Transcript of Tous droits réservés © 2005 CRIM The CRIM Systems for the NIST 2008 SRE Patrick Kenny, Najim...

Tous droits réservés © 2005 CRIM
The CRIM Systems for the The CRIM Systems for the NIST 2008 SRENIST 2008 SRE
Patrick Kenny, Najim Dehak and Pierre Ouellet
Centre de recherche informatique de Montreal (CRIM)

Tous droits réservés © 2005 CRIM
SystemsSystems• CRIM_2 was the primary system for all but
the core condition– Large stand-alone joint factor analysis (JFA)
system trained on pre-2006 data
• CRIM_1 was the primary system for the core condition– CRIM_1 = CRIM_2 + 3 other JFA systems
with different feature sets
• CRIM_3 = CRIM_2 + 2006 SRE data

Tous droits réservés © 2005 CRIM
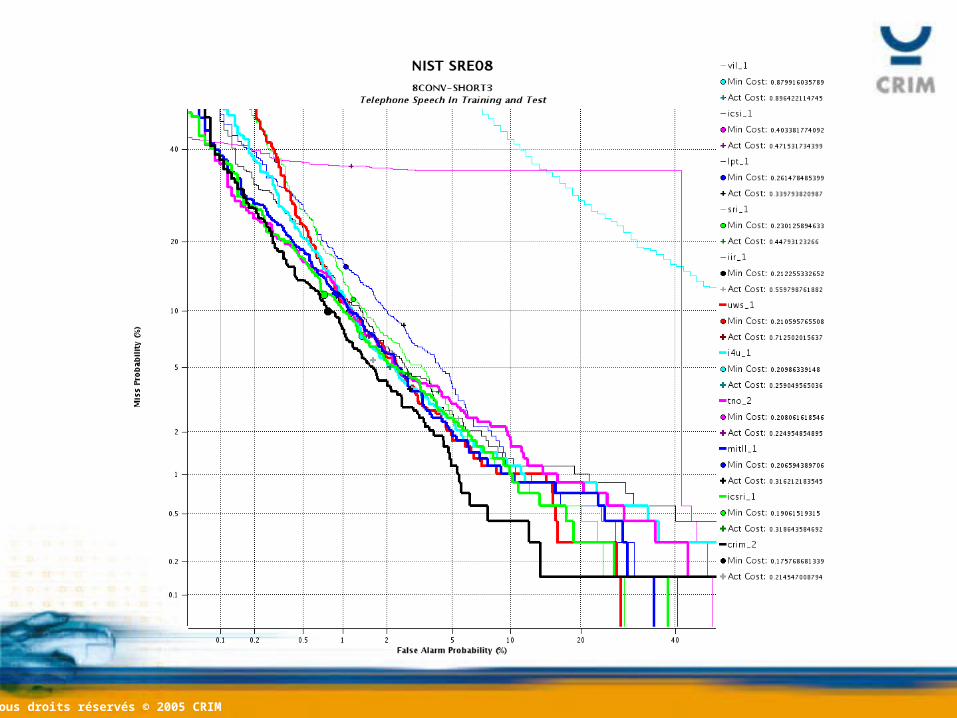
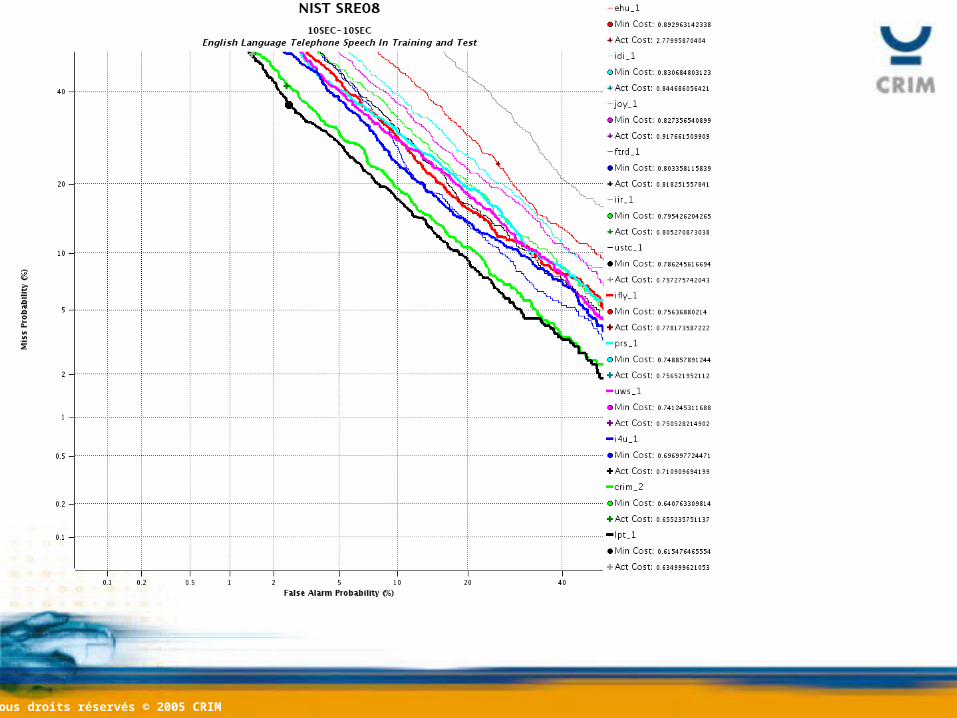
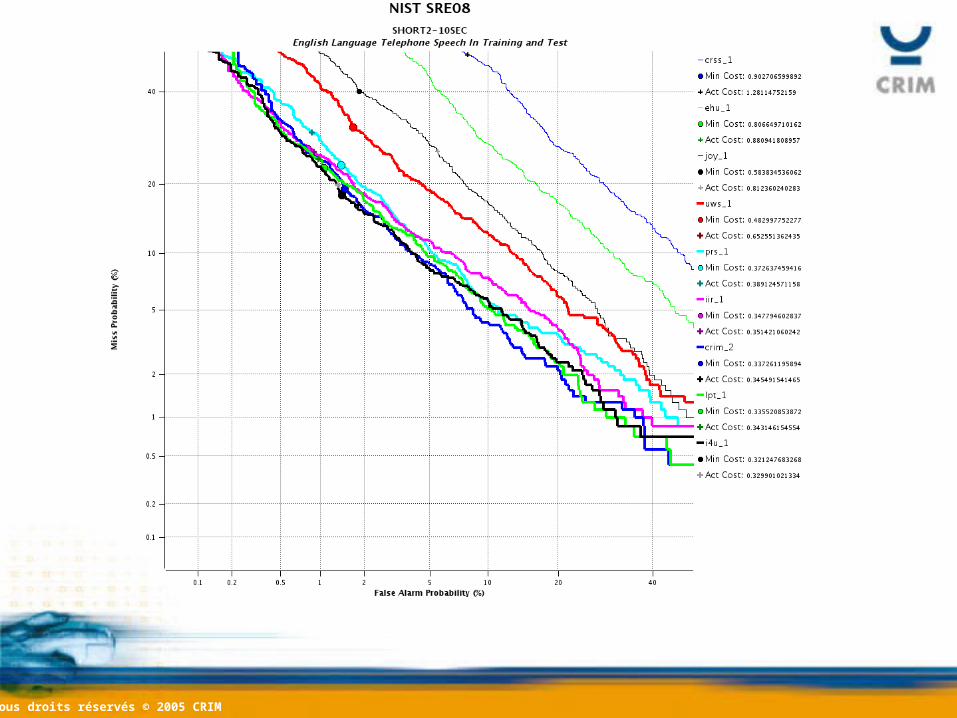
OverviewOverview• Tasks involving multiple enrollment
recordings:– 8conv-short3, 3conv-short3
• Tasks involving 10 sec test recordings:– 10sec-10sec, short2-10sec, 8conv-10sec
• Najim Dehak will talk about– JFA with unconventional features– Post-eval experiments on the interview data
(following LPT and I4U)

Tous droits réservés © 2005 CRIM
Factor Analysis ConfigurationFactor Analysis Configuration
• 2K Gaussians, 60 dimensional features– 20 Gaussianized mfcc’s + first and second
derivatives
• 300 speaker factors
• 100 channel factors for telephone speech
• Additional 100 channel factors for microphone speech

Tous droits réservés © 2005 CRIM
Speaker VariabilitySpeaker Variability Prior distribution on speaker supervectors
s = m + vy + dz– m is the speaker-independent supervector– v is rectangular, low rank (eigenvectors)– d is diagonal– y, z standard Normal random vectors (speaker
factors)

Tous droits réservés © 2005 CRIM
Channel VariabilityChannel Variability Each supervector M is assumed to be a sum of a
speaker supervector and a channel supervector:
M = s + c
Prior distribution on channel supervectors
c = ux – u is rectangular, low rank (eigenchannels)– x standard Normal random

Tous droits réservés © 2005 CRIM
Enrollment: single utteranceEnrollment: single utterance The supervector for the utterance is
m + dz + vy + ux
Calculate the MAP estimates of x, y and z
The speaker supervector is
s + dz + vy
The full posterior distribution of s can be calculated in closed form (but this is messy unless d is 0)

Tous droits réservés © 2005 CRIM
Enrollment: 8conv caseEnrollment: 8conv case
Again the joint posterior distribution of the hidden variablescan be calculated in closed form.Unless d is 0, this is very messyTrick: pool the utterances together and ignore the fact that the x’s are different
8
2
1
uxvydzm
uxvydzm
uxvydzm
Tous droits réservés © 2005 CRIM

Tous droits réservés © 2005 CRIM

Tous droits réservés © 2005 CRIM
10 second test conditions10 second test conditions Many labs have reported difficulty in getting channel
factors or NAP to work under these conditions
The problem may be that it is unrealistic to attempt to produce point estimates (ML or MAP) of channel factors using 10 second test utterances
Probability rules say you should integrate over channel factors instead

Tous droits réservés © 2005 CRIM
Why is this not an issue for Why is this not an issue for long test utterances?long test utterances? If the test utterance is long, the posterior
distribution of the channel factors will be sharply peaked in the neighbourhood of the point estimate (MAP or ML).
MAP
MAP
xxx
xxx
x
xx
unless 0)|(
thatimplies
)()|()()|(
equation then the,at edconcentrat
is ofon distributiposterior theIf
dataP
dataPdataPPdataP
|data) P(
Tous droits réservés © 2005 CRIM
Tous droits réservés © 2005 CRIM

Tous droits réservés © 2005 CRIM

Tous droits réservés © 2005 CRIM
Research ProblemResearch Problem How should factor analysis likelihoods and
posteriors be evaluated so as to take account of all of the relevant uncertainties?
- Uncertainty in the speaker factors
- Uncertainty in the channel factors
- Uncertainty in the assignment of observations to mixture components

Tous droits réservés © 2005 CRIM
Current SolutionCurrent Solution• Use point estimate of speaker factors
– Bayesian approach (using full posterior) doesn’t seem to help
• Integrate over the channel factors• Use the UBM to align frames with mixture
components– Tractable posterior + Jensen’s inequality gives lower
bound on likelihood (Niko Brummer) – Very fast if combined with LPT assumption
• Paradoxical results if speaker/channel dependent GMM’s used in place of UBM

Tous droits réservés © 2005 CRIM
Ideal Solution: Integrate over Ideal Solution: Integrate over all hidden variablesall hidden variables• Robbie Vogt (Odyssey 2004) did this for a
diagonal factor analysis model– No speaker or channel factors– Exact dynamic programming solution
• Variational Bayes offers an approximate solution in the general case– Assume that the posterior distribution factorizes into 3
terms (speaker factors, channel factors, assignments of frames to mixture components)
– Cycle through the factors to update them (like EM)– Jensen’s inequality gives lower bound on the
likelihood which increases on successive iterations

Tous droits réservés © 2005 CRIM
FusionFusion
• Fusing long term and short term features
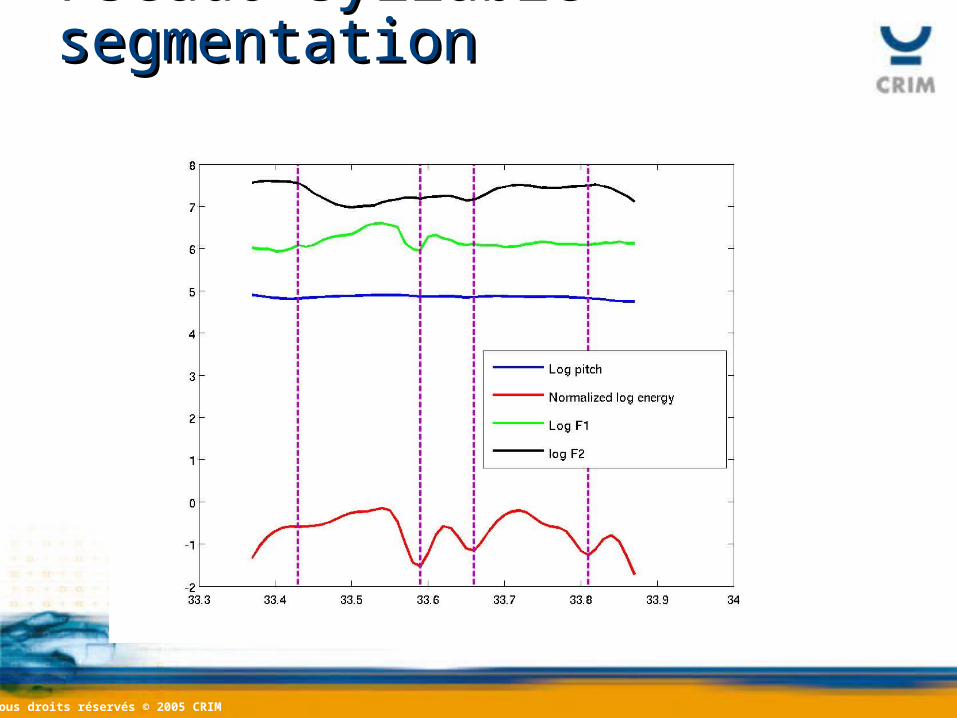
• Pseudo-syllable unsupervised prosodic and MFCC’s contours segmentation.
• Six Legendre Polynomial coefficients for each contour.
• JFA without common factor (d=0)
• Logistic regression function (Focal).
Tous droits réservés © 2005 CRIM
Pseudo-syllable segmentationPseudo-syllable segmentation

Tous droits réservés © 2005 CRIM
Long term featuresLong term features
• Three long term systems:– 512 G, Features : Pitch + energy + duration
(13 dimension)– 1024 G, Features : 12 MFCCs contours +
energy + duration (79 dimension)– 1024 G, Features : 12 MFCCs contours +
pitch + energy + duration (85 dimension)
Tous droits réservés © 2005 CRIM
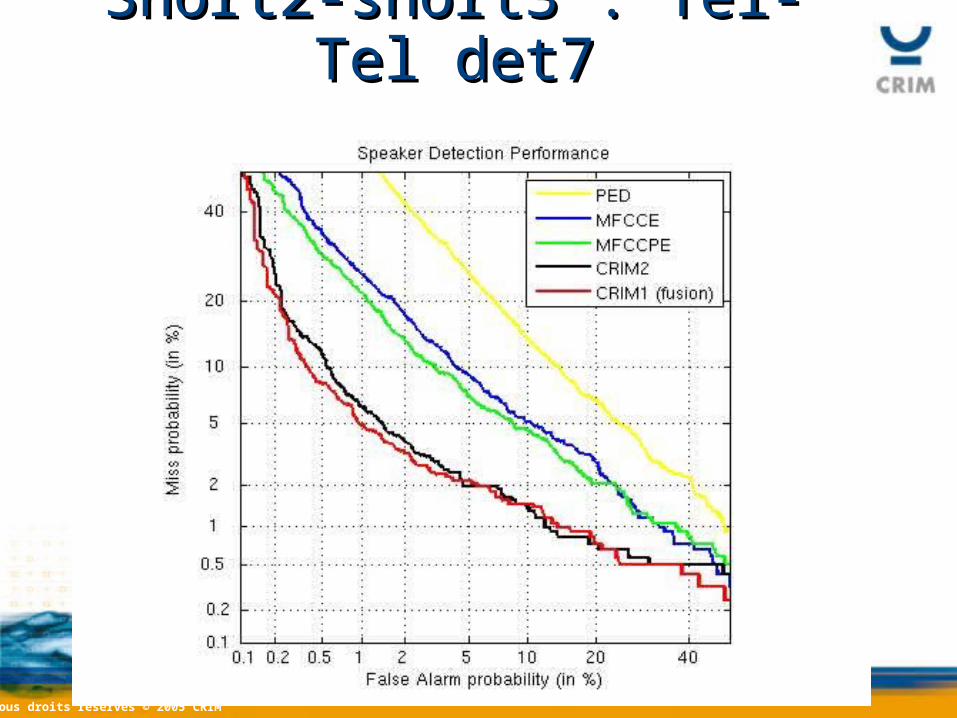
Short2-short3 : Tel-Tel det7Short2-short3 : Tel-Tel det7
Tous droits réservés © 2005 CRIM
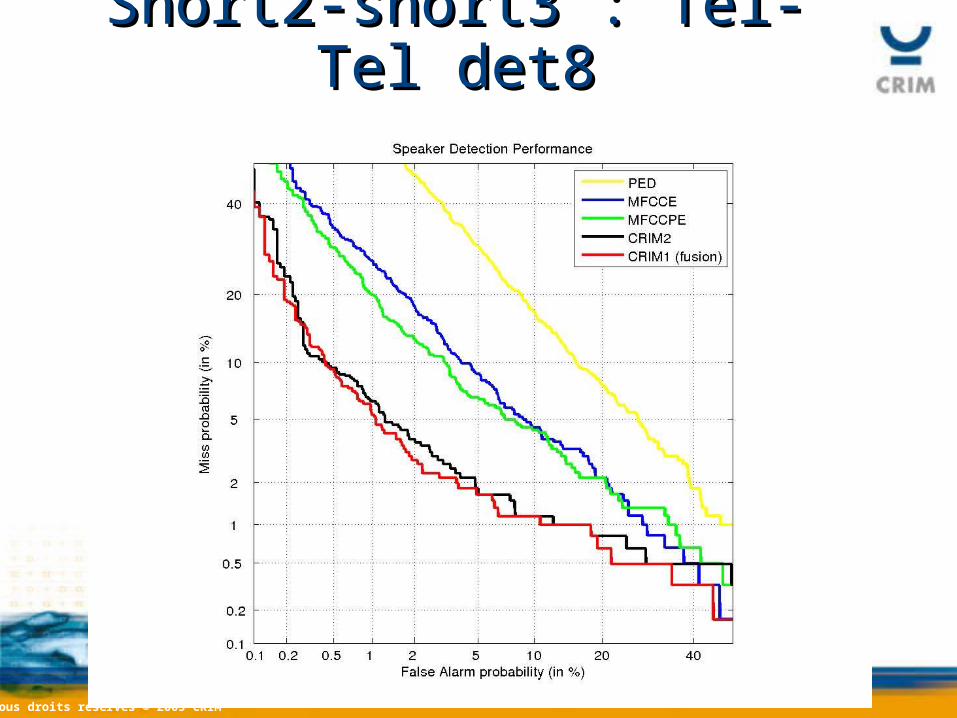
Short2-short3 : Tel-Tel det8Short2-short3 : Tel-Tel det8

Tous droits réservés © 2005 CRIM
How to deal with interview How to deal with interview data?data?
• Interview eigenchannel trained on interview development data (as LPT and I4U).
• Small configuration of the Factor analayis– Features 20 Gaussianized MFCC’s + first derivatives– 300 speaker factors , d=0 (no common factor), 100
telephone channel factors.
• We carried out two experiments :– 50 TeL-Mic channel factors.– 50 TeL-Mic channel factors + 50 interview channel
factors.

Tous droits réservés © 2005 CRIM
NIST 2008 : Interview data –NIST 2008 : Interview data –det1det1

Tous droits réservés © 2005 CRIM
NIST 2008 : Interview data –NIST 2008 : Interview data –det1det1EER (%) MinDCF
Without interview eigenchannels
8.9% 0.0477389
Interview speaker utterances means
5.5% 0.0342164
Interview channel_2 utterance as means
5.7% 0.0360786
Interview & microphone
eigenchannels
5.7% 0.033472

Tous droits réservés © 2005 CRIM
ReferencesReferences
• A Study of Inter-Speaker Variability in Speaker Verification.
• Modeling prosodic features with joint factor analysis for speaker verification.
www.crim.ca/perso/patrick.kenny


















